Compression-Assisted Adaptive ECC and RAID Scattering for NAND Flash Storage Devices



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background and Related Work
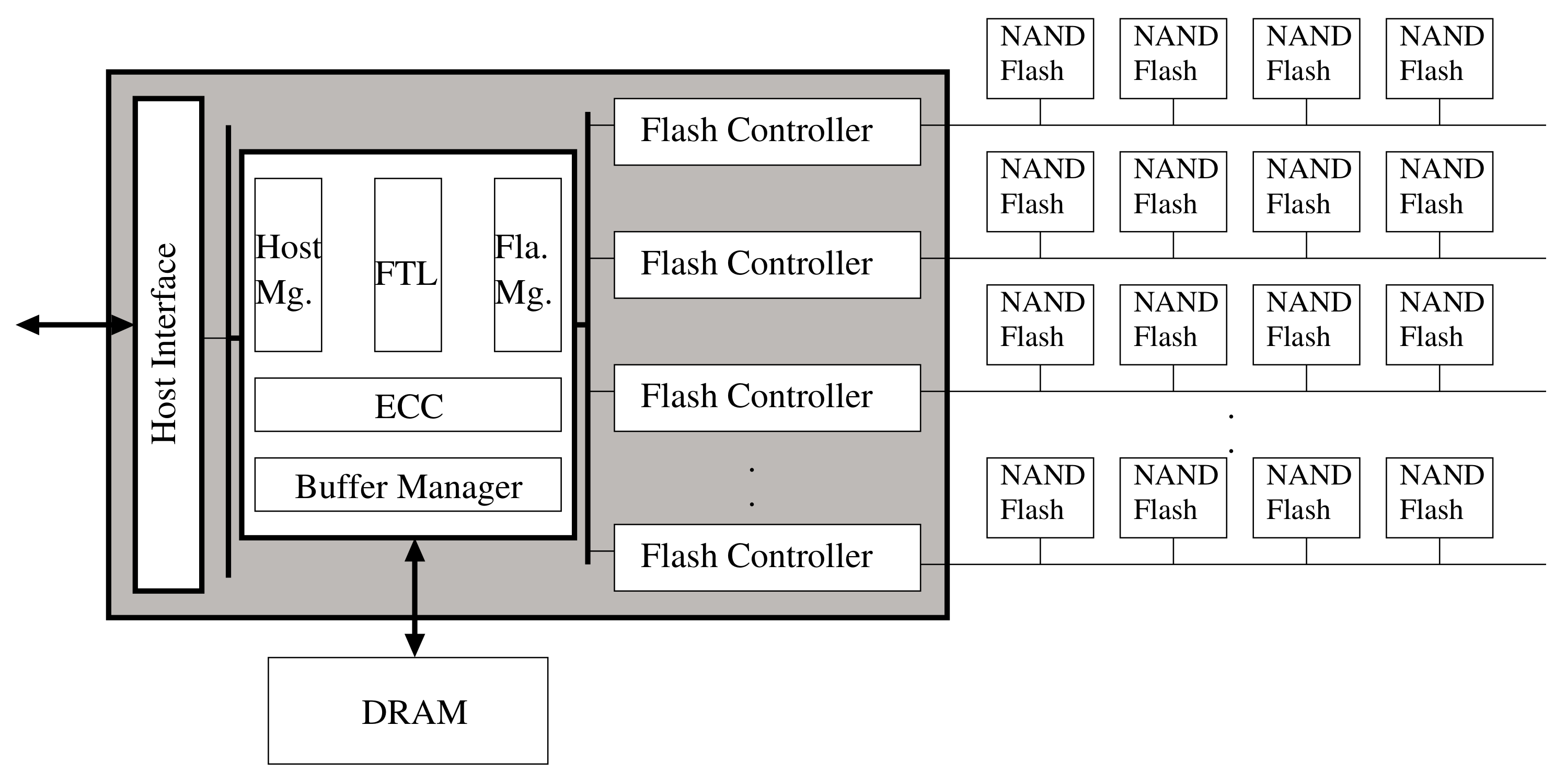
2.1. NAND Flash Memory-Based Storage Devices
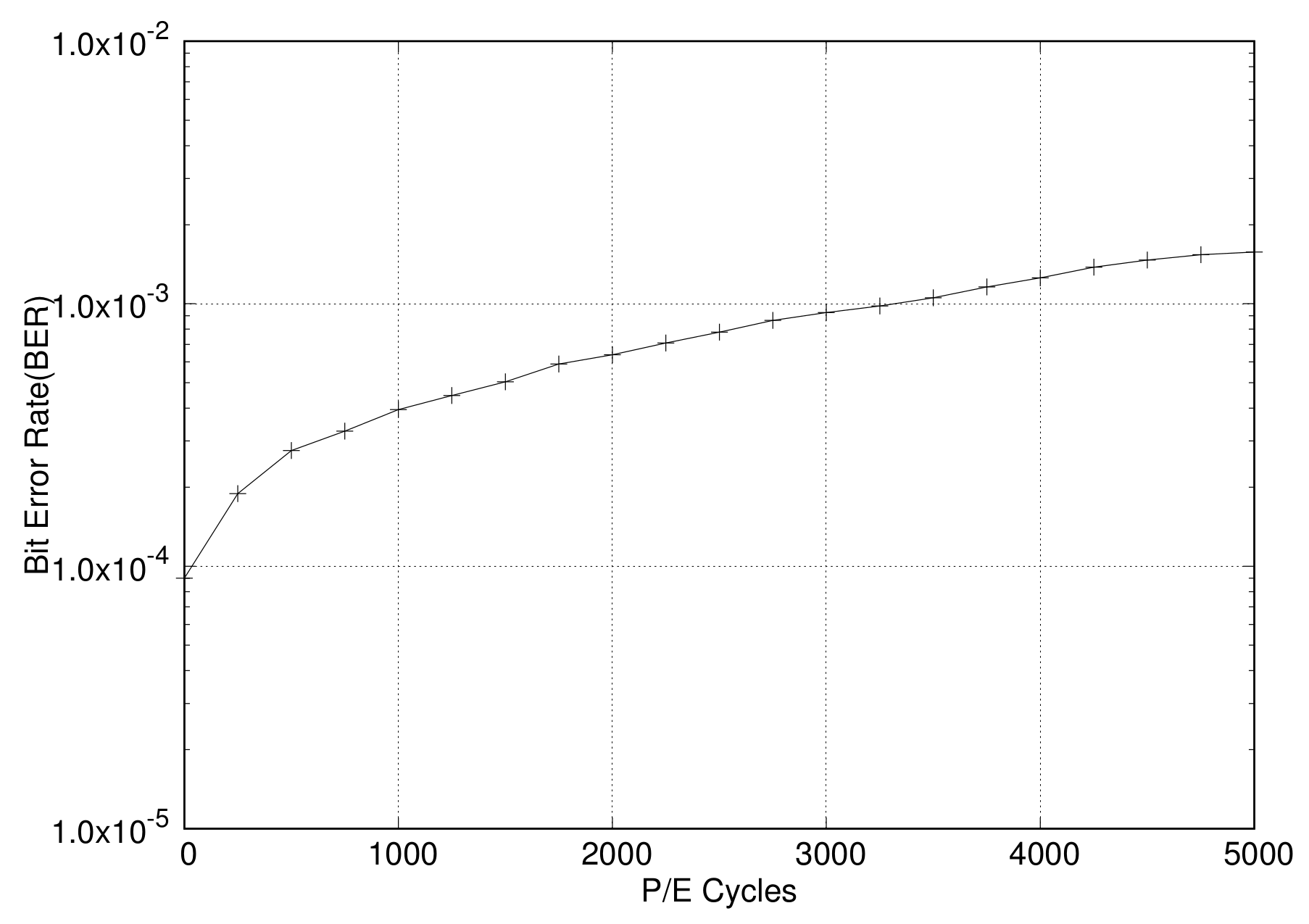
2.2. Error Correction Codes for Flash Memory
2.3. Parity with RAID
3. Compression-Assisted Adaptive ECC and RAID Scattering
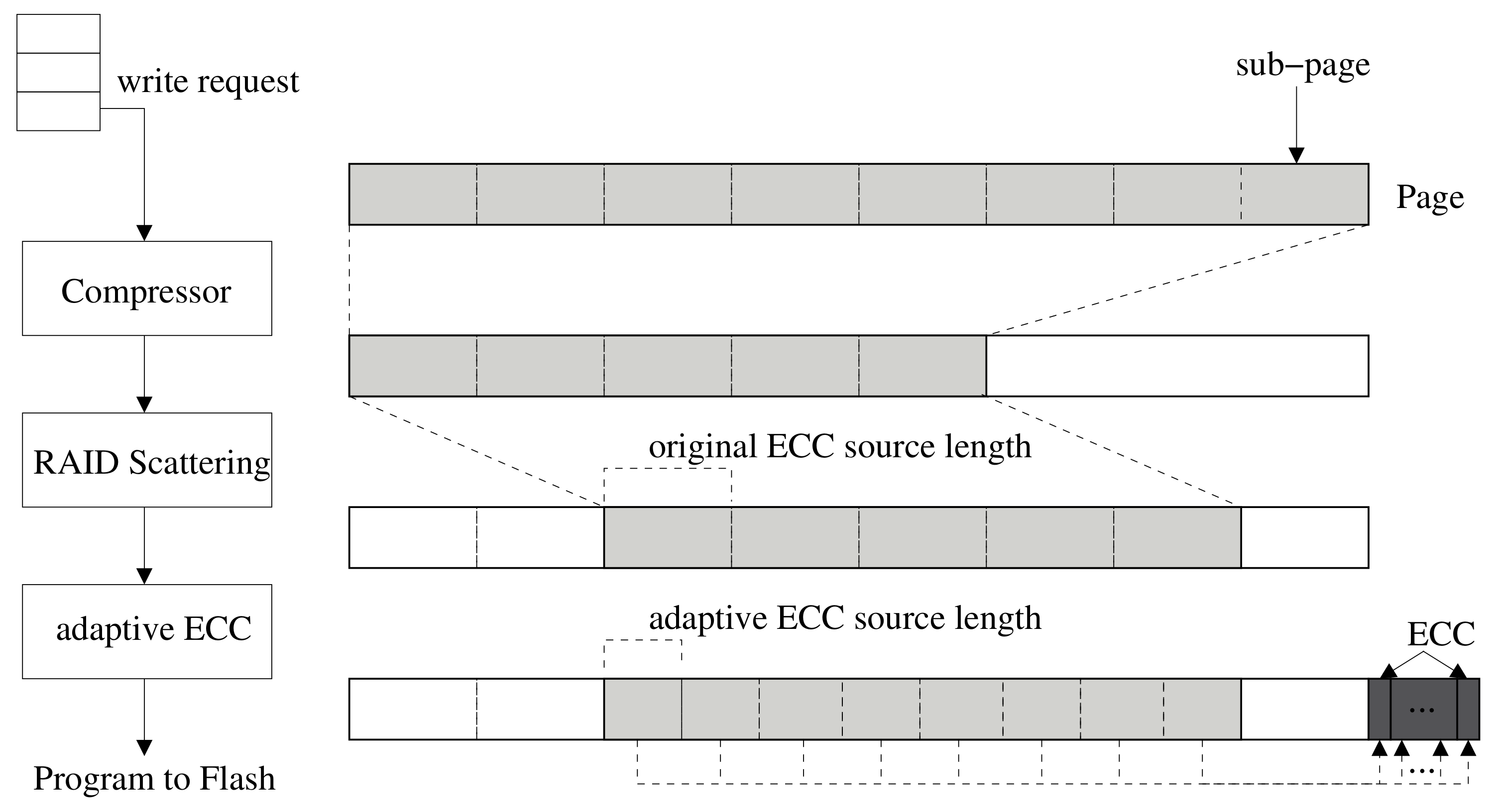
3.1. Compression-Assisted Adaptive ECC
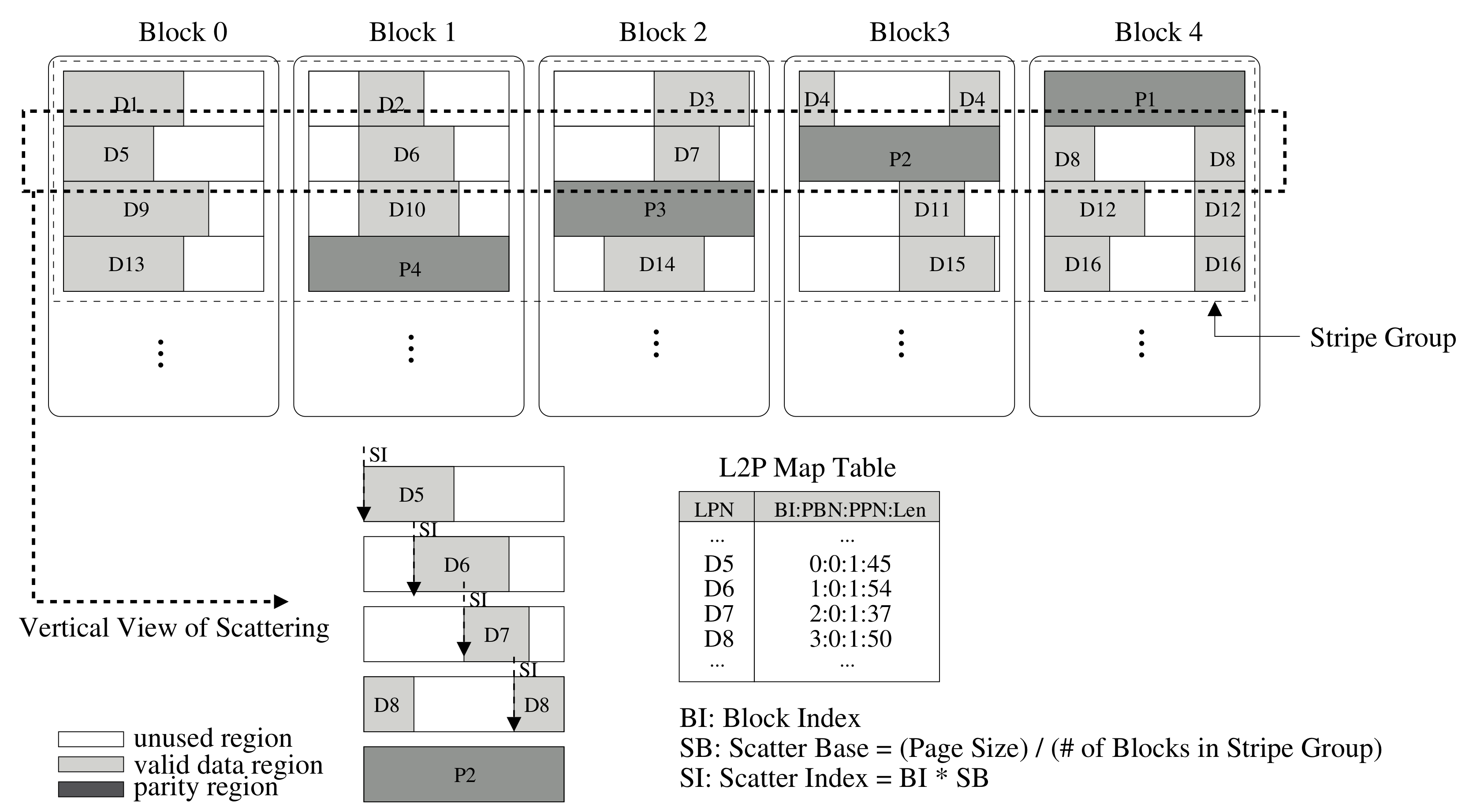
3.2. RAID Scattering
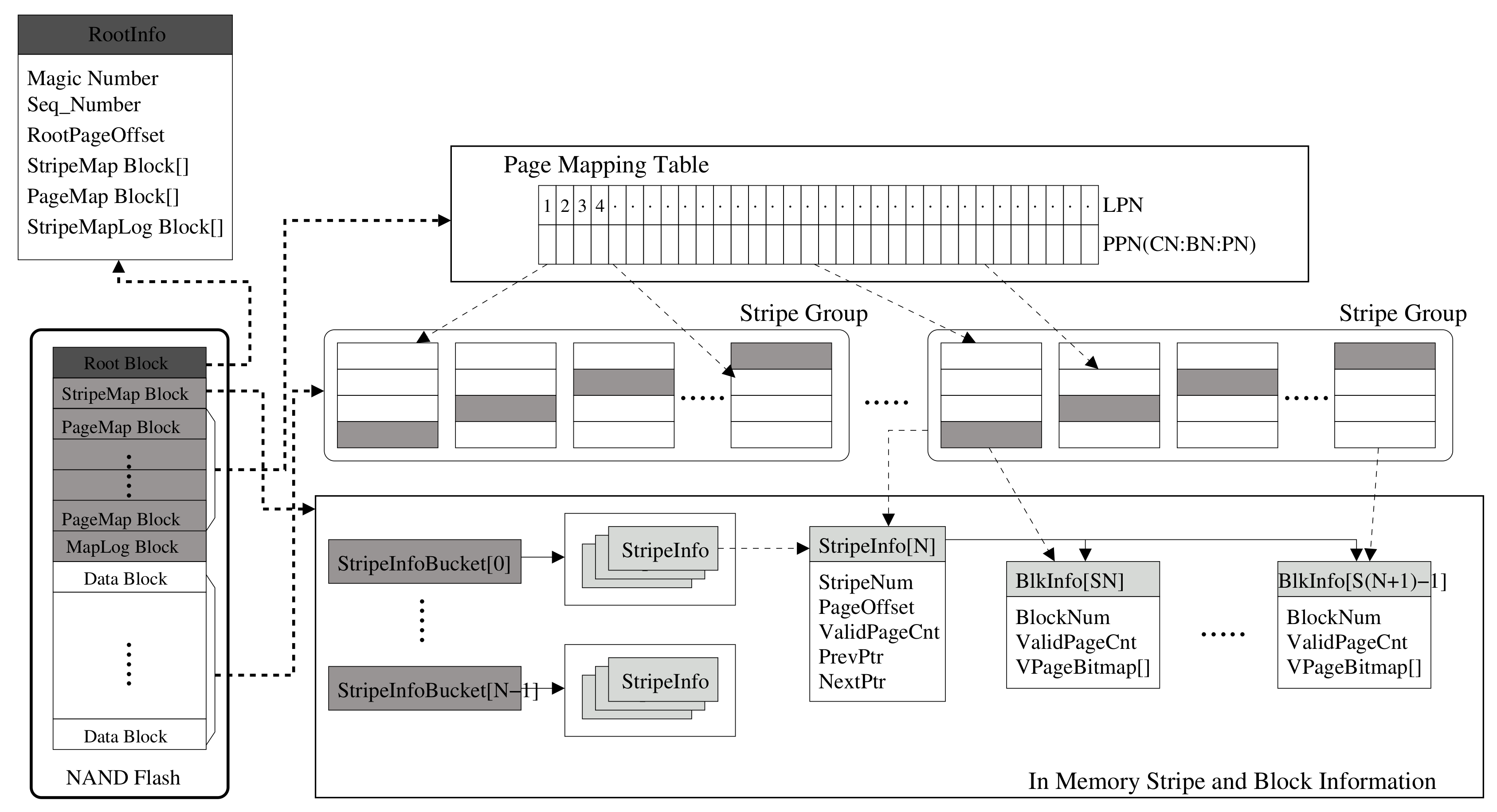
3.3. Metadata Structure and Parity Management
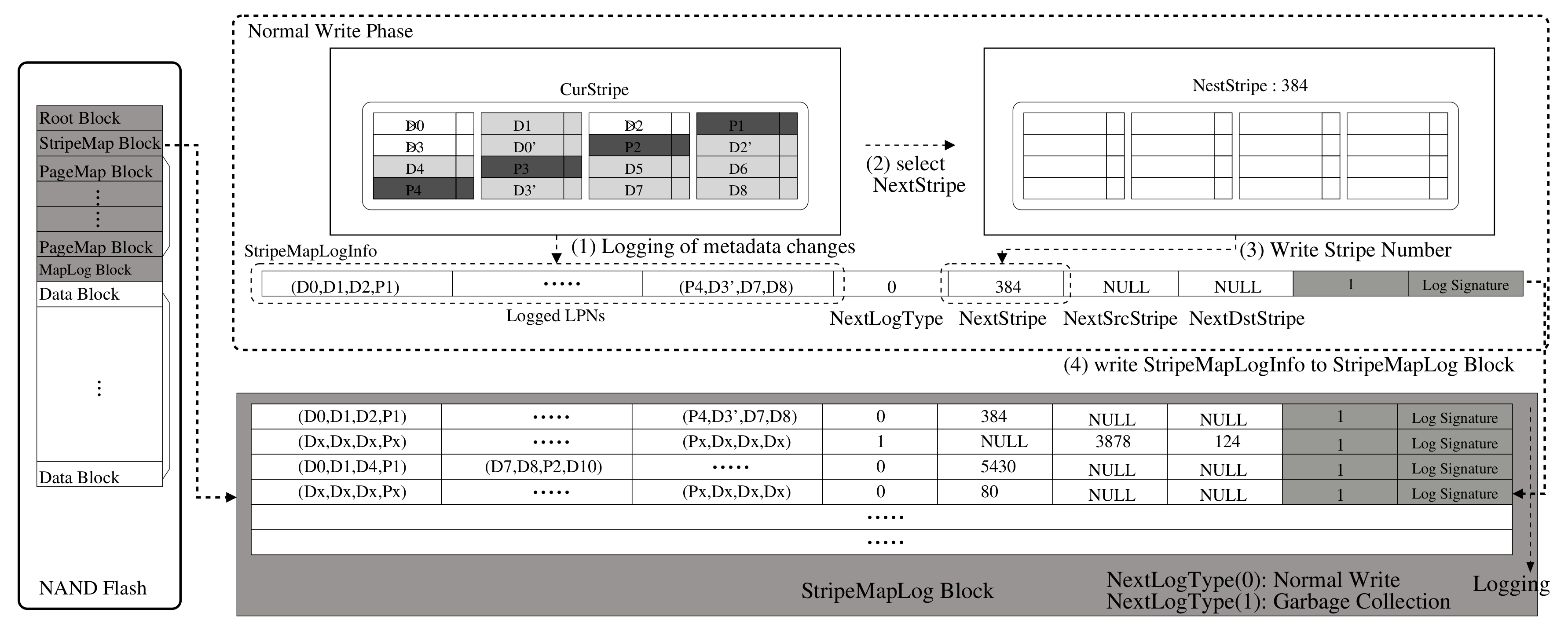
3.4. Power Loss Recovery Step of Metadata Log and Partial Parity
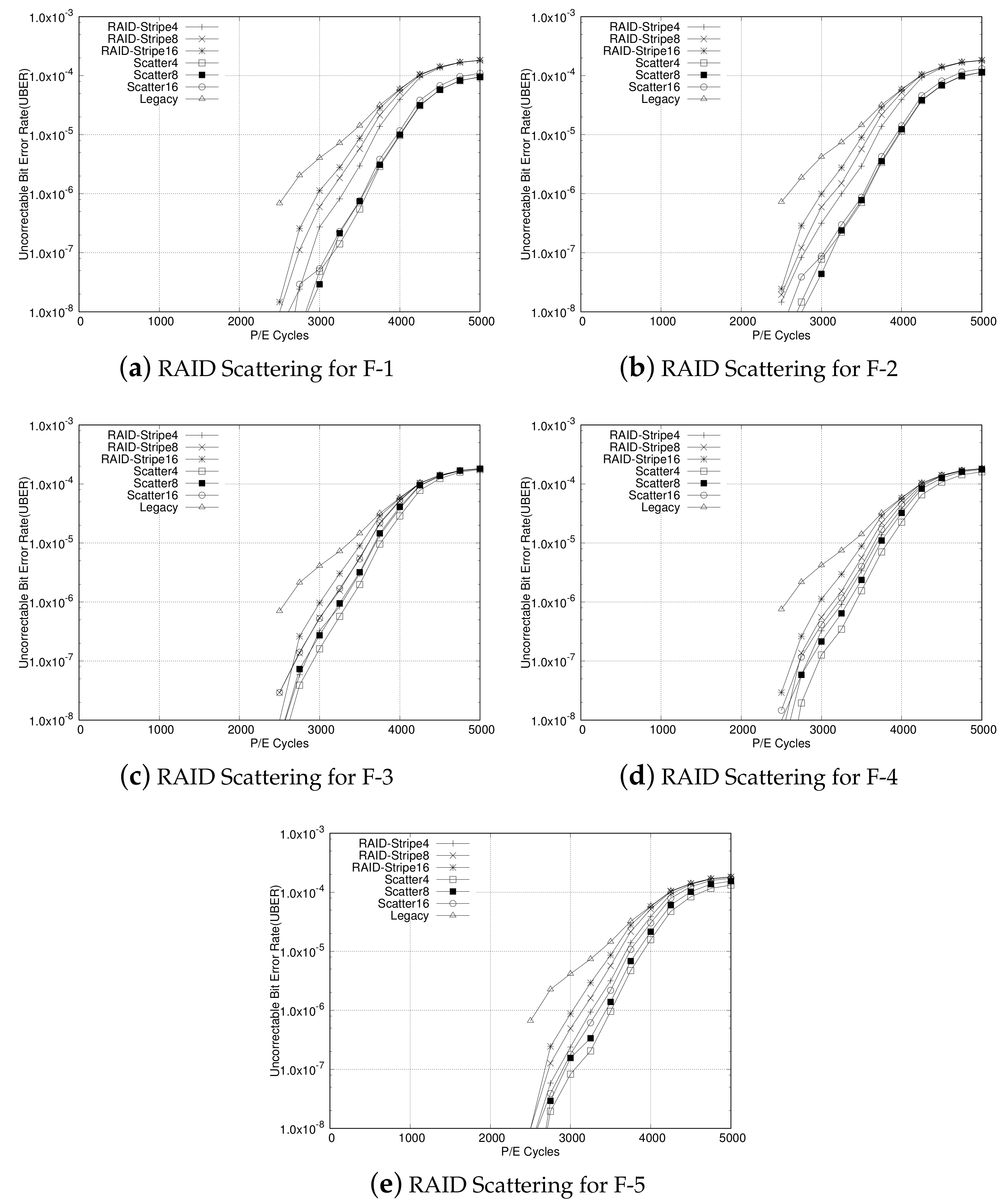
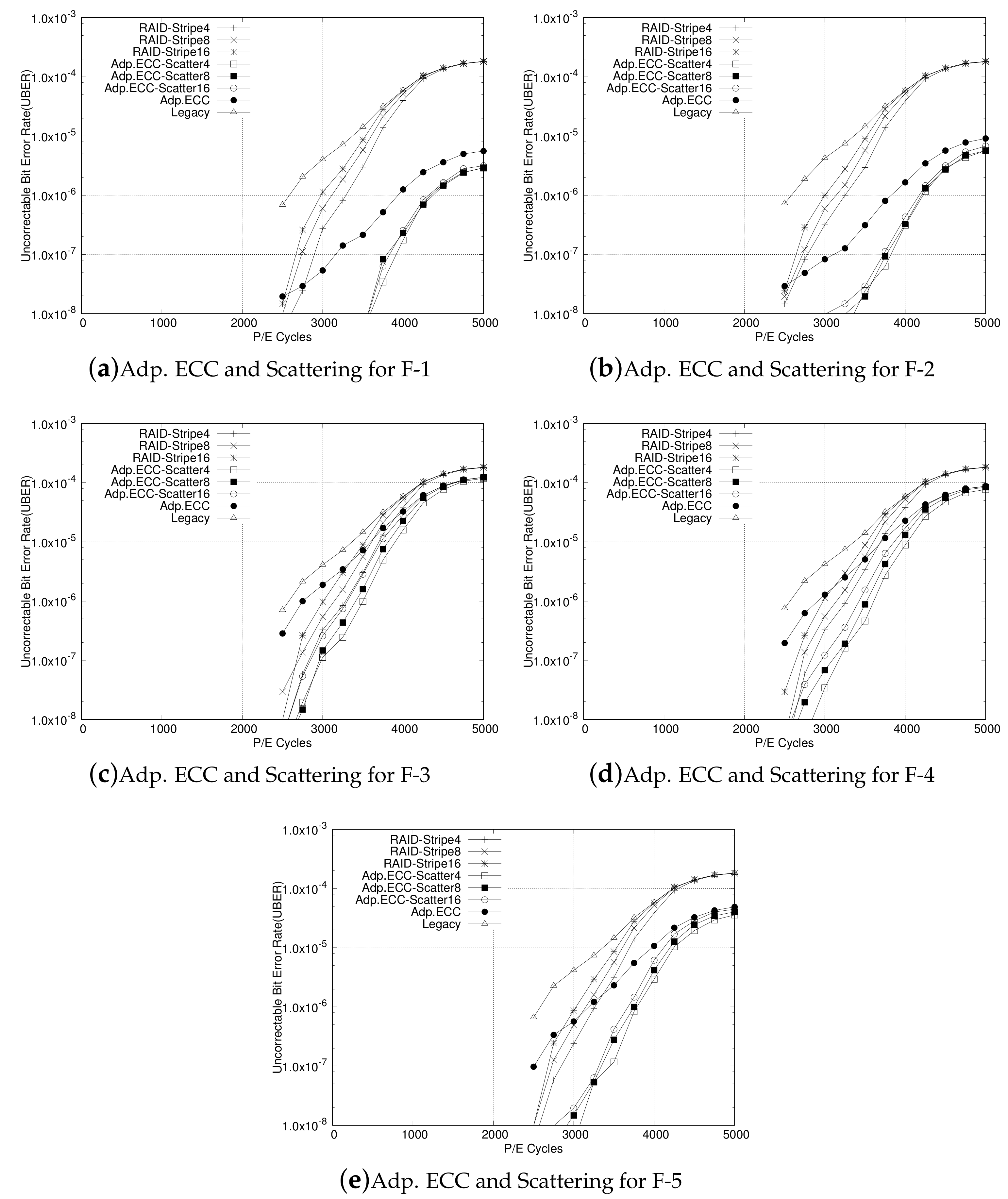
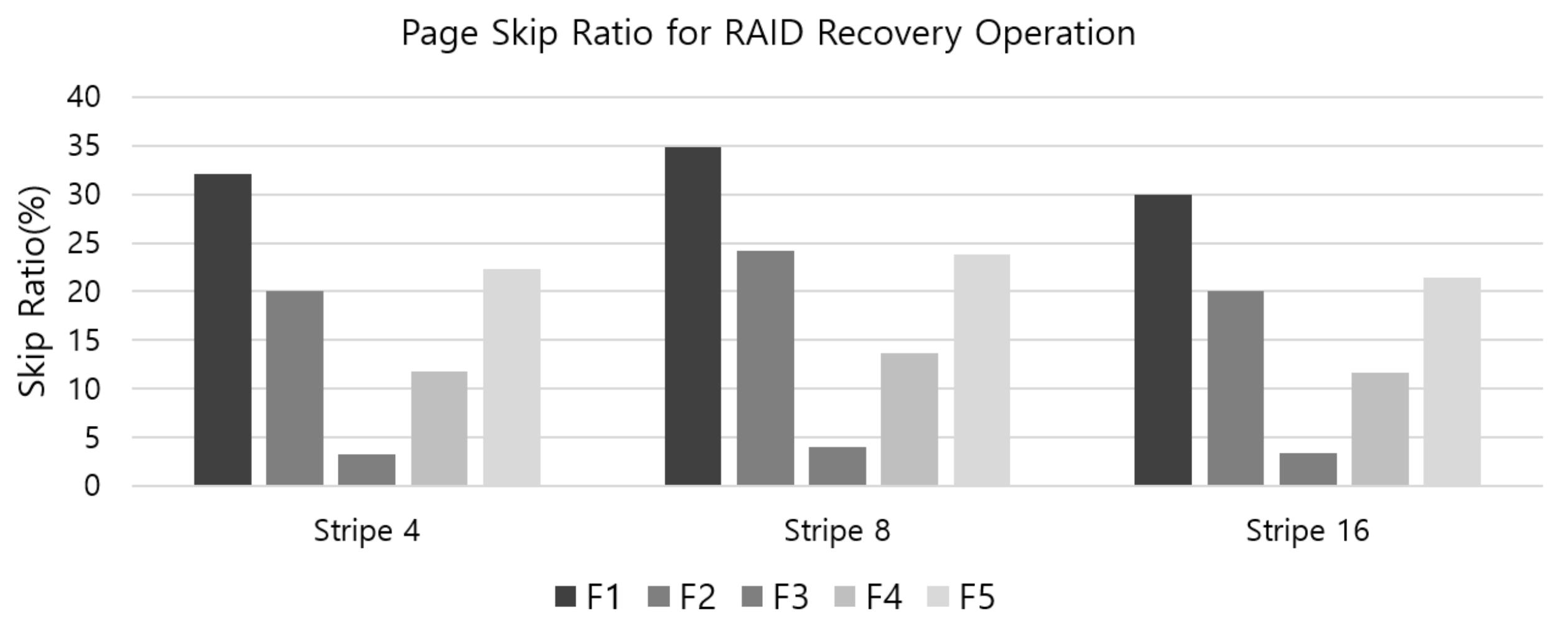
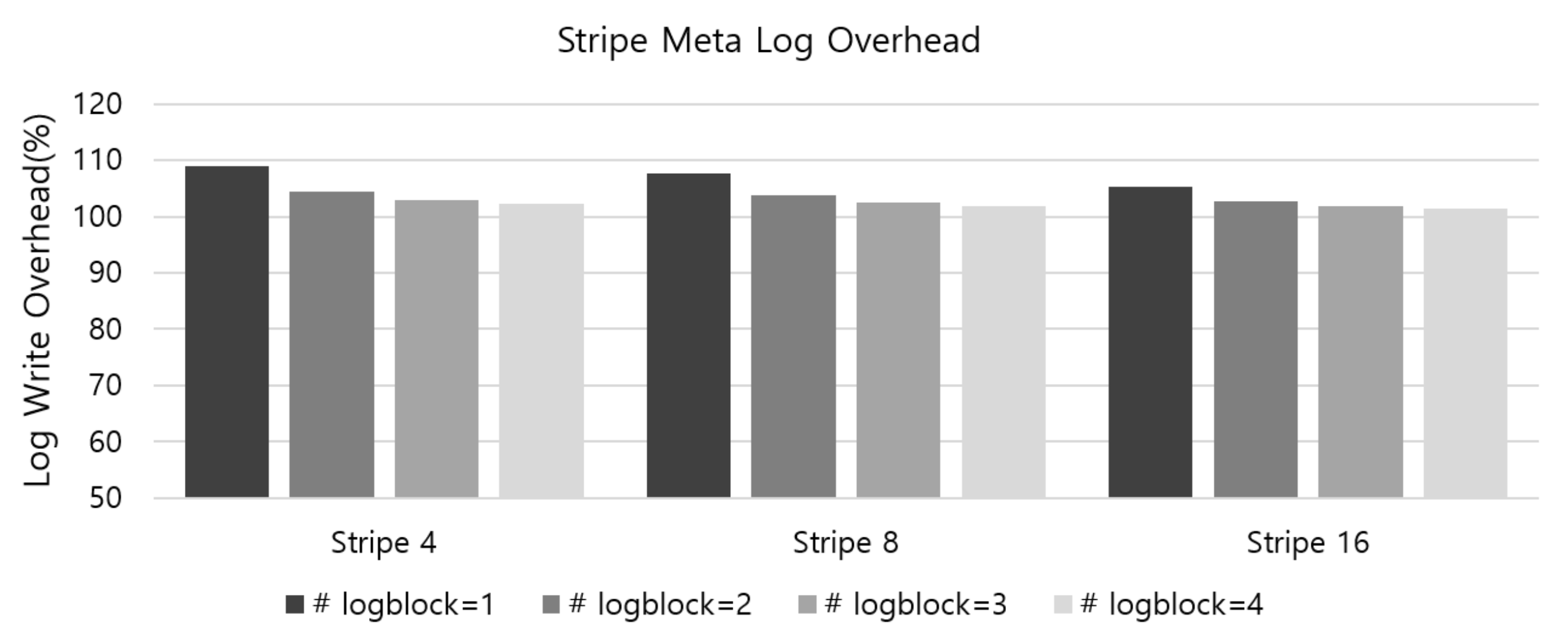
4. Evaluation
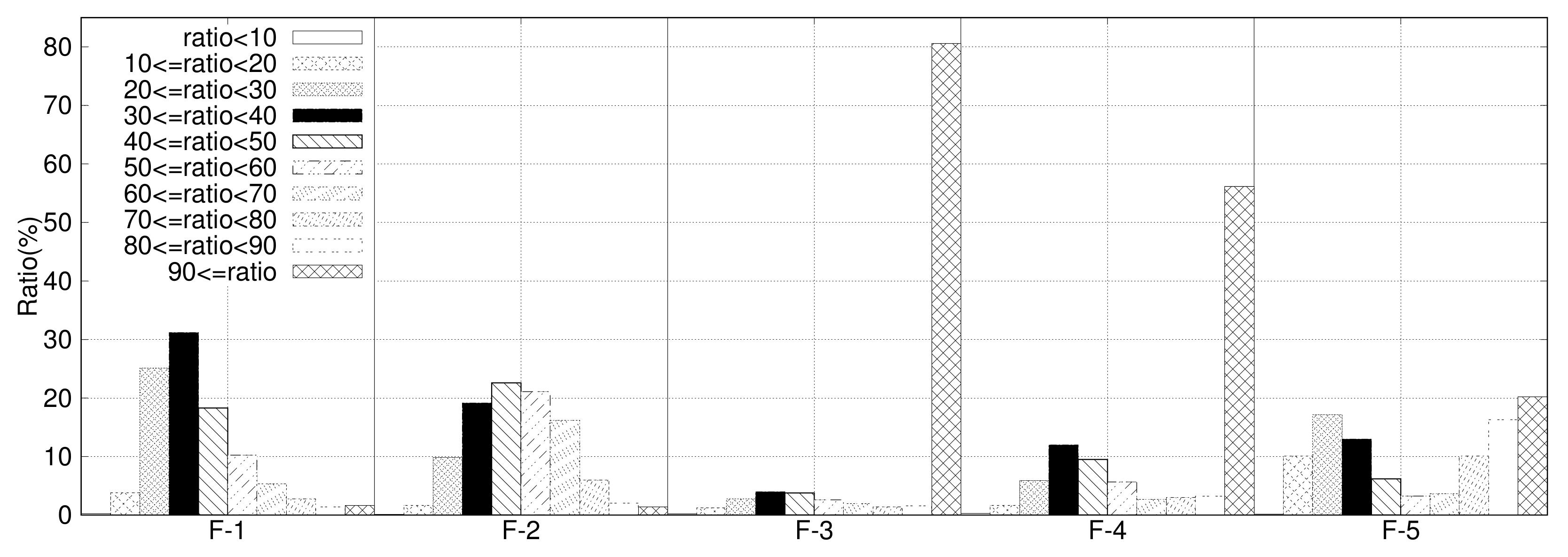
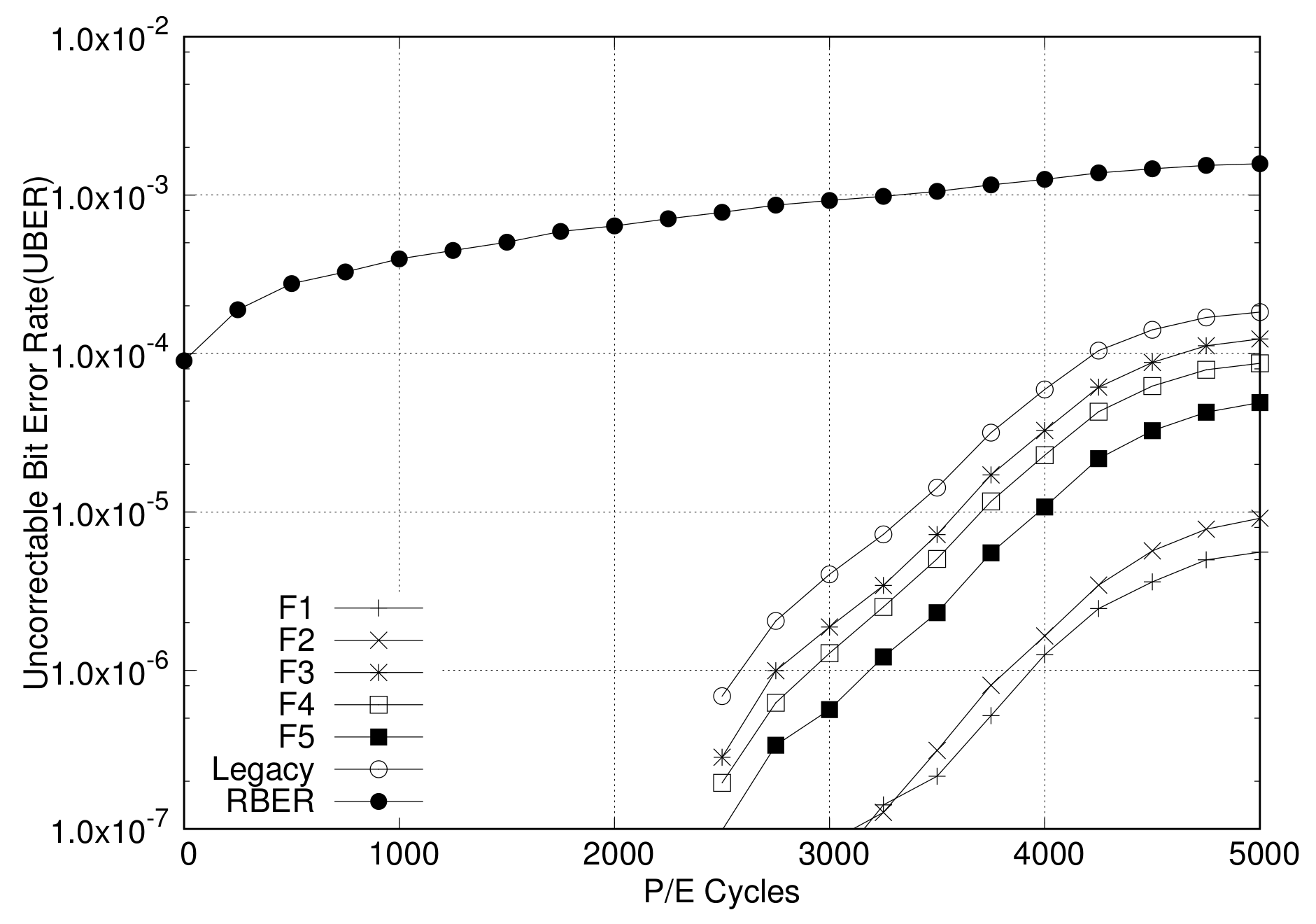
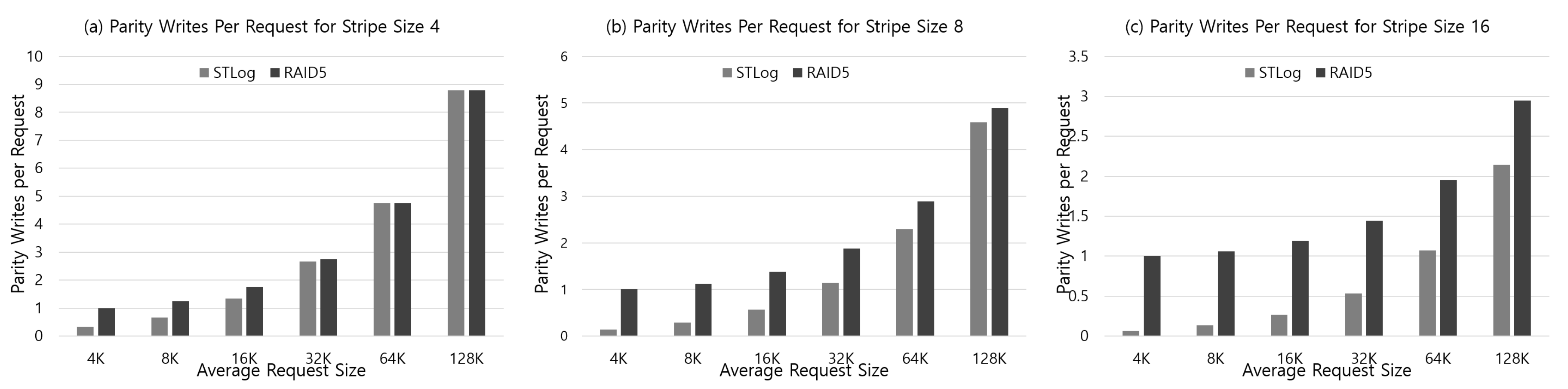
4.1. Analysis of Adaptive ECC and RAID Scattering
4.2. Analysis of Metadata and Parity Overhead
4.3. Discussion about Compression Module
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ECC | Error Correction Code |
| RAID | Redundant Array of Independent Disks |
| SLC | Single-level cell |
| MLC | Multi-level cell |
| TLC | Triple-level cell |
| OOB | Out-of-Band |
| BCH | Block Hamming Code |
| LDPC | Low-Density Parity Check |
| SSD | Solid-State Disks |
| GC | Garbage Collection |
| FTL | Flash Translation Layer |
| LPN | Logical Page Number |
| PPN | Physical Page Number |
| SG | Stripe Group |
| BER | Bit Error Rate |
| RBER | Raw Bit Error Rate |
| UBER | Uncorrectable Bit Error Rate |
| NVRAM | Non-Volatile Random Access Memory |
| GC | Garbase Collection |
References
- Mielke, N.; Marquart, T.; Wu, N.; Kessenich, J.; Belgal, H.; Schares, E.; Trivedi, F.; Goodness, E.; Nevill, L.R. Bit error rate in NAND Flash memories. In Proceedings of the 2008 IEEE International Reliability Physics Symposium, Phoenix, AZ, USA, 27 April–1 May 2008. [Google Scholar] [CrossRef]
- Cai, Y.; Mutlu, O.; Haratsch, E.F.; Mai, K. Program interference in MLC NAND flash memory: Characterization, modeling, and mitigation. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 123–130. [Google Scholar]
- Micron. Enabling Software BCH ECC on a Linux Platform; Technical Note, TN-29-71; Micron: Boise, ID, USA, 2012. [Google Scholar]
- Zhao, K.; Zhao, W.; Sun, H.; Zhang, X.; Zheng, N.; Zhang, T. LDPC-in-SSD: Making advanced Error Correction Codes Work Effectively in Solid State Drives. In Proceedings of the 11th USENIX Conference on File and Storage Technologies, San Jose, CA, USA, 12–15 February 2013; pp. 243–256. [Google Scholar]
- Xie, N.; Dong, G.; Zhang, T. Using lossless data compression in data storage systems: Not for saving space. IEEE Trans. Comput. 2011, 60, 335. [Google Scholar] [CrossRef]
- Ahrens, T.; Rajab, M.; Freudenberger, J. Compression of short data blocks to improve the reliability of non-volatile flash memories. In Proceedings of the 2016 International Conference on Information and Digital Technologies (IDT), Rzeszow, Poland, 5–7 July 2016; pp. 1–4. [Google Scholar]
- Chen, P.M.; Lee, E.K. Striping in a RAID level 5 disk array? In Proceedings of the 1995 ACM SIGMETRICS Joint International Conference on Measurement and Modeling of Computer Systems, Ottawa, ON, Canada, 15–19 May 1995; p. 136. [Google Scholar]
- Lee, Y.; Jung, S.; Song, Y.H. FRA: A flash-aware redundancy array of flash storage devices. In Proceedings of the 7th IEEE/ACM International Conference on Hardware/Software Codesign and System Synthesis, Grenoble, France, 11–16 October 2009; p. 163. [Google Scholar]
- Qin, Y.; Feng, D.; Liu, J.; Tong, W.; Hu, Y.; Zhu, Z. A Parity Scheme to Enhance Reliability for SSDs. In Proceedings of the 7th International Conference on Networking, Architecture, and Storage, Xiamen, China, 28–30 June 2012; pp. 293–297. [Google Scholar]
- Kim, J.; Lee, E.; Choi, J.; Lee, D.; Noh, S.H. Chip-Level RAID with Flexible Stripe Size and Parity Placement for Enhanced SSD Reliability. IEEE Trans. Comput. 2016, 65, 1116. [Google Scholar] [CrossRef]
- Kim, K.; Lim, S.H. Compression and Variable-Sized ECC Scheme for the Reliable Flash Memory System. In Advances in Computer Science and Ubiquitous Computing; Springer: Singapore, 2017. [Google Scholar]
- Intel Corporation. Understanding the Flash Translation Layer (FTL) Specification; Application Note; Intel Corporation: Santa Clara, CA, USA, 1998. [Google Scholar]
- Kim, J.; Kim, J.M.; Noh, S.H.; Min, S.L.; Cho, Y. A space-efficient flash translation layer for CompactFlash systems. IEEE Trans. Consum. Electron. 2002, 48, 366–375. [Google Scholar]
- Kang, J.U.; Jo, H.; Kim, J.S.; Lee, J. A superblock-based flash translation layer for NAND Flash memory. In Proceedings of the 6th ACM & IEEE International Conference on Embedded Software, Seoul, Korea, 22–25 October 2006; pp. 161–170. [Google Scholar]
- Lee, S.W.; Choi, W.K.; Park, D.J. FAST: An efficient flash translation layer for flash memory. In International Conference on Embedded and Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 879–887. [Google Scholar]
- Gupta, A.; Kim, Y.; Urgaonkar, B. DFTL: A Flash Translation Layer Employing Demand-based Selective Caching of Page-level Address Mappings. In Proceedings of the 14th International Conference on Architectural Support for Programming Languages and Operating Systems, Washington, DC, USA, 7–11 March 2009; pp. 229–240. [Google Scholar]
- Ma, D.; Feng, J.; Li, G. LazyFTL: A Page-level Flash Translation Layer Optimized for NAND Flash Memory. Proceesings of the ACM SIGMOD, Athens, Greece, 12–16 June 2011; pp. 1–12. [Google Scholar]
- Chen, F.; Lee, R.; Zhang, X. Essential roles of exploiting internal parallelism of flash memory based solid state drives in high-speed data processing. In Proceedings of the International Symposium on High Performance Computer Architecture (HPCA), San Antonio, TX, USA, 12–16 February 2011; pp. 266–277. [Google Scholar]
- Agrawal, N.; Prabhakaran, V.; Wobber, T.; Davis, J.D.; Manasse, M.; Panigrahy, R. Design tradeoffs for SSD performance. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 22–27 June 2008; pp. 57–70. [Google Scholar]
- Seong, Y.J.; Nam, E.H.; Yoon, J.H.; Kim, H.; Choi, J.Y.; Lee, S.; Bae, Y.H.; Lee, J.; Cho, Y.; Min, S.L. Hydra: A Block-Mapped Parallel Flash Memory Solid-State Disk Architecture. IEEE Trans. Comput. 2010, 59, 905–921. [Google Scholar] [CrossRef]
- Hu, Y.; Jiang, H.; Feng, D.; Tian, L.; Luo, H.; Zhang, S. Performance impact and interplay of ssd parallelism through advanced commands, allocation strategy and data granularity. In Proceedings of the International Conference on Supercomputing, Tucson, AZ, USA, 31 May–4 June 2011; pp. 96–107. [Google Scholar]
- Jung, M.; Kandemir, M. An evaluation of different page allocation strategies on high-speed SSDs. Proceedings of HotStorage, Boston, MA, USA, 13–14 June 2012. [Google Scholar]
- Bjorling, M.; Axboe, J.; Nellans, D.; Bonnet, P. Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems. In Proceedings of the 6th Intetnational Systems and Storage Conference, Haifa, Israel, 30 June–2 July 2013; pp. 1–10. [Google Scholar]
- Yaakobi, E.; Grupp, L.; Siegel, P.H.; Swanson, S.; Wolf, J.K. Characterization and error-correcting codes for TLC flash memories. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 486–491. [Google Scholar]
- Yang, J. Novel ECC architecture enhances storage system reliability. In Proceedings of the Flash Memory Summit, Santa Clara, CA, USA, 22–24 August 2012. [Google Scholar]
- Yeo, E. An LDPC-enabled flash controller in 40 nm CMOS. In Proceedings of the Flash Memory Summit, Santa Clara, CA, USA, 22–24 August 2012. [Google Scholar]
- Motwani, R.; Ong, C. Robust decoder architecture for multi-level flash memory storage channels. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 492–496. [Google Scholar]
- Tanakamaru, S.; Yanagihara, Y.; Takeuchi, K. Over-10x-extended-lifetime 76%-reduced-error solid-state drives (SSDs) with error-prediction LDPC architecture and error-recovery scheme. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 19–23 February 2012; pp. 424–426. [Google Scholar]
- Chen, P.M.; Lee, E.K.; Gibson, G.A.; Katz, R.H.; Patterson, D.A. Patterson, RAID: High-Performance, Reliable Secondary Storage. ACM Comput. Surv. 1994, 26, 145–185. [Google Scholar] [CrossRef]
- Im, S.; Shin, D. Flash-Aware RAID Techniques for Dependable and High-Performance Flash Memory SSD. IEEE Trans. Comput. 2011, 60, 80–92. [Google Scholar] [CrossRef]
- Kulkarni, P.; Douglis, F.; LaVoie, J.D.; Tracey, J.M. Redundancy elimination within large collections of files. In Proceedings of the USENIX 2004 Annual Technical Conference, Boston, MA, USA, 27 June–2 July 2004; pp. 59–72. [Google Scholar]
- Meyer, D.T.; Bolosky, W.J. A study of practical deduplication. ACM Trans. Storage 2012, 7, 14. [Google Scholar] [CrossRef]
- Park, J.; Park, J.; Bhunia, S. VL-ECC: Variable Data-Length Error Correction Code for Embedded Memory in DSP Applications. IEEE Trans. Circ. Syst. II 2014, 6, 120–124. [Google Scholar] [CrossRef]
- Kim, Y.; Tauras, B.; Gupta, A.; Urgaonkar, B. FlashSim: A Simulator for NAND Flash-based Solid-State Drives. In Proceedings of the First International Conference on Advances in System Simulation, Porto, Portugal, 20–25 September 2009; pp. 125–131. [Google Scholar]
- Matias Bjorling. Extended FlashSim. GitHub. Available online: https://github.com/MatiasBjorling/flashsim (accessed on 1 August 2018).
- Gailly, J.; Adler, M. zlib: A Massively Spiffy Yet Delicately Unobtrusive Compression Library. Available online: https://zlib.net (accessed on 1 December 2018).
- Xilinx Corporation. GZIP/ZLIB/Deflate Data Compression Core. Available online: https://www.xilinx.com/products/intellectual-property/1-7aisy9.html#overview (accessed on 20 March 2020).
- Intel Corporation. Intelligent Storage Acceleration Library. Available online: https://software.intel.com/en-us/isa-l (accessed on 20 March 2020).













© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, S.-H.; Park, K.-W. Compression-Assisted Adaptive ECC and RAID Scattering for NAND Flash Storage Devices. Sensors 2020, 20, 2952. https://doi.org/10.3390/s20102952
Lim S-H, Park K-W. Compression-Assisted Adaptive ECC and RAID Scattering for NAND Flash Storage Devices. Sensors. 2020; 20(10):2952. https://doi.org/10.3390/s20102952
Chicago/Turabian StyleLim, Seung-Ho, and Ki-Woong Park. 2020. "Compression-Assisted Adaptive ECC and RAID Scattering for NAND Flash Storage Devices" Sensors 20, no. 10: 2952. https://doi.org/10.3390/s20102952
APA StyleLim, S.-H., & Park, K.-W. (2020). Compression-Assisted Adaptive ECC and RAID Scattering for NAND Flash Storage Devices. Sensors, 20(10), 2952. https://doi.org/10.3390/s20102952