3D Tensor Based Nonlocal Low Rank Approximation in Dynamic PET Reconstruction


Abstract
:1. Introduction
- (1)
- An innovative form of a nonlocal low rank tensor constraint is adopted in the Poisson’s model, which captures data correlation in multiple dimensions in dynamic PET, beyond just spatiotemporal correlation. For one thing, without any additional information, Poisson’s model exploits the temporal information among the frames themselves, effectively complementing the structures in low-active frames and recovering severely corrupted data. For the other, it exploits the spatial information from nonlocal self-similarities within each frame, thereby enhancing the structured sparsity for each image.
- (2)
- As an additional regularization, the total variation (TV) constraint is employed to extract local structure and further complement the denoising function. On the other hand, the expectation–maximization method is employed as a fidelity term to incorporate hidden data in the objective function and thus increase efficiency in optimization.
- (3)
- In the optimization procedure, we develop a distributed optimization framework inspired by the alternative direction method of multipliers (ADMM) [30]. In this way, the mentioned terms can be explicitly organized in a united objective function and effectively handled as three subproblems during the iterations.
2. Background
2.1. Dynamic PET Imaging Model
2.2. Tensor Decomposition
3. Method
| Algorithm 1: Dynamic PET reconstruction via Nonlocal Low-rank Tensor Approximation and Total Variation |
| Input: Sinogram and system matrix , weighting parameters , and the reference frame index . |
| 1: Initialization: . |
| 2: Repeat: |
| 3: Compute the patch sets based on the -th frame using (7). |
| 4: Construct the nonlocal featured tensor by (8) and (9). 5: Approximate the low-rank tensor by adopting t-SVT method in (13) and (21). |
| 6: Construct by updating the differential vector via (22). 7: Update the Lagrangian multiplier via (23). |
| 8: Repeat: |
| 9: E-step: Introduce the expectation variable and construct the relevant objective function in (24). |
| 10: M-step: Update using (25) and (26). |
| 11: Until: Inner Relative change |
| 12: |
| 13: Until: Relative change |
| 14: Output: Reconstructed image sequence . |
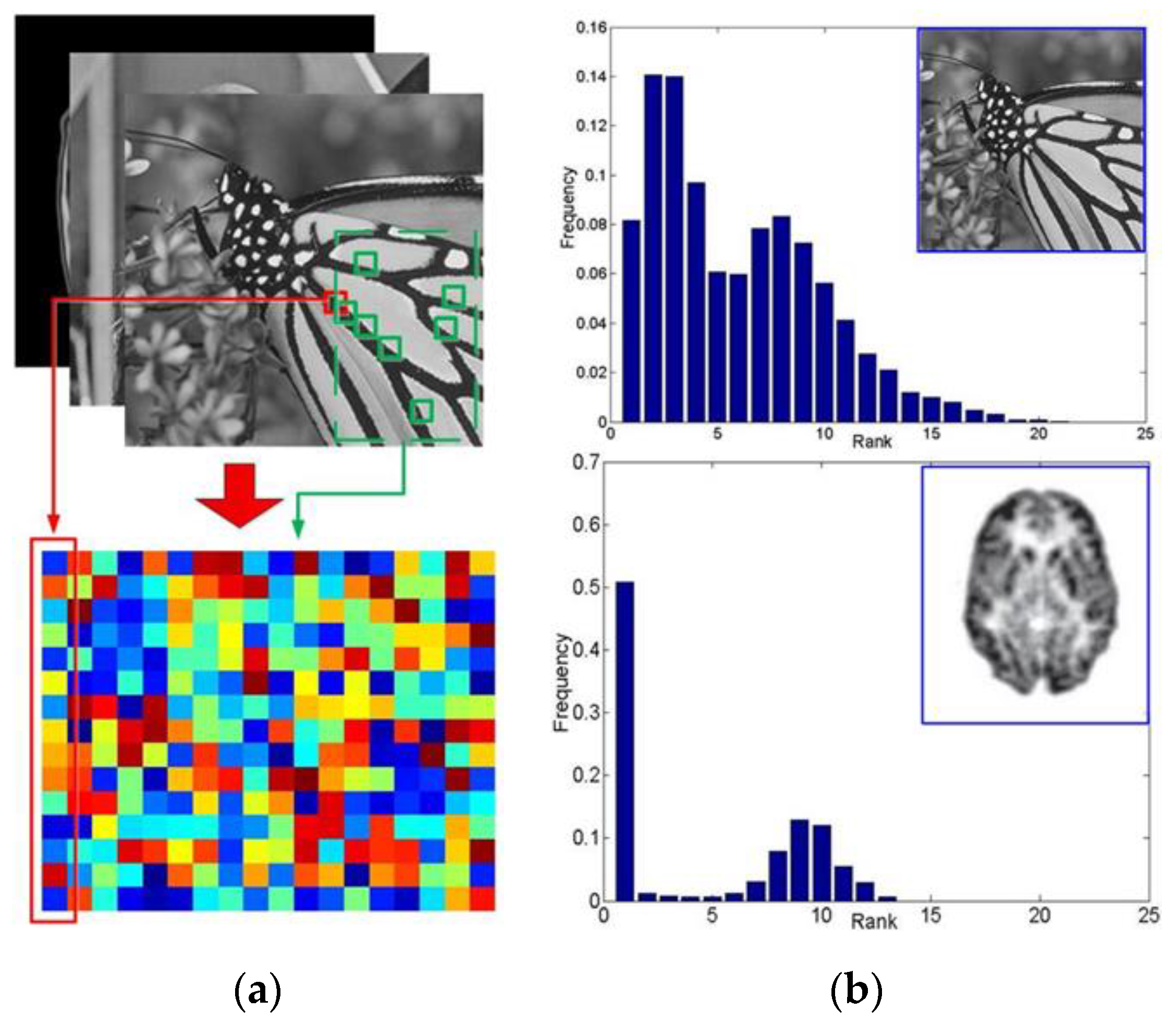
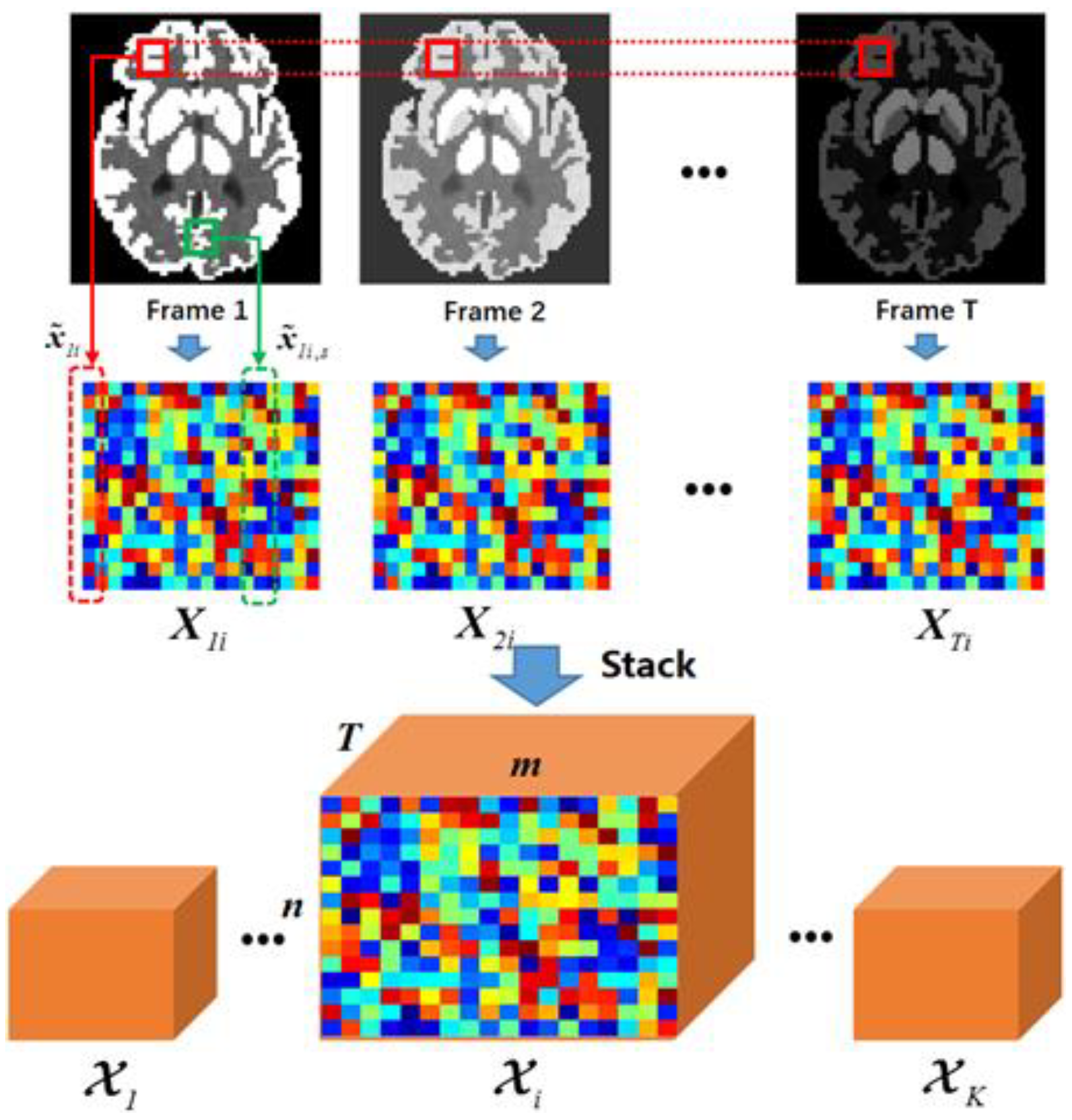
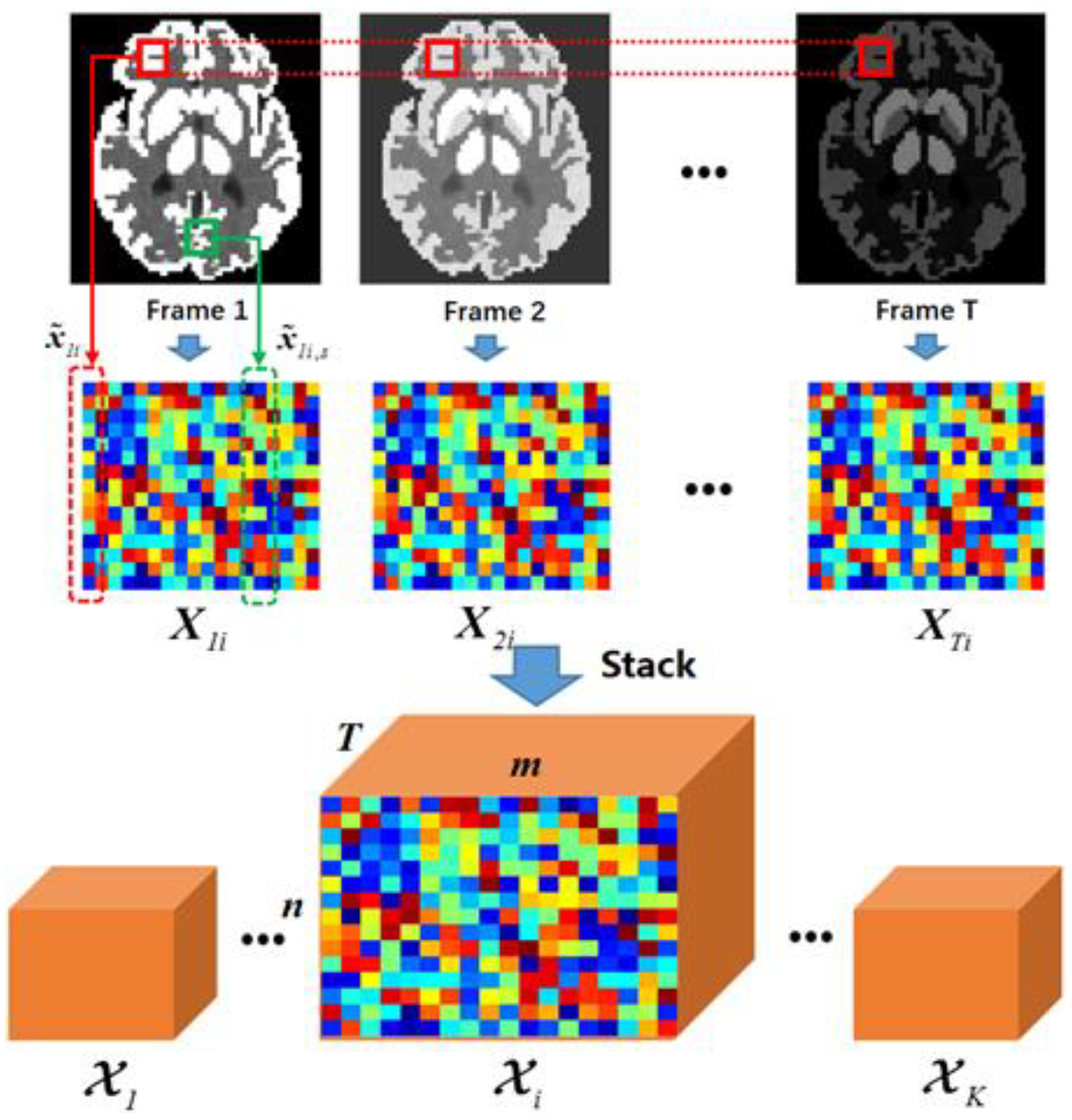
3.1. Nonlocal Low Rank Tensor Approximation
3.1.1. Tensor Formulation
3.1.2. Low Rank Tensor Approximation
3.2. Total Variation Regularization in Dynamic PET
3.3. Expectation Maximization for Fidelity Term
- E-step: This step employs the expectation = as the substitute for the hidden variable in Equation (18):
- M-step: This step maximizes the likelihood by zeroing the derivative of Equation (19):
3.4. The Overall Optimization Framework
- (1)
- -subproblem. Let denote the updated variable after the k-th iteration; e.g., represents the computed image sequence after the k-th iteration. In the (k + 1)-th iteration, nonlocal low-rank approximation is first implemented. After the formulation of nonlocal feature tensors , as illustrated in Section 3.1, we can obtain the function related to each low rank tensor:with
- (2)
- -subproblem. Unlike updating , the discrete gradient is updated frame by frame. As shown in Equation (15), we update by employing the shrinkage operator [44]:Correspondingly, the multiplier vector updates by:
- (3)
- -subproblem. After the update of and , the last critical process is to update . In addition to the fidelity term in Equation (18), the former mentioned regularizations must be considered. In this procedure, we adopt the EM algorithm and hence reform Equation (20) into a joint function relevant to (or ):
4. Experiments and Results
4.1. Implementations
4.1.1. Evaluation Criteria
4.1.2. Dataset
4.1.3. Comparative Algorithms
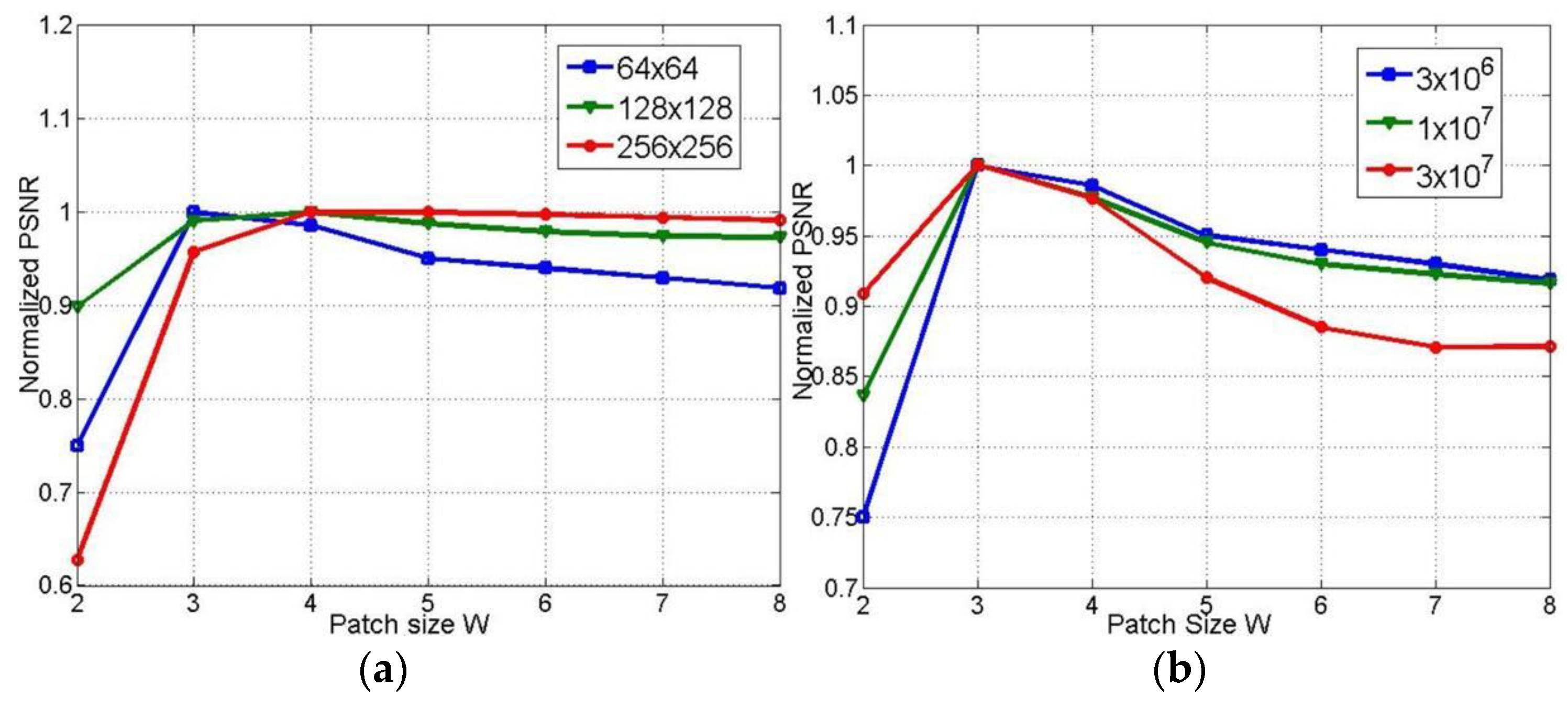
4.1.4. Parameters Setting
4.1.5. Experiment Description
4.2. Results
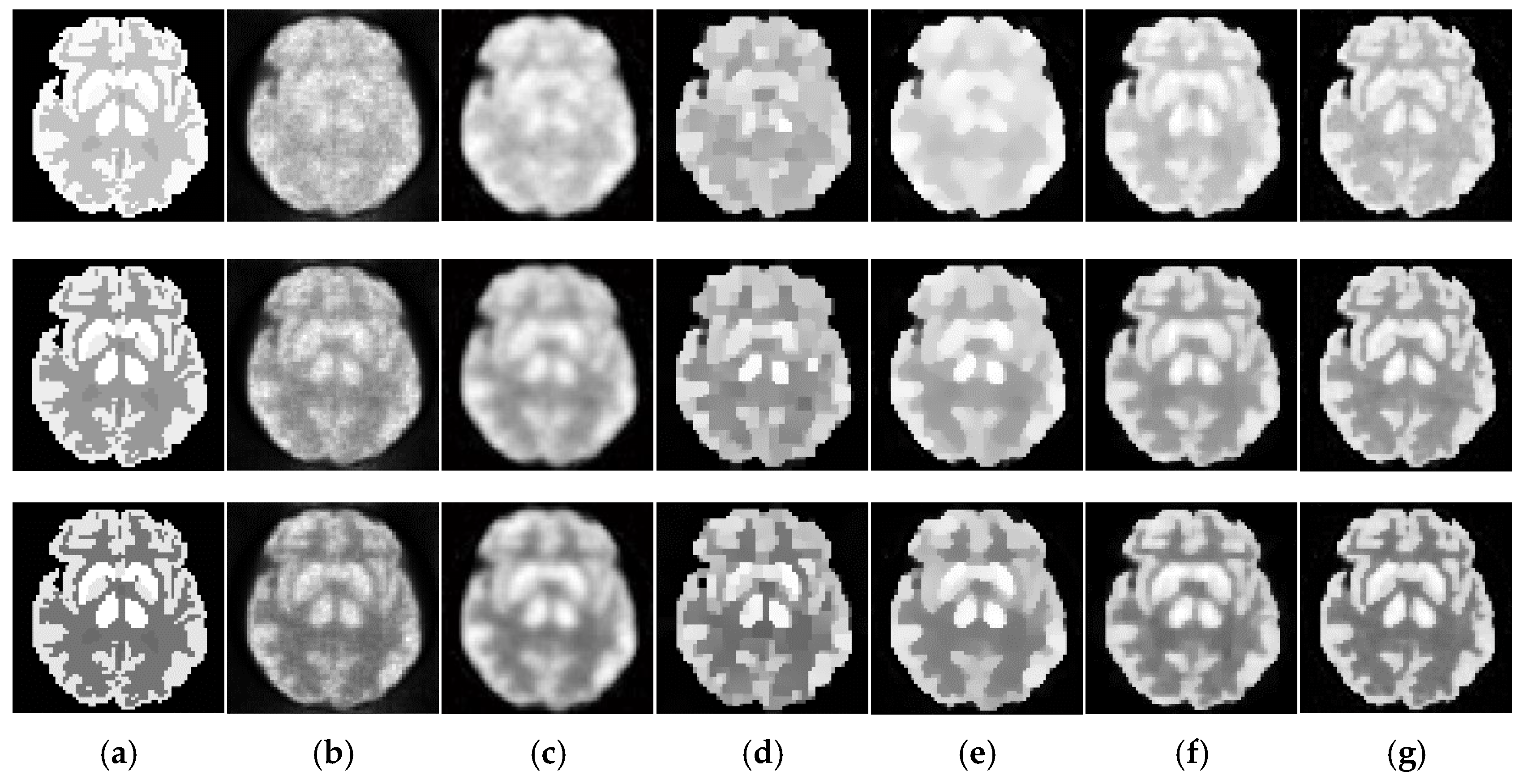
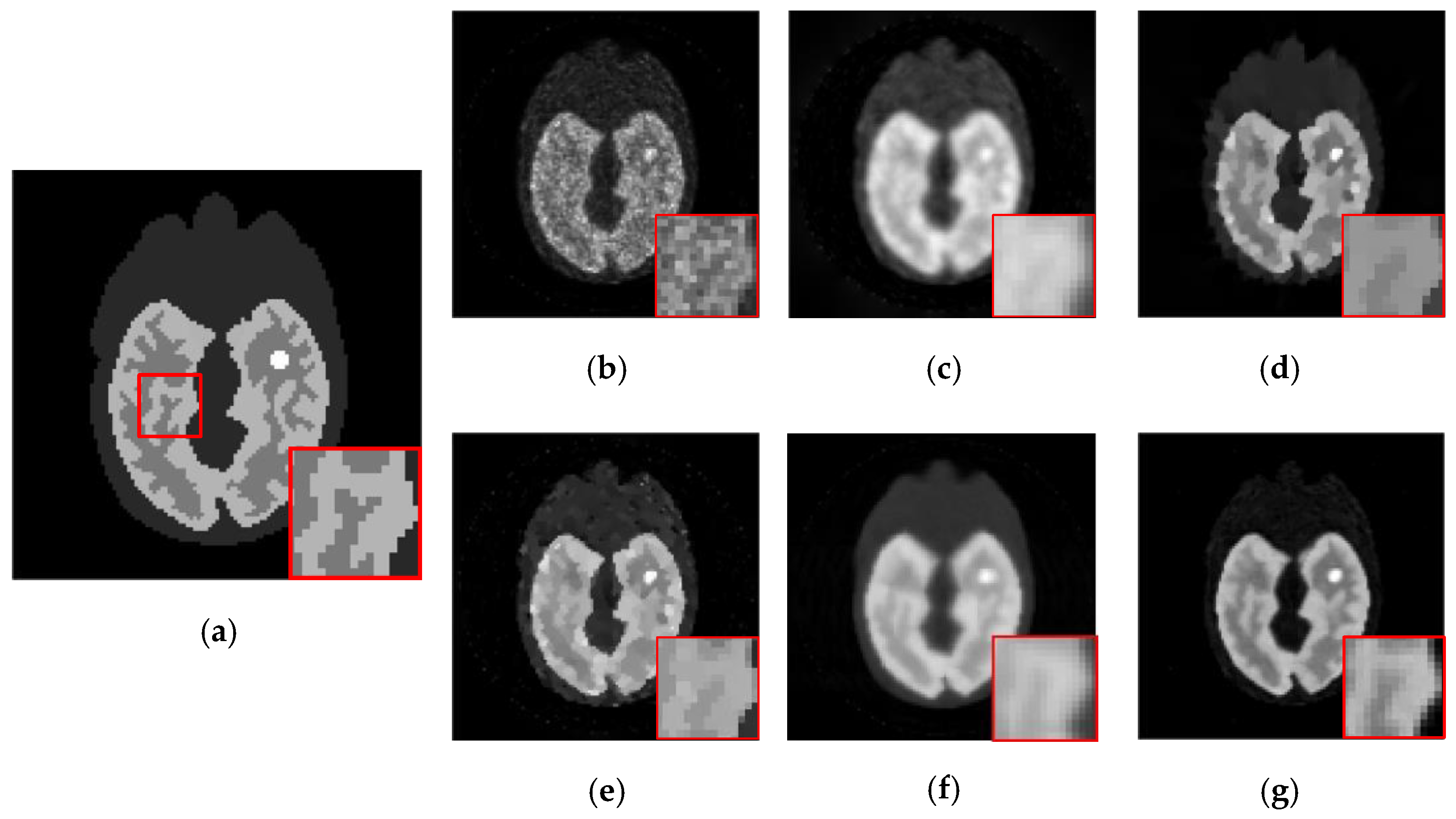
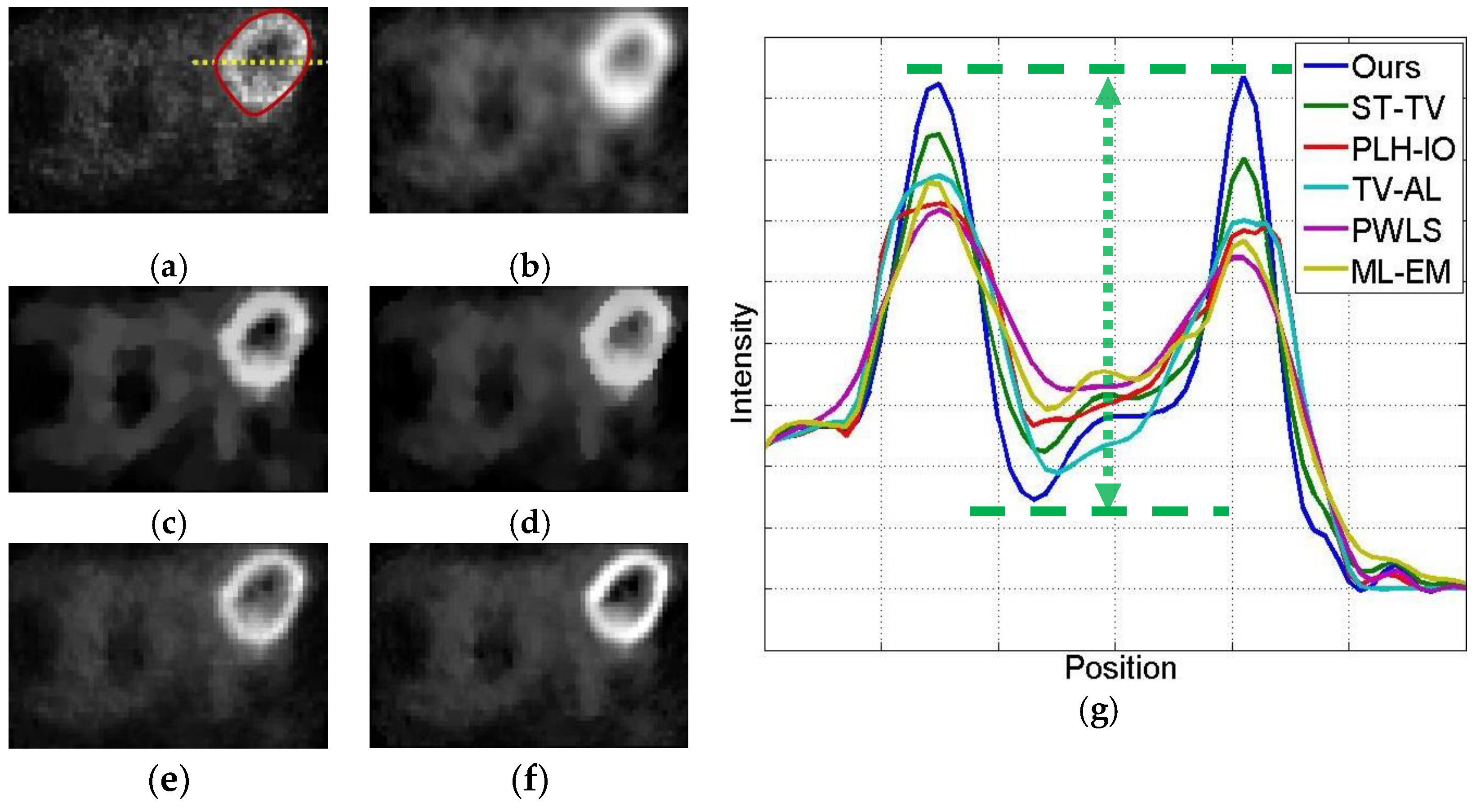
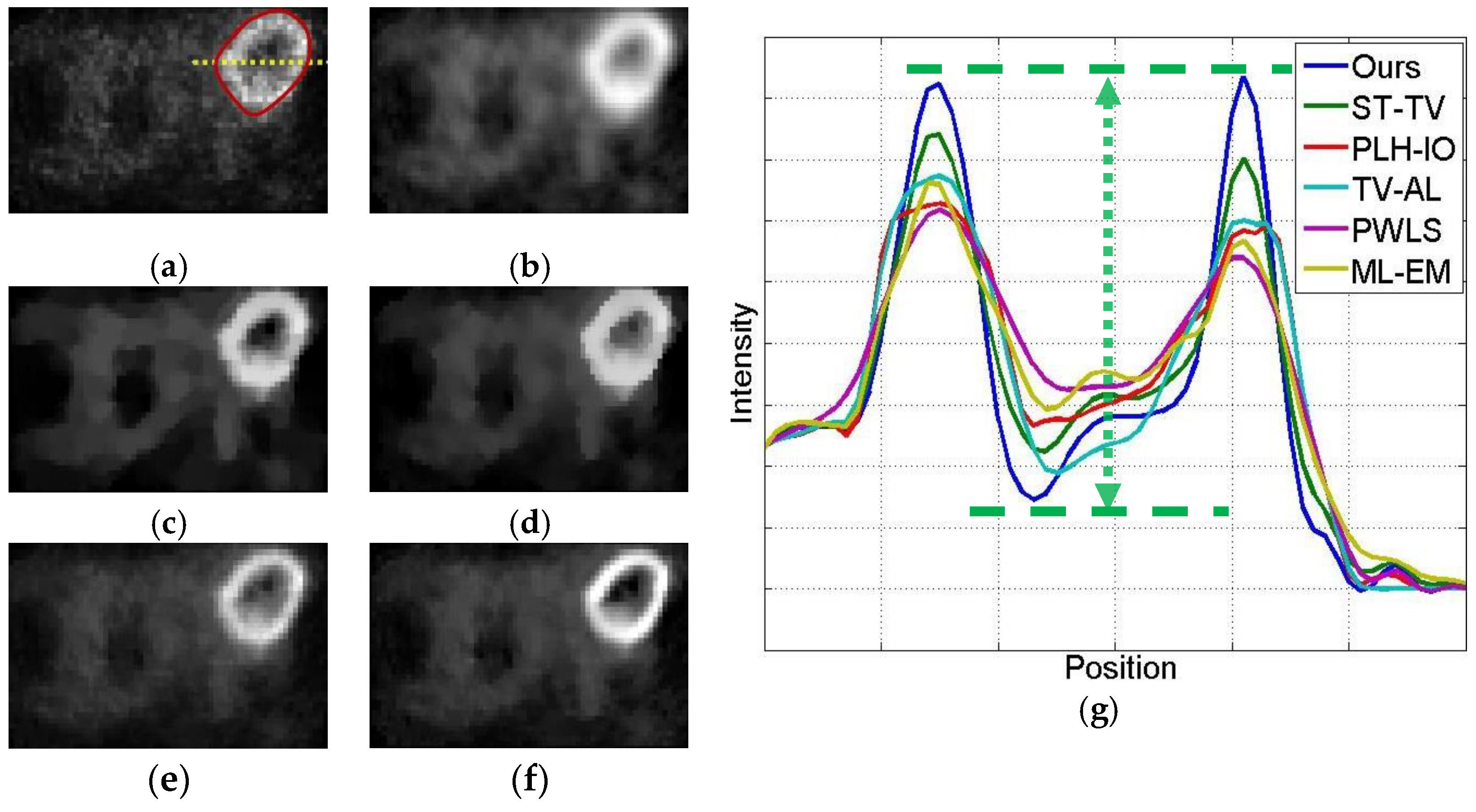
4.2.1. Qualitative Evaluation
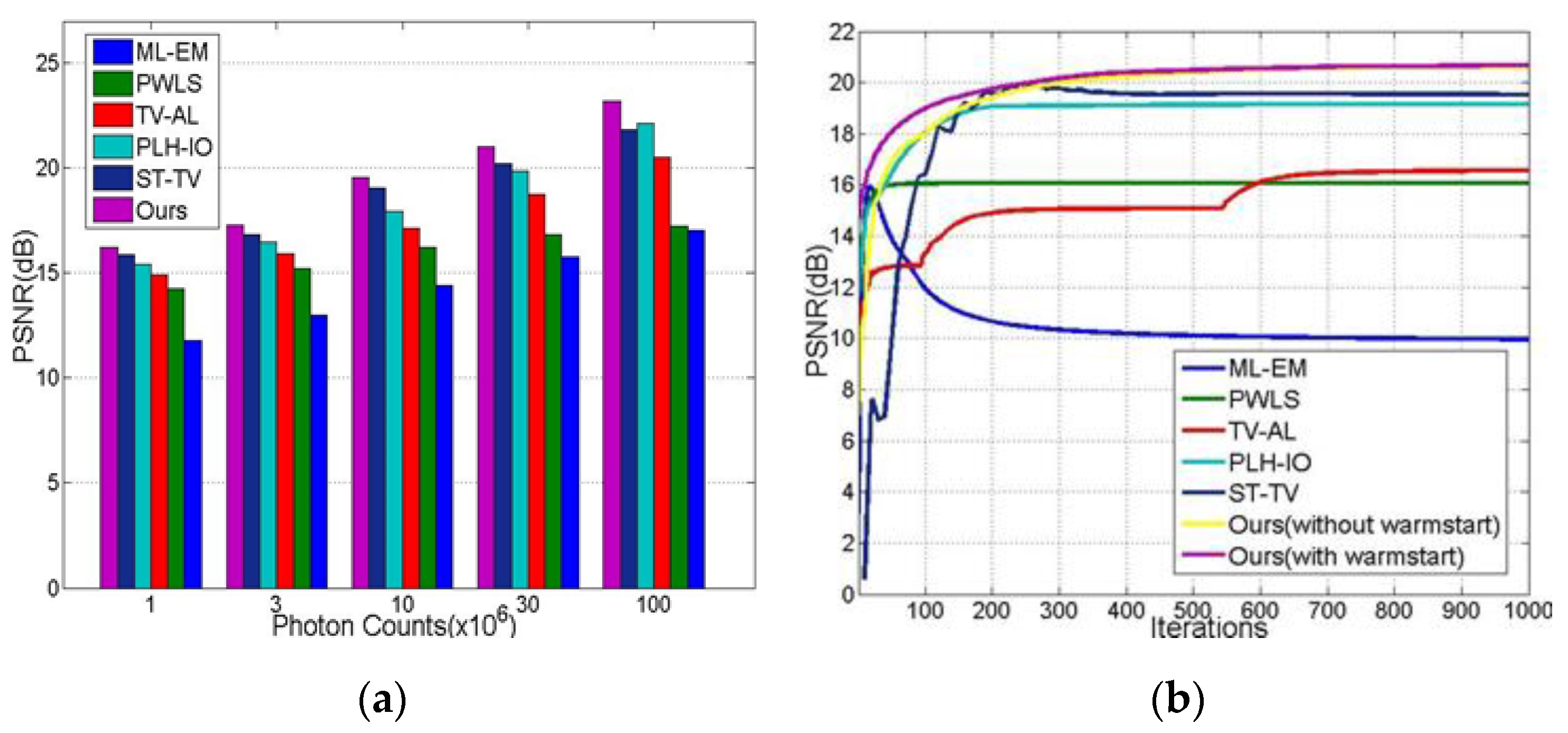
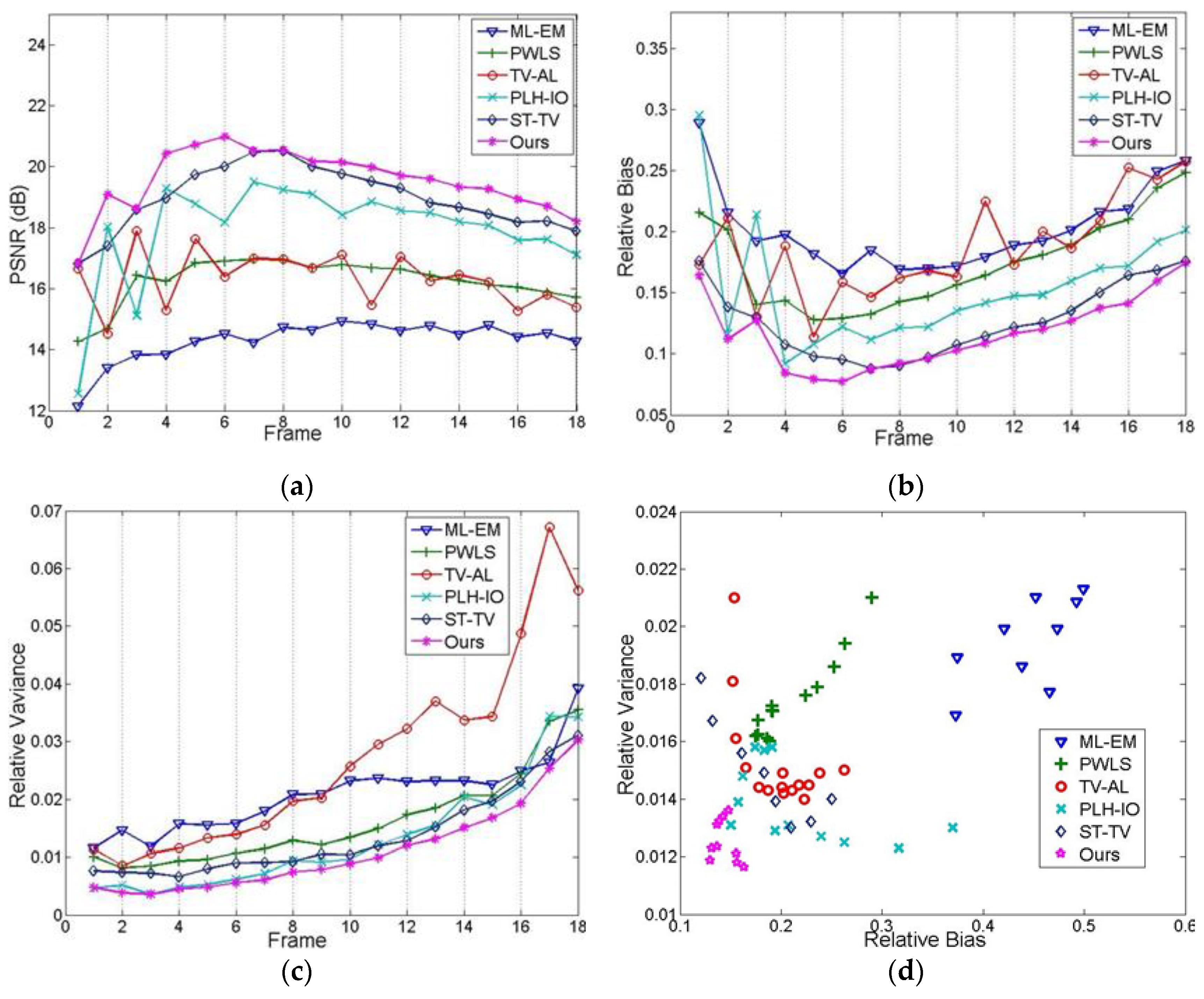
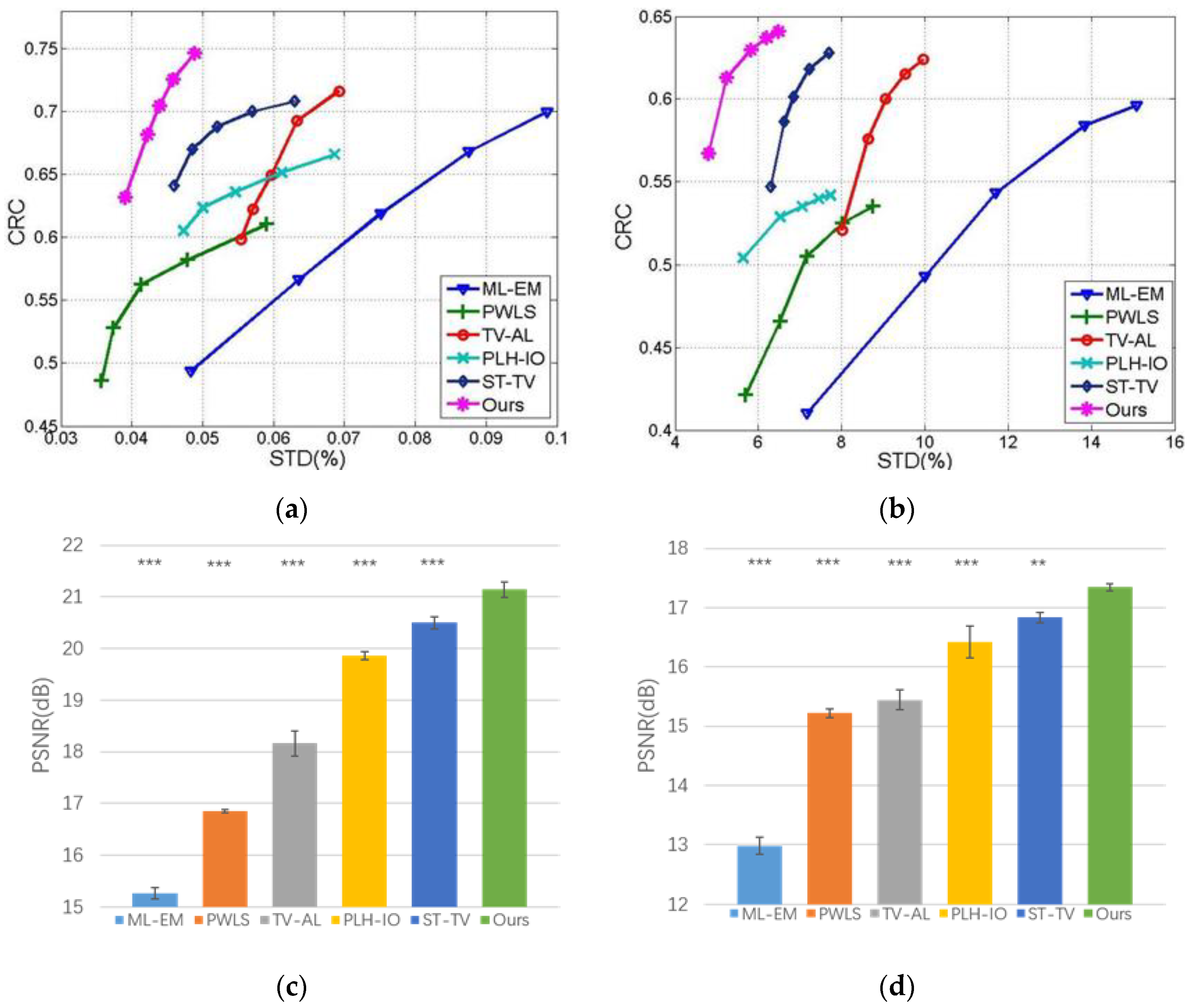
4.2.2. Quantitative Evaluation
4.2.3. Robustness and Convergence Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bohuslavizki, K.H.; Klutmann, S.; Kroger, S.; Sonnemann, U.; Buchert, R.; Werner, J.A.; Mester, J.; Clausen, M. FDG PET detection of unknown primary tumors. J. Nucl. Med. 2000, 41, 816. [Google Scholar] [PubMed]
- Ichiya, Y.; Kuwabara, Y.; Sasaki, M.; Yoshida, T.; Akashi, Y.; Murayama, S.; Nakamura, K.; Fukumura, T.; Masuda, K. FDG-PET in infectious lesions: The detection and assessment of lesion activity. Ann. Nucl. Med. 1996, 10, 185–191. [Google Scholar] [CrossRef] [PubMed]
- Basu, S.; Bresler, Y. O(N/sup 2/log/sub 2/N) filtered Backprojection Reconstruction Algorithm for Tomography. IEEE Trans. Image Process. 2000, 9, 1760–1773. [Google Scholar] [CrossRef] [PubMed]
- Kaufman, L. Maximum likelihood, least squares, and penalized least squares for PET. IEEE Trans. Med. Imaging 1993, 12, 200–214. [Google Scholar] [CrossRef]
- Shepp, L.A.; Vardi, Y. Maximum likelihood reconstruction for emission tomography. IEEE Trans. Med. Imaging 1982, 1, 113–122. [Google Scholar] [CrossRef]
- Qi, J.; Leahy, R.M. Iterative reconstruction techniques in emission computed tomography. Phys. Med. Biol. 2006, 51, R541. [Google Scholar] [CrossRef]
- Levitan, E.; Herman, G.T. A maximum a posteriori probability expectation maximization algorithm for image reconstruction in emission tomography. IEEE Trans. Med. Imaging 1987, 6, 185–192. [Google Scholar] [CrossRef]
- Fessler, J.A. Penalized weighted least-squares image reconstruction for positron emission tomography. IEEE Trans. Med. Imaging 1994, 13, 290–300. [Google Scholar] [CrossRef]
- Relaxation, S. Gibbs Distributions, and the Bayesian Restoration of Images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar]
- Bouman, C.A.; Sauer, K. A unified approach to statistical tomography using coordinate descent optimization. IEEE Trans. Image Process. 1996, 5, 480–492. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Figueiredo, M.A.T.; Bioucas-Dias, J.M. Restoration of poissonian images using alternating direction optimization. IEEE Trans. Image Process. 2010, 19, 3133–3145. [Google Scholar] [CrossRef] [PubMed]
- Tong, S.; Shi, P. Tracer kinetics guided dynamic PET reconstruction. In Proceedings of the Biennial International Conference on Information Processing in Medical Imaging, Kerkrade, The Netherlands, 2–6 July 2007; pp. 421–433. [Google Scholar]
- Kamasak, M.E.; Bouman, C.A.; Morris, E.D.; Sauer, K. Direct reconstruction of kinetic parameter images from dynamic PET data. IEEE Trans. Med. Imaging 2005, 24, 636–650. [Google Scholar] [CrossRef] [PubMed]
- Kawamura, N.; Yokota, T.; Hontani, H.; Sakata, M.; Kimura, Y. Parametric PET Image Reconstruction via Regional Spatial Bases and Pharmacokinetic Time Activity Model. Entropy 2017, 19, 629. [Google Scholar] [CrossRef]
- Wang, G.; Qi, J. PET image reconstruction using kernel method. IEEE Trans. Med. Imaging 2015, 34, 61–71. [Google Scholar] [CrossRef]
- An, L.; Zhang, P.; Adeli, E.; Wang, Y.; Ma, G.; Shi, F.; Lalush, D.S.; Lin, W.; Shen, D. Multi-level canonical correlation analysis for standard-dose PET image estimation. IEEE Trans. Med. Imaging 2016, 25, 3303–3315. [Google Scholar] [CrossRef]
- Chen, S.; Liu, H.; Hu, Z.; Zhang, H.; Shi, P.; Chen, Y. Simultaneous reconstruction and segmentation of dynamic PET via low-rank and sparse matrix decomposition. IEEE Trans. Biomed. Eng. 2015, 62, 1784–1795. [Google Scholar] [CrossRef]
- Kawai, K.; Yamada, J.; Hontani, H.; Yokota, T.; Sakata, M.; Kimura, Y. A robust PET image reconstruction using constrained non-negative matrix factorization. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1815–1818. [Google Scholar]
- Kawai, K.; Hontani, H.; Yokota, T.; Sakata, M.; Kimura, Y. Simultaneous PET Image Reconstruction and Feature Extraction Method using Non-negative, Smooth, and Sparse Matrix Factorization. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1334–1337. [Google Scholar]
- Yokota, T.; Kawai, K.; Sakata, M.; Kimura, Y.; Hontani, H. Dynamic PET Image Reconstruction Using Nonnegative Matrix Factorization Incorporated with Deep Image Prior. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October 2019. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 60–65. [Google Scholar]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2862–2869. [Google Scholar]
- Egiazarian, K.; Foi, A.; Katkovnik, V. Compressed sensing image reconstruction via recursive spatially adaptive filtering. In Proceedings of the Image Processing (ICIP 2007), San Antonio, TX, USA, 16 September–19 October 2007; pp. I-549–I-552. [Google Scholar]
- Zhang, X.; Yuan, X.; Carin, L. Nonlocal Low-Rank Tensor Factor Analysis for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8232–8241. [Google Scholar]
- Wang, L.; Xiong, Z.; Shi, G.; Wu, F.; Zeng, W. Adaptive nonlocal sparse representation for dual-camera compressive hyperspectral imaging. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2104–2111. [Google Scholar] [CrossRef]
- Dong, W.; Shi, G.; Li, X.; Ma, Y.; Huang, F. Compressive sensing via nonlocal low-rank regularization. IEEE Trans. Image Process. 2014, 23, 3618–3632. [Google Scholar] [CrossRef]
- Zhu, L.; Fu, C.W.; Brown, M.S.; Heng, P.A. A non-local low-rank framework for ultrasound speckle reduction. In Proceedings of the 2017 IE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’17), Honolulu, HI, USA, 21–26 July 2017; pp. 5650–5658. [Google Scholar]
- Xie, N.; Chen, Y.; Liu, H. Nonlocal Low-Rank and Total Variation Constrained PET Image Reconstruction. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3874–3879. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor Decompositions and Applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Romera-Paredes, B.; Pontil, M. A new convex relaxation for tensor completion. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis: Exact recovery of corrupted low-rank tensors via convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5249–5257. [Google Scholar]
- Zhang, Z.; Aeron, S. Exact tensor completion using t-SVD. IEEE Trans. Signal Process. 2015, 65, 1511–1526. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Its Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef]
- Yokota, T.; Hontani, H. Simultaneous visual data completion and denoising based on tensor rank and total variation minimization and its primal-dual splitting algorithm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3732–3740. [Google Scholar]
- Lu, C.; Feng, J.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Hestenes, M.R. Multiplier and gradient methods. J. Optim. Theor. Appl. 1969, 4, 303–320. [Google Scholar] [CrossRef]
- Powell, M.J.D. A method for nonlinear constraints in minimization problems. Optimization 1969, 5, 283–298. [Google Scholar]
- Lange, K.; Carson, R. EM reconstruction algorithms for emission and transmission tomography. J. Comput. Assisted Tomogr. 1984, 8, 306–316. [Google Scholar]
- Elad, M. Why Simple Shrinkage Is Still Relevant for Redundant Representations? IEEE Trans. Inf. Theory 2006, 52, 5559–5569. [Google Scholar] [CrossRef]
- Ahn, S.; Fessler, J.A.; Blatt, D.; Hero, A.O. Incremental optimization transfer algorithms: Application to transmission tomography. In Proceedings of the IEEE Symposium Conference Record Nuclear Science, Rome, Italy, 16–22 October 2004; pp. 2835–2839. [Google Scholar]
- Gong, K.; Cheng-Liao, J.; Wang, G.; Chen, K.T.; Catana, C.; Qi, J. Direct patlak reconstruction from dynamic PET data using the kernel method with MRI information based on structural similarity. IEEE Trans. Med. Imaging 2017, 37, 955–965. [Google Scholar] [CrossRef] [PubMed]
- Dutta, J.; Ahn, S.; Li, Q. Quantitative statistical methods for image quality assessment. Theranostics 2013, 3, 741. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Yin, W.; Jiang, H.; Zhang, Y. An efficient augmented Lagrangian method with applications to total variation minimization. Comput. Optim. Appl. 2013, 56, 507–530. [Google Scholar] [CrossRef]
- Lingenfelter, D.J.; Fessier, J.A. Augmented Lagrangian methods for penalized likelihood reconstruction in emission tomography. In Proceedings of the Nuclear Science Symposium Conference Record (NSS/MIC), Knoxville, TN, USA, 30 October–6 November 2010; pp. 3288–3291. [Google Scholar]
- Abascal, J.; Lage, E.; Herraiz, J.L.; Martino, M.E.; Desco, M.; Vaquero, J.J. Dynamic PET reconstruction using the split bregman formulation. In Proceedings of the 2016 IEEE Nuclear Science Symposium, Medical Imaging Conference and Room-Temperature Semiconductor Detector Workshop (NSS/MIC/RTSD), Strasbourg, France, 29 October–6 November 2016; pp. 1–4. [Google Scholar]
- Zhou, P.; Lu, C.; Lin, Z.; Zhang, C. Tensor factorization for low-rank tensor completion. IEEE Trans. Image Process. 2017, 27, 1152–1163. [Google Scholar] [CrossRef]
- Battaglino, C.; Ballard, G.; Kolda, T.G. A practical randomized CP tensor decomposition. SIAM J. Matrix Anal. Appl. 2018, 39, 876–901. [Google Scholar] [CrossRef]
- Henderson, J.; Malin, B.A.; Denny, J.C.; Kho, A.N.; Sun, J.; Ghosh, J.; Ho, J.C. CP Tensor Decomposition with Cannot-Link Intermode Constraints. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 711–719. [Google Scholar]
- Chakaravarthy, V.T.; Choi, J.W.; Joseph, D.J.; Murali, P.; Pandian, S.S.; Sabharwal, Y.; Sreedhar, D. On optimizing distributed Tucker decomposition for sparse tensors. In Proceedings of the International Conference on Supercomputing, Beijing, China, 12–15 June 2018; pp. 374–384. [Google Scholar]
- Smith, S.; Karypis, G. Accelerating the tucker decomposition with compressed sparse tensors. In Proceedings of the European Conference on Parallel Processing, Cham, Switzerland, 28 August–1 September 2017; pp. 653–668. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | PSNR (dB) | Relative Bias | Relative Variance | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 × 106 | 1 × 107 | 3 × 107 | 3 × 106 | 1 × 107 | 3 × 107 | 3 × 106 | 1 × 107 | 3 × 107 | |
| ML-EM | 13.00 | 14.39 | 15.75 | 0.2374 | 0.2024 | 0.1742 | 0.0252 | 0.0147 | 0.0138 |
| PWLS | 15.20 | 16.25 | 16.81 | 0.2054 | 0.1747 | 0.1627 | 0.0217 | 0.0162 | 0.0154 |
| TV-AL | 15.91 | 17.13 | 18.76 | 0.1804 | 0.1548 | 0.1286 | 0.0303 | 0.0161 | 0.0152 |
| PLH-IO | 16.48 | 17.92 | 19.87 | 0.1883 | 0.1539 | 0.1225 | 0.0205 | 0.0131 | 0.0115 |
| ST-TV | 16.85 | 19.07 | 20.21 | 0.1725 | 0.1359 | 0.1139 | 0.0161 | 0.0125 | 0.0097 |
| Ours | 17.29 | 19.54 | 21.03 | 0.1609 | 0.1172 | 0.0983 | 0.0148 | 0.0111 | 0.0083 |
| Algorithm | Relative Bias | Relative Variance | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Whole | ROI1 | ROI2 | ROI3 | ROI4 | Whole | ROI1 | ROI2 | ROI3 | ROI4 | |
| ML-EM | 0.2374 | 0.2353 | 0.3909 | 0.4407 | 0.2654 | 0.0252 | 0.0260 | 0.0105 | 0.0292 | 0.0410 |
| PWLS | 0.2054 | 0.1955 | 0.1853 | 0.2381 | 0.1801 | 0.0217 | 0.0377 | 0.0054 | 0.0176 | 0.0217 |
| TV-AL | 0.1804 | 0.1905 | 0.1758 | 0.2114 | 0.1522 | 0.0303 | 0.0464 | 0.0056 | 0.0215 | 0.0303 |
| PLH-IO | 0.1883 | 0.2601 | 0.1560 | 0.1680 | 0.2077 | 0.0205 | 0.0285 | 0.0035 | 0.0205 | 0.0205 |
| ST-TV | 0.1725 | 0.2001 | 0.1388 | 0.1700 | 0.1791 | 0.0161 | 0.0210 | 0.0042 | 0.0151 | 0.0190 |
| Ours | 0.1609 | 0.1864 | 0.1235 | 0.1591 | 0.1671 | 0.0148 | 0.0203 | 0.0035 | 0.0118 | 0.0186 |
| Method | ML-EM | PWLS | TV-AL | PLH-IO | ST-TV | Ours |
|---|---|---|---|---|---|---|
| Computational time (s/iteration) | 0.04375 | 0.3163 | 0.07935 | 0.3507 | 0.1639 | 4.379 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, N.; Chen, Y.; Liu, H. 3D Tensor Based Nonlocal Low Rank Approximation in Dynamic PET Reconstruction. Sensors 2019, 19, 5299. https://doi.org/10.3390/s19235299
Xie N, Chen Y, Liu H. 3D Tensor Based Nonlocal Low Rank Approximation in Dynamic PET Reconstruction. Sensors. 2019; 19(23):5299. https://doi.org/10.3390/s19235299
Chicago/Turabian StyleXie, Nuobei, Yunmei Chen, and Huafeng Liu. 2019. "3D Tensor Based Nonlocal Low Rank Approximation in Dynamic PET Reconstruction" Sensors 19, no. 23: 5299. https://doi.org/10.3390/s19235299
APA StyleXie, N., Chen, Y., & Liu, H. (2019). 3D Tensor Based Nonlocal Low Rank Approximation in Dynamic PET Reconstruction. Sensors, 19(23), 5299. https://doi.org/10.3390/s19235299