Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning


Abstract
1. Introduction
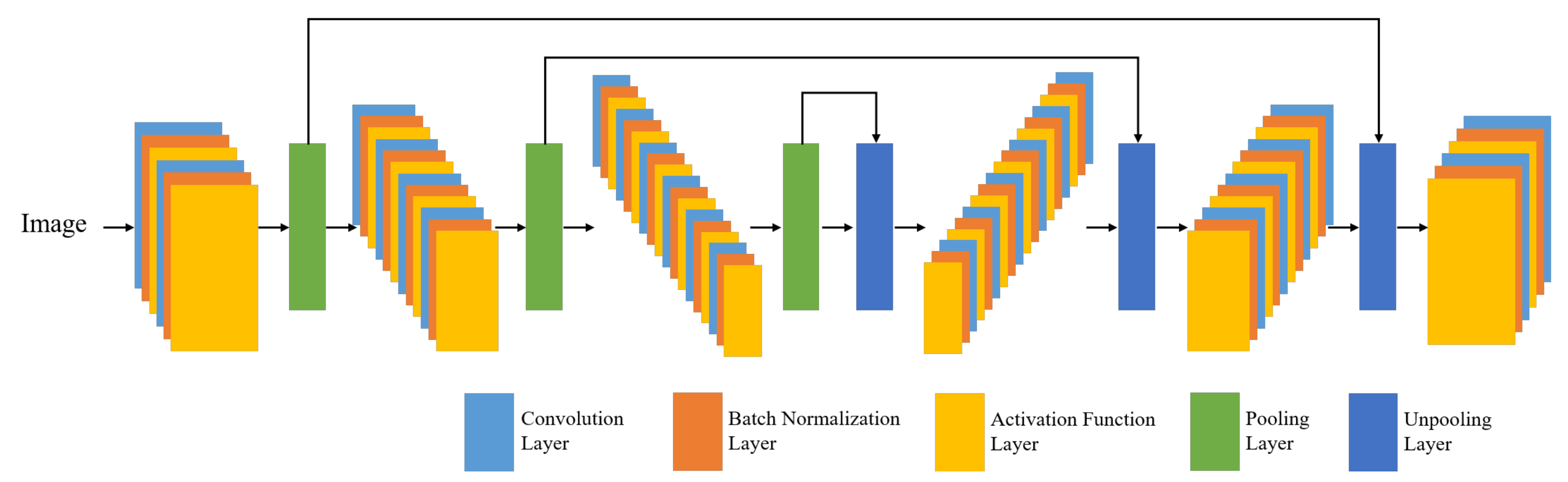
2. Fully Convolutional Neural Networks
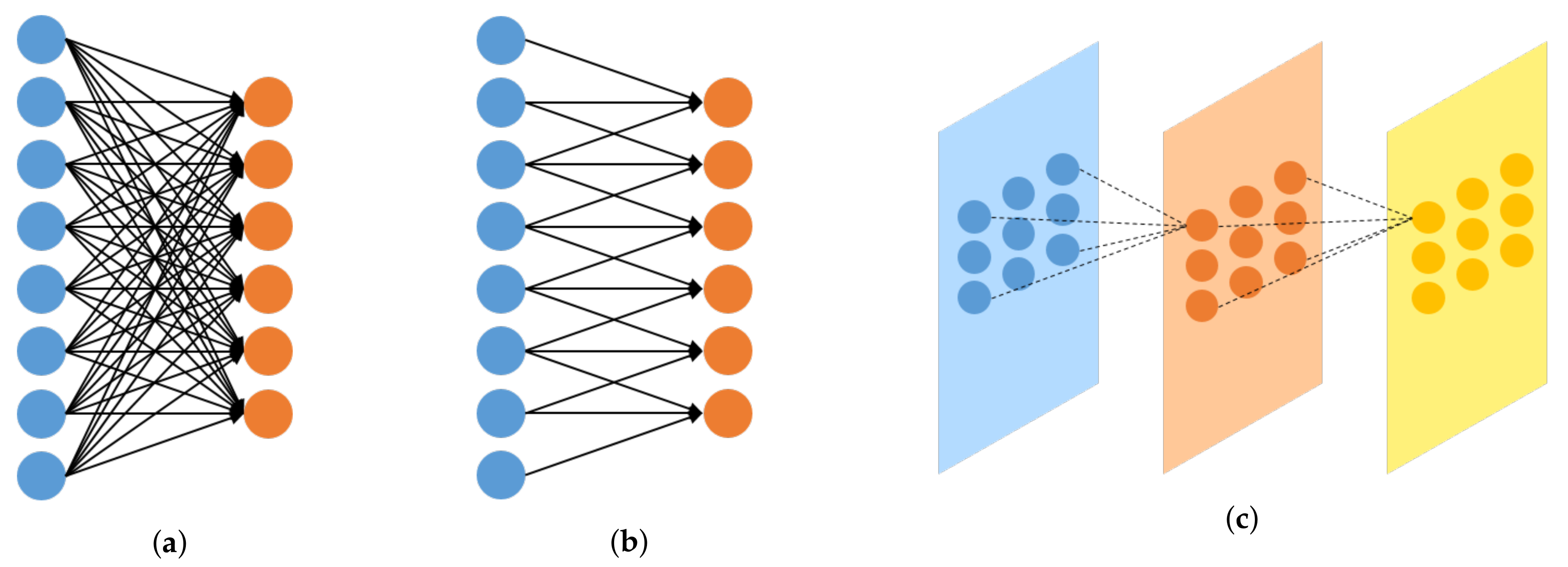
2.1. Convolutional Neural Network (CNN)
2.2. Deconvolutional Neural Network
2.3. Batch Normalization and Activation Function
2.4. Skip Connections
3. Road Surface Damage Detection
3.1. Creating the Training DB
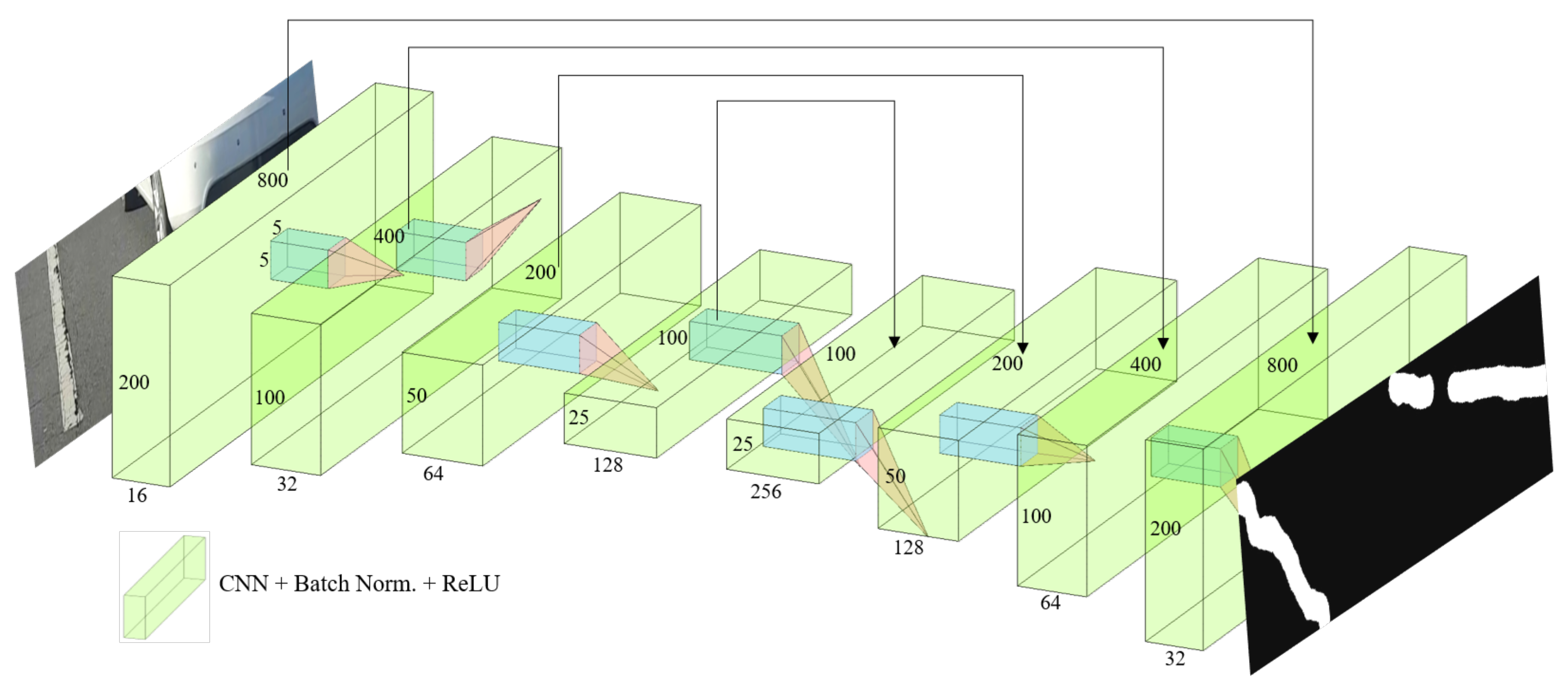
3.2. Neural Network Architecture
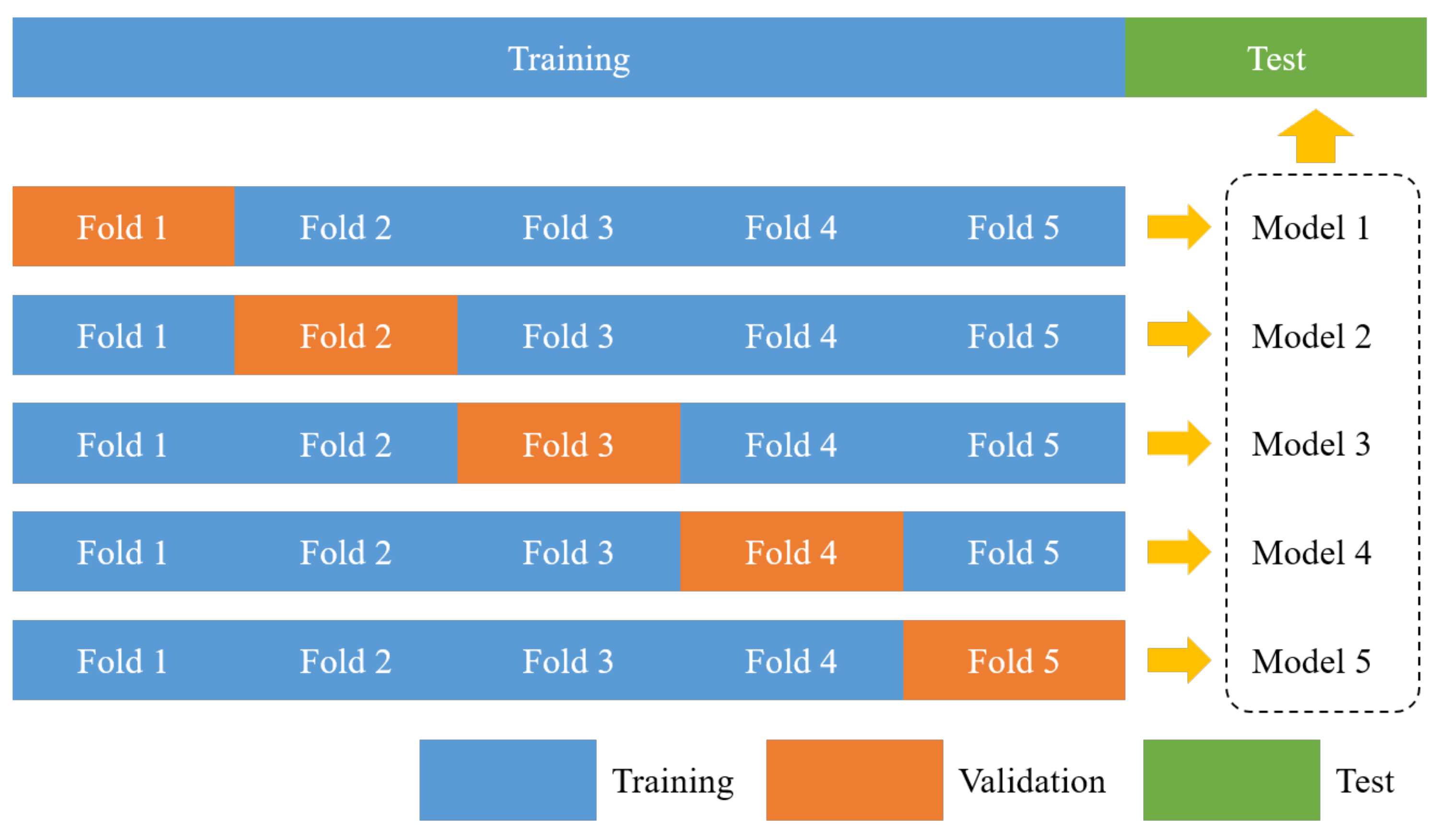
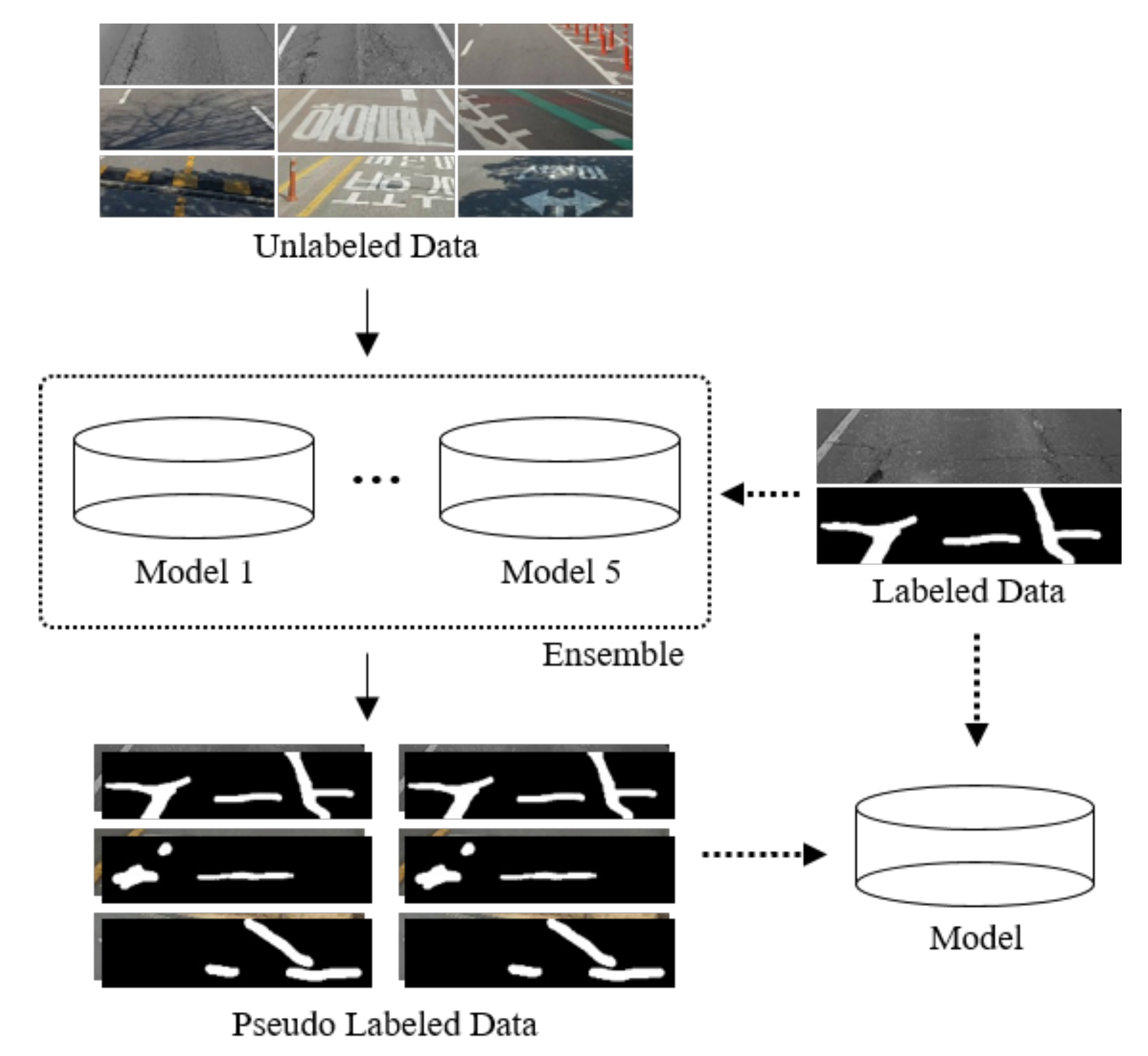
4. Semi-Supervised Learning Using Pseudo Labels
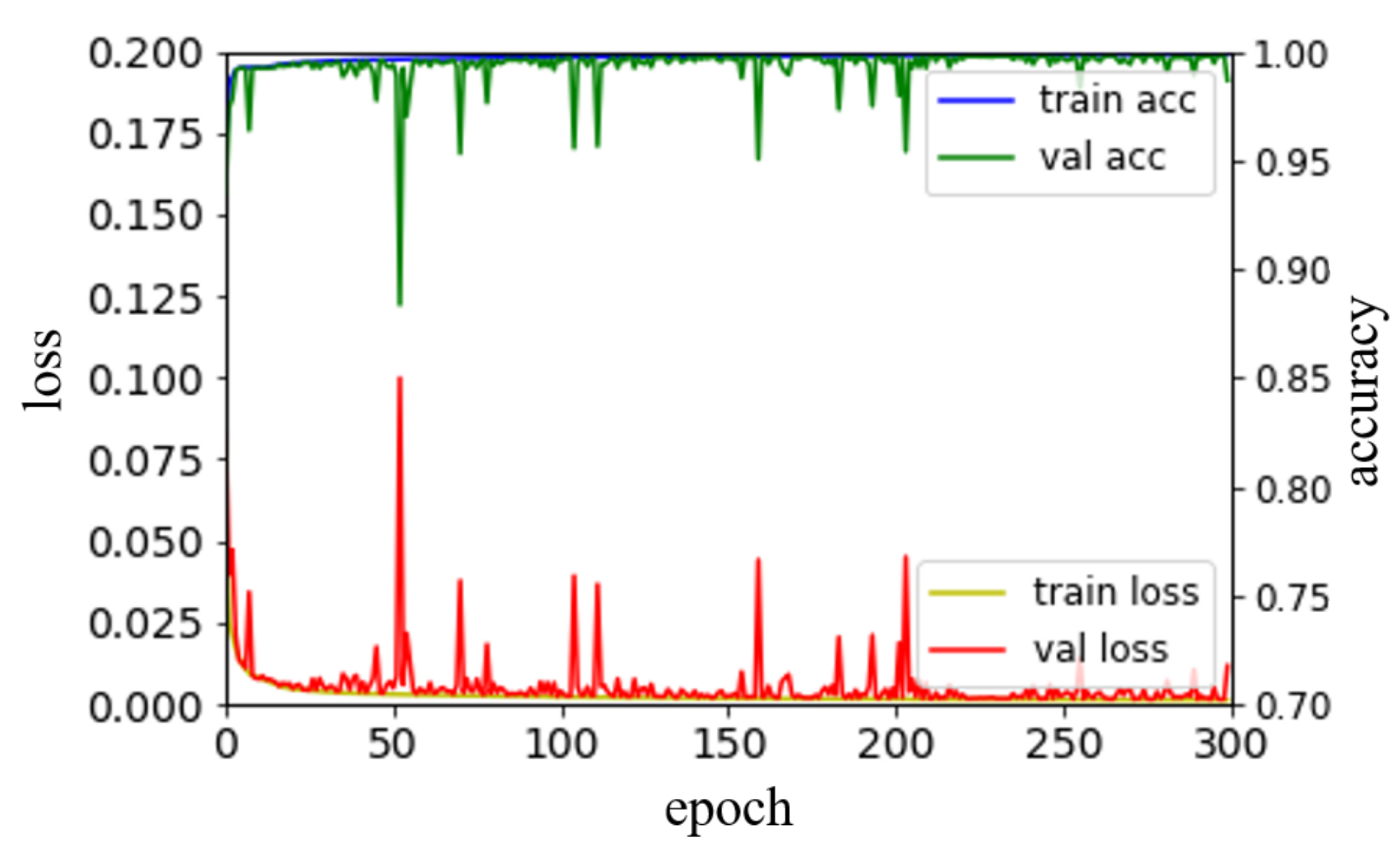
5. Performance Results and Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, T.; Ryu, S.-K. Review and analysis of pothole detection methods. J. Emerg. Trends Comput. Inf. Sci. 2014, 5, 603–608. [Google Scholar]
- Mednis, A.; Strazdins, G.; Zviedris, R.; Kanonirs, G.; Selavo, L. Real time pothole detection using Android smartphones with accelerometers. In Proceedings of the IEEE International Conference on Distributed Computing in Sensor Systems and Workshops, Barcelona, Spain, 27–29 June 2011. [Google Scholar] [CrossRef]
- Yamada, T.; Ito, T.; Ohya, A. Detection of road surface damage using mobile robot equipped with 2D laser scanner. In Proceedings of the 2013 IEEE/SICE International Symposium on System Integration, Kobe, Japan, 15–17 December 2013; pp. 250–256. [Google Scholar] [CrossRef]
- Jo, Y.; Ryu, S.-K. Pothole detection system using a black-box camera. Sensors 2015, 15, 29316–29331. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, ON, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection using deep neural networks with images captured through a smartphone. arXiv 2018, arXiv:1801.09454v1. [Google Scholar]
- Angulo, A.A.; Vega-Fernández, J.A.; Aguilar-Lobo, L.M.; Natraj, S.; Ochoa-Ruiz, G. Road damage detection acquisition system based on deep neural networks for physical asset management. arXiv 2019, arXiv:1909.08991v1. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Cholaquidis, A.; Fraimand, R.; Sued, M. On semi-supervised learning. arXiv 2018, arXiv:1805.09180v2. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local deno ising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. Proc. Interspeech 2013, 1, 436–440. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. arXiv 2014, arXiv:1404.7828v4. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image restoration using convolutional auto-encoders with symmetric skip connections. arXiv 2016, arXiv:1606.08921v3. [Google Scholar]
- Han, W.; Wu, C.; Zhang, X.; Sun, M.; Min, G. Speech enhancement based on improved deep neural networks with MMSE pretreatment features. In Proceedings of the IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Maclin, R.; Opitz, D. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the 27th European Conference on Advances in Information Retrieval Research (ECIR), Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Marking | Facilities | Grooving | Shadows | Vehicles | Damages | Total | |
|---|---|---|---|---|---|---|---|
| # of images | 1260 | 587 | 599 | 451 | 681 | 3178 | 6756 |
| Percentage | 18.7% | 8.7% | 8.9% | 6.7% | 10.1% | 47.0% | 100.0% |
| Tp | Tn | Fp | Fn | Precision | Recall | Accuracy | F1-Score | ||
|---|---|---|---|---|---|---|---|---|---|
| Supervised | Expert I | 112 | 281 | 47 | 10 | 0.7044 | 0.9180 | 0.8733 | 0.7972 |
| Expert II | 105 | 263 | 77 | 5 | 0.5769 | 0.9545 | 0.8178 | 0.7192 | |
| Expert III | 125 | 263 | 51 | 11 | 0.7102 | 0.9191 | 0.8622 | 0.8013 | |
| Expert IV | 111 | 311 | 18 | 10 | 0.8605 | 0.9174 | 0.9378 | 0.8880 | |
| Total | 453 | 1118 | 193 | 36 | 0.7012 | 0.9264 | 0.8728 | 0.7982 | |
| Semi- supervised | Expert I | 119 | 308 | 13 | 10 | 0.9015 | 0.9225 | 0.9489 | 0.9119 |
| Expert II | 111 | 309 | 14 | 16 | 0.8880 | 0.8740 | 0.9333 | 0.8810 | |
| Expert III | 119 | 313 | 13 | 15 | 0.9015 | 0.8881 | 0.9391 | 0.8947 | |
| Expert IV | 108 | 312 | 10 | 20 | 0.9153 | 0.8438 | 0.9333 | 0.8781 | |
| Total | 457 | 1242 | 50 | 61 | 0.9014 | 0.8822 | 0.9387 | 0.8917 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chun, C.; Ryu, S.-K. Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning. Sensors 2019, 19, 5501. https://doi.org/10.3390/s19245501
Chun C, Ryu S-K. Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning. Sensors. 2019; 19(24):5501. https://doi.org/10.3390/s19245501
Chicago/Turabian StyleChun, Chanjun, and Seung-Ki Ryu. 2019. "Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning" Sensors 19, no. 24: 5501. https://doi.org/10.3390/s19245501
APA StyleChun, C., & Ryu, S.-K. (2019). Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning. Sensors, 19(24), 5501. https://doi.org/10.3390/s19245501