Large-Scale Place Recognition Based on Camera-LiDAR Fused Descriptor


Abstract
1. Introduction
2. Related Works
2.1. Visual Feature Extractor
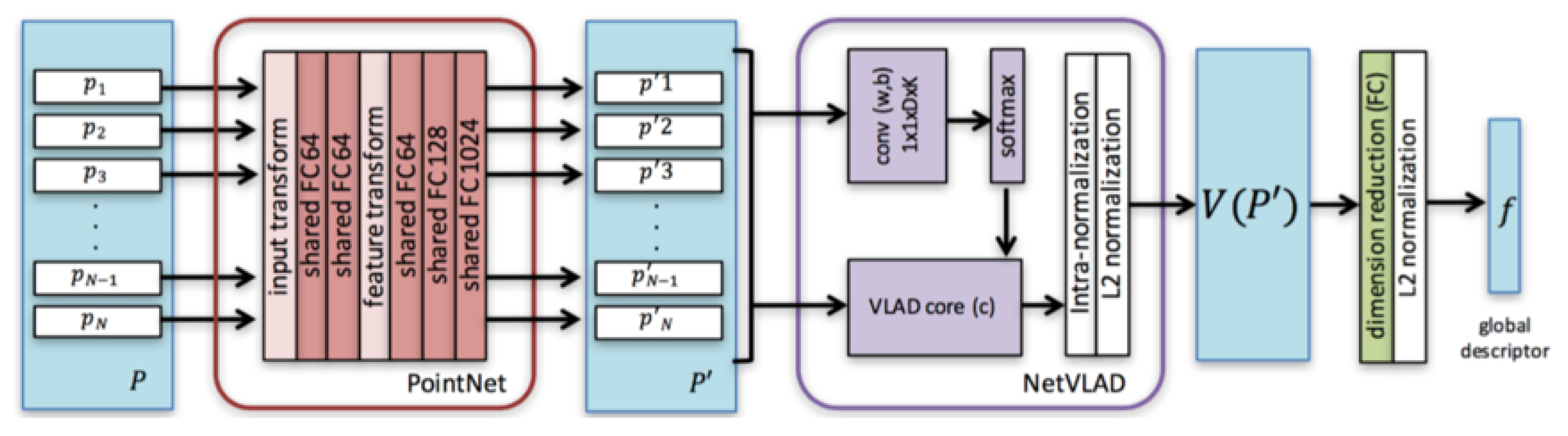
2.2. Global Descriptor of 3D Point Cloud via Netvlad
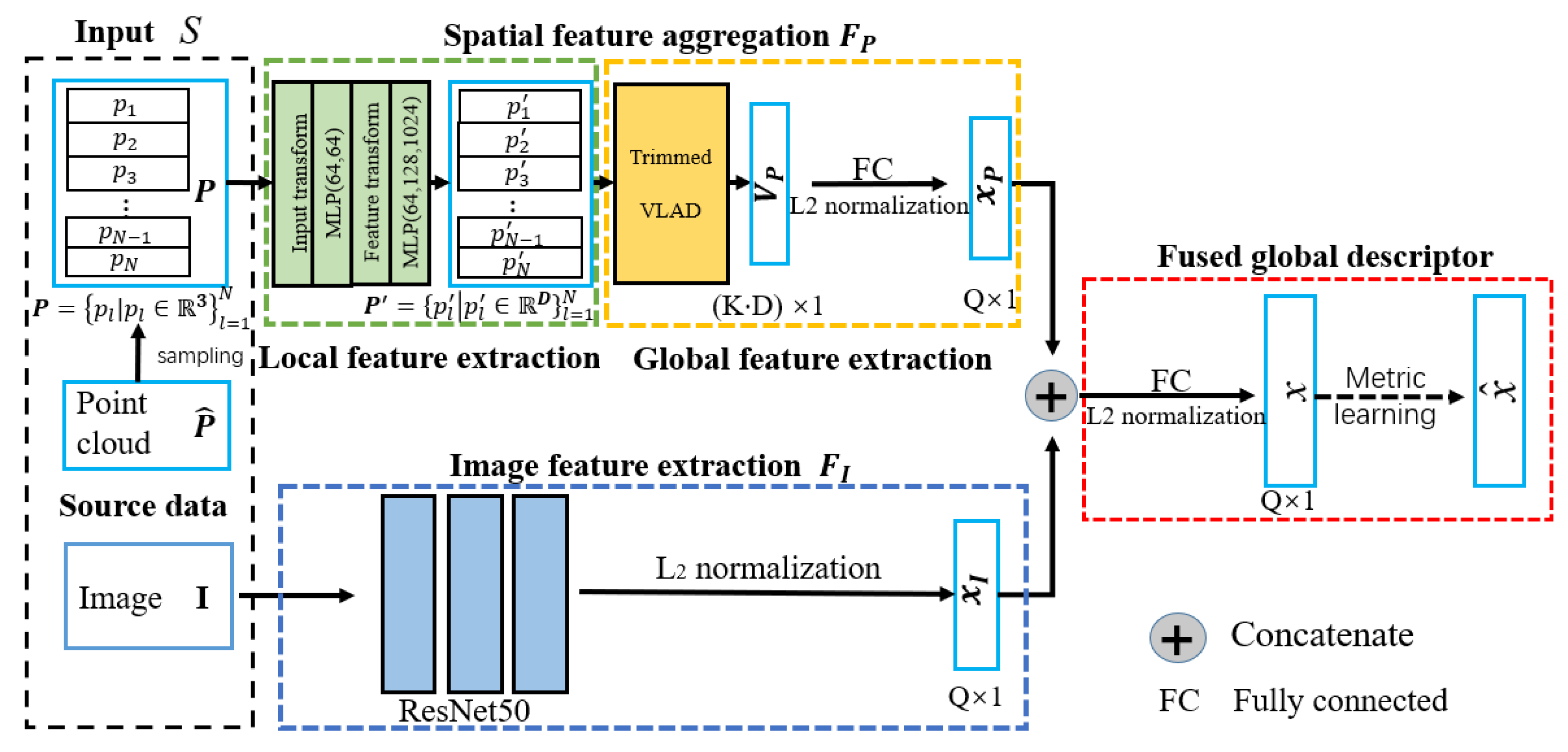
3. Proposed Method
3.1. Spatial Feature Aggregation with Trimmed Strategy
3.1.1. Local Feature Extraction for Point Cloud
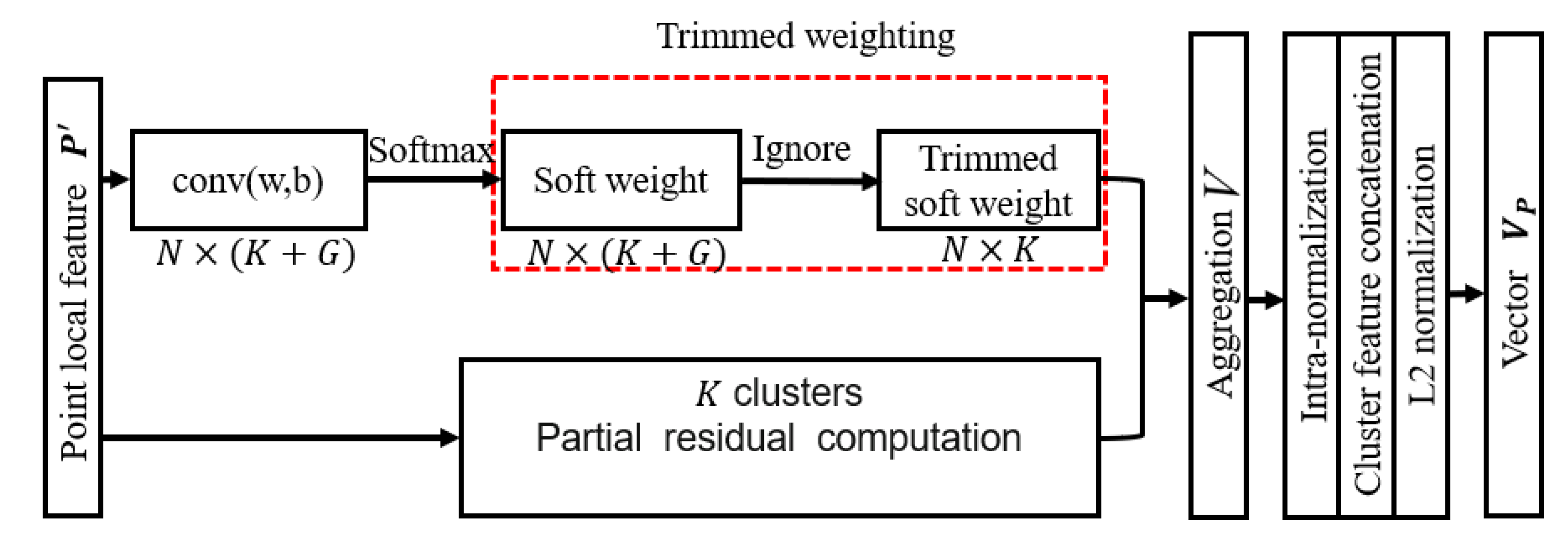
3.1.2. Global Feature Extraction with Trimmed Clustering
3.2. Image Feature Extraction
3.3. Metric Learning for Fused Global Descriptors
4. Experiments and Results
4.1. Datasets and Pre-Processing
4.1.1. Kitti Dataset
4.1.2. Kaist Dataset
4.1.3. Our Campus Data
4.1.4. Triplet Tuple
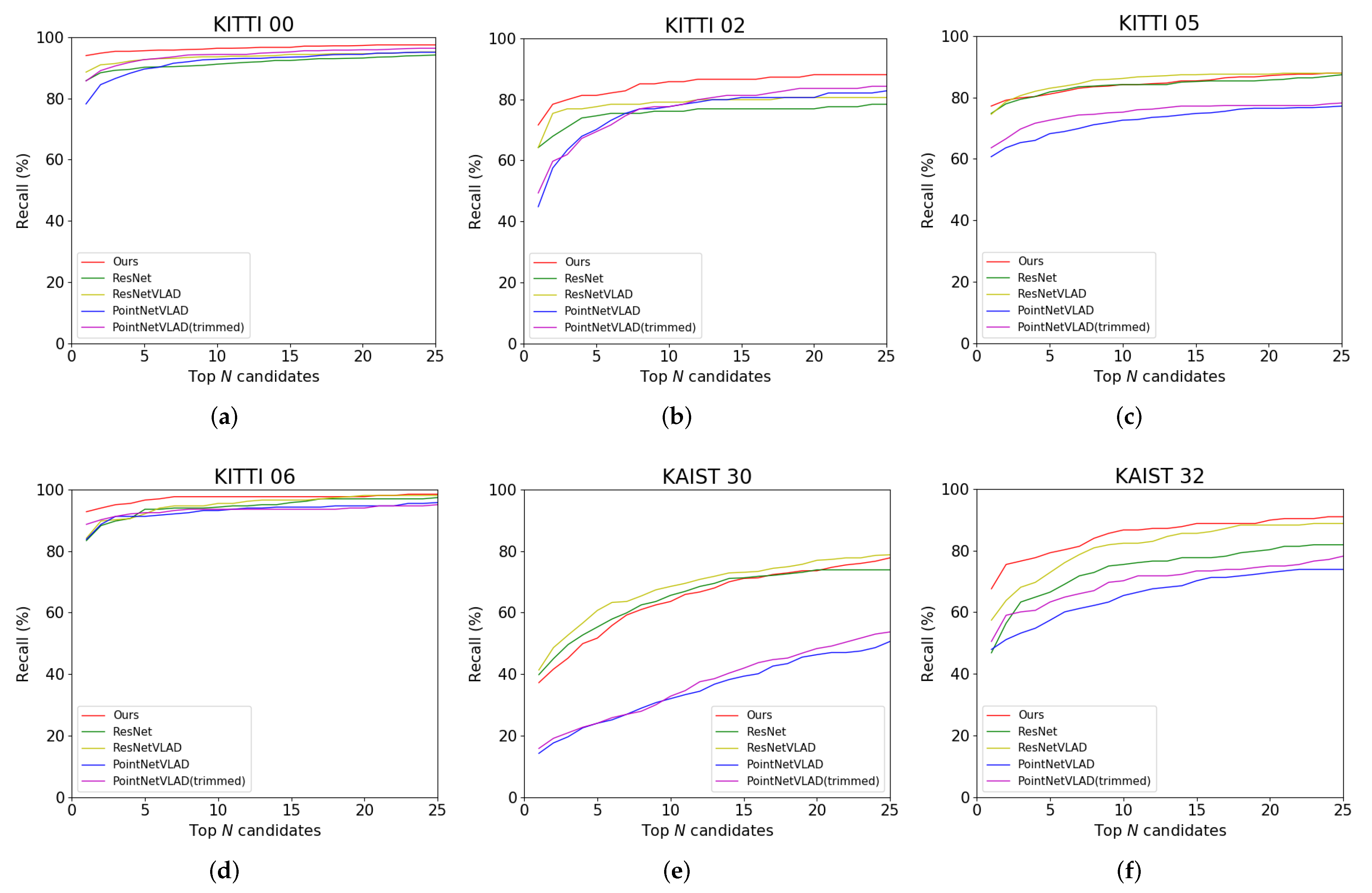
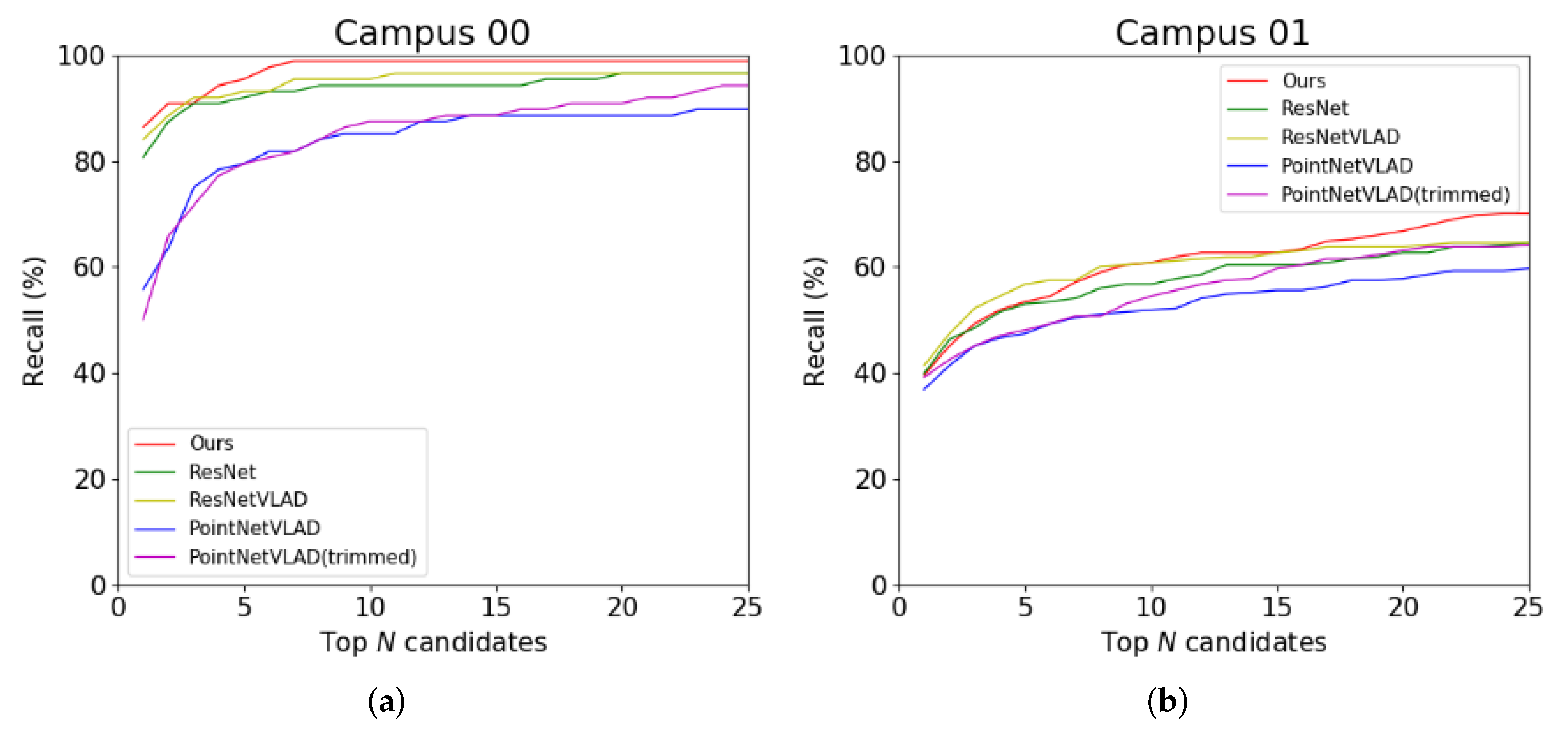
4.2. Place Recognition Results
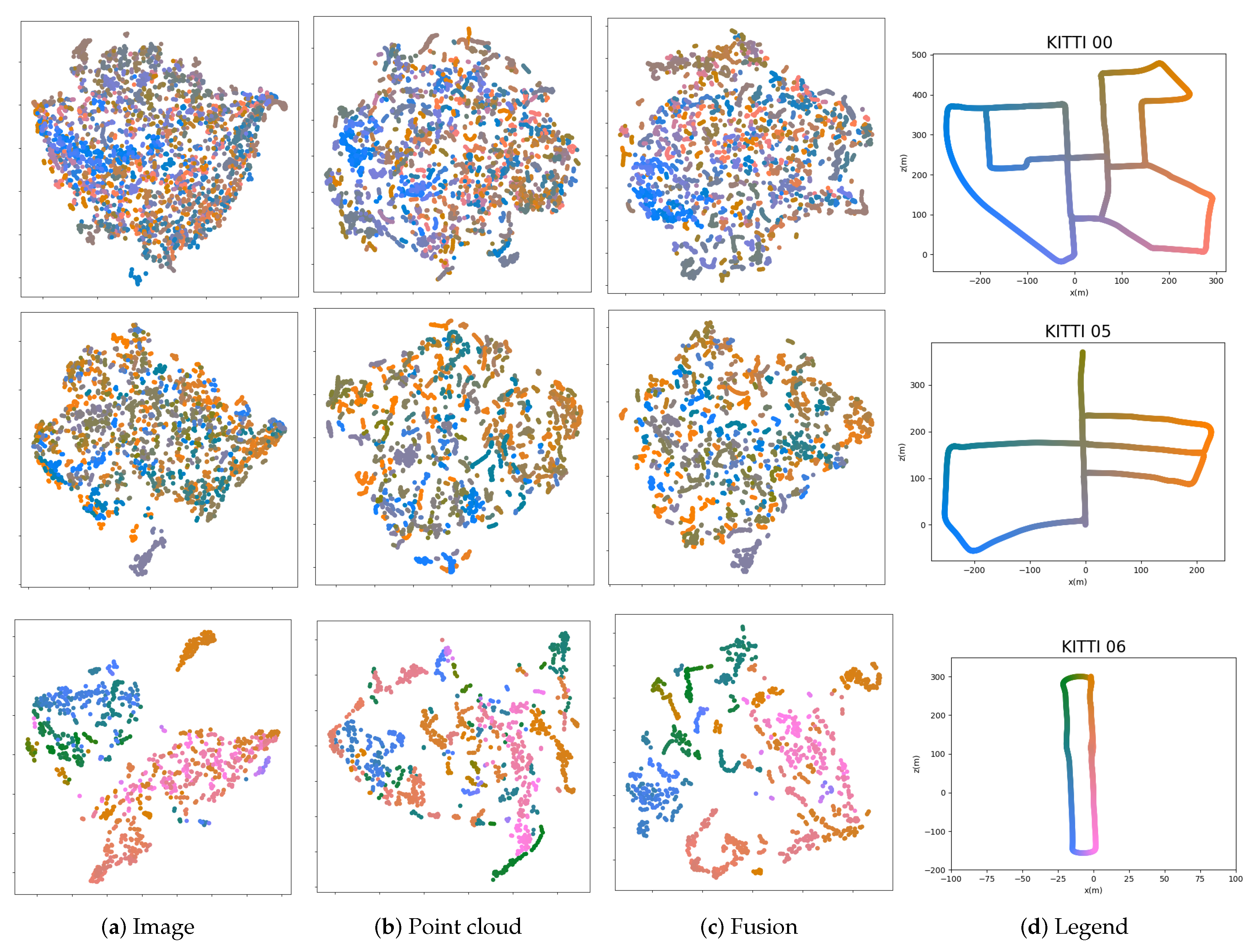
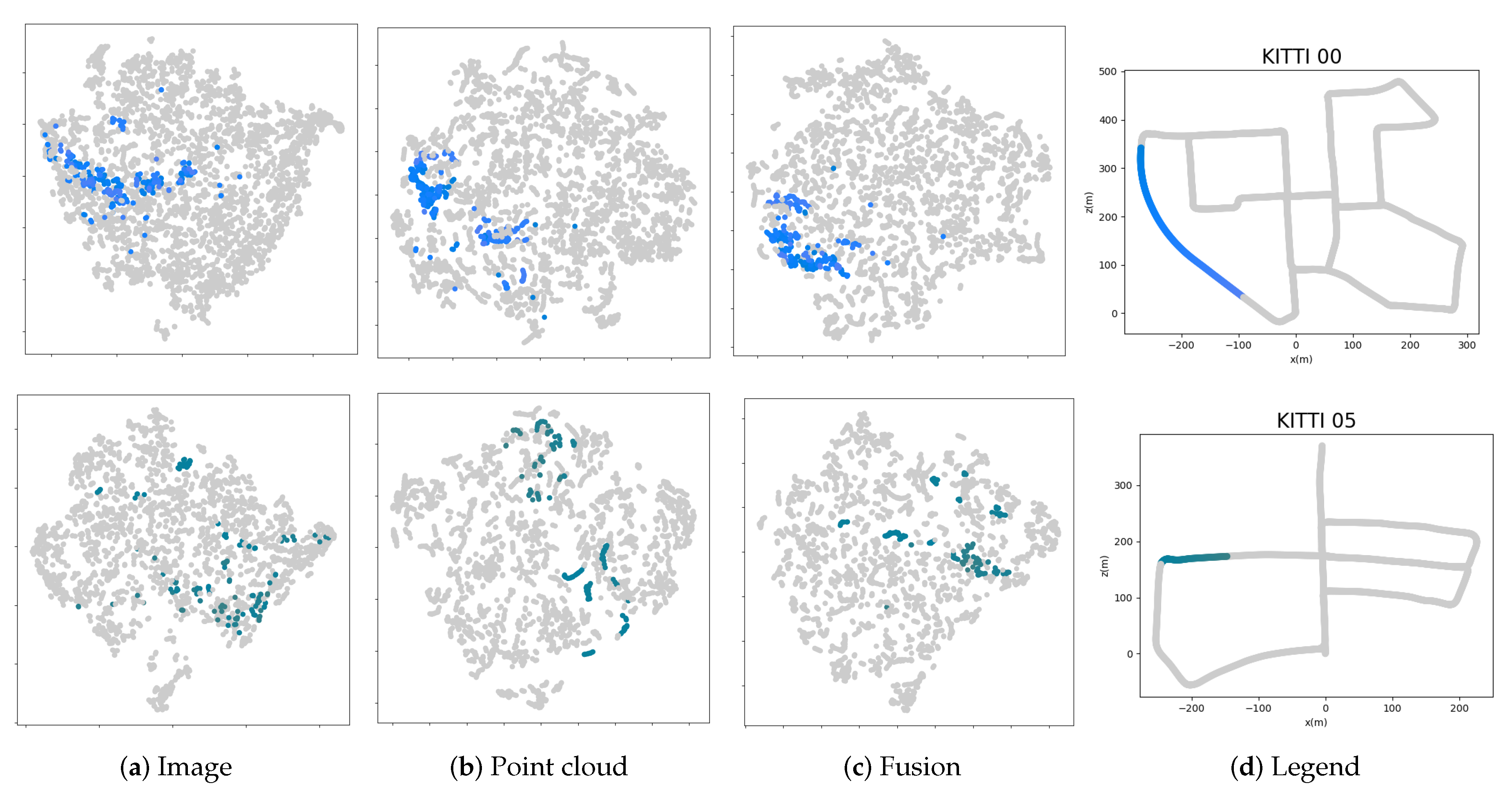
4.3. Analysis and Discussion
4.3.1. Number of Points
4.3.2. Number of Cluster Centers
4.3.3. Effect of the Non-Informative Clusters
4.3.4. Different Image Features
4.3.5. Effect of Learned Descriptors
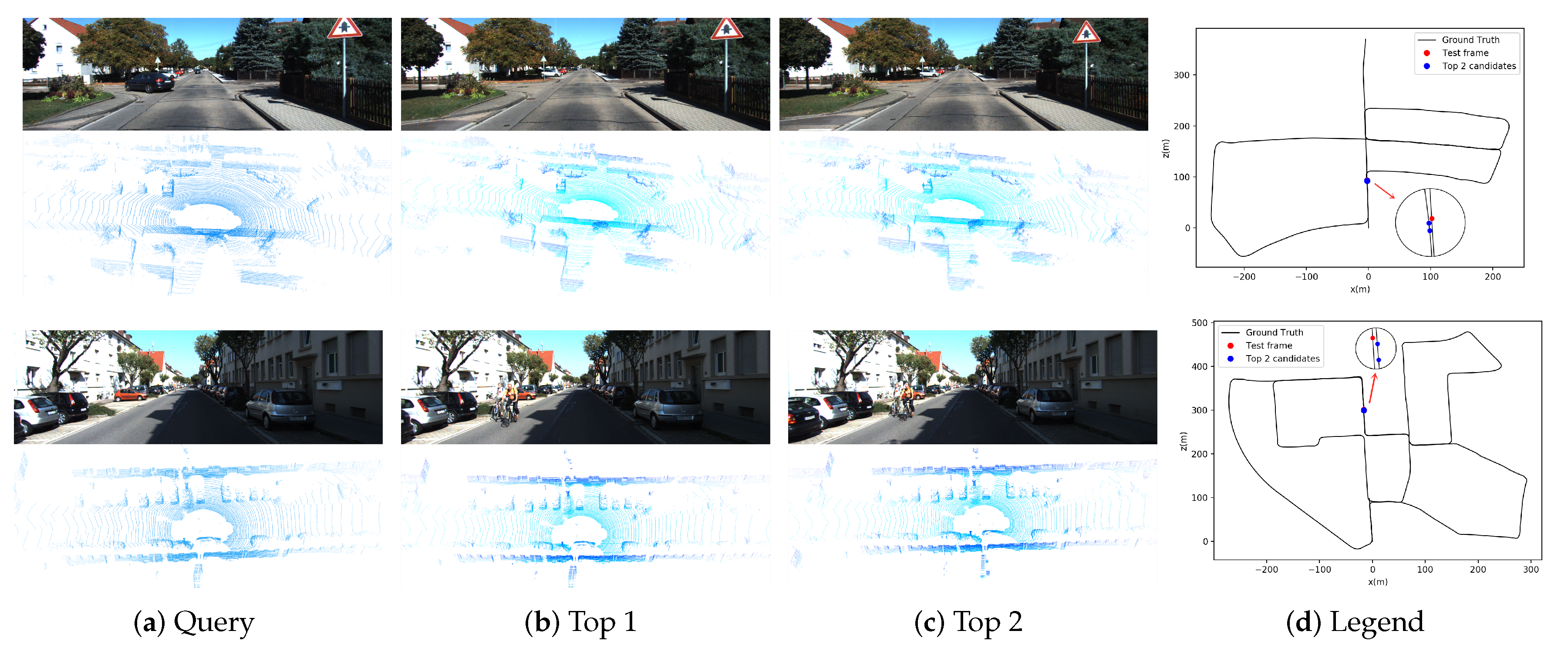
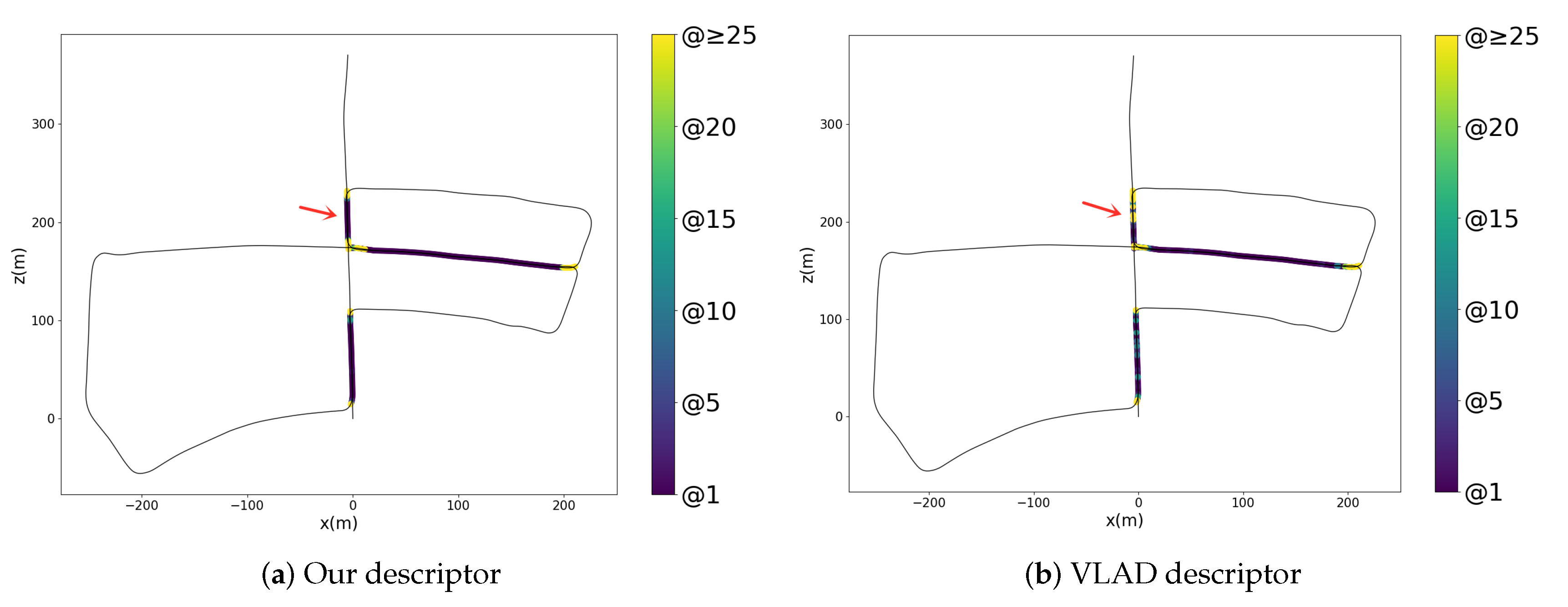
4.3.6. Usability
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arandjelovi, R.; Zisserman, A. DisLocation: Scalable Descriptor Distinctiveness for Location Recognition. Lect. Notes Comput. Sci. 2015, 9006, 188–204. [Google Scholar]
- Cao, S.; Snavely, N. Graph-Based Discriminative Learning for Location Recognition. Int. J. Comput. Vis. 2015, 112, 239–254. [Google Scholar] [CrossRef]
- Chen, D.M.; Baatz, G.; Koser, K.; Tsai, S.S.; Vedantham, R.; Pylvanainen, T.; Roimela, K.; Chen, X.; Bach, J.; Pollefeys, M.; et al. City-scale Landmark Identification on Mobile Devices. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 737–744. [Google Scholar]
- Gronat, P.; Sivic, J.; Obozinski, G.; Pajdla, T. Learning and Calibrating Per-Location Classifiers for Visual Place Recognition. Int. J. Comput. Vis. 2016, 118, 319–336. [Google Scholar] [CrossRef][Green Version]
- Sattler, T.; Havlena, M.; Radenovic, F.; Schindler, K.; Pollefeys, M. Hyperpoints and Fine Vocabularies for Large-Scale Location Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2102–2106. [Google Scholar]
- Bonardi, F.; Ainouz, S.; Boutteau, R.; Dupuis, Y.; Savatier, X.; Vasseur, P. PHROG: A Multimodal Feature for Place Recognition. Sensors 2017, 17, 1167. [Google Scholar] [CrossRef] [PubMed]
- Ouerghi, S.; Boutteau, R.; Savatier, X.; Tlili, F. Visual Odometry and Place Recognition Fusion for Vehicle Position Tracking in Urban Environments. Sensors 2018, 18, 939. [Google Scholar] [CrossRef] [PubMed]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic Localization and Mapping in the Space of Appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Dube, R.; Dugas, D.; Stumm, E.; Nieto, J.; Siegwart, R.; Cadena, C. SegMatch: Segment Based Place Recognition in 3D Point Clouds. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 5266–5272. [Google Scholar]
- Fraundorfer, F.; Heng, L.; Honegger, D.; Lee, G.H.; Meier, L.; Tanskanen, P.; Pollefeys, M. Vision-Based Autonomous Mapping and Exploration Using a Quadrotor MAV. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 4557–4564. [Google Scholar]
- Middelberg, S.; Sattler, T.; Untzelmann, O.; Kobbelt, L. Scalable 6-DOF Localization on Mobile Devices. Lect. Notes Comput. Sci. 2014, 8690, 268–283. [Google Scholar]
- Qiao, Y.; Cappelle, C.; Ruichek, Y.; Yang, T. ConvNet and LSH-based Visual Localization Using Localized Sequence Matching. Sensors 2019, 19, 2439. [Google Scholar] [CrossRef]
- He, L.; Wang, X.; Zhang, H. M2DP: A Novel 3D Point Cloud Descriptor and Its Application in Loop Closure Detection. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 231–237. [Google Scholar]
- Kim, G.; Kim, A. Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 4802–4809. [Google Scholar]
- Mur-Artal, R.; Montiel, J.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching in Videos. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003. [Google Scholar]
- Li, T.; Mei, T.; Kweon, I.S.; Hua, X.S. Contextual Bag-of-Words for Visual Categorization. IEEE Trans. Circ. Syst. Video Technol. 2011, 21, 381–392. [Google Scholar] [CrossRef]
- Jegou, H.; Douze, M.; Schmid, C.; Perez, P. Aggregating Local Descriptors into a Compact Image Representation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Perronnin, F.; Liu, Y.; Sanchez, J.; Poirier, H. Large-scale Image Retrieval with Compressed Fisher Vectors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3384–3391. [Google Scholar]
- Chum, O.; Mikulik, A.; Perdoch, M.; Matas, J. Total Recall II: Query Expansion Revisited. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 889–896. [Google Scholar]
- Delhumeau, J.; Gosselin, P.H.; Jegou, H.; Perez, P. Revisiting the VLAD Image Representation. In Proceedings of the 2013 ACM Multimedia Conference, Barcelona, Spain, 21–25 October 2013; pp. 653–656. [Google Scholar]
- Jegou, H.; Chum, O. Negative Evidences and Co-occurences in Image Retrieval: The Benefit of PCA and Whitening. Lect. Notes Comput. Sci. 2012, 7573, 774–787. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Hamming Embedding and Weak Geometric Consistency for Large Scale Image Search. Lect. Notes Comput. Sci. 2008, 5302, 304–317. [Google Scholar]
- Torii, A.; Sivic, J.; Okutomi, M.; Pajdla, T. Visual Place Recognition with Repetitive Structures. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2346–2359. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, Z.; Lam, O.; Jacobson, A.; Milford, M. Convolutional Neural Network-based Place Recognition. arXiv 2014, arXiv:1411.1509. [Google Scholar]
- Sunderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the Performance of ConvNet Features for Place Recognition. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Gordo, A.; Almazan, J.; Revaud, J.; Larlus, D. Deep Image Retrieval: Learning Global Representations for Image Search. Lect. Notes Comput. Sci. 2016, 9910, 241–257. [Google Scholar]
- Chen, Z.; Jacobson, A.; Sunderhauf, N.; Upcroft, B.; Liu, L.; Shen, C.; Reid, I.; Milford, M. Deep Learning Features at Scale for Visual Place Recognition. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 3223–3230. [Google Scholar]
- Radenovi, F.; Tolias, G.; Chum, O. CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples. Lect. Notes Comput. Sci. 2016, 9905, 3–20. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef]
- Zhong, Y.; Arandjelović, R.; Zisserman, A. GhostVLAD for Set-Based Face Recognition. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 35–50. [Google Scholar]
- Uy, M.A.; Lee, G.H. PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4470–4479. [Google Scholar]
- Yang, Y.; Fan, D.; Du, S.; Wang, M.; Chen, B.; Gao, Y. Point Set Registration with Similarity and Affine Transformations Based on Bidirectional KMPE Loss. IEEE Trans. Cybern. 2019, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Frome, A.; Huber, D.; Kolluri, R.; Bülow, T.; Malik, J. Recognizing Objects in Range Data Using Regional Point Descriptors. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 224–237. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning Point Cloud Views using Persistent Feature Histograms. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391. [Google Scholar]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique Signatures of Histograms for Surface and Texture Description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Zhao, J.; Li, C.; Tian, L.; Zhu, J. FPFH-based Graph Matching for 3D Point Cloud Registration. Proc. Int. Soc. Opt. Eng. 2018, 10696, 106960M. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A 3-Dimensional SIFT Descriptor and its Application to Action Recognition. In Proceedings of the ACM International Multimedia Conference and Exhibition, Augsburg, Germany, 25–29 September 2007; pp. 357–360. [Google Scholar]
- Wohlkinger, W.; Vincze, M. Ensemble of Shape Functions for 3D Object Classification. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Karon Beach, Phuket, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]
- Steder, B.; Rusu, B.; Konolige, K.; Burgard, W. NARF: 3D Range Image Features for Object Recognition. In Proceedings of the Workshop on Defining and Solving Realistic Perception Problems in Personal Robotics at the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 Ocotber 2010. [Google Scholar]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D Recognition and Pose using the Viewpoint Feature Histogram. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 Ocotber 2010; pp. 2155–2162. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Qi, C.R.; Su, H.; Niebner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-View CNNs for Object Classification on 3D Data. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5100–5109. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- You, H.; Ji, R.; Feng, Y.; Gao, Y. PVNet: A Joint Convolutional Network of Point Cloud and Multi-view for 3D Shape Recognition. In Proceedings of the 2018 ACM Multimedia Conference, Seoul, Korea, 22–26 October 2018; pp. 1310–1318. [Google Scholar]
- Fernandez, A.; Wis, M.; Vecchione, G.; Silva, P.; Colomina, I.; Angelats, E.; Pares, M. Real-time Navigation and Mapping with Mobile Mapping Systems using LiDAR/Camera/INS/GNSS Advanced Hybridization Algorithms: Description and Test Results. In Proceedings of the International Technical Meeting of the Satellite Division of the Institute of Navigation, Tampa, FL, USA, 8–12 September 2014. [Google Scholar]
- Vyroubalova, J. LiDAR and Stereo Camera Data Fusion in Mobile Robot Mapping. Available online: http://excel.fit.vutbr.cz/submissions/2017/042/42.pdf (accessed on 3 May 2017).
- Ying, S.; Wen, Z.; Shi, J.; Peng, Y.; Peng, J.; Qiao, H. Manifold Preserving: An Intrinsic Approach for Semisupervised Distance Metric Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2731–2742. [Google Scholar] [CrossRef] [PubMed]
- Weinberger, K.Q.; Blitzer, J.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1473–1480. [Google Scholar]
- Peng, Y.; Zhang, N.; Li, Y.; Ying, S. A Local-to-Global Metric Learning Framework From the Geometric Insight. IEEE Access 2020, 8, 16953–16964. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Jeong, J.; Cho, Y.; Shin, Y.S.; Roh, H.; Kim, A. Complex Urban Dataset with Multi-level Sensors from Highly Diverse Urban Environments. Int. J. Robot. Res. 2019, 38, 642–657. [Google Scholar] [CrossRef]
- Himmelsbach, M.; Hundelshausen, F.V.; Wuensche, H.J. Fast Segmentation of 3D Point Clouds for Ground Vehicles. In Proceedings of the IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 560–565. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ResNet | ResNetVLAD | PointNetVLAD | PointNetVLAD (trimmed) | Ours | |
|---|---|---|---|---|---|
| KITTI 00 | 95.6 | 96.3 | 96.4 | 97.6 | 98.1 |
| KITTI 02 | 80.6 | 83.6 | 84.3 | 84.3 | 88.1 |
| KITTI 05 | 87.6 | 87.9 | 78.2 | 78.6 | 88.1 |
| KITTI 06 | 94.7 | 95.5 | 93.6 | 93.6 | 97.7 |
| KAIST 30 | 84.2 | 83.7 | 72.6 | 72.4 | 87.3 |
| KAIST 32 | 88.3 | 92.6 | 86.7 | 93.1 | 95.2 |
| KITTI 00 | 57.5 | 71.7 | 76.1 | 76.6 |
| KITTI 02 | 21.6 | 34.3 | 35.1 | 43.3 |
| KITTI 05 | 41.0 | 52.7 | 56.3 | 58.5 |
| KITTI 06 | 50.6 | 70.2 | 80.0 | 83.0 |
| KITTI 00 | 78.0 | 78.9 | 78.8 | 76.6 |
| KITTI 02 | 38.8 | 45.5 | 46.3 | 43.3 |
| KITTI 05 | 59.7 | 61.7 | 60.9 | 58.5 |
| KITTI 06 | 81.5 | 83.4 | 82.3 | 83.0 |
| @1% | @1 | |||
|---|---|---|---|---|
| ResNet | ResNetVLAD | ResNet | ResNetVLAD | |
| KITTI 00 | 98.1 | 97.4 | 93.1 | 87.3 |
| KITTI 02 | 88.1 | 86.6 | 73.9 | 54.5 |
| KITTI 05 | 88.1 | 76.9 | 76.5 | 63.6 |
| KITTI 06 | 97.7 | 95.5 | 94.7 | 86.8 |
| @1 | Time | |||
|---|---|---|---|---|
| VLAD | Ours | VLAD | Ours | |
| KITTI 00 | 88.6 | 92.7 | 0.046 | 0.025 |
| KITTI 02 | 63.4 | 64.9 | ||
| KITTI 05 | 66.0 | 76.9 | ||
| KITTI 06 | 82.3 | 92.5 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, S.; Pan, C.; Peng, Y.; Liu, K.; Ying, S. Large-Scale Place Recognition Based on Camera-LiDAR Fused Descriptor. Sensors 2020, 20, 2870. https://doi.org/10.3390/s20102870
Xie S, Pan C, Peng Y, Liu K, Ying S. Large-Scale Place Recognition Based on Camera-LiDAR Fused Descriptor. Sensors. 2020; 20(10):2870. https://doi.org/10.3390/s20102870
Chicago/Turabian StyleXie, Shaorong, Chao Pan, Yaxin Peng, Ke Liu, and Shihui Ying. 2020. "Large-Scale Place Recognition Based on Camera-LiDAR Fused Descriptor" Sensors 20, no. 10: 2870. https://doi.org/10.3390/s20102870
APA StyleXie, S., Pan, C., Peng, Y., Liu, K., & Ying, S. (2020). Large-Scale Place Recognition Based on Camera-LiDAR Fused Descriptor. Sensors, 20(10), 2870. https://doi.org/10.3390/s20102870