Application of Machine Learning for the in-Field Correction of a PM2.5 Low-Cost Sensor Network


Abstract
1. Introduction
2. Materials and Methods
2.1. Sensor Network Introduction
2.2. The Data Correction Models
2.3. Evaluation of the Correction Models
3. Results
3.1. Measurements of AS-LUNG-O Sets and EPA Stations
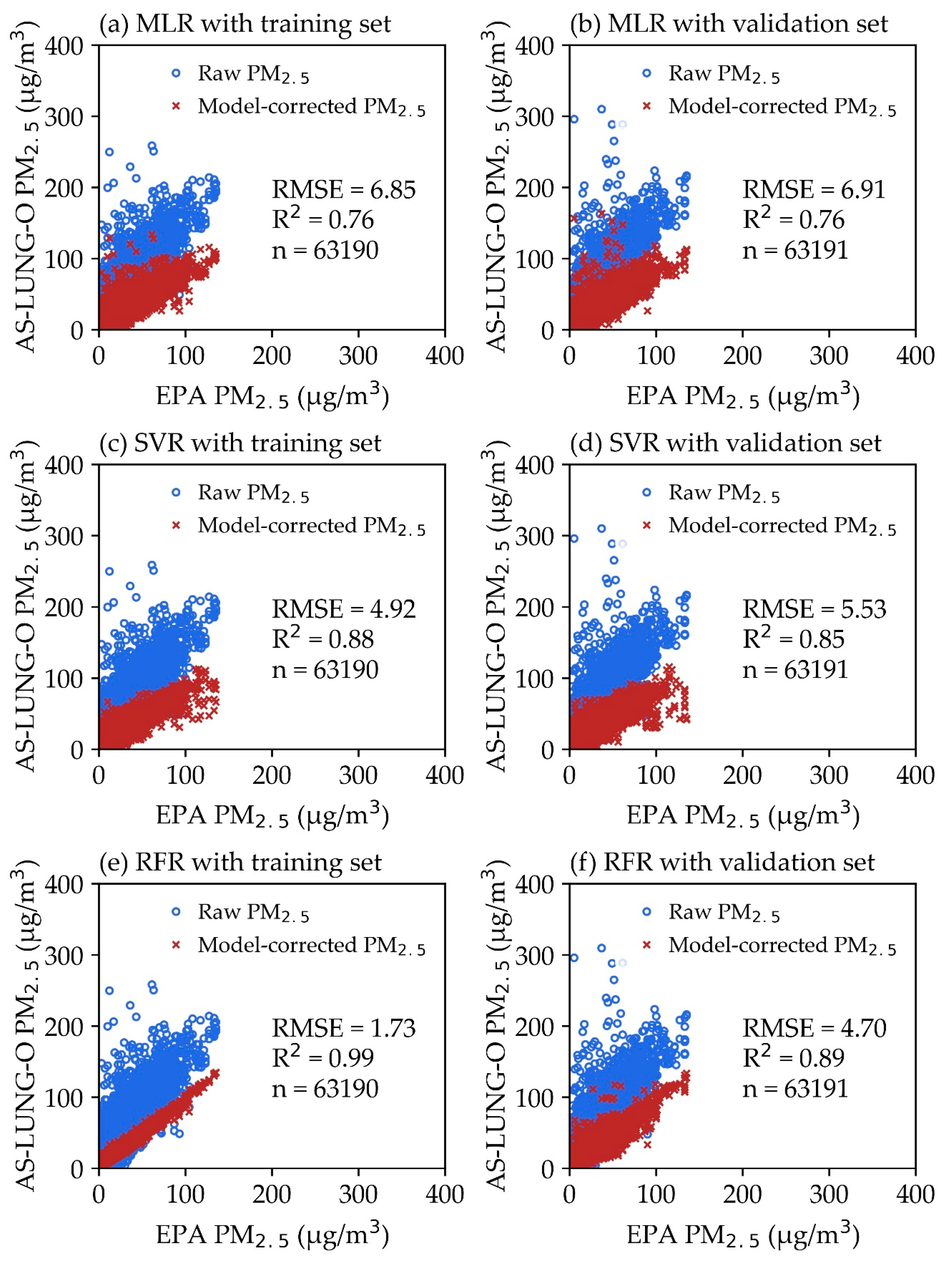
3.2. Performance Evaluation of the Correction Models
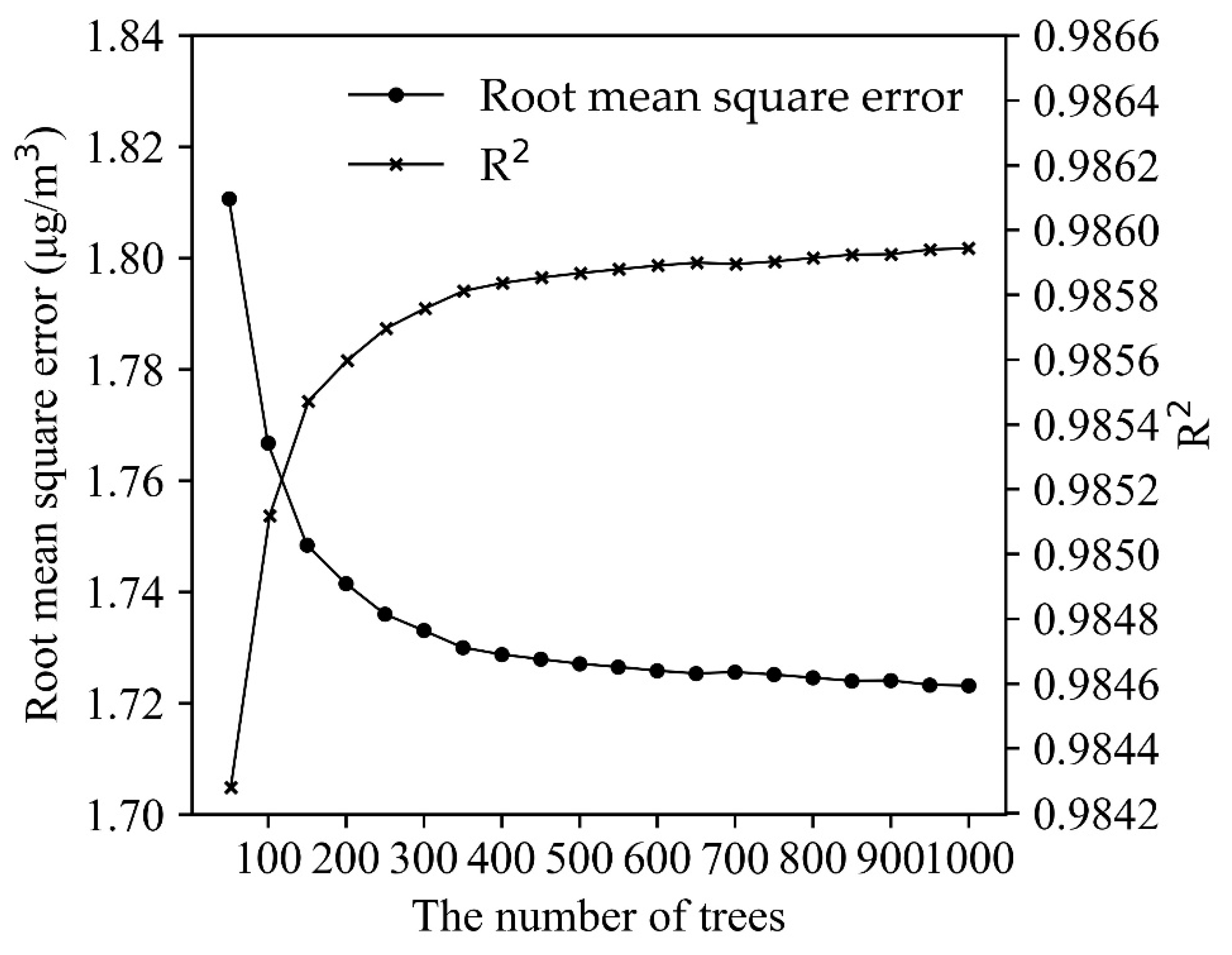
3.3. Sensitivity Analysis of RFR
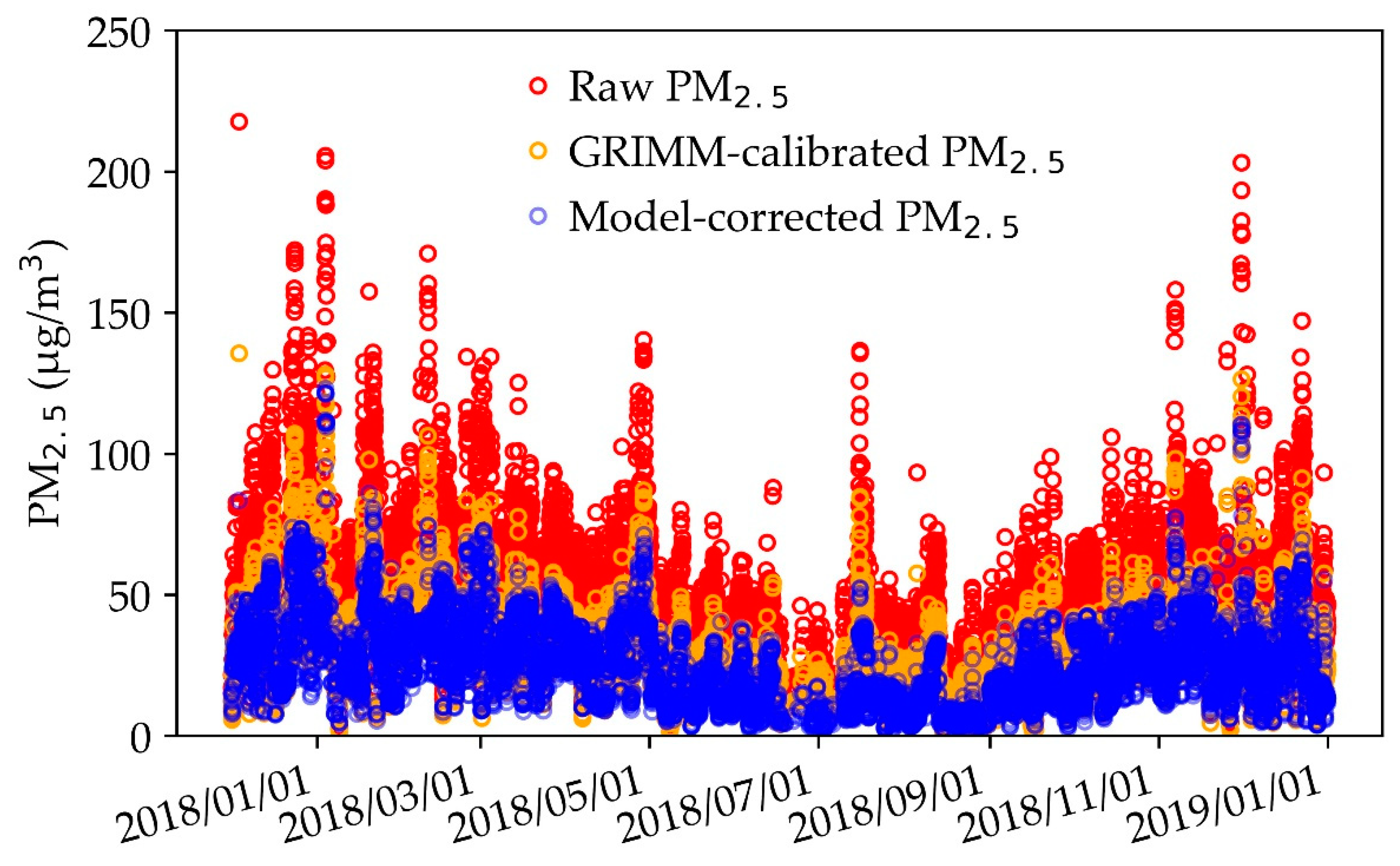
3.4. Comparison of the Model-Corrected PM2.5 and GRIMM-Calibrated PM2.5
3.4.1. RFR with Whole-Day and Nighttime Patterns
3.4.2. PM2.5 Corrections by RFR
4. Discussion
4.1. Comparison of in-Field PM2.5 Correction Models
4.2. Limitations of This Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Forouzanfar, M.H.; Afshin, A.; Alexander, L.T.; Anderson, H.R.; Bhutta, Z.A.; Biryukov, S.; Brauer, M.; Burnett, R.; Cercy, K.; Charlson, F.J.; et al. Global, regional, and national comparative risk assessment of 79 behavioural, environmental and occupational, and metabolic risks or clusters of risks, 1990–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lancet 2016, 388, 1659–1724. [Google Scholar] [CrossRef]
- Lelieveld, J.; Evans, J.S.; Fnais, M.; Giannadaki, D.; Pozzer, A. The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 2015, 525, 367–371. [Google Scholar] [CrossRef] [PubMed]
- Loomis, D.; Grosse, Y.; Lauby-Secretan, B.; El Ghissassi, F.; Bouvard, V.; Benbrahim-Tallaa, L.; Guha, N.; Baan, R.; Mattock, H.; Straif, K.; et al. The carcinogenicity of outdoor air pollution. Lancet Oncol. 2013, 14, 1262–1263. [Google Scholar] [CrossRef]
- Betha, R.; Behera, S.N.; Balasubramanian, R. 2013 Southeast Asian smoke haze: Fractionation of particulate-bound elements and associated health risk. Environ. Sci. Technol. 2014, 48, 4327–4335. [Google Scholar] [CrossRef]
- Ji, X.; Yao, Y.X.; Long, X.L. What causes PM2.5 pollution? Cross-economy empirical analysis from socioeconomic perspective. Energ. Policy 2018, 119, 458–472. [Google Scholar] [CrossRef]
- van Donkelaar, A.; Martin, R.V.; Brauer, M.; Boys, B.L. Use of satellite observations for long-term exposure assessment of global concentrations of fine particulate matter. Environ. Health Persp. 2015, 123, 135–143. [Google Scholar] [CrossRef]
- Chen, C.; Zeger, S.; Breysse, P.; Katz, J.; Checkley, W.; Curriero, F.C.; Tielsch, J.M. Estimating indoor PM2.5 and CO concentrations in households in southern Nepal: The Nepal cookstove intervention trials. PLoS ONE 2016, 11. [Google Scholar] [CrossRef]
- Lung, S.C.C.; Hsiao, P.K.; Wen, T.Y.; Liu, C.H.; Fu, C.B.; Cheng, Y.T. Variability of intra-urban exposure to particulate matter and CO from Asian-type community pollution sources. Atmos. Environ. 2014, 83, 6–132014. [Google Scholar] [CrossRef]
- Lung, S.C.C.; Mao, I.F.; Liu, L.J.S. Residents’ particle exposures in six different communities in Taiwan. Sci. Total Environ. 2007, 377, 81–92. [Google Scholar] [CrossRef]
- Lung, S.C.C.; Wang, W.C.V.; Wen, T.Y.J.; Liu, C.H.; Hu, S.C. A versatile low-cost sensing device for assessing PM2.5 spatiotemporal variation and quantifying source contribution. Sci. Total Environ. 2020, 716, 137145. [Google Scholar] [CrossRef]
- Taiwan Environmental Protection Agency (Taiwan EPA), Taiwan Air Quality Monitoring Network. Available online: https://airtw.epa.gov.tw/ENG/default.aspx (accessed on 30 June 2020).
- USEPA, Air Sensor Guidebook. United States Environmental Protection Agency (USEPA). 2014. Available online: https://www.epa.gov/air-sensor-toolbox/how-use-air-sensors-air-sensor-guidebook (accessed on 20 June 2020).
- The Citizen Air Quality Network (CAQN). Available online: https://airbox.edimaxcloud.com (accessed on 20 June 2020).
- Chen, L.J.; Ho, Y.H.; Lee, H.C.; Wu, H.C.; Liu, H.M.; Hsieh, H.H.; Huang, Y.T.; Lung, S.C.C. An Open Framework for Participatory PM2.5 Monitoring in Smart Cities. IEEE Access 2017, 5, 14441–14454. [Google Scholar] [CrossRef]
- Lee, C.H.; Wang, Y.B.; Yu, H.L. An efficient spatiotemporal data calibration approach for the low-cost PM2.5 sensing network: A case study in Taiwan. Environ. Int. 2019, 130, 104838. [Google Scholar] [CrossRef] [PubMed]
- Kuula, J.; Makela, T.; Aurela, M.; Teinila, K.; Varjonen, S.; Gonzalez, O.; Timonen, H. Laboratory evaluation of particle-size selectivity of optical low-cost particulate matter sensors. Atmos. Meas. Tech. 2020, 13, 2413–2423. [Google Scholar] [CrossRef]
- Holstius, D.M.; Pillarisetti, A.; Smith, K.R.; Seto, E. Field calibrations of a low-cost aerosol sensor at a regulatory monitoring site in California. Atmos. Meas. Tech. 2014, 7, 1121–1131. [Google Scholar] [CrossRef]
- Kelly, K.E.; Whitaker, J.; Petty, A.; Widmer, C.; Dybwad, A.; Sleeth, D.; Martin, R.; Butterfield, A. Ambient and laboratory evaluation of a low-cost particulate matter sensor. Environ. Pollut. 2017, 221, 491–500. [Google Scholar] [CrossRef]
- Mukherjee, A.; Stanton, L.G.; Graham, A.R.; Roberts, P.T. Assessing the utility of low-cost particulate matter sensors over a 12-week period in the Cuyama Valley of California. Sensors 2017, 17, 1805. [Google Scholar] [CrossRef]
- Wang, W.C.V.; Lung, S.C.C.; Liu, C.H.; Shui, C.K. Laboratory evaluation of correction equations with multiple choices for seed low-cost particle sensing devices in sensor networks. Sensors 2020, 20, 3661. [Google Scholar] [CrossRef]
- Dacunto, P.J.; Klepeis, N.E.; Cheng, K.C.; Acevedo-Bolton, V.; Jiang, R.T.; Repace, J.L.; Ott, W.R.; Hildemann, L.M. Determining PM2.5 calibration curves for a low-cost particle monitor: Common indoor residential aerosols. Environ. Sci. Process Impacts 2015, 17, 1959–1966. [Google Scholar] [CrossRef]
- Wang, Y.; Li, J.Y.; Jing, H.; Zhang, Q.; Jiang, J.K.; Biswas, P. Laboratory evaluation and calibration of three low-cost particle sensors for particulate matter measurement. Aerosol Sci. Technol. 2015, 49, 1063–1077. [Google Scholar] [CrossRef]
- Liu, H.Y.; Schneider, P.; Haugen, R.; Vogt, M. Performance Assessment of a low-cost PM2.5 sensor for a near four-month period in Oslo, Norway. Atmosphere 2019, 10, 41. [Google Scholar] [CrossRef]
- Zamora, M.L.; Xiong, F.L.Z.; Gentner, D.; Kerkez, B.; Kohrman-Glaser, J.; Koehler, K. Field and laboratory evaluations of the low-cost Plantower particulate matter sensor. Environ. Sci. Technol. 2019, 53, 838–849. [Google Scholar] [CrossRef] [PubMed]
- Zheng, T.S.; Bergin, M.H.; Johnson, K.K.; Tripathi, S.N.; Shirodkar, S.; Landis, M.S.; Sutaria, R.; Carlson, D.E. Field evaluation of low-cost particulate matter sensors in high-and low-concentration environments. Atmos. Meas. Tech. 2018, 11, 4823–4846. [Google Scholar] [CrossRef]
- Tryner, J.; L’Orange, C.; Mehaffy, J.; Miller-Lionberg, D.; Hofstetter, J.C.; Wilson, A.; Volckens, J. Laboratory evaluation of low-cost PurpleAir PM monitors and in-field correction using co-located portable filter samplers. Atmos. Environ. 2020, 220, 117067. [Google Scholar] [CrossRef]
- Cavaliere, A.; Carotenuto, F.; Di Gennaro, F.; Gioli, B.; Gualtieri, G.; Martelli, F.; Matese, A.; Toscano, P.; Vagnoli, C.; Zaldei, A. Development of low-cost air quality stations for next generation monitoring networks: Calibration and validation of PM2.5 and PM10 sensors. Sensors 2018, 18, 2843. [Google Scholar] [CrossRef]
- Jiao, W.; Hagler, G.; Williams, R.; Sharpe, R.; Brown, R.; Garver, D.; Judge, R.; Caudill, M.; Rickard, J.; Davis, M.; et al. Community Air Sensor Network (CAIRSENSE) project: Evaluation of low-cost sensor performance in a suburban environment in the southeastern United States. Atmos. Meas. Tech. 2016, 9, 5281–5292. [Google Scholar] [CrossRef]
- Morawska, L.; Thai, P.K.; Liu, X.T.; Asumadu-Sakyi, A.; Ayoko, G.; Bartonova, A.; Bedini, A.; Chai, F.H.; Christensen, B.; Dunbabin, M.; et al. Applications of low-cost sensing technologies for air quality monitoring and exposure assessment: How far have they gone? Environ. Int. 2018, 116, 286–299. [Google Scholar] [CrossRef]
- Cheng, Y.; He, X.; Zhou, Z.; Thiele, L. ICT: In-field Calibration Transfer for Air Quality Sensor Deployments. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 6. [Google Scholar] [CrossRef]
- Pandey, G.; Zhang, B.; Jian, L. Predicting submicron air pollution indicators: A machine learning approach. Environ. Sci. Process. Impacts 2013, 15, 996–1005. [Google Scholar] [CrossRef]
- Hsieh, H.P.; Lin, S.D.; Zheng, Y. Inferring air quality for station location recommendation based on urban big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; ACM: Sydney, Australia, 2015; pp. 437–446. [Google Scholar]
- Zheng, Y.; Yi, X.; Li, M.; Li, R.; Shan, Z.; Chang, E.; Li, T. Forecasting fine-grained air quality based on big data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; ACM: Sydney, Australia, 2015; pp. 2267–2276. [Google Scholar]
- Paas, B.; Stienen, J.; Vorlander, M.; Schneider, C. Modelling of urban near-road atmospheric pm concentrations using an artificial neural network approach with acoustic data input. Environments 2017, 4, 26. [Google Scholar] [CrossRef]
- Peng, H.P.; Lima, A.R.; Teakles, A.; Jin, J.; Cannon, A.J.; Hsieh, W.W. Evaluating hourly air quality forecasting in Canada with nonlinear updatable machine learning methods. Air Qual. Atmos. Health 2017, 10, 195–211. [Google Scholar] [CrossRef]
- Zimmerman, N.; Presto, A.A.; Kumar, S.P.N.; Gu, J.; Hauryliuk, A.; Robinson, E.S.; Robinson, A.L.; Subramanian, R. A machine learning calibration model using random forests to improve sensor performance for lower-cost air quality monitoring. Atmos. Meas. Tech. 2018, 11, 291–313. [Google Scholar] [CrossRef]
- Sayahi, T.; Kaufman, D.; Becnel, T.; Kaur, K.; Butterfield, A.E.; Collingwood, S.; Zhang, Y.; Gaillardon, P.E.; Kelly, K.E. Development of a calibration chamber to evaluate the performance of low-cost particulate matter sensors. Environ. Pollut. 2019, 255, 113131. [Google Scholar] [CrossRef] [PubMed]
- Taiwan Central Weather Bureau (Taiwan CWB). Available online: https://www.cwb.gov.tw/eng (accessed on 28 June 2020).
- Introduction to Air Quality Monitoring Stations of Taiwan EPA. Available online: https://airtw.epa.gov.tw/ENG/EnvMonitoring/Central/article_station.aspx (accessed on 30 June 2020).
- Carrico, C.; Gennings, C.; Wheeler, D.C.; Factor-Litvak, P. Characterization of weighted quantile sum regression for highly correlated data in a risk analysis setting. JABES 2015, 20, 100–120. [Google Scholar] [CrossRef]
- Tanner, E.M.; Bornehag, C.G.; Gennings, C. Repeated holdout validation for weighted quantile sum regression. MethodsX 2019, 6, 2855–2860. [Google Scholar] [CrossRef] [PubMed]
- Vapnik, V.N.; Lerner, A. Pattern recognition using generalized portrait method. Autom. Remote Control 1963, 24, 774–780. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A. A note on one class of perceptrons. Autom. Remote Control 1964, 25, 821–837. [Google Scholar]
- Smola, A.J.; Scholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Rai, A.C.; Kumar, P.; Pilla, F.; Skouloudis, A.N.; Di Sabatino, S.; Ratti, C.; Yasar, A.; Rickerby, D. End-user perspective of low-cost sensors for outdoor air pollution monitoring. Sci. Total Environ. 2017, 607, 691–705. [Google Scholar] [CrossRef] [PubMed]
- Borrego, C.; Costa, A.M.; Ginja, J.; Amorim, M.; Coutinho, M.; Karatzas, K.; Sioumis, T.; Katsifarakis, N.; Konstantinidis, K.; De Vito, S.; et al. Assessment of air quality microsensors versus reference methods: The EuNetAir joint exercise. Atmos. Environ. 2016, 147, 246–263. [Google Scholar] [CrossRef]
- Borrego, C.; Ginja, J.; Coutinho, M.; Ribeiro, C.; Karatzas, K.; Sioumis, T.; Katsifarakis, N.; Konstantinidis, K.; De Vito, S.; Esposito, E.; et al. Assessment of air quality microsensors versus reference methods: The EuNetAir Joint Exercise—Part II. Atmos. Environ. 2018, 193, 127–142. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Raw PM2.5 of AS-LUNG | EPA PM2.5 | n | |||
|---|---|---|---|---|---|
| Mean (SD) | Range (Min, Max) | Mean (SD) | Range (Min, Max) | ||
| Spring | 48.0 (20.6) | (3.1, 295.9) | 24.3 (13.6) | (2.0, 100.0) | 19,924 |
| Summer | 28.4 (21.3) | (1.0, 249.8) | 12.9 (13.0) | (2.0, 75.0) | 37,638 |
| Fall | 36.8 (15.3) | (1.0, 223.6) | 19.3 (8.1) | (2.0, 127.0) | 43,624 |
| Winter | 51.5 (29.2) | (1.0, 309.8) | 27.0 (18.2) | (2.0, 135.0) | 25,195 |
| Overall | Season | RMSE 1 | Pearson Correlation | n | ||
|---|---|---|---|---|---|---|
| Mean (SD 2) | Range (Min, Max) | Mean (SD) | Range (Min, Max) | |||
| RFR with whole-day patterns | Spring | 7.3 (2.6) | (4.1, 14.1) | 0.83 (0.15) | (0.34, 0.96) | 19,924 |
| Summer | 5.4 (1.7) | (3.1, 11.2) | 0.82 (0.11) | (0.33, 0.93) | 37,638 | |
| Fall | 6.1 (1.6) | (3.7, 10.0) | 0.85 (0.08) | (0.53, 0.94) | 43,624 | |
| Winter | 6.8 (2.3) | (3.5, 12.9) | 0.90 (0.04) | (0.79, 0.97) | 25,195 | |
| RFR with nighttime patterns | Spring | 6.7 (2.4) | (2.6, 10.9] | 0.92 (0.05) | (0.80, 0.98) | 19,924 |
| Summer | 5.7 (1.7) | (2.8, 11.3) | 0.88 (0.07) | (0.57, 0.95) | 37,638 | |
| Fall | 5.7 (1.6) | (3.2, 9.9) | 0.88 (0.08) | (0.68, 0.96) | 43,624 | |
| Winter | 6.1 (2.3) | (2.4, 14.4) | 0.94 (0.03) | (0.86, 0.98) | 25,195 | |
| Street-Level | Season | RMSE 1 | Pearson Correlation | n | ||
|---|---|---|---|---|---|---|
| Mean (SD 2) | Range (Min, Max) | Mean (SD) | Range (Min, Max) | |||
| RFR with whole-day patterns | Spring | 7.1 (2.7) | (4.1, 14.1) | 0.84 (0.15) | (0.34, 0.96) | 17,255 |
| Summer | 5.4 (1.8) | (3.1, 11.2) | 0.83 (0.11) | (0.33, 0.93) | 30,710 | |
| Fall | 5.8 (1.5) | (3.7, 10.0) | 0.85 (0.09) | (0.53, 0.94) | 32,606 | |
| Winter | 6.5 (2.2) | (3.5, 12.9) | 0.91 (0.04) | (0.79, 0.97) | 19,448 | |
| RFR with nighttime patterns | Spring | 6.5 (2.5) | (2.6, 10.9) | 0.93 (0.04) | (0.81, 0.98) | 17,255 |
| Summer | 5.6 (1.8) | (2.8, 11.3) | 0.89 (0.07) | (0.57, 0.95) | 30,710 | |
| Fall | 5.7 (1.7) | (3.2, 9.9) | 0.89 (0.08) | (0.68, 0.96) | 32,606 | |
| Winter | 5.9 (2.4) | (2.4, 14.4) | 0.94 (0.02) | (0.89, 0.98) | 19,448 | |
| High-Level | Season | RMSE 1 | Pearson Correlation | n | ||
|---|---|---|---|---|---|---|
| Mean (SD 2) | Range (Min, Max) | Mean (SD) | Range (Min, Max) | |||
| RFR with whole-day patterns | Spring | 8.8 (2.3) | (7.2, 10.4) | 0.78 (0.15) | (0.68, 0.89) | 2669 |
| Summer | 5.7 (1.3) | (3.6, 7.6) | 0.78 (0.07) | (0.70, 0.88) | 6928 | |
| Fall | 7.3 (2.0) | (4.6, 9.9) | 0.84 (0.07) | (0.75, 0.91) | 11,018 | |
| Winter | 8.0 (2.9) | (4.6, 12.9) | 0.88 (0.04) | (0.83, 0.94) | 5747 | |
| RFR with nighttime patterns | Spring | 8.2 (1.9) | (6.8, 9.5) | 0.87 (0.09) | (0.80, 0.94) | 2669 |
| Summer | 5.8 (1.3) | (4.1, 7.9) | 0.85 (0.06) | (0.76, 0.94) | 6928 | |
| Fall | 6.2 (1.7) | (4.9, 9.3) | 0.88 (0.09) | (0.75, 0.95) | 11,018 | |
| Winter | 6.7 (2.2) | (4.3, 9.6) | 0.92 (0.03) | (0.86, 0.94) | 5747 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.-C.V.; Lung, S.-C.C.; Liu, C.-H. Application of Machine Learning for the in-Field Correction of a PM2.5 Low-Cost Sensor Network. Sensors 2020, 20, 5002. https://doi.org/10.3390/s20175002
Wang W-CV, Lung S-CC, Liu C-H. Application of Machine Learning for the in-Field Correction of a PM2.5 Low-Cost Sensor Network. Sensors. 2020; 20(17):5002. https://doi.org/10.3390/s20175002
Chicago/Turabian StyleWang, Wen-Cheng Vincent, Shih-Chun Candice Lung, and Chun-Hu Liu. 2020. "Application of Machine Learning for the in-Field Correction of a PM2.5 Low-Cost Sensor Network" Sensors 20, no. 17: 5002. https://doi.org/10.3390/s20175002
APA StyleWang, W.-C. V., Lung, S.-C. C., & Liu, C.-H. (2020). Application of Machine Learning for the in-Field Correction of a PM2.5 Low-Cost Sensor Network. Sensors, 20(17), 5002. https://doi.org/10.3390/s20175002