Robotic Active Information Gathering for Spatial Field Reconstruction with Rapidly-Exploring Random Trees and Online Learning of Gaussian Processes †


Abstract
:1. Introduction
- We provide a more detailed description of the algorithms and the underlying methods. This helps the reader to better understand the algorithm implementation and simulation results.
- This paper also performs an analysis of the algorithm’s computational complexities.
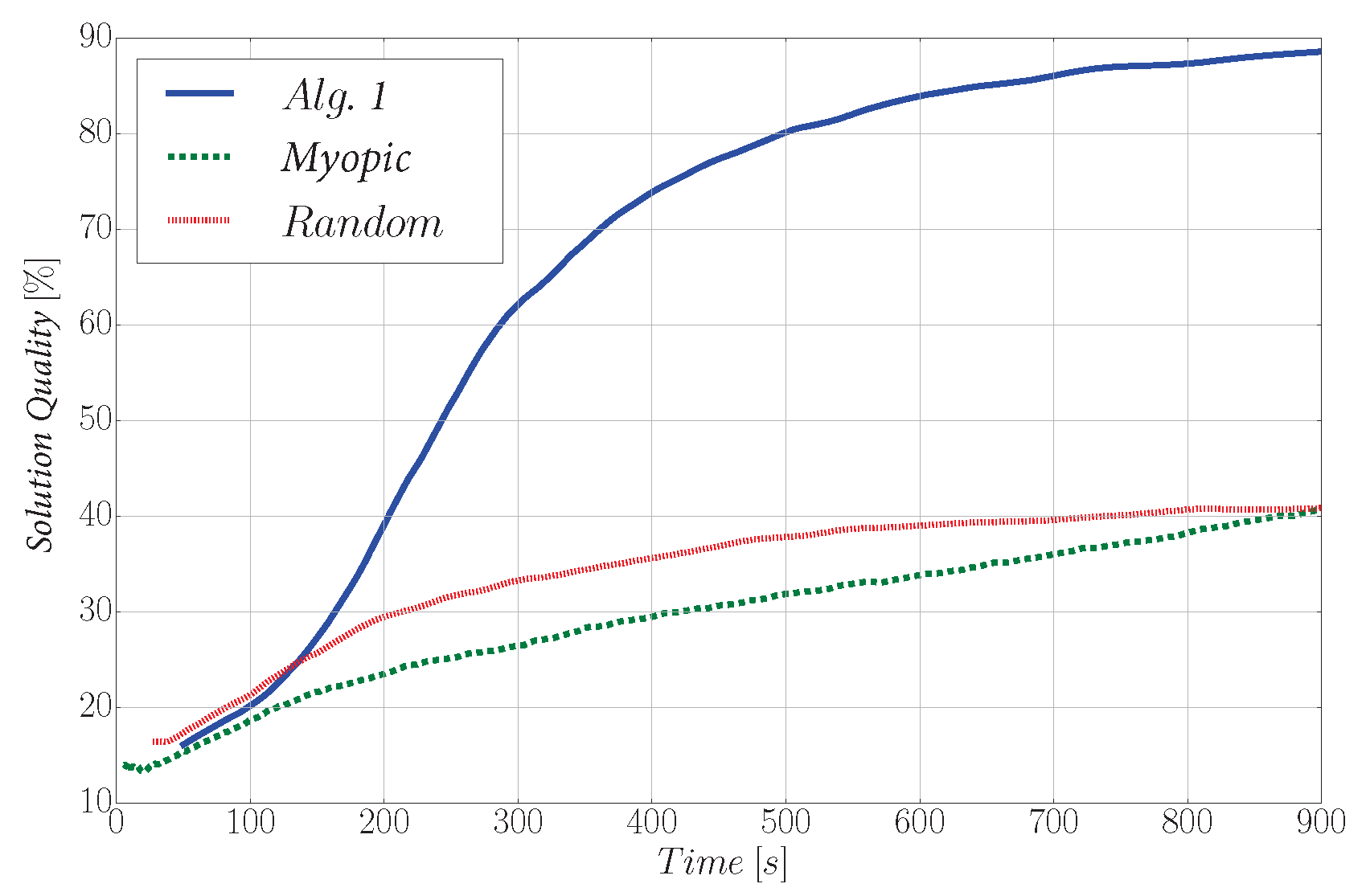
- Also, additional simulations are presented and analyzed. Specifically, we carry out a detailed analysis of the proposed RRT*-based informative path planner. Moreover, we include an additional scenario to test the whole exploration strategy described in the paper. Moreover, a metric that benchmarks state-of-the-art algorithms according to their solution quality is also introduced.
- In this paper we also include an evaluation of the online learning of the GP hyperparameters and discuss the effect of online hyperparameter learning on the algorithms performance.
- Finally, we include an experiment with a real robot performing on exploration and reconstruction of a magnetic field using a sensor. We describe in detail the experimental setup and discuss the obtained results.
2. Related Work
3. Problem Statement
- The physical process takes place in an environment populated with obstacles. The borders and obstacles that define the environment are a priori known. This assumption allows us to abstract the exploration of the physical process from the perception and mapping of the environment.
- The physical process is time-invariant during the information gathering task.
- The robot’s position is known exactly and is noise-free. We assume that there exists an external positioning system that provides us with a highly accurate localization, e.g., a Real Time Kinematic Global Positioning System (GPS-RTK) for outdoor scenarios, or a motion tracking system for indoor cases. Uncertainty in positioning can also be accounted for using e.g., GPs [35].
4. Gaussian Processes for Spatial Data
5. Efficient Information Gathering Using RRT-Based Planners and GPs
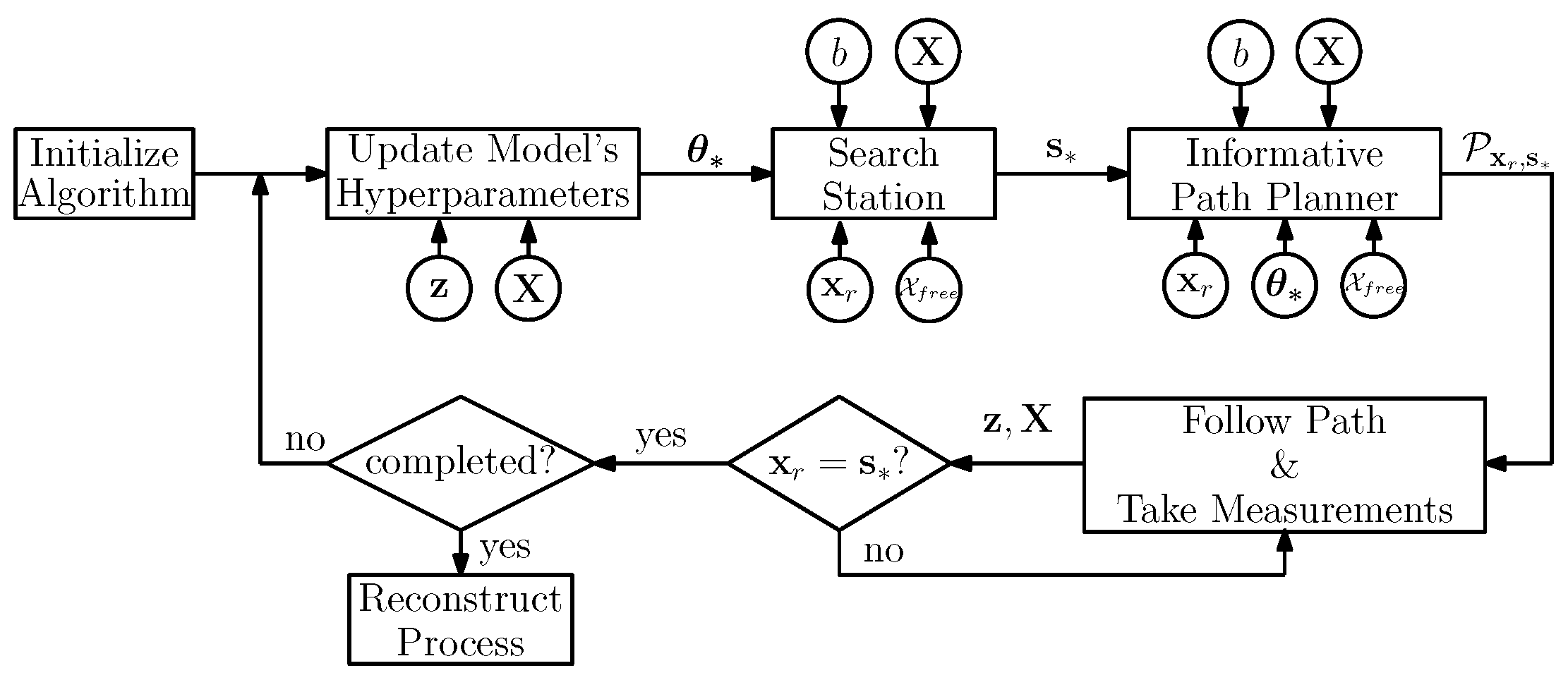
5.1. Algorithm Overview
| Algorithm 1. |
 |
| Algorithm 2. |
 |
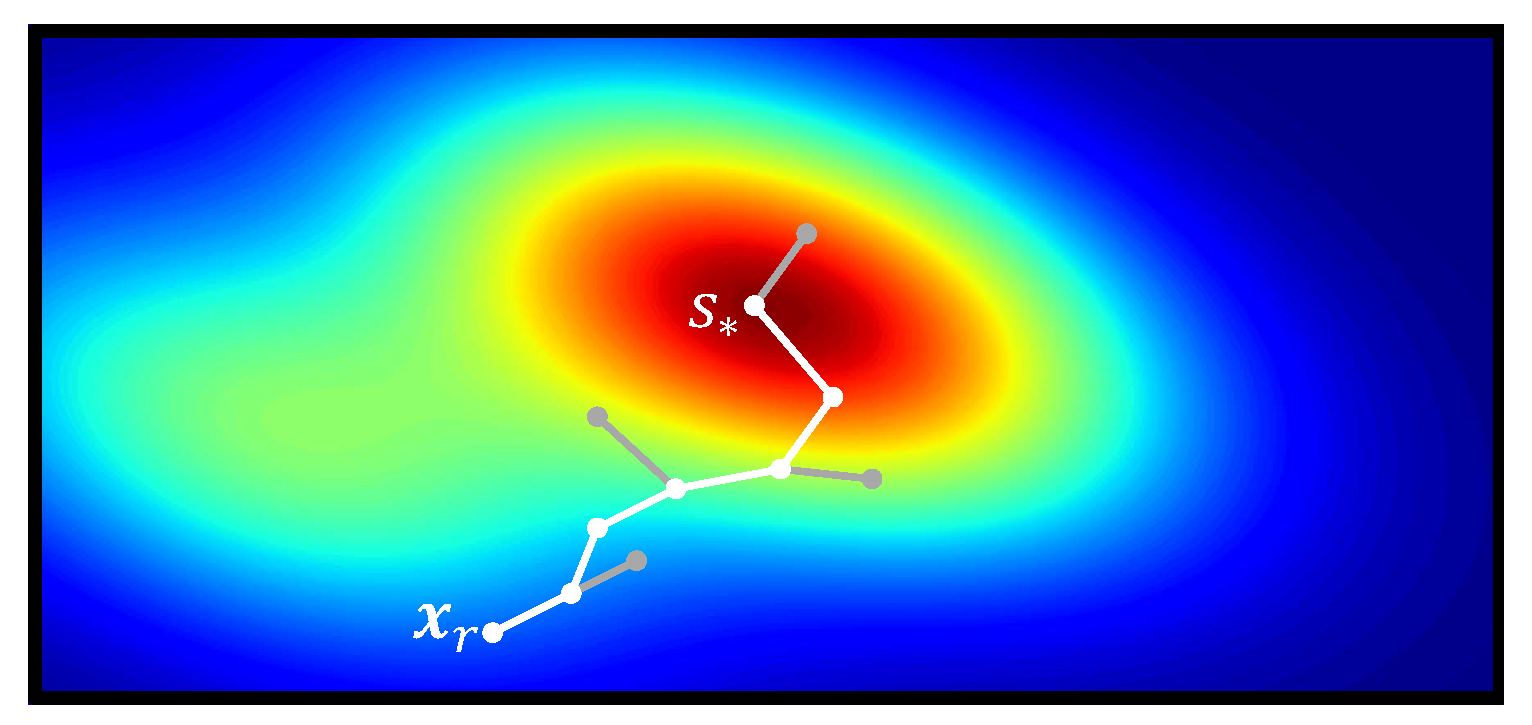
5.2. Search for Highly Informative Stations
5.3. Informative Path Planner Using RRT*
Non-Monotonicity of the Utility Function
5.4. Information Metric
5.4.1. Mutual Information
| Algorithm 3. |
 |
5.4.2. Mean Entropy
5.5. Computational Complexity
6. Simulations and Discussion of Results
6.1. Simulations Setup
6.2. Analysis of the Informative Path Planner
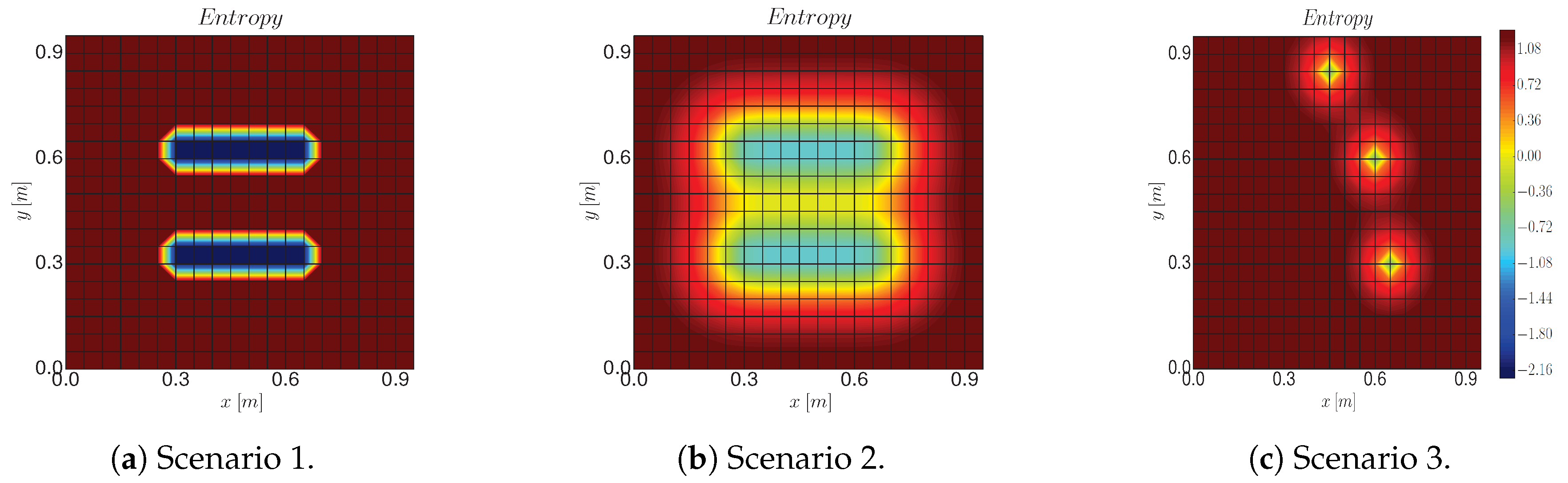
6.2.1. Setup
- Scenario 1 recreates a physical process with low spatial correlation in which a robot has already gathered two patches of measurements. The blue areas correspond to the measured areas and the red areas to the non-measured positions. We employ the following : , , .
- Scenario 2 recreates the same scenario, but now we consider a process with higher spatial correlation. Here we set , , .
- Scenario 3 corresponds to three measurements that are taken randomly for each of the simulation runs. For this case we consider the same hyperparameters as for scenario 2.
6.2.2. Choice of the Information Function
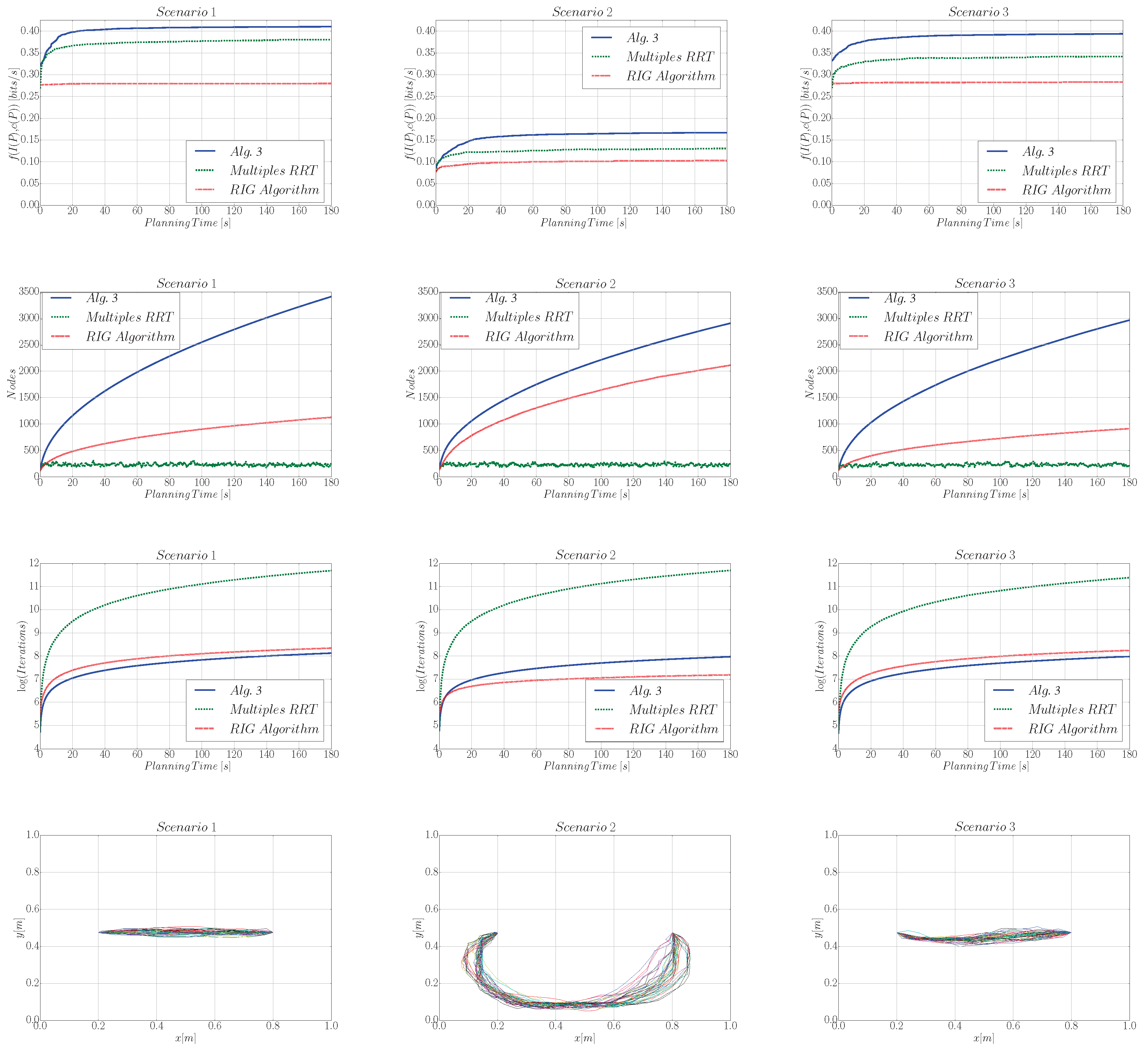
6.2.3. Performance Analysis
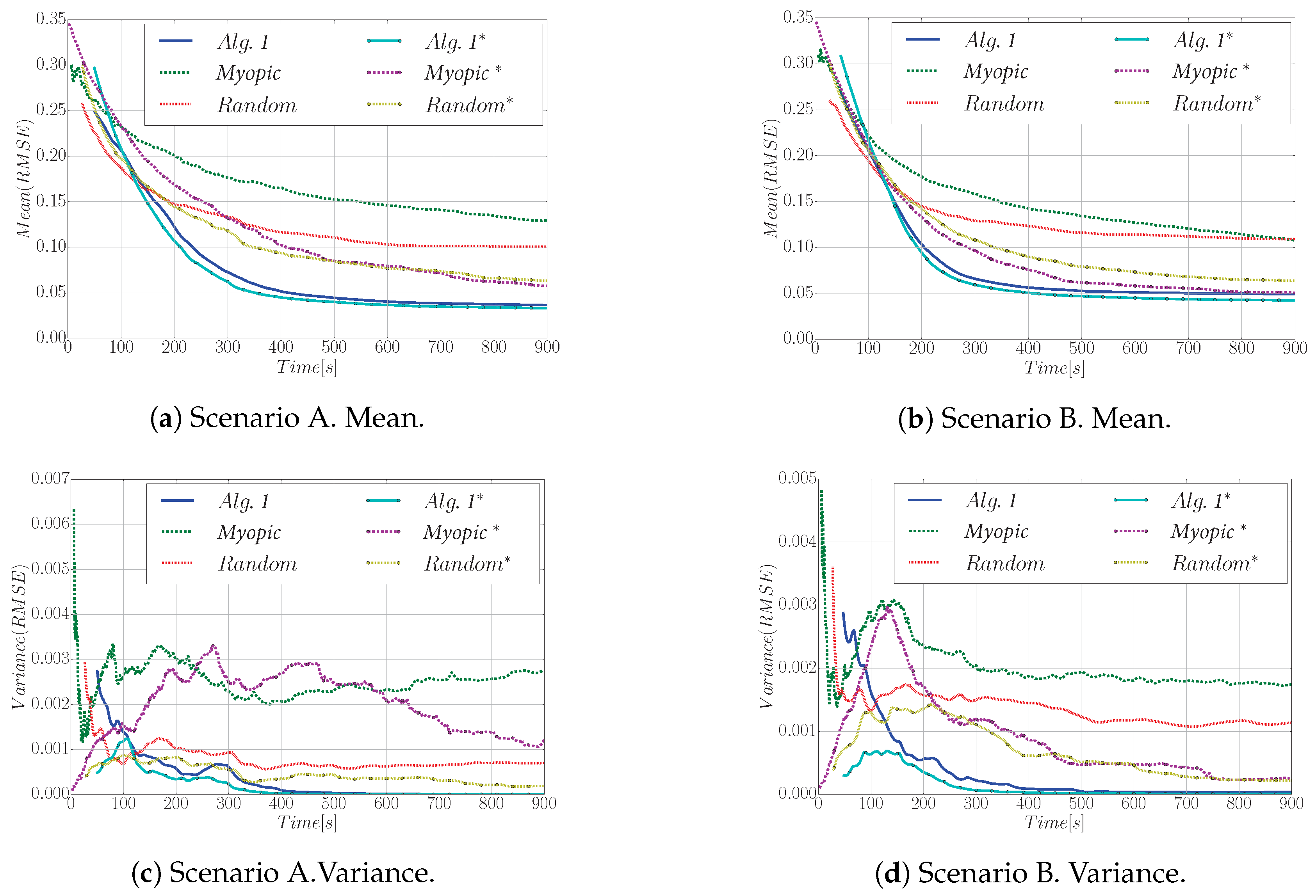
6.3. Analysis of the Exploration Strategy
6.3.1. Setup
6.3.2. Performance Analysis
- Random approach: an RRT is grown from for the same planning time and budget b as in algorithm. The next station is selected randomly as one of the leaves of the RRT. The path that links to the selected leaf is then followed by the robot.
6.3.3. Hyperparameters Analysis
7. Experiments and Discussion of Results
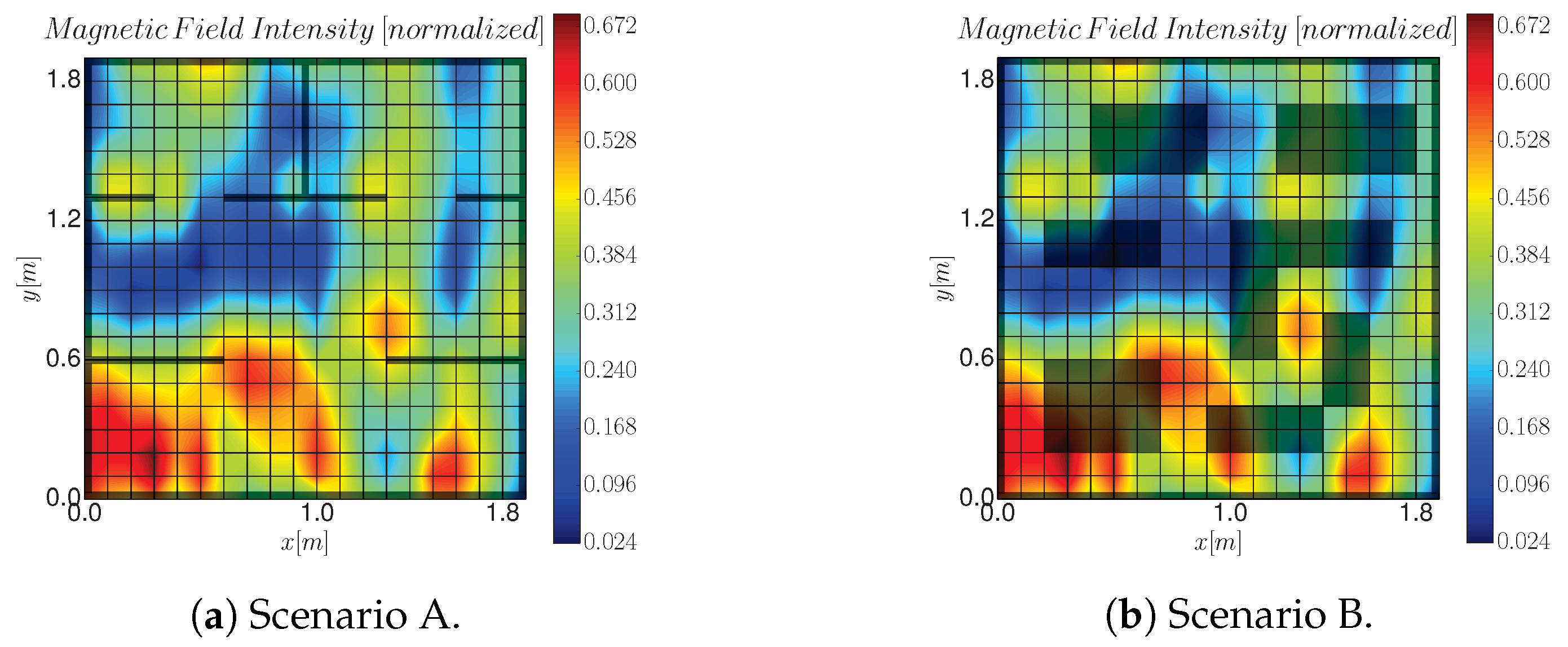
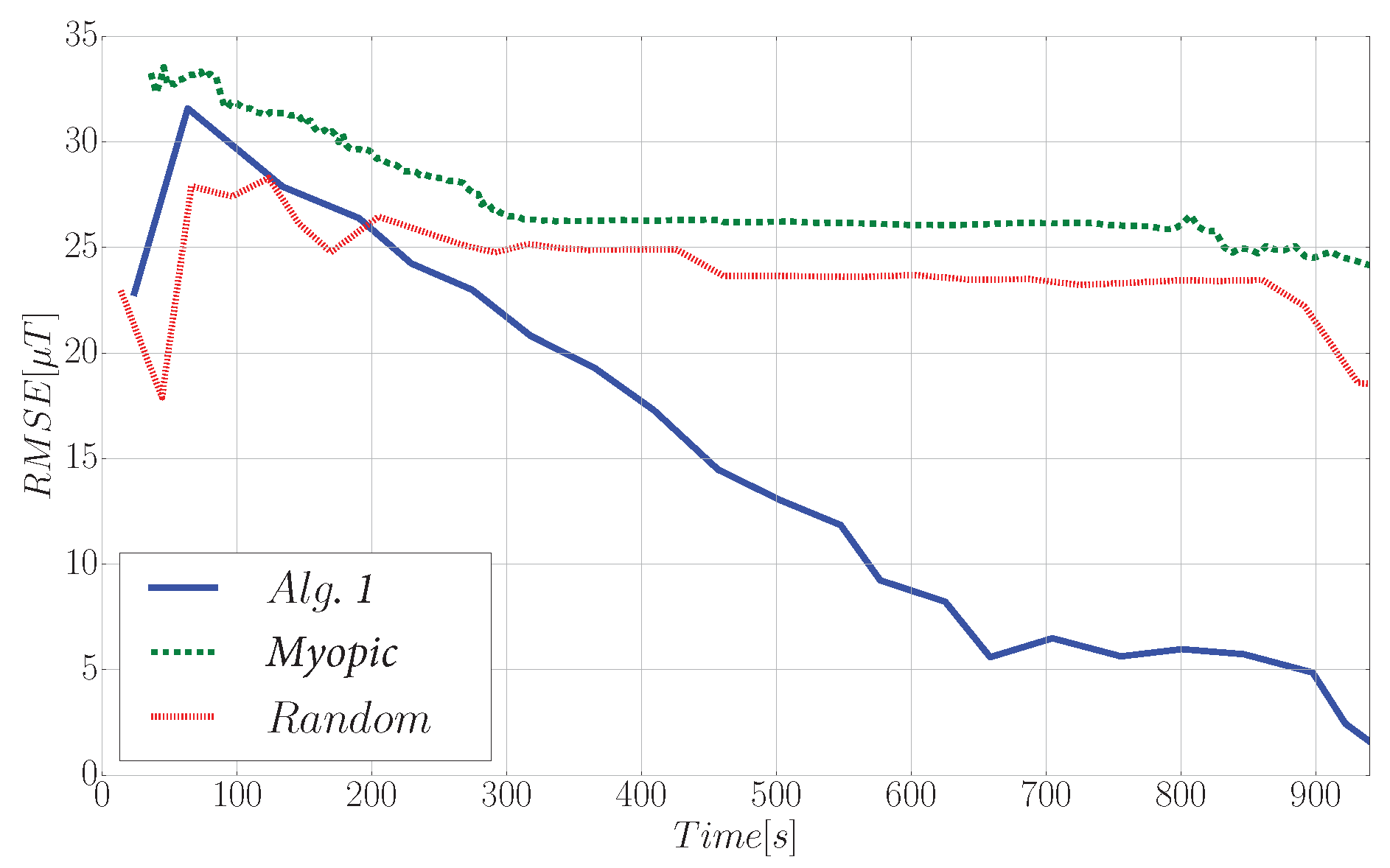
7.1. Experimental Setup
7.2. Experimental Results
8. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Marchant, R.; Ramos, F. Bayesian optimisation for intelligent environmental monitoring. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 2242–2249. [Google Scholar]
- Viseras, A.; Wiedemann, T.; Manss, C.; Magel, L.; Mueller, J.; Shutin, D.; Merino, L. Decentralized multi-agent exploration with online-learning of Gaussian processes. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4222–4229. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Merino, L.; Caballero, F.; Ollero, A. Active Sensing for Range-Only Mapping using Multiple Hypothesis. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 37–42. [Google Scholar]
- Ouyang, R.; Low, K.H.; Chen, J.; Jaillet, P. Multi-robot active sensing of non-stationary Gaussian process-based environmental phenomena. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; pp. 573–580. [Google Scholar]
- Singh, A.; Krause, A.; Kaiser, W.J. Nonmyopic Adaptive Informative Path Planning for Multiple Robots. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 14–17 July 2009. [Google Scholar]
- Low, K.H.; Dolan, J.M.; Khosla, P. Adaptive multi-robot wide-area exploration and mapping. In Proceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems, Estoril, Portugal, 12–16 May 2008; pp. 23–30. [Google Scholar]
- Meliou, A.; Krause, A.; Guestrin, C.; Hellerstein, J.M. Nonmyopic informative path planning in spatio-temporal models. In Proceedings of the 22nd National Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; Volume 10, pp. 16–17. [Google Scholar]
- Viseras Ruiz, A.; Olariu, C. A General Algorithm for Exploration with Gaussian Processes in Complex, Unknown Environments. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 3388–3393. [Google Scholar]
- Klyubin, A.S.; Polani, D.; Nehaniv, C.L. Empowerment: A universal agent-centric measure of control. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–5 September 2005; Volume 1, pp. 128–135. [Google Scholar]
- Levine, D.S. Information-Rich Path Planning Under General Constraints Using Rapidly-Exploring Random Trees. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2010. [Google Scholar]
- Julian, B.J.; Karaman, S.; Rus, D. On mutual information-based control of range sensing robots for mapping applications. Int. J. Robot. Res. 2014, 33, 1375–1392. [Google Scholar] [CrossRef]
- Krause, A.; Singh, A.; Guestrin, C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. J. Mach. Learn. Res. 2008, 9, 235–284. [Google Scholar]
- Krause, A.; Guestrin, C. Nonmyopic active learning of gaussian processes: An exploration-exploitation approach. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 449–456. [Google Scholar]
- Yamauchi, B. A frontier-based approach for autonomous exploration. In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation, Monterey, CA, USA, 10–11 July 1997; pp. 146–151. [Google Scholar]
- Viseras, A.; Shutin, D.; Merino, L. Online information gathering using sampling-based planners and GPs: An information theoretic approach. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 123–130. [Google Scholar]
- Leahy, K.J.; Aksaray, D.; Belta, C. Informative Path Planning under Temporal Logic Constraints with Performance Guarantees. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 1859–1865. [Google Scholar] [CrossRef]
- Cliff, O.M.; Fitch, R.; Sukkarieh, S.; Saunders, D.L.; Heinsohn, R. Online localization of radio-tagged wildlife with an autonomous aerial robot system. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015; pp. 13–17. [Google Scholar]
- Miller, L.M.; Murphey, T.D. Optimal Planning for Target Localization and Coverage Using Range Sensing. In Proceedings of the 2015 IEEE International Conference on Automation Science and Engineering (CASE), Gothenburg, Sweden, 24–28 August 2015; pp. 501–508. [Google Scholar]
- Chung, J.J.; Lawrance, N.R.; Sukkarieh, S. Learning to soar: Resource-constrained exploration in reinforcement learning. Int. J. Robot. Res. 2015, 34, 158–172. [Google Scholar] [CrossRef]
- MacDonald, R.A.; Smith, S.L. Active Sensing for Motion Planning in Uncertain Environments via Mutual Information Policies. Int. J. Robot. Res. 2018. [Google Scholar] [CrossRef]
- Ghaffari Jadidi, M.; Valls Miro, J.; Dissanayake, G. Gaussian Processes Autonomous Mapping and Exploration for Range-Sensing Mobile Robots. Auton. Robots 2018, 42, 273–290. [Google Scholar] [CrossRef]
- Hitz, G.; Galceran, E.; Garneau, M.E.; Pomerleau, F.; Siegwart, R. Adaptive Continuous-Space Informative Path Planning for Online Environmental Monitoring. J. Field Robot. 2017, 34, 1427–1449. [Google Scholar] [CrossRef]
- Popović, M.; Hitz, G.; Nieto, J.; Sa, I.; Siegwart, R.; Galceran, E. Online Informative Path Planning for Active Classification Using UAVs. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5753–5758. [Google Scholar] [CrossRef]
- Hollinger, G.A.; Sukhatme, G.S. Sampling-based robotic information gathering algorithms. Int. J. Robot. Res. 2014, 33, 1271–1287. [Google Scholar] [CrossRef]
- Nguyen, J.L.; Lawrance, N.R.; Fitch, R.; Sukkarieh, S. Real-time path planning for long-term information gathering with an aerial glider. Auton. Robots 2016, 40, 1017–1039. [Google Scholar] [CrossRef]
- Singh, A.; Krause, A.; Guestrin, C.; Kaiser, W.J. Efficient informative sensing using multiple robots. J. Artif. Intell. Res. 2009, 34, 707–755. [Google Scholar] [CrossRef]
- LaValle, S.M.; Kuffner, J.J. Randomized kinodynamic planning. Int. J. Robot. Res. 2001, 20, 378–400. [Google Scholar] [CrossRef]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Bry, A.; Roy, N. Rapidly-exploring random belief trees for motion planning under uncertainty. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 723–730. [Google Scholar]
- Yang, K.; Keat Gan, S.; Sukkarieh, S. A Gaussian process-based RRT planner for the exploration of an unknown and cluttered environment with a UAV. Adv. Robot. 2013, 27, 431–443. [Google Scholar] [CrossRef]
- Lan, X.; Schwager, M. Planning periodic persistent monitoring trajectories for sensing robots in gaussian random fields. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 2415–2420. [Google Scholar]
- Vasudevan, S.; Ramos, F.; Nettleton, E.; Durrant-Whyte, H. Gaussian process modeling of large-scale terrain. J. Field Robot. 2009, 26, 812–840. [Google Scholar] [CrossRef]
- Stranders, R.; Farinelli, A.; Rogers, A.; Jennings, N.R. Decentralised coordination of mobile sensors using the max-sum algorithm. In Proceedings of the 21st International Jont Conference on Artifical Intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 299–304. [Google Scholar]
- Muppirisetty, L.S.; Svensson, T.; Wymeersch, H. Spatial wireless channel prediction under location uncertainty. IEEE Transa. Wirel. Commun. 2016, 15, 1031–1044. [Google Scholar] [CrossRef]
- Charrow, B.; Liu, S.; Kumar, V.; Michael, N. Information-theoretic mapping using cauchy-schwarz quadratic mutual information. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4791–4798. [Google Scholar]
- Ma, K.; Ma, Z.; Liu, L.; Sukhatme, G.S. Multi-Robot Informative and Adaptive Planning for Persistent Environmental Monitoring. In Proceedings of the 13th International Symposium on Distributed Autonomous Robotic Systems, DARS, London, UK, 7–9 November 2016. [Google Scholar]
- Izquierdo-Cordova, R.; Morales, E.F.; Sucar, L.E.; Murrieta-Cid, R. Searching Objects in Known Environments: Empowering Simple Heuristic Strategies. In RoboCup 2016: Robot World Cup XX; Behnke, S., Sheh, R., Sarıel, S., Lee, D.D., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 380–391. [Google Scholar]
- Godsil, C.; Royle, G.F. Algebraic Graph Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 207. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Ramirez-Paredes, J.P.; Doucette, E.A.; Curtis, J.W.; Gans, N.R. Optimal Placement for a Limited-Support Binary Sensor. IEEE Robot. Autom. Lett. 2016, 1, 439–446. [Google Scholar] [CrossRef]
- pyGPs—A Package for Gaussian Processes Regression and Classification. J. Mach. Learn. Res. 2015, 16, 2611–2616.
- Quigley, M.; Gerkey, B.; Conley, K.; Faust, J.; Foote, T.; Leibs, J.; Berger, E.; Wheeler, R.; Ng, A. ROS: An open-source Robot Operating System. Available online: http://www.willowgarage.com/sites/default/files/icraoss09-ROS.pdf (accessed on 22 February 2019).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [s] | Differential Entropy [bits] | Cost [s] | |
|---|---|---|---|
| Mean Entropy (6) | |||
| Mutual Information |
| Differential Entropy [bits] | Path Cost [s] | |
|---|---|---|
| Algorithm 3 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viseras, A.; Shutin, D.; Merino, L. Robotic Active Information Gathering for Spatial Field Reconstruction with Rapidly-Exploring Random Trees and Online Learning of Gaussian Processes. Sensors 2019, 19, 1016. https://doi.org/10.3390/s19051016
Viseras A, Shutin D, Merino L. Robotic Active Information Gathering for Spatial Field Reconstruction with Rapidly-Exploring Random Trees and Online Learning of Gaussian Processes. Sensors. 2019; 19(5):1016. https://doi.org/10.3390/s19051016
Chicago/Turabian StyleViseras, Alberto, Dmitriy Shutin, and Luis Merino. 2019. "Robotic Active Information Gathering for Spatial Field Reconstruction with Rapidly-Exploring Random Trees and Online Learning of Gaussian Processes" Sensors 19, no. 5: 1016. https://doi.org/10.3390/s19051016
APA StyleViseras, A., Shutin, D., & Merino, L. (2019). Robotic Active Information Gathering for Spatial Field Reconstruction with Rapidly-Exploring Random Trees and Online Learning of Gaussian Processes. Sensors, 19(5), 1016. https://doi.org/10.3390/s19051016