1. Introduction
Wearable internet of things (IoT) devices have the potential to change the landscape in health and activity monitoring [
1,
2]. They are already employed for in-home monitoring of movement disorders to provide doctors better insight into their patients’ daily activities [
3]. Wearable devices are also used for new applications, including gait analysis, obesity management, and physical activity promotion [
4,
5]. These applications enable automatic tracking of the activities of users, such as walking, which can then provide valuable insight to both users and health specialists, since self-recording is inconvenient and unreliable. Therefore, human activity recognition (HAR) using low-power wearable devices can revolutionize health and activity monitoring applications.
Recent advances in low-cost motion sensors and mobile computing have fueled interest in human activity recognition [
6,
7,
8,
9,
10]. For instance, smartphones equipped with accelerometer and gyroscope sensors enable recognition of activities, such as walking, standing, sitting, and lying down [
8,
11,
12]. The activity information is then used for rehabilitation instruction, fall detection of the elderly, and reminding users to be active [
13,
14]. The successful design of activity recognition algorithms depends critically on the availability of sensor data that captures the activities of interest. Research studies typically employ wearable inertial sensors or smartphones to collect the data while the users are performing the activities of interest. The data is then used to train and evaluate algorithms for activity recognition. However, the data is rarely made publicly available [
15]. As a result, it is difficult to reproduce the results and obtain comparisons with existing approaches. Therefore, there is a critical need for open-source datasets that provide a common platform for HAR research.
This paper first presents wearable HAR (w-HAR), an open-source dataset for HAR. Our dataset is collected using the wearable system shown in
Figure 1. It integrates an IMU and textile-based wearable stretch sensors to provide two modalities of motion data. In contrast, other HAR datasets [
15,
16,
17,
18] typically use accelerometers and gyroscopes as their primary sensors. However, accelerometers and gyroscopes are notoriously noisy, leading to challenges in data segmentation and classification. The stretch sensor provides low-noise motion data that allows us to generate non-uniform activity segments ranging from one to three seconds. Using the wearable setup, we first perform extensive data collection with 22 user subjects. We record the IMU (accelerometer and gyroscope) and stretch sensor data of each user while they perform activities in the set {jump, lie down, sit, stand, stairs down, stairs up, walk}. Then, we manually label the data such that it can be used to train machine learning algorithms. w-HAR is the first dataset in the literature that includes both IMU and stretch sensor data. The dataset has been publicly released along with this paper to enable further research on activity recognition algorithms.
We provide three versions of the dataset such that users can choose the most appropriate version for their application. The first version includes the raw data obtained from the sensors without any pre-processing. This version is most useful when users want to develop their own segmentation and pre-processing algorithms for HAR, along with feature generation and classifier design. The second version of the dataset uses the segmentation algorithm in [
6] to generate variable-length segments. This version allows users to develop their own features and classifiers. Finally, the third version provides the set of features used in our work such that users can focus solely on classifier design.
In addition to the dataset, we also present a comprehensive framework for designing human activity recognition classifiers. Our framework consists of the following steps:
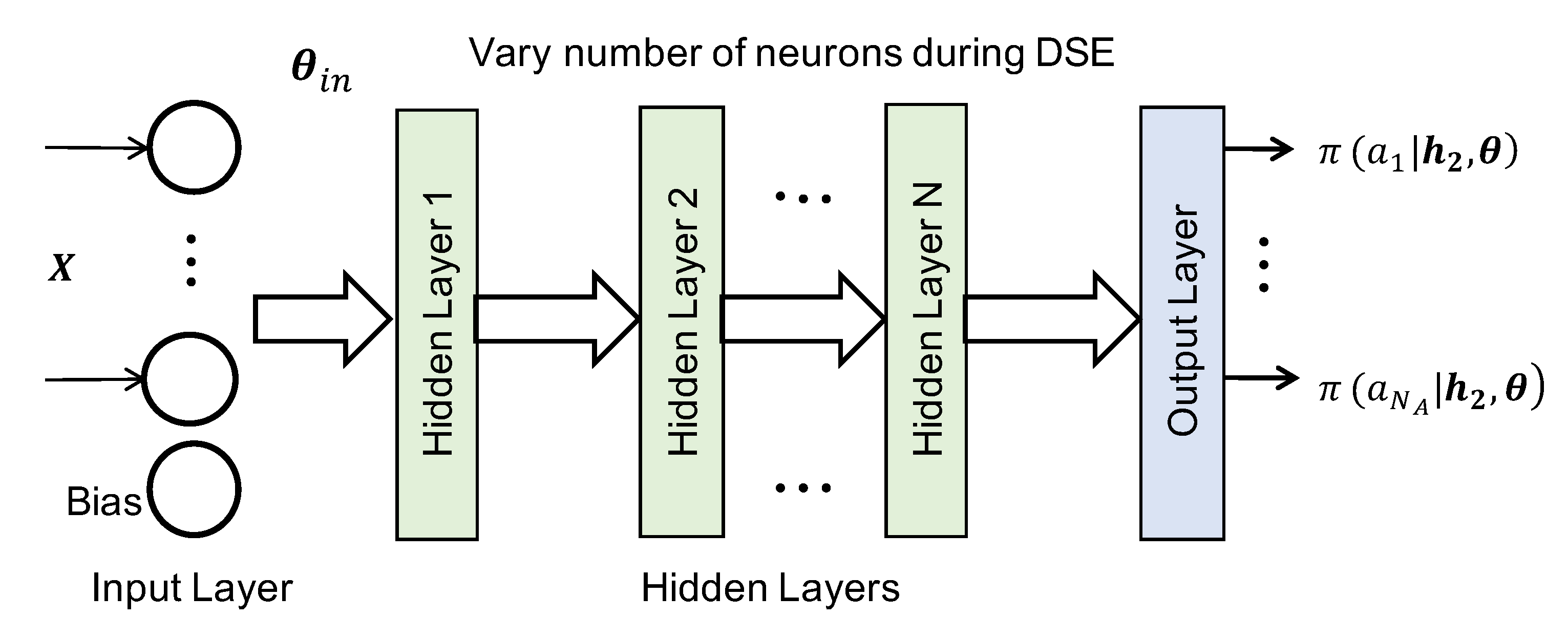
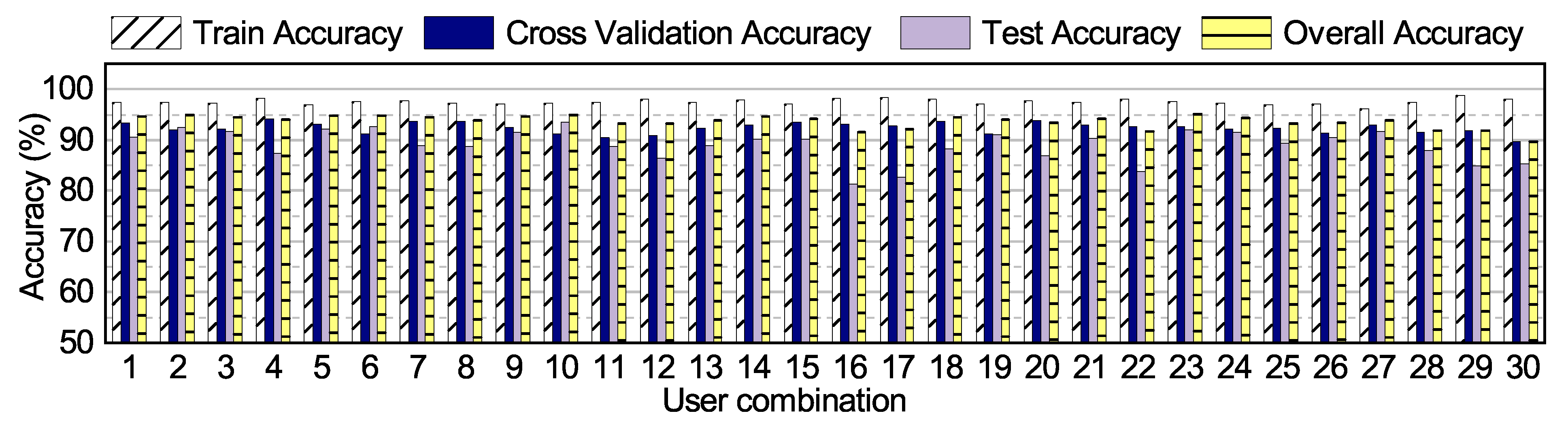
Design Space Exploration for Offline Classifier: It is critical to choose a robust and resource-efficient classifier. Resource efficiency is important to ensure that the classifier can execute on wearable devices with power and memory constraints. To this end, we start with commonly used classifiers such as neural networks, random forest, support vector machine (SVM) and k-nearest neighbor (k-NN). Among these, we focus on neural networks, since they can be easily updated online using both reinforcement learning (RL) [
19] and supervised learning techniques with low overhead. Once we choose neural networks as our classifier, we perform a design space exploration (DSE) to determine the appropriate structure for the network. The DSE helps us in ensuring that the classifier is robust to multiple sets of users while satisfying the requirement of low resource requirements to run on the wearable device.
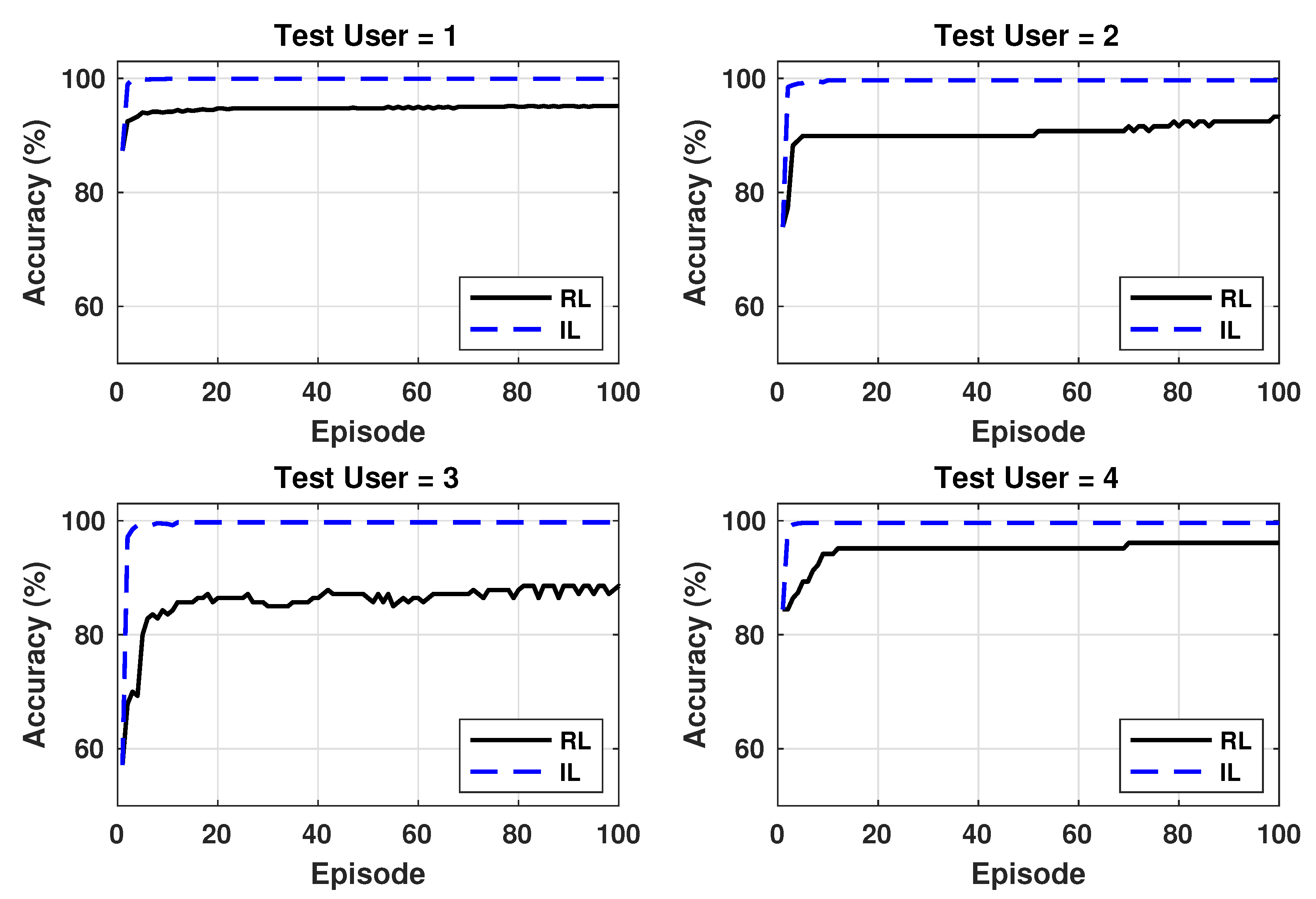
Online Learning: State-of-the-art approaches for HAR typically train classifiers offline and only perform the activity classification online [
7,
8]. This approach is not scalable when the device is used by new users with potentially different activity characteristics. Therefore, we also perform online training of the classifiers such that it can adapt to new users who are not involved in the training process. We make use of two approaches to continuously update the weights of the neural network as a function of the feedback available from users. When users can provide the actual activity performed, we incrementally update the policy using supervised learning. Otherwise, we use the policy gradient algorithm [
19] when the user can only tell whether the activity is classified correctly. Experiments with our dataset show that these algorithms improve the accuracy of unseen users by as much as 40%.
In summary, the novel contributions of this work are as follows:
An activity recognition dataset with accelerometer and stretch sensor data from 22 users. It is the first public dataset that includes stretch sensor data for HAR.
Design space exploration of neural networks to choose the structure of the offline classifier such that it is robust to input from different users.
An online learning algorithm using incremental supervised learning that provides an order of magnitude faster convergence compared to reinforcement learning. To the best of our knowledge, this is the first time incremental supervised learning has been used to improve the accuracy of classification for new, unseen users.
An end-to-end framework for HAR development. Most previous approaches provide only algorithms or datasets for HAR. In contrast to these, we provide a customizable framework for HAR, where users have the freedom to insert their algorithms at any step of the framework, including segmentation, feature selection, and classification.
Experimental validation of the DSE and online learning algorithms on a low-power wearable device using the w-HAR dataset.
We also note that this paper is an extended version of our work in [
6]. In comparison to [
6], this paper makes the following contributions:
The conference paper presented only the use of reinforcement learning using the policy gradient algorithm for online adaptation. This paper presents an efficient incremental learning technique that converges an order of magnitude faster than reinforcement learning. We provide a detailed comparison and discuss the advantages and drawbacks of these two approaches in
Section 6.
The conference paper used data from only nine users. This paper includes a labeled dataset from 22 users. Also, the conference paper did not provide the details of the dataset and a public release. This paper provides detailed descriptions of the raw sensor data, segmented data, features, and the experimental protocol for collecting the data.
This paper includes new activities (stairs up and down) to capture more daily human activities.
The rest of the paper is organized as follows.
Section 2 presents the related work. The details of the w-HAR dataset and framework are presented in
Section 3.
Section 4 describes the design space exploration of HAR classifier, while
Section 5 presents the online learning algorithms. Finally,
Section 6 and
Section 7 present the experimental results and conclusions, respectively.
2. Related Research
Human activity recognition has received increased attention in recent years due to its wide-ranging applications in health monitoring, gait analysis, patient rehabilitation, and physical activity promotion [
4,
20,
21,
22]. Furthermore, HAR using body-mounted sensors is possible due to advances in sensors and low-power microcontrollers [
23]. HAR studies typically start with datasets that are then used to develop the recognition algorithms. With a given dataset, typical steps for activity recognition using sensors include segmentation, feature extraction, and classification.
Several prior studies have presented datasets for HAR [
15,
16,
17,
18]. Most of the datasets presented earlier focus on acquiring data from smartphones and performing HAR on them. For instance, Micucci et al. [
15] present a dataset for HAR using accelerometers on smartphones that include data from thirty subjects and nine activities of daily living. The authors also present a review of other publicly available datasets collected using smartphones. Wearable sensors have also been used in HAR datasets since multiple devices can be easily mounted on different parts of the body. For instance, the Opportunity dataset presented in [
17] uses multiple inertial measurement units and accelerometers to collect data from four users. Similarly, Zhang et al. [
18] use a single motion sensing unit to obtain data from 14 users. While these datasets are useful for HAR, they primarily contain data from accelerometers, which is known to be noisy. As a result, studies using these datasets resort to fixed-length windows, instead of creating a window for each activity. In contrast, the dataset presented in this paper includes data from a textile-based stretch sensor and IMU, which allows us to create variable-length segments tailored to each activity.
HAR approaches in the literature typically use fixed-length windows to identify user activities [
11,
20,
24]. For instance, studies in [
11,
20] use 10 s windows for activity recognition. A longer window length increases the accuracy since it provides more information and features about the underlying activity [
22]. At the same time, longer windows make it harder to capture transitions between activities, such as stand to sit. Furthermore, long windows can have data from multiple activities, which leads to inaccurate activity classification [
22]. To address this problem, Chen et al. [
25] develop a step detection algorithm to segment activities from accelerometer data. However, due to the high noise in the accelerometer data, the algorithm uses a one-second sliding window filter (with a 50% overlap) to mitigate the noise. The filtering mechanism’s increased memory requirement makes the approach in [
25] impractical for devices with small memory capacities. Due to the limitations of using accelerometer data for segmentation, Chen et al. [
25] also highlight the need for better segmentation algorithms to improve HAR accuracy. Therefore, in our dataset, we use a segmentation algorithm that produces variable-length segments as a function of the user activity [
6]. Using these windows, we generate fast Fourier transform and discrete wavelet transform of the data for use in the activity classifier. We include these feature sets as part of our dataset release.
Several studies in the literature proposed classification algorithms for HAR [
20,
26,
27], as summarized in
Table 1. This table lists the device used for processing, sensors, classifiers, and accuracy of the HAR approaches. It also lists the power consumption of the approach, when available. Arif et al. [
20] use an accelerometer on a smartphone to classify six activities. The authors achieve 95% accuracy using a KNN classifier. Similarly, Ignatov et al. [
28] employ CNNs to recognize activities from smartphone accelerometer data. The CNN achieves 90–97% accuracy on three publicly available datasets. The work in [
29] uses a wearable device consisting of heart rate, respiration rate, and accelerometer sensors to record the data when the user is moving. Then, the data is transmitted to a smartphone for classification. Using a decision tree classifier, the approach obtains 96% accuracy. Approaches in [
26,
30,
31] use wearables for both sensing and classification. For instance, Attal et al. [
26] use three accelerometers and a wearable node to recognize 12 activities. They use three classifiers with accuracies ranging from 95% to 99%. However, this approach has a power consumption of 2.7 W, which is not sustainable for light-weight wearable devices with a small battery size. Samie et al. [
30] and Khalifa et al. [
31] reduce the HAR power consumption on wearable devices. In particular, Khalifa et al. use a piezoelectric harvester as the sensor, thus allowing them to harvest energy and identify motion simultaneously. As a result, the power consumption reduces to 3.2 mW, albeit at a reduced accuracy of 85%. However, none of the previous approaches support online updates of the classifier for new users. Instead, they only use offline training with the user data available at design time. Offline training alone is not sufficient as it can lead to a lower accuracy when used on unseen users. To overcome this limitation, we present an online learning framework for HAR in this paper. We first train a neural network offline to generate an initial implementation of the HAR system. Then, we use reinforcement learning or incremental supervised learning at runtime to improve the accuracy of the system for new users. Our system has a power consumption of 12.5 mW, which is slightly larger than approaches without any online learning.
Non-contact methods for HAR have also been studied recently [
32,
33,
34,
35,
36,
37]. These approaches use ambient Wi-Fi signals or radars to track user activities. The techniques based on Wi-Fi signals use the channel state information from Wi-Fi signals to infer human activities [
34,
35,
37]. In particular, Taylor et al. [
37] use radio signals from a USRP radio system to identify standing up and sitting down. The system uses changes in channel state information from the radio signals to identify the activities. Specifically, it looks at how the channel state information changes due to stand up and sit down motions. The channel state information is then used in machine learning algorithms such as random forest, KNN, SVM, and neural networks. The results from these classifiers are used by an ensemble classifier that identifies the activity using majority voting. Similarly, radar-based approaches emit modulated signals in an indoor environment and analyze the received signals to identify human activities. These non-contact methods are complementary to our approach of using wearable devices. In our vision, both wearable and non-contact methods can be used inside a home setting. However, wearable devices are more suitable for activity monitoring outside the home environment due to privacy issues of user tracking with public Wi-Fi signals. In summary, we envision that our algorithms will enable personalized HAR devices that adapt continuously to the unique activity pattern of their users.
3. Human Activity Recognition Dataset
The availability of datasets is crucial for human activity recognition research. Therefore, we open-source our dataset to enable further research in this area. The dataset in this paper is the first to integrate readings from a wearable stretch sensor and an inertial motion unit (IMU). The stretch sensor allows us to create variable-length segments. The variable-length segments make it easier for the classifiers to recognize activities, as we show in the experiments. In this section, we describe the details of the data collection setup, protocol, user demographics, and the labeling process.
3.1. Wearable System Setup
We use a combination of Invensense-9250 IMU and stretch sensors to collect the data, as shown in
Figure 1. The IMU is integrated into the TI-CC2650 Sensortag device, and the stretch sensor is another discrete module. We mount the IMU on the right ankle of the user since this captures the swing of the user’s leg [
12]. The stretch sensor is sewed to a knee sleeve, as shown in
Figure 1. During the experiment, the user wears the sleeve on the knee to capture the knee movements while performing the activities. Both the sensor devices are equipped with the Bluetooth low energy (BLE) protocol for communication. Using the BLE protocol, the sensors transmit the data to a smartphone which stores the data to a file. In our future work, we plan to integrate the IMU and the stretch sensor into a single device such that a single stream of data can be transmitted. To synchronize the data from the sensors, we record the wall clock time for each data sample from the sensors. Then, using the offset between the sensors, we align the sensor readings using the approach in [
38].
Wearable System Sensor Parameters: We sample the IMU at 250 Hz and the stretch sensor at 25 Hz. These sampling frequencies are sufficient to capture the frequency of human movements, which are in the order of a few Hz. We use a significantly higher frequency for the accelerometer since it typically exhibits higher noise. Therefore, the higher sampling frequency allows us to smooth and sub-sample the data using a moving average filter while preserving the data signatures.
3.2. User Studies
We obtain motion data from twenty-two users with the wearable device setup. The users are recruited using the snowball sampling technique. Each user signed a consent form as approved by the institutional review board at Arizona State University. We experiment with a total of twenty-two users (consisting of fourteen males and eight females), with ages 20–45 years and heights 150–180 cm. The set of activities performed by the users is summarized in
Table 2. Each user performs a series of experiments shown in
Table 3. In addition to this protocol, we also perform experiments where the users are free to perform any activities they choose. Next, we perform the labeling of the dataset, as described below.
Data Labeling: After collecting the data from the users, we use the segmentation algorithm to divide the data into variable-length windows. Then, the generated windows are analyzed by four human experts to assign the labels. To achieve accurate labeling, we mark the time stamps of each activity during the data collection. For example, we mark the time the subject starts and stops jumping. Furthermore, the labels assigned by one expert are verified by others to ensure that wrong labels are not assigned. The labels assigned to each activity window are also assigned to each sample in the raw data before segmentation such that we know the user’s activity in each sampling period. Moreover, we revisit the assigned labels during the testing phase of the HAR classifier to ensure that the errors made by the classifier are not due to mislabeling.
3.3. Dataset Description
After labeling the data, we generate three versions of the dataset for public release as follows.
Raw Data: This version of the dataset contains the raw data obtained from the stretch and IMU (accelerometer + gyroscope) sensors without any pre-processing. We synchronize the stretch and IMU data such that the time indices for both sensors are aligned. Consequently, users do not have to run any synchronization algorithms on the data. The raw data version of w-HAR is ideal for researchers who want to design their algorithms for all steps of HAR from segmentation to classification.
Segmented Data: The segmented dataset uses the segmentation algorithm proposed in [
6] and summarized in
Section 3.4.1 to generate variable length activity segments. This version is suitable for users who want to focus on feature generation and classification algorithms. The breakdown of the total segments of each activity is summarized in
Table 4.
Feature Data: We also release the features used in [
6] as part of w-HAR. The features included in this version are summarized in
Section 3.4.2. The feature data version allows users to focus on developing classifiers for HAR and obtain reproducible comparisons among different algorithms.
3.4. Flow for Using the w-HAR Dataset
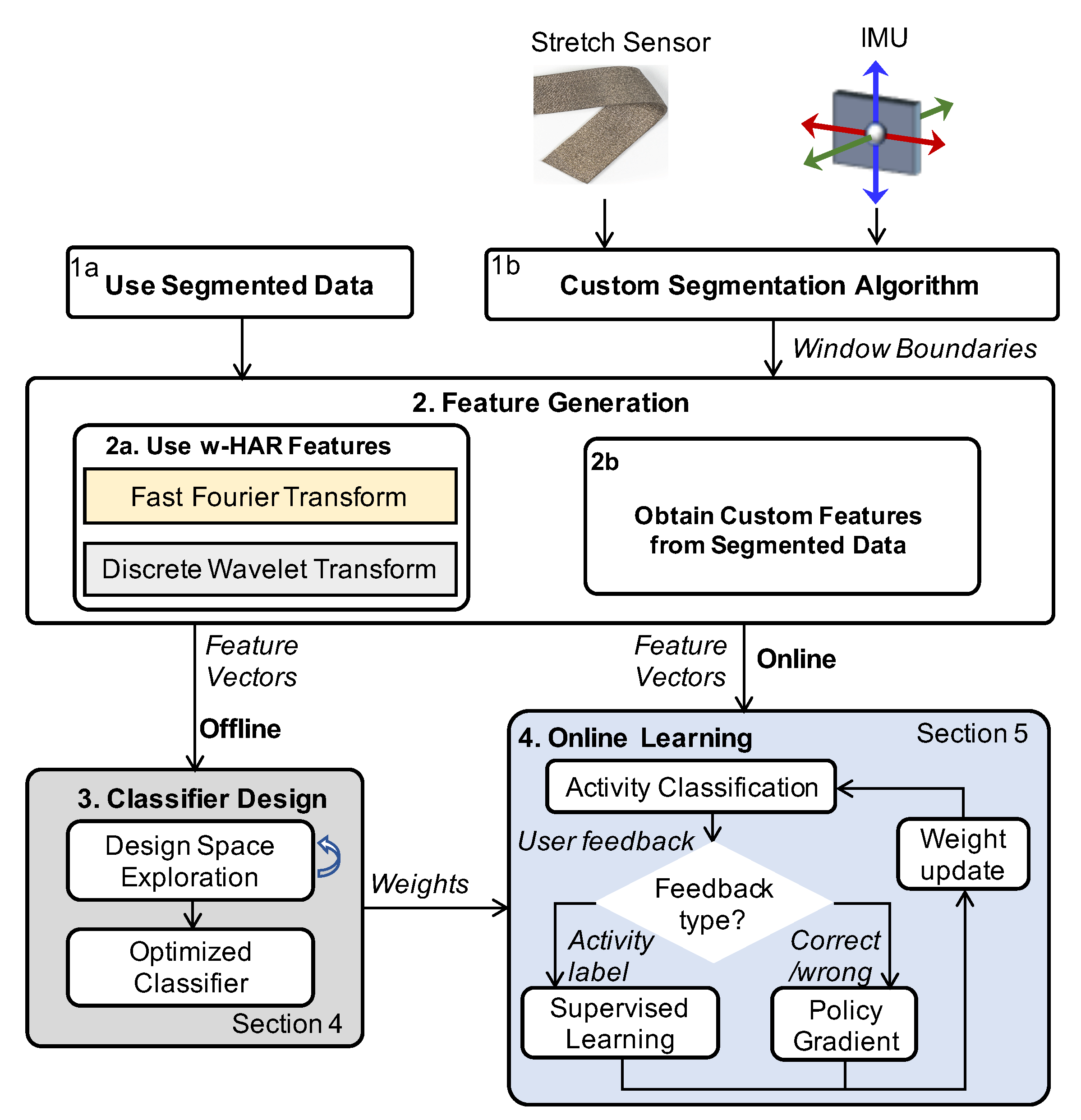
This section describes the flow for incorporating the w-HAR dataset for developing new algorithms or reproducing the results reported in this paper, as shown in
Figure 2. The first step after obtaining the dataset is to segment the raw data into windows. To this end, users can either use the windows provided along with the dataset or develop their segmentation algorithm, as shown using paths 1a and 1b, respectively. The next step is to generate features for each window generated by the segmentation algorithm. Here, the users are free to generate their features or use the baseline feature set provided with the dataset. The feature data and the labels are then used to design a classifier for activity classification. It involves a design space exploration for determining the optimal classifier, as shown in
Figure 2. We also provide a baseline neural network classifier such that it is easy to obtain reproducible comparisons with new approaches. Finally, the last step of the design flow is to use the classifier designed offline to identify activities at runtime. In this step, user feedback is used to update the weights of the classifier to improve the accuracy of the classifier. As shown in
Figure 2, our implementation of the framework uses either reinforcement learning or incremental supervised learning depending on the level of user feedback available. When the user provides the actual label of the activity performed, we use the supervised learning approach to update the classifier weights, as shown in
Figure 2. However, if the user can only indicate whether an activity is correctly classified, i.e., correct or wrong, then we use the policy gradient approach. We envision that further research on HAR using our dataset will enable new online learning algorithms for personalized activity recognition and healthcare. Next, we describe the segmentation algorithm used to generate the segmented data in w-HAR. We also go over the feature set that is released as part of w-HAR.
3.4.1. Segmentation Algorithm
The length of the activity window must be carefully chosen to capture the activities while minimizing the power consumption of the device. For example, fast activities, such as jump, require shorter windows while static activities, such as sitting, can save power by using longer windows. Fixed-length windows are not suitable for this purpose as they may contain fragments of multiple activities, thus adding to classification complexity. Therefore, we use the activity-based segmentation in [
6] to generate the segments in w-HAR. We refer the readers to [
6] for details of the algorithm and provide a summary here.
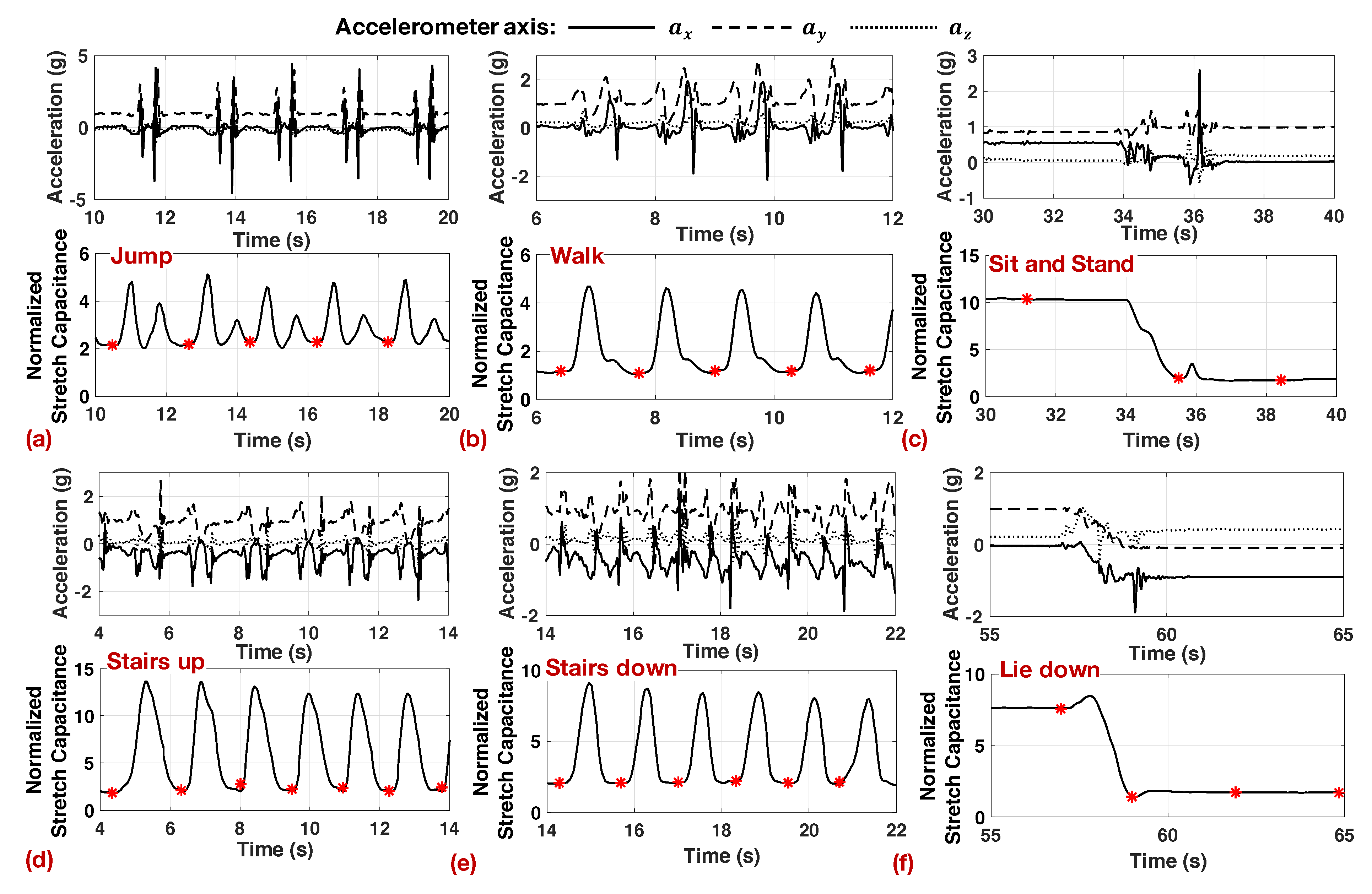
Figure 3 shows the sensor data for all seven activities. In each sub-figure, the top half shows the accelerometer data, while the bottom half shows the stretch sensor data. We see that the accelerometer data exhibits significantly more variations when compared to the stretch sensor for activities that involve the movement of the legs (jump, walk, stairs up/down). In contrast, the stretch sensor data exhibits periodic repetitions with each repetition of these activities. Even for static activities (sit, stand, and lie down), the accelerometer exhibits high variation when there is a slight movement of the legs. For the same activities, the stretch sensor follows a smooth pattern, as shown in
Figure 3. The variations in the accelerometer data lead to false positives when it is used for segmentation [
25]. Therefore, the segmentation algorithm uses the stretch sensor data to obtain segments as a function of the activity.
Using the insights obtained from
Figure 3, the segmentation algorithm in [
6] divides the streaming data into distinct segments by detecting the deviation of the stretch sensor from its neutral value at rest. For instance, each repetition of jump, walk, stairs up/down in
Figure 3a,b,d,e starts with an increase from a local minimum in the stretch sensor and ends with another local minimum. Even for activities with longer static periods (sit, stand, and lie down), the beginning and end of the activity are marked by rise from a local minimum or drop down to a minimum, as seen in
Figure 3c,f. Therefore, the algorithm uses this observation to continuously monitor the derivative of the stretch sensor to mark the activity boundaries. The pseudo-code for the algorithm is presented in the
Appendix A for interested readers.
The segments obtained from the algorithm for all the activities are shown in
Figure 3 using red asterisks. The algorithm clearly marks each step in jump, walk, and stairs up/down activities. For sit, stand, and lie down activities, the algorithm uses a 3 s window whenever the sensor data is static. At the same time, whenever there are transitions, such as from sit to stand in
Figure 3c, the segmentation algorithm detects this and marks a new segment for the transition.
3.4.2. Feature Set in w-HAR
The next step after segmenting the streaming data is to generate features that are used by a classifier. As shown in
Figure 2, users of w-HAR can use the default feature set provided with the dataset or develop their own feature set. Here, we provide a summary of the features provided in the dataset, while the detailed motivation for choosing these is presented in [
6]. We generate features from the accelerometer and stretch sensor data present in w-HAR. We do not use the gyroscope data since it does not provide accuracy improvements, even though it has up to 10 mW overhead in power consumption at runtime. At the same time, the w-HAR release includes gyroscope data such that other researchers can use it when developing their classifiers for HAR. The features described in this section can be used by researchers directly to train a classifier, or the underlying feature generation algorithms can be used along with a custom segmentation algorithm.
Stretch sensor features: The stretch sensor exhibits repetitive patterns for walking, jump, stairs up, and stairs down activities, as shown in
Figure 3. In contrast, it shows a steady value for sit, stand, and lie down activities. The segmentation algorithm divides these activities into windows that range from 1 s to 3 s in length. As a result of this, the number of samples in each window varies with the length of the window. At the same time, feature generation blocks typically expect a fixed number of input samples for processing. Therefore, as the first step in feature generation, we standardize the data to ensure that each window contains a fixed number of samples. We choose to maintain 32 samples for the stretch sensor data after sub-sampling. This translates to a sampling rate of 10 Hz for windows with 3 s duration and 32 Hz for windows with 1 s duration. These sampling frequencies are sufficient since human activities are typically in the order of a few Hz. When a segment has more than 32 samples due to either longer duration or higher sampling frequency, we standardize the number of samples to 32 using the sub-sample and smoothen equation below:
where
is the subsampling rate, and
is the value of the data after applying the sub-sample and smoothen equation. If the number of samples in a segment is lower than 32, we pad zeroes to the segment to obtain 32 samples.
Next, we evaluate the FFT coefficients of the current and previous windows to capture the repetitive patterns present in the data. More specifically, we use the leading 16 FFT coefficients of the 64-point FFT of the stretch sensor data. The leading coefficients allow us to capture the frequency range that has most of the energy in the data, i.e., [0–8] Hz. In addition to FFT coefficients, we include the minimum and maximum value of the stretch sensor in each window as it provides useful insight into the underlying activity. Overall, we include a total of 18 features from the stretch sensor data.
Accelerometer features: The accelerometer data exhibits higher frequency variations when compared to the stretch sensor, as seen in
Figure 3. Therefore, we maintain
points of accelerometer data in each activity segment. We use Equation (
1) to sub-sample and smoothen the data when there are more than 64 samples in the segment. The three-axis accelerometer in our experimental setup provides the acceleration
,
, and
along
-,
-, and
-axes, respectively. In addition, the body acceleration
after removing the gravitational acceleration
g is also computed since it provides useful information about the user activity. After standardizing the accelerometer data, we calculate the first level approximation coefficients
using the Haar discrete wavelet transform, which corresponds to the 0–32 Hz frequency range. With 64 samples in each window, this amounts to 32 approximation coefficients. In the w-HAR dataset, we use the DWT coefficients for
,
, and
. We do not take the DWT of the
axis since we do not expect any activity in the lateral direction. Furthermore, the effect of any lateral movement is already captured by the body acceleration. In addition to the DWT coefficient, we also compute the variance of
,
,
, and
and use them as features. Overall, the dataset includes a total of 101 features for the accelerometer data.
General features: The time duration of the segment also carries important information about the activity. In particular, it provides information on the time scale of the activity, which is otherwise not available after normalizing the number of data points in each segment. Therefore, we add it to our feature set to obtain a total of 120 features.
After obtaining the features for each activity segment in the dataset, we normalize the feature vectors by mean and variance of each feature. That is, the mean of each feature is subtracted from it and divided by its variance to obtain the normalized feature set. We include this step in our framework to ensure that each feature has a zero mean and unit variance.
3.5. Comparisons with Existing HAR Datasets
This section presents a comparative analysis of our dataset with other publicly available HAR datasets. We choose the datasets that focus on the activities that are common to our dataset and use either smartphones or wearables as their data collection device.
Table 5 summarizes the major characteristics of the datasets. All the previous datasets use a single modality of sensing, i.e., the accelerometer. In contrast, the proposed dataset is the first one to integrate data from accelerometer, gyroscope, and stretch sensors. Having data only from the accelerometer limits previous datasets to fixed-length windows, as shown in the last column of the table. The only exception is the DU-MD dataset [
39], which reports variable-length segments. However, variable-length segments in DU-MD are obtained manually, thus making the approach unsuitable for runtime algorithms. The proposed dataset overcomes this problem by using the stretch sensor data to enable variable-length segments that can be obtained at runtime. We acknowledge that the number of user subjects in our dataset is lower compared to some previous studies. We plan to resolve this by continuing to augment our dataset in the future.
5. Online Learning for Human Activity Recognition
We implement the trained NN on the wearable device shown in
Figure 1 for online activity recognition. The device is also given to new users whose data is not available during the offline classifier design phase. These new users may have activity patterns that do not match the patterns seen by the NN during the offline training process. Moreover, the activity patterns of the same user may change temporarily due to an injury. Therefore, there is a strong need to develop approaches that continuously update the weights of the NN to adapt to changes in the user or user patterns.
We propose two online learning algorithms for HAR that can be used depending on the level of feedback available from the users since online learning depends critically on feedback from users. The user can provide feedback at varying time scales. For example, when the error is high, the feedback can be given after every activity classification, e.g., every step during walking. As the accuracy of the classifier improves, the frequency of the feedback can be reduced such that the feedback is provided after completing a set of activities, such as walking and sitting. In such cases, the feedback will be provided for multiple activity segments. When the user can indicate whether the inferred activity is correct or wrong, we use the policy gradient algorithm. In contrast, when the user can provide the actual label for the misclassified activities, we incrementally update the weights of the neural network using supervised learning. If the user does not provide any feedback after an activity, the weights of the NN are not updated. In the following, we provide details on each of the above approaches.
5.1. Policy Gradient Algorithm for Online Weight Updates
Supervised learning methods are not suitable for online learning if the user is unable to provide the activity labels for misclassifications. Instead, the user only indicates if the classification is correct or wrong. Reinforcement learning is a powerful technique that enables online learning when a correct or wrong feedback is available [
19]. Reinforcement learning achieves this by updating the parameters of a policy, such as a neural network, as a function of the feedback received from the user. Common reinforcement learning approaches include Q-learning and policy gradient algorithms [
19]. Q-learning algorithm is not suitable for wearable devices since it has to maintain a table of Q-values, which can incur significant memory cost. In contrast, the policy gradient algorithm directly learns the policy, i.e., activity probabilities in Equation (
3), without the need to store a Q-table. Therefore, we use the policy gradient algorithm when the feedback only indicates if the classification is correct or wrong. We define the state, action, policy, and the reward for the policy gradient algorithm as follows.
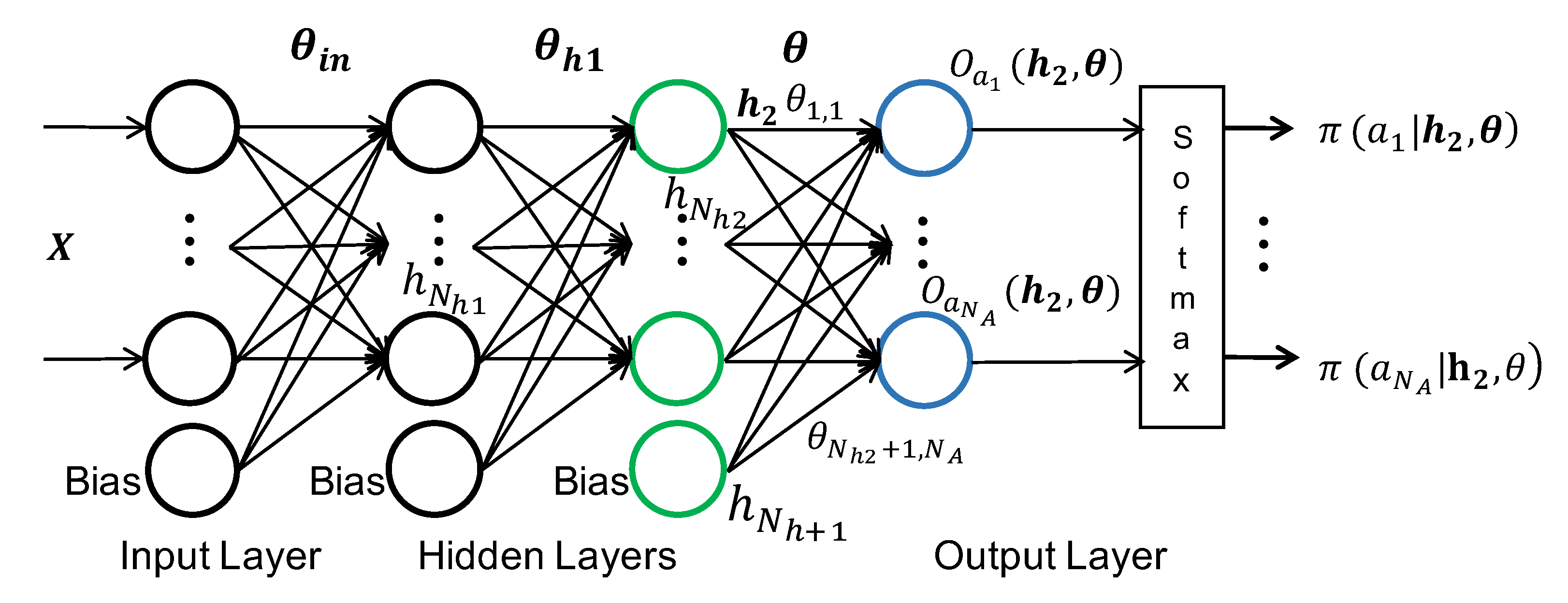
State: The state space in the RL framework is given by the stretch sensor and accelerometer data in a segment. The state space is continuous since the sensors can take any real number within their operating limits. The state information from the stretch sensor and accelerometer is then processed by feature generation algorithms to obtain the input feature vector for the NN.
Policy: The activity probabilities that are generated at the output of NN form the policy in the RL framework. It is obtained by propagating the input features through the NN.
Action: We use the activity of the user in a given segment as the action for the policy gradient algorithm. As described in
Section 4.1.2, it is obtained by choosing the activity with the maximum probability.
Reward: RL techniques give a positive reward when the action is correct, while a negative reward is given for incorrect actions. Following this, we set the reward as
when the activity is classified correctly. Otherwise, we set the reward to
. Moreover, following common RL terminology [
19] we define an epoch as the set of segments over which the reward is given, i.e., the number of segments for which the feedback is given. Similarly, each training period is defined as an episode. For example, if a user wears the device for ten minutes before turning it off, the ten minute period forms an episode. Each episode includes a set of epochs for which the reward is given.
Objective: The goal in reinforcement learning is to maximize the value function of a state. The value function is given by the sum of rewards obtained starting at the state and taking actions using the policy until the episode ends. Following this, the goal of the policy gradient algorithm is to maximize the total reward obtained over an episode. The total reward is a function of the classifier weights since we modify the weights to update the policy towards higher rewards.
Policy Gradient Weight Updates: RL techniques often update all the policy weights after every epoch [
19]. This approach is beneficial when we start from a completely untrained network with random weight initialization. However, in the w-HAR framework, we start with a NN that is trained offline using the data available at design time. It has been that shown initial layers of a trained network provide general features that are applicable to a wide range of users [
42]. Therefore, we update only the weights of the output layer
in our RL framework. As a result, the NN is able to use the general features learned in the offline phase and minimize the computational cost at runtime.
The policy gradient approach uses the gradient of the objective function with respect to the policy parameters to update the weights. As described above, we use the value function as the objective function. The gradient of the value function has been shown to be proportional to the gradient of the policy in [
19]. Using this property, we can write the weight update equation as:
where
and
are the current and updated weight matrices, respectively. Similarly,
is the activity classified by the classifier at time
t,
is the current reward for the policy, and
is the vector of outputs generated at the second hidden layer. In order to obtain the new weights using the update rule, we need to calculate the gradient of the policy with respect to the output layer weights
. The value of this gradient depends on whether a given weight connects to the neuron that corresponds to the output activity
or not. To this end, we first generate two sets
and
. The set
includes the weights that directly connect to the neuron corresponding to the output activity
, while
contains the other weights. Note that each weight belongs to only one of the sets, i.e., they are disjoint. Using the definition of
and
, the weight update rule can be written as:
The detailed proof of the update rule can be found in [
6].
5.2. Online Updates with Incremental Supervised Learning
Online learning using the policy gradient algorithm is most useful when the activity labels are not available. While it can be used when activity labels are available, the convergence rates of the policy gradient algorithm are lower when compared to supervised learning. Therefore, we use supervised learning for performing incremental weight updates when the user can provide activity labels at runtime, as outlined in Algorithm 1. The algorithm takes the offline trained weights of the NN as its input. The first step in the algorithm is to initialize a buffer
B of size
M that is used to store the training data for weight updates. With this initialization, we start the online phase of the algorithm. For each activity segment
t, we first obtain the feature vector
and use it with the weights to determine the activity probabilities (lines 4–5). Then, we assign the activity with the maximum probability as the output activity. This activity is shown to the user who then provides the actual activity label
to the algorithm. If the actual activity label
does not match the activity output of the NN, we store both the feature vector
and the label
in the buffer
B (lines 7–10). Otherwise, we proceed to the next activity. This process continues until the buffer is full. Once the buffer is full, we use the training data in the buffer to update the weights of the NN using the backpropagation algorithm. Similar to the policy gradient approach, we update only the weights in the output layer. Finally, we reset the data in buffer
B so that training data from the updated network can be collected.
| Algorithm 1: Weight Update via Supervised Learning |
 |
In summary, the weights of the output layer are updated online using either of the two algorithms after user feedback. We note that the weights of the hidden layers can be updated similarly by computing the gradient of the hidden layers with respect to their weights. Detailed results for the improvement in accuracy using the online learning approaches and a comparison among them are presented in
Section 6.5.
7. Conclusions
Human activity recognition has wide-ranging applications from movement disorders to patient rehabilitation to activity promotion in the general population. Successful research in HAR critically depends on the availability of open-source datasets. In order to address this need, we presented a w-HAR, an open-source dataset for human activity recognition that, for the first time, includes data from both wearable stretch and IMU (accelerometer + gyroscope) sensors. We provide three versions of the sensor data as part of w-HAR. The first version provides raw sensor data that allows researchers to develop their own algorithms for all steps of HAR. Secondly, we provide segmented data that gives researchers the freedom to just focus on feature generation and classification. Finally, we also provide a baseline feature set for researchers who want to focus only on classifier development. The baseline feature set includes the discrete wavelet transform of the accelerometer and fast Fourier transform of the stretch sensor data. The baseline features do not include the gyroscope data. However, researchers can use the raw gyroscope data to generate features from it. After presenting the dataset, we performed a DSE of neural network classifiers for HAR. After the DSE, we obtained a NN classifier that achieved 95% accuracy for user data available at design time. Then, we introduced two online learning algorithms to continuously improve the classifier weights for new user subjects as a function of user feedback. The online learning algorithms improved the accuracy for new users by as much as 40%.
The HAR framework presented in this paper can be easily extended to other activities, such as jogging, bending down, falling, and cycling. The addition of new activities will require data collection for a subset of users and training the classifier. We can also perform DSE to identify new NN architectures if the current architecture cannot achieve high accuracy. Once the classifier is trained with a subset of users, it will adapt to new users with the help of online learning algorithms proposed in this paper. As part of our future work, we plan to grow the dataset with additional subjects and activities. Specifically, we plan to include users with limited mobility in the dataset to provide a wider range of coverage. We also plan to develop online learning algorithms that can adapt efficiently to movement disorder patients.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}