Malware Detection of Hangul Word Processor Files Using Spatial Pyramid Average Pooling



Abstract
1. Introduction
2. Related Work
2.1. Static Analysis of Non-Executable Malware
2.2. Byte Stream of Hangul Word Processor Files
2.3. Neural Networks for Malware Detection
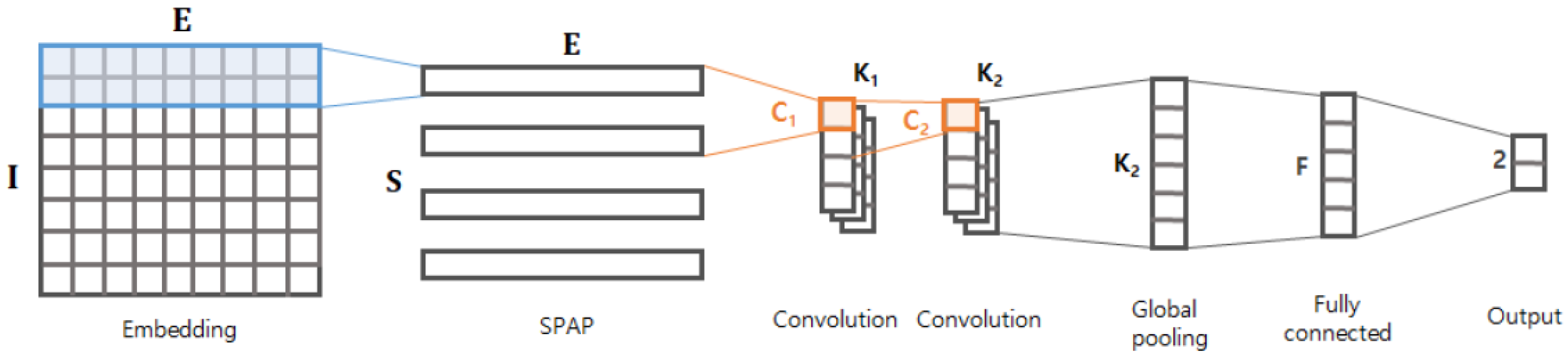
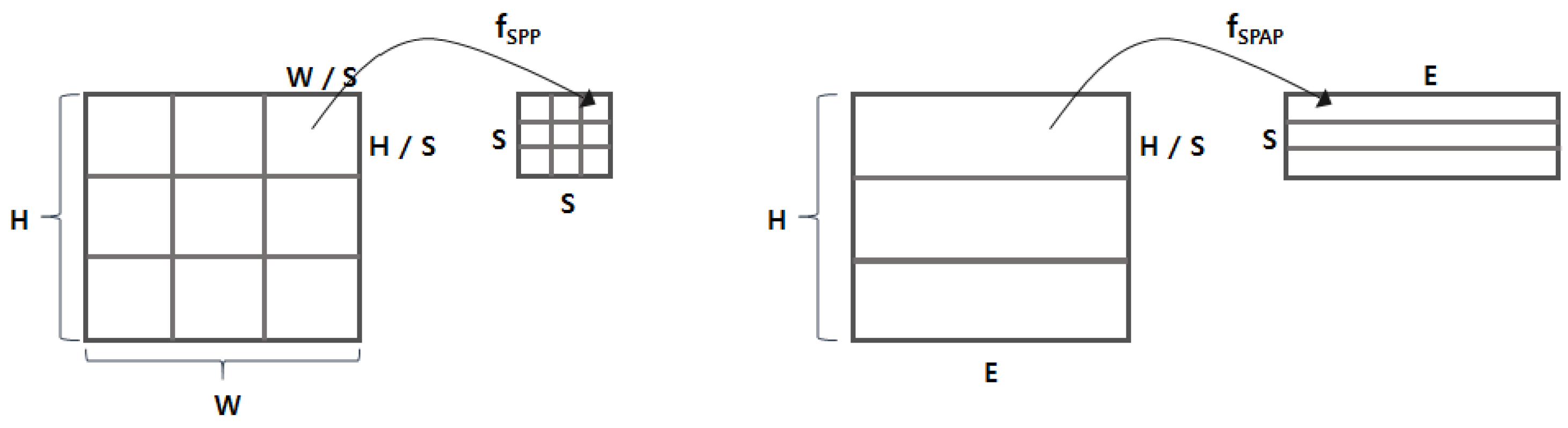
3. Proposed Method
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Park, J.; Rowe, N.C.; Cisneros, M. South Korea’s Options in Responding to North Korean Cyberattacks. J. Inf. Warf. 2016, 15, 86–99. [Google Scholar]
- Kim, C.W.; Polito, C. The Evolution of North Korean Cyber Threats; The Asan Institute for Policy Studies: Seoul, Korea, 2019; pp. 1–12. [Google Scholar]
- Jeong, Y.S.; Woo, J.; Kang, A.R. Malware Detection on Byte Streams of Hangul Word Processor Files. Appl. Sci. 2019, 9, 5178. [Google Scholar] [CrossRef]
- Burges, C.J.C. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Yan, J.; Qi, Y.; Rao, Q. Detecting Malware with an Ensemble Method Based on Deep Neural Network. Secur. Commun. Netw. 2018, 2018, 7247095. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Woo, J.; Kang, A.R. Malware Detection on Byte Streams of PDF Files Using Convolutional Neural Networks. Secur. Commun. Netw. 2019, 6, 1–9. [Google Scholar] [CrossRef]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C. Malware detection by eating a whole EXE. In Proceedings of the Workshops of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 268–276. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Norton. Available online: https://us.norton.com/ (accessed on 1 September 2020).
- Kaspersky. Available online: https://www.kaspersky.co.kr/ (accessed on 1 September 2020).
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep Learning for Classification of Malware System Call Sequences. In Proceedings of the 29th Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 5–8 December 2016; pp. 137–149. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Xiao, F.; Lin, Z.; Sun, Y.; Ma, Y. Malware Detection Based on Deep Learning of Behavior Graphs. Math. Probl. Eng. 2019, 2019, 1–10. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Shalaginov, A.; Banin, S.; Dehghantanha, A.; Franke, K. Machine Learning Aided Static Malware Analysis: A Survey and Tutorial. Cyber Threat Intell. Adv. Inf. Secur. 2018, 70, 7–45. [Google Scholar]
- Nath, H.V.; Mehtre, B.M. Static Malware Analysis Using Machine Learning Methods. In Proceedings of the International Conference on Security in Computer Networks and Distributed Systems, Trivandrum, India, 13–14 March 2014; pp. 440–450. [Google Scholar]
- Ranveer, S.; Hiray, S. SVM Based Effective Malware Detection System. Int. J. Comput. Sci. Inf. Technol. 2015, 6, 3361–3365. [Google Scholar]
- VXheavens. Available online: http://vx.netlux.org (accessed on 1 September 2020).
- Morales-Molina, C.D.; Santamaria-Guerrero, D.; Sanchez-Perez, G.; Toscano-Medina, K.; Perez-Meana, H.; Hernandez-Suarez, A. Methodology for Malware Classification using a Random Forest Classifier. In Proceedings of the IEEE International Autumn Meeting on Power, Electronics and Computing, Ixtapa, Mexico, 14–16 November 2018; pp. 1–6. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Darus, F.M.; Ahmad, N.A.; Ariffin, A.F.M. Android Malware Classification Using XGBoost On Data Image Pattern. In Proceedings of the IEEE International Conference on Internet of Things and Intelligence System, Bali, Indonesia, 5–7 November 2019; pp. 118–122. [Google Scholar]
- Oliva, A.; Torralba, A. Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Saif, D.; El-Gokhy, S.M.; Sallam, E. Deep Belief Networks-based framework for malware detection in Android systems. Alex. Eng. J. 2018, 57, 4049–4057. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Rhode, M.; Burnap, P.; Jones, K. Early-stage malware prediction using recurrent neural networks. Comput. Secur. 2018, 77, 578–594. [Google Scholar] [CrossRef]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press: New York, NY, USA, 1999. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Yan, J.; Wang, K.; Liu, Y.; Xu, K.; Kang, L.; Chen, X.; Zhu, H. Mining social lending motivations for loan project recommendations. Expert Syst. Appl. 2018, 111, 100–106. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Jeon, Y.; Kim, J. Constructing Fast Network through Deconstruction of Convolution. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Siem Reap, Cambodia, 13–16 December 2018; pp. 5955–5965. [Google Scholar]
- Fragkos, G.; Angelopoulou, O.; Xynos, K. Antivirus False Positives Alerts, Evading Malware Detection and Cyber-Security Issues. J. Inf. Warf. 2013, 12, 26–40. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name (*Storage or Stream) | Length |
|---|---|---|
| File recognition information | FileHeader | fixed |
| Document information | DocInfo | fixed |
| *BodyText | ||
| Main document | Section 0 | unfixed |
| Section 1 | ||
| Document summary | HWPSummaryInformation | fixed |
| *BinData | ||
| Binary data | BinaryData0 | unfixed |
| BinaryData1 | ||
| Preview text | PrvText | fixed |
| Preview image | PrvImage | unfixed |
| *DocOptions | ||
| Document options | LinkDoc | unfixed |
| DrmLicense | ||
| *Scripts | ||
| Script | DefaultJScript | unfixed |
| JScriptVersion | ||
| *XML Template | ||
| XML template | Schema | unfixed |
| Instance | ||
| *DocHistory | ||
| Document history | VersionLog0 | unfixed |
| VersionLog1 |
| Total | Malicious | Benign | |
|---|---|---|---|
| Train + Test | 6520 | 3668 | 2852 |
| Train | 5868 | 3265 | 2603 |
| Test | 652 | 403 | 249 |
| #Params | FLOPS | Runtime | |
|---|---|---|---|
| Cons-Conv | 2,056,354 | 4,112,896 | 15.8662 |
| Mal-Conv | 1,043,074 | 2,085,384 | 0.8572 |
| SPAP-Conv | 70,274 | 143,453 | 0.9831 |
| Model | F1 (%) | Precision (%) | Recall (%) | |
|---|---|---|---|---|
| stretch | Cons-Conv | 81.32/89.99 | 89.81/85.65 | 74.30/94.79 |
| Mal-Conv | 89.05/92.06 | 81.61/98.58 | 97.99/86.35 | |
| SPAP-Conv | 92.86/95.08 | 87.28/99.46 | 99.20/91.07 | |
| tail | Cons-Conv | 80.00/88.54 | 84.07/86.15 | 76.31/91.07 |
| Mal-Conv | 86.83/90.72 | 80.69/95.86 | 93.98/86.10 | |
| SPAP-Conv | 86.96/92.33 | 89.74/90.67 | 84.34/94.04 |
| F1 (%) | Precision (%) | Recall (%) | |
|---|---|---|---|
| SPAP-Conv with max-pooling | 84.67/92.27 | 98.40/86.21 | 74.30/99.26 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, Y.-S.; Woo, J.; Lee, S.; Kang, A.R. Malware Detection of Hangul Word Processor Files Using Spatial Pyramid Average Pooling. Sensors 2020, 20, 5265. https://doi.org/10.3390/s20185265
Jeong Y-S, Woo J, Lee S, Kang AR. Malware Detection of Hangul Word Processor Files Using Spatial Pyramid Average Pooling. Sensors. 2020; 20(18):5265. https://doi.org/10.3390/s20185265
Chicago/Turabian StyleJeong, Young-Seob, Jiyoung Woo, SangMin Lee, and Ah Reum Kang. 2020. "Malware Detection of Hangul Word Processor Files Using Spatial Pyramid Average Pooling" Sensors 20, no. 18: 5265. https://doi.org/10.3390/s20185265
APA StyleJeong, Y.-S., Woo, J., Lee, S., & Kang, A. R. (2020). Malware Detection of Hangul Word Processor Files Using Spatial Pyramid Average Pooling. Sensors, 20(18), 5265. https://doi.org/10.3390/s20185265