Classification Accuracy Improvement for Small-Size Citrus Pests and Diseases Using Bridge Connections in Deep Neural Networks


Abstract
1. Introduction
2. Related Work
3. Image Dataset Description
4. Network Architecture
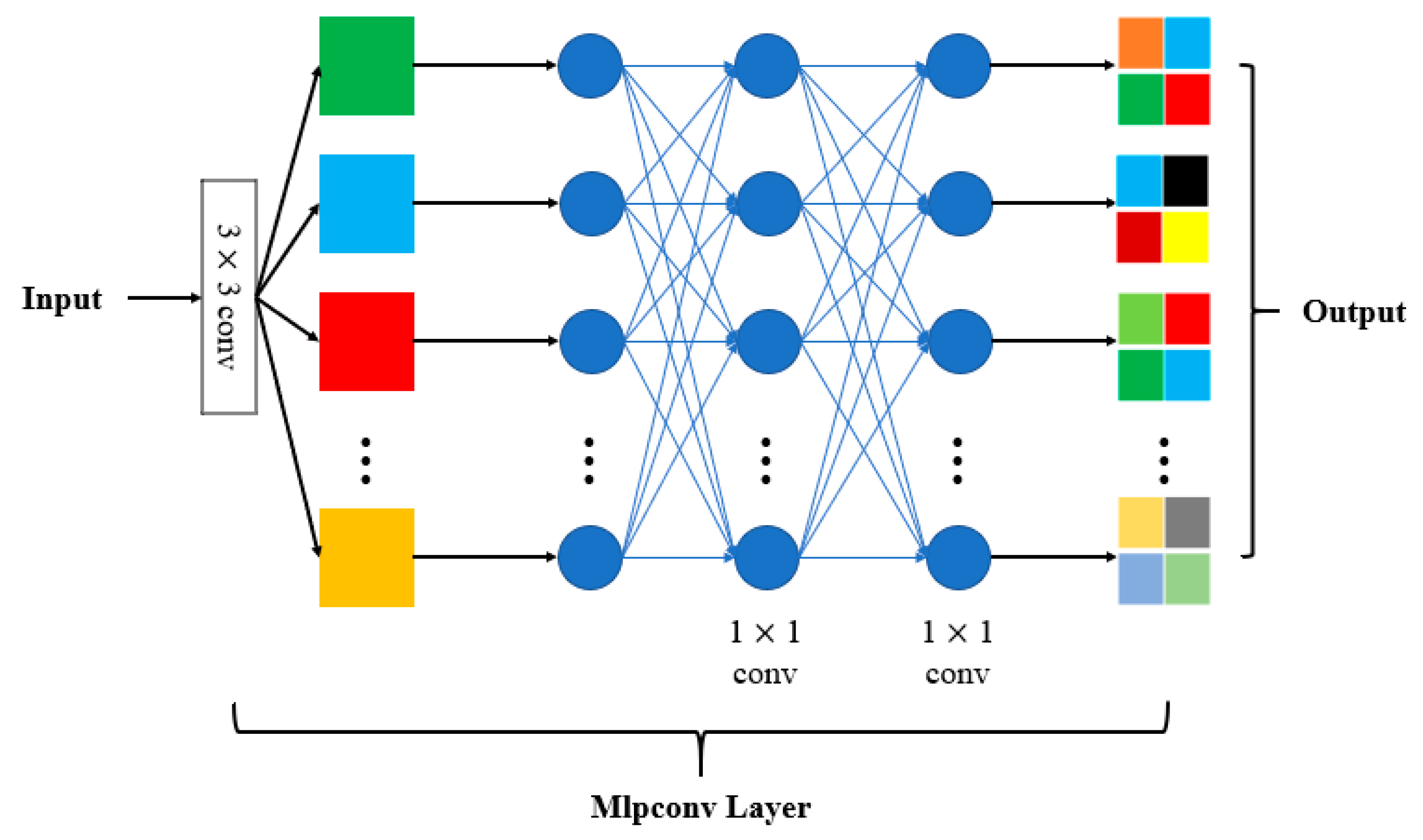
4.1. Microstructure of Building Unit
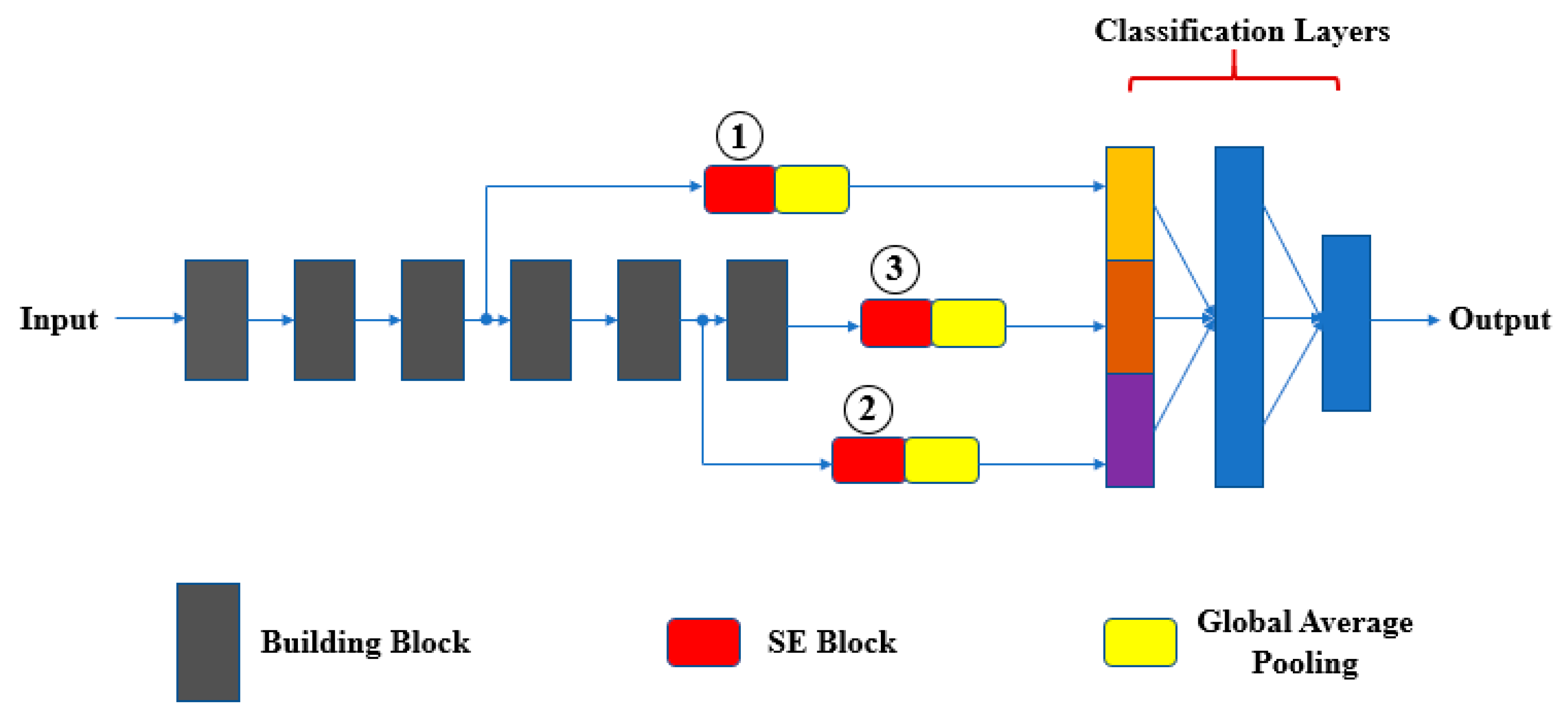
4.2. Macro Connection between Building Blocks
4.3. Adaption to Object Scale in the Image
- Channel compression: To reduce the number of useless features, the number of output channels from the 1 × 1 convolution is fewer than the number of input channels. This function is similar to the transition layer of DenseNet.
- Feature retention: Unlike a 3 × 3 convolution, a 1 × 1 convolution performs a simple linear transformation, which can largely preserve input feature information. To further strengthen output feature quality, two 1 × 1 convolutions were stacked after the concatenation operation.
5. Experiments and Results
5.1. Experiment Preparation
5.2. Classification Performance
5.3. Ablation Study
6. Conclusion and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Al Bashish, D.; Braik, M.; Bani-Ahmad, S. A framework for detection and classification of plant leaf and stem diseases. In Proceedings of the 2010 International Conference on Signal and Image Processing, Chennai, India, 15–17 December 2010. [Google Scholar]
- Ali, H.; Lali, M.I.; Nawaz, M.Z.; Sharif, M.; Saleem, B.A. Symptom based automated detection of citrus diseases using color histogram and textural descriptors. Comput. Electron. Agric. 2017, 138, 92–104. [Google Scholar] [CrossRef]
- Wen, C.; Guyer, D.E.; Li, W. Local feature-based identification and classification for orchard insects. Biosyst. Eng. 2009, 104, 299–307. [Google Scholar] [CrossRef]
- Xie, C.; Zhang, J.; Li, R.; Li, J.; Hong, P.; Xia, J.; Chen, P. Automatic classification for field crop insects via multiple-task sparse representation and multiple-kernel learning. Comput. Electron. Agric. 2015, 119, 123–132. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, Y.; Chen, Y.; Wu, Y.; Yue, Y. Pest identification via deep residual learning in complex background. Comput. Electron. Agric. 2017, 141, 351–356. [Google Scholar] [CrossRef]
- Shen, Y.; Zhou, H.; Li, J.; Jian, F.; Jayas, D.S. Detection of stored-grain insects using deep learning. Comput. Electron. Agric. 2018, 145, 319–325. [Google Scholar] [CrossRef]
- Alom, M.; Tha, T.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.; Hasan, M.; Essen, B.; Awwal, A.; Asari, V. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- He, K.; Girshick, R.; Dollár, P. Rethinking imagenet pre-training. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993v5. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 28th International Conference on Neural Information Processing Systems (NeurIPS), Montreal, PQ, Canada, 8–13 December 2014. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Xing, S.; Lee, M.; Lee, K.K. Citrus Pests and Diseases Recognition Model Using Weakly Dense Connected Convolution Network. Sensors 2019, 19, 3195. [Google Scholar] [CrossRef] [PubMed]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Alves, A.N.; Souza, W.S.; Borges, D.L. Cotton pests classification in field-based images using deep residual networks. Comput. Electron. Agric. 2020, 174, 105488. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Zhang, D.; Sun, Y.; Nanehkaran, Y.A. Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agric. 2020, 173, 105393. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Fractalnet: Ultra-deep neural networks without residuals. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V. Do cifar-10 classifiers generalize to cifar-10? arXiv 2018, arXiv:1806.00451. [Google Scholar]
- Wang, G.; Sun, Y.; Wang, J. Automatic image-based plant disease severity estimation using deep learning. Comput. Intell. Neurosci. 2017, 2017, 2917536. [Google Scholar] [CrossRef]
- Barbedo, J.G.; Castro, G.B. Influence of image quality on the identification of psyllids using convolutional neural networks. Biosyst. Eng. 2019, 182, 151–158. [Google Scholar] [CrossRef]
- Thenmozhi, K.; Reddy, U.S. Crop pest classification based on deep convolutional neural network and transfer learning. Comput. Electron. Agric. 2019, 164, 104906. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400v3. [Google Scholar]
- Engstrom, L.; Tsipras, D.; Schmidt, L.; Madry, A. A rotation and a translation suffice: Fooling cnns with simple transformations. arXiv 2017, arXiv:1712.02779. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ng, A.Y. Feature selection, L1 vs. L2 regularization, and rotational invariance. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.E.; Hinton, G.E. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation Name. | Value |
|---|---|
| Rotation | [0°, 30°] |
| Width shift | [0, 0.2] |
| Height shift | [0, 0.2] |
| Zoom | [0.8, 1.2] |
| Horizontal flip | - |
| Brightness | [0.6, 1.4] |
| The Number of Low-Level Features (Value 0.6) | The Number of Mid-Level Features (0.6 Value 0.95) | The Number of High-Level Features (Value 0.95) | ||
|---|---|---|---|---|
| Large-size canker | SE block 1 | 102 | 26 | 0 |
| SE block 2 | 350 | 162 | 0 | |
| SE block 3 | 138 | 138 | 236 | |
| Total | 590 | 326 | 236 | |
| Middle-size canker | SE block 1 | 104 | 24 | 0 |
| SE block 2 | 343 | 169 | 0 | |
| SE block 3 | 139 | 198 | 175 | |
| Total | 586 | 391 | 175 | |
| Small-size canker | SE block 1 | 108 | 20 | 0 |
| SE block 2 | 326 | 186 | 0 | |
| SE block 3 | 137 | 222 | 153 | |
| Total | 571 | 428 | 153 | |
| Large-size green stink bug | SE block 1 | 107 | 21 | 0 |
| SE block 2 | 334 | 178 | 0 | |
| SE block 3 | 142 | 184 | 186 | |
| Total | 583 | 383 | 186 | |
| Middle-size green stink bug | SE block 1 | 107 | 21 | 0 |
| SE block 2 | 336 | 176 | 0 | |
| SE block 3 | 147 | 208 | 157 | |
| Total | 590 | 405 | 157 | |
| Small-size green stink bug | SE block 1 | 103 | 25 | 0 |
| SE block 2 | 323 | 189 | 0 | |
| SE block 3 | 143 | 238 | 131 | |
| Total | 569 | 452 | 131 |
| Building Unit | Output Dimension | ||
|---|---|---|---|
| Initial Block | 56 56 32 | ||
| Normal Block | 56 56 96 | ||
| Reduction Block | 28 28 192 | ||
| Normal Block | 28 28 384 | ||
| Reduction Block | Feature Reuse Block | 14 14 768 | 14 14 256 |
| Mlpconv Layer with Max Pooling | Feature Reuse Block | 7 7 512 | 7 7 512 |
| Feature Reuse Block without Max Pooling | 7 7 512 | ||
| Classification Block | 1 24 | ||
| Model Hyper-Parameter | Method/Value |
|---|---|
| Weight initialization | He normal [37] |
| Batch size | 16 |
| Weight decay | L2/0.005 [38] |
| Optimizer | SGD |
| Momentum | Nesterov/0.9 [39] |
| Dropout rate | 0.5 [40] |
| Initial learning rate | Training from scratch/0.001 |
| ImageNet pre-training/0.0001 | |
| Learning rate schedule | Adaptive [18] |
| Training epoch | 500 |
| Model Name | Training Accuracy (%) | Validation Accuracy (%) | Test Accuracy (%) | Model Size (MB) | Training Speed ms/Batch Size |
|---|---|---|---|---|---|
| VGG-16 | 99.82 | 93 | 92.93 | 120.2 | 303 |
| Pre-trained VGG-16 | 99.79 | 94.96 | 94.45 | 120.2 | 303 |
| VGG-16 with bridge connections | 99.89 | 94.17 | 93.89 | 126 | 343 |
| VGG-16 with deformable convolutions | 99.59 | 92.63 | 92.38 | 161 | 635 |
| VGG-19 | 99.89 | 93.8 | 93.57 | 155 | 352 |
| Pre-trained VGG-19 | 99.91 | 95.2 | 95.01 | 155 | 352 |
| VGG-19 with bridge connections | 99.93 | 95.33 | 94.73 | 167 | 392 |
| Weakly DenseNet-19 | 99.79 | 94.03 | 93.71 | 56.6 | 139 |
| CBAMNet | 99.97 | 91.42 | 90.79 | 49.5 | 139 |
| MSN-19 | 99.8 | 94.5 | 94.24 | 66.9 | 142 |
| BridgeNet-19 | 99.97 | 95.61 | 95.47 | 68.9 | 140 |
| Number | Test Error (%) | Model Size (MB) |
|---|---|---|
| 0 | 6.29 | 56.6 |
| 2 | 4.57 | 67.6 |
| 3 | 4.53 | 68.9 |
| 4 | 4.62 | 69.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, S.; Lee, M. Classification Accuracy Improvement for Small-Size Citrus Pests and Diseases Using Bridge Connections in Deep Neural Networks. Sensors 2020, 20, 4992. https://doi.org/10.3390/s20174992
Xing S, Lee M. Classification Accuracy Improvement for Small-Size Citrus Pests and Diseases Using Bridge Connections in Deep Neural Networks. Sensors. 2020; 20(17):4992. https://doi.org/10.3390/s20174992
Chicago/Turabian StyleXing, Shuli, and Malrey Lee. 2020. "Classification Accuracy Improvement for Small-Size Citrus Pests and Diseases Using Bridge Connections in Deep Neural Networks" Sensors 20, no. 17: 4992. https://doi.org/10.3390/s20174992
APA StyleXing, S., & Lee, M. (2020). Classification Accuracy Improvement for Small-Size Citrus Pests and Diseases Using Bridge Connections in Deep Neural Networks. Sensors, 20(17), 4992. https://doi.org/10.3390/s20174992