Multi-Level Features Extraction for Discontinuous Target Tracking in Remote Sensing Image Monitoring

 , ,
, ,  and
and 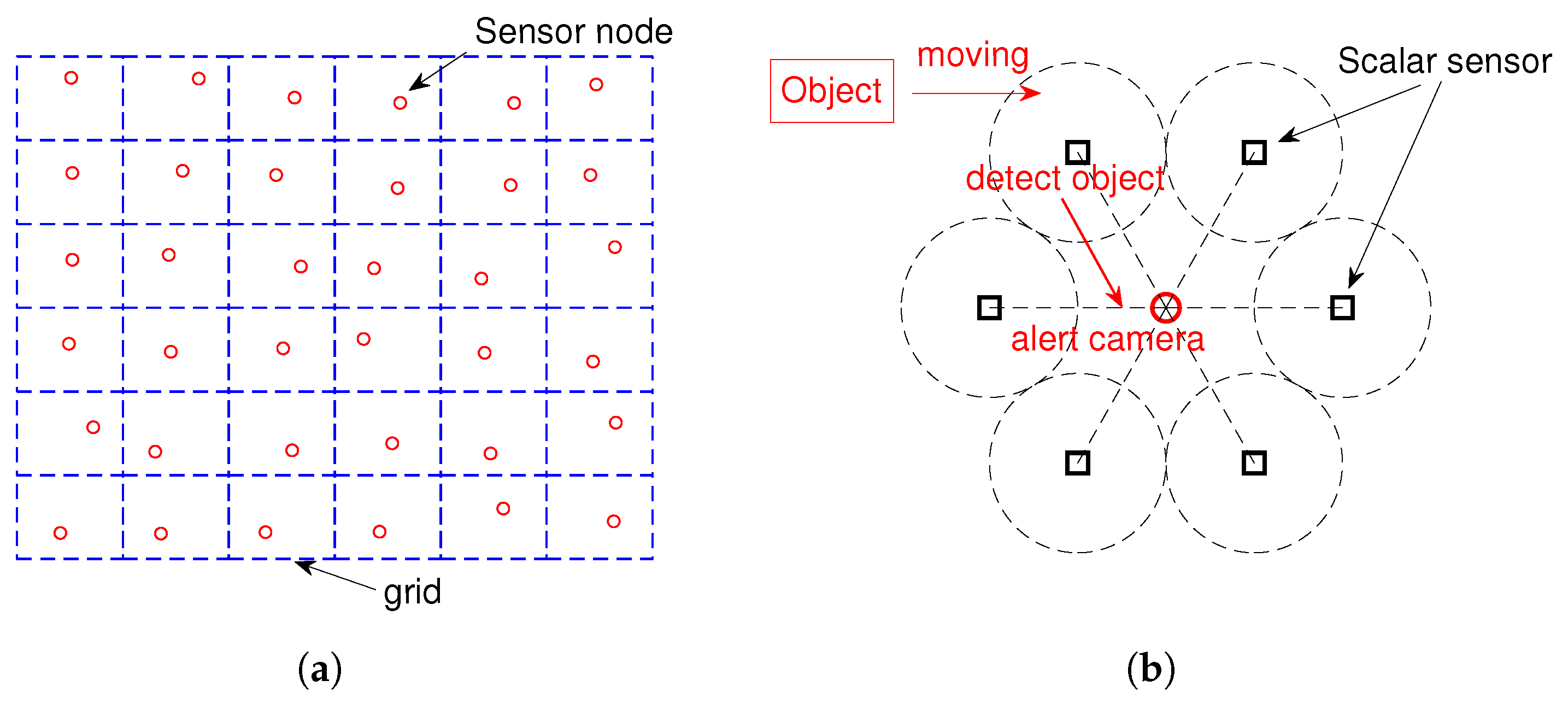{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Fundamentals
2.1. Remote Sensing and Wireless Multimedia Sensor Networks
2.2. Multi-Cam Tracking and Re-Identification
2.3. Feature Extraction
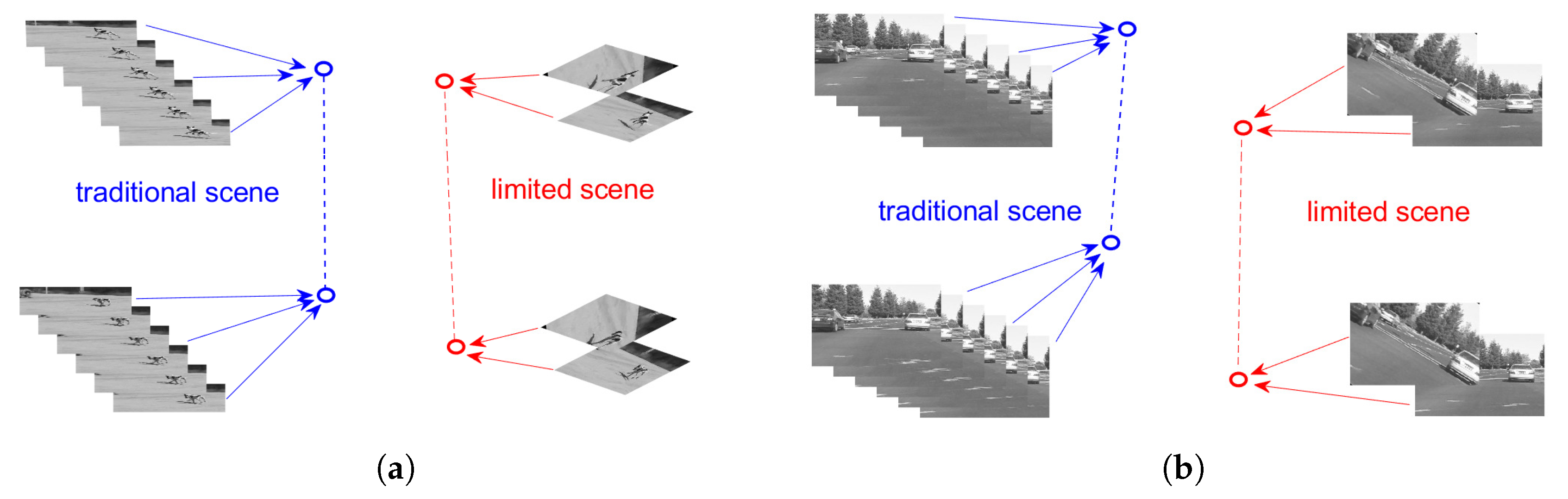
3. Proposed Method
3.1. Optimal Selection to the Principle Components
3.2. Image Matching via Refined Feature Describing
- Step 1.
- Determine candidate key-points via peak selection in the difference of Gaussian space;
- Step 2.
- key-point checking and orientation assignment;
- Step 3.
- Eight direction statistics and key-point describing.
3.3. Evaluation of the Matching Results
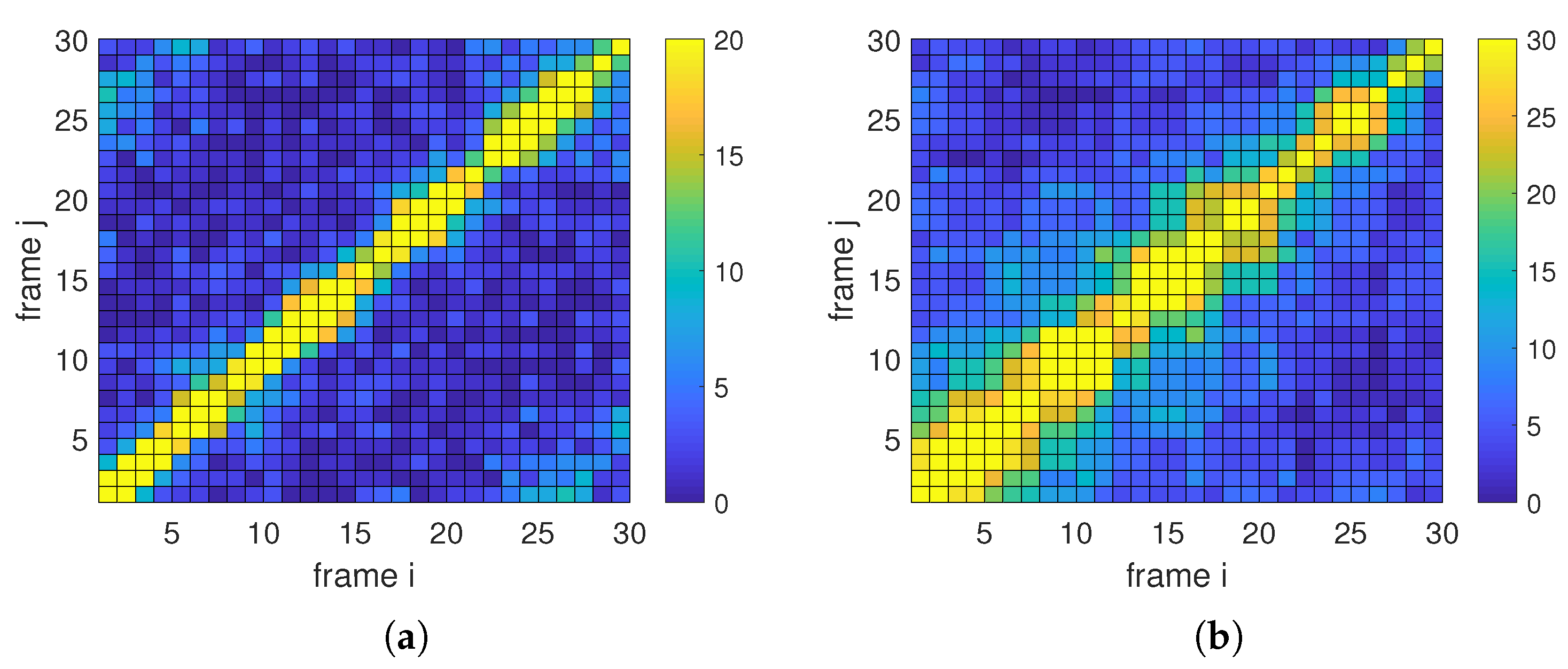
4. Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, G. Remote Sensing Image Monitoring and Recognition Technology for the Conservation of Rare Wild Animals. Rev. Cient. 2019, 29, 301–311. [Google Scholar]
- Roopa, D.; Chaudhari, S. A survey on Geographic Multipath Routing Techniques in Wireless Sensor Networks. In Proceedings of the IEEE 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 257–262. [Google Scholar]
- Küçükkeçeci, C.; Yazıcı, A. Big data model simulation on a graph database for surveillance in wireless multimedia sensor networks. Big Data Res. 2018, 11, 33–43. [Google Scholar] [CrossRef]
- Aguirre-Gutiérrez, J.; Seijmonsbergen, A.C.; Duivenvoorden, J.F. Optimizing land cover classification accuracy for change detection, a combined pixel-based and object-based approach in a mountainous area in Mexico. Appl. Geogr. 2012, 34, 29–37. [Google Scholar] [CrossRef]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic Object-based Image Analysis (GEOBIA): Emerging trends and future opportunities. GIScie. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Melodia, T.; Chowdhury, K.R. A survey on wireless multimedia sensor networks. Comput. Netw. 2007, 51, 921–960. [Google Scholar] [CrossRef]
- Abbas, N.; Yu, F.; Fan, Y. Intelligent Video Surveillance Platform for Wireless Multimedia Sensor Networks. Appl. Sci. 2018, 8, 348. [Google Scholar] [CrossRef]
- Amjad, M.; Rehmani, M.H.; Mao, S. Wireless multimedia cognitive radio networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2018, 20, 1056–1103. [Google Scholar] [CrossRef]
- Usman, M.; Jan, M.A.; He, X.; Chen, J. A mobile multimedia data collection scheme for secured wireless multimedia sensor networks. IEEE Trans. Netw. Sci. Eng. 2018. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Yu, H.X.; Zheng, W.S.; Wu, A.; Guo, X.; Gong, S.; Lai, J.H. Unsupervised Person Re-identification by Soft Multilabel Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2148–2157. [Google Scholar]
- Li, M.; Zhu, X.; Gong, S. Unsupervised Tracklet Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef]
- Küçükkeçeci, C.; Yazici, A. Multilevel Object Tracking in Wireless Multimedia Sensor Networks for Surveillance Applications Using Graph-based Big Data. IEEE Access 2019. [Google Scholar] [CrossRef]
- Xu, R.; Guan, Y.; Huang, Y. Multiple human detection and tracking based on head detection for real-time video surveillance. Multimed. Tools Appl. 2015, 74, 729–742. [Google Scholar] [CrossRef]
- Xiao, S.; Li, W.; Jiang, H.; Xu, Z.; Hu, Z. Trajectroy prediction for target tracking using acoustic and image hybrid wireless multimedia sensors networks. Multimed. Tools Appl. 2018, 77, 12003–12022. [Google Scholar] [CrossRef]
- Dominguez-Morales, J.P.; Rios-Navarro, A.; Dominguez-Morales, M.; Tapiador-Morales, R.; Gutierrez-Galan, D.; Cascado-Caballero, D.; Jimenez-Fernandez, A.; Linares-Barranco, A. Wireless sensor network for wildlife tracking and behavior classification of animals in Doñana. IEEE Commun. Lett. 2016, 20, 2534–2537. [Google Scholar] [CrossRef]
- Rehman, Y.A.U.; Tariq, M.; Sato, T. A novel energy efficient object detection and image transmission approach for wireless multimedia sensor networks. IEEE Sens. J. 2016, 16, 5942–5949. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the 1999 7th IEEE International Conference on Computer Vision; IEEE Computer Society: Los Alamitos, CA, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J.; Kwok, N.M. A comprehensive performance evaluation of 3D local feature descriptors. Int. J. Comput. Vis. 2016, 116, 66–89. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Alvey Vision Conference; Citeseer: Princeton, NJ, USA, 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Förstner, W.; Gülch, E. A fast operator for detection and precise location of distinct points, corners and centres of circular features. In Proceedings of the ISPRS Intercommission Conference on Fast Processing of Photogrammetric Data, Interlaken, Switzerland, 2–4 June 1987; pp. 281–305. [Google Scholar]
- Li, Y.; Li, Q.; Liu, Y.; Xie, W. A spatial-spectral SIFT for hyperspectral image matching and classification. In Pattern Recognition Letters; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Rodríguez, M.; Delon, J.; Morel, J.M. Fast Affine Invariant Image Matching. Image Process. Line 2018, 8, 251–281. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 2, p. II. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin, Germany, 2006; pp. 404–417. [Google Scholar]
- Todorovic, S.; Ahuja, N. Region-based hierarchical image matching. Int. J. Comput. Vis. 2008, 78, 47–66. [Google Scholar] [CrossRef]
- Tau, M.; Hassner, T. Dense correspondences across scenes and scales. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 875–888. [Google Scholar] [CrossRef]
- Shao, Z.; Fu, H.; Li, D.; Altan, O.; Cheng, T. Remote sensing monitoring of multi-scale watersheds impermeability for urban hydrological evaluation. Remote Sens. Environ. 2019, 232, 111338. [Google Scholar] [CrossRef]
- Long, N.; Millescamps, B.; Guillot, B.; Pouget, F.; Bertin, X. Monitoring the topography of a dynamic tidal inlet using UAV imagery. Remote Sens. 2016, 8, 387. [Google Scholar] [CrossRef]
- Masazade, E.; Niu, R.; Varshney, P.K. Dynamic bit allocation for object tracking in wireless sensor networks. IEEE Trans. Signal Process. 2012, 60, 5048–5063. [Google Scholar] [CrossRef]
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Zajdel, W.; Zivkovic, Z.; Krose, B. Keeping track of humans: Have I seen this person before? In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 2081–2086. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Xu, Y.; Ma, B.; Huang, R.; Lin, L. Person search in a scene by jointly modeling people commonness and person uniqueness. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 937–940. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. Freak: Fast retina keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Gheissari, N.; Sebastian, T.B.; Hartley, R. Person reidentification using spatiotemporal appearance. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1528–1535. [Google Scholar]
- Visual Tracker Benchmark. Available online: http://www.visual-tracking.net (accessed on 30 July 2019).










© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, B.; Duan, X.; Ye, D.; Wei, W.; Woźniak, M.; Połap, D.; Damaševičius, R. Multi-Level Features Extraction for Discontinuous Target Tracking in Remote Sensing Image Monitoring. Sensors 2019, 19, 4855. https://doi.org/10.3390/s19224855
Zhou B, Duan X, Ye D, Wei W, Woźniak M, Połap D, Damaševičius R. Multi-Level Features Extraction for Discontinuous Target Tracking in Remote Sensing Image Monitoring. Sensors. 2019; 19(22):4855. https://doi.org/10.3390/s19224855
Chicago/Turabian StyleZhou, Bin, Xuemei Duan, Dongjun Ye, Wei Wei, Marcin Woźniak, Dawid Połap, and Robertas Damaševičius. 2019. "Multi-Level Features Extraction for Discontinuous Target Tracking in Remote Sensing Image Monitoring" Sensors 19, no. 22: 4855. https://doi.org/10.3390/s19224855
APA StyleZhou, B., Duan, X., Ye, D., Wei, W., Woźniak, M., Połap, D., & Damaševičius, R. (2019). Multi-Level Features Extraction for Discontinuous Target Tracking in Remote Sensing Image Monitoring. Sensors, 19(22), 4855. https://doi.org/10.3390/s19224855