Spatio–Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks †

 , ,
, ,  , and
, and 
Abstract
1. Introduction
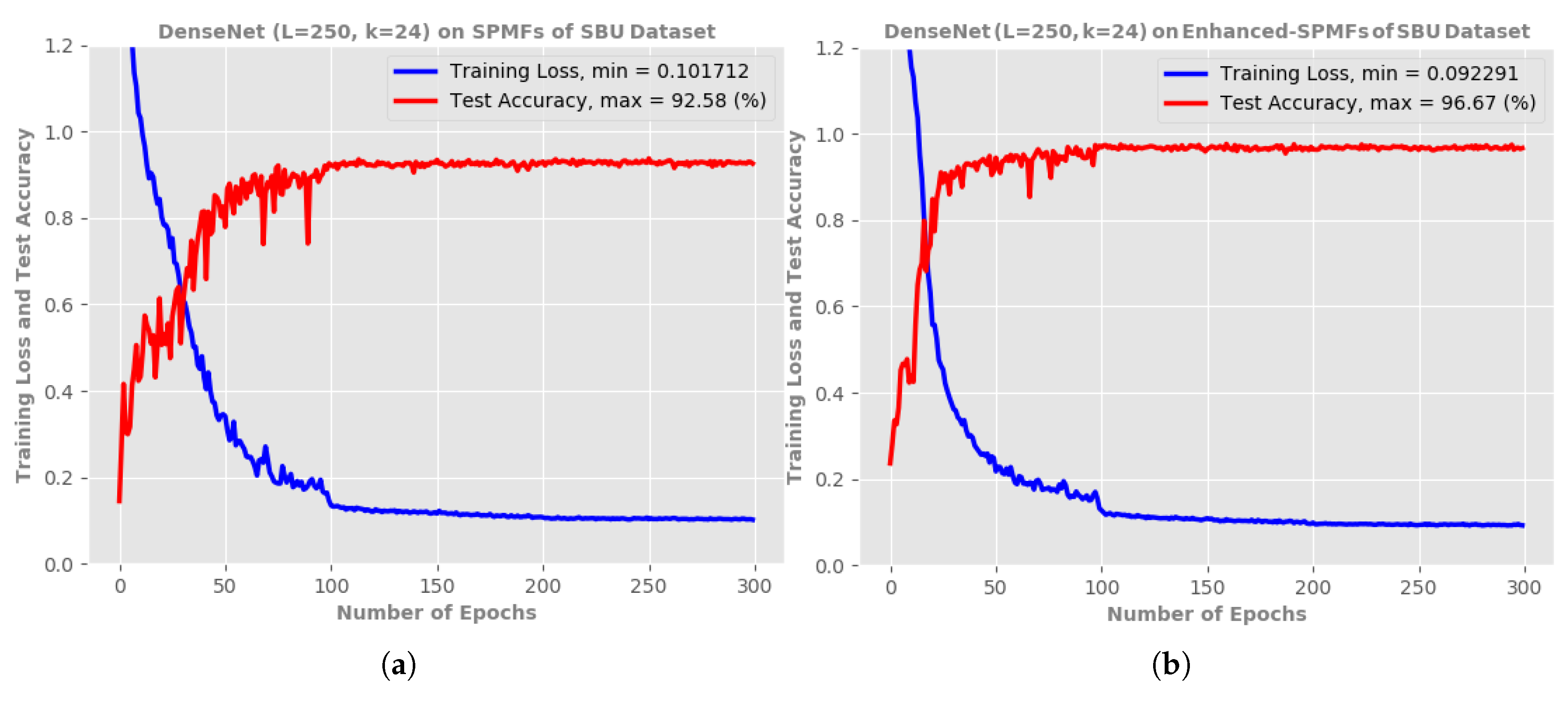
- Firstly, we present Enhanced-SPMF, a new skeleton-based representation for 3D human action recognition from skeletal data. This work is an extended version of our paper published in the 25th IEEE International Conference on Image Processing (ICIP) [48] in which the Enhanced-SPMF is an extension of SPMF (Skeleton Pose-Motion Feature). Compared to our previous work, the current work aims to improve the efficiency of the 3D motion representation via a smoothing filter and a color enhancement technique. The smoothing filter helps us to reduce the effect of noise on skeletal data, meanwhile the color enhancement technique could make the proposed Enhanced-SPMF more robust and discriminative for recognition task. An ablation study on the Enhanced-SPMF demonstrated that the new representation leads to better overall action recognition performance than the SPMF [48].
- Secondly, we present a deep learning framework (The implementation and models will be made publicly available at https://github.com/cerema-lab/Sensors-2018-HAR-SPMF). based on the DenseNet architecture [50] for learning discriminative features from the proposed Enhanced-SPMF and performing action classification. The framework directly learns an end-to-end mapping between skeleton sequences and their action labels with little pre-processing. We evaluate the proposed method on four highly competitive benchmark datasets and demonstrate significantly improvement over existing state-of-the-art approaches. Our computational efficiency evaluations show that the proposed method is able to achieve high-level of performance whilst requiring low computational time for both the training and inference stages. Compared to our previous work that exploited the Residual Inception v2 network [48], the current work uses a more powerful deep learning model for action recognition task
2. Related Work
2.1. Hand-Crafted Approaches for Skeleton-Based Human Action Recognition
2.2. Deep Learning Approaches for Skeleton-Based Human Action Recognition
3. Method
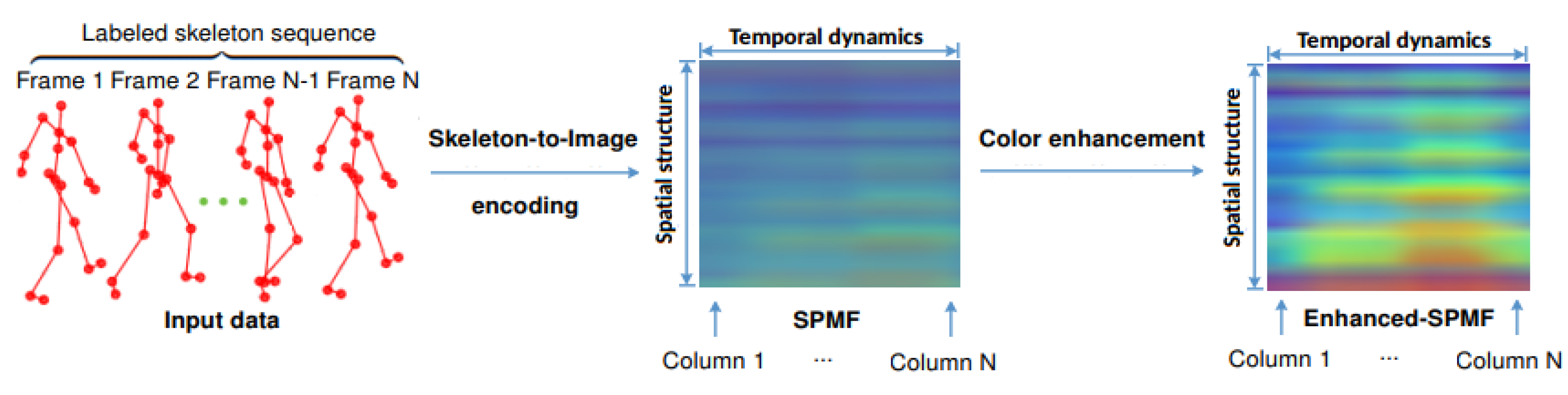
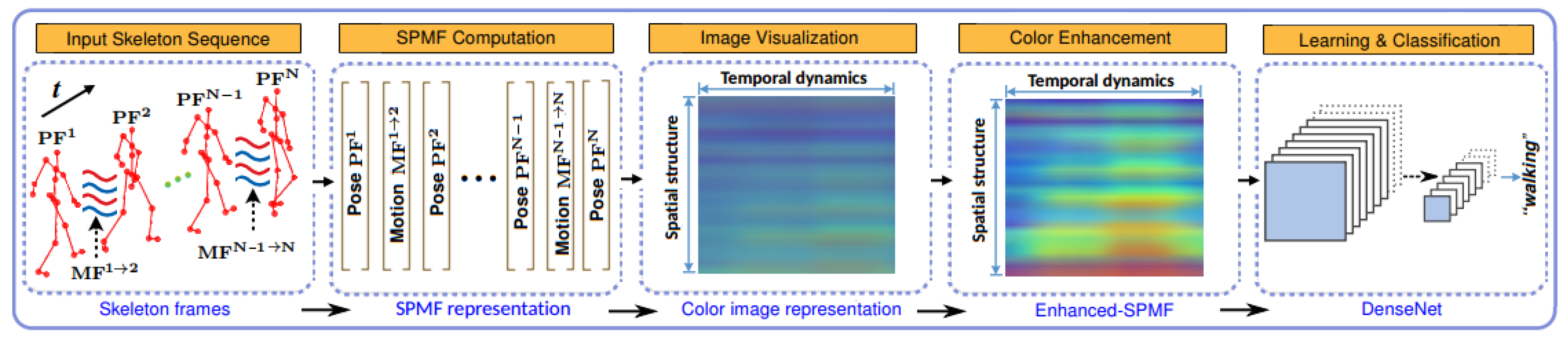
3.1. SPMF: Building Action Map from Skeletal Data
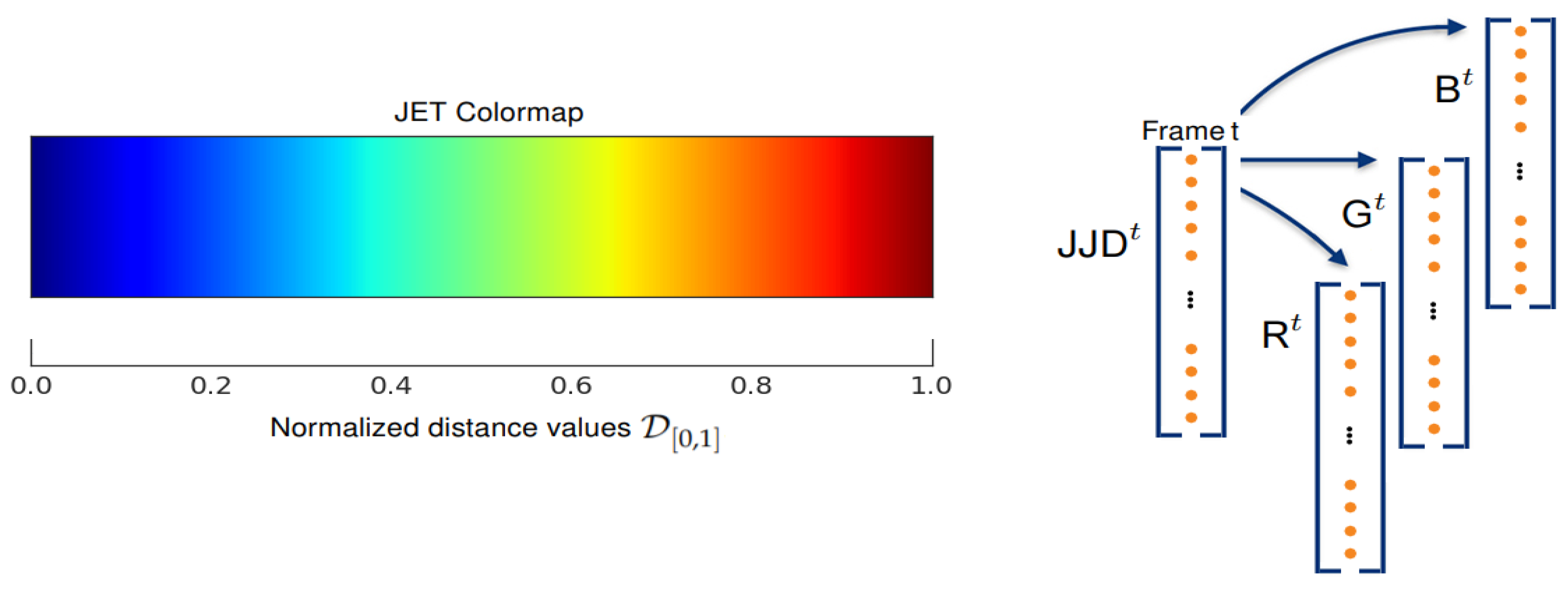
3.1.1. Pose Features (PFs) Computation
3.1.2. Motion Features (MFs) Computation
3.1.3. Building Global Action Map from PFs and MFs
3.2. Enhanced-SPMF: Building Enhanced Action Map
3.3. Deep Learning Model
3.3.1. Densely Connected Convolutional Networks
3.3.2. Network Design
4. Experiments
4.1. Datasets and Settings
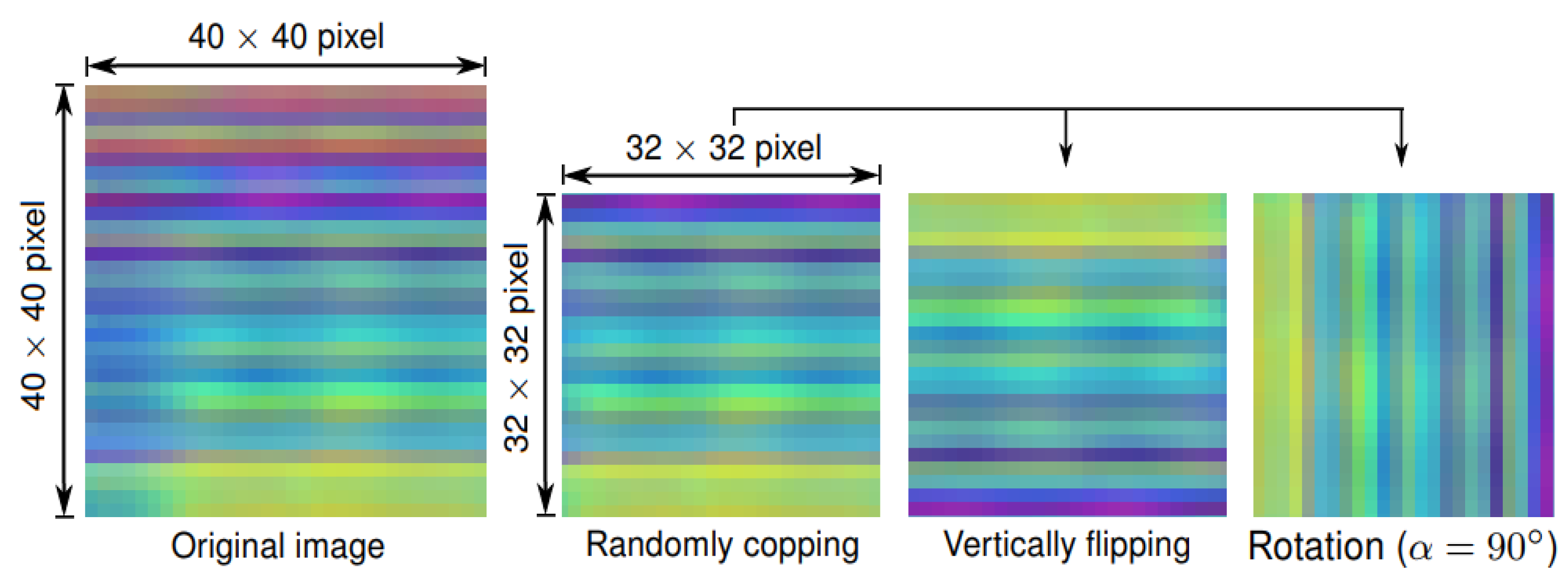
4.2. Implementation Details
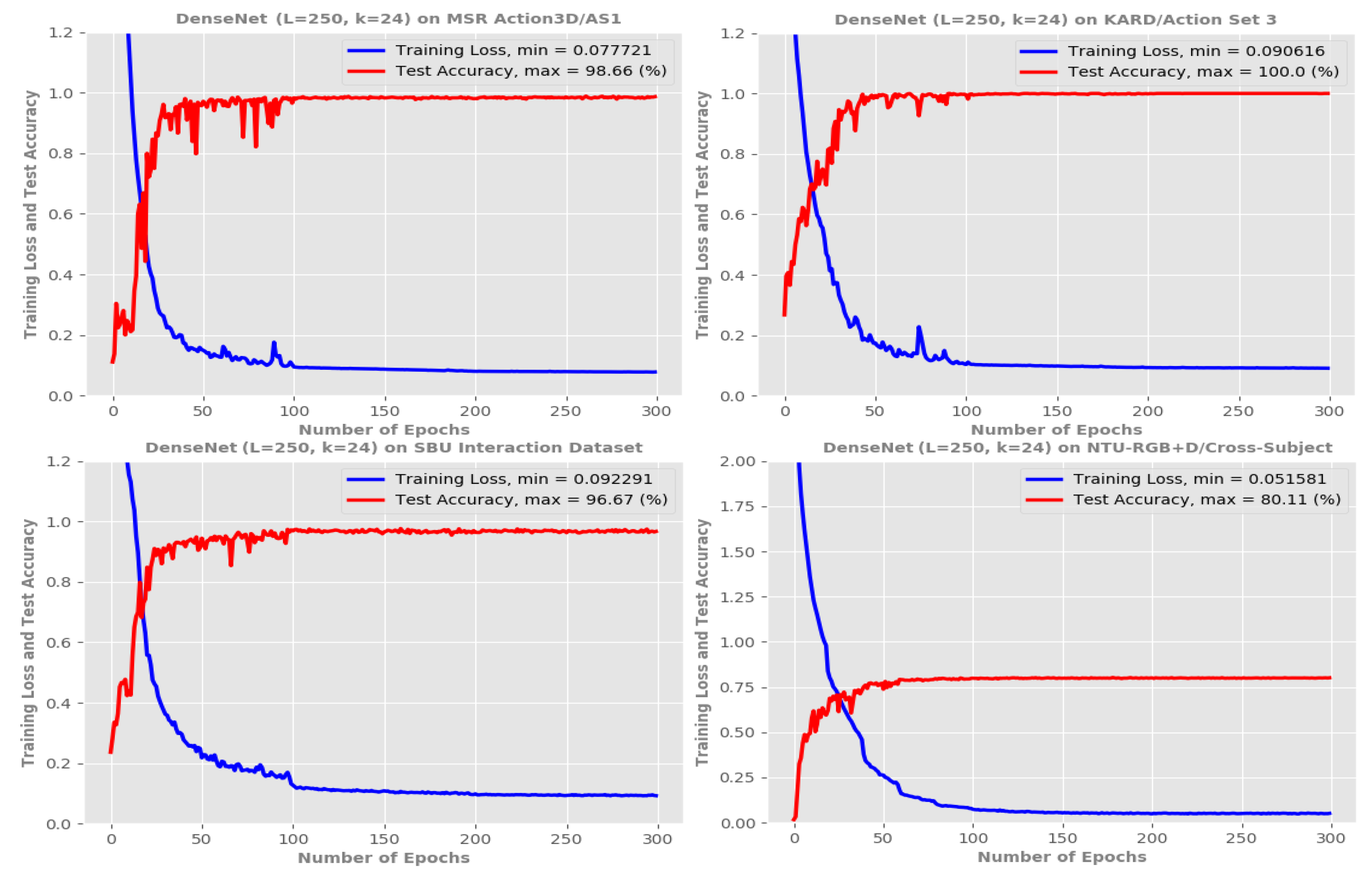
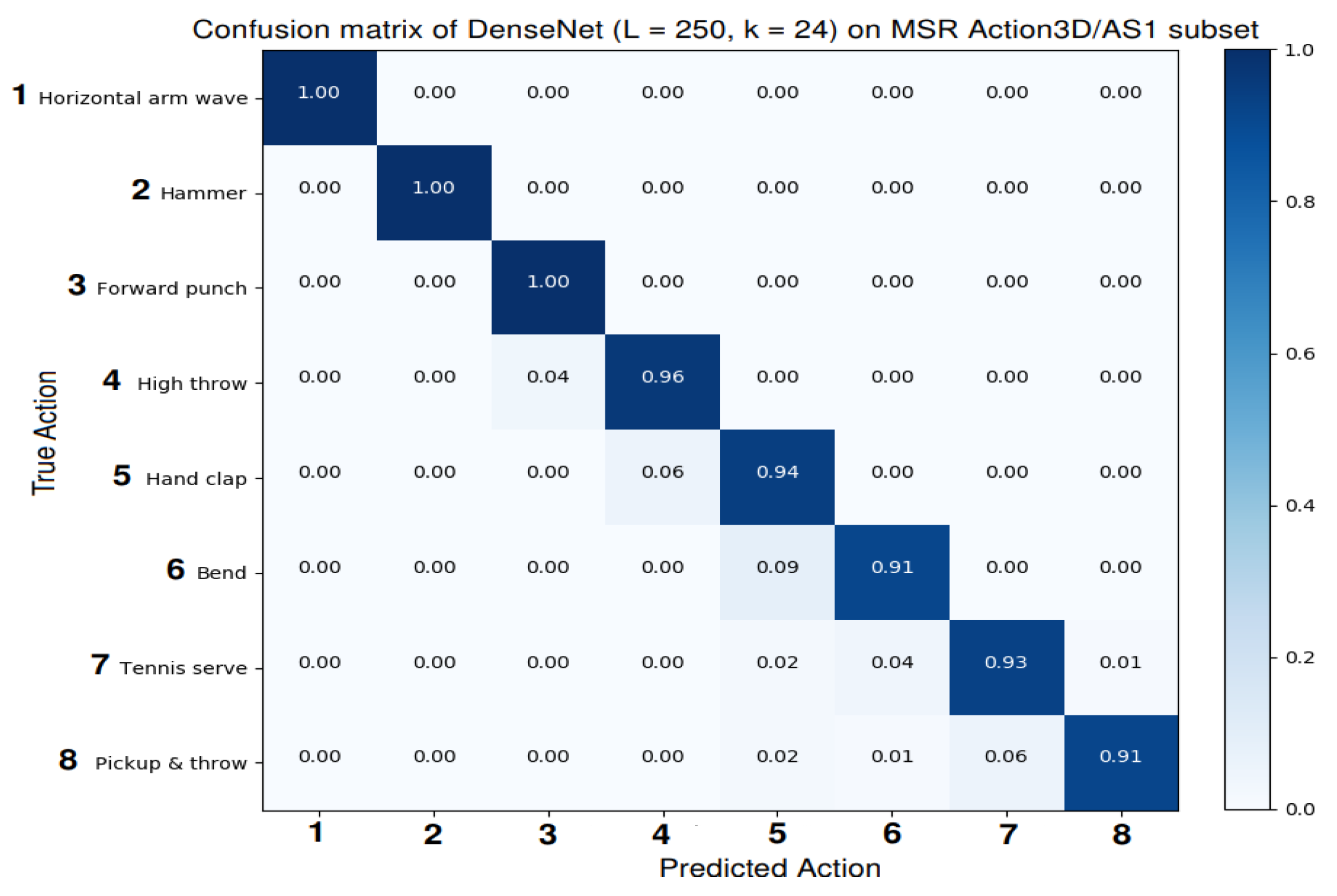
5. Experimental Result and Analysis
5.1. Results and Comparisons with the State-of-the-Art
5.2. An Ablation Study on the Proposed Enhanced-SPMF Representation
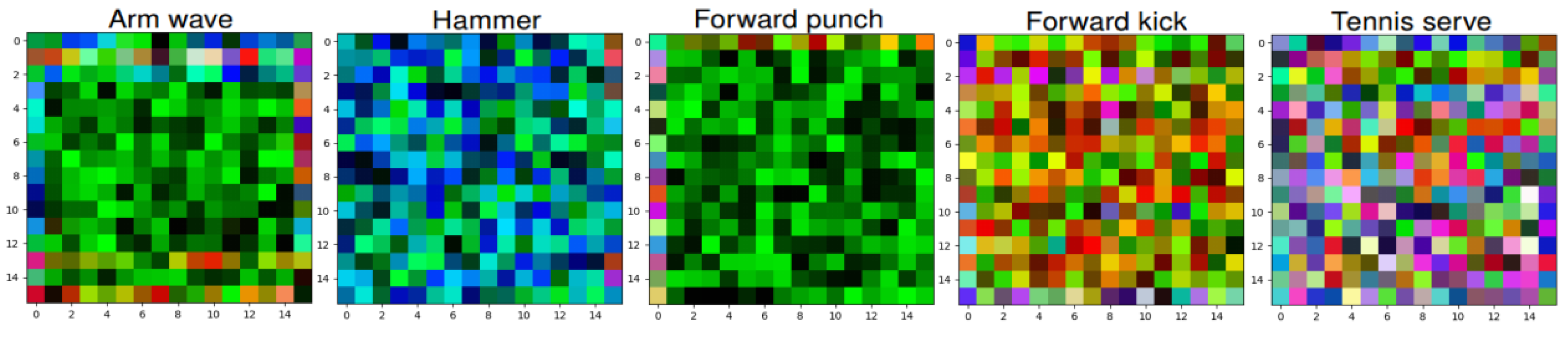
5.3. Visualization of Deep Feature Maps
5.4. Computational Efficiency Evaluation
5.5. Limitations
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Savitzky-Golay Smoothing Filter
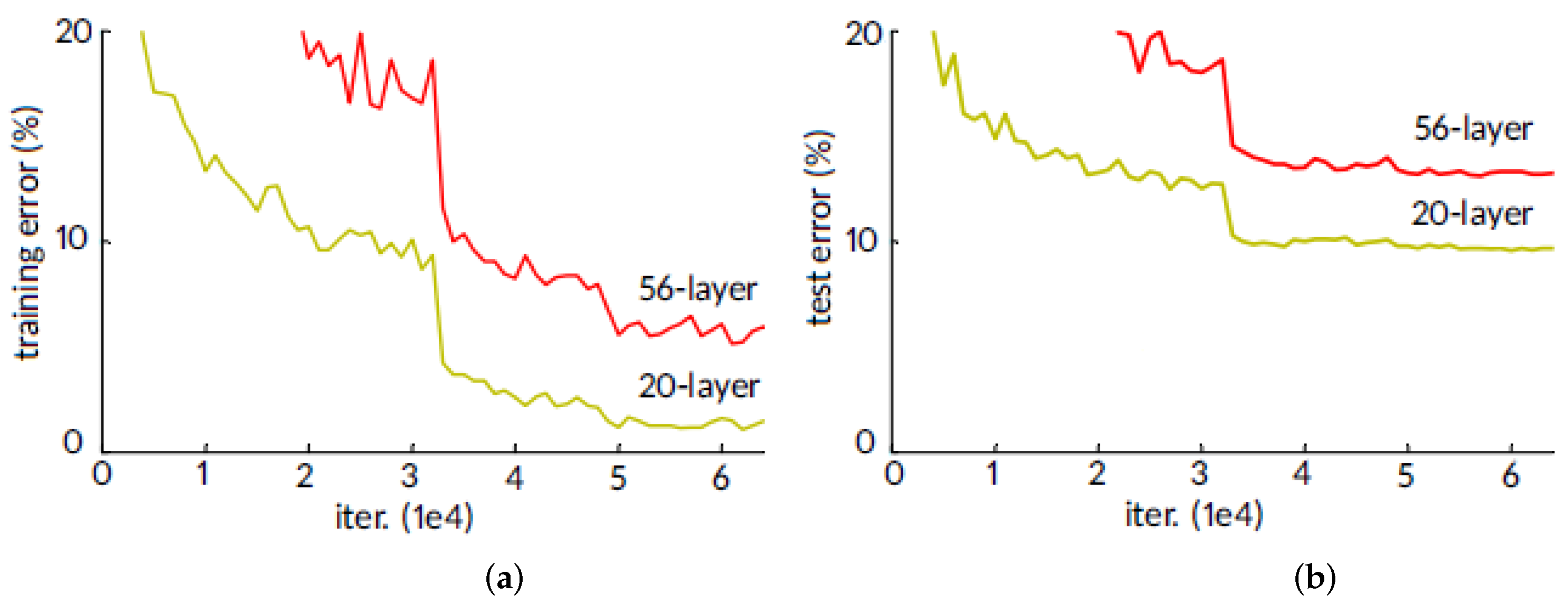
Appendix B. Degradation Phenomenon in Training Very Deep Neural Networks

References
- Aggarwal, J.; Ryoo, M. Human Activity Analysis: A Review. ACM Comput. Surv. 2011, 43, 16. [Google Scholar] [CrossRef]
- Boiman, O.; Irani, M. Detecting Irregularities in Images and in Video. Int. J. Comput. Vis. 2007, 74, 17–31. [Google Scholar] [CrossRef]
- Lin, W.; Sun, M.T.; Poovandran, R.; Zhang, Z. Human activity recognition for video surveillance. In Proceedings of the IEEE International Symposium on Circuits and Systems, Seattle, WA, USA, 18 May–21 August 2008. [Google Scholar]
- Gupta, A.; Kembhavi, A.; Davis, L.S. Observing Human-Object Interactions: Using Spatial and Functional Compatibility for Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1775–1789. [Google Scholar] [CrossRef]
- Yao, B.; Fei-Fei, L. Recognizing Human-Object Interactions in Still Images by Modeling the Mutual Context of Objects and Human Poses. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1691–1703. [Google Scholar]
- Dagli, I.; Brost, M.; Breuel, G. Action Recognition and Prediction for Driver Assistance Systems Using Dynamic Belief Networks. In Agent Technologies, Infrastructures, Tools, and Applications for E-Services; Springer: Berlin/Heidelberg, Germany, 2003; pp. 179–194. [Google Scholar]
- Fridman, L.; Brown, D.E.; Glazer, M.; Angell, W.; Dodd, S.; Jenik, B.; Terwilliger, J.; Kindelsberger, J.; Ding, L.; Seaman, S.; et al. MIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation. arXiv 2017, arXiv:1711.06976. [Google Scholar]
- Poppe, R. A survey on vision-based human action recognition. Image Visi. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Weinland, D.; Ronfard, R.; Boyer, E. A survey of vision-based methods for action representation, segmentation and recognition. Comput. Vis. Image Underst. 2011, 115, 224–241. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Klaeser, A.; Marszalek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of the the British Machine Vision Conference, Leeds, UK, 1–4 September 2008; pp. 1–10. [Google Scholar]
- Dollar, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Breckenridge, CO, USA, 7 January 2005; pp. 65–72. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Willems, G.; Tuytelaars, T.; Van Gool, L. An Efficient Dense and Scale-Invariant Spatio-Temporal Interest Point Detector. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 650–663. [Google Scholar]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE MultiMed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Oreifej, O.; Liu, Z. HON4D: Histogram of Oriented 4D Normals for Activity Recognition from Depth Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Xia, L.; Aggarwal, J.K. Spatio-temporal Depth Cuboid Similarity Feature for Activity Recognition Using Depth Camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2834–2841. [Google Scholar]
- Rahmani, H.; Mahmood, A.; Huynh, D.Q.; Mian, A. HOPC: Histogram of Oriented Principal Components of 3D Pointclouds for Action Recognition. In Proceedings of the European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2014; pp. 742–757. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 588–595. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning Actionlet Ensemble for 3D Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 914–927. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Tian, Y. Super Normal Vector for Human Activity Recognition with Depth Cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1028–1039. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Ye, M.; Shen, Y.; Du, C.; Pan, Z.; Yang, R. Real-Time Simultaneous Pose and Shape Estimation for Articulated Objects Using a Single Depth Camera. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1517–1532. [Google Scholar] [CrossRef]
- Gu, J.; Ding, X.; Wang, S.; Wu, Y. Action and Gait Recognition From Recovered 3-D Human Joints. IEEE Trans. Syst. Man Cybern. Part B 2010, 40, 1021–1033. [Google Scholar]
- Johansson, G. Visual motion perception. Sci. Am. 1975, 232, 76–89. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Ogunbona, P.O.; Wang, P.; Tang, C. RGB-D-based action recognition datasets: A survey. Pattern Recognit. 2016, 60, 86–105. [Google Scholar] [CrossRef]
- Xia, L.; Chen, C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Chaudhry, R.; Ofli, F.; Kurillo, G.; Bajcsy, R.; Vidal, R. Bio-inspired Dynamic 3D Discriminative Skeletal Features for Human Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 471–478. [Google Scholar]
- Ding, W.; Liu, K.; Fu, X.; Cheng, F. Profile HMMs for skeleton-based human action recognition. Signal Process. Image Commun. 2016, 42, 109–119. [Google Scholar] [CrossRef]
- Han, L.; Wu, X.; Liang, W.; Hou, G.; Jia, Y. Discriminative human action recognition in the learned hierarchical manifold space. Image Vis. Comput. 2010, 28, 836–849. [Google Scholar] [CrossRef]
- Luo, J.; Wang, W.; Qi, H. Group Sparsity and Geometry Constrained Dictionary Learning for Action Recognition from Depth Maps. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 1809–1816. [Google Scholar]
- Wang, P.; Yuan, C.; Hu, W.; Li, B.; Zhang, Y. Graph Based Skeleton Motion Representation and Similarity Measurement for Action Recognition. In Proceedings of the European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2016; pp. 370–385. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Veeriah, V.; Zhuang, N.; Qi, G. Differential Recurrent Neural Networks for Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4041–4049. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition. In Proceedings of the European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2016; pp. 816–833. [Google Scholar]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence Feature Learning for Skeleton Based Action Recognition Using Regularized Deep LSTM Networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3697–3703. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.; Kot, A.C. Global Context-Aware Attention LSTM Networks for 3D Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3671–3680. [Google Scholar]
- Lv, F.; Nevatia, R. Recognition and Segmentation of 3-D Human Action Using HMM and Multi-class AdaBoost. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 359–372. [Google Scholar]
- Schuster, M.; Paliwal, K. Bidirectional Recurrent Neural Networks. Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition. In Artificial Neural Networks: Formal Models and Their Applications; Springer: Berlin/Heidelberg, Germany, 2005; pp. 799–804. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Pham, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Skeletal Movement to Color Map: A Novel Representation for 3D Action Recognition with Inception Residual Networks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3483–3487. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Pham, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Learning to recognise 3D human action from a new skeleton-based representation using deep convolutional neural networks. IET Comput. Visi. 2019, 13, 319–328. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Telgarsky, M. Benefits of depth in neural networks. arXiv 2016, arXiv:1602.04485. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Gaglio, S.; Re, G.L.; Morana, M. Human Activity Recognition Process Using 3-D Posture Data. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 586–597. [Google Scholar] [CrossRef]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time representation of people based on 3D skeletal data: A review. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining; AAAI Press: Seattle, WA, USA, 1994; pp. 359–370. [Google Scholar]
- Eddy, S.R. Hidden Markov models. Curr. Opin. Struct. Biol. 1996, 6, 361–365. [Google Scholar] [CrossRef]
- Kirk, A.G.; O’Brien, J.F.; Forsyth, D.A. Skeletal parameter estimation from optical motion capture data. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, p. 1185. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Bearman, A.; Dong, C. Human Pose Estimation and Activity Classification Using Convolutional Neural Networks. CS231n Course Project Reports. 2015. Available online: http://www.catherinedong.com/pdfs/231n-paper.pdf (accessed on 22 April 2019).
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; Volume 385. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time Human Action Recognition Based on Depth Motion Maps. J. Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Weng, J.; Weng, C.; Yuan, J. Spatio-Temporal Naive-Bayes Nearest-Neighbor (ST-NBNN) for Skeleton-Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 445–454. [Google Scholar]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble Deep Learning for Skeleton-Based Action Recognition Using Temporal Sliding LSTM Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar]
- Tanfous, A.B.; Drira, H.; Amor, B.B. Coding Kendall’s Shape Trajectories for 3D Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 2840–2849. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, X.; Xiao, J. On Geometric Features for Skeleton-Based Action Recognition Using Multilayer LSTM Networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 148–157. [Google Scholar]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 Octorber 2015; pp. 681–687. [Google Scholar]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32th International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Weng, J.; Weng, C.; Yuan, J.; Liu, Z. Discriminative Spatio-Temporal Pattern Discovery for 3D Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1077–1089. [Google Scholar] [CrossRef]
- Xu, H.; Chen, E.; Liang, C.; Qi, L.; Guan, L. Spatio-Temporal Pyramid Model based on depth maps for action recognition. In Proceedings of the IEEE 17th International Workshop on Multimedia Signal Processing, Xiamen, China, 19–21 October 2015; pp. 1–6. [Google Scholar]
- Cippitelli, E.; Gasparrini, S.; Gambi, E.; Spinsante, S. A human activity recognition system using skeleton data from RGB-D sensors. Comput. Intell. Neurosci. 2016, 2016. [Google Scholar] [CrossRef]
- Ling, J.; Tian, L.; Li, C. 3D Human Activity Recognition Using Skeletal Data from RGB-D Sensors. In Advances in Visual Computing; Springer International Publishing: Cham, Switzerland, 2016; pp. 133–142. [Google Scholar]
- Li, W.; Wen, L.; Chuah, M.C.; Lyu, S. Category-Blind Human Action Recognition: A Practical Recognition System. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4444–4452. [Google Scholar]
- Ji, Y.; Ye, G.; Cheng, H. Interactive body part contrast mining for human interaction recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo Workshops, Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 1, pp. 4263–4270. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Wang, H.; Wang, L. Modeling Temporal Dynamics and Spatial Configurations of Actions Using Two-Stream Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3633–3642. [Google Scholar]
- Liu, J.; Wang, G.; Duan, L.; Abdiyeva, K.; Kot, A.C. Skeleton-Based Human Action Recognition with Global Context-Aware Attention LSTM Networks. IEEE Trans. Image Process. 2018, 27, 1586–1599. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Zheng, W.; Lai, J.; Zhang, J. Jointly Learning Heterogeneous Features for RGB-D Activity Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2186–2200. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Rahmani, H.; Bennamoun, M. Learning Action Recognition Model from Depth and Skeleton Videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5833–5842. [Google Scholar]
- Tas, Y.; Koniusz, P. CNN-based Action Recognition and Supervised Domain Adaptation on 3D Body Skeletons via Kernel Feature Maps. In Proceedings of the British Machine Vision Conference 2018, Newcastle, UK, 3–6 September 2018; p. 158. [Google Scholar]
- Kulkarni, K.; Evangelidis, G.; Cech, J.; Horaud, R. Continuous Action Recognition Based on Sequence Alignment. Int. J. Comput. Vis. 2015, 112, 90–114. [Google Scholar] [CrossRef]
- Kviatkovsky, I.; Rivlin, E.; Shimshoni, I. Online action recognition using covariance of shape and motion. Comput. Vis. Image Underst. 2014, 129, 15–26. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Xu, K.; Ba, J.L.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32th International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Zang, J.; Wang, L.; Liu, Z.; Zhang, Q.; Hua, G.; Zheng, N. Attention-Based Temporal Weighted Convolutional Neural Network for Action Recognition. In Artificial Intelligence Applications and Innovations; Springer International Publishing: Cham, Switzerland, 2018; pp. 97–108. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- LeCun, Y.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 9–50. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method & Authors | Data Modalities | Year | Advantages/Disadvantages |
|---|---|---|---|
| Bag of 3D Points [59] | Depth maps | 2010 | Simple and fast/Low accuracy, viewpoint dependent. |
| Lie Group Representation [23] | Skeletal data | 2014 | Robust to temporal misalignment and noise/Low accuracy. |
| Hierarchical LSTM [37] | Skeletal data | 2015 | Fast and high accuracy/ Easy to overfit. |
| Depth Motion Maps [69] | Depth maps | 2016 | Real-time latency/Low accuracy. |
| ST-LSTM Trust Gates [40] | Skeletal data | 2016 | View-invariant representation, robust to noise and occlusion/High computational cost. |
| Graph-Based Motion [36] | Skeletal data | 2016 | Robust to noise, high accuracy/Complex, parameter-dependent. |
| ST-NBNN [70] | Depth maps | 2017 | Simple and low computational cost/Parameter-dependent. |
| Ensemble TS-LSTM v2 [71] | Skeletal data | 2017 | High accuracy, robust to scale, rotation and translation/Data-hungry, high computational cost. |
| Bi-LSTM [72] | Skeletal data | 2018 | Invariant representation/Complex, low accuracy. |
| Our proposed method | Skeletal data | 2019 | View-invariant representation, real-time latency, high accuracy/Data-hungry, sensitive to data error of local fragments. |
| AS1 | AS2 | AS3 |
|---|---|---|
| [a02] Horizontal arm wave | [a01] High arm wave | [a06] High throw |
| [a03] Hammer | [a04] Hand catch | [a14] Forward kick |
| [a05] Forward punch | [a07] Draw x | [a15] Side kick |
| [a06] High throw | [a08] Draw tick | [a16] Jogging |
| [a10] Hand clap | [a09] Draw circle | [a17] Tennis swing |
| [a13] Bend | [a11] Two hand wave | [a18] Tennis serve |
| [a18] Tennis serve | [a12] Forward kick | [a19] Golf swing |
| [a20] Pickup & Throw | [a14] Side-boxing | [a20] Pickup & Throw |
| Action Set 1 | Action Set 2 | Action Set 3 |
|---|---|---|
| Horizontal arm wave | High arm wave | Draw tick |
| Two-hand wave | Side kick | Drink |
| Bend | Catch cap | Sit down |
| Phone call | Draw tick | Phone call |
| Stand up | Hand clap | Take umbrella |
| Forward kick | Forward kick | Toss paper |
| Draw X | Bend | High throw |
| Walk | Sit down | Horizontal arm wave |
| Method (Protocol of [59]) | Year | AS1 | AS2 | AS3 | Aver. |
|---|---|---|---|---|---|
| Bag of 3D Points [59] | 2010 | 72.90% | 71.90% | 71.90% | 74.70% |
| Depth Motion Maps [69] | 2016 | 96.20% | 83.20% | 92.00% | 90.47% |
| Bi-LSTM [72] | 2018 | 92.72% | 84.93% | 97.89% | 91.84% |
| Lie Group Representation [23] | 2014 | 95.29% | 83.87% | 98.22% | 92.46% |
| FTP-SVM [72] | 2018 | 95.87% | 86.72% | 100.0% | 94.19% |
| Hierarchical LSTM [37] | 2015 | 99.33% | 94.64% | 95.50% | 94.49% |
| ST-LSTM Trust Gates [40] | 2016 | N/A | N/A | N/A | 94.80% |
| Graph-Based Motion [36] | 2016 | 93.60% | 95.50% | 95.10% | 94.80% |
| ST-NBNN [70] | 2017 | 91.50% | 95.60% | 97.30% | 94.80% |
| ST-NBMIM [83] | 2018 | 92.50% | 95.60% | 98.20% | 95.30% |
| S-T Pyramid [84] | 2015 | 99.10% | 92.90% | 96.40% | 96.10% |
| Ensemble TS-LSTM v2 [71] | 2017 | 95.24% | 96.43% | 100.0% | 97.22% |
| SPMF Inception-ResNet-222 [48] | 2018 | 97.54% | 98.73% | 99.41% | 98.56% |
| Enhanced-SPMF DenseNet (L = 100, k = 12) (ours) | 2018 | 98.52% | 98.66% | 99.09% | 98.76% |
| Enhanced-SPMF DenseNet (L = 250, k = 24) (ours) | 2018 | 98.83% | 99.06% | 99.40% | 99.10% |
| Enhanced-SPMF DenseNet (L = 190, k = 40) (ours) | 2018 | 98.60% | 98.87% | 99.36% | 98.94% |
| Method (Protocol of [60]) | Year | Acc. (%) |
|---|---|---|
| Hand-crafted Features [60] | 2015 | 90.83% |
| Posture Feature+Multi-class SVM [85] | 2016 | 97.20% |
| Key Postures+Multi-class SVM [86] | 2016 | 99.30% |
| Enhanced-SPMF DenseNet (L = 100, k = 12) (ours) | 2018 | 99.74% |
| Enhanced-SPMF DenseNet (L = 250, k = 24) (ours) | 2018 | 99.98% |
| Enhanced-SPMF DenseNet (L = 190, k = 40) (ours) | 2018 | 99.88% |
| Method (Protocol of [61]) | Year | Acc. (%) |
|---|---|---|
| Raw Skeleton [61] | 2012 | 49.70% |
| Joint Features [61] | 2012 | 80.30% |
| HBRNN [37] (reported in [91] ) | 2015 | 80.40% |
| CHARM [87] | 2015 | 83.90% |
| Deep LSTM [41] | 2017 | 86.03% |
| Joint Features [88] | 2014 | 86.90% |
| ST-LSTM [40] | 2016 | 88.60% |
| Co-occurrence+Deep LSTM [41] | 2018 | 90.41% |
| STA-LSTM [89] | 2017 | 91.51% |
| ST-LSTM+Trust Gates [40] | 2018 | 93.30% |
| ST-NBMIM [83] | 2018 | 93.30% |
| Clips+CNN+MTLN [90] | 2017 | 93.57% |
| CNN Kernel Feature Map [96] | 2018 | 94.36% |
| Two-stream RNN [91] | 2017 | 94.80% |
| GCA-LSTM network [92] | 2018 | 94.90% |
| Enhanced-SPMF DenseNet (L = 100, k = 12) (ours) | 2018 | 94.81% |
| Enhanced-SPMF DenseNet (L = 250, k = 24) (ours) | 2018 | 96.67% |
| Enhanced-SPMF DenseNet (L = 190, k = 40) (ours) | 2018 | 97.86% |
| Method (Protocol of [39]) | Year | Cross-Subject | Cross-View |
|---|---|---|---|
| Lie Group Representation [23] | 2014 | 50.10% | 52.80% |
| Hierarchical RNN [37] | 2016 | 59.07% | 63.97% |
| Dynamic Skeletons [93] | 2015 | 60.20% | 65.20% |
| Two-Layer P-LSTM [39] | 2016 | 62.93% | 70.27% |
| ST-LSTM Trust Gates [40] | 2016 | 69.20% | 77.70% |
| Skeleton-based ResNet [51] | 2018 | 73.40% | 80.40% |
| Geometric Features [74] | 2017 | 70.26% | 82.39% |
| Two-Stream RNN [91] | 2017 | 71.30% | 79.50% |
| Enhanced Skeleton [94] | 2017 | 75.97% | 82.56% |
| Lie Group Skeleton+CNN [95] | 2017 | 75.20% | 83.10% |
| CNN Kernel Feature Map [96] | 2018 | 75.35% | N/A |
| GCA-LSTM [92] | 2018 | 76.10% | 84.00% |
| SPMF Inception-ResNet-222 [48] | 2018 | 78.89% | 86.15% |
| Enhanced-SPMF DenseNet (L = 100, k = 12) (ours) | 2018 | 79.31% | 86.64% |
| Enhanced-SPMF DenseNet (L = 250, k = 24) (ours) | 2018 | 80.11% | 86.82% |
| Enhanced-SPMF DenseNet (L = 190, k = 40) (ours) | 2018 | 79.28% | 86.68% |
| Stage | Average Processing Time (Second/Sequence) |
|---|---|
| 1 | (Intel Core i7 3.2 GHz CPU) |
| 2 | 0.164 (GTX 1080 Ti GPU) |
| 3 | (CPU + GPU time) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Spatio–Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks. Sensors 2019, 19, 1932. https://doi.org/10.3390/s19081932
Pham HH, Salmane H, Khoudour L, Crouzil A, Zegers P, Velastin SA. Spatio–Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks. Sensors. 2019; 19(8):1932. https://doi.org/10.3390/s19081932
Chicago/Turabian StylePham, Huy Hieu, Houssam Salmane, Louahdi Khoudour, Alain Crouzil, Pablo Zegers, and Sergio A. Velastin. 2019. "Spatio–Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks" Sensors 19, no. 8: 1932. https://doi.org/10.3390/s19081932
APA StylePham, H. H., Salmane, H., Khoudour, L., Crouzil, A., Zegers, P., & Velastin, S. A. (2019). Spatio–Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks. Sensors, 19(8), 1932. https://doi.org/10.3390/s19081932