Learning Reward Function with Matching Network for Mapless Navigation


Abstract
1. Introduction
2. Related Work
2.1. Navigation Algorithm
2.2. Mapless Navigation
2.3. Meta-Reinforcement Learning
2.4. Automatic Reward Shaping
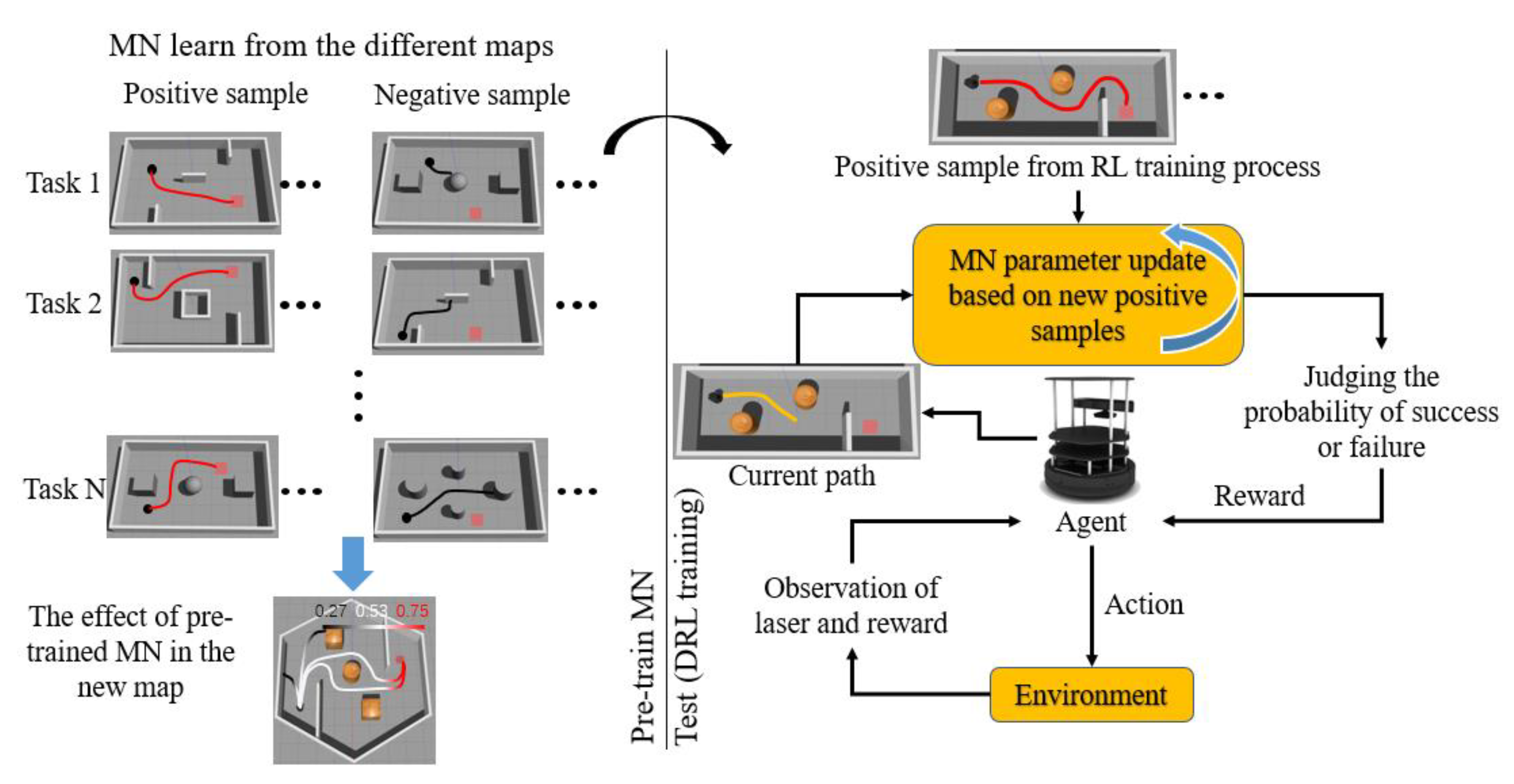
3. DRL with MNR
3.1. Problem Formulation
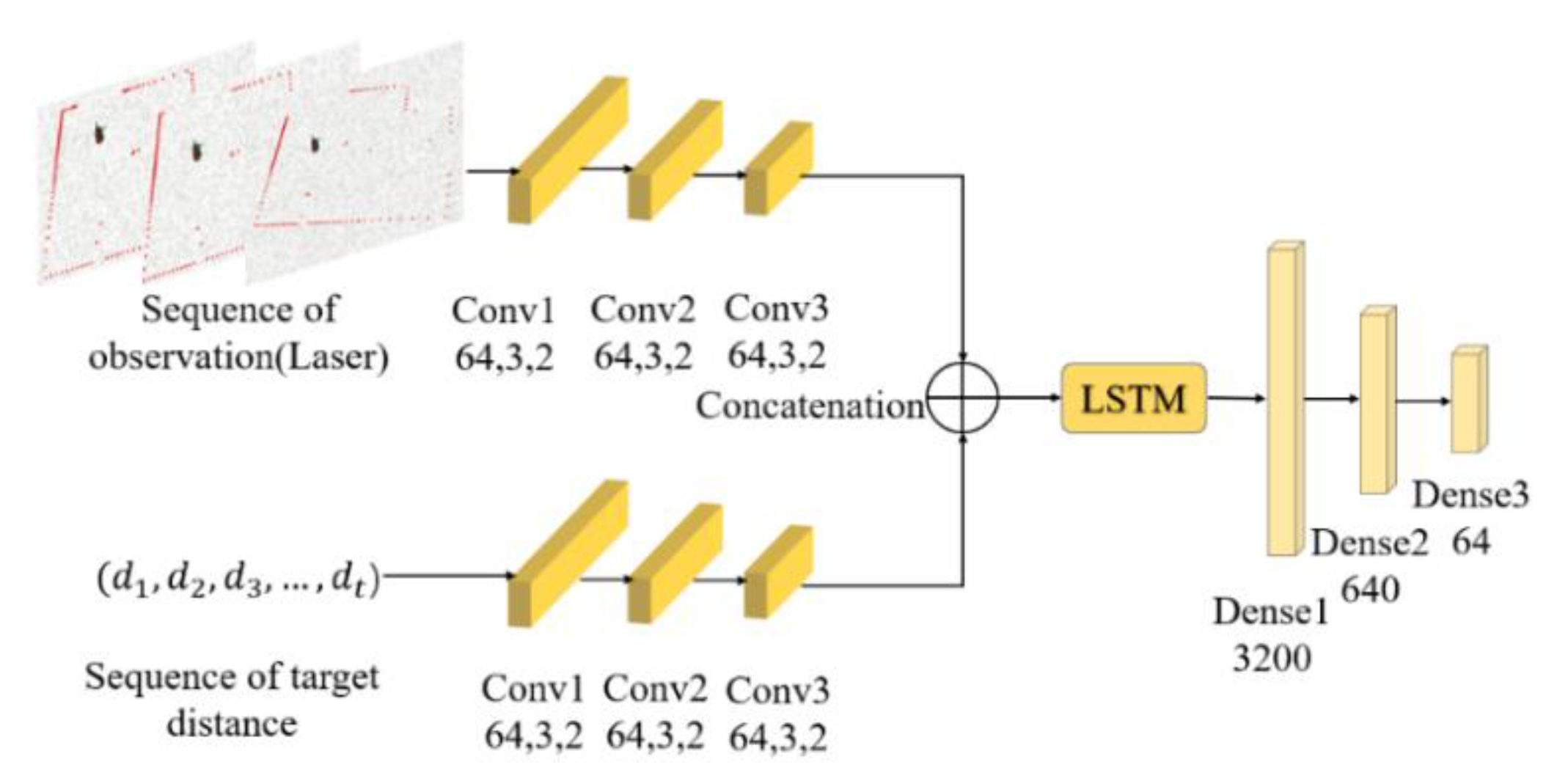
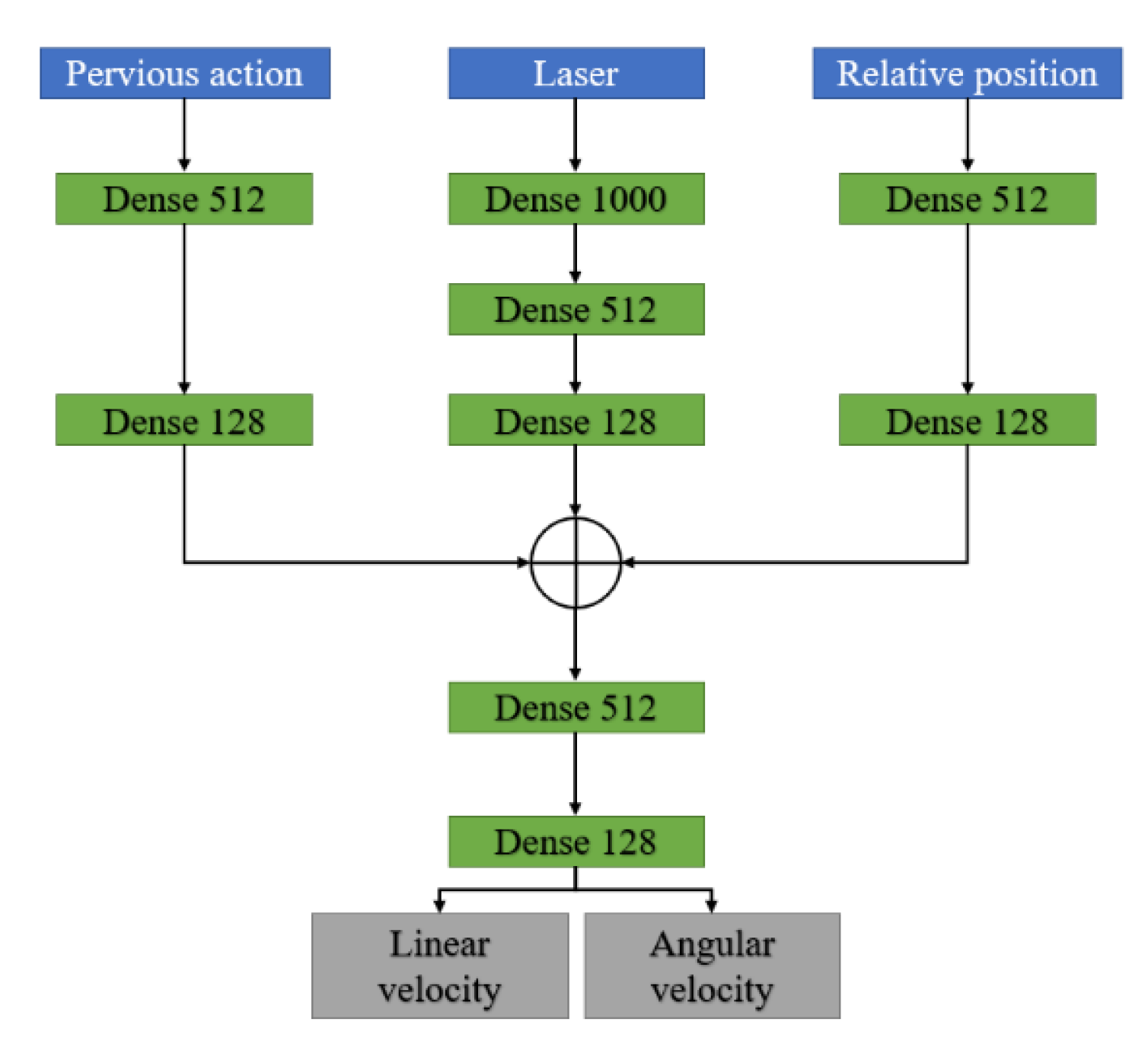
3.2. Model Architecture
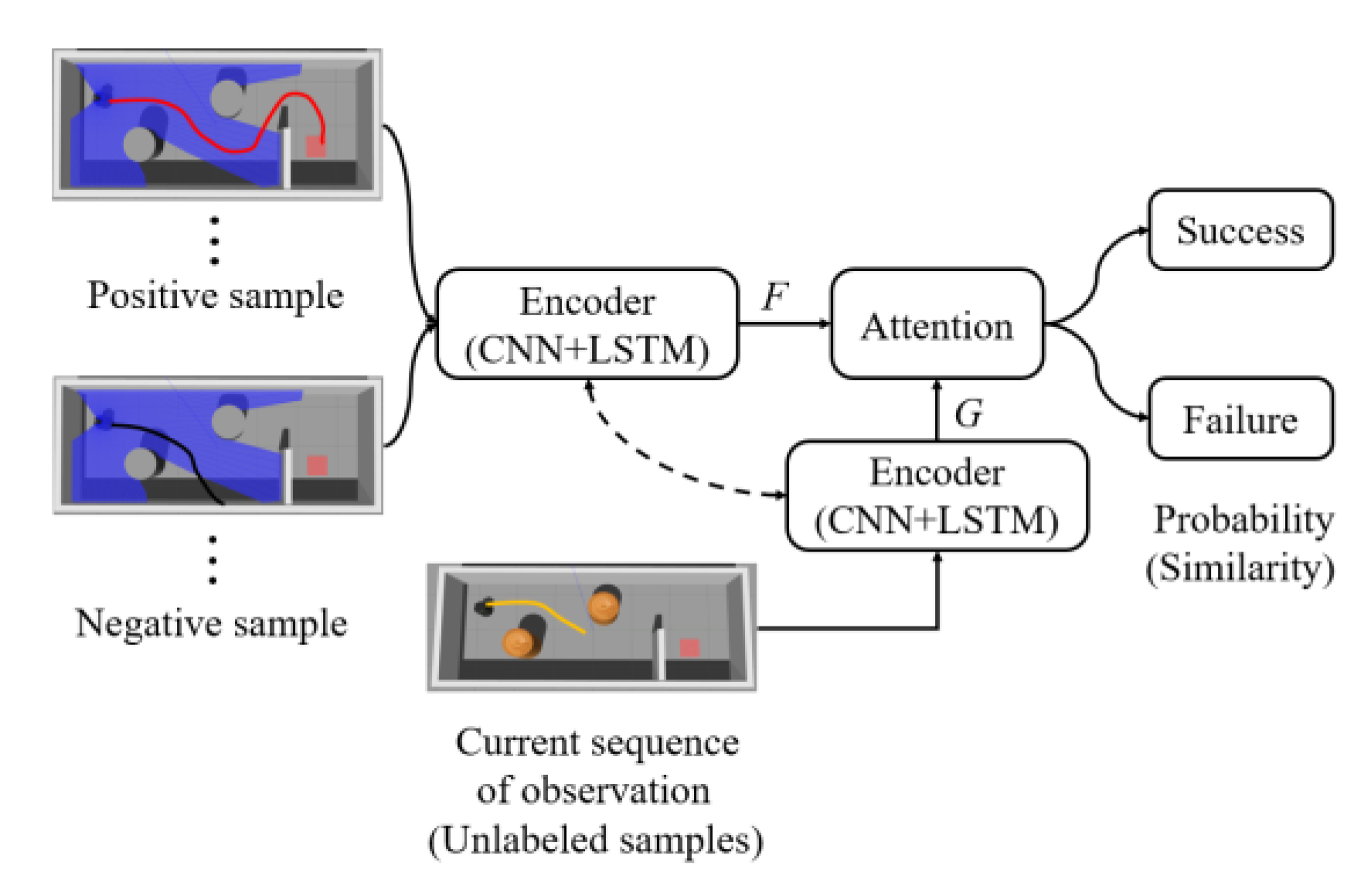
4. Matching Network Based Reward
4.1. MN Network Structure
4.2. MN Training Strategy
| Algorithm 1. Pre-Training Matching Network (MN) |
| Input: Data set |
| 1: Initialize MN parameter x |
| 2: For each iteration do |
| 3: Sample training task from the data set, each task includes support set and query set |
| 4: Support set and query set were coded to get G and F |
| 5: Calculate the similarity between G and F |
| 6: Calculate the loss |
| 7: Update the parameters x through Adam optimizer |
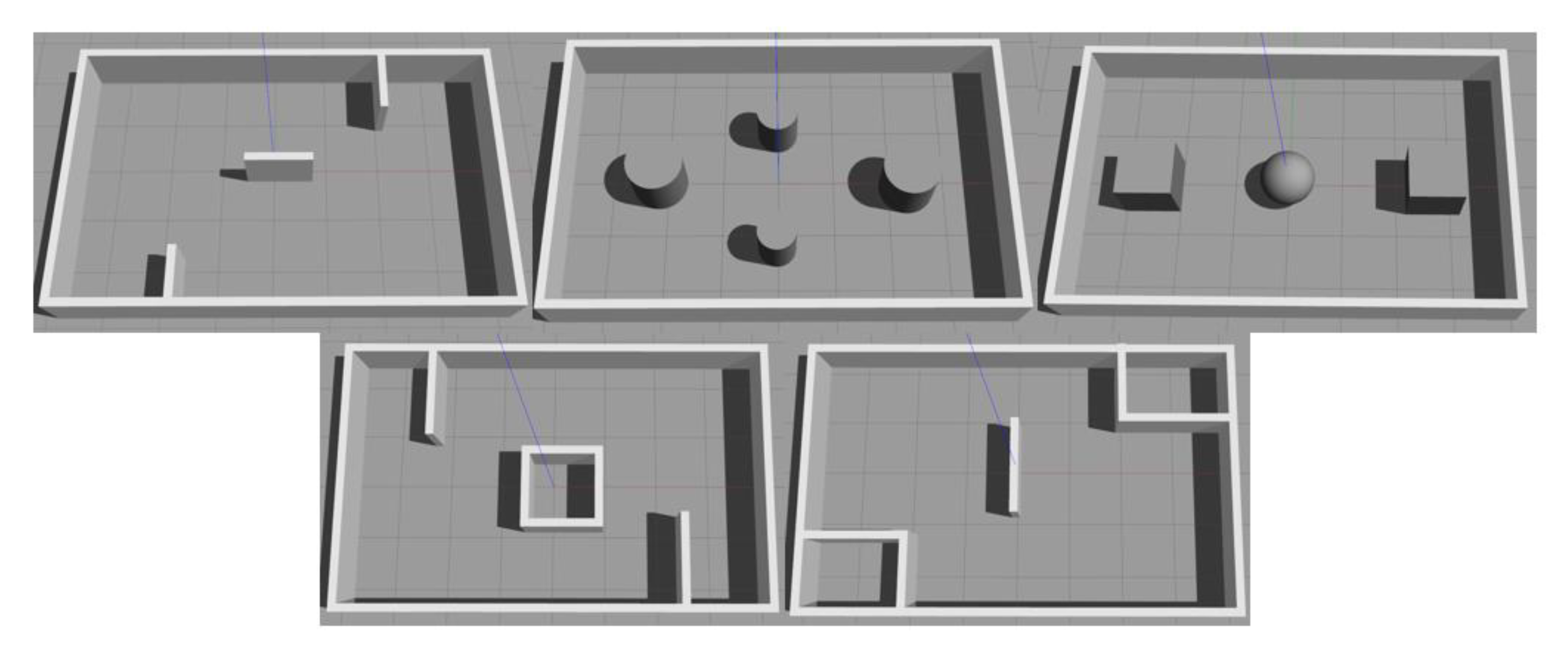
4.3. Sample Collection
4.4. Pre-Training MN and Result Analysis
5. Using MN-Based Rewards in PPO
5.1. PPO with MNR
| Algorithm 2. Proximal Policy Optimization (PPO) with Pre-Trained MN Reward |
| Input: Pre—date set , load the parameter of pre-trained MN |
| 1: Initialize PPO parameter and policy |
| 2: For each iteration do |
| 3: While the robot does not reach the target position do |
| 4: Initializes the robot position |
| 5: Get state (including laser scan state and relative position ) |
| 6: Run generate action |
| 7: Add to the queue |
| 8: Input into MN |
| 9: Get reward from MN and environment |
| 10: Collect |
| 11: Add and task result (Label) to the MN’s data set |
| 12: If is a multiple of 3 then |
| 13: Update parameter of MN by with few epochs |
| 14: Compute estimated advantage |
| 15: Update with K epochs |
5.2. Reward Function Design and Policy Invariance
- ER (Euclidean reward): in this process, we only used the Euclidean reward function, , which is the benchmark for our tests.
- MNR: in this step, we tested whether the matching network can provide effective guidance. The value generated by the MN was amplified as the reward function, .
- ER+CAML: in this step, we used the Euclidean and CAML as a reward function, . Note that CAML was pre-trained by the samples described in Section 4.2. During DRL training, we artificially provided positive samples for fine-tuning of CAML.
- ER+MNR (Ours): in this step, we combined the environment rewards function with MN, .
6. Navigation Experiment
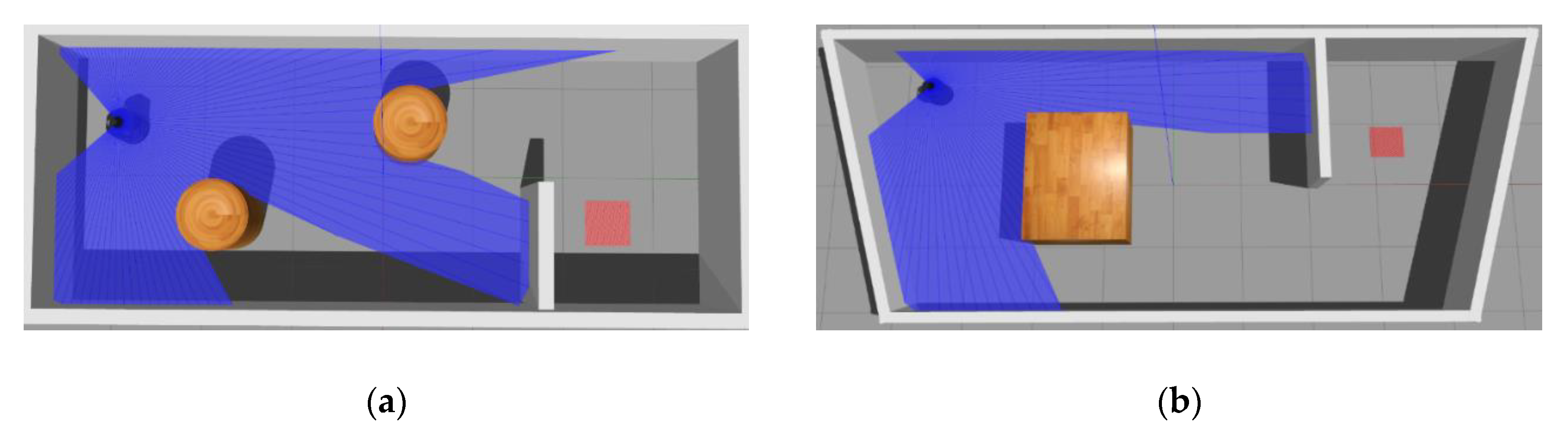
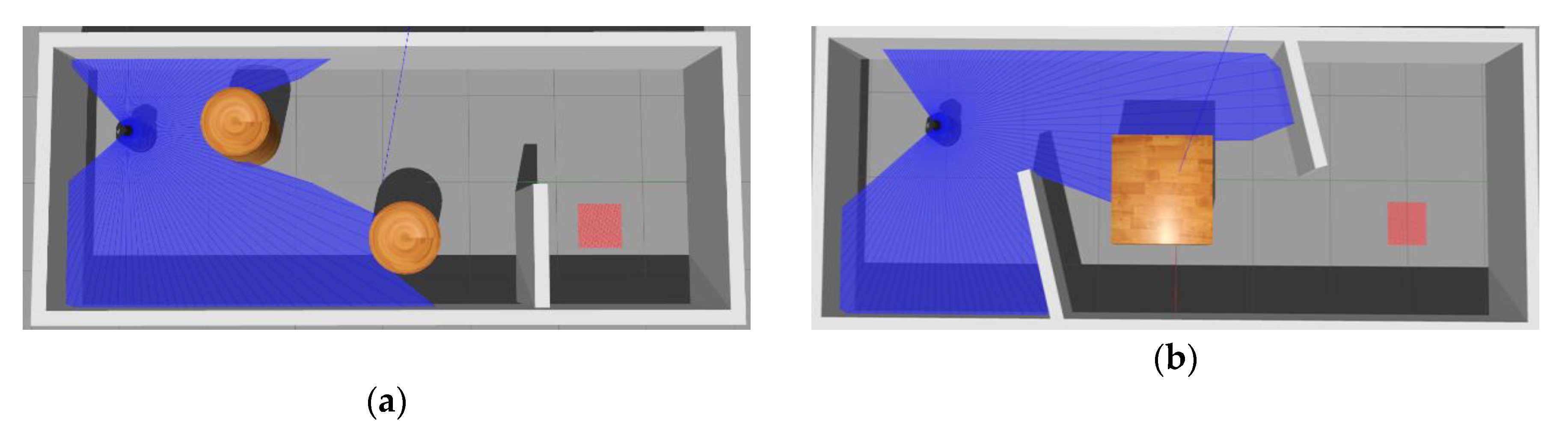
6.1. Navigation Experiment with Static Obstacles
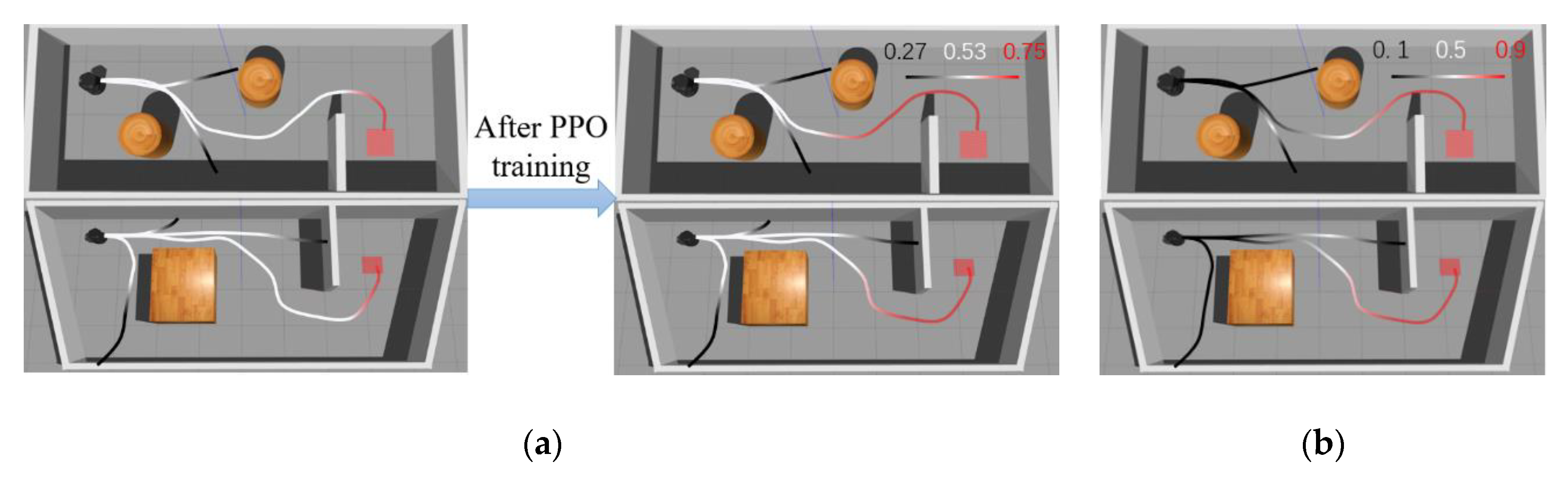
6.1.1. MN Update
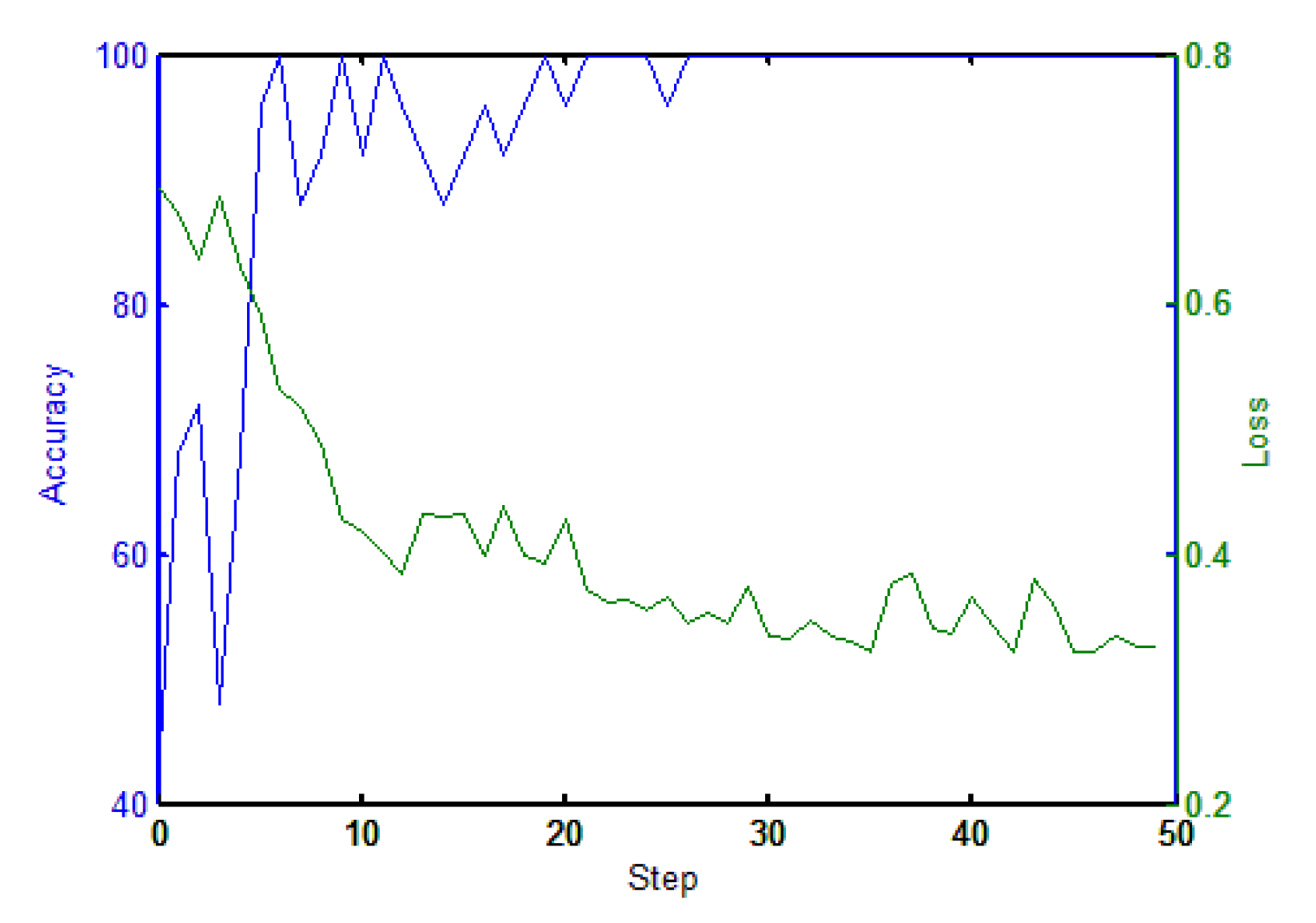
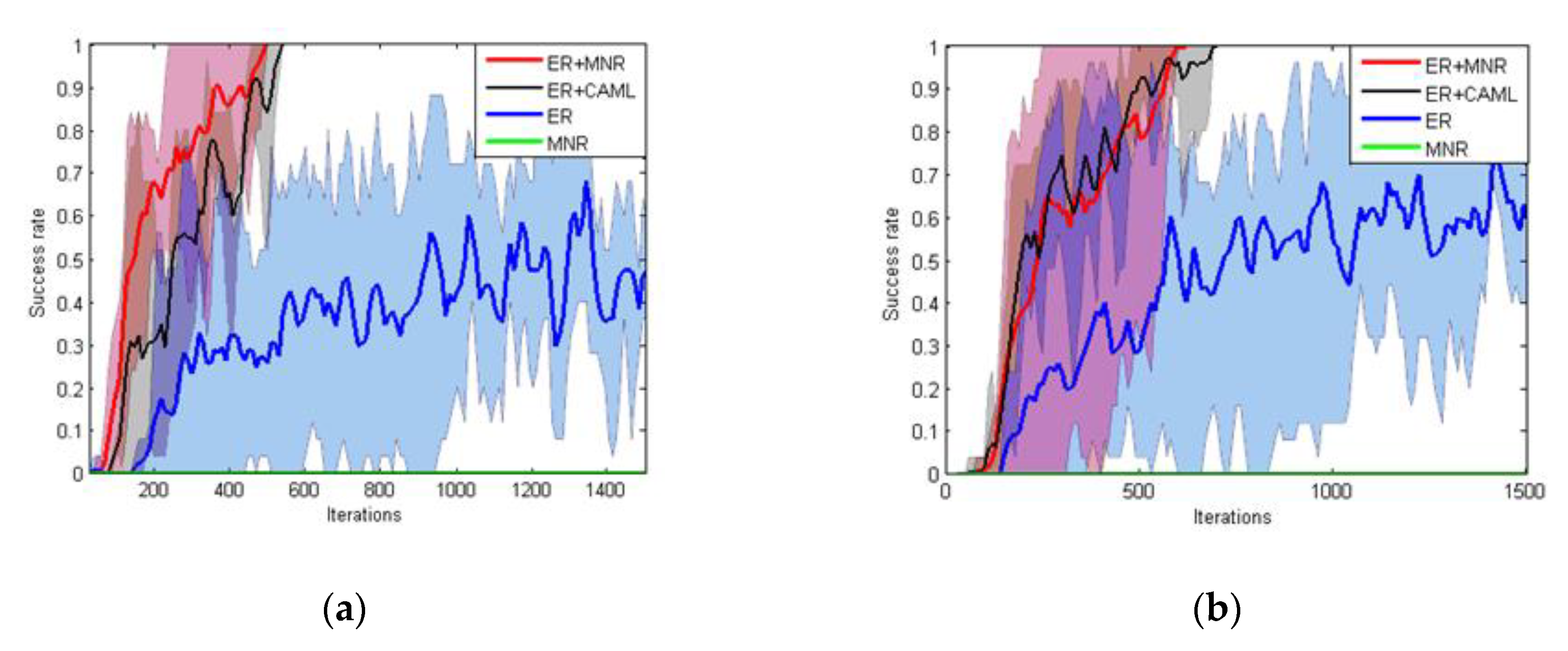
6.1.2. Results and Discussion
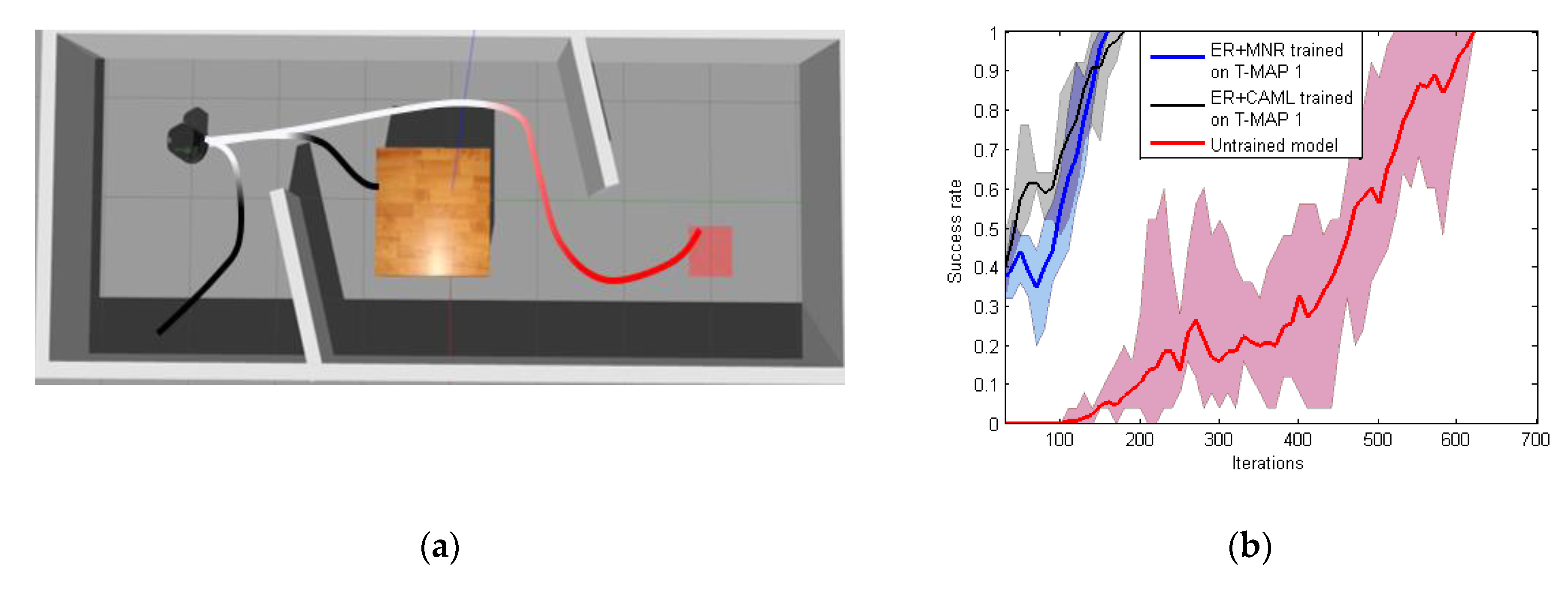
- Success rate: the success rate means the success rate of navigation task of the last 25 iterations. Starting with the 30th iteration, we recorded the success rate every 10 iterations. In Figure 10, the X-axis represents the number of training iterations and the Y-axis represents the success rate. If the accuracy reached 100%, the robot could be considered to have completed the navigation task.
- Training iterations: training iterations means the number of iterations that the robot trains when the success rate reaches the maximum in 1500 iterations of training.
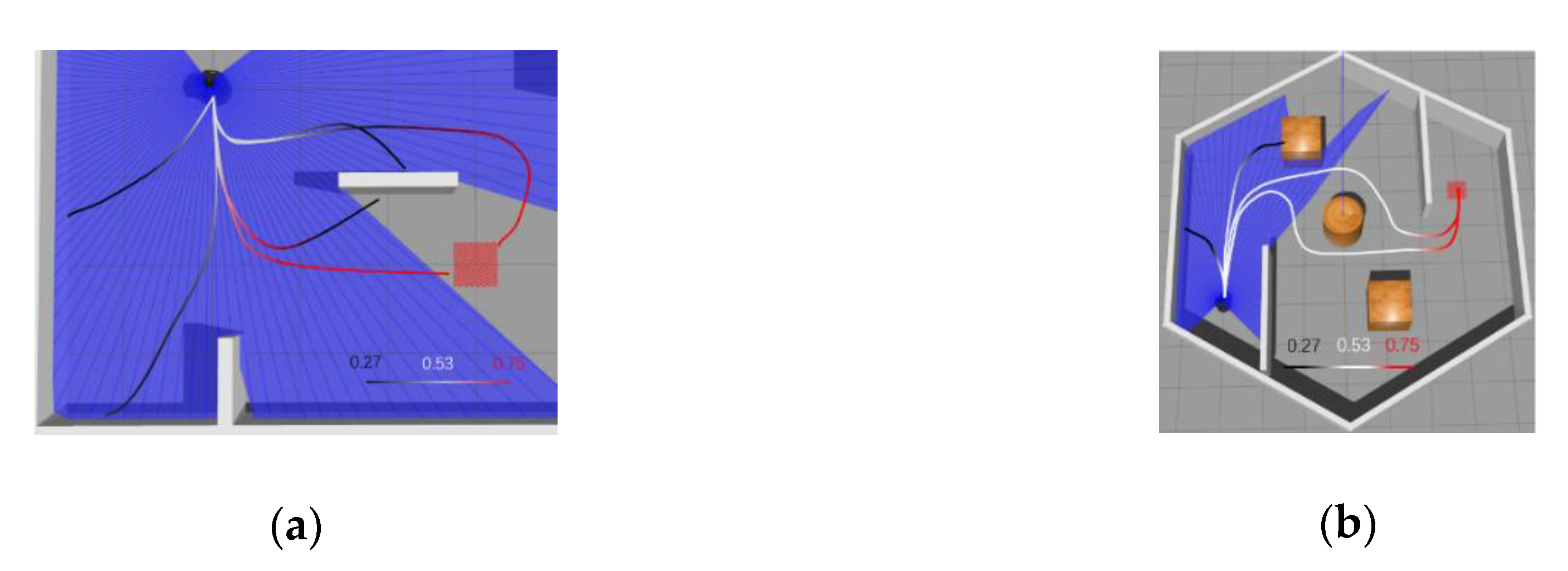
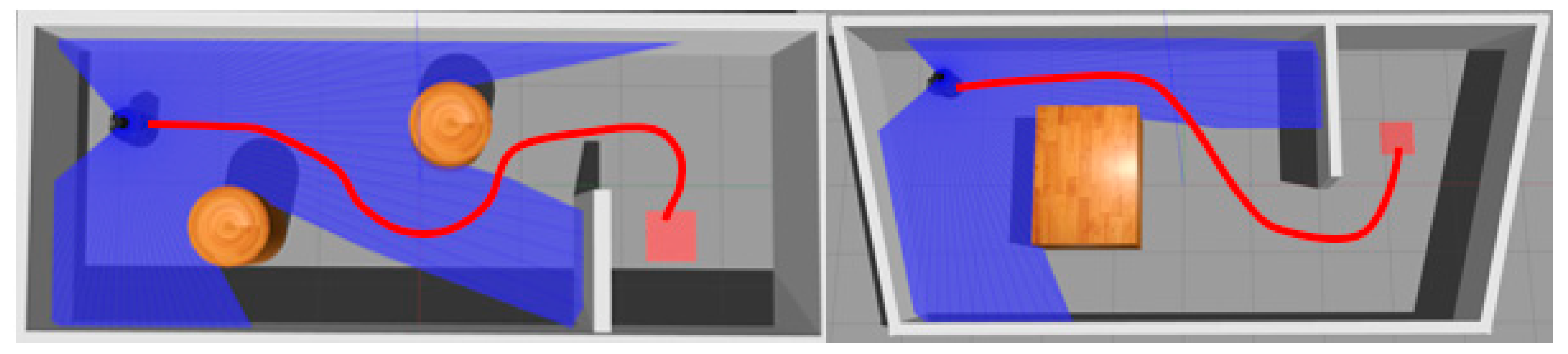
6.1.3. Generalization Test on New Maps
6.2. Navigation Experiment with Dynamic Obstacles
7. Conclusion and Future Work
- On the whole, the output value of MN was closer to the discrete value, and the guidance effect on the robot was poor, so other reward functions need to be introduced.
- The robot performed well in a static environment, but in a dynamic map, the robot lacked the ability of predicting the movement of obstacles, which led to a slightly poorer navigation effect of the robot in a dynamic environment.
- Our proposed model is universal and we will also apply the model to other fields in future work.
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.L.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Ort, T.; Paull, L.; Rus, D. Autonomous vehicle navigation in rural environments without detailed prior maps. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2040–2047. [Google Scholar]
- Lample, G.; Chaplot, D.S. Playing fps games with deep reinforcement learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv: Learning 2013, arXiv:1312.5602. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Wang, C.; Zhang, Q.; Tian, Q.; Li, S.; Wang, X.; Lane, D.M.; Petillot, Y.; Wang, S. Learning Mobile Manipulation through Deep Reinforcement Learning. Sensors 2020, 20, 939. [Google Scholar] [CrossRef]
- Kulhanek, J.; Derner, E.; De Bruin, T.; Babuska, R. Vision-based navigation using deep reinforcement learning. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019. [Google Scholar]
- Zhelo, O.; Zhang, J.; Tai, L.; Liu, M.; Burgard, W. Curiosity-driven exploration for mapless navigation with deep reinforcement learning. arXiv: Robotics 2018, arXiv:1804.00456. [Google Scholar]
- Mirowski, P.; Grimes, M.K.; Malinowski, M.; Hermann, K.M.; Anderson, K.; Teplyashin, D. Learning to navigate in cities without a map. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Hu, Z.; Wan, K.; Gao, X.; Zhai, Y.; Wang, Q. Deep Reinforcement Learning Approach with Multiple Experience Pools for UAV’s Autonomous Motion Planning in Complex Unknown Environments. Sensors 2020, 20, 1890. [Google Scholar] [CrossRef]
- Hu, B.; Shao, S.; Cao, Z.; Xiao, Q.; Li, Q.; Ma, C. Learning a Faster Locomotion Gait for a Quadruped Robot with Model-Free Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 1097–1102. [Google Scholar]
- Hussein, A.; Elyan, E.; Gaber, M.M.; Jayne, C. Deep reward shaping from demonstrations. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 510–517. [Google Scholar]
- Ng, A.Y.; Russell, S. Algorithms for inverse reinforcement learning. Int. Conf. Mach. Learn. 2000, 67, 663–670. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 49–58. [Google Scholar]
- Fu, J.; Luo, K.; Levine, S. Learning robust rewards with adversarial inverse reinforcement learning. arXiv: Learning 2017, arXiv:1710.11248. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4565–4573. [Google Scholar]
- Fu, J.; Singh, A.; Ghosh, D.; Yang, L.; Levine, S. Variational inverse control with events: A general framework for data-driven reward definition. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 8538–8547. [Google Scholar]
- Zhou, W.; Li, W. Safety-aware apprenticeship learning. In Proceedings of the International Conference on Computer Aided Verification, Oxford, UK, 14–17 July 2018; pp. 662–680. [Google Scholar]
- Abbeel, P.; Coates, A.; Ng, A.Y. Autonomous helicopter aerobatics through apprenticeship learning. Int. J. Robot. Res. 2010, 29, 1608–1639. [Google Scholar] [CrossRef]
- Singh, A.; Yang, L.; Finn, C.; Levine, S. End-to-end robotic reinforcement learning without reward engineering. In Proceedings of the Robotics Science and Systems, Freiburg im Breisgau, Germany, 22–26 June 2019. [Google Scholar]
- Xie, A.; Singh, A.; Levine, S.; Finn, C. Few-shot goal inference for visuomotor learning and planning. arXiv: Learning 2018, arXiv:1810.00482. [Google Scholar]
- Vecerik, M.; Sushkov, O.; Barker, D.; Rothorl, T.; Hester, T.; Scholz, J. A practical approach to insertion with variable socket position using deep reinforcement learning. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 754–760. [Google Scholar]
- Zou, H.; Ren, T.; Yan, D.; Su, H.; Zhu, J. Reward shaping via meta-learning. arXiv: Learning 2019, arXiv:1901.09330. [Google Scholar]
- Yang, Y.; Caluwaerts, K.; Iscen, A.; Tan, J.; Finn, C. Norml: No-reward meta learning. In Proceedings of the International Foundation for Autonomous Agents and Multiagent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 323–331. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Sun, X.; Xv, H.; Dong, J.; Zhou, H.; Chen, C.; Li, Q. Few-shot Learning for Domain-specific Fine-grained Image Classification. IEEE Trans. Ind. Electron. 2020, 99, 1-1. [Google Scholar] [CrossRef]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bertinetto, L.; Henriques, J.F.; Valmadre, J.; Torr, P.H.; Vedaldi, A. Learning feed-forward one-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 523–531. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Hoy, M.; Matveev, A.S.; Savkin, A.V. Algorithms for collision-free navigation of mobile robots in complex cluttered environments: A survey. Robotica 2015, 33, 463–497. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization: Artificial ants as a computational intelligence technique. IEEE Comput. Intell. Mag. 2016, 1, 28–39. [Google Scholar] [CrossRef]
- Wodzinski, M.; Krzyzanowska, A. Sequential Classification of Palm Gestures Based on A* Algorithm and MLP Neural Network for Quadrocopter Control. Metrol. Meas. Syst. 2017, 24, 265–276. [Google Scholar] [CrossRef]
- Mayne, D.Q.; Rawlings, J.B.; Rao, C.V.; Scokaert, P.O. Survey Constrained model predictive control: Stability and optimality. Automatica 2000, 36, 789–814. [Google Scholar] [CrossRef]
- Shi, E.; Cai, T.; He, C.; Guo, J. Study of the New Method for Improving Artifical Potential Field in Mobile Robot Obstacle Avoidance. In Proceedings of the International Conference on Automation and Logistics, Jinan, China, 18–21 August 2007. [Google Scholar]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Patle, B.K.; Pandey, A.; Parhi, D.R.K.; Jagadeesh, A. A review: On path planning strategies for navigation of mobile robot. Def. Technol. 2019, 15, 582–606. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Labonté, G. Comparison of parallel genetic algorithm and particle swarm optimization for real-time UAV path planning. IEEE Trans. Ind. Inform. 2012, 9, 132–141. [Google Scholar] [CrossRef]
- Zoumponos, G.T.; Aspragathos, N.A. Fuzzy logic path planning for the robotic placement of fabrics on a work table. Robot. Comput. Integr. Manuf. 2008, 24, 174–186. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Li, S.; Wu, Y.; Cui, X.; Dong, H.; Fang, F.; Russell, S. Robust Multi-Agent Reinforcement Learning via Minimax Deep Deterministic Policy Gradient. In Proceedings of the National Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Wang, X.; Zhuang, Z.; Zou, L.; Zhang, W. An accelerated asynchronous advantage actor-critic algorithm applied in papermaking. In Proceedings of the Chinese Control Conference, Guangzhou, China, 27–30 July 2019. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv: Learning 2017, arXiv:1707.06347. [Google Scholar]
- Long, P.; Fanl, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Ma, L.; Chen, J.; Liu, Y. Using RGB Image as Visual Input for Mapless Robot Navigation. arXiv preprint 2019, arXiv:1903.09927. [Google Scholar]
- Mirowski, P.; Pascanu, R.; Viola, F.; Soyer, H.; Ballard, A.J.; Banino, A.; Denil, M.; Goroshin, R.; Sifre, L.; Kavukcuoglu, K.; et al. Learning to Navigate in Complex Environments. arXiv preprint 2016, arXiv:1611.0367. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Palan, M.; Landolfi, N.C.; Shevchuk, G.; Sadigh, D. Learning Reward Functions by Integrating Human Demonstrations and Preferences. arXiv preprint 2019, arXiv:1906.08928. [Google Scholar]
- Duan, Y.; Schulman, J.; Chen, X.; Bartlett, P.L.; Sutskever, I.; Abbeel, P. Rl2: Fast reinforcement learning via slow reinforcement learning. arXiv: Artificial Intelligence 2016, arXiv:1611.02779. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Sun, L.; Peng, C.; Zhan, W.; Tomizuka, M. A fast integrated planning and control framework for autonomous driving via imitation learning. In Proceedings of the Dynamic Systems and Control Conference. American Society of Mechanical Engineers, Atlanta, GA, USA, 30 September–3 October 2018; Volume 51913, p. V003T37A012. [Google Scholar]
- Cheng, C.; Yan, X.; Wagener, N.; Boots, B. Fast policy learning through imitation and reinforcement. arXiv: Learning 2018, arXiv:1805.10413. [Google Scholar]
- Ghasemipour, S.K.S.; Gu, S.S.; Zemel, R. SMILe: Scalable Meta Inverse Reinforcement Learning through Context-Conditional Policies. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 7879–7889. [Google Scholar]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 278–287. [Google Scholar]
- Devlin, S.; Kudenko, D. Dynamic potential-based reward shaping. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012; pp. 433–440. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MN | CAML | |
|---|---|---|
| Pre-training goals | The goal is to give the network the ability to measure the similarity between two samples. | The goal is to make CAML learn the optimal initialization by updating on different tasks. |
| Need fine-tuning | MN can achieve classification tasks without fine-tuning, but the values generated after fine-tuning are more accurate. | Yes |
| Fine-tuning process | MN predicts new samples, and the error between the predicted value and the label is used to update the network parameters. | CAML updates parameters by one or a few steps of gradient descent with a few positive examples from the new task. |
| T-MAP 1 | T-MAP 2 | |||
|---|---|---|---|---|
| Average Maximum Success Rate | Average Training Iterations | Average Maximum Success Rate | Average Training Iterations | |
| ER+MNR | 100% | 500 | 100% | 620 |
| ER+CAML (Provide positive samples manually) | 100% | 520 | 100% | 680 |
| ER | 64% | 1350 | 74% | 1420 |
| MNR | 0 | / | 0 | / |
| The Map | The Success Rate of ER+MNR | The Success Rate of ER+CAML |
|---|---|---|
| GT-MAP 1 | 85% | 85% |
| GT-MAP 2 | 36% | 42% |
| Average Maximum Success Rate | Average Training Iterations | |
|---|---|---|
| ER+MNR | 89% | 1053 |
| ER+CAML | 72% | 1120 |
| ER | 69% | 1380 |
| ER+MNR trained in T-Map1 | 79% | Untrained |
| ER+CAML trained in T-Map1 | 52% | Untrained |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Zhu, M.; Zou, L.; Li, M.; Zhang, Y. Learning Reward Function with Matching Network for Mapless Navigation. Sensors 2020, 20, 3664. https://doi.org/10.3390/s20133664
Zhang Q, Zhu M, Zou L, Li M, Zhang Y. Learning Reward Function with Matching Network for Mapless Navigation. Sensors. 2020; 20(13):3664. https://doi.org/10.3390/s20133664
Chicago/Turabian StyleZhang, Qichen, Meiqiang Zhu, Liang Zou, Ming Li, and Yong Zhang. 2020. "Learning Reward Function with Matching Network for Mapless Navigation" Sensors 20, no. 13: 3664. https://doi.org/10.3390/s20133664
APA StyleZhang, Q., Zhu, M., Zou, L., Li, M., & Zhang, Y. (2020). Learning Reward Function with Matching Network for Mapless Navigation. Sensors, 20(13), 3664. https://doi.org/10.3390/s20133664