Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles

 ,
,  ,
,  , , and
, , and 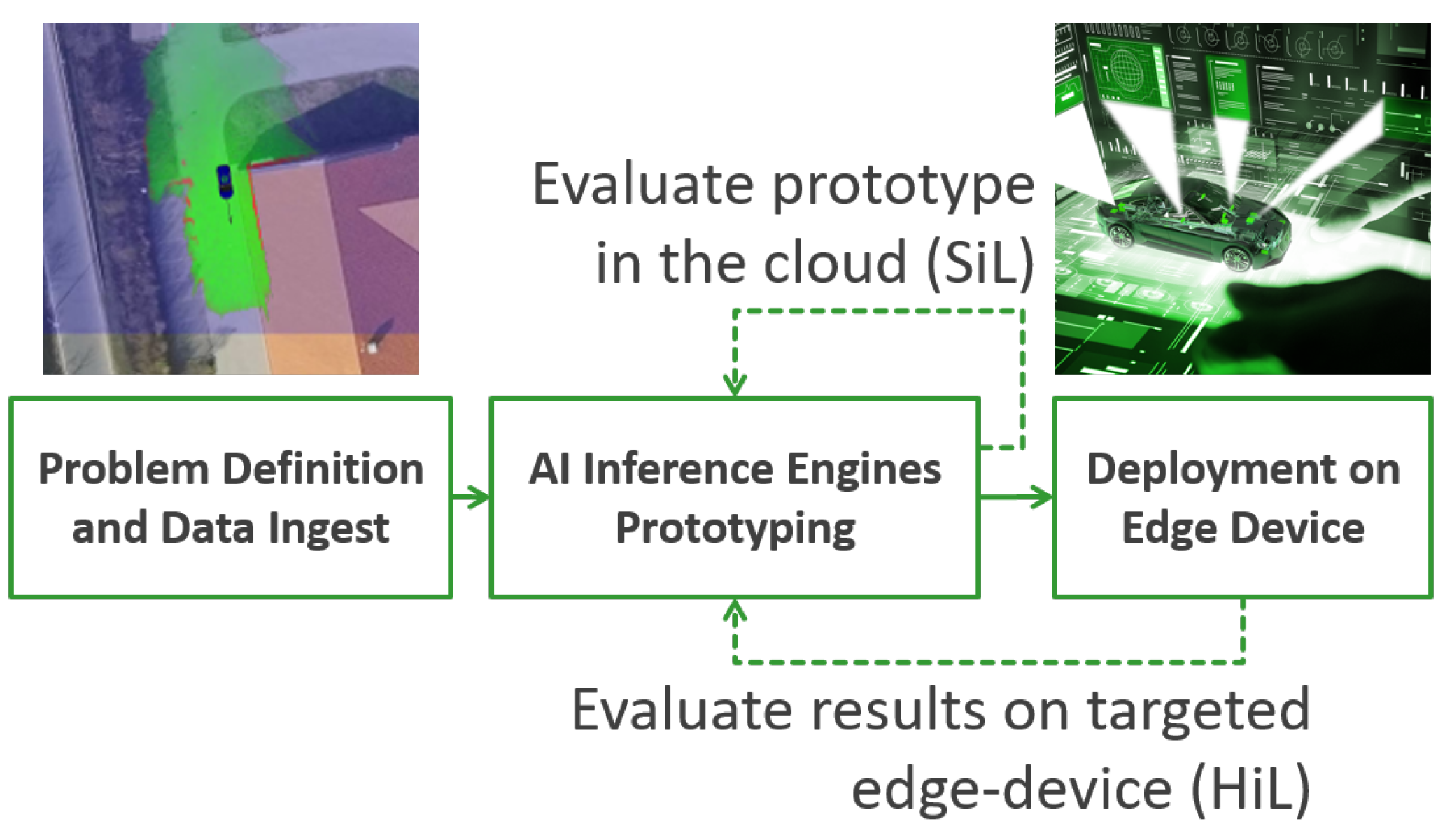{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. The EB-AI Framework
- Ability to digest automotive specific input data such as video streams, LiDAR and/or radar data;
- Providing tunable state of the art DNN architectures for a broad spectrum of autonomous driving applications;
- Ability to deploy and evaluate the obtained AI Inference Engines via HiL testing on edge devices (e.g., target ECUs).
1.2. Contributions
- A simple yet elegant AI Inference Engine concept, based on the SiL and HiL principles;
- A data-driven V-Model approach guiding the design of AI-based autonomous driving applications;
- A modular Cloud2Edge AI framework for autonomous driving applications coined EB-AI;
- An elastic framework able to overcome network bandwidth and privacy concerns by dynamically deploying deep learning training tasks among Edge and Cloud;
- The development of two real-world AI Inference Engines for environment perception and most probable path prediction;
- A discussion on the advantages of such a hybrid deployment, in terms of training parallelization, privacy-preservation, fault tolerance and scalability.
2. Background and Related Work
2.1. Deep Learning Overview
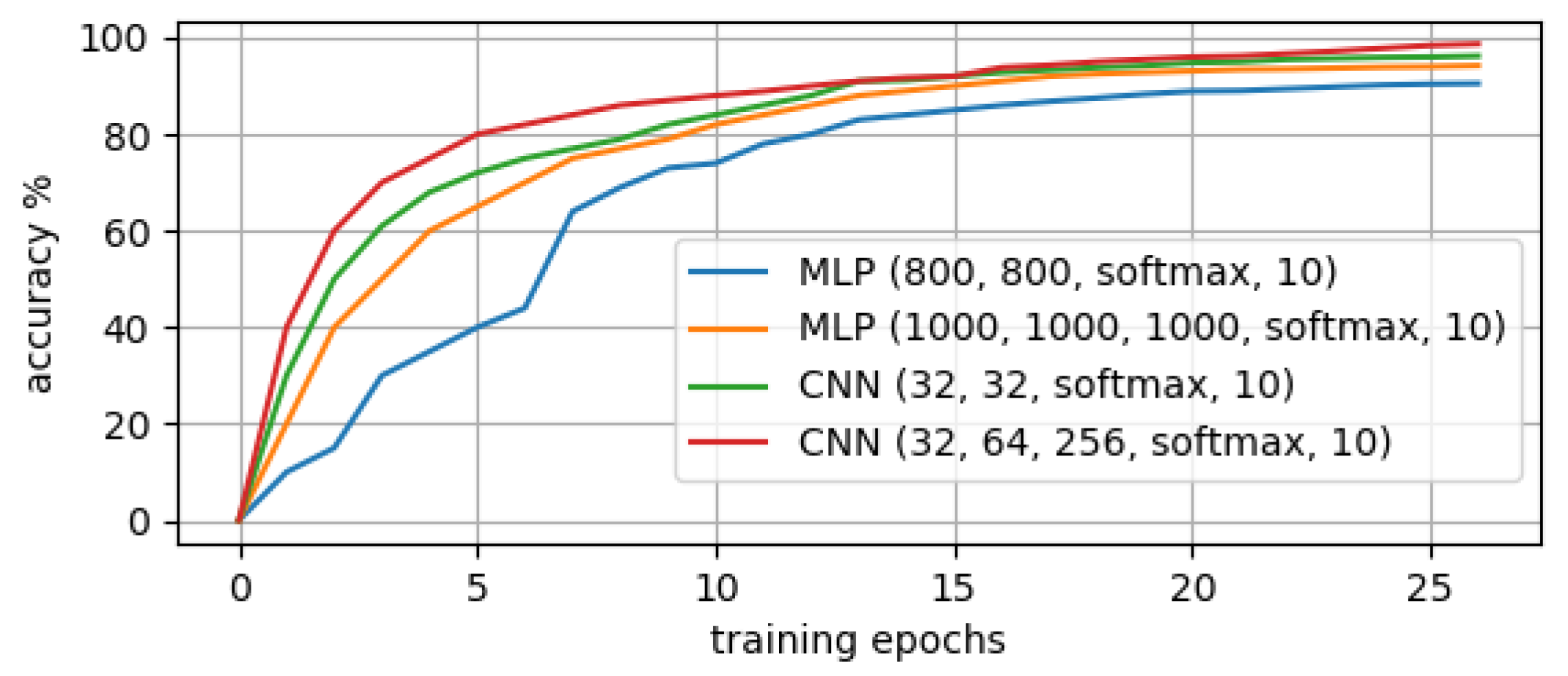
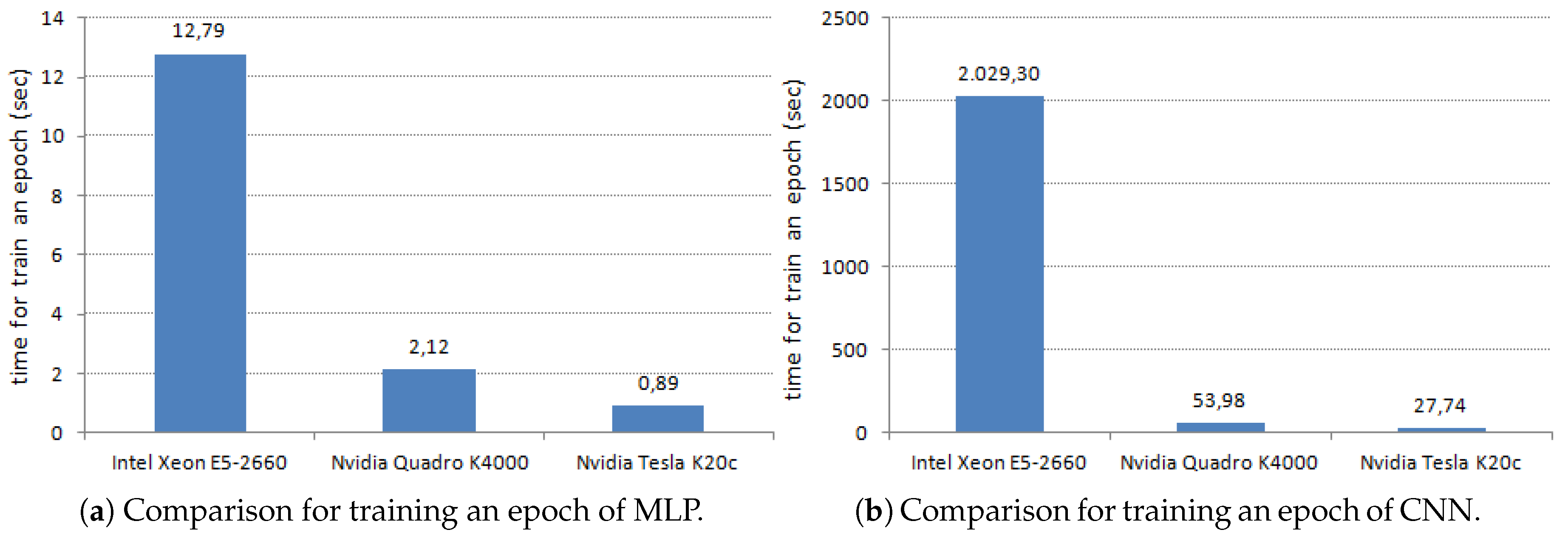
2.2. Deep Learning Libraries and Tools
2.3. AI Frameworks in Autonomous Driving
3. EB-AI Toolchain
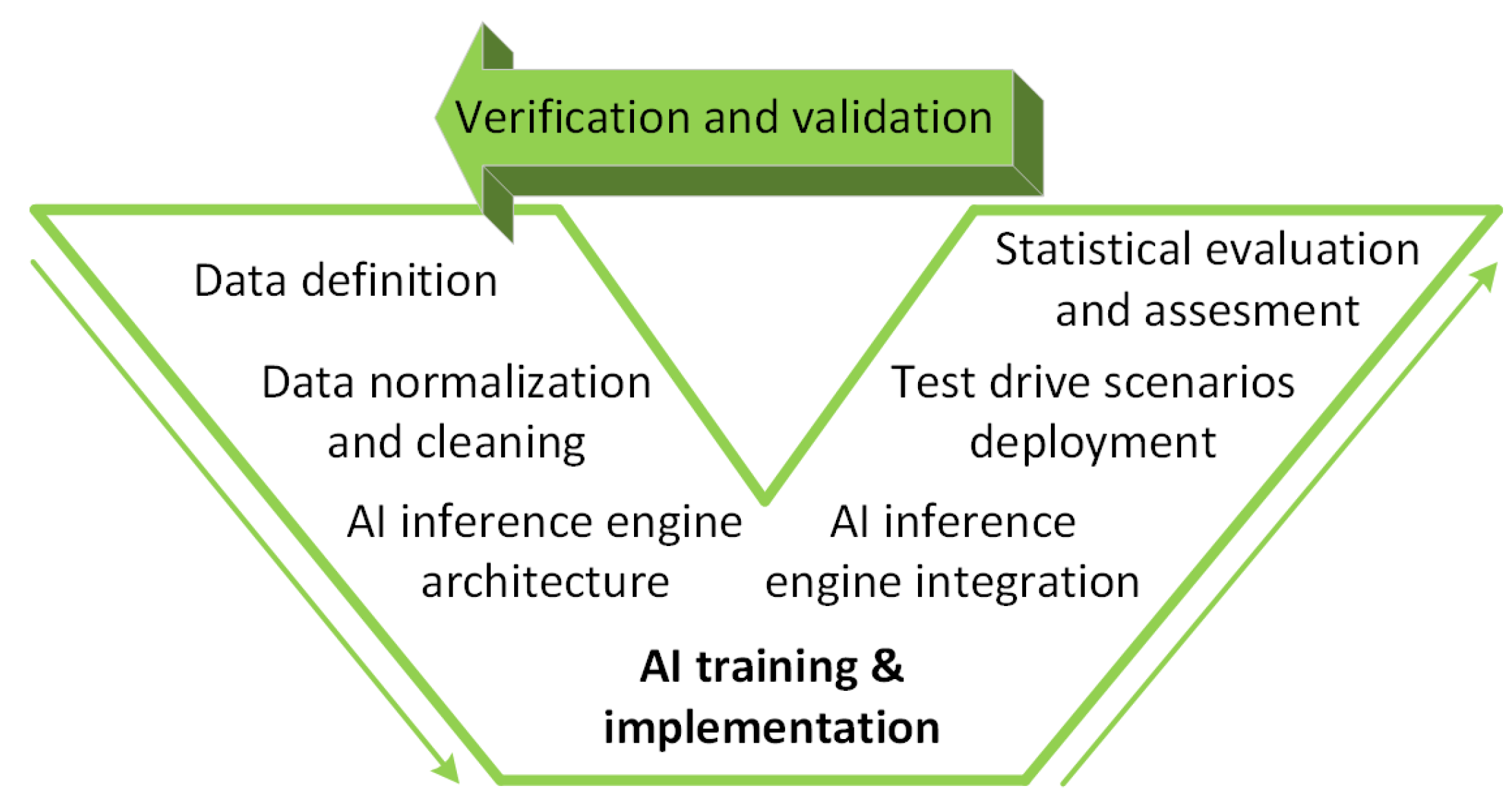
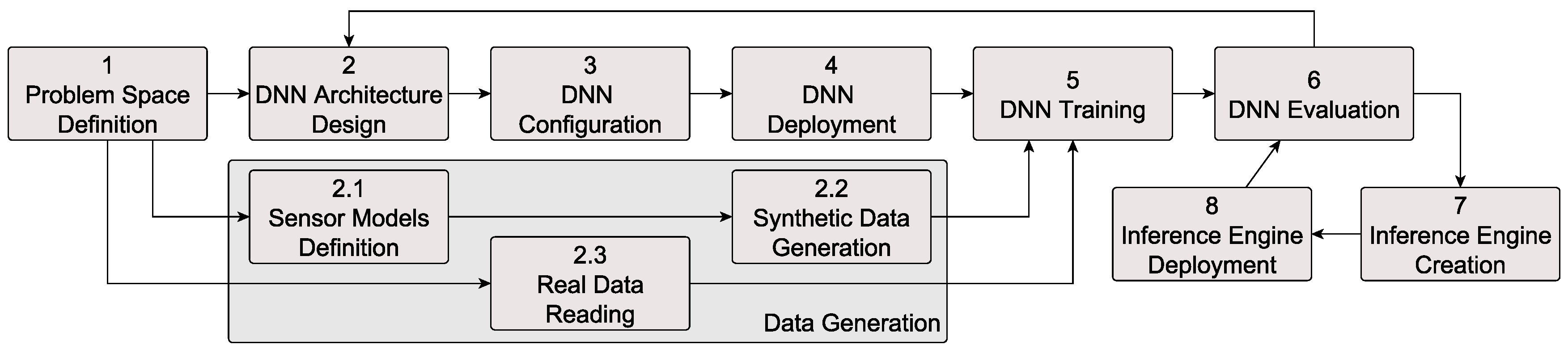
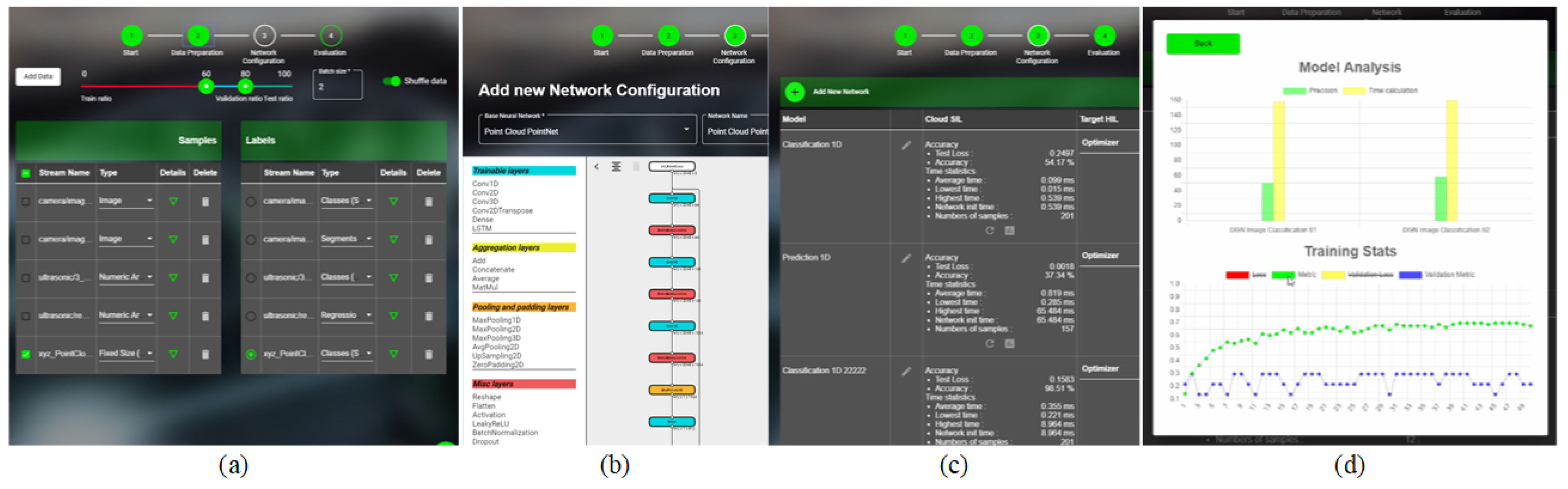
3.1. V-Model and Workflow
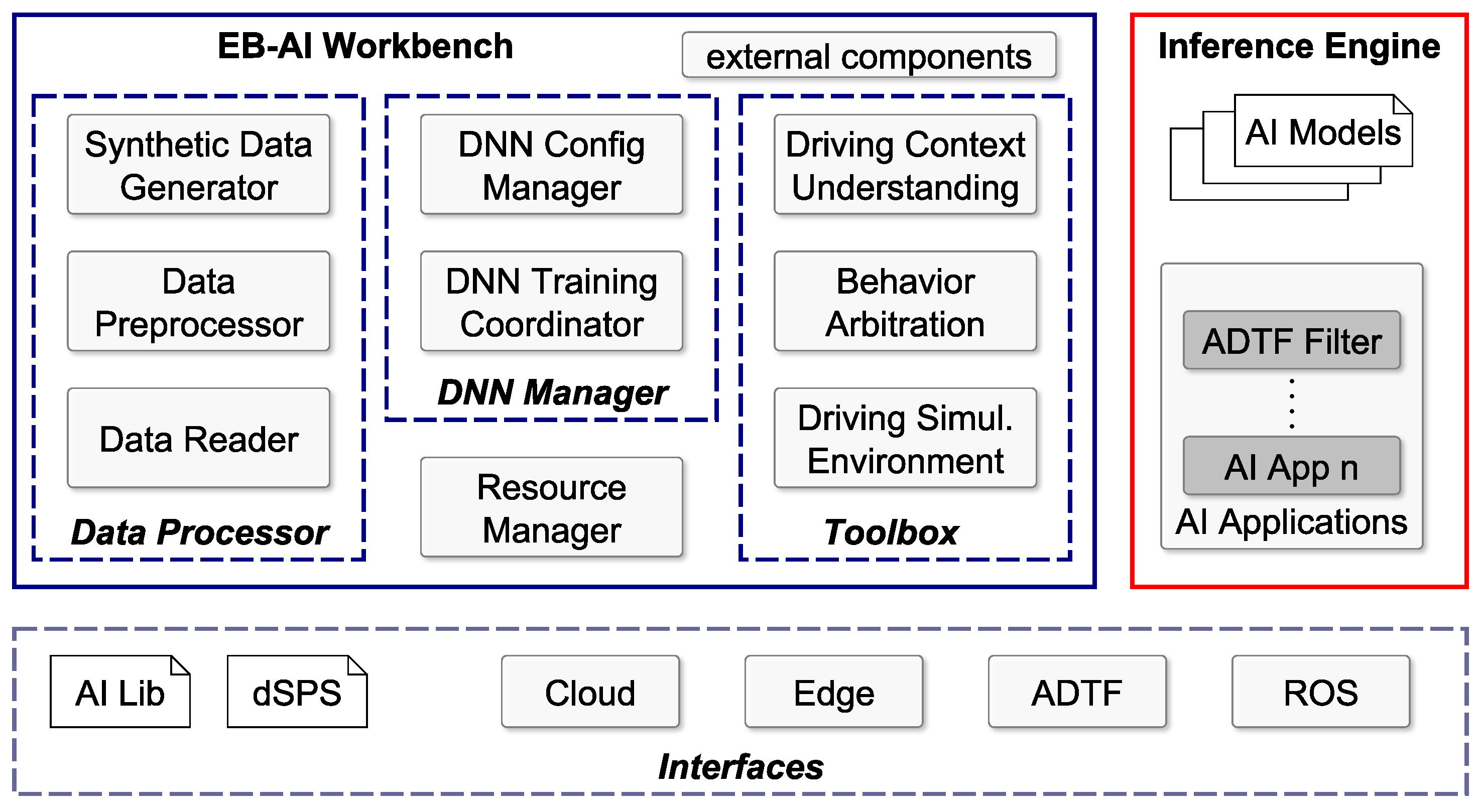
3.2. EB-AI Architecture
4. Hybrid Deployment Advantages
4.1. Privacy-Preserving Techniques
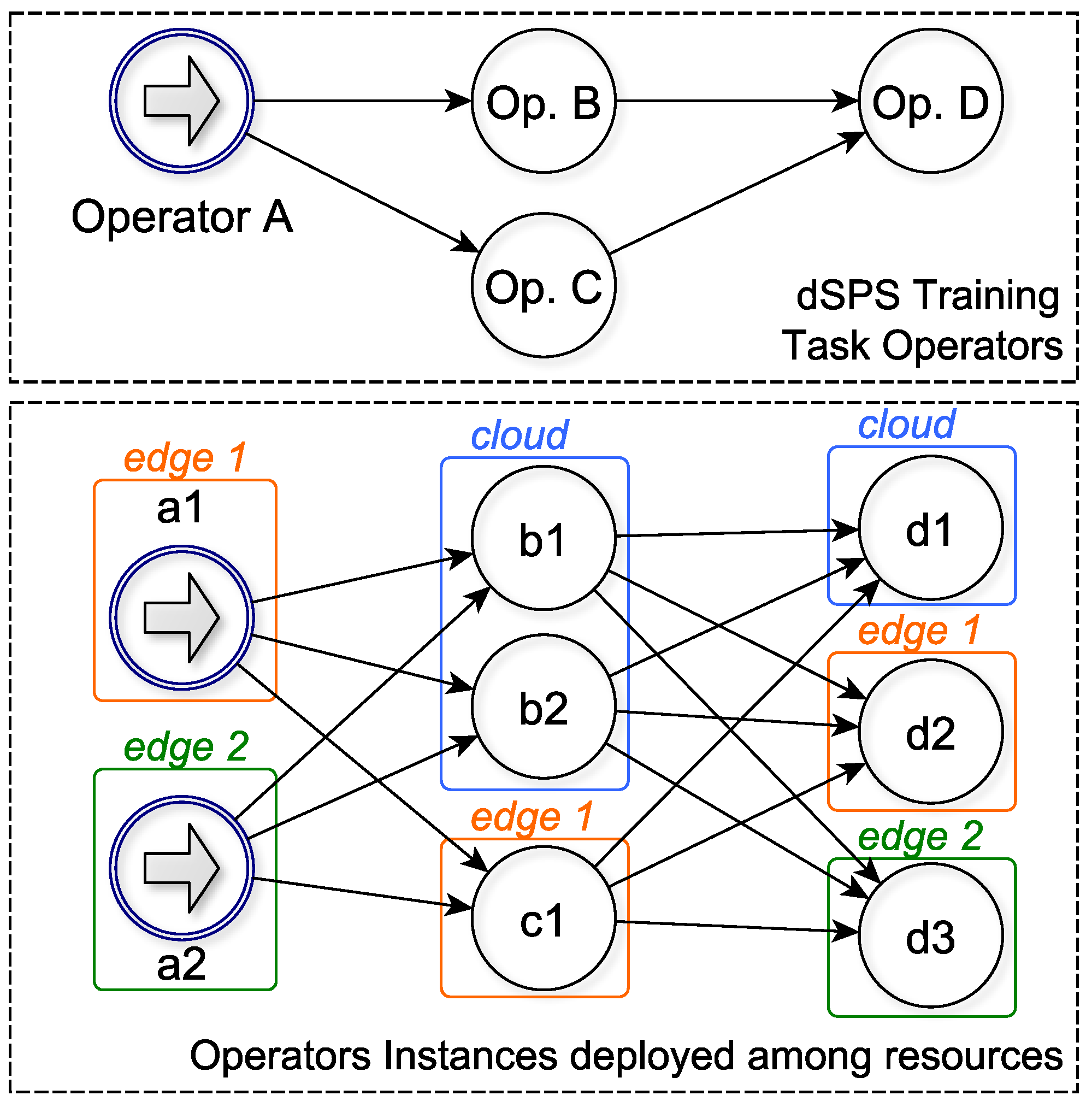
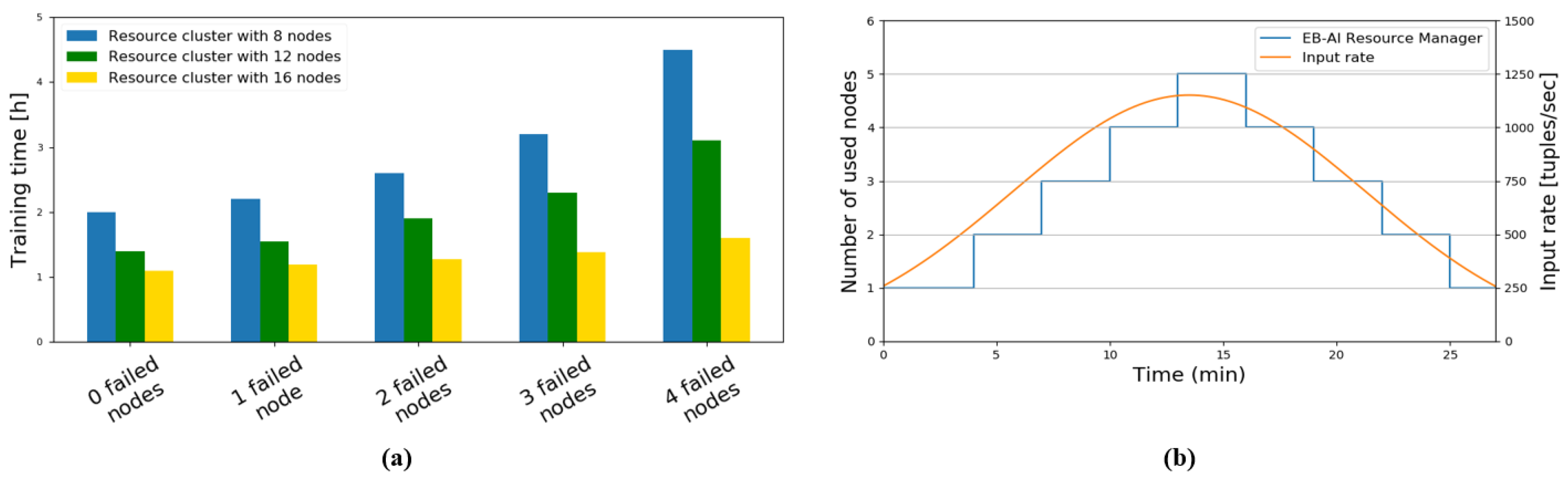
4.2. Fault Tolerance and Elastic Scalability
5. EB-AI Use Cases
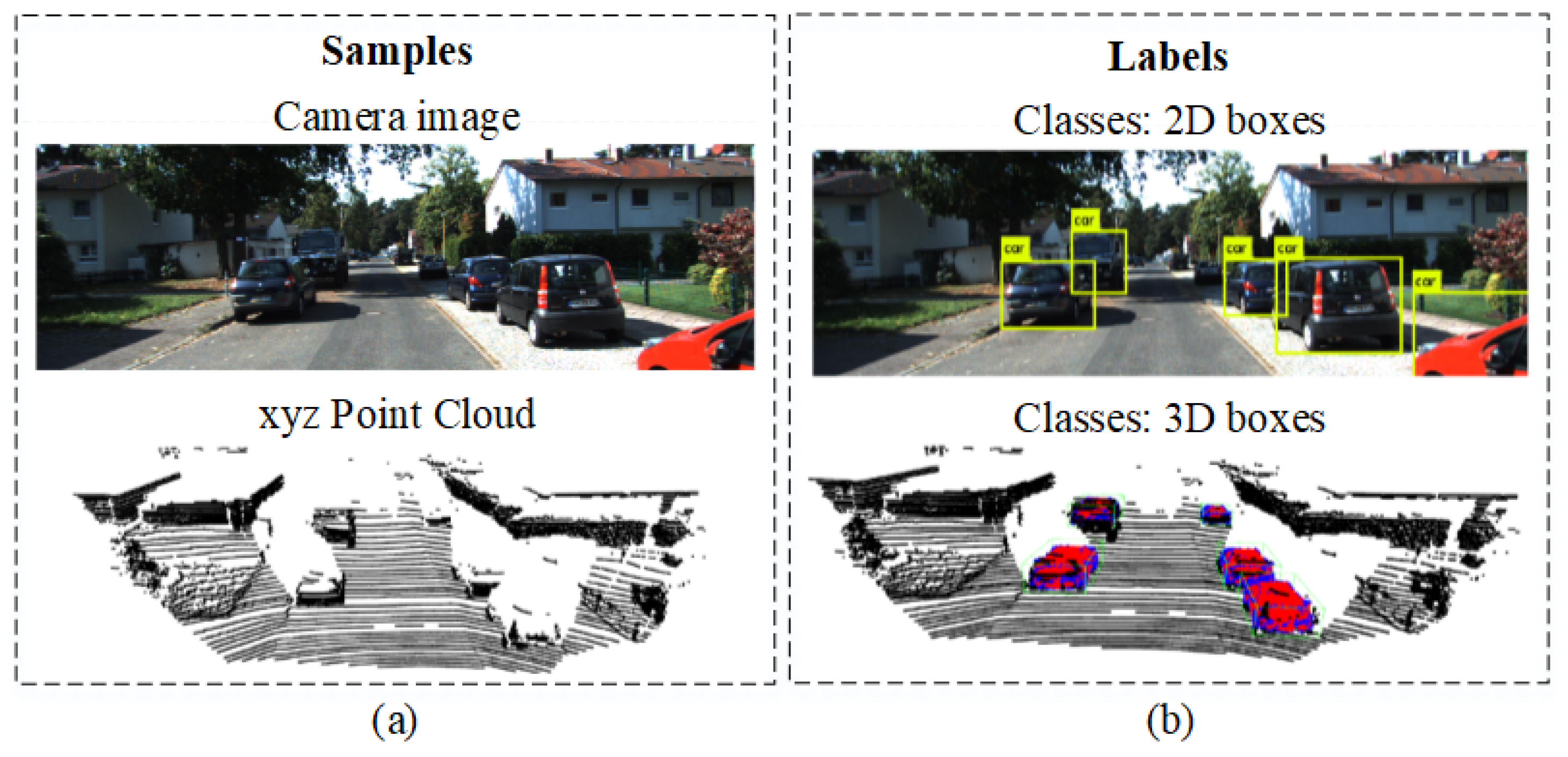
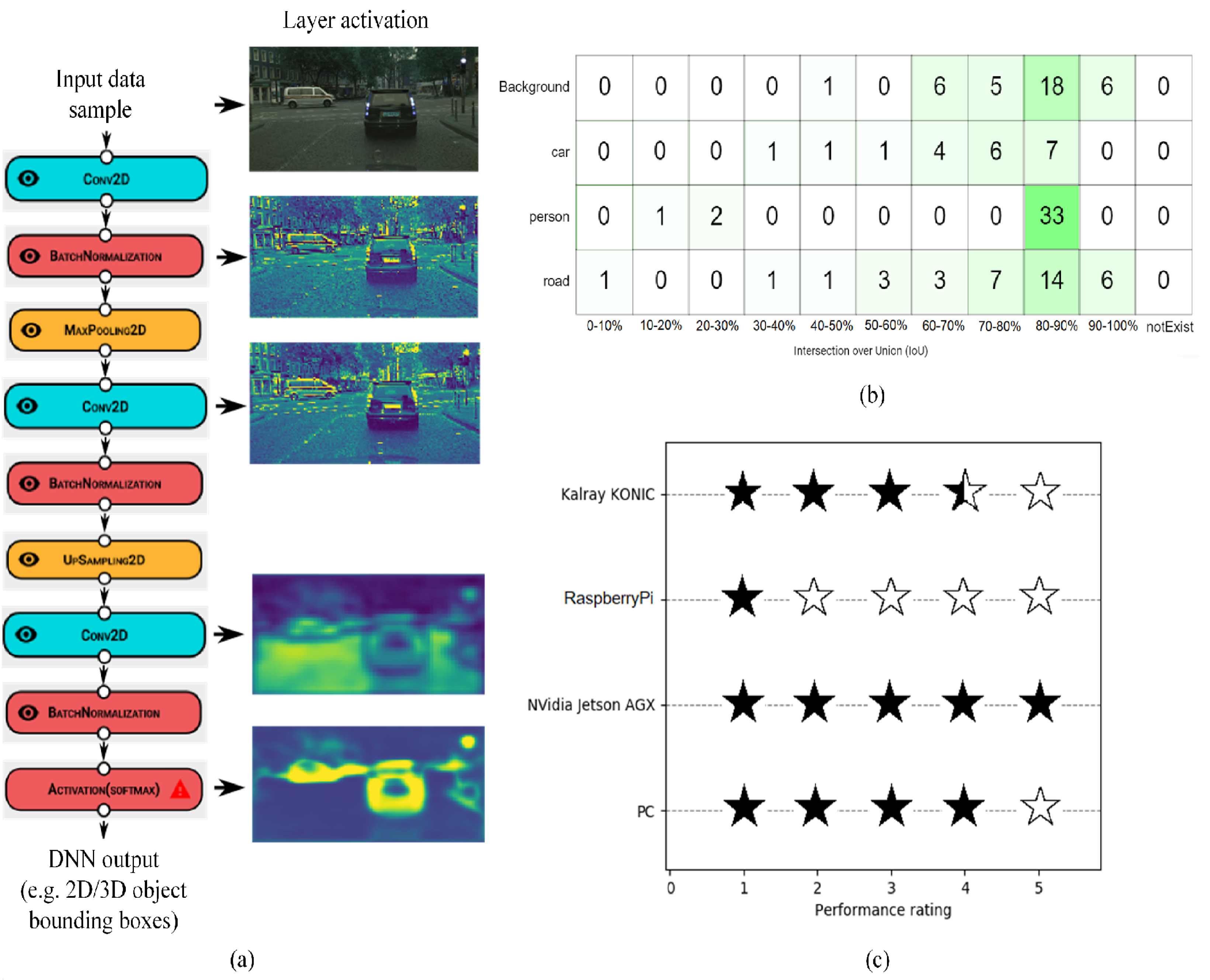
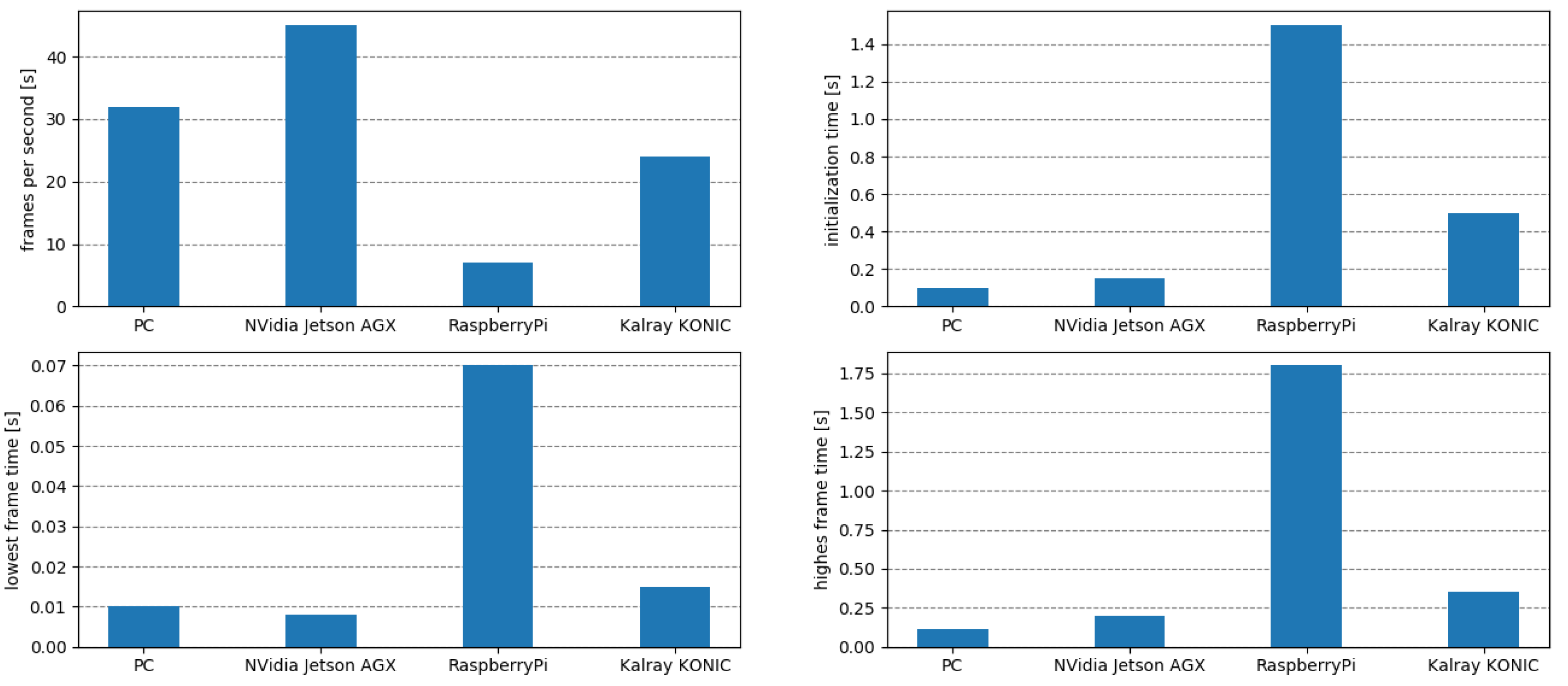
5.1. Use Case 1: Driving Environment Perception
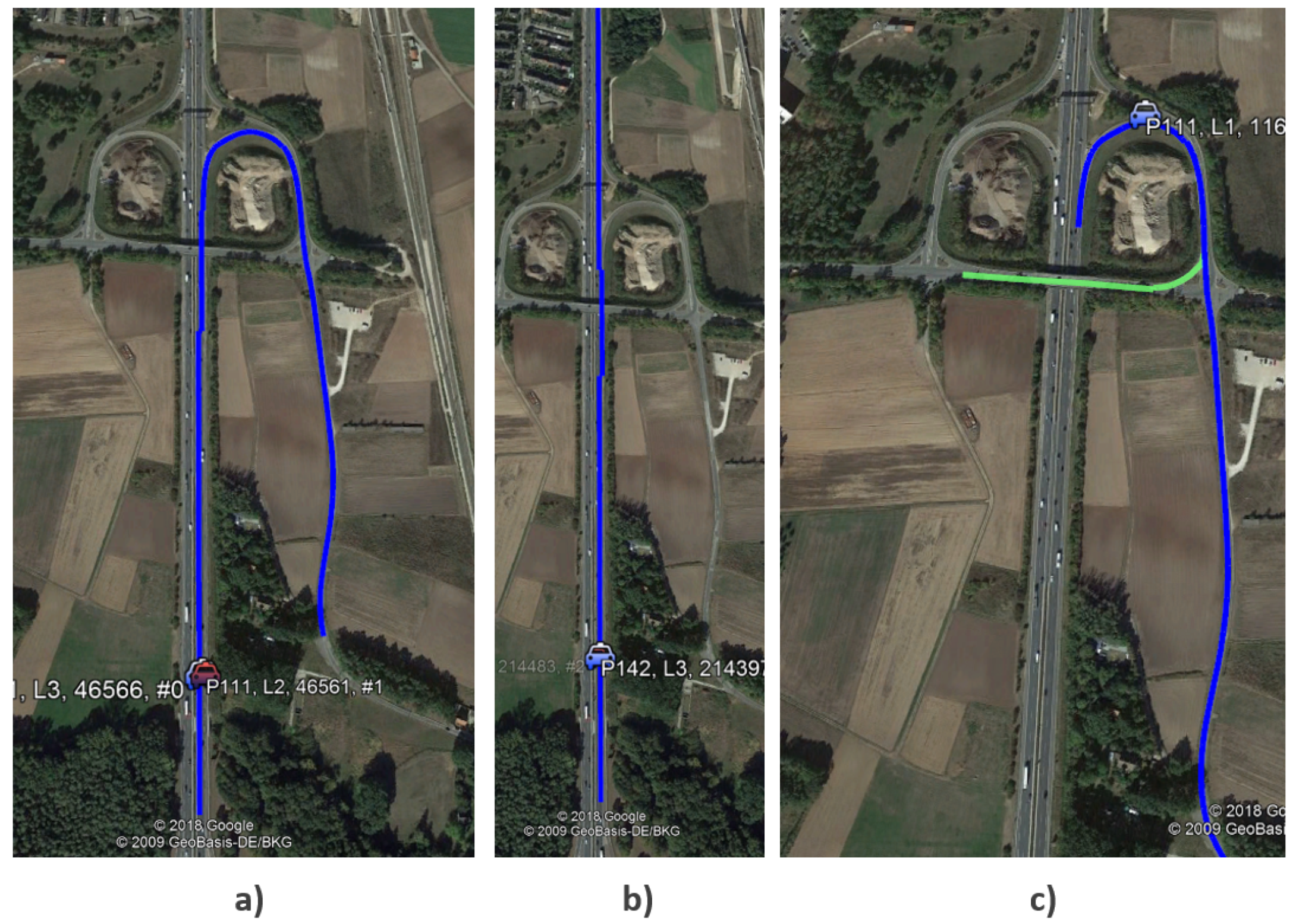
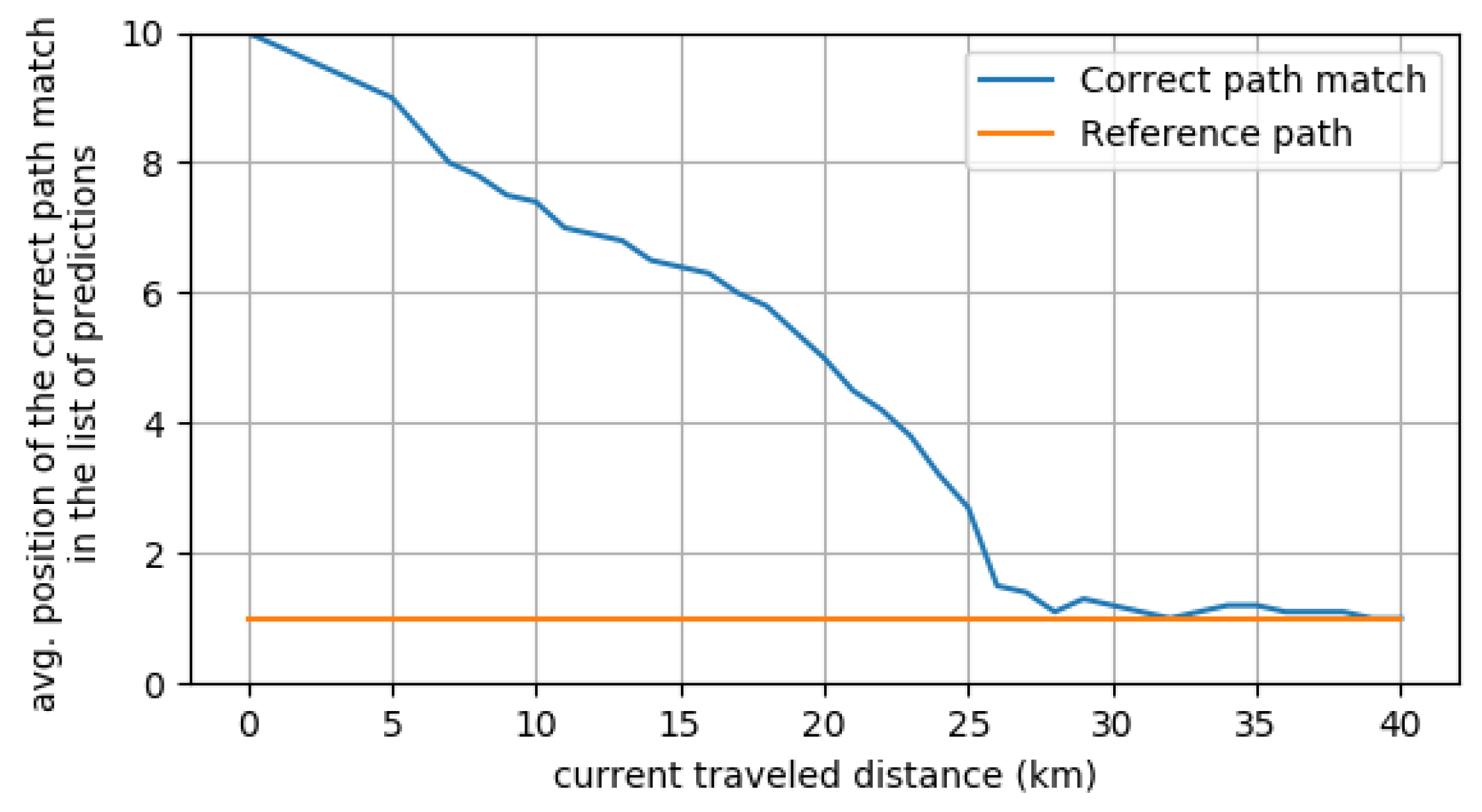
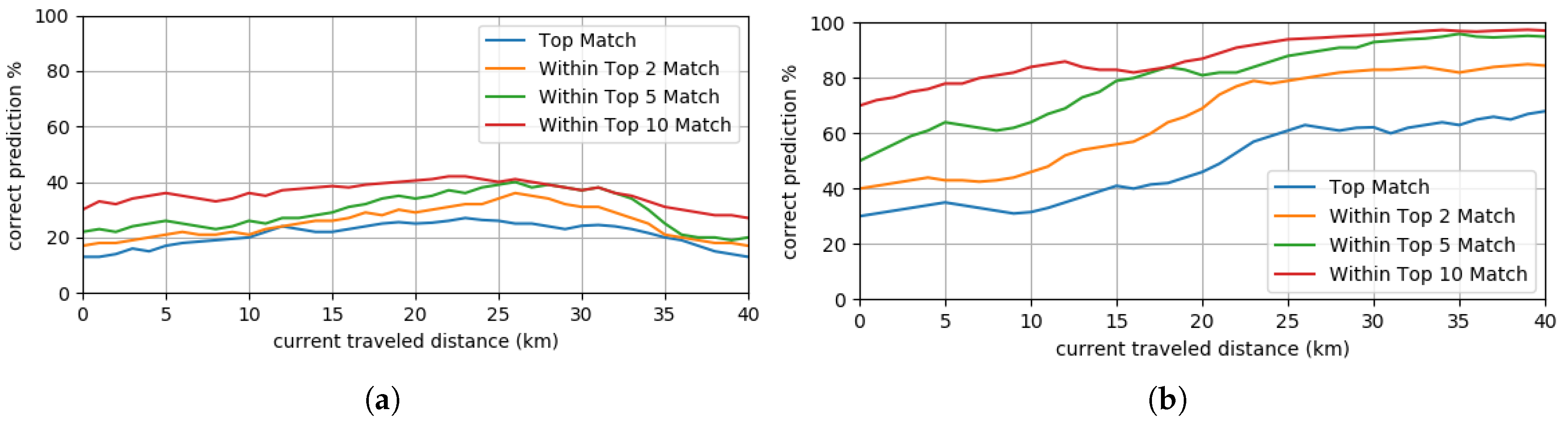
5.2. Use Case 2: Most Probable Path Prediction
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver Assistant Systems |
| ADTF | Automotive Data and Time-Triggered Framework |
| AI | Artificial Intelligence |
| AV | Autonomous Vehicle |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| dSPS | distributed Stream Processing Systems |
| DNN | Deep Neural Network |
| DP | Differential Privacy |
| EB | EletktroBit |
| GOL | Generative One-shot Learning |
| GPU | Graphic Processing Unit |
| HiL | Hardware-in-the-Loop |
| IoT | Internet-of-Things |
| IoU | Intersection over Union |
| ML | Machine Learning |
| MLP | Multi-Layer Perceptron |
| MPC | Multi-Party Computation |
| OTA | Over-the-Air |
| ReLu | Rectified Linear Unit |
| RM | Resource Manager |
| RNN | Recurrent Neural Network |
| ROS | Robotic Operative System |
| SiL | Software-in-the-Loop |
| TC | Training Coordinator |
Appendix A


References
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A Survey of Deep Learning Techniques for Autonomous Driving. J. Field Robot. 2019, 37, 362–386. [Google Scholar] [CrossRef]
- Villalonga, A.; Beruvides, G.; Castaño, F.; Haber, R.E. Cloud-Based Industrial Cyber–Physical System for Data-Driven Reasoning: A Review and Use Case on an Industry 4.0 Pilot Line. IEEE Trans. Ind. Inform. 2020, 16, 5975–5984. [Google Scholar] [CrossRef]
- MATLAB. 9.7.0.1190202 (R2019b); The MathWorks Inc.: Natick, MA, USA, 2018. [Google Scholar]
- Deep Learning on AWS. Available online: https://aws.amazon.com/training/course-descriptions/deep-learning/ (accessed on 12 August 2020).
- The Analyst Toolbox. Available online: http://coppelia.io/2014/06/the-analysts-toolbox/ (accessed on 12 August 2020).
- Salay, R.; Queiroz, R.; Czarnecki, K. An Analysis of ISO 26262: Using Machine Learning Safely in Automotive Software. arXiv 2017, arXiv:1709.02435. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale machine learning on heterogeneous distributed systems. In Proceedings of the 12th Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 28 October 2017).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22Nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 675–678. [Google Scholar] [CrossRef]
- Batiz-Benet, J.; Slack, Q.; Sparks, M.; Yahya, A. Parallelizing machine learning algorithms. In Proceedings of the 24th ACM Symposium on Parallelism in Algorithms and Architectures, Pittsburgh, PA, USA, 25–27 June 2012; pp. 25–27. [Google Scholar]
- Nangare, S. Gartner’s Strategic Tech Trends Show the Need for an Empowered Edge and Network for a Smarter World. Available online: http://cloudcomputing-news.net/news/2018/oct/17/gartners-strategic-tech-trends-show-need-empowered-edge-and-network-smarter-world/ (accessed on 17 October 2018).
- Wiles, J. Top Risks for Legal and Compliance Leaders in 2018. Available online: https://www.gartner.com/smarterwithgartner/top-risks-for-legal-and-compliance-leaders-in-2018/ (accessed on 30 March 2018).
- Greenough, J. The Connected Car Report: Forecasts, Competing Technologies, and Leading Manufacturers. Available online: https://www.businessinsider.in/THE-CONNECTED-CAR-REPORT-Forecasts-competing-technologies-and-leading-manufacturers/articleshow/46436661.cms (accessed on 18 August 2016).
- Khurram, M.; Kumar, H.; Chandak, A.; Sarwade, V.; Arora, N.; Quach, T. Enhancing connected car adoption: Security and over the air update framework. In Proceedings of the 2016 IEEE 3rd World Forum on Internet of Things, Reston, VA, USA, 12–14 December 2016; pp. 194–198. [Google Scholar]
- Huang, Y.; Ma, X.; Fan, X.; Liu, J.; Gong, W. When deep learning meets edge computing. In Proceedings of the Computer Society, Toronto, ON, Canada, 10–13 October 2017; pp. 1–2. [Google Scholar]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Huang, Y.; Zhu, Y.; Fan, X.; Ma, X.; Wang, F.; Liu, J.; Wang, Z.; Cui, Y. Task scheduling with optimized transmission time in collaborative cloud-edge learning. In Proceedings of the 2018 27th International Conference on Computer Communication and Networks (ICCCN), Hangzhou, China, 30 July–2 August 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Zemel, R.S. Autoencoders, minimum description length and Helmholtz free energy. In Proceedings of the 6th International Conference on Neural Information Processing Systems Morgan, San Mateo, CA, USA, 29 November 1994; Kaufmann Publishers Inc.: San Francisco, CA, USA, 1994; pp. 3–10. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. NuScenes: A multimodal Dataset for Autonomous Driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- Cityscapes. Cityscapes Data Collection. Available online: https://www.cityscapes-dataset.com/ (accessed on 17 February 2018).
- Grigorescu, S.M. Generative One-Shot Learning (GOL): A semi-parametric approach to one-shot learning in autonomous vision. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7127–7134. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Xing, E.P.; Ho, Q.; Xie, P.; Wei, D. Strategies and principles of distributed machine learning on big data. Engineering 2016, 2, 179–195. [Google Scholar] [CrossRef]
- Toshniwal, A.; Taneja, S.; Shukla, A.; Ramasamy, K.; Patel, J.M.; Kulkarni, S.; Jackson, J.; Gade, K.; Fu, M.; Donham, J.; et al. Storm@ twitter. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; ACM: New York, NY, USA, 2014; pp. 147–156. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Noel, C.; Shi, J.; Feng, A. Large Scale Distributed Deep Learning on Hadoop Clusters. Available online: https://on-demand.gputechconf.com/gtc/2016/presentation/s6836-andy-feng-large-scale-dsitributed-deep-learning-hadoop-clusters.pdf (accessed on 25 September 2015).
- Smith, C.; Nguyen, C.; TensorFlow, U.D. Distributed TensorFlow: Scaling Google’s Deep Learning Library on Spark. Available online: https://arimo.com/machine-learning/deep-learning/2016/arimo-distributed-tensorflow-on-spark/ (accessed on 30 March 2018).
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM TIST 2019, 10, 12:1–12:19. [Google Scholar] [CrossRef]
- Konecný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Chen, J.; Li, K.; Deng, Q.; Li, K.; Yu, P.S. Distributed Deep Learning Model for Intelligent Video Surveillance Systems with Edge Computing. IEEE Trans. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Luckow, A.; Cook, M.; Ashcraft, N.; Weill, E.; Djerekarov, E.; Vorster, B. Deep learning in the automotive industry: Applications and tools. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3759–3768. [Google Scholar]
- Brilli, G.; Burgio, P.; Bertogna, M. Convolutional Neural Networks on embedded automotive platforms: A qualitative comparison. In Proceedings of the 2018 International Conference on High Performance Computing & Simulation (HPCS), Orleans, France, 16–20 July 2018; pp. 496–499. [Google Scholar]
- Fridman, L.; Brown, D.E.; Glazer, M.; Angell, W.; Dodd, S.; Jenik, B.; Terwilliger, J.; Kindelsberger, J.; Ding, L.; Seaman, S.; et al. Mit autonomous vehicle technology study: Large-scale deep learning based analysis of driver behavior and interaction with automation. arXiv 2017, arXiv:1711.06976. [Google Scholar]
- The Society of Automotive Engineers. Available online: https://blog.ansi.org/2018/09/sae-levels-driving-automation-j-3016-2018/#gref (accessed on 12 September 2018).
- Litman, T. Autonomous Vehicle Implementation Predictions; Victoria Transport Policy Institute: Victoria, BC, Canada, 2019. [Google Scholar]
- Lu, S.; Yao, Y.; Shi, W. Collaborative learning on the edges: A case study on connected vehicles. In 2nd USENIX Workshop on Hot Topics in Edge Computing (HotEdge 19); USENIX Association: Renton, WA, USA, 2019. [Google Scholar]
- Jiang, L.; Lou, X.; Tan, R.; Zhao, J. Differentially private collaborative learning for the IoT edge. In Proceedings of the 2019 International Conference on Embedded Wireless Systems and Networks (EWSN’19), Beijing, China, 25–27 February 2019; Junction Publishing: Junction, TX, USA, 2019; pp. 341–346. [Google Scholar]
- Yuan, J.; Yu, S. Privacy Preserving Back-Propagation Neural Network Learning Made Practical with Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 212–221. [Google Scholar] [CrossRef]
- Mohassel, P.; Zhang, Y. SecureML: A system for scalable privacy-preserving machine learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 19–38. [Google Scholar] [CrossRef]
- Bogdanov, D.; Laur, S.; Willemson, J. Sharemind: A framework for fast privacy-preserving computations. In Proceedings of the 13th European Symposium on Research in Computer Security: Computer Security (ESORICS’08), Egham, UK, 9–13 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 192–206. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Lombardi, F.; Aniello, L.; Bonomi, S.; Querzoni, L. Elastic symbiotic scaling of operators and resources in stream processing systems. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 572–585. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Marina, L.; Trasnea, B.; Tiberiu, C.; Vasilcoi, A.; Moldoveanu, F.; Grigorescu, S. Deep Grid Net (DGN): A deep learning system for real-time driving context understanding. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019. [Google Scholar]
- The Cambridge-Driving Labeled Video Database. Available online: http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/ (accessed on 23 July 2019).














© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grigorescu, S.; Cocias, T.; Trasnea, B.; Margheri, A.; Lombardi, F.; Aniello, L. Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles. Sensors 2020, 20, 5450. https://doi.org/10.3390/s20195450
Grigorescu S, Cocias T, Trasnea B, Margheri A, Lombardi F, Aniello L. Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles. Sensors. 2020; 20(19):5450. https://doi.org/10.3390/s20195450
Chicago/Turabian StyleGrigorescu, Sorin, Tiberiu Cocias, Bogdan Trasnea, Andrea Margheri, Federico Lombardi, and Leonardo Aniello. 2020. "Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles" Sensors 20, no. 19: 5450. https://doi.org/10.3390/s20195450
APA StyleGrigorescu, S., Cocias, T., Trasnea, B., Margheri, A., Lombardi, F., & Aniello, L. (2020). Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles. Sensors, 20(19), 5450. https://doi.org/10.3390/s20195450