Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video


Abstract
1. Introduction
2. Related Work
2.1. Hazard Avoidance for the Visually Impaired with RGB-D Sensors
2.2. Semantic Segmentation to Help the Visually Impaired
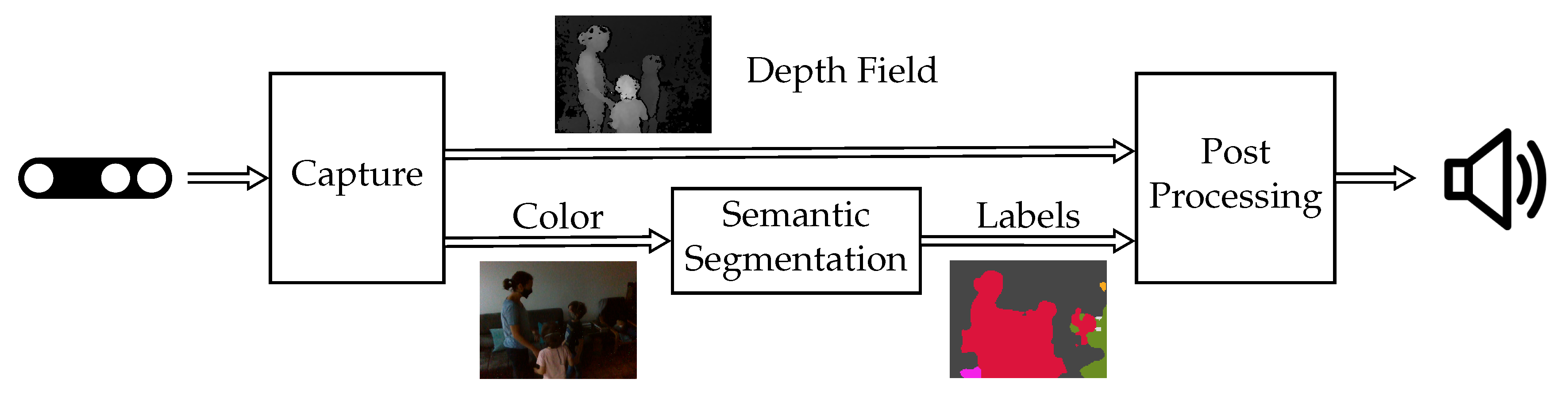
3. System
3.1. Hardware Components
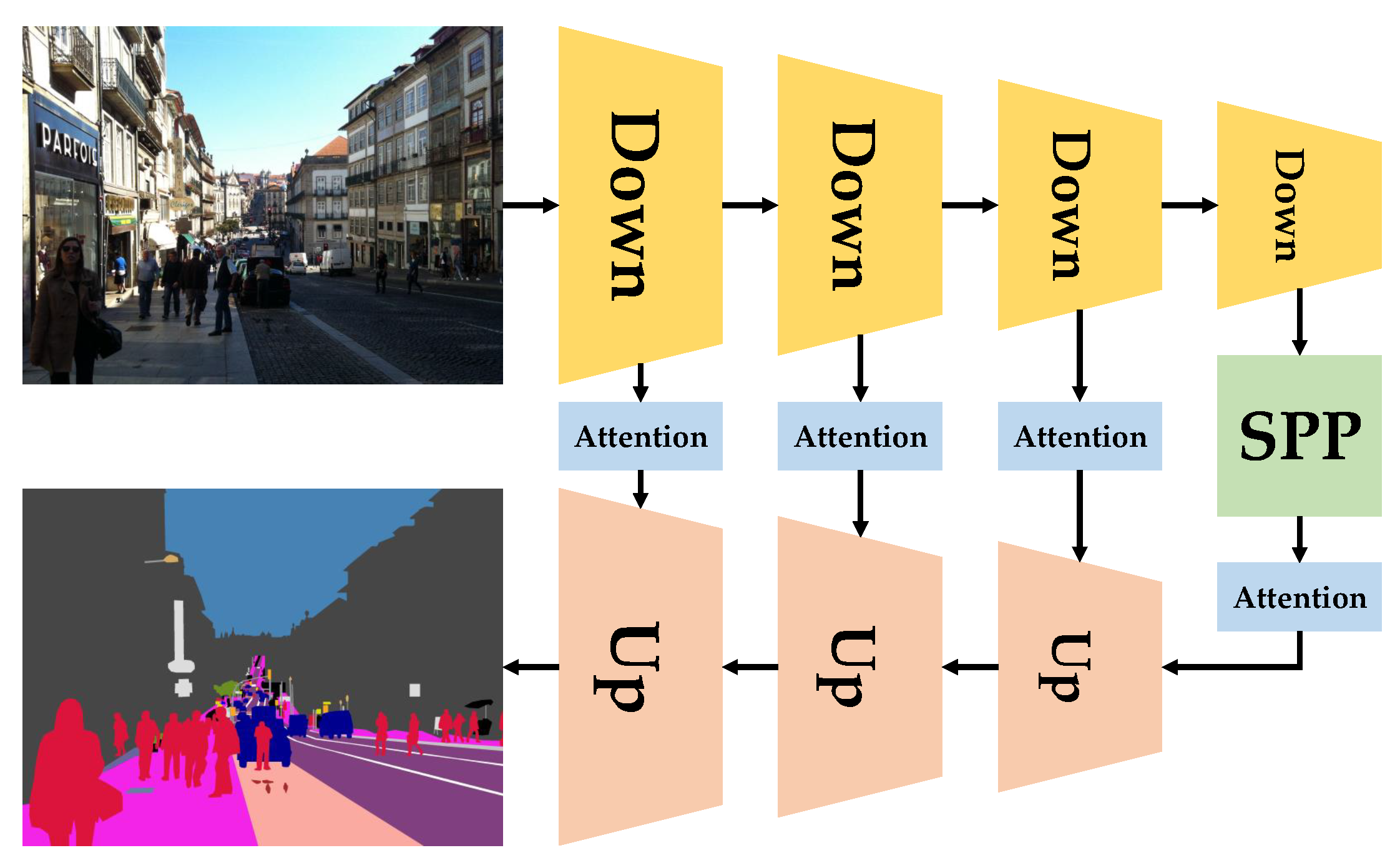
3.2. Software Components
4. Technical Evaluation
5. User Study
- Person obstructing a door, while the blind user aimed to enter the door;
- Group of people having a conversation in the middle of a walkway which the blind person wanted to walk across;
- Persons waiting in a queue at the entrance of a door;
- Having a group conversation, including the blind user;
- Navigating through the building and across the street.
5.1. Motivation
“This [social distancing] is the main problem, because physical distancing became social distancing. In general, I hate social distancing because […] we don’t want to distance socially. It’s physical distancing, but now it is the case that physical distancing became social distancing. People don’t speak, I cannot hear them, I cannot keep my distance and it’s difficult in trains, in the tramway, in shops. Sometimes people help, but in general they don’t communicate because they wear a mask, so they don’t communicate, I can‘t hear them, it’s like Ghostbusters a little bit.”
“[After a long test session] It only recognizes persons. Fascinating. I think it‘s a very good start. And I think that if you implement it as an App, I would want to pay for that. Because this […] distancing is so difficult for us. I hate it from morning to night.”
“I believe that such an aid would be very very helpful to keep distance. Not only because of Corona, but distance, if you are warned […] then I know that I have to be careful with my cane.”
5.2. Cognitive Load
5.3. Usability
5.4. User Comments
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- KR-Vision Technology. Available online: http://krvision.cn (accessed on 7 July 2020).
- Yang, K.; Hu, X.; Chen, H.; Xiang, K.; Wang, K.; Stiefelhagen, R. Ds-pass: Detail-sensitive panoramic annular semantic segmentation through swaftnet for surrounding sensing. arXiv 2019, arXiv:1909.07721. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Bulò, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 91–99. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the International Conference of Robotics and Automation Workshop, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Grier, R. How high is high? A metanalysis of NASA TLX global workload scores. Hum. Factors Ergon. Soc. 2015, 59, 1727–1731. [Google Scholar] [CrossRef]
- NASA Ames Research Center, Human Performance Research Group. NASA Task Load Index. Available online: https://humansystems.arc.nasa.gov/groups/TLX/downloads/TLX.pdf (accessed on 17 July 2020).
- Rodríguez, A.; Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Almazán, J.; Cela, A. Assisting the visually impaired: obstacle detection and warning system by acoustic feedback. Sensors 2012, 12, 17476–17496. [Google Scholar] [CrossRef]
- Schauerte, B.; Koester, D.; Martinez, M.; Stiefelhagen, R. Way to go! Detecting open areas ahead of a walking person. In Proceedings of the European Conference on Computer Vision Workshops, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Elmannai, W.; Elleithy, K. Sensor-based assistive devices for visually-impaired people: Current status, challenges, and future directions. Sensors 2017, 17, 565. [Google Scholar] [CrossRef]
- Aladren, A.; López-Nicolás, G.; Puig, L.; Guerrero, J.J. Navigation assistance for the visually impaired using RGB-D sensor with range expansion. IEEE Syst. J. 2014, 10, 922–932. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Hu, W.; Bai, J. Expanding the detection of traversable area with RealSense for the visually impaired. Sensors 2016, 16, 1954. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.C.; Katzschmann, R.K.; Teng, S.; Araki, B.; Giarré, L.; Rus, D. Enabling independent navigation for visually impaired people through a wearable vision-based feedback system. In Proceedings of the International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017. [Google Scholar]
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Smart guiding glasses for visually impaired people in indoor environment. IEEE Trans. Consum. Electron. 2017, 63, 258–266. [Google Scholar] [CrossRef]
- Long, N.; Wang, K.; Cheng, R.; Yang, K.; Hu, W.; Bai, J. Assisting the visually impaired: multitarget warning through millimeter wave radar and RGB-depth sensors. J. Electron. Imaging 2019, 28, 013028. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Cheng, R.; Hu, W.; Huang, X.; Bai, J. Detecting traversable area and water hazards for the visually impaired with a pRGB-D sensor. Sensors 2017, 17, 1890. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Wang, K.; Lin, S.; Bai, J.; Bergasa, L.M.; Arroyo, R. Long-range traversability awareness and low-lying obstacle negotiation with RealSense for the visually impaired. In Proceedings of the International Conference on Information Science and Systems, Jeju Island, Korea, 27–29 April 2018. [Google Scholar]
- Hua, M.; Nan, Y.; Lian, S. Small Obstacle Avoidance Based on RGB-D Semantic Segmentation. In Proceedings of the International Conference on Computer Vision Workshop, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Martinez, M.; Roitberg, A.; Koester, D.; Stiefelhagen, R.; Schauerte, B. Using Technology Developed for Autonomous Cars to Help Navigate Blind People. In Proceedings of the International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Badino, H.; Franke, U.; Pfeiffer, D. The stixel world-a compact medium level representation of the 3d-world. In Proceedings of the Joint Pattern Recognition Symposium, Jena, Germany, 9–11 September 2009. [Google Scholar]
- Wang, J.; Yang, K.; Hu, W.; Wang, K. An environmental perception and navigational assistance system for visually impaired persons based on semantic stixels and sound interaction. In Proceedings of the International Conference on Systems, Man, and Cybernetics, Miyazaki, Japan, 7–10 October 2018. [Google Scholar]
- Bai, J.; Liu, Z.; Lin, Y.; Li, Y.; Lian, S.; Liu, D. Wearable travel aid for environment perception and navigation of visually impaired people. Electronics 2019, 8, 697. [Google Scholar] [CrossRef]
- Kajiwara, Y.; Kimura, H. Object identification and safe route recommendation based on human flow for the visually impaired. Sensors 2019, 19, 5343. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dimas, G.; Diamantis, D.E.; Kalozoumis, P.; Iakovidis, D.K. Uncertainty-Aware Visual Perception System for Outdoor Navigation of the Visually Challenged. Sensors 2020, 20, 2385. [Google Scholar] [CrossRef] [PubMed]
- Bat Orientation Guide. Available online: http://www.synphon.de/en/fledermaus-orientierungshilfe.html (accessed on 28 July 2020).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Oršic, M.; Krešo, I.; Bevandic, P.; Šegvic, S. In Defense of Pre-Trained ImageNet Architectures for Real-Time Semantic Segmentation of Road-Driving Images. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying terrain awareness for the visually impaired through real-time semantic segmentation. Sensors 2018, 18, 1506. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Bergasa, L.M.; Romera, E.; Sun, D.; Wang, K.; Barea, R. Semantic perception of curbs beyond traversability for real-world navigation assistance systems. In Proceedings of the International Conference on Vehicular Electronics and Safety, Madrid, Spain, 12–14 September 2018. [Google Scholar]
- Cao, Z.; Xu, X.; Hu, B.; Zhou, M. Rapid Detection of Blind Roads and Crosswalks by Using a Lightweight Semantic Segmentation Network. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Yang, K.; Cheng, R.; Bergasa, L.M.; Romera, E.; Wang, K.; Long, N. Intersection perception through real-time semantic segmentation to assist navigation of visually impaired pedestrians. In Proceedings of the International Conference on Robotics and Biomimetics, Kuala Lumpur, Malaysia, 12–15 December 2018. [Google Scholar]
- Mehta, S.; Hajishirzi, H.; Shapiro, L. Identifying most walkable direction for navigation in an outdoor environment. arXiv 2017, arXiv:1711.08040. [Google Scholar]
- Watson, J.; Firman, M.; Monszpart, A.; Brostow, G.J. Footprints and Free Space from a Single Color Image. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Bangkok, Thailand, 9–11 December 2020. [Google Scholar]
- Lin, Y.; Wang, K.; Yi, W.; Lian, S. Deep Learning Based Wearable Assistive System for Visually Impaired People. In Proceedings of the International Conference on Computer Vision Workshop, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Long, N.; Wang, K.; Cheng, R.; Hu, W.; Yang, K. Unifying obstacle detection, recognition, and fusion based on millimeter wave radar and RGB-depth sensors for the visually impaired. Rev. Sci. Instrum. 2019, 90, 044102. [Google Scholar] [CrossRef]
- Yohannes, E.; Shih, T.K.; Lin, C.Y. Content-Aware Video Analysis to Guide Visually Impaired Walking on the Street. In Proceedings of the International Visual Informatics Conference, Bangi, Malaysia, 19–21 November 2019. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Mao, W.; Zhang, J.; Yang, K.; Stiefelhagen, R. Can we cover navigational perception needs of the visually impaired by panoptic segmentation? arXiv 2020, arXiv:2007.10202. [Google Scholar]
- Porzi, L.; Bulò, S.R.; Colovic, A.; Kontschieder, P. Seamless Scene Segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Cristani, M.; Del Bue, A.; Murino, V.; Setti, F.; Vinciarelli, A. The Visual Social Distancing Problem. arXiv 2020, arXiv:2005.04813. [Google Scholar] [CrossRef]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel (R) RealSense (TM) Stereoscopic Depth Cameras. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Nvidia. Jetson AGX Xavier Developer Kit. Available online: https://developer.nvidia.com/embedded/jetson-agx-xavier-developer-kit (accessed on 7 July 2020).
- Intel. RealSense Technology. Available online: https://github.com/IntelRealSense/librealsense (accessed on 7 July 2020).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Open Source Computer Vision Library. Available online: https://github.com/opencv/opencv (accessed on 13 July 2020).
- Open Audio Library. Available online: https://www.openal.org (accessed on 13 July 2020).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, K.; Hu, X.; Bergasa, L.M.; Romera, E.; Wang, K. Pass: Panoramic annular semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2019. [Google Scholar] [CrossRef]
- Nielsen, J.; Landauer, T.K. A Mathematical Model of the Finding of Usability Problems. In Proceedings of the INTERACT ’93 and CHI ’93 Conference on Human Factors in Computing Systems, Amsterdam, The Netherlands, 24–29 April 1993. [Google Scholar]
- Martinez, M.; Constantinescu, A.; Schauerte, B.; Koester, D.; Stiefelhagen, R. Cognitive evaluation of haptic and audio feedback in short range navigation tasks. In Proceedings of the International Conference on Computers for Handicapped Persons, Paris, France, 9–11 July 2014. [Google Scholar]
- Brooke, J. SUS: A quick and dirty usability scale. In Usability Evaluation in Industry; Taylor & Francis Group: Abingdon, UK, 1996. [Google Scholar]
- Bangor, A.; Kortum, P.T.; Miller, J.T. An Empirical Evaluation of the System Usability Scale. Int. J. Human Comput. Interact. 2008, 24, 574–594. [Google Scholar] [CrossRef]
- TensorFlow Lite, an Open Source Deep Learning Framework for On-Device Inference. Available online: http://www.tensorflow.org/lite (accessed on 9 September 2020).
- Coral: A Complete Toolkit to Build Products with Local AI. Available online: http://coral.ai (accessed on 9 September 2020).
- Intel® Movidius™ Vision Processing Units (VPUs). Available online: https://www.intel.com/content/www/us/en/products/processors/movidius-vpu.html (accessed on 9 September 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pole | Street Light | Billboard | Traffic Light | Car | Truck | Bicycle | Motorcycle | Bus | Sign Front | Sign Back | Road | Sidewalk | Curb Cut |
| 47.5% | 35.8% | 43.4% | 62.8% | 90.3% | 70.4% | 55.9% | 59.1% | 75.1% | 69.5% | 38.7% | 88.6% | 68.8% | 14.7% |
| Plain | Bike Lane | Curb | Fence | Wall | Building | Person | Rider | Sky | Vegetation | Terrain | Marking | Crosswalk | mIoU |
| 17.4% | 37.3% | 55.5% | 55.0% | 46.7% | 86.6% | 69.9% | 47.3% | 98.2% | 89.7% | 63.7% | 53.5% | 62.3% | 59.4% |
| Resolution | Mean IoU | IoU of Person Seg. | Delay on the Laptop | Delay on Nvidia Xavier |
|---|---|---|---|---|
| 960 × 720 | 68.3% | 81.8% | 600.6 | 108.9 |
| 640 × 480 | 66.9% | 80.4% | 292.1 | 57.9 |
| 480 × 360 | 55.1% | 77.7% | 184.0 | 52.6 |
| 320 × 240 | 50.8% | 63.3% | 107.9 | 46.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez, M.; Yang, K.; Constantinescu, A.; Stiefelhagen, R. Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video. Sensors 2020, 20, 5202. https://doi.org/10.3390/s20185202
Martinez M, Yang K, Constantinescu A, Stiefelhagen R. Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video. Sensors. 2020; 20(18):5202. https://doi.org/10.3390/s20185202
Chicago/Turabian StyleMartinez, Manuel, Kailun Yang, Angela Constantinescu, and Rainer Stiefelhagen. 2020. "Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video" Sensors 20, no. 18: 5202. https://doi.org/10.3390/s20185202
APA StyleMartinez, M., Yang, K., Constantinescu, A., & Stiefelhagen, R. (2020). Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video. Sensors, 20(18), 5202. https://doi.org/10.3390/s20185202