1. Introduction
Human pose tracking, also known as motion capture (MoCap), has been studied for decades and is still a very active and challenging research topic. MoCap is widely used in industries such as gaming, virtual/augmented reality, film making and computer graphics animation, among others, as a means to provide body (and/or facial) motion data for virtual character animation, humanoid robot motion control, computer interaction, and more. To date, a specialized computer vision and marker-based MoCap technique, called Optical Motion Capture [
1], constitutes the gold-standard for accurate and robust motion capture [
2]. Optical MoCap solutions [
3,
4,
5] employ multiple optical sensors and passive or active markers (passive markers are coated with retro-reflective material to reflect light, while active markers are powered to emit it; for passive marker-based MoCap systems, IR emitters are also used to cast IR light on the markers) placed on the body of the subject to be captured. The 3D positions of the markers are extracted by intersecting the projections of two or more spatio-temporally aligned optical sensors. These solutions precisely capture the body movements, i.e., the body joint 3D positions and orientations per frame in high frequency (ranging from 100 to 480 Hz).
In the last decade, professional optical MoCap technologies have seen rapid development due to the high demand of the industry and the strong presence of powerful game engines [
6,
7,
8], allowing for immediate and easy consumption of motion capture data. However, difficulties in using traditional optical MoCap solutions still exist. Purchasing a professional optical MoCap system is extremely expensive, while the equipment is cumbersome and sensitive. With respect to its setup, several steps should be carefully followed, ideally by a technical expert, to appropriately setup the required hardware/software and to rigidly install the optical MoCap cameras on walls or other static objects [
1,
9]. In addition, time-expensive and non-trivial post-processing is required for optical data cleaning and MoCap data production [
10]. To this end, there still exists an imperative need for robust MoCap methods that overcome the aforementioned barriers.
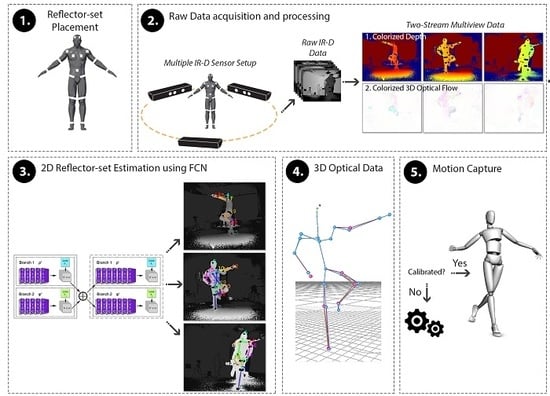
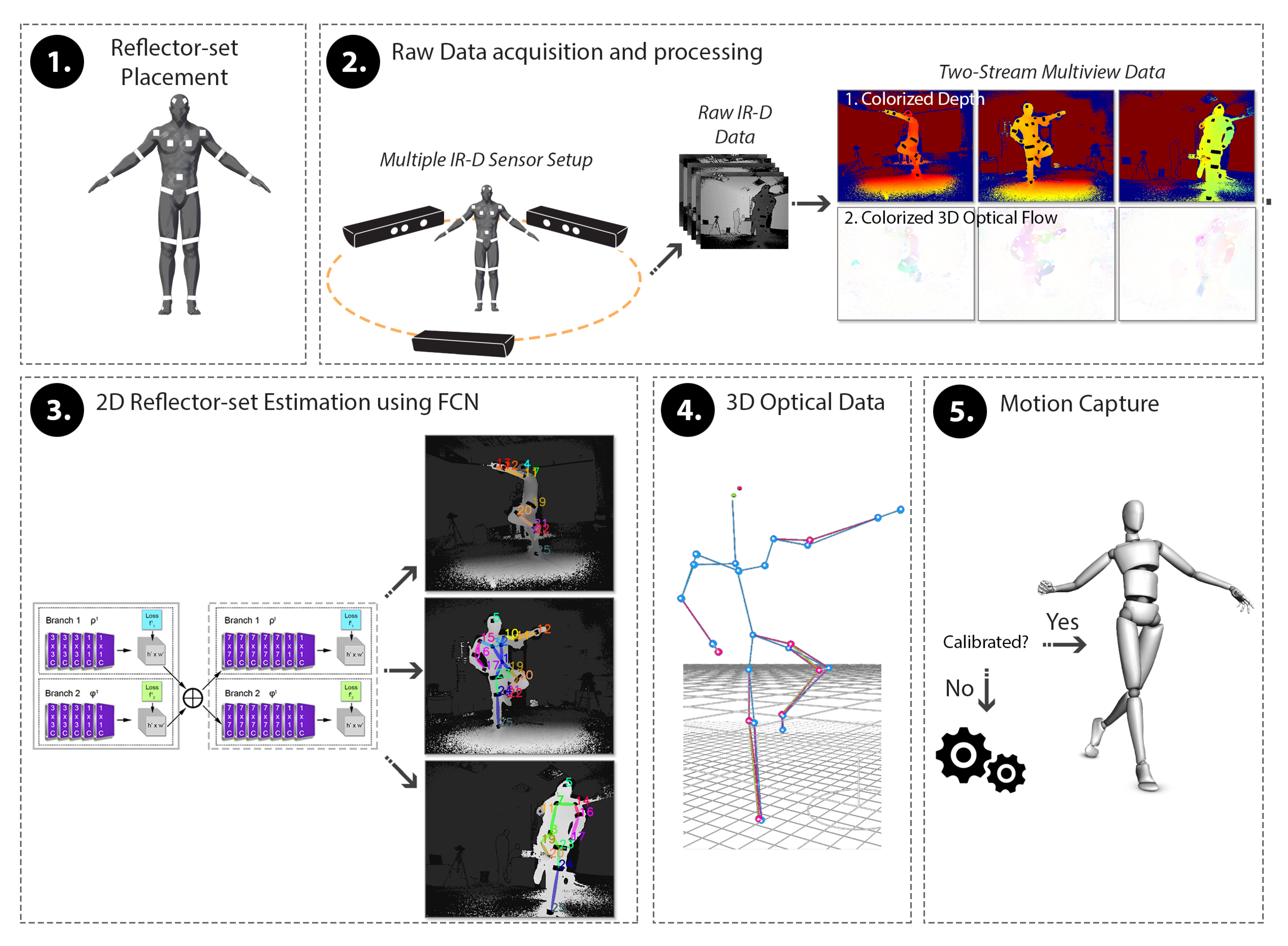
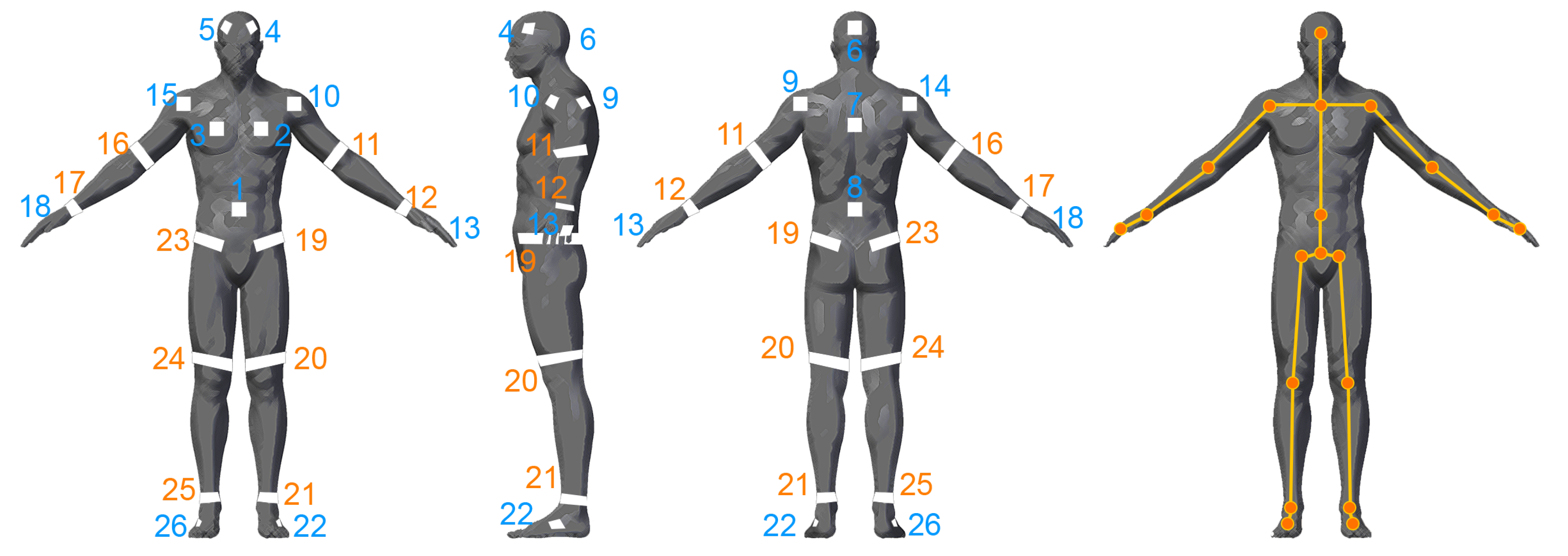
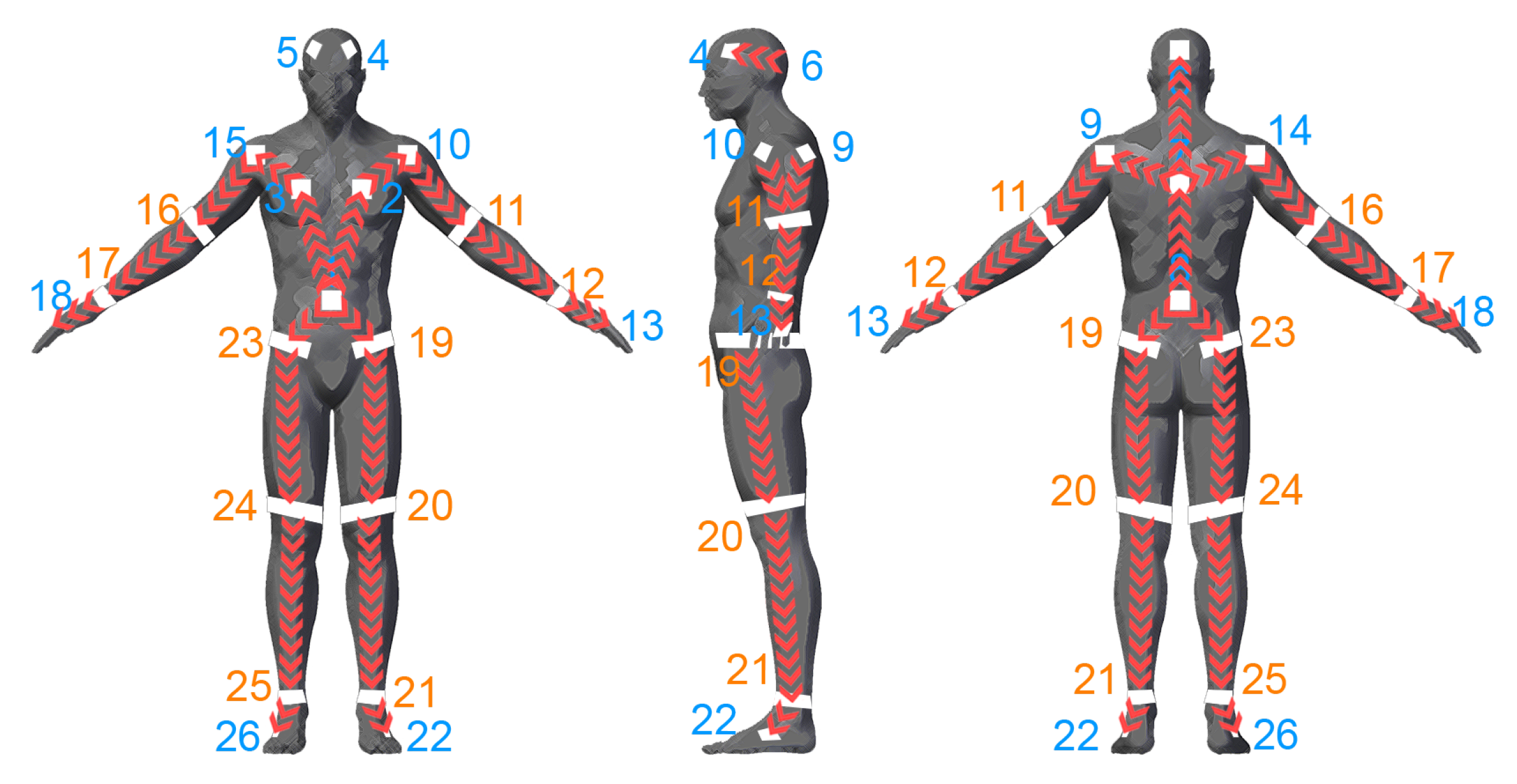
In this paper, a low-cost, fast motion capture method is proposed, namely DeepMoCap, approaching marker-based optical MoCap by combining Infrared-Depth (IR-D) imaging, retro-reflective materials (similarly to passive markers usage) and fully convolutional neural networks (FCN). In particular, DeepMoCap deals with single-person, marker-based motion capture using a set of retro-reflective straps and patches (reflector-set: a set of retro-reflective straps and patches, called reflectors for the sake of simplicity) from off-the-shelf materials (retro-reflective tape) and relying on the feed of multiple spatio-temporally aligned IR-D sensors. Placing reflectors on and IR-D sensors around the subject, the body movements are fully captured, overcoming one-side view limitations such as partial occlusions or corrupted image data. The rationale behind using reflectors is the exploitation of the intense reflections they provoke to the IR streams of the IR-D sensors [
11,
12], enabling their detection on the depth images. FCN [
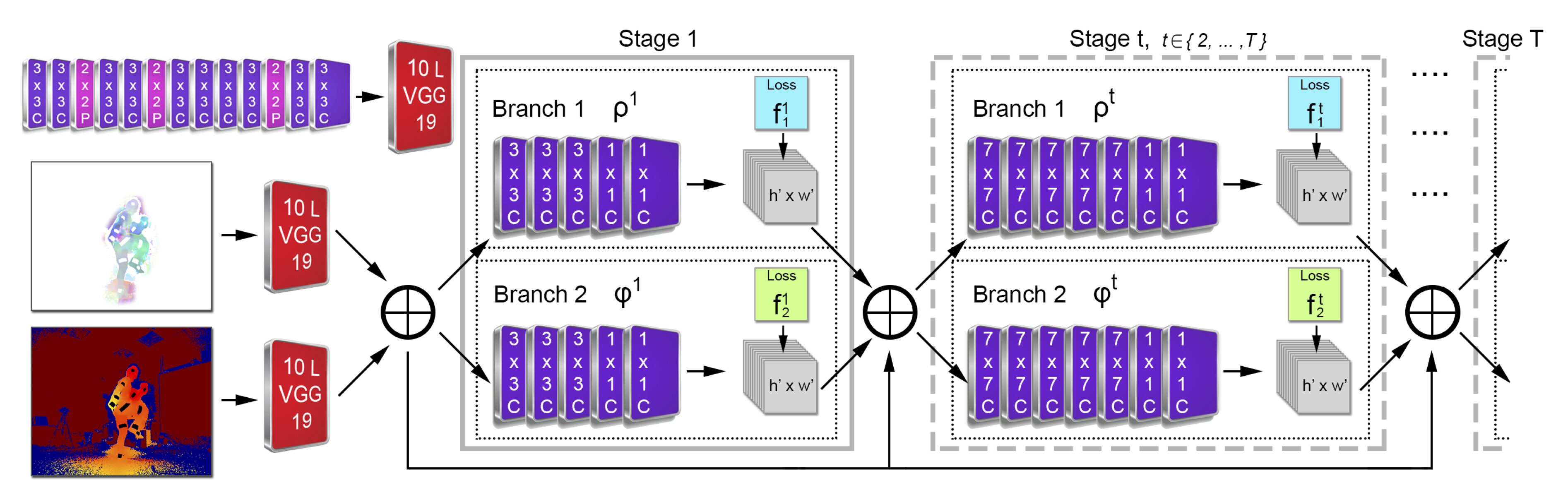
13], instead of using computationally expensive fully connected layers, are applied on the multi-view IR-D captured data, resulting in reflector 2D localization and labeling. Spatially mapping and aligning the detected 2D points to 3D Cartesian coordinates with the use of depth data and intrinsic and extrinsic IR-D camera parameters, enables frame-based 3D optical data extraction. Finally, the subject’s motion is captured by fitting an articulated template model to the sequentially extracted 3D optical data.
The main contributions of the proposed method are summarized as follows:
A low-cost, robust and fast optical motion capture framework is introduced, using multiple IR-D sensors and retro-reflectors. Contrary to the gold-standard marker-based solutions, the proposed setup is flexible and simple, the required equipment is low-cost, the 3D optical data are automatically labeled and the motion capture is immediate, without the need for post-processing.
To the best of our knowledge, DeepMoCap is the first approach that employs fully convolutional neural networks for automatic 3D optical data localization and identification based on IR-D imaging. This process, denoted as “2D reflector-set estimation”, replaces the manual marker labeling and tracking tasks required in traditional optical MoCap.
The convolutional pose machines (CPM) architecture proposed in [
14] has been extended, inserting the notion of time by adding a second 3D optical flow input stream and using 2D Vector Fields [
14] in a temporal manner.
A pair of datasets consisting of (i) multi-view colorized depth and 3D optical flow annotated images and (ii) spatio-temporally aligned multi-view depthmaps along with Kinect skeleton, inertial and ground truth MoCap [
5] data, have been created and made publicly available (
https://vcl.iti.gr/deepmocap/dataset).
The remainder of this paper is organized as follows:
Section 2 overviews related work;
Section 3 explains in detail the proposed method for 2D reflector-set estimation and motion capture;
Section 4 presents the published datasets;
Section 5 gives and describes the experimental frameworks and results; finally,
Section 6 concludes the paper and discusses future work.
2. Related Work
The motion capture research field consists of a large variety of research approaches. These approaches are marker-based or marker-less, while the input they are applied on is acquired using RGB or RGB-D IR/stereo cameras, optical motion capture or inertial among other sensors. Moreover, they result in single- or multi-person 2D/3D motion data outcome, performing in real-time, close to real-time or offline. The large variance of the MoCap methods resulting from the multiple potential combinations of the above led us to classify and discuss them according to an “Input–Output” perspective. At first, approaches that consume 2D data and yield 2D and 3D motion capture outcome are presented. These methods are highly relevant to the present work since, in a similar fashion, the proposed FCN approaches 2D reflector-set estimation by predicting heat maps for each reflector location and optical flow. Subsequently, 3D motion capture methods that acquire and process 2.5D or 3D data from multiple RGB-D cameras similarly to the proposed setup are discussed. Finally, methods that fuse RGB-D with inertial data for 3D motion capture are presented, including one of the methods that are compared against DeepMoCap in the experimental evaluation.
2D Input–2D Output: Intense research effort has been devoted to the 2D pose recovery task for MoCap, providing efficient methods being effective in challenging and “in-the-wild” datasets. Pose machines architectures for efficient articulated pose estimation [
15] were recently introduced, employing implicit learning of long-range dependencies between image and multi-part cues. Later on, multi-stage pose machines were extended to CPM [
14,
16,
17] by combining pose machine rationale and FCN, allowing for learning feature representations for both image and spatial context directly from image data. At each stage, the input image feature maps and the outcome given by the previous stage, i.e., confidence maps and 2D vector fields, are used as input refining the predictions over successive stages with intermediate supervision. Beyond discrete 2D pose recovery, 2D pose tracking approaches have been introduced imposing the sequential geometric consistency by capturing the temporal correlation among frames and handling severe image quality degradation (e.g., motion blur or occlusions). In [
18], the authors extend CPM by incorporating a spatio-temporal relation model and proposing a new deep structured architecture. Allowing for end-to-end training of body part regressors and spatio-temporal relation models in a unified framework, this model improves generalization capabilities by spatio-temporally regularizing the learning process. Moreover, the optical flow computed for sequential frames is taken into account by introducing a flow warping layer that temporally propagates joint prediction heat maps. Luo et al. [
19] also extend CPM to capture the spatio-temporal relation between sequential frames. The multi-stage FCN of CPM has been re-written as a Recurrent Neural Network (RNN), also adopting Long Short-Term Memory (LSTM) units between sequential frames, to effectively learn the temporal dependencies. This architecture, called LSTM Pose Machines, captures the geometric relations of the joints in time, increasing motion capture stability.
2D Input–3D Output: During the last years, computer vision researchers approach 3D pose recovery on single-view RGB data [
20,
21,
22,
23] for 3D MoCap. In [
24], a MoCap framework is introduced, realizing 3D pose recovery, that consists of a synthesis between discriminative image-based and 3D pose reconstruction approaches. This framework combines image-based 2D part location estimates and model-based 3D pose reconstruction, so that they can benefit from each other. Furthermore, to improve the robustness of the approach against person detection errors, occlusions, and reconstruction ambiguities, temporal filtering is imposed on the 3D MoCap task. Similarly to CPM, 2D keypoint confidence maps representing the positional uncertainty are generated with a FCN. The generated maps are combined with a sparse model of 3D human pose within an Expectation-Maximization framework to recover the 3D motion data. In [
25], a real-time method that estimates temporally consistent global 3D pose for MoCap from one single-view RGB video is presented, extending top performing single-view RGB convolutional neural network (CNN) methods for MoCap [
20,
23]. For best quality at real-time frame rates, a shallower variant is extended to a novel fully convolutional formulation, enabling higher accuracy in 2D and 3D pose regression. Moreover, CNN-based joint position regression is combined with an efficient optimization step for 3D skeleton fitting in a temporally stable way, yielding MoCap data. In [
26], an existing “in-the-wild” dataset of images with 2D pose annotations is augmented by applying image-based synthesis and 3D MoCap data. To this end, a new synthetic dataset with a large number of new “in-the-wild” images is created, providing the corresponding 3D pose annotations. On top of that, the synthetic dataset is used to train an end-to-end CNN architecture for motion capture. The proposed CNN clusters a 3D pose to
K pose classes on per-frame basis, while a
way CNN classifier returns a distribution over probable pose classes.
2.5D / 3D Input–3D Output: With respect to 2.5D/3D data acquisition and 3D MoCap, particular reference should be made to the Microsoft Kinect sensor [
27], beyond its discontinuation, since it was the first low-cost RGB-D sensor for depth estimation and 3D motion capture, leading to a massive release of MoCap approaches that use the Kinect streams or are compared to Kinect motion capture [
28,
29,
30,
31]. This sensor triggered the massive production of low-cost RGB-D cameras, allowing a wide community of researchers to study on RGB-D imaging and, subsequently, resulting in a plethora of efficient MoCap approaches applied on 2.5D/3D data [
32,
33,
34,
35,
36]. In [
37], a multi-view and real-time method for multi-person motion capture is presented. Similarly to the proposed setup, multiple spatially aligned RGB-D cameras are placed to the scene. Multi-person motion capture is achieved by fusing single-view 2D pose estimates from CPM, as proposed in [
14,
16], extending them to 3D by means of depth information. Shafaei et al. [
38] use multiple externally calibrated RGB-D cameras for 3D MoCap, splitting the multi-view pose estimation task into (i) dense classification, (ii) view aggregation, and (iii) pose estimation steps. Applying recent image segmentation techniques to depth data and using curriculum learning, a CNN is trained on purely synthetic data. The body parts are accurately localized without requiring an explicit shape model or any other a priori knowledge. The body joint locations are then recovered by combining evidence from multiple views in real-time, treating the problem of pose estimation for MoCap as a linear regression. In [
39], a template-based fitting to point-cloud motion capture method is proposed using multiple depth cameras to capture the full body motion data, overcoming self-occlusions. A skeleton model consisting of articulated ellipsoids equipped with spherical harmonics encoded displacement and normal functions is used to estimate the 3D pose of the subject.
Inertial (+2.5D) Input–3D Output: Inertial data [
40,
41,
42,
43], as well as their fusion with 2.5D data from RGB-D cameras, are also used to capture the human motion. In [
44], Kinect for Xbox One [
27] skeleton tracking is fused with inertial data for motion capture. In particular, inertial sensors are placed on the limbs and the torso of the subject to provide body bone rotational information by applying orientation filtering on inertial data. Initially, using Kinect, the lengths of the bones and the rotational offset between the Kinect and inertial sensors coordinate systems are estimated. Then, the bones hierarchically follow the inertial sensor rotational movements, while the Kinect camera provides the root 3D position. In a similar vain, a light-weight, robust method [
45] for real time motion and performance capture is introduced using one single depth camera and inertial sensors. Considering that body movements follow articulated structures, this approach captures the motion by constructing an energy function to constrain the orientations of the bones using the orientation measurements of their corresponding inertial sensors. In [
46], inertial motion capture is achieved on the basis of a very sparse inertial sensor setup, i.e., two units placed on the wrists and one on the lower trunk, and ground contact information. Detecting and identifying ground contact from the lower trunk sensor signals and combining this information with a fast database look-up enables data-driven motion reconstruction.
Despite the appearance of the aforementioned methods, traditional marker-based optical MoCap still remains the top option for robust and efficient motion capture. That is due to the stability of the marker-based optical data extraction and the deterministic way of motion tracking. To this end, the proposed method approaches marker-based optical motion capture, however overcoming restrictions of traditional marker-based optical MoCap solutions by:
using off-the-shelf retro-reflective straps and patches to replace the spherical retro-reflective markers, which are sensitive due to potential falling off;
automatically localizing and labeling the reflectors on a per-frame basis without the need for manual marker labeling and tracking;
extracting the 3D optical data by means of the IR-D sensor depth.
Taking the above into consideration, DeepMoCap constitutes an alternative, low-cost and flexible marker-based optical motion capture method that results in high quality and robust motion capture outcome.
6. Conclusions
In the present work, a deep marker-based optical motion capture method is introduced, using multiple IR-D sensors and retro-reflectors. DeepMoCap constitutes a robust, fast and flexible approach that automatically extracts labeled 3D optical data and performs immediate motion capture without the need for post-processing. For this purpose, a novel two-stream, multi-stage CPM-based FCN is proposed that introduces a non-parametric representation to encode the temporal correlation among pairs of colorized depthmaps and 3D optical flow frames, resulting in retro-reflector 2D localization and labeling. This step enables the 3D optical data extraction from multiple spatio-temporally aligned IR-D sensors and, subsequently, motion capture. For research and evaluation purposes, two new datasets were created and made publicly available. The proposed method was evaluated with respect to the 2D reflector-set estimation and the motion capture accuracy on these datasets, outperforming recent and robust methods in both tasks. Taking into consideration this comparative evaluation, we conclude that the joint usage of traditional marker-based optical MoCap rationale and recent deep learning advancements in conjunction with 2.5D and 3D vision techniques can significantly contribute to the MoCap field, introducing a new way of approaching the task.
With respect to the limitations, the side-view capturing and the highly complex body poses that occlude or merge reflectors on the image views constitute the main barriers. These limitations can be eliminated by increasing the number of IR-D sensors around the subject, however, increasing the cost and complexity of the method. Next steps of this research would include the study of recent deep learning approaches in 3D pose recovery and motion capture, investigating key features that will allow us to address main MoCap challenges such as real-time performance, efficient multi-person capturing, in outdoor environments, with more degrees of freedom of the body to be captured and higher accuracy.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}