A Trajectory Privacy Preserving Scheme in the CANNQ Service for IoT



Abstract
:1. Introduction
2. Related Work
2.1. Private Nearest Neighbor Query Scheme
2.2. Aggregate Nearest Neighbor Query
2.3. Our Contributions
- (1)
- We propose a new PCANNQ scheme based on the TAS. The TAS helps the group of users to send group requests that satisfy spatial K-anonymity to the LSP. It prevents the LSP from directly obtaining the real location of the group of users, thus, protecting the location privacy of the group of users in snapshot queries.
- (2)
- We propose a circular secure areas construction method suitable for continuous queries. On one hand, the method ensures that the optimal aggregate nearest neighbor remains unchanged when the users move within the areas, on the other hand, the secure areas can conceal the real locations of the users, thus, reducing the probability of the LSP reconstructing the users’ trajectories.
- (3)
- We propose an efficient aggregate nearest neighbor query algorithm. The algorithm includes a search phase and a prune phase. The search phase is designed to limit the minimum search scope of POIs, based on the aggregate subgroup, and the prune phase is designed to filter the non-nearest neighbors quickly, thus, improving the response speed of the query algorithm.
- (4)
- We experimentally compared the performance of our scheme with peer algorithms, in terms of security, average processing overhead, query efficiency, etc. The experimental results showed that our scheme could protect the location and trajectory privacy of the group of users, while ensuring the overall performance of the service, which achieved the expectation of the paper.
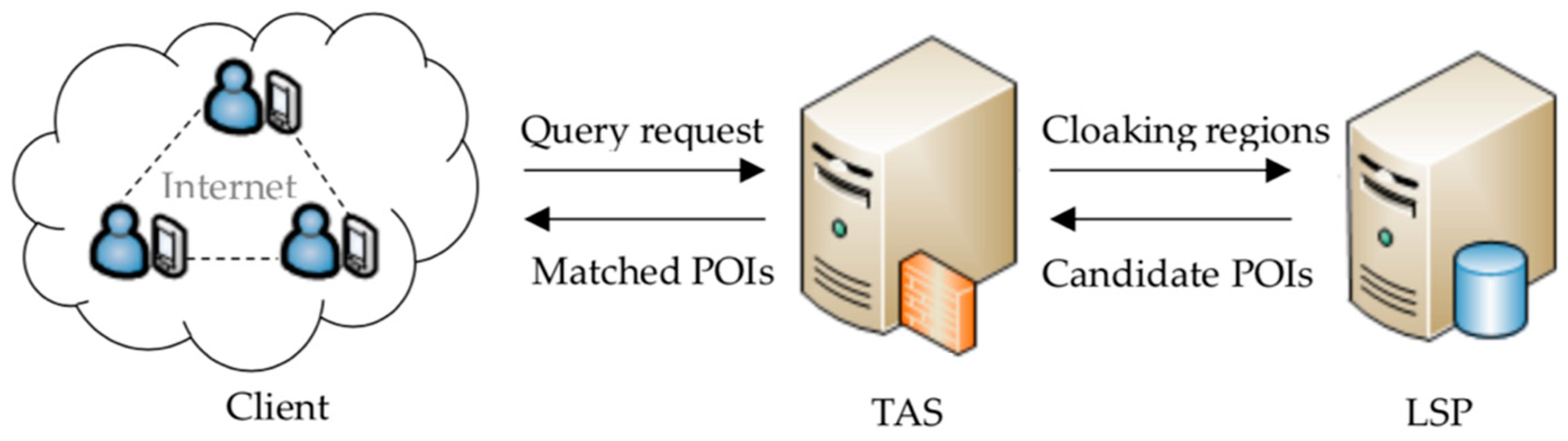
3. System Model and Definition
3.1. Problem Statement
3.2. System Model
- (1)
- Client. Each mobile client carries a mobile device with functions, such as information processing, data storage, and global positioning (e.g., GPS) to quickly connect to the IOT. The users participating in the LBS queries trust each other, and there is no collusion attack between any users and the LSP.
- (2)
- TAS. The TAS is trusted. Its main functions include concealing users’ identities, generating cloaking regions satisfying the spatial K-anonymity for users, and filtering out the query results belonging to the real user, in the query results. In the continuous queries, TAS can also generate secure areas, according to whether the query result changes, which dynamically conceal the users’ moving paths.
- (3)
- LSP. The LSP is semi-trusted. On one hand, the LSP stores map resources and location-related POIs, such as restaurants, hospitals, and tourist attractions, to provide users with timely location-based query services. On the other hand, users do not know whether the LSP-stored trajectory data generated in the query process, and whether the private information contained in the trajectories is abused or not, is also unknown.
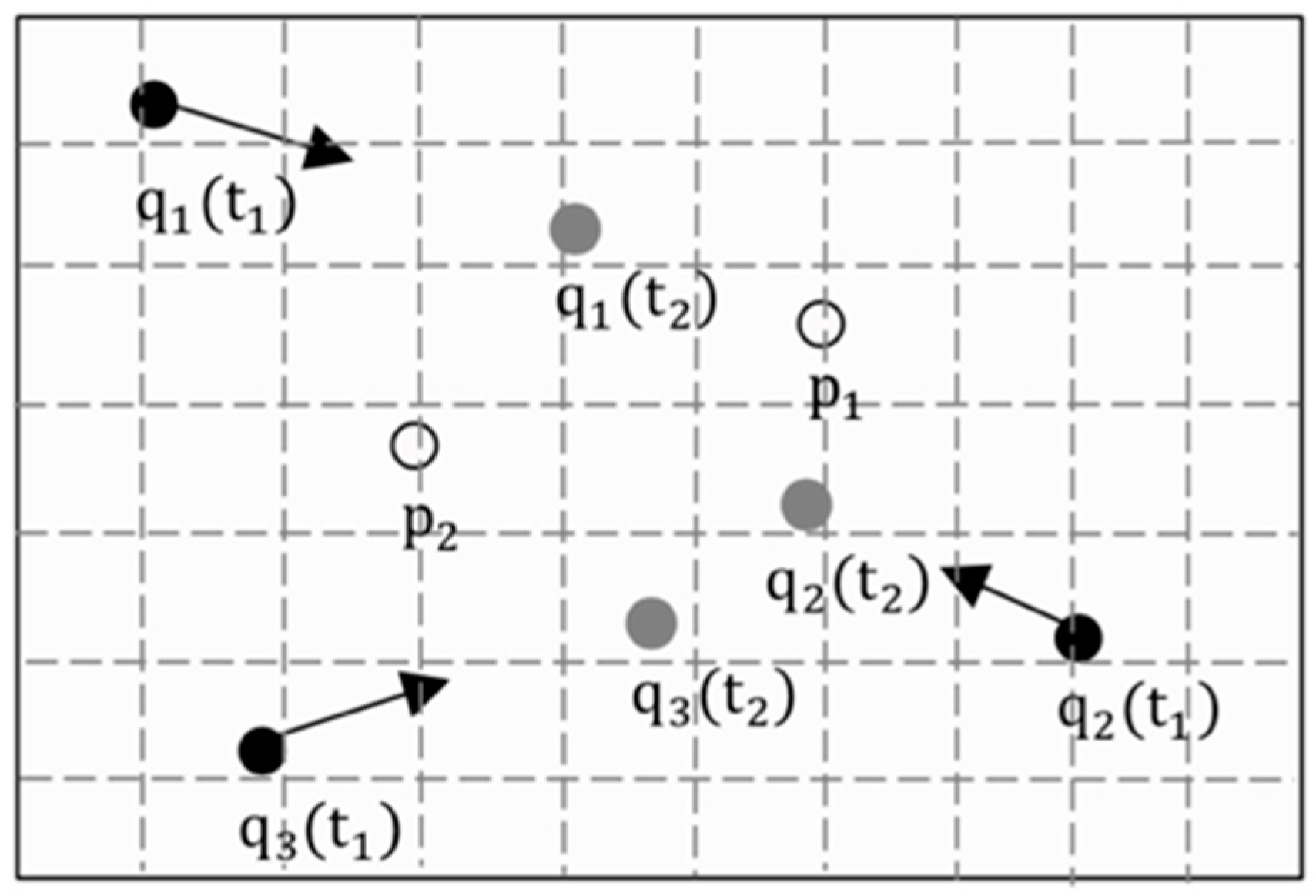
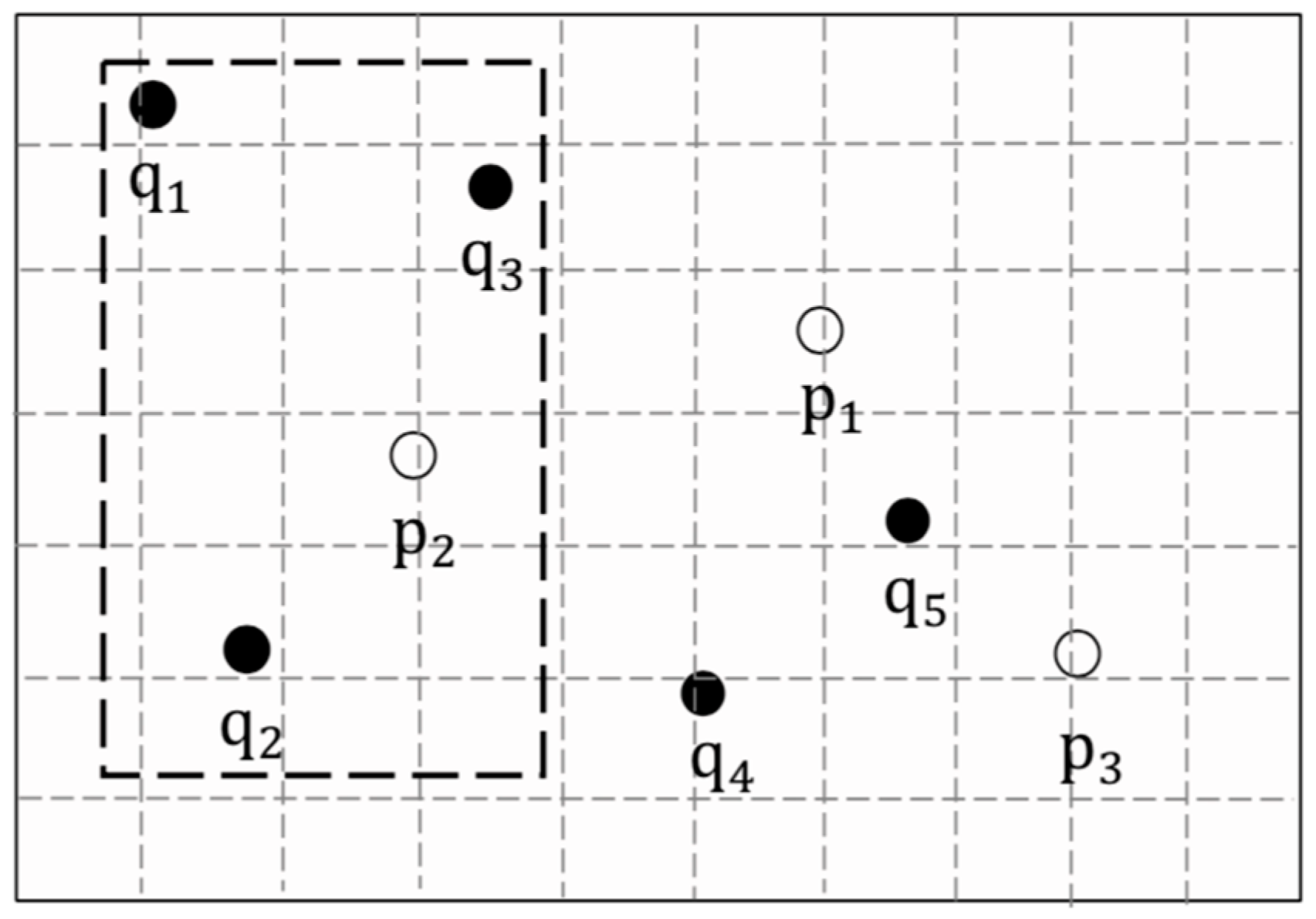
3.3. Continuous Aggregate Nearest Neighbor Query
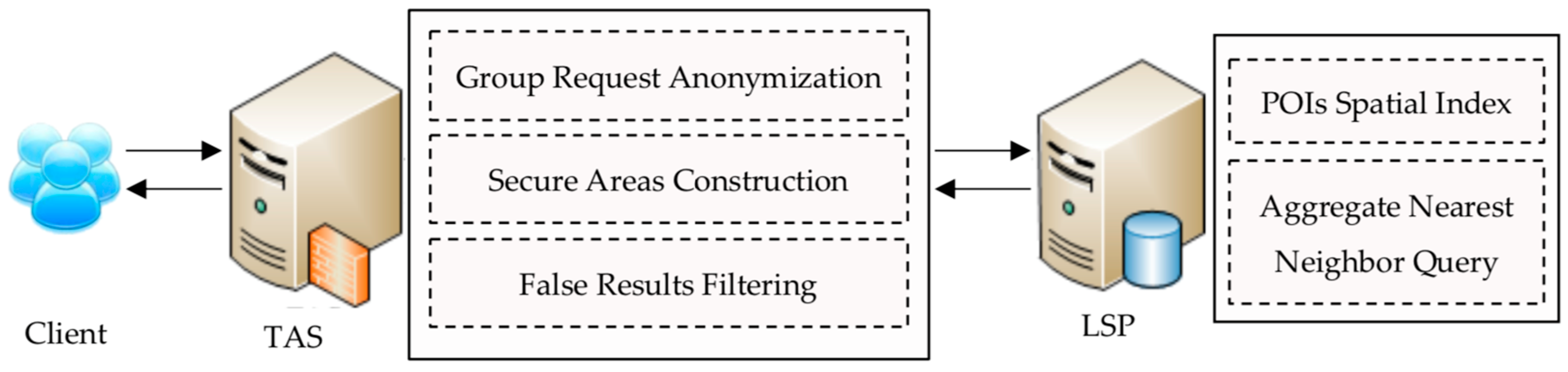
4. Our PCANNQ Scheme
4.1. System Architecture
4.2. Process of PCANNQ
- Step1.
- Users send requests to the TAS to build a query group. where , and represents the identity of user q, the location of user q and the type of POIs, respectively.
- Step2.
- After receiving the request , the TAS determines whether it is the first time for the user group to issue the query, if so, turn to Step 3–7, and if not, turn to Step 8.
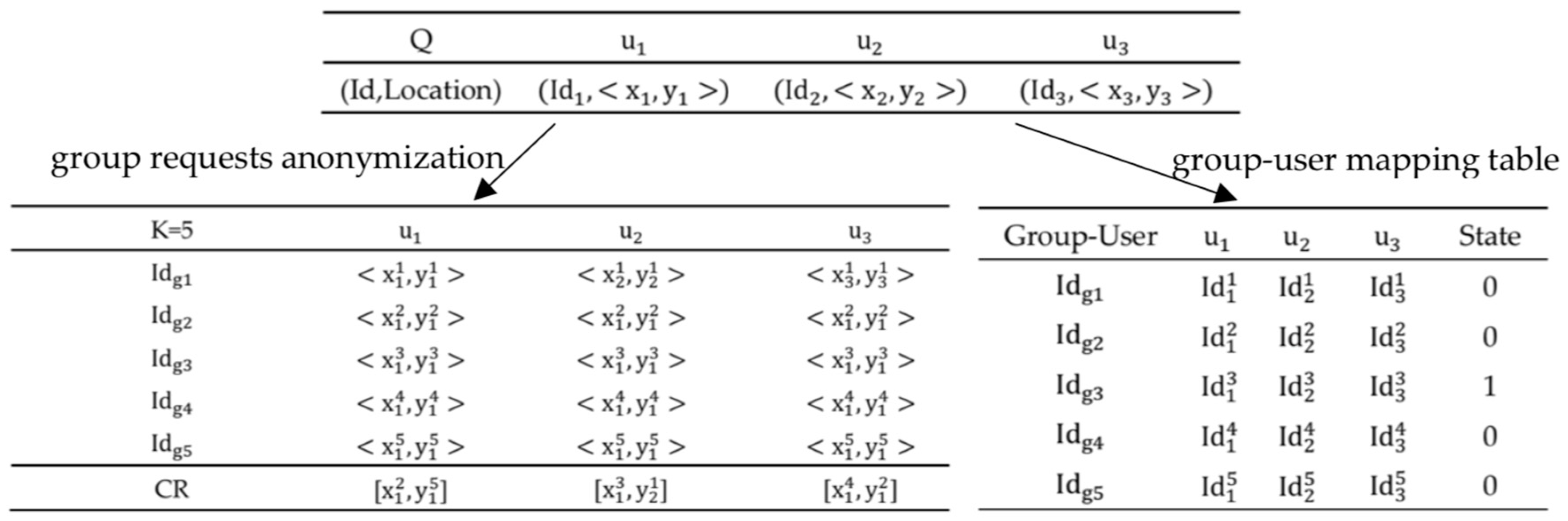
- Step3.
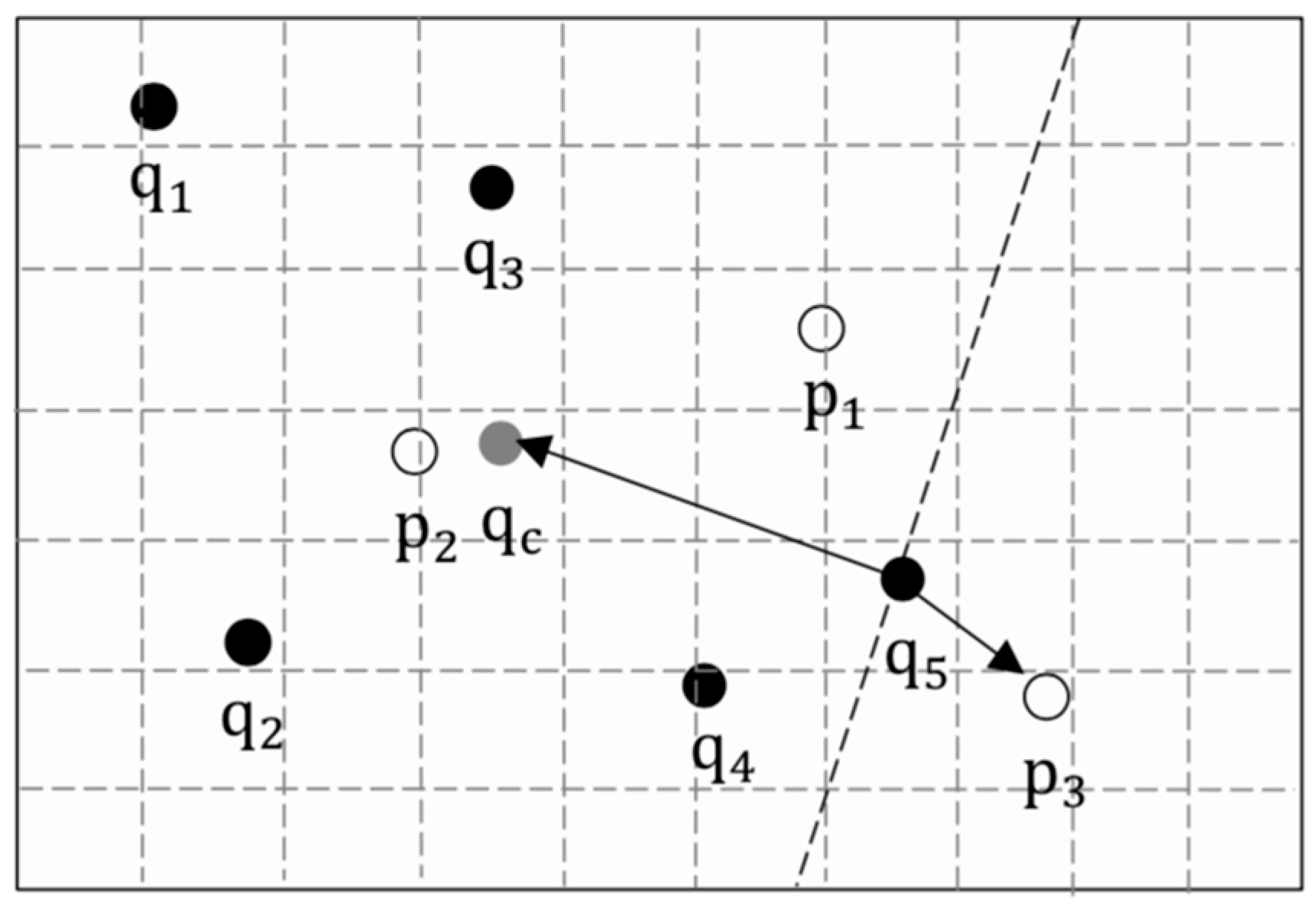
- The TAS constructs the cloaking regions for every user in the group, which covers their true locations to satisfy spatial k-anonymity, and then converts these cloaking regions into k group requests sent to the LSP. where represents the identity of the group which replaces . As shown in Figure 5, the TAS represents all users’ Id as a group Id, and five indistinguishable group requests are generated in this anonymous process.
- Step4.
- The TAS maintains a group-user mapping table locally, which records the corresponding relationship between the group Id and user Id. When the LSP returns the results, the table can help the TAS to quickly filter out the false results. As shown in Figure 5, the number of users , the degree of anonymity . A record with a value of 1 in the ‘State’ field (e.g., the third record) represents the real group of users, and the other items are k-anonymized false records.
- Step5.
- The LSP performs an ANNQ, based on strategy optimization (see Section 6 for details) for all requests, generates a lists of nearest neighbors and then returns the results to the TAS. where .
- Step6.
- The TAS filters the results based on the group-user mapping table and returns the true neighbor lists to the true group of users.
- Step7.
- The TAS calculates the radius by and , and constructs circular secure areas for the group of users (see Section 5 for details).
- Step8.
- The TAS monitors the group of users in real-time to see whether the users exceed their secure areas. If someone exceeds, the user group is prompted to update the query results. If the request needs to be resubmitted, turn to Step 3. If not, continue to monitor until the group of users end the query.
4.3. Security Analysis
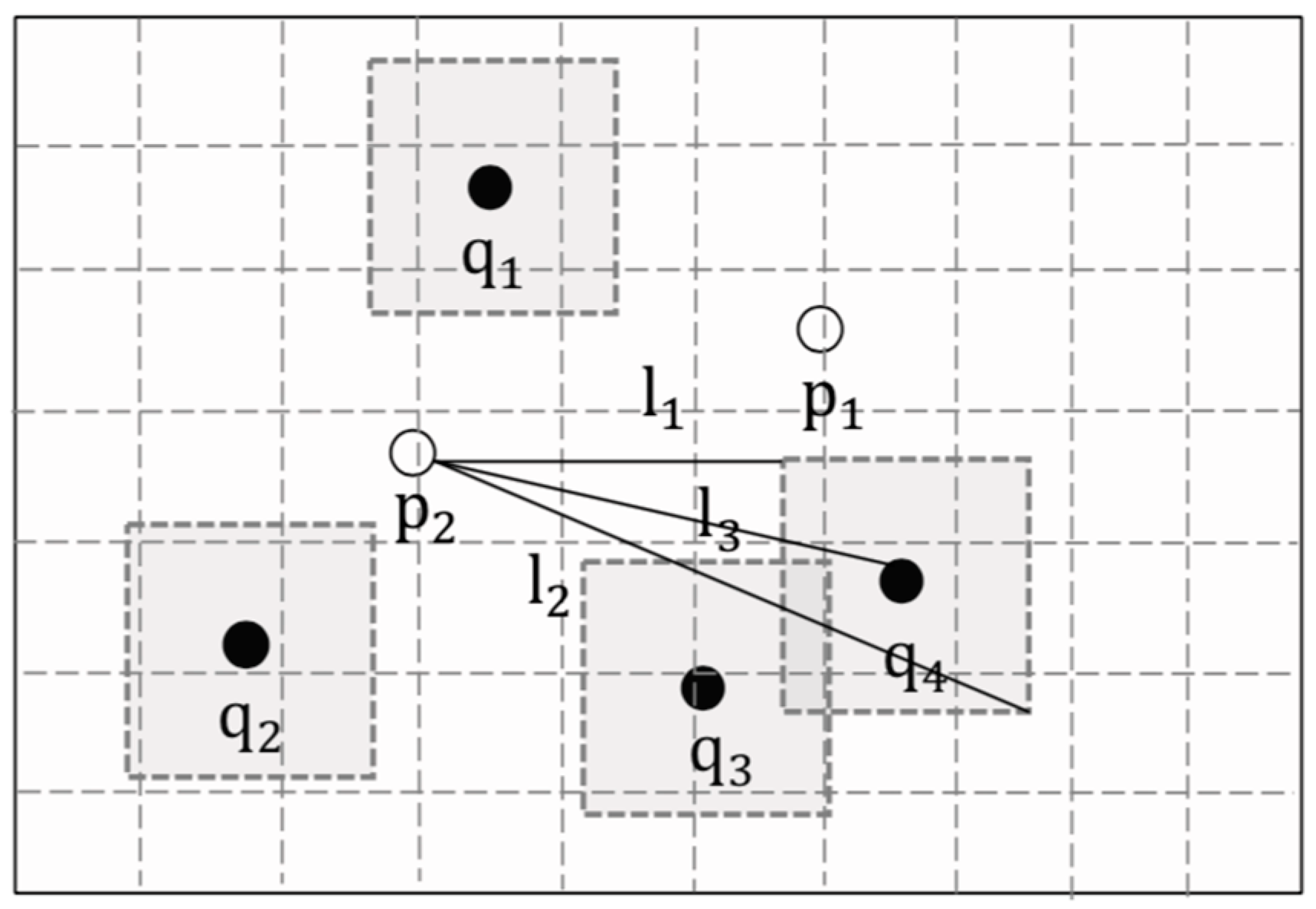
5. Circular Secure Areas
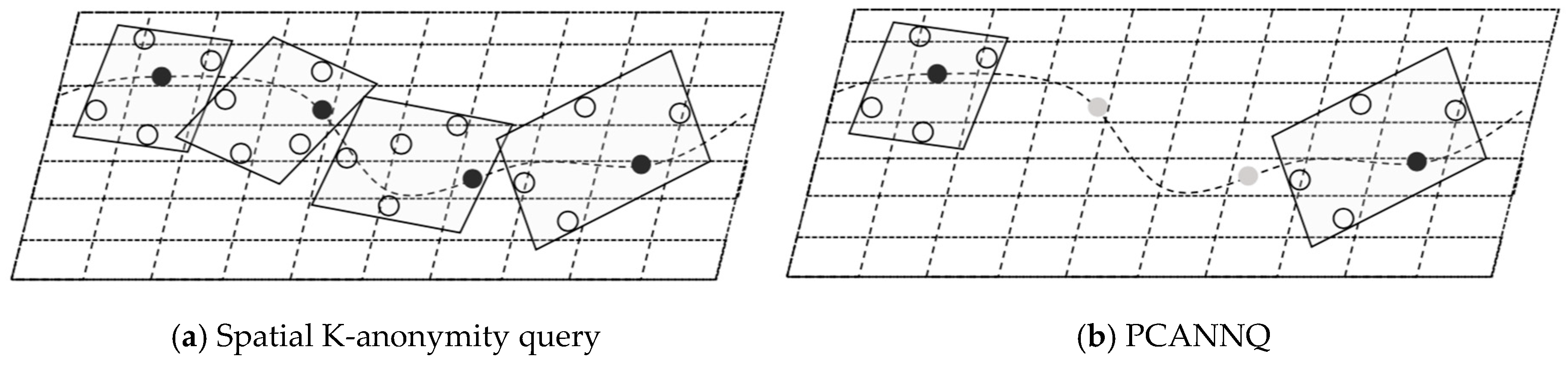
5.1. Motivation
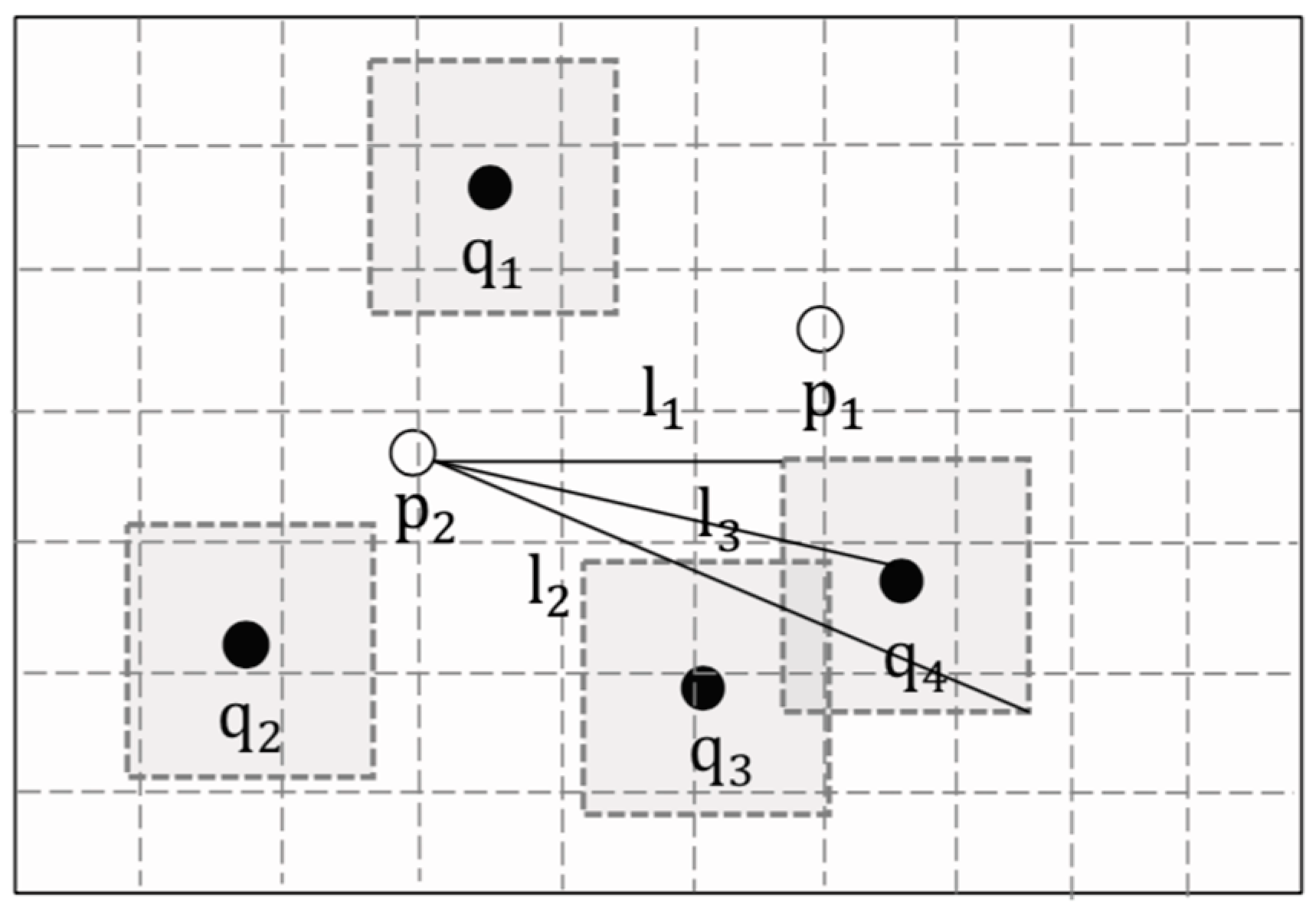
5.2. Verification of Secure Areas
- Let .
- By definition 4, , .
- .
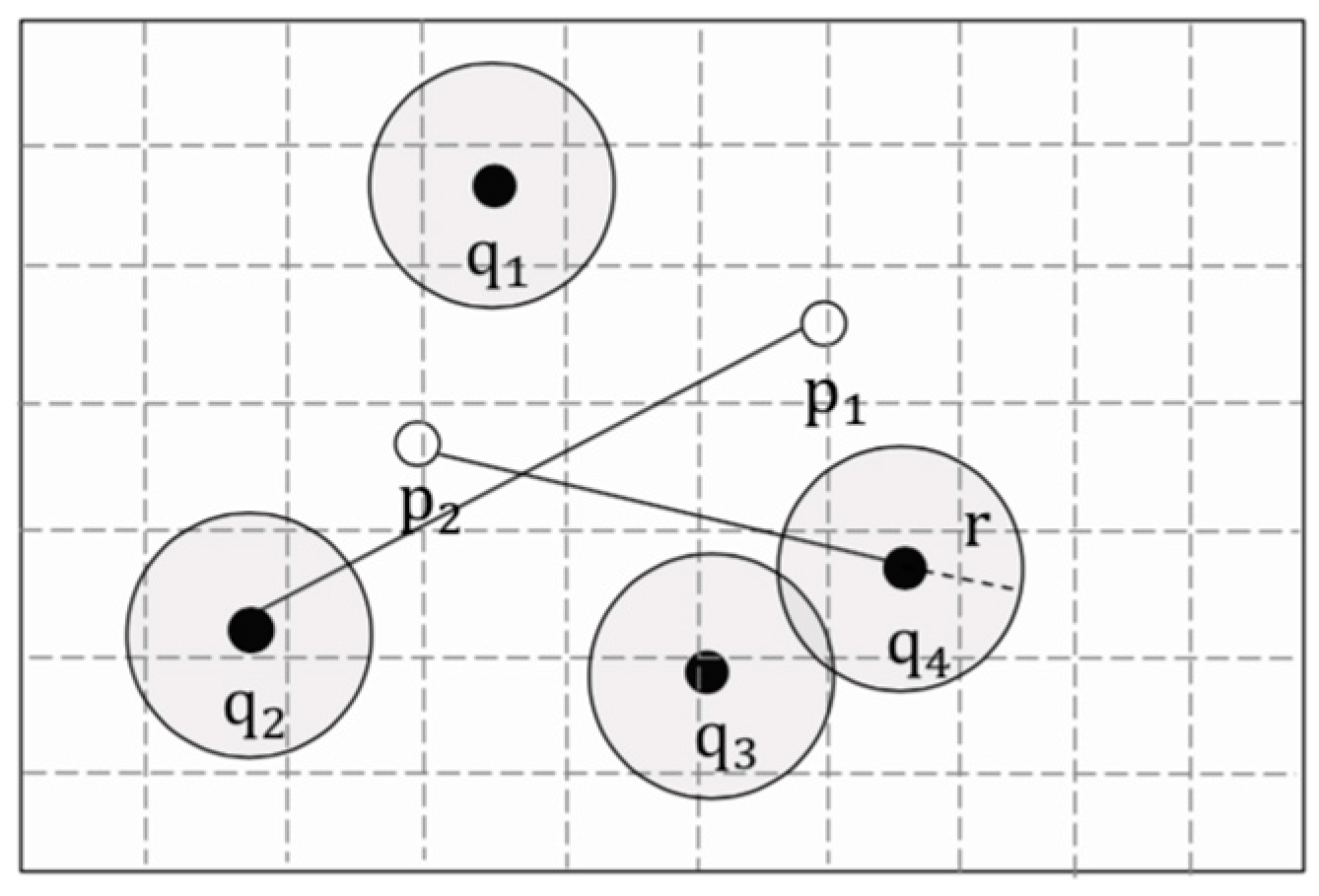
5.3. Construction of Secure Areas
- Let .
- By definition 7, , and .
- By condition (6), , satisfy .
- , .
- .
| Algorithm 1: Circular secure areas construction Input: Output: |
|
6. ANNQ Based on Strategy Optimization
6.1. Motivation
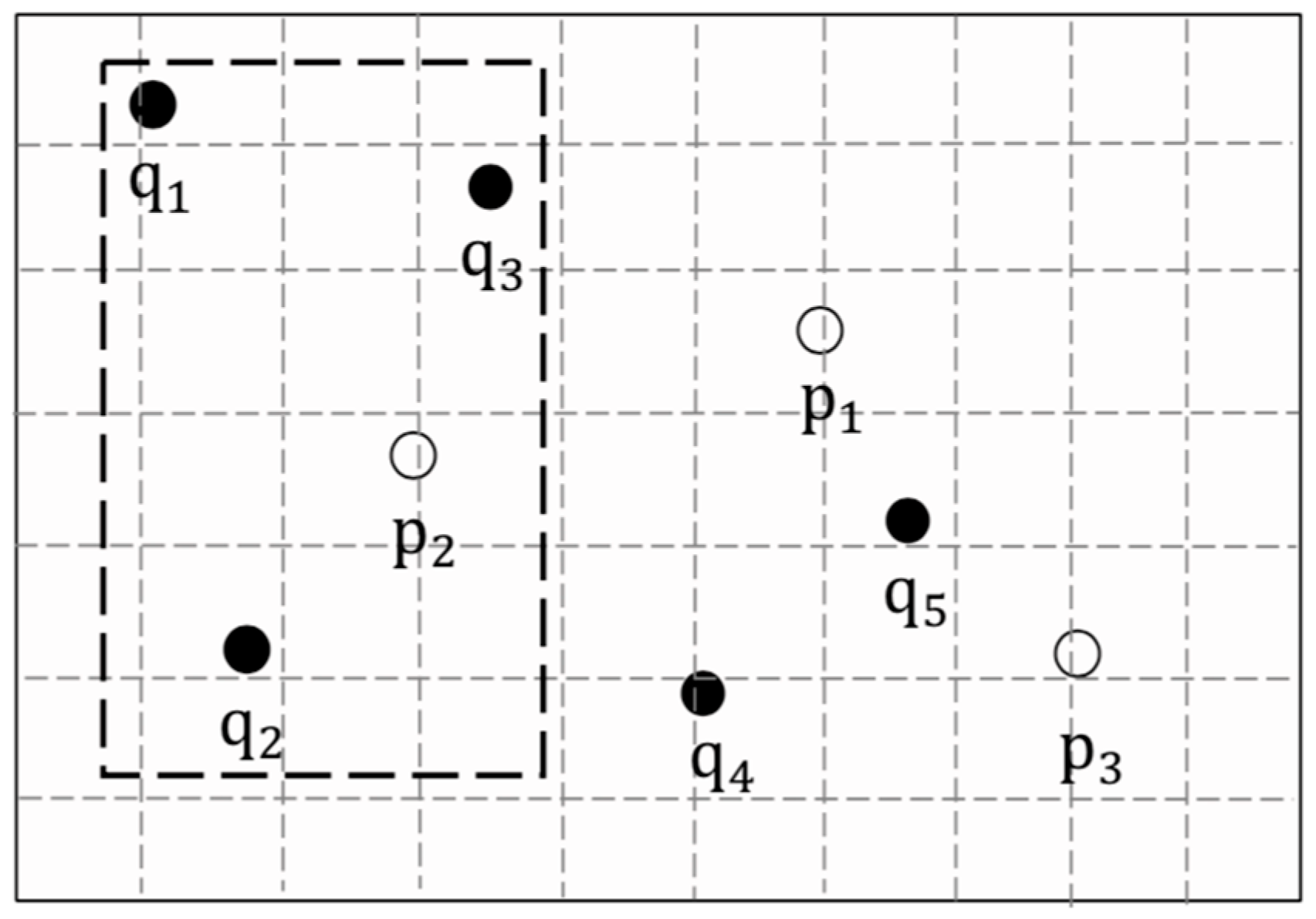
6.2. Search Phase
- Let . Suppose , but .
- .
- .
- Combined with Theorem 3, .
- , .
- . It’s conflicted with above assumption.
| Algorithm 2: Search global public nearest neighbor Input: Output: |
6.3. Prune Phase
| Algorithm 3: Prune non-nearest neighbors Input: Output: |
|
| Algorithm 4 ANNQ based on strategy optimization Input: Output: |
|
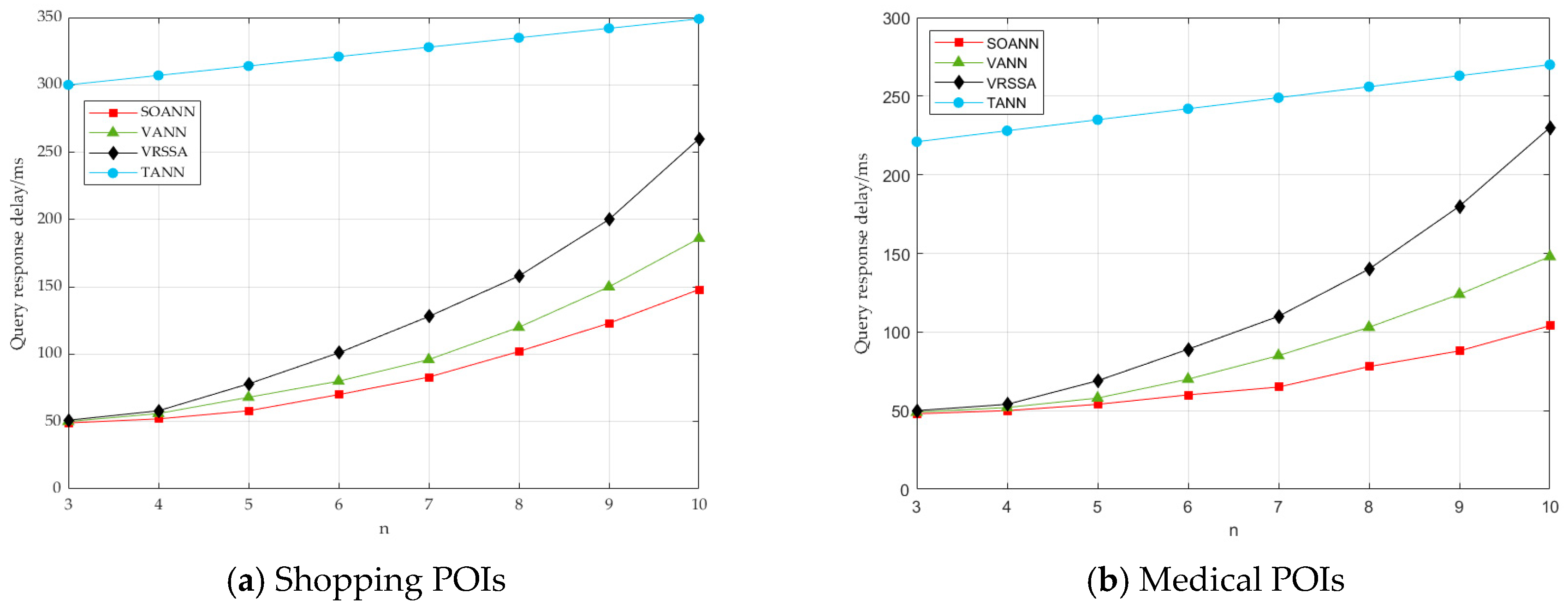
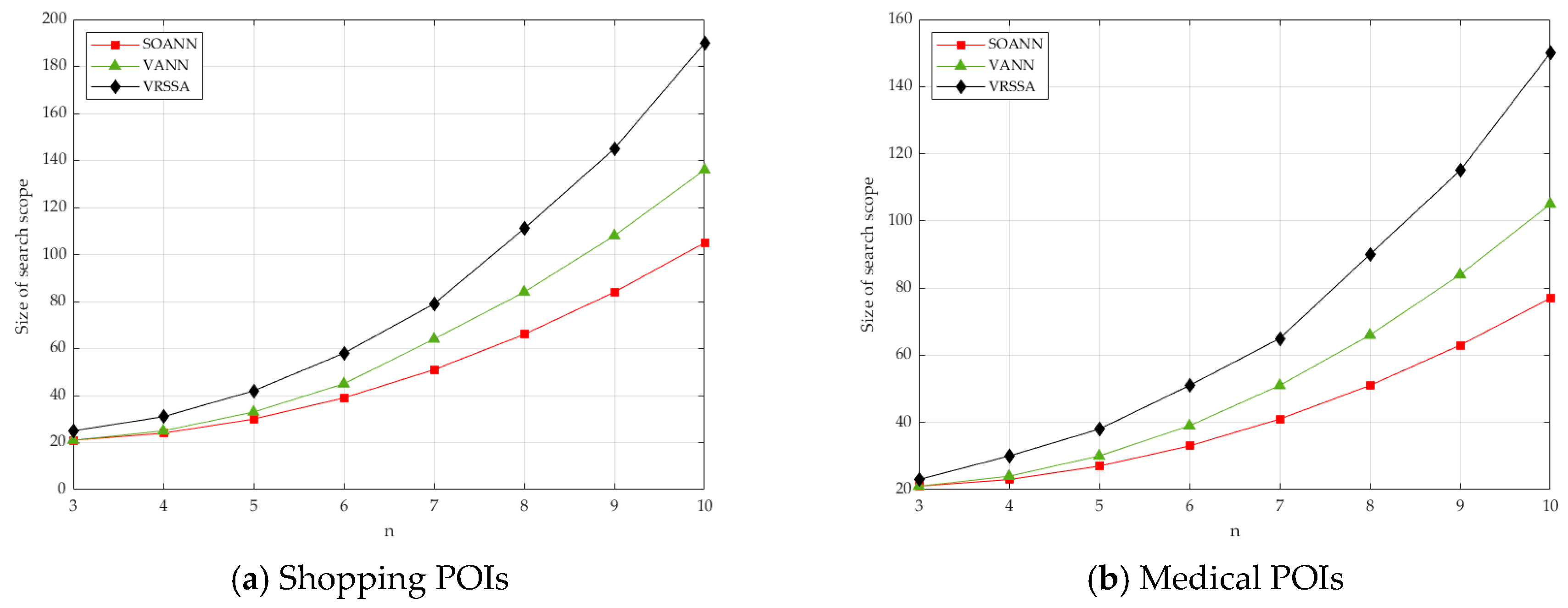
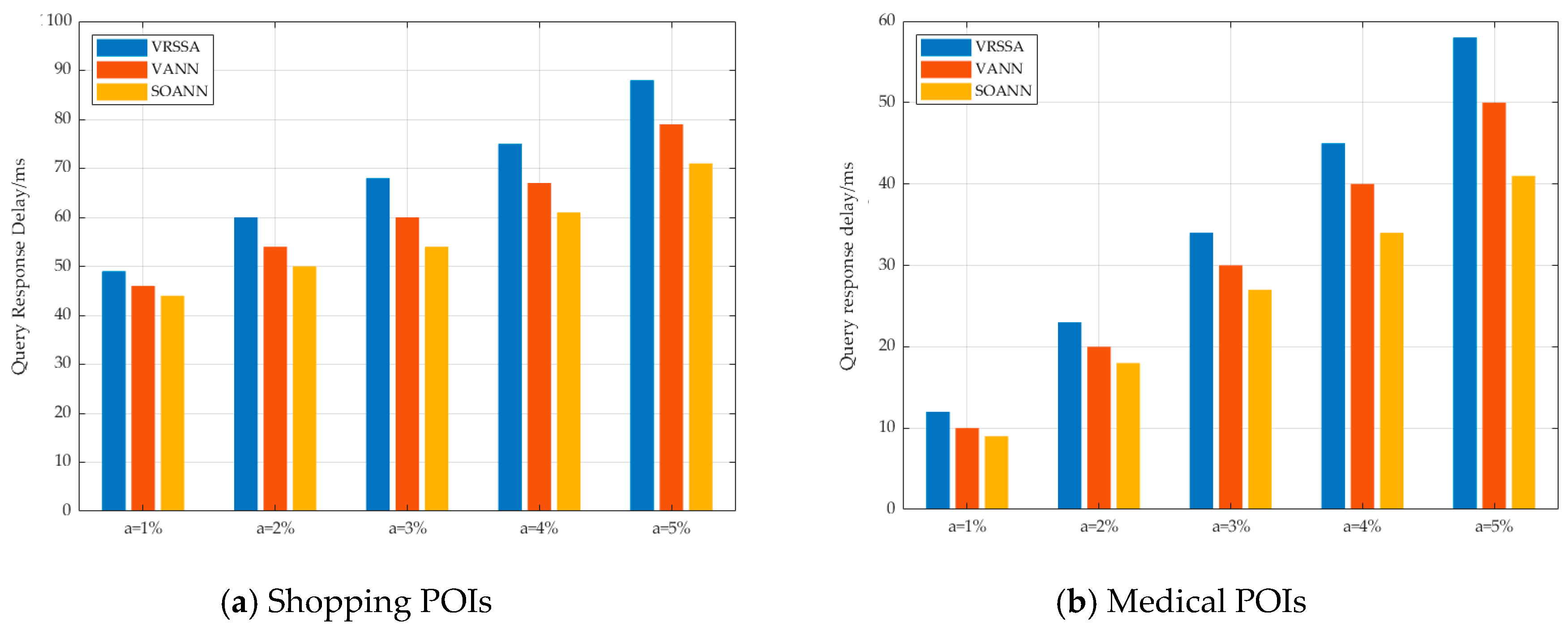
7. Simulation Experiment and Analysis
7.1. Experimental Setup
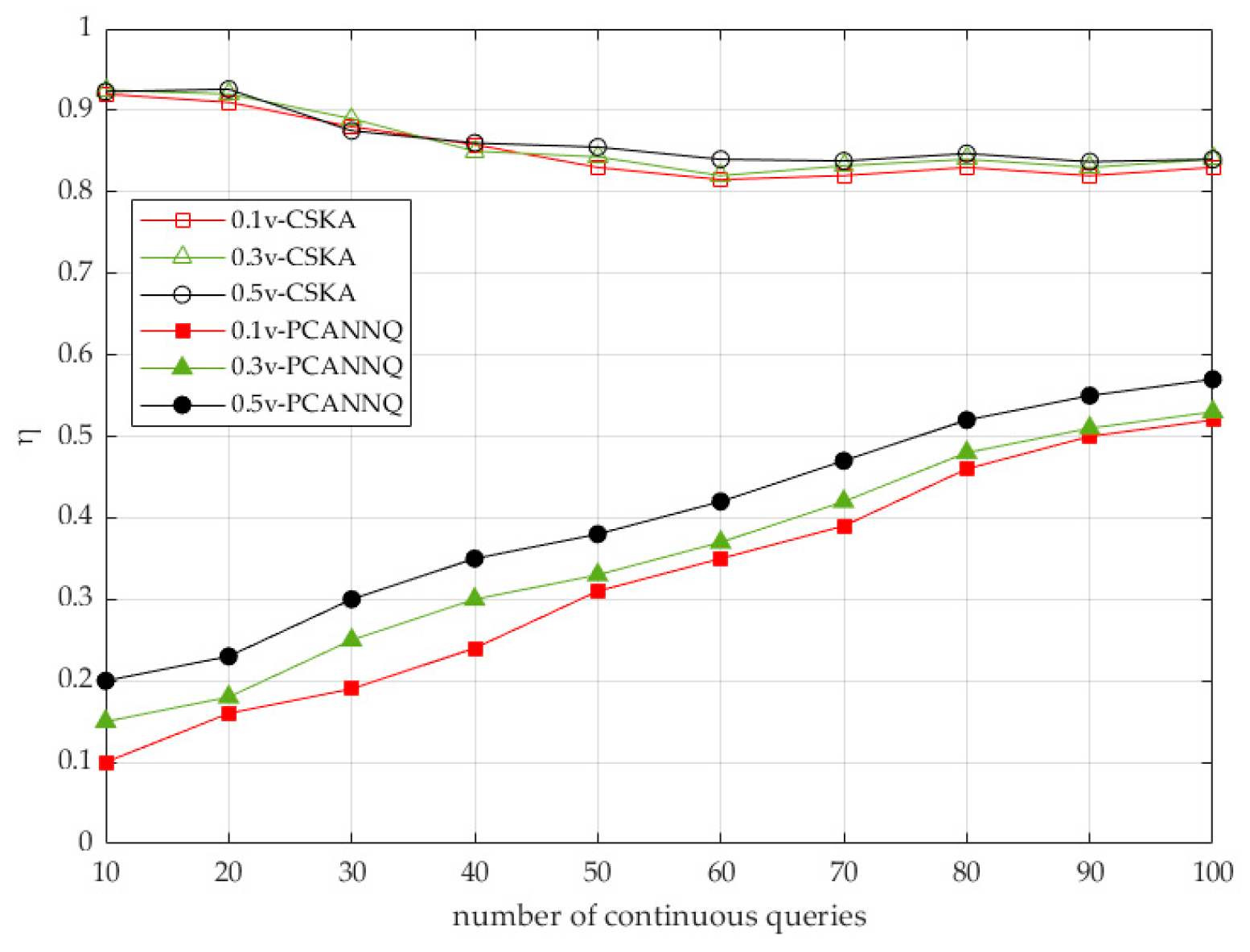
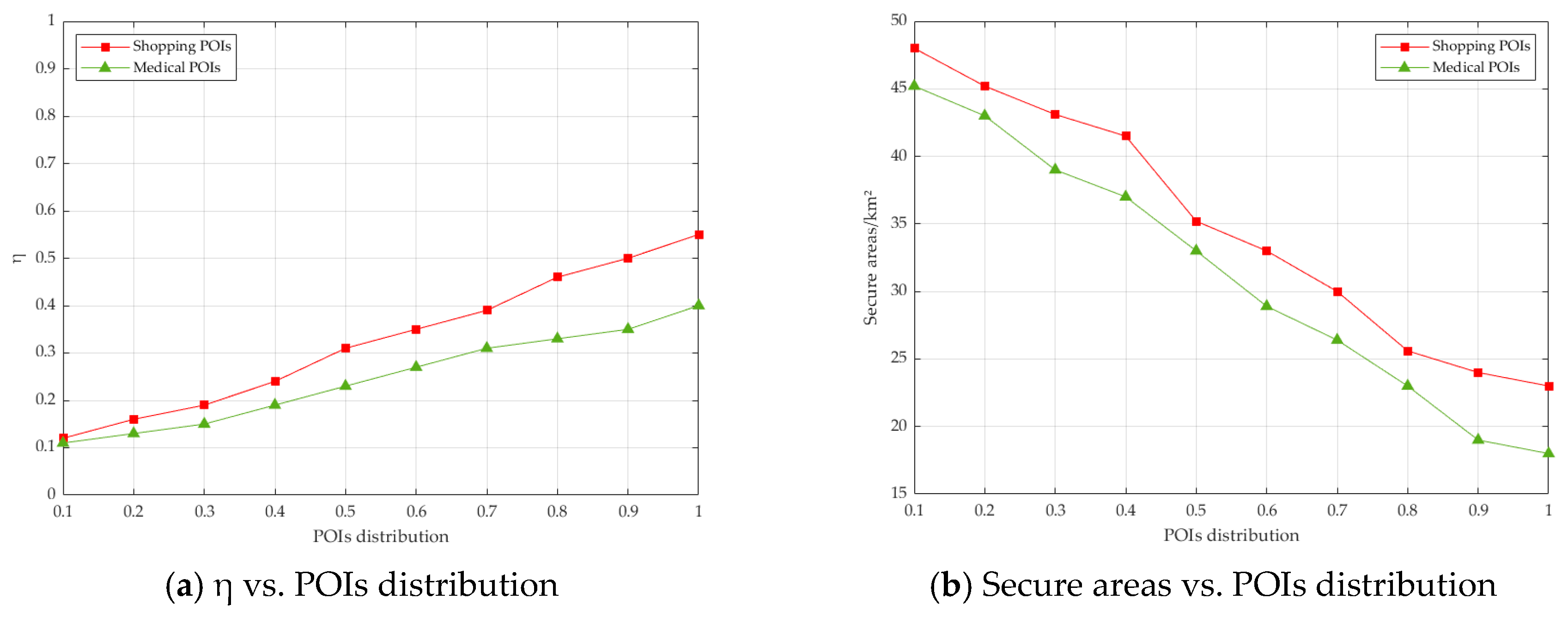
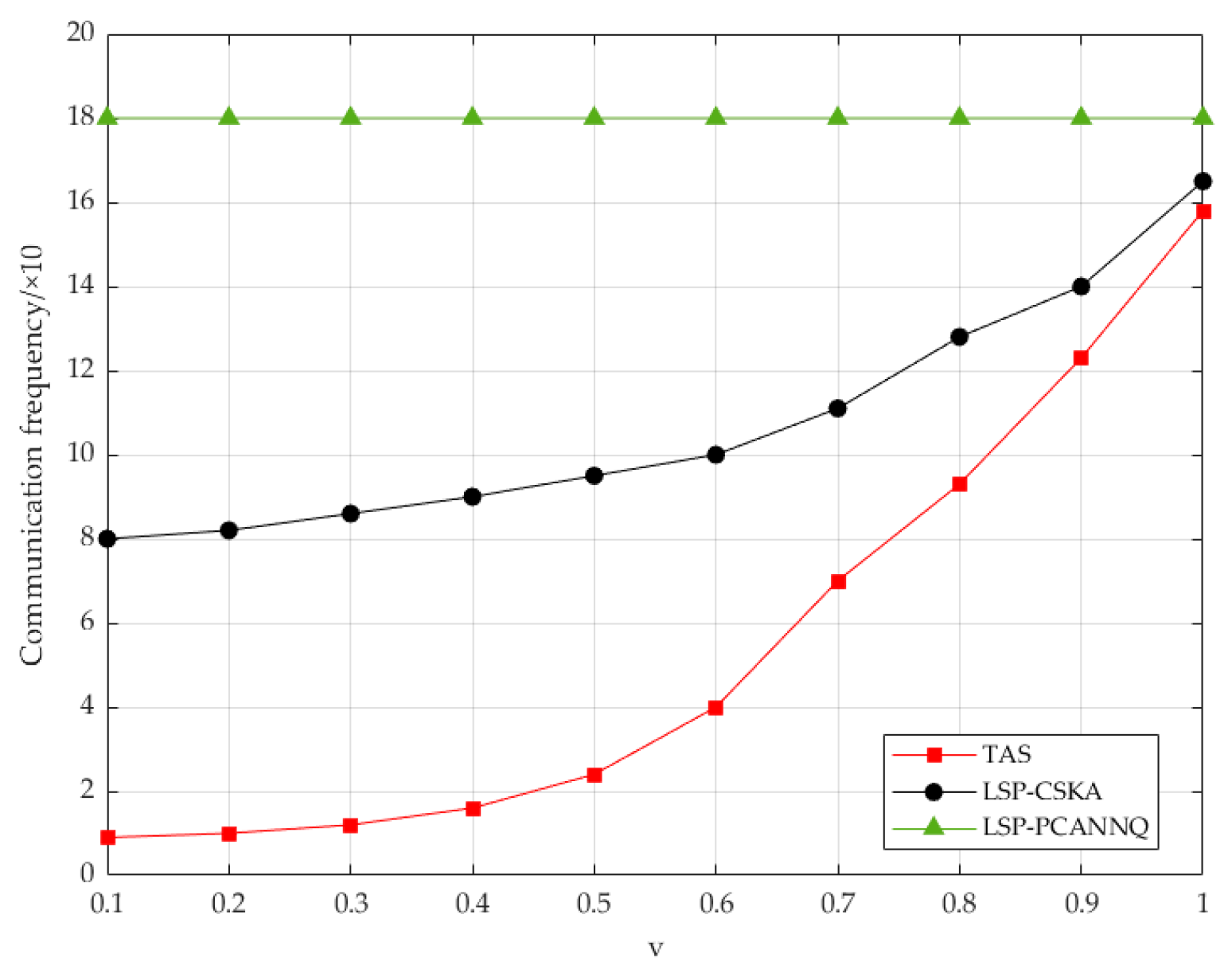
7.2. Security Comparison
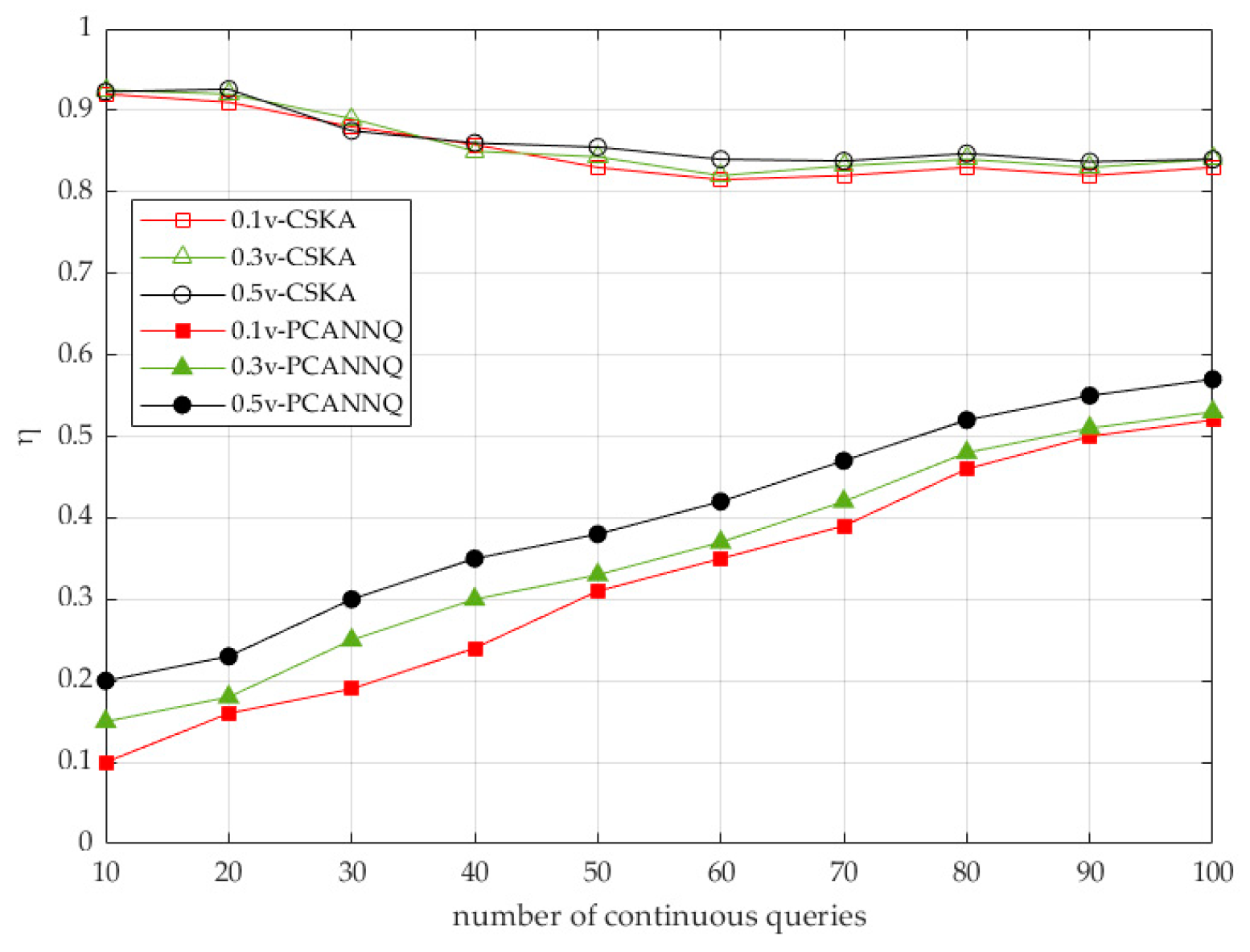
7.3. Efficiency Comparison
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Schlegel, R.; Chow, C.Y.; Huang, Q.; Wong, D.S. Privacy-Preserving Location Sharing Services for Social Networks. IEEE Trans. Serv. Comput. 2016, 99, 1. [Google Scholar] [CrossRef]
- Son, J.; Kim, D.; Bhuiyan, M.Z.; Tashakkori, R.; Seo, J.; Lee, D.H. Privacy Enhanced Location Sharing for Mobile Online Social Networks. IEEE Trans. Sustain. Comput. 2018, 11, 439–443. [Google Scholar] [CrossRef]
- Zhu, S.Z.; Huang, L.; Zhou, C.L.; Ma, Y. A Privacy-Preserving Method Based on POIs Distribution Using Cloaking Region for K Nearest Neighbor Query. Acta Electron. Sin. 2016, 44, 2423–2431. [Google Scholar]
- Pournajaf, L.; Tahmasebian, F.; Xiong, L. Privacy Preserving Reverse k-Nearest Neighbor Queries. In Proceedings of the 2018 19th IEEE International Conference on Mobile Data Management (MDM), Aalborg, Denmark, 26–28 June 2018; pp. 177–186. [Google Scholar]
- Wang, H.Y.; Cao, R.J.; Liu, Y.S.; Liu, W.Y.; Jin, S.F. Dynamic Friend Discovery Based on Privacy for Proximity-based Mobile Social Networking. J. Chin. Comput. Syst. 2016, 37, 104–109. [Google Scholar]
- Luo, E.T.; Wang, G.J.; Chen, S.H.; Pinial, K.B. Privacy Preserving Friend Discovery Cross Domain Scheme Using Re-encryption in Mobile Social Networks. J. Commun. 2017, 38, 81–93. [Google Scholar]
- Tan, R.; Si, W.; Sheng, J. A Privacy-Sensitive Approach for Group Convergence in Location-Based Services. In Proceedings of the IEEE International Conference on Cyberworlds, Chongqing, China, 28–30 September 2016; pp. 1–8. [Google Scholar]
- Sun, Y.M.; Chen, M.; Hu, L.; Qian, Y.F.; Mohammad, M.H. ASA: Against Statistical Attacks for Privacy-Aware Users in Location Based Service. Future Gener. Comput. Syst. 2017, 70, 48–58. [Google Scholar] [CrossRef]
- Gedik, B.; Liu, L. Protecting Location Privacy with Personalized k-Anonymity: Architecture and Algorithms. IEEE Trans. Mob. Comput. 2007, 7, 1–18. [Google Scholar] [CrossRef]
- Schlegel, R.; Chow, C.Y.; Huang, Q.; Wong, D.S. User-Defined Privacy Grid System for Continuous Location-Based Services. IEEE Trans. Mob. Comput. 2015, 14, 2158–2172. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, G.; Liu, Q.; Abawajy, J.H. A trajectory Privacy-Preserving Scheme Based on Query Exchange in Mobile Social Networks. Soft Comput. 2018, 22, 6121–6133. [Google Scholar] [CrossRef]
- Ni, W.W.; Ma, Z.X.; Chen, X. Safe Region Scheme for Privacy-Preserving Continuous Nearest Neighbor Query on Road Networks. Chin. J. Comput. 2016, 39, 628–642. [Google Scholar]
- Yiu, M.L.; Jensen, C.S.; Huang, X.; Lu, H. SpaceTwist: Managing the Trade-Offs Among Location Privacy, Query Performance, and Query Accuracy in Mobile Services. In Proceedings of the International Conference on Data Engineering, Cancún, México, 7–12 April 2008; pp. 266–375. [Google Scholar]
- Chow, C.Y.; Mokbel, M.F.; Aref, W.G. Casper*: Query processing for location services without compromising privacy. ACM Trans. Database Syst. 2009, 34, 1–48. [Google Scholar] [CrossRef]
- Chow, C.Y.; Mokbel, M.F.; Liu, X. Spatial Cloaking for Anonymous Location-Based Services in Mobile Peer-to-Peer Environments. Geoinformatica 2011, 15, 351–380. [Google Scholar] [CrossRef]
- Khoshgozaran, A.; Shahabi, C. Blind Evaluation of Nearest Neighbor Queries Using Space Transformation to Preserve Location Privacy. In Proceedings of the International Conference on Advances in Spatial and Temporal Databases, Boston, MA, USA, 16–18 July 2007; pp. 239–257. [Google Scholar]
- Zhang, S.B.; Liu, Q.; Wang, G.J. A Caching-Based Privacy-Preserving Scheme for Continuous Location-Based Services. In Proceedings of the Security, Privacy and Anonymity in Computation, Communication and Storage, Zhangjiajie, China, 16–18 November 2016; pp. 73–82. [Google Scholar]
- Zhang, S.B.; Li, X.; Tan, Z.Y.; Peng, T.; Wang, G.J. A Caching and Spatial K-Anonymity Driven Privacy Enhancement Scheme in Continuous Location-Based Services. Future Gener. Comput. Syst. 2019, 94, 40–50. [Google Scholar] [CrossRef]
- Hwang, R.H.; Hsueh, Y.L.; Chung, H.W. A Novel Time-Obfuscated Algorithm for Trajectory Privacy Protection. IEEE Trans. Serv. Comput. 2014, 7, 126–139. [Google Scholar] [CrossRef]
- Peng, T.; Liu, Q.; Meng, D.C.; Wang, G.J. Collaborative Trajectory Privacy Preserving Scheme in Location-Based Services. Inf. Sci. 2017, 387, 165–179. [Google Scholar] [CrossRef]
- Papadias, D.; Tao, Y.; Mouratidis, K.; Hui, C.K. Aggregate Nearest Neighbor Queries in Spatial Databases. ACM Trans. Database Syst. 2005, 30, 529–576. [Google Scholar] [CrossRef]
- Yiu, M.L.; Mamoulis, N.; Papadias, D. Aggregate nearest Neighbor Queries in Road Networks. IEEE Trans. Knowl. Data Eng. 2005, 17, 820–833. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, H.; Furuse, K.; Ohbo, N. Efficient Methods in Finding Aggregate Nearest Neighbor by Projection-Based Filtering. In Proceedings of the International Conference on Computational Science & Its Applications, Kuala Lumpur, Malaysia, 26–29 August 2007; pp. 821–833. [Google Scholar]
- Hashem, T.; Kulik, L.; Zhang, R. Privacy preserving group nearest neighbor queries. In Proceedings of the International Conference on Extending Database Technology, Lausanne, Switzerland, 22 March 2010; pp. 489–500. [Google Scholar]
- Elmongui, H.G.; Mokbel, M.F.; Aref, W.G. Continuous aggregate nearest neighbor queries. Geoinformatica 2013, 17, 63–95. [Google Scholar] [CrossRef]
- Sun, W.W.; Chen, C.N.; Zhu, L.; Gao, Y.J.; Jing, Y.N.; Li, Q. On Efficient Aggregate Nearest Neighbor Query Processing in Road Networks. J. Comput. Sci. Technol. 2015, 30, 781–798. [Google Scholar] [CrossRef]
- Yao, B.; Chen, Z.; Gao, X.; Shang, S.; Ma, S.; Guo, M. Flexible Aggregate Nearest Neighbor Queries in Road Networks. In Proceedings of the IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018. [Google Scholar]
- Guttman, A. R Trees: A Dynamic Index Structure for Spatial Searching. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar]
- Sharifzadeh, M.; Shahabi, C. VoR-Tree: R-trees with Voronoi Diagrams for Efficient Processing of Spatial Nearest Neighbor Queries. In Proceedings of the 36th International Conference on Very Large Data Bases, Singapore, 13–17 September 2010. [Google Scholar]
- Lin, Q.; Zhang, Y.; Zhang, W.; Lin, X. AVR-Tree: Speeding Up the NN and ANN Queries on Location Data. In Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 116–130. [Google Scholar]
- Brinkhoff, T. A Framework for Generating Network-Based Moving Objects. GeoInformatica 2002, 6, 153–180. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description | Notation | Description |
|---|---|---|---|
| set of POIs | global public nearest neighbor | ||
| set of users | local public nearest neighbor | ||
| nearest neighbor set of user q | prune set | ||
| nearest neighbor set of group Q | the kth aggregate nearest neighbor | ||
| distance between p and q | dominated POI | ||
| aggregate distance between p and Q | set of secure areas | ||
| the jth nearest neighbor of | set of maximum secure areas |
| /km | ||
|---|---|---|
| Type | Name | Amount |
|---|---|---|
| POI set | Dongcheng District, Beijing | 165,326 |
| Trajectory set | Thomas Brinkhoff | 120 |
| Description | Notation | Ranges | Default Values |
|---|---|---|---|
| Number of users | n | 3–10 | 5 |
| Number of POIs | m | 5 K–15 K | 10 K |
| Distribution of users | a | 1–5% | 3% |
| Moving speed | v | 5–100 km/h | 50 km/h |
| Distribution of POIs | d | 10–100% | 50% |
| Anonymity degree | k | 2–10 | 6 |
| Number of continuous queries | q | 10–100 | 50 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Jin, C.; Huang, H.-p.; Fu, X.; Wang, R.-c. A Trajectory Privacy Preserving Scheme in the CANNQ Service for IoT. Sensors 2019, 19, 2190. https://doi.org/10.3390/s19092190
Zhang L, Jin C, Huang H-p, Fu X, Wang R-c. A Trajectory Privacy Preserving Scheme in the CANNQ Service for IoT. Sensors. 2019; 19(9):2190. https://doi.org/10.3390/s19092190
Chicago/Turabian StyleZhang, Lin, Chao Jin, Hai-ping Huang, Xiong Fu, and Ru-chuan Wang. 2019. "A Trajectory Privacy Preserving Scheme in the CANNQ Service for IoT" Sensors 19, no. 9: 2190. https://doi.org/10.3390/s19092190
APA StyleZhang, L., Jin, C., Huang, H.-p., Fu, X., & Wang, R.-c. (2019). A Trajectory Privacy Preserving Scheme in the CANNQ Service for IoT. Sensors, 19(9), 2190. https://doi.org/10.3390/s19092190