1. Introduction
Recent years have witnessed huge interest in accelerating Magnetic Resonance Imaging (MRI) acquisition and improving the achievable quality of MRI images based on compressed sensing [
1,
2,
3]. Reconstruction of a magnetic resonance image
is formulated as the following optimization problem
where
are measurements obtained through partially observed Fourier transform
,
[
4].
denotes analysis operator and
is a regularization function, with the parameter
.
is typically the
-norm:
when
denotes a wavelet-like transformation of the signal
, e.g,
, or the TV pseudo-norm
when
is the identity operator. With compound regularization, the problem in (
1) becomes
Many reported methods, including [
4,
5,
6,
7] combine
and TV regularization:
,
,
,
, which proved to be beneficial over either of these regularization functions alone.
Apart from CS-MRI iterative algorithms for solving the problem in (
1), deep learning, which has been successful in solving many computer vision problems, has also been proved beneficial in tackling image reconstruction problems [
8,
9]. In particular, deep convolutional neural networks (CNNs) are extremely powerful and efficient in learning signal representation [
10]. Wang et al. in [
11] train a deep CNN from downsampled reconstruction MRI images to learn a fully sampled reconstruction and then use deep learning results either as an initialization or as a regularization term (
1). Following the same principle, the authors of [
12] trained a reconstruction function from undersampled/full sampled image pairs, utilizing a more complex network structure based on U-net architecture [
13] compared to the one used in [
11]. In [
14], motivated by a linkage between CNNs and Hankel matrix decomposition, the authors propose a fully data-driven deep learning algorithm for
k-space interpolation of undersampled measurements. A trend of designing complex network architectures for constructing de-aliasing MRI reconstruction function was continued in [
15,
16] with the involvement of Generative Adversarial Network (GAN) [
17] and U-net architectures and in [
18,
19] where a deep cascaded CNNs and its stochastic variation are used. A GAN based network architecture demonstrated also promising performances in the task of super-resolution (SR) for image enhancement which has great importance in medical image applications [
20,
21,
22,
23]. However, besides very good performances, the training procedure of deep CNNs, especially GANs, demands good hyperparameters tuning to achieve training convergence, which without experience is a quite difficult and time-consuming task. Another observation is that most of the results of trained deep CNNs are reported for the brain MRI scans, which means that their usage for the MRI images of another anatomy would possibly require a new training cycle.
Recent research showed that MRI reconstruction benefits from modelling statistically the spatial clustering properties of the important transform coefficients, i.e., modelling the coefficient support. Representatives are wavelet-tree sparsity methods [
24,
25] and methods that employ MRF priors [
26,
27,
28,
29]. A work of Panić et al. [
29] demonstrated a superior reconstruction performance of MRF-based approaches over wavelet-tree sparsity methods. The reconstruction algorithm in [
29] is an augmented Lagrangian method inspired by [
30] and extended with an MRF prior. A variant of this algorithm, also reported in [
29] with compound regularization consisting of a MRF-based and TV regularization terms demonstrated significant improvements over several state-of-the-art methods, including [
25,
31,
32]. Although the algorithms in [
29] perform well over a wide range of the parameters of the MRF model, on the analysed human brain images, they require parameter tuning when imaging different anatomical structures. We also found that hard-thresholding rule in [
29] based on the estimated sparse signal support leads to some small oscillations around the convergence state, which do not affect noticeably the quality of the reconstruction but may impair practical determination of the stopping criterion.
In this paper, we aim to develop a more robust model, with automatic estimation of the parameters and with improved stability. We also extend the isotropic MRF model used in [
29] to a more flexible non-isotropic model that can better capture the properties of various anatomic structures and adapt to these automatically through efficient parameter estimation. To solve the resulting optimisation problem, we develop a novel numerical method that involves a Nesterov acceleration step [
33,
34]. The main technical novelties are in: (i) developing a compressed sensing approach for MRI images with an anisotropic MRF model and deriving automatic estimation of its parameters; (ii) deriving a more stable solver, which replaces hard selection of the coefficients by a soft-thresholding (note that the resulting estimator is derived analytically by introducing the corresponding proximal operators for MRF-based and TV regularization functions); (iii) we extend this approach such that it is applicable not only for the reconstruction of the magnitude images as in [
29], but also to complex images and to multi-coil data.
The paper is organized as follows. The formulation of the problem with the proposed regularization function is given in
Section 2.1. In
Section 2.2 we derive the efficient solver, and in
Section 2.3 we develop an efficient method for the estimation of the MRF parameters.
Section 2.4 introduces algorithm extensions to reconstruction of complex images from one or more coil measurements.
Section 3 presents experimental results and comparison with state-of-the-art methods. In
Section 4 we provide our conclusions.
2. Methodology
2.1. MRF Priors in MRI Reconstruction
Consider a Bayesian approach to recovering jointly representation coefficients
and their bi-level significance map
with the maximum a posteriori probability (MAP) criterion:
. Here,
are the latent variables formed in a lattice that encode the significance of the representation coefficients:
on those positions
i in lattice where
is significant, and
conversely.
is the prior probability of
while
and
are conditional probability density functions (p.d.f.). Equivalent formulations of the graphical model were presented, e.g., in [
27,
28,
29] and a similar one in [
26,
35] for the signal sparse in image domain. Using the negative log transformation of
, the MAP criterion translates into the joint minimization with respect to (w.r.t.)
and
:
We make a connection between (
3) and formulations of type (
1) by reordering the terms as follows:
Assuming that measurements
are corrupted by independent identically distributed (i.i.d.) Gaussian noise, we have that
=
. It then follows that the first term
in (
4) using a relation
becomes equal to data fidelity part
in (
1).
is the new type of regularization function, which is taking the role of the second term
term from (
1). Assuming conditional independence
and a Laplacian prior for image coefficients
we define accordingly conditionals
as follows:
for
and zero otherwise while
is defined oppositely with respect to
B. The threshold
B is related to the noise level and estimated from the highest-frequency subband coefficients; the scale parameter
b is adaptively estimated per subband [
29]. We choose the Gibbs distribution (MRF prior) for the
’s support model
, where the normalizing constant
represents the partition function, and the temperature
T controls the peaking in the probability density [
36]. We employ a common model with pair-site cliques. However, in contrast to our previous work [
27,
28,
29], we allow for different interaction coefficients for cliques of different orientations, which models better the actual subband statistics. The energy function of this anisotropic MRF is
where
expresses the a priori preference for labels of one type over the other and
the interaction strength for cliques with orientation
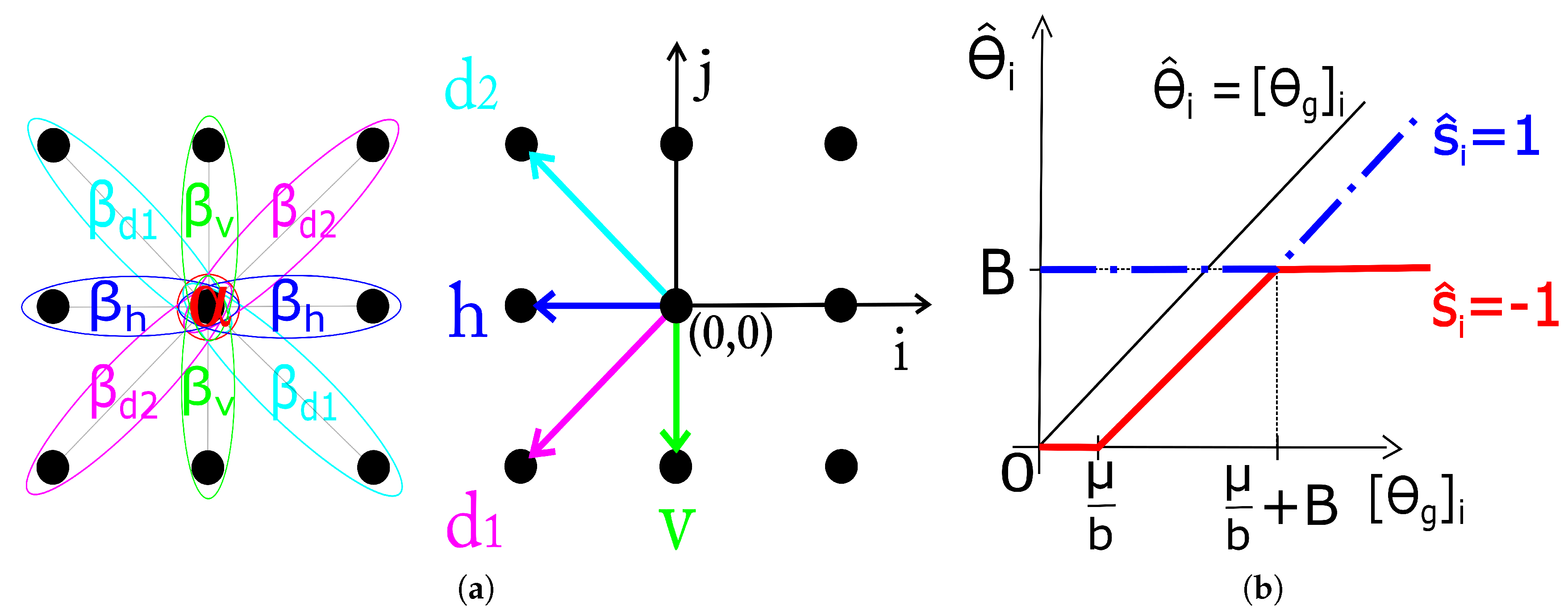
shown in
Figure 1. The estimation of the MRF parameters (
) is treated in
Section 2.3.
Involving the composition of the MRF-based regularization function
and TV norm
, defined as
, we arrive at the proposed optimization problem formulation:
The optimization problem (
6) is non-convex in general due to the presence of the non-convex
regularization function and is very hard to globally solve exactly. In the following section we propose a computationally efficient method to suboptimally solve (
6).
2.2. Proposed Algorithm
To solve the problem (
6) we adopt the idea of fast composite splitting from [
37] and extend this algorithm to deal with the MRF-based regularization. The key difference is that our model involves
instead of
-norm in [
37]. Hence, we have to solve the proximal map
:
Note that, in notation , is the function for which the proximal map is calculated, and is the argument at which it is evaluated. Since the evaluation of this proximal map is very hard, we adopt a suboptimal, block-coordinate approach explained in the following.
The key novel ingredient of the proposed algorithm is a computationally efficient approximation of the proximal map in (
7) for a fixed
. From (
4), it is clear that the minimization in (
7) needs to be carried out jointly w.r.t.
and
in order to evaluate (
7) exactly. We adopt a suboptimal yet computationally efficient approach where we first minimize the second term in (
4) w.r.t.
for a fixed
; then we fix the obtained
and minimize the objective in (
7) w.r.t.
. For the former minimization step, we adopt notation
. The step is done via the Metropolis sampler procedure using a “warm-start” initial
as in [
28,
29]. The latter minimization (w.r.t.
for a fixed
), as shown here, can be done in closed-form and leads to a novel soft-thresholding operation. This is accomplished by solving the following minimization problem
Equation (
8) is derived from (
7) using a simple algebraic manipulation and omitting the terms that do not depend on
. With the analytic form of
for
(see
Section 2.1), the closed form solution for each single component of
(it turns out that the solution decouples component-wise) is derived in (
9) (index
i in the equation is omitted for notation simplicity). The solution (
9) is illustrated in
Figure 1 on range
due to its (odd) symmetry about the origin.
The described block-coordinate cyclic procedure should in principle proceed in several iterative rounds. As we demonstrate here numerically, it is sufficient to perform a single cycle. Once the approximation of the proximal map in (
7) is available, we incorporate it in a fast-splitting framework akin to the one in [
37]. That is, we first carry out a gradient-like step on
w.r.t. data fidelity term. Then, we perform in parallel the proximal maps that correspond to the two regularization functions in (
6). The two outputs of the proximal mappings are then simply averaged and fed into a Nesterov-acceleration-like step. The motivation for the parallel-proximal-then-average approach is computational efficiency, as carrying out a joint proximal map (even approximate) w.r.t.
and
would be very hard. The motivation for the Nesterov-acceleration step is to further speed-up the method.
The overall method is presented in Algorithm 1. Recall the definition of
from (
8). Note that steps 3-4 are the single block-coordinate cycle to approximate the operation in (
7). The parameters
for simplicity are all set to 1, although these are not the optimal values, unless it is otherwise stated. We refer to the proposed method as Fast Composite Lattice and TV regularization (FCLaTV). A version without acceleration CLaTV can also be used, and it is obtained after omitting steps 7 and 8 from FCLaTV and replacing
in the step 1 with
. Extensive numerical studies demonstrate that Algorithm 1 always converges. The rigorous convergence analysis is left for future work.
| Algorithm 1 FCLaTV |
Require:- 1:
repeat - 2:
- 3:
- 4:
- 5:
- 6:
- 7:
- 8:
- 9:
- 10:
until some stopping criterion is satisfied - 11:
return
|
2.3. Parameter Estimation for the Anisotropic MRF Prior
Here we propose a data-driven approach for specifying the parameters of the MRF model. The core idea is to relate the parameters of the prior for the support of to some measurable characteristics of the observed . The representation coefficients are re-estimated in each iteration of Algorithm 1 and so are the MRF parameters.
The four interaction coefficients
represent the clustering strength of the coefficient labels
in the corresponding four directions for the observed subband. We reason that the clustering strength in a particular direction should be proportional to the correlation among the corresponding representation coefficients
in that direction. Therefore, we base the estimation of interaction coefficients on magnitude of representation coefficients
. In order to reduce the effect the noise present in
on estimation of the interaction coefficients, we used squared magnitude of
and account only for those that were marked as significant by the initial
prior to its MAP estimation
. In what follows,
denotes a subband in which all the coefficients that were selected as significant by
are left unchanged (
if
) while others are set to zero (
if
). To express two-dimensional (2D) correlation, we need to revert to 2D spatial indices
. Let
denote the correlation coefficient for squared
corresponding to the spatial shift
:
We take four correlation coefficients corresponding to the smallest possible spatial shifts in the corresponding directions, indicated by arrows in
Figure 1. These are:
,
,
and
. Note that by symmetry
,
,
and
. The mapping
translates these index pairs into a single index
. With
we have that
is the correlation coefficient in the 45
(
-direction),
the horizontal,
the 135
(
-direction) and
in the vertical direction. Now we can specify the four interaction coefficients as normalized correlation coefficients of
:
The normalization by -norm here is optional (as only the relative values of the MRF parameters with respect to each other actually matter) but we find it convenient in practice to have these parameters in the range as it is now guaranteed. We also tested and for the purpose of this normalization, but led to best performances in our experiments.
It still remains to specify the parameter
, which represents a priori preference for one type of labels (
or
) over the other. With
both labels are a priori equally likely and as
increases in magnitude the more preference goes to one of these labels. For
, the labels
will be favoured, which means that significant coefficients (labelled by
) will be sparse. We specify
as the mean energy of the coefficients in
relative to the energy of the largest coefficient in that subband:
Note that we have omitted the iteration indices for compactness. In fact, we have sequences , and , , , , that get improved through iterations k.
2.4. Complex Image Reconstruction and Multi-Coil Reconstruction
The proposed approach is developed for the reconstruction of MR image magnitude. Here we extend it for the reconstruction of complex images (magnitude and phase) and the reconstruction of magnitude images from multi-coil measurements. In cases where it is of interest to recover the image phase together with the magnitude, steps 4 and 5 in Algorithm 1 are repeated twice: first for the regularization of the real part and then, equivalently, for the regularization of the imaginary part of a complex image
. This approach showed promising performances as it will be seen in the following section. A multi-coil image reconstruction demands knowledge of sensitivity profiles for each coil and therefore different construction of the operator
during the reconstruction procedure. If we denote with
the sensitivity profile for coil
i then undersampled measurements from the same coil are
. Let us collect all available measurements from
coils in one vector
and create an augmented vectorized image
with the usage of matrix
which is formed by stacking the identity matrix
times row-wise. Then the acquisition process is defined through the following equation
where
consists of repeated
along the diagonal while
is formed by stacking coil sensitivity maps
along diagonal. This way a multi-coil reconstruction problem can be solved using the single-coil reconstruction method developed in this paper. This generalization in the definition of the measurement operator
is easily introduced in step 2 in Algorithm 1 instead of
corresponding to the single-coil reconstruction scenario. The computational complexity is marginally increased and doesn’t require additional code optimization.
3. Results
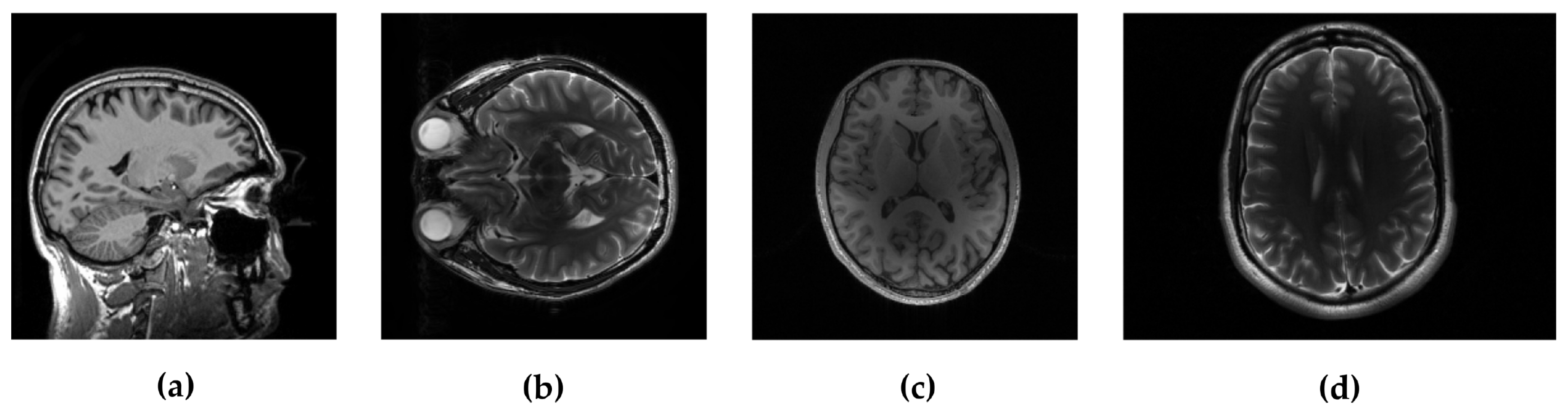
In the experimental evaluation we used different MRI images, starting from high-resolution MRI images, shown in
Figure 2, and using real data acquired in
k-space. For the following experiments, we used simulated sampling trajectories on a Cartesian grid with different sampling rates, except for the last experiment, when the measurements are undersampled with the non-Cartesian radial sampling trajectory used in a real scan. First, we consider reconstruction of MR image magnitude for different sampling rate (SR) obtained using various sampling trajectories. For this we utilize dataset of 248 T1 MRI brain slices acquired on a Cartesian grid at Ghent University hospital (one
sagittal slice is presented in
Figure 2). Then we focus on the reconstruction of complex MR images from single and multi-coil undersampled measurements. Complex T2-weighted brain images
axial-1, axial-3 from [
31] and [
38] respectively (their magnitudes are presented in
Figure 2) are used in experiments for the reconstruction of single-coil complex images while the T1-weighted brain image
axial-2 [
38] is used in the multi-coil reconstruction experiment. We also present the reconstruction results on real radially acquired measurements in
k-space on non-Cartesian grid. These data, consisting of the acquisitions of a pomelo fruit were supplied by the Bioimaging Lab in Antwerp. In our experiments for sparse signal representation we used the non-decimated wavelet transform with 3 scales. For comparison, we report the results of LaSAL and LaSAL2 from [
29], FCSA [
5], FCSANL [
39] and WaTMRI [
25] with the original implementations. All these methods, except LaSAL, employ a compound regularization. The reconstruction results for complex images from single-coil and multi-coil measurements, are compared with the corresponding results of pFISTA [
31] and P-LORAKS [
38,
40] methods.
For quantitative comparison between the reconstructed and the reference MR image we adopt Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM). PSNR is defined as:
where
denotes squared maximum possible pixel value in the magnitude of MR image and
is the mean squared error between magnitudes of reconstructed
and reference image
. For the calculation of SSIM index we used the simplified equation form:
where
are the local means, standard deviations, and cross-covariance for images
,
and
and
are regularization constants to avoid instability in index calculation. Local statistics is calculated using isotropic Gaussian function with radius 1.5. Through experiments pixel values are stored in double-precision floating-point format with dynamic range of
unless otherwise stated.
3.1. Data Sets Acquired on Cartesian Grid
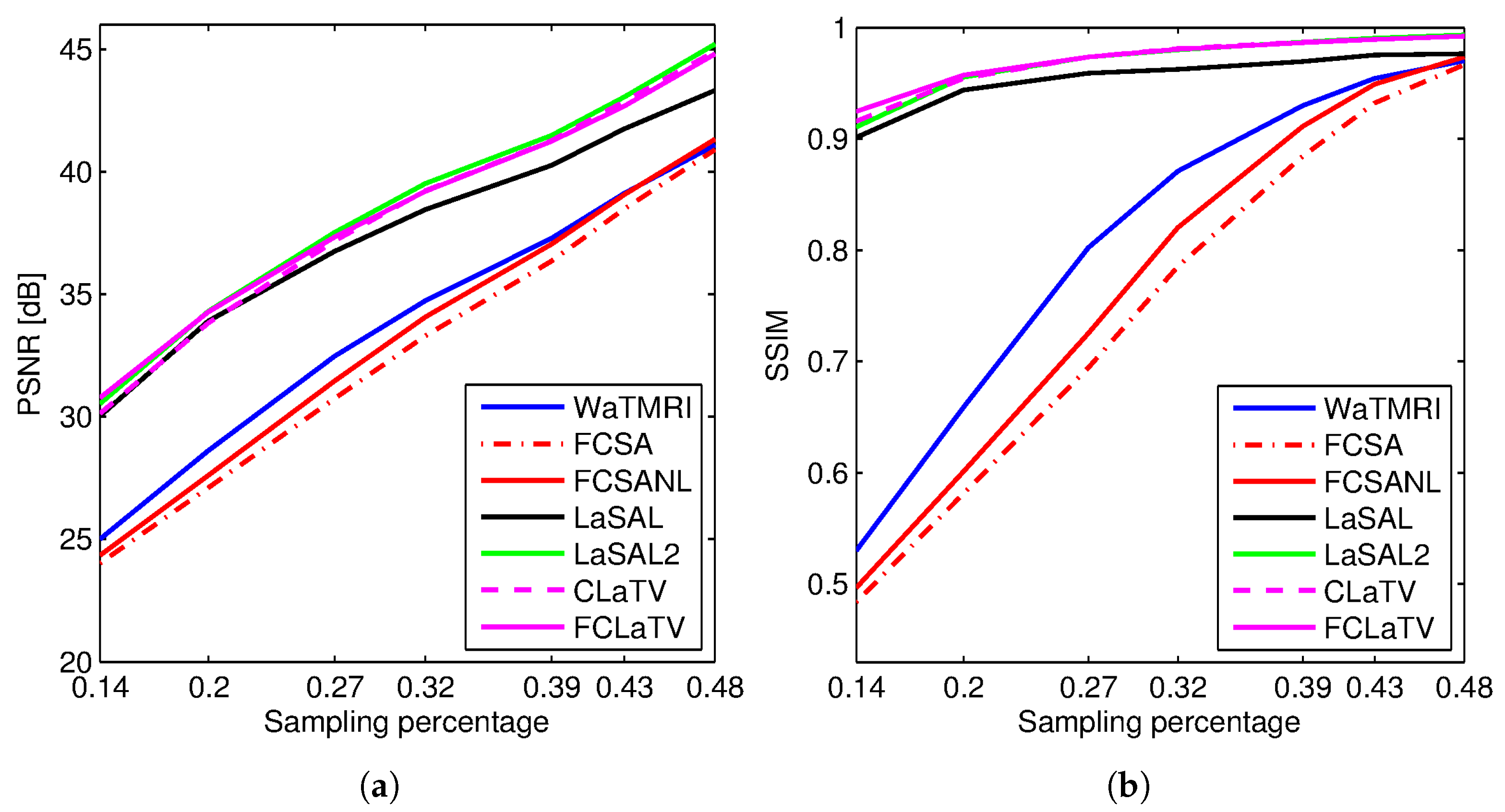
Figure 3 shows the PSNR and SSIM for the reconstructed
sagittal MR image from radially undersampled measurements with sampling rate (SR) ranging from 14% to 48%. The MRF-based methods LaSAL, LaSAL2, CLaTV and FCLaTV achieve a consistent and significant improvement in PSNR (at some sampling rates more than 4 dB) compared to WaTMRI, FCSA and FCSANL. The proposed methods CLaTV and FCLaTV outperform LaSAL and yield only slightly lower reconstruction PSNR and equally good SSIM as the best reference method LaSAL2. These results are achieved with automatic estimation of MRF parameters and without tuning the regularization parameters (the
,
and
parameters are all set to 1).
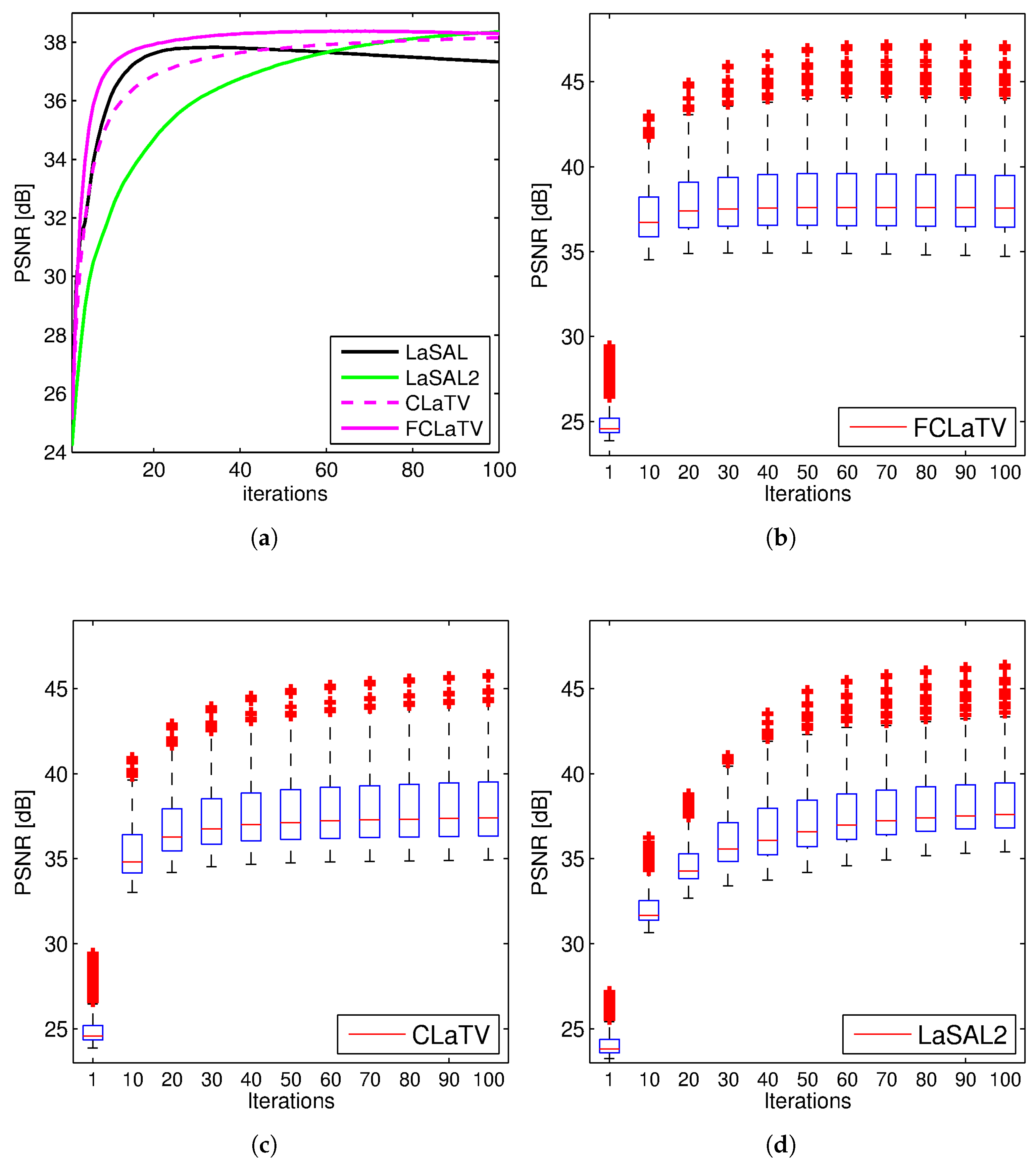
Performances of the proposed methods are further tested through reconstruction of all 248 T1 MRI slices from data set. Results are shown in
Figure 4 where besides mean PSNR values through iterations we also provide distribution of PSNR values for CLaTV, FCLaTV and LaSAL2 methods. On average, FCLaTV reached the peak performance much before CLaTV and LaSAL2. The LaSAL2 achieved its highest PSNR in average after 80 iterations which is 2 times more after FCLaTV. CLaTV, FCLaTV and LaSAL2 reached the same maximal median PSNR value of 37.5 dB through all iterations. The proposed methods need less iterations than LaSAL2 to reach this value which is presented in
Figure 4 with the shift of PSNR distribution towards higher values in the first 20 iterations.
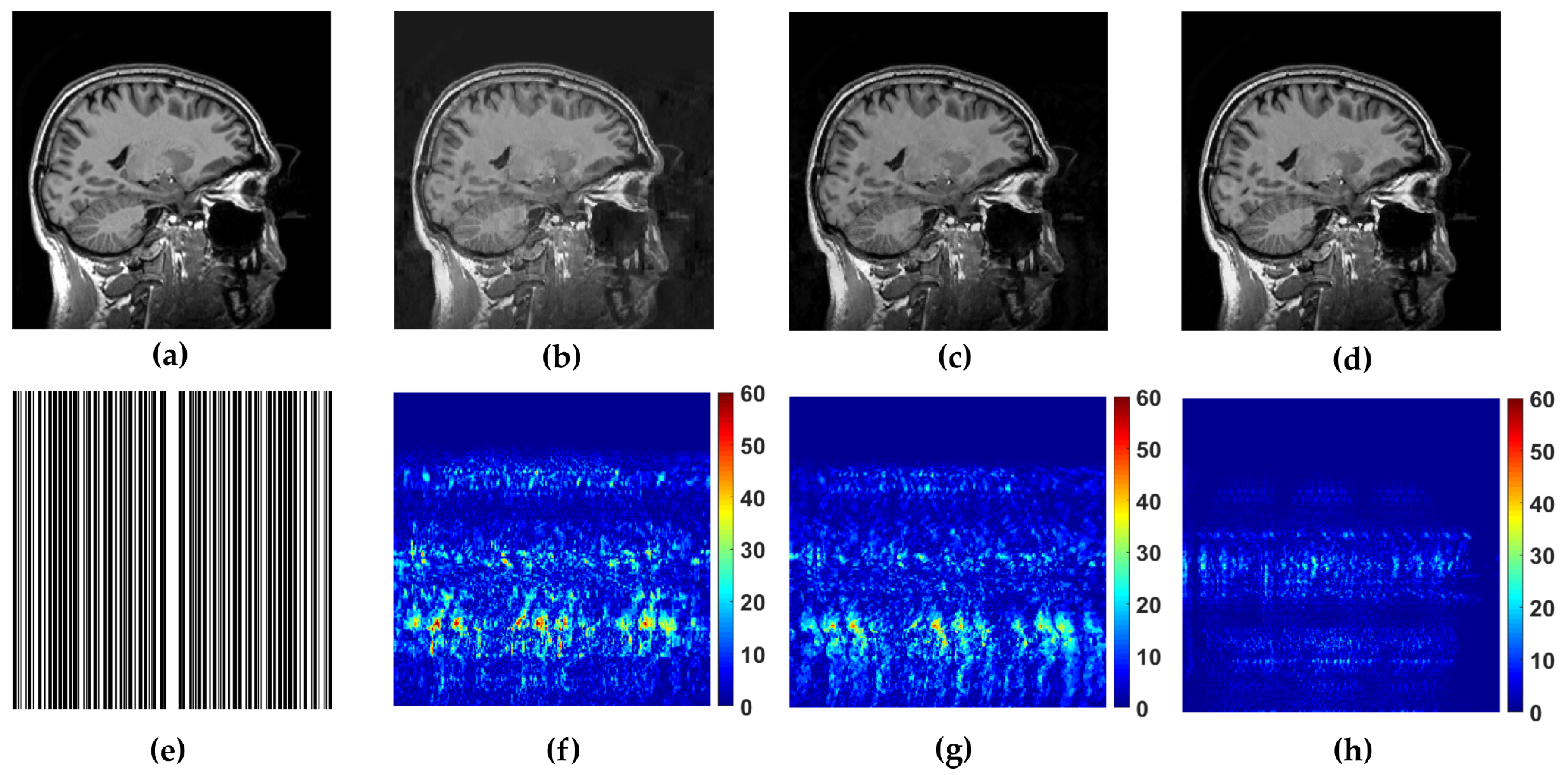
WaTMRI, LaSAL2 and FCLaTV are further tested in reconstruction from measurements undersampled with straight vertical lines in
k-space which is usual sampling trajectory in real scanners. From the results of this experiment, shown in
Figure 5, the FCLaTV method outperforms WaTMRI and LaSAL2 visually and in terms of PSNR and SSIM measure.
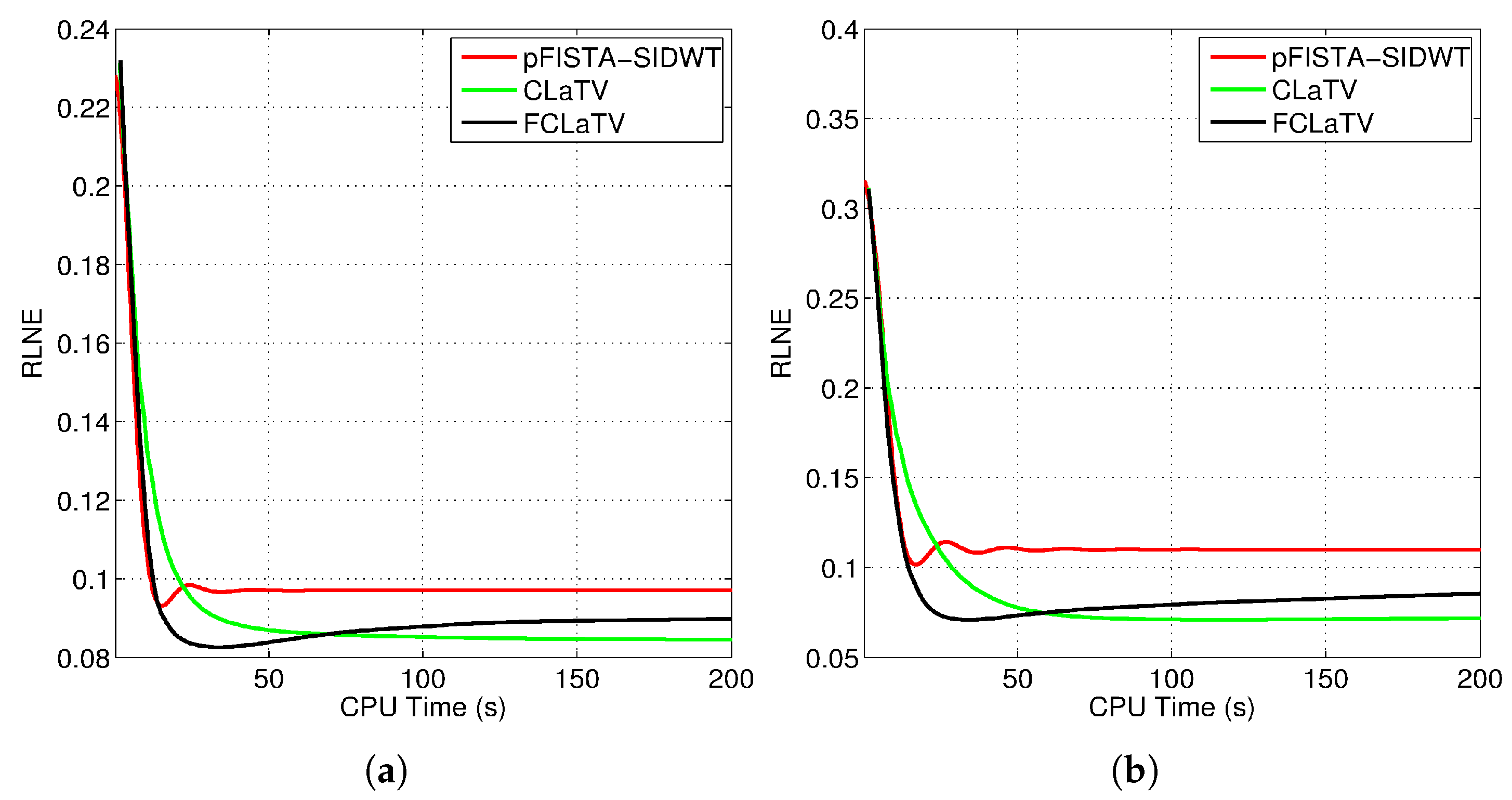
We tested the proposed methods in the reconstruction of a complex T2-weighted MR image
axial-1 slice, the magnitude of which is shown in
Figure 2. For the performance measure we use relative
norm error (RLNE), defined as
where
is the reference image recovered from all measurements while
denotes the estimated (reconstructed) image from undersampled measurements. Algorithm steps 4 and 5, which refer to proximal operators are simultaneously applied on real and imaginary parts of the temporary reconstructed image
obtained from step 2. We found that this adaptation of algorithm for handling reconstruction of complex images achieves the best performances. For the reference methods we use the pFISTA method from [
31] with the Shift Invariant Discrete Wavelet Transform (SIDWT) as a tight frame for sparse signal representation. Results are shown in
Figure 6 with respect to amount of CPU (Intel(R) Core(TM) i7-4700MQ CPU @ 2.4GHz, 8GB of RAM memory) time needed for reconstruction. For the both trajectories, CLaTV and FCLaTV outperform pFISTA-SIDWT in terms of RLNE measure. FCLaTV in less than 50s reaches the lowest RLNE for both trajectories, 0.0826 for radial and 0.0709 for random, while CLaTV needs around 70s to reach RLNE of 0.0846 for radial and 0.0711 for random trajectory.
A comparison of FCLaTV with the P-LORAKS [
40] method is conducted by reconstructing the single channel T2-weighted complex brain image
axial-3 from 50% of measurements sampled by random and uniform trajectory. The results are presented in
Table 1 where for both sampling strategies FCLaTV achieved lower RLNE value than the reference P-LORAKS method.
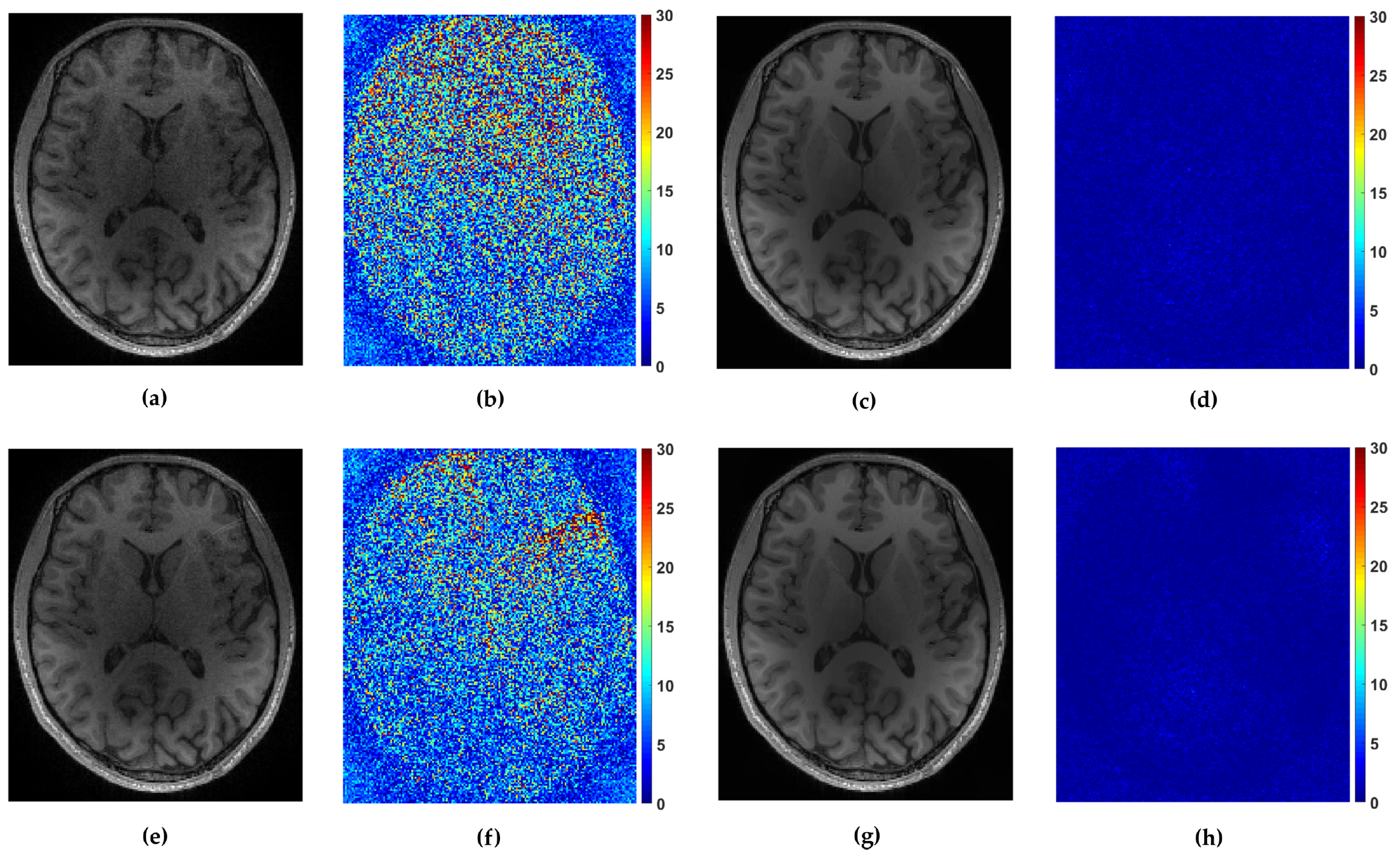
For the multi-coil reconstruction scenario, we used a T1 weighted brain image
axial-2 from [
38], shown in
Figure 2, and measurements gathered from 4 coils with known given sensitivity profiles. We incorporate random and uniform sampling trajectories with sampling rate of 14% per each coil. For both trajectories, the proposed FCLaTV achieved lower RLNE values reported in
Table 1.
Figure 7 shows visual comparison of reconstructions between FCLaTV and P-LORAKS methods.
3.2. Data Sets Acquired on Non-Cartesian Grid
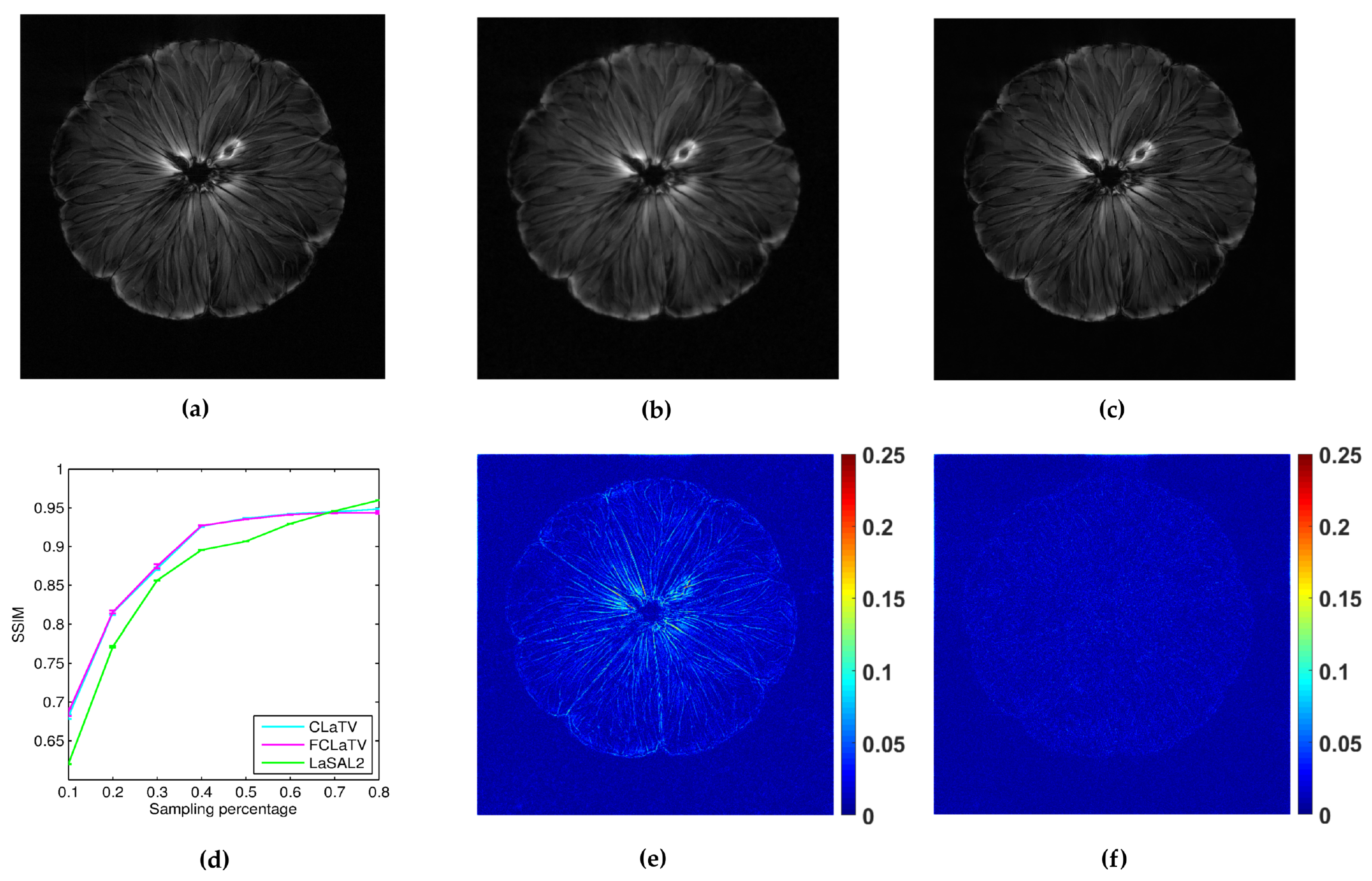
In the following we present the reconstruction of a
pomelo, acquired with radial sampling in the
k-space. The data consist of 1608 radial lines, each with 1024 samples. We form undersampled versions by leaving out some of the radial lines. In particular, we aim to implement undersampling based on the golden ratio profile spacing [
41], which guarantees a nearly uniform coverage of the space for an arbitrary number of the remaining radial lines. Starting from an arbitrary selected radial line, each next line is chosen by skipping an azimuthal gap of
until we reach desired sampling rate. In practice we cannot always achieve this gap precisely (since we have a finite, although large, number of lines to start with). Therefore we choose the nearest available radial line relative to the position obtained after moving. Since we deal here with non-uniformly sampled
k-space data, we need to employ the non-uniform FFT procedures [
41], which are commonly used in MRI reconstruction and readily available. For the reference method we used LaSAL2 [
29]. During the reconstruction we add different amount of Gaussian noise on undersampled measurements with zero mean and the following standard deviations: 0.01, 0.02, 0.03, 0.04 and 0.05. For each amount we perform 10 experiments of reconstruction with different noise realizations. From the obtained average performances of reconstruction in terms of SSIM for different standard deviation of noise, we calculate average across all suggested standard deviations and present results in the form of mean line with standard deviation bars in
Figure 8. We empirically set
to 140 and 130 for CLaTV and FCLaTV respectively due to the different dynamic range of reference image [0,1]. Regularization parameters for LaSAL2 method are taken from [
29]. As expected, standard deviation of performances reduce as the sampling rate increase and the mean SSIM becomes greater for all methods. At relatively small sampling rates, up to 60% CLaTV and FCLaTV outperforms LaSAL2 which is presented in visual comparison shown in the same
Figure 8. CLaTV and FCLaTV much better recover structure in the image than LaSAL2 which is demonstrated visually in the images of reconstruction error.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}