An Integrated Strategy for Autonomous Exploration of Spatial Processes in Unknown Environments



Abstract
1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Contribution
- It selects intermediate goals in multi-step exploration for efficiently exploring the environment, while reducing the reconstruction error of the spatial process.
- It imposes visitation of intermediate goals as a routing problem for minimizing the traversed distance between two multi-exploration steps.
- It combines the strategy with efficient modelling using the GRBCM [29] to maintain online computational capabilities when exploring larger areas.
2. Gaussian Process Regression
2.1. Gaussian Process
2.2. Large-Scale Gaussian Process Regression
3. Integrated Exploration
3.1. Sensors and Robot
3.1.1. Sensors
3.1.2. Robot
3.2. Mapping and Localization, Navigation
3.2.1. Mapping
3.2.2. Localization
3.2.3. Navigation
3.3. GP Estimator
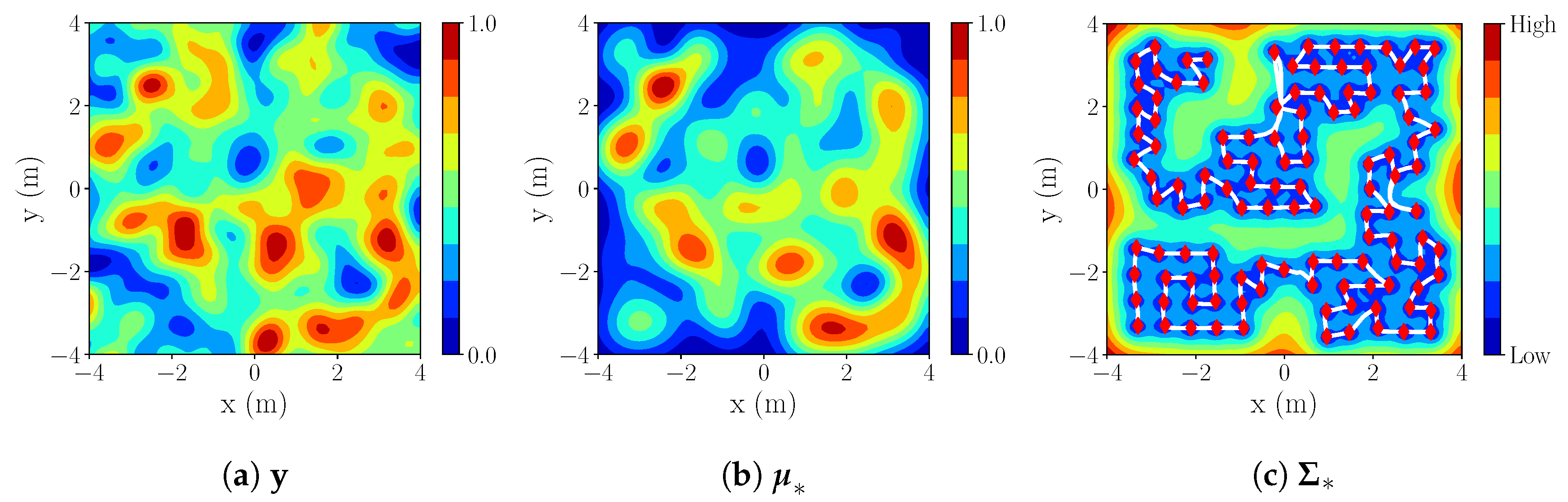
3.4. Exploration Strategy
- Efficient spatial process exploration: Minimization of the process error in comparison to the ground truth.
- Efficient coverage strategy: Increasing coverage of the environment map to reduce unknown portions of the map.
3.4.1. POI Detection
| Algorithm 1 informative candidates sampling. |
| Require: current location , map , radius r, sampling distance k, threshold Ensure: POI 1: Extract from the . 2: 3: BFS (): 4: 5: |
3.4.2. Goals Detection
- As a start depot, set the current location .
- If the frontier centroid , then .
- Otherwise, we set to be , that has the shortest distance to frontier centroid (to preserve the direction favoring area coverage).
3.5. All Components of Our Integrated Exploration Strategy
Algorithm Work-Flow
- Mapping and Localization: The robot continuously perceives the environment and accordingly updates the map and its current location estimate .
- Navigation: Until any unvisited exists, it continues following precomputed goal poses (ordered representation of ).
- At each reached, collect the process measurement .
- GP Estimator: Estimate GP process at probe locations over the whole environment.
- Integrated Exploration If is empty, detect the next frontier on according to the procedure described in Section 3.4.1 and:
- −
- Sample locations within r as described in Section 3.4.1—producing unordered , a list of candidates where we want to obtain our next measurements to increase knowledge about the process.
- −
- From , create a distance matrix, representing computed distances between POI.
- −
- Order POI according to the procedure described in Section 3.4.2 so that all POI are visited and total travelled distance is minimized, resulting in .
- −
- If Algorithm 1 finds no suitable candidates within the limited horizon r, extend the horizon to cover all discovered cells on the map. Select only the closest candidate location that satisfies as the next goal location . Otherwise terminate the mission.
4. System Evaluation
- What is the scalability of GRBCM for exploration of spatial processes?—Simulations (Section 5.1).
- What is the correlation between sampling distance k and error decrease in the process reconstruction for the IE strategy? How does it affect total exploration distance?—Simulations, experiment (Section 5.2 and Section 6.2).
- How does the IE perform against the benchmarks in various scenarios?—Simulations, experiment (Section 5.3.3 and Section 6.2).
4.1. General System Setup
4.1.1. Robotic Platform
4.1.2. Perception Sensor
4.1.3. Process Sensor
5. Simulations
5.1. Scalability of Gaussian Processes for Spatial Modelling
Simulation Results
5.2. Sampling Distance
Simulation Results
5.3. Evaluation of the Strategy in Simulation
5.3.1. Applied Baselines
5.3.2. System Simulation Setup
5.3.3. System Simulation Results
6. Experiments
6.1. Experimental Setup
- Finite horizon, m.
- Sampling distance .
6.2. Experimental Results
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| GP | Gaussian process |
| NBC | nuclear, biological, chemical |
| SLAM | Simultaneous Localization and Mapping |
| BCM | Bayesian Committee Machine |
| RBCM | Robust Bayesian Committee Machine |
| TSP | Traveling Salesman Problem |
| FOV | field of view |
| GRBCM | Generalized Robust Bayesian Committee Machine |
| SE | squared exponential |
| LIDAR | Light Detection and Ranging |
| POI | Point of Interest |
| ICP | Iterative Closest Point |
| TEB | Time Elastic Band |
| WFD | Wavefront Frontier Detector |
| BFS | Breadth-first search |
| VRP | Vehicle Routing Problem |
| IE | Integrated exploration |
| NMSE | Normalized Mean Square Error |
| GGE | Greedy global entropy |
| GLGE | Greedy local-global entropy |
| SS | Sequential strategy |
| ROS | Robot Operating System |
References
- He, X.; Bourne, J.R.; Steiner, J.A.; Mortensen, C.; Hoffman, K.C.; Dudley, C.J.; Rogers, B.; Cropek, D.M.; Leang, K.K. Autonomous chemical-sensing aerial robot for urban/suburban environmental monitoring. IEEE Syst. J. 2019, 13, 3524–3535. [Google Scholar] [CrossRef]
- Bird, B.; Griffiths, A.; Martin, H.; Codres, E.; Jones, J.; Stancu, A.; Lennox, B.; Watson, S.; Poteau, X. A robot to monitor nuclear facilities: Using autonomous radiation-monitoring assistance to reduce risk and cost. IEEE Robot. Autom. Mag. 2018, 26, 35–43. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Carrillo, H.; Reid, I.; Castellanos, J.A. On the comparison of uncertainty criteria for active SLAM. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 2080–2087. [Google Scholar]
- Valencia, R.; Andrade-Cetto, J. Active pose SLAM. In Mapping, Planning and Exploration with Pose SLAM; Springer: Berlin, Germany, 2018; pp. 89–108. [Google Scholar]
- Yamauchi, B. A frontier-based approach for autonomous exploration. In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA’97), Monterey, CA, USA, 10–11 July 1997; Volume 97, pp. 146–151. [Google Scholar]
- Bourgault, F.; Makarenko, A.A.; Williams, S.B.; Grocholsky, B.; Durrant-Whyte, H.F. Information based adaptive robotic exploration. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; Volume 1, pp. 540–545. [Google Scholar]
- Viseras, A.; Shutin, D.; Merino, L. Robotic active information gathering for spatial field reconstruction with rapidly-exploring random trees and online learning of Gaussian processes. Sensors 2019, 19, 1016. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Krause, A.; Singh, A.; Guestrin, C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar]
- Singh, A.; Ramos, F.; Whyte, H.D.; Kaiser, W.J. Modeling and decision making in spatio-temporal processes for environmental surveillance. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 4–8 May 2010; pp. 5490–5497. [Google Scholar]
- Julian, B.J.; Angermann, M.; Schwager, M.; Rus, D. Distributed robotic sensor networks: An information- theoretic approach. Int. J. Robot. Res. 2012, 31, 1134–1154. [Google Scholar] [CrossRef]
- Marchant, R.; Ramos, F. Bayesian Optimisation for informative continuous path planning. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6136–6143. [Google Scholar]
- Fink, J.; Kumar, V. Online methods for radio signal mapping with mobile robots. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010; pp. 1940–1945. [Google Scholar]
- Carrillo, H.; Dames, P.; Kumar, V.; Castellanos, J.A. Autonomous robotic exploration using a utility function based on Rényi’s general theory of entropy. Auton. Robot. 2018, 42, 235–256. [Google Scholar] [CrossRef]
- Elfes, A. Using occupancy grids for mobile robot perception and navigation. Computer 1989, 22, 46–57. [Google Scholar] [CrossRef]
- Ghaffari Jadidi, M.; Valls Miro, J.; Valencia, R.; Andrade-Cetto, J. Exploration on continuous Gaussian process frontier maps. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6077–6082. [Google Scholar]
- Lilienthal, A.J.; Loutfi, A.; Blanco, J.L.; Galindo, C.; Gonzalez, J. Integrating SLAM into gas distribution mapping. In Proceedings of the ICRA Workshop on Robotic Olfaction, Towards Real Applications (ICRA), Rome, Italy, 10 April–14 April 2007; pp. 21–28. [Google Scholar]
- Jung, J.; Oh, T.; Myung, H. Magnetic field constraints and sequence-based matching for indoor pose graph SLAM. Robot. Auton. Syst. 2015, 70, 92–105. [Google Scholar] [CrossRef]
- Prágr, M.; Čížek, P.; Bayer, J.; Faigl, J. Online incremental learning of the terrain traversal cost in autonomous exploration. In Proceedings of the Robotics: Science and Systems 2019, Freiburg im Breisgau, Germany, 22–26 June 2019. [Google Scholar]
- Kulich, M.; Faigl, J.; Přeučil, L. On distance utility in the exploration task. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 4455–4460. [Google Scholar]
- Oßwald, S.; Bennewitz, M.; Burgard, W.; Stachniss, C. Speeding-up robot exploration by exploiting background information. IEEE Robot. Autom. Lett. 2016, 1, 716–723. [Google Scholar]
- Kulich, M.; Kubalík, J.; Přeučil, L. An integrated approach to goal selection in mobile robot exploration. Sensors 2019, 19, 1400. [Google Scholar] [CrossRef] [PubMed]
- Basilico, N.; Amigoni, F. Exploration strategies based on multi-criteria decision making for searching environments in rescue operations. Auton. Robot. 2011, 31, 401. [Google Scholar] [CrossRef]
- Amigoni, F.; Gallo, A. A multi-objective exploration strategy for mobile robots. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 3850–3855. [Google Scholar]
- Calisi, D.; Farinelli, A.; Iocchi, L.; Nardi, D. Multi-objective exploration and search for autonomous rescue robots. J. Field Robot. 2007, 24, 763–777. [Google Scholar] [CrossRef]
- Stachniss, C.; Burgard, W. Exploring unknown environments with mobile robots using coverage maps. In Proceedings of the IJCAI, Acapulco, Mexico, 9–15 August 2003; Volume 2003, pp. 1127–1134. [Google Scholar]
- Choquet, G. Theory of capacities. Annales de l’institut Fourier 1954, 5, 131–295. [Google Scholar] [CrossRef]
- Liu, H.; Cai, J.; Wang, Y.; Ong, Y.S. Generalized robust bayesian committee machine for large-scale Gaussian process regression. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3137–3146. [Google Scholar]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2018, 85, 1–16. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Pomerleau, F.; Colas, F.; Siegwart, R.; Magnenat, S. Comparing ICP Variants on Real-World Data Sets. Auton. Robot. 2013, 34, 133–148. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 July 2014; Volume 2, p. 9. [Google Scholar]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Dubé, R.; Cramariuc, A.; Dugas, D.; Nieto, J.; Siegwart, R.; Cadena, C. SegMap: 3D segment mapping using data-driven descriptors. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Rösmann, C.; Hoffmann, F.; Bertram, T. Integrated online trajectory planning and optimization in distinctive topologies. Robot. Auton. Syst. 2017, 88, 142–153. [Google Scholar] [CrossRef]
- Keidar, M.; Kaminka, G.A. Efficient frontier detection for robot exploration. Int. J. Robot. Res. 2014, 33, 215–236. [Google Scholar] [CrossRef]
- Toth, P.; Vigo, D. The Vehicle Routing Problem; SIAM: Philadelphia, PA, USA, 2002; p. 367. [Google Scholar] [CrossRef]
- GPy. GPy: A Gaussian Process Framework in Python. Available online: http://github.com/SheffieldML/GPy (accessed on 18 June 2019).
- Van Omme, N.; Perron, L.; Furnon, V. Or-Tools User’s Manual; Technical Report; Google: Mountain View, CA, USA, 2014. [Google Scholar]
- Viseras-Ruiz, A.; Wiedemann, T.; Manss, C.; Magel, L.; Carsten-Mueller, J.; Shutin, D.; Merino, L. Decentralized multi-agent exploration with online-learning of Gaussian processes. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4222–4229. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Process | Operating Environment | Dimensions |
|---|---|---|---|
| S1 | Process 1 | Obstacle-free | |
| S2 | Process 1 | Small room-like environment, obstacles introduced | |
| S3 | Process 2 | Large room-like environment, obstacles introduced | |
| E1 | Magnetic field intensity | Obstacles introduced |
| Process | Dimensions () | l (m) | (m) | |
|---|---|---|---|---|
| Process 1 | 0.03 | 0.2 | 0.0001 | |
| Process 2 | 0.04 | 0.25 | 0.0001 | |
| Magnetic field | 0.0001 |
| Method | Prediction Time [s] | NMSE | |
|---|---|---|---|
| 37, 100 | GRBCM | 21.28 | 0.151 |
| 18, 200 | GRBCM | 20.74 | 0.093 |
| 12, 300 | GRBCM | 20.26 | 0.073 |
| 10, 350 | GRBCM | 19.26 | 0.070 |
| 9, 400 | GRBCM | 22.42 | 0.068 |
| 7, 500 | GRBCM | 24.31 | 0.062 |
| 1, 7592 | Full GP | 102.34 | 0.060 |
| Strategy | Radius r (m) | Step Size k (m) | Multi-Step Planner |
|---|---|---|---|
| GGE | explored map | , explored map] | No. |
| GLGE | (i) fixed r, (ii) explored map | (i) , (ii) , explored map] | No. |
| SS | explored map | (i) fixed = , (ii) , explored map] | No. |
| our IE | (i) fixed r, (ii) explored map | (i) , (ii) , explored map] | Yes. |
| Strategy | Distance (m) | |
|---|---|---|
| GGE | ||
| GLGE | ||
| IE m | ||
| IE m | ||
| IE |
| Strategy | Distance (m) Map Explored | Proc. NMSE Map Explored | Distance (m) Proc. Explored | ||
|---|---|---|---|---|---|
| GGE | |||||
| GLGE | |||||
| SS | |||||
| IE m | |||||
| IE m |
| Strategy | Distance (m) Map Explored | Proc. NMSE Map Explored | Distance (m) Proc. Explored | ||
|---|---|---|---|---|---|
| GLGE | 1398.45 | 2027 | 0.29 | 2977.52 | 3228 |
| IE m | 1393.46 | 1852 | 0.33 | 2847.06 | 3423 |
| IE m | 1888.78 | 2530 | 0.32 | 2872.52 | 3567 |
| Strategy | Distance (m) Proc. Explored | Distance (m) Proc. Explored | ||
|---|---|---|---|---|
| IE m | 92.84 | 144 | 55.63 | 75 |
| IE m | 93.56 | 146 | 58.23 | 74 |
| Strategy | Distance (m) Map Explored | Proc. NMSE Map Explored | Distance (m) Proc. Explored | ||
|---|---|---|---|---|---|
| GGE | 17.28 | 17 | 0.71 | 170.94 | 53 |
| GLGE | 44.91 | 54 | 0.62 | 64.81 | 75 |
| SS | 33.24 | 48 | 0.68 | 73.36 | 77 |
| IE m | 47.45 | 62 | 0.54 | 55.62 | 75 |
| IE m | 53.08 | 66 | 0.53 | 58.23 | 74 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karolj, V.; Viseras, A.; Merino, L.; Shutin, D. An Integrated Strategy for Autonomous Exploration of Spatial Processes in Unknown Environments. Sensors 2020, 20, 3663. https://doi.org/10.3390/s20133663
Karolj V, Viseras A, Merino L, Shutin D. An Integrated Strategy for Autonomous Exploration of Spatial Processes in Unknown Environments. Sensors. 2020; 20(13):3663. https://doi.org/10.3390/s20133663
Chicago/Turabian StyleKarolj, Valentina, Alberto Viseras, Luis Merino, and Dmitriy Shutin. 2020. "An Integrated Strategy for Autonomous Exploration of Spatial Processes in Unknown Environments" Sensors 20, no. 13: 3663. https://doi.org/10.3390/s20133663
APA StyleKarolj, V., Viseras, A., Merino, L., & Shutin, D. (2020). An Integrated Strategy for Autonomous Exploration of Spatial Processes in Unknown Environments. Sensors, 20(13), 3663. https://doi.org/10.3390/s20133663