A Deep Learning Approach to Position Estimation from Channel Impulse Responses †

 ,
, 
Abstract
:1. Introduction
2. Related Work
3. Background and Problem Formulation
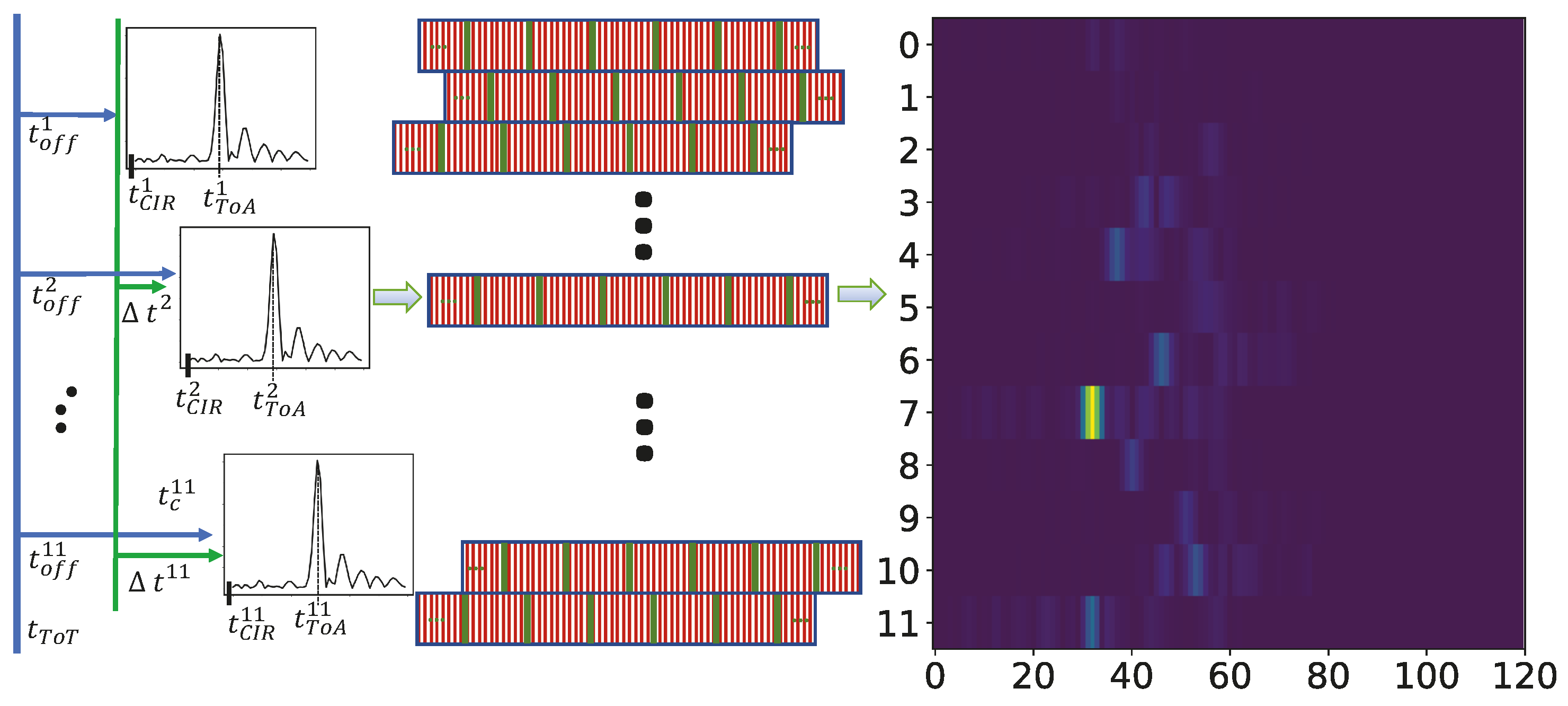
3.1. Channel Estimation
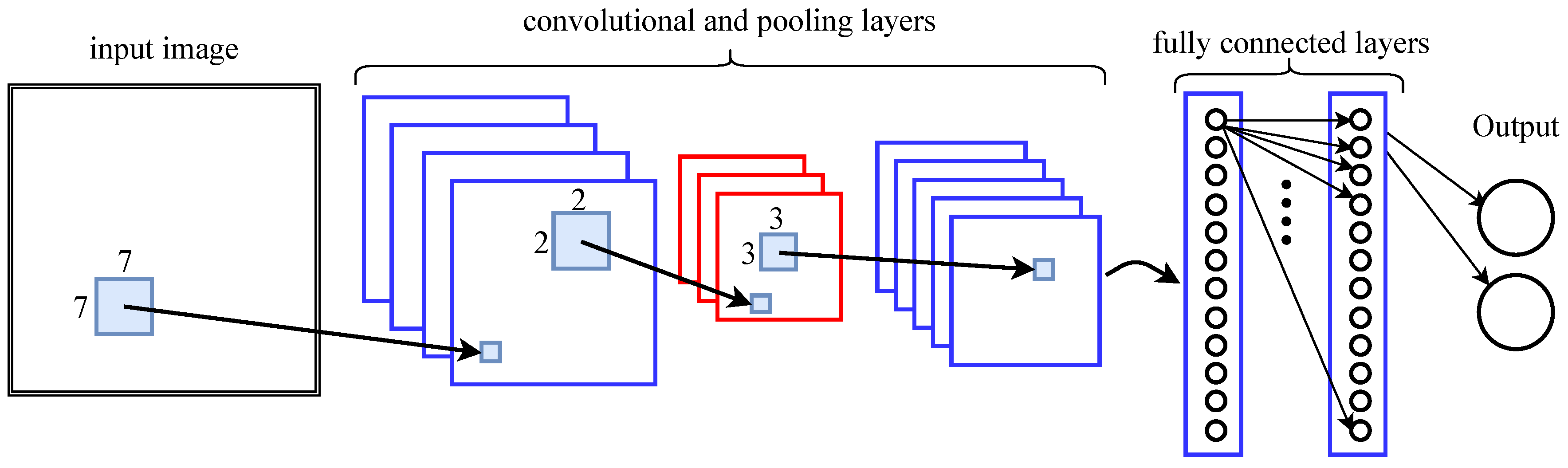
3.2. (Convolutional) Neural Networks
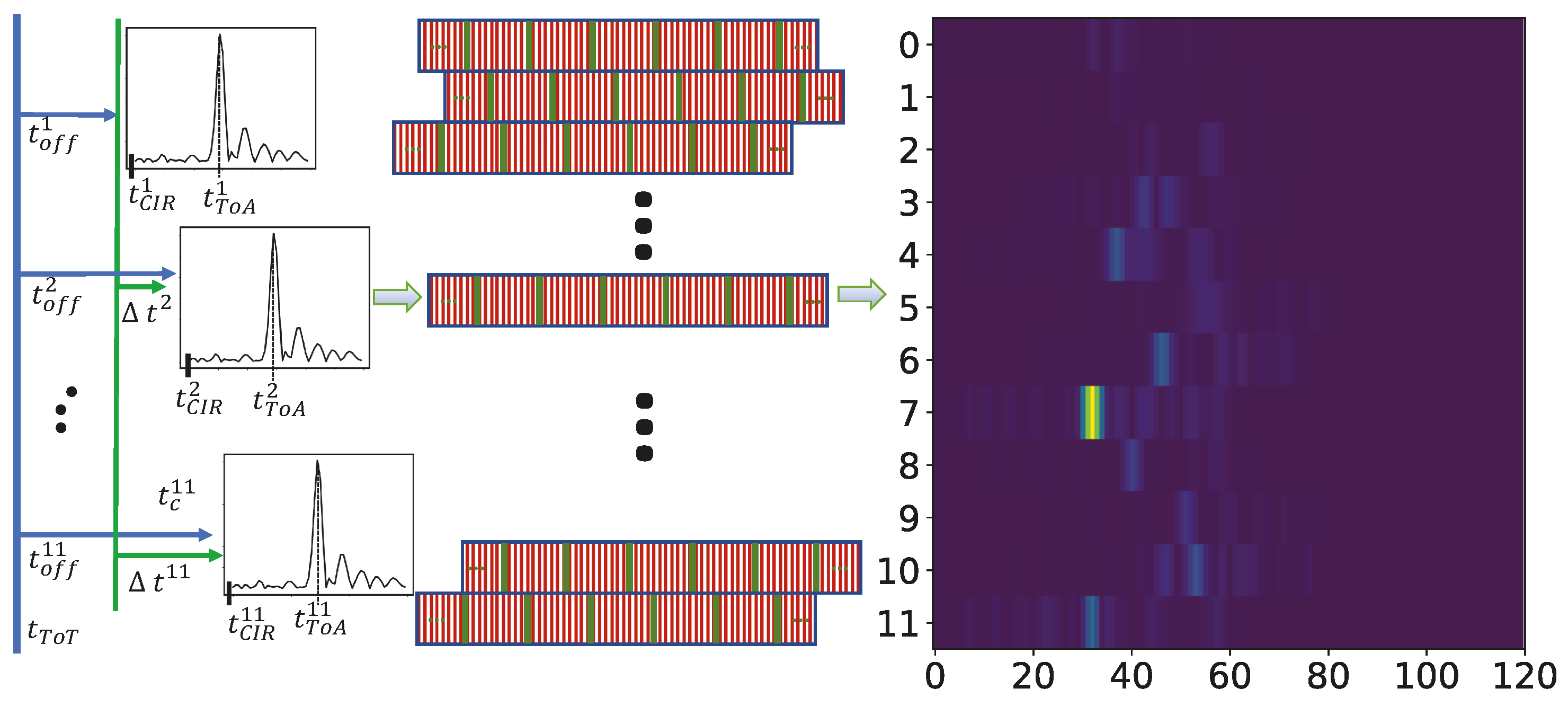
4. Data Preparation
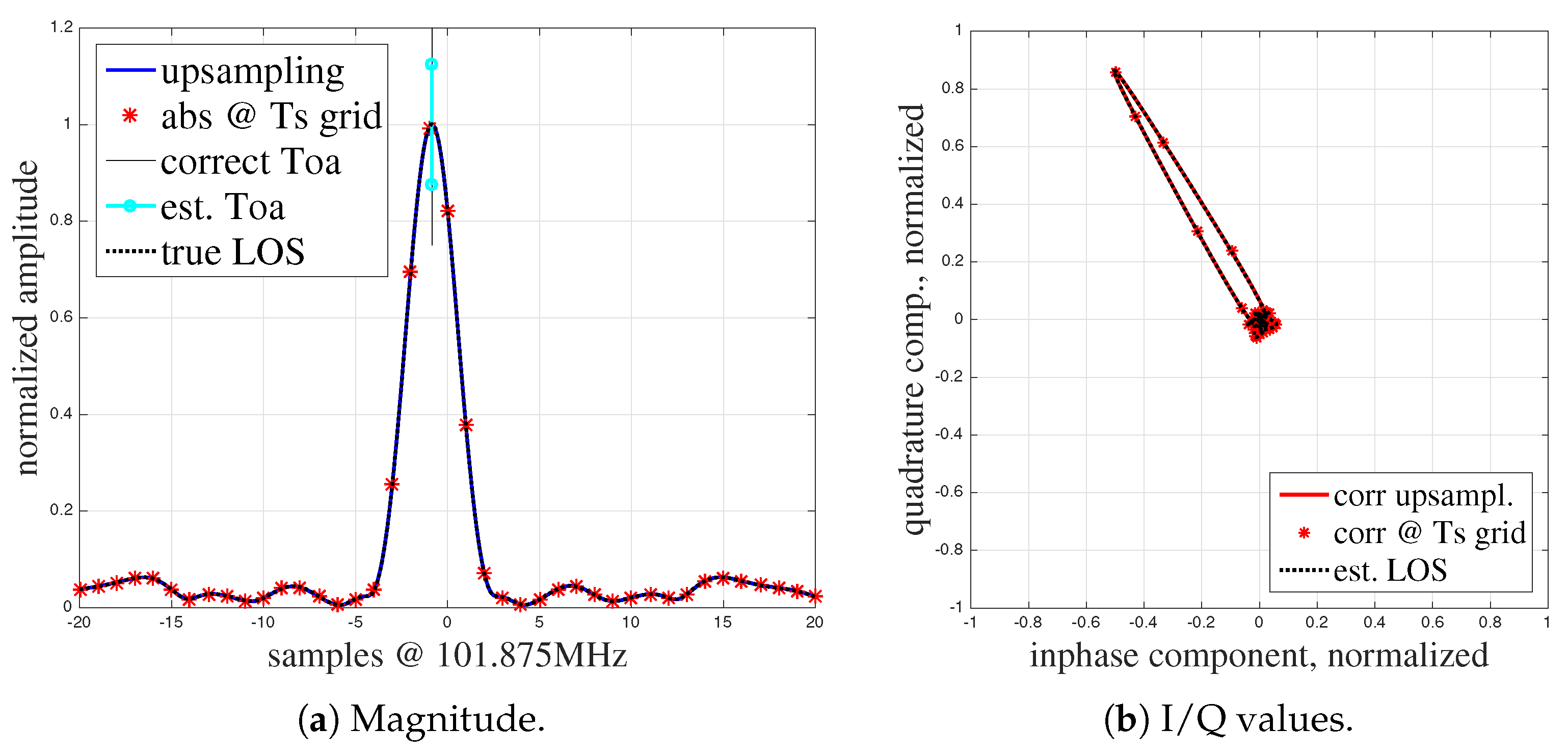
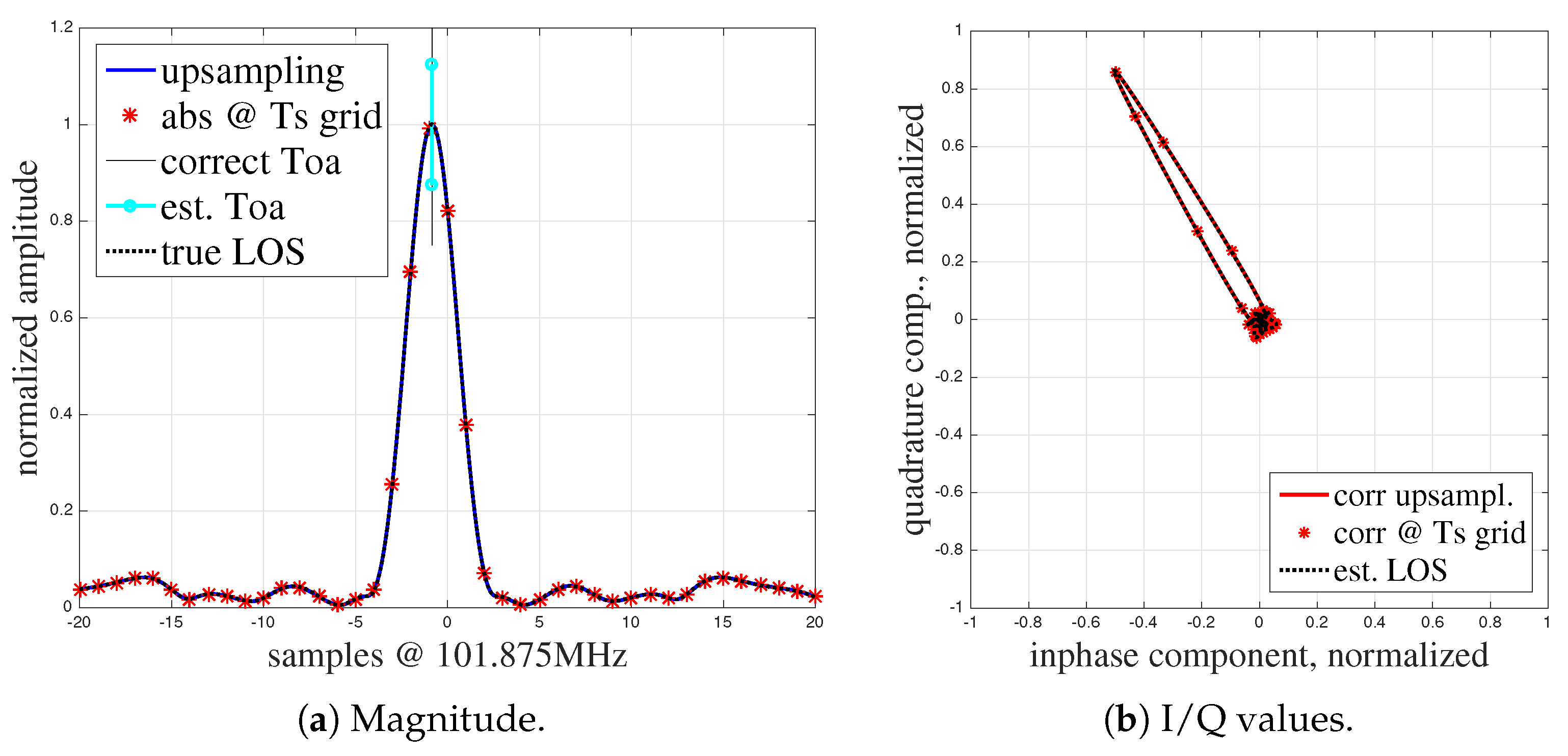
4.1. Calibration of the CIR-s
4.2. Normalization of Data
5. Experimental Setup
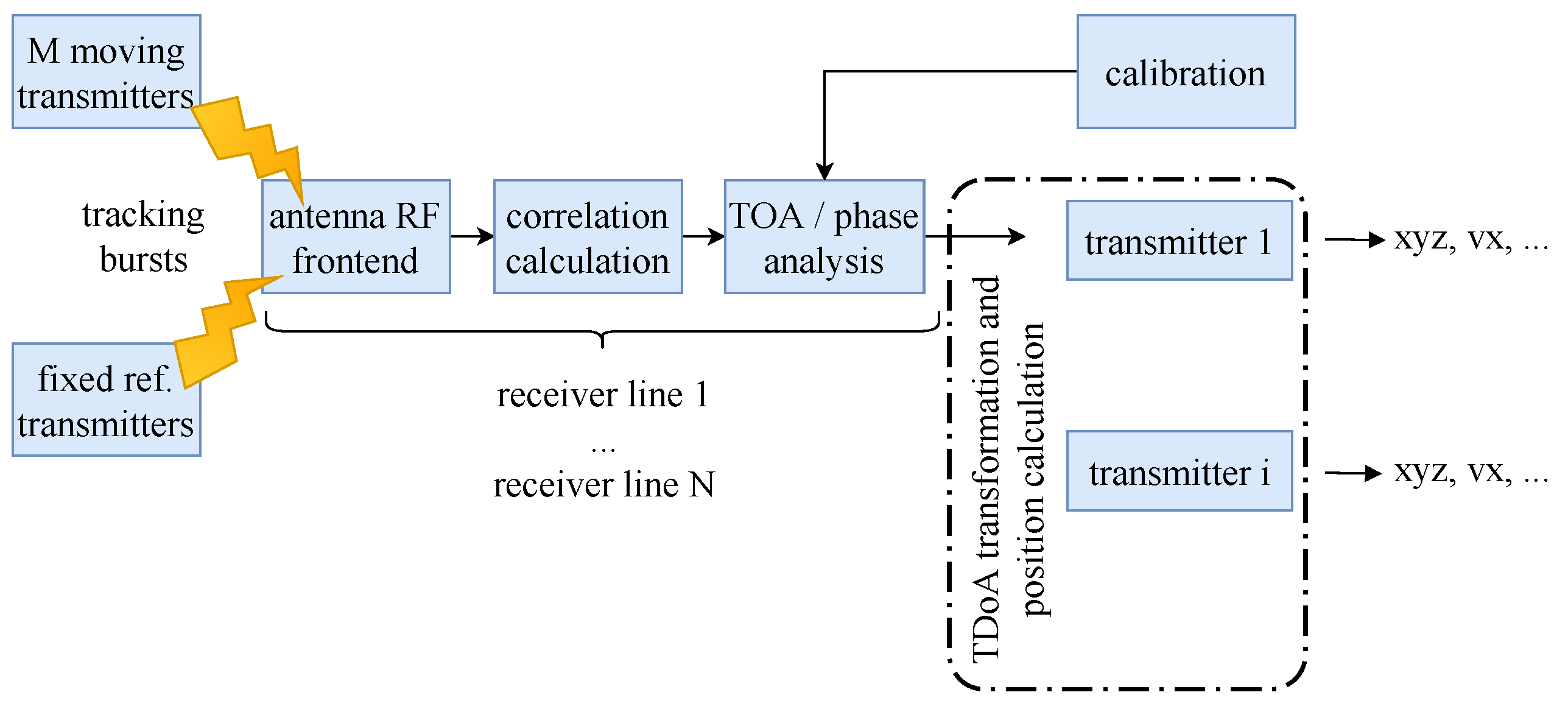
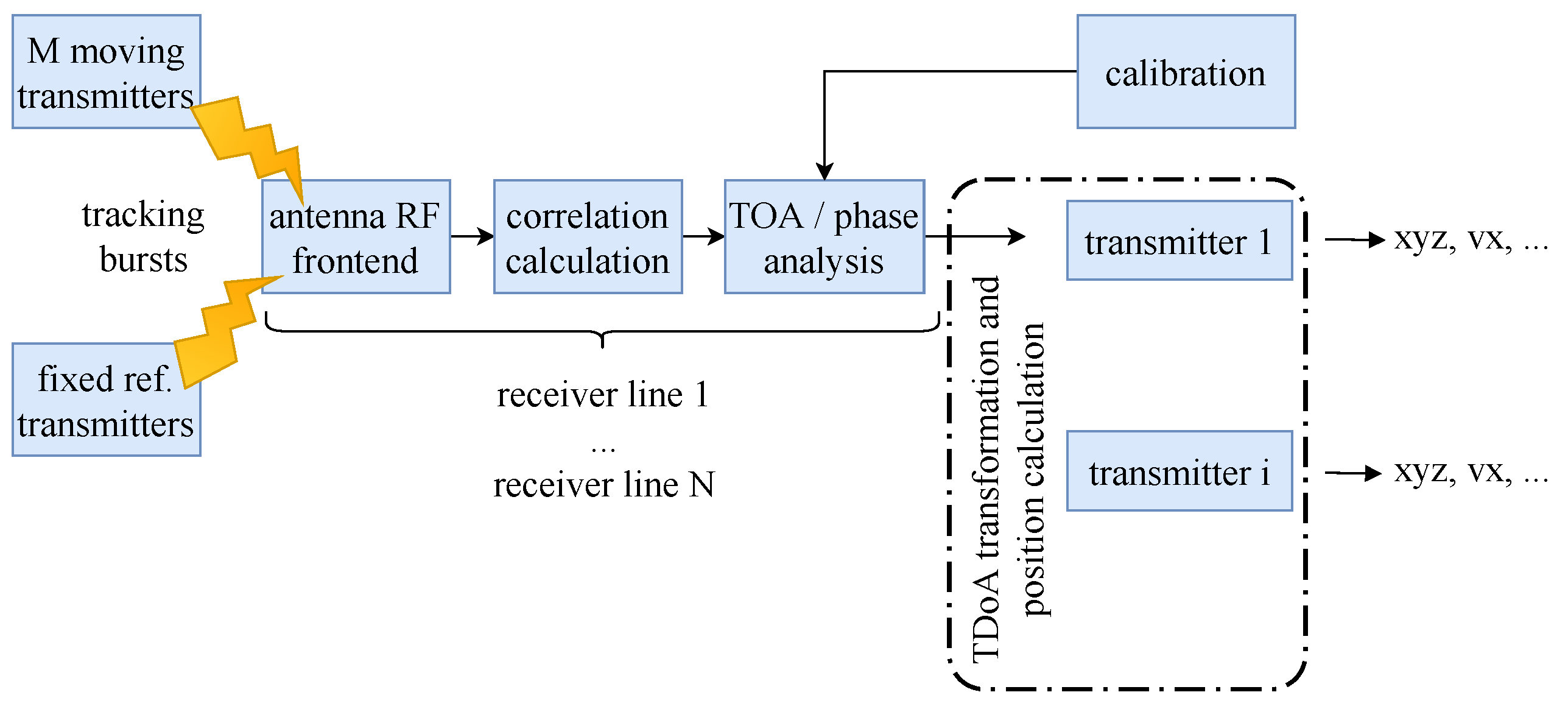
5.1. Measurement Infrastructure
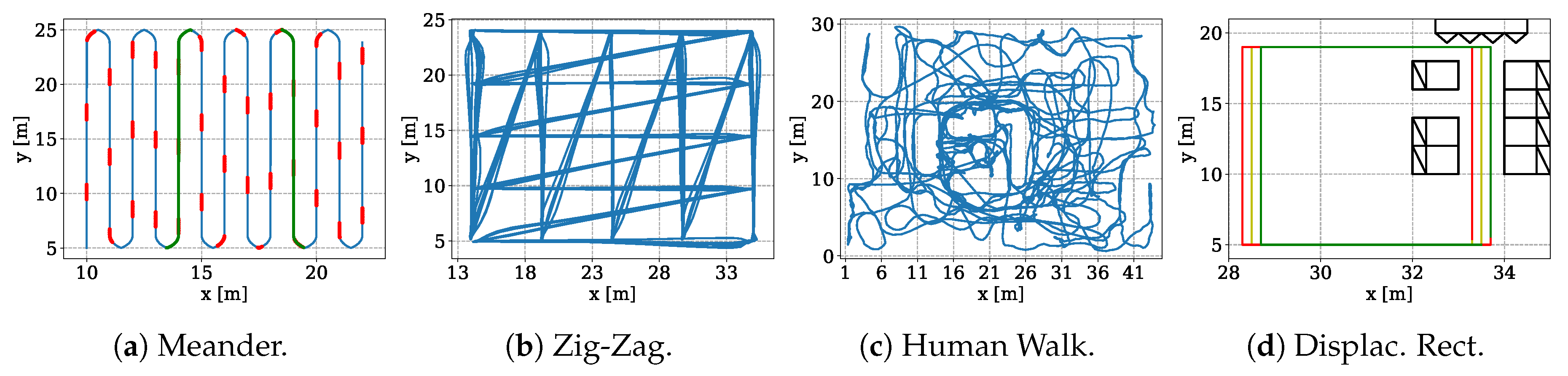
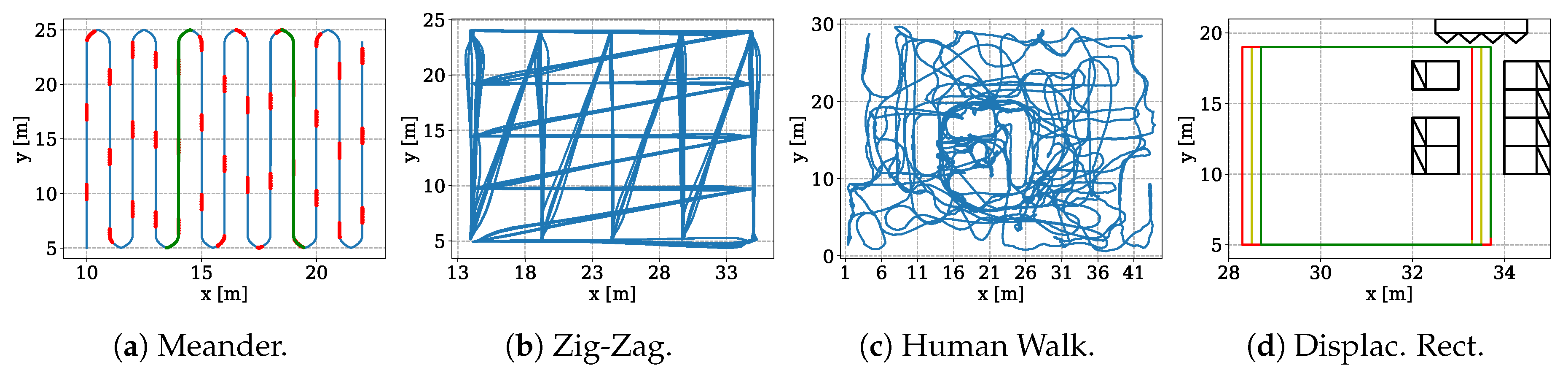
5.2. Datasets
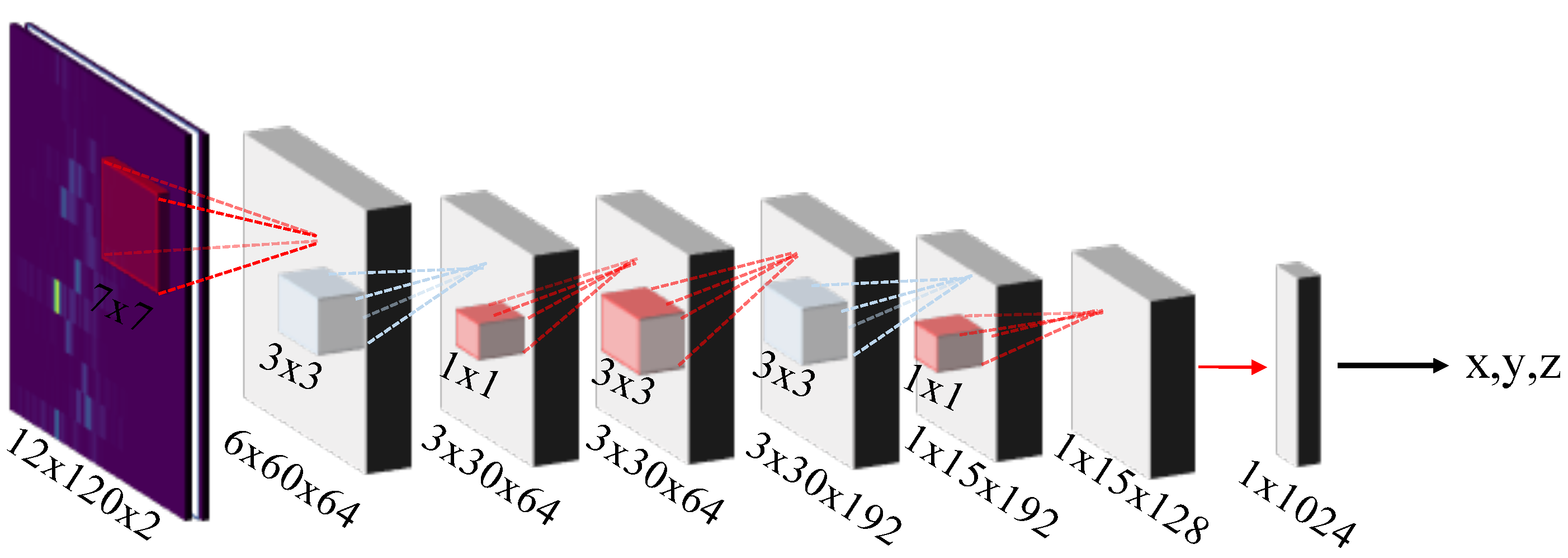
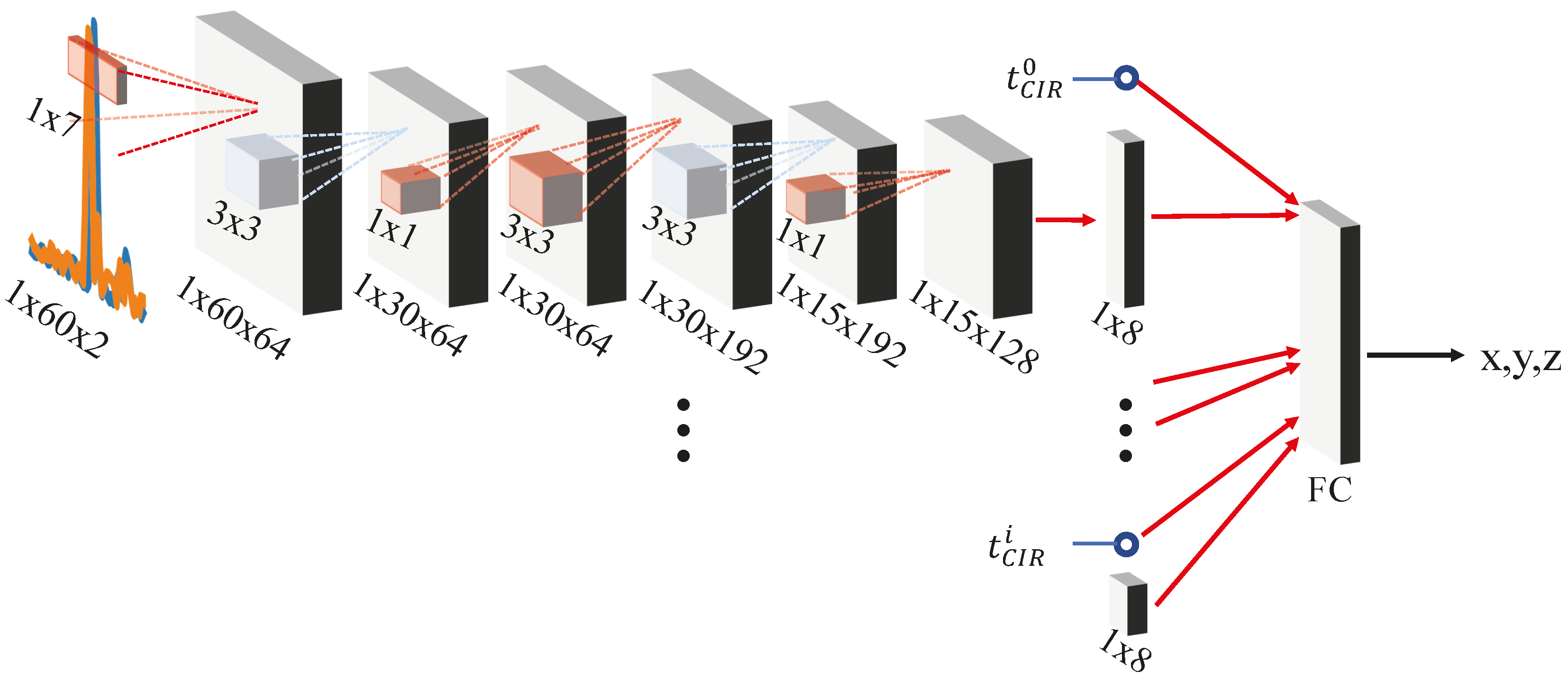
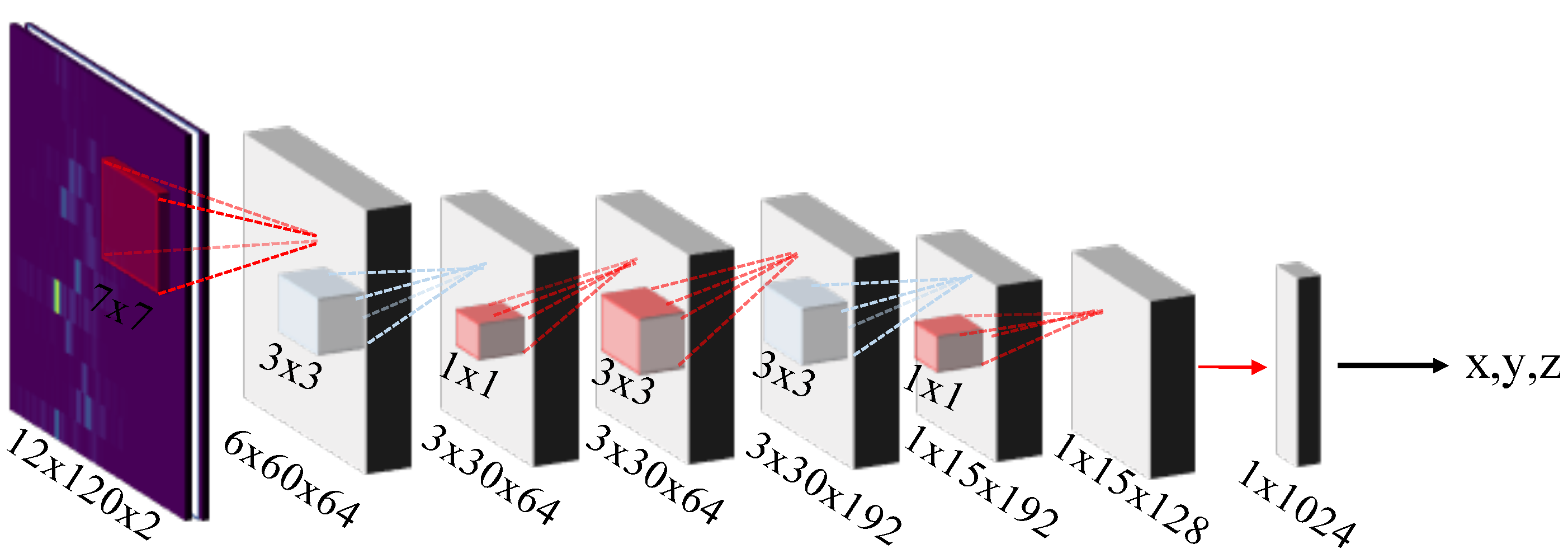
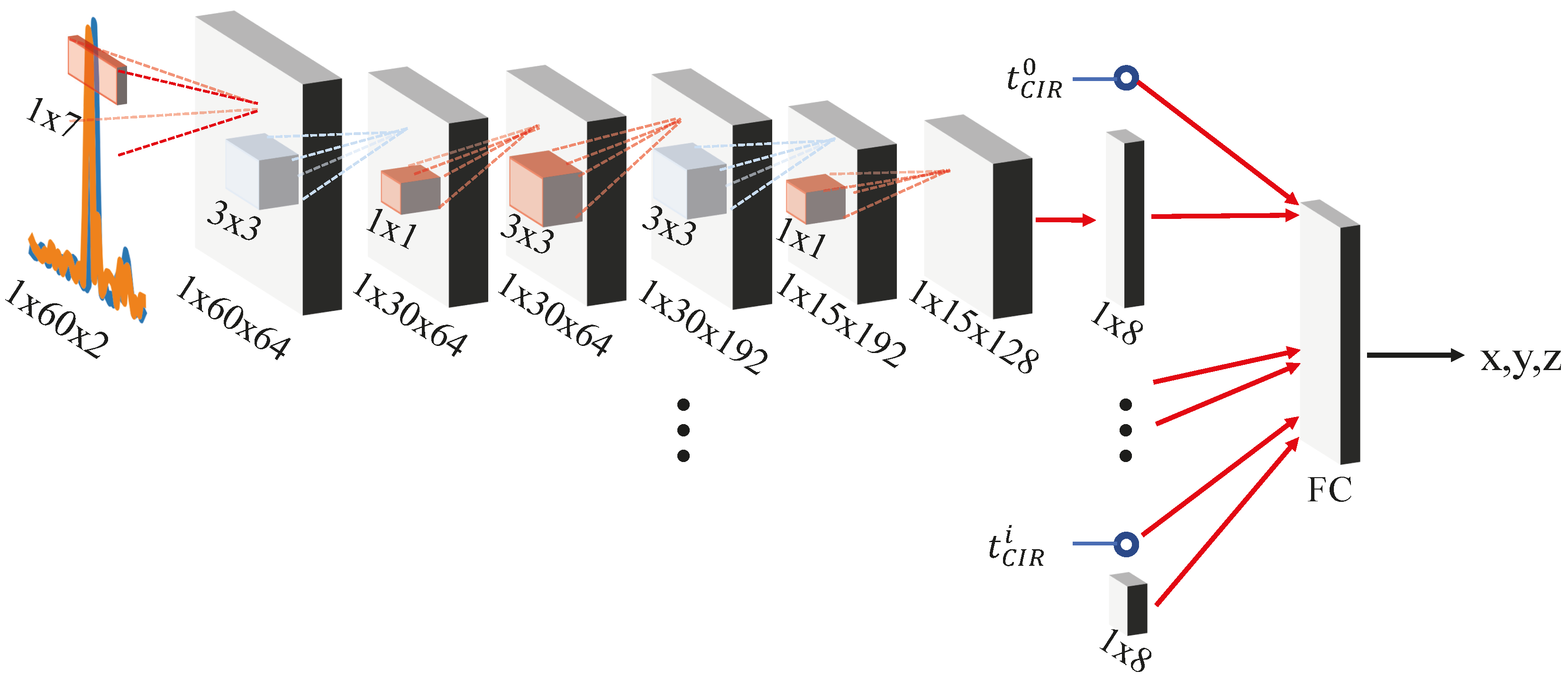
5.3. Deep Learning Setup, Model Configuration and Data Processing
- We replace each of the 3 softmax classifiers by affine regressors (Euclidean distance).
- We replace the fully connected (FC) layer that has 1000 output units (before the classifier) by an FC layer of 2 units outputting a vector of positions .
- We modify the max-pooling layer after the 2nd inception module to have a kernel size of 2 instead of 3, the avg-pooling layer at the first and second classifier to a kernel size of 3 instead of 5, and the max-pooling layer before final inception modules to a kernel size of 2 instead of 3.
6. Results
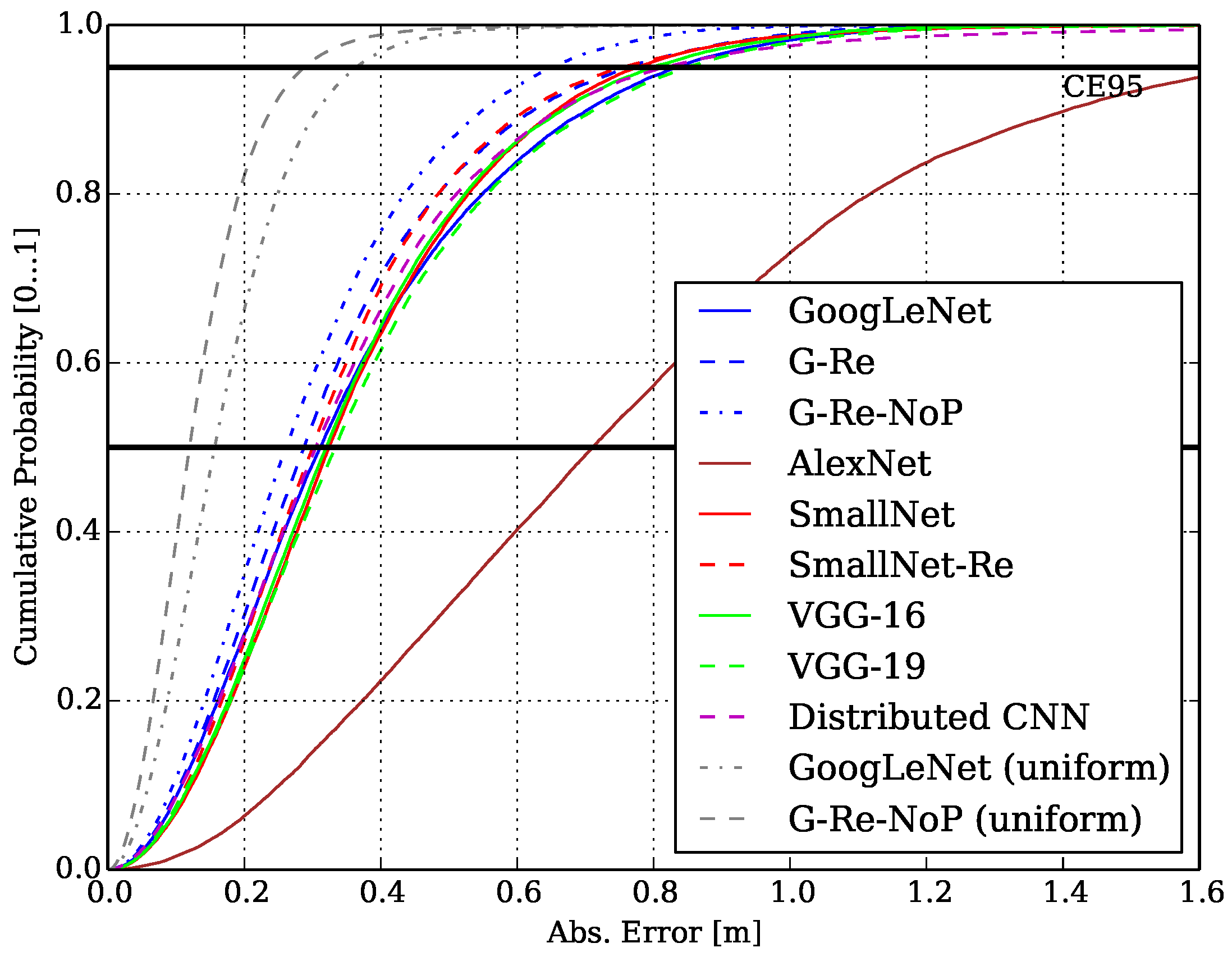
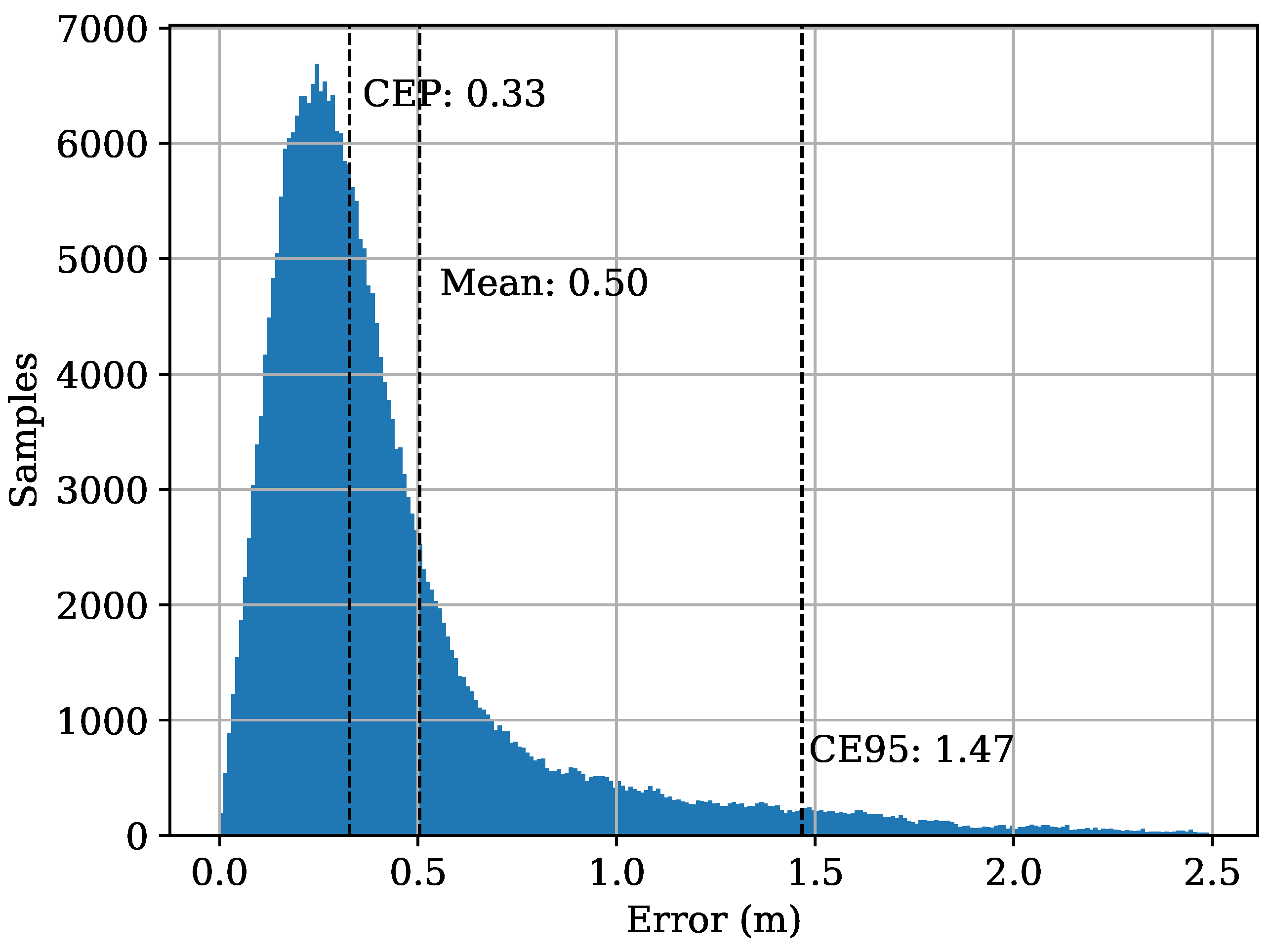
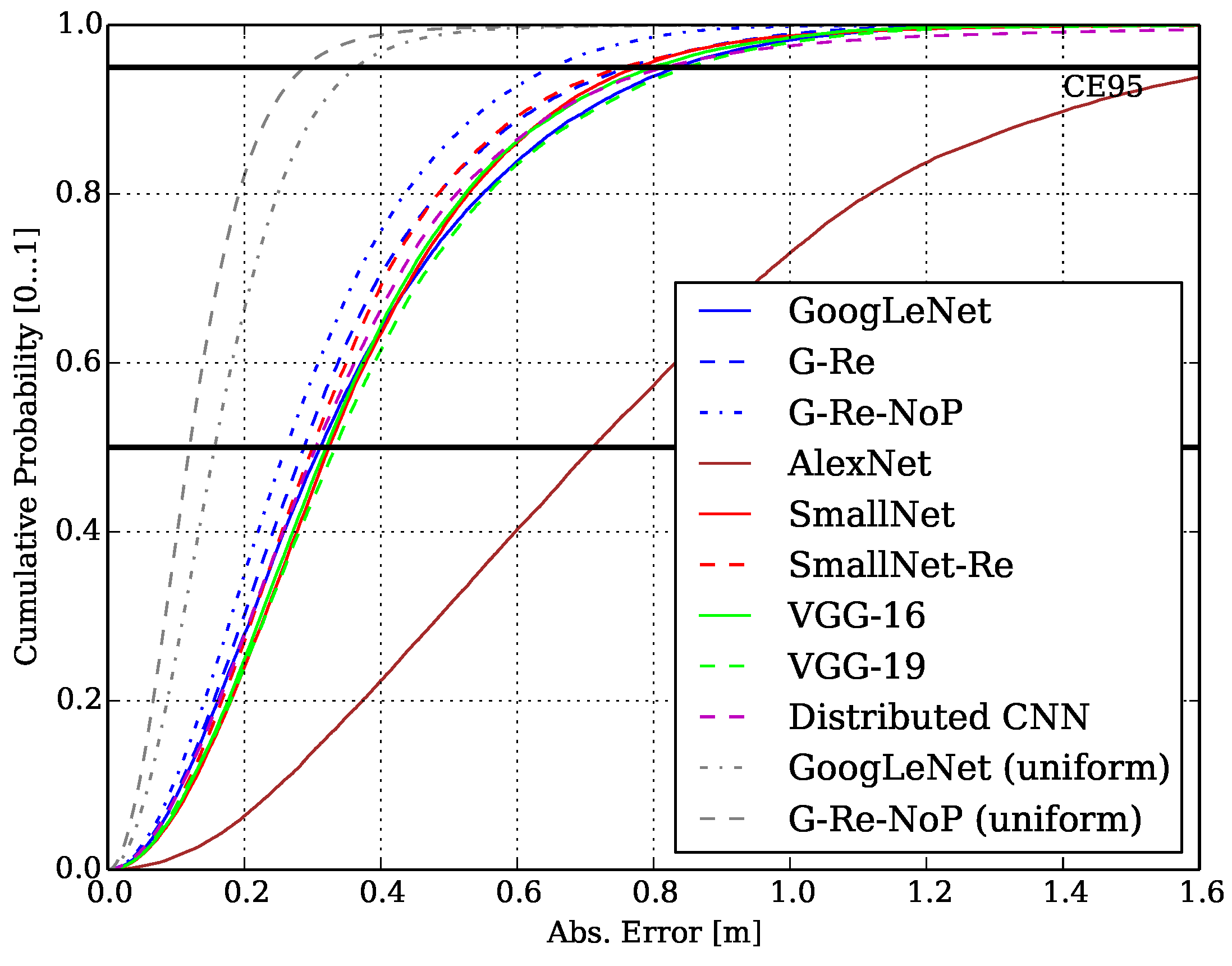
6.1. General Performance Evaluation of the ML Approach.
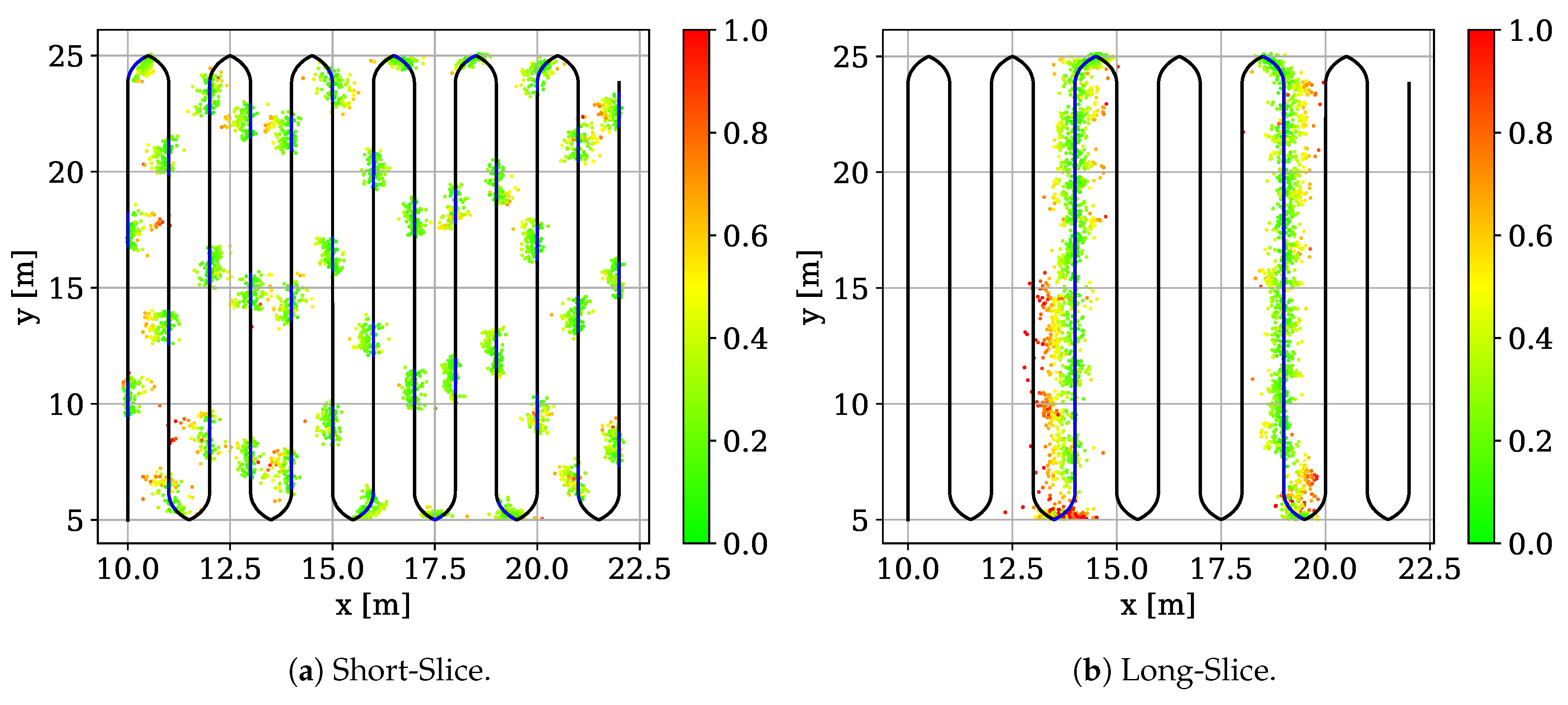
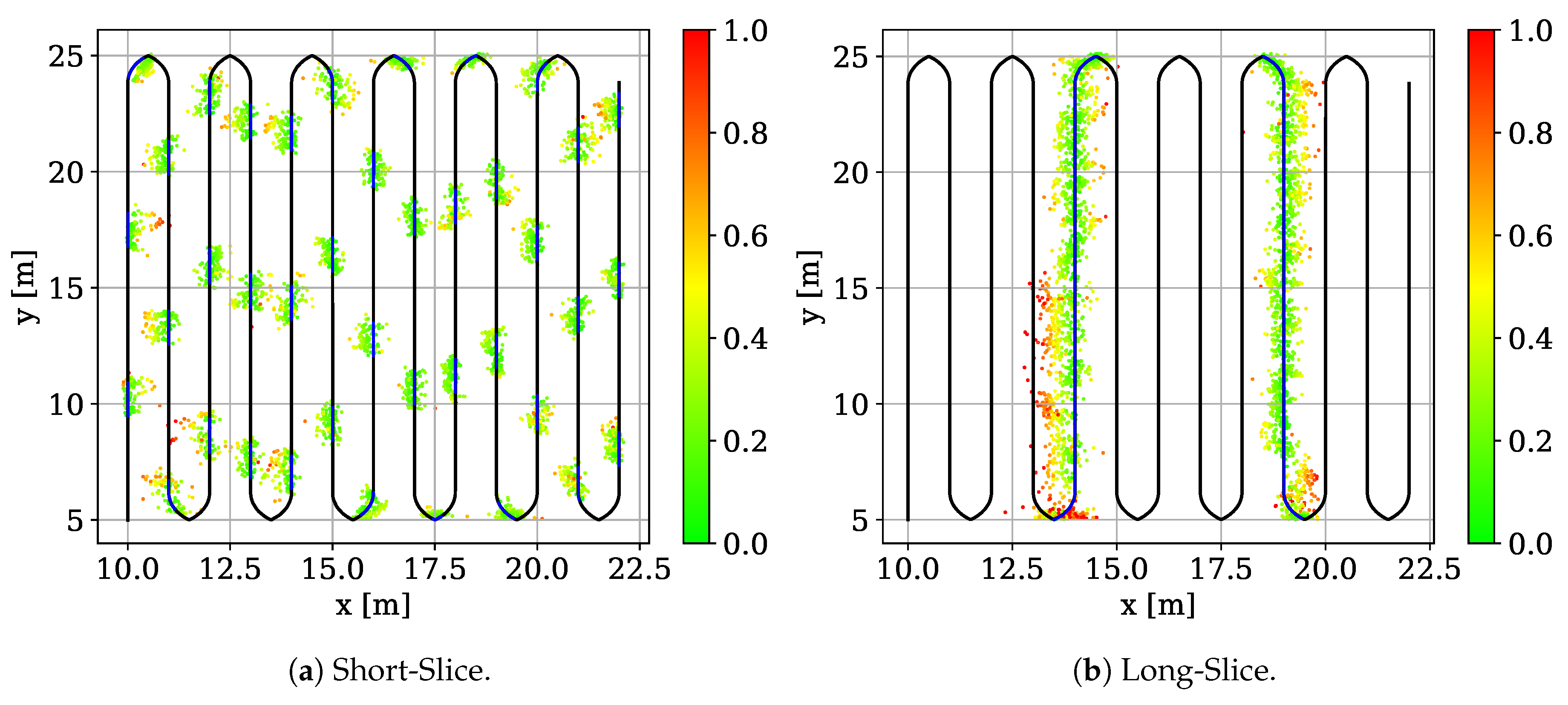
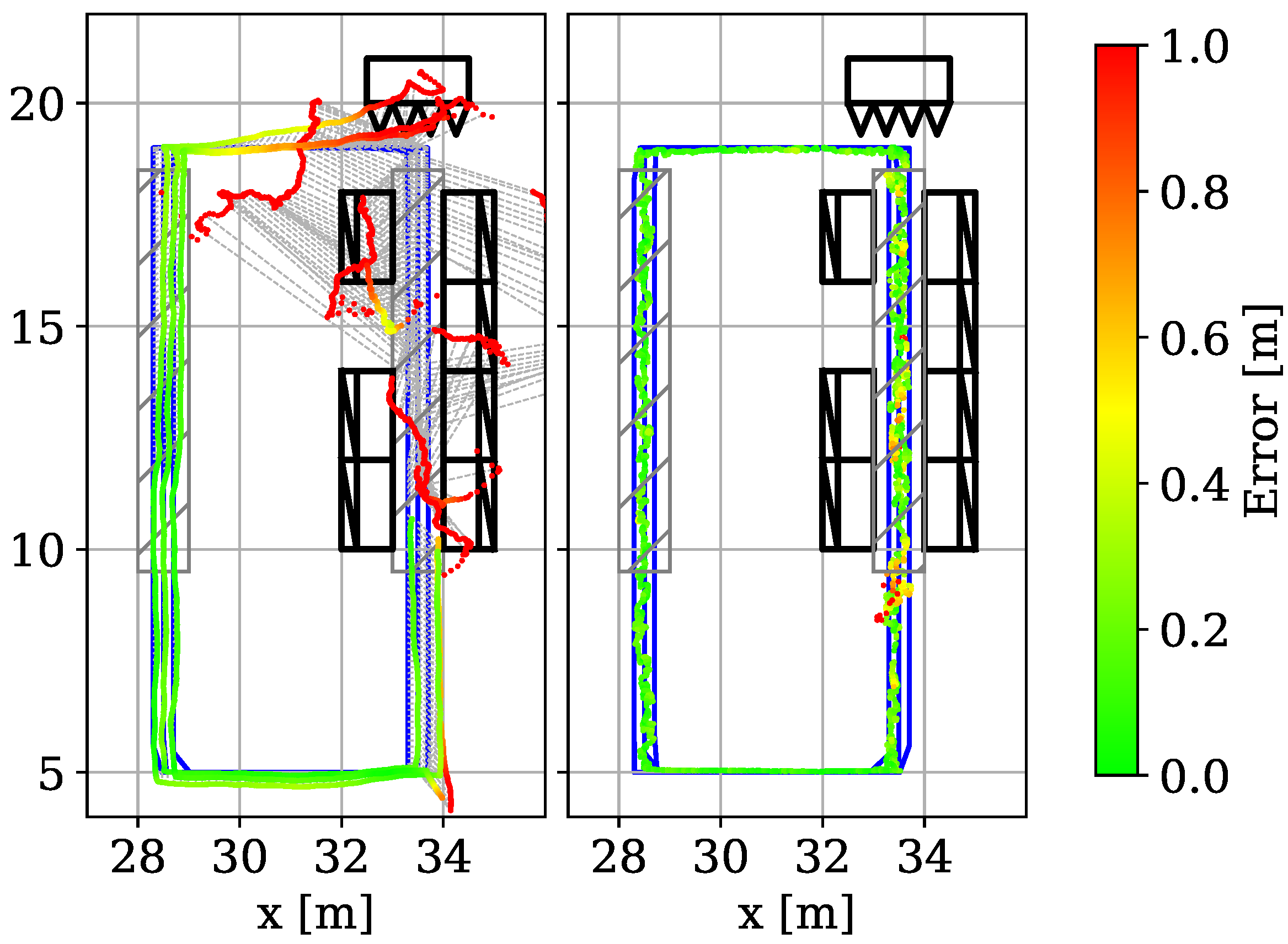
6.2. Slicing Evaluation
6.3. Architecture Evaluation
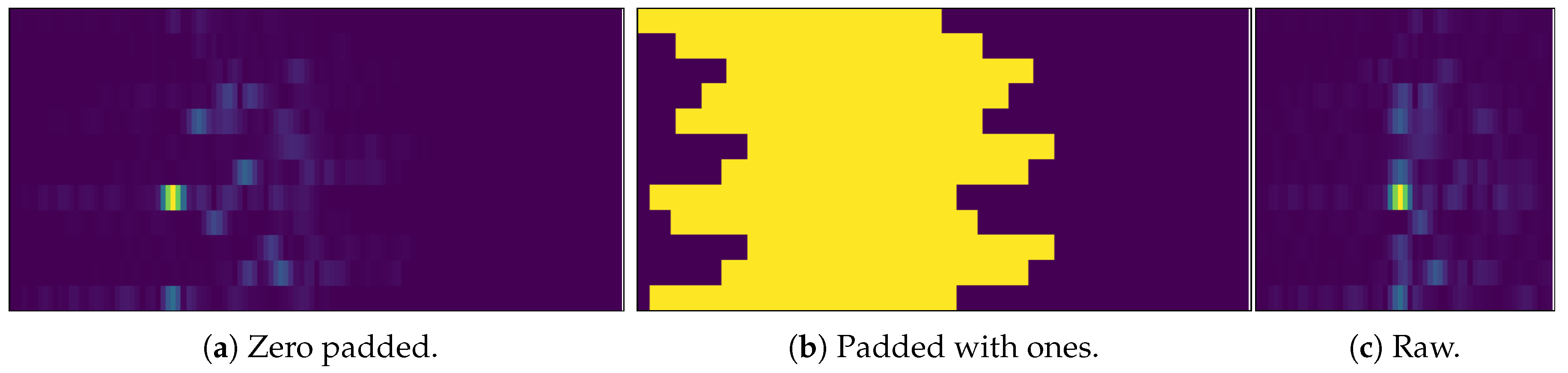
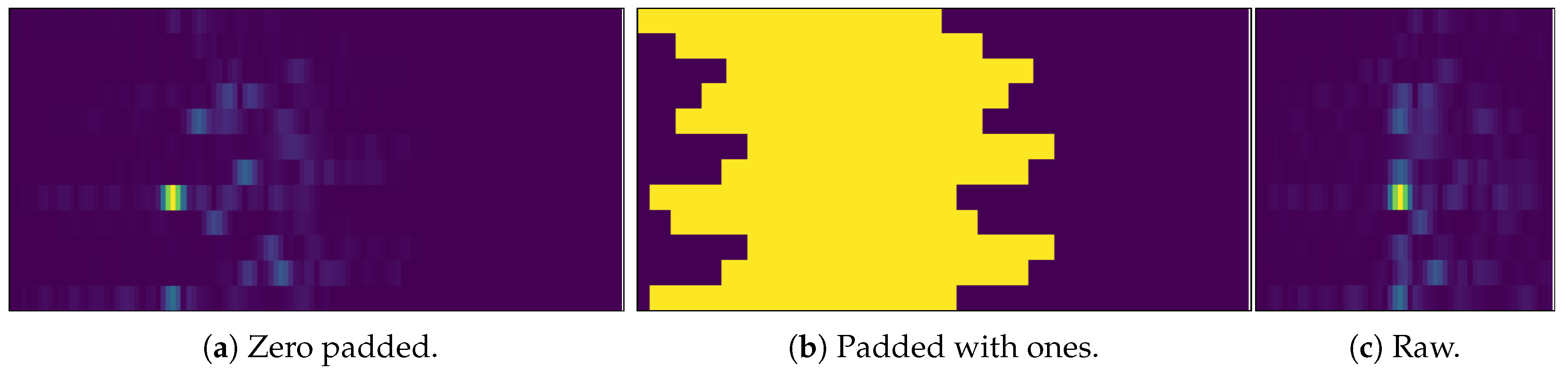
6.4. Data Preprocessing and Zero Padding
6.5. Distributed CNN
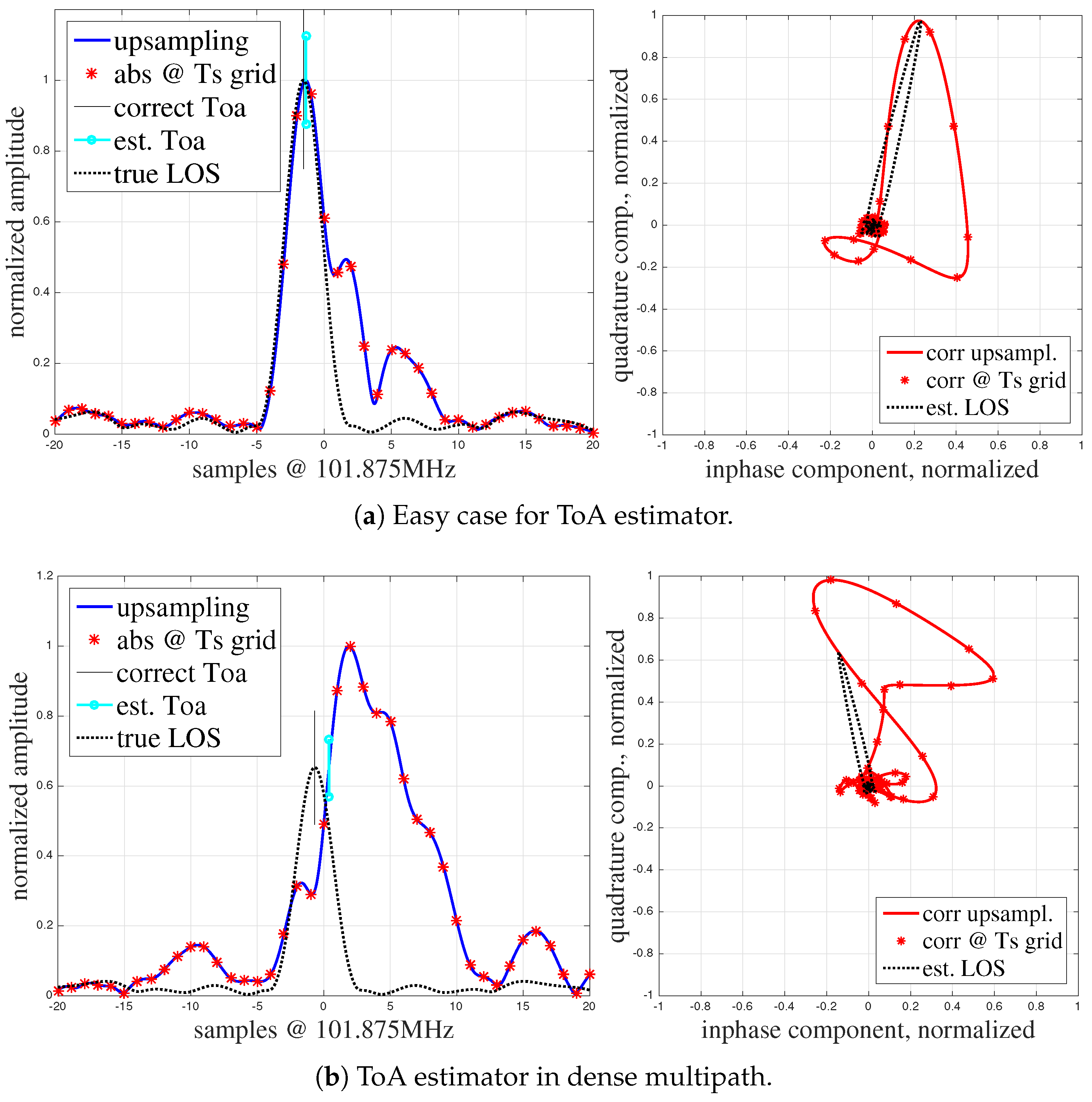
6.6. Multipath Scenario
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Niitsoo, A.; Edelhäußer, T.; Mutschler, C. Convolutional Neural Networks for Position Estimation in TDoA-Based Locating Systems. In Proceedings of the 9th International Conference on Indoor Positioning and Indoor Navigation, Nantes, France, 24–27 September 2018; pp. 1–8. [Google Scholar]
- Gradl, S.; Eskofier, B.M.; Eskofier, D.; Mutschler, C.; Otto, S. Virtual and augmented reality in sports: An overview and acceptance study. In Proceedings of the 2016 ACM International Conference on Pervasive and Ubiquitous Computing, UbiComp Adjunct 2016, Heidelberg, Germany, 12–16 September 2016; pp. 885–888. [Google Scholar]
- Feigl, T.; Mutschler, C.; Philippsen, M. Supervised Learning for Yaw Orientation Estimation. In Proceedings of the 9th International Conference on Indoor Positioning and Indoor Navigation, Nantes, France, 24–27 September 2018; pp. 206–212. [Google Scholar]
- Roth, D.; Kleinbeck, C.; Feigl, T.; Mutschler, C.; Latoschik, M.E. Beyond Replication: Augmenting Social Behaviors in Multi-User Virtual Realities. In Proceedings of the IEEE Conference on Virtual Reality and 3D User Interfaces, Reutlingen, Germany, 18–22 March 2018; pp. 215–222. [Google Scholar]
- Ruiz, A.R.J.; Granja, F.S. Comparing Ubisense, BeSpoon, and DecaWave UWB Location Systems: Indoor Performance Analysis. IEEE Trans. Instrum. Meas. 2017, 66, 2106–2117. [Google Scholar] [CrossRef]
- Nowak, T.; Eidloth, A. Dynamic Multipath Mitigation applying Unscented Kalman Filters in Local Positioning Systems. Int. J. Microw. Wirel. Technol. 2011, 3, 365–372. [Google Scholar] [CrossRef]
- Zhang, C.; Bao, X.; Wei, Q.; Ma, Q.; Yang, Y.; Wang, Q. A Kalman filter for UWB positioning in LOS/NLOS scenarios. In Proceedings of the 4th International Conference on Ubiquitous Positioning, Indoor Navigation and Location Based Services, Shanghai, China, 2–4 November 2016; pp. 73–78. [Google Scholar]
- He, J.; Geng, Y.; Liu, F.; Xu, C. CC-KF: Enhanced TOA Performance in Multipath and NLOS Indoor Extreme Environment. IEEE Sens. J. 2014, 14, 3766–3774. [Google Scholar]
- Exel, R.; Bigler, T. ToA Ranging using Subsample Peak Estimation and Equalizer-based Multipath Reduction. In Proceedings of the IEEE Wireless Communications and Networking Conference, Istanbul, Turkey, 6–9 April 2014; pp. 2964–2969. [Google Scholar]
- Driusso, M.; Babich, F.; Knutti, F.; Sabathy, M.; Marshall, C. Estimation and Tracking of LTE signals Time of Arrival in a Mobile Multipath Environment. In Proceedings of the 9th International Symposium on Image and Signal Processing and Analysis, Zagreb, Croatia, 7–9 September 2015; pp. 276–281. [Google Scholar]
- Jin, B.; Xu, X.; Zhang, T. A Fast Location Algorithm Based on TDOA. In Proceedings of the 4th International Conference on Control, Mechatronics and Automation, Barcelona, Spain, 7–11 December 2016; pp. 168–172. [Google Scholar]
- Jin, B.; Xu, X.; Zhang, T. Robust Time-Difference-of-Arrival (TDOA) Localization Using Weighted Least Squares with Cone Tangent Plane Constraint. Sensors 2018, 18, 778. [Google Scholar]
- Al-Jazzar, S.; Caffery, J.; You, H.R. A Scattering Model based Approach to NLOS Mitigation in TOA Location Systems. In Proceedings of the 55th IEEE Conference on Vehicular Technology, Birmingham, AL, USA, 6–9 May 2002; pp. 861–865. [Google Scholar]
- Al-Jazzar, S.; Caffery, J. ML and Bayesian TOA location estimators for NLOS environments. In Proceedings of the 56th IEEE Conference on Vehicular Technology, Vancouver, BC, Canada, 24–28 September 2002; pp. 1178–1181. [Google Scholar]
- Li, L.; Krolik, J.L. Simultaneous Target and Multipath Positioning. IEEE J. Sel. Top. Signal Process. 2014, 8, 153–165. [Google Scholar] [CrossRef]
- He, J.; Geng, Y.; Pahlavan, K. Toward Accurate Human Tracking: Modeling Time-of-Arrival for Wireless Wearable Sensors in Multipath Environment. IEEE Sens. J. 2014, 14, 3996–4006. [Google Scholar]
- Meissner, P.; Leitinger, E.; Witrisal, K. UWB for Robust Indoor Tracking: Weighting of Multipath Components for Efficient Estimation. IEEE Wirel. Commun. Lett. 2014, 3, 501–504. [Google Scholar] [CrossRef]
- Garcia, N.; Wymeersch, H.; Larsson, E.G.; Haimovich, A.M.; Coulon, M. Direct Localization for Massive MIMO. IEEE Trans. Signal Process. 2017, 65, 2475–2487. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the 2015 International Conference on Computer Vision, Santiago de Chile, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Mascharka, D.; Manley, E. LIPS: Learning Based Indoor Positioning System using mobile phone-based sensors. In Proceedings of the 13th IEEE Annual Consumer Communications and Networking Conference, Las Vegas, NV, USA, 9–12 January 2016; pp. 968–971. [Google Scholar]
- Martinez Sala, A.; Quir’os, R.; L’opez, E. Using neural networks and Active RFID for indoor location services. In Proceedings of the European Workshop Smart Objects: Systems, Technologies and Applications, Ciudad, Spain, 15–16 June 2010; pp. 1–9. [Google Scholar]
- Luo, J.; Gao, H. Deep Belief Networks for Fingerprinting Indoor Localization Using Ultrawideband Technology. Int. J. Distrib. Sens. Netw. 2016, 12, 1–8. [Google Scholar] [CrossRef]
- Prasad, K.N.R.S.V.; Hossain, E.; Bhargava, V.K. Machine Learning Methods for RSS-Based User Positioning in Distributed Massive MIMO. IEEE Trans. Wirel. Commun. 2018, 17, 8402–8417. [Google Scholar] [CrossRef]
- Prasad, K.N.R.S.V.; Hossain, E.; Bhargava, V.K.; Mallick, S. Analytical Approximation-Based Machine Learning Methods for User Positioning in Distributed Massive MIMO. IEEE Access 2018, 6, 18431–18452. [Google Scholar] [CrossRef]
- Vaghefi, S.Y.M.; Vaghefi, R.M. A Novel Multilayer Network Model for TOA-Based Localization in Wireless Sensor Networks. In Proceedings of the International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 3079–3084. [Google Scholar]
- Singh, P.; Agrawal, S. TDOA Based Node Localization in WSN using Neural Networks. In Proceedings of the International Conference on Communication Systems and Network Technologies, Gwalior, India, 6–8 April 2013; pp. 400–404. [Google Scholar]
- Lewandowski, A.; Köster, V.; Wietfeld, C.; Michaelis, S. Support Vector Machines for Non-Linear Radio Fingerprint Recognition in Real-Life Industrial Environments. In Proceedings of the International Conference on Technical Meeting, San Diego, CA, USA, 24–26 January 2011; pp. 628–634. [Google Scholar]
- Chen, C.S. Artificial Neural Network for Location Estimation in Wireless Communication Systems. Sensors 2012, 12, 2798–2817. [Google Scholar] [CrossRef] [PubMed]
- Le, D.V.; Meratnia, N.; Havinga, P.J.M. Unsupervised Deep Feature Learning to Reduce the Collection of Fingerprints for Indoor Localization Using Deep Belief Networks. In Proceedings of the 9th International Conference on Indoor Positioning and Indoor Navigation, Nantes, France, 24–27 September 2018; pp. 1–7. [Google Scholar]
- Félix, G.; Siller, M.; Álvarez, E.N. A Fingerprinting Indoor Localization Algorithm based Deep Learning. In Proceedings of the 8th International Conference on Ubiquitous and Future Networks, Vienna, Austria, 5–8 July 2016; pp. 1006–1011. [Google Scholar]
- Kim, K.S.; Lee, S.; Huang, K. A Scalable Deep Neural Network Architecture for Multi-Building and Multi-Floor Indoor Localization based on Wi-Fi Fingerprinting. Big Data Anal. 2018, 3, 4. [Google Scholar] [CrossRef]
- Kuo, R.; Tseng, W.; Tien, F.; Liao, W. Application of an Artificial Immune System-based Fuzzy Neural Network to a RFID-based Positioning System. J. Comput. Ind. Eng. 2012, 63, 943–956. [Google Scholar] [CrossRef]
- Savic, V.; Larsson, E.G. Fingerprinting-Based Positioning in Distributed Massive MIMO Systems. In Proceedings of the 82nd IEEE Conference on Vehicular Technology, Boston, MA, USA, 6–9 September 2015; pp. 1–5. [Google Scholar]
- Akram, B.A.; Akbar, A.H.; Shafiq, O. HybLoc: Hybrid Indoor Wi-Fi Localization Using Soft Clustering-Based Random Decision Forest Ensembles. IEEE Access 2018, 6, 38251–38272. [Google Scholar] [CrossRef]
- Iqbal, Z.; Luo, D.; Henry, P.; Kazemifar, S.; Rozario, T.; Yan, Y.; Westover, K.; Lu, W.; Nguyen, D.; Long, T.; et al. Accurate Real Time Localization Tracking in A Clinical Environment using Bluetooth Low Energy and Deep Learning. PLoS ONE 2017, 13, e0205392. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, M.; Torki, M.; ElNainay, M. CNN based Indoor Localization using RSS Time-Series. In Proceedings of the 2018 IEEE Symposium on Computers and Communications, Natal, Brazil, 25–28 June 2018; pp. 1044–1049. [Google Scholar]
- Sahar, A.; Han, D. An LSTM-based Indoor Positioning Method Using Wi-Fi Signals. In Proceedings of the 2nd International Conference on Vision, Image and Signal Processing, Las Vegas, NV, USA, 27–29 August 2018; pp. 43:1–43:5. [Google Scholar]
- Feigl, T.; Nowak, T.; Philippsen, M.; Edelhäußer, T.; Mutschler, C. Recurrent Neural Networks on Drifting Time-of-Flight Measurements. In Proceedings of the 9th International Conference on Indoor Positioning and Indoor Navigation, Nantes, France, 24–27 September 2018; pp. 206–212. [Google Scholar]
- Mohammadi, M.; Al-Fuqaha, A.; Guizani, M.; Oh, J.S. Semisupervised Deep Reinforcement Learning in Support of IoT and Smart City Services. IEEE Internet Things J. 2018, 5, 624–635. [Google Scholar] [CrossRef]
- Ye, X.; Yin, X.; Cai, X.; Yuste, A.P.; Xu, H. Neural-Network-Assisted UE Localization Using Radio-Channel Fingerprints in LTE Networks. IEEE Access 2017, 5, 12071–12087. [Google Scholar] [CrossRef]
- Lin, Y.; Tseng, P.; Chan, Y.; He, J.; Wu, G. A Super-resolution-assisted Fingerprinting Method based on Channel Impulse Response Measurement for Indoor Positioning. IEEE Trans. Mob. Comput. 2018. [Google Scholar] [CrossRef]
- Yu, L.; Laaraiedh, M.; Avrillon, S.; Uguen, B. Fingerprinting localization based on neural networks and ultra-wideband signals. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology, Bilbao, Spain, 14–17 December 2011; pp. 184–189. [Google Scholar]
- Hong, A.N.; Rath, M.; Kulmer, J.; Grebien, S.; Van, K.N.; Witrisal, K. Gaussian Process Modeling of UWB Multipath Components. In Proceedings of the 2018 IEEE 7th International Conference on Communications and Electronics, Hue, Vietnam, 18–20 July 2018; pp. 291–296. [Google Scholar]
- Marano, S.; Gifford, W.M.; Wymeersch, H.; Win, M.Z. NLOS Identification and Mitigation for Localization based on UWB Experimental Data. IEEE J. Sel. Areas Commun. 2010, 28, 1026–1035. [Google Scholar] [CrossRef]
- Li, W.; Zhang, T.; Zhang, Q. Experimental researches on an UWB NLOS Identification Method based on Machine learning. In Proceedings of the 15th IEEE International Conference on Communication Technology, Guilin, China, 17–19 November 2013; pp. 473–477. [Google Scholar]
- De Reyna, E.A.; Dardari, D.; Closas, P.; Djuric, P.M. Estimation of Spatial Fields of Nlos/Los Conditions for Improved Localization in Indoor Environments. In Proceedings of the 2018 IEEE Statistical Signal Processing Workshop, Freiburg, Germany, 10–13 June 2018; pp. 658–662. [Google Scholar]
- Choi, J.; Lee, W.; Lee, J.; Lee, J.; Kim, S. Deep Learning Based NLOS Identification With Commodity WLAN Devices. IEEE Trans. Veh. Technol. 2018, 67, 3295–3303. [Google Scholar] [CrossRef]
- Bregar, K.; Mohorčič, M. Improving Indoor Localization Using Convolutional Neural Networks on Computationally Restricted Devices. IEEE Access 2018, 6, 17429–17441. [Google Scholar] [CrossRef]
- Cui, X.; Zhang, H.; Gulliver, T. Threshold Selection for Ultra-Wideband TOA Estimation based on Neural Networks. J. Netw. 2012, 7, 1311–1318. [Google Scholar] [CrossRef]
- Savic, V.; Larsson, E.G.; Ferrer-Coll, J.; Stenumgaard, P. Kernel Methods for Accurate UWB-Based Ranging With Reduced Complexity. IEEE Trans. Wirel. Commun. 2016, 15, 1783–1793. [Google Scholar] [CrossRef]
- Ergüt, S.; Rao, R.; Dural, O.; Sahinoglu, Z. Localization via TDOA in a UWB sensor network using Neural Networks. In Proceedings of the International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 2398–2403. [Google Scholar]
- Jin, Y.; Soh, W.; Wong, W. Indoor Localization with Channel Impulse Response based Fingerprint and Nonparametric Regression. IEEE Trans. Wirel. Commun. 2010, 9, 1120–1127. [Google Scholar] [CrossRef]
- Ghourchian, N.; Allegue-Martinez, M.; Precup, D. Real-Time Indoor Localization in Smart Homes Using Semi-Supervised Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–7 February 2017; pp. 4670–4677. [Google Scholar]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-Based Fingerprinting for Indoor Localization: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2017, 66, 763–776. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Mao, S. CSI Phase Fingerprinting for Indoor Localization With a Deep Learning Approach. IEEE Internet Things J. 2016, 3, 1113–1123. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Mao, S. CiFi: Deep Convolutional Neural Networks for Indoor Localization with 5 GHz Wi-Fi. In Proceedings of the IEEE International Conference on Communications, Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Wang, X.; Gao, L.; Mao, S. BiLoc: Bi-Modal Deep Learning for Indoor Localization With Commodity 5 GHz WiFi. IEEE Access 2017, 5, 4209–4220. [Google Scholar] [CrossRef]
- Berruet, B.; Baala, O.; Caminada, A.; Guillet, V. DelFin: A Deep Learning Based CSI Fingerprinting Indoor Localization in IoT Context. In Proceedings of the 9th International Conference on Indoor Positioning and Indoor Navigation, Nantes, France, 24–27 September 2018. [Google Scholar]
- Shao, W.; Luo, H.; Zhao, F.; Ma, Y.; Zhao, Z.; Crivello, A. Indoor Positioning based on Dingerprint-Image and Deep Learning. IEEE Access 2018, 6, 74699–74712. [Google Scholar] [CrossRef]
- Wang, Y.; Xiu, C.; Zhang, X.; Yang, D. WiFi Indoor Localization with CSI Fingerprinting-Based Random Forest. Sensors 2018, 18, 2869. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Tseng, P. A Deep Neural Network-Based Indoor Positioning Method using Channel State Information. In Proceedings of the International Conference on Computing, Networking and Communications, Maui, HI, USA, 5–8 March 2018; pp. 290–294. [Google Scholar]
- Yazdanian, P.; Pourahmadi, V. DeepPos: Deep Supervised Autoencoder Network for CSI Based Indoor Localization. arXiv, 2018; arXiv:1811.12182. [Google Scholar]
- Khatab, Z.E.; Hajihoseini, A.; Ghorashi, S.A. A Fingerprint Method for Indoor Localization Using Autoencoder Based Deep Extreme Learning Machine. IEEE Sens. Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Tiemann, J.; Pillmann, J.; Wietfeld, C. Ultra-Wideband Antenna-Induced Error Prediction Using Deep Learning on Channel Response Data. In Proceedings of the 85th Vehicular Technology Conference, Sydney, Australia, 4–7 June 2017; pp. 1–5. [Google Scholar]
- Vieira, J.; Leitinger, E.; Sarajlic, M.; Li, X.; Tufvesson, F. Deep Convolutional Neural Networks for Massive MIMO Fingerprint-Based Positioning. In Proceedings of the 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications, Montreal, QC, Canada, 8–13 October 2017; pp. 1–6. [Google Scholar]
- Decurninge, A.; Ordóñez, L.G.; Ferrand, P.; He, G.; Li, B.; Zhang, W.; Guillaud, M. CSI-based Outdoor Localization for Massive MIMO: Experiments with a Learning Approach. In Proceedings of the 15th International Symposium on Wireless Communication Systems, Lisbon, Portugal, 28–31 August 2018; pp. 1–6. [Google Scholar]
- Arnold, M.; Dorner, S.; Cammerer, S.; Brink, S.T. On Deep Learning-Based Massive MIMO Indoor User Localization. In Proceedings of the 19th IEEE International Workshop on Signal Processing Advances in Wireless Communications, Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Comiter, M.Z.; Crouse, M.B.; Kung, H.T. A Structured Deep Neural Network for Data Driven Localization in High Frequency Wireless Networks. Int. J. Comput. Netw. Commun. 2017, 9, 21–39. [Google Scholar] [CrossRef]
- Comiter, M.Z.; Kung, H. Localization Convolutional Neural Networks Using Angle of Arrival Images. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018. [Google Scholar]
- Xiao, C.; Yang, D.; Chen, Z.; Tan, G. 3-D BLE Indoor Localization Based on Denoising Autoencoder. IEEE Access 2017, 5, 12751–12760. [Google Scholar] [CrossRef]
- Guenter Hofmann, M.B. Device and Method for Determining a Time of Arrival of a Receive Sequence. U.S. Patent 7,627,063, 1 December 2009. [Google Scholar]
- Mutschler, C.; Ziekow, H.; Jerzak, Z. The DEBS 2013 Grand Challenge. In Proceedings of the 7th ACM International Conference on Distributed Event-Based Systems, Arlington, TX, USA, 29 June 2013; pp. 289–294. [Google Scholar]
- Feigl, T.; Mutschler, C.; Philippsen, M. Human Compensation Strategies for Orientation Drifts. In Proceedings of the 25th IEEE International Conference on Virtual Reality and 3D User Interfaces, Reutlingen, Germany, 18–22 March 2018; pp. 409–414. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2014; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 24 May 2012; pp. 1097–1105. [Google Scholar]
- Zoubir, A.M.; Koivunen, V.; Chakhchoukh, Y.; Muma, M. Robust Estimation in Signal Processing: A Tutorial-Style Treatment of Fundamental Concepts. IEEE Signal Process. Mag. 2012, 29, 61–80. [Google Scholar] [CrossRef]
- Taylor, J.R. An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements, 2nd ed.; University Science Books: Sausalito, CA, USA, 1996. [Google Scholar]
- Ross, S. Peirce’s criterion for the elimination of suspect experimental data. J. Eng. Technol. 2003, 20, 38–41. [Google Scholar]
- Löffler, C.; Riechel, S.; Fischer, J.; Mutschler, C. Evaluation Criteria for Inside-Out Indoor Positioning Systems Based on Machine Learning. In Proceedings of the 9th International Conference on Indoor Positioning and Indoor Navigation, Nantes, France, 24–27 September 2018; pp. 1–8. [Google Scholar]
- Ma, Y.; Wang, B.; Pei, S.; Zhang, Y.; Zhang, S.; Yu, J. An Indoor Localization Method Based on AOA and PDOA Using Virtual Stations in Multipath and NLOS Environments for Passive UHF RFID. IEEE Access 2018, 6, 31772–31782. [Google Scholar] [CrossRef]
- Ulmschneider, M.; Luz, D.C.; Gentner, C. Exchanging transmitter maps in multipath assisted positioning. In Proceedings of the IEEE/ION Position, Location and Navigation Symposium (PLANS), Monterey, CA, USA, 23–26 April 2018; pp. 1020–1025. [Google Scholar]
- Aditya, S.; Mloisch, A.F.; Behairy, H.M. A Survey on the Impact of Multipath on Wideband Time-of-Arrival Based Localization. Proc. IEEE 2018, 106, 1183–1203. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Samples | Covered Area (w × h) | Height | Platform |
|---|---|---|---|---|
| Meander | 200,390 (211,416) | 13 m × 20 m | 2.5 m | Positioning System |
| Zig-Zag | 304,120 (349,025) | 22 m × 19 m | 0.29 m | Segway |
| Human Walk | 404,687 (691,680) | 45 m × 30 m | 0.96 m–2.1 m | Human |
| Displaced Rectangles | 92,724 (218,752) | 5 m × 14 m | 2.8 m | Positioning System |
| Dataset | CEP | CE95 | MAE |
|---|---|---|---|
| Meander | 0.16 m | 0.36 m | 0.17 m |
| Zig-Zag | 024 m | 0.67 m | 0.29 m |
| Human Walk | 0.30 m | 0.87 m | 0.36 m |
| Displaced Rectangles | 0.10 m | 0.24 m | 0.12 m |
| Model | # Params | Avg. FP (ms) | MAE (m) | CEP (m) | CE95 (m) |
|---|---|---|---|---|---|
| GoogLeNet | 6,894,976 | 66.30 | 0.36 | 0.31 | 0.83 |
| G-Re | 7,422,336 | 130.68 | 0.33 | 0.28 | 0.76 |
| G-Re-NoP | 8,778,112 | 411.68 | 0.29 | 0.26 | 0.65 |
| AlexNet | 34,535,104 | 24.46 | 0.79 | 0.71 | 1.68 |
| SmallNet | 2,113,664 | 10.83 | 0.36 | 0.32 | 0.77 |
| SmallNet-Re | 11,938,944 | 37.70 | 0.34 | 0.30 | 0.75 |
| VGG-16 | 39,883,904 | 158.24 | 0.36 | 0.32 | 0.80 |
| VGG-19 | 45,192,320 | 197.18 | 0.38 | 0.33 | 0.85 |
| Distributed CNN | 1,975,136 | 120.19 | 0.36 | 0.30 | 0.84 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niitsoo, A.; Edelhäußer, T.; Eberlein, E.; Hadaschik, N.; Mutschler, C. A Deep Learning Approach to Position Estimation from Channel Impulse Responses. Sensors 2019, 19, 1064. https://doi.org/10.3390/s19051064
Niitsoo A, Edelhäußer T, Eberlein E, Hadaschik N, Mutschler C. A Deep Learning Approach to Position Estimation from Channel Impulse Responses. Sensors. 2019; 19(5):1064. https://doi.org/10.3390/s19051064
Chicago/Turabian StyleNiitsoo, Arne, Thorsten Edelhäußer, Ernst Eberlein, Niels Hadaschik, and Christopher Mutschler. 2019. "A Deep Learning Approach to Position Estimation from Channel Impulse Responses" Sensors 19, no. 5: 1064. https://doi.org/10.3390/s19051064
APA StyleNiitsoo, A., Edelhäußer, T., Eberlein, E., Hadaschik, N., & Mutschler, C. (2019). A Deep Learning Approach to Position Estimation from Channel Impulse Responses. Sensors, 19(5), 1064. https://doi.org/10.3390/s19051064