Ensemble Dictionary Learning for Single Image Deblurring via Low-Rank Regularization

Abstract
:1. Introduction
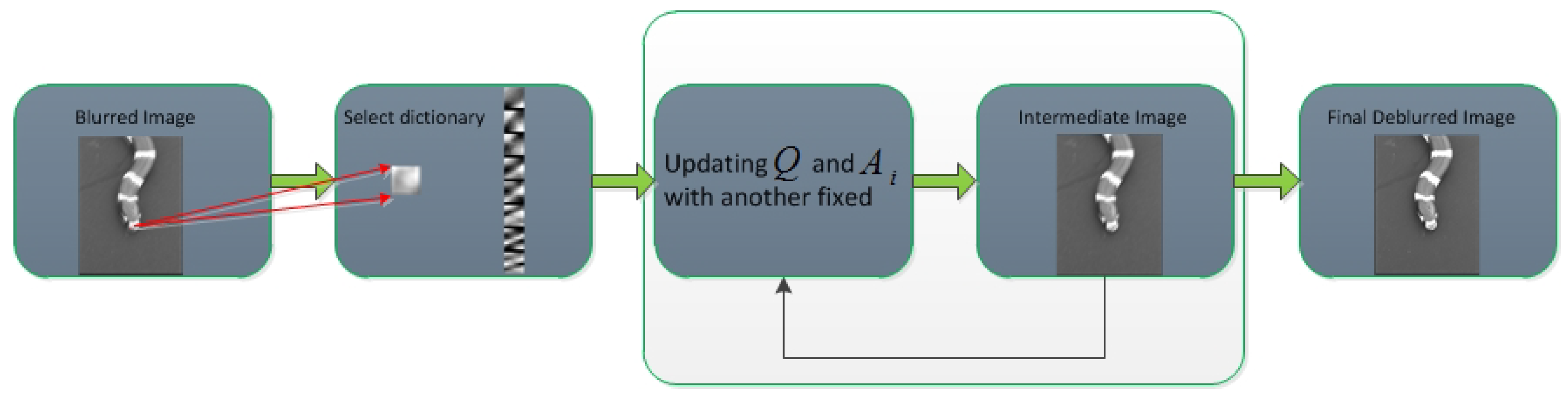
2. The Proposed Method
2.1. Patch Clustering and Ensemble Dictionary Learning
2.2. Sparse Representation Model via Low-Rank Constraint
2.3. Optimization for the Proposed Regularization
2.3.1. Updating Q by Fixing
2.3.2. Updating by Fixing Q
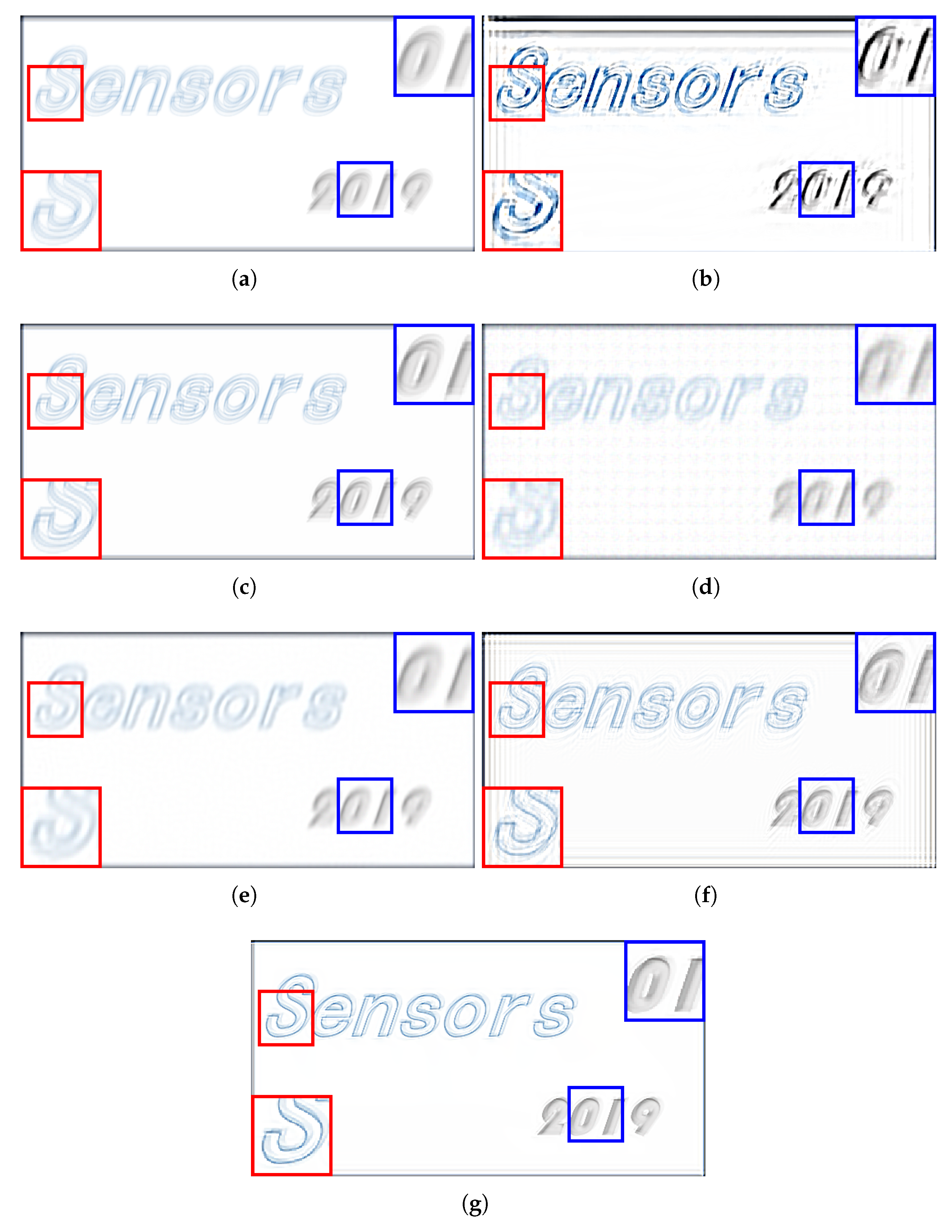
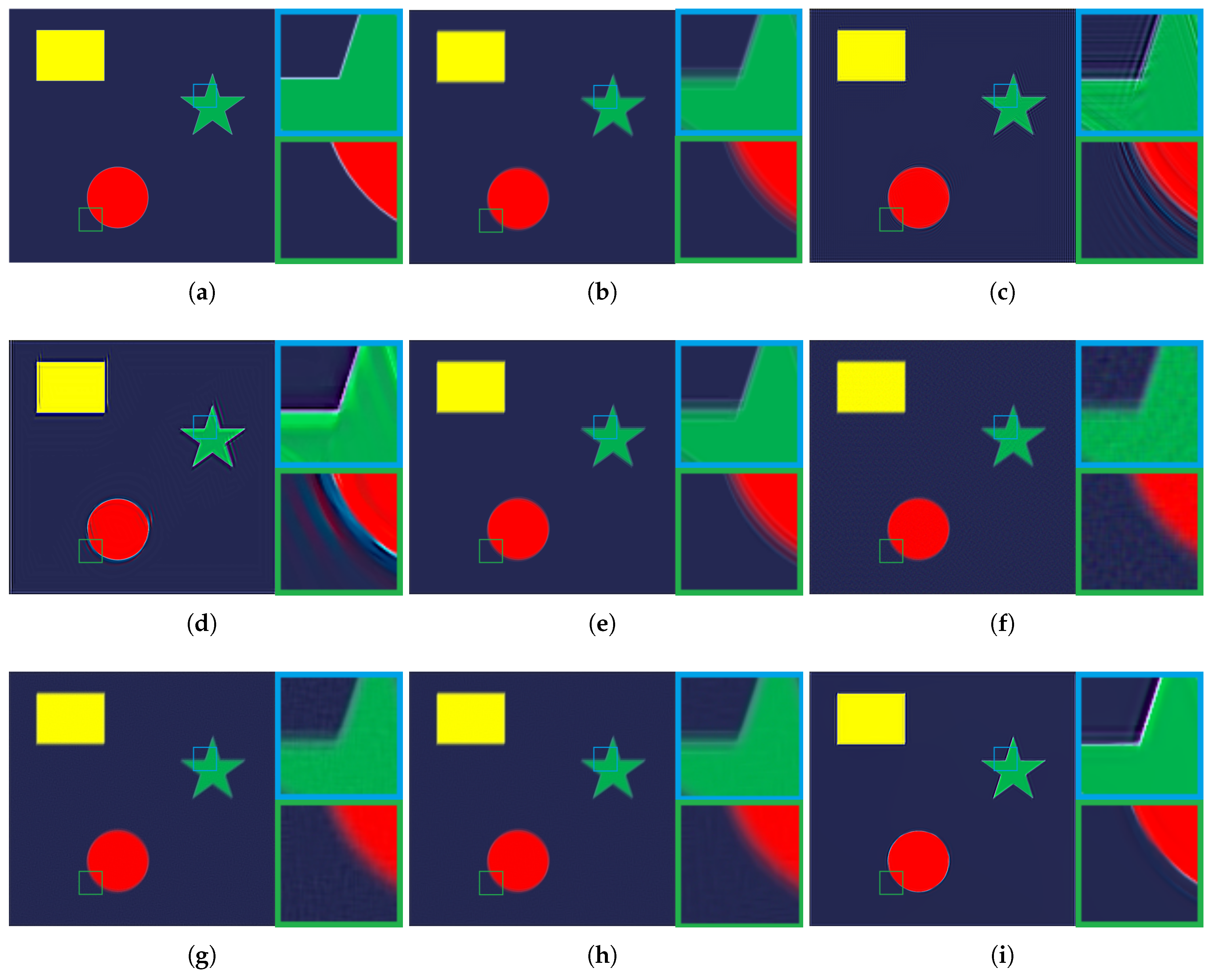
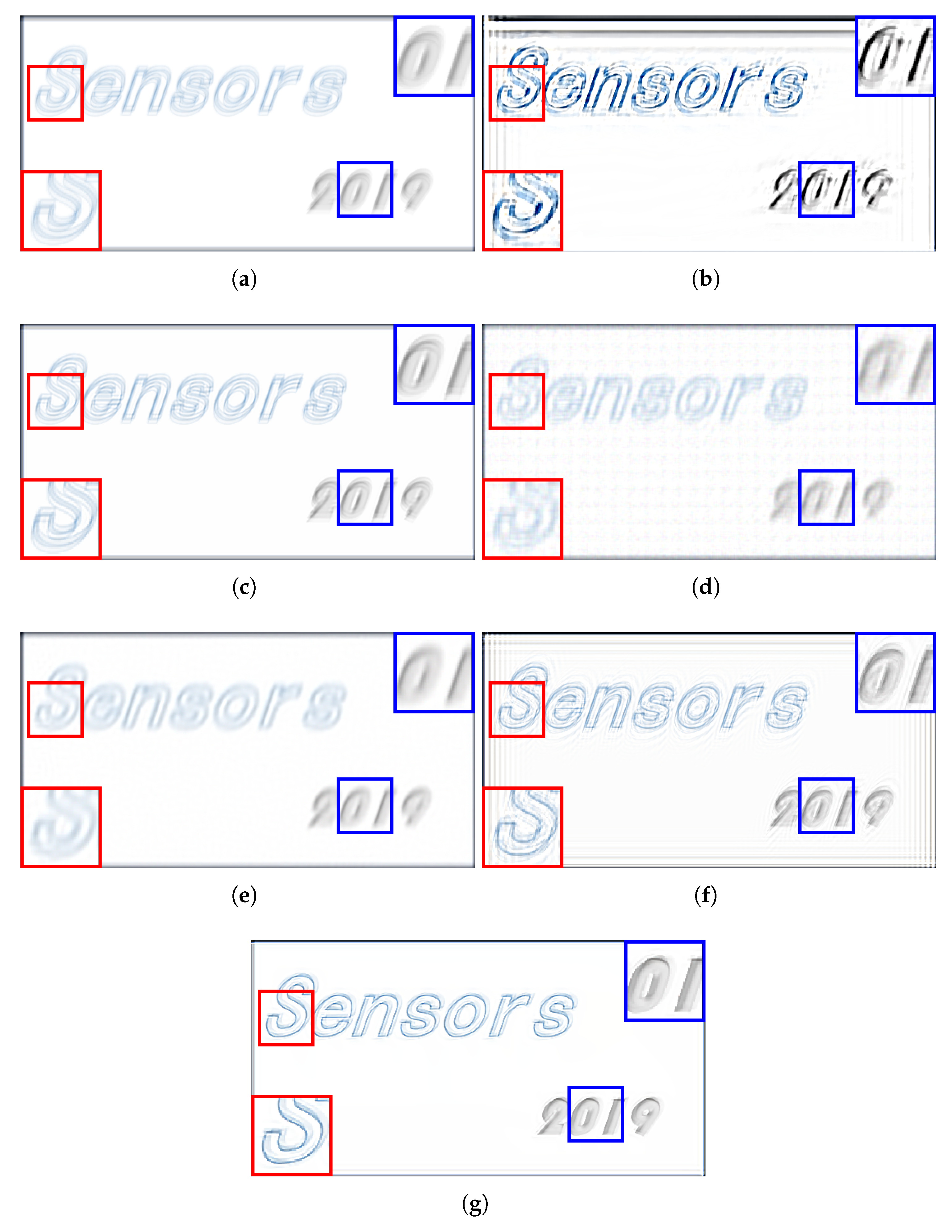
3. Experimental Results and Evaluations
3.1. Comparison with State-of-the-Art Methods
3.2. Comparisons and Evaluations
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, W.; Quan, W.; Guo, L. Blurred Star Image Processing for Star Sensors under Dynamic Conditions. Sensors 2012, 12, 6712–6726. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhang, B.; Shi, Y. Scattering Removal for Finger Vein Image Restoration. Sensors 2012, 12, 3627–3640. [Google Scholar] [CrossRef] [PubMed]
- Manfredi, M.; Bearman, G.; Williamson, G.; Kronkright, D.; Doehne, E.; Jacobs, M.; Marengo, E. A New Quantitative Method for the Non-Invasive Documentation of Morphological Damage in Painting Using RTI Surface Normals. Sensors 2014, 14, 12271–12284. [Google Scholar] [CrossRef] [PubMed]
- El-Sallam, A.A.; Boussaid, F. Spectral-Based Blind Image Restoration Method for Thin TOMBO Imagers. Sensors 2008, 8, 6108–6123. [Google Scholar] [CrossRef] [PubMed]
- Hocking, R.R. The analysis and selection of variables in linear regression. Biometrics 1976, 32, 1–49. [Google Scholar] [CrossRef]
- Dong, W.; Shi, G.; Ma, Y.; Li, X. Image restoration via simultaneous sparse coding: Where structured sparsity meets gaussian scale mixture. Int. J. Comput. Vis. 2015, 114, 217–232. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef]
- Bruckstein, A.M.; Donoho, D.L.; Elad, M. From sparse solutions of systems of equations to sparse modeling of signals and images. SIAM Rev. 2009, 51, 34–81. [Google Scholar] [CrossRef]
- Chen, S.S.; Saunders, D.M.A. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Donoho, D. For most large underdetermined systems of linear equations the minimal l1-norm solution is also the sparsest solutions. Commun. Pure Appl. Math. 2010, 59, 797–829. [Google Scholar] [CrossRef]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2016, 57, 1413–1457. [Google Scholar] [CrossRef]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv, 2009; arXiv:1009.5055. [Google Scholar]
- Zhang, X.; Burger, M.; Bresson, X.; Osher, S. Bregmanized nonlocal regularization for deconvolution and sparse reconstruction. SIAM J. Imaging Sci. 2010, 3, 253–276. [Google Scholar] [CrossRef]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2790–2797. [Google Scholar]
- Chartrand, R. Exact reconstruction of sparse signals via nonconvex minimization. IEEE Signal Process. Lett. 2007, 3, 707–710. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K.O. Image restoration by sparse 3d transform-domain collaborative filtering. Int. Soc. Opt. Photonics 2008, 22, 681207. [Google Scholar]
- Shi, J.; Xu, L.; Jia, J. Just Noticeable Defocus Blur Detection and Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 657–665. [Google Scholar]
- Li, J.; Liu, Z.; Yao, Y. Defocus Blur Detection and Estimation from Imaging Sensors. Sensors 2018, 18, 1135. [Google Scholar]
- Dong, W.; Shi, G.; Li, X. Nonlocal Image Restoration With Bilateral Variance Estimation: A Low-Rank Approach. IEEE Trans. Image Process. 2013, 22, 700–711. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. 2013, 35, 171–184. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online learning for matrix factorization and sparse coding. J. Mach. Learn. Res. 2009, 11, 19–60. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Singal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Mairal, J.; Sapiro, G.; Elad, M. Learning multiscale sparse representation for image and video restoration. SIAM Multiscale Model. Simul. 2008, 7, 214–241. [Google Scholar] [CrossRef]
- Ravishankar, S.; Bresler, Y. MR image reconstruction from highly undersampled k-space data by dictionary learning. IEEE Trans. Med. Imaging. 2011, 30, 1028. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Zhang, L.; Shi, G.; Wu, X. Image Deblurring and Super-Resolution by Adaptive Sparse Domain Selection and Adaptive Regularization. IEEE Trans. Image Process. 2011, 20, 1838–1857. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Lukac, R.; Wu, X.; Zhang, D. PCA-Based Spatially Adaptive Denoising of CFA Images for Single-Sensor Digital Cameras. IEEE Trans. Image Process. 2009, 18, 797–821. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Shao, M.; Fu, Y. Deep Robust Encoder Through Locality Preserving Low-Rank Dictionary. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 567–582. [Google Scholar]
- Cai, J.; Candés, E.; Shen, Z. A Singular Value Thresholding Algorithm for Matrix Completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Khoramian, S. An iterative Thresholding Algorithm for Linear Inverse Problems with Multi-Constraints and Its Applications. Appl. Comput. Harmon. Anal. 2012, 32, 109–130. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Kim, S.; Koh, K.; Lustig, M.; Boyd, S. An Efficient Method for Compressed Sensing. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; pp. 117–120. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural L0 Sparse Representation for Natural Image Deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Melbourne, Australia, 15–18 September 2013; pp. 1107–1114. [Google Scholar]
- Shen, C.; Hwang, W.; Pei, S. Spatially-Varying Out-of-Focus Image Deblurring with L1-2 Optimization and a Guided Blur Map. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 1069–1072. [Google Scholar]
- Yang, J.; Zhang, Y.; Yin, W. An Efficient TVL1 Algorithm for Deblurring Multichannel Images Corrupted by Impulsive Noise. SIAM J. Sci. Comput. 2008, 31, 2842–2865. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G. Centralized sparse representation for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Zhangjiajie, China, 25–27 May 2012; pp. 1259–1266. [Google Scholar]
- Shi, J.; Xu, L.; Jia, J. Discriminative blur detection features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2965–2972. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | motion0015 | motion0105 | out_of_focus0122 | out_of_focus0290 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||||
| Xu’s method | 26.03 | 0.89 | 23.18 | 0.81 | 25.54 | 0.89 | 15.05 | 0.58 | |||
| Shen’s method | 29.65 | 0.94 | 36.46 | 0.97 | 30.26 | 0.94 | 33.34 | 0.96 | |||
| Yang’s method | 27.82 | 0.84 | 28.88 | 0.82 | 29.51 | 0.87 | 29.51 | 0.87 | |||
| Dong’s method | 29.65 | 0.88 | 30.86 | 0.87 | 29.98 | 0.93 | 27.91 | 0.87 | |||
| CSR method | 30.02 | 0.91 | 31.27 | 0.89 | 32.13 | 0.95 | 30.27 | 0.93 | |||
| Wiener filter | 8.99 | 0.04 | 12.53 | 0.13 | 9.81 | 0.09 | 10.71 | 0.11 | |||
| Proposed method | 31.57 | 0.95 | 40.21 | 0.97 | 32.19 | 0.96 | 35.40 | 0.95 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Liu, Z. Ensemble Dictionary Learning for Single Image Deblurring via Low-Rank Regularization. Sensors 2019, 19, 1143. https://doi.org/10.3390/s19051143
Li J, Liu Z. Ensemble Dictionary Learning for Single Image Deblurring via Low-Rank Regularization. Sensors. 2019; 19(5):1143. https://doi.org/10.3390/s19051143
Chicago/Turabian StyleLi, Jinyang, and Zhijing Liu. 2019. "Ensemble Dictionary Learning for Single Image Deblurring via Low-Rank Regularization" Sensors 19, no. 5: 1143. https://doi.org/10.3390/s19051143
APA StyleLi, J., & Liu, Z. (2019). Ensemble Dictionary Learning for Single Image Deblurring via Low-Rank Regularization. Sensors, 19(5), 1143. https://doi.org/10.3390/s19051143