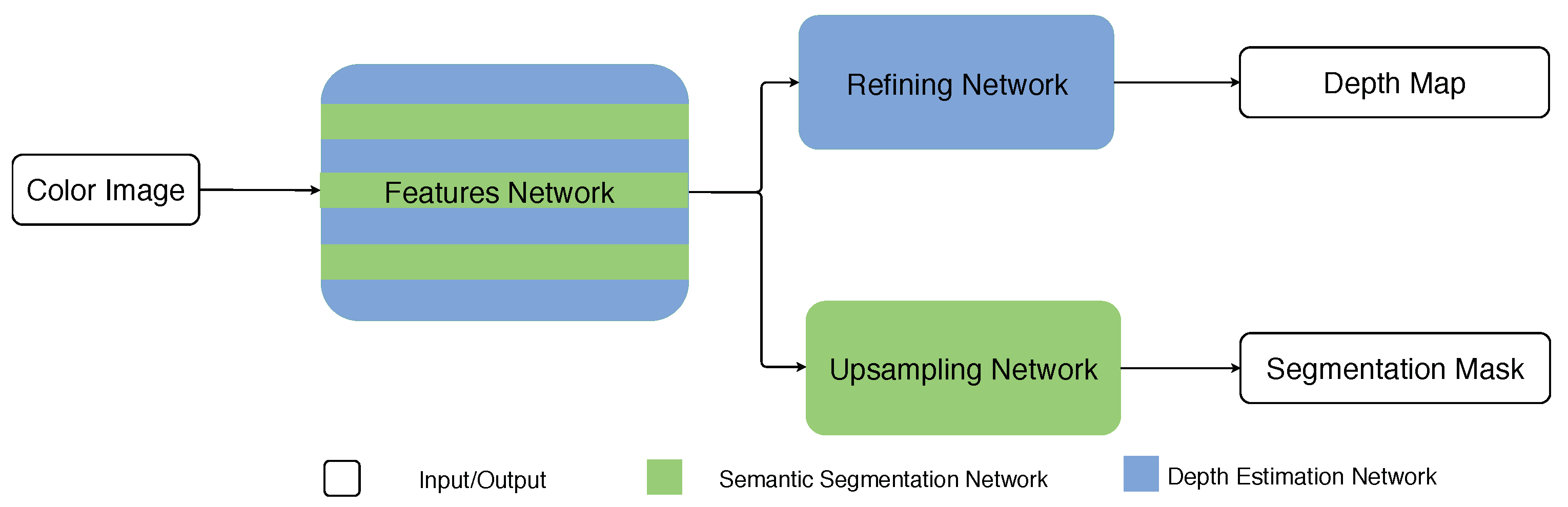
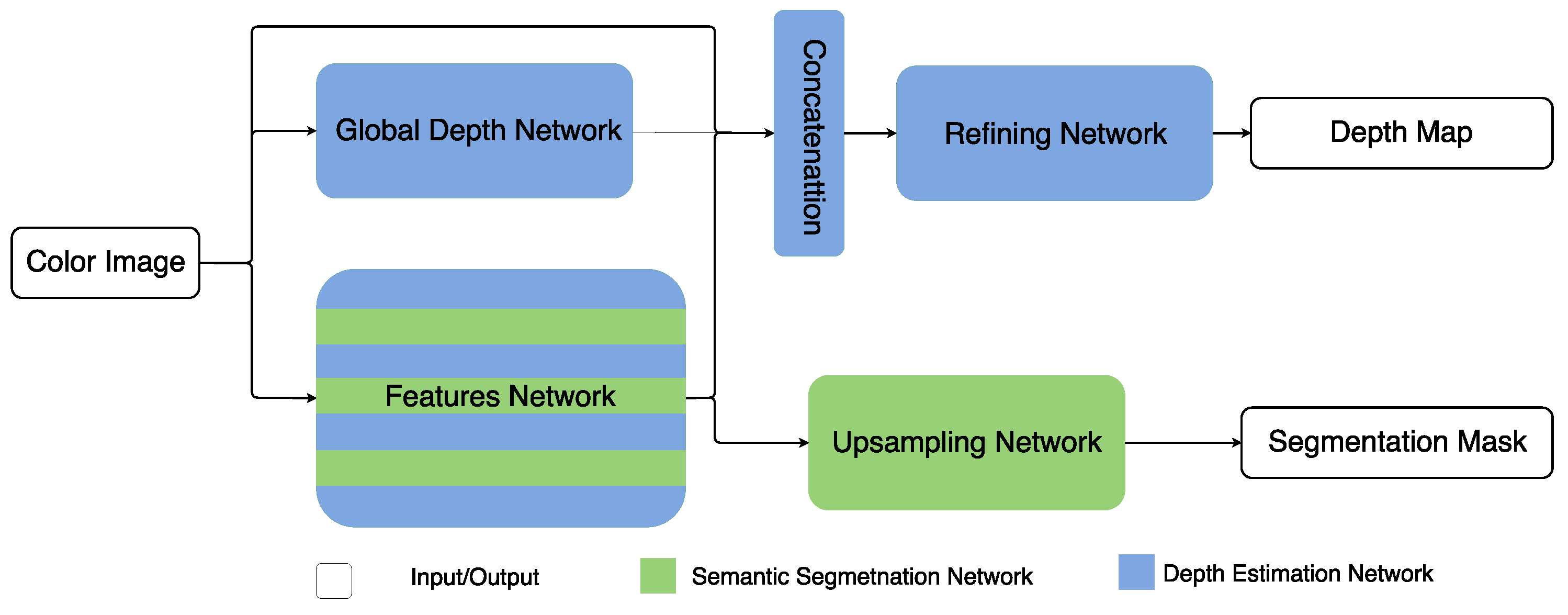
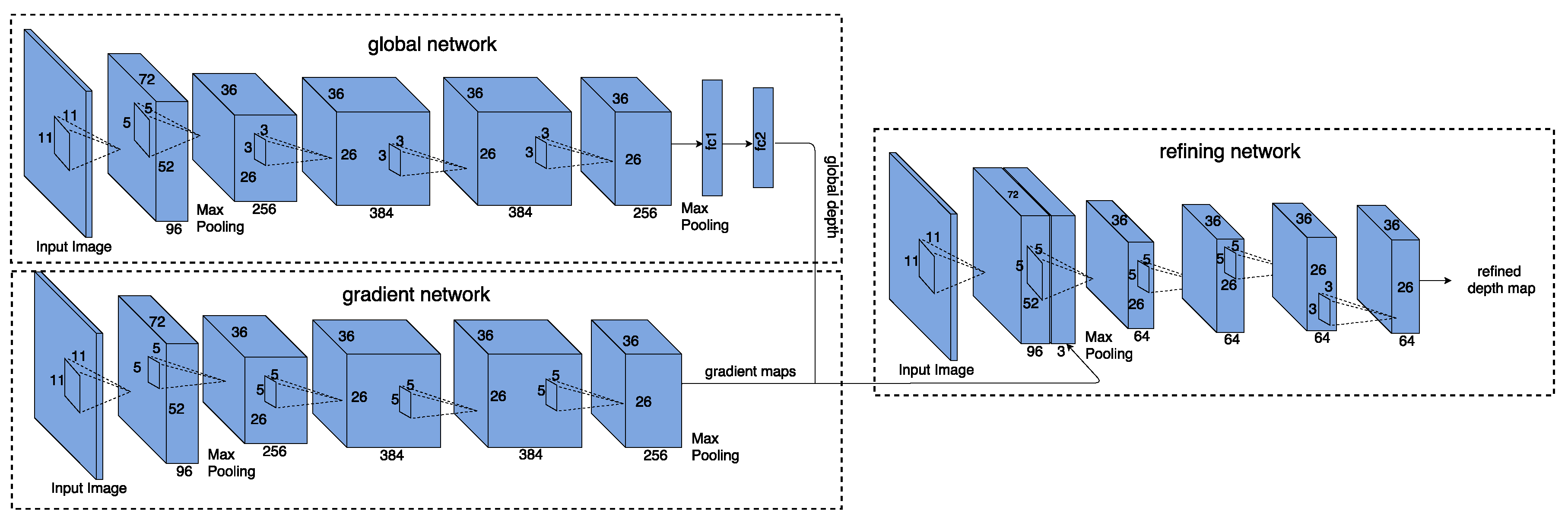
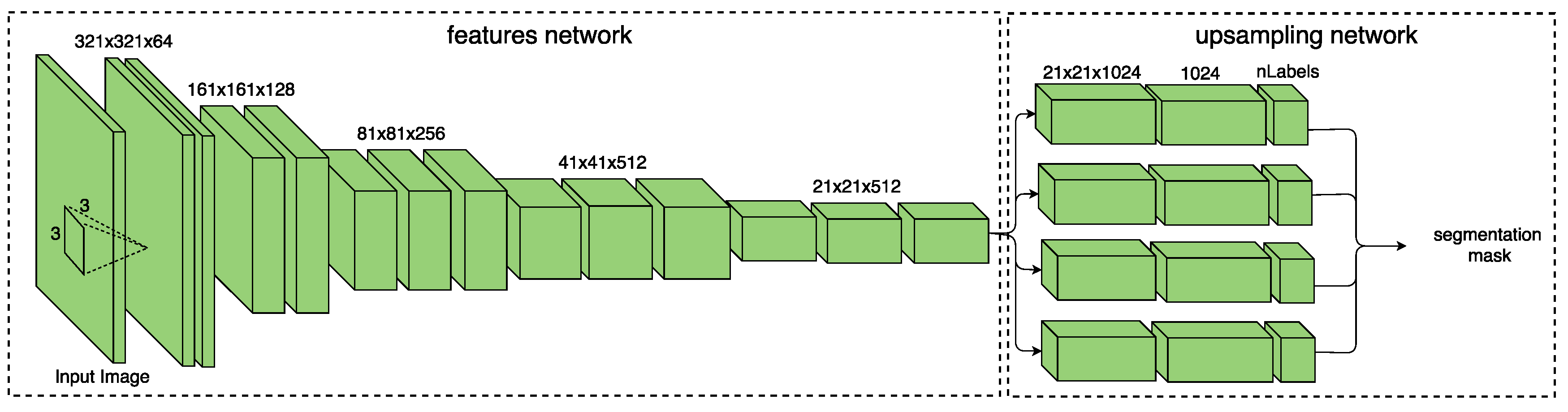
We quantify the performance of the proposed architectures on both semantic segmentation and depth estimation in different scenes using our Caffe implementation. We first evaluate the proposed architectures in road scenes which is of current practical interest for various autonomous driving related problems. Secondly, the proposed architectures are evaluated in indoor scenes which is of immediate interest to possible augmented reality (AR) applications.
5.1. Road Scene
In this section, we present the evaluation of the proposed architectures in road scenes. Several road scene datasets are available for semantic parsing [
30,
31,
32]. Since we evaluate the proposed architecture from both semantic segmentation and depth estimation perspective, we employ Cityscapes dataset [
32] in our experiment, which provides not only the ground truth of semantic labels but the depth information of each frame. Cityscapes contains 5000 RGB images manually selected from 27 different cities for dense pixel-level annotation to ensure high diversity of foreground objects, background, and overall scene layout. Along with each of the 5000 RGB images, Cityscapes dataset provides the depth map obtained from a stereo vision system. The 5000 images in the dataset are split into 2975 training RGB images of size
along with their corresponding 2D ground truth object labels for 19 outdoor scenes classes and depth information, 500 RGB images for test validation with their corresponding annotations and, for benchmarking purposes, 1525 test RGB images.
In practice, the training process of our approach was performed using the 2975 images of Cityscapes training set that provides a depth map and object labels of 19 classes for each RGB image. To evaluate the performance of the proposed architectures, we group the 500 images of the validation set and the 1525 images of the test set in the Cityscapes dataset into a single evaluation set of 2025 images. In the training phase, images in the training set are shuffled and randomly cropped to fit the input image size of the hybrid architecture. Training data augmentation is done by flipping and mirroring the original images, to enlarge the training set. In the testing phase, we crop the test image with the original size of into a group of images with the size of 321 by 321 which cover the whole test image while having the minimum overlapped area. These images are tested one by one and grouped to obtain the final prediction of the segmentation mask and depth map. Please note that a score map is obtained for each image, which shows the degree that a pixel belongs to a label. For the overlapped area, we compare the normalized score maps and take the label with higher score as predicted labels on the segmentation mask. Likewise, for the overlapped area, the predicted depth values on the depth map are computed as the mean values.
Our first aim is to determine if the features obtained in the shared part of the proposed architectures solving the two tasks simultaneously provide better results than the ones that we would obtain using two identical networks trained separately. This is why, in addition to the results of the proposed architectures, we present the results obtained by the models that solve these two tasks separately for comparison. The models used to train semantic segmentation and depth estimation independently are denoted as DeepLab-ASPP [
16] and DepthNet [
19], respectively. We trained these two models using the code provided by the authors with the same training data in Cityscapes dataset and the same training configuration than the proposed architectures. Apart from that, we also compare different ways of unifying single-task architectures proposed in
Section 3, to justify whether the unifying strategy is better. Besides, the comparison between the proposed architectures and a hybrid method in the state of the art [
25] is also made in Cityscapes dataset. The hybrid approach proposed in [
25] is similar to HybridNet A1, in which the encoder network in FCN [
11] is employed as the feature network shared by three different tasks and the decoder network in FCN is then employed for each task to decode the commonly extracted features. The three tasks that [
25] tackles are semantic segmentation, depth layering, boundary detection, which is similar to our target. However, in the depth layering task, ref. [
25] focuses on estimating a depth label for each object, instead of estimating the real depth value of the whole scene at pixel level. This is also the reason that we only compare the performance between our approach and [
25] in semantic segmentation. We present the results in our experiments in the following two subsections specifying the evaluation in semantic segmentation and depth estimation, respectively.
5.1.1. Semantic Segmentation
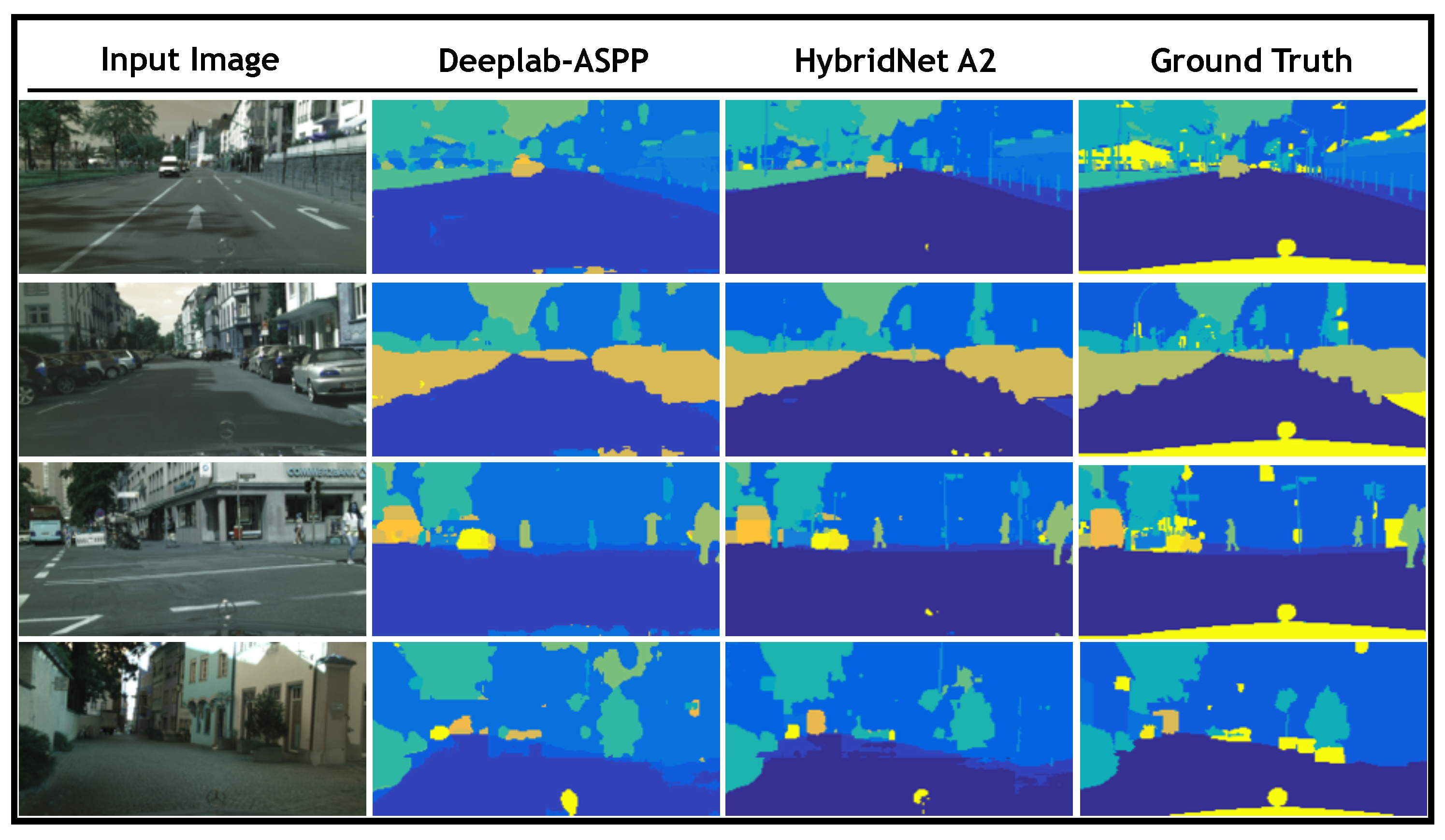
Figure 5 provides four examples from the evaluation set for visual comparison between the results obtained by our hybrid model and ground truth as well as those obtained by DeepLab-ASPP. The purpose of this figure is to depict the differences between a single-task and a multi-task approach. In
Figure 5 the input image is displayed in the first column, second and third columns show the results obtained by DeepLab-ASPP and our hybrid model, respectively. Finally, in the fourth column the ground truth is presented for reference. This figure shows how the segmentation performed by the proposed HybridNet A2 retains with a greater detail the geometrical characteristics of the objects contained in the scene. For instance, in the 3rd row where the shapes of a pedestrian and a car can be better distinguished in the estimation obtained by Hybrid A2 than the one obtained by DeepLab-ASPP.
In addition to qualitative results, we employ three commonly used metrics, to measure quantitatively the segmentation performance: the global accuracy (G), the class average accuracy (C) and mean intersection over union (mIoU). The global accuracy counts the percentage of pixels which are correctly labeled with respect to the ground truth labeling. The class average accuracy is the mean of the pixel accuracy in each class. The mean intersection over union measures the average Jaccard scores over all classes.
Table 2 presents the quantitative results and confirms that the proposed HybridNet outperforms the results obtained by DeepLab-ASPP. Please note that the global accuracy and the class average accuracy evaluation of PLEDL are not provided due to the unavailability of the source code, whereas the evaluation of mIoU is reported in [
25].
The improvements obtained by our method against DeepLab-ASPP confirm the hypothesis that sharing the feature-extraction network between tasks leads to an improvement in terms of segmentation accuracy. The strategy of unifying two single-task architectures affects the segmentation performance of hybrid methods. HybridNet A2 where common and specific attributes between two different tasks are better clarified outperforms HybridNet A1 in which the feature-extraction process is totally shared for the two tasks. The improvement that HybridNet A1 obtains against DeepLab-ASPP is very limited (HybridNet A1 58.1% mIoU against DeepLab-ASPP 58.02% mIoU); however, Hybrid A2 improves the mIoU by around
. We also compare our architectures against a state-of-the-art hybrid method [
25] in
Table 2. HybridNet A2 has a better segmentation performance in all three metrics, than the work in [
25]. For additional evaluation, comparisons between our approach against other well adopted single-task methods [
11,
13,
16,
33] are presented in
Table 2.
5.1.2. Depth Estimation
For depth estimation evaluation,
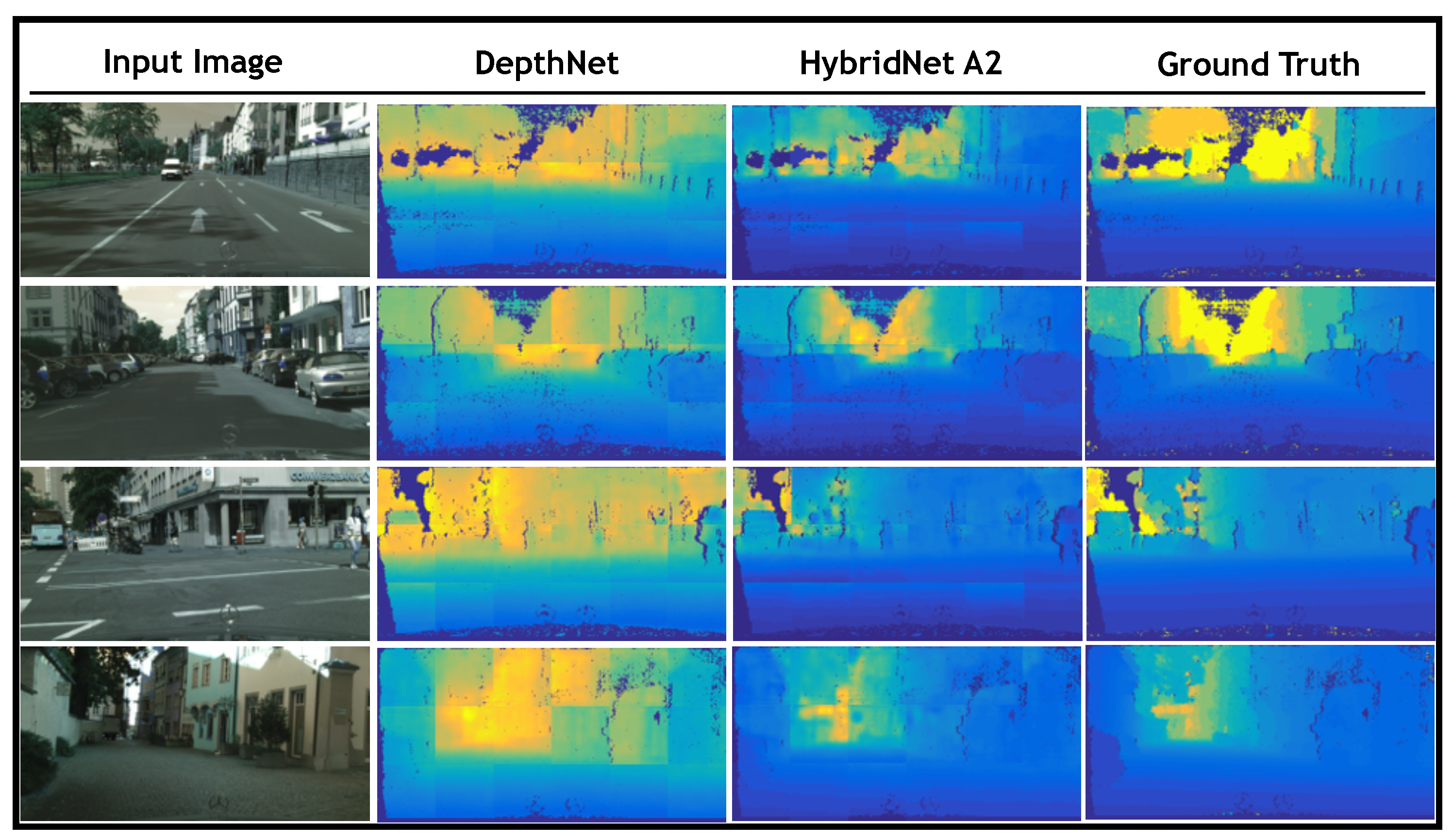
Figure 6 presents a visual comparison of the results obtained by Hybrid A2 as well as those obtained by the single-task approach presented in [
19] against the ground truth. The figure displays, row-wise the same four examples depicted in
Figure 5.
Figure 6 depicts the input image in the first column, the depth map obtained by DepthNet in the second column, while third and fourth columns show the depth map obtained by HybridNet A2 and ground truth, respectively. Note how the results obtained by Hybrid A2 are more consistent with the ground truth than those obtained by DepthNet in terms of the depth layering.
Additionally to qualitative analysis, we evaluate the performance of our methodology for depth estimation employing 6 commonly used metrics: Percentage of Pixel (PP), Mean Variance Normalized Percentage of Pixel (PP-MVN), Absolute Relative Difference (ARD), Square Relative Difference (SRD), Linear Root Mean Square Error (RMSE-linear), Log Root Mean Square Error (RMSE-log) and Scale-Invariant Error (SIE).
Table 3 shows the definition for these metrics employed in the evaluation process.
d and
represent the estimated depth and ground truth, respectively.
N stands for the number of pixels with valid depth value in the ground truth depth map.
In the quantitative experiment, we compare the proposed hybrid architectures and DepthNet.
Table 4 shows the quantitative results of the proposed hybrid architectures and DepthNet under the different evaluation metrics introduced above. HybridNet A2 outperforms in 6 out of 9 metrics, which proves that training the feature-extraction network for the simultaneous tasks of semantic segmentation and depth estimation also improves the depth estimation results. The better performance of HybridNet A2 in comparison to DepthNet illustrates that the shared features obtained with the semantic segmentation task in HybridNet A2 have richer information and are more relevant in the depth estimation task than the information extracted from the depth gradient in DepthNet. The comparison between Hybrid A2 and Hybrid A1 shows the necessity of clarifying the common and specific attributes of different tasks. Sharing only the common attributes of tasks in the feature-extraction process leads to a better performance in-depth estimation. We also verify the standard deviation of the performance of these methods among all testing samples to ensure the statistical significance of the results. Since very similar results are observed, we do not present them in
Table 4 for conciseness.
5.2. Indoor Scene
Road scene images have relatively limited variation in terms of the involved semantics and their spatial arrangements. They are usually captured by a camera fixed on a moving vehicle where the view direction of the camera is always parallel to the ground. This limits the variability of road scene images and makes it easier for the convolutional networks to learn to segment them robustly. In comparison, images of indoor scenes are more complex due to the free view point, the larger number of semantics in the scene, widely varying sizes of objects and their various spatial arrangements. On the other hand, although indoor scenes have smaller depth range than road scenes, they usually have more complex spatial layout, which provides challenges for depth estimation.
In this section, we evaluate the proposed architectures on indoor scene data for both semantic segmentation and depth estimation. We employ RGB-D Scene Understanding Benchmark dataset [
34] (SUN-RGBD) for the experiments. SUN-RGBD contains over 10k RGB-D images of indoor scenes captured by 4 types of depth sensors, including also RGB-D images from NYU depth v2 [
35], Berkeley B3DO [
36], and SUN3D [
37]. It provides 2D ground truth object labels for 37 indoor scene classes, such as wall, floor, ceiling, table, chair etc. and depth maps of different resolutions. Our task is to segment the objects within these 37 classes in each image while estimating its depth. In practice, we split the dataset into 5285 training and 5050 testing images, following the experiment configuration introduced in [
13].
Similarly to the experiments in Cityscapes dataset, we perform training data augmentation by random cropping, flipping, and mirroring the original training images. However, in the testing phase, instead of cropping the test image as we did in the Cityscapes dataset, we downsample the test image to fit the input size of the hybrid architecture. Since the difference between the size of the test image and input size is not large in SUNR-GBD dataset, directly downsampling the test image to fit the input size strongly improves the efficiency in the testing phase, while not losing the important information in the test data.
5.2.1. Semantic Segmentation
SUN-RGBD is a very challenging indoor scene dataset for semantic segmentation, in which object classes come in various shapes, sizes, and different poses. There are also frequent partial occlusions between objects, which is typical in indoor scenes, due to the fact that many object classes are presented in each of the test images.
Figure 7 provides a visual comparison for the estimated segmentation mask against ground truth. The figure presents, row-wise, 7 out-of-training examples where the first row shows the input images, the 2nd and 3rd row show the estimated segmentation mask from HybridNet A2 and DeepLab-ASPP respectively, and the last row shows the ground truth. HybridNet A2 exhibits stronger performance in distinguishing different objects in indoor scenes compared to DeepLab-ASPP.
Additionally, to qualitative results, we follow the three metrics introduced in
Section 5.1.1: the global accuracy (G), the class average accuracy (C) and mean intersection over union (mIoU) to evaluate the segmentation performance quantitatively. We also benchmark the proposed architectures against several other well adopted architectures for semantic segmentation, such as FCN [
11], SegNet [
13], DeepLab [
16] and DeconvNet [
38]. For FCN, the parameters for the deconvolutional layers are learned from the training process instead of using fixed parameters to perform bilinear upsampling. For DeepLab, three architectures are employed, which are DeepLab-ASPP, DeepLab-LargeFOV, and DeepLab-LargeFOV-denseCRF. They use the same VGGNet architecture for feature map extraction, which is similar to the proposed architectures. DeepLab-LargeFOV performs single scale upsampling on the feature map, while DeepLab-ASPP performs multi-scale upsampling. DeepLab-LargeFOV-denseCRF introduces a dense conditional random field as a post-processing step for DeepLab-LargeFOV.
Table 5 shows the quantitative results of the proposed architectures (HybridNet A1 and A2) compared with other methods. HybridNet A2 achieves the best results in C and mIoU over all the 7 methods while also obtaining a (71.63%) in G close to the best (73.87%) obtained in DeepLab-ASPP. The higher global accuracy and lower per-class accuracy obtained in DeepLab-ASPP in comparison to HybridNet A2 illustrates that DeepLab-ASPP prefers to better cover large objects in the scene such as floor and wall, which provides good results in global evaluation. However, this affects its performance in smaller objects, which results in its lower per-class accuracy, as well as mIoU. The improvement against DeepLab-ASPP verifies again the idea of the multi-task learning, that estimating depth in addition to semantic segmentation helps the segmentation task (6.1% and 5.1% improvement in C and mIoU respectively). The performance of HybridNet A1 is even worse than the single-task method DeepLab-ASPP, which indicates that the idea of benefiting from unifying two single tasks in a hybrid architecture can hardly be achieved by simply sharing the feature-extraction process in more complex indoor scenes. The best segmentation performance obtained by HybridNet A2 compared with HybridNet A1 shows the importance of selecting a suitable unifying strategy in a multi-task learning problem and verifies the efficiency of the strategy employed in HybridNet A2.
5.2.2. Depth Estimation
For depth estimation evaluation
Figure 8 depicts a qualitative analysis of results. The figure presents, column-wise, the same 7 out-of-training examples presented in
Figure 7, where the first row shows the input images, the 2nd and 3rd row show the estimated depth map from HybridNet A2 and DeepLab-ASPP respectively, and the last row shows the ground truth. The depth maps estimated by HybridNet A2 are more consistent with the ground truth than those obtained by DepthNet in terms of the depth layering.
Additionally, to qualitative analysis, we evaluate the performance following the metrics introduced in
Section 5.1.2: PP, Mean Variance Normalized Pixel of Percentage (PP-MVN), ARD, SRD, Linear Root Mean Square Error (RMSE-linear), Log Root Mean Square Error (RMSE-log) and SIE.
Table 6 shows the quantitative results of the proposed architectures (HybridNet A1 and A2) and DepthNet under different metrics. HybridNet A2 outperforms over all the metrics which proves that performing semantic segmentation in addition to depth estimation helps the depth estimation task. The better performance of HybridNet A2 in comparison to A1 confirms the efficiency of the unifying strategy proposed in HybridNet A2 in more complex indoor scenes.
5.2.3. Comparison with Other Hybrid Architectures
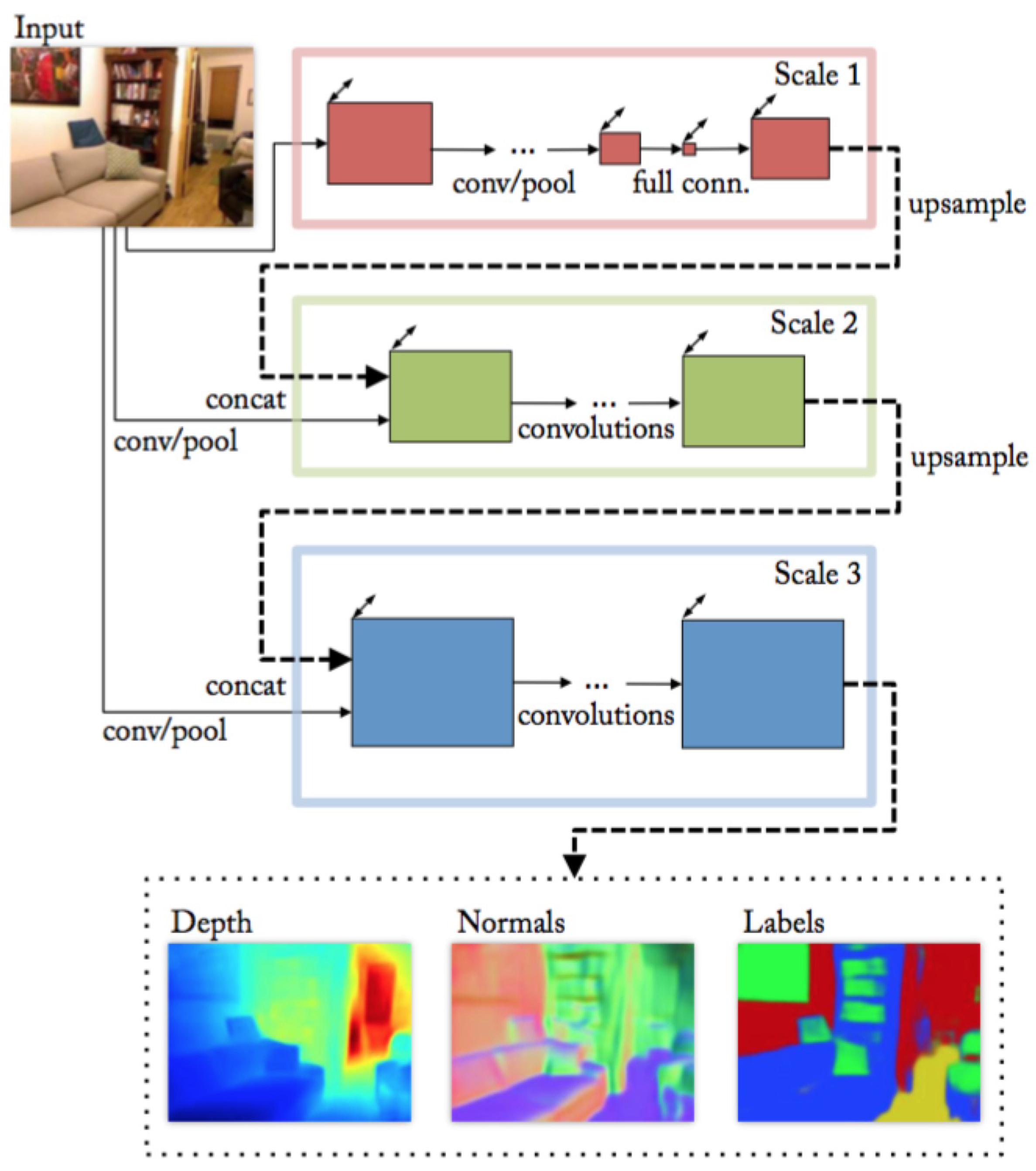
To compare HybridNet A2 with other hybrid architectures in the state of the art, the method proposed in [
21] is chosen. This method addresses three different tasks including semantic segmentation, depth estimation, and surface normal estimation. The architecture is designed as a stacking of three VGG structures [
28] representing different scales of feature extraction (shown in
Figure 9). Each of the VGG structures takes the output of the previous one along with the input color image as its input. Among the three tasks, depth estimation, and surface normal estimation are two tasks tackled jointly, which means that these two tasks share the network in scale 1 while the networks in scale 2-3 are separately assembled for each task. For the semantic segmentation task, the architecture shown in
Figure 9 is used again. However, different from the other two tasks, the architecture of semantic segmentation allows two additional input channels which are depth and normal channels. This architecture is only fine-tuned from the model previously trained on depth and normal estimation to generate semantic segmentation masks.
Although the source code of this method was not available, the performance evaluation is reported in a public dataset (NYU Depth V2 dataset [
35]). To make the comparison with this approach, we trained and evaluated our approach on NYU Depth V2 dataset. This data set includes RGB images and their corresponding 2D ground truth object labels for 40 indoor scene classes and depth map. NYU depth V2 dataset is divided into 795 images for training and 654 for testing. Due to the small number of images available for training, we augment the training set by random cropping, flipping, and mirroring.
Table 7 and
Table 8 show the quantitative results of HybridNet A2 for both tasks and provides a comparison with the approach proposed in [
21], denoted as Eigen. Semantic segmentation results in
Table 7 show that HybridNet A2 outperforms Eigen in class average accuracy (C) and mean intersection over union (mIoU) while keeping similar results than Eigen in Global accuracy (G). It also illustrates that addressing RGB-D-based semantic segmentation task under a multi-task learning scheme better uses the depth information than directly feeding the depth information to the network as an extra input channel. On the other hand, depth estimation results in
Table 8 show that HybridNet A2 has a better performance in the relative measure SIE, while in the absolute measures Eigen outperforms HybridNet A2. The better performance of HybridNet A2 in the relative measure shows that HybridNet A2 has a better depth layering capability than Eigen, which is more relevant in real applications. For absolute measures, we believe that the worse performance of HybridNet A2 is due to the weaker ability in describing the global layout of the scene. HybridNet A2 employs a much simpler architecture (AlexNet structure) for global depth network compared with the network of scale 1 (VGG structure) in Eigen.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}