Single Image Super-Resolution Based on Global Dense Feature Fusion Convolutional Network

Abstract
:1. Introduction
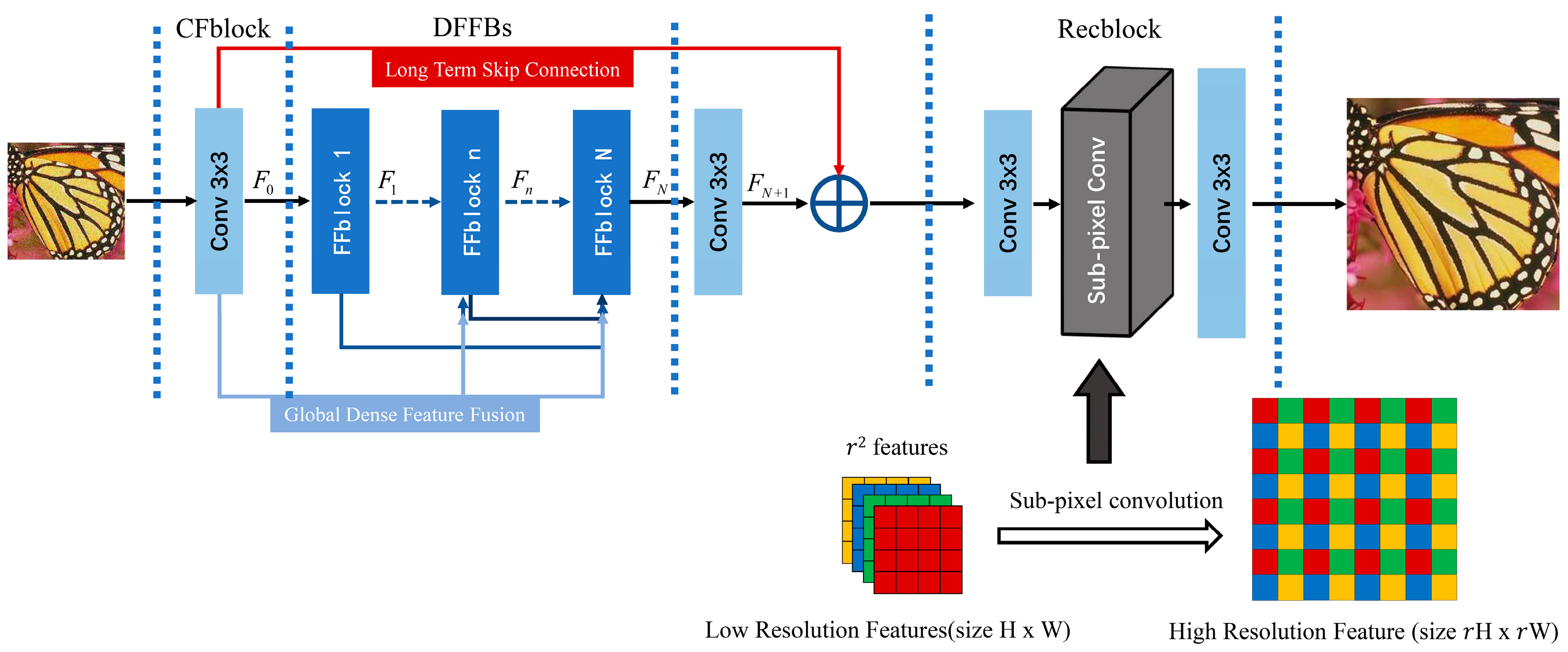
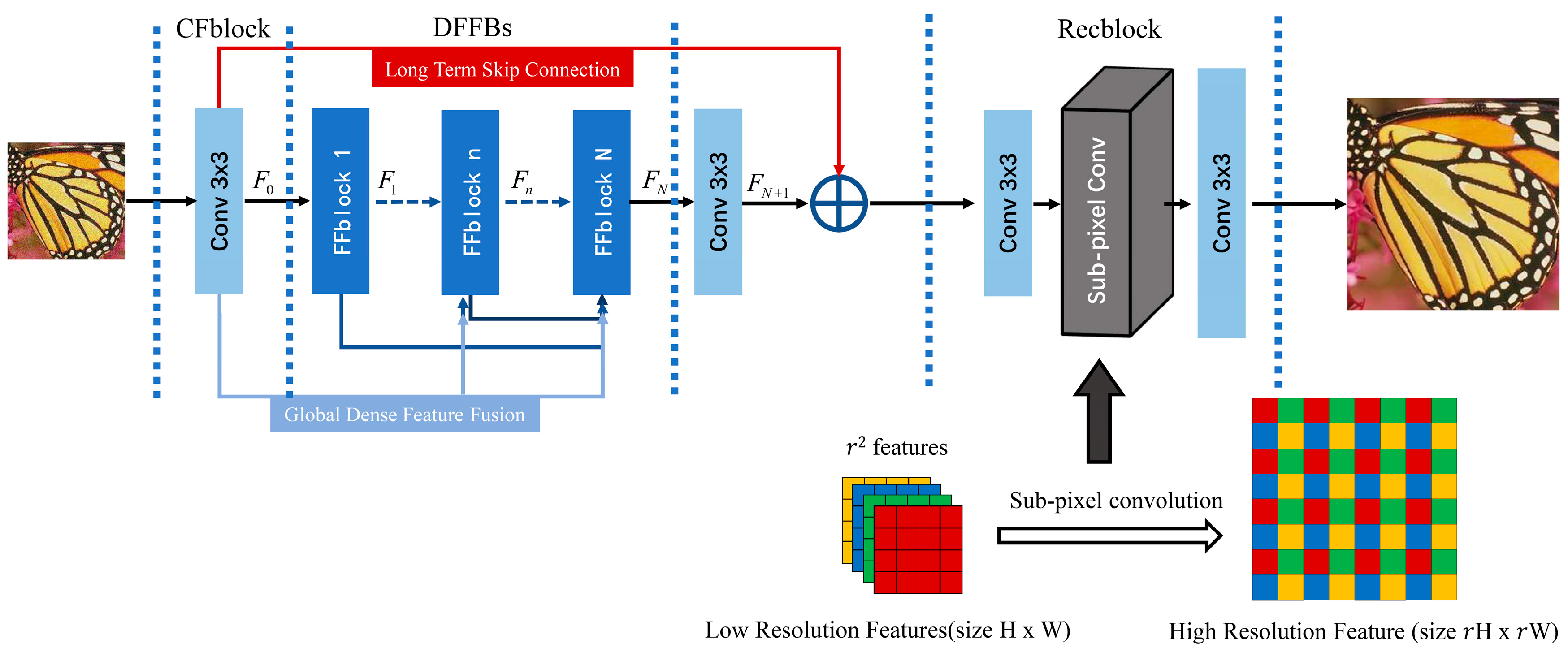
- A deep end-to-end unified framework global dense feature fusion convolutional network (DFFNet) is proposed for single image super-resolution of different scale factors. The network can learn the dense features from the original LR image and intermediate blocks and directly reconstruct HR images without any image scaling preprocessing.
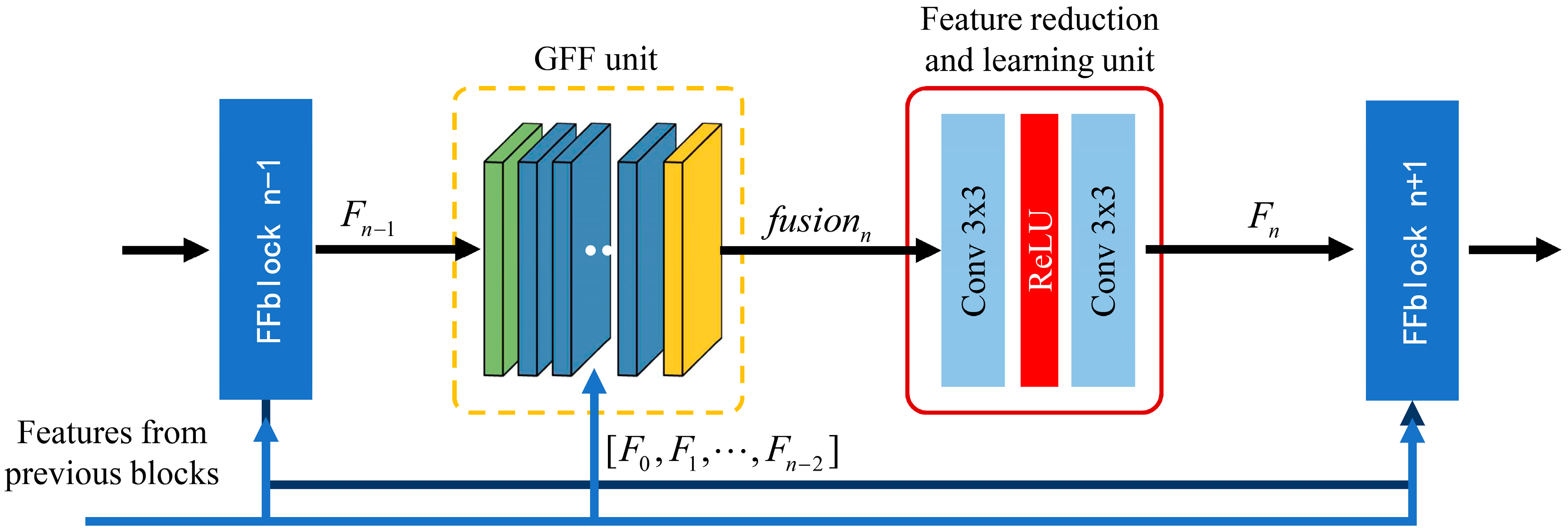
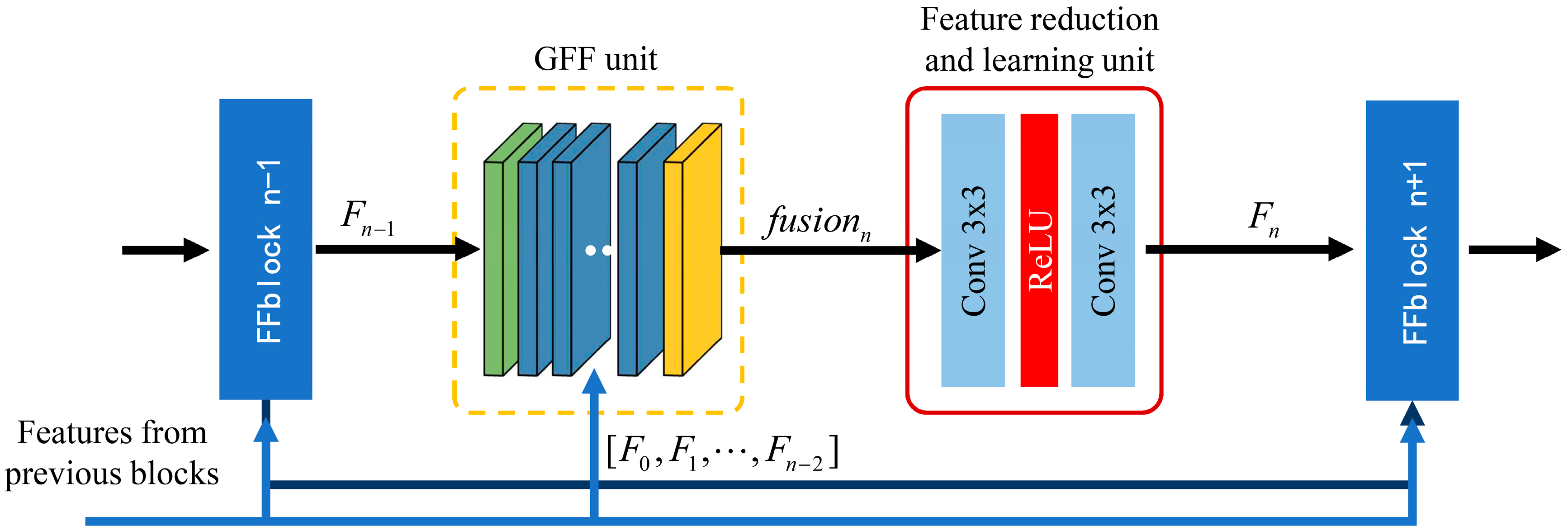
- A feature fusion block (FFblock) is introduced in DFFNet, which builds a direct connection between any two blocks through global feature fusion (GFF) unit, FFblock learns the feature spatial correlation and channel correlation from the previous global features to extract higher order features.
- Dense feature fusion blocks (DFFBs) consisting of cascaded FFblocks, build global dense feature fusion so that previous global raw features can be directly learnt by the current FFblock at any stage in the network, and each FFblock in the DFFBs would adaptively decide how many of these features to be reserved, leading to a continuous global information memory mechanism.
2. Related Work
3. DFFNet for Image Super-Resolution
3.1. Basic Architecture
3.2. Feature Fusion Block
3.3. Reconstruction Block
3.4. Implementation Details
4. Discussions
5. Experiments
5.1. Datasets and Metrics
5.2. Training Details
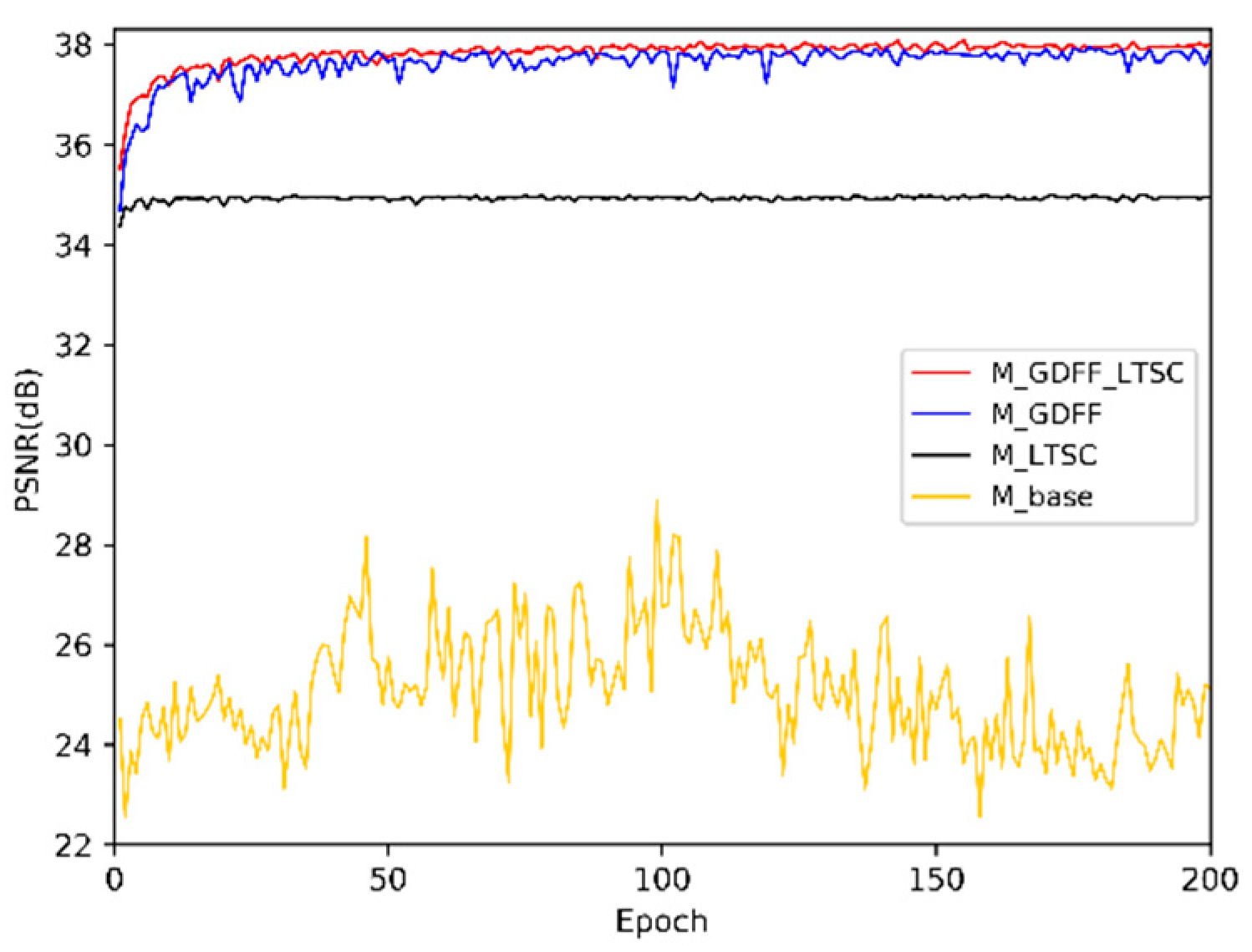
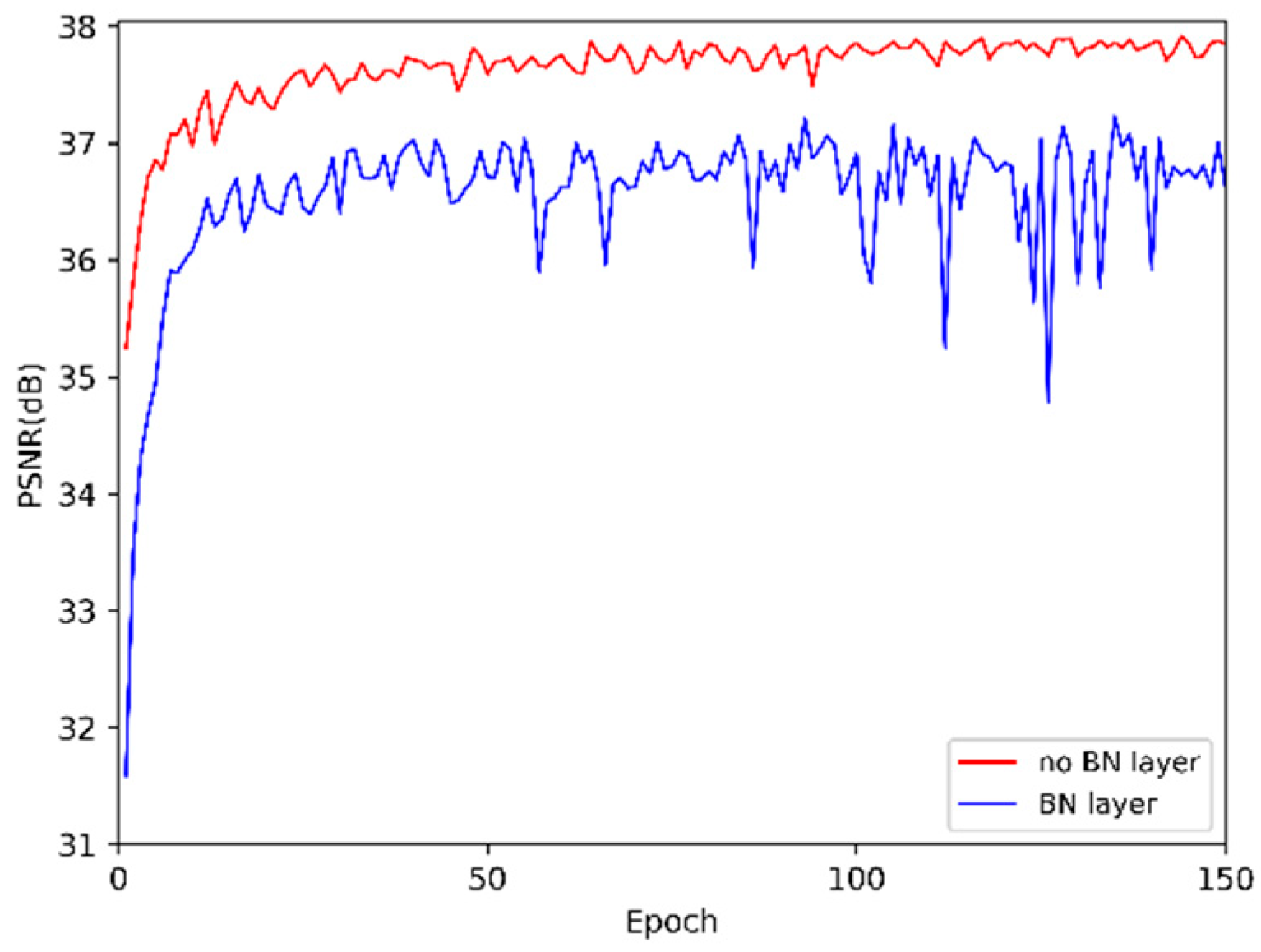
5.3. Ablation Study
5.4. Benchmark Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CFBlock | Filters | Size | Output | |||||
|---|---|---|---|---|---|---|---|---|
| 32 | 3 × 3 | 48 × 48 × 32 | ||||||
| GFF Unit | FRL Unit | |||||||
| C_1 | C_2 | |||||||
| Output | Filters | Size | Output | Filters | Size | Output | ||
| FFblock | 1 | 48 × 48 × 32 | 8 | 3 × 3 | 48 × 48 × 8 | 32 | 3 × 3 | 48 × 48 × 32 |
| 2 | 48 × 48 × 64 | 16 | 3 × 3 | 48 × 48 × 16 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 3 | 48 × 48 × 96 | 24 | 3 × 3 | 48 × 48 × 24 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 4 | 48 × 48 × 128 | 32 | 3 × 3 | 48 × 48 × 32 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 5 | 48 × 48 × 160 | 40 | 3 × 3 | 48 × 48 × 40 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 6 | 48 × 48 × 192 | 48 | 3 × 3 | 48 × 48 × 48 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 7 | 48 × 48 × 224 | 56 | 3 × 3 | 48 × 48 × 56 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 8 | 48 × 48 × 256 | 64 | 3 × 3 | 48 × 48 × 64 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 9 | 48 × 48 × 288 | 72 | 3 × 3 | 48 × 48 × 72 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 10 | 48 × 48 × 320 | 80 | 3 × 3 | 48 × 48 × 80 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 11 | 48 × 48 × 352 | 88 | 3 × 3 | 48 × 48 × 88 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 12 | 48 × 48 × 384 | 96 | 3 × 3 | 48 × 48 × 96 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 13 | 48 × 48 × 416 | 104 | 3 × 3 | 48 × 48 × 104 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 14 | 48 × 48 × 448 | 112 | 3 × 3 | 48 × 48 × 112 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 15 | 48 × 48 × 480 | 120 | 3 × 3 | 48 × 48 × 120 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 16 | 48 × 48 × 512 | 128 | 3 × 3 | 48 × 48 × 128 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 17 | 48 × 48 × 544 | 136 | 3 × 3 | 48 × 48 × 136 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 18 | 48 × 48 × 576 | 144 | 3 × 3 | 48 × 48 × 144 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 19 | 48 × 48 × 608 | 152 | 3 × 3 | 48 × 48 × 152 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 20 | 48 × 48 × 640 | 160 | 3 × 3 | 48 × 48 × 160 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 21 | 48 × 48 × 672 | 168 | 3 × 3 | 48 × 48 × 168 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 22 | 48 × 48 × 704 | 176 | 3 × 3 | 48 × 48 × 176 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 23 | 48 × 48 × 736 | 184 | 3 × 3 | 48 × 48 × 184 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 24 | 48 × 48 × 768 | 192 | 3 × 3 | 48 × 48 × 192 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 25 | 48 × 48 × 800 | 200 | 3 × 3 | 48 × 48 × 200 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 26 | 48 × 48 × 832 | 208 | 3 × 3 | 48 × 48 × 208 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 27 | 48 × 48 × 864 | 216 | 3 × 3 | 48 × 48 × 216 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 28 | 48 × 48 × 896 | 224 | 3 × 3 | 48 × 48 × 224 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 29 | 48 × 48 × 928 | 232 | 3 × 3 | 48 × 48 × 232 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 30 | 48 × 48 × 960 | 240 | 3 × 3 | 48 × 48 × 240 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 31 | 48 × 48 × 992 | 248 | 3 × 3 | 48 × 48 × 248 | 32 | 3 × 3 | 48 × 48 × 32 | |
| 32 | 48 × 48 × 1024 | 256 | 3 × 3 | 48 × 48 × 256 | 32 | 3 × 3 | 48 × 48 × 32 | |
| Mid_conv | filters | size | output | |||||
| 32 | 3 × 3 | 48 × 48 × 32 | ||||||
| For scale factor ×2 | ||||||||
| Recblock | Re_conv_1 | filters | size | output | ||||
| 256 | 3 × 3 | 48 × 48 × 256 | ||||||
| Re_sub_pixel | filters | size | output | |||||
| / | / | 96 × 96 × 64 | ||||||
| Re_conv_2 | filters | size | output | |||||
| 3 | 3 × 3 | 96 × 96 × 3 | ||||||
| For scale factor ×3 | ||||||||
| Recblock | Re_conv_1 | filters | size | output | ||||
| 576 | 3 × 3 | 48 × 48 × 576 | ||||||
| Re_sub_pixel | filters | size | output | |||||
| / | / | 144 × 144 × 64 | ||||||
| Re_conv_2 | filters | size | output | |||||
| 3 | 3 × 3 | 144 × 144 × 3 | ||||||
| For scale factor ×4 | ||||||||
| Recblock | Re_conv_1_1 | filters | size | output | ||||
| 256 | 3 × 3 | 48 × 48 × 256 | ||||||
| Re_sub_pixel_1 | filters | size | output | |||||
| / | / | 96 × 96 × 64 | ||||||
| Re_conv_1_2 | filters | size | output | |||||
| 256 | 3 × 3 | 96 × 96 × 256 | ||||||
| Re_sub_pixel_2 | filters | size | output | |||||
| / | / | 192 × 192 × 64 | ||||||
| Re_conv_2 | filters | size | output | |||||
| 3 | 3 × 3 | 192 × 192 × 3 | ||||||
References
- Ziwei, L.; Chengdong, W.; Dongyue, C.; Yuanchen, Q.; Chunping, W. Overview on image super resolution reconstruction. In Proceedings of the IEEE Control and Decision Conference, Changsha, China, 31 May–2 June 2014; pp. 2009–2014. [Google Scholar]
- Xu, S.; Xiao-Guang, L.; Jia-Feng, L.; Li, Z. Review on Deep Learning Based Image Super-resolution Restoration Algorithms. Acta Autom. Sin. 2017, 43, 697–709. [Google Scholar]
- Timofte, R.; Smet, V.D.; Gool, L.V. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]
- Jiang, J.; Ma, X.; Chen, C.; Lu, T.; Wang, Z.; Ma, J. Single Image Super-Resolution via Locally Regularized Anchored Neighborhood Regression and Nonlocal Means. IEEE Trans. Multimedia 2017, 19, 15–26. [Google Scholar] [CrossRef]
- Chen, C. Noise Robust Face Image Super-Resolution through Smooth Sparse Representation. IEEE Trans. Cybern. 2016, 47, 3991–4002. [Google Scholar]
- Zhu, Z.; Guo, F.; Yu, H.; Chen, C. Fast single image super-resolution via self-example learning and sparse representation. IEEE Trans. Multimedia 2014, 16, 2178–2190. [Google Scholar] [CrossRef]
- Chen, C.; Fowler, J.E. Single-image super-resolution using multihypothesis prediction. In Proceedings of the 2012 IEEE Conference Record of the Forty Sixth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 4–7 November 2012; pp. 608–612. [Google Scholar]
- Jin, Y.; Kuwashima, S.; Kurita, T. Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Springer: Cham, Switzerland, 2017; pp. 217–225. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. arXiv, 2016; arXiv:1611.06612. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv, 2017; arXiv:1706.05587. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the ECCV 2014, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kim, J.; Le, J.K.; Le, K.M. Deeply-recursive convolutional network for image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv, 2016; arXiv:1609.04802. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Hu, Y.; Gao, X.; Li, J.; Huang, Y.; Wang, H. Single Image Super-Resolution via Cascaded Multi-Scale Cross Network. arXiv, 2018; arXiv:1802.08808. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the European Conference on Computer Vision 2016, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the CVPR 2017 Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the AISTATS 2011, Ft. Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Dai, D.; Timofte, R.; Gool, L.V. Jointly Optimized Regressors for Image Super-resolution. Comput. Gr. Forum 2015, 34, 95–104. [Google Scholar] [CrossRef]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L.; Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M.; et al. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the CVPR 2017 Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the BMVC 2012, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super resolution from transformed self-exemplars. In Proceedings of the CVPR 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. arXiv, 2017; arXiv:1704.03915. [Google Scholar]
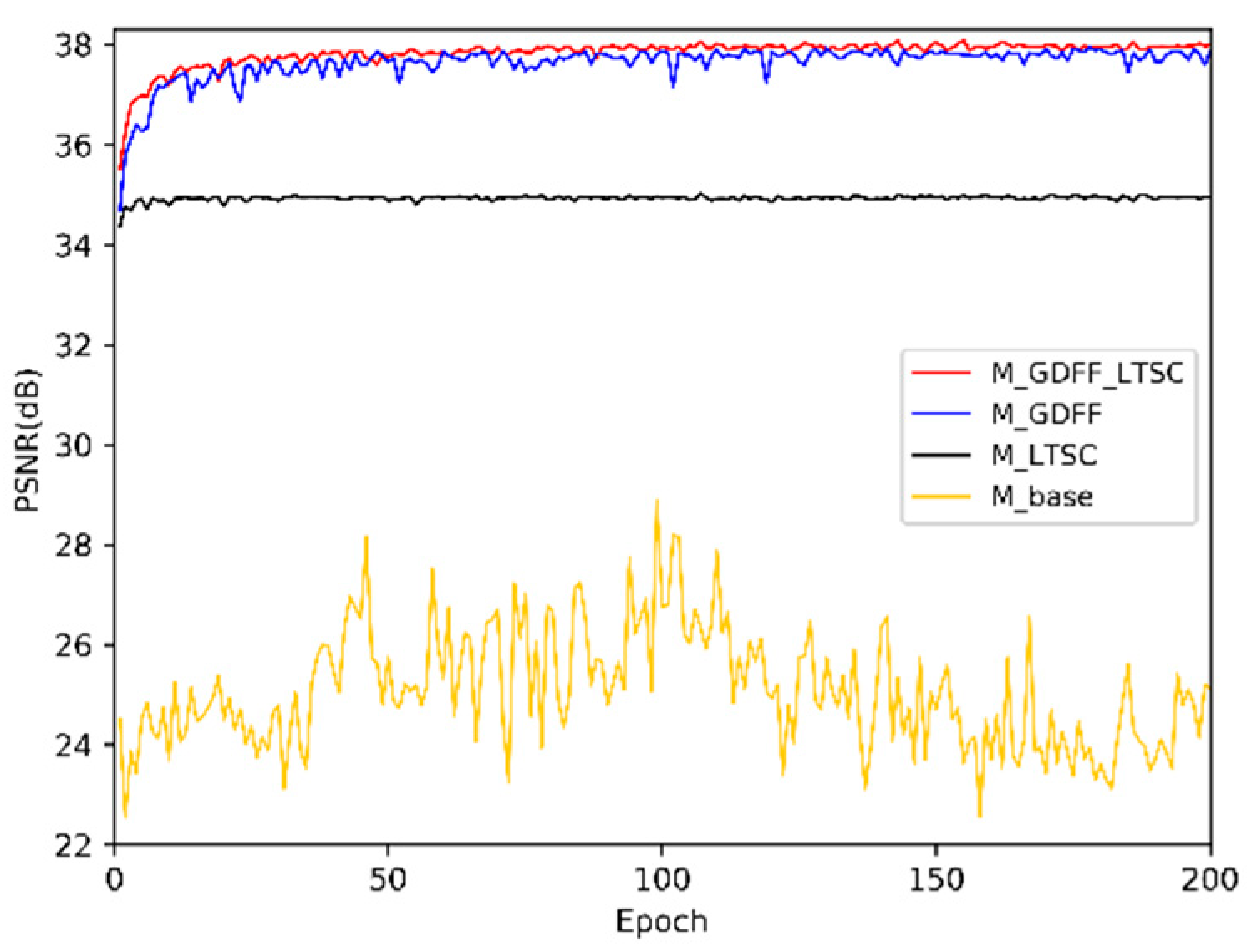




| M_Base | M_LTSC | M_GDFF | M_GDFF_LTSC | |
|---|---|---|---|---|
| GDFF | × | × | √ | √ |
| LTSC | × | √ | × | √ |
| PSNR | 28.87 | 35.00 | 37.94 | 38.08 |
| Dataset | Scale | Bicubic | SRCNN | DRCN | SRResNet | VDSR | LapSRN | CMSC | SRDenseNet | MemNet | DFFNet |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Set5 | ×2 | 33.66/0.9299 | 36.66/0.9542 | 37.63/0.9588 | -/- | 37.53/0.9587 | 37.52/0.9591 | 37.89/0.9605 | -/- | 37.78/0.9597 | 38.13/0.9607 |
| ×3 | 30.39/0.8682 | 32.75/0.9090 | 33.82/0.9226 | -/- | 33.66/0.9213 | 33.82/0.9227 | 34.24/0.9266 | -/- | 34.09/0.9248 | 34.58/0.9272 | |
| ×4 | 28.42/0.8104 | 30.48/0.8628 | 31.53/0.8854 | 32.05/0.8810 | 31.35/0.8838 | 31.51/0.8855 | 31.91/0.8923 | 32.08/0.8934 | 31.74/0.8893 | 32.44/0.8949 | |
| Set14 | ×2 | 30.24/0.8688 | 32.42/0.9063 | 33.04/0.9118 | -/- | 33.03/0.9124 | 33.08/0.9130 | 33.41/0.9153 | -/- | 33.28/0.9142 | 33.62/0.9176 |
| ×3 | 27.55/0.7742 | 29.28/0.8208 | 29.76/0.8311 | -/- | 29.77/0.8314 | 29.79/0.8320 | 30.09/0.8371 | -/- | 30.00/0.8350 | 30.32/0.8408 | |
| ×4 | 26.00/0.7027 | 27.49/0.7503 | 28.02/0.7670 | 28.53/0.7804 | 28.01/0.7674 | 28.19/0.7720 | 28.35/0.7751 | 28.50/0.7782 | 28.26/0.7723 | 28.65/0.7810 | |
| BSD100 | ×2 | 29.56/0.8431 | 31.36/0.8879 | 31.85/0.8942 | -/- | 31.90/0.8960 | 30.41/0.9101 | 32.15/0.8992 | -/- | 32.08/0.8978 | 32.29/0.9002 |
| ×3 | 27.21/0.7382 | 28.41/0.7863 | 28.80/0.7963 | -/- | 28.82/0.7976 | 27.07/0.8272 | 29.01/0.8024 | -/- | 28.96/0.8001 | 29.21/0.8057 | |
| ×4 | 25.96/0.6675 | 26.90/0.7101 | 27.23/0.7233 | 27.57/0.7354 | 27.29/7251 | 25.21/0.7553 | 27.46/0.7308 | 27.53/0.7337 | 27.40/0.7281 | 27.76/0.7376 | |
| Urban100 | ×2 | 26.88/0.8403 | 29.50/0.8946 | 30.75/0.9133 | -/- | 30.76/0.9140 | 37.27/0.9740 | 31.47/0.9220 | -/- | 31.31/0.9195 | 32.32/0.9302 |
| ×3 | 24.46/0.7349 | 26.24/0.7989 | 27.15/0.8276 | -/- | 27.14/0.8279 | 32.19/0.9334 | 27.69/0.8411 | -/- | 27.56/0.8376 | 28.25/0.8545 | |
| ×4 | 23.14/0.6577 | 24.52/0.7221 | 25.14/0.7510 | 26.07/0.7839 | 25.18/0.7524 | 29.09/0.8893 | 25.64/0.7692 | 26.05/0.7819 | 25.50/0.7630 | 26.20/0.7893 |
| SRCNN | VDSR | MemNet | DFFNet (ours) | |
|---|---|---|---|---|
| Parameters (M) | 0.02 | 0.90 | 2.44 | 27.75 |
| Inference speed (s) | 0.004 | 0.03 | 0.369 | 0.113 |
| PSNR (dB) | 29.28 | 29.77 | 30.00 | 30.32 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, W.; Chen, R.; Huang, B.; Zhang, X.; Liu, C. Single Image Super-Resolution Based on Global Dense Feature Fusion Convolutional Network. Sensors 2019, 19, 316. https://doi.org/10.3390/s19020316
Xu W, Chen R, Huang B, Zhang X, Liu C. Single Image Super-Resolution Based on Global Dense Feature Fusion Convolutional Network. Sensors. 2019; 19(2):316. https://doi.org/10.3390/s19020316
Chicago/Turabian StyleXu, Wang, Renwen Chen, Bin Huang, Xiang Zhang, and Chuan Liu. 2019. "Single Image Super-Resolution Based on Global Dense Feature Fusion Convolutional Network" Sensors 19, no. 2: 316. https://doi.org/10.3390/s19020316
APA StyleXu, W., Chen, R., Huang, B., Zhang, X., & Liu, C. (2019). Single Image Super-Resolution Based on Global Dense Feature Fusion Convolutional Network. Sensors, 19(2), 316. https://doi.org/10.3390/s19020316