1. Introduction
Smart cities appear as “the next stage of urbanization, subsequent to the knowledge-based economy, digital economy, and intelligent economy” [
1]. Smart cities aim to “not only exploit physical and digital infrastructure for urban development but also the intellectual and social capital as its core ingredient for urbanization” [
1]. Smart cities are driven by, or involve, integration of multiple city systems, such as transport, healthcare, and operations, and hence are considered a major driver for the transformation of many industries. Smart society is an extension of the smart cities concept, “a digitally-enabled, knowledge-based society, aware of and working towards social, environmental and economic sustainability” [
1].
Road transportation is the backbone of modern economies, albeit it annually costs
million deaths and another 20–50 million injuries to people [
2]. This equals daily a shocking 3400 deaths and 50,000–137,000 injuries to people. Moreover, trillions of dollars of the global economy are lost due to road congestion in addition to the congestion causing air pollution that damages public health and the environment [
3].
INRIX Research conducted the biggest study on congestion costs based on the data acquired by 300 million vehicles and devices from 1360 cities in 38 countries during 2017 [
4]. They revealed that Los Angeles was the worst congested city globally where drivers spent 102 peak hours in congestion, equaling an average of
of their total drive time, the congestion in the city costing
billion to the drivers and US economy. The cost of congestion in New York was the highest at
billion for any single city in the world. The total congestion cost across the US, UK, and Germany was about
billion. The cost of congestion to the United States economy, alone, exceeds
billion (see [
4,
5]). Texas Transportation reports that
billion gallons of fuel was wasted in the USA alone during 2012 due to traffic congestion [
6], and this causes, in addition to the economic losses, damage to the environment and public health. It is reported [
7] that 40% of the road congestion is caused due to the bottlenecks on the road networks, 25% is because of the traffic crashes and other incidents, 15% is caused due to the bad weather, and the remaining 20% includes other causes such as roadworks and poor traffic signal control. Better insights into the causes of road congestion, and its management, are of vital significance to avoid or minimize loss to public health, deaths and injuries, and other socio-economic losses and environmental damages.
Many road traffic modeling, analysis, and prediction methods have been developed to understand the causes of road traffic congestion, and to prevent and manage road congestion. The forecasting or prediction of road traffic characteristics, such as speed, flow and occupancy, allows planning new road networks, modifications to existing road networks, or developing new traffic control strategies. Real-time traffic prediction allows dynamic control of road traffic using traffic signal controls, variable lane control, variable message signs (VMS), and other methods. Simulations and modeling methods have been widely used in the past for road traffic management and congestion prevention (see, e.g., [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18]). In recent years, statistical methods, artificial intelligence (AI) and data mining techniques are increasingly being used to analyze road traffic data and predict future traffic characteristics. These include the Autoregressive Integrated Moving Average (ARIMA) [
19], and its variants Seasonal Autoregressive Integrated Moving Average (SARIMA) [
20], and KARIMA (Kohonen Maps with ARIMA) [
21]. Support vector machines (SVM) [
22] are also popular for the analysis of transportation problems. Deep learning is being used recently for traffic prediction purpose [
23,
24,
25,
26,
27,
28,
29,
30]. Deep learning is a branch of machine learning that uses hierarchical architectures to learn high-level abstractions in the data [
31].
The focus of this work is on the use of deep learning for road traffic prediction. The existing literature on the use of deep learning for road traffic prediction is in its infancy and falls short in multiple respects. Firstly, the datasets that have been used are relatively small in terms of the time duration of the road traffic data. Secondly, some of the deep learning works use data from cameras installed by the researchers and, although useful and complementary, this renders such datasets limited in their scopes as compared to the data systematically collected by transportation authorities. Thirdly, the existing deep learning works have not reported in-depth analysis of the configurations of deep learning networks. Therefore, further work is needed on the use of deep learning for road traffic modeling and prediction.
Relatedly, the last few decades have seen an increasing surge in the technological advancements. The penetration of these technologies to all spheres of everyday life has given rise to the smart infrastructure developments; smart transportation infrastructure is at the forefront of these developments [
1,
32,
33,
34,
35,
36]. The use of GPS devices and mobile signals to collect vehicle location and congestion data [
37]; the use of big data [
38,
39,
40] and high performance computing (HPC) [
38,
40,
41,
42] technologies; mobile, cloud and fog computing [
37,
43,
44,
45,
46]; image processing and artificial intelligence (AI) for traffic analysis [
47]; urban logistics prototyping [
48]; vehicular ad hoc networks [
44,
49,
50,
51,
52]; autonomous driving [
47]; autonomic transportation systems [
53,
54,
55]; and the use of social media for traffic event detection [
56,
57,
58] are a few examples. There is a need for innovative uses of the cutting-edge technologies in transportation.
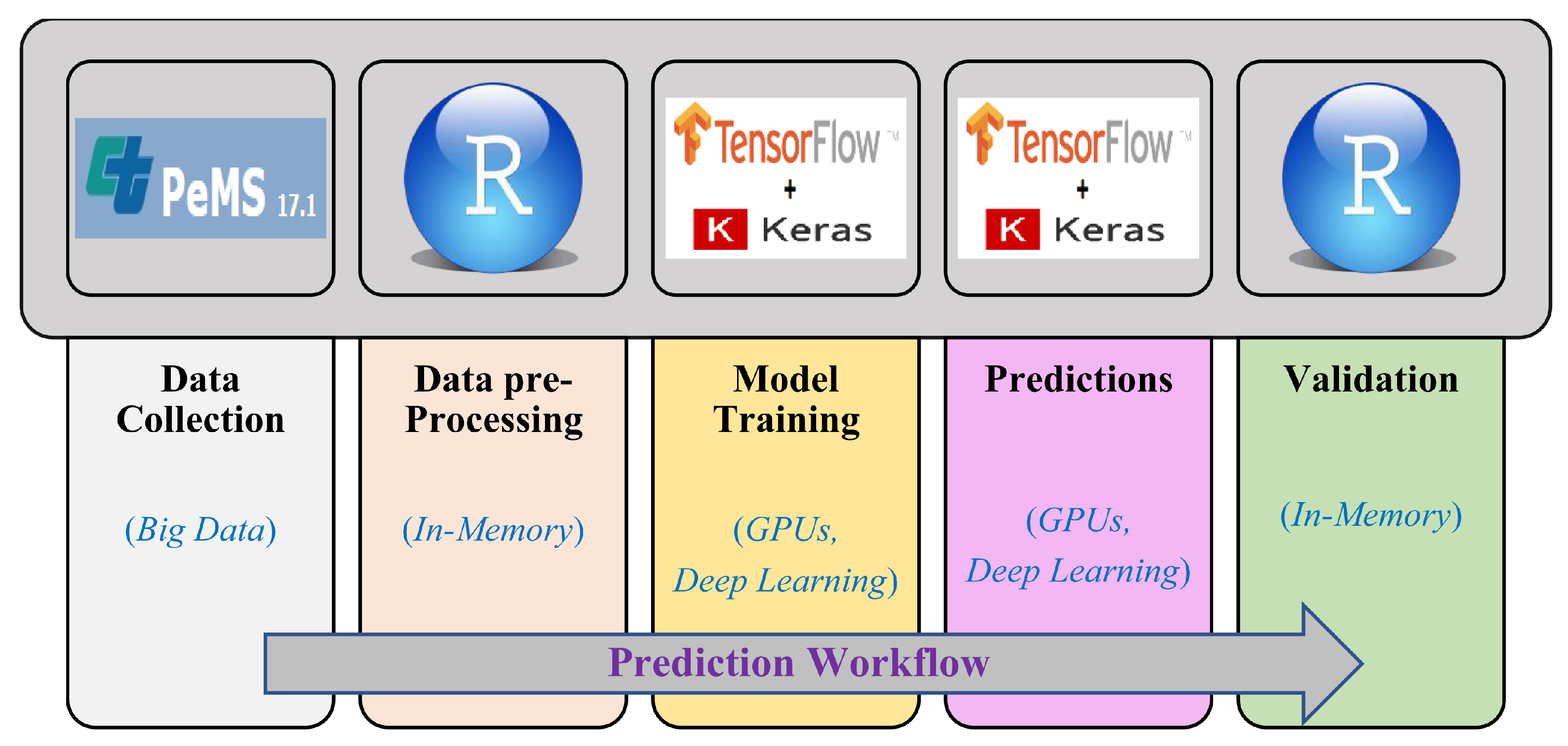
This paper addresses the challenges of road traffic prediction by bringing four complementary cutting-edge technologies together: big data, deep learning, in-memory computing, and high performance computing (Graphics Processing Units (GPUs)). The approach presented in this paper provides a novel and comprehensive approach toward large-scale, faster, and real-time road traffic prediction. The road traffic characteristics that we predict are flow, speed, and occupancy. Big data refers to the “emerging technologies that are designed to extract value from data having four Vs characteristics; volume, variety, velocity and veracity” [
59]. GPUs provide massively parallel computing power to speed up computations. Big data leverages distributed and high performance computing (HPC) technologies, such as GPUs, to manage and analyze data. Big data and HPC technologies are converging to address their individual limitations and exploit their synergies [
60,
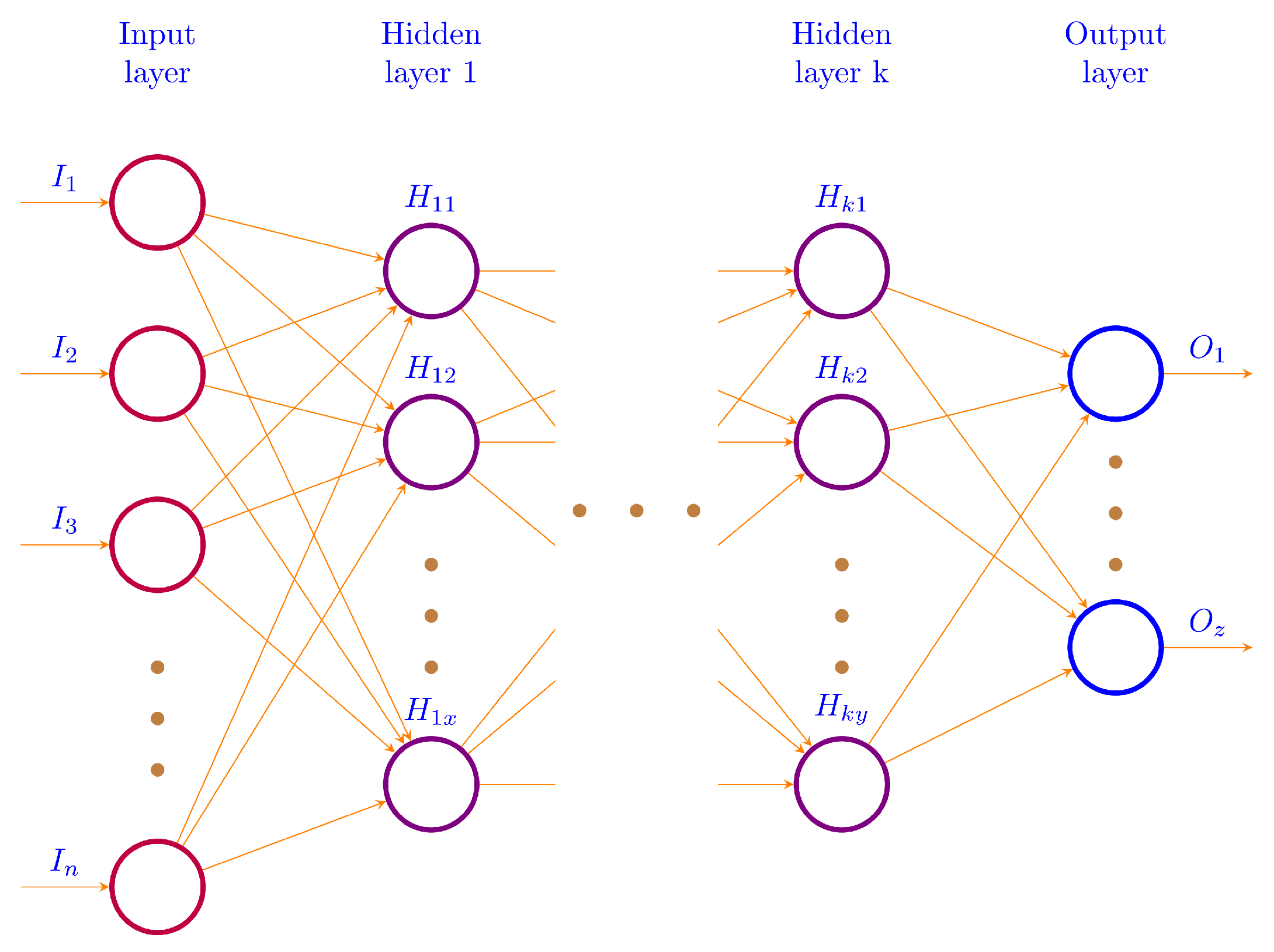
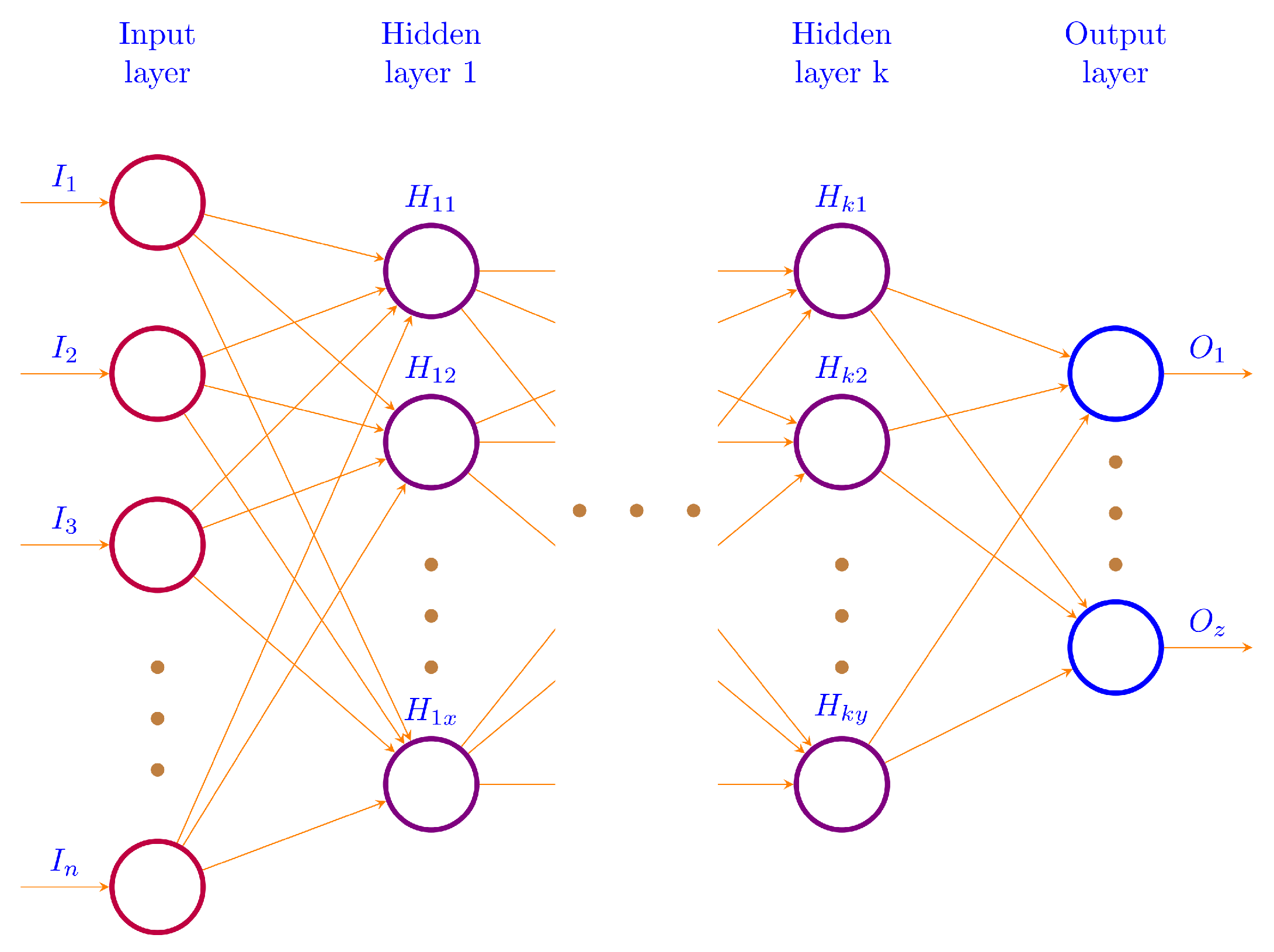
61]. In-memory computing allows faster analysis of data by the use of random access memories (RAMs) as opposed to the secondary memories. We used Convolutional Neural Networks (CNNs) in our deep learning model.
The dataset we used is provided publicly by the California Department of Transportation (Caltrans) Performance Measurement System (PeMS) [
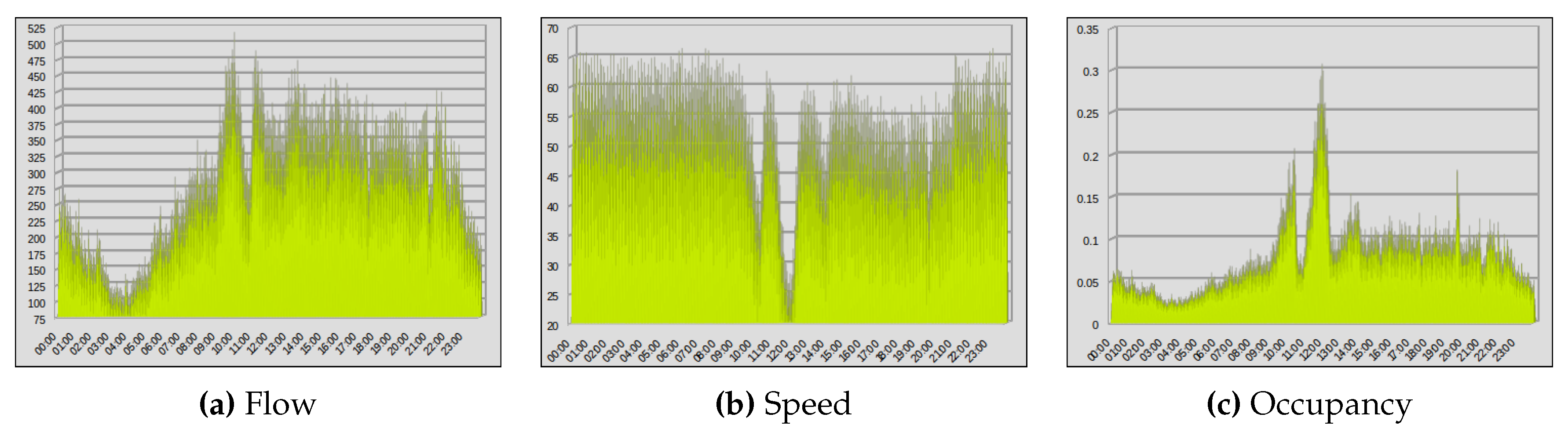
62]. The road traffic dataset provides five-minute interval traffic data on the freeways. It includes vehicle flow, speed, occupancy, the ID of the Vehicle Detector Station (VDS), and other data. The dataset is used for the training of deep convolution neural networks. We analyzed over 11 years of PeMS road traffic data from 2006 to 2017 collected from the 26 VDSs on a selected chunk of a big corridor I5-N in California. To the best of our knowledge, this is the largest data, in terms of the time duration, that has been used in a deep learning based study. Big data veracity issues have been discussed in detail and methods to address the incompleteness and errors in data have been described.
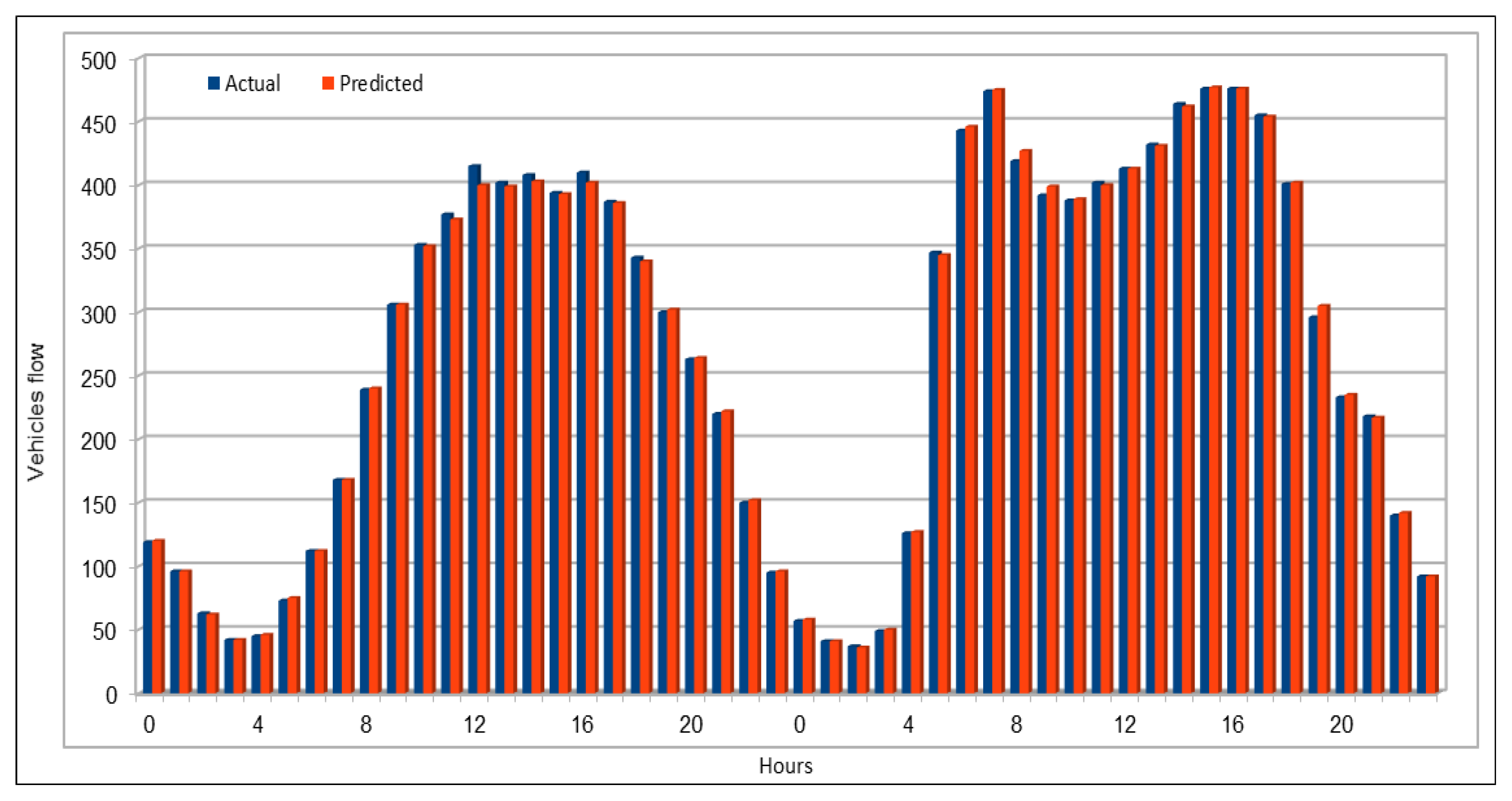
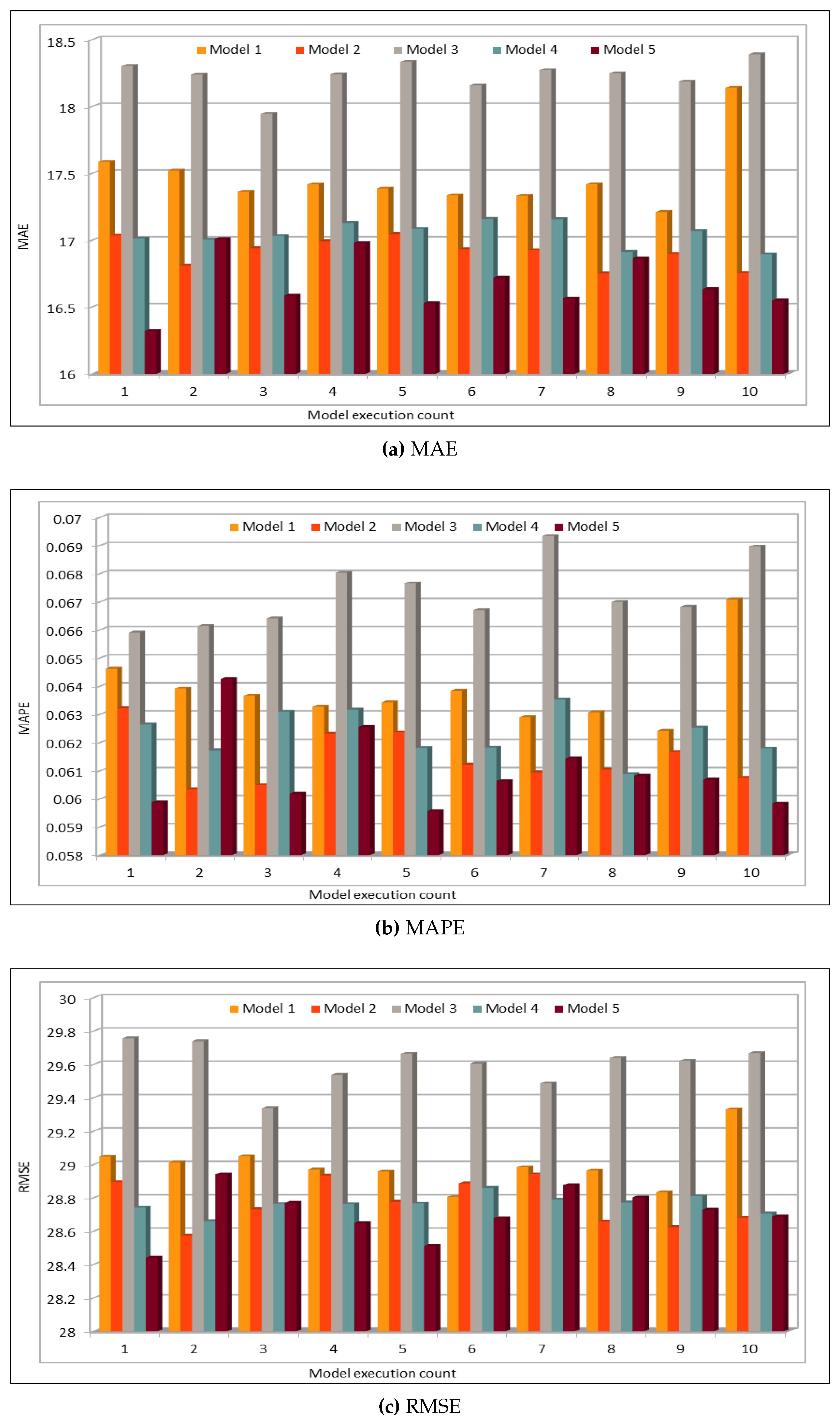
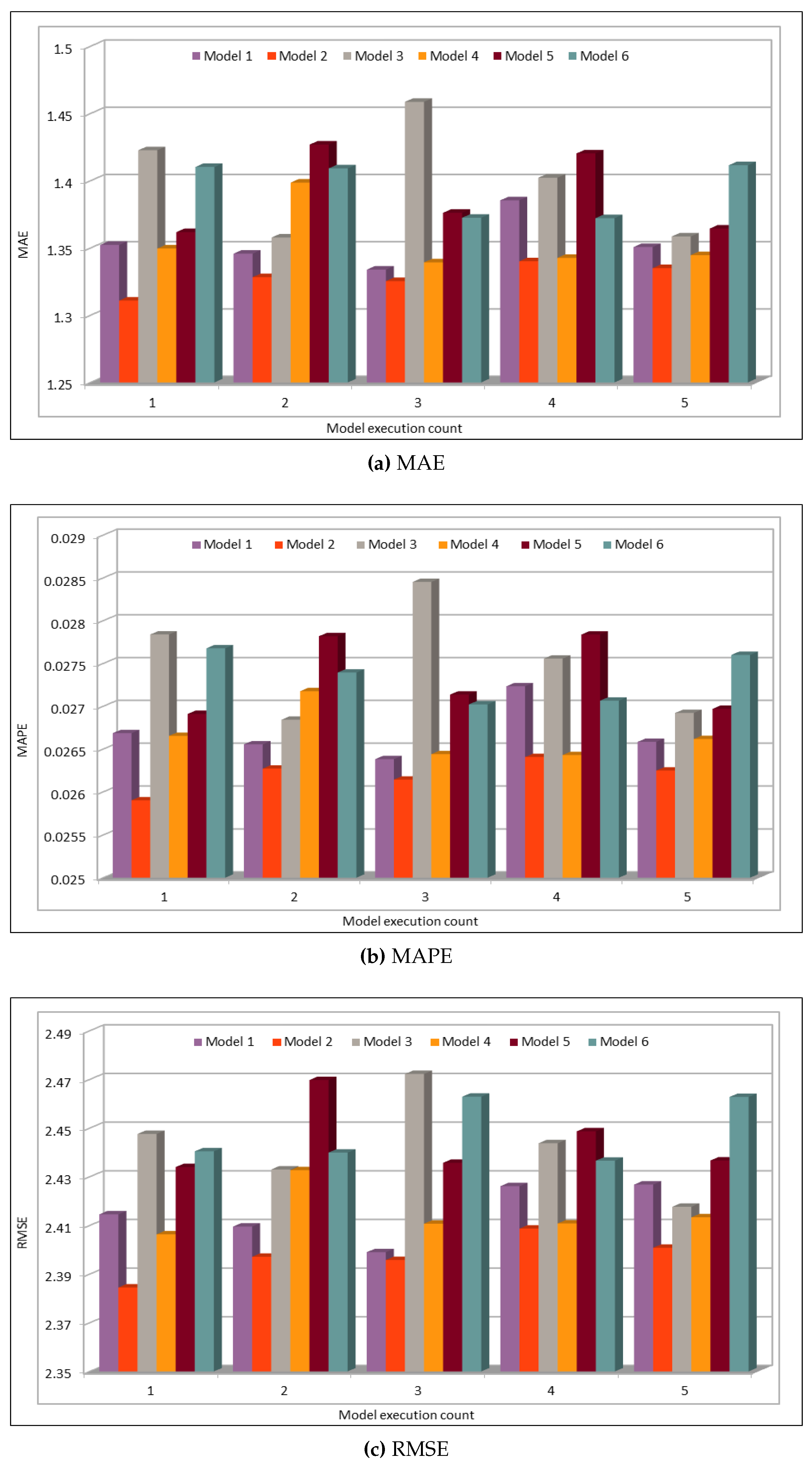
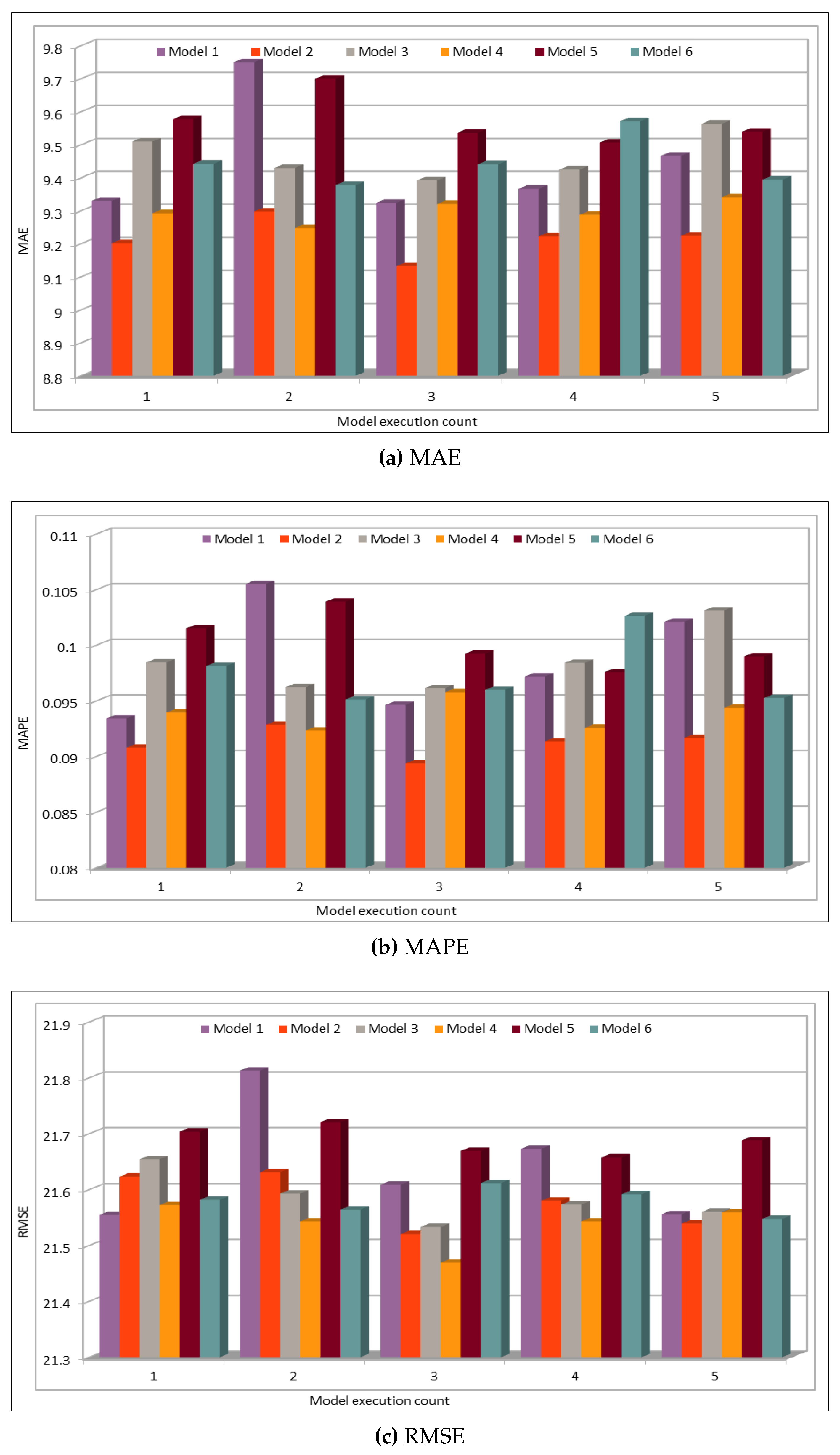
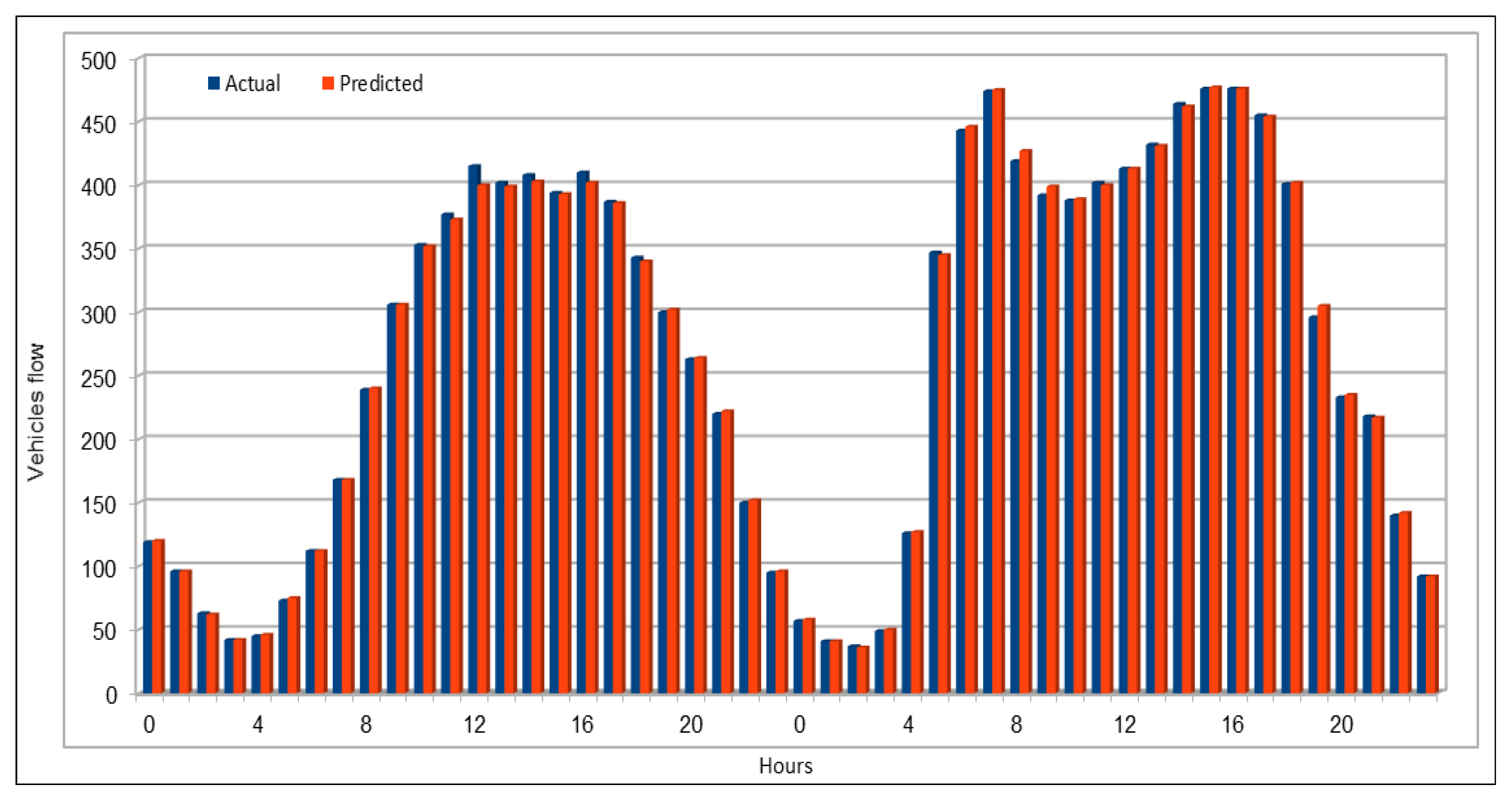
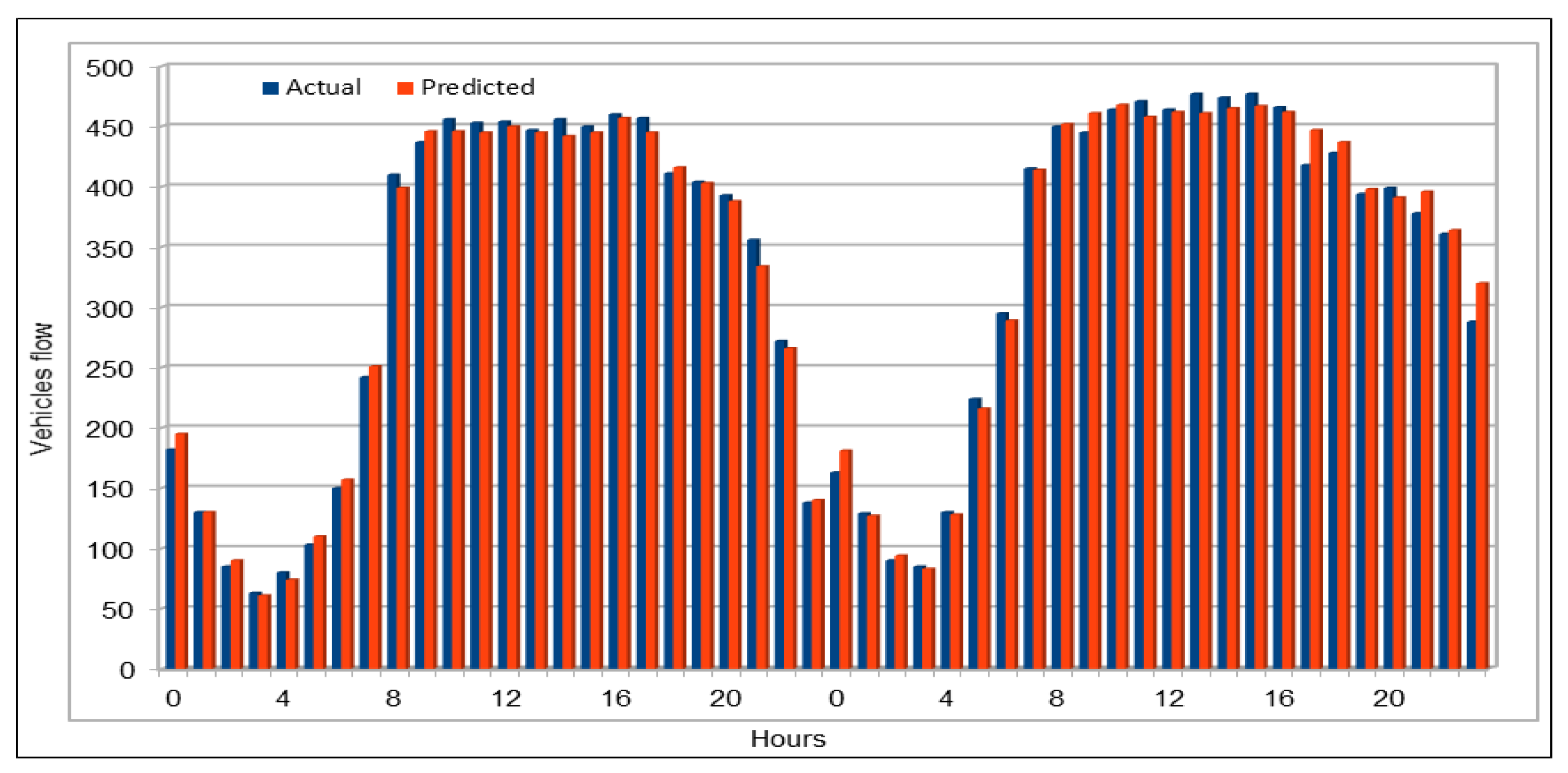
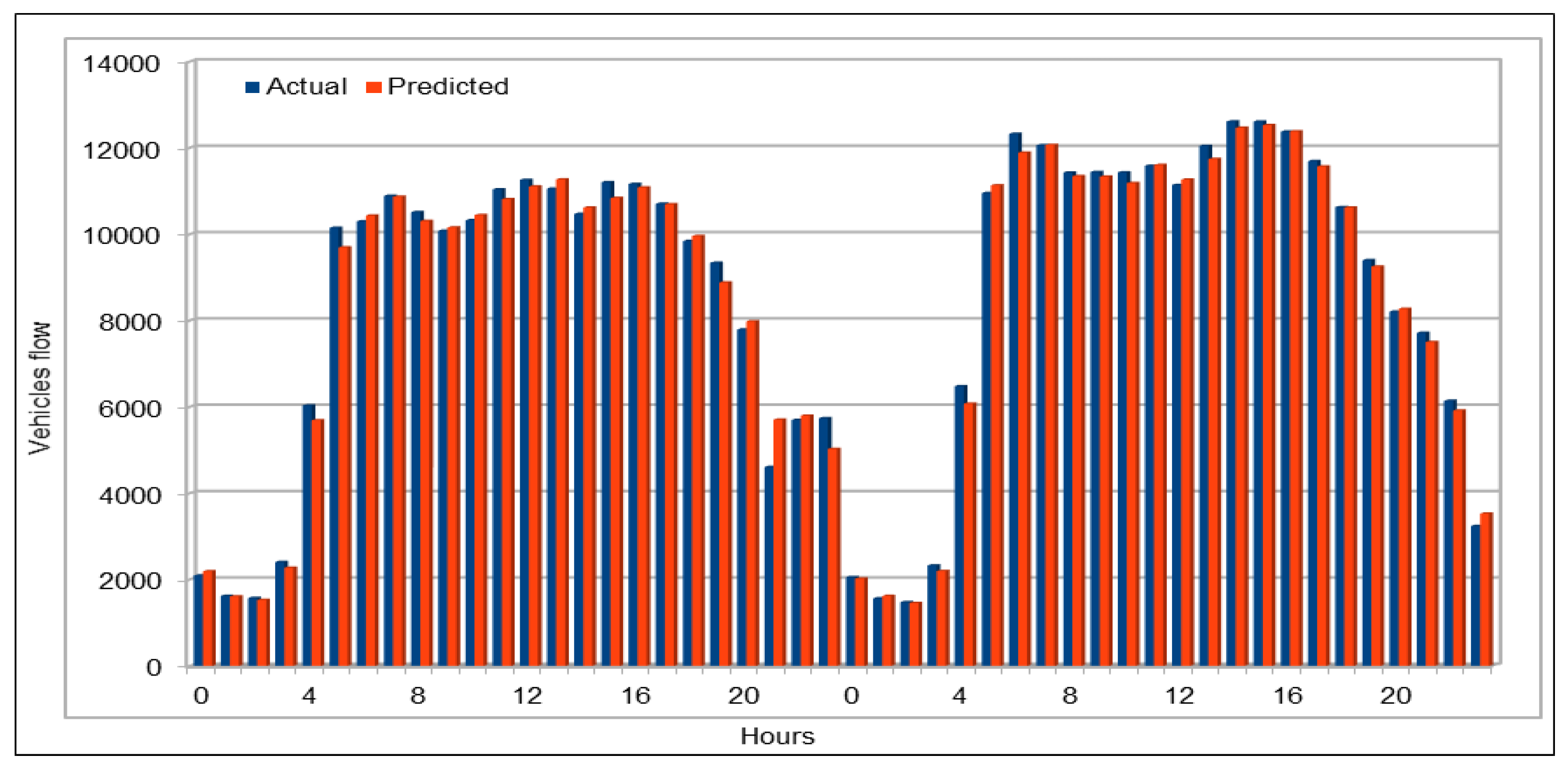
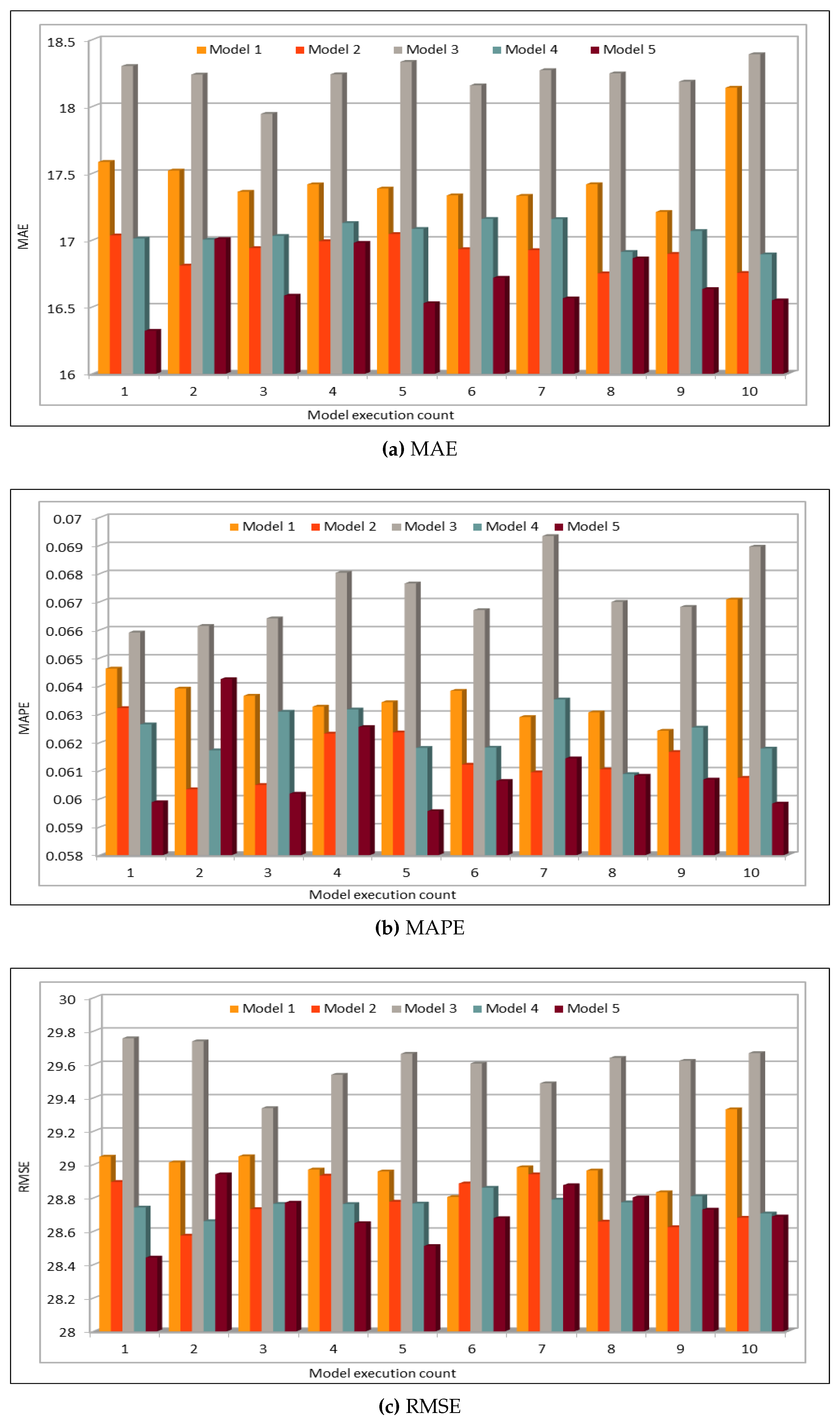
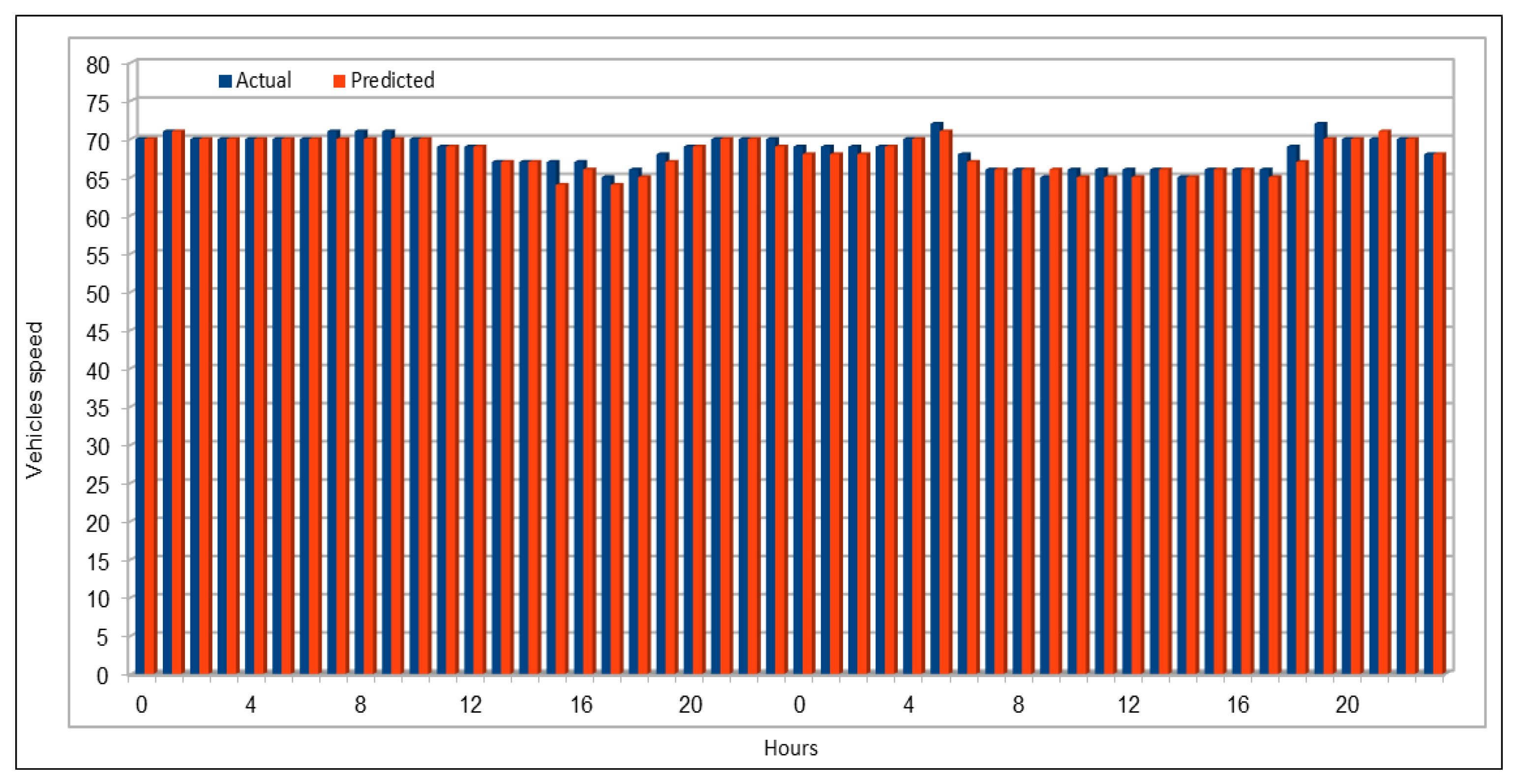
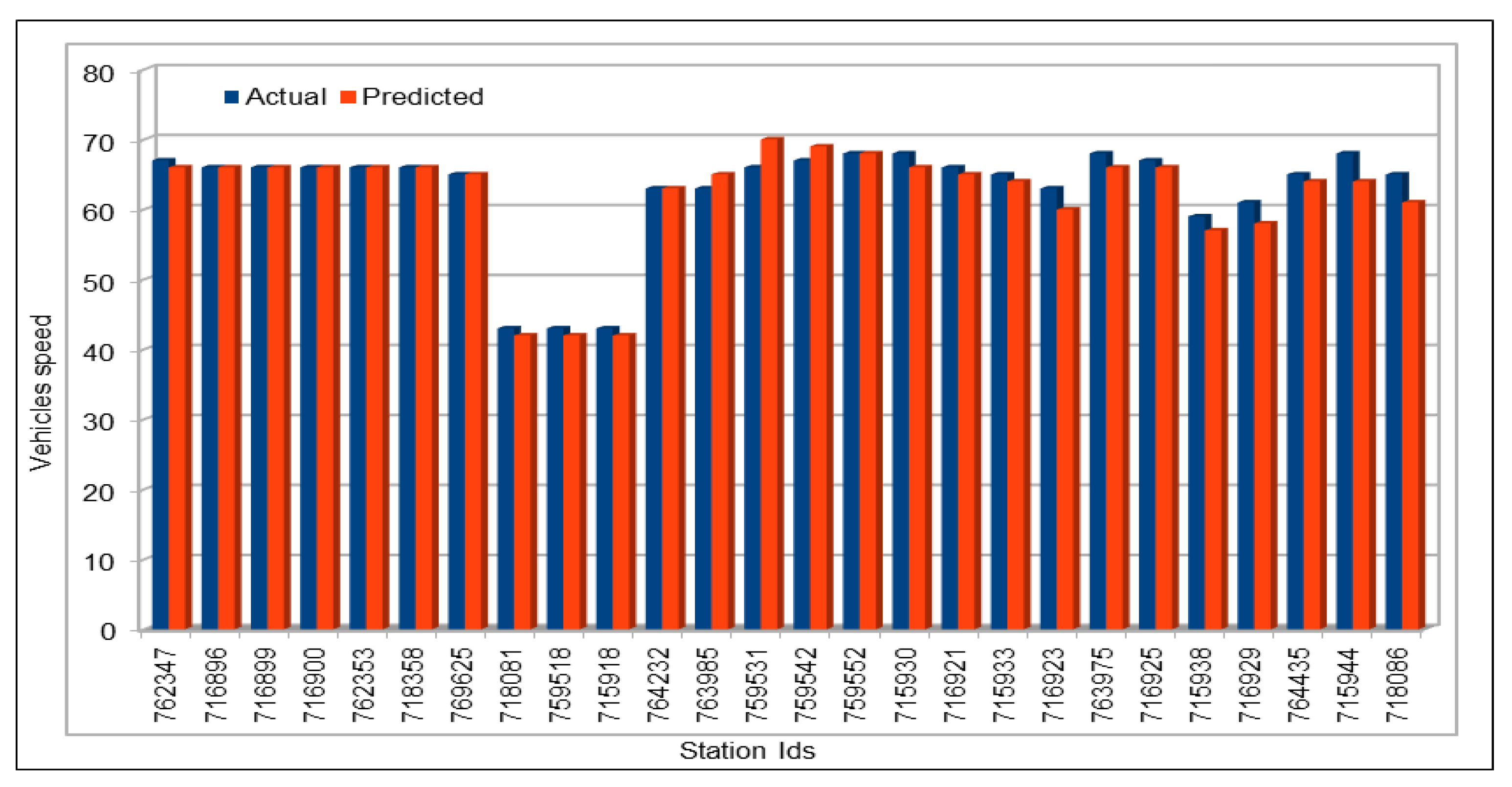
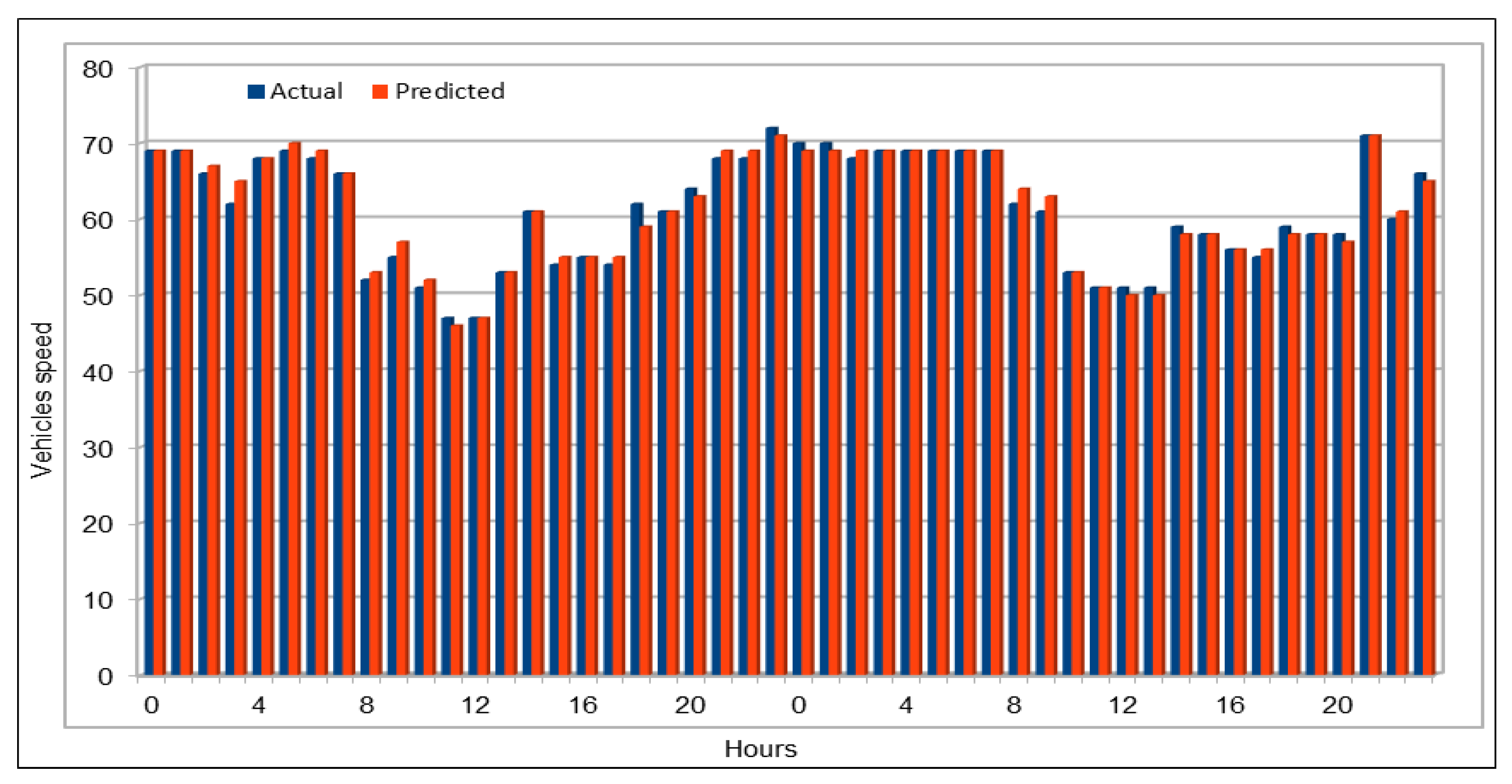
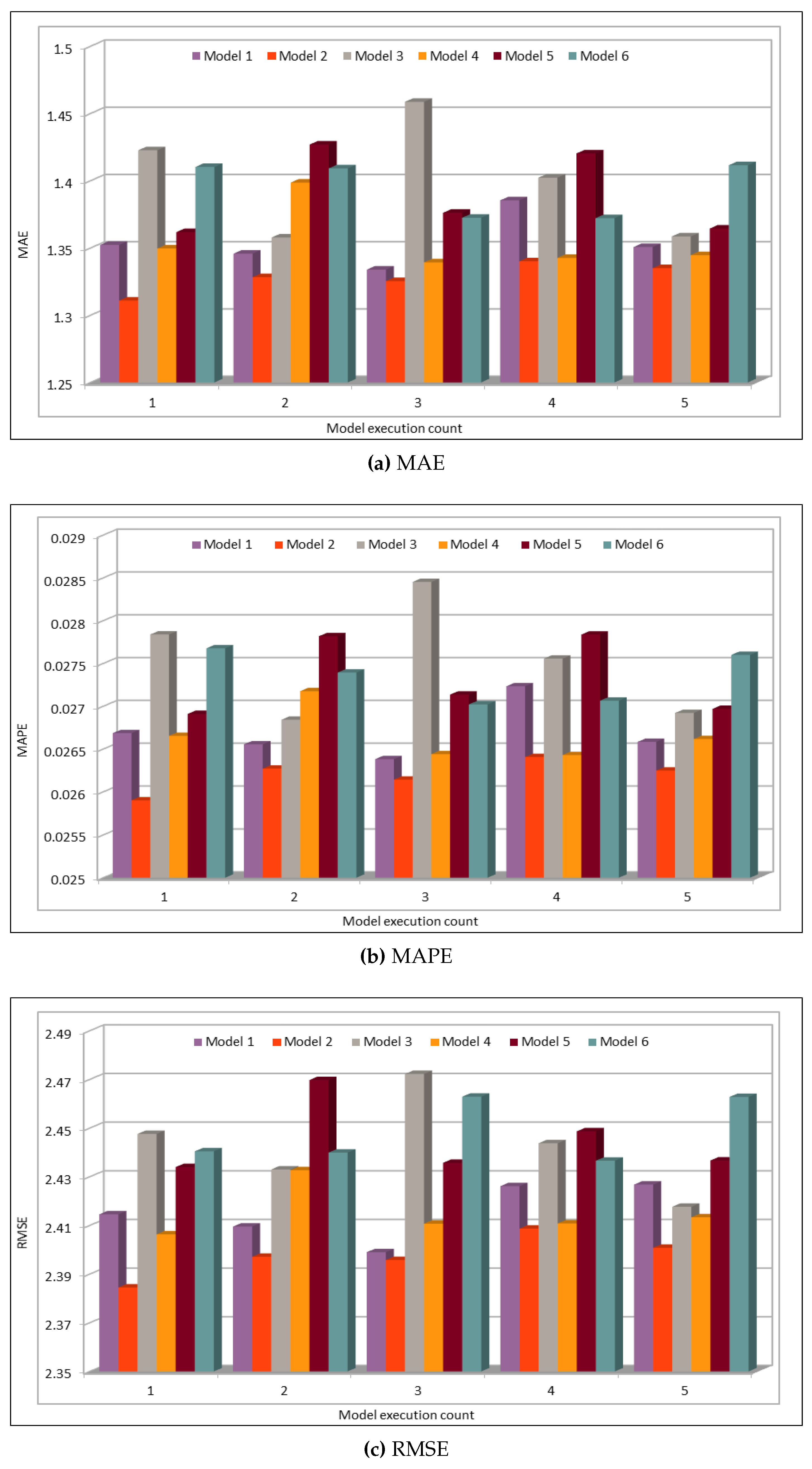
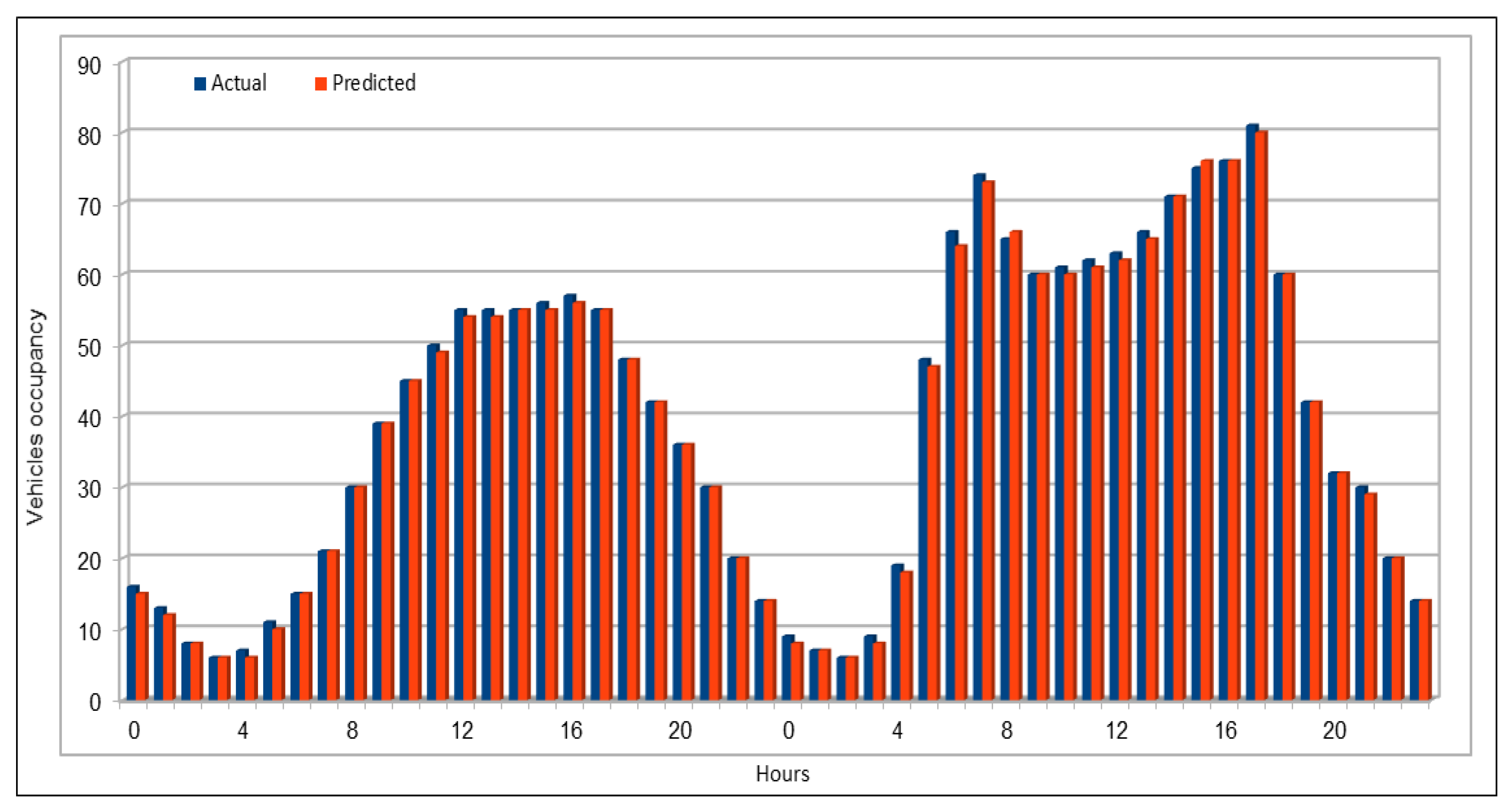
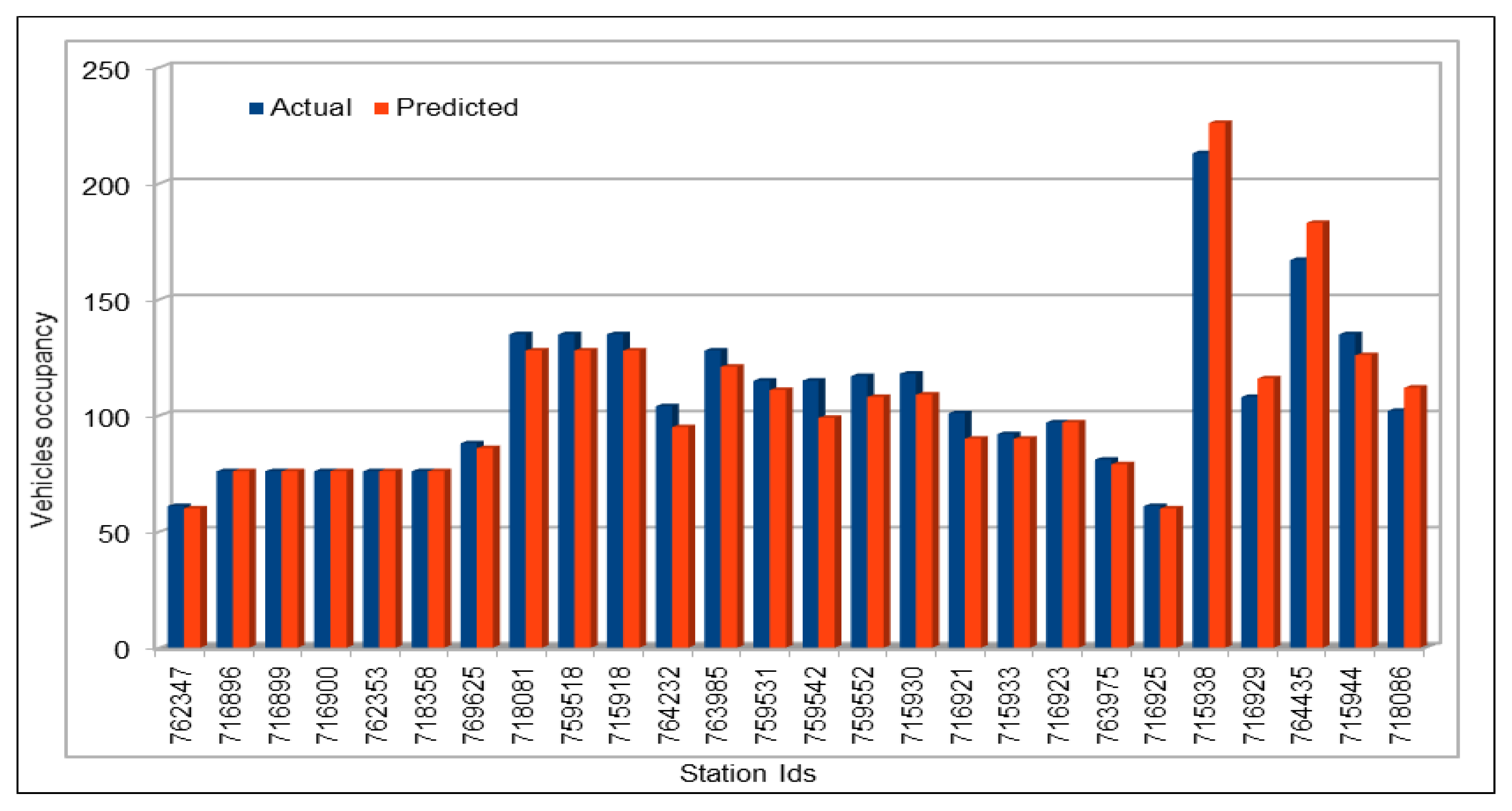
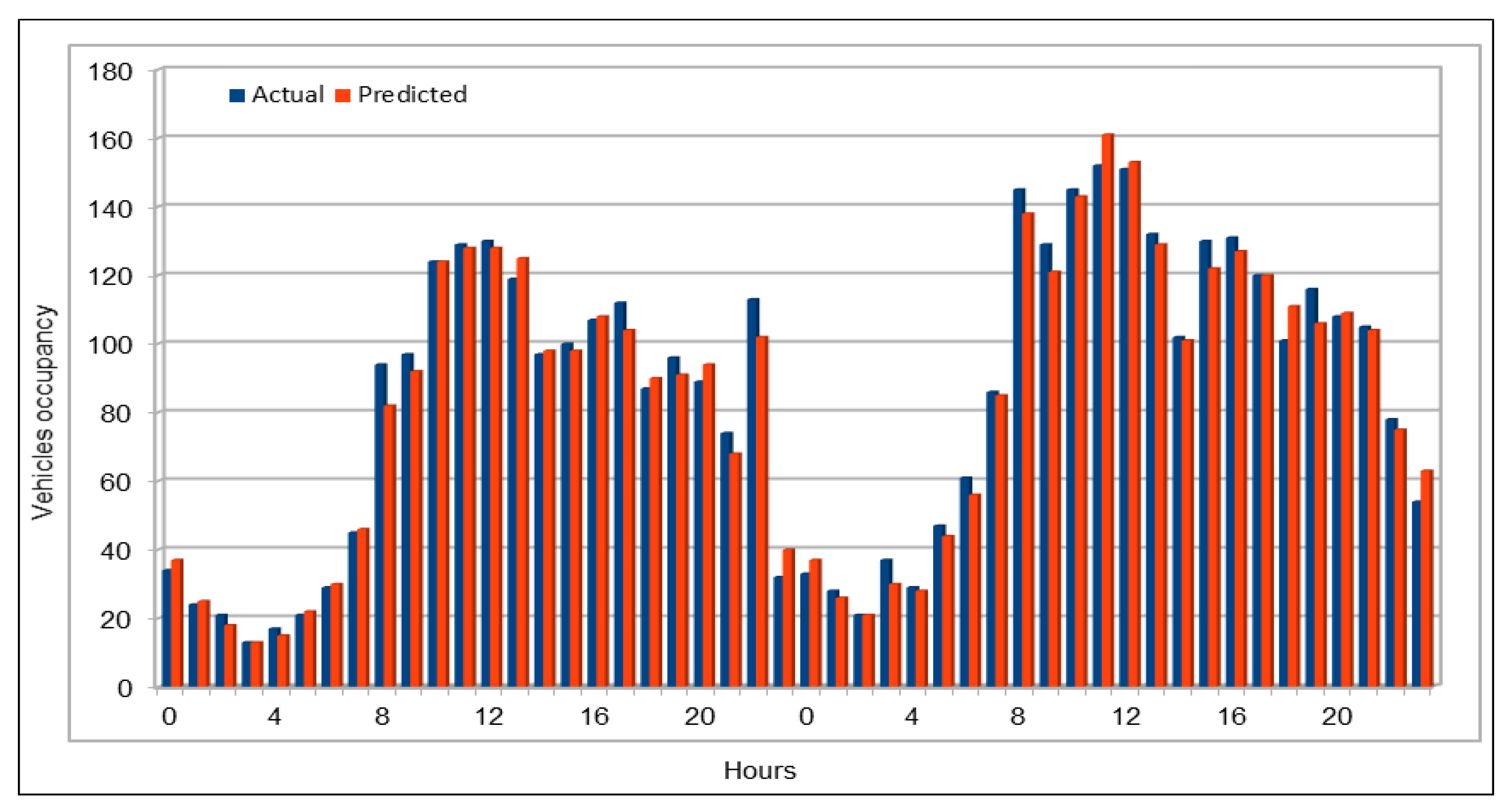
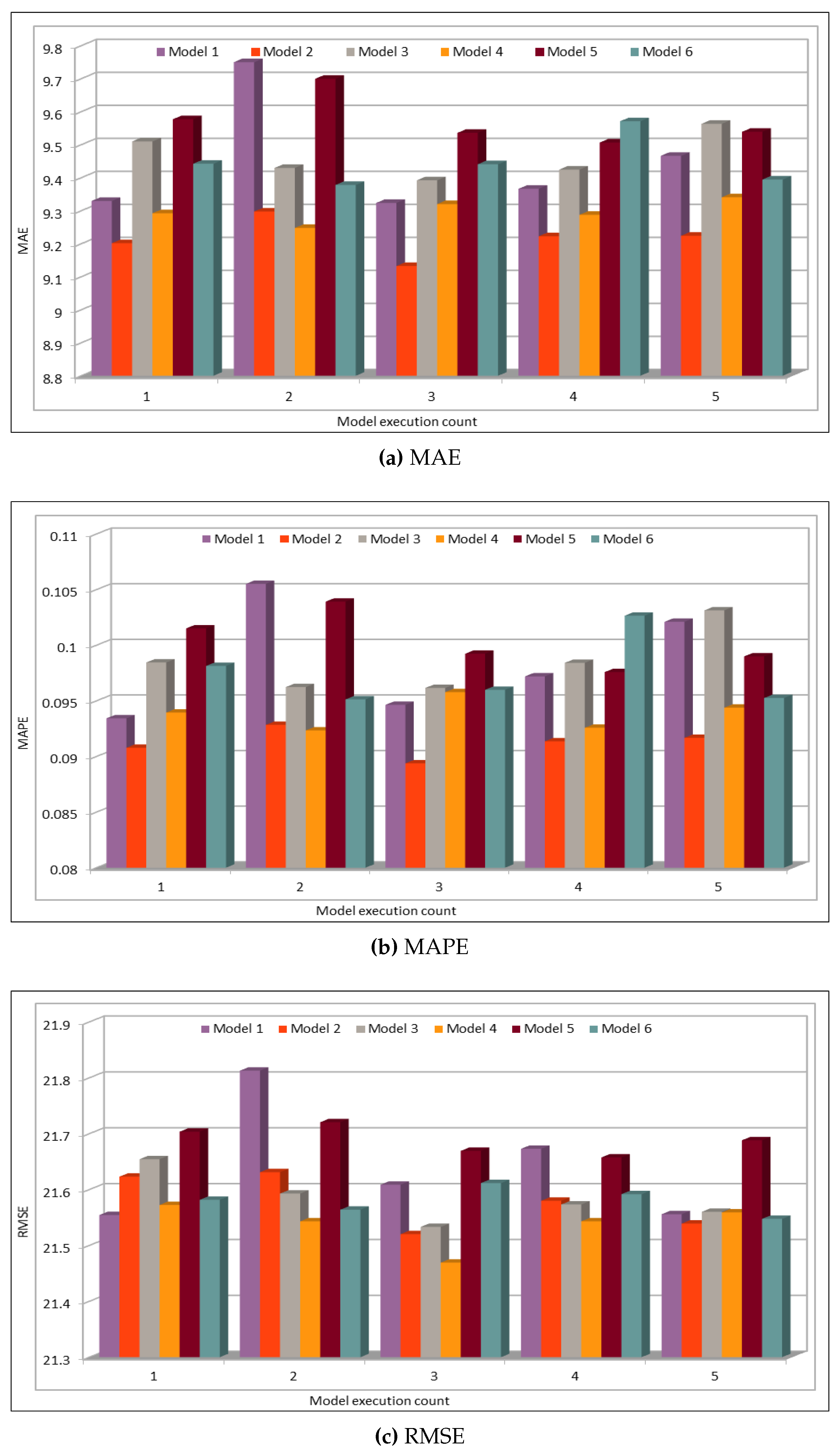
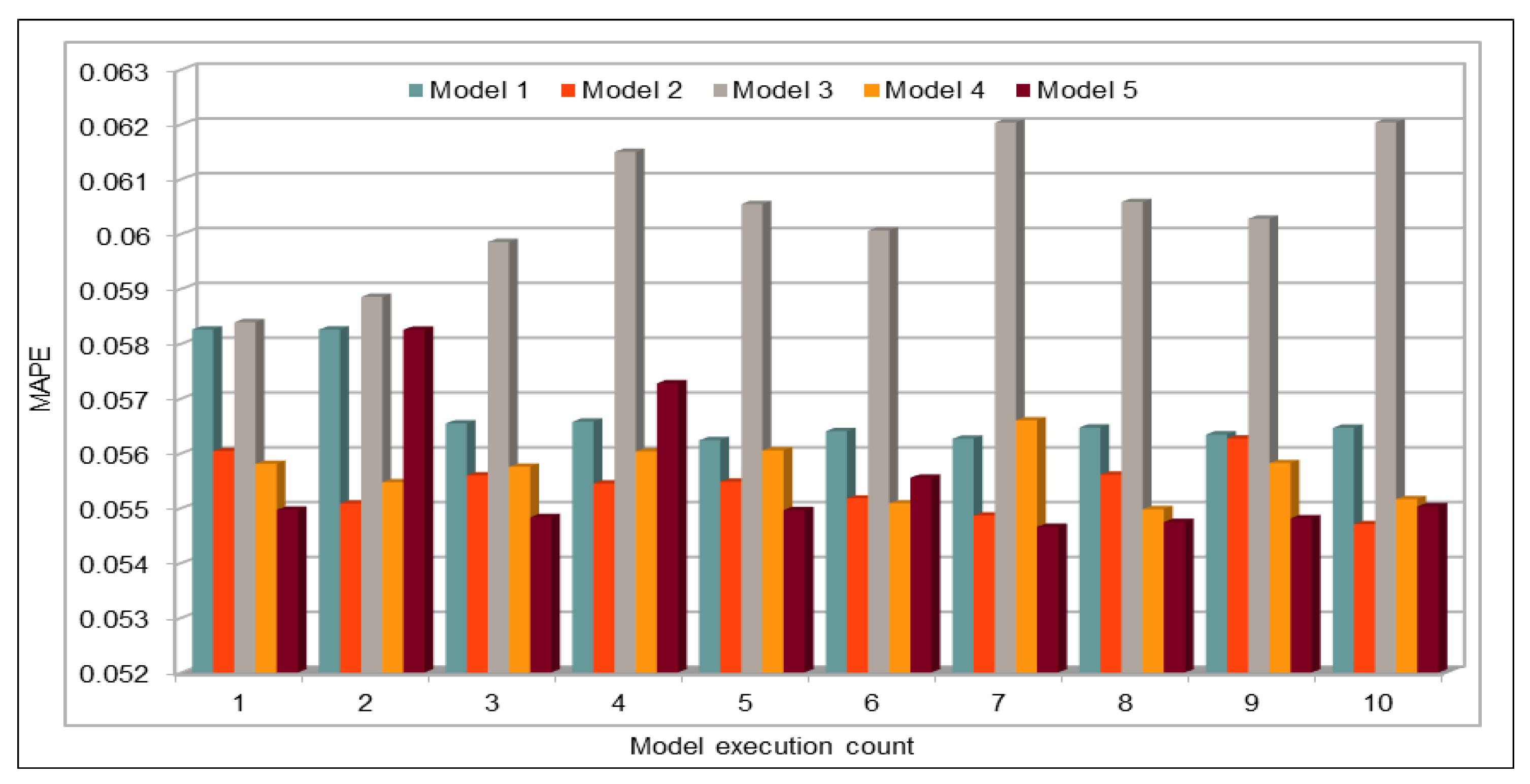
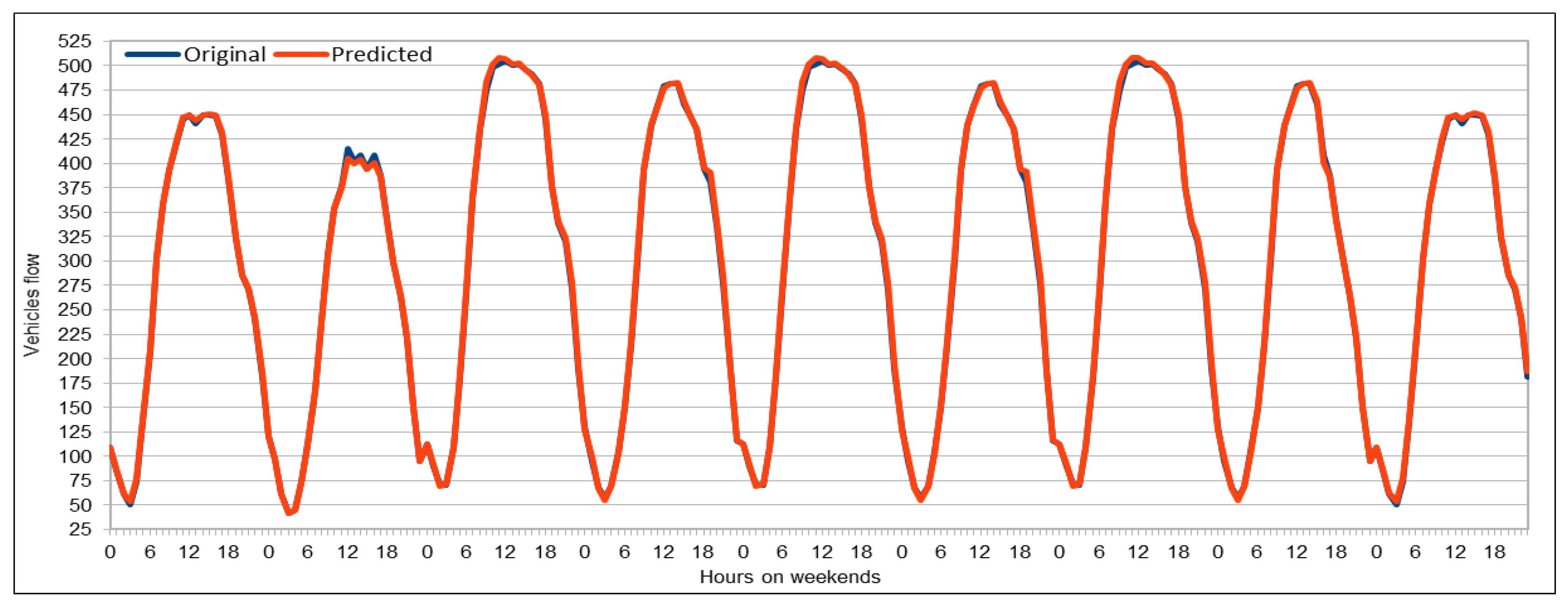
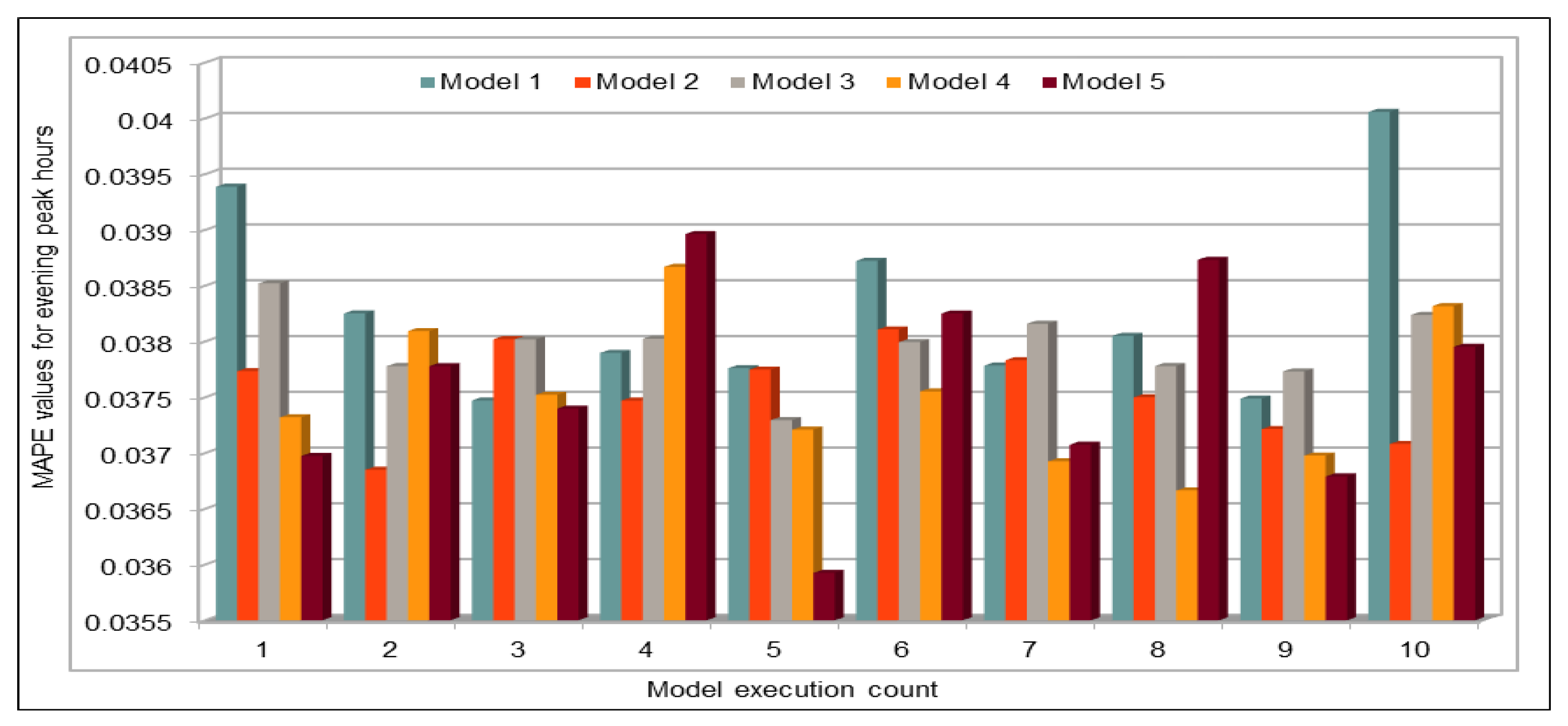
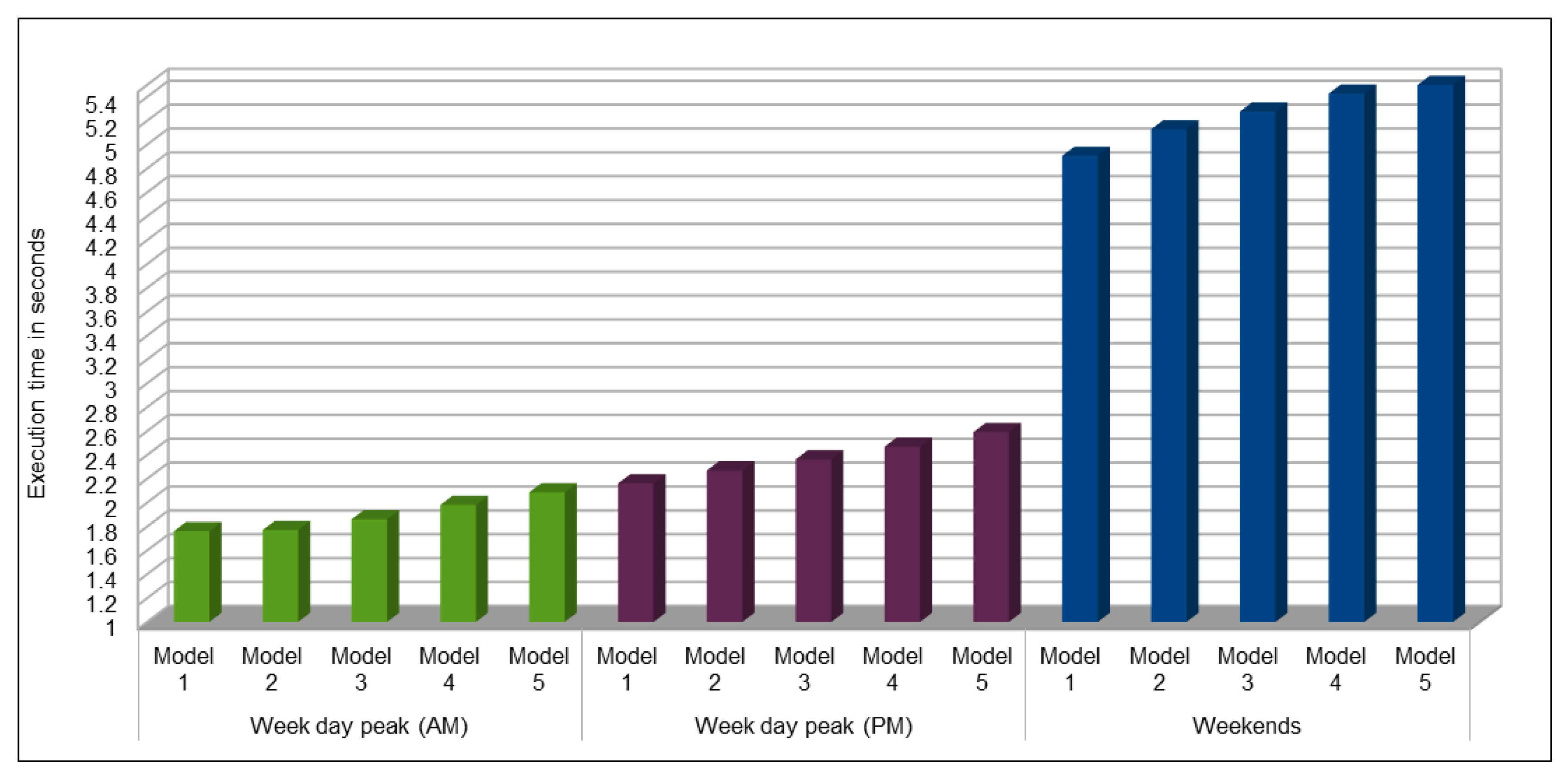
Several combinations of the input attributes of the data along with various network configurations of the deep learning models are investigated for the training and prediction purposes. Different configuration sets of the deep learning networks have been executed multiple times, where the batch sizes and the number of epochs have been varied with different combinations, and each combination has been executed multiple times. These multiple configurations show consistency of the accuracy of the results. The training of a deep model is a compute intensive job, particularly when the size of the dataset is large. The use of GPUs provides a speedy deep learning training process, and we verified this by comparing the execution time performance of the training process on GPUs with CPUs. Moreover, we explored the possibility of real-time prediction by saving the pre-trained deep learning models for traffic prediction using the complete 11 years of data, and subsequently using it on smaller datasets for near real-time traffic predictions using GPUs. This is a first step towards the real-time prediction of road traffic and will be further explored in our future work. For the accuracy evaluation of our deep prediction models, we used three well-known evaluation metrics: mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean squared error (RMSE). Additionally, we have provided the comparison of actual and predicted values of the road traffic characteristics. The results demonstrate remarkably high accuracy.
The paper contributes novel deep learning models, algorithms, implementation and an analytics methodology, and a software tool for smart cities, big data, HPC, and their convergence. The paper also serves as a preliminary investigation into the convergence of big data and higher performance computing [
60] using the transportation case study. These convergence issues will be further explored in the future with the aim of devising novel multidisciplinary technologies for transportation and other sectors.
The rest of this paper is organized as follows.
Section 2 reviews the work done by others in the area of traffic behavior prediction. The details about our methodology and the deep learning model are given in
Section 3. The input dataset and pre-processing details are also described in this section.
Section 4 discusses the results. The proposed approach for the near real-time prediction of road traffic is discussed in
Section 5. Finally, we conclude in
Section 6 and give directions for future work.
2. Literature Review
A great deal of works have been done on traffic modeling, analysis, and prediction, and in the broader area of transportation. Some of these works have already been mentioned and discussed in
Section 1. Our focus in this paper is on the road traffic characteristics prediction using deep learning approaches, and, hence, in the rest of this section, we review the notable works relevant to our main focus area in this paper.
A deep learning approach to predict traffic flow for short intervals on road networks is proposed in [
26]. A traffic prediction method based on long short-term memory (LSTM) was used by the authors for prediction purpose. An origin destination correlation (ODC) matrix is used as input to the training algorithm. The dataset used for this process is retrieved from the Beijing Traffic Management Bureau and is collected from more than 500 observation stations or sensors containing around 26 million records. Five-minute interval data from 1 January 2015 to 30 June 2015 are collected where the data for first five months are used for training and the rest of the data were are for testing purposes. For evaluation of proposed model, mean absolute error (MAE), mean square error (MSE), and mean relative error (MRE) are calculated. Input data are used to predict the flow in 15-, 30-, 45-, and 60-min time intervals. The authors selected three observation points with high, medium, and low flow rates to compare the actual flow and predicted flow values on those observation points. MRE values for 15-min interval flow prediction reported in this work are 6.41%, 6.05%, and 6.21%. They compared the result with the other approaches including RNN, ARIMA, SVM, RBF, etc. and concluded that for time interval shorter than 15 min, RNN is relatively accurate, but, with big time intervals, error increases. Overall, it performs better than other older machine learning models. Therefore, it is concluded that LSTM is an appropriate choice for long time intervals.
Another traffic flow prediction approach has been proposed in [
23] that uses autoencoders for training, testing and to make predictions. The model is named as stacked autoencoder (SAE) model. Data for this purpose are also collected from PeMS [
62]. They used weekdays (Monday–Friday) data for first three months of 2013 giving vehicles flow on a highway on five-minute interval basis. Data for first two months are used for training and remaining one-month data are used for the testing. By using five-minute interval data, the authors predicted the aggregate flow for 15-, 30-, 45-, and 60-min intervals in this model. Three months of data for all the highways available in the system are used in this model. Although this is a large amount of data that requires gigabytes of storage capacity, the key point to mention is that data from one highway can only be used to predict the flow on that particular highway. Thus, if they used each highway’s data to predict the flow of vehicles on each highway, then it means that they executed the proposed model with different small datasets (few MBs each) to predict the flow values for each highway. Therefore, no big data technology is used to store or process the input datasets. Support vector machines (SVM) have been used for comparison purpose by using three performance metrics, i.e., mean absolute error (MAE), mean relative error (MRE), and root mean squared error (RMSE). Flow values for four time-intervals (15-, 30-, 45-, and 60-min) are predicted and the authors claimed the average accuracy for all four intervals of 93% obtained by using MRE% values (i.e., 1 − MRE%).
In another work [
27], a deep learning approach using CNN and LSTM is proposed to predict the traffic flow and congestion on highways. First, CNN is applied on the traffic flow data collected from the nearest stations on different time intervals and then the output combined with the incidents data is passed to RNN to predict flow on specific stations. They predicted the flow for a 30-min interval window by using the flow values of nearby stations for defined (e.g., four, five, etc.) time intervals. Data used for training and testing purposes are normalized using defined criteria. Five-minute interval vehicles flow data are obtained from PeMS [
62] for training and testing of DL model. For validation purpose, root mean square error (RMSE) is used. Results show that they successfully predicted the flow values for specified stations on highways without using the historic data and were able to predict the flow in real time, but the method needs improvement as the predicted values are affected by different factors such as rush hours, holidays, any incident, etc. Thus, although the authors used the incident data, improvements are needed to make more accurate predictions. Data used for deep models are real, but the amount of data used for training the model is small because they used two months of five-min interval data for 60 consecutive locations for training and testing of deep model.
Ma et al. [
30] used LSTM neural network to predict traffic speed for short time intervals. They used LSTM to predict speed on road networks for different short intervals of one to four minutes using historical data. Two-minute interval data from two sensors capturing traffic data on two opposite directions on a road are collected for one month (June 2013). MAPE and MSE are used as performance metrics and each model is executed 10 times to observe prediction consistency. Performance is compared with other models including Elman NN, time-delay NN, nonlinear autoregressive with exogenous input NN, SVM, ARIMA, etc. Two different type of input datasets are used for training, one of them includes historic speed values to be used as input for training and the other one includes historic speed and volume values as input for training. Results shows that the dataset using both speed and volume produces slightly better results than the results where only speed value is used. Furthermore, results show that LSTM performs much better than the other models and its results remains stable for all the time slots used for prediction purpose, but the other models improves their accuracy when time lags are increased. Results show a very high accuracy rate due to very low MAPE values but these could be high (MAPE) when time intervals are big. In addition, data are collected from only two sensors for a very short period thus they are almost uniform without any big change in the data and this could also be the reason for high accuracy rate.
Fu et al. also used LSTM and gated recurrent units (GRU) to predict vehicles flow using data from PeMS in [
63]. They used one month of five-minute interval flow data collected from 50 sensors. The first three weeks of data are used for training and the last week of data are used for testing. Five-minute intervals data (flow values) for 30 min are used to predict the flow for next five minutes and the missing values in the dataset are replaced by historic average values. The prediction results are compared with the ARIMA and results are analyzed using MSE and MAE.
In another work, Jia et al. used a deep learning approach called deep belief networks (DBN) to predict the vehicles speed on a road network [
25]. In this work, they used Restricted Boltzmann Machines (RBMs) for unsupervised learning and then used the labeled data for fine tuning. The dataset used is obtained from Beijing Traffic Management Bureau (BTMB). Three months of data (June–August 2013) are used which provide two-minute interval data collected from the detectors installed on a specified segment of road in Beijing, China. Around 11 weeks of data are used for training purpose, whereas the last week of data are used for testing purpose. This provides two-minute interval speed, flow and occupancy values and by using this two-minute interval data, the authors predicted speed for intervals of 2, 10, and 30 min. Furthermore, for performance analysis, three performance metrics are used: mean absolute percentage error (MAPE), root mean squared error (RMSE), and normalized root mean squared error (RMSN). No mechanism was mentioned by the authors to deal with the erroneous or missing data values and also no big data technology is used for data management. In addition, no specific information about data, e.g., number of detectors, etc., is given to know about the size of data. For deep model configurations, they executed the model with different configurations and, based on the MAPE values, they selected the best configurations. With best selected configurations, MAPE value for 2-min interval is 5.81, 7.33 for 10-min interval, and its value is 8.48 for 30-minute interval. This shows that it performs better for short time intervals and cannot cope with the stochastic fluctuations in long time intervals. Although results are quite good for speed prediction, how it behaves when some other information are included still needs to be investigated, e.g., we do not know whether data from multiple detectors are used or separate data for each detector are used because, in the former case, there would be more fluctuations in the data compared to the latter case. In addition, the size of data could also change the results.
A hybrid deep learning approach to predict traffic flow is proposed in [
64]. In this approach, the authors combined convolutional neural networks (CNNs) and long short-term memory (LSTM) to use the correlation between the spatial and temporal features to achieve the goal of forecasting traffic flow. Data are collected from PeMS [
62] that include 33 locations on one side of a highway. Fifteen months of five-minute interval data ew used. For comparison purpose, MAE are MAPE are calculated. In addition, to analyze the forecasting correctness of spatial distribution, average correlation error (ACE)is calculated. In this work, although they combined temporal and spatial features to get high accuracy, which they achieved, the method cannot be considered very effective as compared to the other approaches used in this work for comparison purpose. Use of both spatial and temporal features helps in improving the accuracy but they still need to investigate the best combinations to improve the accuracy.
Deep learning is also used for crash predictions on the road network. In [
65], the authors proposed a dynamic Bayesian network approach to predict the crashes on highways in real-time by using the traffic speed conditions data. In this work, the relation between the crash incidents and the traffic states is established, so that it could be used to predict the possibility of crashes on highways. Traffic states on the crash site are divided into the upstream and downstream states. Here, upstream is the state just before the crash and downstream is the state just after the crash in traffic flow direction. A vehicle speed threshold of 45 km/h is defined to identify the free flow (FF), i.e., traffic state is FF if the vehicles average speed is above 45 km/h. Average speed below 20 km/h identifies the jam flow (JF) and it is considered congested traffic (CT) if the flow is between the FF and JF threshold values. By using these three states values, nine combinations (upstream and downstream) are defined to identify the occurrence of crashes in those states combinations. Crash reports data used in this work include 551 records where 411 records are used for training and the remaining 140 records are used for the testing purpose. A confusion matrix is created to see the results. Several metrics based on the confusion matrix data are used to analyze the prediction results. Best DBN accuracy reported in this work is 76.4% where the false alarm rate reported in this case is 23.7%.
Deep learning approaches are also used by many other researchers, who used them for traffic flow prediction [
66,
67,
68,
69,
70,
71,
72,
73]. Some others used it for traffic condition prediction on the road networks [
29]. In addition to the vehicles flow data to predict traffic flow on highways, some researchers used other datasets with the flow dataset to predict vehicle flow on the roads. In [
74], weather information is included with the input dataset, i.e., weather data from [
75] are combined with the vehicles flow data to predict vehicles flow. In addition to the deep learning approaches for prediction, some researchers worked on traffic flow or travel time prediction using other approaches [
76,
77,
78]. Therefore, we can say that this area has gained the focus of the research community, various approaches to predict the traffic behavior on road networks are used for effective traffic management. Among those approaches, prediction of traffic behavior by using deep learning approaches has a significant importance because of its ability to learn from many data and to learn the patterns more accurately as compared to the other approaches. By using deep learning, traffic behavior can be predicted by gaining high prediction accuracy but still it can be questioned as only a few methods use big traffic data as an input to the deep models. Deep learning with big input datasets requires more resources because of its highly compute intensive nature and also takes a lot of time for training. Thus, researchers try not to use big datasets for their deep models, thus not only compromising their accuracy but also restricting them to predict only for a specific duration by using the small input datasets. Because the training process takes a lot of time, no one has proposed a deep learning approach to predict the traffic behavior in real-time. To address the input dataset issue, we used a very large input dataset for more than 11 years so that our deep model could learn all possible trends of traffic data including a number of social and cultural events during this duration. In addition, to predict the traffic behavior in near real-time fashion, we used the pre-trained models to predict the behavior using the recent traffic data.
6. Conclusions and Future Work
Smart cities appear as “the next stage of urbanization, subsequent to the knowledge-based economy, digital economy, and intelligent economy” [
1,
32]. Road transportation is the backbone of modern economies, albeit it costs
million deaths annually. Trillions of dollars of the global economy are lost due to road congestion in addition to the congestion causing air pollution that damages public health and the environment. Road congestion is caused by multiple factors including bottlenecks on the road networks, road traffic crashes, bad weather, roadworks, poor traffic signal control, and other incidents. Better insights into the causes of road congestion, and its management, are of vital significance to avoid or minimize loss to public health, deaths and injuries, and other socio-economic losses and environmental damages.
Many road traffic modeling, analysis, and prediction methods have been developed to understand the causes of road traffic congestion, and to prevent and manage road congestion. The forecasting or prediction of road traffic characteristics, such as speed, flow and occupancy, allows planning new road networks, modifications to existing road networks, or developing new traffic control strategies. Deep learning is among the leading-edge methods used for transportation related predictions. However, the existing works are in their infancy, and fall short in multiple respects, including the use of datasets with limited sizes and scopes, and insufficient depth of the deep learning studies. Further work is needed on the use of deep learning for road traffic modeling and prediction. Moreover, the rapid ICT developments such as high performance computing (HPC) and big data demand for non-stop innovative. multidisciplinary, uses of the cutting-edge technologies in transportation.
This paper addresses the challenges of road traffic prediction by bringing four complementary cutting-edge technologies together: big data, deep learning, in-memory computing, and HPC. The approach presented in this paper provides a novel and comprehensive approach toward large-scale, faster, and real-time road traffic prediction. The road traffic characteristics that we have predicted are flow, speed, and occupancy. We used Convolutional Neural Networks (CNNs) in our deep learning models for the training of deep networks using over 11 years of PeMS road traffic data from 2006 to 2017. This is the largest dataset that has been used in a deep learning based study. Big data veracity issues have been discussed in detail and methods to address the incompleteness and errors in data have been described. Several combinations of the input attributes of the data along with various network configurations of the deep learning models were investigated for the training and prediction purposes. These multiple configurations show consistency of the accuracy of the results.
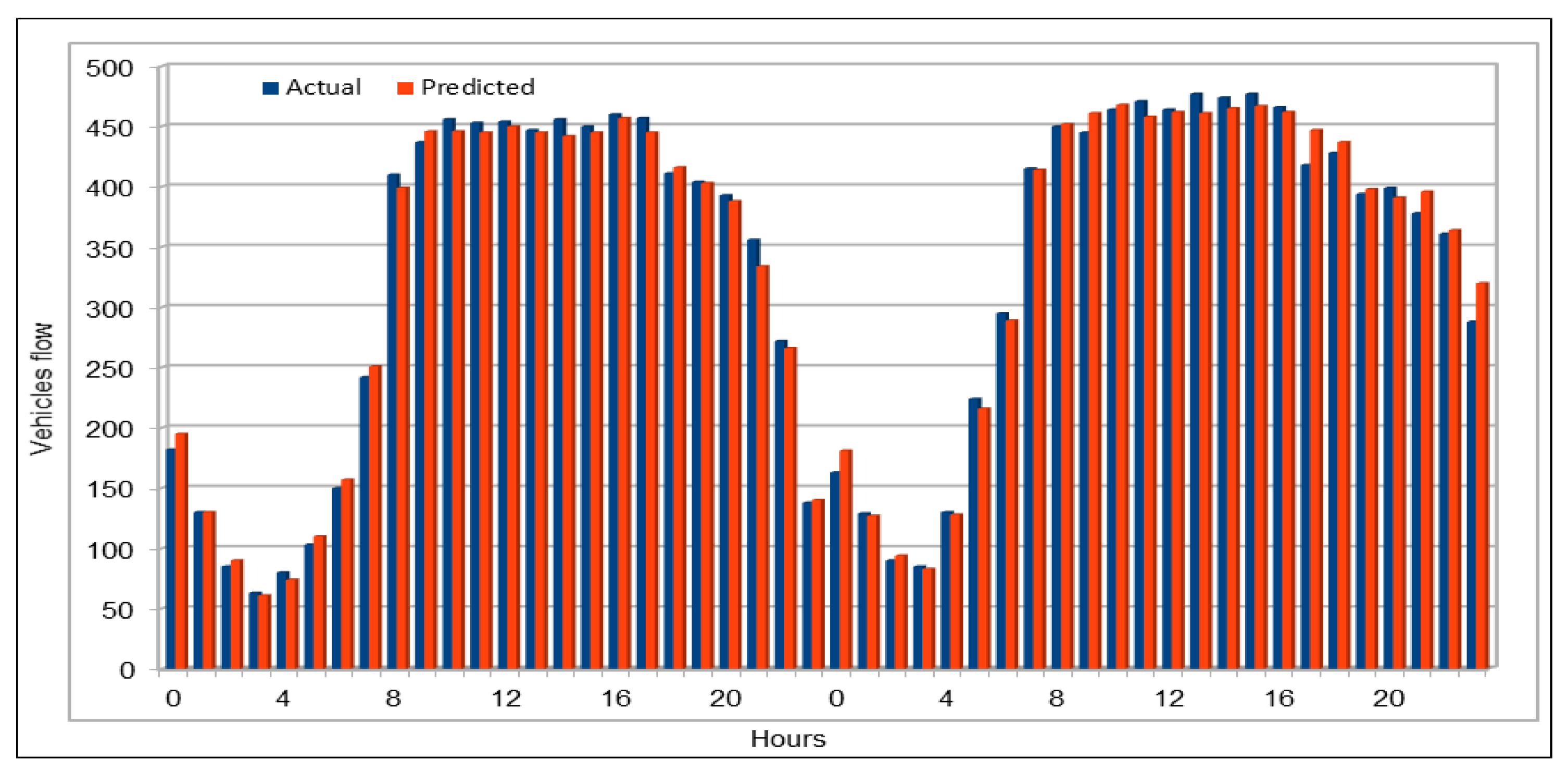
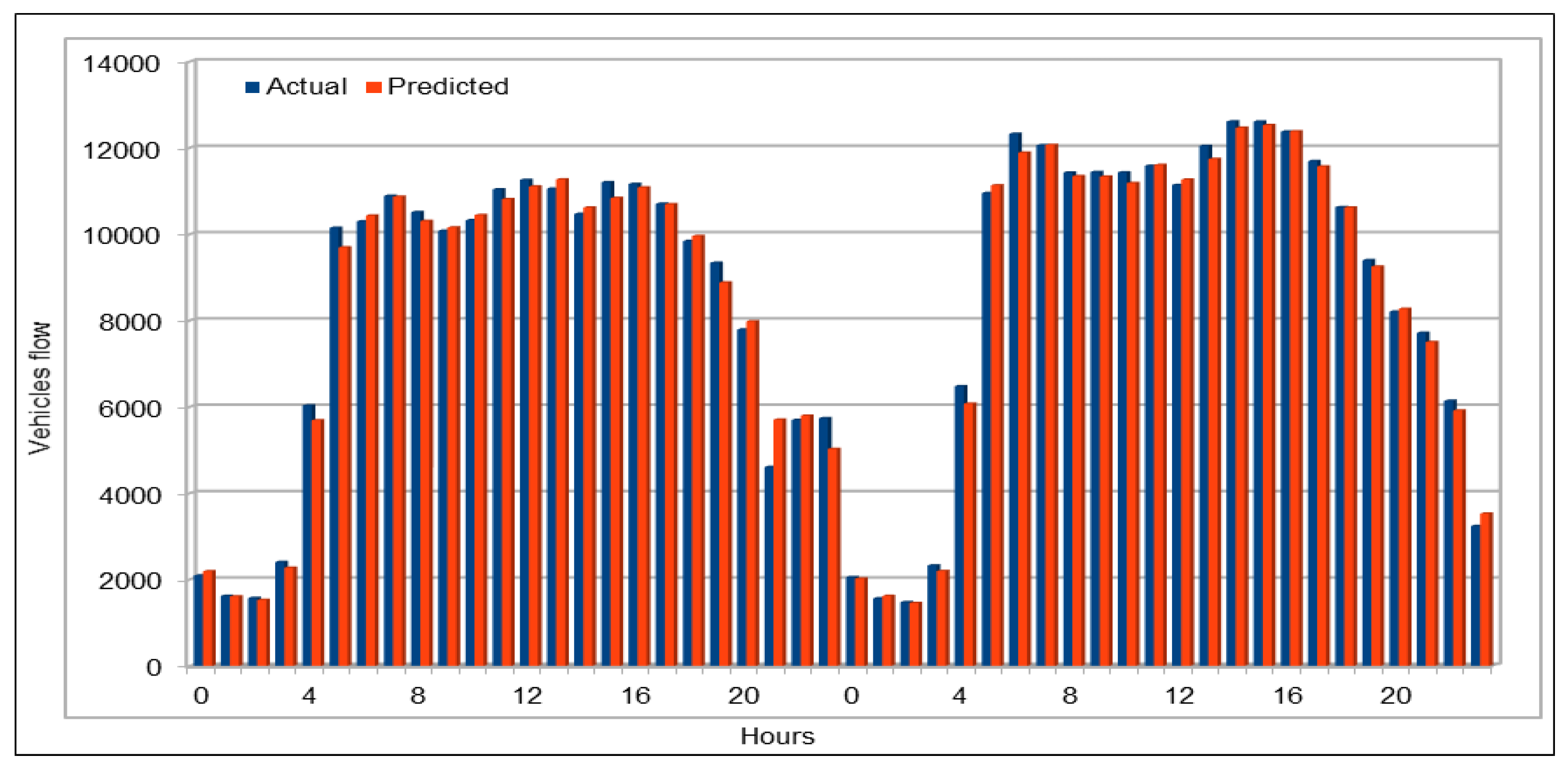
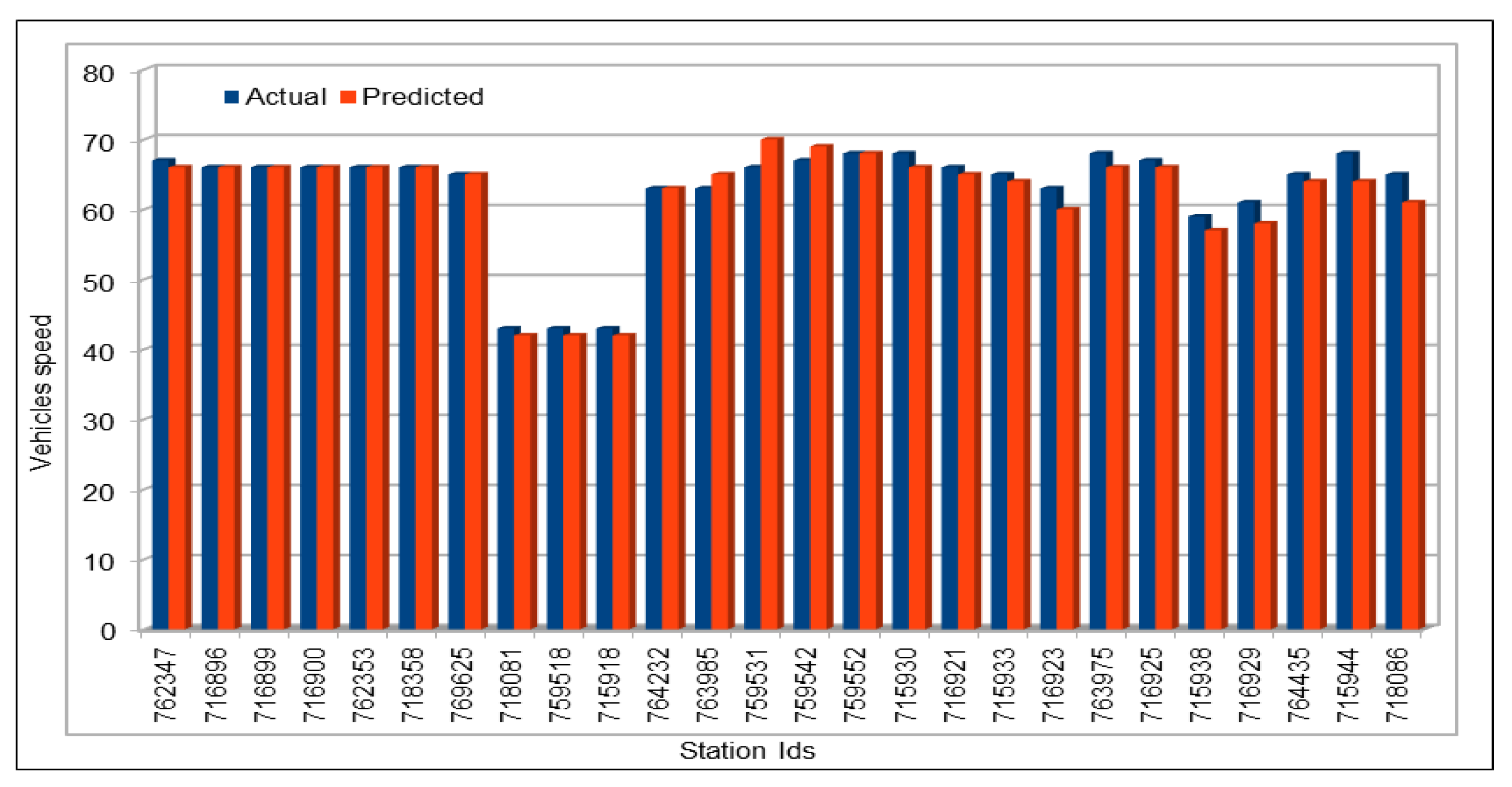
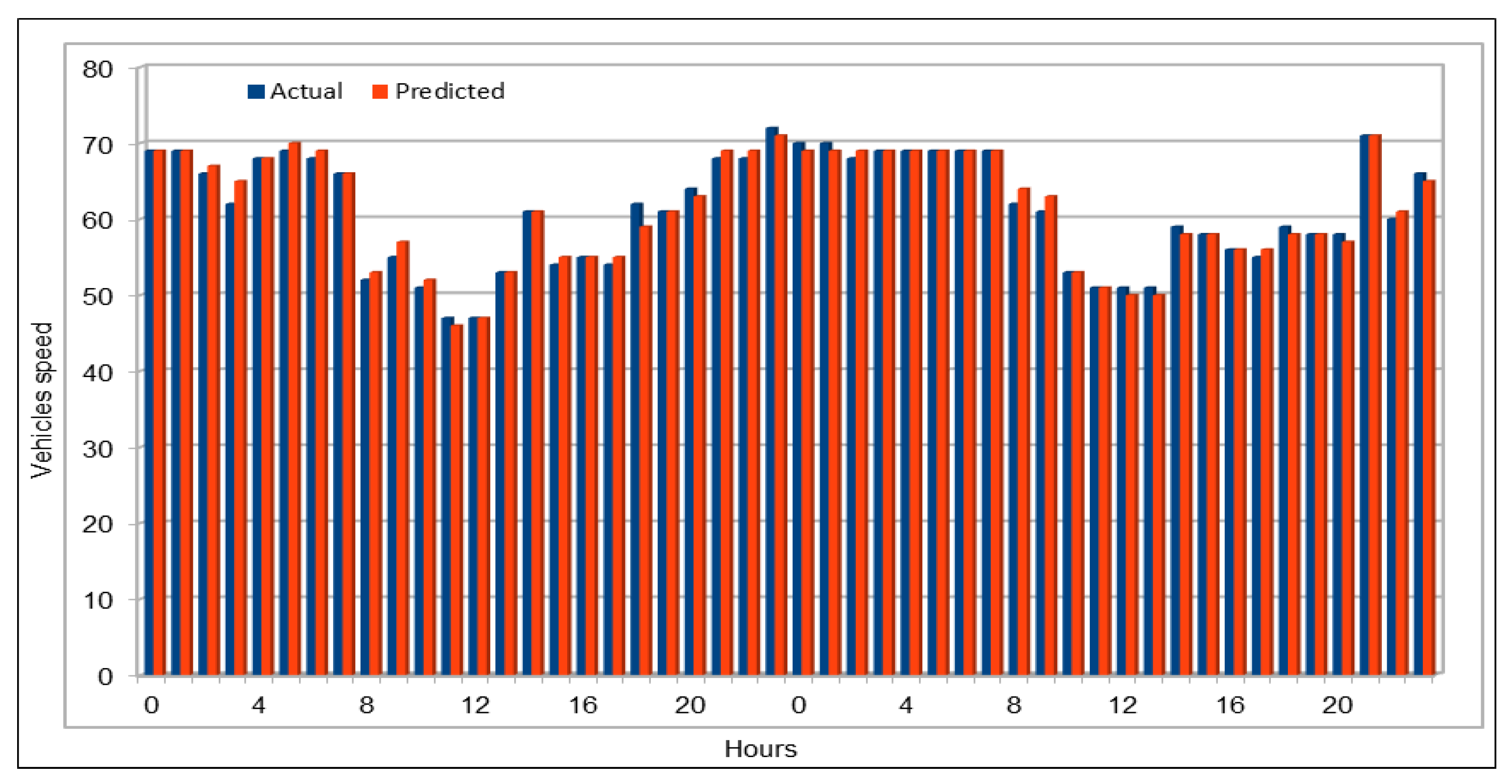
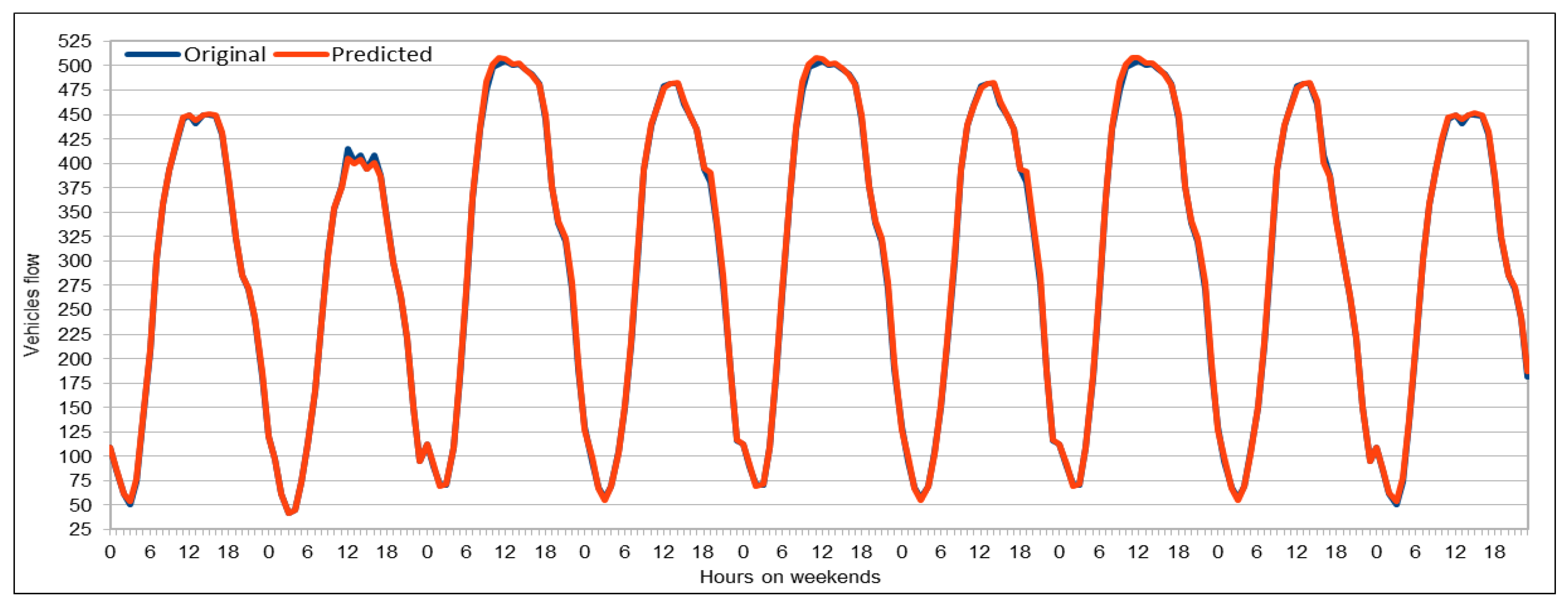
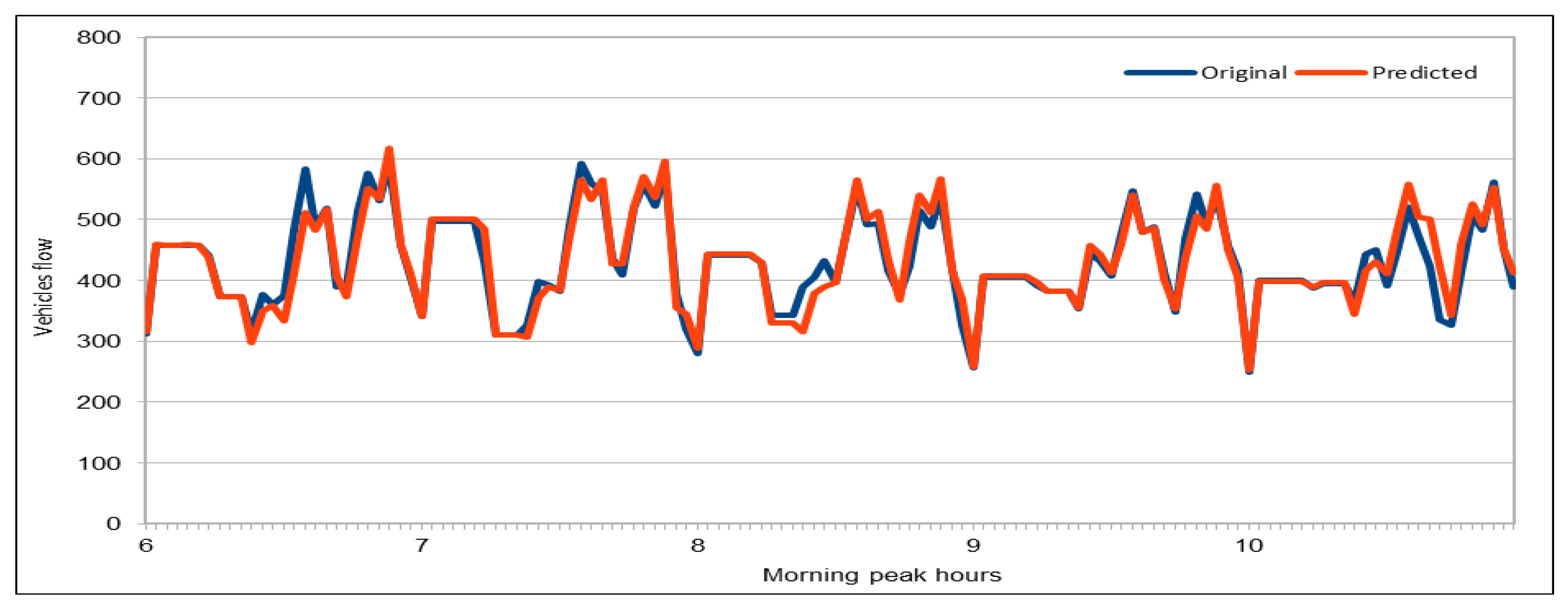
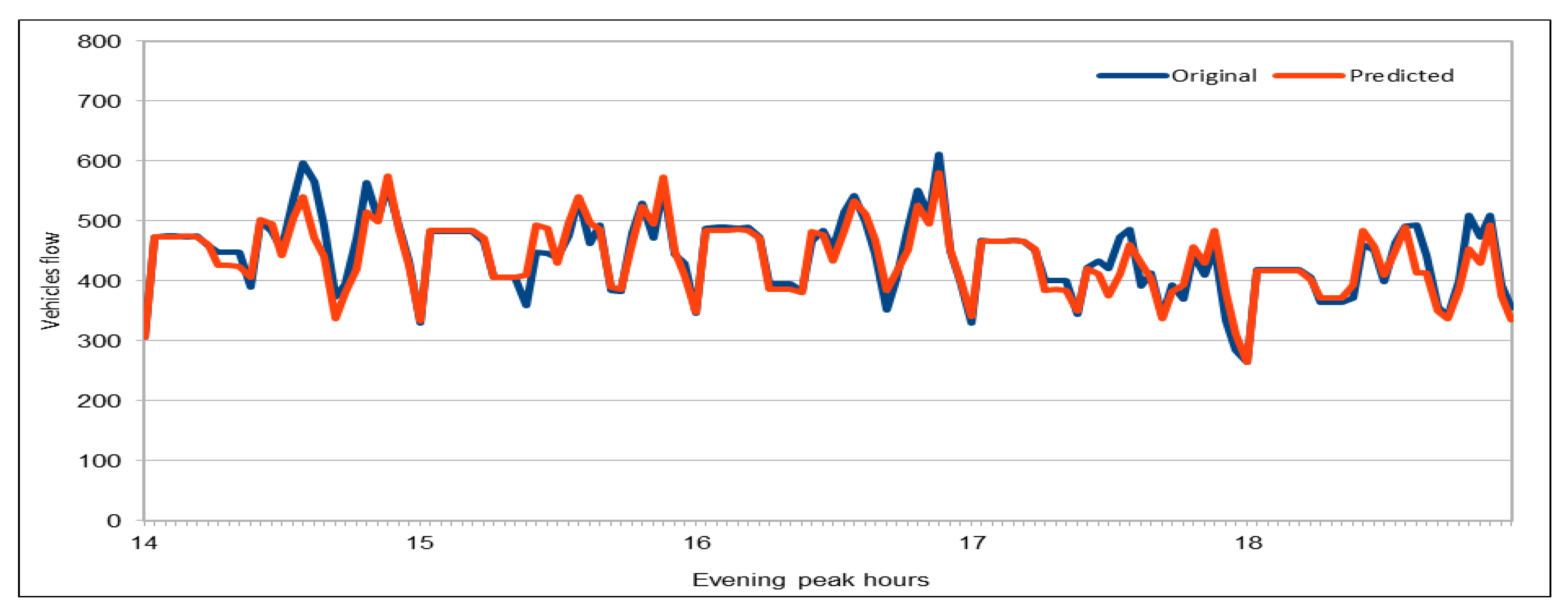
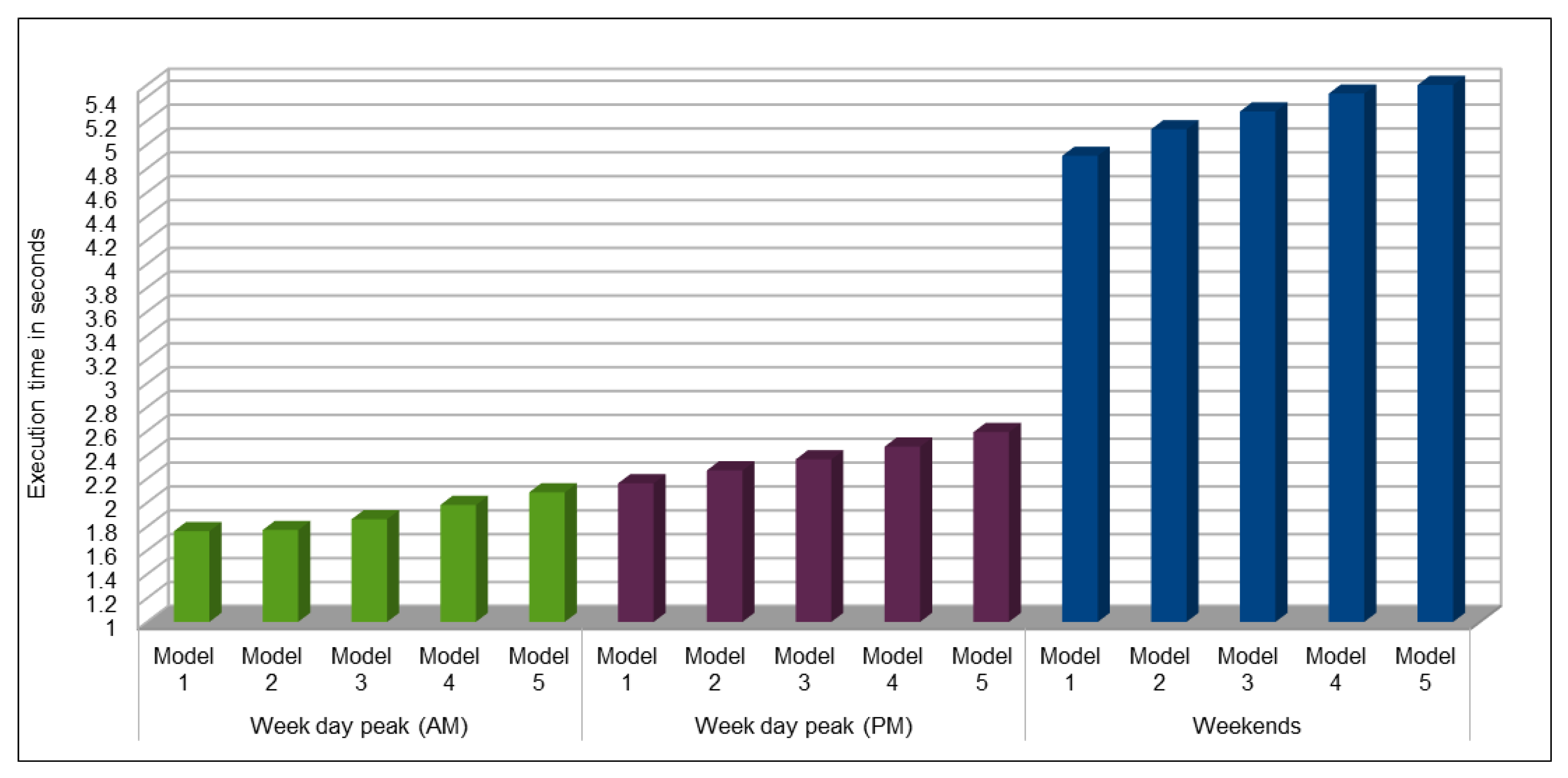
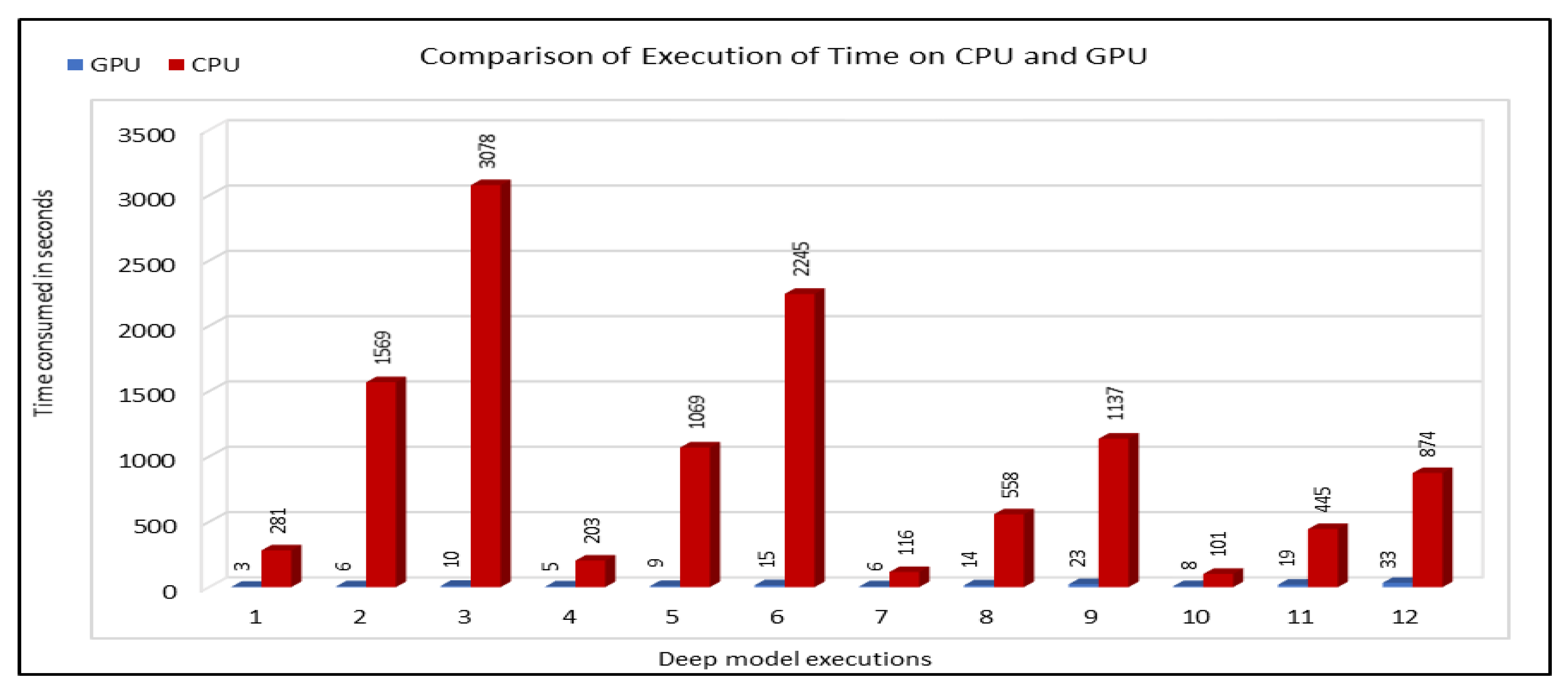
The use of GPUs provides a speedy deep learning training process, and this has been demonstrated by comparing the execution time performance of the training process on GPUs with CPUs. The possibility of real-time prediction by using pre-trained deep learning models have also been discussed in detail. The accuracy of our deep models was investigated using MAE, MAPE, and RMSE. The results demonstrate remarkably high accuracy. The comparison of actual and predicted values of the road traffic characteristics have also added to the insights.
The future work will focus on considering larger datasets; investigating different combinations of flow, occupancy, speed and other road traffic characteristics, in order to enhance prediction accuracy; improving prediction methodologies and analytics; using diverse types of road traffic datasets; fusing multiple datasets; and using multiple deep learning models.
We have explored the possibility of real-time prediction by saving the pre-trained deep learning models for traffic prediction using larger dataset, and subsequently using it on smaller datasets for near real-time traffic predictions using GPUs. This was a first step towards the real-time prediction of road traffic and it will be further explored in our future work with the aim to develop real-time predictions for dynamic road traffic management.
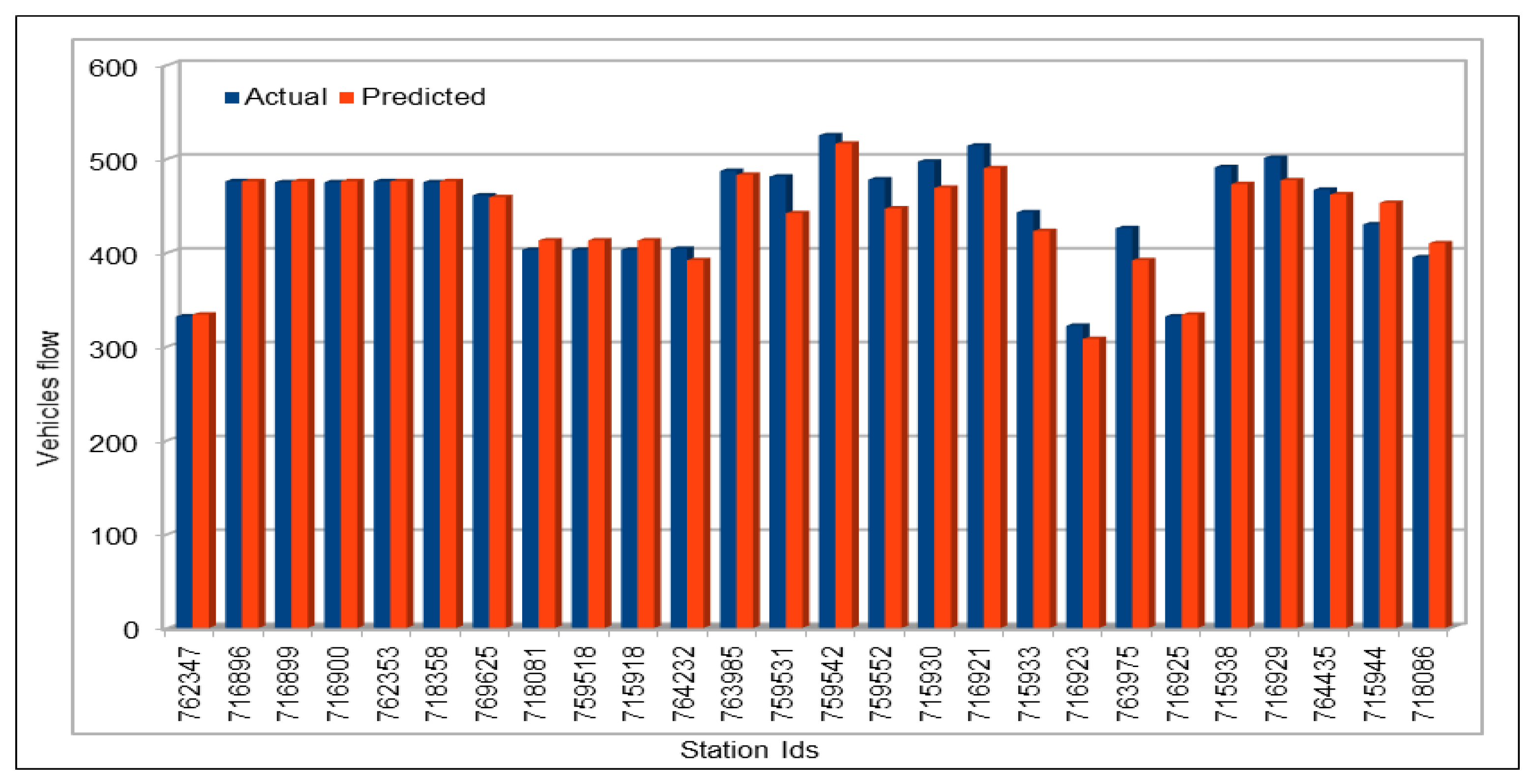
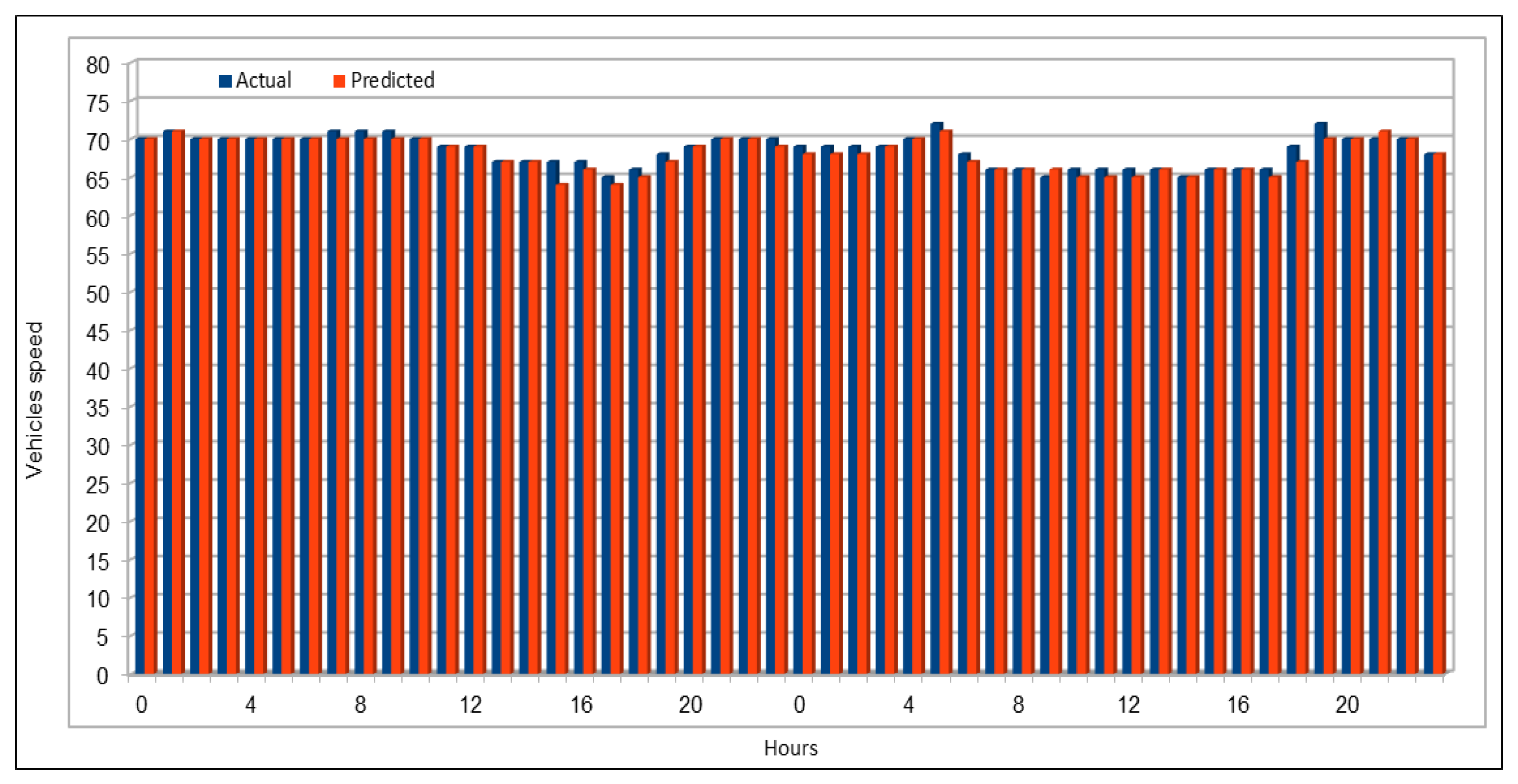
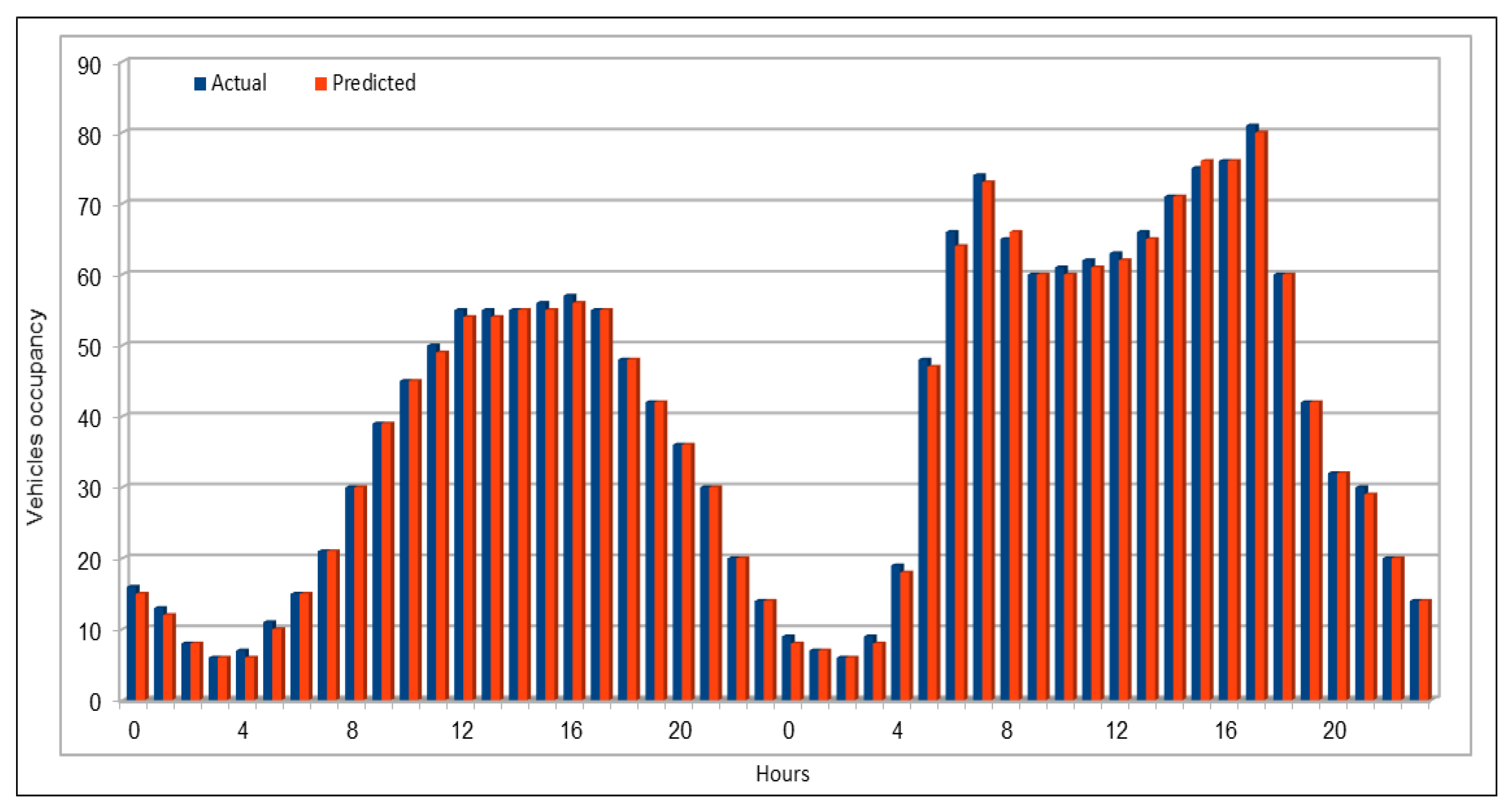
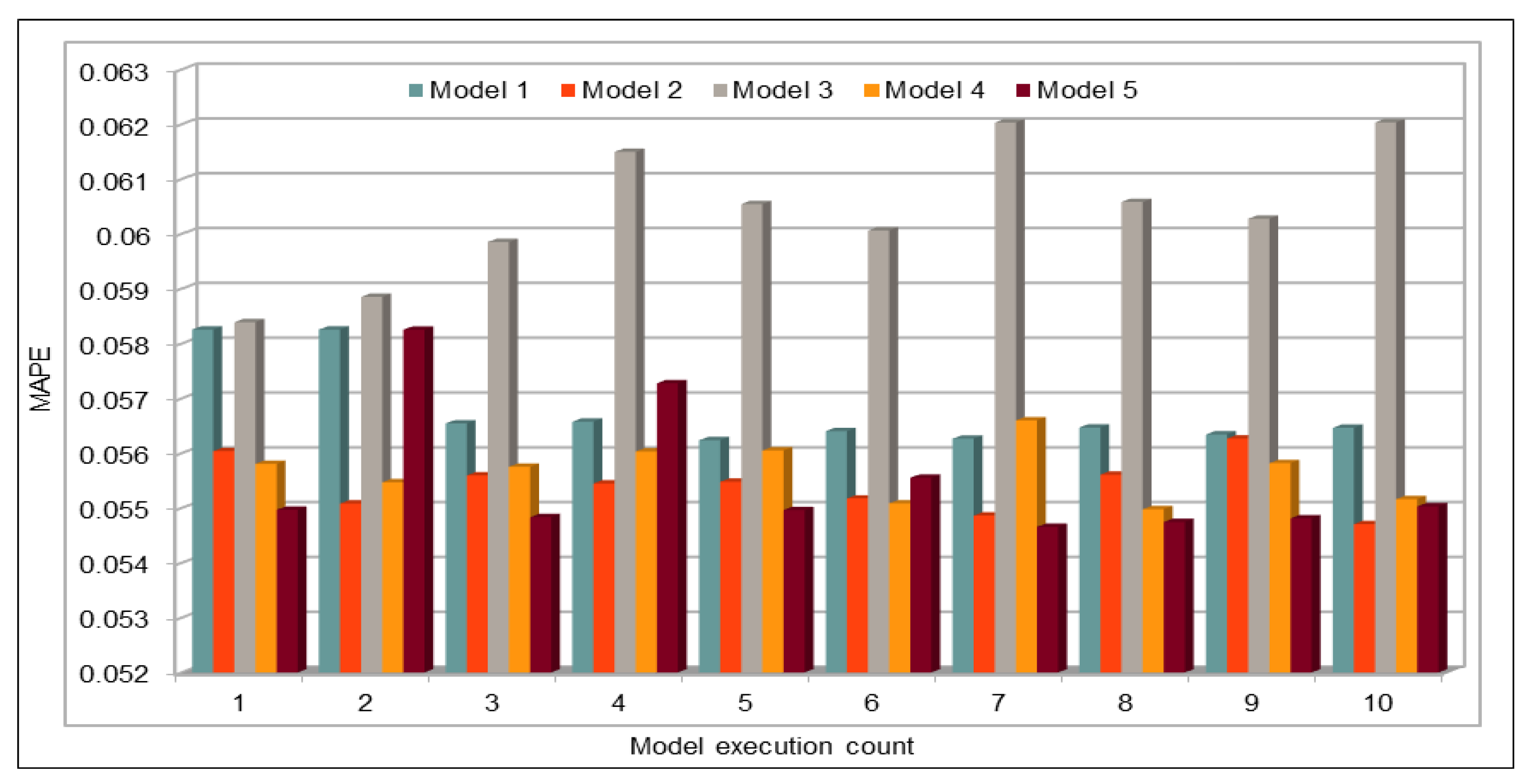
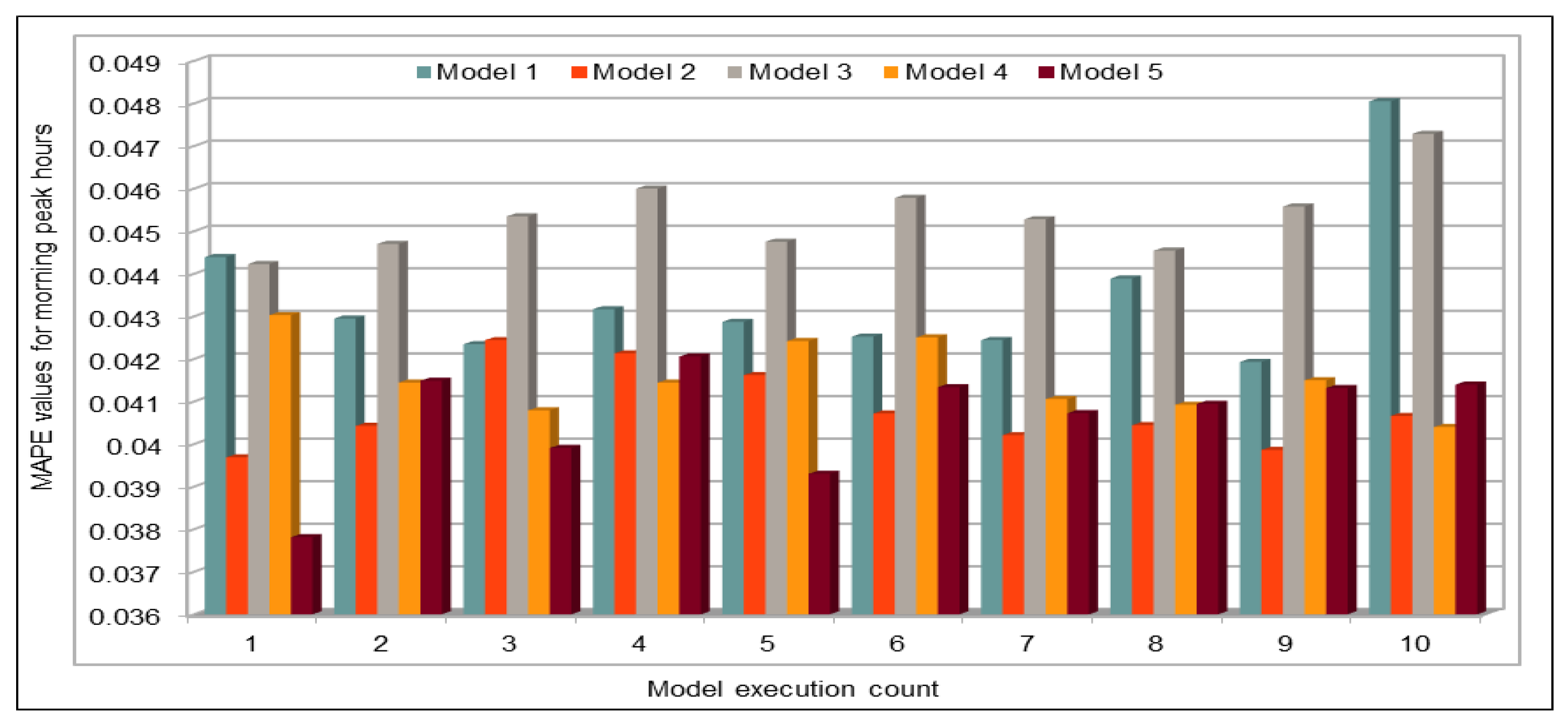
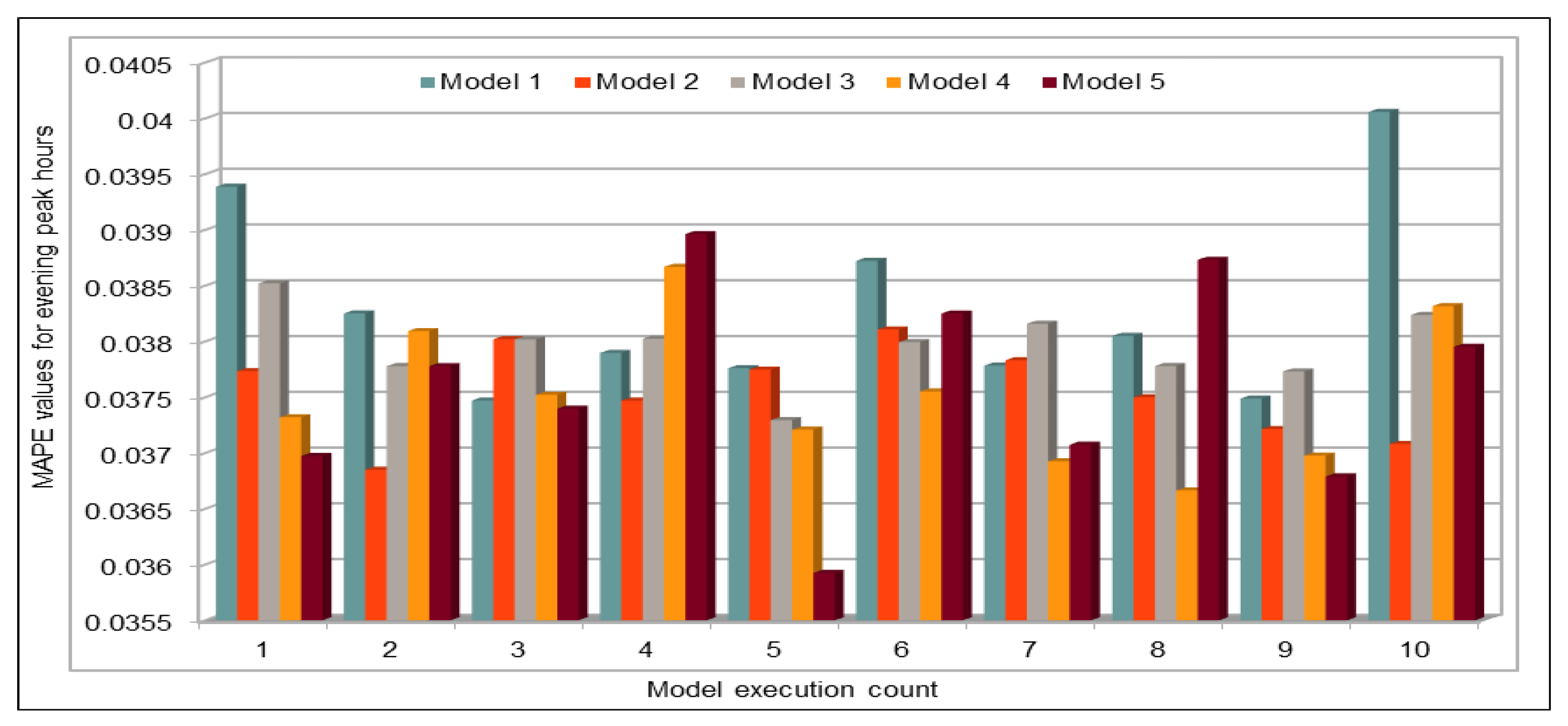
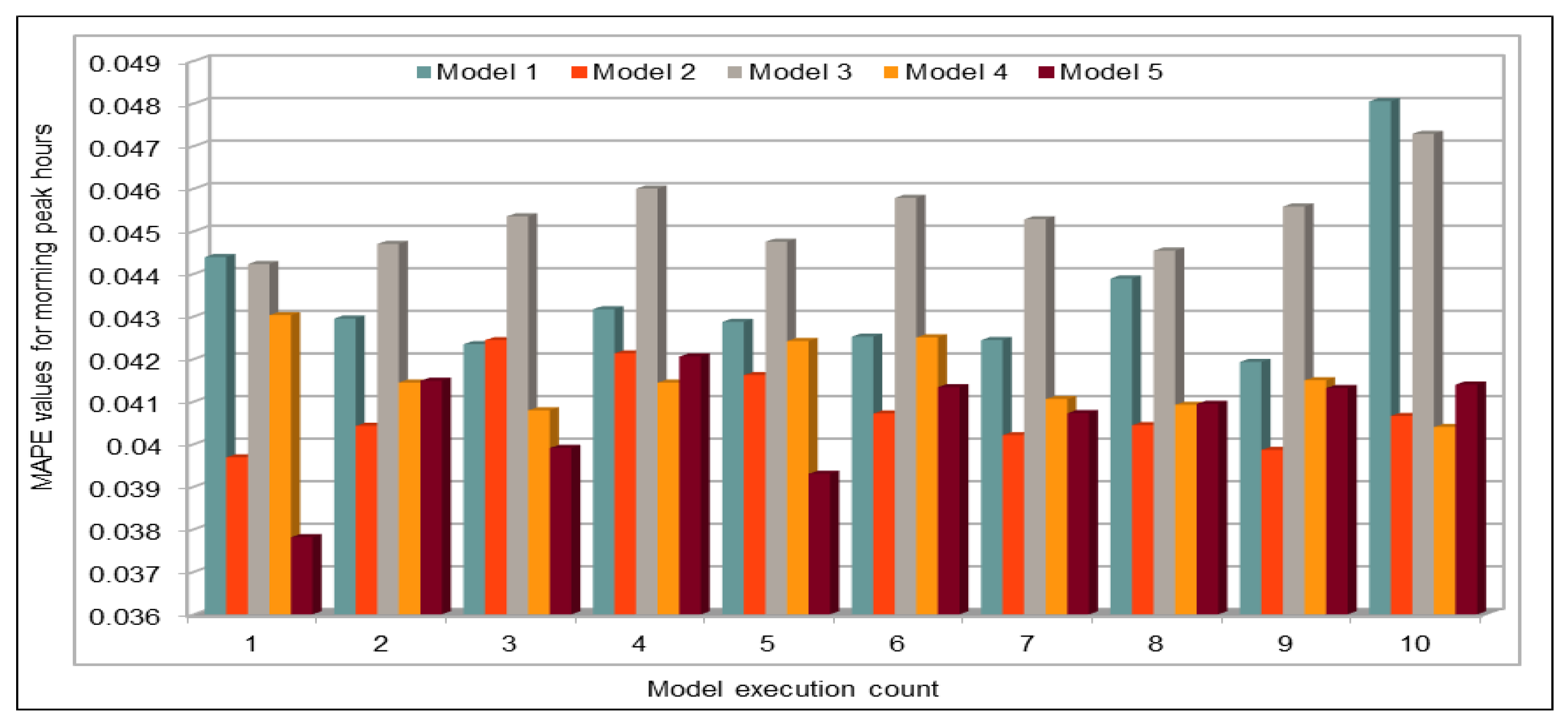
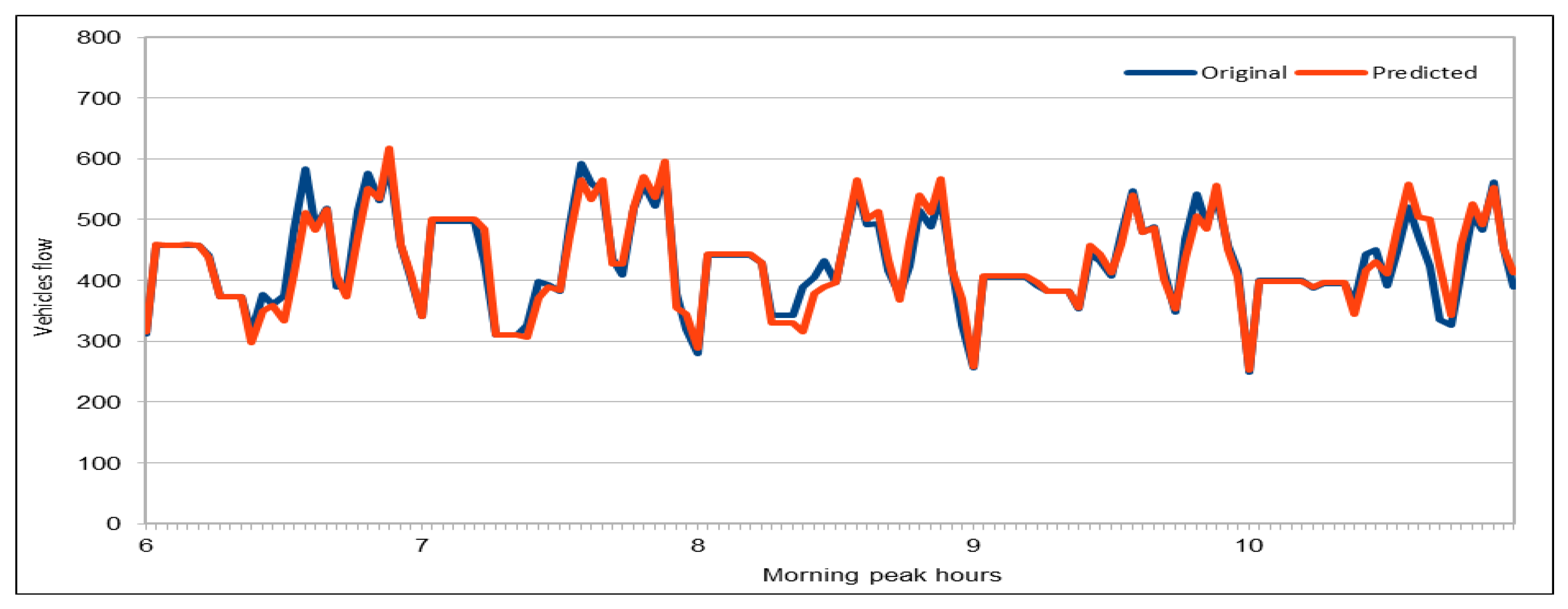
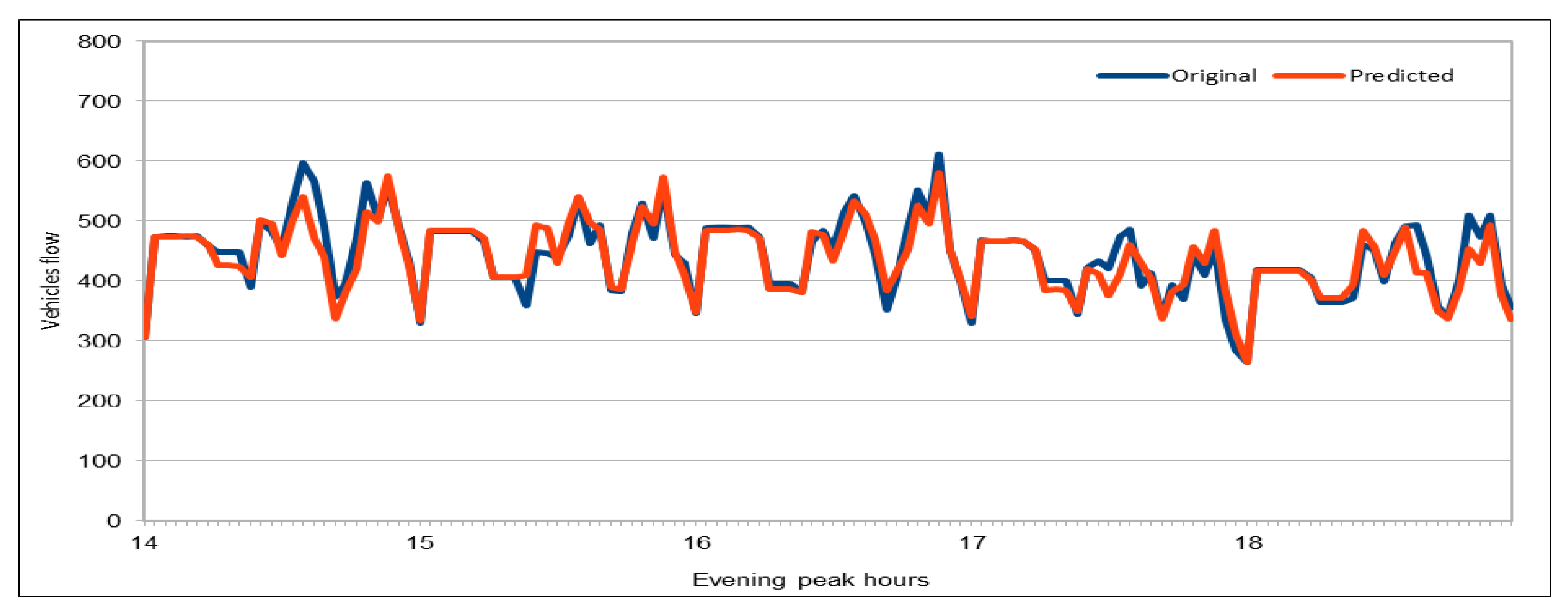
An important concern in predicting road traffic is the credibility of the prediction model under non-recurrent situations, particularly in those situations where additional external data—such as incident data—are not available or could not be incorporated in the prediction models. In this study, we used 11 years of traffic data over a fairly large stretch of freeway, which we believe incorporate the non-recurrent road traffic behavior in a considerable manner. For instance, the use of traffic data for a shorter period of time is very likely to lead to poor training in terms of recurrent behavior. Nonetheless, predicting non-recurrent behavior is a challenge and, even in our case, despite the use of data of very long duration, we have seen in some instances relatively higher error rates during rush hours (see
Figure 20). It will be a challenge for the pre-trained models too and would require retraining of the deep learning models with every emerging non-recurrent traffic behavior. This topic needs further investigation in the future and we are very hopeful that the concerted efforts of artificial intelligence and other scientific communities will continue to improve methods for predicting non-recurrent behavior.
The study presented in this paper used 11 years of road traffic data for training and prediction purposes. The practice to collect road traffic inductive loop data has become a norm in several developed countries such as in Europe and the US. They are being collected now for over a decade in countries such as the UK and the US. However, many countries around the world, and particularly in urban environments (in contrast to freeways), inductive loop or other road traffic data are not available in such large quantities. Therefore, the conclusions presented in this paper cannot be generalized. Future work will look into this.
Finally, the paper contributes novel deep learning models, algorithms, implementation, analytics methodology, and software tool for smart cities, big data, HPC, and their convergence. The paper also serves as a preliminary investigation into the convergence of big data and higher performance computing [
60] using the transportation case study. These convergence issues will be further explored in the future with the aim to devise novel multidisciplinary technologies for transportation and other sectors.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}