JLVEA: Lightweight Real-Time Video Stream Encryption Algorithm for Internet of Things


Abstract
1. Introduction
2. Related Work
2.1. Block Cipher-Based Video Encryption
2.2. Permutation-based Video Encryption
3. Proposed Algorithm
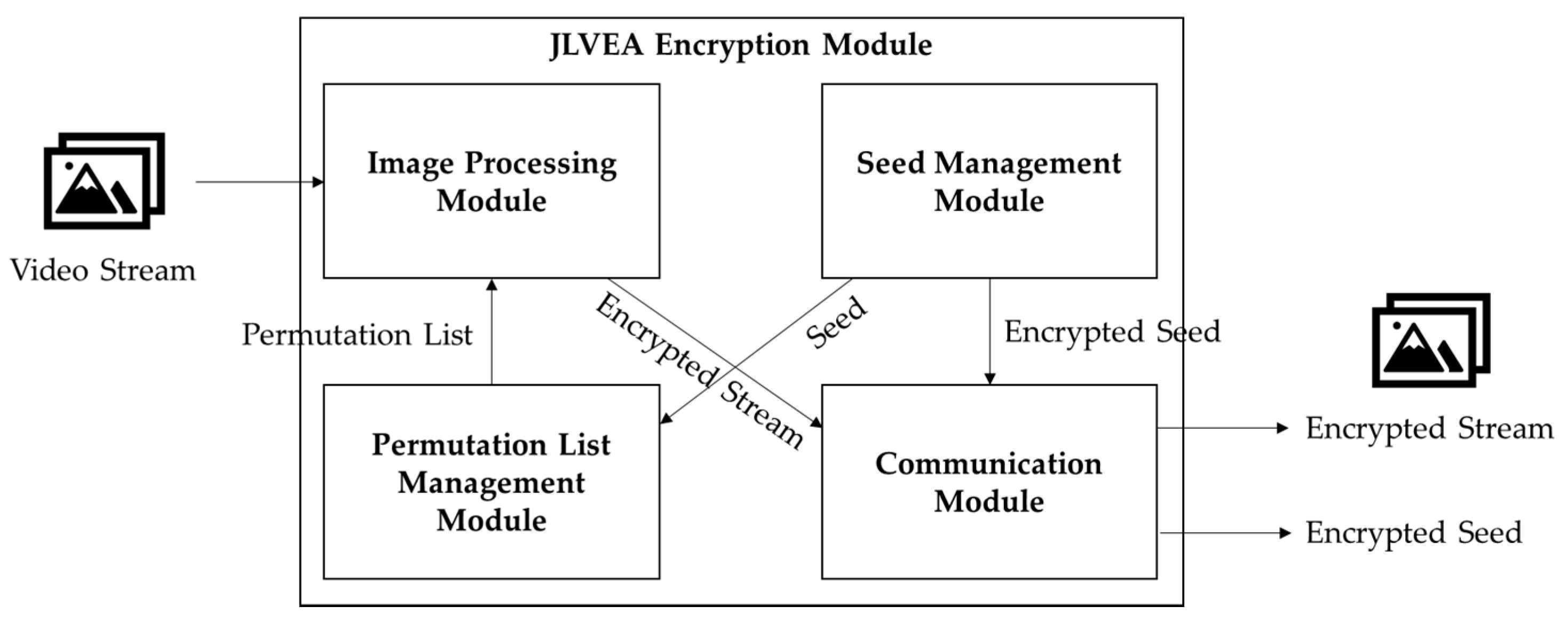
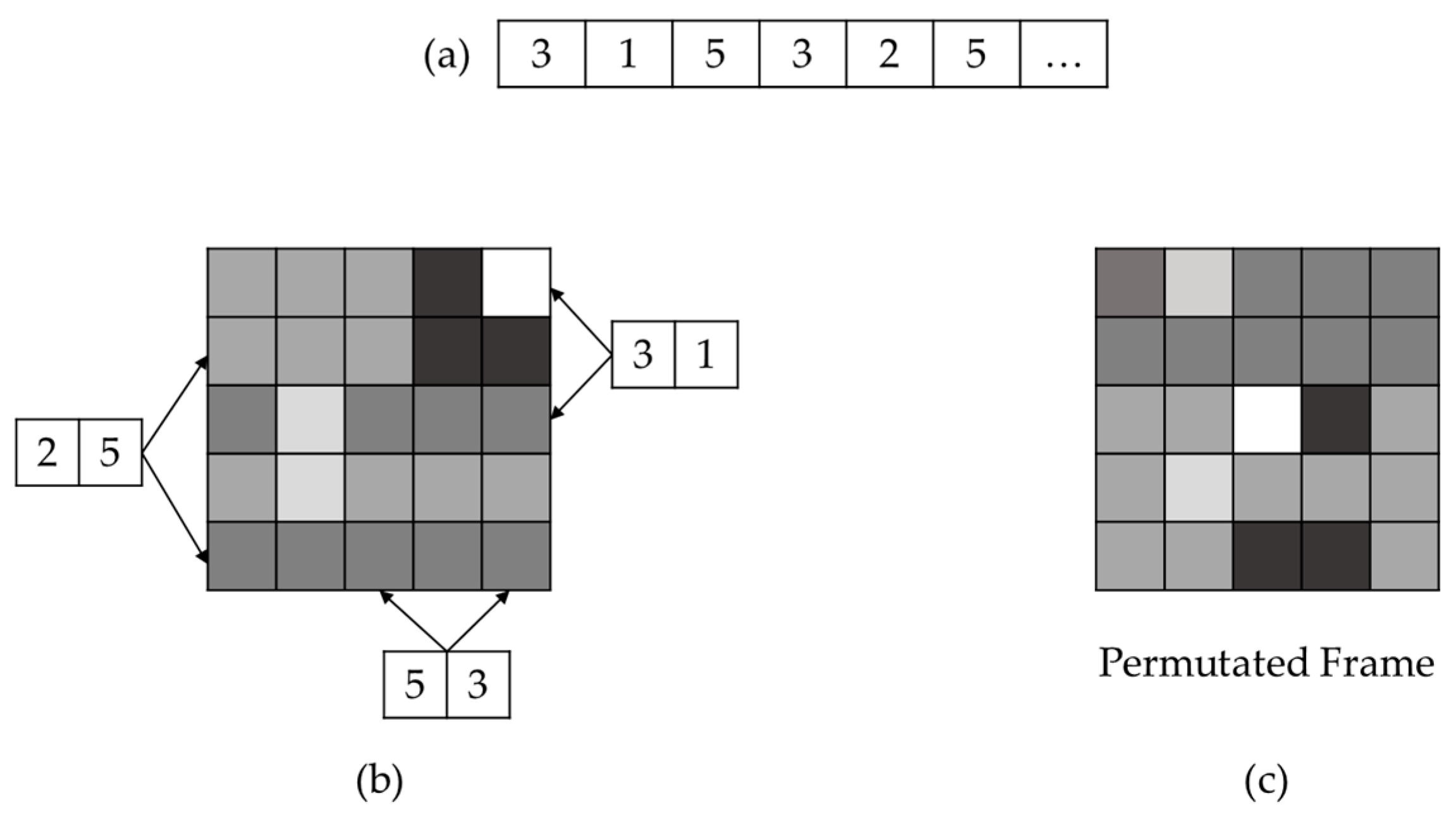
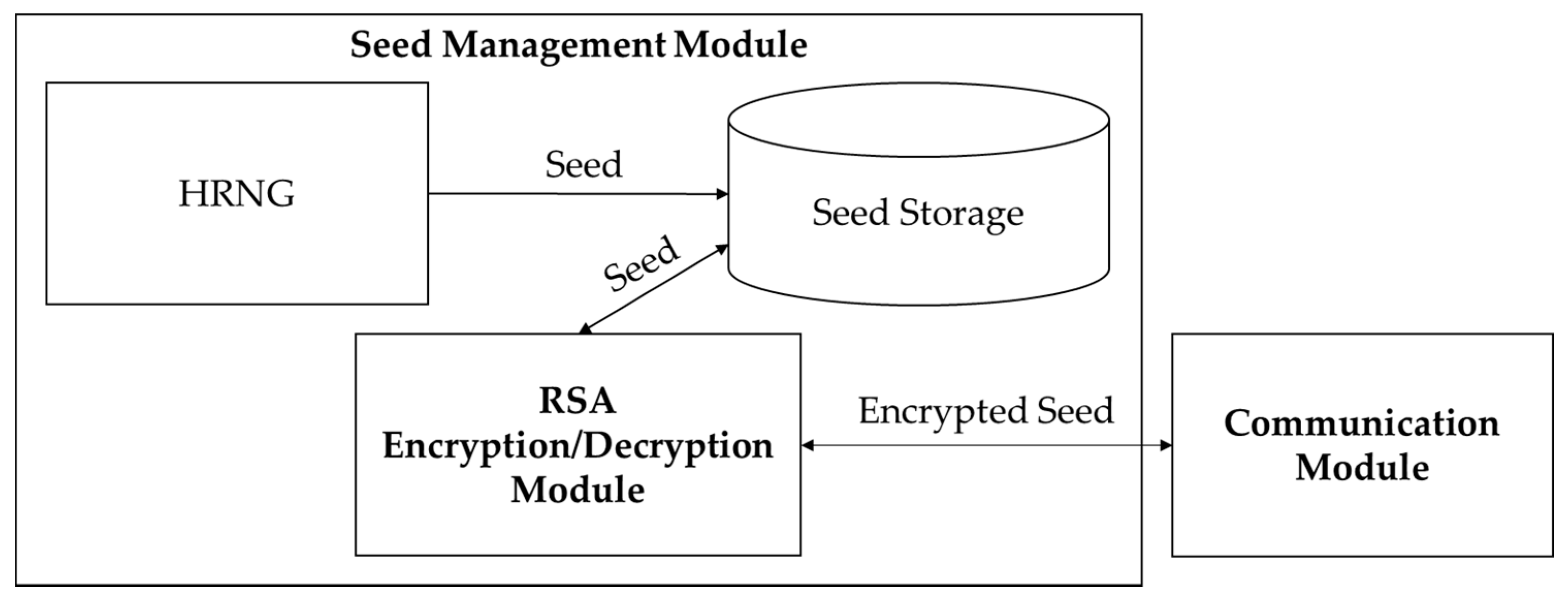
3.1. Encryption Module Structure
| Algorithm 1: Permutation List Update. |
| Input: Frame width w, height h, and permutation list P |
| Output: Updated permutation list P |
| 01: for p in P do |
| 02: if index of p % 2 == 0, then |
| 03: r = random(-w, w) |
| 04: else, then |
| 05: r = random(-h, h) |
| 06: end if |
| 07: p = p + r |
| 08: if index of p % 2 == 0, then |
| 09: if p > w then |
| 10: p = p – w |
| 11: else if p < 0, then |
| 12: p = p + w |
| 13: end if |
| 14: else, then |
| 15: if p > h, then |
| 16: p – h |
| 17: elseif p < 0, then |
| 18: p + h |
| 19: end if |
| 20: end if |
| 21: end for |
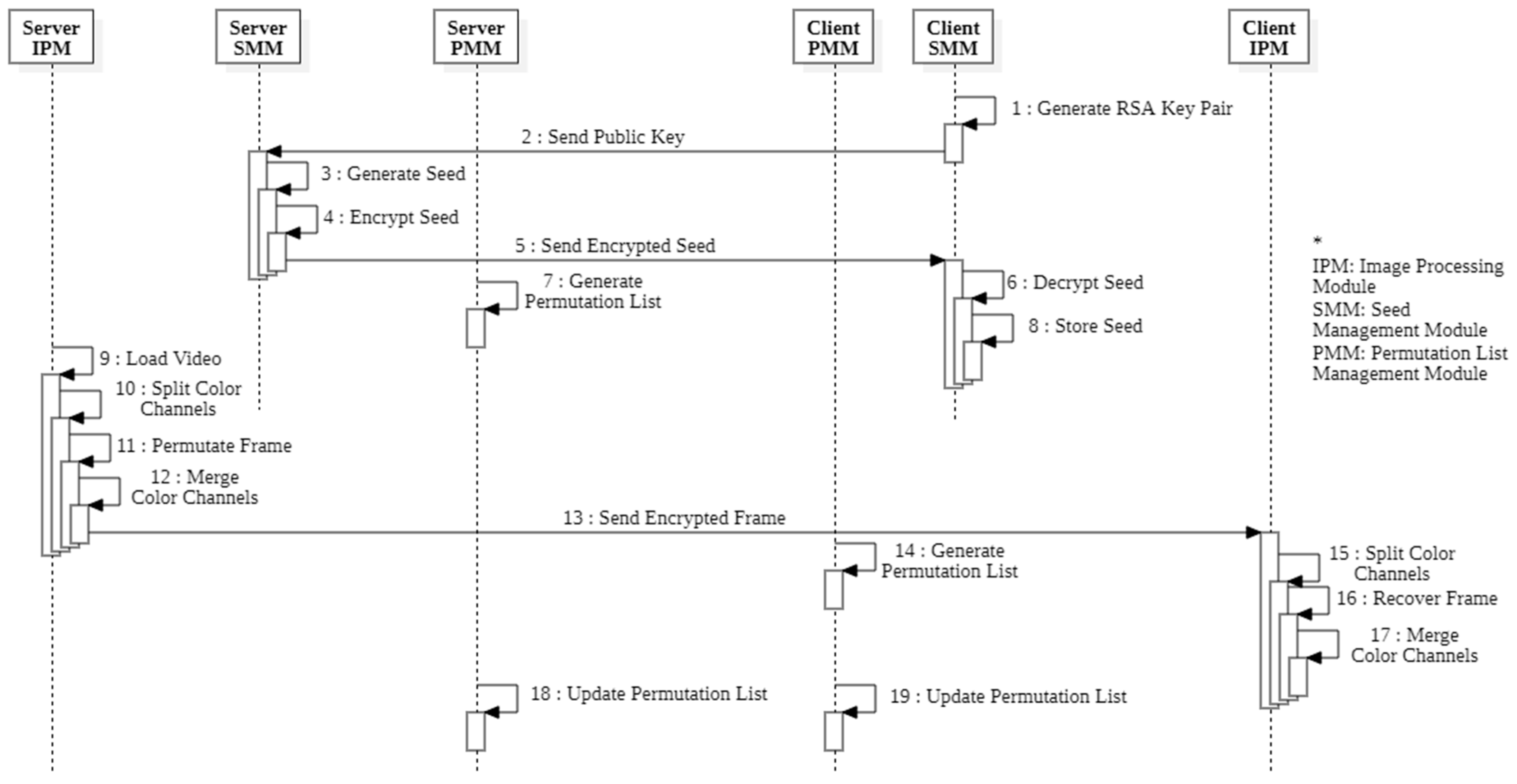
3.2. Encryption Flow
4. Performance Evaluation
4.1. Security Evaluation
4.2. Encryption Time Analysis
4.3. Memory Efficiency Analysis
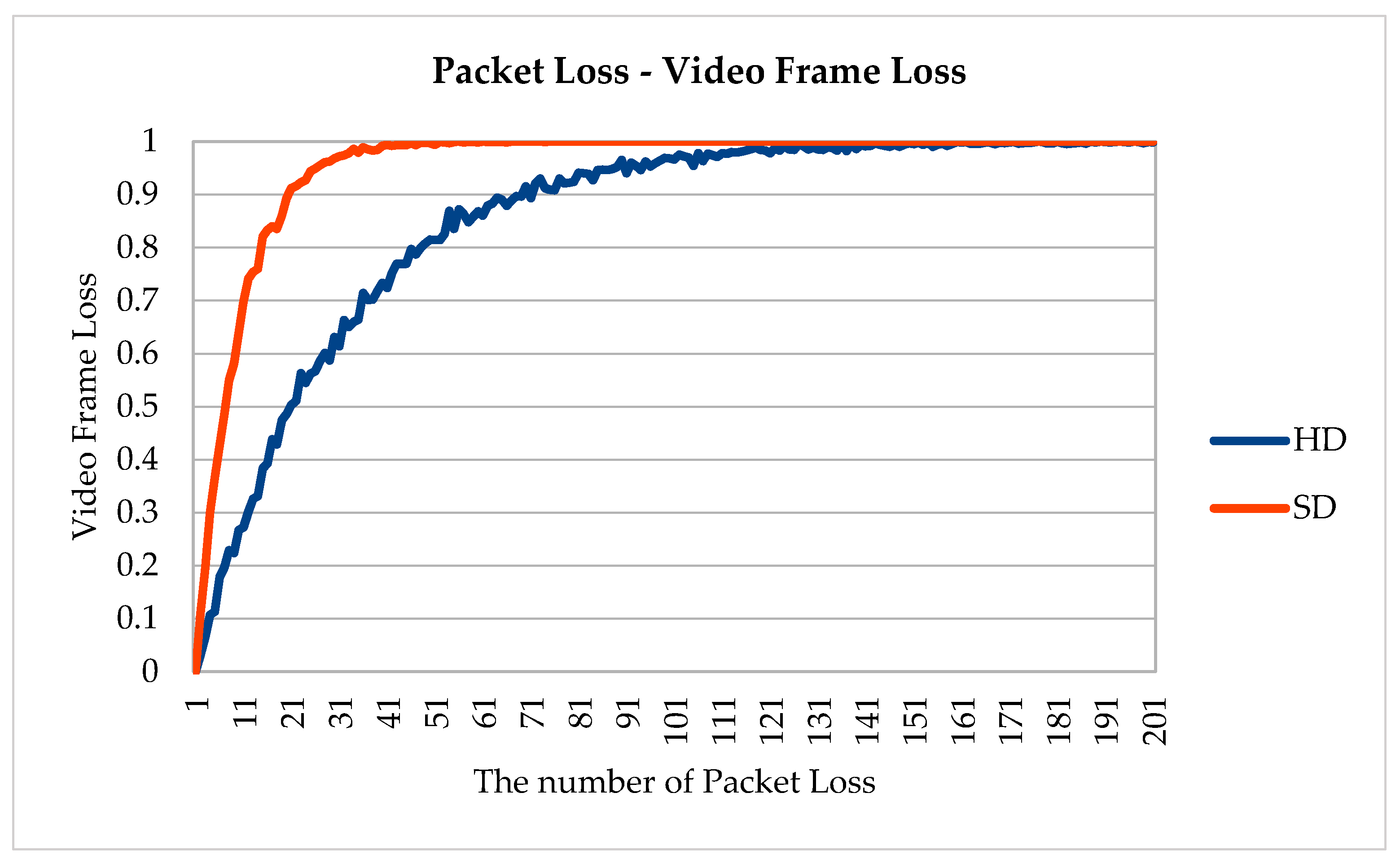
4.4. Communication Loss Resistance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Robles, R.J.; Kim, T.H. A review on security in smart home development. IJAST 2010, 15, 13–22. [Google Scholar]
- Lin, H.; Bergmann, N.W. IoT privacy and security challenges for smart home environments. Information 2016, 7, 44. [Google Scholar] [CrossRef]
- Zhang, Y.; Kasahara, S.; Shen, Y.; Jiang, X.; Wan, J. Smart contract-based access control for the internet of things. IEEE IoT-J 2018, 6, 1594–1605. [Google Scholar] [CrossRef]
- Riad, K.; Hamza, R.; Yan, H. Sensitive and energetic IoT access control for managing cloud electronic health records. IEEE Access 2019, 7, 86384–86393. [Google Scholar] [CrossRef]
- Xu, H.; Tong, X.; Meng, X. An efficient chaos pseudo-random number generator applied to video encryption. Optik 2016, 127, 9305–9319. [Google Scholar] [CrossRef]
- Liu, B.; Liu, J.; Wang, S.; Zhong, M.; Li, B.; Liu, Y. HEVC Video Encryption Algorithm Based on Integer Dynamic Coupling Tent Mapping. JACIII 2020, 24, 335–345. [Google Scholar] [CrossRef]
- Gusmeroli, S.; Piccione, S.; Rotondi, D. IoT access control issues: A capability based approach. In Proceedings of the 2012 Sixth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Washington, DC, USA; 2012; pp. 787–792. [Google Scholar]
- Zhang, Z.K.; Cho, M.C.Y.; Wang, C.W.; Hsu, C.W.; Chen, C.K.; Shieh, S. IoT security: Ongoing challenges and research opportunities. In Proceedings of the 2014 IEEE 7th International Conference on Service-Oriented Computing and Applications, Matsue, Japan, 17 November 2014; pp. 230–234. [Google Scholar]
- Sallam, A.I.; El-Rabaie, E.S.M.; Faragallah, O.S. Efficient HEVC selective stream encryption using chaotic logistic map. Multimedia Syst. 2018, 24, 419–437. [Google Scholar] [CrossRef]
- Kartsch, V.; Guermandi, M.; Benatti, S.; Montagna, F.; Benini, L. An Energy-Efficient IoT node for HMI applications based on an ultra-low power Multicore Processor. In Proceedings of the 2019 IEEE Sensors Applications Symposium, Sophia Antipolis, France, 11 March 2019; pp. 1–6. [Google Scholar]
- Jayakumar, H.; Lee, K.; Lee, W.S.; Raha, A.; Kim, Y.; Raghunathan, V. Powering the internet of things. In Proceedings of the 2014 International Symposium on Low Power Electronics and Design, La Jolla, CA, USA; 2014; pp. 375–380. [Google Scholar]
- Heron, S. Advanced encryption standard (AES). Netw. Secur. 2009, 2009, 8–12. [Google Scholar] [CrossRef]
- Lee, H.J.; Lee, S.J.; Yoon, J.H.; Cheon, D.H.; Lee, J.I. The SEED encryption algorithm. 2005. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.374.3466 (accessed on 23 June 2020).
- Liu, F.; Koenig, H. Puzzle-A novel video encryption algorithm. In Proceedings of the IFIP International Conference on Communications and Multimedia Security, Berlin, Germany, 19 September 2005; pp. 88–97. [Google Scholar]
- Sultana, S.F.; Shubhangi, D.C. Video encryption algorithm and key management using perfect shuffle. IJERA 2017, 7, 1–5. [Google Scholar] [CrossRef]
- Shelby, Z.; Hartke, K.; Bormann, C. The constrained application protocol. 2014. Available online: https://datatracker.ietf.org/doc/rfc7252/ (accessed on 23 June 2020).
- Kothmayr, T.; Schmitt, C.; Hu, W.; Brunig, M.; Carle, G. DTLS based security and two-way authentication for the Internet of Things. Ad Hoc Networks 2013, 11, 2710–2723. [Google Scholar] [CrossRef]
- Nurrohman, A.; Abdurohman, M. High Performance Streaming Based on H264 and Real Time Messaging Protocol (RTMP). In Proceedings of the 2018 6th International Conference on Information and Communication Technology, Bandung, Indonesia, 3 May 2018; pp. 174–177. [Google Scholar]
- Hamalainen, P.; Alho, T.; Hannikainen, M.; Hamalainen, T.D. Design and implementation of low-area and low-power AES encryption hardware core. In Proceedings of the 9th EUROMICRO Conference on Digital System Design, Dubrovnik, Croatia, 30 August 2006; pp. 577–583. [Google Scholar]
- Akhter, A.S.; Islam, S.; Hossain, M.J.; Deb, R.; Uddin, M.B. MPEG Encryption by Zigzag, Partitioning and Swapping. IJCSNS 2010, 10, 116. [Google Scholar]
- Yan, Z.; Govindaraju, V.; Zheng, Q.; Wang, Y. IEEE Access Special Section Editorial: Trusted Computing. IEEE Access 2020, 8, 25722–25726. [Google Scholar] [CrossRef]
- Genç, Z.A.; Lenzini, G.; Ryan, P.Y. NoCry: No More Secure Encryption Keys for Cryptographic Ransomware. In Proceedings of the International Workshop on Emerging Technologies for Authorization and Authentication, Luxembourg City, Luxembourg, 27 September 2019; pp. 69–85. [Google Scholar]
- GnuTLS. Available online: https://www.gnutls.org/ (accessed on 22 June 2020).
- PyCrypto. Available online: https://pypi.org/project/pycrypto/ (accessed on 20 May 2020).
- BCM2837– Raspberry Pi Documentation. Available online: https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2837/README.md (accessed on 20 May 2020).
- Zhou, X.; Tang, X. Research and implementation of RSA algorithm for encryption and decryption. In Proceedings of the 2011 6th International Forum on Strategic Technology, Harbin, China, 22 August 2011; pp. 1118–1121. [Google Scholar]
- Johnson, D.; Menezes, A.; Vanstone, S. The elliptic curve digital signature algorithm (ECDSA). IJIS 2001, 1, 36–63. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Liu and Koenig [14] | Sultana and Shubhangi [15] | Akhter et al. [20] | |
|---|---|---|---|
| Encryption Position | Post-compression | Pre-compression | While-compression |
| Weakness | File internal information-based Inference, Streaming Overhead | Permutation list brute-force, Known-plaintext attack | Can adapt to MPEG only, Known-plaintext attack |
| Key Exchange | Each frame | Once | Once |
| Video Format Generality | Yes | Yes | No |
| SEED Mod 5 | Color Channel Merging Order |
|---|---|
| 0 | RBG |
| 1 | BGR |
| 2 | BRG |
| 3 | GRB |
| 4 | GBR |
| Hardware Component | Specification |
|---|---|
| CPU | ARMv8 64 bit 1.4 GHz |
| SoC | BCM2837 |
| RAM | 1 GB LPDDR2 |
| Networking | Gigabit Ethernet, 802.11 b/g/n/ac WLAN |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, J.; Kim, M. JLVEA: Lightweight Real-Time Video Stream Encryption Algorithm for Internet of Things. Sensors 2020, 20, 3627. https://doi.org/10.3390/s20133627
Yun J, Kim M. JLVEA: Lightweight Real-Time Video Stream Encryption Algorithm for Internet of Things. Sensors. 2020; 20(13):3627. https://doi.org/10.3390/s20133627
Chicago/Turabian StyleYun, Junhyeok, and Mihui Kim. 2020. "JLVEA: Lightweight Real-Time Video Stream Encryption Algorithm for Internet of Things" Sensors 20, no. 13: 3627. https://doi.org/10.3390/s20133627
APA StyleYun, J., & Kim, M. (2020). JLVEA: Lightweight Real-Time Video Stream Encryption Algorithm for Internet of Things. Sensors, 20(13), 3627. https://doi.org/10.3390/s20133627