Measurement Noise Recommendation for Efficient Kalman Filtering over a Large Amount of Sensor Data



Abstract
1. Introduction
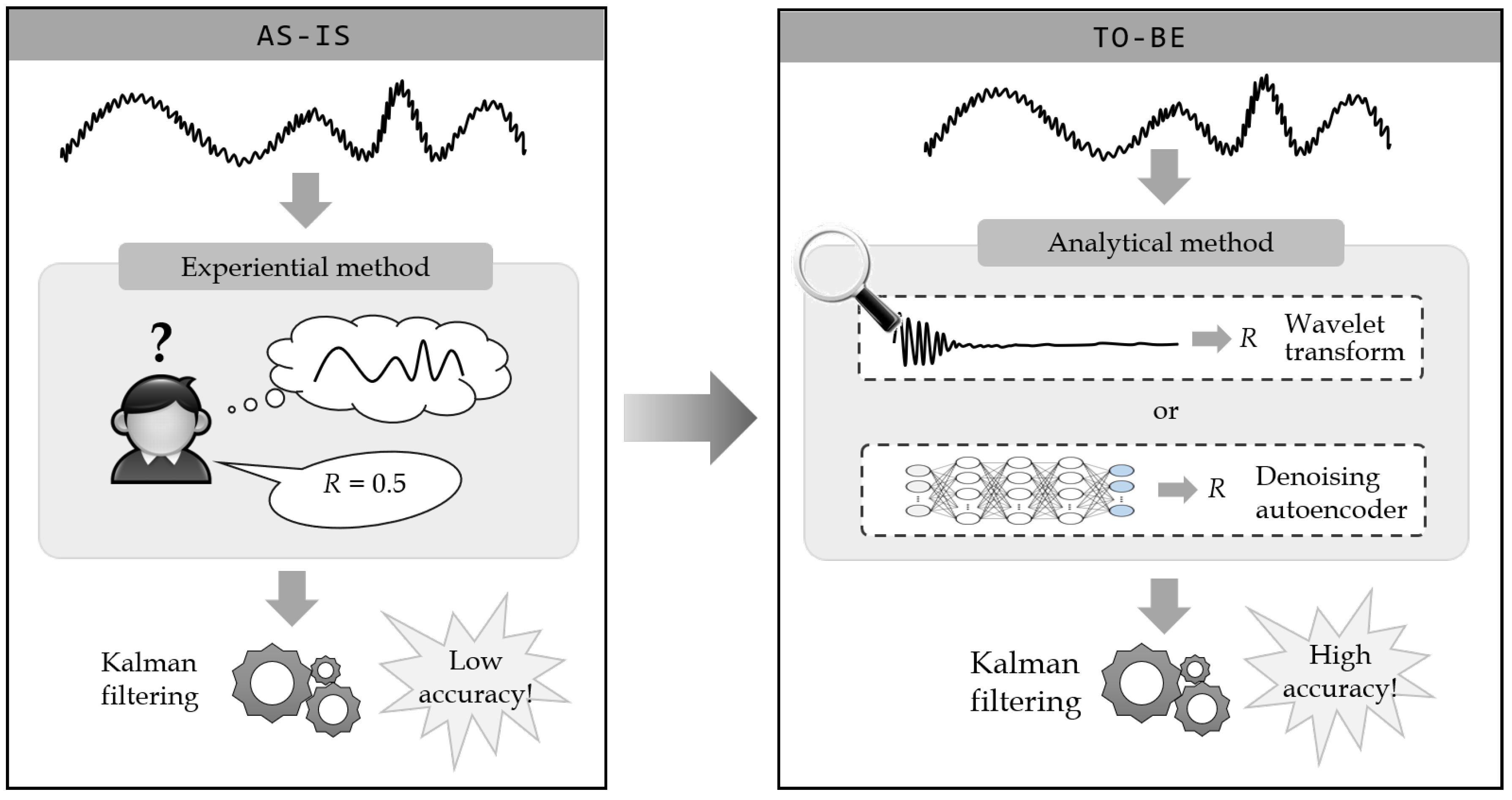
- To estimate the measurement noise variance accurately, two analytical methods are proposed: one a transform-based method using a wavelet transform and the other a learning-based method using a denoising autoencoder.
- A practical approach for Kalman filtering for streaming data is presented, which exploits the recommended measurement noise variance by the proposed methods.
- Through extensive experiments on real datasets, the effectiveness of the proposed methods was validated, and it was shown that they estimated the measurement noise variance accurately.
2. Related Work
2.1. Kalman Filtering
2.2. Wavelet Transforms
2.3. Denoising Autoencoders
3. Kalman Filtering Using the Recommended Measurement Noise Variance
| Algorithm 1 Kalman filtering using the recommended measurement noise variance. |
| Input: : a numeric sequence of sensor data; : a function for a measurement noise variance recommendation; w: a window size used for computing the measurement noise variance; Output: : a filtered sequence by the Kalman Filter; begin (1) (2) ; // Use the first w entries of S for as it is. (3) while do (4) ; // Determine R by using the w entries. (5) ; // Increase i by w. (6) KalmanFilter; // Adjust the next w entries by applying R to the Kalman filter. (7) end (8) return ; end |
4. Measurement Noise Variance Recommendation Methods
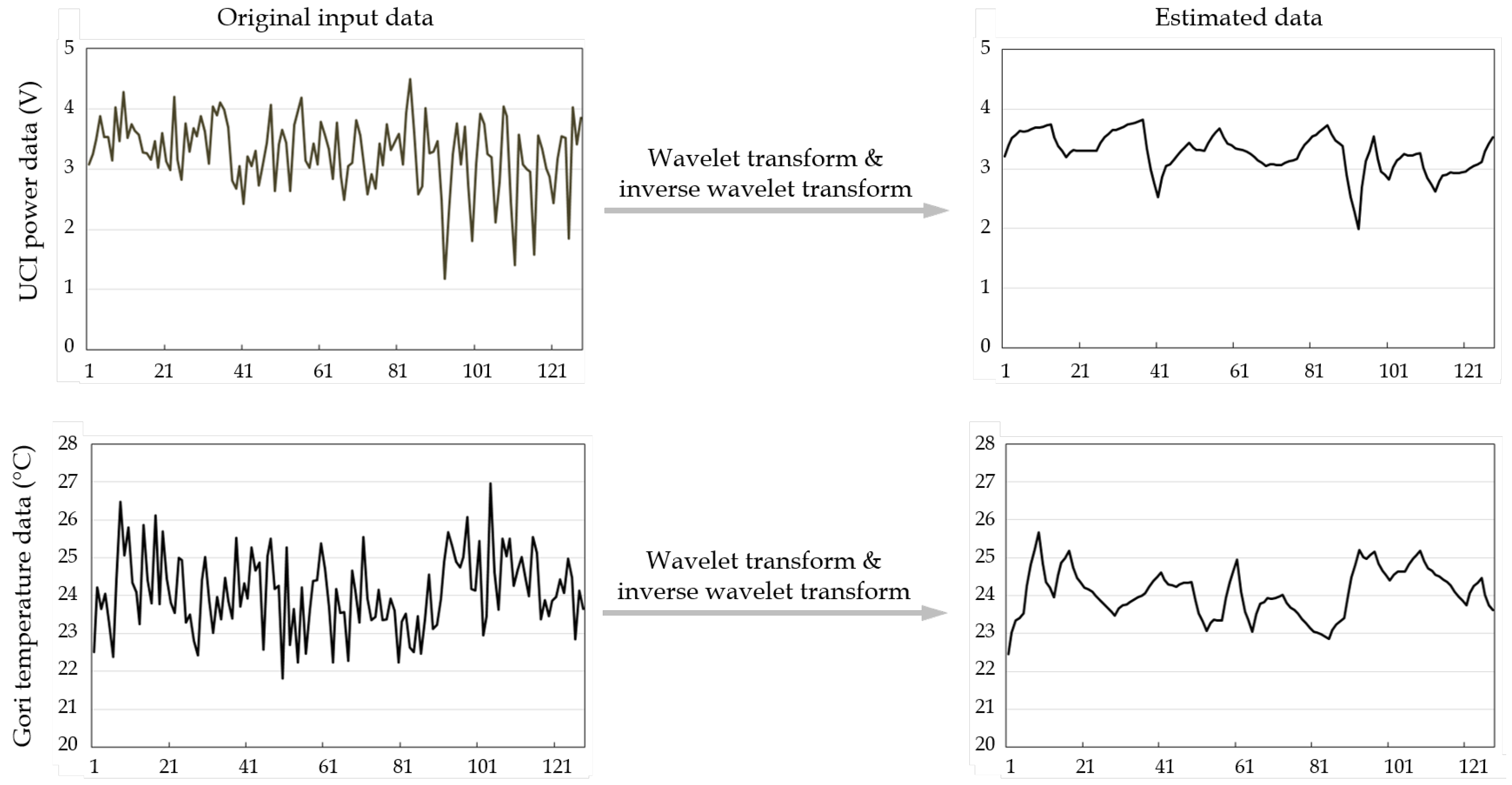
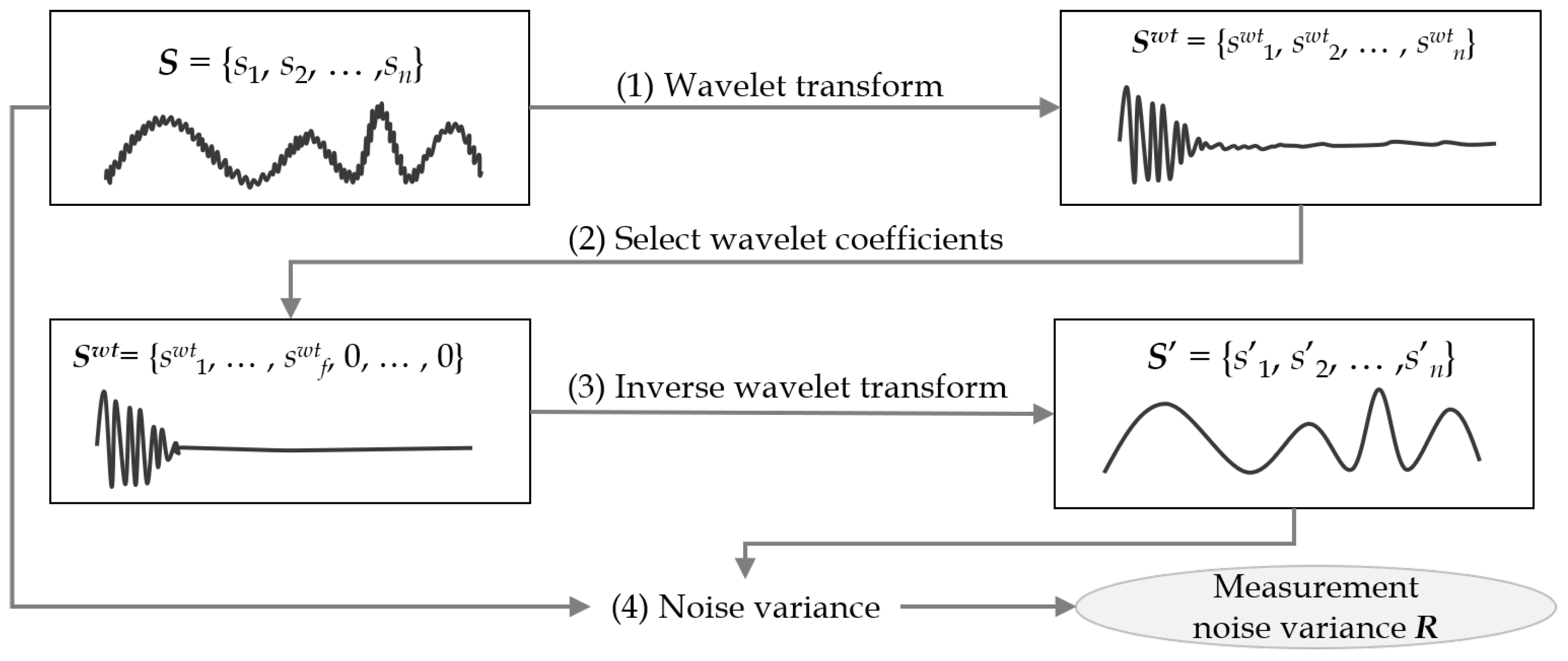
4.1. Wavelet Transform-Based Measurement Noise Variance
| Algorithm 2: Measurement noise variance by wavelet transform. |
| Input: : a numeric sequence of sensor data, (); f: the number of wavelet coefficients to be selected; Output: R: measurement noise variance of ; begin (1) WaveletTransform; (2) ConcatenateArray.zeros; // Take high energy coefficients. (3) InverseWaveletTransform; (4) CalculateVAR; // Calculate the variance between two sequences. (5) return R; end |
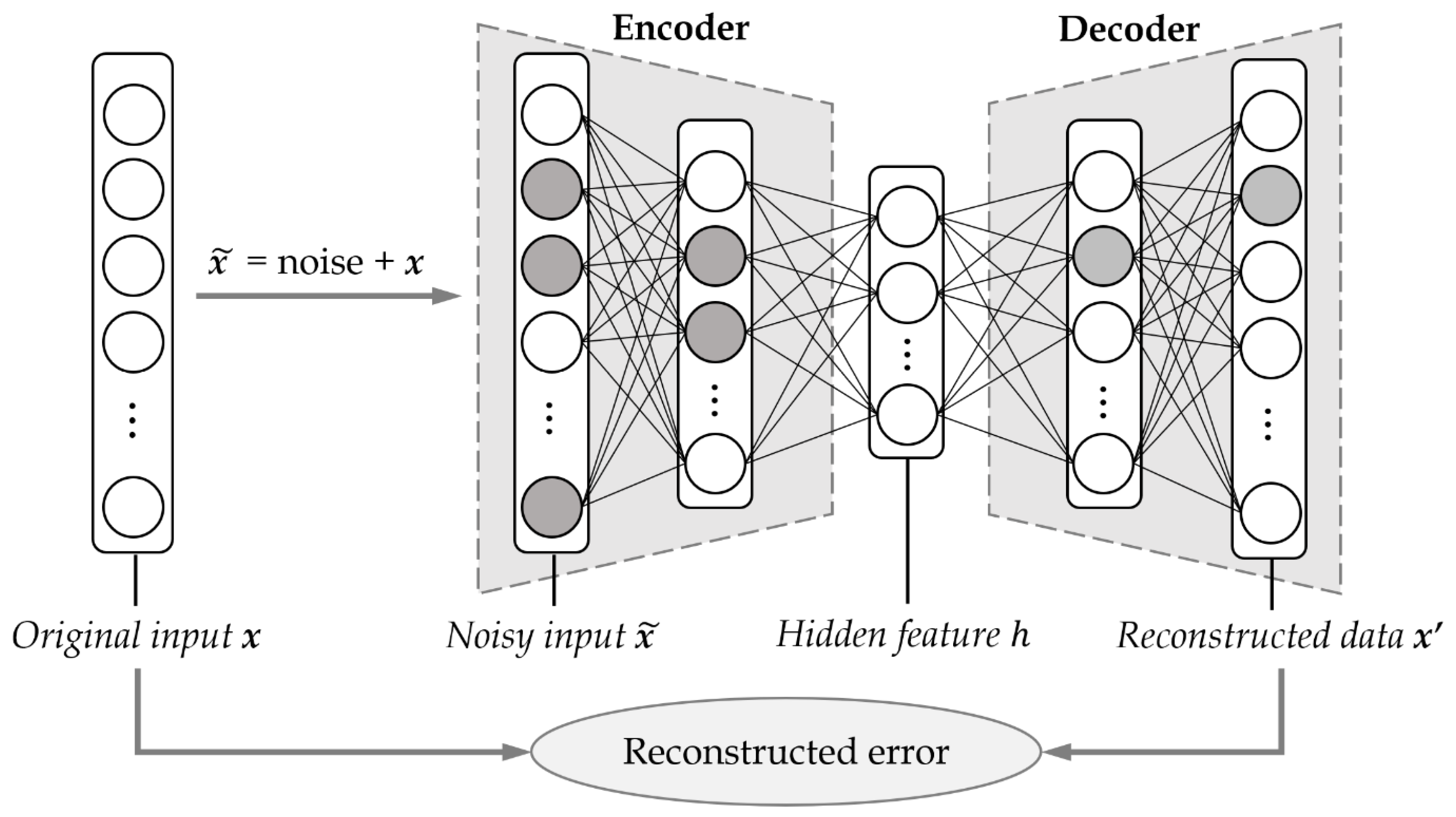
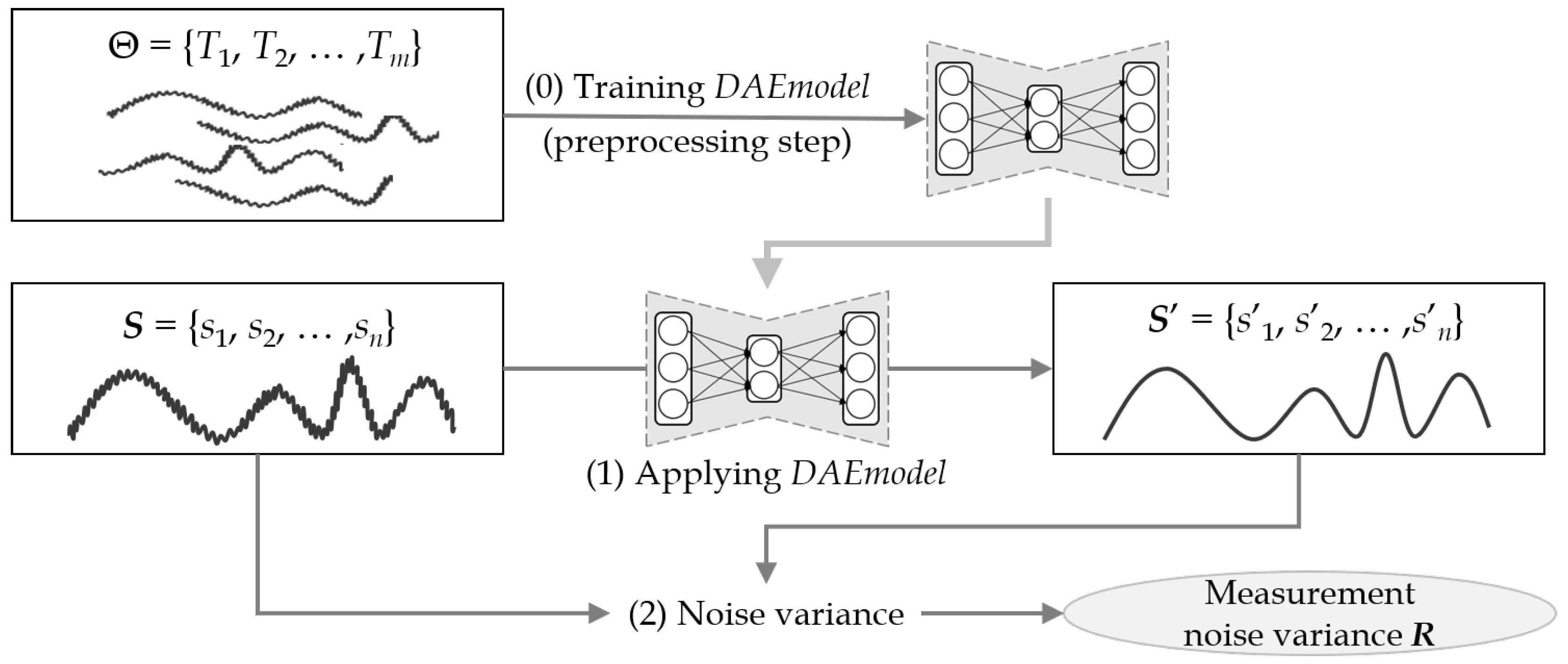
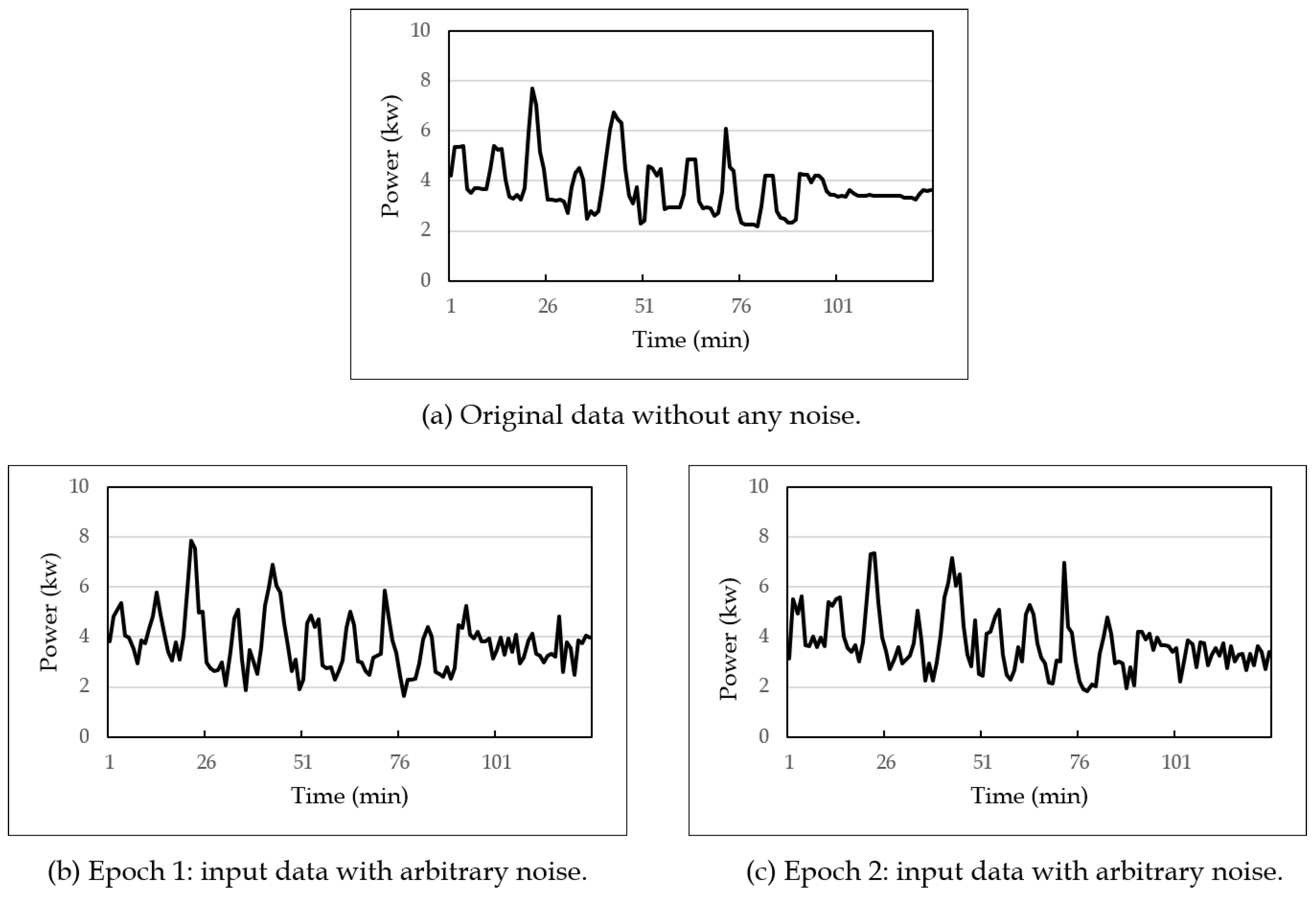
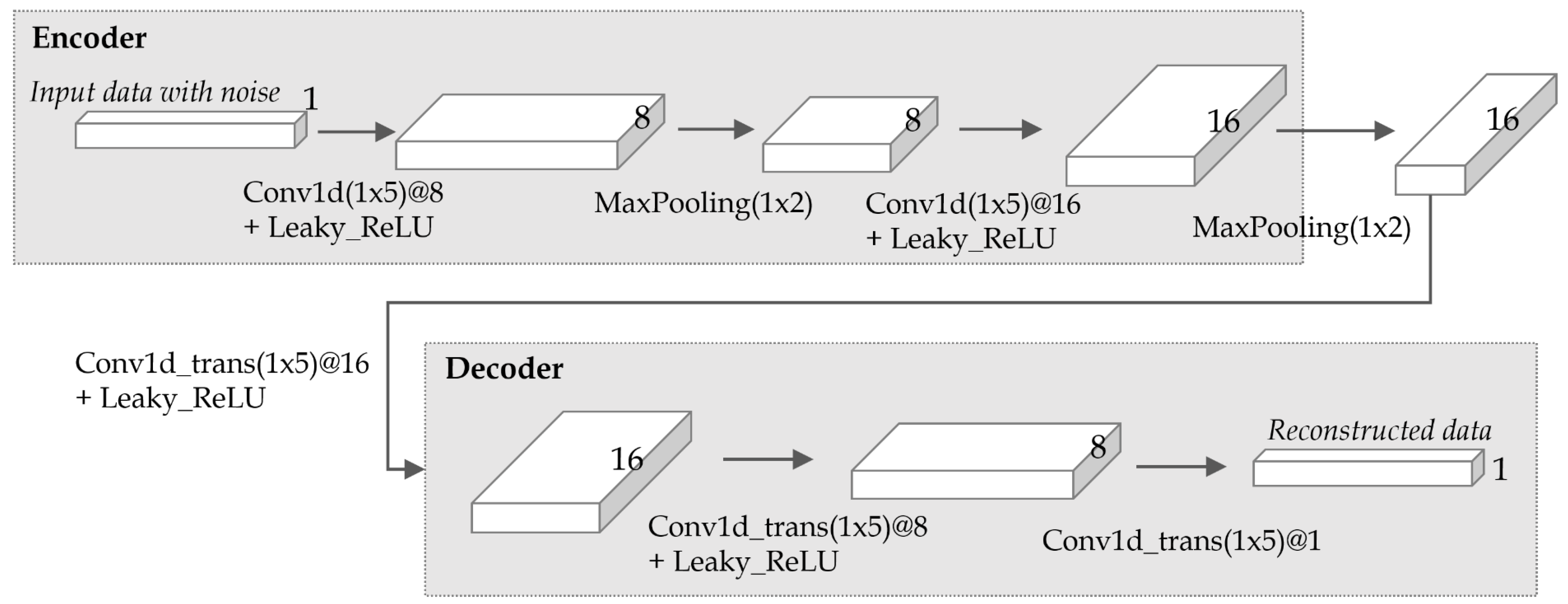
4.2. Denoising Autoencoder-Based Measurement Noise Variance
| Algorithm 3: Measurement noise variance by denoising autoencoder. |
| Input: : a training set of m sensor data; : a numeric sequence of input sensor data; Output: R: measurement noise variance of ; begin (0) DAEmodel TrainModel; // Build a denoising autoencoder model in the preprocessing step. (1) ApplyModel; (2) CalculateVAR; // Calculate the variance between two sequences. (3) return R; end |
5. Experimental Evaluation
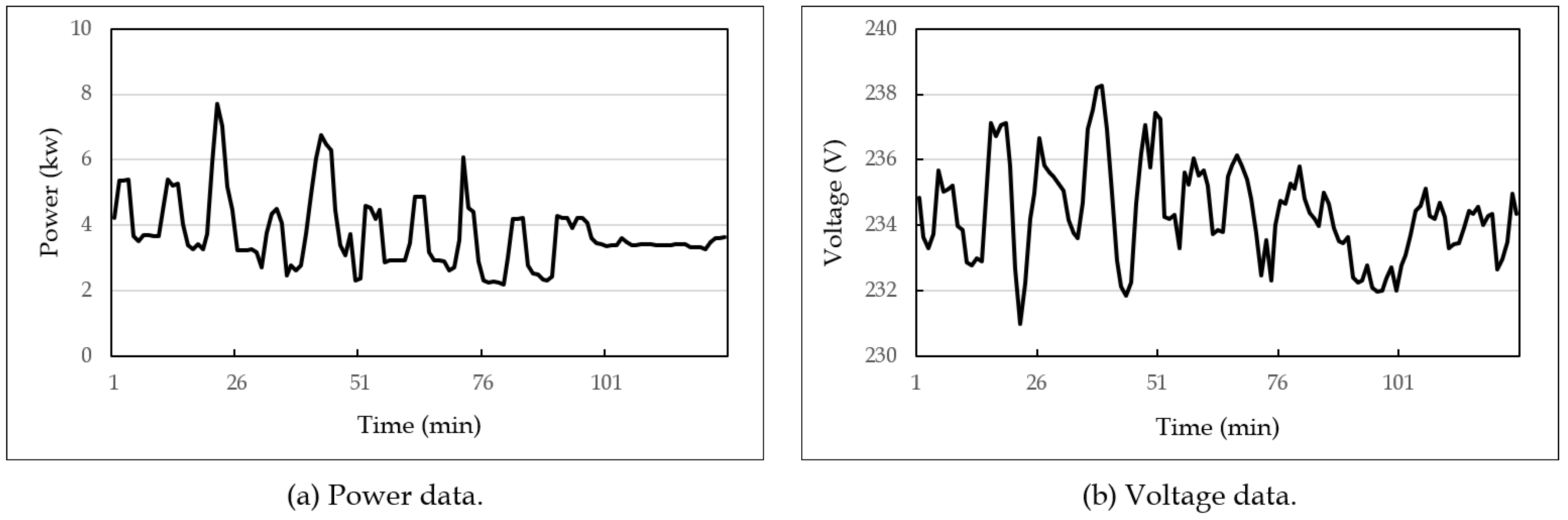
5.1. Experimental Setup
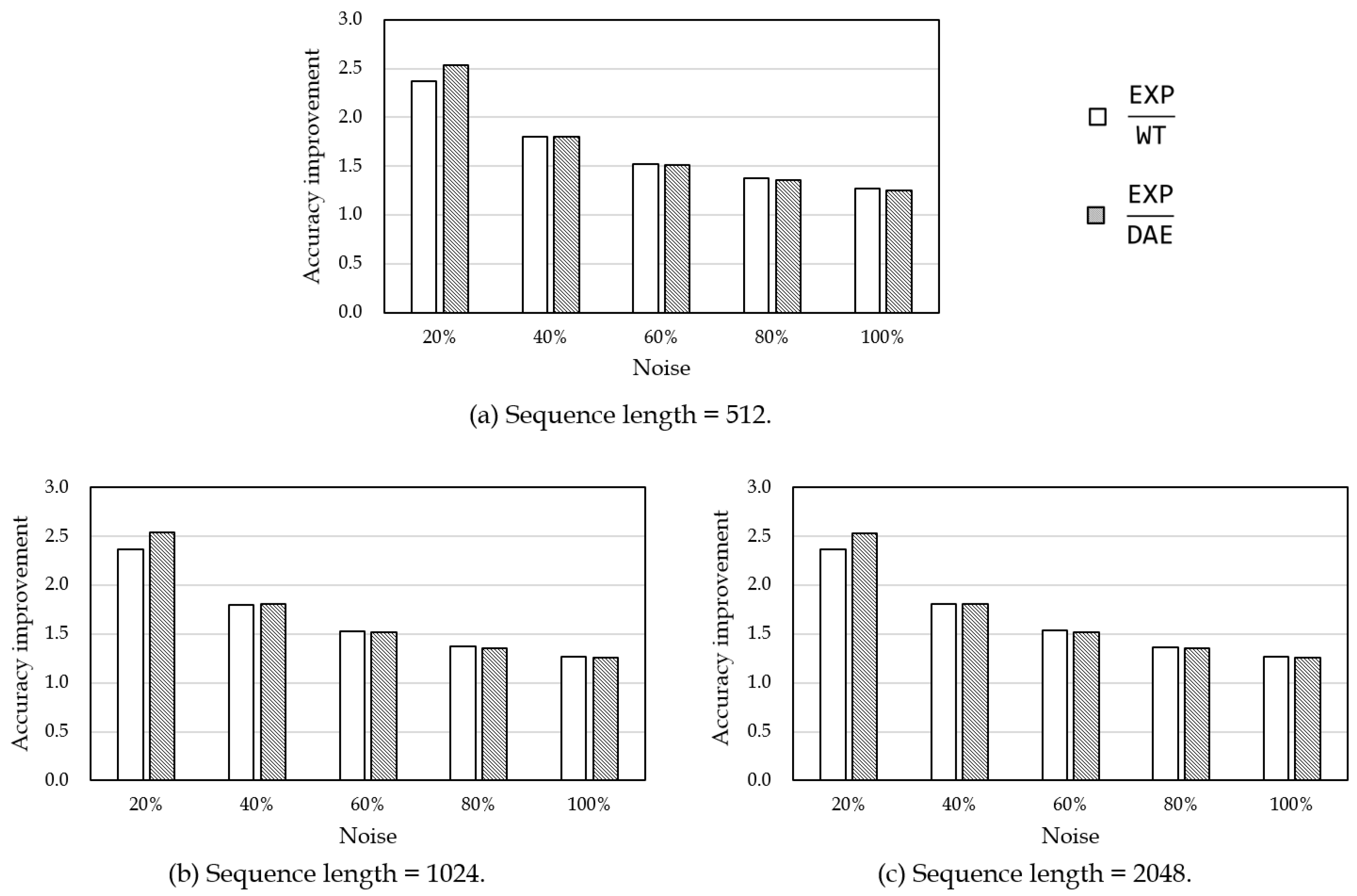
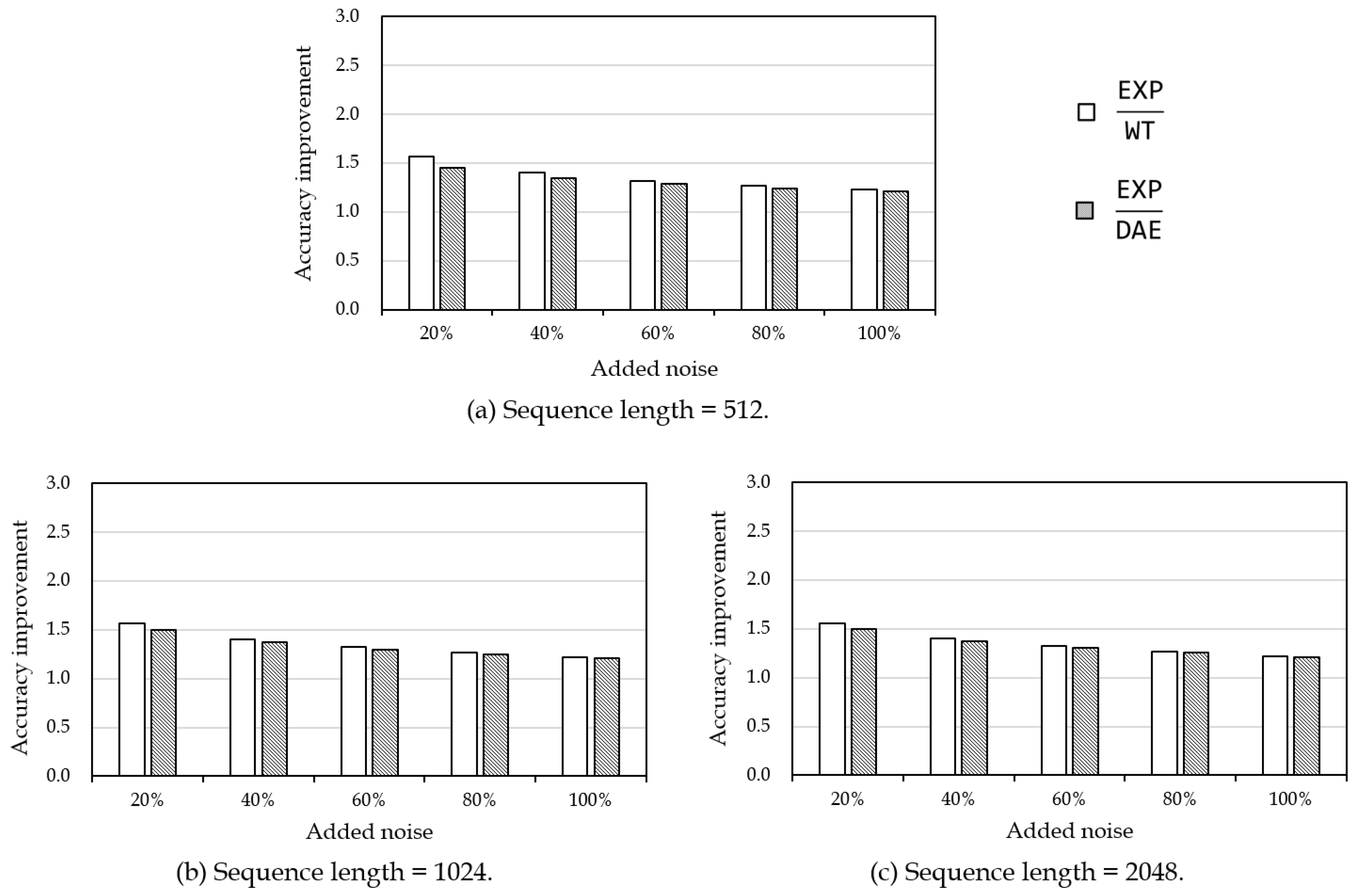
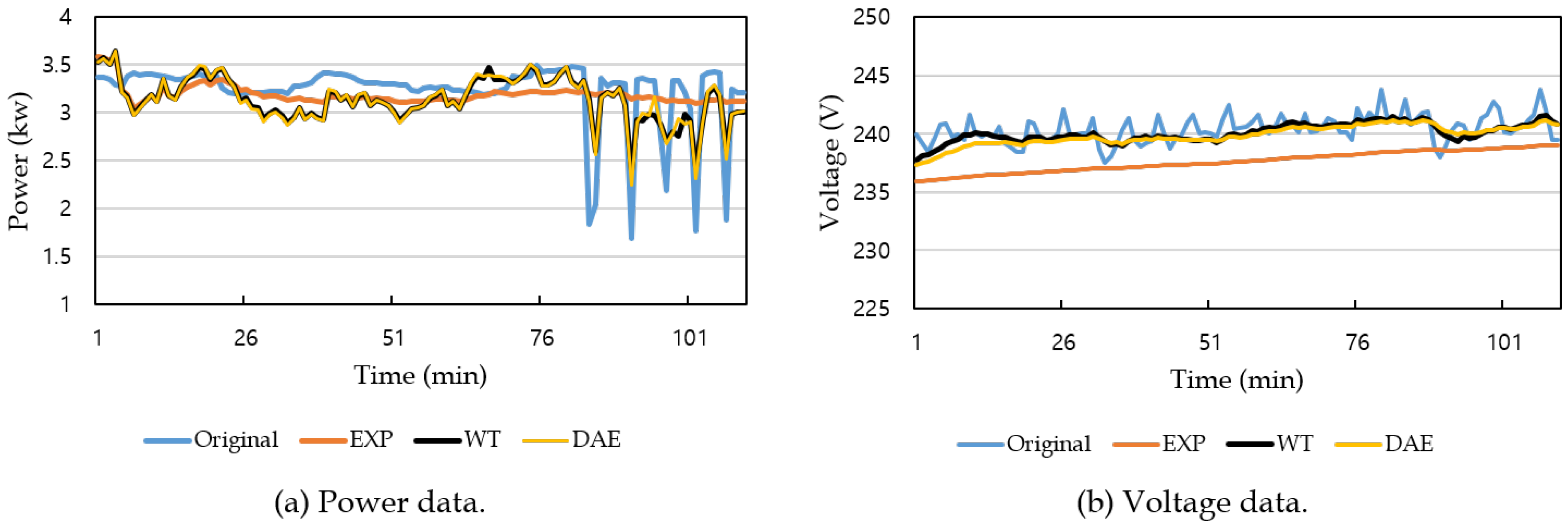
5.2. Accuracy Evaluation of Kalman Filtering
5.3. Accuracy Evaluation of Measurement Noise Variance Estimation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Centenaro, M.; Vangelista, L.; Zanella, A.; Zorzi, M. Long-range communications in unlicensed bands: The rising stars in the IoT and smart city scenarios. IEEE Wirel. Commun. 2016, 23, 60–67. [Google Scholar] [CrossRef]
- Fernández-Caramés, T.M.; Fraga-Lamas, P. Towards The Internet of Smart Clothing: A Review on IoT Wearables and Garments for Creating Intelligent Connected E-Textiles. Electronics 2018, 7, 405. [Google Scholar] [CrossRef]
- Park, J.-S.; Youn, T.-Y.; Kim, H.-B.; Rhee, K.-H.; Shin, S.-U. Smart contract-based review system for an IoT data marketplace. Sensors 2018, 18, 3577. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Sow, D.; Vespa, P.; Hu, X. Real-time processing of continuous physiological signals in a neurocritical care unit on a stream data analytics platform. Intracranial Pressure Brain Monit. 2016, 15, 75–80. [Google Scholar]
- Cho, W.; Gil, M.-S.; Choi, M.-J.; Moon, Y.-S. Storm-based distributed sampling system for multi-source stream environment. Int. J. Distrib. Sens. Netw. 2018, 14, 1–12. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. Trans. ASME J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Ligorio, G.; Sabatini, A.M. A novel Kalman filter for human motion tracking with an inertial-based dynamic inclinometer. IEEE Trans. Biomed. Eng. 2015, 62, 2033–2043. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Welch, G.; Bishop, G.; Huang, Z. A two-stage Kalman filter approach for robust and real-time power system state estimation. IEEE Trans. Sustain. Energy 2014, 5, 629–636. [Google Scholar] [CrossRef]
- Valade, A.; Acco, P.; Grabolosa, P.; Fourniols, J.-Y. A Study about Kalman Filters Applied to Embedded Sensors. Sensors 2017, 17, 2810. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, S.; Mitra, M. Application of cross wavelet transform for ECG pattern analysis and classification. IEEE Trans. Instrum. Meas. 2014, 63, 326–333. [Google Scholar] [CrossRef]
- Mets, K.; Depuydt, F.; Develder, C. Two-stage load pattern clustering using fast wavelet transformation. IEEE Trans. Smart Grid 2016, 7, 2250–2259. [Google Scholar] [CrossRef]
- Daubechies, I. Orthonormal bases of compactly supported wavelets. Commun. Pure Appl. Math. 1988, 41, 909–996. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Li, J.; Struzik, Z.; Zhang, L.; Cichocki, A. Feature learning from incomplete EEG with denoising autoencoder. Neurocomputing 2015, 165, 23–31. [Google Scholar] [CrossRef]
- Zhao, M.; Wang, D.; Zhang, Z.; Zhang, X. Music removal by convolutional denoising autoencoder in speech recognition. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 338–341. [Google Scholar]
- Moon, Y.-S.; Whang, K.-Y.; Loh, W.-K. Efficient time-series subsequence matching using duality in constructing windows. Inf. Syst. 2001, 26, 279–293. [Google Scholar] [CrossRef]
- Moon, Y.-S.; Whang, K.-Y.; Han, W.-S. General match: A subsequence matching method in time-series databases based on generalized windows. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD ’02), Madison, WI, USA, 3–6 June 2002; pp. 382–393. [Google Scholar]
- Welch, G.; Bishop, G. An introduction to the Kalman Filter. SIGGRAPH 2001 Course 8. Available online: http://www.cs.unc.edu/~tracker/ref/s2001/kalman/ (accessed on 28 January 2019).
- Olfati-Saber, R. Distributed Kalman filtering for sensor networks. In Proceedings of the 2007 46th IEEE Conference on Decision and Control, New Orleans, LA, USA, 12–14 December 2007; pp. 5492–5498. [Google Scholar]
- Valenti, R.G.; Dryanovski, I.; Xiao, J. A linear Kalman filter for MARG orientation estimation using the algebraic quaternion algorithm. IEEE Trans. Instrum. Meas. 2016, 65, 467–481. [Google Scholar] [CrossRef]
- Mehra, R. On the identification of variances and adaptive Kalman filtering. IEEE Trans. Autom. Control 1970, 15, 175–184. [Google Scholar] [CrossRef]
- Kailath, T. An innovations approach to least-squares estimation–Part I: Linear filtering in additive white noise. IEEE Trans. Autom. Control 1968, 13, 646–655. [Google Scholar] [CrossRef]
- Godbole, S. Kalman filtering with no a priori information about noise–white noise case: identification of covariances. IEEE Trans. Autom. Control 1974, 19, 561–563. [Google Scholar] [CrossRef]
- Lee, T. A direct approach to identify the noise covariances of Kalman filtering. IEEE Trans. Autom. Control 1980, 25, 841–842. [Google Scholar] [CrossRef]
- Bulut, Y.; Vines-Cavanaugh, D.; Bernal, D. Process and Measurement Noise Estimation for Kalman Filtering. Struct. Dyn. 2011, 3, 375–386. [Google Scholar]
- Mehra, R. Approaches to adaptive filtering. IEEE Trans. Autom. Control 1972, 17, 693–698. [Google Scholar] [CrossRef]
- Särkkä, S.; Nummenmaa, A. Recursive noise adaptive Kalman filtering by variational Bayesian approximations. IEEE Trans. Autom. Control 2009, 54, 596–600. [Google Scholar] [CrossRef]
- Adiloğlu, K.; Vincent, E. Variational bayesian inference for source separation and robust feature extraction. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1746–1758. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Y.; Wu, Z.; Li, N.; Chambers, J. A Novel Adaptive Kalman Filter With Inaccurate Process and Measurement Noise Covariance Matrices. IEEE Trans. Autom. Control 2018, 63, 594–601. [Google Scholar] [CrossRef]
- Sun, C.; Zhang, Y.; Wang, G.; Gao, W. A New Variational Bayesian Adaptive Extended Kalman Filter for Cooperative Navigation. Sensors 2018, 18, 2538. [Google Scholar] [CrossRef] [PubMed]
- Mallat, S. A Wavelet Tour of Signal Processing, 2nd ed.; Academic Press: San Diego, CA, USA, 1999. [Google Scholar]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017; Available online: http://archive.ics.uci.edu/ml (accessed on 28 January 2019).
- Open Data Portal in Korea. Available online: https://www.data.go.kr (accessed on 28 January 2019).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. Parallel Distrib. Process. Explor. Microstruct. Cognit. 1986, 1, 318–362. [Google Scholar]
- Baldi, P. Autoencoders, Unsupervised Learning, and Deep Architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011; pp. 37–49. [Google Scholar]
- Bernabé, G.; Cuenca, J.; Garcia, L.P.; Gimenez, D. Improving an autotuning engine for 3D fast wavelet transform on manycore systems. J. Supercomput. 2014, 70, 830–844. [Google Scholar] [CrossRef]
- Wang, Z.; Balog, R.S. Arc fault and flash signal analysis in DC distribution systems using wavelet transformation. IEEE Trans. Smart Grid 2015, 6, 1955–1963. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning (ICML) Workshop on Deep Learning for Audio, Speech, and Language Processing, Atlanta, GA, USA, 16 June 2013. [Google Scholar]
- Lin, J.; Keogh, E.; Lonardi, S.; Chiu, B. A symbolic representation of time series, with implications for streaming algorithms. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, San Diego, CA, USA, 13 June 2003; pp. 2–11. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Remark |
|---|---|---|
| Learning rate | 0.01 | A value which determines how much the weights of the model are adjusted. |
| Batch size | 200 | The number of training sequences used in each iteration. |
| Optimizer | Adam | An algorithm used to update the weights of the model. |
| # of epochs | 500 | An epoch is one complete presentation of the entire training data to the model. |
| Noise | Sequence Length = 512 | Sequence Length = 1024 | Sequence Length = 2048 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EXP | WT | DAE | EXP | WT | DAE | EXP | WT | DAE | |
| 20% | 871.7 | 368.0 | 343.4 | 869.5 | 367.6 | 342.5 | 866.5 | 366.3 | 341.8 |
| 40% | 874.4 | 486.1 | 484.8 | 874.6 | 485.1 | 484.0 | 875.6 | 484.4 | 483.6 |
| 60% | 875.7 | 575.3 | 580.5 | 879.0 | 574.4 | 579.7 | 882.3 | 573.9 | 579.4 |
| 80% | 887.1 | 646.3 | 653.5 | 884.1 | 645.7 | 652.9 | 883.1 | 645.2 | 652.6 |
| 100% | 894.3 | 704.5 | 712.2 | 895.5 | 704.0 | 711.7 | 893.7 | 703.6 | 711.4 |
| Noise | Sequence Length = 512 | Sequence Length = 1024 | Sequence Length = 2048 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EXP | WT | DAE | EXP | WT | DAE | EXP | WT | DAE | |
| 20% | 2391 | 1527 | 1642 | 2390 | 1526 | 1599 | 2378 | 1524 | 1585 |
| 40% | 2395 | 1707 | 1777 | 2395 | 1707 | 1749 | 2386 | 1705 | 1740 |
| 60% | 2407 | 1823 | 1873 | 2408 | 1823 | 1853 | 2408 | 1821 | 1846 |
| 80% | 2416 | 1908 | 1946 | 2408 | 1907 | 1930 | 2414 | 1906 | 1924 |
| 100% | 2428 | 1981 | 2012 | 2422 | 1983 | 1999 | 2422 | 1979 | 1994 |
| Sequence Length | Power Data | Voltage Data | ||
|---|---|---|---|---|
| WT | DAE | WT | DAE | |
| 512 | 9.32 | 2.14 | 9.46 | 2.20 |
| 1024 | 18.68 | 2.58 | 19.17 | 2.80 |
| 2048 | 37.25 | 3.64 | 36.08 | 3.71 |
| Noise | Sequence Length = 512 | Sequence Length = 1024 | Sequence Length = 2048 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rreal | RWT | RDAE | Rreal | RWT | RDAE | Rreal | RWT | RDAE | |
| 20% | 0.045 | 0.071 | 0.050 | 0.045 | 0.071 | 0.050 | 0.045 | 0.070 | 0.050 |
| 40% | 0.179 | 0.172 | 0.169 | 0.179 | 0.171 | 0.169 | 0.179 | 0.171 | 0.169 |
| 60% | 0.402 | 0.340 | 0.373 | 0.402 | 0.340 | 0.373 | 0.402 | 0.339 | 0.373 |
| 80% | 0.715 | 0.575 | 0.662 | 0.715 | 0.574 | 0.662 | 0.715 | 0.574 | 0.664 |
| 100% | 1.118 | 0.876 | 1.039 | 1.118 | 0.876 | 1.040 | 1.118 | 0.876 | 1.041 |
| Noise | Sequence Length = 512 | Sequence Length = 1024 | Sequence Length = 2048 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rreal | RWT | RDAE | Rreal | RWT | RDAE | Rreal | RWT | RDAE | |
| 20% | 0.420 | 0.502 | 1.661 | 0.420 | 0.497 | 1.166 | 0.420 | 0.495 | 1.030 |
| 40% | 1.680 | 1.446 | 2.613 | 1.680 | 1.442 | 2.118 | 1.680 | 1.439 | 1.983 |
| 60% | 3.780 | 3.018 | 4.185 | 3.780 | 3.014 | 3.694 | 3.780 | 3.012 | 3.560 |
| 80% | 6.719 | 5.227 | 6.390 | 6.719 | 5.223 | 5.905 | 6.719 | 5.223 | 5.769 |
| 100% | 10.50 | 8.059 | 9.186 | 10.50 | 8.057 | 8.708 | 10.50 | 8.058 | 8.580 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.; Gil, M.-S.; Im, H.; Moon, Y.-S. Measurement Noise Recommendation for Efficient Kalman Filtering over a Large Amount of Sensor Data. Sensors 2019, 19, 1168. https://doi.org/10.3390/s19051168
Park S, Gil M-S, Im H, Moon Y-S. Measurement Noise Recommendation for Efficient Kalman Filtering over a Large Amount of Sensor Data. Sensors. 2019; 19(5):1168. https://doi.org/10.3390/s19051168
Chicago/Turabian StylePark, Sebin, Myeong-Seon Gil, Hyeonseung Im, and Yang-Sae Moon. 2019. "Measurement Noise Recommendation for Efficient Kalman Filtering over a Large Amount of Sensor Data" Sensors 19, no. 5: 1168. https://doi.org/10.3390/s19051168
APA StylePark, S., Gil, M.-S., Im, H., & Moon, Y.-S. (2019). Measurement Noise Recommendation for Efficient Kalman Filtering over a Large Amount of Sensor Data. Sensors, 19(5), 1168. https://doi.org/10.3390/s19051168