Pyramid Inter-Attention for High Dynamic Range Imaging





Abstract
:1. Introduction
- We propose a novel CNN-based framework for ghost-free HDR imaging by leveraging pyramid inter-attention module (PIAM) which effectively aligns LDR images.
- We propose a dual excitation block (DEB), which recalibrates features both spatially and channel-wise by highlighting the informative features and excluding harmful components.
2. Related Work
2.1. HDR Imaging without Alignment
2.2. HDR Imaging with Alignment
2.3. Deep-Learning-Based Methods
2.4. Optical Flow
2.5. Attention Mechanisms
3. Proposed Method
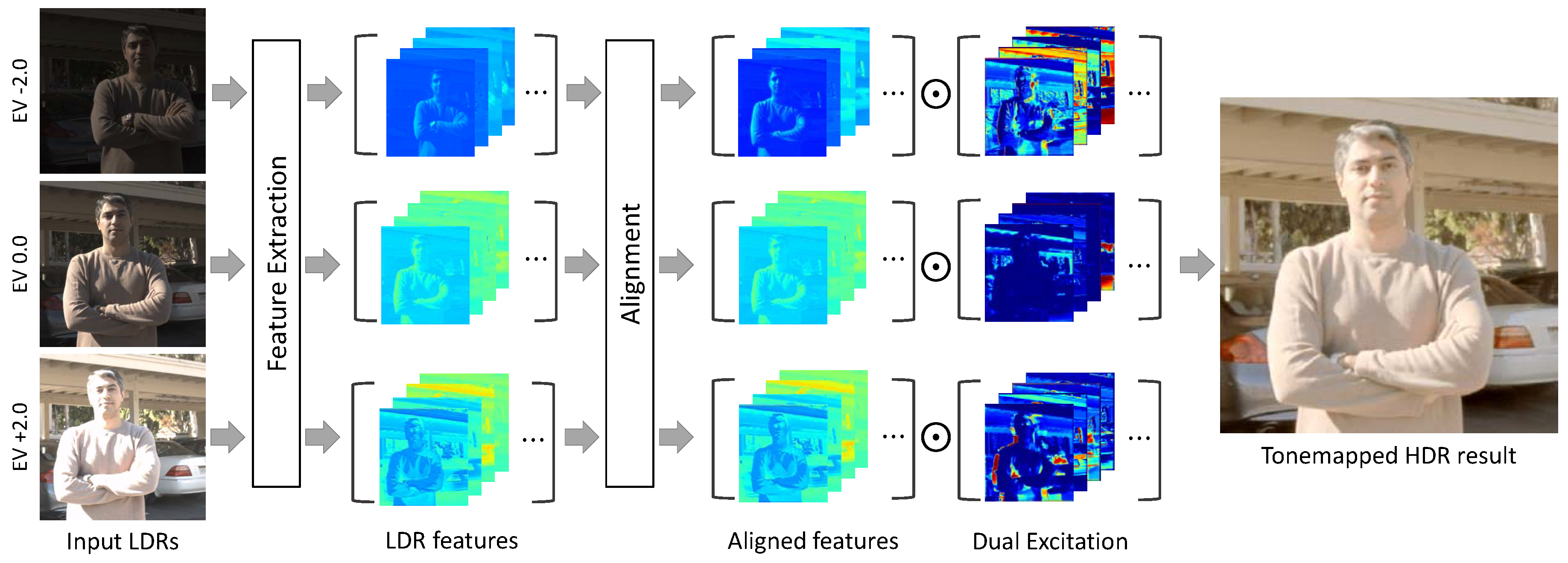
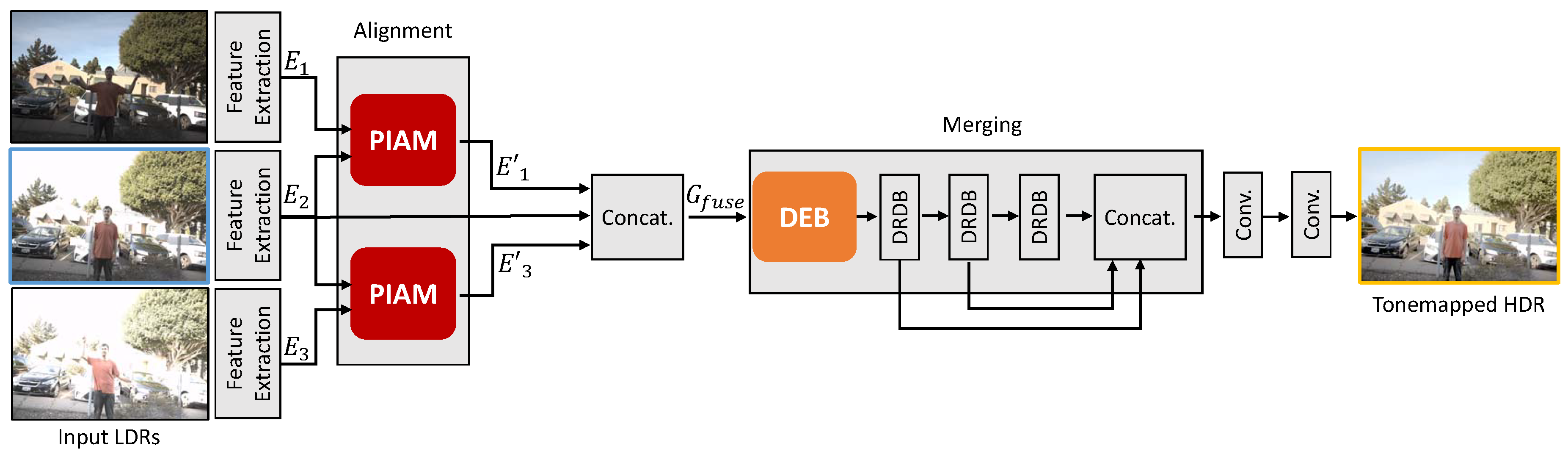
3.1. Overview
3.2. Alignment Network
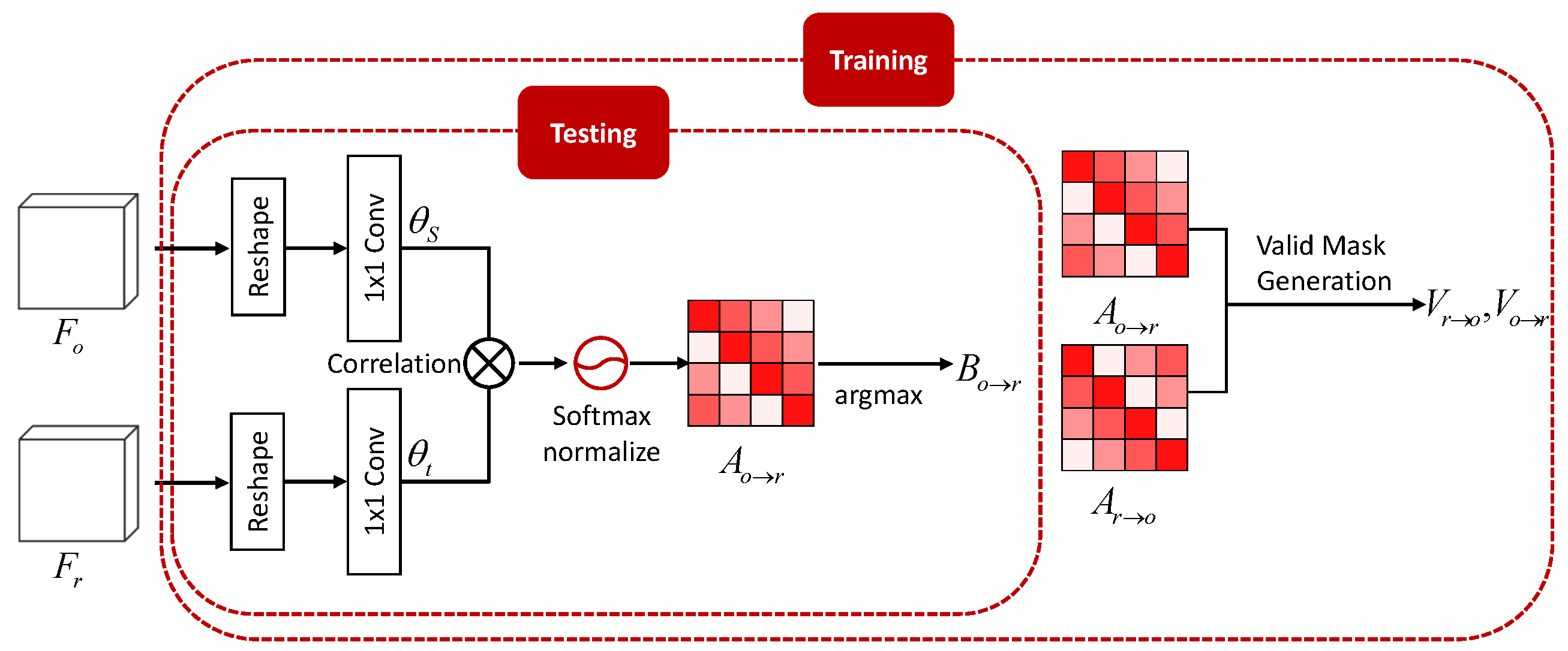
3.2.1. Inter Attention Module
3.2.2. Pyramid Inter-Attention Module
3.3. Merging Network
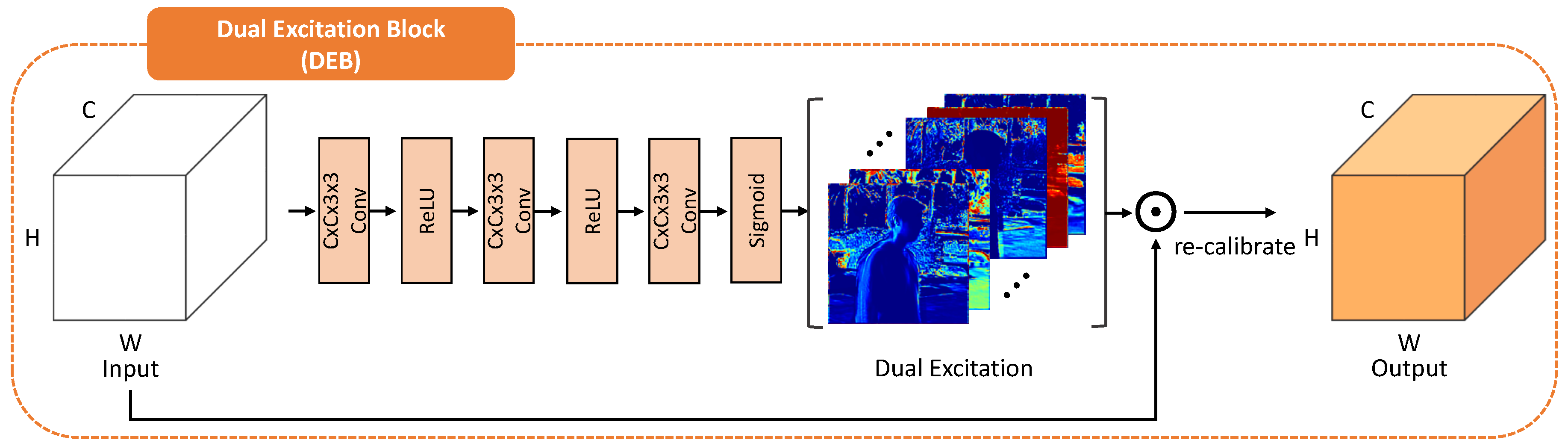
3.3.1. Dual Excitation Block (DEB)
3.3.2. Dilated Residual Dense Block (DRDB)
3.4. Training Losses
3.4.1. Alignment Loss
3.4.2. HDR Reconstruction Loss
4. Experiments
4.1. Implementation Details
4.2. Experimental Settings
4.2.1. Datasets
4.2.2. Evaluation Metrics
4.3. Comparison with the State-of-the-Art Methods
4.4. Experiments on Kalantari et al.’s Dataset
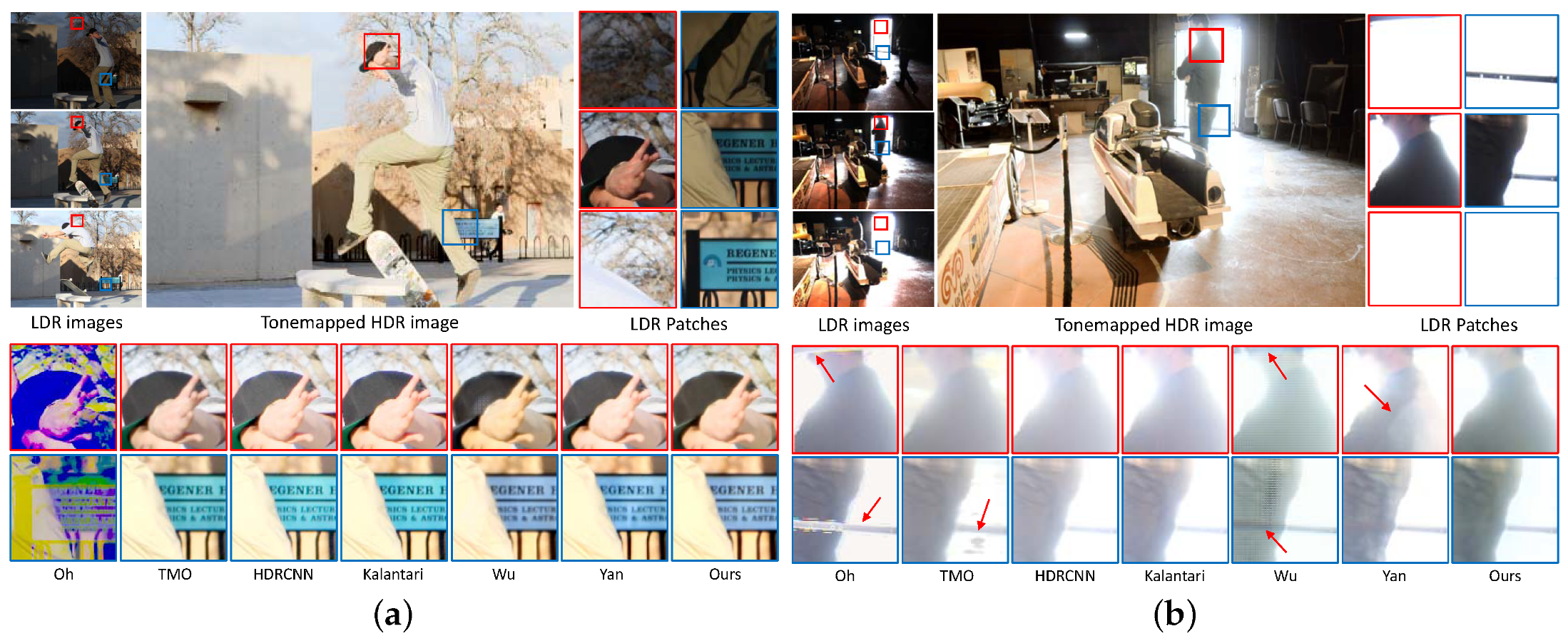
4.4.1. Qualitative Comparison
4.4.2. Quantitative Comparison
4.5. Experiments on Datasets without Ground Truth
Qualitative Comparison
4.6. Analysis
4.6.1. Ablation Studies
4.6.2. Matching Accuracy Comparison
4.6.3. Run Time Comparison
4.6.4. Cellphone Example
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Banterle, F.; Artusi, A.; Debattista, K.; Chalmers, A. Advanced High Dynamic Range Imaging; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Mann, S.; Rosalind, W. On being undigital with digital cameras: Extending dynamic range by combining exposed pictures. In Proceedings of the IST 48th Annual Conference Society for Imaging Science and Technology, Cambridge, MA, USA, 7–11 May 1995. [Google Scholar]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. ACM SIGGRAPH 2008, 1–10. [Google Scholar] [CrossRef]
- Zhang, W.; Cham, W.K. Gradient-directed multiexposure composition. IEEE Trans. Image Process. 2011, 21, 2318–2323. [Google Scholar] [CrossRef] [PubMed]
- Jacobs, K.; Loscos, C.; Ward, G. Automatic high-dynamic range image generation for dynamic scenes. IEEE Comput. Graph. Appl. 2008, 28, 84–93. [Google Scholar] [CrossRef] [PubMed]
- Grosch, T. Fast and robust high dynamic range image generation with camera and object movement. Vision, Model. Vis. Rwth Aachen 2006, 277284, 139–152. [Google Scholar]
- Pece, F.; Kautz, J. Bitmap movement detection: HDR for dynamic scenes. In Proceedings of the 2010 Conference on Visual Media Production, London, UK, 17–18 November 2010. [Google Scholar]
- Heo, Y.S.; Lee, K.M.; Lee, S.U.; Moon, Y.; Cha, J. Ghost-free high dynamic range imaging. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010. [Google Scholar]
- Kang, S.B.; Uyttendaele, M.; Winder, S.; Szeliski, R. High dynamic range video. ACM Trans. Graph. (TOG) 2003, 22, 319–325. [Google Scholar] [CrossRef]
- Bogoni, L. Extending dynamic range of monochrome and color images through fusion. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000. [Google Scholar]
- Sen, P.; Kalantari, N.K.; Yaesoubi, M.; Darabi, S.; Goldman, D.B.; Shechtman, E. Robust patch-based hdr reconstruction of dynamic scenes. ACM Trans. Graph. (TOG) 2012, 31, 203. [Google Scholar] [CrossRef]
- Hafner, D.; Demetz, O.; Weickert, J. Simultaneous HDR and optic flow computation. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014. [Google Scholar]
- Tomaszewska, A.; Mantiuk, R. Image registration for multi-exposure high dynamic range image acquisition. In Proceedings of the 15th International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision 2007 in co-operation with EUROGRAPHICS, Prague, Czech Republic, 29 January–1 February 2007. [Google Scholar]
- Gallo, O.; Troccoli, A.; Hu, J.; Pulli, K.; Kautz, J. Locally non-rigid registration for mobile HDR photography. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Hu, J.; Gallo, O.; Pulli, K.; Sun, X. HDR deghosting: How to deal with saturation? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zimmer, H.; Bruhn, A.; Weickert, J. Freehand HDR imaging of moving scenes with simultaneous resolution enhancement. Comput. Graph. Forum 2011, 30, 405–414. [Google Scholar] [CrossRef]
- Endo, Y.; Kanamori, Y.; Mitani, J. Deep reverse tone mapping. ACM Trans. Graph. (TOG) 2017, 36, 177. [Google Scholar] [CrossRef]
- Jung, H.; Kim, Y.; Jang, H.; Ha, N.; Sohn, K. Unsupervised Deep Image Fusion With Structure Tensor Representations. IEEE Trans. Image Process. 2020, 29, 3845–3858. [Google Scholar] [CrossRef] [PubMed]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. (TOG) 2017, 36, 144. [Google Scholar] [CrossRef]
- Wu, S.; Xu, J.; Tai, Y.W.; Tang, C.K. Deep high dynamic range imaging with large foreground motions. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yan, Q.; Gong, D.; Shi, Q.; Hengel, A.V.D.; Shen, C.; Reid, I.; Zhang, Y. Attention-guided Network for Ghost-free High Dynamic Range Imaging. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR image reconstruction from a single exposure using deep CNNs. ACM Trans. Graph. (TOG) 2017, 36, 1–15. [Google Scholar] [CrossRef]
- Liu, C. Beyond Pixels: Exploring New Representations and Applications for Motion Analysis. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2009. [Google Scholar]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. An objective deghosting quality metric for HDR images. Comput. Graph. Forum 2016, 35, 139–152. [Google Scholar] [CrossRef]
- Unger, J.; Gustavson, S. High-dynamic-range video for photometric measurement of illumination. In Sensors, Cameras, and Systems for Scientific/Industrial Applications VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6501, p. 65010E. [Google Scholar]
- Khan, E.A.; Akyuz, A.O.; Reinhard, E. Ghost removal in high dynamic range images. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006. [Google Scholar]
- Lee, C.; Li, Y.; Monga, V. Ghost-free high dynamic range imaging via rank minimization. IEEE Signal Process. Lett. 2014, 21, 1045–1049. [Google Scholar]
- Oh, T.H.; Lee, J.Y.; Tai, Y.W.; Kweon, I.S. Robust high dynamic range imaging by rank minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1219–1232. [Google Scholar] [CrossRef]
- Jinno, T.; Okuda, M. Motion blur free HDR image acquisition using multiple exposures. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Smagt, P.V.D.; Cremers, D.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Li, G.; He, X.; Zhang, W.; Chang, H.; Dong, L.; Lin, L. Non-locally enhanced encoder-decoder network for single image de-raining. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 12–16 October 2018. [Google Scholar]
- Wang, L.; Wang, Y.; Liang, Z.; Lin, Z.; Yang, J.; An, W.; Guo, Y. Learning parallax attention for stereo image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 19–21 June 2018. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liang, Z.; Feng, Y.; Guo, Y.; Liu, H.; Chen, W.; Qiao, L.; Zhang, J. Learning for disparity estimation through feature constancy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Wang, Y.; Yang, Y.; Yang, Z.; Zhao, L.; Wang, P.; Xu, W. Occlusion aware unsupervised learning of optical flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Trans. Graph. (TOG) 2011, 30, 1–14. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size of Tensors | |||
|---|---|---|---|
| IAM | 4,294,967,296 | 377,487,360,000 | |
| PIAM | 16 + 65,536 | 9,600 + 614,400 |
| PSNR- | PSNR-M | PSNR-L | HDR-VDP-2 | |
|---|---|---|---|---|
| Sen [11] | 40.924 | 30.572 | 37.934 | 55.145 |
| Hu [15] | 32.021 | 24.982 | 30.610 | 55.104 |
| Oh [28] | 26.151 | 21.051 | 25.131 | 45.526 |
| TMO [17] | 8.612 | 24.384 | 7.904 | 43.394 |
| HDRCNN [22] | 14.387 | 24.503 | 13.704 | 46.790 |
| Kalantari [19] | 41.170 | 30.705 | 40.226 | 59.909 |
| Wu [20] | 39.345 | 31.159 | 38.782 | 59.296 |
| Yan [21] | 42.017 | 31.798 | 40.978 | 61.104 |
| Ours | 43.212 | 32.415 | 41.697 | 62.481 |
| PSNR- | PSNR-M | PSNR-L | HDR-VDP-2 | ||
|---|---|---|---|---|---|
| baseline network | 38.514 | 31.475 | 38.021 | 58.457 | |
| +PIAM | 41.824 | 31.595 | 39.945 | 60.184 | |
| +DEB | 41.524 | 31.518 | 40.211 | 60.858 | |
| +PIAM +DEB | 43.212 | 32.415 | 41.697 | 62.481 |
| W/o Alignment | SIFT-Flow [23] | PWC-Net [33] | PIAM | |
|---|---|---|---|---|
| SSIM | 0.4326 | 0.6342 | 0.6042 | 0.6614 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.; Cho, J.; Song, W.; Choe, J.; Yoo, J.; Sohn, K. Pyramid Inter-Attention for High Dynamic Range Imaging. Sensors 2020, 20, 5102. https://doi.org/10.3390/s20185102
Choi S, Cho J, Song W, Choe J, Yoo J, Sohn K. Pyramid Inter-Attention for High Dynamic Range Imaging. Sensors. 2020; 20(18):5102. https://doi.org/10.3390/s20185102
Chicago/Turabian StyleChoi, Sungil, Jaehoon Cho, Wonil Song, Jihwan Choe, Jisung Yoo, and Kwanghoon Sohn. 2020. "Pyramid Inter-Attention for High Dynamic Range Imaging" Sensors 20, no. 18: 5102. https://doi.org/10.3390/s20185102
APA StyleChoi, S., Cho, J., Song, W., Choe, J., Yoo, J., & Sohn, K. (2020). Pyramid Inter-Attention for High Dynamic Range Imaging. Sensors, 20(18), 5102. https://doi.org/10.3390/s20185102