A Safety Computer System Based on Multi-Sensor Data Processing †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Introduction of the Safety Computer into the Train Control System
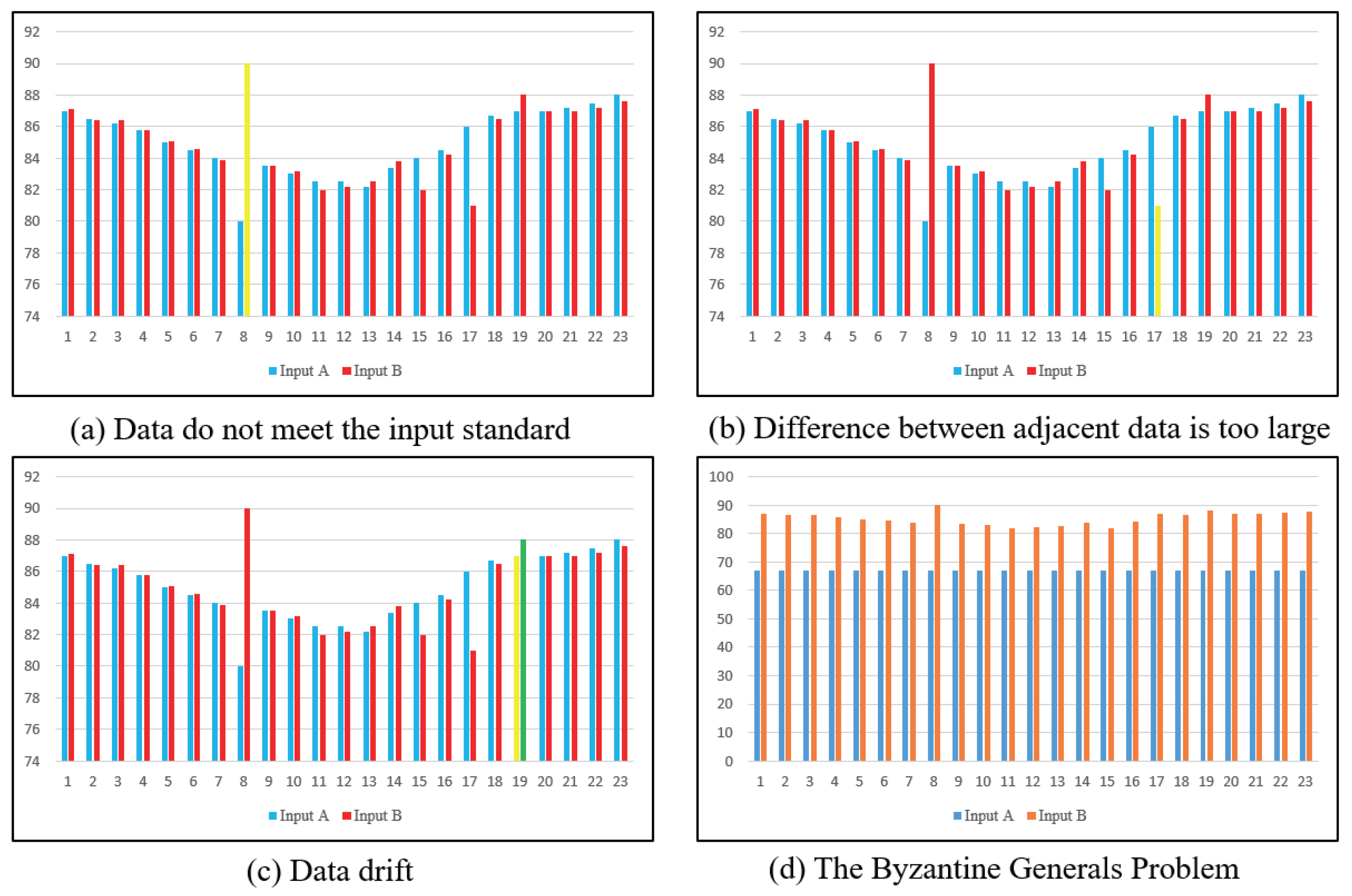
2.1. Non-Strict Multi-Sensor Data Problems in the Safety Computer
2.2. Data Features’ Discussion
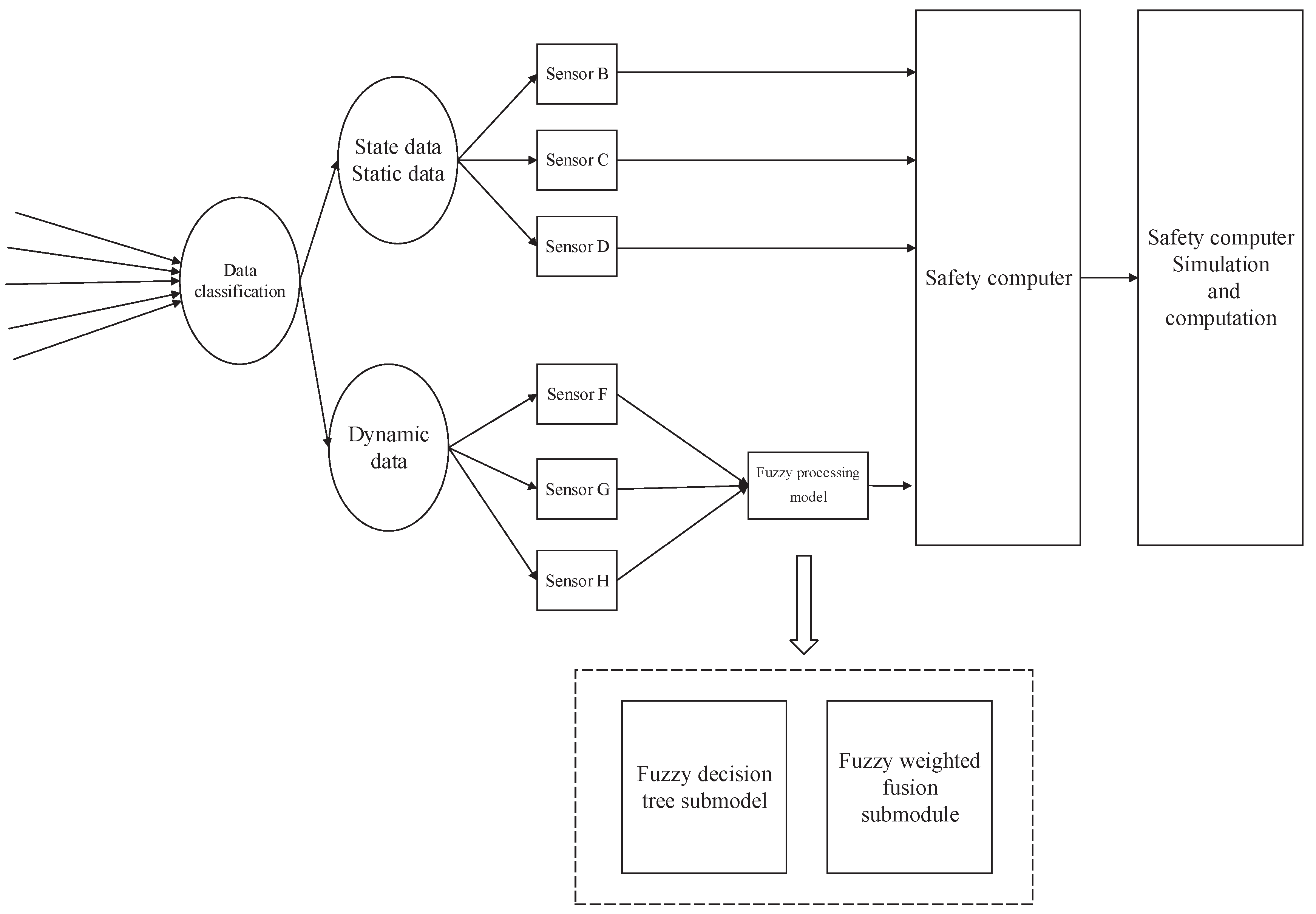
2.3. The Architecture of the Safety Computer in the Train Control System
3. The Introduction of Fuzzy Theory
3.1. Data Feature Extraction and Selection
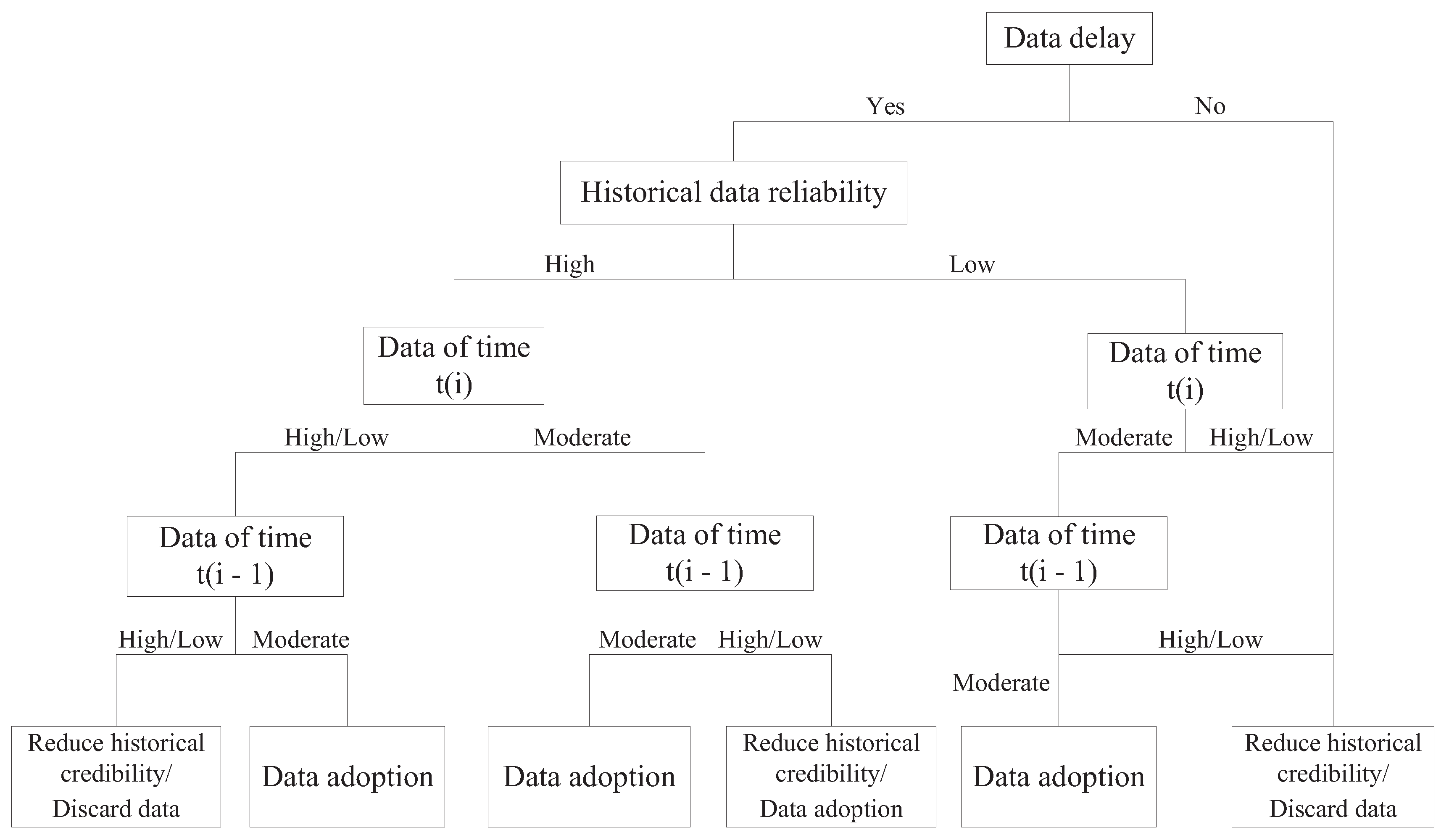
3.2. The Improved Fuzzy Decision Tree
3.3. Fuzzy Weighted Fusion Algorithm
- If is high, then G is ;
- If is medium, then G is ;
- If is low, then G is ;
4. The Modeling of the Fuzzy Processing Model
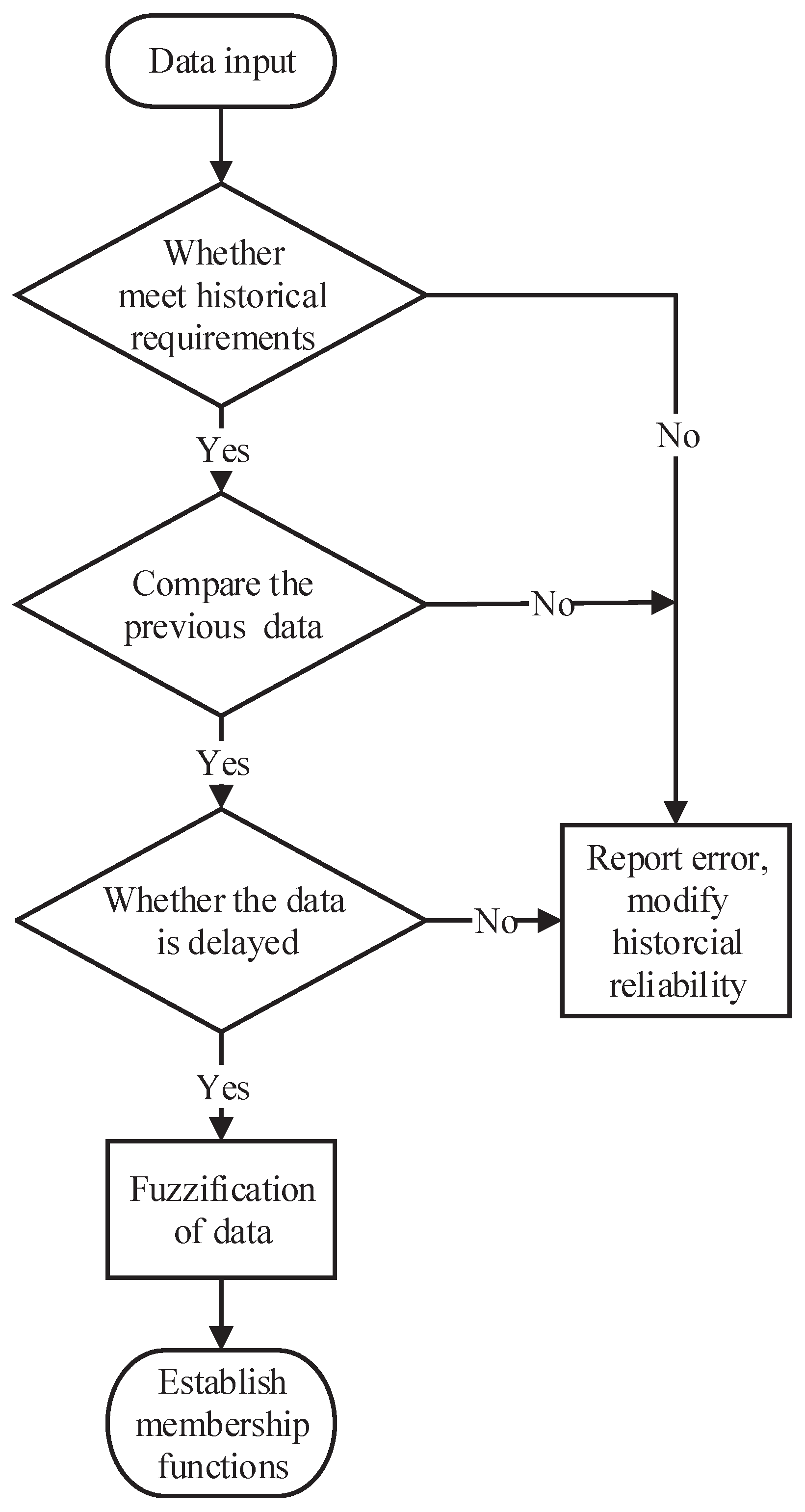
4.1. Fuzzy Decision Tree Submodel
- Step 1:
- The data are input into the historical database. If the historical range is satisfied, turn to Step 2; otherwise, modify the historical credibility.
- Step 2:
- Calculate the simulation speed based on the previous frame speed data and acceleration. The difference between the simulation speed and current frame speed are obtained. If the difference has a reasonable range calculated according to historical data, turn to Step 3; otherwise, modify the historical credibility
- Step 3:
- If data are delayed, modify the historical credibility; otherwise, turn to Step 4.
- Step 4:
- Fuzzify the data to establish membership functions based on slope parameters, environmental factors, and acceleration information.
- IF the data are not delayed AND high historical credibility AND moderate real-time speed AND moderate historical speed, THEN speed adoption (0.97);
- IF data are not delayed AND high historical credibility AND moderate real-time speed AND low/high historical speed, THEN speed adoption (0.93);
- Data are not delayed AND high historical credibility AND low/high real-time speed AND moderate historical speed, THEN speed adoption (0.94);
- IF Data are not delayed AND high historical credibility AND low/high real-time speed AND low/high historical speed, THEN discard speed (0.92);
- IF Data are delayed, THEN discard speed (1);
4.2. Fuzzy Weighted Fusion Submodule
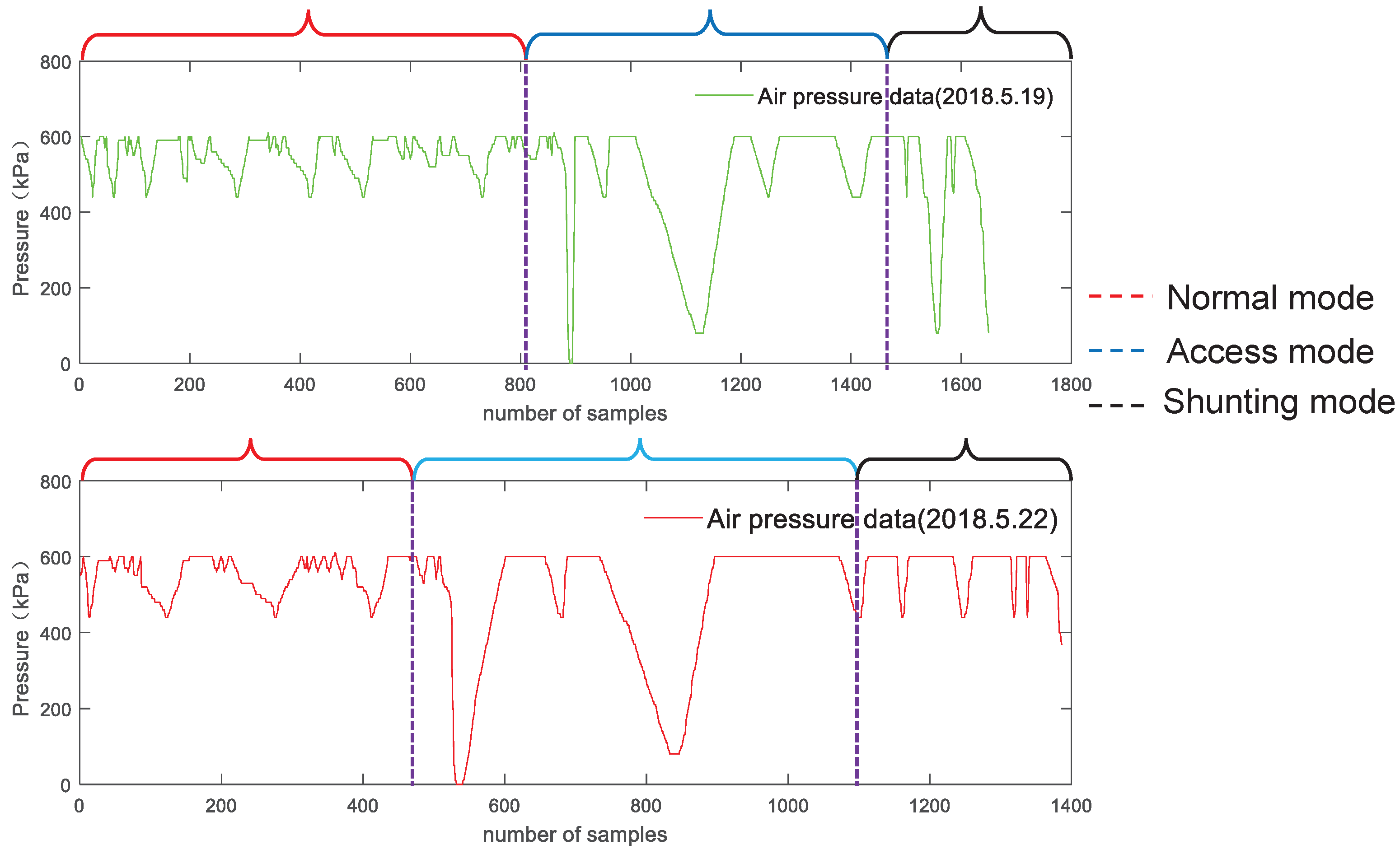
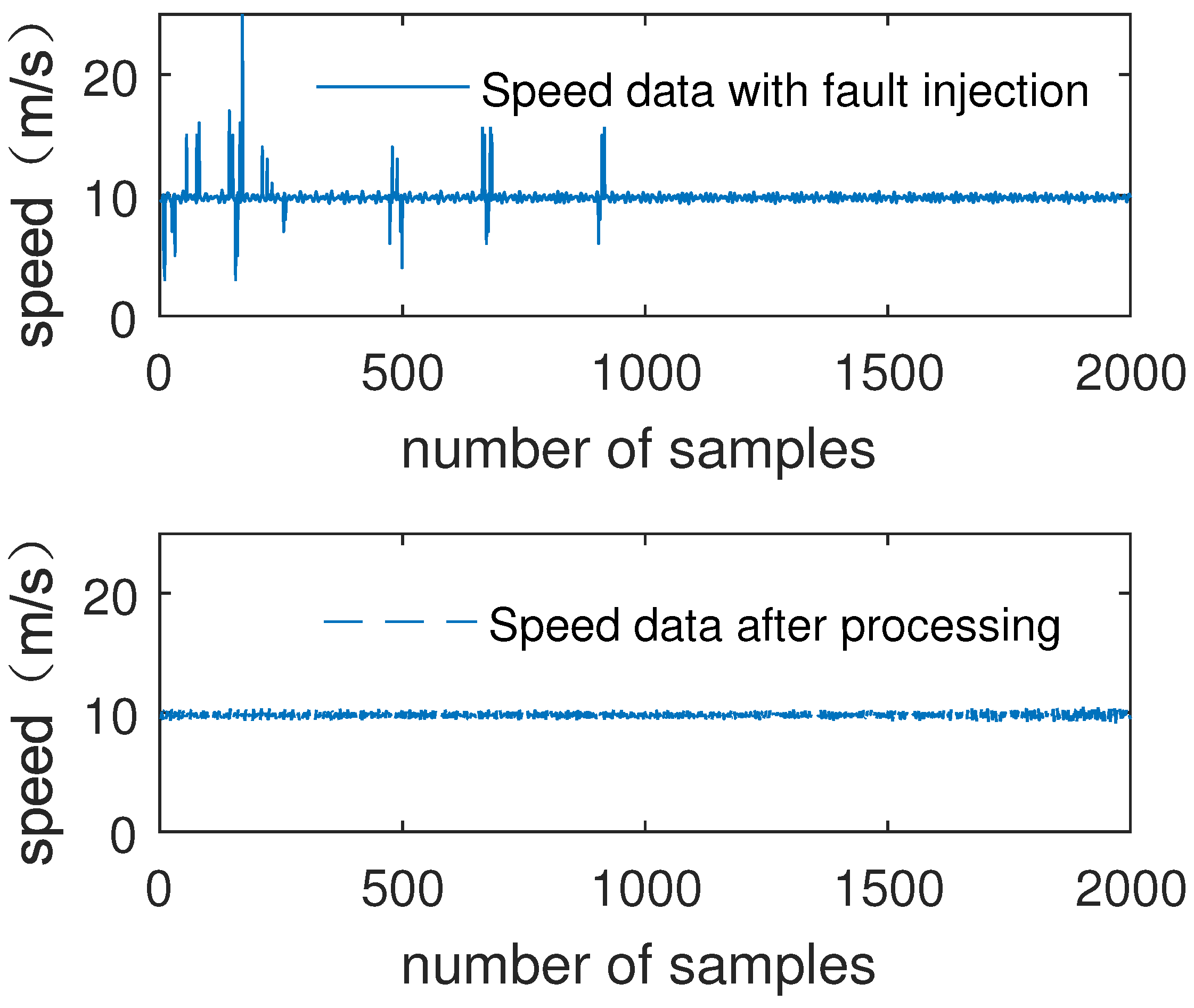
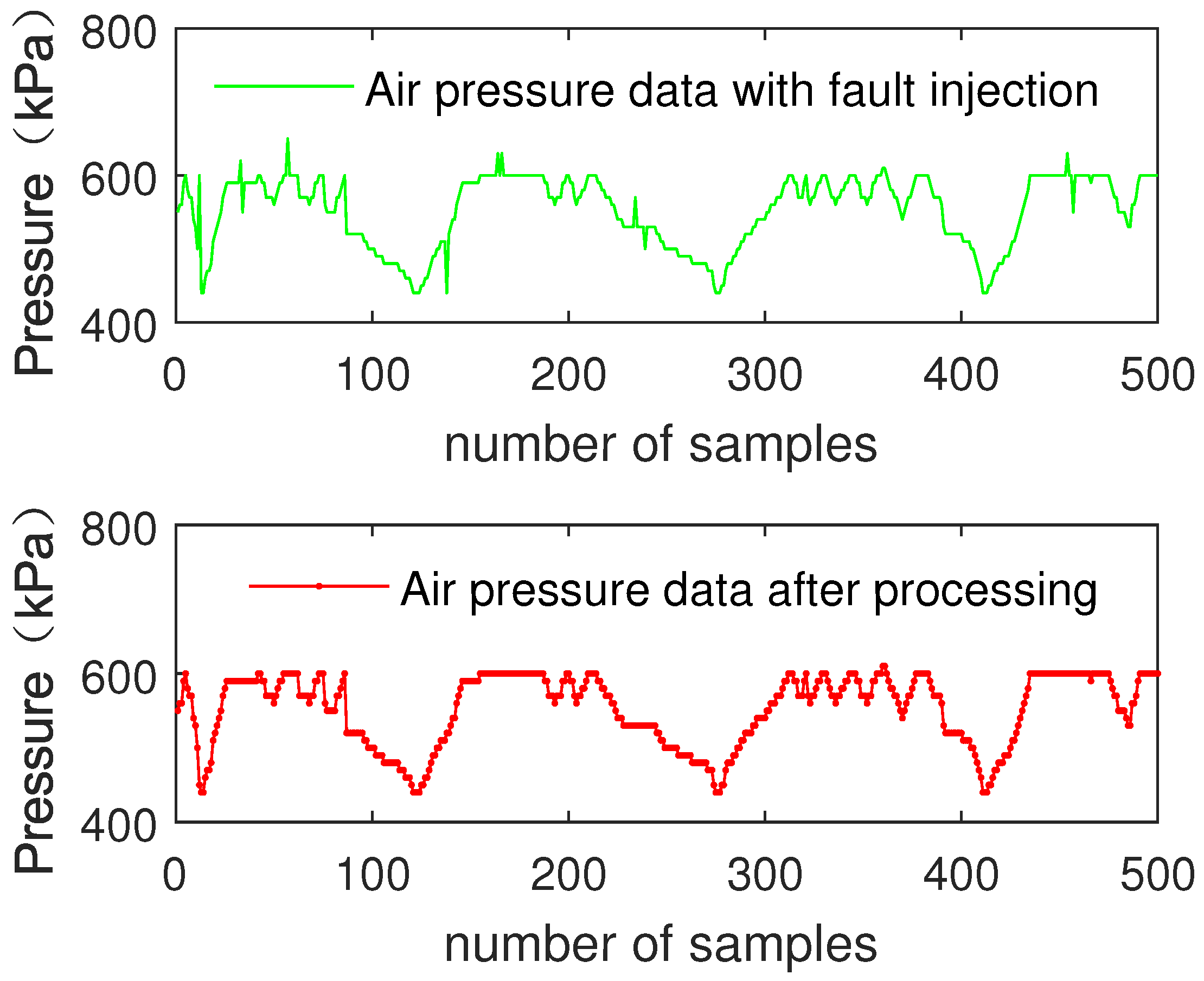
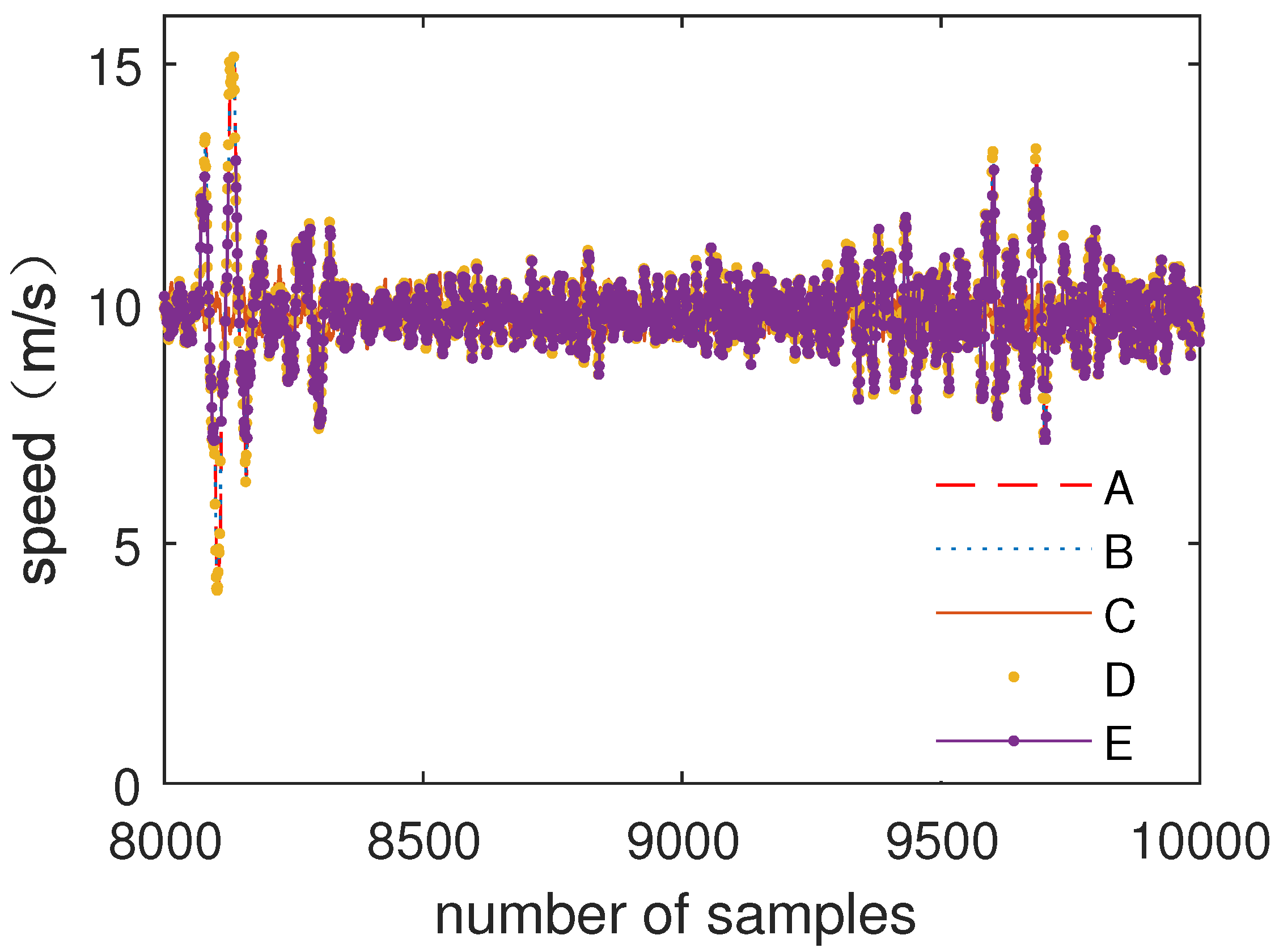
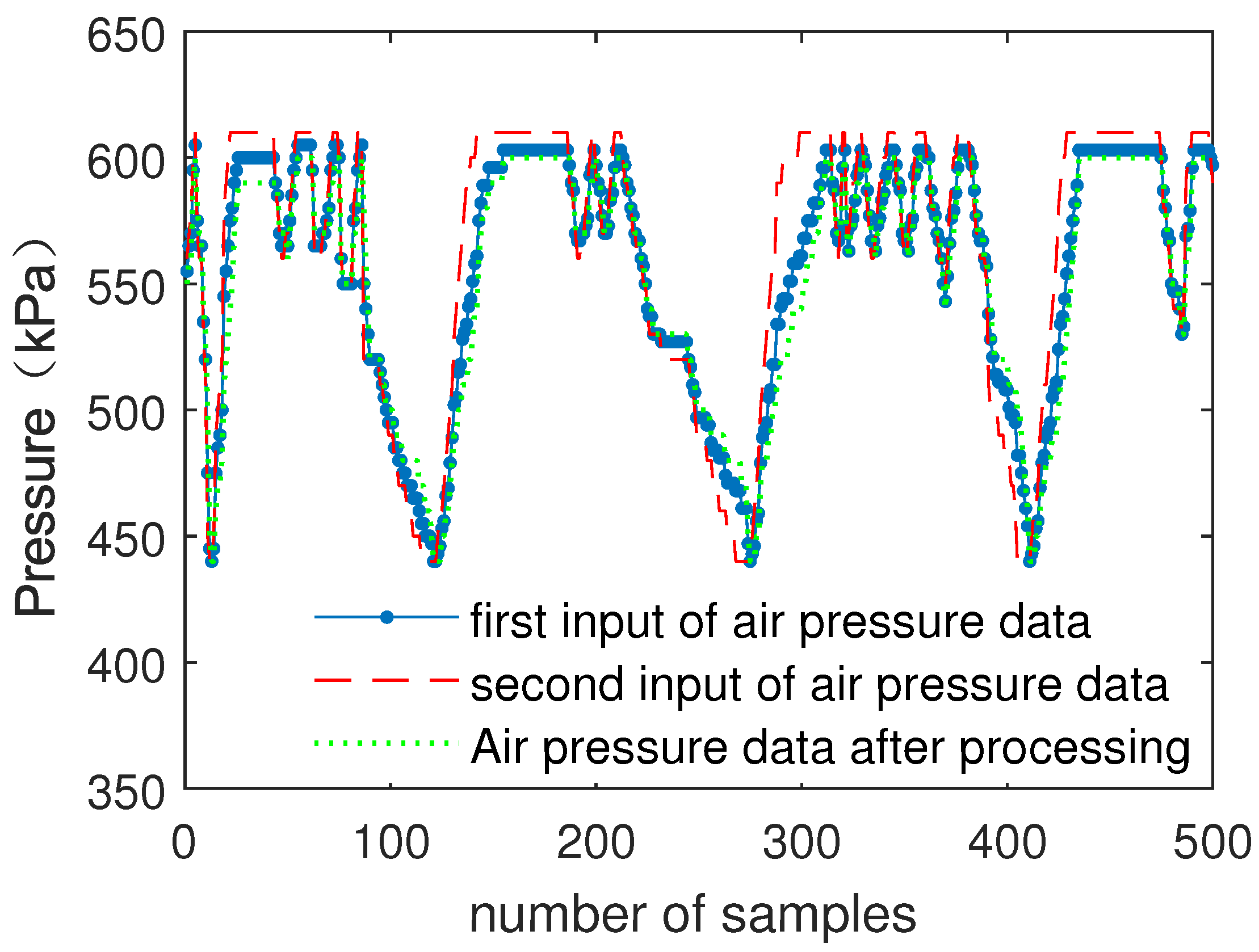
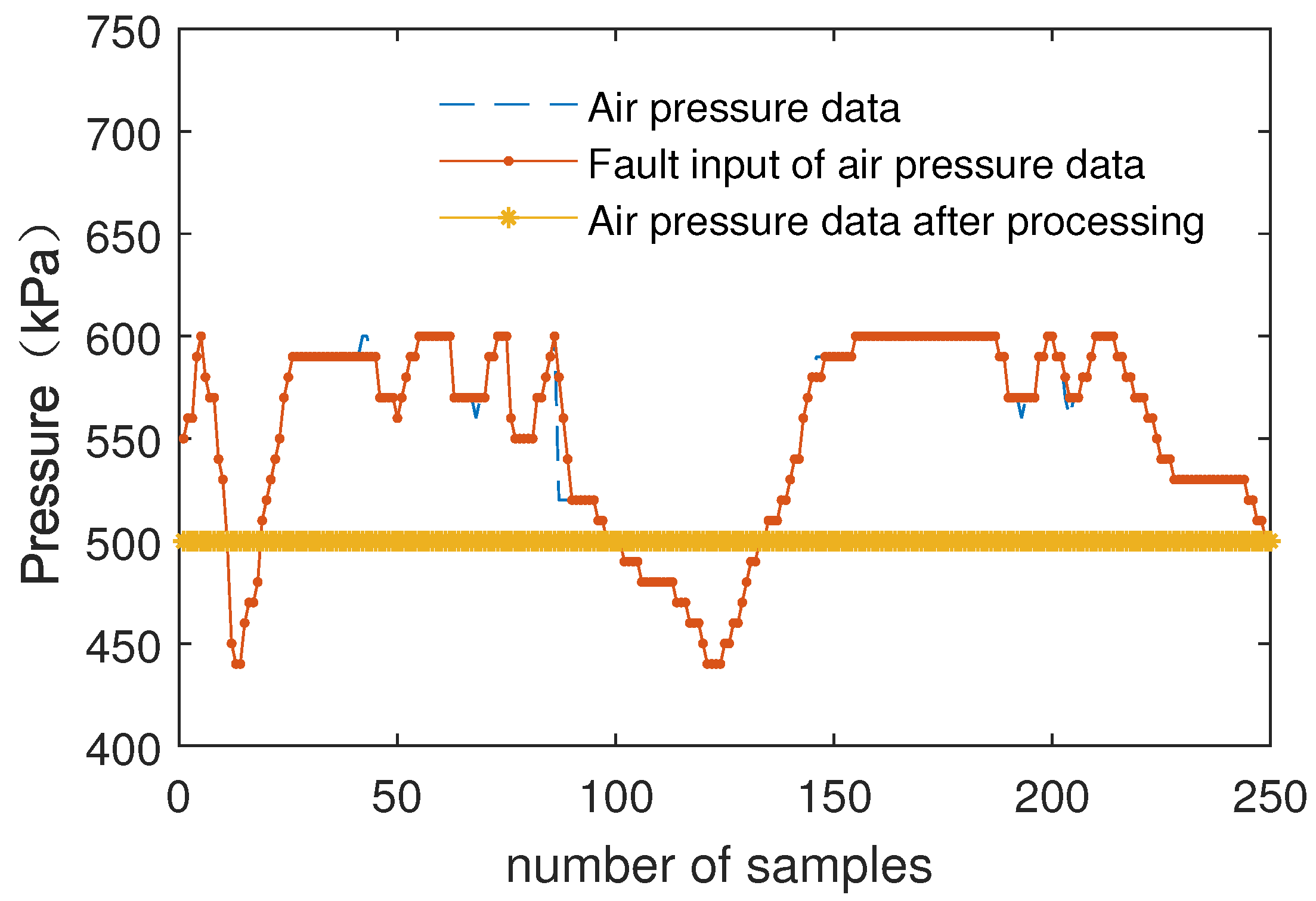
4.3. Algorithm Analysis and Verification
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FID3 | fuzzy iterative dichotomizer 3 |
References
- Zhang, Y.Z.; Cao, Y.Y.; Wen, H.; Liang, L.; Zou, F. Optimization of information interaction protocols in cooperative vehicle-Infrastructure systems. Chin. J. Electron. 2018, 27, 439–444. [Google Scholar] [CrossRef]
- Cao, Y.; Ma, L.C.; Zhang, Y.Z. Application of fuzzy predictive control technology in automatic train operation. Cluster Comput. 2018, 1–10. [Google Scholar] [CrossRef]
- Cao, Y.; Li, P.; Zhang, Y.Z. Parallel processing algorithm for railway signal fault diagnosis data based on cloud computing. Future Gener. Comput. Syst. 2018, 88, 279–283. [Google Scholar] [CrossRef]
- Cao, Y.; Ma, W.G.; Ma, L.C. Local fractional functional method for solving diffusion equations on cantor sets. In Abstract and Applied Analysis; Hindawi: London, UK, 2014; Volume 2014, pp. 279–283. [Google Scholar]
- Yu, H.J. Study on High-Speed Train Speed Information Fusion Technology Based on Weighted Fusion Algorithm; Lanzhou Jiaotong University: Lanzhou, China, 2014. [Google Scholar]
- Meng, X.Y. High-Speed EMU’s Brake and the Air Supply System Simulation and Analysis; Southwest Jiaotong University: Chengdu, China, 2015. [Google Scholar]
- Huang, Q.; Liu, J.; Wang, W. Study on multi-input processing algorithm research based on fuzzy principle in nuclear power plant instrumentation and control system. Chin. J. Nucl. Sci. Eng. 2015, 35, 785–789. [Google Scholar]
- Zhang, S.C. Data processing in nuclear power plant. J. Guangxi Normal Univ. (Nat. Sci. Ed.) 1997, 4, 32–37. [Google Scholar]
- Liu, Q.; Shi, Z.K. A new multi-Input fuzzy logic controller and its application to flight control. Flight Dyn. 1999, 17, 49–54. [Google Scholar]
- Dong, Y.; Yang, J.P.; Cheng, J.Q. Research on Acquisition Method of Analog Signal in Flight Control Computer. Ind. Control Comput. 2015, 2. [Google Scholar] [CrossRef]
- Lu, H.K.; Cao, Y.; Ma, L.C. Analysis on common mode fault of heterogeneous safety computer system based on dynamic fault tree method. Railw. Comput. Appl. 2017, 9. [Google Scholar] [CrossRef]
- Sun, Y.K.; Xie, G.; Cao, Y.; Wen, T. Strategy for fault diagnosis on train plug doors using audio sensors. Sensors 2019, 19, 3. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.J. A Software Effort Estimation Method Based on Fuzzy Decision Tree; National University of Defense Technology: Changsha, China, 2010. [Google Scholar]
- Fu, W.Y. Study on the Application of the Fuzzy Decision Tree and System Design Implement; South China University of Technology: Guangzhou, China, 2014. [Google Scholar]
- Janikow, C.Z. Fuzzy decision trees: Issues and methods. IEEE Trans. Syst. Man Cybern. Part B 1998, 28, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Yager, R.R.; Filev, D.P. Parameterized and-uke and or-like owa operators. Int. J. Gen. Syst. 1994, 22, 297–316. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, X.G.; Lu, G.S. Weighted attribute information fusion based on OWA aggregation operator. Chin. J. Sci. Instrum. 2006, 27, 322–325. [Google Scholar]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decision making. Read. Fuzzy Sets Intell. Syst. 1993, 18, 80–87. [Google Scholar]
- Gong, Y.B.; Liang, X.C. Fuzzy multi-attribute decision making method based on fuzzy C-OWA operator. Syst. Eng. Electron. 2008, 8, 022. [Google Scholar]




© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Lu, H.; Wen, T. A Safety Computer System Based on Multi-Sensor Data Processing. Sensors 2019, 19, 818. https://doi.org/10.3390/s19040818
Cao Y, Lu H, Wen T. A Safety Computer System Based on Multi-Sensor Data Processing. Sensors. 2019; 19(4):818. https://doi.org/10.3390/s19040818
Chicago/Turabian StyleCao, Yuan, Hongkang Lu, and Tao Wen. 2019. "A Safety Computer System Based on Multi-Sensor Data Processing" Sensors 19, no. 4: 818. https://doi.org/10.3390/s19040818
APA StyleCao, Y., Lu, H., & Wen, T. (2019). A Safety Computer System Based on Multi-Sensor Data Processing. Sensors, 19(4), 818. https://doi.org/10.3390/s19040818