Physical and Metrological Approach for Feature’s Definition and Selection in Condition Monitoring †




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
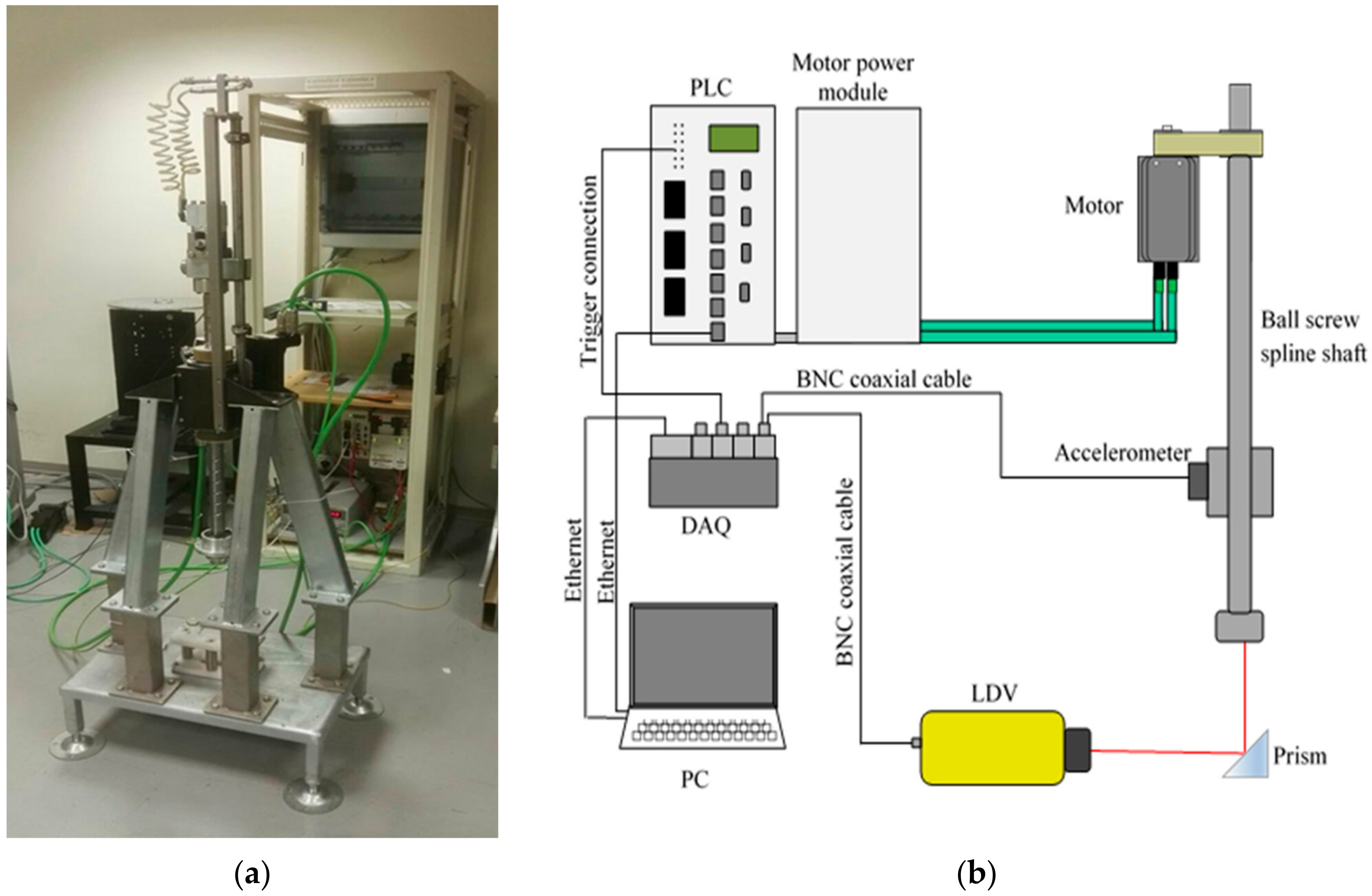
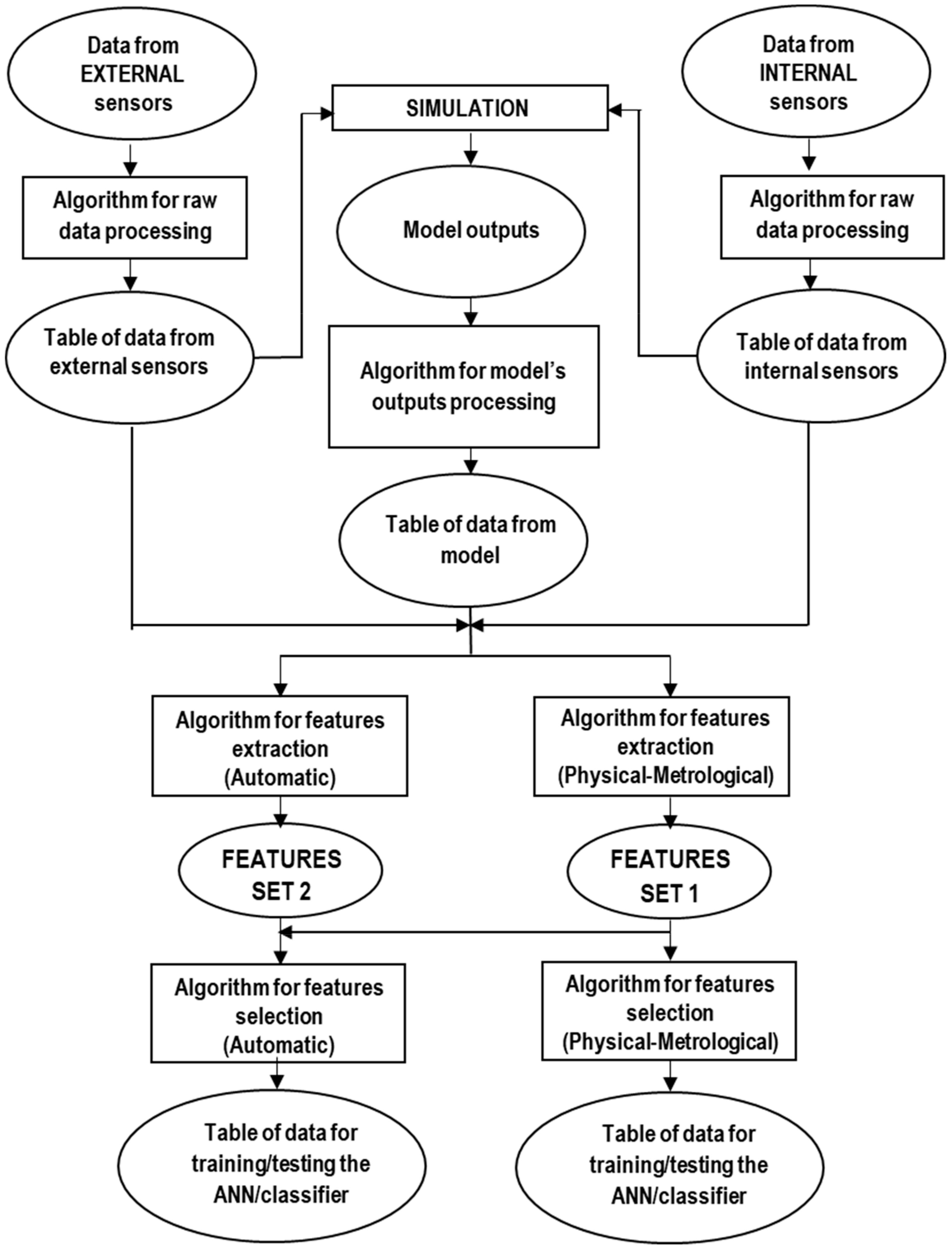
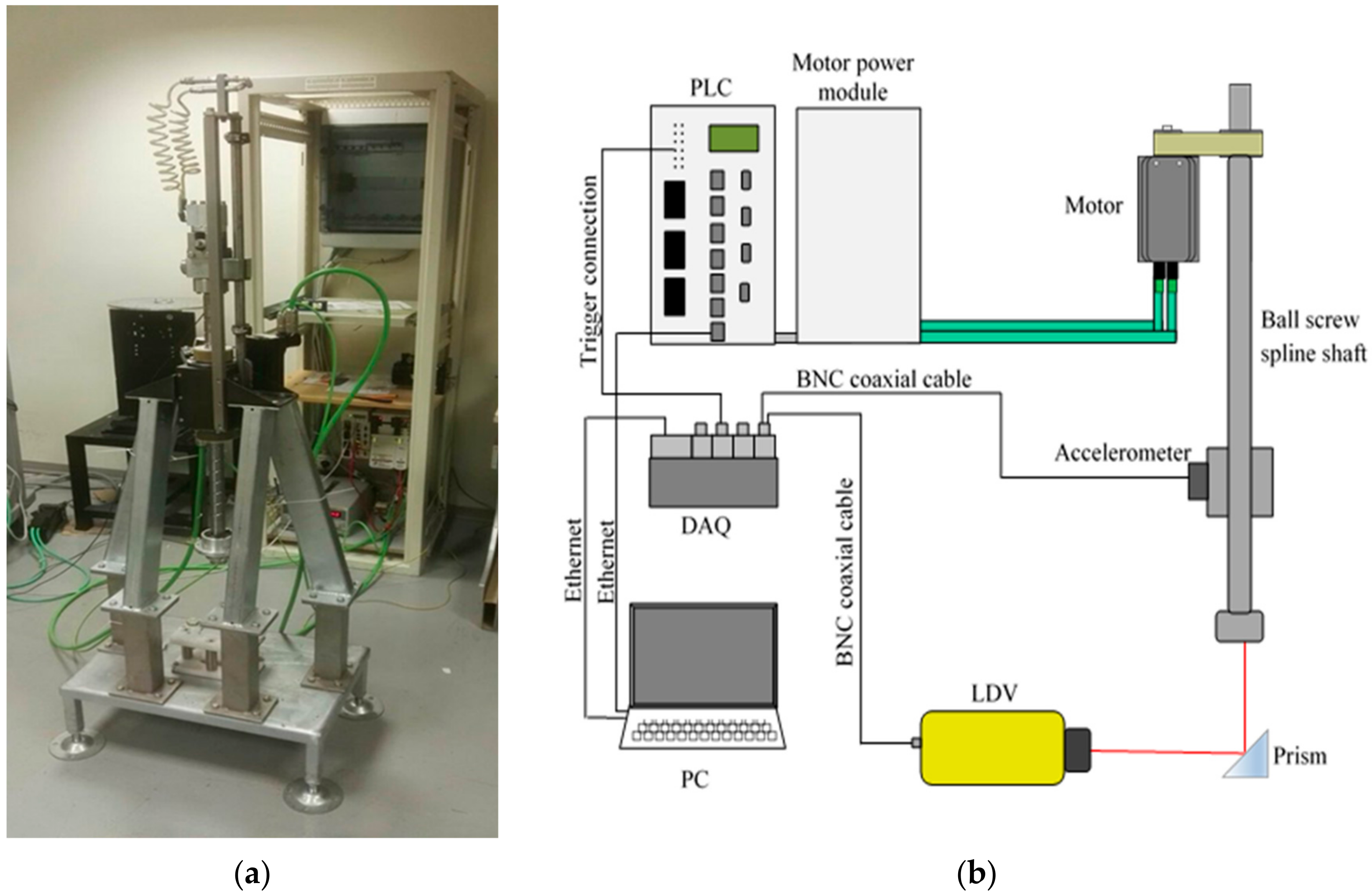
2.1. Test Bench and Simulation Model
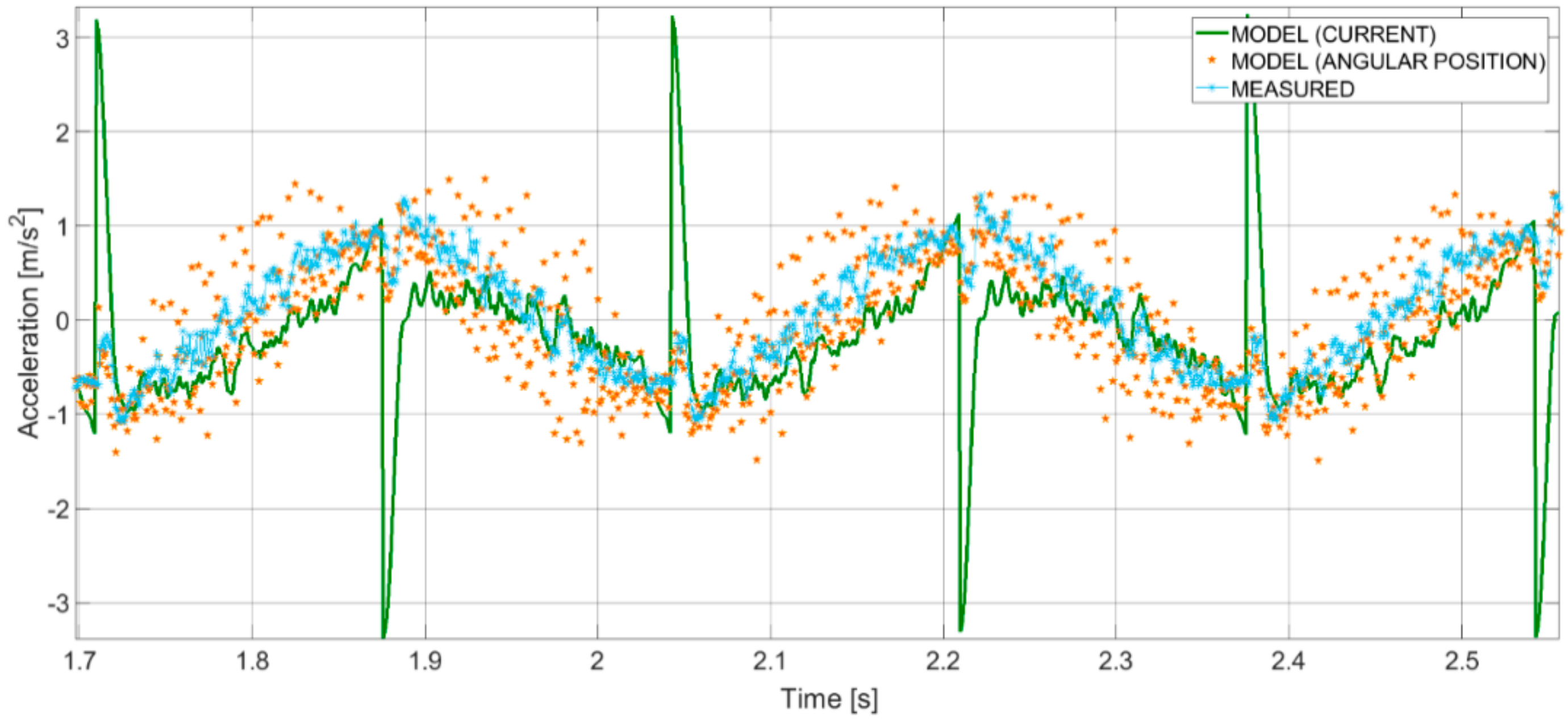
- Realization of a representative kinematic and dynamic model of the system of interest. The theoretical model developed for the system has been extensively described in [10].
- Realization of experiments, corresponding to different operating conditions.
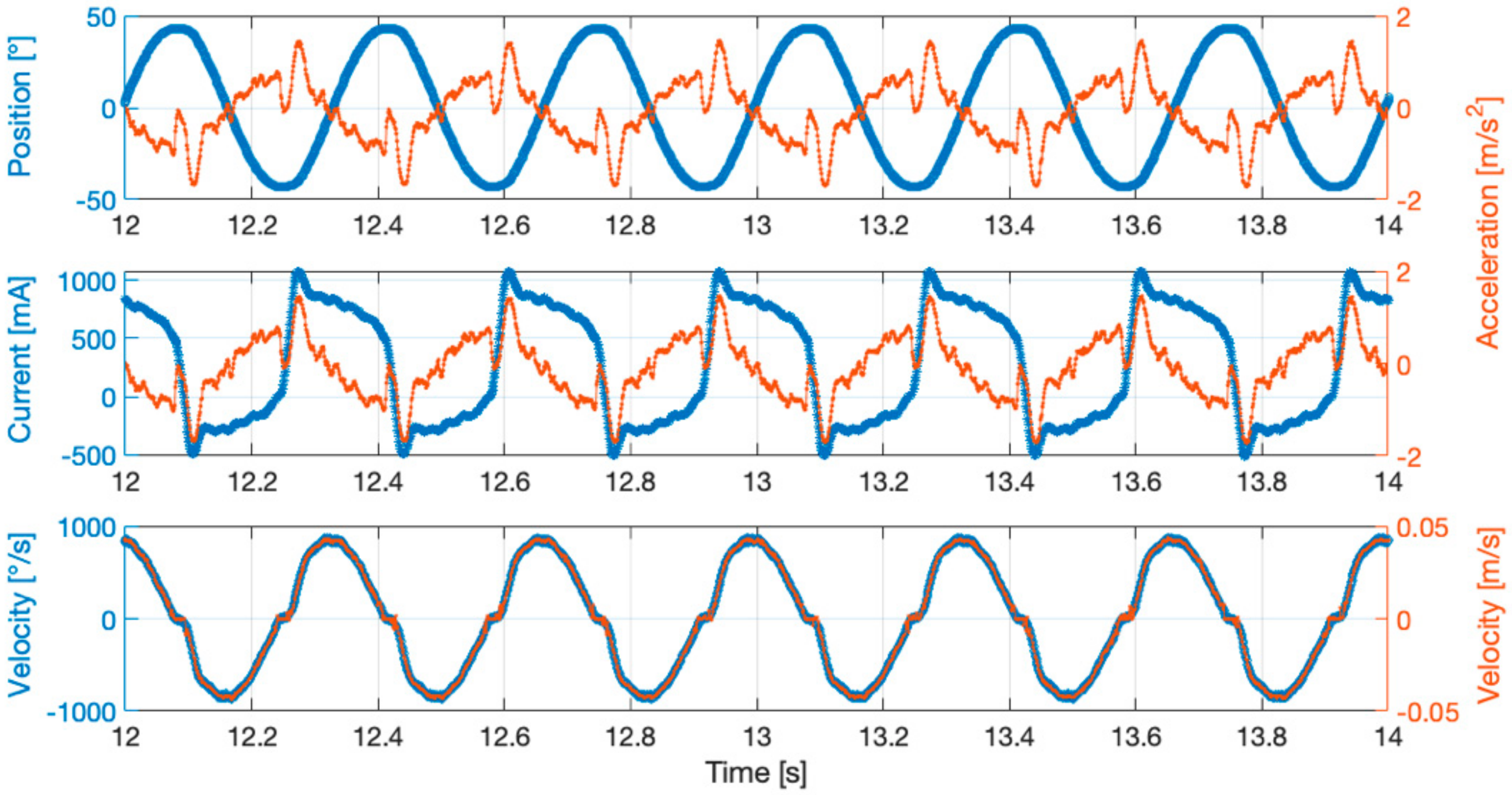
- Multiple runs of the model, considering as input different quantities, theoretical or measured ones [17,28]. The possible inputs are:
- Angular position of the motor axis,
- Angular velocity of the motor axis,
- Electric current at the driving servomotor,
- Linear acceleration of the ball screw shaft,
- Linear velocity of the ball screw shaft.
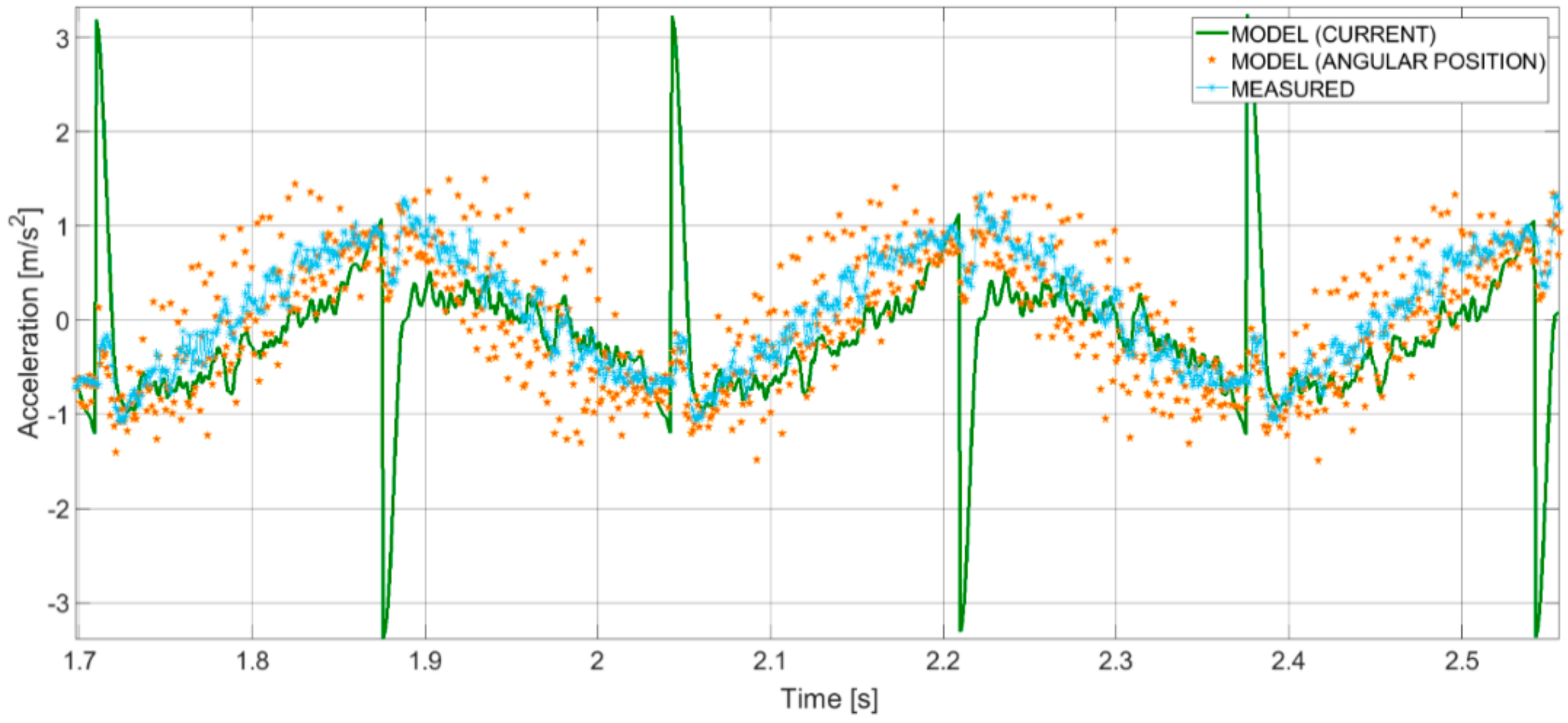
- Comparison between outputs of the model and data deriving from measurements (angular position or velocity of the motor axis from the encoder, electric current at the driving servomotor from the internal sensor, linear acceleration of the ball screw shaft from the accelerometer, linear velocity of the ball screw shaft from the LDV).
- Calculation and selection of the most suitable features for the jload setting [17] and the lubrication state identification. Jload is a parameter of the control system, representing the load inertia at the motor axis.
- Application of advanced data processing techniques for classification.
2.2. Definition of the Initial Set of Features
2.3. Feature Selection
2.4. Design of Experiments
- jload (3.0 kg cm2, 5.5 kg cm2, 8.0 kg cm2),
- lubrication (inadequate lubricant, G0; minimum lubricant, G1; regular lubricant, G2),
- length of the acquisition interval,
- added noise to the experimental data,
- number of test repetitions.
2.5. Training and Testing Procedure for Classifiers and for ANN
- i stands for the name of the group of features, as above-mentioned (SET 1 and SET 2);
- j denotes the total length of acquisition used for training of classifiers/ANN, as one of the following options: 10 s, 15 s, 20 s, 30 s or 40 s, meaning that, considering the whole number of windows on which the features are calculated, the total temporal basis used for the training procedure, is referred to a total length of acquisition of different independent experimental tests of j s; it has to be pointed out that the time duration of acquisition has been set with reference to a range including a minimum number of operation cycles (5 s) and a maximum one related to the need of acquiring too many samples. In addition, 40 s has been considered a correct trade-off, for the latter requirement.
- k specifies the temporal interval of each independent experimental test, on which the features are evaluated (5 s or 10 s). The ratio j/k defines the number of independent experimental tests used for training purposes and, therefore, it also denotes the number of observations used for training;
- w gives us the idea of the number of features used for classification:
- ○
- 101 refers to all of the features of SET 1,
- ○
- 21 refers to 21 features of SET 1, calculated on the basis of Mcur and TD, derived from applying the so-called physical selection method of features,
- ○
- 16 are the features of SET 1 referred to the 98th percentile of both measured and simulated quantities available, derived from applying the so-called physical-metrological method for feature selection;
- ○
- other, depending on the specific situation, as explained in the following.
- ‘linear’,
- ‘diaglinear’,
- ‘quadratic’.
2.6. Advanced Algorithms for Classification
- an ANN classifier,
- classifiers based on algorithms different from ANN.
- Trains a model using the out-of-fold observations,
- Assesses model performance using in-fold data,
- Calculates the average test error over all folds.
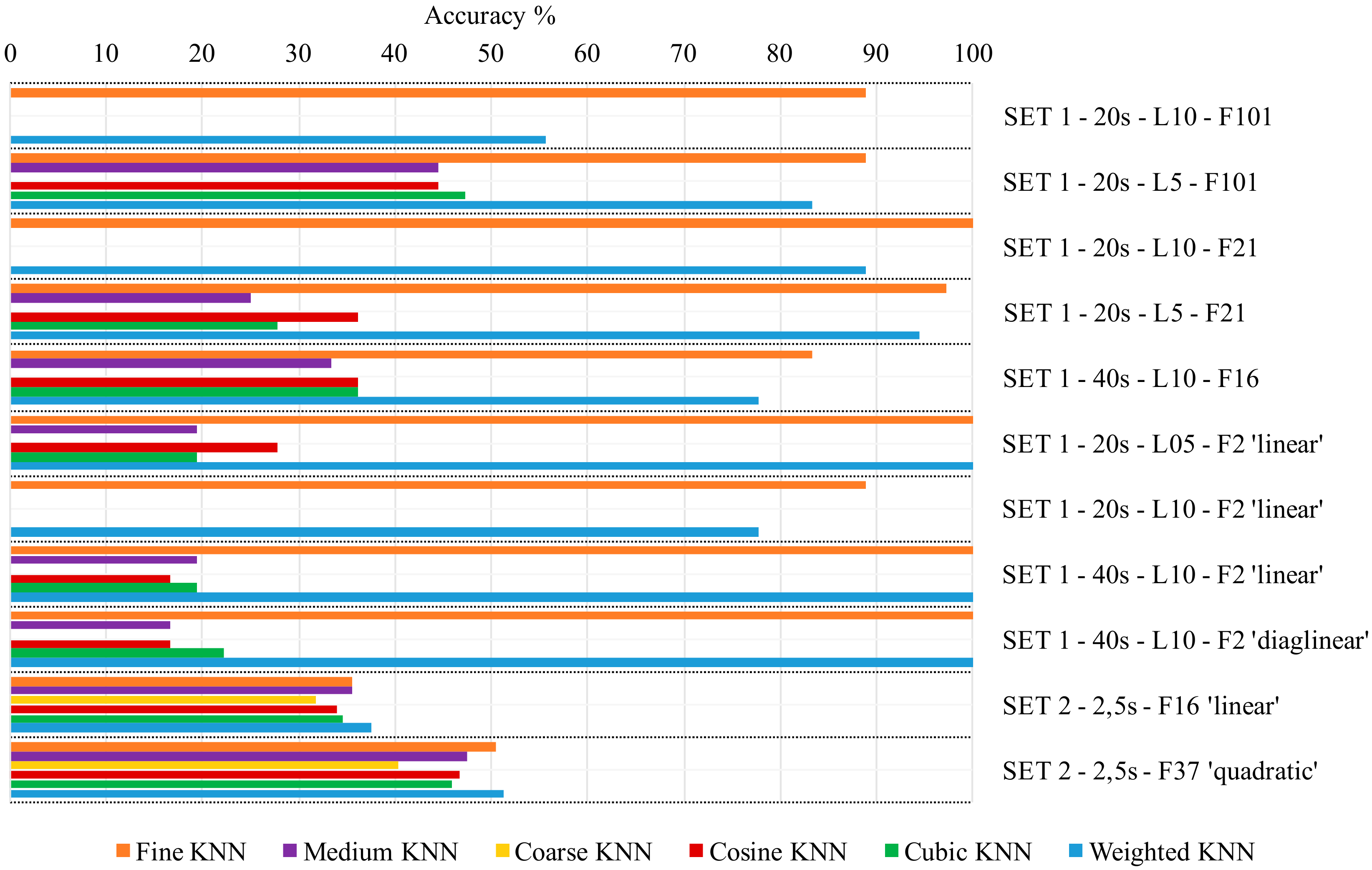
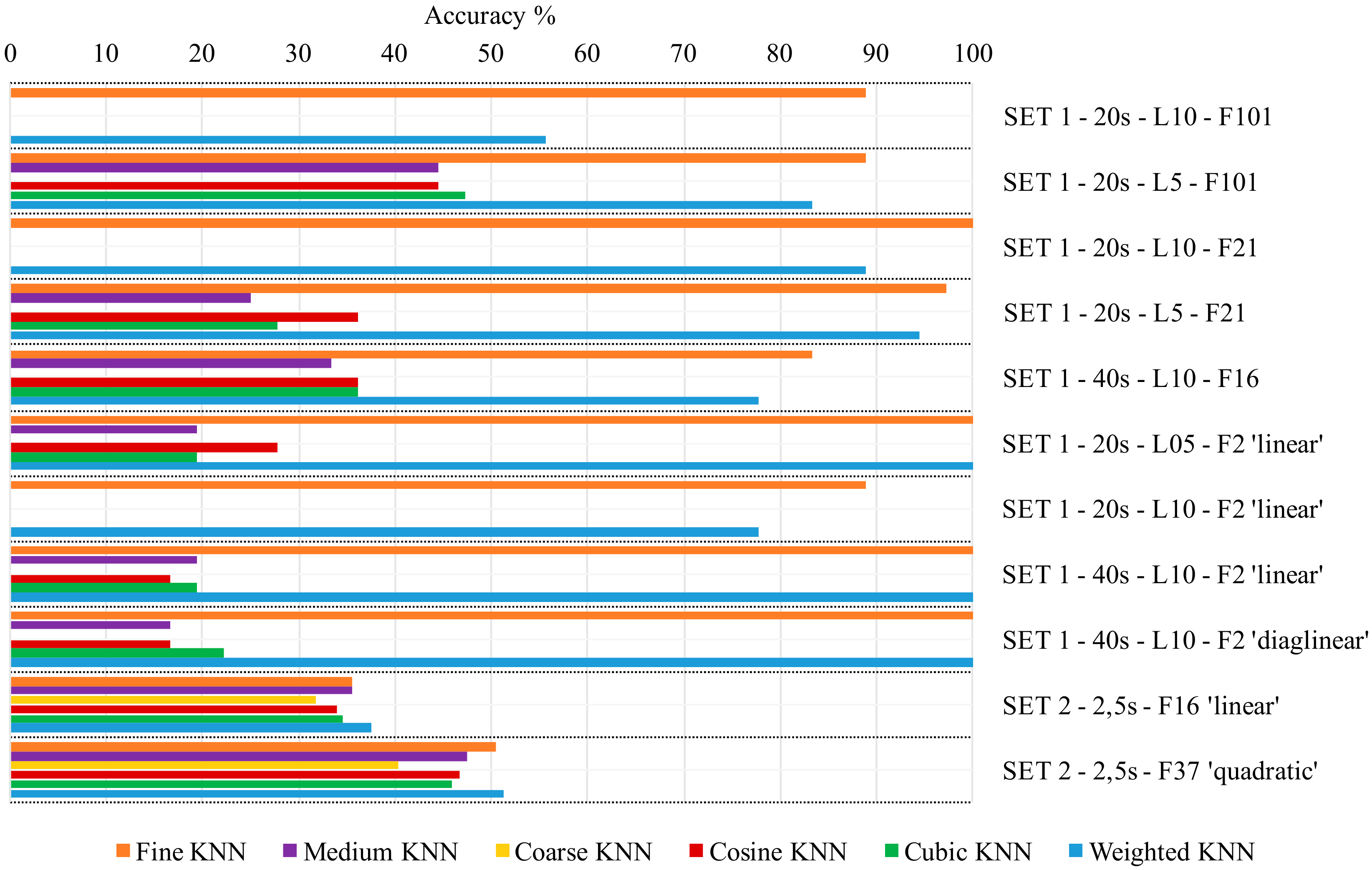
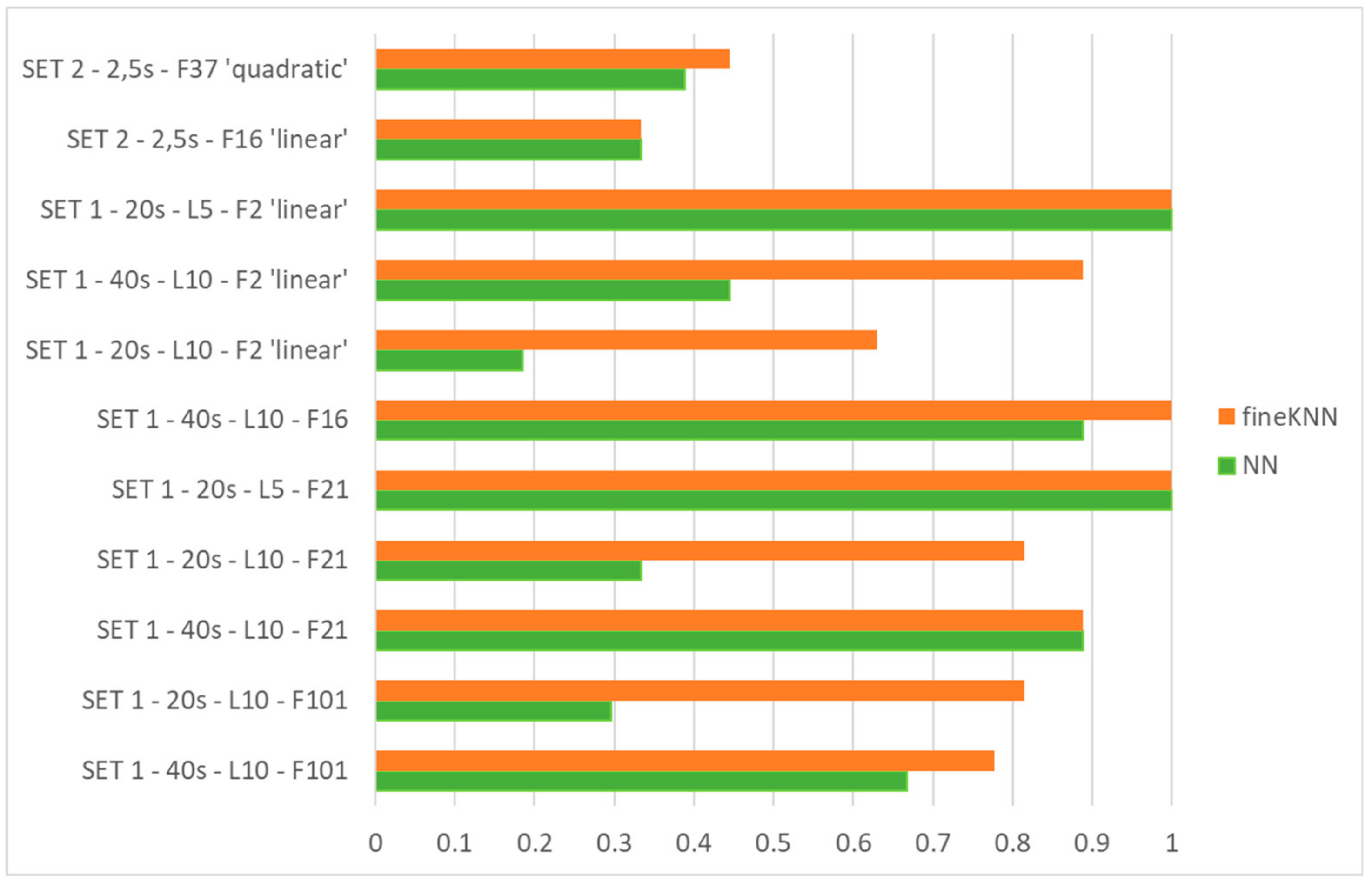
- Discriminant Classifiers, including both Linear and Quadratic Discriminant. Good classification accuracy reached in almost every group of features selected, for Linear Discriminant (accuracy >95%). It fails in almost every case when the Quadratic Discriminant classifier is used.
- Ensemble, including: Boosted Trees (0%, in almost every case), Subspace KNN and Bagged Trees (from 60% to 89%), Subspace Discriminant (from 72.2% up to 100%) and RUSBoosted Trees (<50%).
- Naïve Bayes. It fails in almost all cases with Gaussian Naïve Bayes, it ranges from 5% to 85%, with Kernel Naïve Bayes.
- Support Vector Machine (SVM). It performs well when Quadratic or Cubic SVM (around 90%, up to 100% in some cases), resulting in being aleatory when Linear, Fine Gaussian and Medium Gaussian SVM are chosen (from 0% to 97%).
- Tree, including Fine Tree, Medium Tree, and Coarse Tree. Poor accuracy of classification (around 40% maximum).
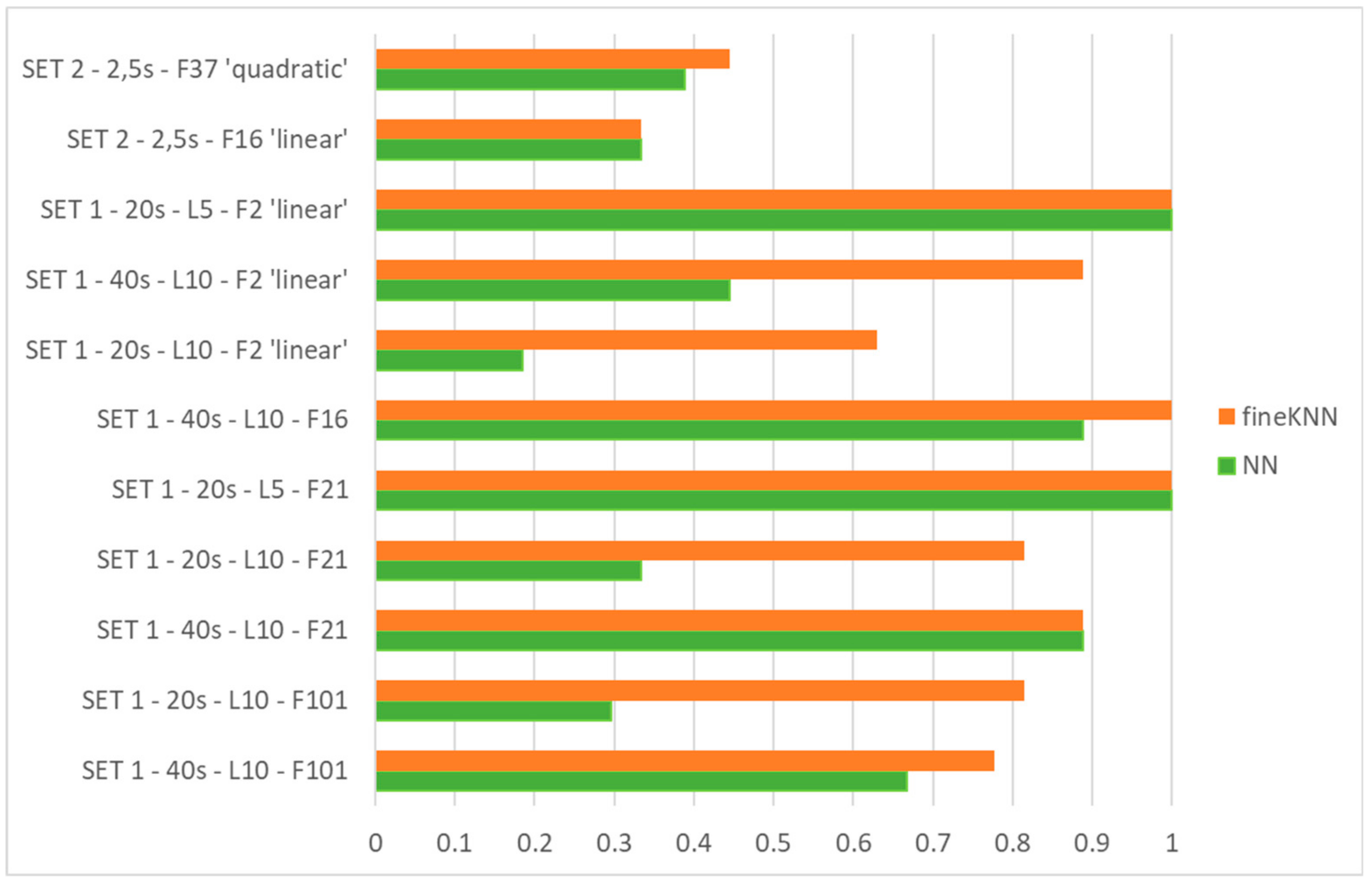
- k-nearest neighbor classifier (KNN), including Fine KNN, Medium KNN, Coarse KNN, Cosine KNN, Cubic KNN, and Weighted KNN. Fine KNN and Weighted KNN reach high accuracy of classification, while the behavior of others is unsatisfactory.
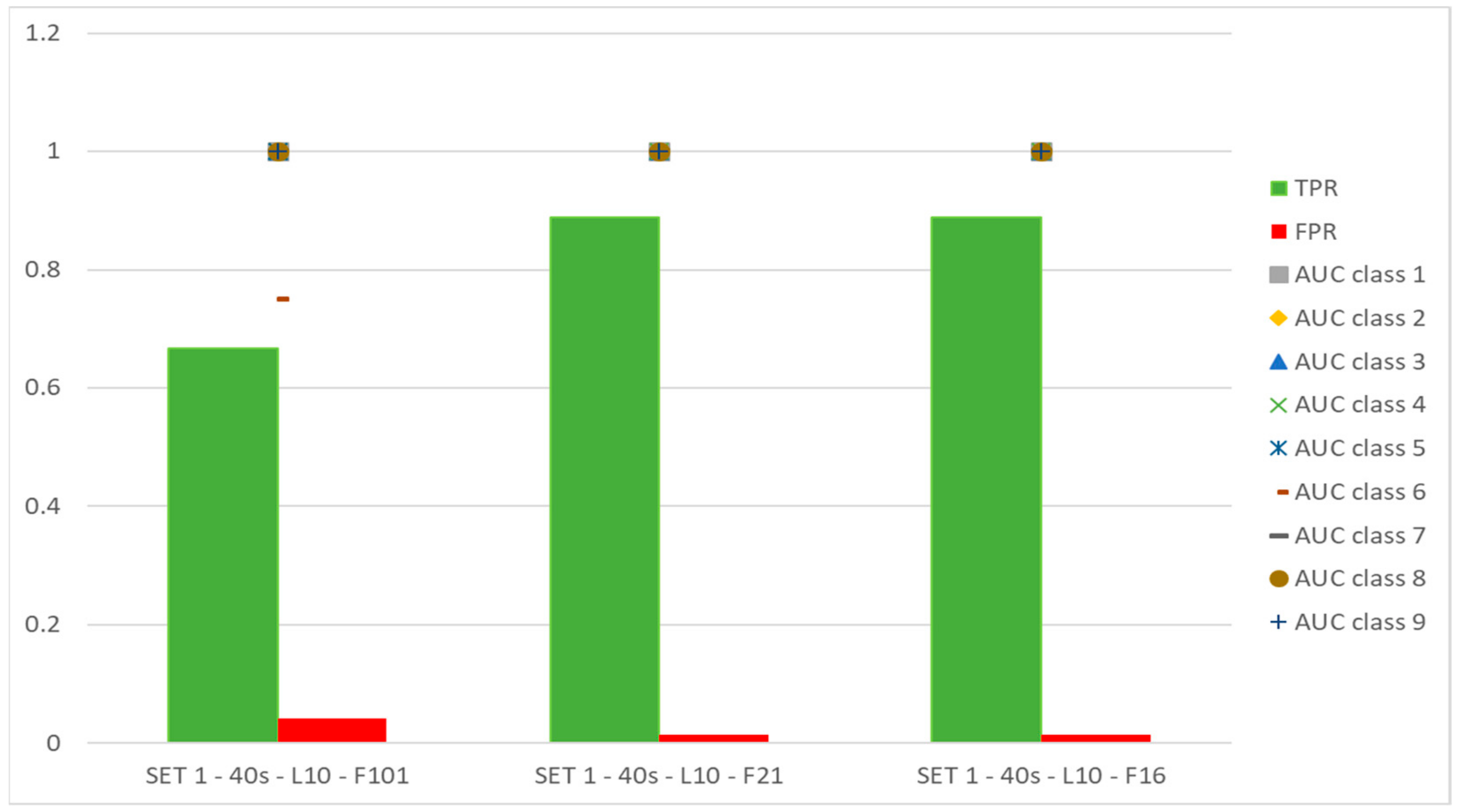
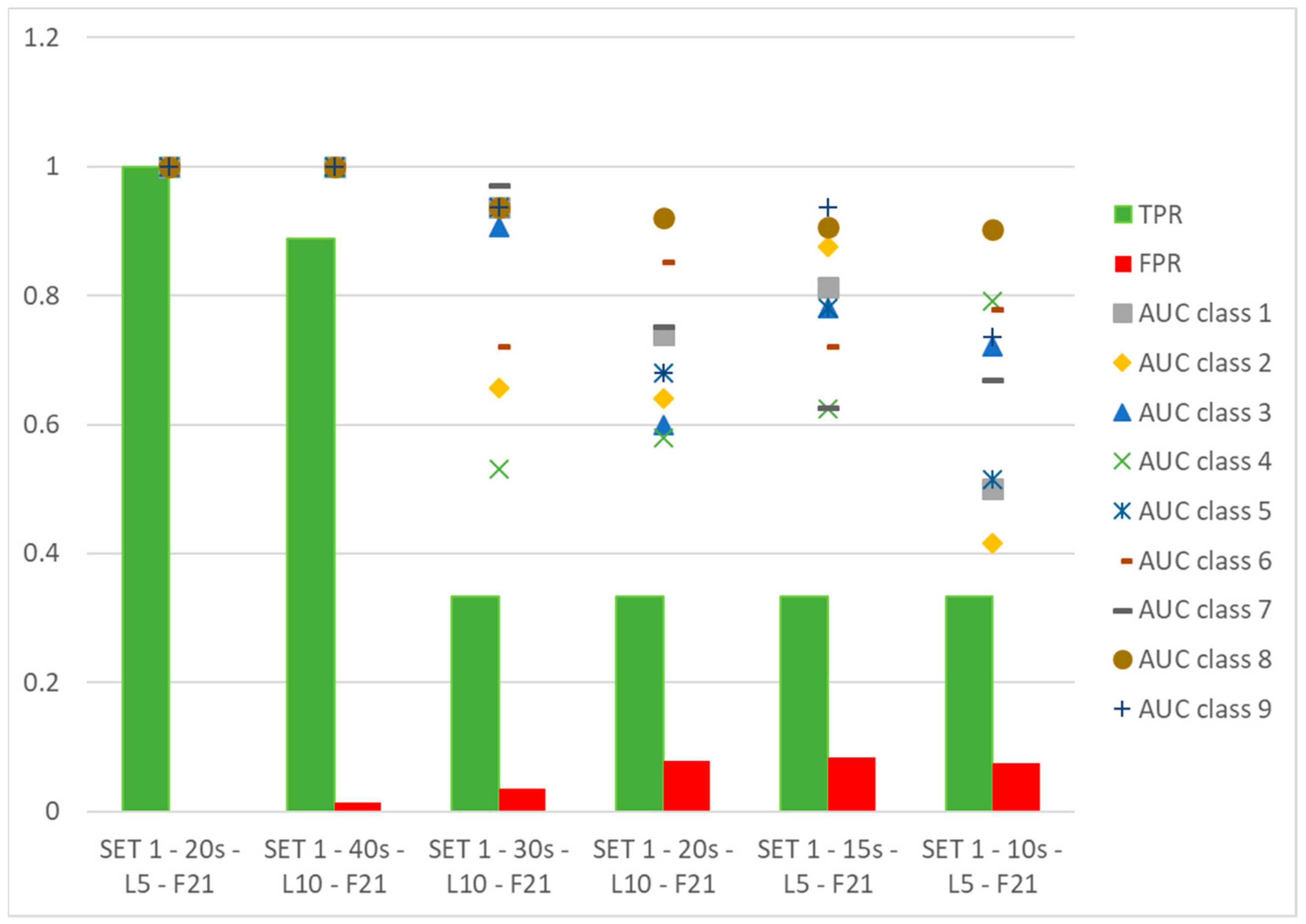
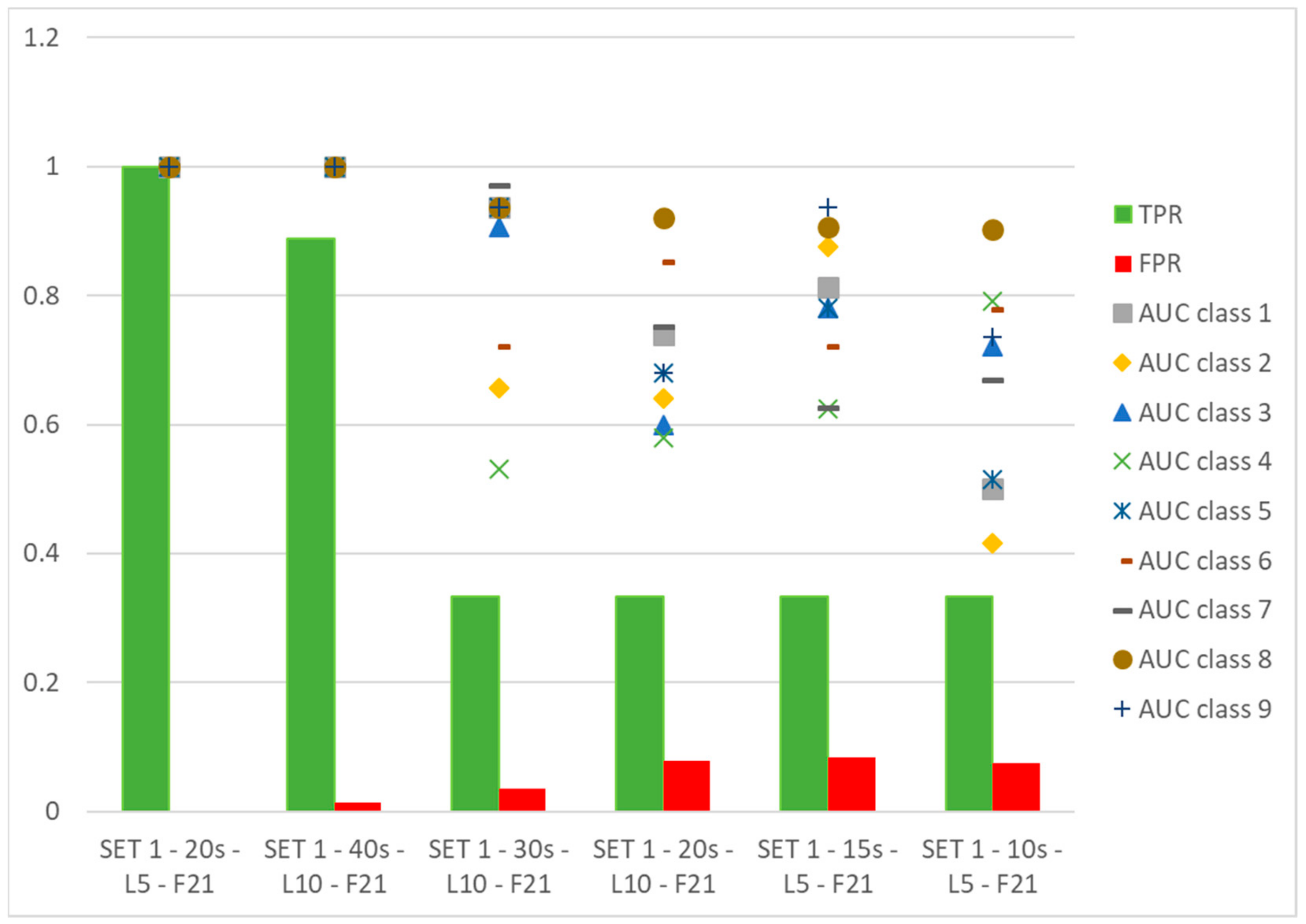
2.7. Performance Metrics
- tpi: true positive,
- fpi: false positive,
- fni: false negative,
- tni: true negative for the class Ci,
- l: number of classes.
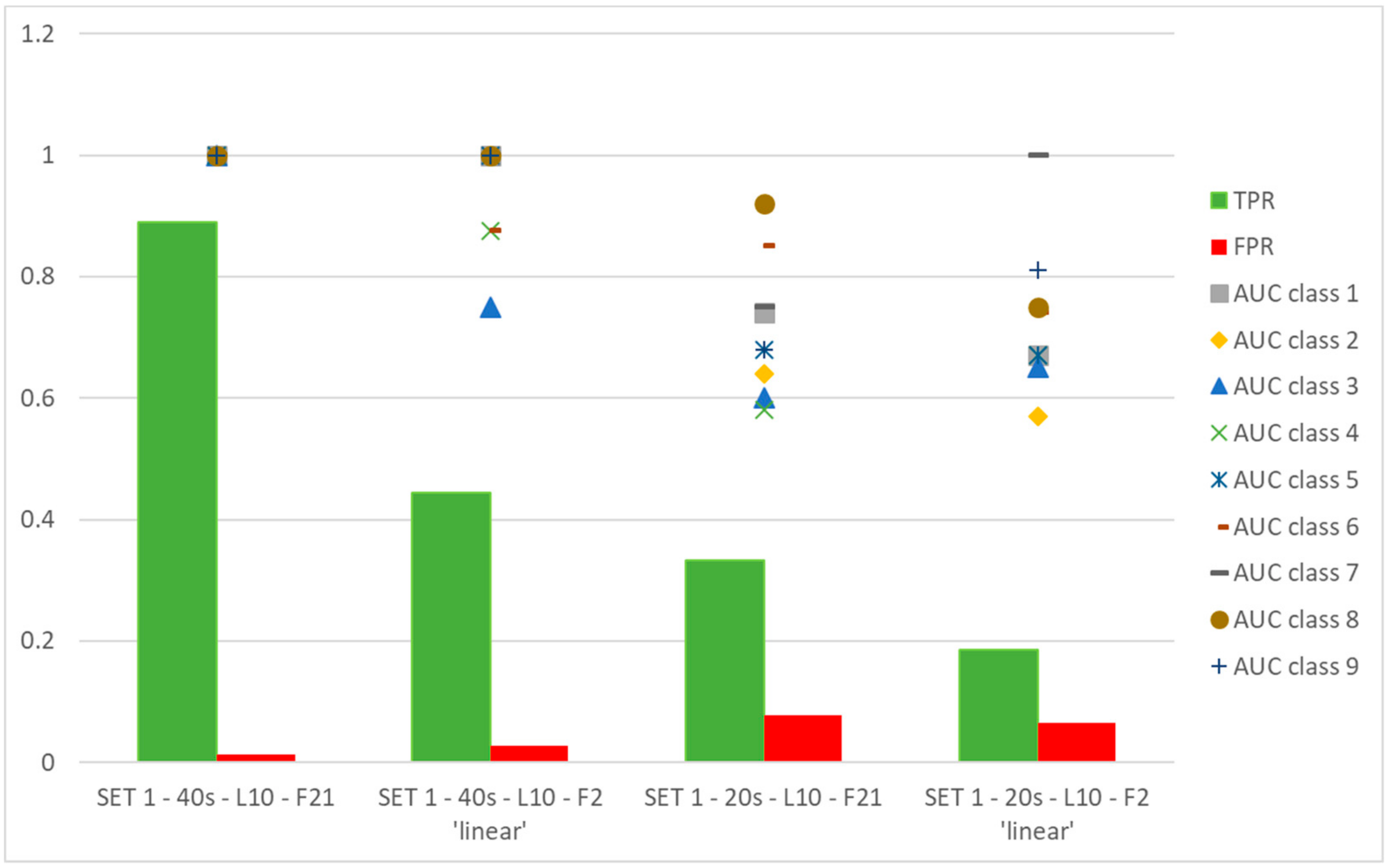
3. Results
- -
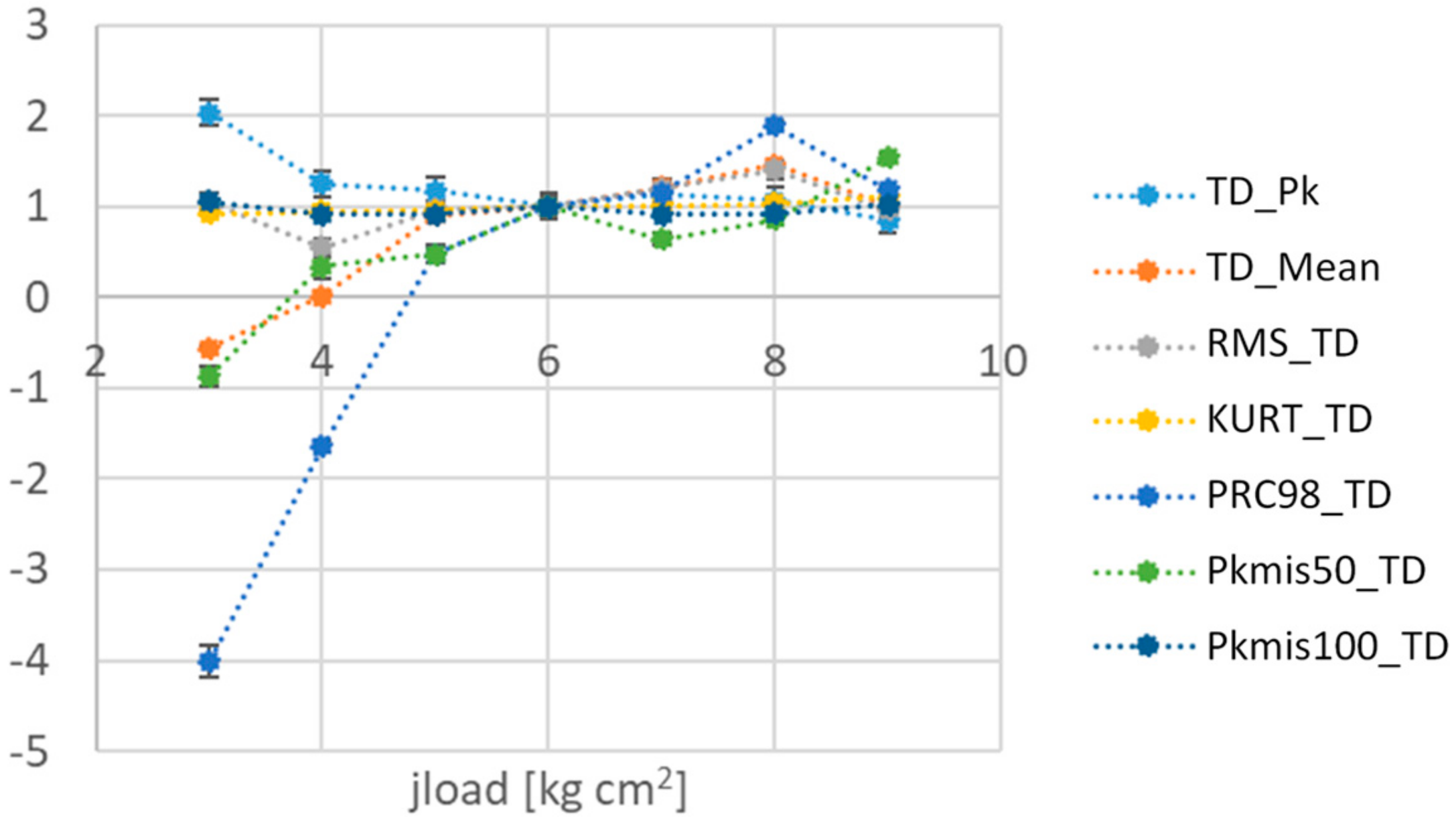
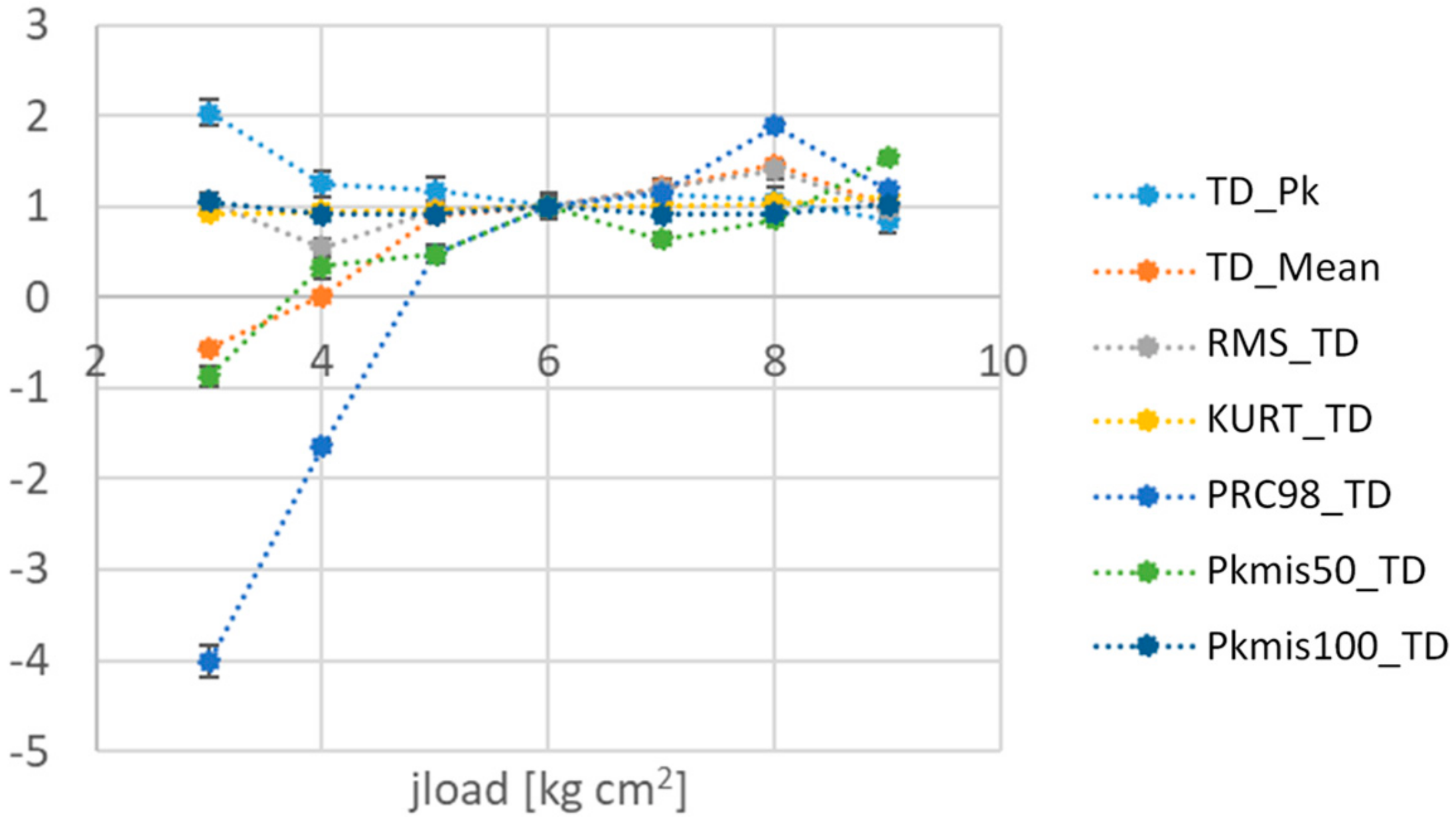
- for the first case, the following features:
- TD_Mean: mean values of TD,
- PRC98_TD: 98th percentile of TD distribution,
- -
- for the second case:
- TD_Pk: range of measured values of TD,
- PRC98_TD: 98th percentile of TD distribution.
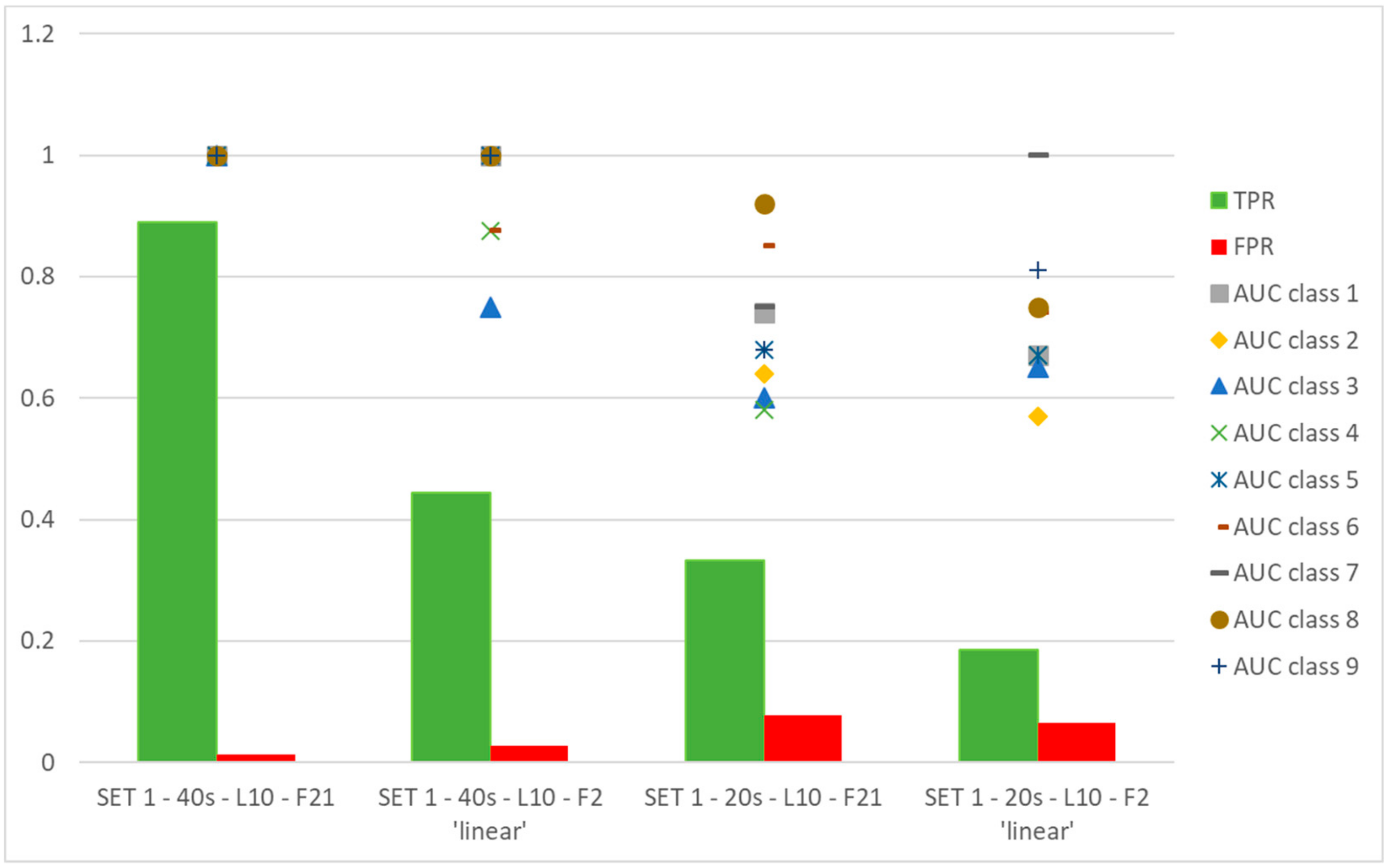
- changing the data set to be processed, the automatic method returns different couples of features, being PRC98_TD and RMS_Scur_Mposa_diff in SET 1-20 s-L10-F2 ‘linear’, where RMS_Scur_Mposa_diff is the RMS of the differences between simulated current values (when the input of the model is the measured angular position) and Mcur. It has to be pointed out that in any case features are identified belonging to SET 1-F21.
- training the ANN with features on the basis of the physical and metrological method produces satisfactory results with respect to the couples of features selected by the automatic classification method.
4. Conclusions
- improvements due to added noise to the data are negligible;
- the acquisition length being fixed, ANN benefits from having more temporal windows for supervised classification.
- a group of very few features can be found for classification purposes;
- the features automatically selected belong to the group suggested by metrological and physical criteria;
- if the tests on which the features are calculated are changed, the selected features are partially changed too, even though they are still in the group suggested by metrological and physical criteria;
- ANN used for classification does not work with automatically selected features, which operate satisfactorily only with some classifiers (e.g., Fine KNN and Weighted KNN).
Author Contributions
Funding
Conflicts of Interest
References
- Goyal, D.; Pabla, B.S. The Vibration Monitoring Methods and Signal Processing Techniques for Structural Health Monitoring: A Review. Arch. Comput. Method Eng. 2016, 23, 585–594. [Google Scholar] [CrossRef]
- Duan, Z.; Wu, T.; Guo, S.; Shao, T.; Malekian, R.; Li, Z. Development and trend of condition monitoring and fault diagnosis of multi-sensors information fusion for rolling bearings: A review. Int. J. Adv. Manuf. Technol. 2018, 96, 803–819. [Google Scholar] [CrossRef]
- D’Emilia, G.; Gaspari, A.; Hohwieler, E.; Laghmouchi, A.; Uhlmann, E. Improvement of defect detectability in machine tools using sensor-based condition monitoring applications. Procedia CIRP 2018, 67, 325–331. [Google Scholar] [CrossRef]
- Teti, R.; Jemielniak, K.; O’Donnell, G.; Dornfeld, D. Advanced monitoring of machining operations. CIRP Ann. Manuf. Technol. 2010, 59, 717–739. [Google Scholar] [CrossRef]
- Hofmeister, J.P.; Goodman, D.; Wagoner, R. Advanced anomaly detection method for condition monitoring of complex equipment and systems. In Proceedings of the Joint Conference on Machinery Failure Prevention Technology Conference, MFPT 2016 and ISA’s 62nd International Instrumentation Symposium, IIS, Code 122447, Montreal, QC, Canada, 15–17 October 2018. [Google Scholar]
- Seneviratne, D.; Catelani, M.; Ciani, L.; Galar, D. Smart maintenance and inspection of linear assets: An Industry 4.0 approach. Acta Imeko 2018, 7, 50–56. [Google Scholar] [CrossRef]
- Zenisek, J.; Holzinger, F.; Affenzeller, M. Machine learning based concept drift detection for predictive maintenance. Comput. Ind. Eng. 2019, 137, 106031. [Google Scholar] [CrossRef]
- Saez, M.; Maturana, F.P.; Barton, K.; Tilbury, D.M. Real-Time Manufacturing Machine and System Performance Monitoring Using Internet of Things. IEEE Trans. Autom. Sci. Eng. 2018, 15, 1735–1748. [Google Scholar] [CrossRef]
- Stief, A.; Ottewill, J.R.; Baranowski, J.; Orkisz, M. A PCA and Two-Stage Bayesian Sensor Fusion Approach for Diagnosing Electrical and Mechanical Faults in Induction Motors. IEEE Trans. Ind. Electron. 2019, 66, 9510–9520. [Google Scholar] [CrossRef]
- Gunerkar, R.S.; Jalan, A.K. Classification of Ball Bearing Faults Using Vibro-Acoustic Sensor Data Fusion. Exp. Tech. 2019, 43, 635–643. [Google Scholar] [CrossRef]
- Lipsett, M.G. How system observability affects fault classification accuracy, and implications for sensor selection and placement for condition monitoring. In Proceedings of the WCCM 2017—1st World Congress on Condition Monitoring, London, UK, 13–16 June 2017. [Google Scholar]
- Diez Olivan, A.; Del Ser, J.; Galar, D.; Sierra, B. Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 4.0. Inf. Fusion 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Zhang, Y.; Duan, L.; Duan, M. A new feature extraction approach using improved symbolic aggregate approximation for machinery intelligent diagnosis. Measurement 2019, 133, 468–478. [Google Scholar] [CrossRef]
- D’Emilia, G.; Natale, E. Instrument comparison for integrated tuning and diagnostics in high performance automated systems. J. Eng. Appl. Sci. 2018, 13, 795–803. [Google Scholar]
- D’Emilia, G.; Gaspari, A. Data validation techniques for measurements systems operating in a Industry 4.0 scenario—A condition monitoring application. In Proceedings of the Conference Metrology for Industry 4.0, Brescia, Italy, 16–18 April 2018; pp. 113–117. [Google Scholar]
- Saxena, S.; Sharma, P. An approach to the analysis of higher linkage mechanisms and its validation via matlab. In Proceedings of the 3rd IEEE International Conference on “Computational Intelligence and Communication Technology”, Ghaziabad, India, 9–10 February 2017. [Google Scholar]
- D’Emilia, G.; Gaspari, A.; Natale, E. Sensor fusion for more accurate features in condition monitoring of mechatronic systems. In Proceedings of the I2MTC, IEEE International Instrumentation and Measurement Conference, Auckland, New Zealand, 20–23 May 2019; pp. 227–232. [Google Scholar]
- Leturiondo, U.; Salgado, O.; Ciani, L.; Galar, D.; Catelani, M. Architecture for hybrid modelling and its application to diagnosis and prognosis with missing data. Measurement 2017, 108, 152–162. [Google Scholar] [CrossRef]
- Silva, R.G.; Wilcox, S.J. Feature evaluation and selection for condition monitoring using a self-organizing map and spatial statistics. AI EDAM 2019, 33, 1–10. [Google Scholar] [CrossRef]
- Yen, C.L.; Lu, M.C.; Chen, J.L. Applying the self-organization feature map (SOP) algorithm to AE-based tool wear monitoring in micro-cutting. Mech. Syst. Signal Process. 2013, 34, 353–366. [Google Scholar] [CrossRef]
- Zhang, B.; Katinas, C.; Shin, Y.C. Robust tool wear monitoring using systematic feature selection in turning processes with consideration of uncertainties. J. Manuf. Sci. Eng. 2018, 140, 081010. [Google Scholar] [CrossRef]
- Ferreira, B.; Silva, R.G.; Pereira, V. Feature selection using non-binary decision trees applied to condition monitoring. In Proceedings of the IEEE International Conference on Emerging Technologies and Factory Automation, ETFA4, Limassol, Cyprus, 12–15 September 2017. [Google Scholar]
- Roffo, G.; Melzi, S.; Castellani, U.; Vinciarelli, A. Infinite latent feature selection: A probabilistic latent Graph-based ranking approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 24 July 2017; pp. 1407–1415. [Google Scholar]
- Schneider, T.; Helwig, N.; Schütze, A. Industrial condition monitoring with smart sensors using automated feature extraction and selection. Meas. Sci. Technol. 2018, 29, 094002. [Google Scholar] [CrossRef]
- Schneider, T.; Helwig, N.; Schuütze, A. Automatic Feature Extraction and Selection for Condition Monitoring and related Datasets. In Proceedings of the IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018. [Google Scholar]
- Sheikhpoura, R.; Sarrama, M.A.; Gharaghanib, S.; Zare Chahookia, M.A. A Survey on semi-supervised feature selection methods. Pattern Recognit. 2017, 64, 141–158. [Google Scholar] [CrossRef]
- Shao, C.; Paynabar, K.; Kim, T.H.; Jin, J.; Hu, S.J.; Spicer, J.P.; Wang, H.; Abell, J.A. Feature selection for manufacturing process monitoring using cross-validation. J. Manuf. Syst. 2013, 32, 550–555. [Google Scholar] [CrossRef]
- D’Emilia, G.; Gaspari, A.; Natale, E. Integration of model and sensor data for smart condition monitoring in mechatronic devices. In Proceedings of the Workshop on Metrology for Industry 4.0 and IoT, Naples, Italy, 4–6 June 2019. [Google Scholar]
- Dimensionality Reduction and Feature Extraction. Available online: https://www.mathworks.com/help/stats/dimensionality-reduction.html (accessed on 8 November 2019).
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer Series in Operations Research; Springer Verlag: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Le, Q.V.; Karpenko, A.; Ngiam, J.; Ng, A.Y. ICA with reconstruction cost for efficient overcomplete feature learning. In Proceedings of the ICA with Reconstruction Cost for Efficient Overcomplete Feature Learning, Granada, Spain, 12–15 December 2011; pp. 1017–1025. [Google Scholar]
- Ngiam, J.; Zhenghao, C.; Bhaskar, S.A.; Koh, P.W.; Ng, A.Y. Sparse Filtering. Adv. Neur. In. 2011, 24, 1125–1133. [Google Scholar]
- Feature Selection. Available online: https://www.mathworks.com/help/stats/feature-selection.html (accessed on 8 November 2019).
- John, G.; Kohavi, R. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 272–324. [Google Scholar]
- Krzanowski, W.J. Principles of Multivariate Analysis: A User’s Perspective; Oxford University Press: New York, NY, USA, 1988. [Google Scholar]
- Seber, G.A.F. Multivariate Observations; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1984. [Google Scholar]
- Classification Learner. Available online: https://it.mathworks.com/help/stats/classificationlearner-app.html (accessed on 8 November 2019).
- D’Emilia, G.; Gaspari, A.; Natale, E. Mechatronics applications of measurements for smart manufacturing in an industry 4.0 scenario. IEEE Instrum. Meas. Mag. 2019, 22, 35–43. [Google Scholar] [CrossRef]
- Select Data and Validation for Classification Problem. Available online: https://www.mathworks.com/help/stats/select-data-and-validation-for-classification-problem.html (accessed on 8 November 2019).
- Deng, X.; Liu, Q.; Deng, Y.; Mahadevan, S. An improved method to construct basic probability assignment based on the confusion matrix for classification problem. Inf. Sci. 2016, 340, 250–261. [Google Scholar] [CrossRef]
- Eapa, B.G.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar]
- Kim, C.; Cha, S.H.; An, Y.J.; Wilson, N. On ROC Curve Analysis of Artificial Neural Network Classifiers. In Proceedings of the Thirtieth International Flairs Conference, Marco Island, FL, USA, 22–24 May 2017. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. Data mining in metric space: An empirical analysis of supervised learning performance criteria. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 69–78. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Emilia, G.; Gaspari, A.; Natale, E. Physical and Metrological Approach for Feature’s Definition and Selection in Condition Monitoring. Sensors 2019, 19, 5186. https://doi.org/10.3390/s19235186
D’Emilia G, Gaspari A, Natale E. Physical and Metrological Approach for Feature’s Definition and Selection in Condition Monitoring. Sensors. 2019; 19(23):5186. https://doi.org/10.3390/s19235186
Chicago/Turabian StyleD’Emilia, Giulio, Antonella Gaspari, and Emanuela Natale. 2019. "Physical and Metrological Approach for Feature’s Definition and Selection in Condition Monitoring" Sensors 19, no. 23: 5186. https://doi.org/10.3390/s19235186
APA StyleD’Emilia, G., Gaspari, A., & Natale, E. (2019). Physical and Metrological Approach for Feature’s Definition and Selection in Condition Monitoring. Sensors, 19(23), 5186. https://doi.org/10.3390/s19235186