1. Introduction
Illegal drugs can degrade physical and mental health while affecting social stability and economic development. The rapid detection of illicit opium-poppy plants is integral to combatting crimes related to drug-cultivation. Satellite remote sensing has traditionally played an important role in monitoring poppy cultivation. Taylor et al. [
1], along with the U.S. government, used satellite remote sensing to detect poppy plots in Afghanistan for several years. Liu et al. [
2] used ZY-3 satellite imagery to detect poppy plots in Phongsali Province, Laos, using the single-shot detector (SSD)-based object detection method. Jia et al. [
3] studied the spectral characteristics of three different poppy growth stages, showing that the best period for distinguishing poppy from coexisting crops was during flowering. However, new cultivation strategies such as planting small, sporadic, or mixed plots make it more difficult to identify small-scale cultivation in non-traditional settings, such as courtyards. Compared to satellite remote sensing, unmanned aerial vehicles (UAVs) capture images with much higher spatial resolution (<1 cm). UAV platforms are highly flexible: they are able to conduct observations under broader conditions and can fly closer to the ground to capture finer textural features. This ability to capture such detailed features together with the lower cost of UAVs compared to satellite remote sensing are rapidly making UAV systems both an effective alternative and a supplement to satellite remote sensing, particularly in the detection of illegal poppy cultivation.
Poppy identification in UAV images is currently conducted primarily via visual interpretation because of major differences in the characteristics of different growing stages and the complexity of planting environments. A skilled expert usually requires at least 20 s to detect poppy via visual interpretation of a UAV image. This requires extensive human and material resources given the sheer quantity of UAV images that can be collected. Machine learning methods based on manual design features perform well only under limited conditions; such limited conditions currently do not sufficiently account for variation in altitude, exposure, and rotation angle, all of which can significantly affect the appearance of similar ground objects in UAV images and add difficulty to feature recognition. Therefore, a new method to improve work efficiency and detection accuracy is urgently needed; for this purpose, the ongoing development of deep-learning-based object detection holds great promise.
Deep learning has rapidly developed since its initial proposal in 2006, and especially after 2012. Techniques represented by deep convolutional neural networks (DCNNs) have been widely used in various fields of computer vision, including image classification [
4,
5,
6,
7], object detection [
8,
9,
10,
11,
12,
13], and semantic segmentation [
14,
15,
16,
17,
18]. Compared with traditional machine learning methods based on manual design features, DCNNs have a more complex structure that is capable of extracting deeper semantic features and learning more powerful general image representations. Currently, convolutional neural networks (CNNs) are mainly composed of several convolution layers that may include pooling layers, followed by several full connection layers. The feature map generated by the convolution layer is usually activated by the rectified linear unit (ReLU) and regularized by batch normalization (BN) [
19] to prevent network overfitting. Researchers have continuously expanded network depth and width or reduced the complexity of the network model to improve the accuracy or speed of image classification; alongside such advances, complex networks have been proposed, such as the Inception series [
5,
19,
20,
21] and Residual series models [
7,
22], which expand the width and deepen the network layer, or the lightweight networks, such as SqueezeNet [
23], MobileNet [
24,
25,
26], and ShuffleNet [
27,
28].
CNN’s successful performances in image classification tasks has advanced the development of object detection. Traditional object detection relies on a search framework based on sliding windows, which divide a graph into several sub-graphs with different positions and scales; a classifier is then used to distinguish parts that do not contain specified objects by sub-graph. This method requires designing different feature extraction methods and classification algorithms for different objects. Object detection methods based on deep learning are mainly divided into two categories based on region proposal and regression. Region proposal methods (such as Regions with CNN features (R-CNN) [
8], Fast R-CNN [
29], and Faster R-CNN [
9]) mainly use texture, edge, color, or other information in the image to determine the possible location of an object in the image in advance and then use the CNNs to classify and extract the features of these locations. Although this method can achieve good accuracy, it is difficult to implement in real-time detection. Regression methods (such as OverFeat [
30], You Only Look Once (YOLO) [
10,
31,
32], and SSD [
11,
33]) use a single end-to-end CNN to directly predict the location and category of an object’s bounding box in multiple locations within the image, greatly accelerating the speed of object detection.
Deep-learning-based object detection methods have been widely used in remote sensing applications. For example, Ammour et al. [
34] combined the CNN and support vector machine (SVM) methods to conduct vehicle identification research using aerial photographs. Bazi and Melgani [
35] constructed a convolutional support vector machine network (CSVM) for the detection of vehicles and solar panels using an UAV dataset. Chen et al. [
36] used Faster R-CNN object detection to identify airports from aerial photography. Rahnemoonfar et al. [
37] built an end-to-end network (DisCountNet) to count animals in UAV images. Ampatzidis and Partel [
38] used the YOLOv3 model with normalized difference vegetation index (NDVI) data to detect trees in low-altitude UAV photos.
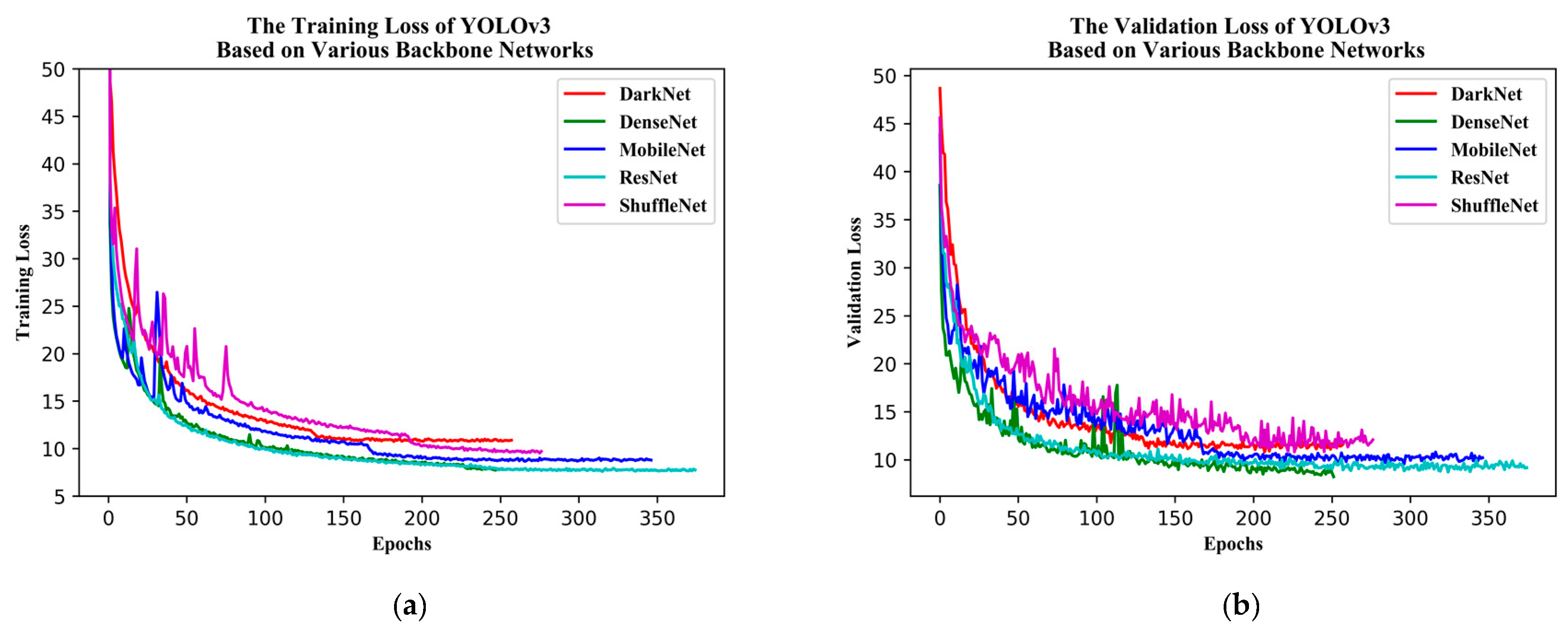
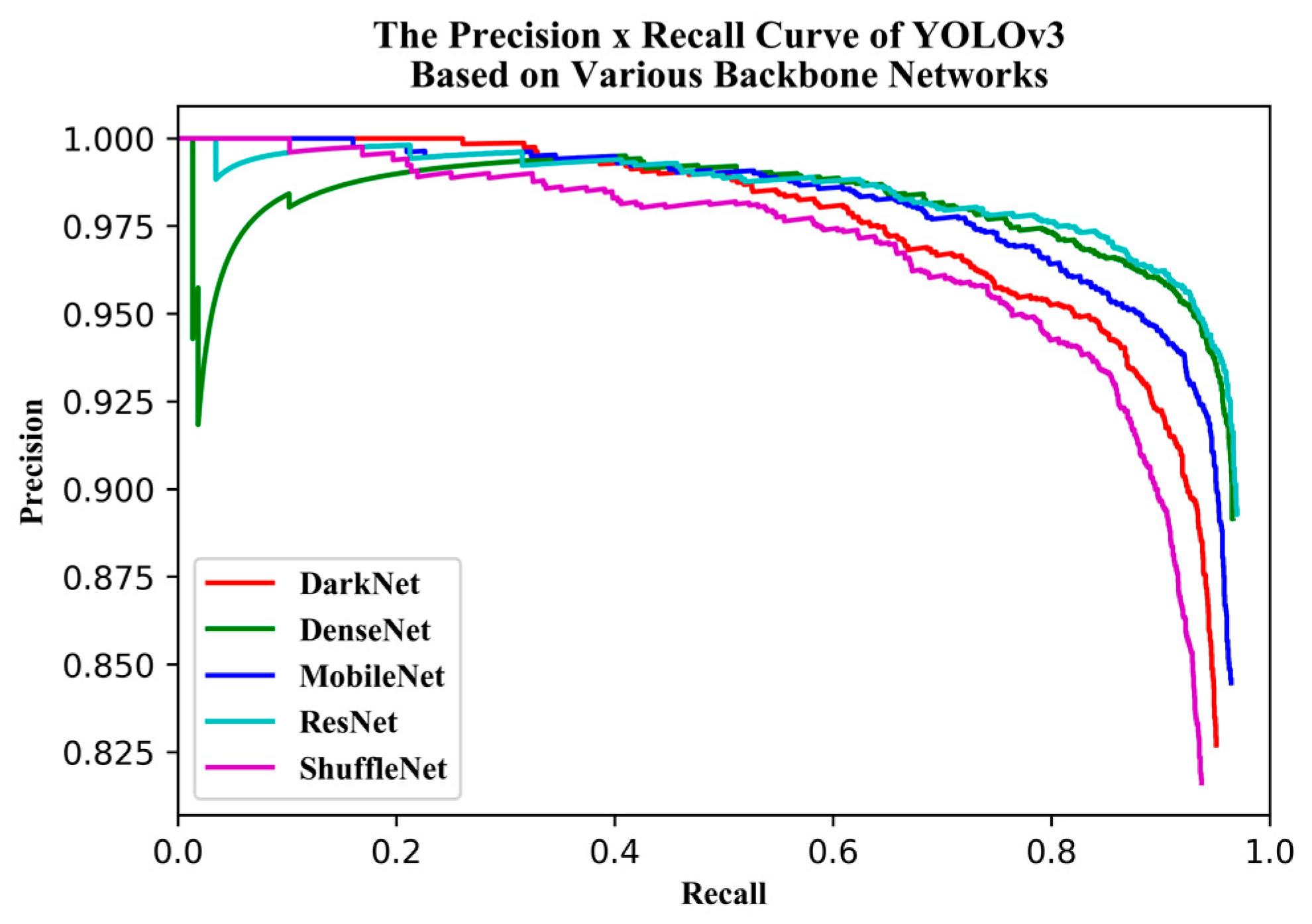
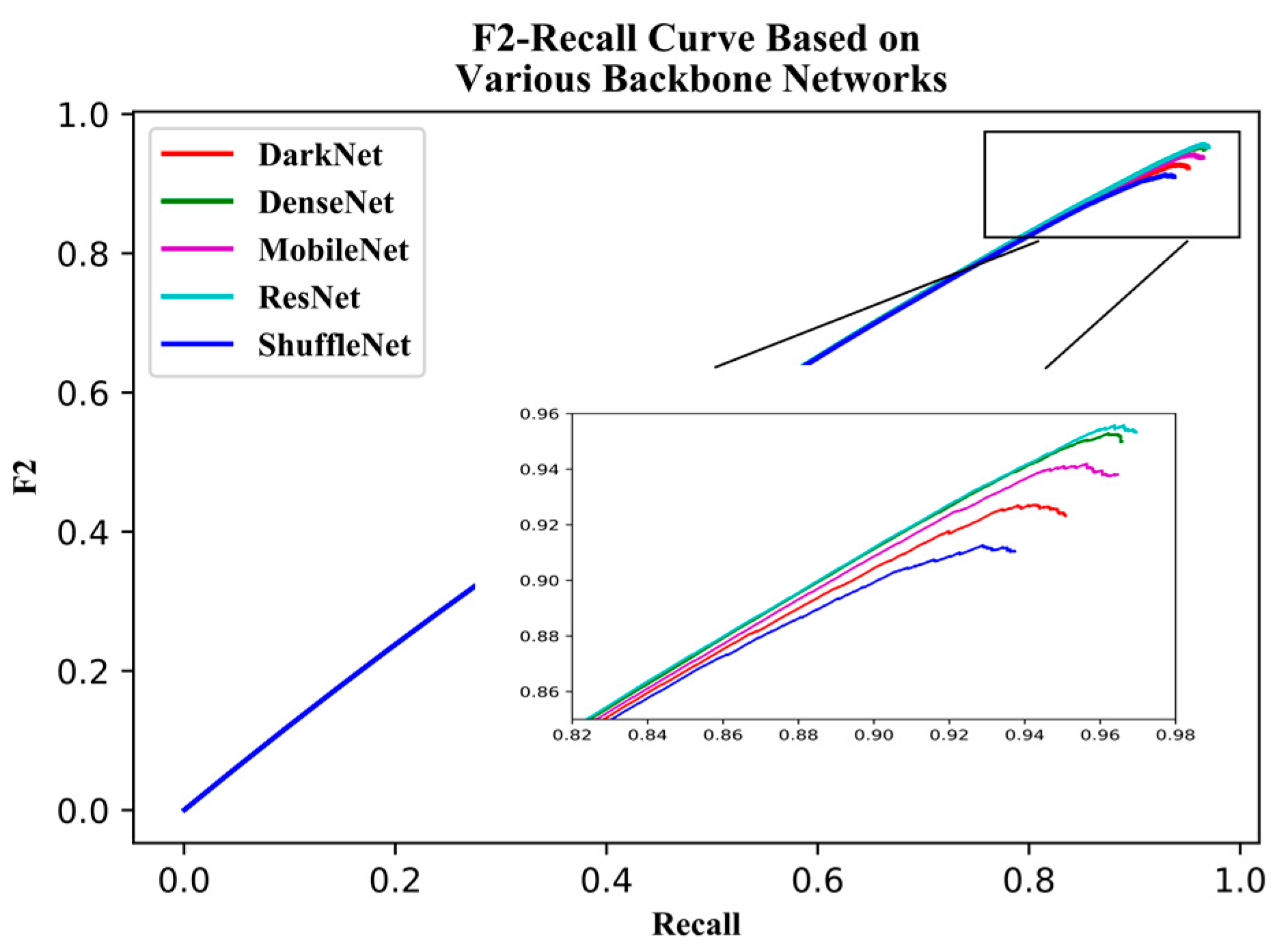
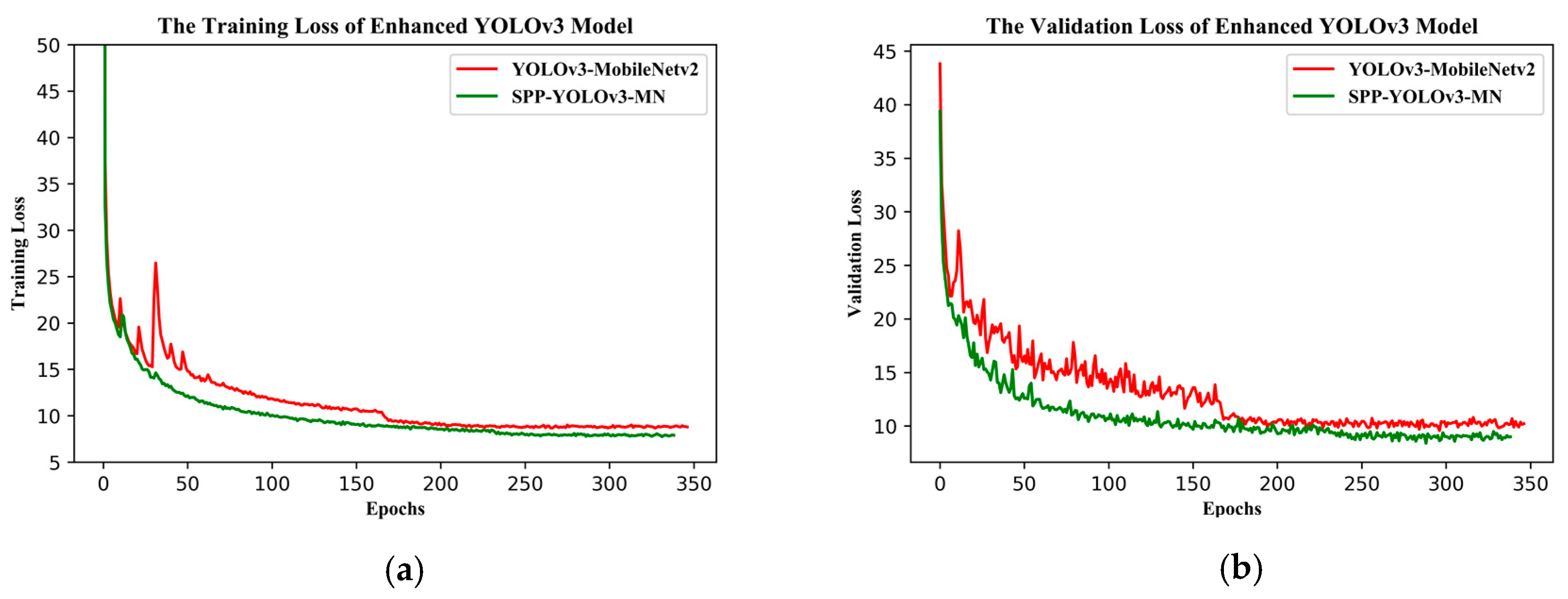
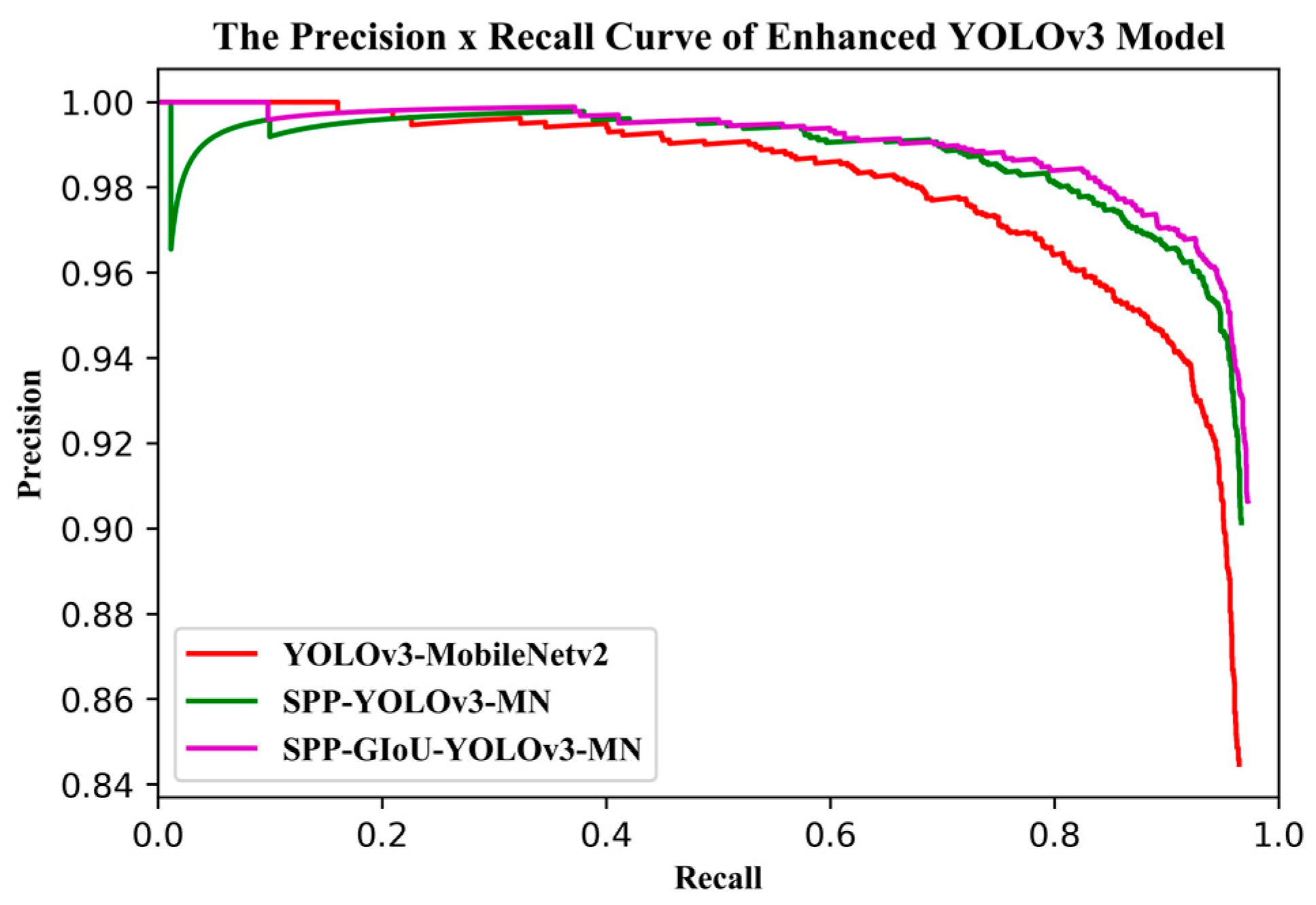
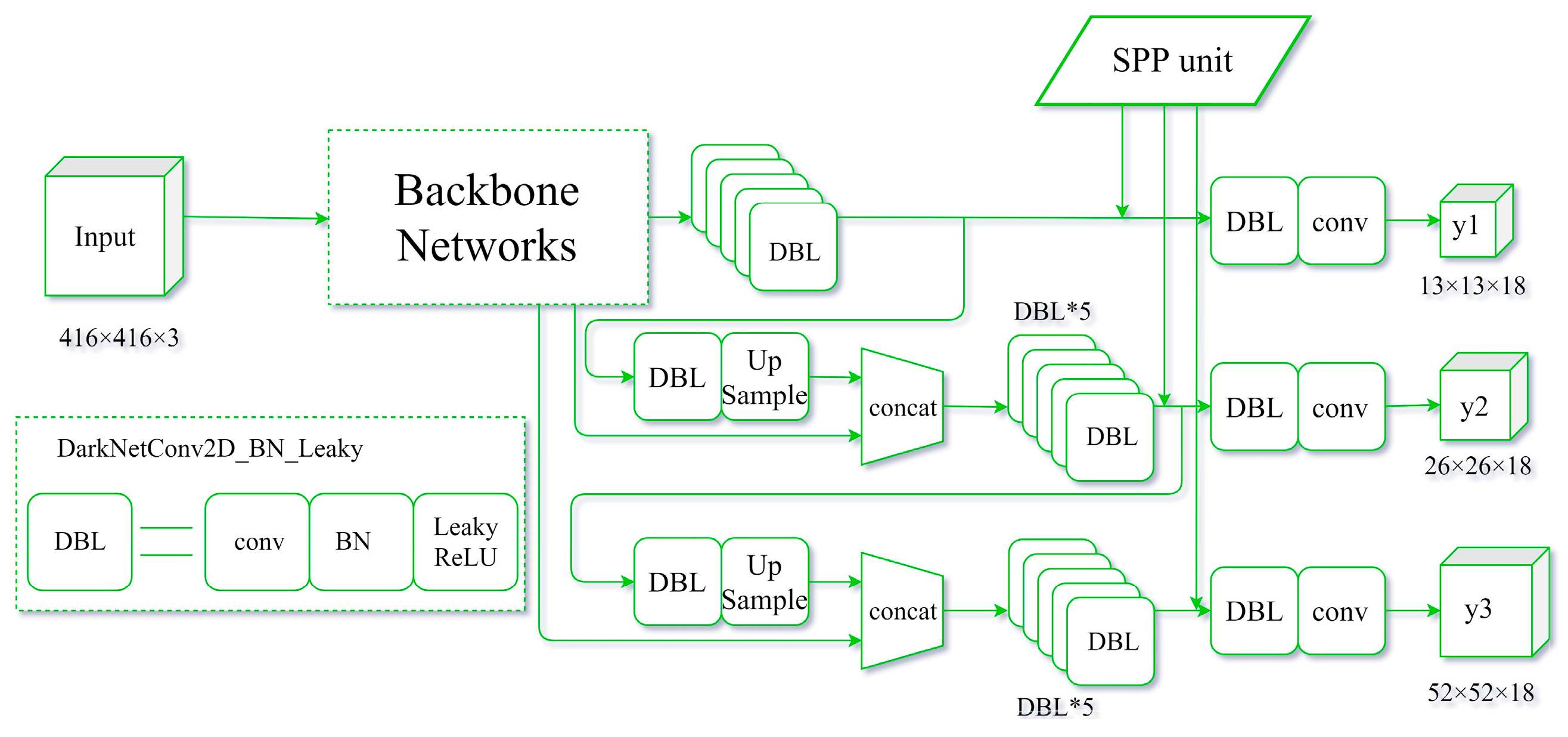
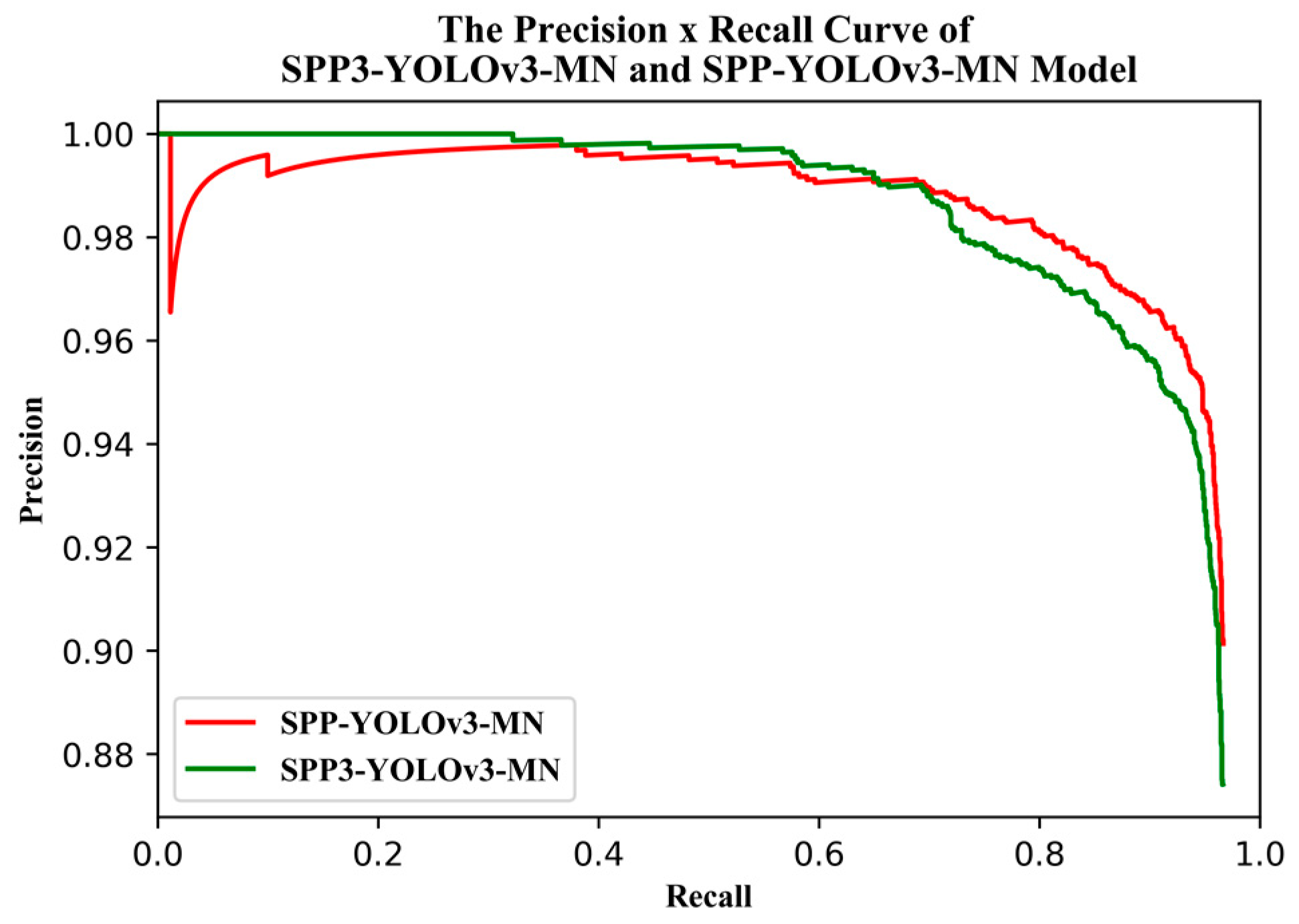
YOLOv3 is one of the state-of-the-art one-stage detection networks; the detection speed is very fast and detection accuracy is quite high in the current one-stage detection model. The YOLOv3 model has been successfully applied in the field of remote sensing and UAV. Given these successful past applications, we chose to base this study on the YOLOv3 model. Firstly, we used the beta distribution as a ratio to mix-up backgrounds and objects, then applied random augmentation metrics to enlarge the dataset. Secondly, we assessed the performance of various backbone networks, added a spatial pyramid pooling unit, and used the generalized intersection over union (GIoU) method to compute the bounding box regression loss. Thirdly, we used various evaluation metrics to assess the model results in terms of superiority, efficiency, and model applicability. The remaining sections of the paper are presented in the following order: study area and data, research methods, model evaluation metrics, results, discussion, and conclusions.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}