Smartphone-Based Activity Recognition for Indoor Localization Using a Convolutional Neural Network †



Abstract
:1. Introduction
2. Related Works
2.1. Sensors Used for Human Activity Recognition
2.1.1. Ambient Sensors
2.1.2. Wearable Sensors
2.2. Methods Used for Human Activity Recognition
2.2.1. Traditional Machine Learning Methods
2.2.2. Deep Learning Methods
3. Methodology
3.1. Activities for Indoor Localization
3.2. Hardware and Software Setup
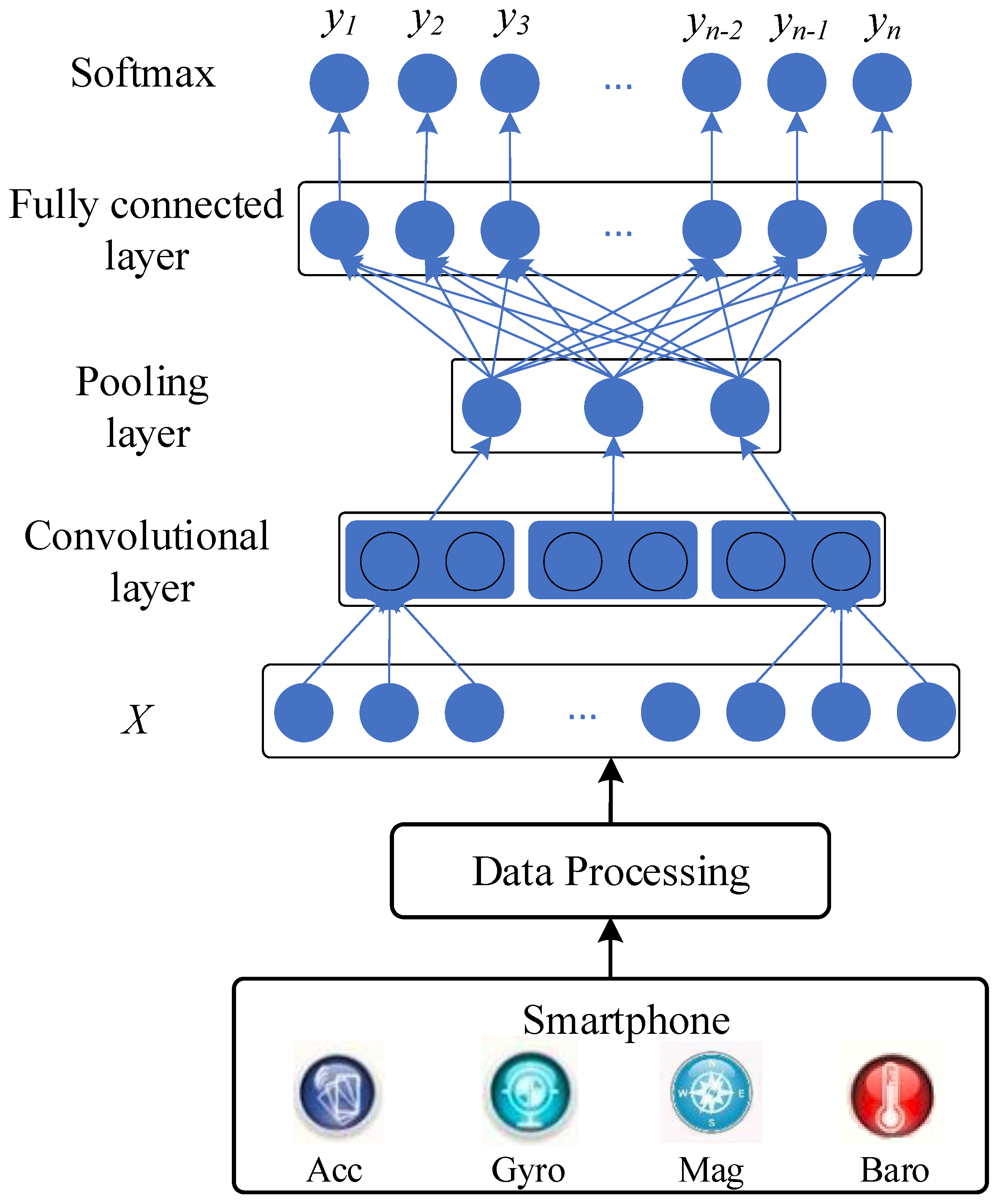
3.3. Proposed CNN-Based Method
3.3.1. Architecture
3.3.2. Data Segmentation
3.3.3. CNN for Activity Recognition
3.3.4. Training Strategies
4. Experiments and Results
4.1. Dataset and Experimental Setup
4.2. Hyperparameter Settings
4.3. Impact of Different Parameters
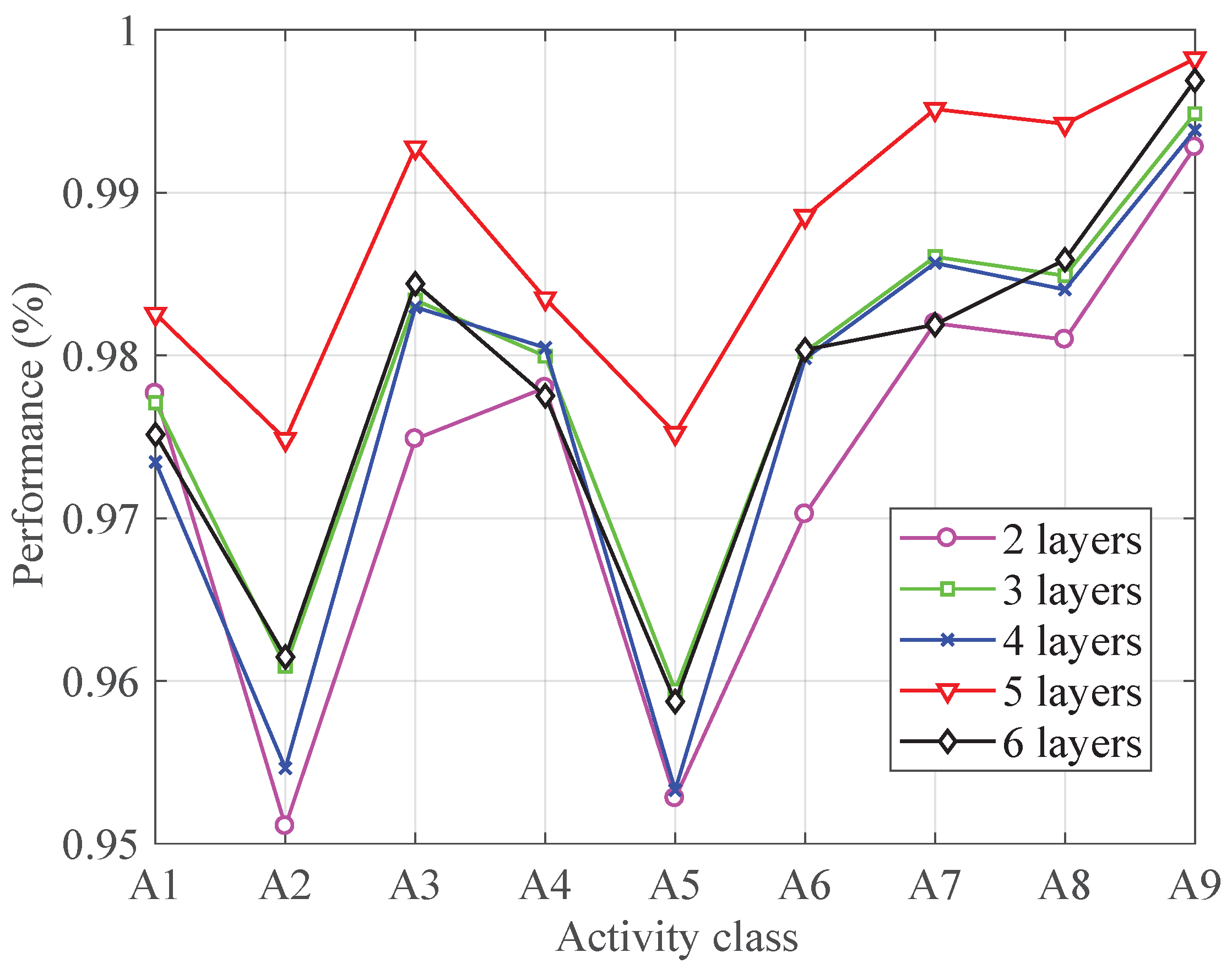
4.3.1. Number of Layers
4.3.2. Filter Size
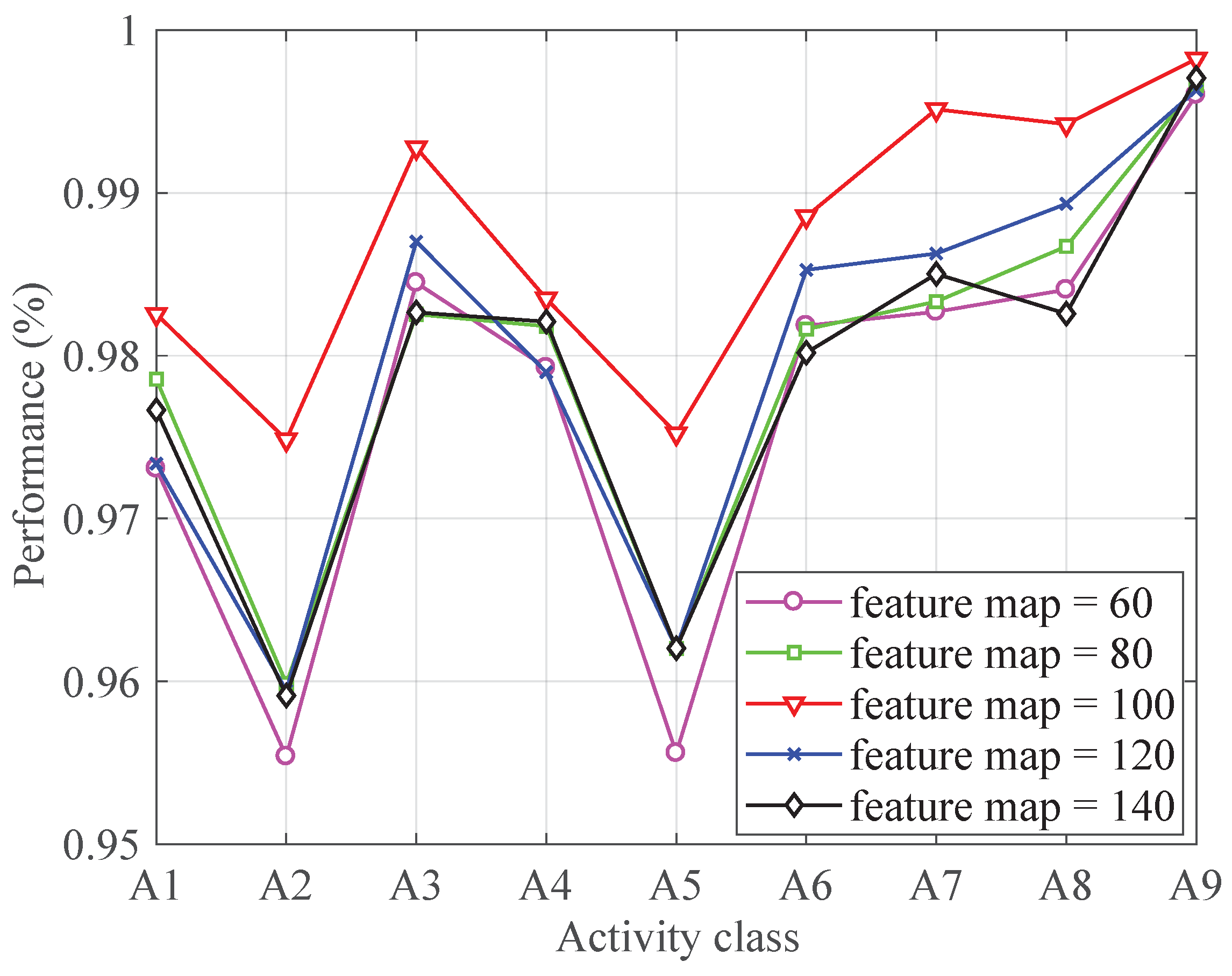
4.3.3. Number of Feature Maps
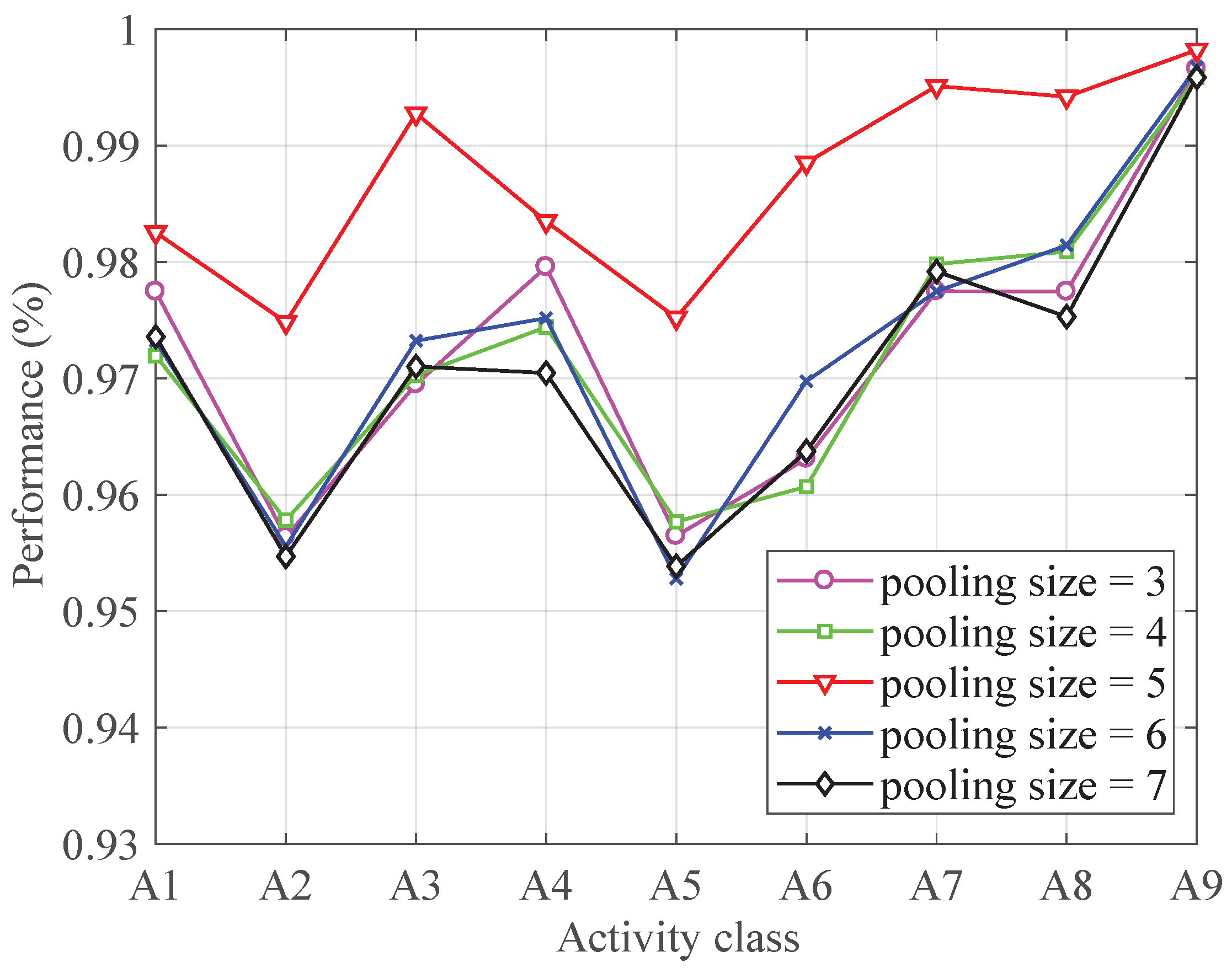
4.3.4. Pooling Size
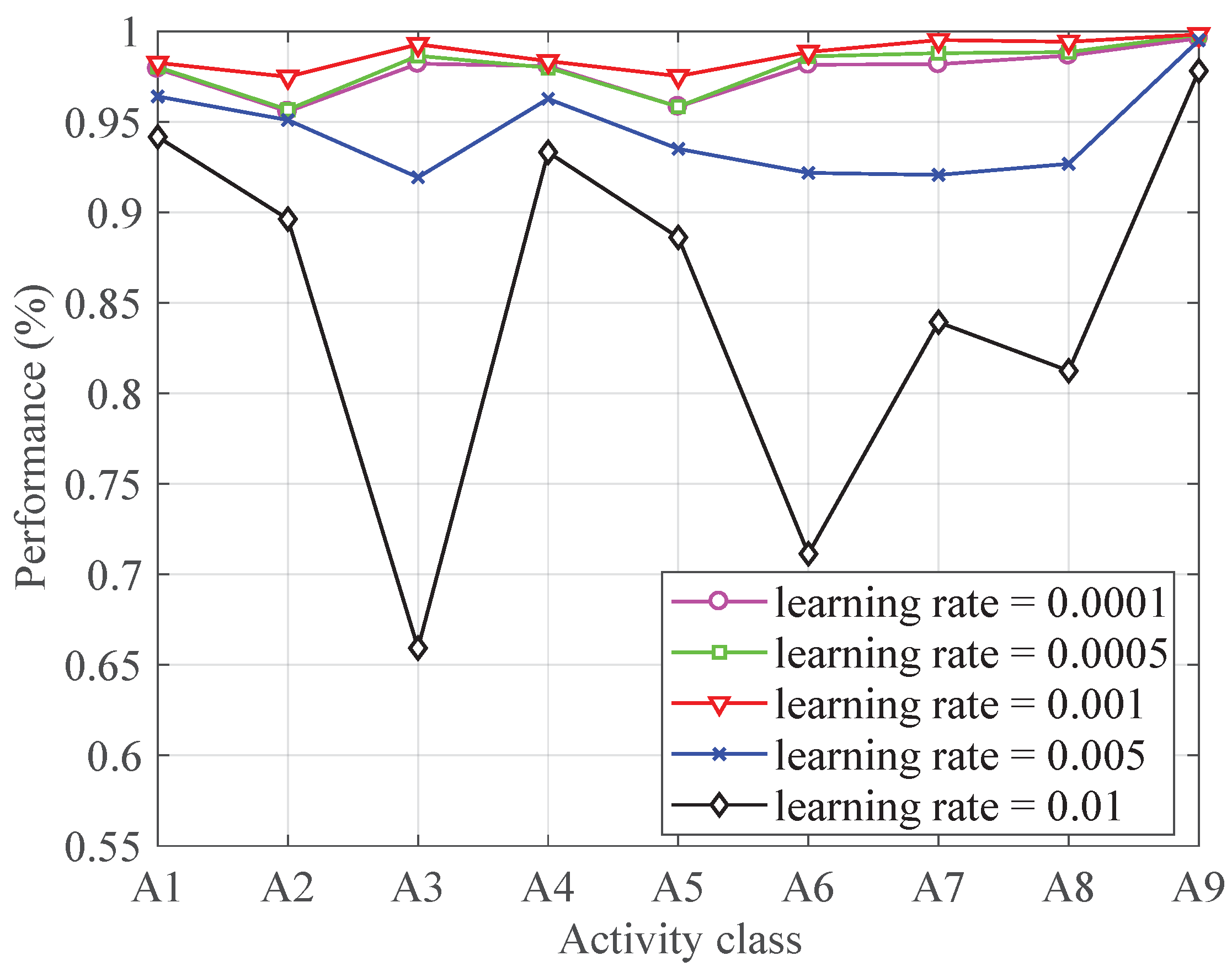
4.3.5. Learning Rate
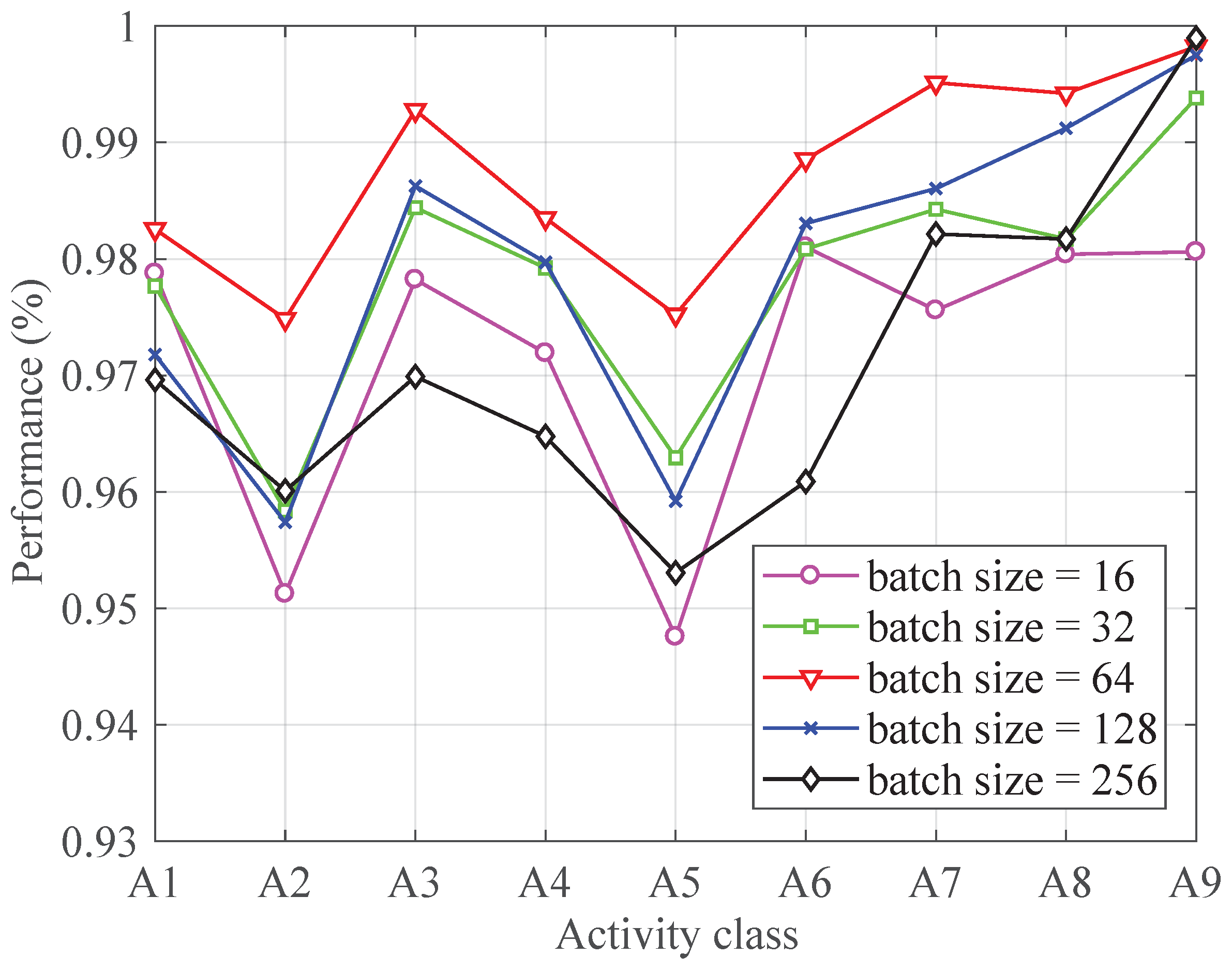
4.3.6. Batch Size
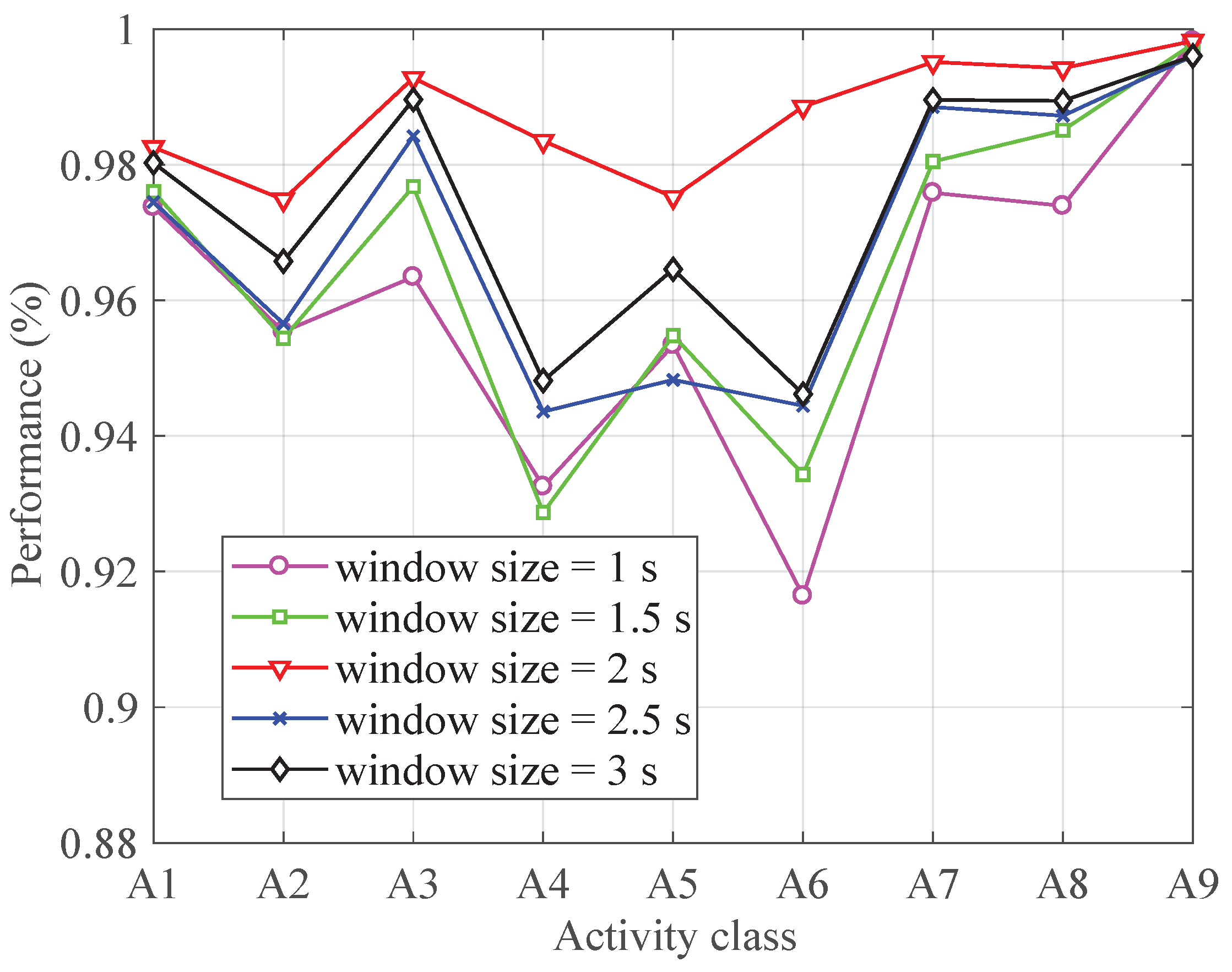
4.4. Impact of Different Window Size
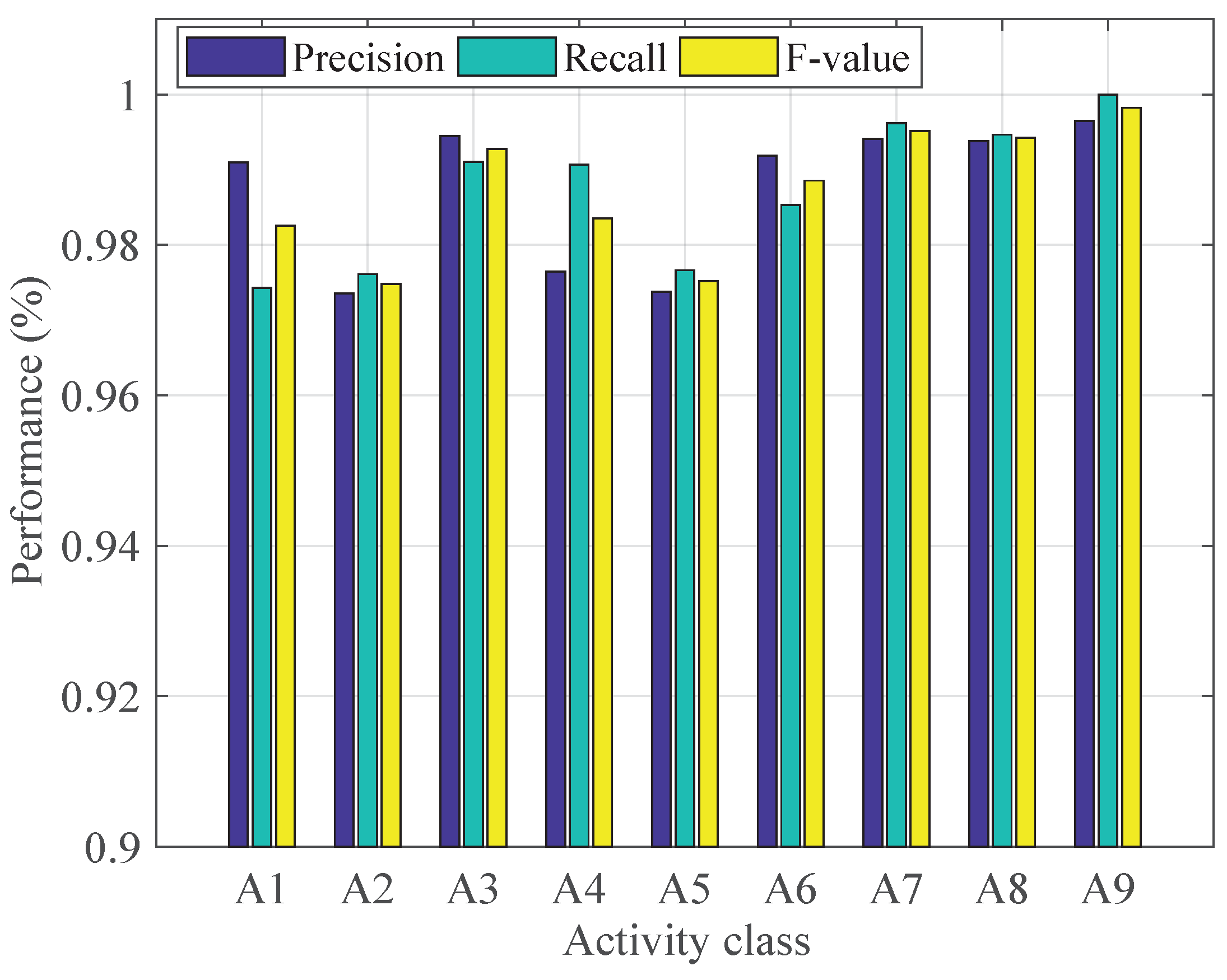
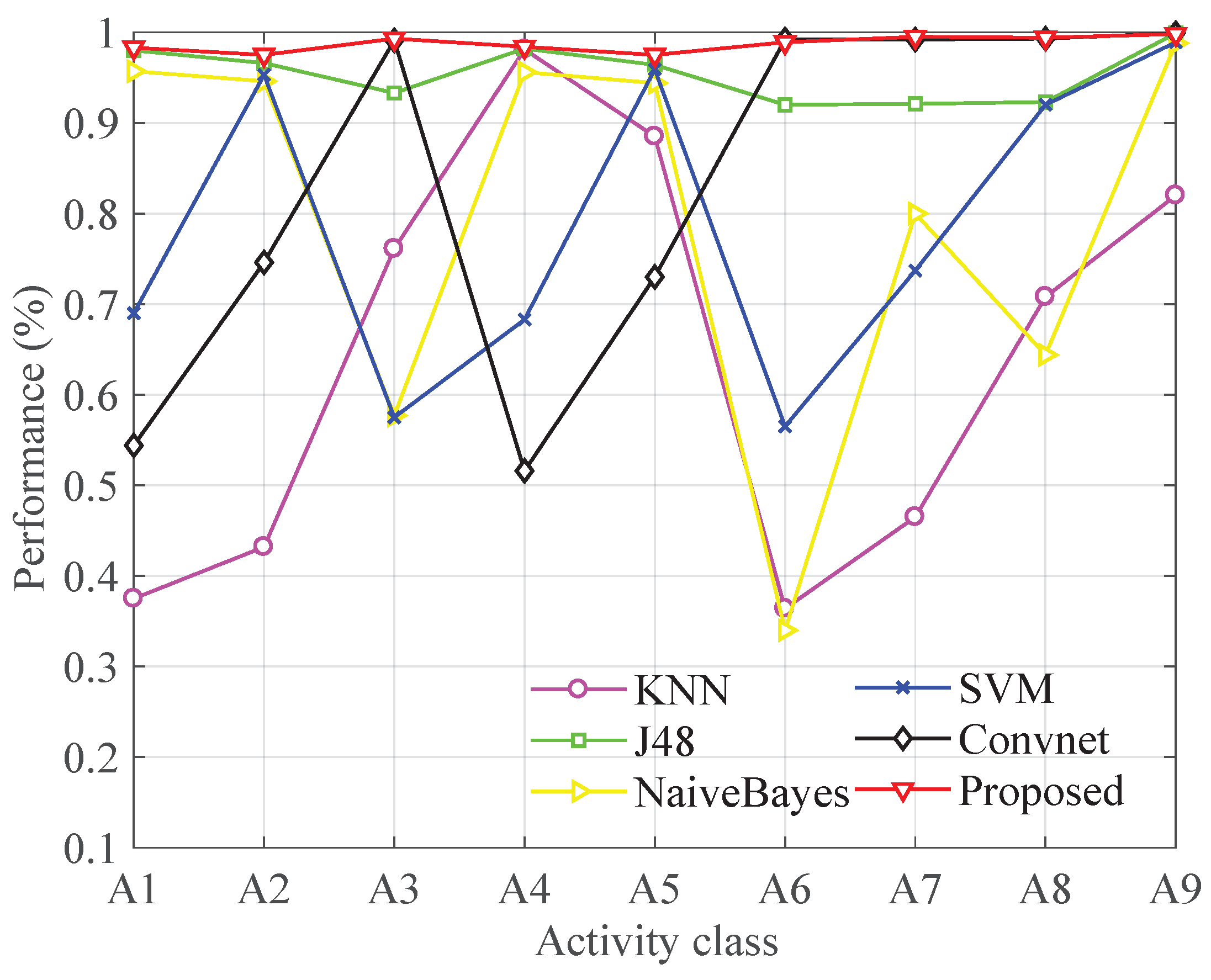
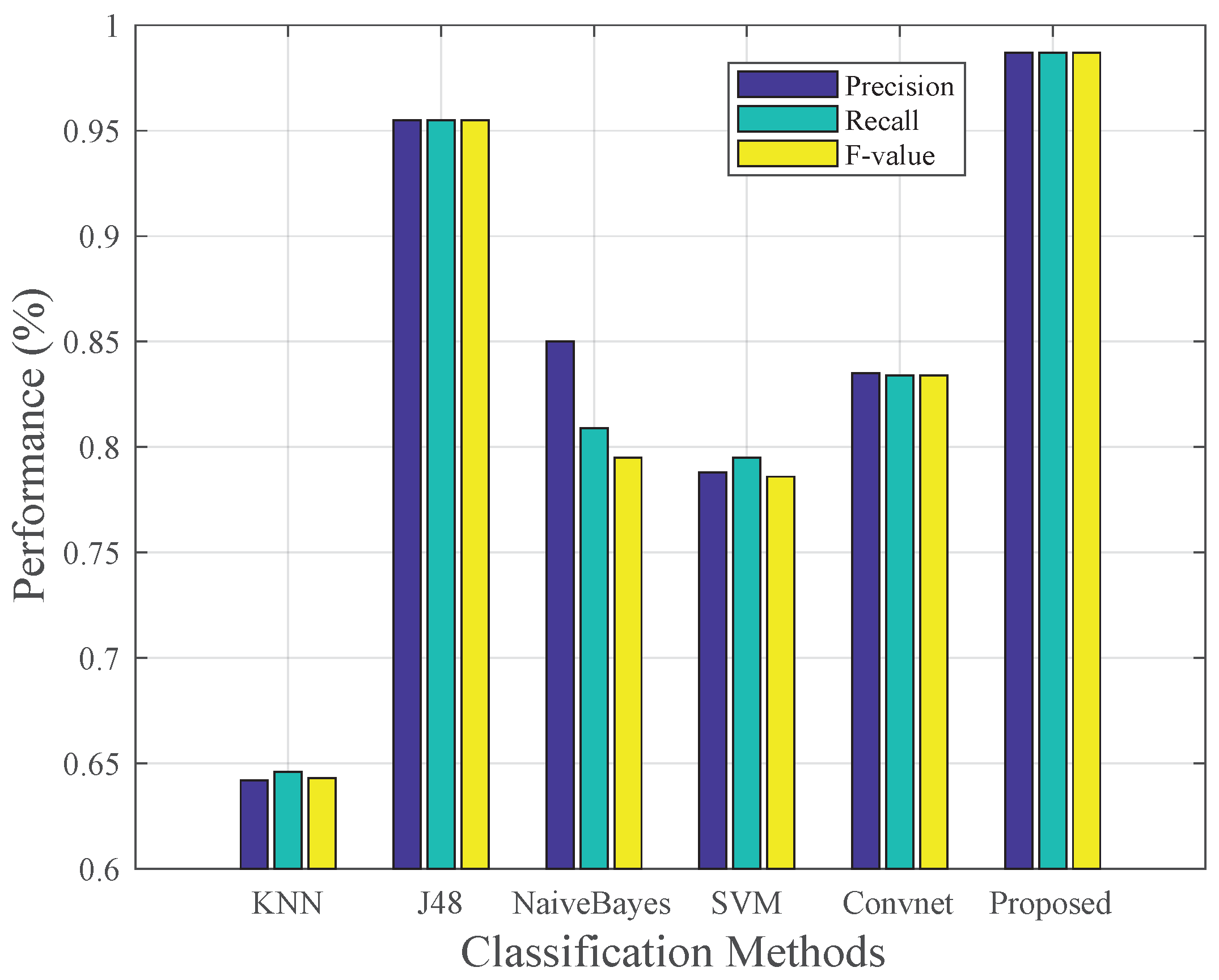
4.5. Classification Performance
4.6. Comparison with Other Classification Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, H.; Sen, S.; Elgohary, A.; Farid, M.; Youssef, M.; Choudhury, R.R. No need to war-drive: Unsupervised indoor localization. In Proceedings of the 10th International Conference on Mobile Systems, Applications, and Services, Lake District, UK, 26–29 June 2012; pp. 197–210. [Google Scholar]
- Zhou, B.; Li, Q.; Mao, Q.; Tu, W.; Zhang, X. Activity sequence-based indoor pedestrian localization using smartphones. IEEE Trans. Hum. Mach. Syst. 2015, 45, 562–574. [Google Scholar] [CrossRef]
- Zhou, B.; Li, Q.; Mao, Q.; Tu, W.; Zhang, X.; Chen, L. ALIMC: Activity landmark-based indoor mapping via crowdsourcing. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2774–2785. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Mohamed, R.; Elgohary, A.; Alzantot, M.F.; Wang, H.; Sen, S.; Choudhury, R.R.; Youssef, M. SemanticSLAM: Using environment landmarks for unsupervised indoor localization. IEEE Trans. Mob. Comput. 2016, 15, 1770–1782. [Google Scholar] [CrossRef]
- Zhou, B.; Li, Q.; Mao, Q.; Tu, W. A robust Crowdsourcing-based indoor localization system. Sensors 2017, 17, 864. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Gao, Q.; Wang, J.; Ma, X.; Feng, X.; Wang, H. CSI-Based Device-Free Wireless Localization and Activity Recognition Using Radio Image Features. IEEE Trans. Veh. Technol. 2017, 66, 10346–10356. [Google Scholar] [CrossRef]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.Y. A comparative study on human activity recognition using inertial sensors in a smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Plötz, T.; Hammerla, N.Y.; Olivier, P. Feature learning for activity recognition in ubiquitous computing. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; Volume 22, p. 1729. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; The MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Proc. Lett. 2014, 21, 65–68. [Google Scholar] [CrossRef]
- Fang, S.H.; Fei, Y.X.; Xu, Z.; Tsao, Y. Learning Transportation Modes From Smartphone Sensors Based on Deep Neural Network. IEEE Sens. J. 2017, 17, 6111–6118. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-based fingerprinting for indoor localization: A deep learning approach. IEEE Trans. Veh. Technol. 2017, 66, 763–776. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3d data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, K.; Ni, L.M. Wifall: Device-free fall detection by wireless networks. IEEE Trans. Mob. Comput. 2017, 16, 581–594. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Chen, Y.; Gruteser, M.; Yang, J.; Liu, H. E-eyes: device-free location-oriented activity identification using fine-grained wifi signatures. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 617–628. [Google Scholar]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Understanding and modeling of wifi signal based human activity recognition. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, Paris, France, 7–11 September 2015; pp. 65–76. [Google Scholar]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Device-Free Human Activity Recognition Using Commercial WiFi Devices. IEEE J. Sel. Areas Commun. 2017, 35, 1118–1131. [Google Scholar] [CrossRef]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of posture and motion by accelerometry: A validation study in ambulatory monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Proceedings of the International Conference on Pervasive Computing, Augsburg, Germany, 23–26 March 2004; pp. 1–17. [Google Scholar]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; Volume 5, pp. 1541–1546. [Google Scholar]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. A triaxial accelerometer-based physical-activity recognition via augmented-signal features and a hierarchical recognizer. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1166–1172. [Google Scholar] [CrossRef]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical human activity recognition using wearable sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A mobile platform for real-time human activity recognition. In Proceedings of the Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 667–671. [Google Scholar]
- Sharma, A.; Lee, Y.D.; Chung, W.Y. High accuracy human activity monitoring using neural network. In Proceedings of the Third International Conference on Convergence and Hybrid Information Technology, Busan, Korea, 11–13 November 2008; Volume 1, pp. 430–435. [Google Scholar]
- Wu, W.; Dasgupta, S.; Ramirez, E.E.; Peterson, C.; Norman, G.J. Classification accuracies of physical activities using smartphone motion sensors. J. Med. Internet Res. 2012, 14, e130. [Google Scholar] [CrossRef] [PubMed]
- Riboni, D.; Bettini, C. COSAR: hybrid reasoning for context-aware activity recognition. Pers. Ubiquitous Comput. 2011, 15, 271–289. [Google Scholar] [CrossRef]
- He, Z.Y.; Jin, L.W. Activity recognition from acceleration data using AR model representation and SVM. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; Volume 4, pp. 2245–2250. [Google Scholar]
- Lee, S.; Le, H.X.; Ngo, H.Q.; Kim, H.I.; Han, M.; Lee, Y.K. Semi-Markov conditional random fields for accelerometer-based activity recognition. Appl. Intell. 2011, 35, 226–241. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time series classification using multi-channels deep convolutional neural networks. In Proceedings of the International Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; pp. 298–310. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Gu, F.; Khoshelham, K.; Valaee, S.; Shang, J.; Zhang, R. Locomotion Activity Recognition Using Stacked Denoising Autoencoders. IEEE Intenet Things 2018, 99, 2085–2093. [Google Scholar] [CrossRef]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2005, 27, 861–874. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Activity | Definition |
|---|---|---|
| A1 | down elevator | Taking an elevator downward |
| A2 | down escalator | Taking an escalator downward |
| A3 | downstairs | Going down stairs |
| A4 | up elevator | Taking an elevator upward |
| A5 | up escalator | Taking an escalator upward |
| A6 | upstairs | Going up stairs |
| A7 | turning | Turn a corner |
| A8 | walking | The user walks naturally |
| A9 | still | The user remains static |
| Software & Hardware | Configuration |
|---|---|
| CPU | Intel Xeon(R) CPU E5-2690 V4 @2.60 GHz × 28 |
| Memory | 64 GB |
| Graphics card | GeForce GTX 1080Ti× 2 |
| CUDA | Cuda 8.0 |
| cuDNN | Cudnn 6.0 |
| GCC | Gcc 5.4.0 |
| Python | Python 2.7 |
| Tensorflow | Tensorflow 1.4.0 |
| No. | Height (cm) | Gender | Age |
|---|---|---|---|
| 1 | 163 | female | 25 |
| 2 | 168 | male | 24 |
| 3 | 173 | male | 26 |
| 4 | 180 | male | 22 |
| 5 | 180 | male | 25 |
| 6 | 168 | male | 24 |
| 7 | 165 | female | 23 |
| 8 | 186 | male | 22 |
| 9 | 162 | female | 24 |
| 10 | 172 | male | 31 |
| Hyperparmeters | Description | Values |
|---|---|---|
| Number of convolutional layers | 2, 3, 4, 5, 6 | |
| Filter size | 2, 5, 10, 15, 20 | |
| Number of feature maps | 60, 80, 100, 120, 140 | |
| Pooling size | 3, 4, 5, 6, 7 | |
| Learning rate | 0.0001, 0.0005, 0.001, 0.005, 0.01 | |
| Batch size | 16, 32, 64, 128, 256, 512 |
| Predicted | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Actual | ||||||||||
| A1 | 3294 | 18 | 2 | 58 | 3 | 4 | 0 | 0 | 2 | |
| A2 | 15 | 3352 | 0 | 1 | 66 | 0 | 0 | 0 | 0 | |
| A3 | 4 | 1 | 3435 | 5 | 0 | 9 | 5 | 6 | 1 | |
| A4 | 7 | 3 | 2 | 3398 | 16 | 1 | 0 | 1 | 2 | |
| A5 | 2 | 65 | 0 | 11 | 3345 | 1 | 0 | 0 | 1 | |
| A6 | 1 | 3 | 9 | 6 | 4 | 3281 | 12 | 9 | 5 | |
| A7 | 0 | 0 | 5 | 0 | 0 | 3 | 3372 | 5 | 0 | |
| A8 | 1 | 1 | 1 | 1 | 1 | 9 | 3 | 3353 | 1 | |
| A9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3384 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, B.; Yang, J.; Li, Q. Smartphone-Based Activity Recognition for Indoor Localization Using a Convolutional Neural Network. Sensors 2019, 19, 621. https://doi.org/10.3390/s19030621
Zhou B, Yang J, Li Q. Smartphone-Based Activity Recognition for Indoor Localization Using a Convolutional Neural Network. Sensors. 2019; 19(3):621. https://doi.org/10.3390/s19030621
Chicago/Turabian StyleZhou, Baoding, Jun Yang, and Qingquan Li. 2019. "Smartphone-Based Activity Recognition for Indoor Localization Using a Convolutional Neural Network" Sensors 19, no. 3: 621. https://doi.org/10.3390/s19030621
APA StyleZhou, B., Yang, J., & Li, Q. (2019). Smartphone-Based Activity Recognition for Indoor Localization Using a Convolutional Neural Network. Sensors, 19(3), 621. https://doi.org/10.3390/s19030621