Echo measurements were performed for different target positions and angles. During these, a signal was emitted by an ultrasonic speaker, reflected off a target, then received by a measurement microphone and digitized by an ADC interface card. Calculations for feature preprocessing and target classification were conducted on a desktop computer with Matlab R2018b.
2.1. Measurement Setup and Procedure
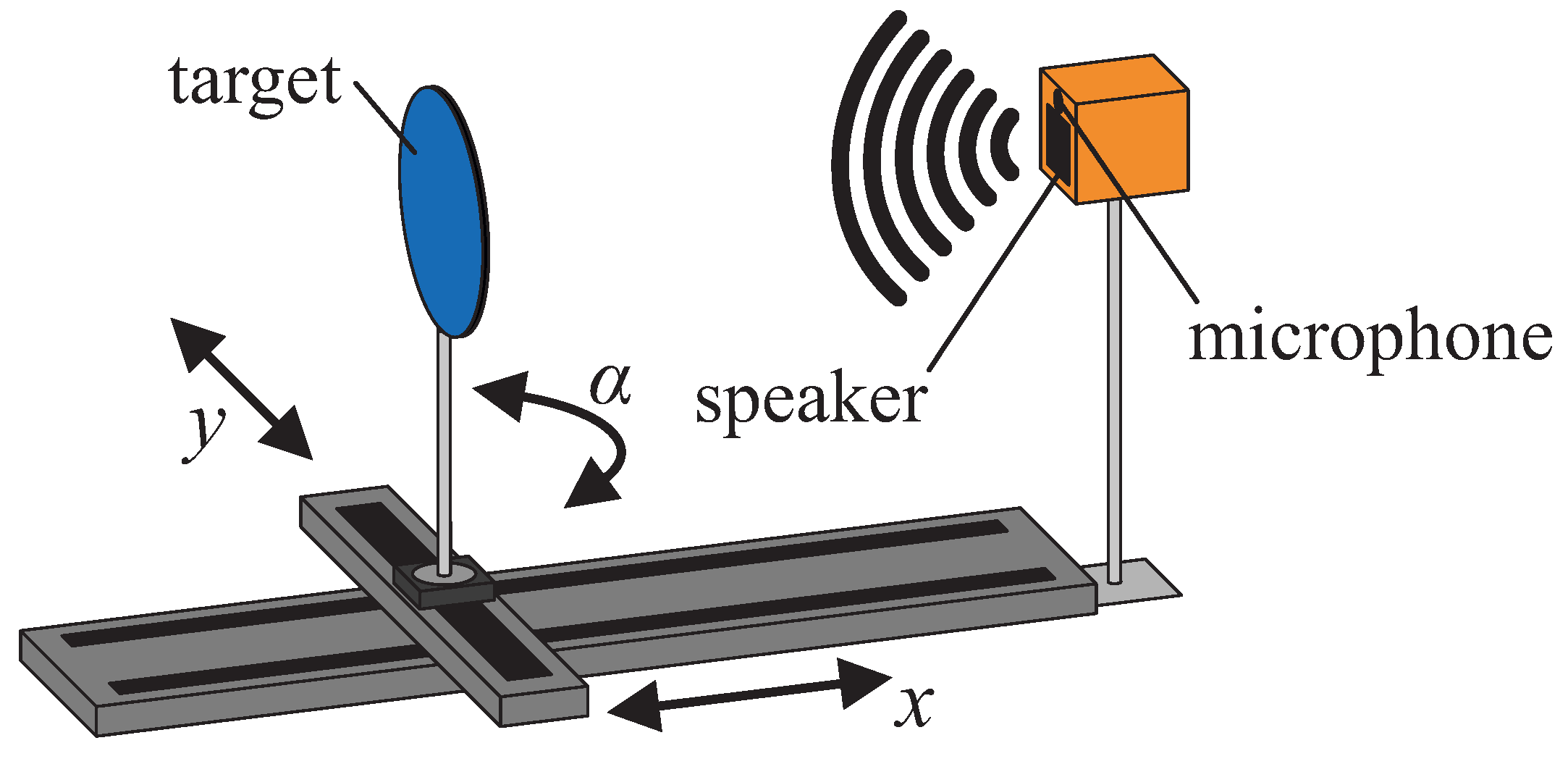
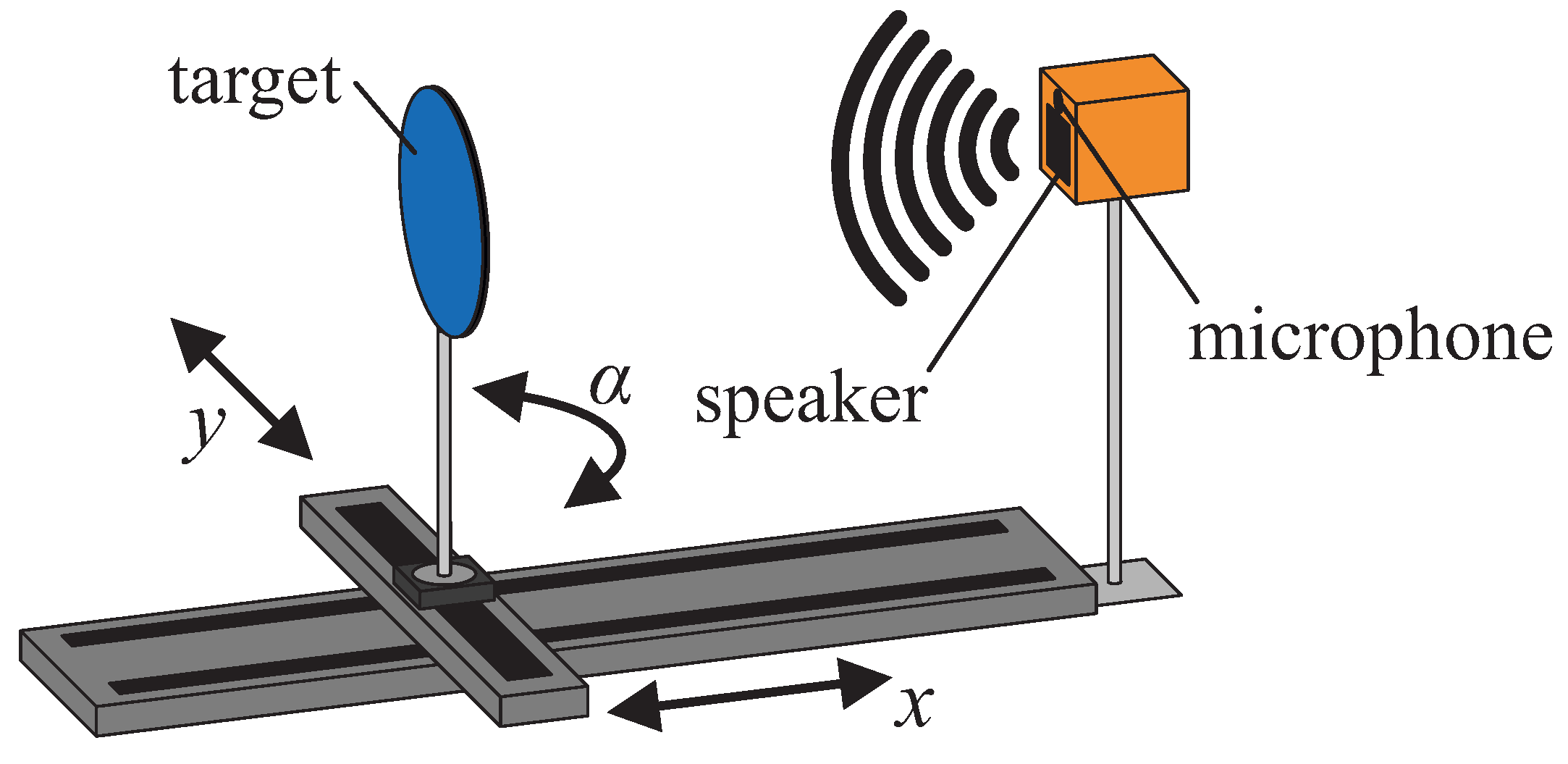
The measurement setup (as shown in
Figure 1) consists of a two-axis translation stage, a rotation stage on top of the translation stage on which the targets were attached, a 1/4” Bruel&Kjaer measurement microphone (Type 4939-A-011) with an amplifier (G.R.A.S. 12AK), a wideband electrostatic ultrasonic speaker (Senscomp 7000 series, also formerly known as capacitive
Polaroid transducers [
24]) with a custom-built high voltage amplifier (0
–400
, 0
–200
, sine) and a National Instruments data acquisition device for analog IO (NI-USB-6356, 1.25 MS/s, 16 bit). The speaker is capable of sound emission in a frequency range of 20
up to more than 150
at sound pressure levels above 85 (with the standard reference value of 20
for sound in air), which has been experimentally verified.
As an alternative, transducers based on ferroelectric materials, such as PVDF (Polyvinylidene Fluoride) [
25,
26,
27] and EMFi (Electro Mechanical Film) [
28,
29], may be used as they are also suitable for wideband ultrasound emission, but must be custom-built. The custom-built amplifier is necessary as the ultrasonic speaker requires a bias voltage of 200
and a maximum peak–peak voltage of 400
. The microphone and the speaker are mounted closely together (20 mm center distance) at the end of the
x-axis translation stage. All measurements were performed in an anechoic chamber, so there was no influence of other sound sources from outside the chamber. It has to be noted that the chamber walls are optimized for absorption of audible sound but strongly reflect ultrasound waves. As a consequence, our whole measurement setup had to be optimized especially so that there is no detectable direct echo from itself nor the walls that would interfere with the main target echoes. This includes that the targets, microphone and speaker are located 1
above the floor. Moreover, all parts are placed with the largest distance possible to the closest walls (at least 1
). Surfaces facing the setup are covered with Basotect material, which absorbs acoustic waves in the ultrasonic range. In doing so, it could be achieved that echoes resulting from multiple reflections, appear after the target echoes in the measured waveforms and do not interfere with these.
For ANN training, validation and test, sample echoes were required. The targets were automatically moved along a grid and were also rotated—
x-direction (0.5
to 1.8
,
steps);
y-direction (−0.15
to 0.15
,
steps); angles (
, −60
to 60
, 15
steps, compare
Figure 2). We applied downward modulated, rectified, wideband chirp signals for electrical excitation of the electrostatic Senscomp speaker (
wb, 150
to 20
, 1
duration). In additional measurements, narrowband chirp signals (
nb, 52
to 48
, 1
duration) were employed since we are also interested in the performance that may be achieved if a common narrowband ultrasonic sensor is utilized, such as a piezoelectric-based transducer [
30]. Chirp signals were chosen as they make it possible to gain information regarding a large portion of the spectrum from a single echo.
2.2. Targets
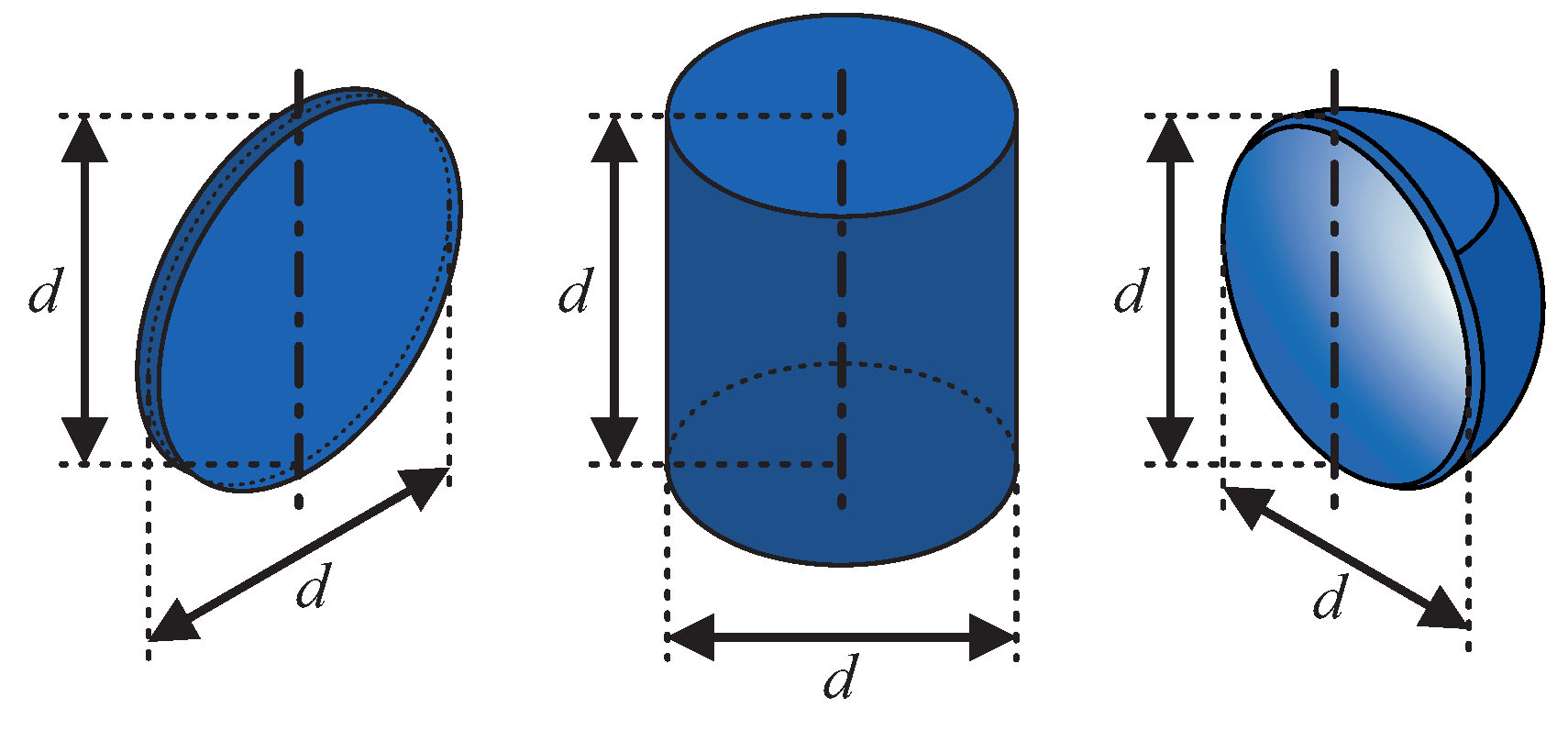
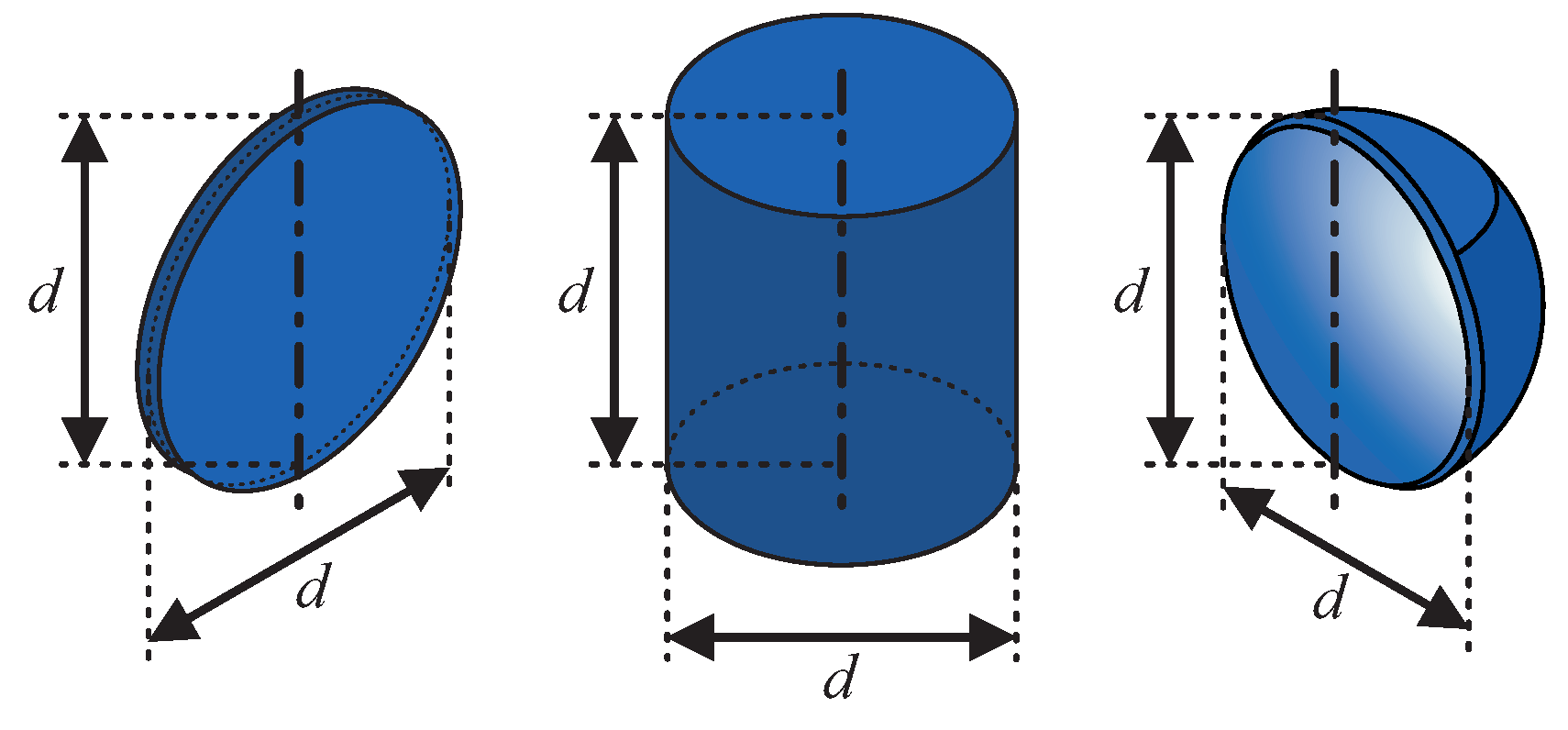
We collected and characterized ultrasound echoes from six different targets. Those can be grouped into three basic target shapes (
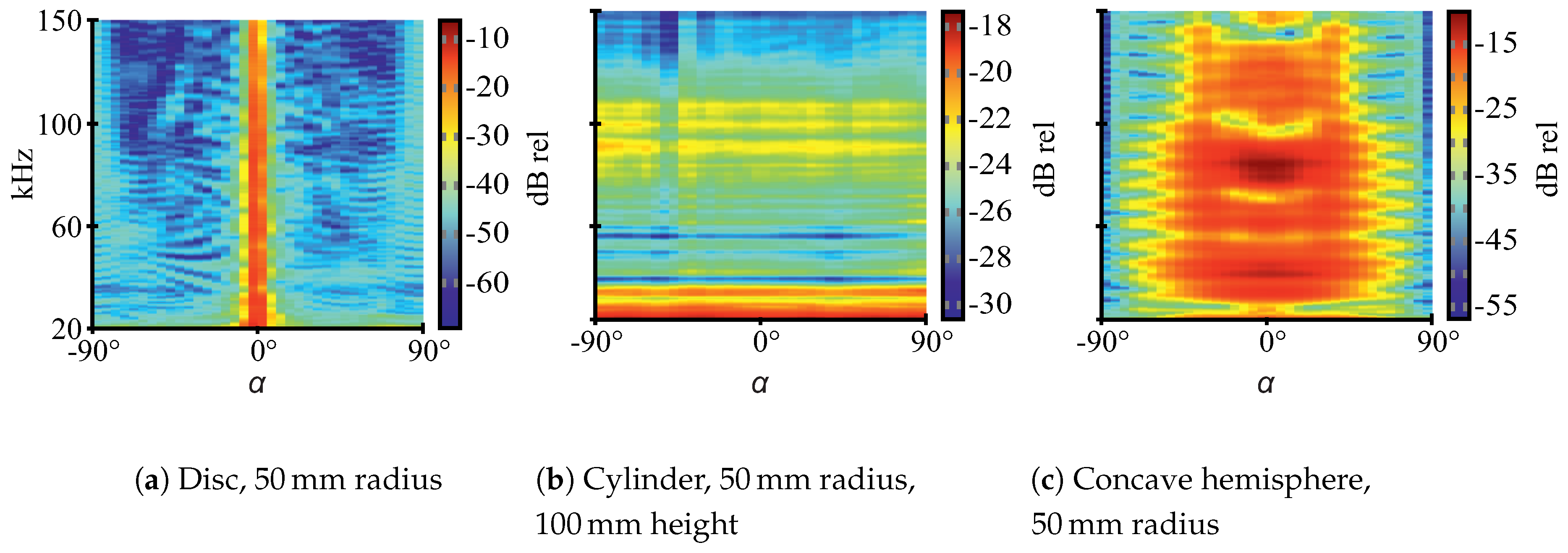
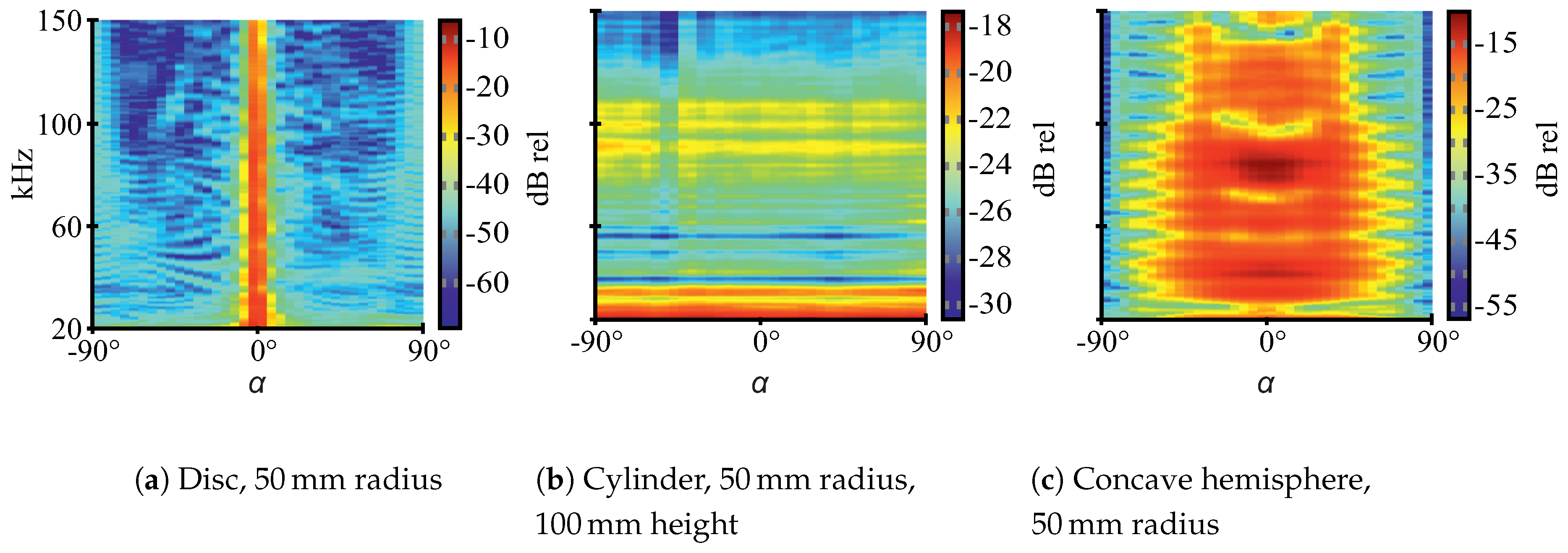
Figure 2): flat, convex and concave. The mentioned grouping was chosen because the shapes show quite different reflective behavior with respect to insonification angle and echo magnitude, as visualized by the acoustic fingerprints in
Figure 3. The targets in [
20] can be grouped accordingly. More details regarding the acoustic fingerprints will be examined later in this section. As we wanted to use basic and generic shapes, we chose to use discs, cylinders and hollow hemispheres. For each shape, we analyzed two different sizes so that binary classification was performed as far as size discrimination is concerned. The characteristic dimension
d was chosen to be 60
and 100
, respectively. The disc thickness is 4
and the cylinders as well as the hemispheres have 2
wall thickness. All targets were manufactured with a 3D printer (Ultimaker 2) and consist of ABS plastic.
The three different geometric shapes show characteristic acoustic fingerprints (
Figure 3)—spectral TS versus rotation angle plots (see
Section 2.4 for detailed explanations regarding TS). At flat targets, a single reflection occurs which shows low angular spread and high magnitude. At convex targets, there is also a single reflection but with wide angular spread and, consequently, lower magnitudes for the reflected wave as its energy is distributed across a larger volume. Inside concave targets, multiple reflections are possible which may lead to specific spectral properties due to interference [
15]. Concave targets can also have retroreflecting properties, such as a corner reflector for radar systems. As a consequence, echoes for the selected shapes should significantly differ in magnitude and spectral composition, particularly with respect to the insonification angle. Thus, the shapes should be well-distinguishable. More detailed explanations regarding the hollow hemispheres’ acoustic properties can be found in [
15].
Note that the depicted acoustic fingerprints are for illustration purposes only and are based on additional measurements, whose data is not part of the ANN training data. The measurement procedure for the acoustic fingerprints is different as well. The data for the fingerprints was obtained at 1
distance between speaker and targets (“echoes”) or speaker and microphone (“transmission”), respectively. The targets were rotated from −90
to 90
at 5
steps (compare
Figure 2 for 0
orientation) and swept single-frequency sine burst excitation was used with a frequency step size of
. To obtain TS values, the ratios between transmission and echo RMS values are calculated. This approach is necessary for reliable results since the employed electrostatic ultrasonic speaker shows noticeable harmonic distortion at all excitation frequencies, which has been observed in laboratory measurements. Thus, before RMS calculations for the echo fingerprints, the signals are narrowly bandpass-filtered at each center frequency so that only the relevant baseband components are considered.
2.3. Neural Networks
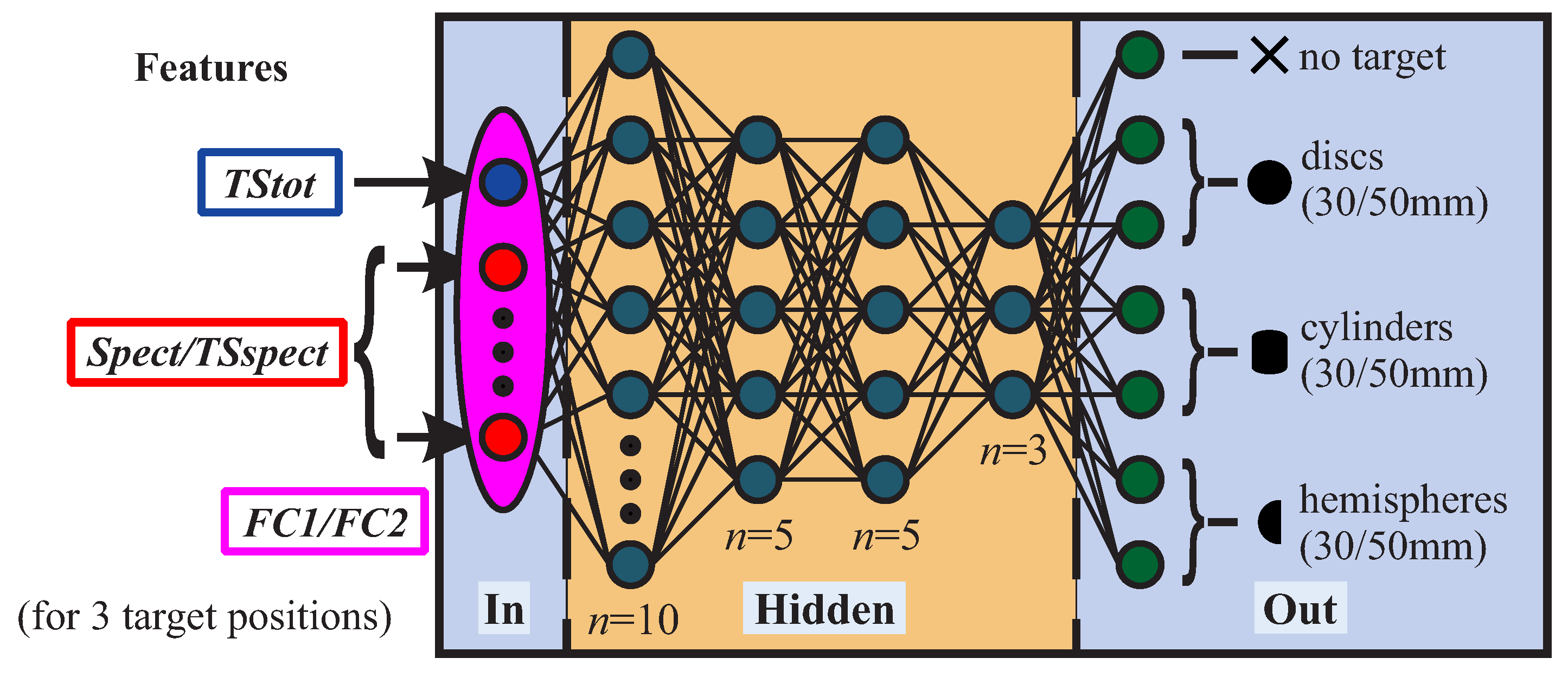
Multi-layer perceptrons (MLPs) are applied as ANNs (
Figure 4). We selected MLPs on purpose since they are more susceptible to variations in feature quality in comparison to other types of ANNs and should hence be better suited for estimates of feature performance. Our ANNs comprise four hidden layers in order to achieve good generalization and to avoid overfitting to training data. Due to the multi-layer structure, more meaningful and thus compressed information for the classification task needs to be represented/passed by each node if compared to a single layer network with the same total amount of nodes. This reduces the risk of overfitting to the training data [
16,
17]. The hidden layers comprise 10, 5, 5 and 3 neurons, respectively. To obtain a well-working network, we utilized a randomized parameter study in which several different hidden layer as well as node numbers were tested. The selected network architecture shows the best performance for all tested feature sets. Risk of overfitting was also minimized by choosing a low number of nodes for the hidden layers in comparison to other networks that are applied for similar classification tasks [
21,
22].
Seven output classes were created—one for each target and a separate one for non-target samples. For each class, roughly the same number of samples was created so that there is an even distribution among the classes. A scaled conjugate gradient backpropagation algorithm with a crossentropy error function was chosen for training (see [
16,
17] and [
18] for details). Supervised learning is performed as the target positions as well as the target classes are known from the measurement procedure (see
Section 2.1). Therefore, labeled data sets could be created. Of each dataset, 20 are picked for training, 10 for validation and 70 for testing. We chose the mentioned distribution as a larger training set might result in overfitting due to redundant echoes caused by symmetry in the measurement setup.
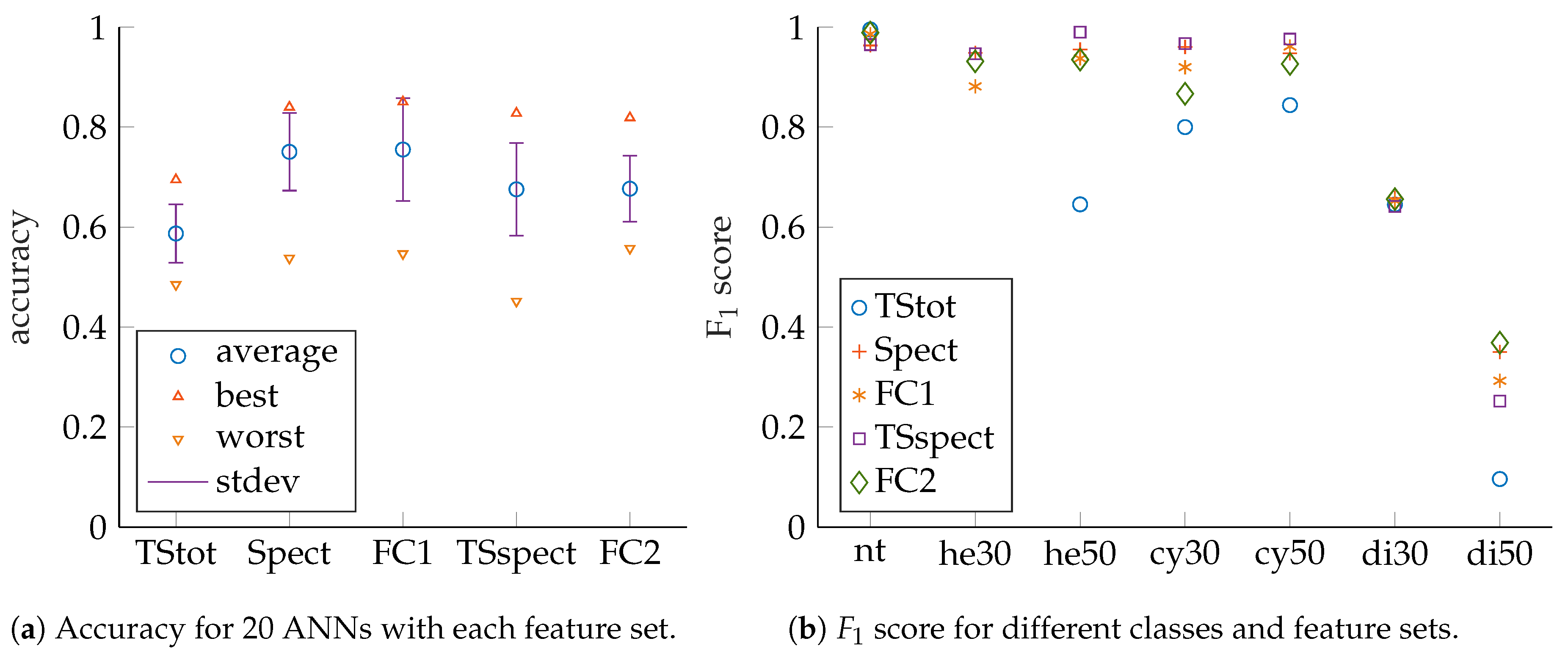
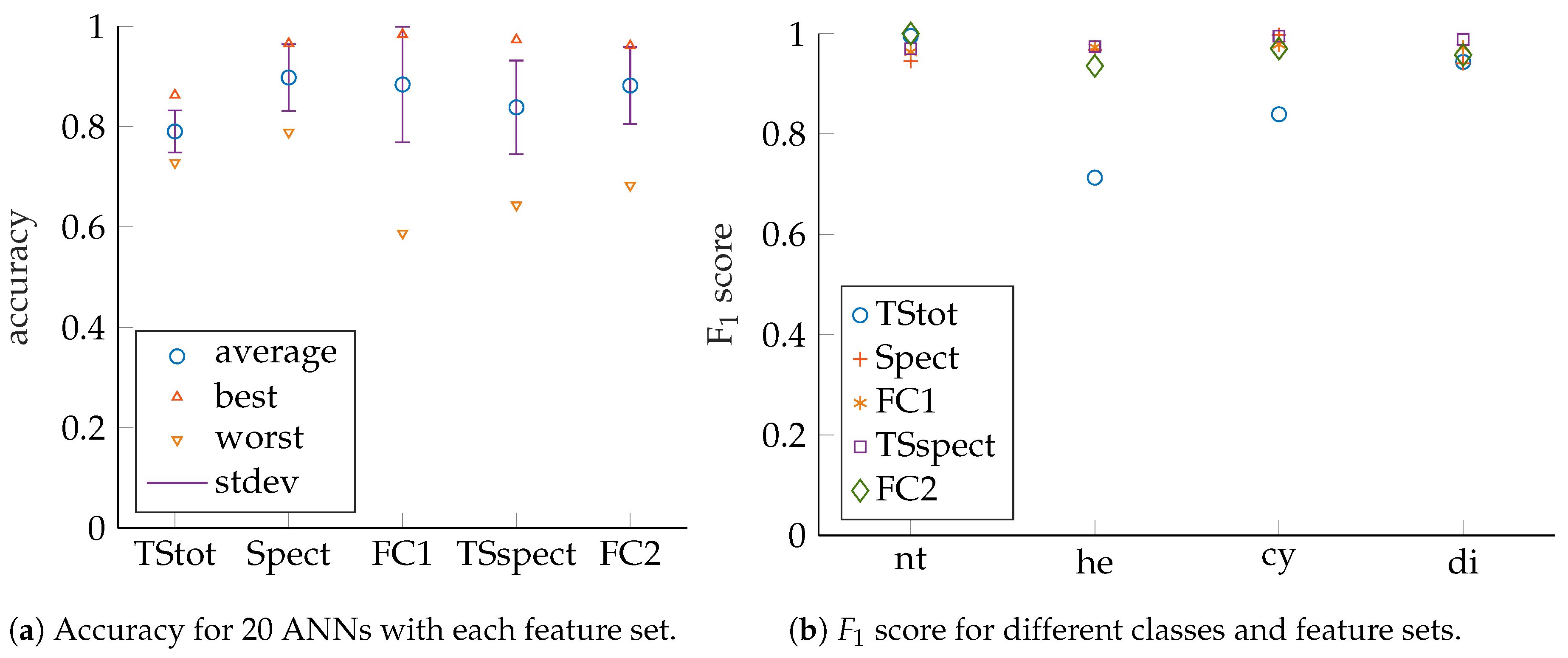
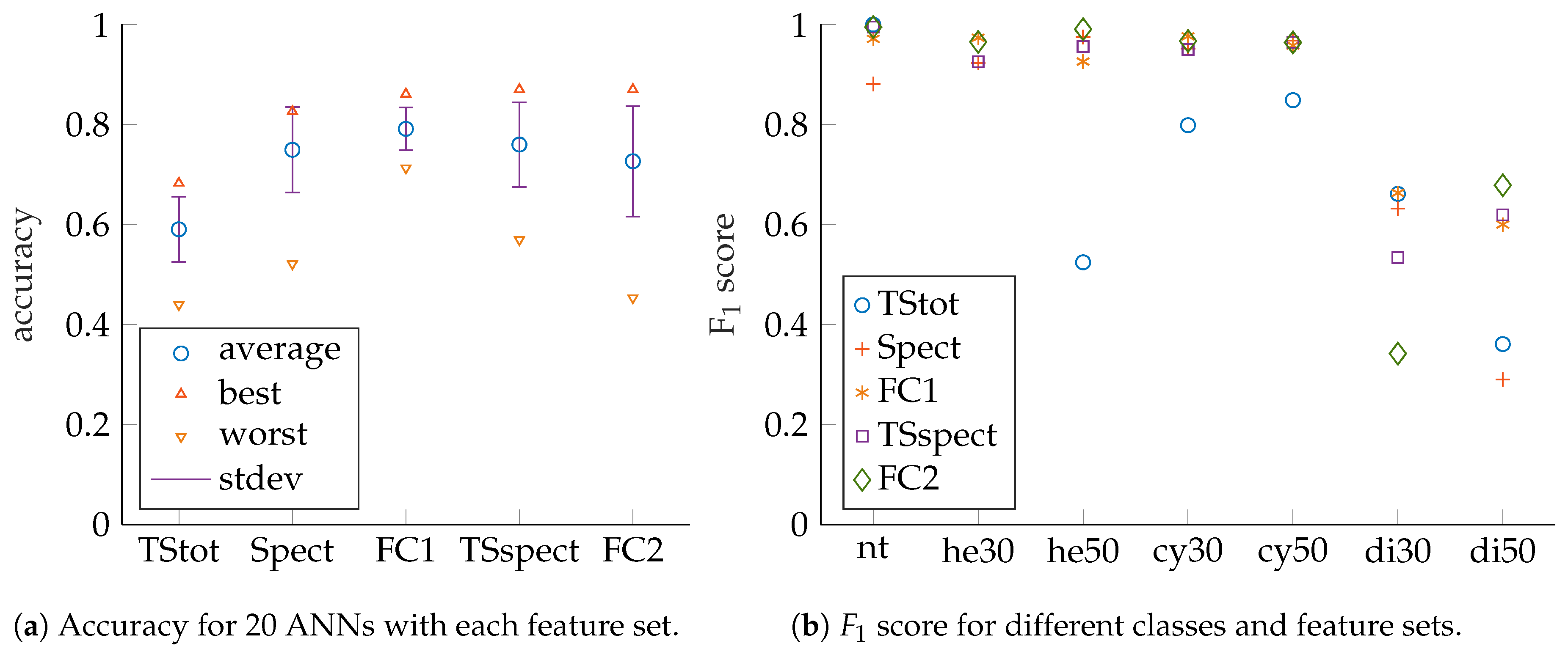
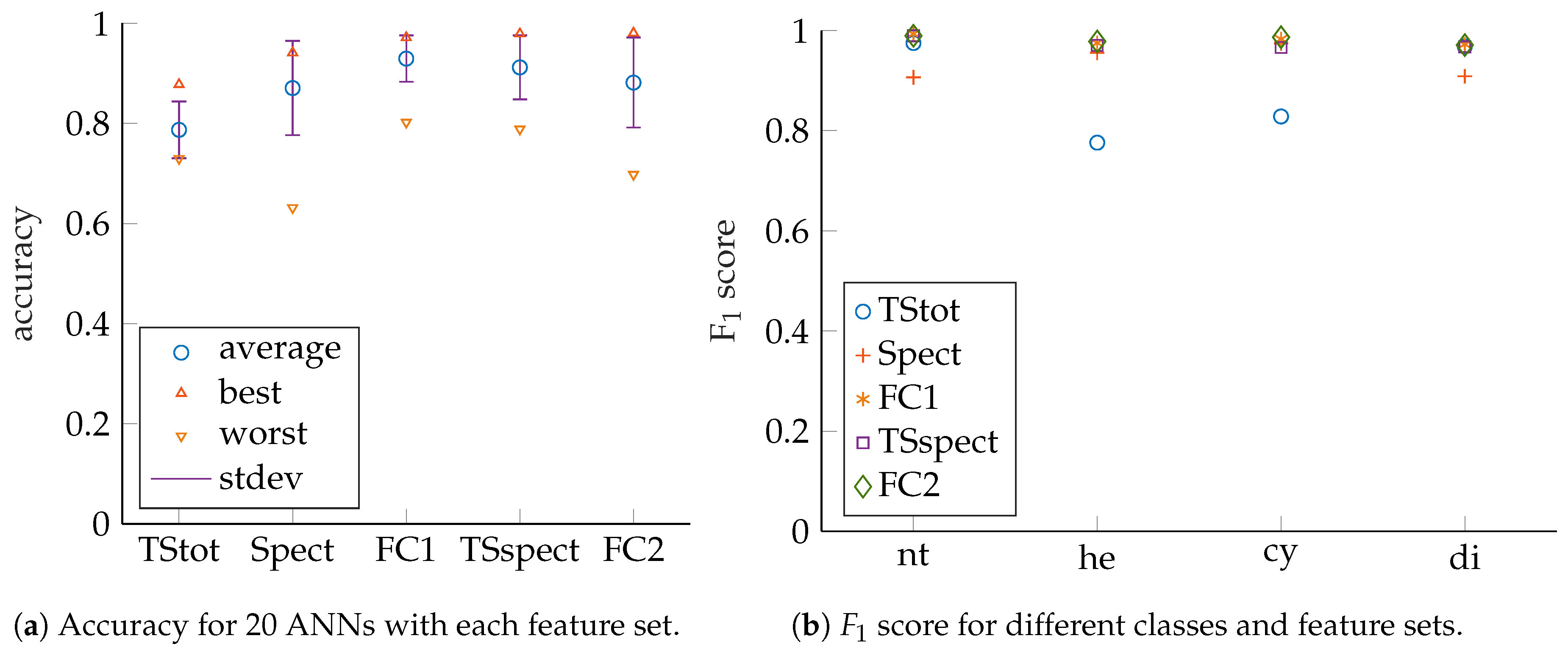
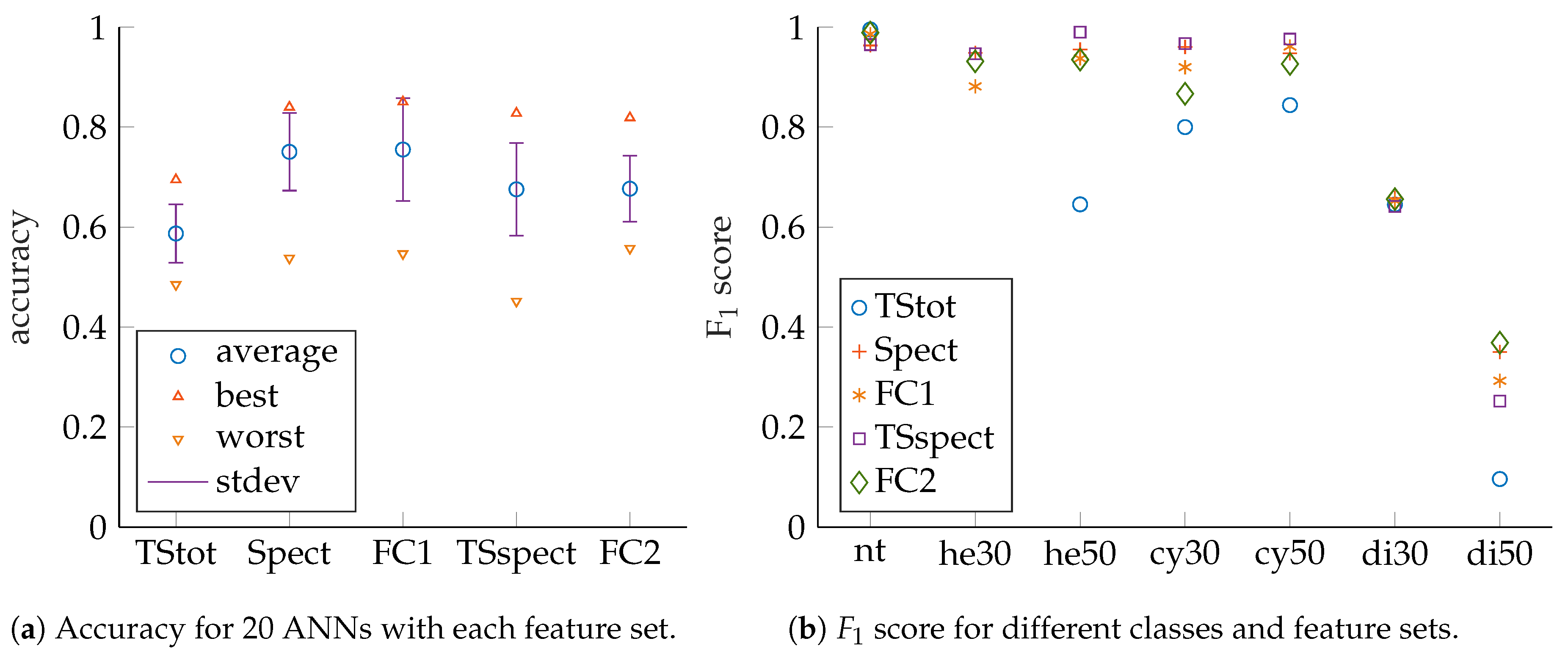
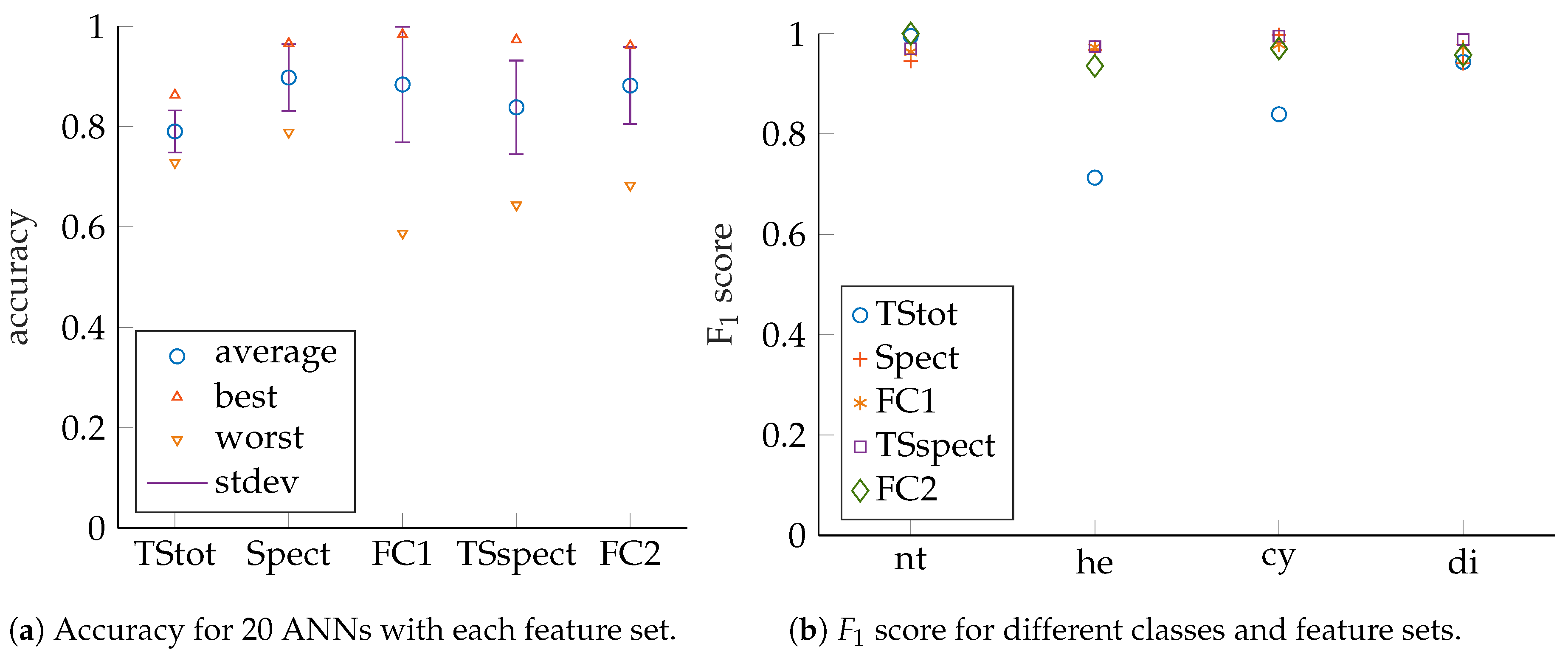
ANN performance evaluation is based on prediction accuracy, precision, recall as well as
scores for test sets that have no common samples with their corresponding training or validation sets (see [
16,
17] and [
18] for details). The measures can be obtained from confusion matrices, which show classification result counts, grouped by actual input classes and predicted output classes. Accuracy is to be maximized towards 100 and is defined as (compare [
16,
31,
32] and [
33]).
where
a denotes the total accuracy,
the total number of correct classifications in the test set and
the total number of samples in the test set. Accuracy alone is usually not sufficient as a performance measure because it is only a measure for overall performance but does not contain information on ANNs’ performances for different classes. Thus, an ANN’s overall performance can seem very good, but it will still be possible for single classes to be identified very badly if multiple classes exist and especially if data set sizes vary for different classes. Hence, for evaluation of single-class classification performance, precision and recall are applied. Precision and recall values are both to be maximized towards 100% and are calculated for each target class by the given equations (compare [
16,
31,
32] and [
33]).
in which
p is precision,
r is recall,
is the total number of true positives for a given class,
is the total number of false positives for a given class, and
is the total number of false negatives for a given class. Precision is a measure for certainty of correct classification for a sample of a specific output class, whereas recall is the percentage of correctly identified samples of available samples for a target class. Recall is also known as sensitivity in statistics [
33]. The meaning of the terms true positive, true negative, false positive and false negative shall be illustrated. For the multi-class case here, we always consider the current target class, for which precision and recall are calculated, as positives and all other classes are summarized as negatives. This means for the mentioned terms:
true positive: correct classification of current target class (e.g., hemisphere classified as hemisphere),
true negative: correct classification of current non-target class (e.g., non-hemisphere classifed as non-hemisphere, where non-hemisphere may be anything but a hemisphere),
false positive: wrong classification of current non-target class (e.g., non-hemisphere classifed as hemisphere),
false negative: wrong classification of current target class (e.g., hemisphere classifed as non-hemisphere).
Evaluation of feature performance based on precision and recall can be cumbersome since a 2D plot must be created for each trained ANN. As a consequence, the
score is introduced as a scalar measure, which combines precision and recall. The
score is to be maximized towards 100 and is calculated as
Care must be taken for classes with small sample counts, but in our case this does not apply as our samples are evenly distributed among the different classes. For more detailed explanations regarding ANNs and their performance measures, see [
16,
17] and [
18].
2.4. Echo Preprocessing and Features
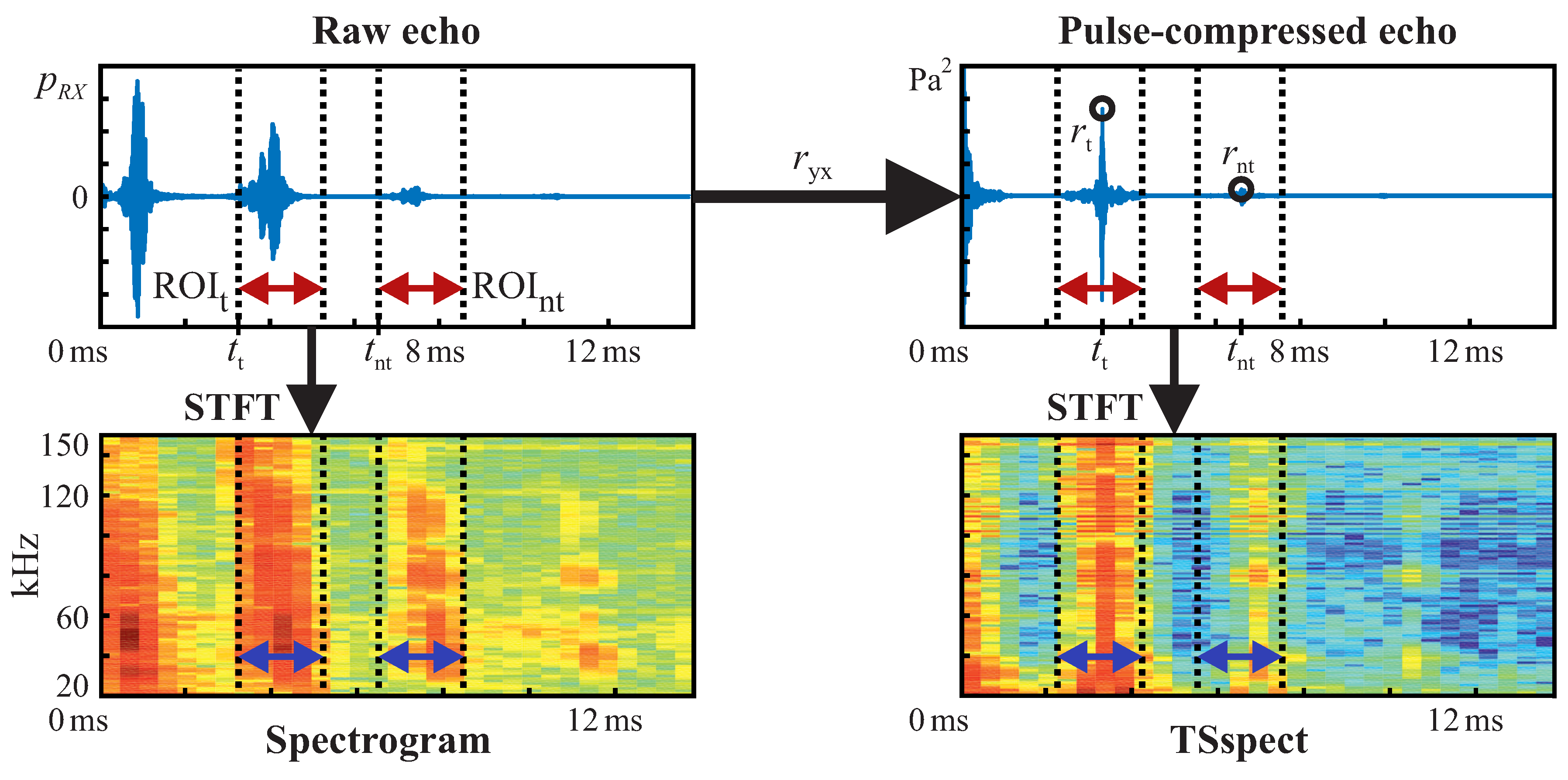
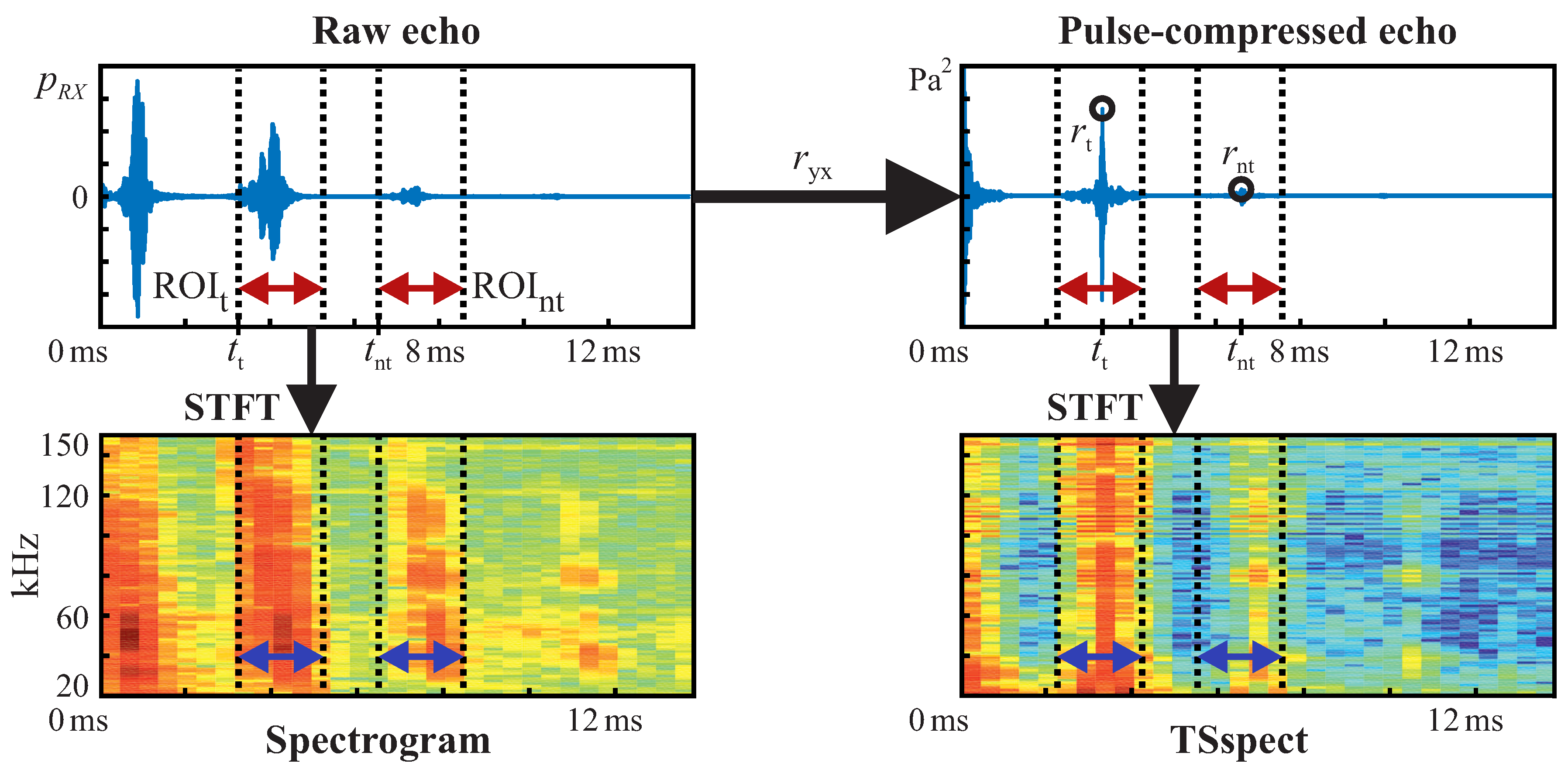
The recorded raw echo signals (top left in
Figure 5) are processed before classification by ANNs. The signals are preprocessed since known relations can be extracted from data efficiently with rule-based approaches and so the ANNs do not need to learn those relations from the training data. Accordingly, learning focuses on aspects of information that are not modeled explicitly but may be important for the given classification task. The data which contains relevant information is part of the input to ANNs and is generally denoted as “input feature vector” or just “features” in the machine learning context [
16,
17,
18]. Possible input features are raw data, alternative raw data representations (e.g., based on transformation to frequency or time-frequency spaces) as well as raw data on which basic mathematical operations are performed, such as multiplication of elements, squaring elements, calculation of various norms etc. Such features are often used for deep learning [
16]. In addition, there are also specifically engineered features that are motivated by domain knowledge (common for traditional machine learning and pattern recognition [
17,
18]) as well as combinations of previously mentioned features. For our application, we created and evaluated aforementioned feature types, which are explained later on in this section. The main echo preprocessing and feature calculation steps are sketched in
Figure 5. First, bandpass filtering is performed according to the excitation signal bandwidth. This is done to remove out-of-band noise, which is not related to the target echoes and is not relevant for classification. Then, each echo signal’s cross-correlation
with the corresponding emitted acoustic chirp signal is calculated (top right part of
Figure 5). Therefore, much irrelevant/unrelated in-band information is filtered out as well, such as noise and uncorrelated sounds from other sources. Consequently, the ANNs do not need to learn how to filter out a large portion of the information that is not relevant. The peaks in correlated signals can now be considered echoes from targets. Accordingly, peak positions correspond to targets’ propagation delays. This approach is also known as pulse compression in the area of sonar and radar systems (see also [
34,
35,
36], and [
37]). The emitted chirp signal had been recorded before at 1
distance and was averaged ten times to improve its signal to noise ratio—in contrast to the measured target echoes, for which no averaging was performed (single echoes).
From each of the recorded echoes (raw as well as pulse-compressed), a region of interest (ROI) of 2
is selected for feature calculations (indicated by dotted lines with enclosed arrows in
Figure 5). For each target’s echo, its ROI (
in
Figure 5) is centered around the largest corresponding peak in its pulse-compressed echo. Peak detection in pulse-compressed echo signals is a common method for identification of possible targets in sonar as well as radar systems (see also [
34,
35,
36] and [
37]) and is therefore assumed to be a valid step before target classification in our case. ROIs for non-target samples (
in
Figure 5) are randomly put outside target ROIs, but inside possible ranges for target echoes. Non-target ROIs are also centered around their highest peak in the pulse-compressed waveforms. ROIs in general are selected so that feature calculations do not need to be performed on the whole recorded waveforms, which would lead to larger ANN input feature vectors and therewith increased calculation cost. Another advantage of ROI selection is that only parts of the recorded signals are presented to the ANNs, which are actually related to the targets. So, no features are learned which may result from the measurement setup, such as additional echoes that might appear due to multiple reflections off targets and the setup. In doing so, training only happens on relevant parts of our echo signals and the risk of problems due to long feature vectors is largely reduced, e.g., overfitting due to curse of dimensionality [
16,
17,
18]. The ROI length does not represent the proposed sonar’s working range, which was tested up to a target distance of
in our case. Therefore, total echo recording durations were set to 15
. The distance limitation is given due to the sizes of the translation stages as well as the anechoic chamber dimensions (compare also
Section 2.1). Tests are planned for greater distances outside the anechoic chamber in the future.
In particular, we consider three features:
- (i)
Spect: the raw echoes’ spectrogram representation (bottom left plot in
Figure 5),
- (ii)
TStot: an estimate of total TS and
- (iii)
TSspect: a specifically engineered feature, which is related to the targets’ spectral TS (bottom right plot in
Figure 5).
TStot is based on the pulse-compressed echoes’ peak magnitudes (
,
in
Figure 5), whereas
TSspect is based on a short-time fourier transform (STFT) of the pulse-compressed echoes. Specific relations will be shown later in this section and in the
Supplementary Materials in detail. For
Spect and
TSspect, a frequency ROI was selected according to the excitation chirps’ bandwidths. Based on the mentioned features, we defined different feature sets for performance comparison:
A feature vector was chosen to consist of a feature set for three adjacent measurement grid positions. This is equivalent to a sonar sensor traveling by a target and recording multiple echoes (e.g., robot passing by). Also, to each feature vector, the echo propagation delay is added as additional element. In order to obtain 1D-Feature vectors for our ANNs, 2D data is flattened into 1D arrays.
We chose the spectrogram (STFT) as time–frequency-based raw data representation since this is a common approach for speech recognition and because ANNs are also known to handle pictorial information quite well [
38,
39,
40,
41,
42]. Another possible time-frequency signal representation is the wavelet transform, which was examined by Ayrulu and Barshan in [
20].
TStot and
TSspect are related to an object’s TS, which is a relative measure for acoustic intensity reflected off a target. A compact description of the relations is given in the rest of this section, more detailed explanations can be found in the
Supplementary Materials.
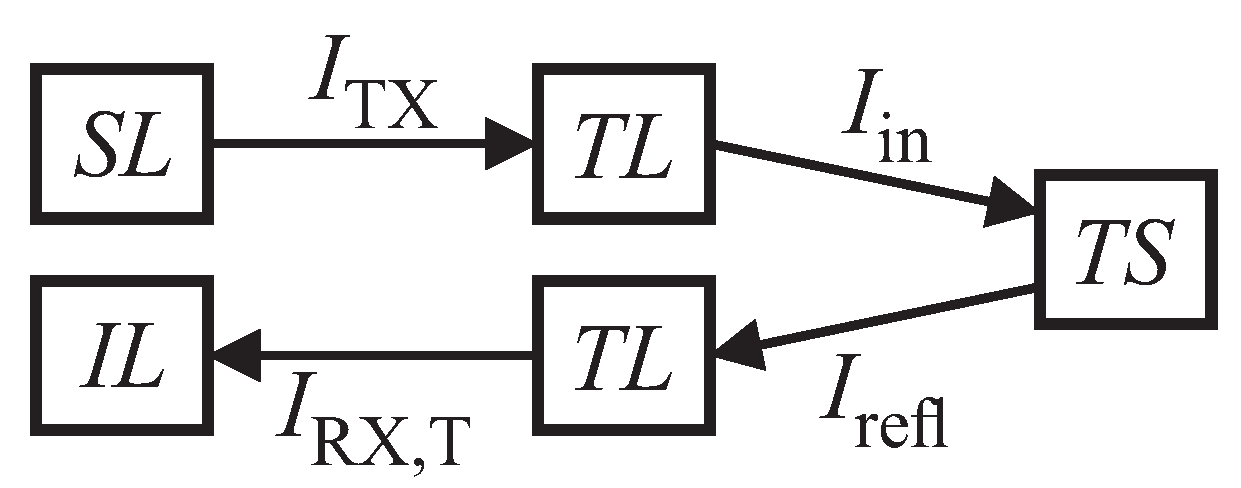
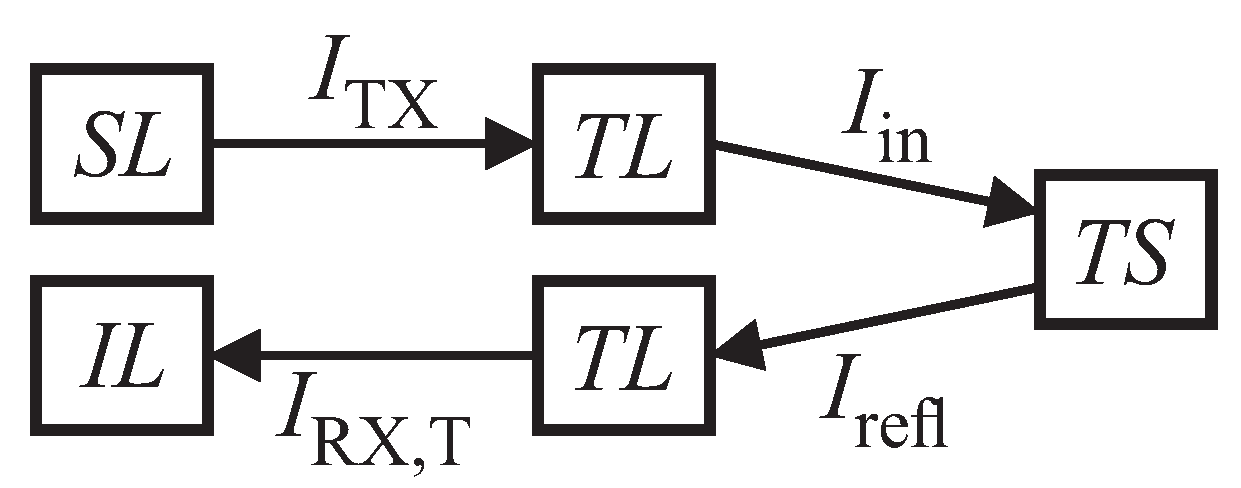
Figure 6 shows the relations for acoustic intensity levels along an echo’s transmission path, which can be put as follows (in analogy to the sonar equation from [
43]):
Here,
is the input level at the receiver,
is the source level at the transmitter,
is the target strength and
is the transmission loss, respectively. For our calculations, the underlying assumption is that
is only caused by geometric spreading. Compensation of frequency-dependent effects is left to the ANNs. The echo
from the target can consist of multiple reflections
i at times
with different magnitudes
The total target strength
for a target with a single echo, such as a disc or a cylinder, is used for
TStot and consists of a variable part
as well as a constant part
with (see also
Supplementary Materials)
where
is an arbitrary time constant,
is the target’s main peak in the pulse-compressed echo,
is the pulse-compressed echo’s value at
,
can be chosen as an arbitrary constant,
c is the speed of sound in air and
is the acoustic excitation signal’s auto-correlation function value at time 0, respectively. For target echoes,
is used for
and for non-target echoes,
is used (compare
Figure 5). We suppose that the impinging echo waves’ surface curvature across the microphone surface is negligible due to the small membrane area and the wave’s geometric spread over a large propagation distance in comparison, which leads to a plane wave assumption. Hence, intensity estimates are deduced from pressure measurements since sound pressure level and acoustic intensity level can be assumed to be equal for plane waves. This simplification suffices in our case as we are mainly interested in an estimate of target strength instead of a highly precise measurement. Compensation of possible variations due to the simplifications is left to the ANNs.
Apart from the total target strength
, also the spectral target strength
contains significant information for a target, especially for ones with multiple echoes such as a hollow hemisphere.
depends on the frequency
f and consists of a variable part
as well as a constant part
where
denotes the cross-power-spectral density of the echo signal with the excitation signal, which can be obtained from
by Fourier transform.
can be chosen arbitrarily and
is the excitation signal’s auto-power-spectral density, which can be obtained from
by Fourier transform. The derivation of the relations can be found in the
Supplementary Materials.
We decided to represent the signal by an STFT for
TSspect due to the same reasons as for the raw signal. The window size was chosen to be close to the excitation chirp duration (see [
21] for considerations regarding STFT window size selection). Consequently, a window size of 1024 samples and an overlap of 50 are set for the STFT.
It is apparent from the TS equations that arbitrary excitation signals can be selected for target insonification. Therefore, use of rectified signals is possible and harmonic distortion is not a problem. We also performed tests with electrical sine as well as rectified chirp excitation and no difference in ANN performance results was detectable. Thus, less complex as well as smaller, lighter and cheaper amplifiers can be built for the ultrasonic speakers in comparison to amplifiers for sine signal excitation [
44]. This is especially important for mobile robotic applications.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}