Robust Wavelength Selection Using Filter-Wrapper Method and Input Scaling on Near Infrared Spectral Data †

 ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Partial Least Square Regression
2.2. Variable Selection Methods
2.2.1. Variable Importance in Projection
2.2.2. Uninformative Variable Elimination
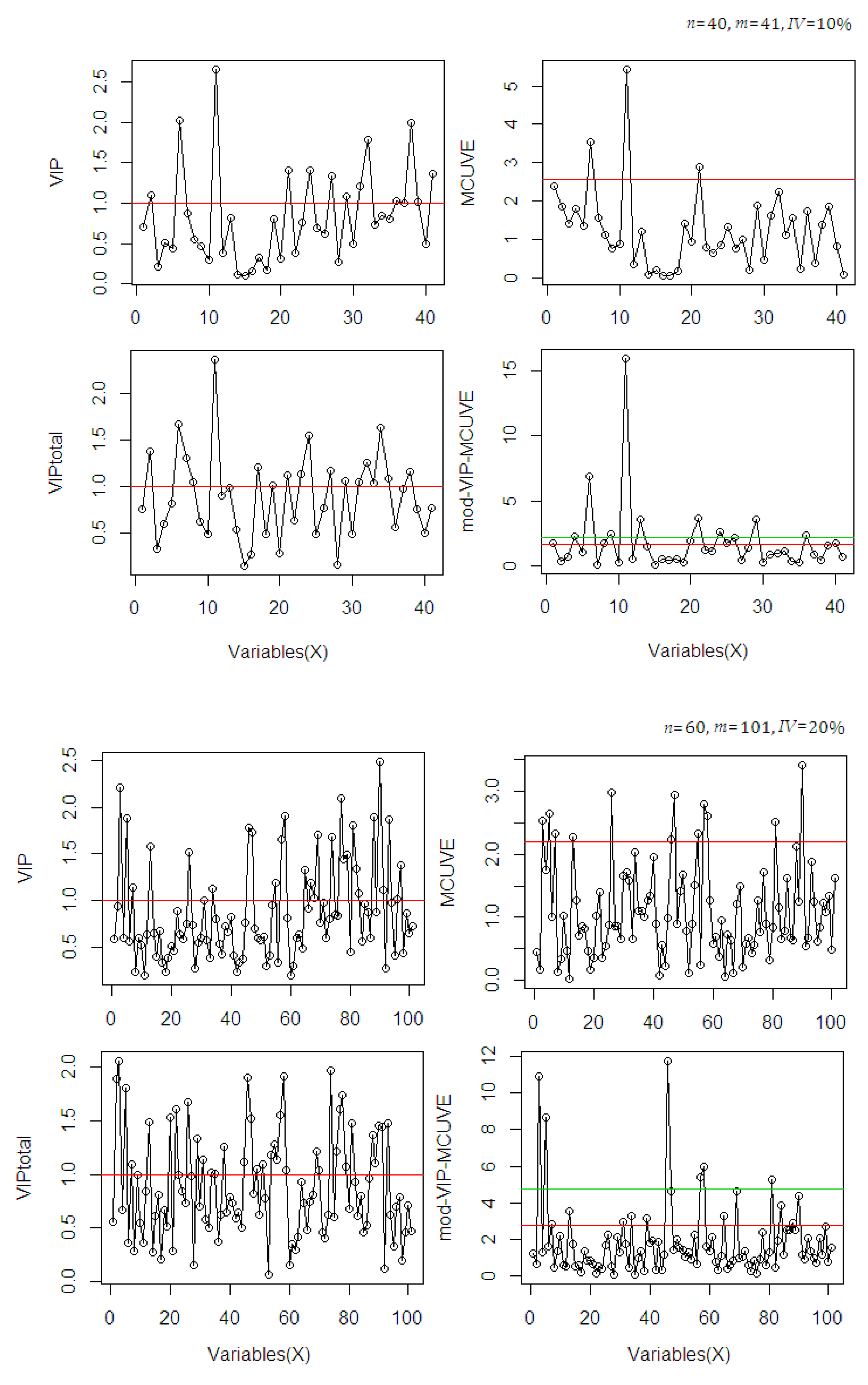
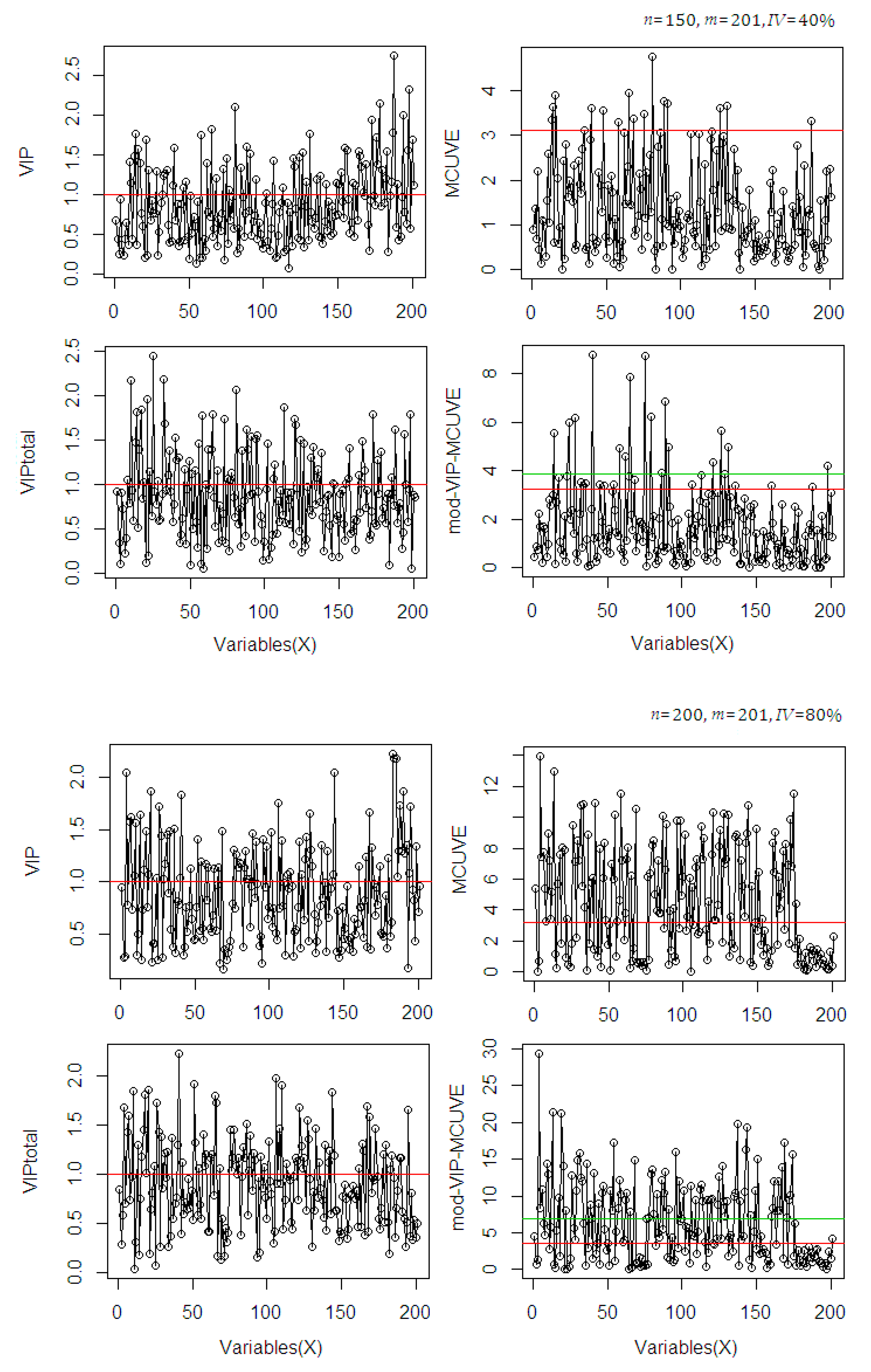
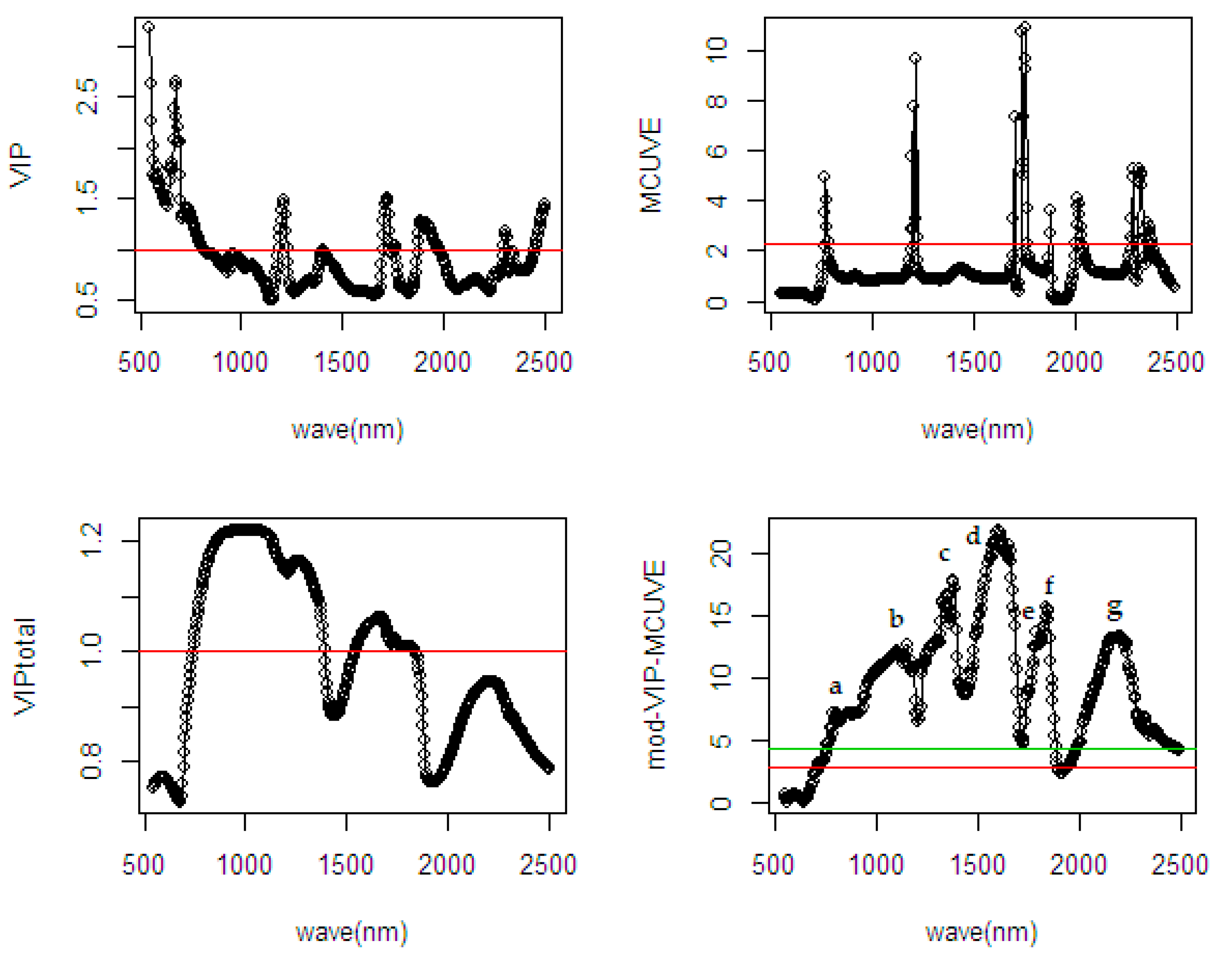
3. Input Scaling of Filter-Wrapper Method
- Step 1: Calculate the OPLS-VIP [19] score as initial input variable scaling matrix.
- Step 2: Run the modified MCUVE procedure using the scaled input matrix of OPLS-VIP to get the reliability scores.
- Step 3: Re-scale the input matrix using the reliability scores as final scaled input matrix in the PLSR model.
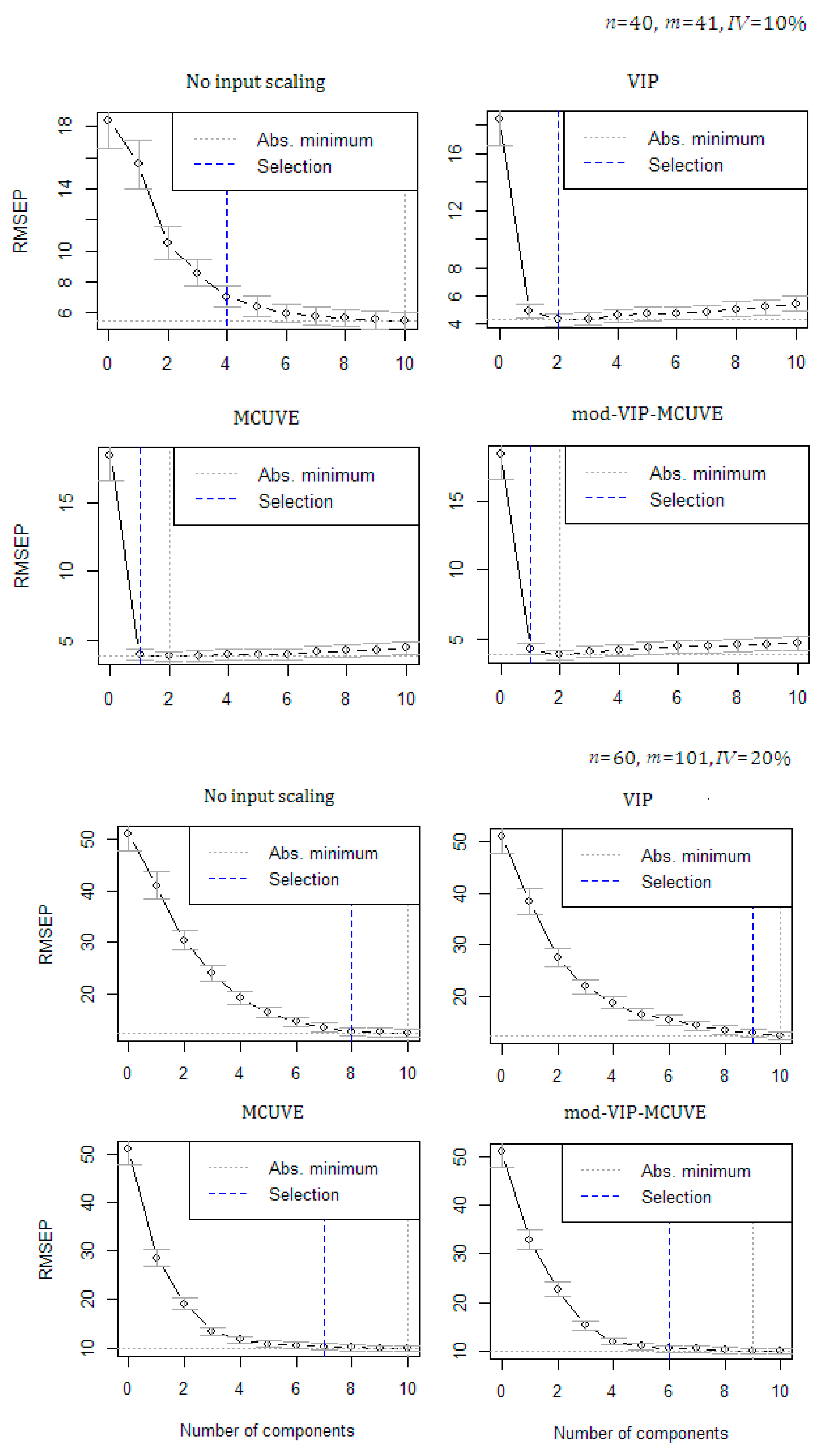
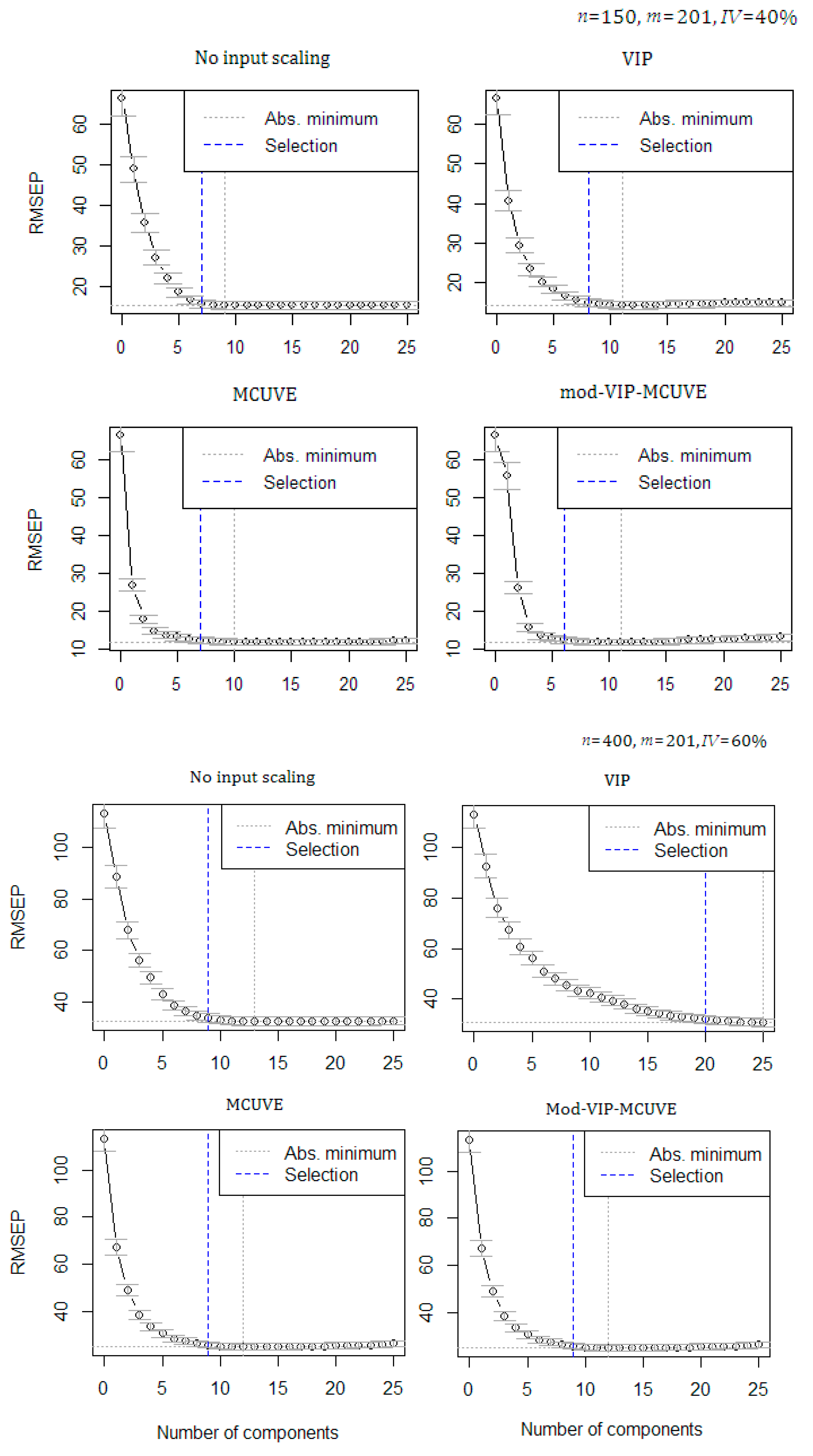
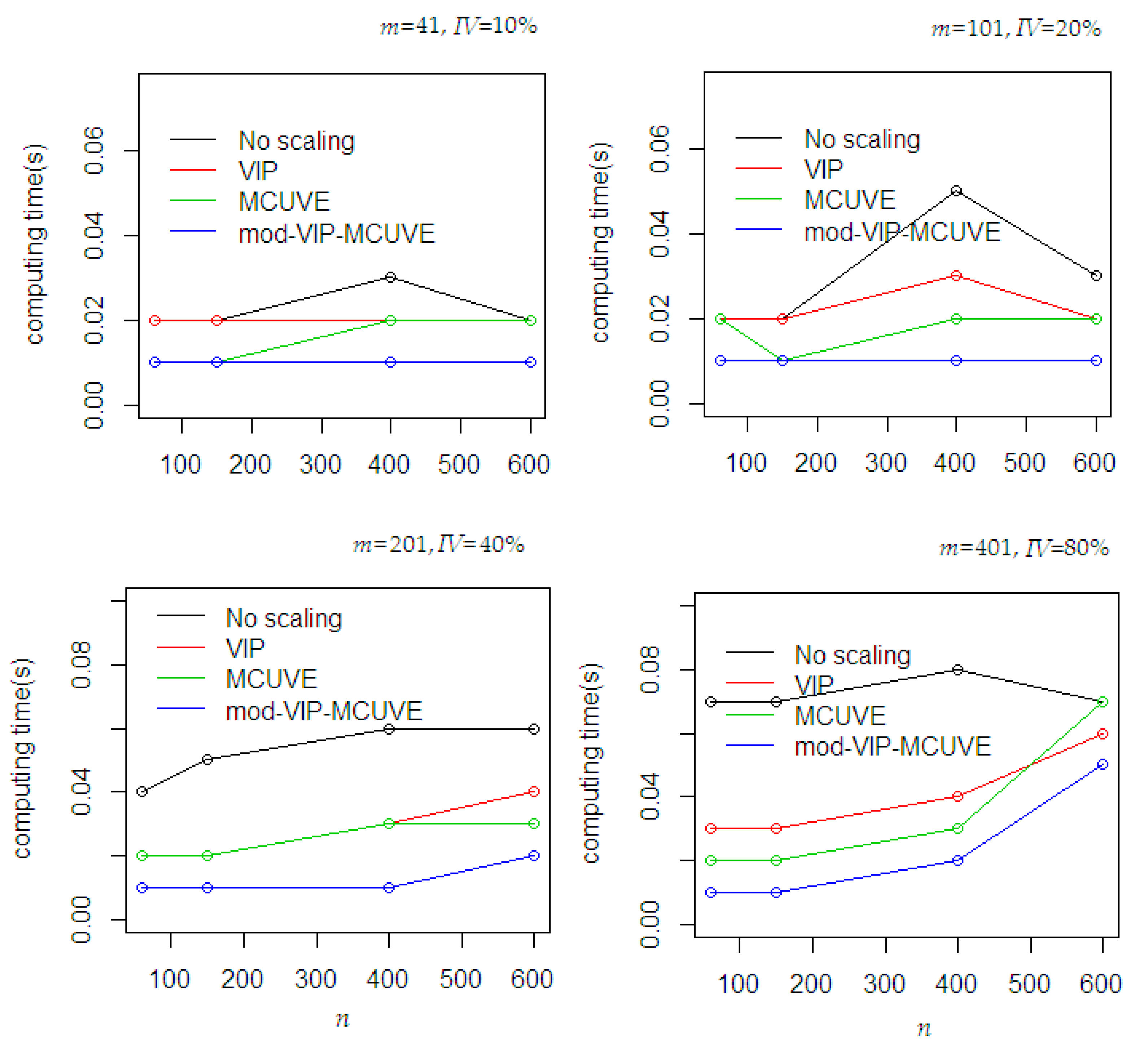
4. Monte Carlo Simulation Study
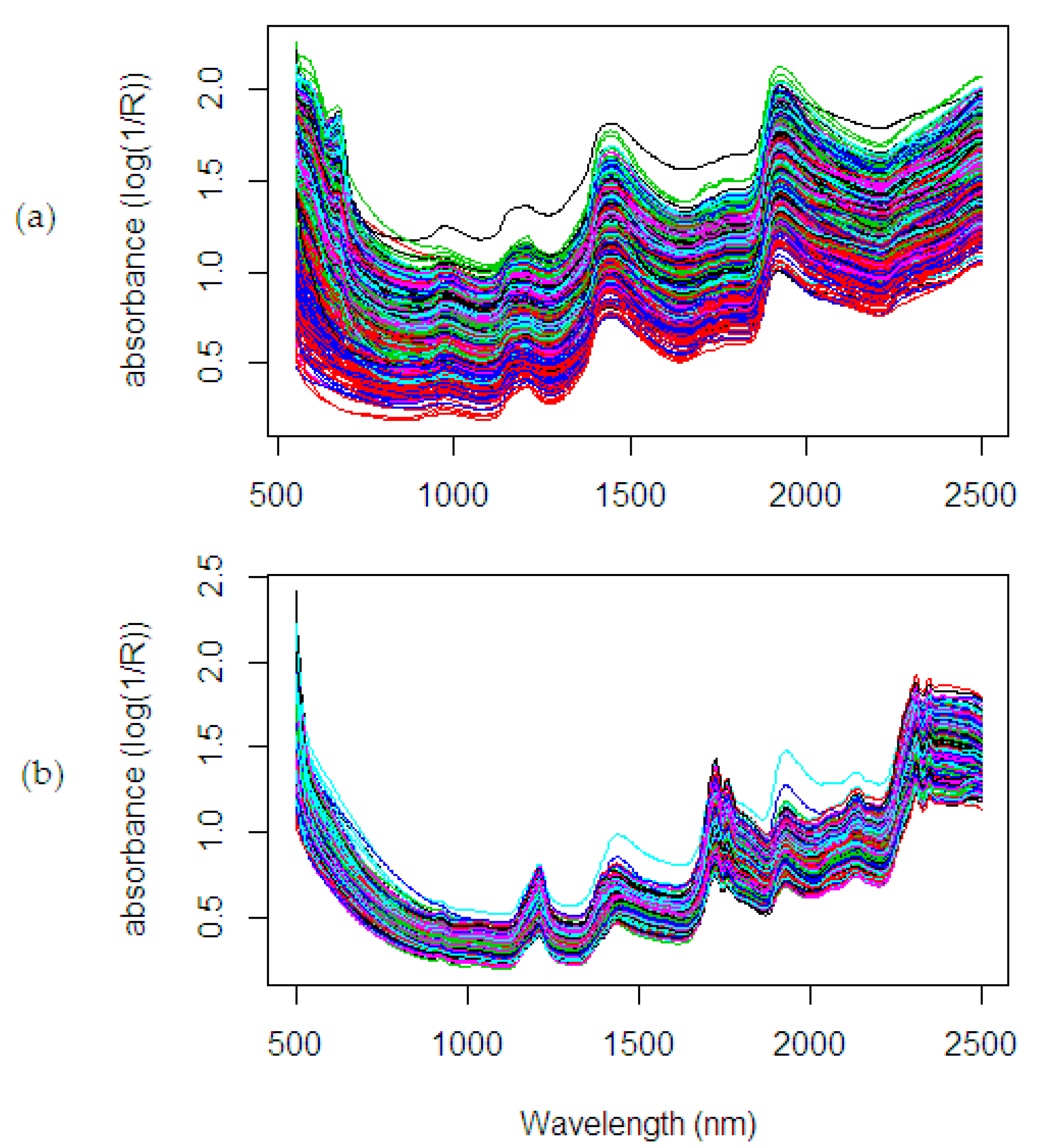
5. NIR Spectral Dataset
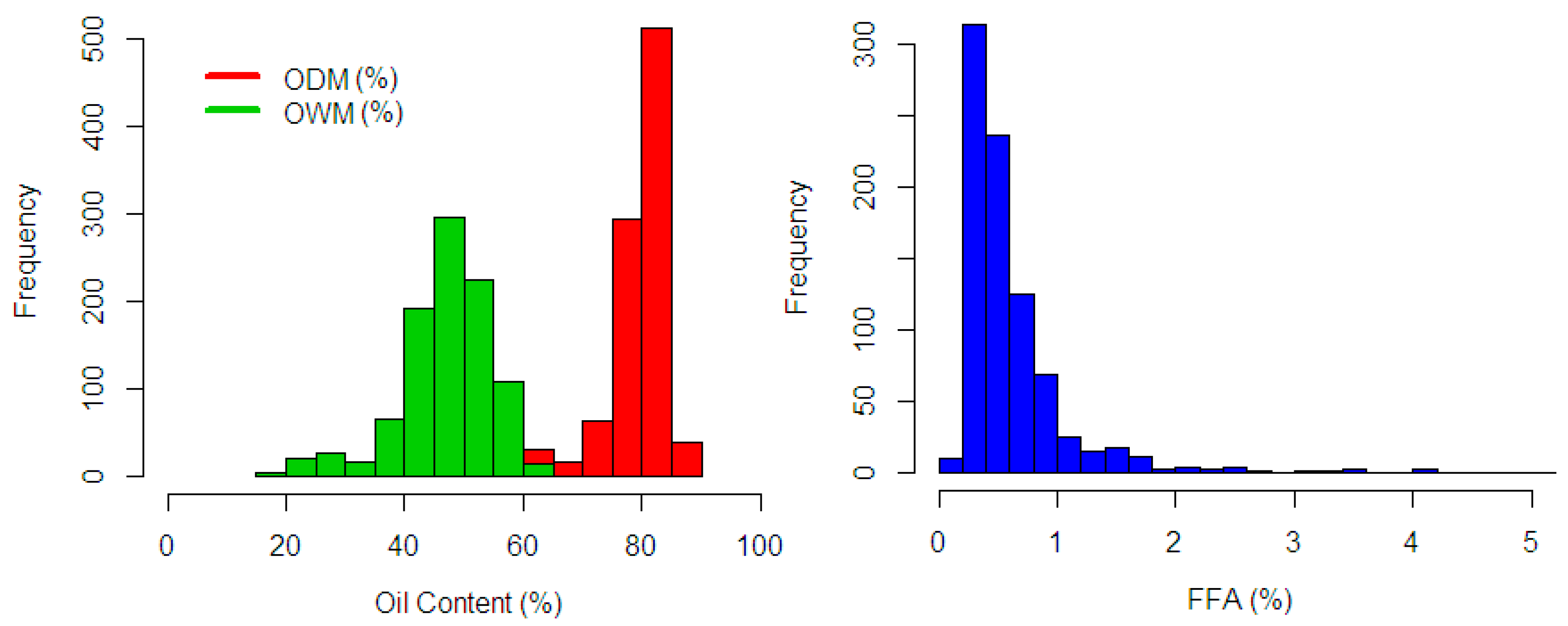
5.1. Oil to Dry Mesocarp
5.2. Oil to Wet Mesocarp
5.3. Fat Fatty Acids
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schowengerdt, R.A. Remote Sensing Models and Methods for Image Processing; Academic Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Hourant, P.; Baeten, V.; Morales, M.T.; Meurens, M.; Aparicio, R. Oil and Fat Classification by Selected Bands of Near-Infrared Spectroscopy. Appl. Spectrosc. 2000, 54, 1168–1174. [Google Scholar] [CrossRef]
- Kasemsumran, S.; Thanapase, W.; Punsuvon, V.; Ozaki, Y. A Feasibility Study on Non-Destructive Determination of Oil Content in Palm Fruits by Visible–Near Infrared Spectroscopy. J. Near Infrared Spectrosc. 2012, 20, 687–694. [Google Scholar] [CrossRef]
- Chong, I.-G.; Jun, C.-H. Performance of some variable selection methods when multicollinearity is present. Chemom. Intell. Lab. Syst. 2005, 78, 103–112. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Mehmood, T.; Martens, H.; Sæbø, S.; Warringer, J.; Snipen, L. A Partial Least Squares based algorithm for parsimonious variable selection. Algorithms Mol. Biol. 2011, 6, 27. [Google Scholar] [CrossRef]
- Wang, S.; Tang, J.; Liu, H. Feature selection. In Encyclopedia of Machine Learning and Data Mining; Springer Science + Business Media: New York, NY, USA, 2016; pp. 1–9. [Google Scholar]
- Reunanen, J. Overfitting in making comparisons between variable selection methods. J. Mach. Learn. Res. 2003, 3, 1371–1382. [Google Scholar]
- Andersen, C.M.; Bro, R. Variable selection in regression—A tutorial. J. Chemom. 2010, 24, 728–737. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Hira, Z.M.; Gillies, D.F. A Review of Feature Selection and Feature Extraction Methods Applied on Microarray Data. Adv. Bioinform. 2015, 2015. [Google Scholar] [CrossRef]
- Kokaly, R.F.; Clark, R.N. Spectroscopic Determination of Leaf Biochemistry Using Band-Depth Analysis of Absorption Features and Stepwise Multiple Linear Regression. Remote Sens. Environ. 1999, 67, 267–287. [Google Scholar] [CrossRef]
- Gidskehaug, L.; Anderssen, E.; Flatberg, A.; Alsberg, B.K. A framework for significance analysis of gene expression data using dimension reduction methods. BMC Bioinform. 2007, 8, 346. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Walczak, B.; Massart, D.; Prebble, K.; Last, I. Spectral transformation and wavelength selection in near-infrared spectra classification. Anal. Chim. Acta 1995, 315, 243–255. [Google Scholar] [CrossRef]
- Oussama, A.; Elabadi, F.; Platikanov, S.; Kzaiber, F.; Tauler, R. Detection of Olive Oil Adulteration Using FT-IR Spectroscopy and PLS with Variable Importance of Projection (VIP) Scores. J. Am. Oil Chem. Soc. 2012, 89, 1807–1812. [Google Scholar] [CrossRef]
- Palermo, G.; Piraino, P.; Zucht, H.-D. Performance of PLS regression coefficients in selecting variables for each response of a multivariate PLS for omics-type data. Adv. Appl. Bioinform. Chem. 2009, 2, 57–70. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Johansson, E.; Cocchi, M. PLS—Partial Least-Squares Projections to Latent Structures. In 3D QSAR in Drug Design. Theory, Methods and Applications; Kubinyi, H., Ed.; ESCOM Science Publishers. B. V.: Leiden, The Netherlands, 1993; pp. 523–550. [Google Scholar]
- Trygg, J.; Wold, S. Orthogonal projections to latent structures (O-PLS). J. Chemom. 2002, 16, 119–128. [Google Scholar] [CrossRef]
- Galindo-Prieto, B.; Eriksson, L.; Trygg, J. Variable influence on projection (VIP) for orthogonal projections to latent structures (OPLS). J. Chemom. 2014, 28, 623–632. [Google Scholar] [CrossRef]
- Leardi, R.; González, A.L. Genetic algorithms applied to feature selection in PLS regression: How and when to use them. Chemom. Intell. Lab. Syst. 1998, 41, 195–207. [Google Scholar] [CrossRef]
- Centner, V.; Massart, D.-L.; De Noord, O.E.; De Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of Uninformative Variables for Multivariate Calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef]
- Forina, M.; Casolino, C.; Pizarro Millan, C. Iterative predictor weighting (IPW) PLS: A technique for the elimination of useless predictors in regression problems. J. Chemom. Soc. 1999, 13, 165–184. [Google Scholar] [CrossRef]
- Guzmán, E.C.; Baeten, V.; Pierna, J.A.F.; García-Mesa, J.A. Application of low-resolution Raman spectroscopy for the analysis of oxidized olive oil. Food Control. 2011, 22, 2036–2040. [Google Scholar] [CrossRef]
- Wang, Z.X.; He, Q.P.; Wang, J. Comparison of variable selection methods for PLS-based soft sensor modeling. J. Process. Control. 2015, 26, 56–72. [Google Scholar] [CrossRef]
- Cai, W.; Li, Y.; Shao, X. A variable selection method based on uninformative variable elimination for multivariate calibration of near-infrared spectra. Chemom. Intell. Lab. Syst. 2008, 90, 188–194. [Google Scholar] [CrossRef]
- Kim, S.; Okajima, R.; Kano, M.; Hasebe, S. Development of soft-sensor using locally weighted PLS with adaptive similarity measure. Chemom. Intell. Lab. Syst. 2013, 124, 43–49. [Google Scholar] [CrossRef]
- Kim, J.; Kiss, B.; Lee, D. An adaptive unscented Kalman filtering approach using selective scaling. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 784–789. [Google Scholar]
- Wold, H. Multivariate Analysis; Krishnaiah, P.R., Ed.; Academic Press: New York, NY, USA, 1973; Volume 3, pp. 383–407. [Google Scholar]
- Martens, H.; Naes, T. Multivariate calibration. Math. Soc. 1992, 68, 337–404. [Google Scholar]
- Han, Q.-J.; Wu, H.-L.; Cai, C.-B.; Xu, L.; Yu, R.-Q. An ensemble of Monte Carlo uninformative variable elimination for wavelength selection. Anal. Chim. Acta 2008, 612, 121–125. [Google Scholar] [CrossRef]
- Gelman, A. Scaling regression inputs by dividing by two standard deviations. Stat. Med. 2008, 27, 2865–2873. [Google Scholar] [CrossRef]
- Saccenti, E.; Westerhuis, J.A.; Smilde, A.K.; Van Der Werf, M.J.; Hageman, J.A.; Hendriks, M.M.W.B. Simplivariate Models: Uncovering the Underlying Biology in Functional Genomics Data. PLoS ONE 2011, 6, e20747. [Google Scholar] [CrossRef]
- Vandeginste, B.G.M.; Massart, D.L.; De Jong, S.; Massaart, D.L.; Buydens, L.M.C. Handbook of Chemometrics and Qualimetrics: Part B; Elsevier BV: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Bakeev, K.A. Process Analytical Technology: Spectroscopic Tools and Implementation Strategies for the Chemical and Pharmaceutical Industries; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Orso, A.; Shi, N.; Harrold, M.J. Scaling regression testing to large software systems. ACM SIGSOFT Softw. Eng. Notes 2004, 29, 241. [Google Scholar] [CrossRef]
- Berg, R.A.V.D.; Hoefsloot, H.C.J.; Westerhuis, J.A.; Smilde, A.K.; Van Der Werf, M.J. Centering, scaling, and transformations: Improving the biological information content of metabolomics data. BMC Genom. 2006, 7, 142. [Google Scholar] [CrossRef]
- Natrella, M.G. Experimental Statistics Handbook 91; US Government Printing Office: Washington, DC, USA, 1963.
- Stuart, B. Infrared Spectroscopy: Fundamentals and Applications; Wiley: Hoboken, NJ, USA, 2004; p. 78. [Google Scholar]
- Siew, W.L.; Tan, Y.A.; Tang, T.S. Methods of Test for Palm Oil and Palm Oil Products: Compiled; Lin, S.W., Sue, T.T., Ai, T.Y., Eds.; Palm Oil Research Institute of Malaysia: Selangor, Malaysia, 1995. [Google Scholar]
- Rao, V.; Soh, A.C.; Corley, R.H.V.; Lee, C.H.; Rajanaidu, N. Critical Reexamination of the Method of Bunch Quality Analysis in Oil Palm Breeding. PORIM Occasional Paper. 1983. Available online: https://agris.fao.org/agris-search/search.do?recordID=US201302543052 (accessed on 1 September 2020).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | m | IV | Method | nPLS | RMSE | R2 | RPD | SE |
|---|---|---|---|---|---|---|---|---|
| 40 | 41 | 10% | PLSR | 5 | 2.130 | 0.994 | 12.824 | 2.164 |
| VIP | 4 | 2.524 | 0.991 | 10.488 | 2.567 | |||
| MCUVE | 2 | 2.016 | 0.994 | 13.133 | 2.050 | |||
| mod-VIP-MCUVE | 2 | 2.025 | 0.994 | 13.072 | 2.060 | |||
| 40 | 101 | 10% | PLSR | 4 | 9.715 | 0.940 | 4.130 | 9.839 |
| VIP | 5 | 9.368 | 0.944 | 4.283 | 9.487 | |||
| MCUVE | 4 | 10.705 | 0.927 | 3.748 | 10.841 | |||
| mod-VIP-MCUVE | 4 | 4.302 | 0.988 | 9.327 | 4.356 | |||
| 40 | 201 | 10% | PLSR | N/A | N/A | N/A | N/A | N/A |
| VIP | N/A | N/A | N/A | N/A | N/A | |||
| MCUVE | 2 | 15.843 | 0.834 | 2.797 | 16.044 | |||
| mod-VIP-MCUVE | 2 | 6.363 | 0.970 | 8.353 | 6.444 | |||
| 60 | 41 | 20% | PLSR | 8 | 4.448 | 0.974 | 7.005 | 4.486 |
| VIP | 6 | 4.848 | 0.973 | 6.322 | 4.889 | |||
| MCUVE | 5 | 5.266 | 0.967 | 5.812 | 5.311 | |||
| mod-VIP-MCUVE | 5 | 4.443 | 0.976 | 7.873 | 4.447 | |||
| 60 | 101 | 20% | PLSR | 5 | 10.248 | 0.968 | 5.601 | 10.335 |
| VIP | 4 | 16.726 | 0.914 | 3.432 | 16.867 | |||
| MCUVE | 7 | 13.579 | 0.943 | 4.227 | 13.693 | |||
| mod-VIP-MCUVE | 4 | 5.143 | 0.992 | 11.160 | 5.187 | |||
| 60 | 201 | 20% | PLSR | N/A | N/A | N/A | N/A | N/A |
| VIP | N/A | N/A | N/A | N/A | N/A | |||
| MCUVE | 2 | 33.192 | 0.735 | 2.544 | 33.472 | |||
| mod-VIP-MCUVE | 3 | 10.678 | 0.962 | 11.028 | 10.768 | |||
| 150 | 41 | 40% | PLSR | 6 | 6.359 | 0.971 | 5.931 | 6.381 |
| VIP | 7 | 7.183 | 0.963 | 5.242 | 7.207 | |||
| MCUVE | 5 | 7.097 | 0.964 | 5.306 | 7.121 | |||
| mod-VIP-MCUVE | 4 | 6.291 | 0.971 | 5.933 | 6.297 | |||
| 150 | 101 | 40% | PLSR | 9 | 8.949 | 0.979 | 7.379 | 8.979 |
| VIP | 8 | 12.947 | 0.958 | 5.047 | 12.991 | |||
| MCUVE | 6 | 11.023 | 0.970 | 5.850 | 11.060 | |||
| mod-VIP-MCUVE | 5 | 8.858 | 0.987 | 7.761 | 8.861 | |||
| 150 | 201 | 40% | PLSR | 5 | 14.798 | 0.975 | 6.406 | 14.847 |
| VIP | 5 | 27.199 | 0.917 | 3.485 | 27.290 | |||
| MCUVE | 5 | 23.706 | 0.937 | 3.999 | 23.785 | |||
| mod-VIP-MCUVE | 2 | 14.809 | 0.975 | 5.347 | 14.852 | |||
| 400 | 41 | 60% | PLSR | 5 | 9.424 | 0.967 | 5.515 | 9.436 |
| VIP | 9 | 10.057 | 0.962 | 5.157 | 10.070 | |||
| MCUVE | 7 | 9.991 | 0.963 | 5.200 | 10.003 | |||
| mod-VIP-MCUVE | 7 | 9.423 | 0.969 | 5.549 | 9.435 | |||
| 400 | 101 | 60% | PLSR | 6 | 14.258 | 0.972 | 6.025 | 14.275 |
| VIP | 9 | 16.240 | 0.964 | 5.290 | 16.260 | |||
| MCUVE | 7 | 15.424 | 0.968 | 5.571 | 15.443 | |||
| mod-VIP-MCUVE | 7 | 14.310 | 0.968 | 5.611 | 14.329 | |||
| 400 | 201 | 60% | PLSR | 10 | 14.258 | 0.972 | 6.025 | 14.275 |
| VIP | 14 | 16.240 | 0.964 | 5.290 | 16.260 | |||
| MCUVE | 10 | 15.424 | 0.968 | 5.571 | 15.443 | |||
| mod-VIP-MCUVE | 7 | 14.310 | 0.968 | 5.611 | 15.319 | |||
| 600 | 41 | 80% | PLSR | 10 | 10.789 | 0.966 | 5.469 | 10.798 |
| VIP | 8 | 11.072 | 0.965 | 5.328 | 11.081 | |||
| MCUVE | 8 | 11.139 | 0.964 | 5.297 | 11.147 | |||
| mod-VIP-MCUVE | 8 | 10.985 | 0.967 | 5.471 | 10.994 | |||
| 600 | 101 | 80% | PLSR | 12 | 16.264 | 0.969 | 5.737 | 16.278 |
| VIP | 10 | 16.998 | 0.967 | 5.495 | 17.012 | |||
| MCUVE | 9 | 17.019 | 0.967 | 5.483 | 17.033 | |||
| mod-VIP-MCUVE | 9 | 16.210 | 0.970 | 5.781 | 16.223 | |||
| 600 | 201 | 80% | PLSR | 12 | 20.988 | 0.975 | 6.305 | 21.005 |
| VIP | 12 | 22.276 | 0.971 | 5.942 | 22.295 | |||
| MCUVE | 8 | 22.588 | 0.971 | 5.855 | 22.607 | |||
| mod-VIP-MCUVE | 8 | 20.295 | 0.976 | 5.940 | 20.314 |
| Dataset | Methods | nPLS | RMSE | R2 | RPD | SE |
|---|---|---|---|---|---|---|
| %ODM | PLSR | 29 | 3.267 | 0.652 | 1.607 | 3.269 |
| VIP | 29 | 3.011 | 0.657 | 1.702 | 3.013 | |
| MCUVE | 26 | 3.107 | 0.633 | 1.650 | 3.108 | |
| mod-VIP-MCUVE | 26 | 3.009 | 0.659 | 1.725 | 3.011 |
| Dataset | Methods | nPLS | RMSE | R2 | RPD | SE |
|---|---|---|---|---|---|---|
| %OWM | PLSR | 20 | 4.558 | 0.651 | 1.693 | −0.067 |
| VIP | 20 | 4.506 | 0.659 | 1.713 | 0.062 | |
| MCUVE | 18 | 4.461 | 0.666 | 1.730 | −0.016 | |
| mod-VIP-MCUVE | 17 | 4.400 | 0.675 | 1.754 | 0.060 |
| Dataset | Methods | nPLS | RMSE | R2 | RPD | SE |
|---|---|---|---|---|---|---|
| %FFA | PLSR | 28 | 0.270 | 0.730 | 1.924 | 0.271 |
| VIP | 28 | 0.266 | 0.734 | 1.932 | 0.267 | |
| MCUVE | 26 | 0.264 | 0.736 | 1.946 | 0.265 | |
| mod-VIP-MCUVE | 25 | 0.265 | 0.735 | 1.940 | 0.266 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silalahi, D.D.; Midi, H.; Arasan, J.; Mustafa, M.S.; Caliman, J.-P. Robust Wavelength Selection Using Filter-Wrapper Method and Input Scaling on Near Infrared Spectral Data. Sensors 2020, 20, 5001. https://doi.org/10.3390/s20175001
Silalahi DD, Midi H, Arasan J, Mustafa MS, Caliman J-P. Robust Wavelength Selection Using Filter-Wrapper Method and Input Scaling on Near Infrared Spectral Data. Sensors. 2020; 20(17):5001. https://doi.org/10.3390/s20175001
Chicago/Turabian StyleSilalahi, Divo Dharma, Habshah Midi, Jayanthi Arasan, Mohd Shafie Mustafa, and Jean-Pierre Caliman. 2020. "Robust Wavelength Selection Using Filter-Wrapper Method and Input Scaling on Near Infrared Spectral Data" Sensors 20, no. 17: 5001. https://doi.org/10.3390/s20175001
APA StyleSilalahi, D. D., Midi, H., Arasan, J., Mustafa, M. S., & Caliman, J.-P. (2020). Robust Wavelength Selection Using Filter-Wrapper Method and Input Scaling on Near Infrared Spectral Data. Sensors, 20(17), 5001. https://doi.org/10.3390/s20175001