Fault-Tolerant Network-On-Chip Router Architecture Design for Heterogeneous Computing Systems in the Context of Internet of Things


 , ,
, ,  and
and 
Abstract
1. Introduction
- This study utilizes the inherent redundancies in the pipeline and lookahead routing to maintain the performance in the presence of faults.
- This study proposes highly fault-tolerant schemes for each stage of the router pipeline.
- This study compares the latency, hardware consumption, and reliability of the proposed architecture with those of the state-of-the-art fault-tolerant router architectures.
2. Related Work
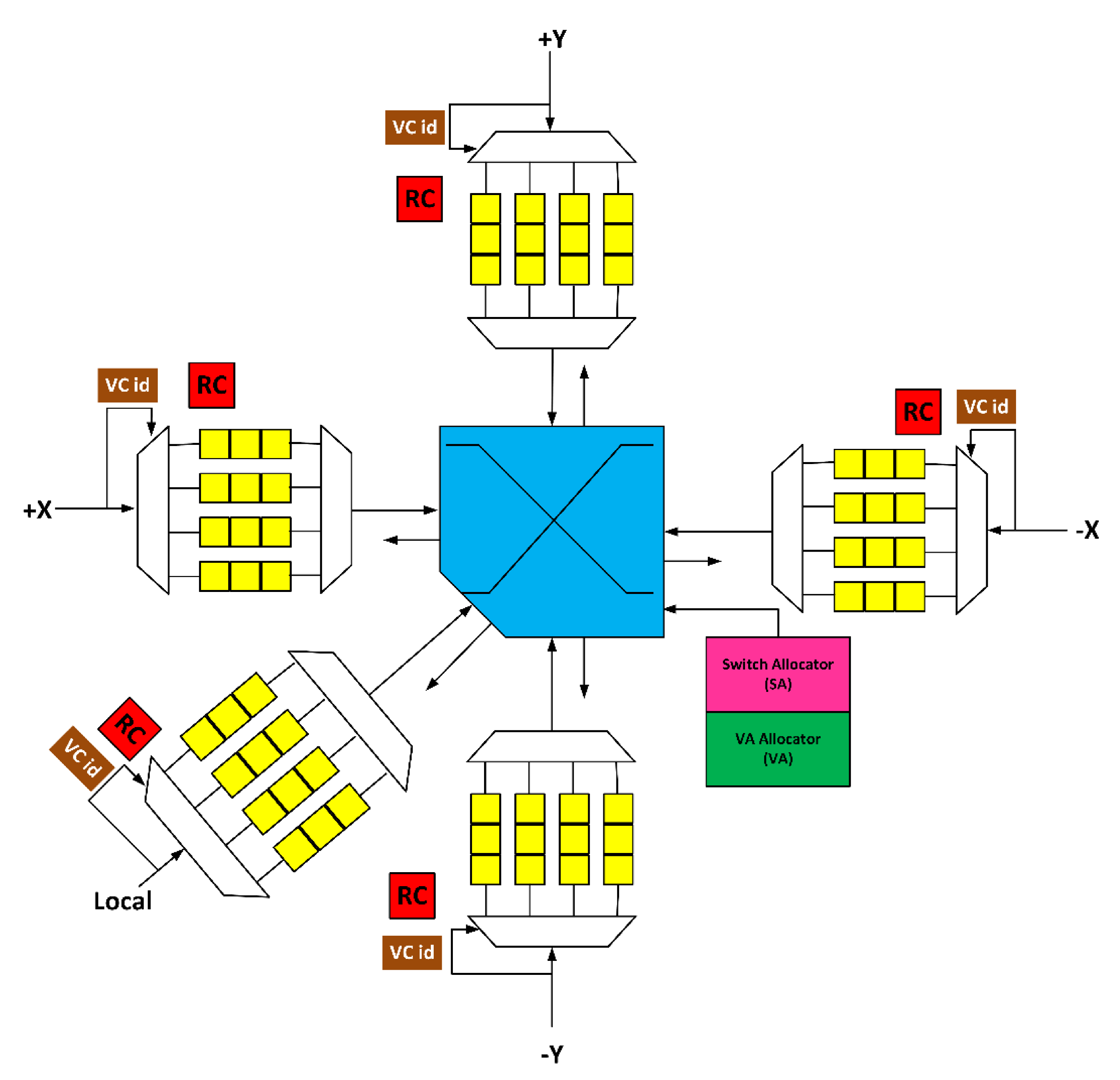
3. Proposed Fault-Tolerant NoC Router Architecture
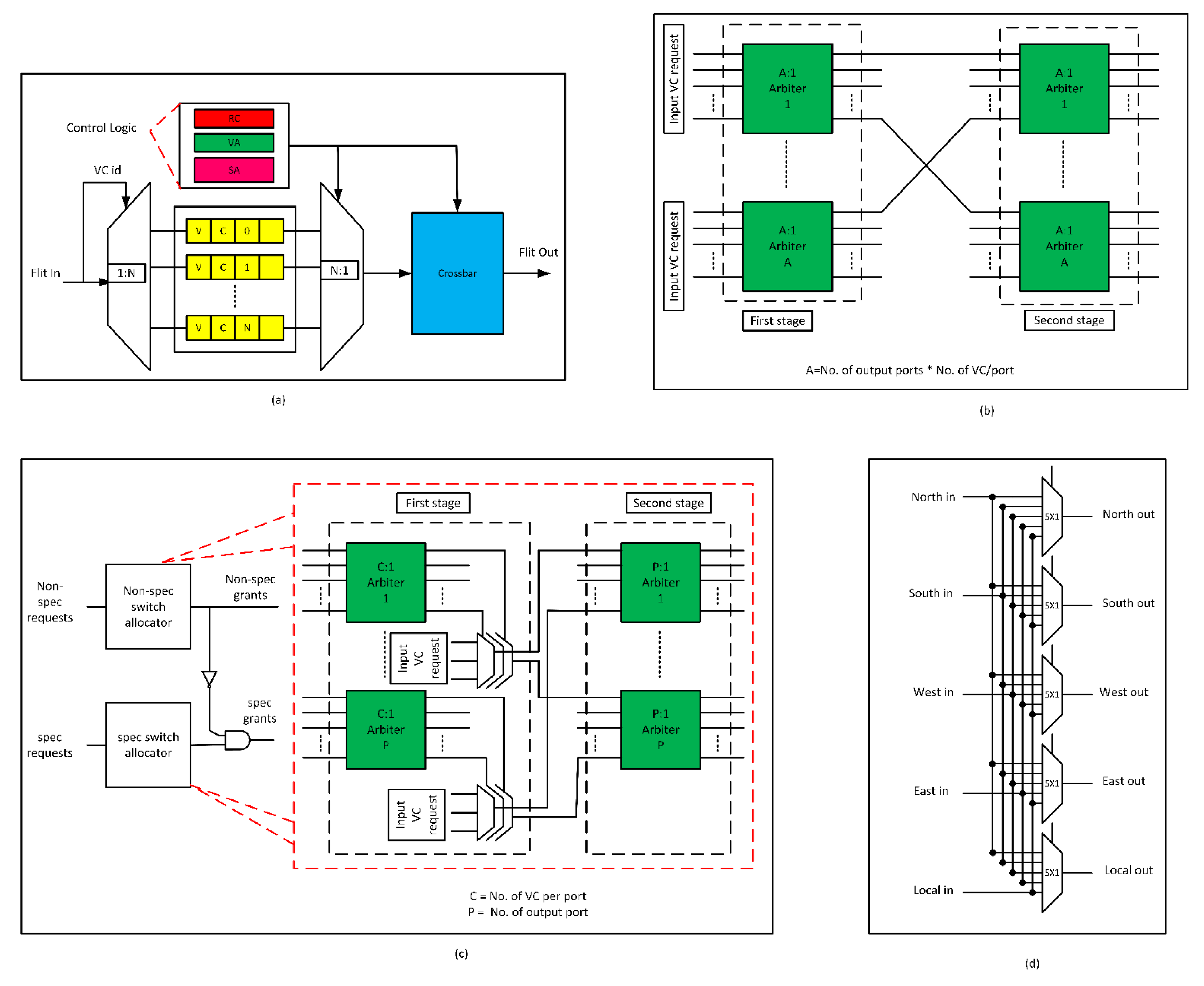
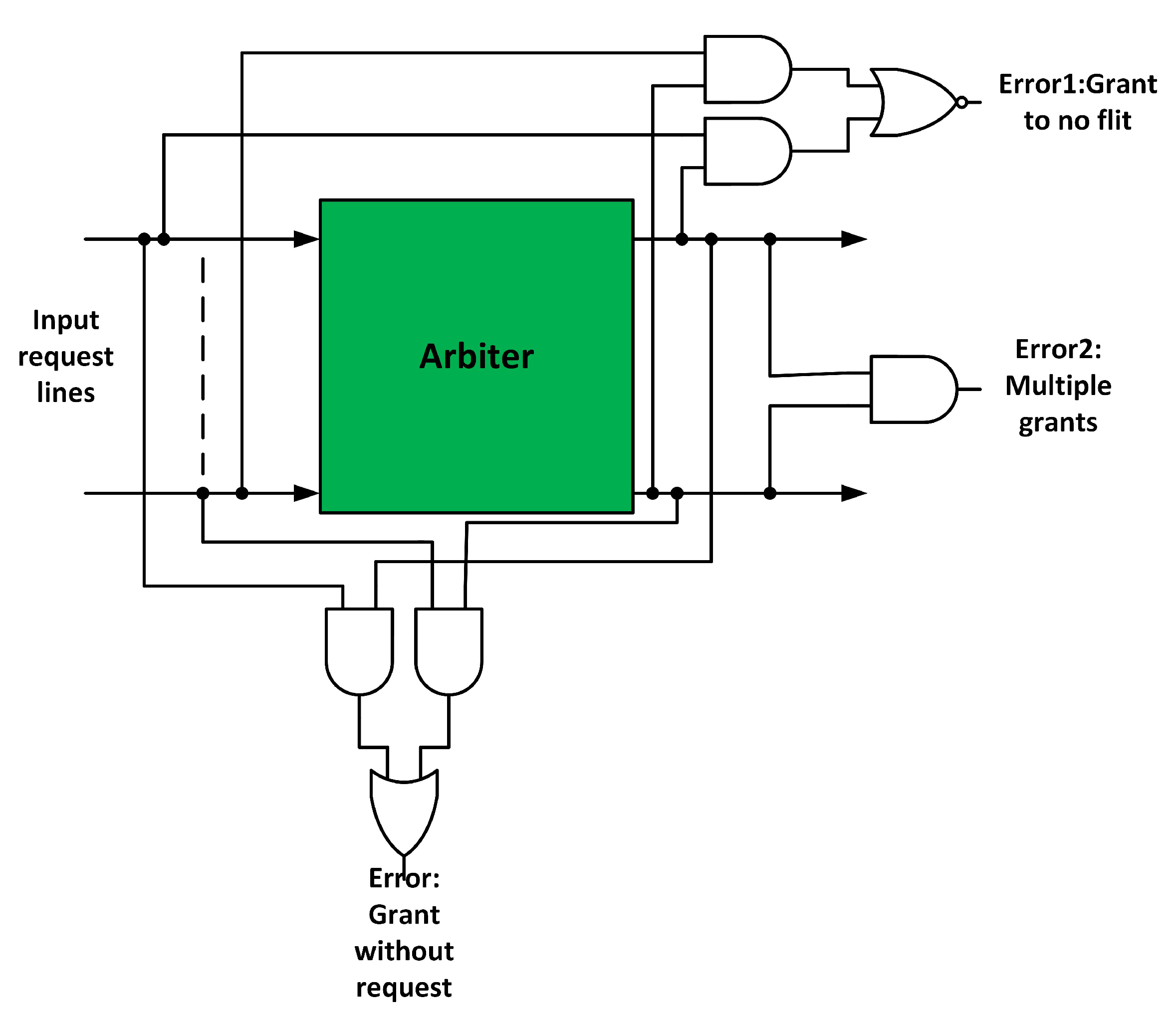
3.1. Fault-Tolerant Design of Input Port
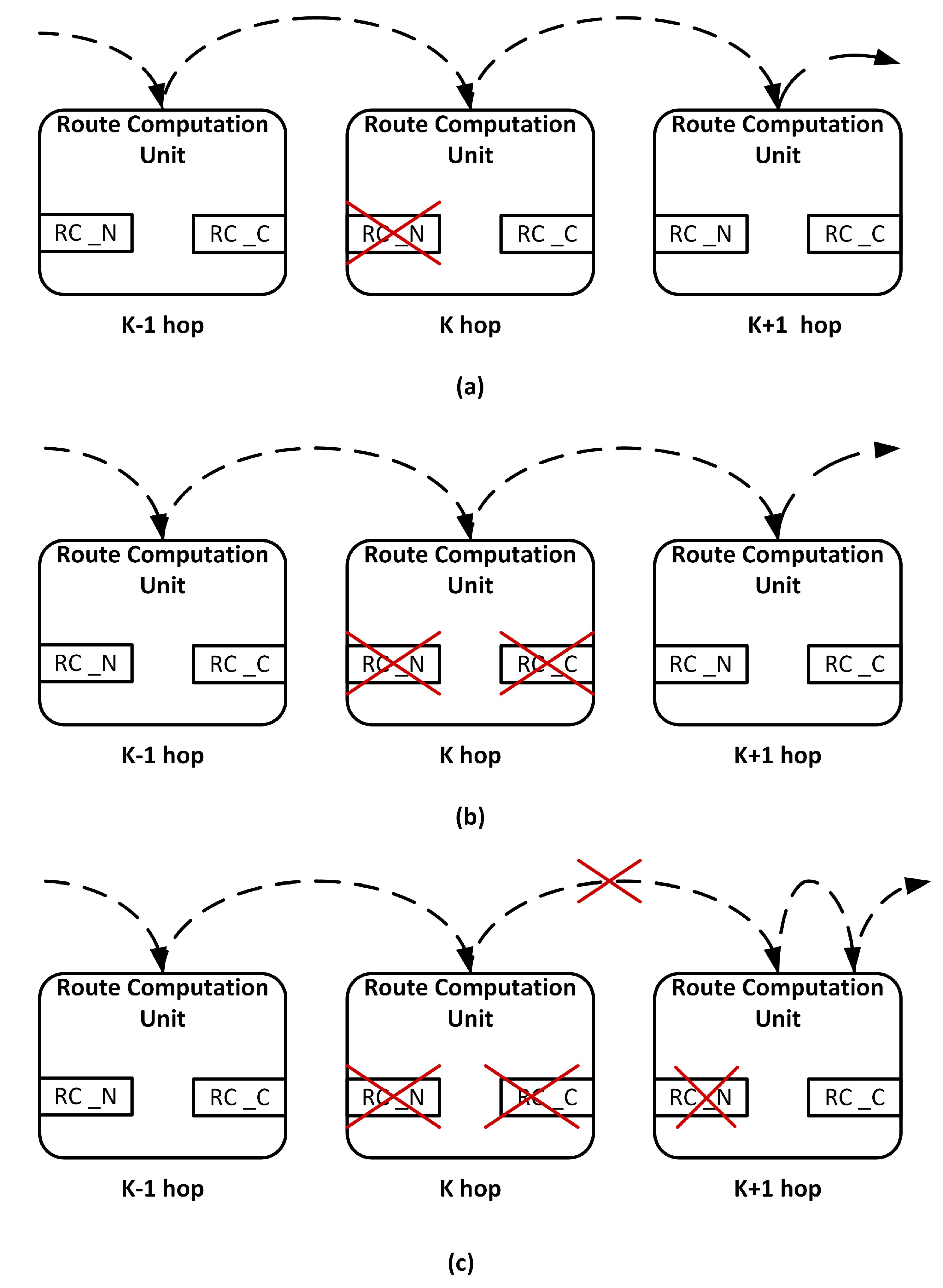
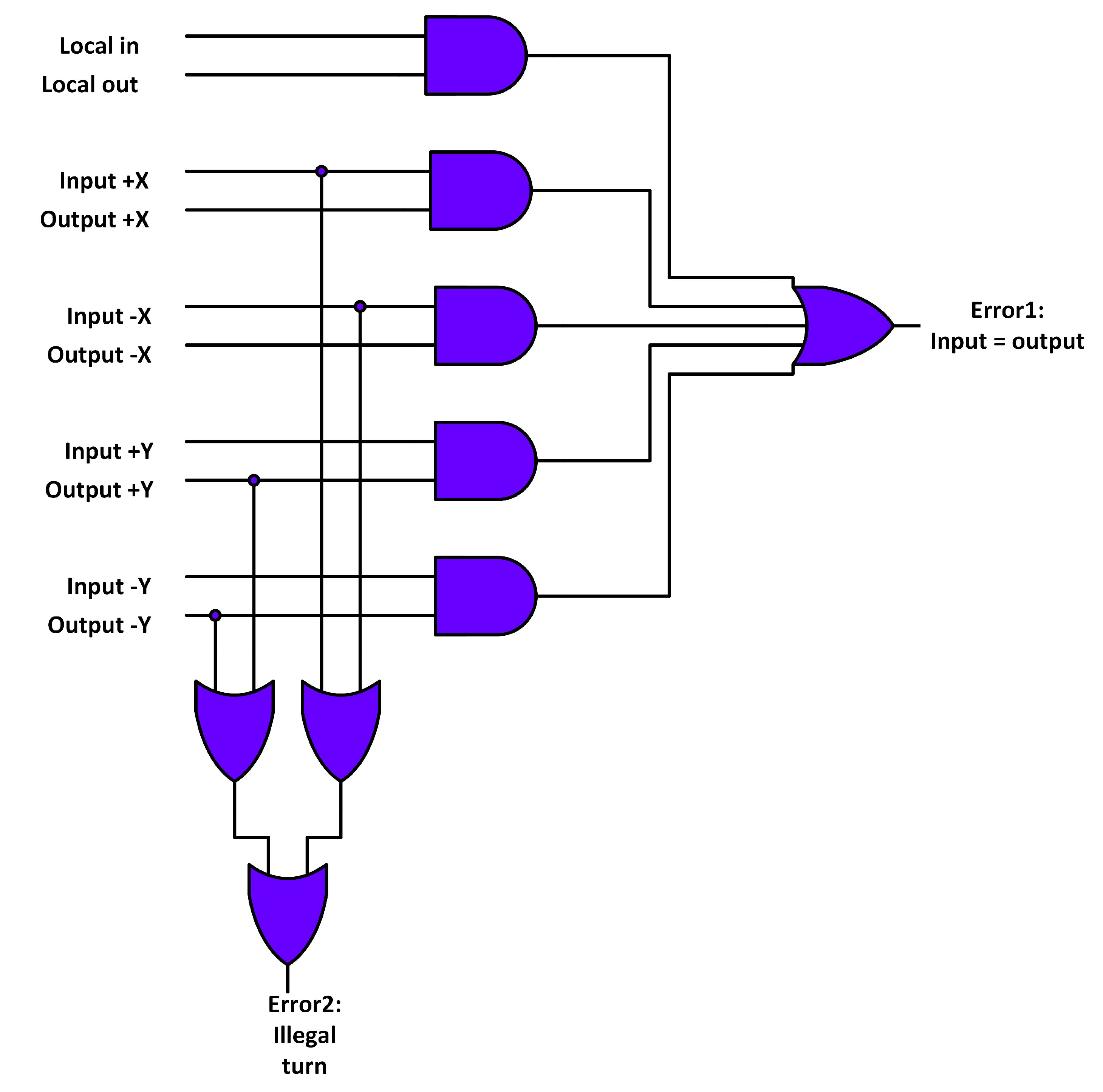
3.2. Fault-Tolerant Design of RC Stage
3.2.1. Scenario 1
3.2.2. Scenario 2
3.2.3. Scenario 3
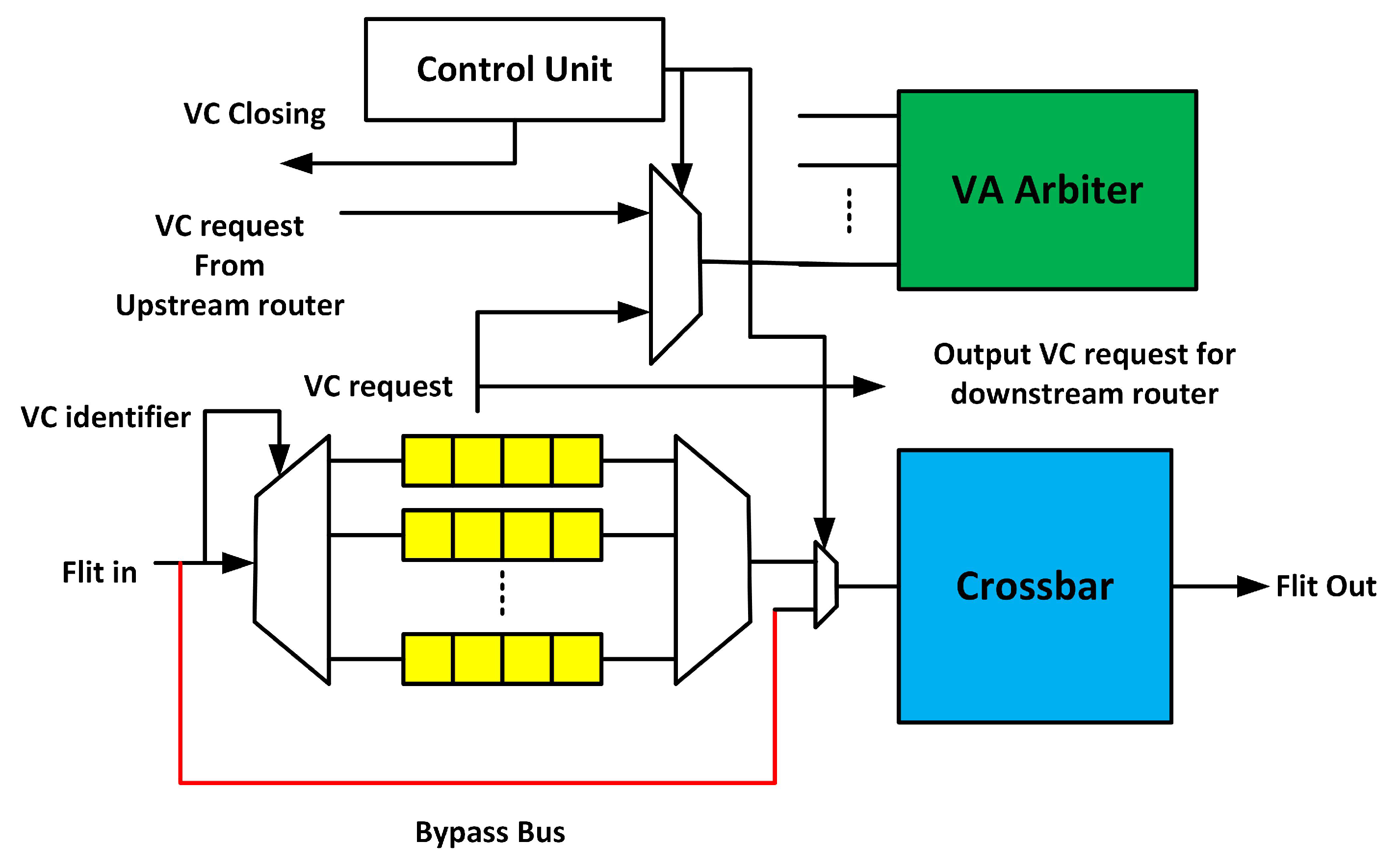
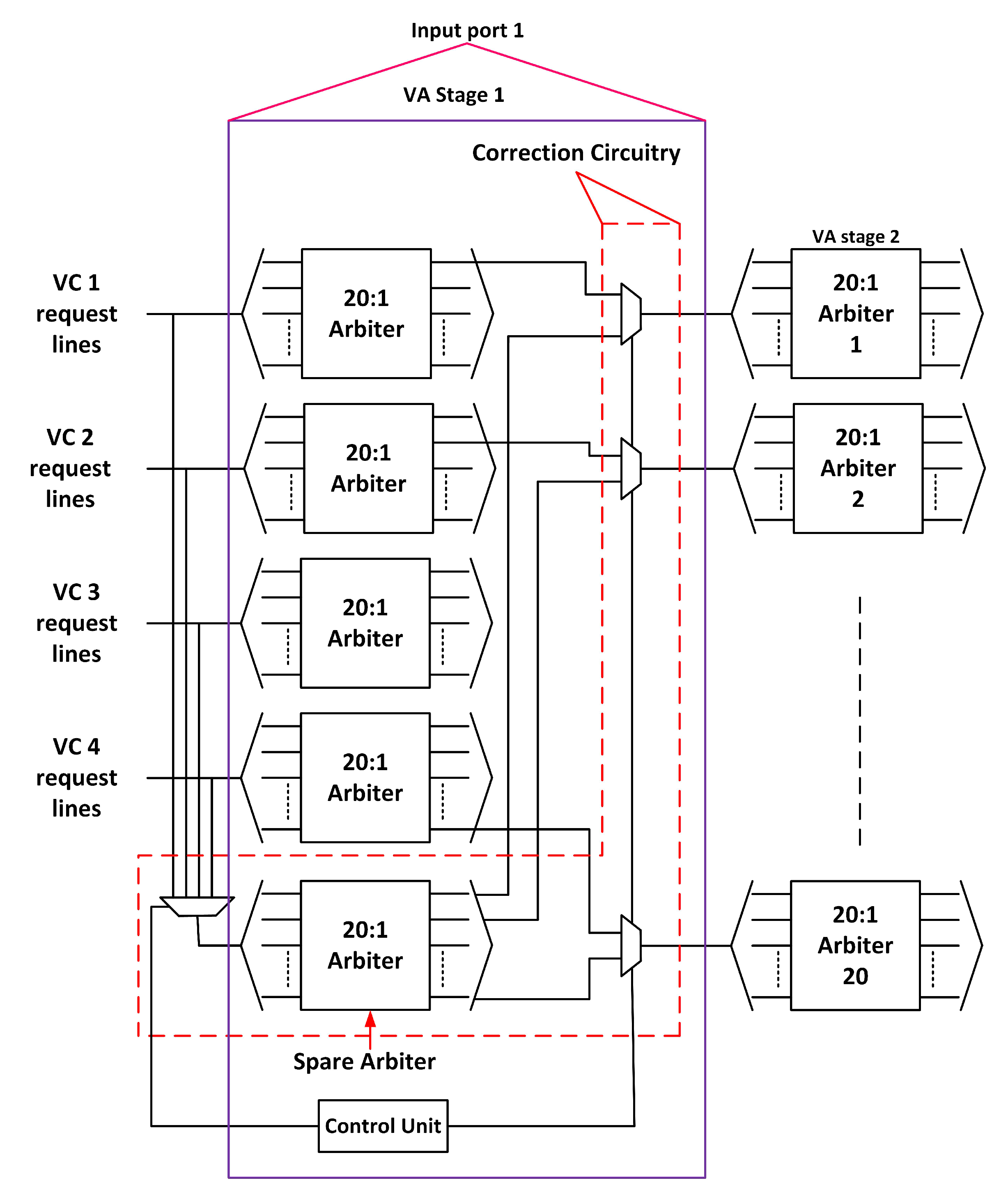
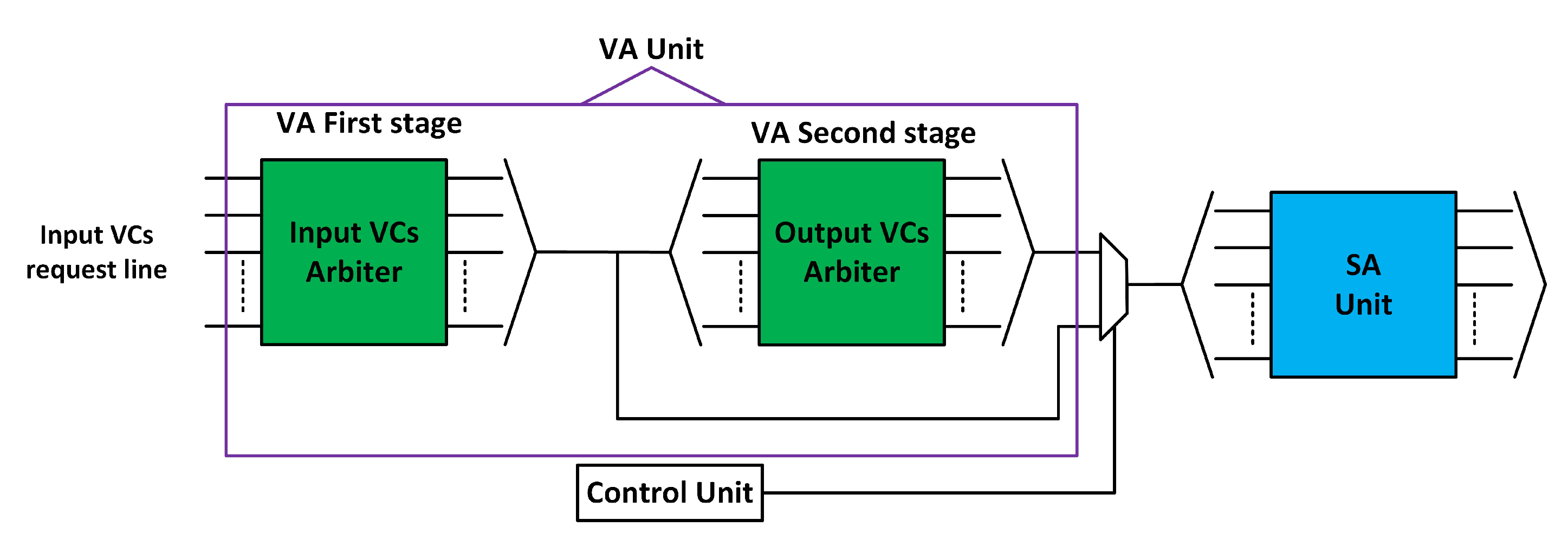
3.3. Fault-Tolerant Design of VA Stage
3.3.1. First Stage of VA (VA1)
3.3.2. Second Stage of VA (VA2)
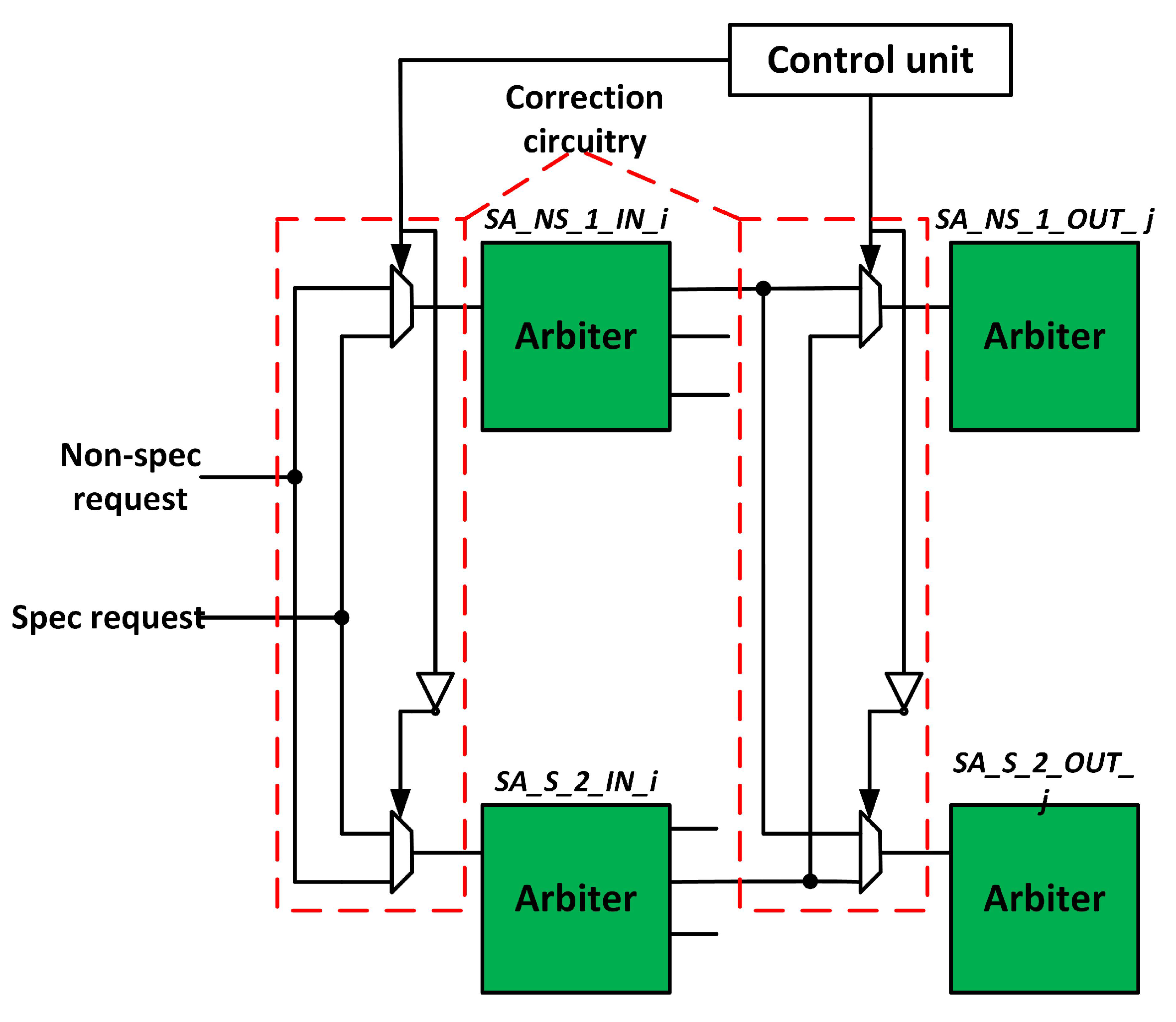
3.4. Fault-Tolerant Design of SA Stage
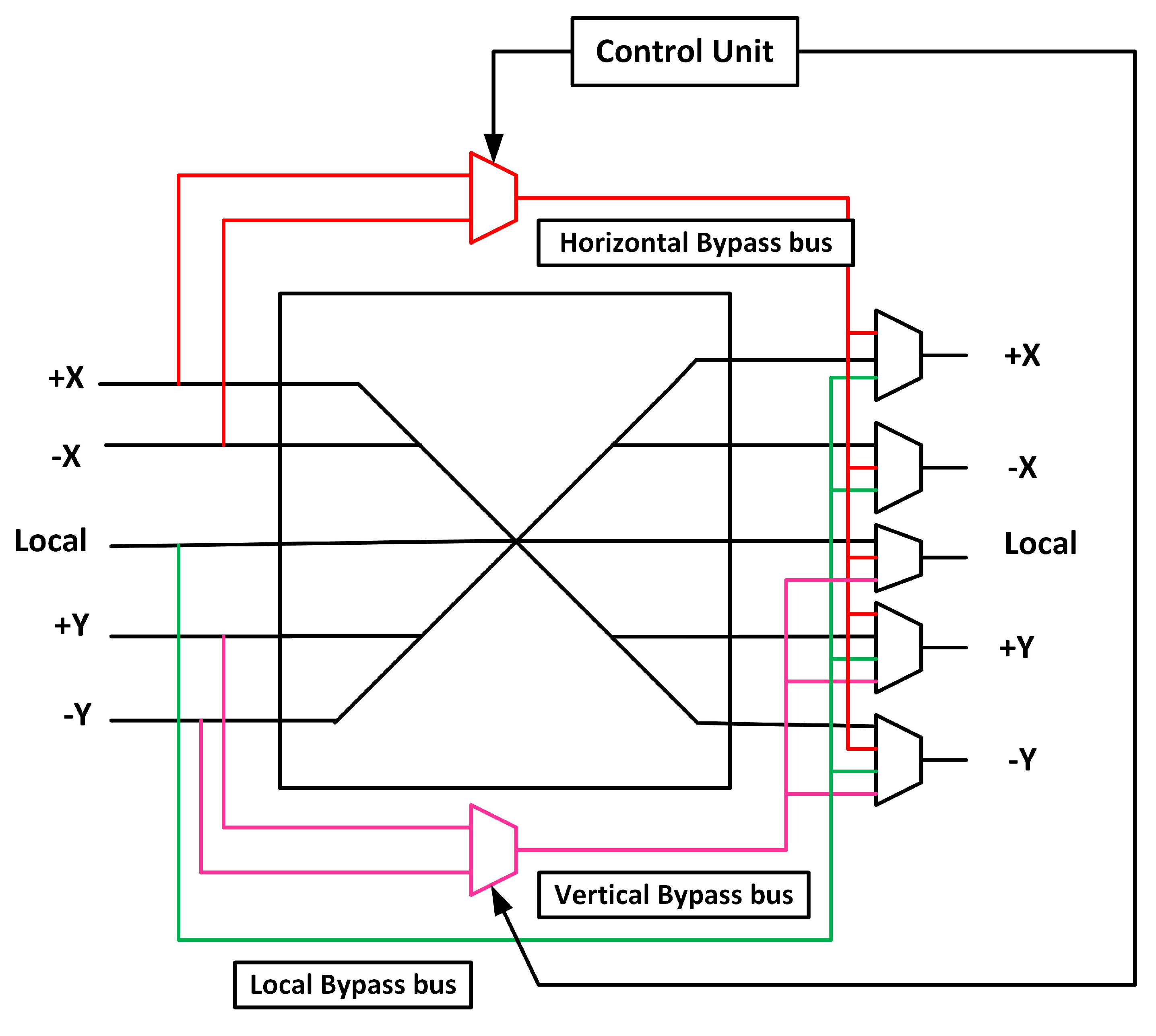
3.5. Fault-tolerant Design of XBAR Stage
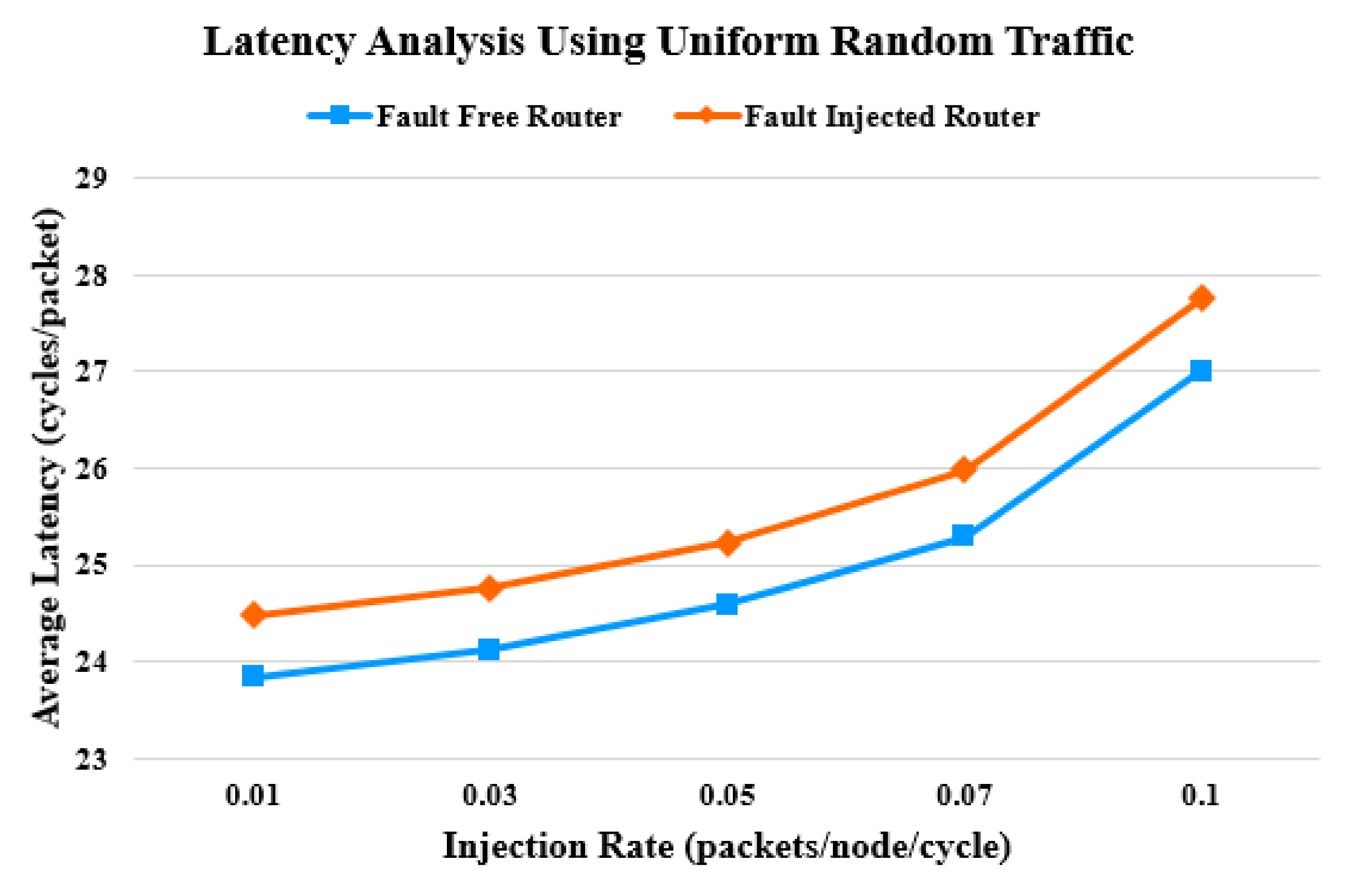
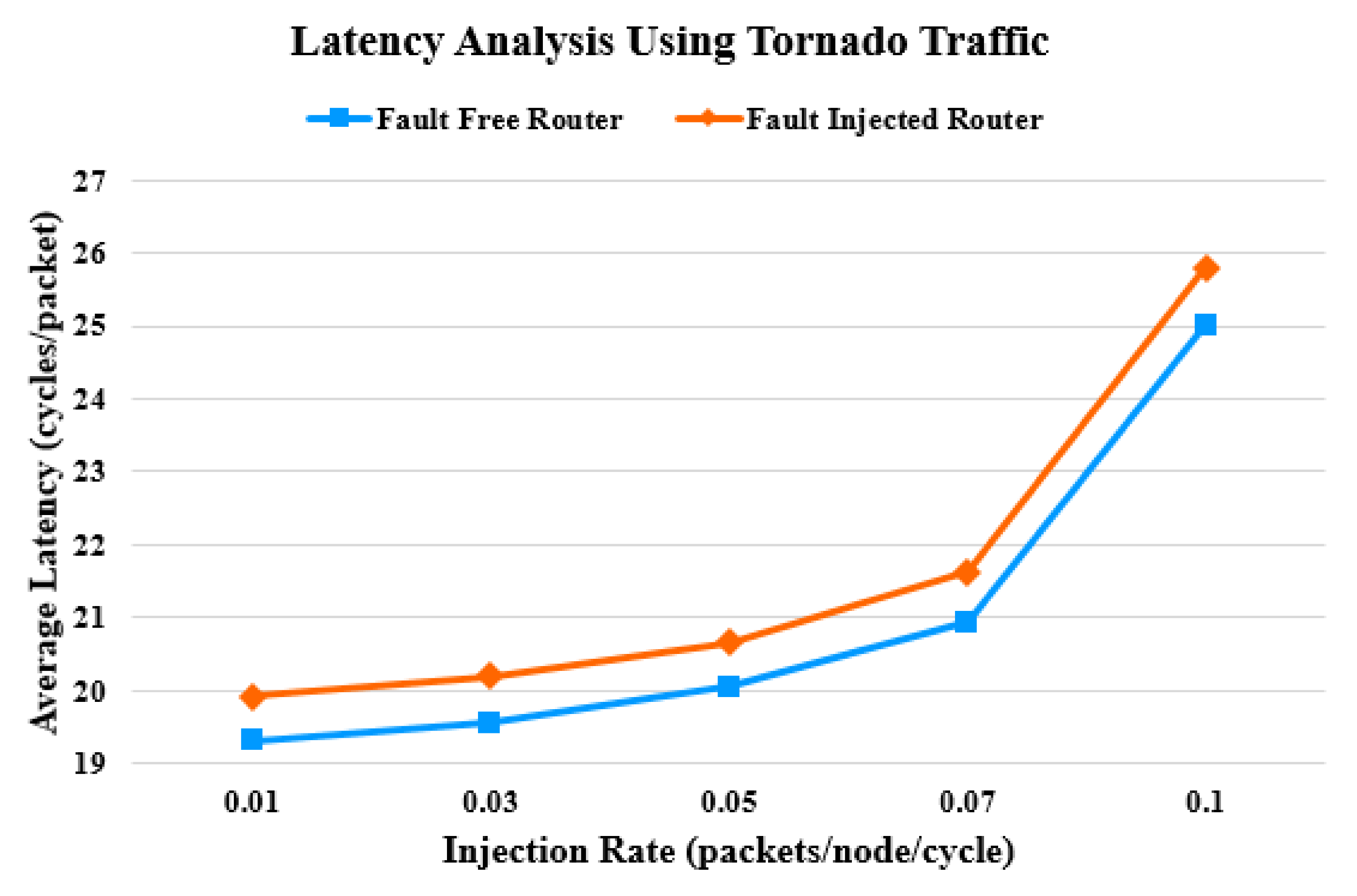
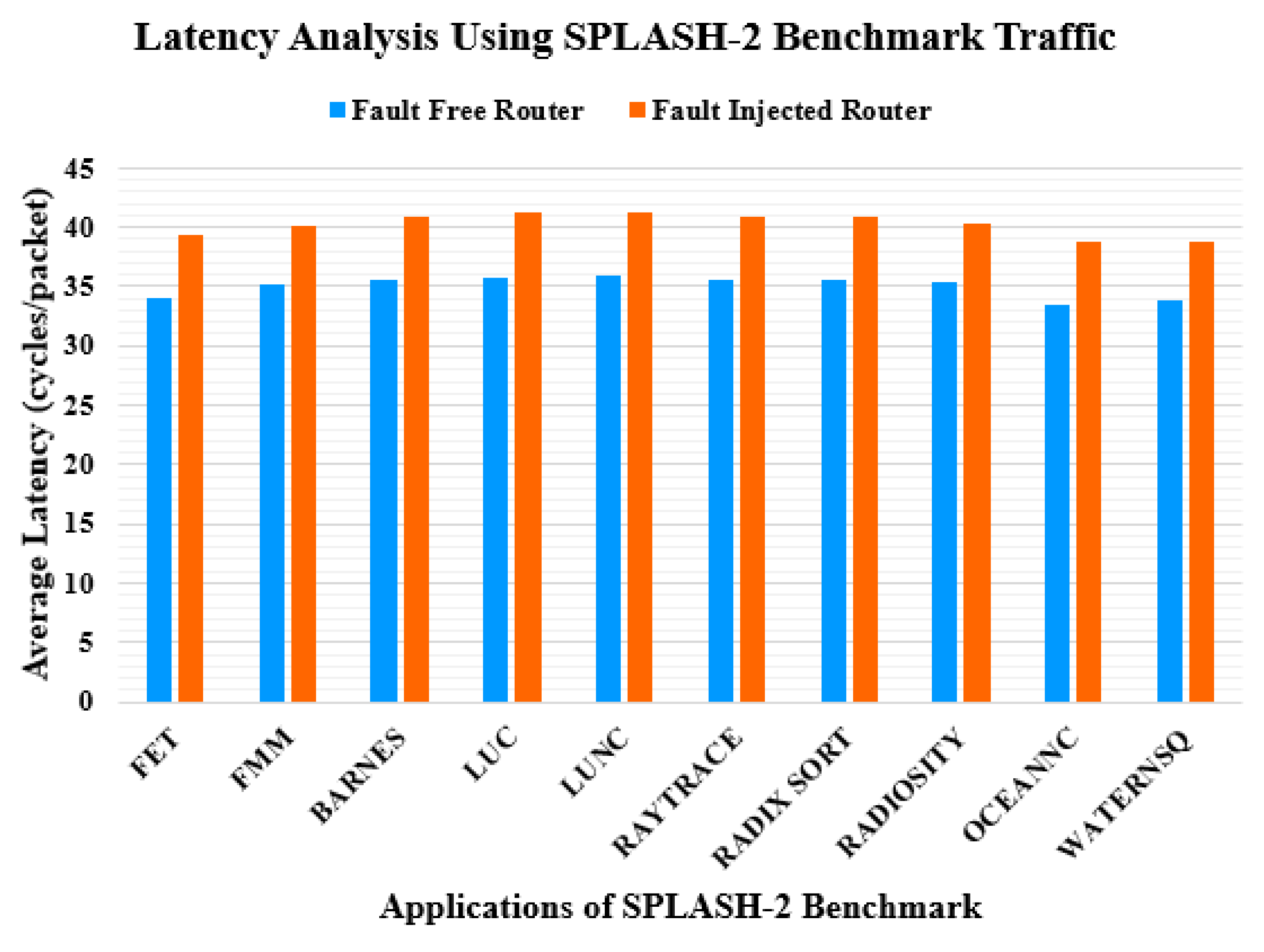
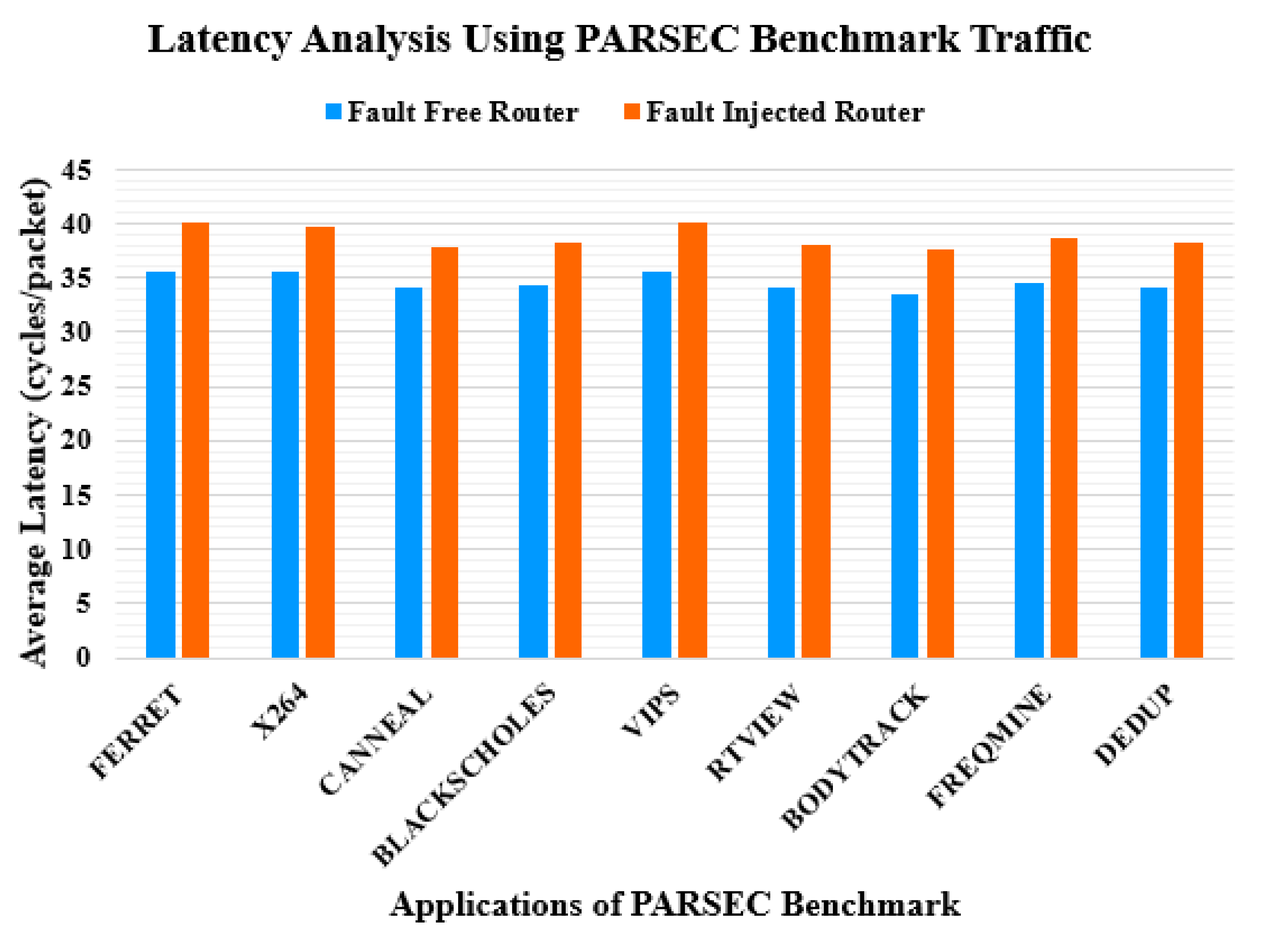
4. Latency Analysis
5. Reliability Analysis
5.1. Hardware Overhead Analysis
5.2. Lifetime Reliability Analysis Using MTTF
5.2.1. FIT Calculation for Baseline Router
5.2.2. FIT Calculation for Correction Circuitry
- Input Port: It employs a 128-bit 2:1 multiplexer at each input port.
- RC Stage: It employs an additional RC unit at each input port.
- VA Stage: VA1 employs an additional 20:1 arbiter and 20-bit 4:1 multiplexer per input port. VA2 employs 40 2:1 multiplexers, 20 of which are used to tolerate the fault of VA1.
- SA Stage: It employs 20 2:1 multiplexers.
- XBAR Stage: It employs 2 128-bit 4:1 multiplexers, 3 128-bit 3:1 multiplexers, and 2 128-bit 2:1 multiplexers.
5.2.3. MTTF Calculation
5.3. Reliability Analysis using SPF
5.3.1. Calculation of Average Number of Defects to Cause Failure
- Input port: The baseline router consists of five input ports. Each port consists of a de-multiplexer, multiplexer, and four VCs. The proposed fault-tolerant methodology tolerates faults in all the six components of an input port. Thus, a router tolerates a maximum of 30 input port defects. A defect in a de-multiplexer/multiplexer and bypass path causes the failure of an input port. Thus, a minimum of 2 defects cause input port failure.
- RC Stage: In the baseline router, each input port has its own RC unit. The proposed fault-tolerant methodology tolerates a maximum of 5 defects per router. If both the RC_N and RC_C units of adjacent routers become faulty, the RC fails. Thus, a minimum of 4 defects cause RC failure.
- VA Stage: The faults for the VA unit can be described as the fault in the arbiters. The number of arbiters in the first stage of VA is 20. The spare arbiter provides fault tolerance if all the arbiters in the first stage of VA are faulty. The second stage of VA also has 20 arbiters. Our pipeline optimization technique for fault tolerance also functions well if all the arbiters in the second stage are faulty. Therefore, our proposed technique can tolerate a maximum of 40 defects in a VA. A minimum of 2 defects cause failure if the original arbiter and the additional arbiter become faulty.
- SA Stage: The baseline router consists of two identical sets of SAs. If a defect occurs in a non-speculative arbiter, the corresponding arbiter in the speculative set performs SA. Thus, it tolerates a maximum of 10 defects. If both the corresponding arbiters fail, the SA fails. Thus, a minimum of 2 defects cause SA failure.
- XBAR Stage: The baseline router consists of a 5x5 crossbar. It has five multiplexers. The proposed triple bypass provides full functionality if all the multiplexers become faulty. Thus, it tolerates a maximum of 5 defects. If a bypass path and multiplexer become faulty, the XBAR fails. Thus, a minimum of 2 defects cause XBAR failure.
5.3.2. SPF Calculation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| IoT | Internet of things |
| NoC | Network-on-chip |
| ICPS | Industrial cyber–physical systems |
| MJS | Markov jump systems |
| HCI | Hot carrier injection |
| TDDB | Time-dependent dielectric breakdown |
| NBTI | Negative-bias temperature instability |
| PEs | Processing elements |
| RC | Routing computation |
| VA | Virtual channel allocation |
| SA | Switch allocation |
| XBAR | Crossbar |
| VC | Virtual channel |
| NMR | N modular redundancy |
| ECC | Error correcting code |
| VA1 | First stage of VA |
| VA2 | Second stage of VA |
| SA1 | First stage of SA |
| SA2 | Second stage of SA |
| FIT | Failure in time |
| MTTF | Mean time to failure |
| SOFR | Sum of failure rate |
| FC | Fundamental component |
| SPF | Silicon protection factor |
References
- Zikria, Y.B.; Afzal, M.K.; Kim, S.W. Internet of Multimedia Things (IoMT): Opportunities, Challenges and Solutions. Sensors 2020, 20, 2334. [Google Scholar] [CrossRef]
- Qadri, Y.A.; Nauman, A.; Zikria, Y.B.; Vasilakos, A.V.; Kim, S.W. The Future of Healthcare Internet of Things: A Survey of Emerging Technologies. IEEE Commun. Surv. Tutorials 2020, 22, 1121–1167. [Google Scholar] [CrossRef]
- Naeem, M.A.; Ali, R.; Alazab, M.; Yhui, M.; Zikria, Y.B. Enabling the content dissemination through caching in the state-of-the-art sustainable information and communication technologies. Sustainable Cities Soc. 2020, 61, 102291. [Google Scholar] [CrossRef]
- Yu, H.; Afzal, M.K.; Zikria, Y.B.; Rachedi, A.; Fitzek, F.H. Tactile Internet: Technologies, test platforms, trials, and applications. Elsevier Future Gener. Comput. Syst. 2020, 106, 685–688. [Google Scholar] [CrossRef]
- Yin, S.; Rodriguez-Andina, J.J.; Jiang, Y. Real-time monitoring and control of industrial cyberphysical systems: With integrated plant-wide monitoring and control framework. IEEE Ind. Electron. Mag. 2019, 13, 38–47. [Google Scholar] [CrossRef]
- Borkar, S. Thousand core chips: A technology perspective. In Proceedings of the 44th annual design automation conference, San Diego, CA, USA, 4–8 June 2007; pp. 746–749. [Google Scholar]
- Hoefflinger, B. ITRS: The international technology roadmap for semiconductors. In Chips 2020; Springer: Berlin/Heidelberg, Germany, 2011; pp. 161–174. [Google Scholar]
- Dally, W.J.; Towles, B. Route packets, not wires: On-chip inteconnection networks. In Proceedings of the 38th annual Design Automation Conference, Las Vegas, NV, USA, 18–22 June 2001; pp. 684–689. [Google Scholar]
- Kumar, A. Intel’s New Mesh Architecture: The ‘Superhighway’of the Data Center. IT Peer Network 2017. [Google Scholar]
- Borkar, S. Design Challenges of Technology Scaling. IEEE Micro 1999, 19, 23–29. [Google Scholar] [CrossRef]
- Kuhn, K.J. Reducing variation in advanced logic technologies: Approaches to process and design for manufacturability of nanoscale CMOS. In Proceedings of the IEEE International Electron Devices Meeting, Washington, DC, USA, 10–12 December 2007; pp. 471–474. [Google Scholar]
- Ziegler, J.F. Terrestrial cosmic ray intensities. IBM J. Res. Dev. 1998, 42, 117–140. [Google Scholar] [CrossRef]
- Sai-Halasz, G.A.; Wordeman, M.R.; Dennard, R.H. Alpha-particle-induced soft error rate in VLSI circuits. IEEE J. Solid-State Circuits 1982, 17, 355–361. [Google Scholar] [CrossRef]
- Groeseneken, G.V. Hot carrier degradation and ESD in submicrometer CMOS technologies: How do they interact? IEEE Trans. Device Mater. Reliab. 2001, 1, 23–32. [Google Scholar] [CrossRef]
- Oussalah, S.; Nebel, F. On the oxide thickness dependence of the time-dependent-dielectric-breakdown. In Proceedings of the IEEE Electron Devices Meeting, Shatin, Hong Kong, 26 June 1999; pp. 42–45. [Google Scholar]
- Mahapatra, S.; Kumar, P.B.; Dalei, T.; Sana, D.; Alam, M. Mechanism of negative bias temperature instability in CMOS devices: Degradation, recovery and impact of nitrogen. IEDM Technical Digest. In Proceedings of the IEEE International Electron Devices Meeting, San Francisco, CA, USA, 11–13 December 2004; pp. 105–108. [Google Scholar]
- Benini, L.; De Micheli, G. Networks on chips: A new SoC paradigm. IEEE Comput. 2002, 35, 70–78. [Google Scholar] [CrossRef]
- Yang, H.; Jiang, Y.; Yin, S. Fault-Tolerant Control of Time-Delay Markov Jump Systems With Ito Stochastic Process and Output Disturbance Based on Sliding Mode Observer. IEEE Trans. Ind. Inf. 2018, 14, 5299–5307. [Google Scholar] [CrossRef]
- Jiang, Y.; Yin, S.; Kaynak, O. Data-driven monitoring and safety control of industrial cyber-physical systems: Basics and beyond. IEEE Access 2018, 6, 47374–47384. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Sinopoli, B.; Garone, E. Feasibility and Detection of Replay Attack in Networked Constrained Cyber-Physical Systems. In Proceedings of the 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 24–27 September 2019; pp. 712–717. [Google Scholar]
- Tu, H.; Xia, Y.; Chi, K.T.; Chen, X. A Hybrid Cyber Attack Model for Cyber-Physical Power Systems. IEEE Access 2020, 8, 114876–114883. [Google Scholar] [CrossRef]
- Constantinides, K.; Plaza, S.; Blome, J.; Zhang, B.; Bertacco, V.; Mahlke, S.; Austin, T.; Orshansky, M. BulletProof: A defect-tolerant CMP switch architecture. In Proceedings of the IEEE Twelfth International Symposium on High-Performance Computer Architecture, Austin, TX, USA, 11–15 February 2006; pp. 5–16. [Google Scholar]
- Kim, J.; Nicopoulos, C.; Park, D.; Narayanan, V.; Yousif, M.S.; Das, C.R. A gracefully degrading and energy-efficient modular router architecture for on-chip networks. ACM SIGARCH Comput. Archit. News 2006, 34, 4–15. [Google Scholar] [CrossRef]
- Fick, D.; DeOrio, A.; Hu, J.; Bertacco, V.; Blaauw, D.; Sylvester, D. Vicis: A reliable network for unreliable silicon. In Proceedings of the 46th Annual Design Automation Conference, San Francisco, CA, USA, 26–31 July 2009; pp. 812–817. [Google Scholar]
- Xie, L.; Mei, K.; Li, Y. Repair: A reliable partial-redundancy-based router in noc. In Proceedings of the IEEE eighth international conference on networking, architecture and storage, Xi’an, China, 17–19 July 2013; pp. 173–177. [Google Scholar]
- Latif, K.; Rahmani, A.M.; Nigussie, E.; Seceleanu, T.; Radetzki, M.; Tenhunen, H. Partial virtual channel sharing: A generic methodology to enhance resource management and fault tolerance in networks-on-chip. J. Electron. Test. 2013, 29, 431–452. [Google Scholar] [CrossRef]
- Valinataj, M.; Shahiri, M. A low-cost, fault-tolerant and high-performance router architecture for on-chip networks. Microprocess. Microsyst. 2016, 45, 151–163. [Google Scholar] [CrossRef]
- Poluri, P.; Louri, A. Shield: A reliable network-on-chip router architecture for chip multiprocessors. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 3058–3070. [Google Scholar] [CrossRef]
- Shafique, M.A.; Baloch, N.K.; Baig, M.I.; Hussain, F.; Zikria, Y.B.; Kim, S.W. NoCGuard: A Reliable Network-on-Chip Router Architecture. Electronics 2020, 9, 342. [Google Scholar] [CrossRef]
- Wang, L.; Ma, S.; Li, C.; Chen, W.; Wang, Z. A high performance reliable NoC router. Integration 2017, 58, 583–592. [Google Scholar] [CrossRef]
- Baloch, N.K.; Baig, M.I.; Daneshtalab, M. Defender: A low overhead and efficient fault-tolerant mechanism for reliable on-chip router. IEEE Access 2019, 7, 142843–142854. [Google Scholar] [CrossRef]
- Prodromou, A.; Panteli, A.; Nicopoulos, C.; Sazeides, Y. Nocalert: An on-line and real-time fault detection mechanism for network-on-chip architectures. In Proceedings of the 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 1–5 December 2012; pp. 60–71. [Google Scholar]
- Dally, W.J.; Towles, B.P. Principles and Practices of Interconnection Networks; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. ACM SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Agarwal, N.; Krishna, T.; Peh, L.S.; Jha, N.K. GARNET: A detailed on-chip network model inside a full-system simulator. In Proceedings of the IEEE international symposium on performance analysis of systems and software, Boston, MA, USA, 26–28 April 2009; pp. 33–42. [Google Scholar]
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 programs: Characterization and methodological considerations. In Proceedings of the 22nd Annual International Symposium on Computer Architecture, New York, NY, USA, June 1995; pp. 24–36. [Google Scholar]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC benchmark suite: Characterization and architectural implications. In Proceedings of the 2008 International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, ON, Canada, 25–29 October 2008; pp. 72–81. [Google Scholar]
- Martins, M.; Matos, J.M.; Ribas, R.P.; Reis, A.; Schlinker, G.; Rech, L.; Michelsen, J. Open cell library in 15nm FreePDK technology. In Proceedings of the International Symposium on Physical Design, Monterey, CA, USA, 1 April 2015; pp. 171–178. [Google Scholar]
- Gaver, D. Time to failure and availability of paralleled systems with repair. IEEE Trans. Reliab. 1963, 12, 30–38. [Google Scholar] [CrossRef]
- Poluri, P.; Louri, A. An improved router design for reliable on-chip networks. In Proceedings of the 28th IEEE International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 283–292. [Google Scholar]
- Srinivasan, J.; Adve, S.V.; Bose, P.; Rivers, J.A. The case for lifetime reliability-aware microprocessors. ACM SIGARCH Comput. Archit. News 2004, 32, 276. [Google Scholar] [CrossRef]
- Trivedi, K.S. Probability and statistics with reliability, queuing, and computer science applications; Englewood Cliffs: Bergen, NJ, USA, 1982. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | FC | FITFC | # of FCs | FITStage |
|---|---|---|---|---|
| Input buffer | 128-bit DFF | 0.5 | 5x64 | 20480 |
| RC stage | 6-bit comparator | 11.7 | 10 | 117 |
| VA stage | 20:1 arbiter | 36.7 | 40 | 1468 |
| 4:1 arbiter | 7.4 | 10 | 215 | |
| SA stage | 5:1 arbiter | 9.3 | 10 | |
| 4:1 multiplexer | 4.8 | 10 | ||
| XBAR stage | 128-bit 5:1 multiplexer | 819.2 | 5 | 4096 |
| Stage | FC | FITFC | # of FCs | FITStage |
|---|---|---|---|---|
| Input buffer | 128-bit 2:1 mux | 204.8 | 5 | 1024 |
| RC | 6-bit comparator | 11.7 | 10 | 117 |
| 20:1 arbiter | 36.7 | 5 | 271.5 | |
| VA | 4:1 multiplexer | 4.8 | 5 | |
| 2:1 multiplexer | 1.6 | 40 | ||
| SA | 2:1 multiplexer | 1.6 | 20 | 32 |
| 128-bit 4:1 multiplexer | 614.4 | 2 | 2867.2 | |
| XBAR | 128-bit 3:1 multiplexer | 409.6 | 3 | |
| 128-bit 2:1 multiplexer | 204.8 | 2 |
| Fault-Tolerant Router | Area Overhead | Average No. of Defects that Cause Failure | SPF Value |
|---|---|---|---|
| BulletProof [22] | 52% | 3.15 | 2.07 |
| VICIS [24] | 42% | 9.3 | 6.55 |
| REPAIR [25] | 50% | 24.5 | 16.34 |
| SHIELD [28] | 34% | 15 | 11.49 |
| HPR [30] | 30% | 28.5 | 21.92 |
| Defender [31] | 28% | 33 | 25.78 |
| NoCGuard [29] | 28% | 28.5 | 22.26 |
| Proposed | 26.6% | 46.5 | 36.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashid, M.; Baloch, N.K.; Shafique, M.A.; Hussain, F.; Saleem, S.; Zikria, Y.B.; Yu, H. Fault-Tolerant Network-On-Chip Router Architecture Design for Heterogeneous Computing Systems in the Context of Internet of Things. Sensors 2020, 20, 5355. https://doi.org/10.3390/s20185355
Rashid M, Baloch NK, Shafique MA, Hussain F, Saleem S, Zikria YB, Yu H. Fault-Tolerant Network-On-Chip Router Architecture Design for Heterogeneous Computing Systems in the Context of Internet of Things. Sensors. 2020; 20(18):5355. https://doi.org/10.3390/s20185355
Chicago/Turabian StyleRashid, Muhammad, Naveed Khan Baloch, Muhammad Akmal Shafique, Fawad Hussain, Shahroon Saleem, Yousaf Bin Zikria, and Heejung Yu. 2020. "Fault-Tolerant Network-On-Chip Router Architecture Design for Heterogeneous Computing Systems in the Context of Internet of Things" Sensors 20, no. 18: 5355. https://doi.org/10.3390/s20185355
APA StyleRashid, M., Baloch, N. K., Shafique, M. A., Hussain, F., Saleem, S., Zikria, Y. B., & Yu, H. (2020). Fault-Tolerant Network-On-Chip Router Architecture Design for Heterogeneous Computing Systems in the Context of Internet of Things. Sensors, 20(18), 5355. https://doi.org/10.3390/s20185355