Gaze in the Dark: Gaze Estimation in a Low-Light Environment with Generative Adversarial Networks



Abstract
1. Introduction
- Can a method based on a deep neural network provide a good estimation of gaze points under low-light and dark illumination conditions? This question is to determine the extent to which low and dark lighting conditions affect the performance of a deep learning-based gaze estimation method. To answer this question, we compared the performance of a conventional deep learning-based gaze estimation for normal, low, and dark illuminated images.
- Could the proposed approach improve the performance of gaze estimation under low illumination conditions? Through this question, we validate the feasibility of the proposed approach which adopts GAN-based image enhancement in the loop. To this end, we conducted experiments to compare the performance of gaze estimation for low-light images between the conventional gaze estimation protocol and the proposed approach.
- Would a GAN-based adaptive enhancement method be more effective than a simple method involving manual brightness adjustment? The proposed approach is based on a deep adversarial technique to enhance the appearance of low-light eye images. However, a simple image processing method, such as adjusting intensity or gamma values of an image, can be also considered an alternative way to enhance the appearance of low-light images. To show the effectiveness of the proposed approach with a generative adversarial network, we compared the performance of the proposed approach with those of baseline methods.
2. Related Work
2.1. Image Enhancement
2.2. Gaze Estimation in a Real-Life Environment
2.2.1. Long-Distance Set-Up
2.2.2. Mobile Environment
2.2.3. Low-Light Conditions
3. Proposed Method
3.1. Dataset
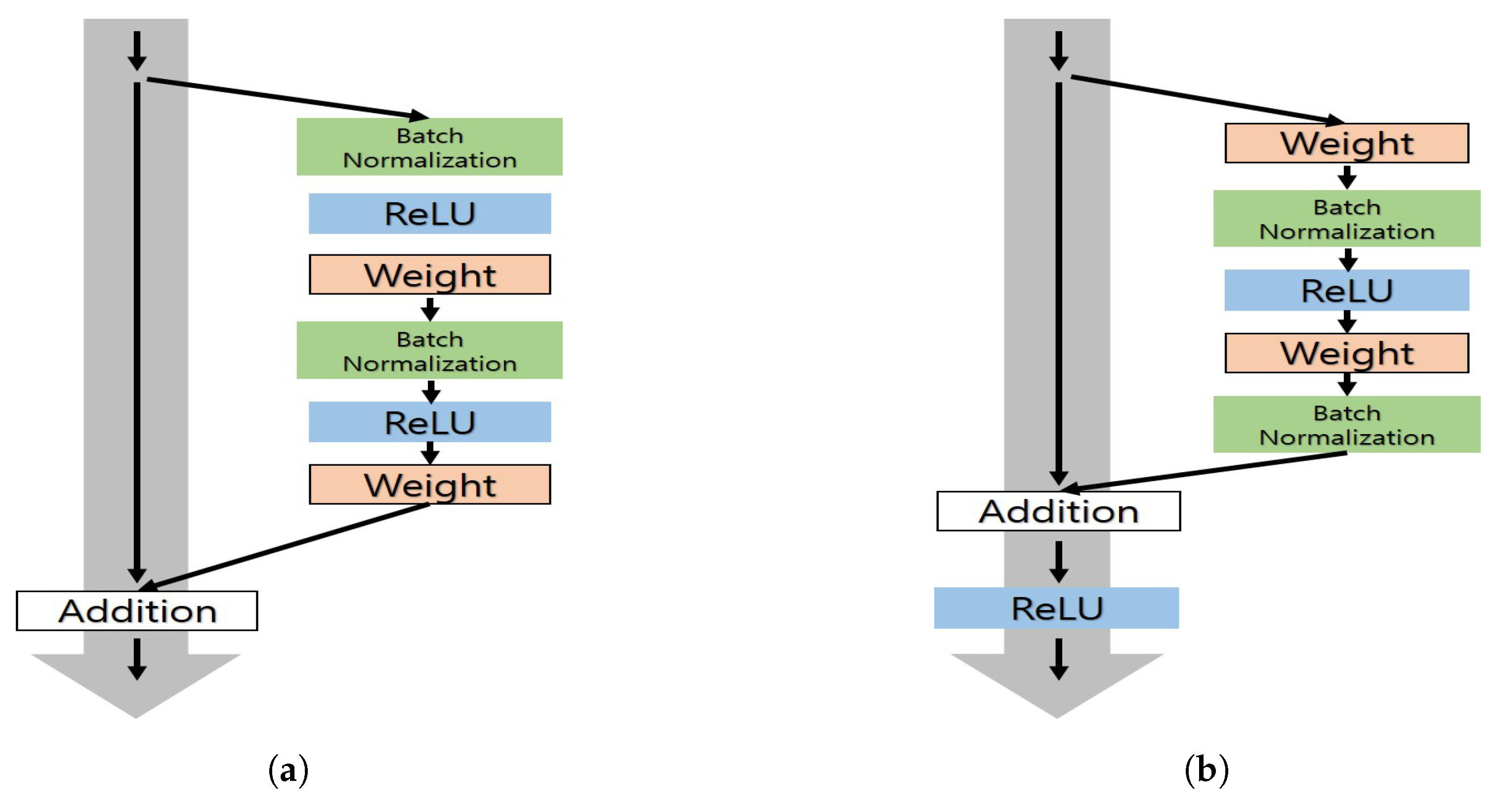
3.2. Enhancing Eye Images with GAN
4. Experiments and Discussion
4.1. Deep Learning-Based Gaze Estimation under Low and Dark Illumination Conditions
4.2. Performance Improvement of the Proposed Approach
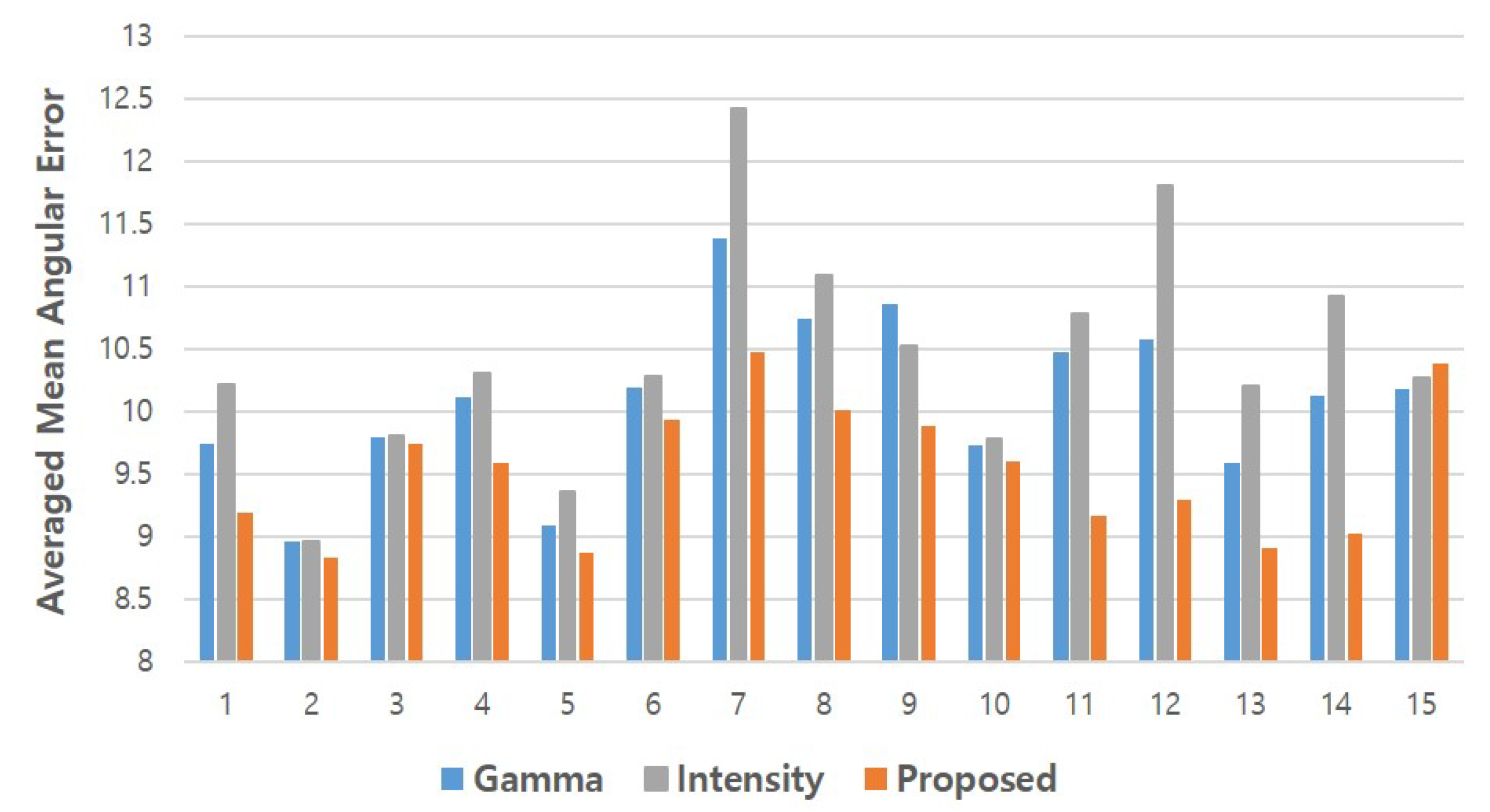
4.3. Comparison with Baseline Methods
- Gamma correction methods: , , and
- -
- Set the gamma value to be 1.5, 2, and 3
- Intensity adjustment methods: , , and
- -
- Increase the intensity by 40, 70, and 110
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kujala, T.; Grahn, H. Visual Distraction Effects of In-Car Text Entry Methods: Comparing Keyboard, Handwriting and Voice Recognition. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’17), Oldenburg, Germany, 24–27 September 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Durairajah, V.; Gobee, S.; Bashanfar, A.S. Wheelchair Navigation Using Voice Command with Obstacles Avoidance. In Proceedings of the 2017 International Conference on Biomedical Engineering and Bioinformatics (ICBEB 2017), Granada, Spain, 6–8 May 2020; Association for Computing Machinery: New York, NY, USA, 2017; pp. 57–64. [Google Scholar] [CrossRef]
- DelPreto, J.; Rus, D. Plug-and-Play Gesture Control Using Muscle and Motion Sensors. In Proceedings of the 2020 ACM/IEEE International Conference on Human-Robot Interaction (HRI’20), Cambridge, UK, 23–36 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 439–448. [Google Scholar] [CrossRef]
- Borghi, G.; Venturelli, M.; Vezzani, R.; Cucchiara, R. POSEidon: Face-from-Depth for Driver Pose Estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5494–5503. [Google Scholar] [CrossRef]
- Hu, Z.; Uchida, N.; Wang, Y.; Dong, Y. Face orientation estimation for driver monitoring with a single depth camera. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 958–963. [Google Scholar] [CrossRef]
- Wang, Y.; Yuan, G.; Mi, Z.; Peng, J.; Ding, X.; Liang, Z.; Fu, X. Continuous Driver’s Gaze Zone Estimation Using RGB-D Camera. Sensors 2019, 19, 1287. [Google Scholar] [CrossRef] [PubMed]
- Chun, S.; Lee, C. Human action recognition using histogram of motion intensity and direction from multiple views. IET Comput. Vis. 2016, 10, 250–256. [Google Scholar] [CrossRef]
- Kwon, B.; Kim, J.; Lee, K.; Lee, Y.K.; Park, S.; Lee, S. Implementation of a Virtual Training Simulator Based on 360∘ Multi-View Human Action Recognition. IEEE Access 2017, 5, 12496–12511. [Google Scholar] [CrossRef]
- Liu, Z.; Chan, S.C.; Wang, C.; Zhang, S. Multi-view articulated human body tracking with textured deformable mesh model. In Proceedings of the 2015 IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 1038–1041. [Google Scholar] [CrossRef]
- Sugano, Y.; Matsushita, Y.; Sato, Y. Learning-by-Synthesis for Appearance-Based 3D Gaze Estimation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–28 June 2014; pp. 1821–1828. [Google Scholar] [CrossRef]
- Sun, L.; Liu, Z.; Sun, M.T. Real Time Gaze Estimation with a Consumer Depth Camera. Inf. Sci. 2015, 320, 346–360. [Google Scholar] [CrossRef]
- Lai, C.; Shih, S.; Hung, Y. Hybrid Method for 3-D Gaze Tracking Using Glint and Contour Features. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 24–37. [Google Scholar] [CrossRef]
- Sesma-Sanchez, L.; Villanueva, A.; Cabeza, R. Gaze Estimation Interpolation Methods Based on Binocular Data. IEEE Trans. Biomed. Eng. 2012, 59, 2235–2243. [Google Scholar] [CrossRef]
- Huang, J.B.; Cai, Q.; Liu, Z.; Ahuja, N.; Zhang, Z. Towards Accurate and Robust Cross-Ratio Based Gaze Trackers through Learning from Simulation. In Proceedings of the ETRA ’14 Symposium on Eye Tracking Research and Applications, Safety Harbor, FL, USA, 26–28 March 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 75–82. [Google Scholar] [CrossRef]
- Sugano, Y.; Matsushita, Y.; Sato, Y. Appearance-Based Gaze Estimation Using Visual Saliency. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 329–341. [Google Scholar] [CrossRef]
- Lian, D.; Hu, L.; Luo, W.; Xu, Y.; Duan, L.; Yu, J.; Gao, S. Multiview Multitask Gaze Estimation with Deep Convolutional Neural Networks. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3010–3023. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 162–175. [Google Scholar] [CrossRef]
- Kim, J.; Choi, S.; Jeong, J. Watch Do: A Smart IoT Interaction System with Object Detection and Gaze Estimation. IEEE Trans. Consum. Electron. 2019, 65, 195–204. [Google Scholar] [CrossRef]
- Cazzato, D.; Leo, M.; Distante, C.; Voos, H. When I Look into Your Eyes: A Survey on Computer Vision Contributions for Human Gaze Estimation and Tracking. Sensors 2020, 20, 3739. [Google Scholar] [CrossRef] [PubMed]
- Kar, A.; Corcoran, P. A Review and Analysis of Eye-Gaze Estimation Systems, Algorithms and Performance Evaluation Methods in Consumer Platforms. IEEE Access 2017, 5, 16495–16519. [Google Scholar] [CrossRef]
- Singh, J.; Modi, N. Use of information modelling techniques to understand research trends in eye gaze estimation methods: An automated review. Heliyon 2019, 5, e03033. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Yan, Y.; Peng, J.; Mi, Z.; Fu, X. Guiding Intelligent Surveillance System by learning-by-synthesis gaze estimation. Pattern Recognit. Lett. 2018, 125, 556–562. [Google Scholar] [CrossRef]
- Dias, P.A.; Malafronte, D.; Medeiros, H.; Odone, F. Gaze Estimation for Assisted Living Environments. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision 2020, Snowmass Village, CO, USA, 2–5 March 2020. [Google Scholar]
- Lemley, J.; Kar, A.; Drimbarean, A.; Corcoran, P. Convolutional Neural Network Implementation for Eye-Gaze Estimation on Low-Quality Consumer Imaging Systems. IEEE Trans. Consum. Electron. 2019, 65, 179–187. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Land, E.H. The Retinex Theory of Color Vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. MSR-net:Low-light Image Enhancement Using Deep Convolutional Network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Wang, W.; Wei, C.; Yang, W.; Liu, J. GLADNet: Low-Light Enhancement Network with Global Awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 751–755. [Google Scholar] [CrossRef]
- Jenicek, T.; Chum, O. No Fear of the Dark: Image Retrieval under Varying Illumination Conditions. arXiv 2019, arXiv:1908.08999. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3291–3300. [Google Scholar] [CrossRef]
- Kim, G.; Kwon, D.; Kwon, J. Low-Lightgan: Low-Light Enhancement Via Advanced Generative Adversarial Network With Task-Driven Training. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2811–2815. [Google Scholar]
- Hua, W.; Xia, Y. Low-Light Image Enhancement Based on Joint Generative Adversarial Network and Image Quality Assessment. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement without Paired Supervision. arXiv 2019, arXiv:1906.06972. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Fischer, T.; Chang, H.J.; Demiris, Y. RT-GENE: Real-Time Eye Gaze Estimation in Natural Environments. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 339–357. [Google Scholar]
- Kellnhofer, P.; Recasens, A.; Stent, S.; Matusik, W.; Torralba, A. Gaze360: Physically Unconstrained Gaze Estimation in the Wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Olson, E. AprilTag: A robust and flexible visual fiducial system. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2011; pp. 3400–3407. [Google Scholar]
- Arar, N.M.; Thiran, J.P. Robust Real-Time Multi-View Eye Tracking. arXiv 2017, arXiv:1711.05444. [Google Scholar]
- Kim, J.H.; Jeong, J.W. A Preliminary Study on Performance Evaluation of Multi-View Multi-Modal Gaze Estimation under Challenging Conditions. In Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems (CHI EA’20); Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye Tracking for Everyone. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2176–2184. [Google Scholar] [CrossRef]
- Huang, Q.; Veeraraghavan, A.; Sabharwal, A. TabletGaze: Dataset and Analysis for Unconstrained Appearance-Based Gaze Estimation in Mobile Tablets. Mach. Vision Appl. 2017, 28, 445–461. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. arXiv 2016, arXiv:1603.05027. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; pp. 8024–8035. [Google Scholar]
- Clark, A. Pillow (PIL Fork) Documentation. 2020. Available online: https://buildmedia.readthedocs.org/media/pdf/pillow/latest/pillow.pdf (accessed on 30 August 2020).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Error | 5.76 | 9.9 | 9.71 | 10.56 | 10.4 | 10.2 | 10.4 | 10.22 |
| Diff to | - | +4.14 | +3.95 | +4.8 | +4.64 | +4.44 | +4.64 | +4.46 |
| Proposed | 9.42 | 9.27 | 9.61 | 9.69 | 9.47 | 9.67 | 9.53 |
| MPIIGaze | 9.9 | 9.71 | 10.56 | 10.4 | 10.2 | 10.4 | 10.22 |
| Improvement (deg) | 0.48 | 0.44 | 0.95 | 0.71 | 0.73 | 0.73 | 0.69 |
| Improvement (%) | 4.8 | 4.53 | 8.9 | 6.8 | 7.15 | 7.01 | 6.75 |
| 9.9 | 9.84 | 9.78 | 9.88 | 10.35 | 10.15 | 9.82 | 9.42 | |
| 9.71 | 9.62 | 9.63 | 9.56 | 10.04 | 9.94 | 9.71 | 9.27 | |
| 10.56 | 10.48 | 10.39 | 10.47 | 11.66 | 11.14 | 10.54 | 9.61 | |
| 10.4 | 10.22 | 10.21 | 10.25 | 10.76 | 10.51 | 10.23 | 9.69 | |
| 10.2 | 10.13 | 10.10 | 10.14 | 10.72 | 10.51 | 10.09 | 9.47 | |
| 10.4 | 10.21 | 10.15 | 10.28 | 10.87 | 10.59 | 10.21 | 9.67 | |
| 10.22 | 10.36 | 10.16 | 10.25 | 10.86 | 10.46 | 10.19 | 9.53 | |
| 10.19 | 10.12 | 10.06 | 10.11 | 10.75 | 10.47 | 10.11 | 9.52 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Jeong, J.-W. Gaze in the Dark: Gaze Estimation in a Low-Light Environment with Generative Adversarial Networks. Sensors 2020, 20, 4935. https://doi.org/10.3390/s20174935
Kim J-H, Jeong J-W. Gaze in the Dark: Gaze Estimation in a Low-Light Environment with Generative Adversarial Networks. Sensors. 2020; 20(17):4935. https://doi.org/10.3390/s20174935
Chicago/Turabian StyleKim, Jung-Hwa, and Jin-Woo Jeong. 2020. "Gaze in the Dark: Gaze Estimation in a Low-Light Environment with Generative Adversarial Networks" Sensors 20, no. 17: 4935. https://doi.org/10.3390/s20174935
APA StyleKim, J.-H., & Jeong, J.-W. (2020). Gaze in the Dark: Gaze Estimation in a Low-Light Environment with Generative Adversarial Networks. Sensors, 20(17), 4935. https://doi.org/10.3390/s20174935