The proposed network architecture was trained on a 1080 Gtx GPU with 10 Gb memory. For hyper-parameter optimization, Adam optimizer was used with a learning rate of .
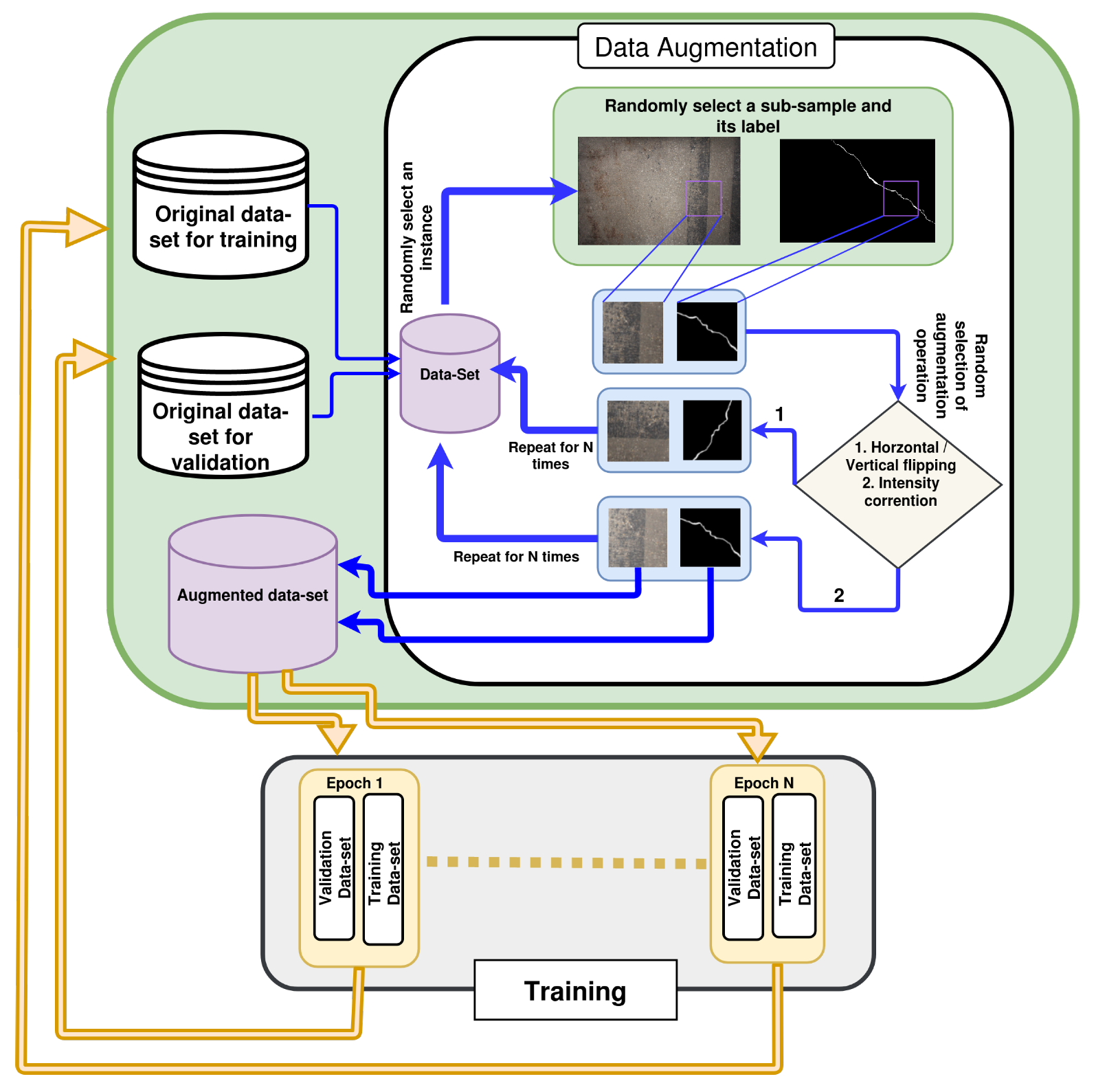
State-of-the-art data augmentation techniques generate an augmented dataset from a handful of low-resolution images for crack detection. As result, training is performed on the same dataset for each epoch. This type of training procedure is highly susceptible to an overfitting problem. Nonetheless, the data-augmentation technique and training process incorporated in this paper generates different training and validation datasets for each epoch at the time of training. As a result, the network sees a range of different types of images. The overfitting problem of the traditional training procedure is overcome through this training procedure.
We evaluate the performance of the pre-trained network using the test dataset of 200 images. The testing image size () was selected to be larger than the training image size () to represent the robustness of the network towards noise in large resolution images. Moreover, the computational complexity involved with large images generates the gradient vanishing problem in a CNN architecture. The effect of the gradient vanishing problem is more evident in large scale images. Therefore, the resolution of test dataset images is twice as large as the train dataset.
The proposed network architecture was evaluated based on three different criteria such as network complexity, qualitative measurement, and qualitative analysis. The complexity of different networks was analyzed in terms of the number of major computations performed. Later, a quantitative and qualitative analysis was performed on the results of different deep network architectures.
3.2.2. Quantitative Comparisons
This section presents the performance of different deep architectures in the literature for concrete crack identification along with ANet-FSM architecture quantitatively. Deep concrete crack detection architectures are categorized as image classification-based architectures (Gibbs [
3]) and encoder-decoder-based architectures (SegNet [
42], InspectionNet [
43], SegNet-SO [
4]). We evaluated the performance of these networks using the test dataset of 200 images of size
.
Statistical measures, shown in
Table 4, such as true positive (TP) rate, false positive (FP) rate, true negative (TN) rate, false negative (FN) rate, error rate, and accuracy generate biased evaluation results toward non-crack pixels because of crack pixels low appearance. The use of effective statistical method, such as specificity, sensitivity, precision, recall, and F1 measure was also employed to distinguish between crack and non-crack pixels within imbalanced datasets. These statistical measures were identified by defining crack pixels as positive class and non-crack pixels as negative class. We define the TP rate as the percentage of accurately identified crack pixels, whereas the TN rate is correctly identified non-crack pixels. The FP rates are delineated as the percentage of wrongly identified crack pixels and FNs are the incorrect identification percentage of non-crack pixels. We measure how exactly a method can distinguish between the crack and non-crack pixels with the precision measure in an imbalanced dataset. We quantify the proportion of crack pixels identified accurately by a network with a recall score. The sensitivity measure evaluates the architecture’s responsiveness toward the aberrant behavior of defected pixels. Specificity measure is used to quantify the behavior of non-crack pixels. The overall performance of a network is evaluated using the F1 score. A summary of the quantitative measures used in this work is shown in
Table 4. In addition, we assigned a ranking to the architectures based on both dependent and independent measures.
We evaluated the results of the proposed ANet-FSM architecture with three different thresholds. For applications in which high specificity and precision are required, higher threshold values should be utilized—see ANet-FSM (hi) in
Table 5. Lower thresholds would be effective in applications that require higher sensitivity and recall score is needed—see ANet-FSM (low) in
Table 5. In addition to these thresholds, we proposed the use of an optimal threshold, calculated using optimal thresholding algorithms such as the Otsu’s method [
52], when no preference is given for performance measure with respect to the positive or the negative classes—see ANet-FSM (opt) in
Table 5.
The overall results of different architecture and their average ranking on all the measures are shown in
Table 6. In addition to this, each network architecture is assigned ranking on individual measures on
Table 5, with 8 being the least accurate. Due to the block-based analysis technique for crack detection, [
3] was ranked at 8, where lower rank corresponds to better performance of the algorithm and vice versa. This architecture classifies a sub-image of size
as crack or non-crack. Since crack pixels occur only a very small portion of an image, an enormous amount of pixels are falsely classified in these blocks. As a result, the false identification rate (both FP rate and FN rate), accuracy as well as the error rate of the Gibbs network is the worst among all the networks. This also represents the inefficiency of image classification methods in concrete crack identification and anomaly detection.
As expected, encoder-decoder architectures in
Table 5 and
Table 6 outperform classification networks such as the Gibbs architecture. Although SegNet [
42] outperformed all the previous architectures for semantic segmentation in the field of scene parsing, the extremely imbalanced nature of concrete defect detection drops the performance of this architecture considerably. Additionally, the effect of the gradient vanishing problem (the result of an excessive number of layers) is reflected in evaluation measures such as FP and FN rates. The high false classification rate is also responsible for non-contributing feature maps generated due to the textured nature of the concrete surface. It is worth noting that these irrelevant feature maps are eliminated in ANet-FSM, as shown in better performance in all measures, compared to SegNet and shown in
Table 6. For these reasons, SegNet architecture is not appropriate for solving the crack identification problem. As a result, SegNet achieves a low overall and individual ranking in all of the evaluation measures in
Table 5 and
Table 6.
The gradient vanishing problem affecting the SegNet was addressed by up-sampling the feature space of each encoder layer in Segnet-SO [
4] architecture. This approach achieved higher TP rate and less error rate than SegNet architecture. Although the InspectionNet architecture improves the TP rate significantly, the highest FP rate in
Table 6 demonstrates the effect of gradient vanishing problem. SegNet-SO architecture is more robust to the gradient vanishing problem despite achieving a lower TP rate than InspectionNet. Therefore, it is worth mentioning that, none of the architectures discussed above represent robustness in all the measures.
The ANet-FSM architectures addresses the drawbacks of SegNet, SegNet-SO, and InspectionNet architectures by eliminating redundant computation. These computationally expensive methods represent a fluctuation in results. For example, InspectionNet obtains outstanding correct classification with the cost of an unacceptable misclassification rate. SegNet-SO degrades the correct classification rate in the course of reducing incorrect classification. To evaluate the stability of the ANet-FSM architecture, we have analyzed its performance without incorporating the FSM (referred to as ANet). The robustness of ANet architecture is reflected by the ranking of 4 in each measure in
Table 5. Although the InspectionNet architecture performs better in positive classification (TP), the low negative classification rate (TN) represents the unfeasible nature of this network towards imbalanced dataset. Therefore ANet architecture is substantially stable (the effect of using
spatial neighborhood in the convolution) despite achieving a lower ranking in some measures. However, the higher false positive rate of this network than InspectionNet represents that it is affected by the vanishing gradient problem because of a
kernel size. The association of the FSM model significantly addresses this problem as well as improves the performance in all measures.
To further investigate the result of feature silencing, we performed the thresholding operation on the result obtained from the ANet-FSM architecture. We discarded the crack pixels having a lower probability than a specific threshold in this operation. Three different threshold values were set experimentally to perform this operation such as high (
), low (
), and optimal (
). It is evident from
Table 5 and
Table 6 that ANet-FSM(low) architecture achieves highest performance in all but four measures. Specifically, ANet-FSM (low) has recognized the highest number of crack pixels among all the networks in
Table 5. However, the lowest TN and FP rates represent this network’s bias toward only positive classification. Therefore, this thresholding is suitable for application requiring to classify only crack locations. On the other hand, when a higher threshold is applied to ANet-FSM architecture, the FP rate significantly drops with the cost of a low TP rate. This thresholding technique is appropriate for applications that need to know healthy concrete locations. An optimal threshold was set experimentally to achieve a better TP rate and moderately lower FP rate than the previous networks. The ANet-FSM (opt) architecture outperforms all the aforesaid networks in every measure with a rank of 2. Although ANet-FSM(opt) does not perform best in all of the measures, the second-best ranking represents its stability in identifying both crack and non-crack pixels.
The above discussion evaluates the result of different architectures based on dependent evaluation measures. As mentioned earlier, these measures are highly biased toward the classification of the overwhelming majority class (non-crack). Nonetheless, to perform fair evaluation we have taken into account some measures such as precision, recall, sensitivity, specificity, and F1-score.
The Gibbs method [
3] and SegNet [
42] architecture have the lowest precision and recall score in
Table 5 and
Table 6. SegNet-SO architecture has a higher precision rate than InspectionNet architecture. However, the recall score represents a reverse relationship between SegNet-SO and InspectionNet. This tension between precision and recall is a well-known phenomenon within classification problems suffering from class-imbalance issues. Moreover, specificity and sensitivity represent similar relationships as precision and recall due to excessive class imbalance present in concrete crack datasets. If a network is highly specific, its sensitivity reduces (SegNet-SO) whereas a high sensitivity rate reduces the specificity of a network (InspectionNet). As a result, the F1 score is widely used to combine the effects of these measures for any machine learning architecture. The F1 score of SegNet-SO and InspectionNet represents that the former is better in terms of overall performance.
On the other hand, the ANet architecture maintains stable precision, recall, specificity, and sensitivity scores (all are assigned the same rank in
Table 5). Consequently, its F1 score is better than SegNet-SO and less than InspectionNet because of lower sensitivity. However, the ANet-FSM architecture with a low threshold achieves exceptional recall scores with relatively low specificity, resulting in the highest F1 score of all the methods. If extreme thresholding is applied, ANet-FSM architecture obtains the highest precision and specificity score with moderately low recall and sensitivity score among all the architectures. The optimal thresholding operation achieves higher precision, recall, specificity, sensitivity, and F1 scores than all the networks in
Table 5 and
Table 6. The same ranking in all of the measures in
Table 5 also demonstrates the stability of the network. This architecture obtains the highest F1-score among all the computationally expensive networks (SegNet, InspectionNet, SegNet-SO). Therefore, it can be concluded that this network is appropriate for use in applications with highly class-imbalanced data.
It is worth mentioning the rationale behind the need for achieving high degrees of accuracy for concrete crack detection compared to generic semantic segmentation applications. In generic semantic segmentation, very high accuracy values (both true positive and true negative rates) might indicate overfitting. Overfitting causes the network to have very low loss values and high accuracy values on training samples by the accuracy will drop on the test samples. In crack detection applications, due to the significant imbalanced nature of the dataset, i.e., significantly fewer crack pixels compared to non-crack pixels, maintaining higher generalization rates becomes important. As it can be seen from
Table 6, generic segmentation networks such as SegNet and InspectionNet might be suffering from overfitting. This can be observed by very high true negative values (98.9%, 99.1%, 98.8%, and 99.0% for SegNet, SegNet-SO, InspectionNet, and ANet, respectively) but a significantly lower true positive rates (72%, 73%, 81%, and 75% for SegNet, SegNet-SO, InspectionNet, and ANet, respectively). However, ANet-FSM
addresses this problem by establishing irrelevant feature maps to crack detection (which suffer from the imbalance in the number of crack and non-crack pixel), while finding an optimal threshold value for the likelihood of a pixel belonging to the distribution of crack pixels vs. non-crack pixels. This fact can be observed by high true negative and true positive values. Moreover, the goal of the network is the detection of crack pixels, and the achieving 87% true positive rate shows that the network has learning discriminating features with high levels of accuracy while avoiding the overfitting problem.
To perform an unbiased comparison, we have evaluated the performance of the proposed architecture using the evaluation metrics from Berkeley segmentation benchmark [
53]. Three evaluation metrics from the benchmark were employed to assess the performance of the networks such as boundary displacement error (BDE), global consistency error (GCE), and variation in information (VI). The BDE measures the distance between the boundary pixels between two segmented images. GCE represents how closely two segmented images can be shown as a representation of one another. The VI is used widely for data clustering applications. It measures the distance between two clusters (resembles mutual information). Since the probabilistic rand index replicates the same measurement as the accuracy of the algorithms, we have avoided this measurement. For comparison purposes, we have considered the SegNet, InspectionNet, and the proposed ANet-FSM architecture. The SegNet architecture was chosen by us to evaluate the effect of gradient vanishing problem on state-of-the-art semantic segmentation network. We have chosen InspectionNet to evaluate the effect of gradient vanishing problem in crack detection architecture. The comparison of different methods on these metrics on different datasets are shown in
Table 7.
We used three different types of datasets for performing a fair evaluation of the proposed method. These metrics were applied on Crack260 [
44], CrackForest [
50] and Illinois Bridge dataset. The Crack260 and CrackForest datasets are published annotated datasets for crack classification. The Illinois Bridge dataset was collected and prepared by the researchers of Advanced Robotics and Automation Lab. In
Table 7, for the Crack260 dataset, SegNet achieves the lowest BDE, whereas InspectionNet achieves the highest BDE. Considering the sheer number of parameters involved in SegNet, this low error rate is reasonable. In InspectionNet the number of parameters is more than SegNet. Due to the parameter degradation problem, the BDE is highest in this network. The ANet-FSM architecture achieves a BDE close to SegNet, despite having almost half the number of parameters as SegNet. On the other hand, for CrackForest and Illinois Bridge datasets, the BDE is lowest in ANet-FSM architecture. This represents that pruning feature space significantly enhances network performance. For Illinois dataset, the BDE of ANet-FSM is seven times lower than InspectionNet and twelve times lower than SegNet. For CrackForest dataset, the BDE of ANet-FSM is
times lower than InspectionNet and
times lower than SegNet. These two datasets significantly represents the effect gradient vanishing problem in complex architectures like SegNet and InspectionNet.
ANet-FSM architecture achieves the lowest GCE in CrackForest and Illinois Bridge datasets. However, for the Crack260 dataset, it achieves the second-best result among all the methods. On the other hand, ANet-FSM architecture achieves best VI for the Illinois Bridge dataset. For CrackForest dataset, InspectionNet achieves the best VI. SegNet achieves the best VI for the Crack260 dataset.
The rand index metric in the Berkeley segmentation benchmark represents the previously analyzed measure accuracy. Since, accuracy is dependent on TP, FP, FN, and TN for measurement, it was not incorporated for evaluation in
Table 7 and
Table 8. In addition, the region uniformity measure is widely used in semantic segmentation architecture evaluation. Region uniformity is more appropriate for image segmentation problems such as scene parsing and medical image analysis. These segmentation problems identify a region containing a substantial amount of pixels. Unlike these regions, crack width length can be of one pixel to several pixels. The crack area encompasses a very small number of pixels (usually five to ten pixels approximately). For this reason, VI and GCE measures are not directly applicable to the crack segmentation problem also. As a result, the GCE present in
Table 7 is higher than usual and the VI measure shows different behavior for each individual dataset.
We have also compared the performance of ANet-FSM architecture with state-of-the-art crack detection architectures such as DeepCrack [
44] and SDDNet [
45]. The results of deep crack and SDDNet were extracted from the experiments reported in [
44]. The ANet-FSM architecture was trained and tested using the dataset [
44] used for the experiment in [
45]. For comparison metrics, we have taken into consideration the mean intersection over union (mIou) [
45], precision, recall, F1 score, and the processing time. The results are shown in
Table 8. SDDNet architecture achieves the highest F1 score and mIou among all the methods. However, the ANet-FSM architecture achieves the highest precision rate and an F1 score close to SDDNet. This phenomenon represents the effect of gradient vanishing in lowest in ANet-FSM among all the methods. Moreover, the processing time of ANet-FSM is 1.14 ms per image, whereas SDDNet has 13.04 ms per image. The processing speed of ANet-FSM architecture is thirteen-time smaller than the SDDNet architecture. Considering this significant fast processing time of ANet-FSM architecture, the smaller mIou score is reasonable. Additionally, this processing time also depicts ANet-FSM architecture is nominally affected by gradient stability problem.
3.2.3. Qualitative Comparisons
The qualitative comparison of several crack identification networks is performed in this section. We first show the results of ANet-FSM architecture in
Figure 10. Then we compare our results with the image classification method (Gibbs [
3]). Finally, the results are compared with the state-of-the-art encoder-decoder architectures such as SegNet [
42], SegNet-SO [
4], and InspectionNet [
43]. We color-coded the true positive pixels (correctly detected crack pixels) with red, FPs (missed crack pixels) with blue, and FNs (pixels incorrectly labeled as crack) with green, respectively. The TN pixels (correctly labeled non-crack) are represented with their original texture.
We have represented the results of ANet-FSM architecture on three thresholding values such as high (
), low(
), and optimal (
) in
Figure 10. If a low threshold is applied, the network becomes more sensitive towards the environmental non-uniformity and gradient vanishing problem. On the other hand the network becomes more specific to correct classification. As a result, the number of falsely identified (blue colors) and correctly classified pixels (red colors) of the network significantly increases (shown in
Figure 10(2)a–c). When a high threshold is applied (shown in
Figure 10(3)a–c) the sensitivity towards noise is resolved but the specificity of correct classification also decreases. Application of an optimal threshold not only reduces the false classification rate but also increases correct classifications significantly. This thresholding obtains a balance between specificity and sensitivity as shown in
Figure 10.
We compared the results of the Gibbs [
3] architecture with ANet-FSM architecture in
Figure 11. Gibbs architecture divides the original image into smaller sub-blocks of size
and classifies them as crack and non-crack. The non-crack blocks are marked as black pixels in
Figure 11 and crack blocks are represented with their original texture. The results represent that, Gibbs architecture falsely identifies many crack blocks as well as fails to identify the exact location of cracks. On the other hand, the ANet-FSM architecture localize and identify crack location more precisely than the Gibbs architecture. For example, in
Figure 11(2)a the Gibbs method falsely identifies four
blocks as crack blocks. The ANet-FSM architecture in
Figure 11(3)a represents the exact crack location as well as misidentifies a very less number of crack pixels in comparison to Gibbs architecture.
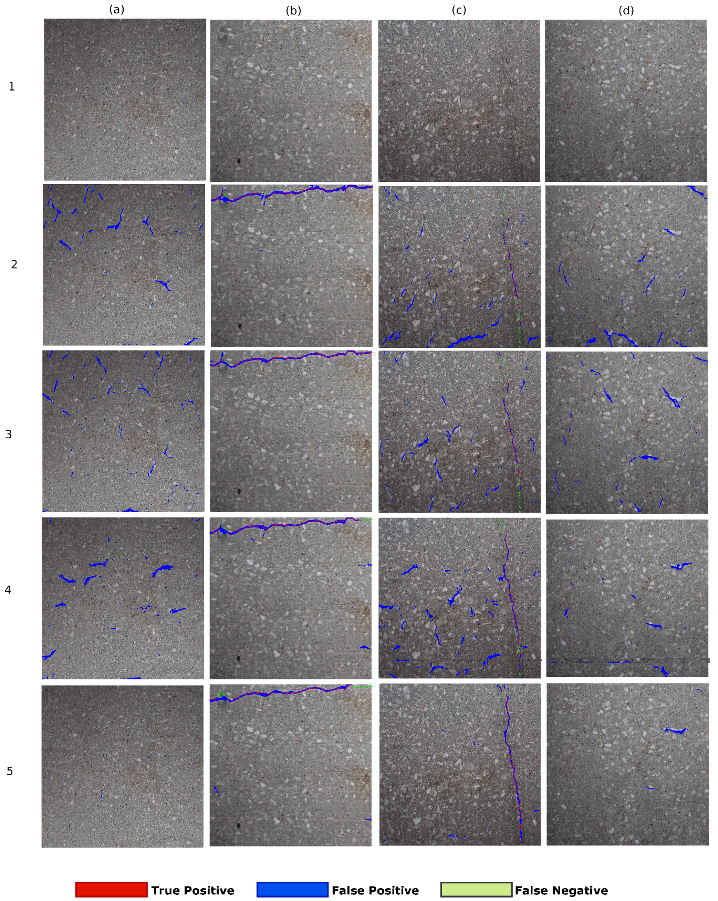
The result of different encoder-decoder networks such as SegNet, SegNet-SO, and InspectionNet and the proposed ANet-FSM architecture is shown in
Figure 12.
The results in
Figure 12(2)a,c,d show that the SegNet architecture has more falsely classified pixels (blue colored) than the remaining networks. The excessive number of feature space (due to maximal network complexity), as well as the vanishing gradients, contribute to this false classification. The SegNet-SO architecture in
Figure 12(3)b moderately removes the false classification present in
Figure 12(2)b. The results in
Figure 12(3)a,c,d represent an considerable amount of falsely classified pixels, specifically in
Figure 12(3)a where no crack pixels are present originally. On the other hand, the InspectionNet architecture represented in
Figure 12(4)a–d shows a performance improvement in comparison to SegNet and SegNet-SO. The results in
Figure 12(4)a,d are less affected by the FP rate than SegNet and SegNet-SO. However, the false identification rate increases more than SegNet-SO architecture when a significant number of crack pixels are present as shown in
Figure 12(3)c. As a result, it can be interpreted that InspectionNet is highly unstable as well as affected by the environmental non-uniformity (lighting and shading). On the other hand, the effect of FPs is significantly low in ANet-FSM architecture in comparison to the results in row-2, row-3, and row-4. It has almost no false identification (blue pixels) in
Figure 12(5)a. There exists a small amount of falsely identified pixels in
Figure 12(5)d, which is considerably lower than the previous networks. Moreover, this network improves the false classification without affecting the correct classification rate (represented as red pixels in
Figure 12(5)b,c), which is the effect of feature silencing. The ANet-FSM architecture not only improves the accuracy of crack identification but also eliminates the effect of false identification significantly with the FSM. Therefore, it can be concluded, ANet-FSM architecture is less effected by the gradient vanishing problem in comparison to the encoder-decoder architectures in [
4,
42,
43]. Based on the percentage of correctly identified crack pixels, it can be concluded that ANet-FSM provides performance that is an improvement on the state-of-the-art encoder decoder network architectures designed for crack detection in the recent past.
Figure 13 showcases the robustness and accuracy of the proposed ANet-FSM architecture in detecting very small cracks on concrete surfaces. The image shown in
Figure 13a contains a crack that passes vertically through the surface, with the middle portion (the red square) being thin and almost not discernible.
Figure 13b shows a magnification of this area. The detection results are shown in
Figure 13c.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}