1. Introduction
Condition-monitoring (CM) is a data driven approach for the supervision of the working conditions of machines and for the detection of failures in an early stage. Based on sensor data, which reflect the physical condition of the machine, the machine’s health state is predicted [
1]. Conventional condition monitoring in industrial automation is based on rigid preestablished rules and thresholds, which have a limited capability to recognize failures in complex multisensory systems. Computational intelligence and machine learning (ML) are promising solutions for smart condition monitoring in real-world industrial applications [
2], since these methods can learn from historical data and are suitable for processing high dimensional data from multiple sources. Condition monitoring itself is an interesting application in industry 4.0, as it allows to detect automatically incipient machine failures [
3]. It is, therefore, an enabling technology for condition-based maintenance (CBM), an industrial predictive maintenance paradigm, which allows to schedule maintenance operations on an on-demand basis. The CBM approach benefits by lower operational costs, reduced machine downtimes and also higher levels of security and safety in the operations of machines since major breakdowns with potential harmful impact on environment and humans are avoided [
4].
In recent years, many investigations have reported highly efficient condition monitoring systems based on deep learning models for different industrial applications [
5]. Interesting examples are the monitoring of wind turbine gearbox bearing [
6] or the supervision of the wear condition in a computer numerical control milling machine cutter [
7]. Both authors present a deep learning architecture built on convolutional neural networks (CNN) [
8] and long short-term memory networks (LSTM). CNNs implement feature extraction and dimensionality reduction, while LSTMs track the temporal evolution of the signal and predict the observed variable. The success of deep learning models in many fields is related to its ability for automatic representation learning of generic features [
9]. This ability is especially valuable in industrial applications as the system should be robust to noise from the environment. Another valuable characteristic of deep learning models is the ability to work directly with raw sensor data avoiding the need for an explicit feature engineering by a human expert from the area. Time series data from sensors are alternatively often studied with feature extraction techniques, such as time-domain (mean, variance, kurtosis or skewness), frequency domain or wavelet domain features [
10,
11].
In this work, we focus specifically on CNNs, because of their capability to learn feature representations from untransformed high dimensional time series data. The convolutional layers can apply nonlinear transformations and yield abstract patterns in a lower dimension discarding irrelevant or redundant information [
12]. In industrial applications, CNN models are used to analyze time series signals of sensors exploiting the network’s ability to learn spatial relationships, which in this case correspond to the temporal evolution of the sensor signal. This type of image analysis on sensor data has been used for fault diagnosis on rolling element bearings [
13] or in a gearbox monitoring system with vibration signals [
14]. The current work follows a similar approach building CNN models on sensor readings from a multisensorial system of a complex hydraulic installation, where several degrees of degradation of the components are observed. The dataset under study is publicly available from the UC Irvine Machine Learning Repository (published by [
15]).
The contribution of the present work is the implementation of ML models for the condition monitoring of the hydraulic, cooler, valve and pump subsystems to predict different levels of degradation of components. The CNN models yield prediction accuracies close to those reported in previous works on the dataset [
15,
16,
17], with the difference that the current approach uses deep learning models and processes the raw sensor data without the need for an explicit feature engineering. Moreover, we carry out a sensitivity analysis of the attributions of the sensor readings for the prediction task of the different degradation states [
18]. This high-level information about the relevance of the sensors in the monitoring system is used to study the feasibility to reduce the number of sensors for the detection of failures in certain subsystems. The trend of ML based condition monitoring systems towards the deployment on edge devices [
19] imposes additional constraints on the design of ML models, such as the requirement of low energy consumption for example. For this reason, an optimization of the number of sensors through feature selection approaches is opportune as data processing is an energy-consuming task [
20] and sensorization by itself additional labor in the engineering of industrial equipment [
21,
22].
The remaining part of the article describes the analysis with CNN models on the hydraulic system dataset. First, the condition monitoring application of the hydraulic system and the dataset are explained in
Section 2. Next, the construction of the ML models is described including the data preprocessing step (
Section 3), feature representation learning (
Section 4) and the ML model construction (
Section 5). In the subsequent sections, the classification performance of the model is discussed (
Section 6 and
Section 7).
Section 8 addresses the attribution analysis of the sensors in the prediction of the degradation states using occlusion maps [
23] as well as the optimization of the ML models. The article concludes in
Section 9 with a discussion about the results and futures lines of works.
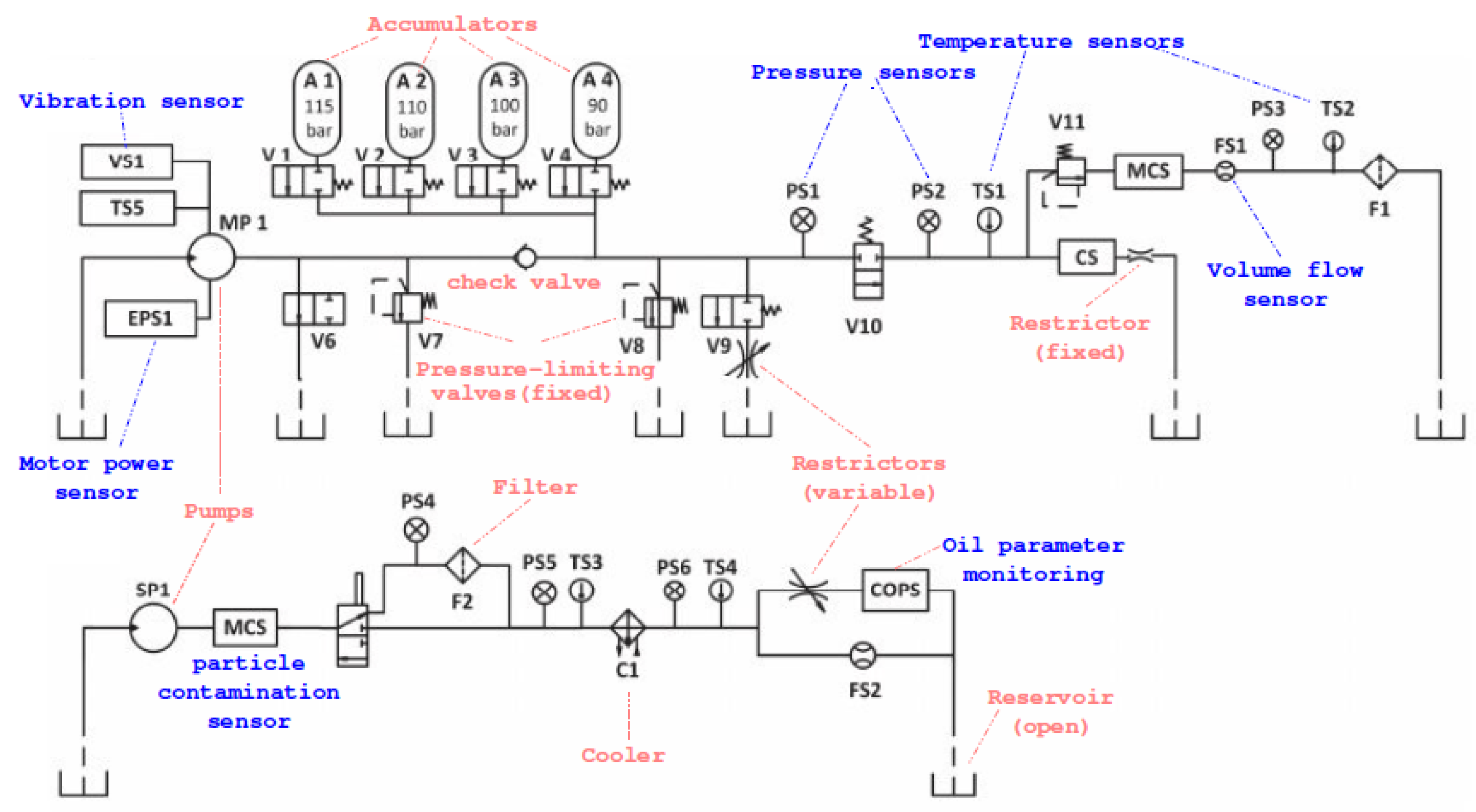
2. Hydraulic System and Sensors
Hydraulic systems are widely used in industrial applications and condition monitoring is therefore important as faults can happen at the hydraulic component itself, the entire hydraulic drive, or the hydraulic fluid [
24]. Cooling water networks are especially relevant and critical in many industrial applications because of their use for overheat protection. Nevertheless, their study is not trivial as these circulating water systems rely on complex hydraulic and thermodynamic models. Forecasting of water temperature is manifold and has been addressed in different applications. Neural network models were applied by [
25] for the monitoring of cooling water networks in a petro–chemical facility. An adaptive neuro–fuzzy inference system [
26] was used for the prediction of the temperature in a reversibly cooling tower, part of a heat pump system, to avoid water freezing.
In the present work, we focus on the study of a hydraulic system, which was presented by [
15,
16] as a test bench in the scope of the iCM Hydraulics project. The authors provide public available data from this hydraulic system for the study of characteristic hydraulic system failures based on sensor readings from a set of sensors installed in the circuit.
As explained in [
27], the hydraulic system (
Figure 1) consists of a primary circuit for the load control and two subsystems with the cooling and filtration circuits, which are connected via the oil tank to the primary circuit. Several typical system failures, such as internal pump leakage, pressure leakage in the accumulator, delayed valve switching or reduced cooling efficiency are studied. The authors collect measurements from 17 sensors (
Table 1) installed in the test bench and take measurements during work cycles of 1 min. The involved sensors are common industrial process sensors, such as pressure, flow, power, temperature and vibration sensors with a sampling rate ranging between 100 Hz and 1 Hz. Data acquisition is carried out using a PLC (Beckhoff CX5020) device with data transference to a PC via EtherCAT.
The authors provide a detailed description of the components of the test bench and the experiment’s approach to reversibly change the state or condition of the hydraulic system’s components [
15]. The approach consists in the simulation of different working conditions during repeated load cycles. A pressure valve (V11) is used to generate variable load levels. In the following the measuring criteria for the simulation of the fault conditions at the different components are described. The main pump (MP) has an electrical motor power of 3.3 kW with a switchable orifice (V9) for simulation of the internal pump leakage. Switching degradation is controlled by the valve’s current (V10) using set-points of its nominal current value according to the intervals of
,
,
and
. Gas leakage is monitored via the accumulator (A1–A4) with four precharge pressures of 90, 100, 110 and 115 bar. Cooling power decrease (Cooler C1) is controlled by the fan duty cycle operating in the range of
to
kW of power consumption.
Table 2 describes the taxonomy of faults of this experiment with detail. There are four condition monitoring target variables: Cooler (for cooling power decrease), Valve (for switching characteristic degradation), Internal Pump Leakage and Hydraulic Accumulator (for gas leakage). Each target variable has multiple classes, which represent different degradation states of the system.
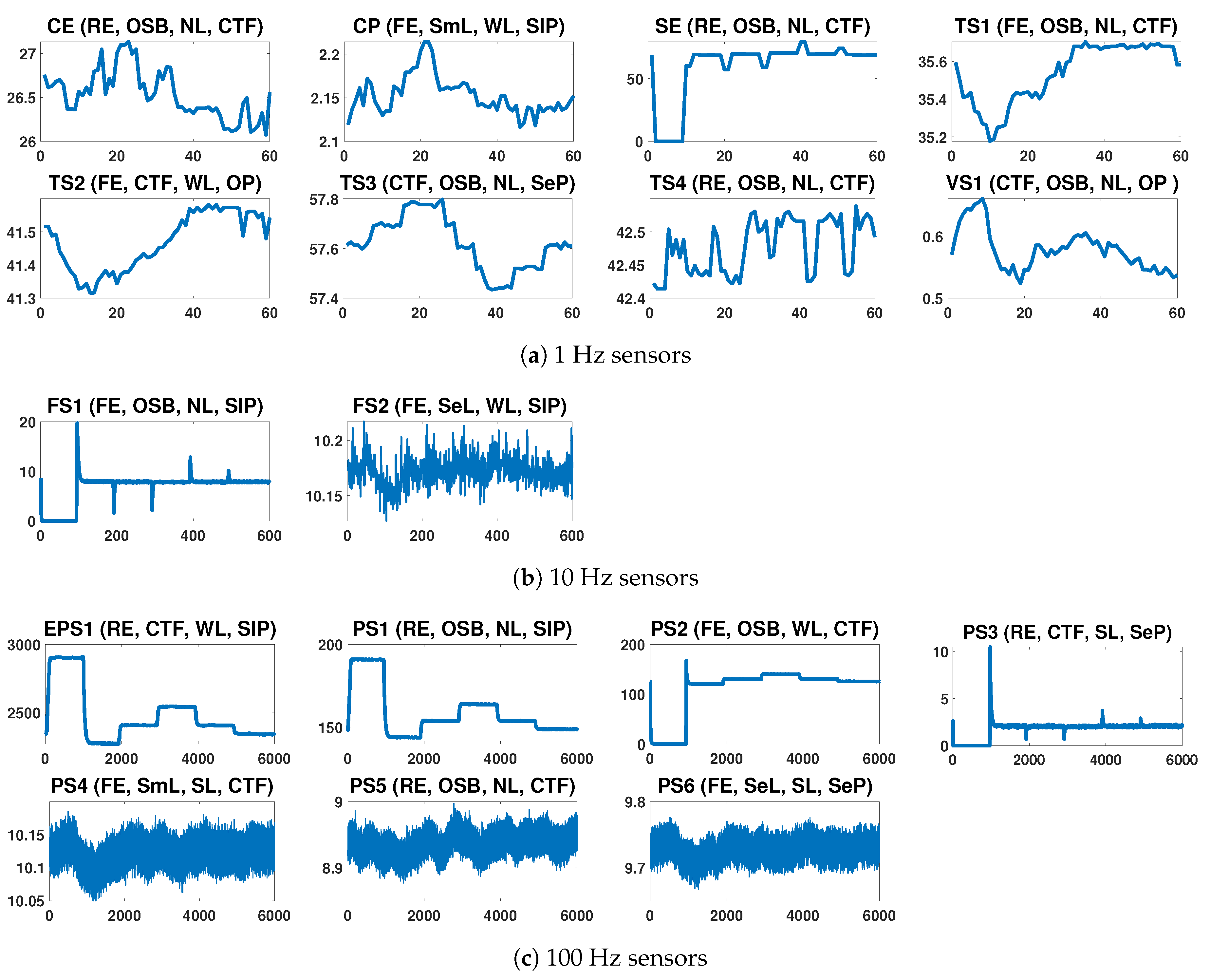
The dataset comprises sensor readings from multiple sensors.
Table 1 shows the details of the measurements of the 17 sensors, which comprise 14 physical sensors—pressure (PS1–PS6), motor power (EPS1), volume flow (FS1–FS2), temperature (TS1–TS4) and vibration (VS1)—and three virtual sensors denoting computed values—efficiency factor (SE), virtual sensors for cooling efficiency (CE) and cooling power (CP). For each sensor, the measurements are recorded during a load cycle of 60 s. As stated in
Table 2, the dataset comprises the measurements during 2205 load cycles. In each cycle, the measurements are labeled with a given degradation state for each of the four condition variables. See
Table 2 for a summary on the distribution of instances for each condition variable target.
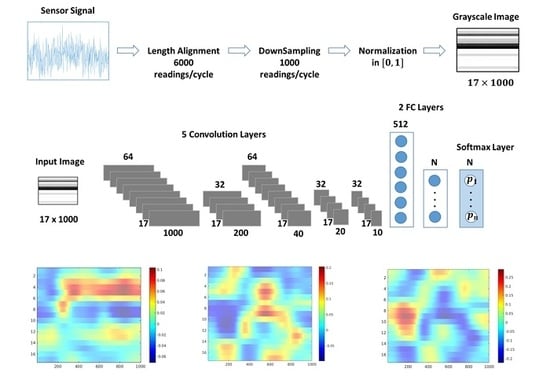
3. Sensory Data Preprocessing
As shown in
Table 1, the original dataset contains sensor streaming data from different types of sensors and sampling rates.
Figure 2 illustrates the signals of the different sensors of the system during some selected load cycles. For each signal the abbreviated sensor name and a short description of the observed degradation states for each of the four condition variable is shown. For example, the signal Cooler Efficiency (CE) is depicted for a load cycle with Reduced Efficiency in the Cooler, Optimal Switching Behavior in the Valve, No Leakage state in the Pump and a Close to Failure state in the Hydraulic system.
Regarding the sampling rates, pressure and motor power are sensed at 100 Hz, volume flow at 10 Hz, and temperature and vibration at 1 Hz. This mismatch between the sampling frequencies of sensors is a common issue in real-world machine monitoring applications. Preprocessing is needed to obtain complete data readings for all variables at given time intervals. This is important as ML based condition monitoring is synchronous presenting a complete dataset with values for all sensor readings to the ML model periodically.
Figure 3 describes the approach of homogenization of the sampling rates for the sensor data.
The first step upsamples sensors readings to the maximum sampling rate of 100 Hz. This implies an increase in the sampling frequency for the volume flow sensors (FS1/2) by 10 and an increase by 100 for the temperature and vibration sensors (TS1–TS4). The result is an aligned dataset with 6000 readings per minute (cycle) for all 17 sensors. As this frequency might be quite high, the dataset is downsampled by taking the average of each six consecutive readings of a sensor yielding a dataset with 1000 values/minute for each sensor. In the following, the data readings of the sensors are normalized in the range. The motivation behind downsampling (in fact, only readings of pressure and motor power sensors are affected) is to obtain a more treatable and reasonable image size for the experiments as the training time of a CNN model increases with the image size.
Finally, the sensor readings corresponding to a cycle are transformed into a data matrix of size
, which is the entry dataset for the deep learning network. The combination of information from different sensors at the data level is referred to as early information fusion of multimodal data [
28]. The use of early fusion with several multimodal datasets has been discussed in [
29] and followed in [
30] in the implementation of a fault detection system in rotatory machines.
4. Feature Representation Learning
The contribution of deep learning models in condition monitoring is attributed to its capability to automatically learn representative features from the raw data delegating feature representation learning to the layers of the network [
2,
5].
In this work, we follow the same strategy using CNNs to learn automatically the temporal relationship of the raw sensor data. CNNs are able to capture spatial relationships in multidimensional data and are high accurate in difficult ML tasks, such as pattern recognition in images and speech analysis [
31]. In our work, we focus on leveraging these capabilities of CNNs to recognize automatically temporal patterns in the raw sensor data. For this reason, we apply CNNs to the 2D representations of the raw sensor data. The
data matrix is represented as a 2D grayscale image for its evaluation in the CNN model, where each row corresponds to the readings of a sensor during a load cycle. Convolution layers are applied to the data matrix to recognize the spatial relationships and location specific patterns. In this case, 1D relationships are analyzed, as the data are sequential sensor readings.
Alternative deep neural networks for automatic feature representation learning are Autoencoders (AE). AEs are deep learning networks, which use encoding and decoding layers to compress the input features in a lower dimensional latent feature space, so that only the relevant characteristics of the features are kept in the lower dimensional space. AEs are frequently used for the processing of raw sensor signals. Ref. [
32] describes AEs for process pattern recognition in industrial processes. Denoising autoencoders (DAEs) are a variant of the AE using random distortion on the input features, so that more robust feature representations are learned by the model, what is especially useful for tackling noise in sensor readings [
14].
Finally, a summary of the feature representations used in related work on the dataset is presented in
Table 3. Previous works on this dataset relied on explicit feature engineering of statistical features from the time-domain of the signal.
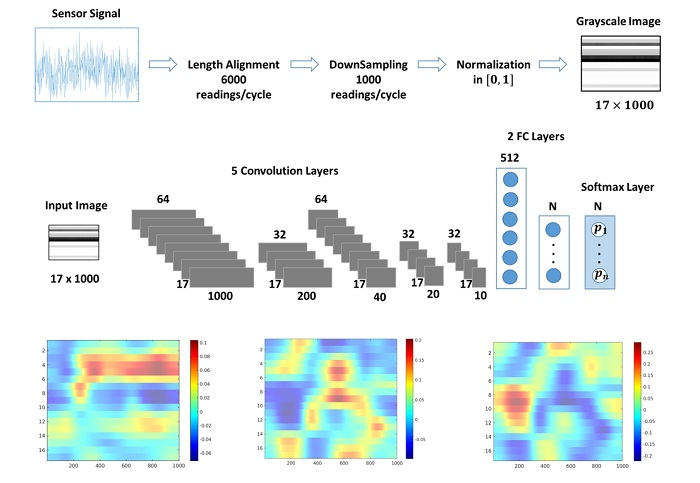
5. CNN Model
The dataset under study contains four independent condition monitoring variables (see
Table 2).
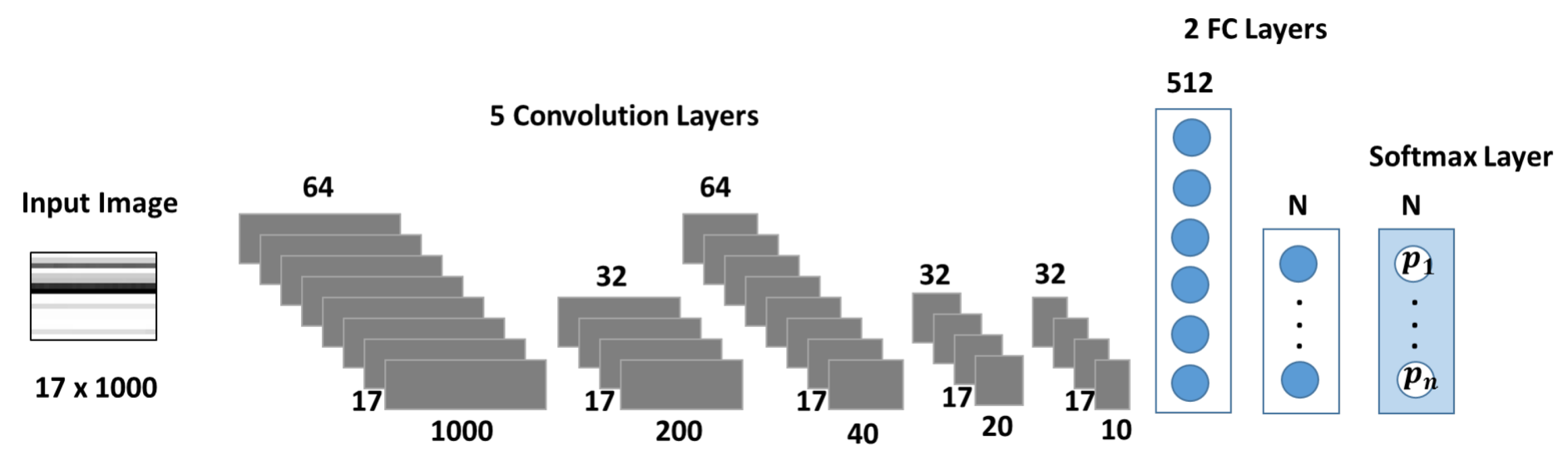
Figure 4 depicts the CNN architecture used as a multiclass classifier for each condition monitoring target. The network’s design focuses on capturing the temporal correlation of the sensor signals, which are one-dimensional time series. A similar architecture was implemented in [
14], where 1D filter banks were used to analyze vibration signals for fault detection in a gearbox. In [
34], a medical application for sleep arousal detection, as well CNNs with 1D architectures were used to analyze multi-channel polysomnogram recordings.
The size of the input layer corresponds to the dimension of the sensor data of
. Each row represents one sequence of sensory data during a load cycle. The network is composed by five primary blocks for feature extraction. Each block is formed by a tuple of {convolution, batch normalization, relu activation} layers. The first and third convolution (convolution) layers have 64 filters, while the other three contain 32 filters in each case. To capture patterns from the temporal evolution of each sensor sequence, convolutions are performed separately on each row of the dataset by using filters (or kernels) with height 1 in all layers, while the lengths varies from 5 in early layers (convolution 1, 2 and 3) to 2 in deeper layers (convolution 4 and 5). In the first convolution layer strides of size
and a same padding are applied. This combination keeps the constructed filter image after the first convolution layer with the same dimensions as the input image, therefore improving the ability of the second layer to recognize more patterns from the input image. In the subsequent layers, strides with a different horizontal lengths are applied in the filters to downsize the dimensions of the features. For example, the stride of size
of the second convolution layer downsizes the constructed filter image to a
format. In consecutive layers, features are further reduced to the dimensions of
,
and
. Feature reduction with strides is an alternative to pooling layers in CNNs [
35,
36].
The last three layers of the network implement the prediction stage. The network architecture comprises two fully connected (fc) layers with 512 neurons in the first layer. The dimension of the second fc layer equals to the number of predicted degradation states of the target under study (size 3 for Cooler and Pump, and 4 for Valve and Hydraulic Accumulator). In the final layer, a softmax funcion is used for the prediction of the label (degradation state).
6. Classification Results
The dataset of each condition monitoring target has been split randomly into training and validation data for model construction and for the model evaluation on a test dataset. An early stopping criterion is applied during training to prevent overfitting the model. In general, for the considered condition variable targets, the proposed models converge in 30 to 50 epochs. We have tested a range of mini-batch sizes yielding a size of 90 a good compromise between training time and generalization ability. The initial learning rate is and a stochastic gradient-descent algorithm with a momentum of is used to train the network. The reported classification results for each condition variable target are the average results from repeating 10 times the construction of the CNN model. The experiments have been carried out under Matlab using a CPU i5, 2.6 GHz with 8 GB RAM.
The prediction of each condition variable represents a multiclass classification problem, where degradation states equal to subclasses. In consequence, several classification metrics are used both to asses the quality of the classifier at the subclass classification level and the multiclass classifier level. At the subclass level, Precision (
Prec), Recall (
Rec) and Mathews Correlation Coefficient (
MCC) are used to evaluate the classification performance for each state.
Prec is a measure of quality as it describes to which extent all predicted positives are true.
Rec focuses on the completeness of the classifier measuring to which extent all true positives are detected. Precision and recall are both relevant metrics in fault detection as the system should neither give false alarms (assessed by precision) nor dismiss any failure (assessed by recall) [
37]. The
MCC is an overall description of the classifier’s quality taking into account all elements of the confusion matrix and being, therefore, a robust measure for unbalanced datasets [
38]. The coefficient takes values from −1 (for complete misclassification) to 1 (for perfect classification) calculating the correlation between the observed and the predicted classification. In condition monitoring, class imbalance is an issue since it is not trivial to obtain representative datasets of potential failure modes or anomalies as equipment manufacturers are not willing to operate machines until the run to failure state [
39]. At the condition monitoring test level, the performance of the multiclass classifier is assessed using the classification accuracy (
Accu), which measures the proportion of correctly classified instances, and the multiclass
MCC [
40].
In the following, we describe the classification results for each condition variable target by reporting the precision, recall and MCC at the subclass level and accuracy and MCC for the multiclass classifier (See
Table 4,
Table 5,
Table 6 and
Table 7). The Cooler target (see
Table 4) and Valve target (see
Table 5) show a high accurate classification performance both at the condition target test level and for the different states achieving nearly perfect precision and recall measures. In fact, authors in [
15] have mentioned in the dataset description that Cooler and Value targets are easy classificable problems, while the other two targets, Pump and Hydraulic Accumulator, are challenging.
In our study, the Hydraulic Accumulator condition achieved an accuracy of 0.98 and MCC of 0.95 (see
Table 7). Focusing on the subclass MCC we observe differences in the correct recognition of each state. The Close to Failure state is recognized best achieving a precision and recall of approximately 0.98. The other degradation states, such as the Severely Reduced Pressure and Slightly Reduced Pressure are more difficult to recognize. An interpretation of the respective precision and recall values in both cases show that these systems are expected to detect the correct degradation state with a precision of 0.93 and 0.96, while the event of degradation is recognized to an extent of 0.95 and 0.92 in each case. Regarding the recognition of the Optimal Pressure state, which is not a degradation state, but its recognition might be important for the operation of the installation, the system has a precision of 0.96 for the state recognition and 0.90 regarding the completeness of detection.
In the case of the Pump variable, the overall classification performance is still quite good achieving an accuracy of 0.97 and MCC of 0.91 (see
Table 6). The state No Leakage is best recognized achieving an MCC of 0.98 while the recognition of the degradation states Weak Leakage and Severe Leakage is approximately 0.90 regarding precision and 0.90–0.92 regarding completeness.
8. Sensitivity Analysis of Sensors
Deep learning models are often seen as black-box models as the underlying prediction functions are not easily explainable or interpretable for humans [
41]. Due to their capability to implement complex and non-linear relationships in deep network architectures, it is challenging to explain the reasoning of the model, since the network’s parameters, such as weights and transformed features are abstract information. Instead, gradient-based attribution methods are often used for the sensitivity analysis of features in neural networks as their representation is understandable for humans [
18]. This approach assigns an attribution value to each input feature of the network, which describes its relevance or contribution to the prediction. The contributions of the features are visualized in an attribution heatmap, “where red and blue colors indicate respectively features that contribute positively to the activation of the target output and features having a suppressing effect on it” [
18].
In this section, we present the results of an attribution analysis for the problem under study using occlusion sensitivity maps [
23]. This technique falls into the category of perturbation-based approaches, where a certain type of perturbations such as removal, masking or alteration of pixels is carried out in order to measure the difference in the prediction of the target. This information is used to analyze the importance of the features in the prediction of the class employing so-called “partial occluders” for regions in the image.
In the following, we discuss the occlusion sensitive maps of the four condition target variables to gain a high-level insight about the contribution of the sensors in the prediction of each state (
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11). The heatmap visualization depicts the absolute value of the contribution to the specified class prediction (red color for positive and blue colors for negative contributions). Such heatmap representations are useful for the visual recognition of the most relevant sensors for the prediction (regions highlighted in red colors) and reveal sensor combinations with common patterns in the contributions. Note that a sensor can have both positive and negative contributions along the sequence of 1000 measurements.
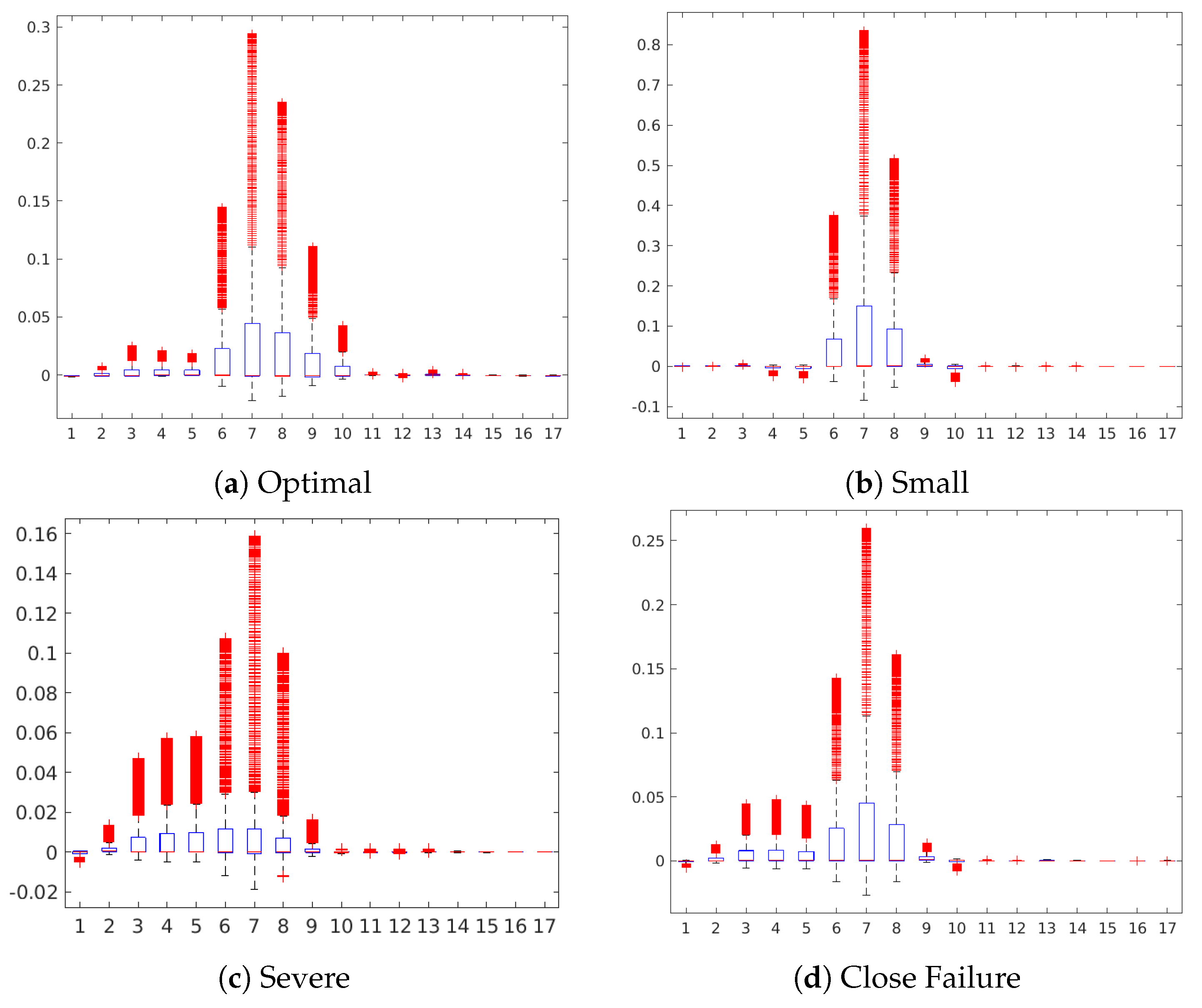
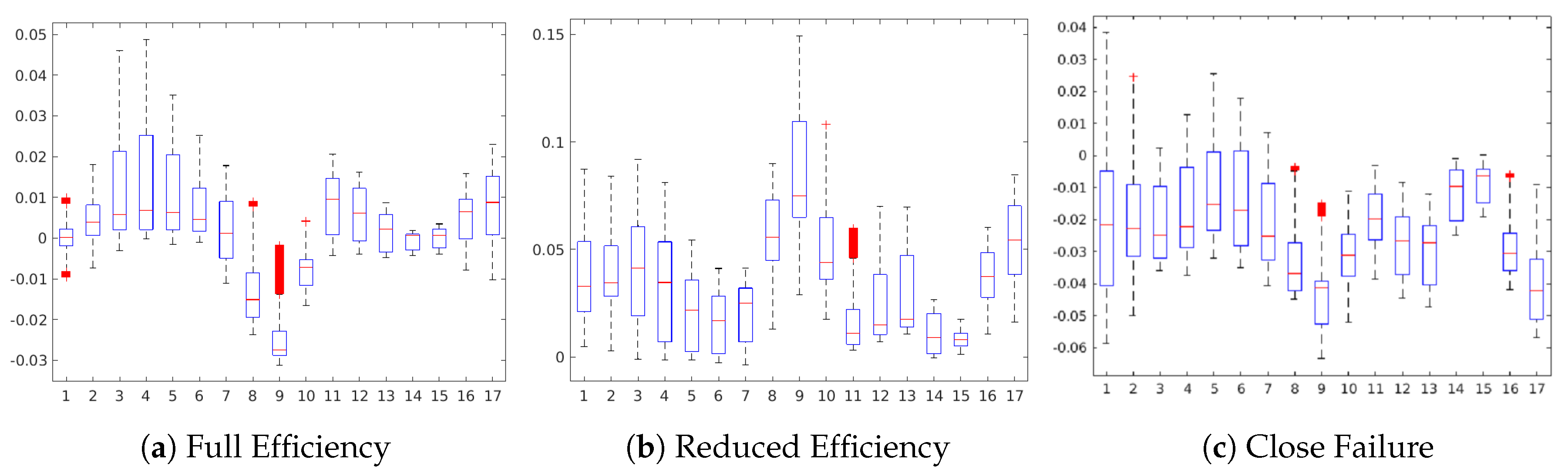
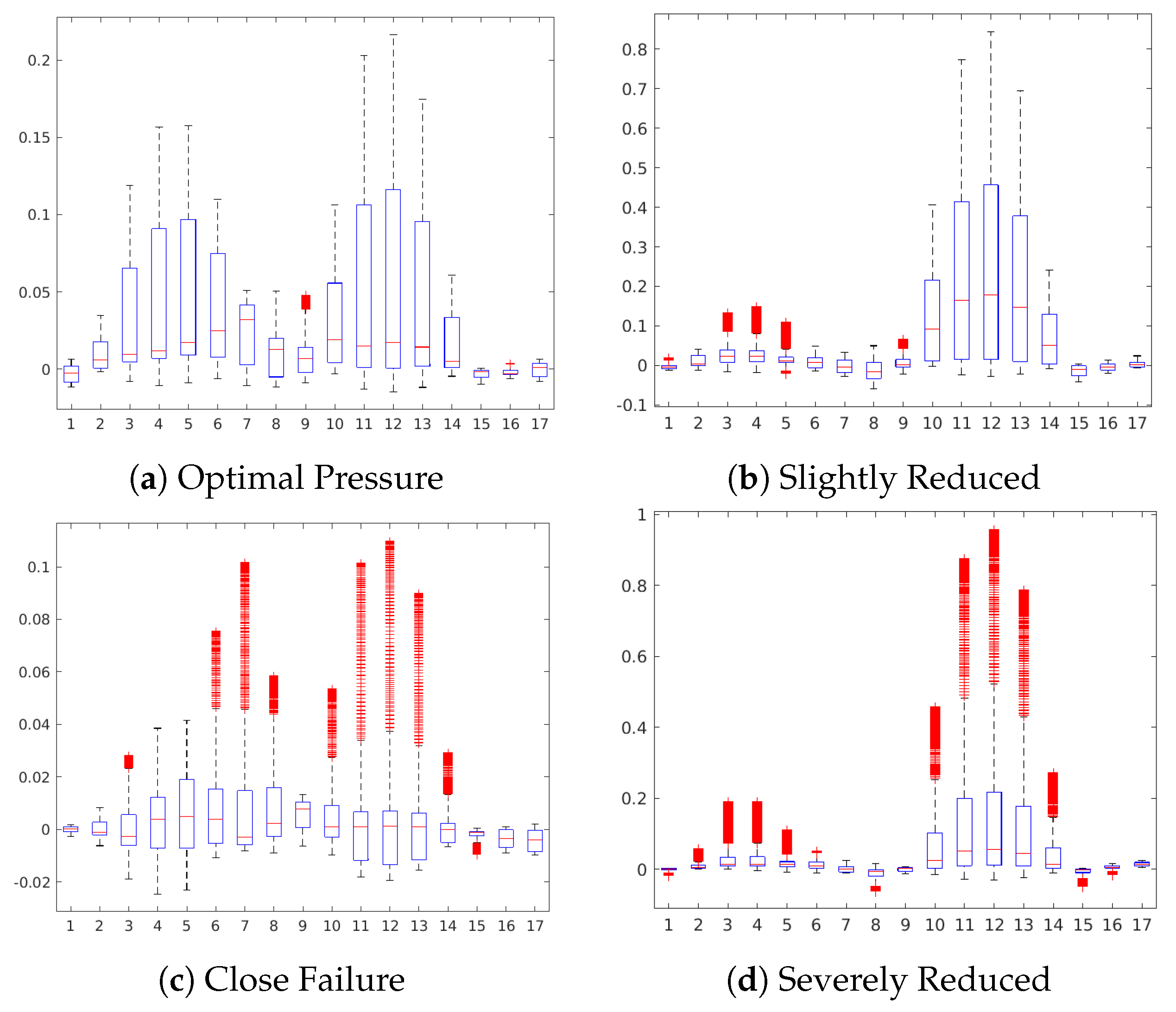
Table 10 shows a statistical summary of the maximum attributions in each map by a sensor. The attributions are shown as relative values in a range from 0.0 to 1.0 about the maximum positive or negative contribution of the map in each case. Additionally, we also show a boxplot to give a complete description of the variation in the contributions of a sensor. This statistical analysis aims to show to which extent a sensor is contributing positively/negatively to the prediction of the target.
Figure 5 shows the occlusion sensitivity maps of the Valve target for the different degradation states. The sensor patterns with positive contributions to the prediction of the states remark all similar regions highlighting especially the contribution of sensors #6 to #9 (pressure sensors). The similitude of the maps indicate that similar sensor combinations are relevant for the predictions hinting that the absolute value of the sensor readings may be decisive for the prediction of the state rather than different combinations of sensors. Namely, pressure sensors P1, PS2, and PS3 are the sensors with the highest positive contribution in the prediction of all three states according to the boxplot representation (
Figure 6) of the attributions and statistical summary reported in
Table 10.
The occlusion sensitivity maps of
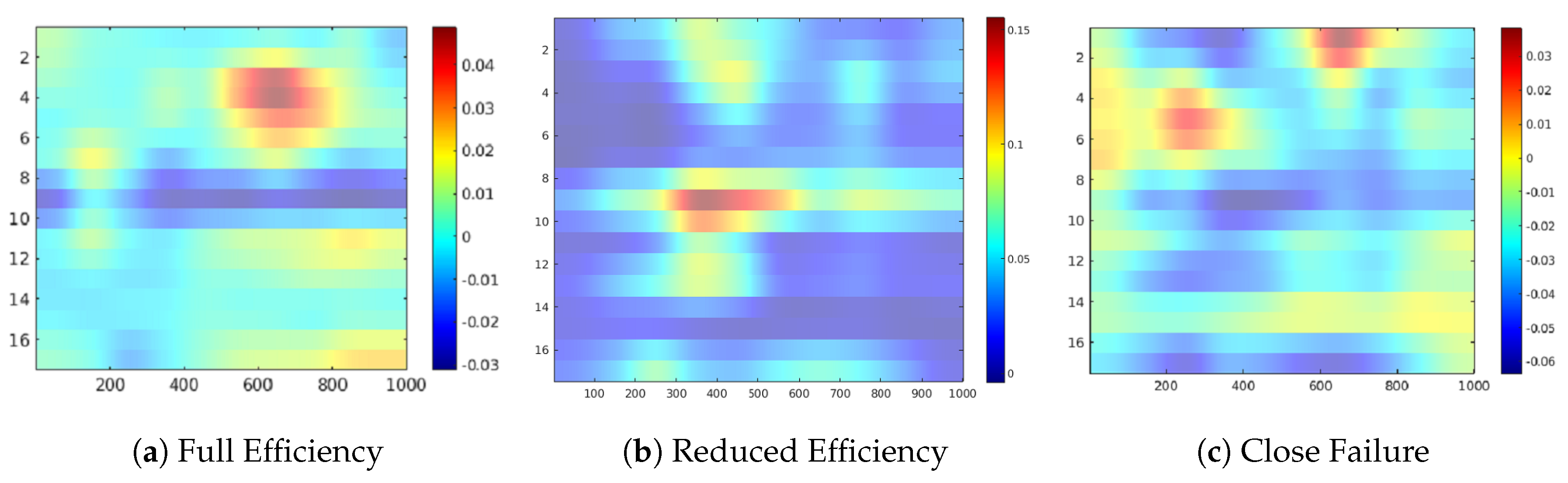
Figure 7 highlights the relevant sensor readings for the Cooler target. In this case, more complex sensor combinations than those of the Valve target are visible in the map suggesting that a higher number of sensors are relevant for the prediction of the degradation states. Different areas of the image are highlighted for each case. Interestingly, the activation pattern of Reduced Efficiency appear to be complementary to those of Close Failure (See
Figure 7b,c). This finding points toward a good separability of the states in the CNN as different combinations of features are involved in the prediction of each state. A more detailed analysis of attributions from the boxplot representation of image of
Figure 8 reveals that sensors #8, #9, and #10 (pressure sensors PS3–PS5) are contributing positively in Reduced Efficiency while they have a suppressing effect in Full Efficiency and Close Failure. For the Full Efficiency state many positive contributing sensors are reported, where sensors #3 to #5 (motor power EPS1 and volume flow FS1/2) are important according to the sensitivity map (see
Figure 7a). The prediction of the Close Failure states seems to involve a complex combination of sensor readings since the sensitivity map describes mainly negative contributions from almost all sensors (see
Figure 7c). Nevertheless, sensors #1 and #2 (cooling efficiency CE and cooling power CP), as well as sensors #5 and #6 (flow sensor FS2 and pressure sensor PS1), reveal some minor positive contributions for this target.
Figure 9 shows the occlusion sensitivity maps of the Internal Pump Leakage target for states No Leakage, Weak Leakage and Severe Leakage. For all three cases, complex combinations of sensor readings are contributing to the prediction of the respective states, where positive and negative contributions are alternated along with the 1000 sensor readings. An analysis of the occlusion map of No Leakage (see
Figure 9a) and the corresponding boxplot (see
Figure 10a) reveals a positive contribution of the sensors #3 to #6 (motor power EPS1, flow sensors FS1/2, pressure sensor PS1) for the prediction of the No Leakage state. Regarding the occlusion maps of Weak Leakage and Severe Leakage (see
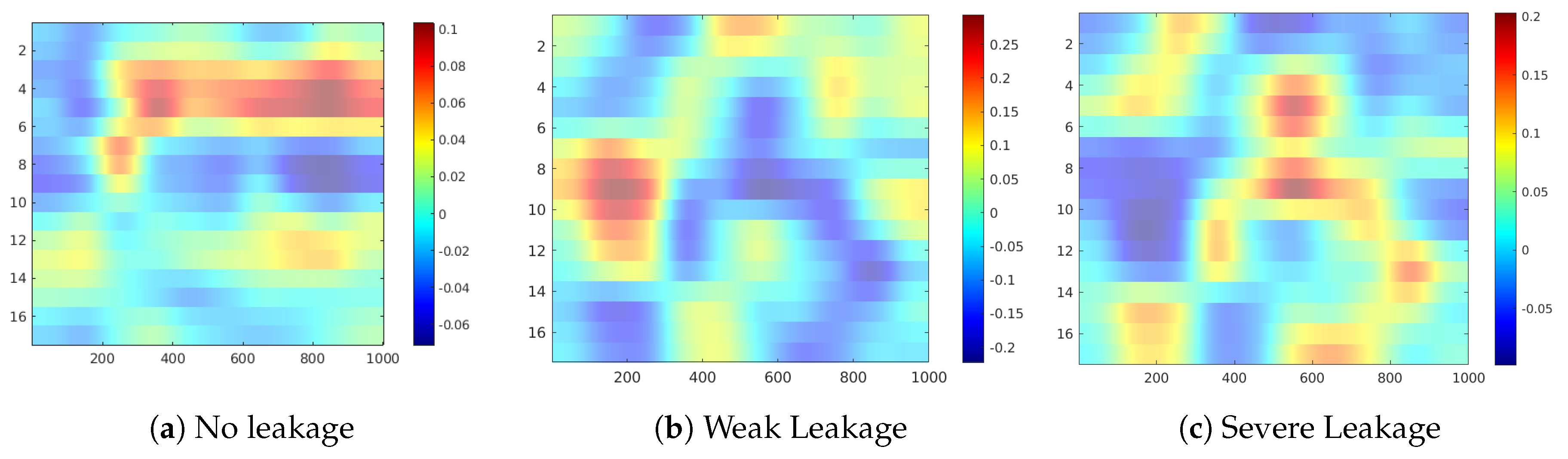
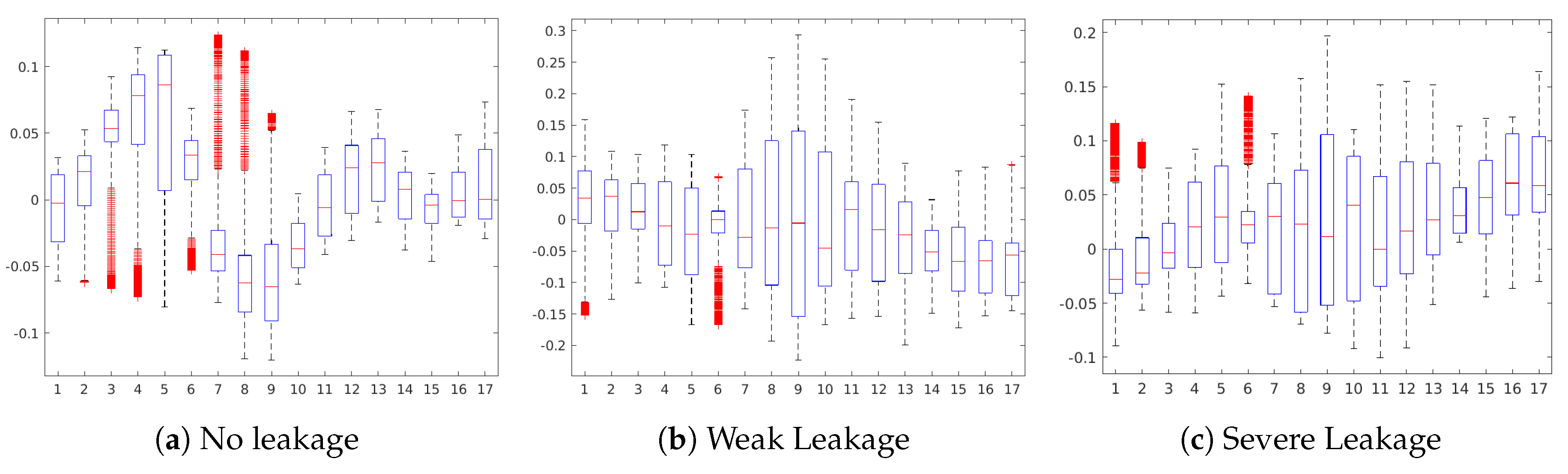
Figure 9b,c), the maps show that the activation patterns of these states are complementary, as the positive contributing regions in each case are not contributing in the prediction of the other state. This attrribution hints towards a clear separability between the states Weak Leakage and Severe Leakage in the CNN model.
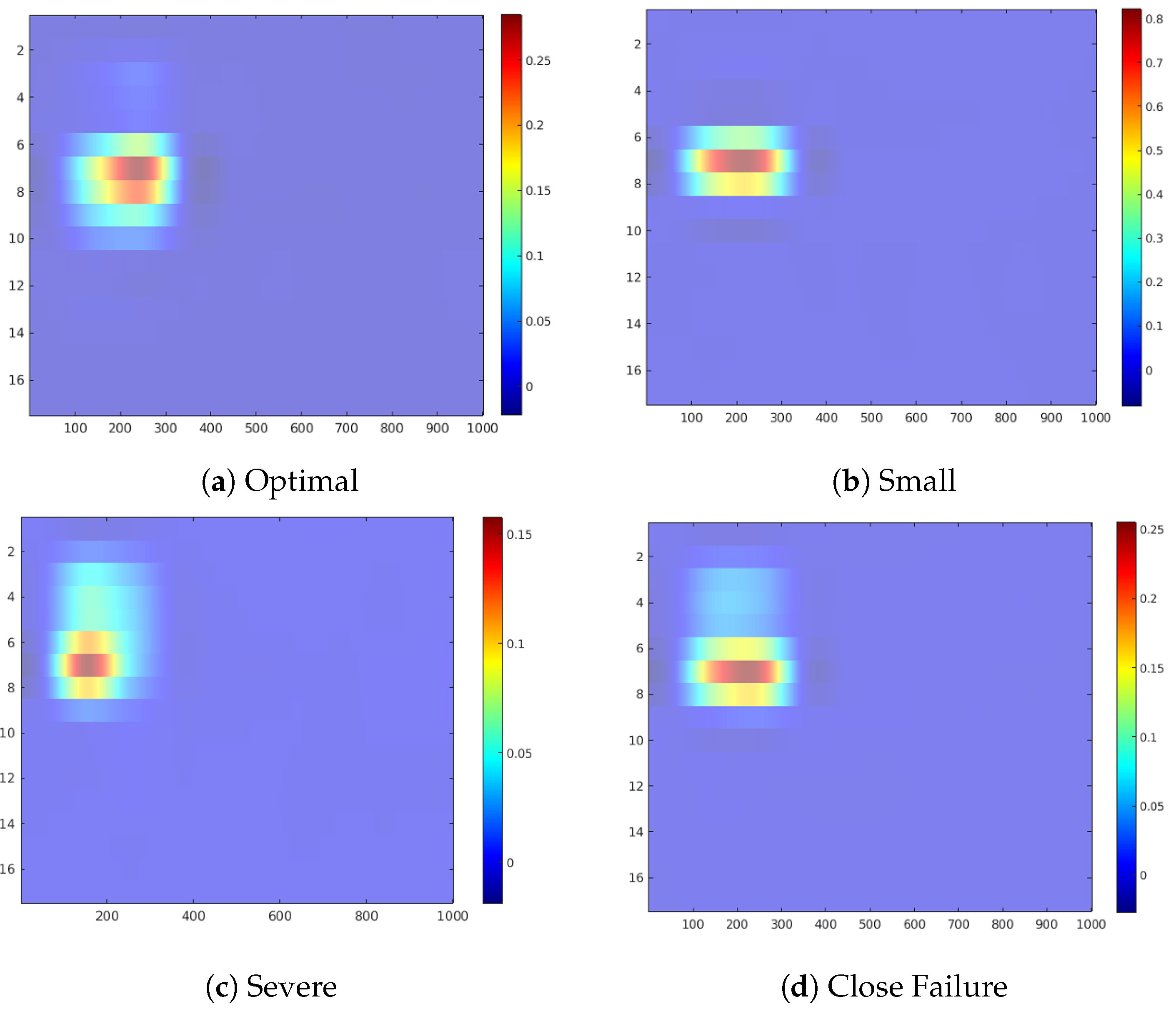
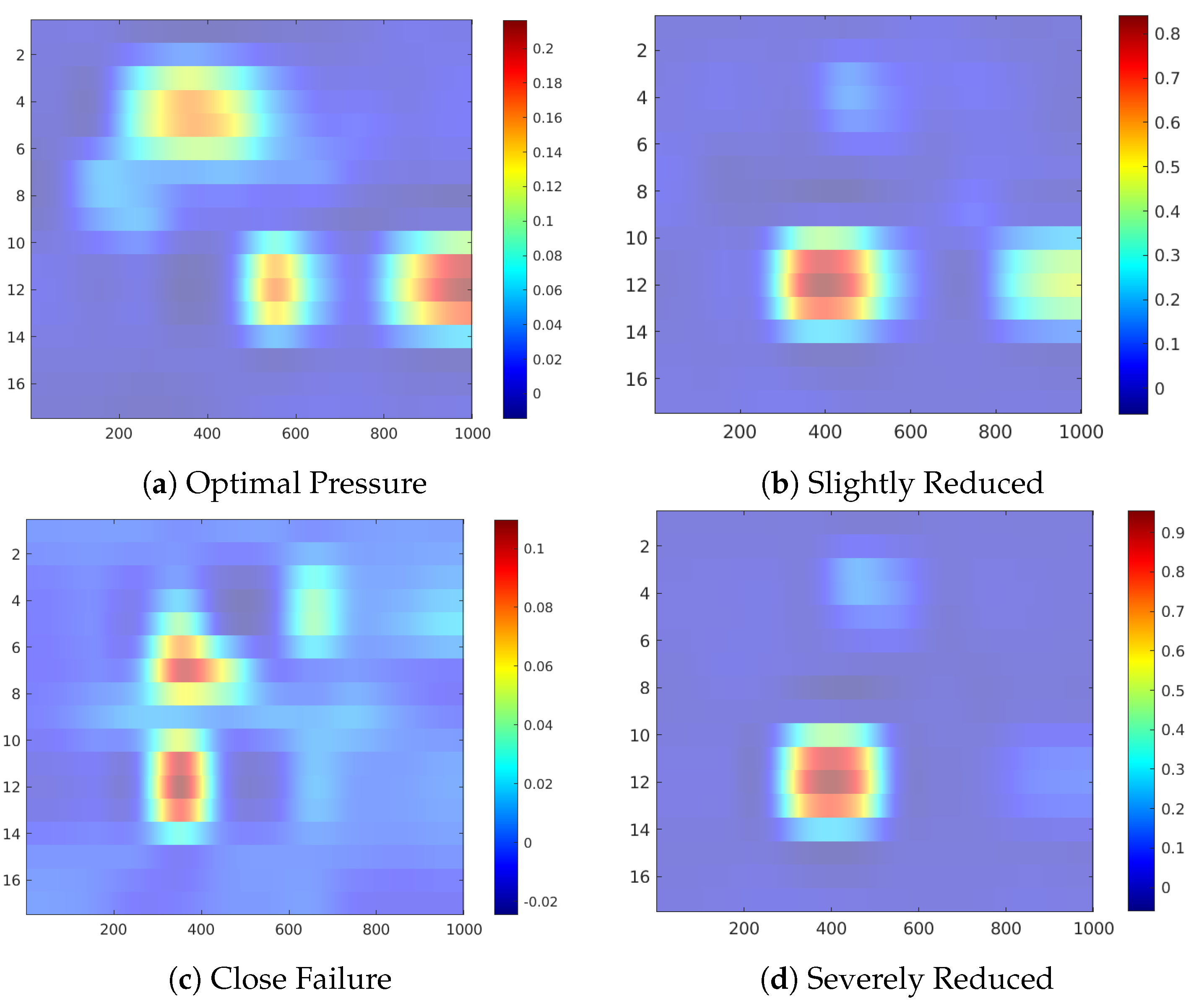
Figure 11 shows the occlusion sensitivity maps for the Hydraulic Accumulator target, while
Figure 12 depicts the distribution of the attribution values of each sensor for the prediction of the different degradation states. The sensitivity maps of Optimal Pressure and Close Failure (
Figure 11a,c) highlight a group of sensors, therefore revealing more complex sensor patterns involved in these predictions. The readings from sensors #11 to #13 (pressure sensor PS6, efficiency factor SE and temperature sensor TS1) are highlighted in both cases, while for the prediction of Optimal Pressure sensors #4 and #5 (volume flow) are highlighted and for Close Failure sensors #6 and #7 (pressure sensors PS1 and PS2).
According to the results of the attribution analysis, we aim to optimize the ML model by reducing the sensor data to only those sensors marked as highly relevant for the given target. For this purpose, we filter the sensor attributions (see
Table 10) by a threshold of
to select those sensors that are contributing positively at least with 50% in a feature to the prediction of the state. The sensors falling above this filtering rate are highlighted in bold in
Table 10. Applying this approach to the four condition variable targets, we can reduce the number of sensors to three for Valve, 12 for Cooler, 16 for Pump and 9 for Accumulator. These findings indicate that solely in the case of Valve and Accumulator a feature reduction is of interest and we decide to build the CNN models for these two targets following the methodology explained in
Section 6. For the Valve target we train the CNN model on the sensor readings of the pressure sensors (PS1–PS3). The classification results are the same as those on the complete set of sensors (See
Table 5). For the Accumulator target we train the CNN model again with the sensors
to
(motor power EPS1, volume flow FS1/2, pressure sensors PS1–PS3) and sensors
to
(pressure sensor PS6, efficiency factor SE and temperature sensor TS1). In this case, the classification results are slightly better than those of the complete set of sensors achieving an MCC of 0.983 and accuracy of 0.993 versus a MCC of 0.982 and accuracy of 0.947 with the entire set of sensors.
9. Conclusions
In this study, we have reported the results of a deep learning based condition monitoring application exemplified on a multisensor dataset of a hydraulic installation from the literature. During the development of the solution, we have considered several important aspects of ML based condition monitoring applications, being the prediction quality and interpretability of the model the most relevant aspects.
We have designed a CNN with a 1D architecture to capture the temporal evolution of the sensor signal. The CNN models for each condition variable were close to those reported in previous research on the dataset [
17,
33]. These previous studies analyzed the performance of several classifiers using time-frequency features and reported results on feature selection and reduction. The main difference of our work regarding those previous studies is the CNN model’s ability to operate directly on multivariate time series data without an explicit feature engineering. Secondly, our work aimed to analyze the classification models at a deeper level. Besides the analysis of classification performance, we also examined the quality of fault detection, detailing the importance of precise and complete detection as condition monitoring systems should neither have false alarms nor dismiss failures. The classifier’s quality was evaluated by the MCC, a robust metric for class imbalance, which is a frequent problem in condition monitoring due to the scarcity of representative datasets of failure modes compared with data from normal operation.
Although the condition monitoring system resulted highly accurate, we have analyzed the misclassifications on the confusion matrix to gain a deeper insight into misclassification patterns. This analysis revealed misclassifications between similar levels of degradation of the condition variable and supported the need to properly characterize faults during the design of a condition monitoring system, as too fine levels of fault detection may difficult the system to operate with high accurate predictions. The proper characterization of faults is a common issue in fault diagnosis. Such a characterization can be done manually on the criteria of an expert of the area or systematically based on the historic failures from a failure database or system log [
42] using component breakdown techniques or statistical analysis of failures and downtimes.
In the second part of the work, we focused on the interpretability of the CNN models. The objective was to analyze how each sensor contributes to the prediction of a condition variable in order to optimize the number of sensors. Initially, the CNN models were built on the entire multi-sensory dataset. Attribution analysis through occlusion maps provided useful high-level information about which sensors contribute positively to the prediction of a degradation state. Although for the Cooler and Pump targets, this analysis revealed more complex sensor combinations for the prediction of the condition variable, in the case of the Valve and Hydraulic the identification of relevant sensors was quite straightforward reducing the number of sensors to three and nine respectively. Validation of the sensor selection through the construction of CNN models on the reduced feature set confirmed the adequacy of the feature selection as the classification accuracy remained the same for both models.
The purpose of the here presented study was to showcase how attribution analysis on CNN sensor image data can be used as a feature selection approach for the reduction of sensors during the design of a condition monitoring system. The example of the Valve condition was quite explicative as the attribution analysis highlighted three pressure sensors. In consequence, it would be feasible to center the design of the valve condition monitoring only on a proper sensorization of the pressures of the installation.
As a future line of research, we would like to investigate about the robustness of the CNN model towards missing sensor readings as in certain situations a sensor may not be operative. For example in the case of industrial maintenance, a sensor may need a replacement, which is often not immediately. Meanwhile, the condition monitoring system may operate on incomplete sensor data and should remain operative. This future research would focus on depth completion techniques to learn data representations invariant to missing values either using sparse architectures or special training approaches [
43].
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}