Speech Discrimination in Real-World Group Communication Using Audio-Motion Multimodal Sensing


Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Data Acquisition
2.3. Data Preprocessing
2.3.1. Audio Data
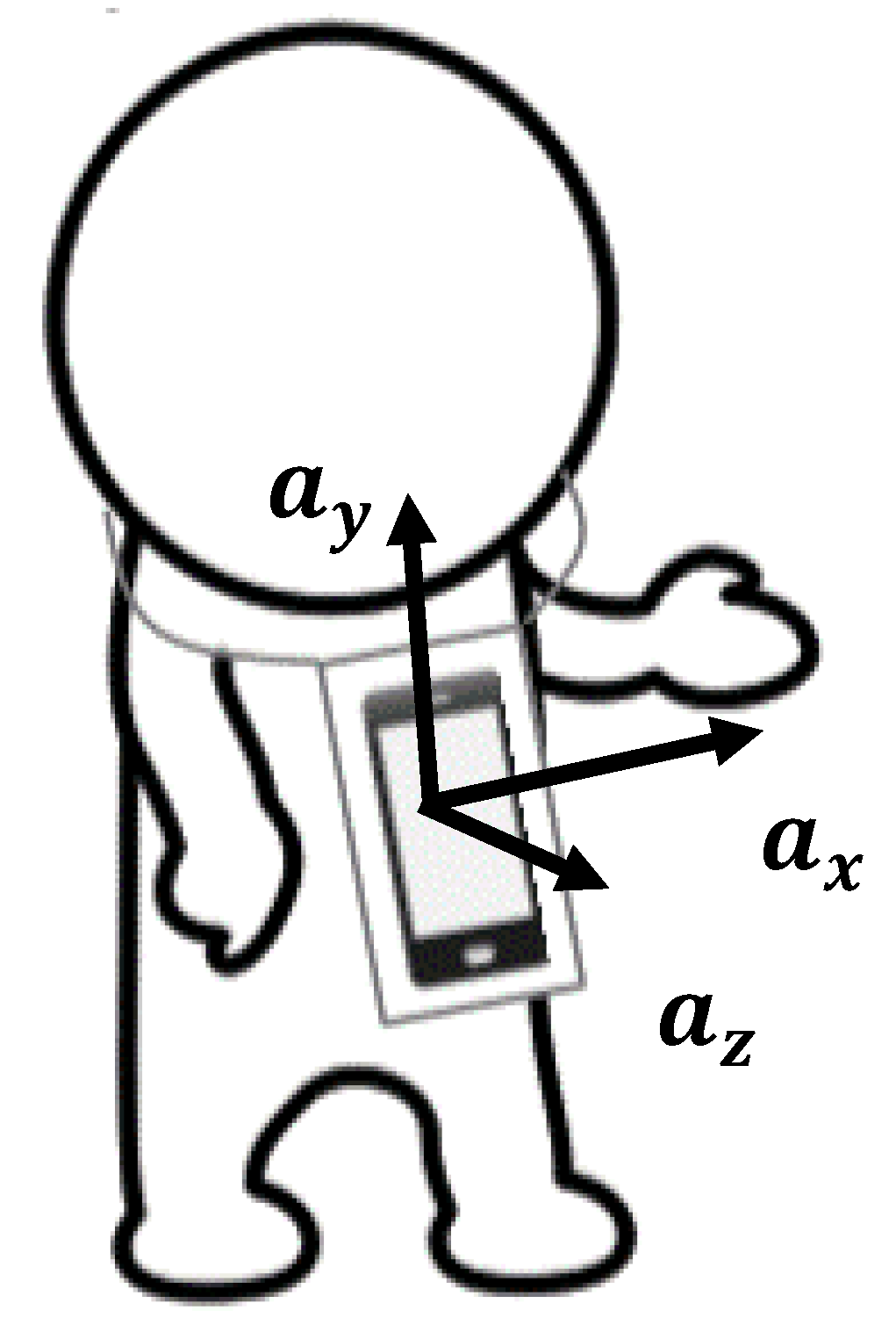
2.3.2. Accelerometer Data
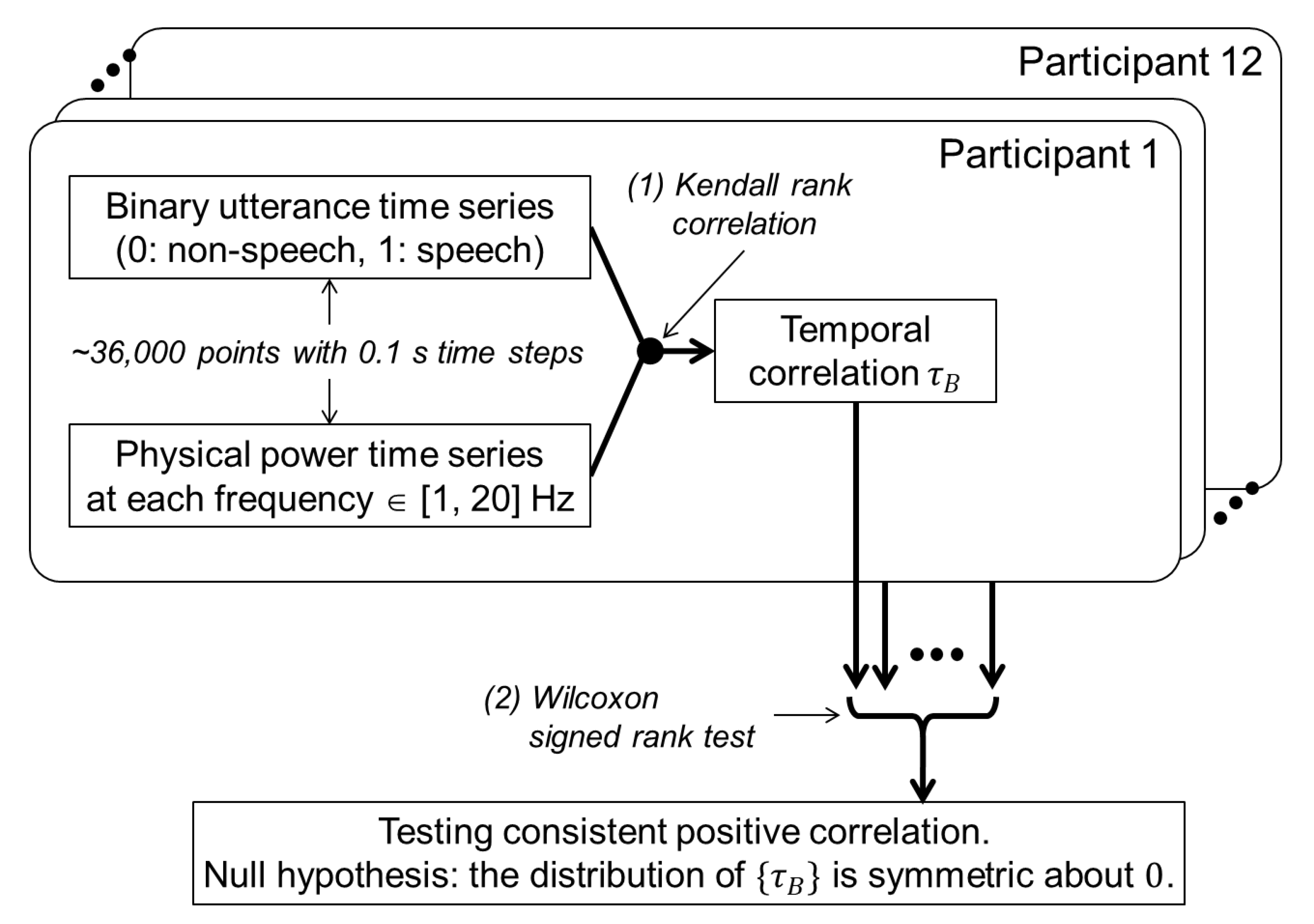
2.4. Analysis to Verify Co-Occurrence of Utterances and Physical Motions
2.5. Utterance Discrimination within Individuals
2.6. Utterance Discrimination over Individuals
3. Results
3.1. Co-Occurrence of Utterances and Physical Motions
3.2. Utterance Discrimination within Individuals
3.3. Utterance Discrimination over Individuals
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Sato, N.; Tsuji, S.; Yano, K.; Otsuka, R.; Moriwaki, N.; Ara, K.; Wakisaka, Y.; Ohkubo, N.; Hayakawa, M.; Horry, Y. Knowledge-creating behavior index for improving knowledge workers’ productivity. In Proceedings of the 2009 Sixth International Conference on Networked Sensing Systems (INSS), Pittsburgh, PA, USA, 17–19 June 2009; pp. 1–4. [Google Scholar]
- Olguin, D.O.; Paradiso, J.A.; Pentland, A. Wearable Communicator Badge: Designing a New Platform for Revealing Organizational Dynamics. In Proceedings of the 10th International Symposium on Wearable Computers (student colloquium), Montreux, Switzerland, 11–14 October 2006; pp. 4–6. [Google Scholar]
- Wu, L.; Waber, B.N.; Aral, S.; Brynjolfsson, E.; Pentland, A. Mining face-to-face interaction networks using sociometric badges: Predicting productivity in an IT configuration task. Available SSRN 2008, 1130251. [Google Scholar] [CrossRef]
- Bigi, B. SPPAS—Multi-lingual approaches to the automatic annotation of speech. Phonetician 2015, 111, 54–69. [Google Scholar]
- Hansen, J.H.; Hasan, T. Speaker recognition by machines and humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Ramirez, J.; Górriz, J.M.; Segura, J.C. Voice activity detection. Fundamentals and speech recognition system robustness. In Robust Speech: Recognition and Understanding; Grimm, M., Kroschel, K., Eds.; IntechOpen: Vienna, Austria, 2007; Volume 6, pp. 1–22. [Google Scholar]
- Minotto, V.P.; Jung, C.R.; Lee, B. Simultaneous-speaker voice activity detection and localization using mid-fusion of SVM and HMMs. IEEE Trans. Multimed. 2014, 16, 1032–1044. [Google Scholar] [CrossRef]
- Bertrand, A.; Moonen, M. Energy-based multi-speaker voice activity detection with an ad hoc microphone array. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 85–88. [Google Scholar]
- Anguera Miro, X.; Bozonnet, S.; Evans, N.; Fredouille, C.; Friedland, G.; Vinyals, O. Speaker diarization: A review of recent research. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 356–370. [Google Scholar] [CrossRef]
- Tranter, S.E.; Reynolds, D.A. An overview of automatic speaker diarization systems. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1557–1565. [Google Scholar] [CrossRef]
- Boakye, K.; Trueba-Hornero, B.; Vinyals, O.; Friedland, G. Overlapped speech detection for improved speaker diarization in multiparty meetings. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 4353–4356. [Google Scholar]
- Friedland, G.; Janin, A.; Imseng, D.; Anguera, X.; Gottlieb, L.; Huijbregts, M.; Knox, M.T.; Vinyals, O. The ICSI RT-09 speaker diarization system. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 371–381. [Google Scholar] [CrossRef]
- Hung, H.; Ba, S.O. Speech/non-speech Detection in Meetings from Automatically Extracted Low Resolution Visual Features; Idiap: Martigny, Switzerland, 2009. [Google Scholar]
- Friedland, G.; Hung, H.; Yeo, C. Multi-modal Speaker Diarization of Real-World Meetings Using Compressed-Domain Video Features. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 4069–4072. [Google Scholar]
- Garau, G.; Dielmann, A.; Bourlard, H. Audio-visual synchronisation for speaker diarisation. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Noulas, A.; Englebienne, G.; Krose, B.J. Multimodal speaker diarization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 79–93. [Google Scholar] [CrossRef]
- Kendon, A. Gesture. Annu. Rev. Anthropol. 1997, 26, 109–128. [Google Scholar] [CrossRef]
- Dittmann, A.T.; Llewellyn, L.G. Body movement and speech rhythm in social conversation. J. Personal. Soc. Psychol. 1969, 11, 98. [Google Scholar] [CrossRef]
- Harrigan, J.A. Listeners’ body movements and speaking turns. Commun. Res. 1985, 12, 233–250. [Google Scholar] [CrossRef]
- Krauss, R.M. Why do we gesture when we speak? Curr. Dir. Psychol. Sci. 1998, 7, 54. [Google Scholar] [CrossRef]
- Vossen, D.L. Detecting Speaker Status in a Social Setting with a Single Triaxial Accelerometer. Unpublished. Master’s Thesis, Department of Artificial Intelligence, University of Amsterdam, Amsterdam, The Netherlands, 2012. [Google Scholar]
- Madan, A.; Cebrian, M.; Moturu, S.; Farrahi, K. Sensing the “health state” of a community. IEEE Pervasive Comput. 2012, 11, 36–45. [Google Scholar] [CrossRef]
- Lee, Y.; Min, C.; Hwang, C.; Lee, J.; Hwang, I.; Ju, Y.; Yoo, C.; Moon, M.; Lee, U.; Song, J. Sociophone: Everyday face-to-face interaction monitoring platform using multi-phone sensor fusion. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 375–388. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Anjum, A.; Ilyas, M.U. Activity Recognition Using Smartphone Sensors. In Proceedings of the 2013 IEEE 10th Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2013; pp. 914–919. [Google Scholar]
- Drugman, T.; Stylianou, Y.; Kida, Y.; Akamine, M. Voice activity detection: Merging source and filter-based information. IEEE Signal Process. Lett. 2015, 23, 252–256. [Google Scholar] [CrossRef]
- Kendall, M.G. The treatment of ties in ranking problems. Biometrika 1945, 33, 239–251. [Google Scholar] [CrossRef]
- Agresti, A. Analysis of Ordinal Categorical Data, 2nd ed.; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Team, R.C. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Gebru, I.D.; Ba, S.; Li, X.; Horaud, R. Audio-visual speaker diarization based on spatiotemporal bayesian fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1086–1099. [Google Scholar] [CrossRef]
- Hung, H.; Englebienne, G.; Kools, J. Classifying social actions with a single accelerometer. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 207–210. [Google Scholar]
- Sohn, J.; Kim, N.S.; Sung, W. A statistical model-based voice activity detection. IEEE Signal Process. Lett. 1999, 6, 1–3. [Google Scholar] [CrossRef]
- Zhang, X.-L.; Wu, J. Deep belief networks based voice activity detection. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 697–710. [Google Scholar] [CrossRef]
- Sehgal, A.; Kehtarnavaz, N. A convolutional neural network smartphone app for real-time voice activity detection. IEEE Access 2018, 6, 9017–9026. [Google Scholar] [CrossRef]
- Martin, A.; Charlet, D.; Mauuary, L. Robust speech/non-speech detection using LDA applied to MFCC. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 1, pp. 237–240. [Google Scholar]
- Sadjadi, S.O.; Hansen, J.H. Unsupervised speech activity detection using voicing measures and perceptual spectral flux. IEEE Signal Process. Lett. 2013, 20, 197–200. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| SNR (dB) | |
|---|---|
| Participant 1 | 8.06 |
| Participant 2 | 9.34 |
| Participant 3 | 9.34 |
| Participant 4 | 10.25 |
| Participant 5 | 8.40 |
| Participant 6 | 7.84 |
| Participant 7 | 7.89 |
| Participant 8 | 7.75 |
| Participant 9 | 10.56 |
| Participant 10 | 9.47 |
| Participant 11 | 8.25 |
| Participant 12 | 5.58 |
| Original | After SMOTE | |||
|---|---|---|---|---|
| Non-Speech | Speech | Non-Speech | Speech | |
| Participant 1 | 34,054 | 1934 | 7736 | 5802 |
| Participant 2 | 30,464 | 5524 | 22,096 | 16,572 |
| Participant 3 | 31,361 | 4627 | 18,508 | 13,881 |
| Participant 4 | 32,583 | 3405 | 13,620 | 10,215 |
| Participant 5 | 32,370 | 3618 | 14,472 | 10,854 |
| Participant 6 | 32,466 | 3522 | 14,088 | 10,566 |
| Participant 7 | 31,318 | 4670 | 18,680 | 14,010 |
| Participant 8 | 33,004 | 2984 | 11,936 | 8952 |
| Participant 9 | 33,713 | 2275 | 9100 | 6825 |
| Participant 10 | 32,901 | 3087 | 12,348 | 9261 |
| Participant 11 | 32,422 | 3566 | 14,264 | 10,698 |
| Participant 12 | 32,809 | 3179 | 12,716 | 9537 |
| Frequency | V-Statistic | p-Value | Bonferroni-Corrected p-Value |
|---|---|---|---|
| 1 Hz | 62 | 0.038574 | 0.77148 |
| 2 Hz | 78 | 0.000244 | 0.00488 |
| 3 Hz | 78 | 0.000244 | 0.00488 |
| 4 Hz | 78 | 0.000244 | 0.00488 |
| 5 Hz | 78 | 0.000244 | 0.00488 |
| 6 Hz | 78 | 0.000244 | 0.00488 |
| 7 Hz | 78 | 0.000244 | 0.00488 |
| 8 Hz | 78 | 0.000244 | 0.00488 |
| 9 Hz | 78 | 0.000244 | 0.00488 |
| 10 Hz | 78 | 0.000244 | 0.00488 |
| 11 Hz | 78 | 0.000244 | 0.00488 |
| 12 Hz | 78 | 0.000244 | 0.00488 |
| 13 Hz | 78 | 0.000244 | 0.00488 |
| 14 Hz | 78 | 0.000244 | 0.00488 |
| 15 Hz | 78 | 0.000244 | 0.00488 |
| 16 Hz | 78 | 0.000244 | 0.00488 |
| 17 Hz | 78 | 0.000244 | 0.00488 |
| 18 Hz | 78 | 0.000244 | 0.00488 |
| 19 Hz | 78 | 0.000244 | 0.00488 |
| 20 Hz | 72 | 0.003418 | 0.06836 |
| Combination | Audio | Physical Motion | ||
|---|---|---|---|---|
| Participant 1 | Accuracy | 90.99 | 77.59 | 85.73 |
| Recall | 88.90 | 68.52 | 83.31 | |
| Precision | 89.96 | 76.69 | 83.40 | |
| Participant 2 | Accuracy | 92.55 | 82.69 | 88.31 |
| Recall | 89.24 | 74.80 | 86.90 | |
| Precision | 93.11 | 83.14 | 85.98 | |
| Participant 3 | Accuracy | 90.93 | 79.11 | 84.65 |
| Recall | 87.56 | 73.11 | 76.77 | |
| Precision | 90.95 | 76.99 | 85.89 | |
| Participant 4 | Accuracy | 94.91 | 81.67 | 90.28 |
| Recall | 94.38 | 76.74 | 93.20 | |
| Precision | 93.79 | 79.71 | 85.46 | |
| Participant 5 | Accuracy | 90.74 | 82.33 | 86.54 |
| Recall | 85.91 | 72.13 | 80.15 | |
| Precision | 91.95 | 84.37 | 87.41 | |
| Participant 6 | Accuracy | 89.59 | 81.10 | 85.22 |
| Recall | 84.59 | 70.92 | 76.69 | |
| Precision | 90.50 | 82.54 | 87.29 | |
| Participant 7 | Accuracy | 92.79 | 79.68 | 88.87 |
| Recall | 90.47 | 69.65 | 88.11 | |
| Precision | 92.54 | 80.32 | 86.22 | |
| Participant 8 | Accuracy | 92.26 | 79.47 | 88.53 |
| Recall | 90.69 | 69.50 | 89.58 | |
| Precision | 91.19 | 79.96 | 84.56 | |
| Participant 9 | Accuracy | 93.54 | 83.60 | 88.22 |
| Recall | 90.84 | 76.02 | 88.48 | |
| Precision | 93.91 | 84.19 | 84.72 | |
| Participant 10 | Accuracy | 95.33 | 84.42 | 91.43 |
| Recall | 94.00 | 76.83 | 92.72 | |
| Precision | 95.05 | 85.36 | 87.94 | |
| Participant 11 | Accuracy | 93.68 | 80.74 | 89.17 |
| Recall | 92.23 | 72.29 | 88.97 | |
| Precision | 92.99 | 80.76 | 86.21 | |
| Participant 12 | Accuracy | 89.43 | 72.24 | 86.75 |
| Recall | 87.14 | 60.08 | 85.04 | |
| Precision | 88.09 | 70.76 | 84.21 | |
| Average | Accuracy | 92.23 | 80.39 | 87.81 |
| Recall | 89.66 | 71.72 | 85.83 | |
| Precision | 92.00 | 80.40 | 85.77 |
| Combination | Audio | Physical Motion | |
|---|---|---|---|
| Accuracy | 83.22 | 67.66 | 71.86 |
| Recall | 74.23 | 72.81 | 59.02 |
| Precision | 84.50 | 60.09 | 70.02 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nozawa, T.; Uchiyama, M.; Honda, K.; Nakano, T.; Miyake, Y. Speech Discrimination in Real-World Group Communication Using Audio-Motion Multimodal Sensing. Sensors 2020, 20, 2948. https://doi.org/10.3390/s20102948
Nozawa T, Uchiyama M, Honda K, Nakano T, Miyake Y. Speech Discrimination in Real-World Group Communication Using Audio-Motion Multimodal Sensing. Sensors. 2020; 20(10):2948. https://doi.org/10.3390/s20102948
Chicago/Turabian StyleNozawa, Takayuki, Mizuki Uchiyama, Keigo Honda, Tamio Nakano, and Yoshihiro Miyake. 2020. "Speech Discrimination in Real-World Group Communication Using Audio-Motion Multimodal Sensing" Sensors 20, no. 10: 2948. https://doi.org/10.3390/s20102948
APA StyleNozawa, T., Uchiyama, M., Honda, K., Nakano, T., & Miyake, Y. (2020). Speech Discrimination in Real-World Group Communication Using Audio-Motion Multimodal Sensing. Sensors, 20(10), 2948. https://doi.org/10.3390/s20102948