An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video


Abstract
:1. Introduction
2. Related Works
3. Proposed 3D CNN-Based Method
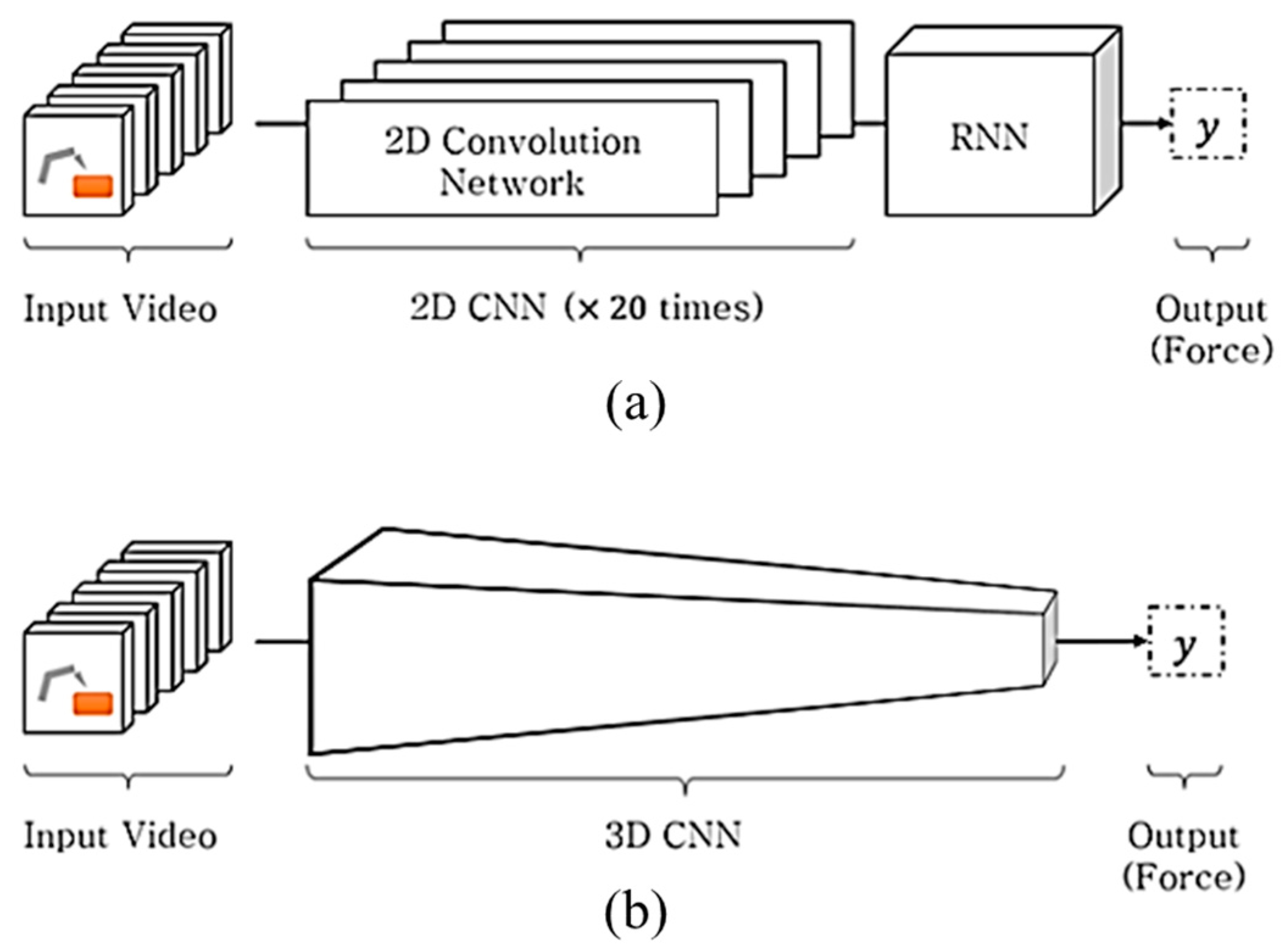
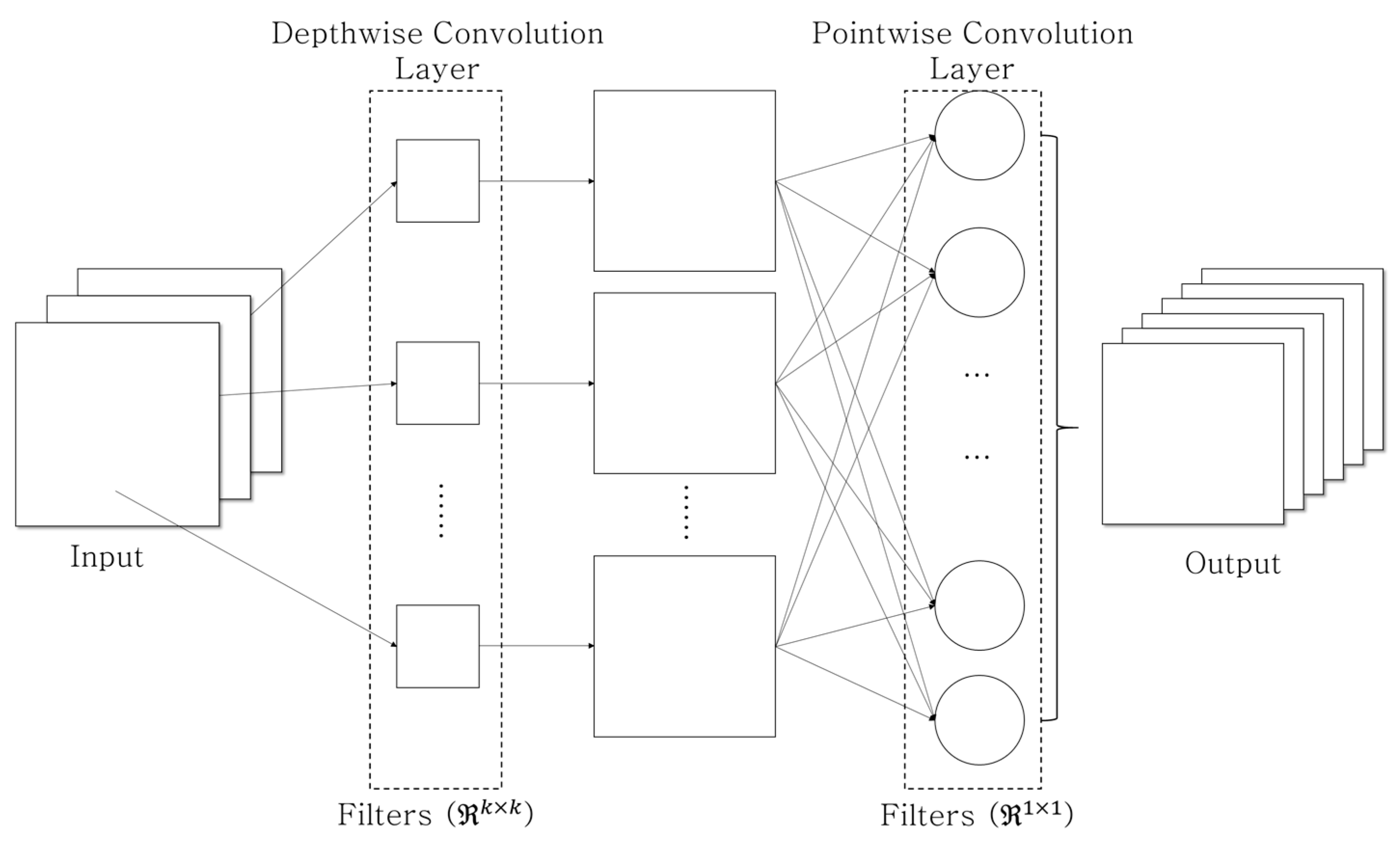
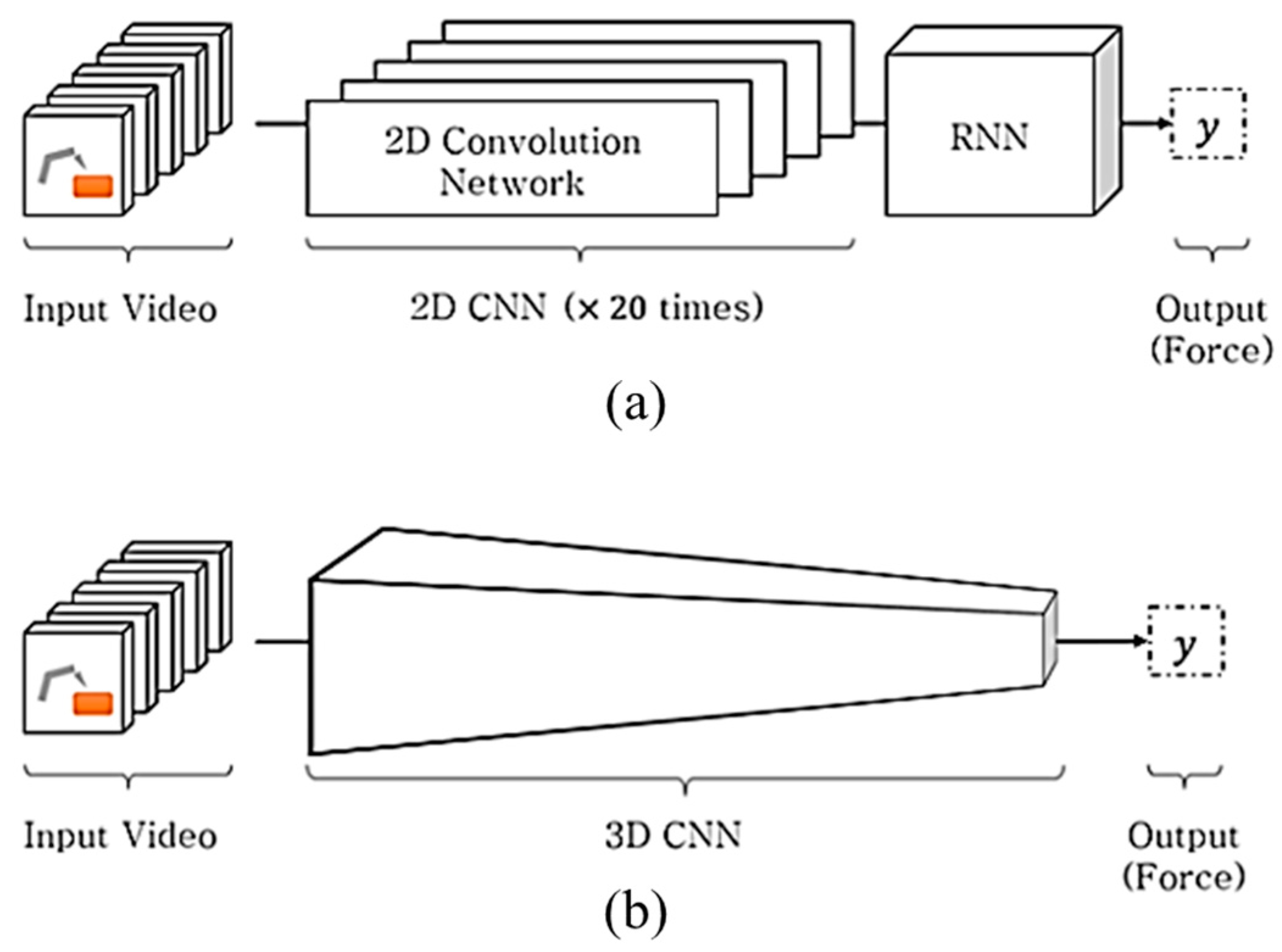
3.1. Two-Dimensional Depthwise Separable Convolution (DSC) Neural Network
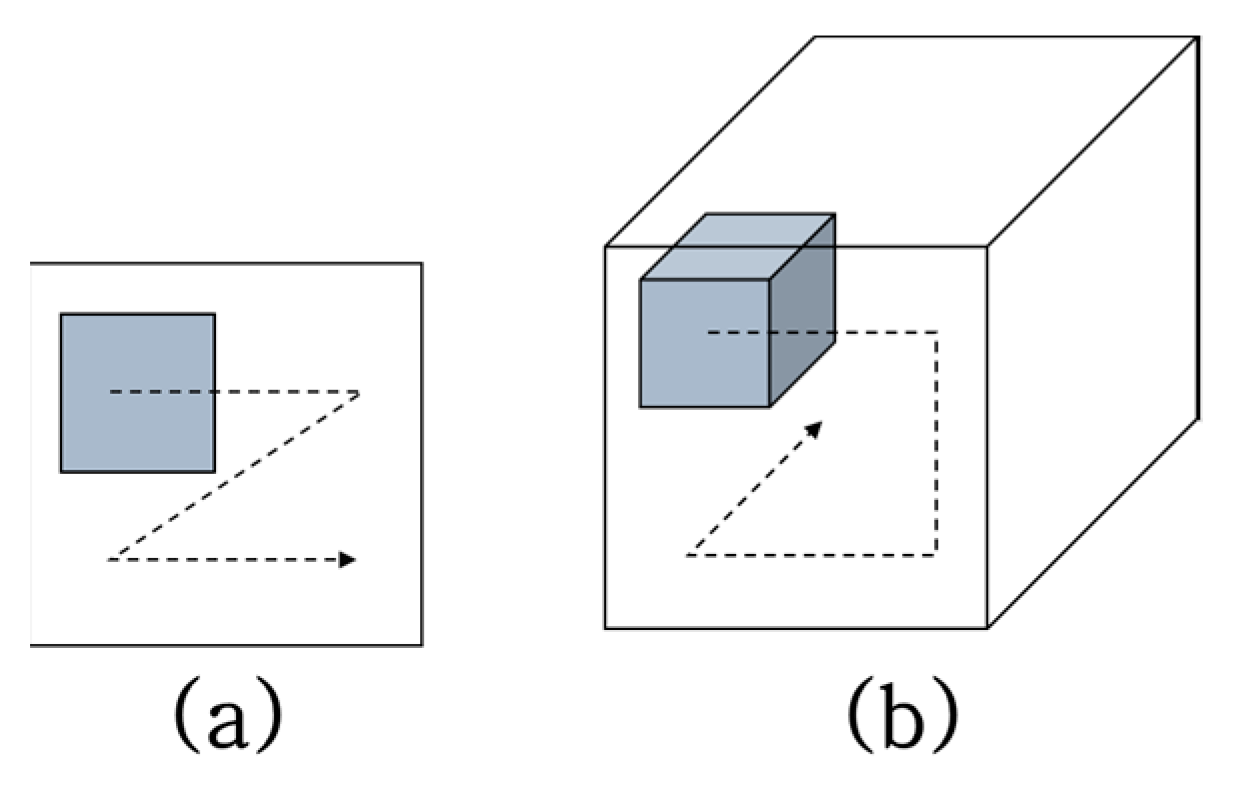
3.2. Three-Dimensional Convolutional Neural Network
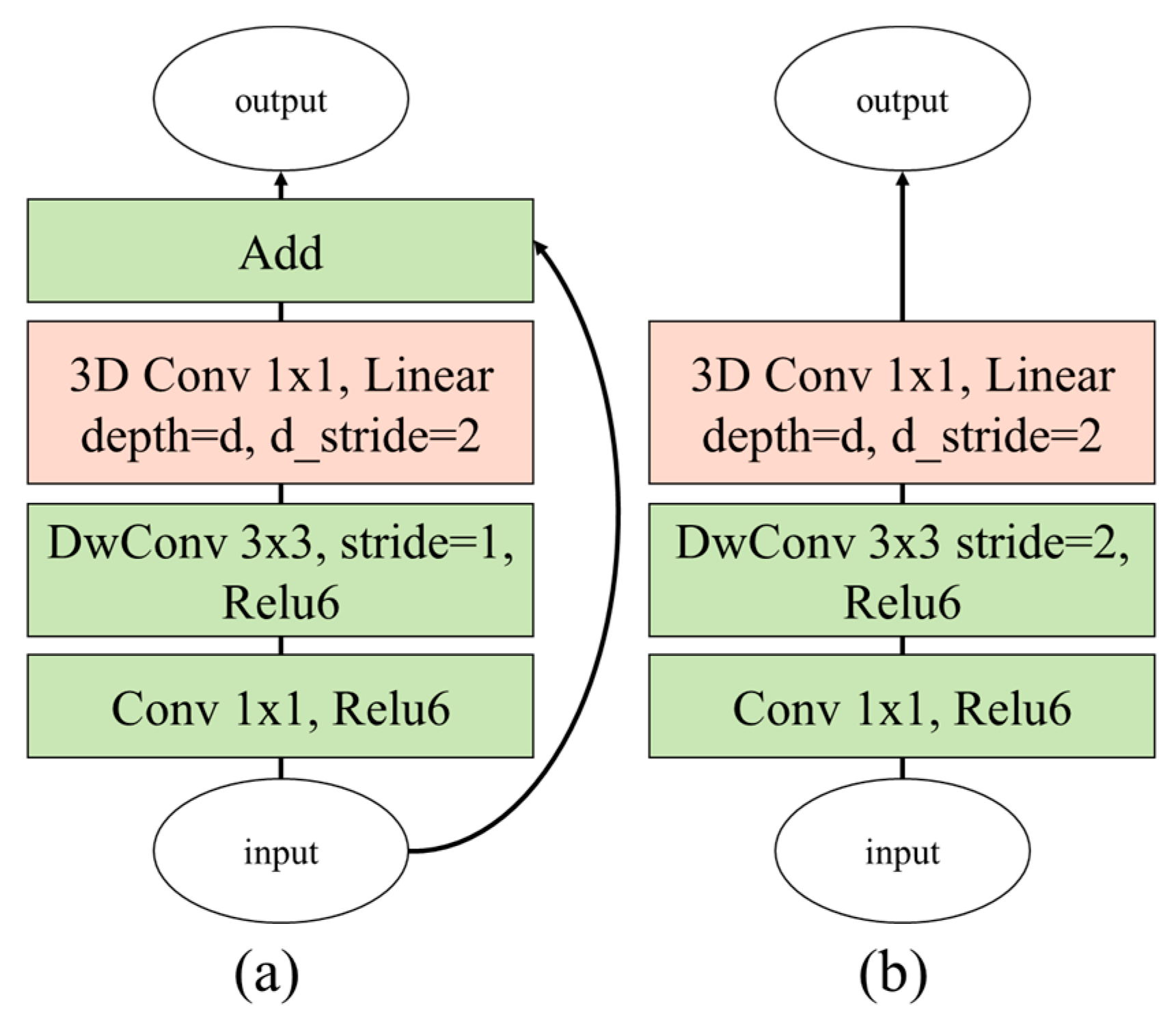
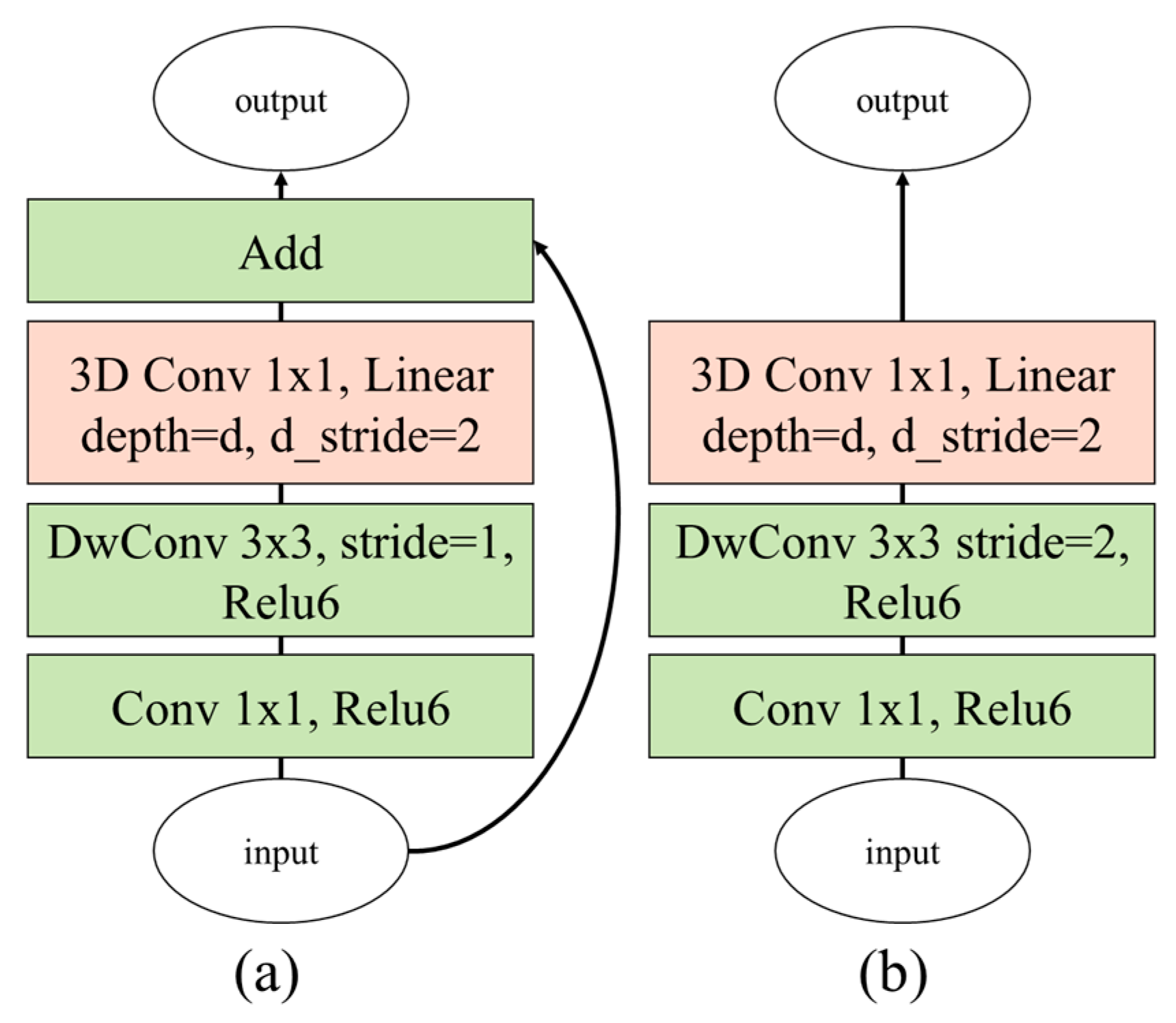
3.3. Proposed 3D Depthwise Separable Convolution Neural Network
4. Database and Evaluation Protocol for Interaction Force Estimation
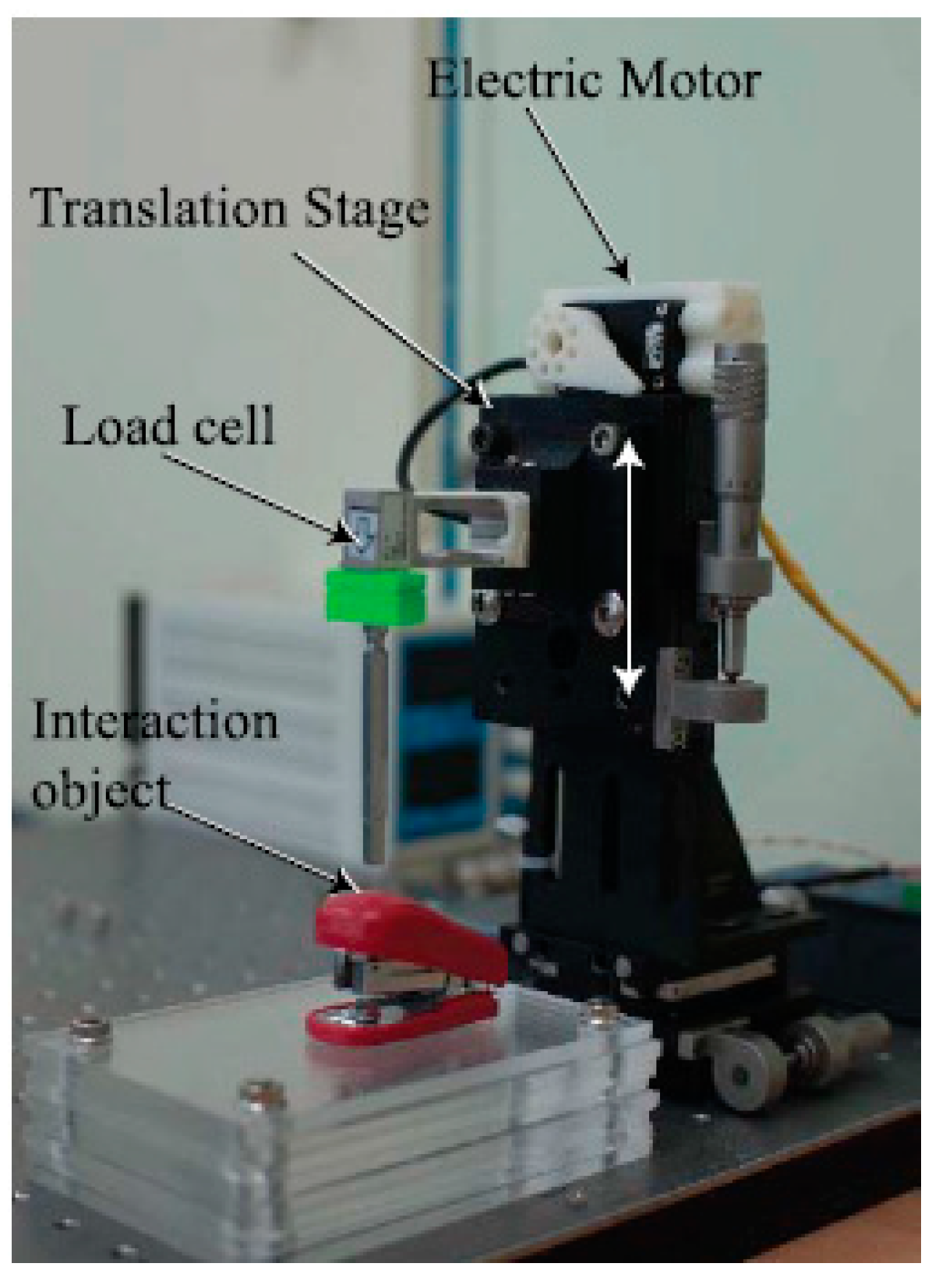
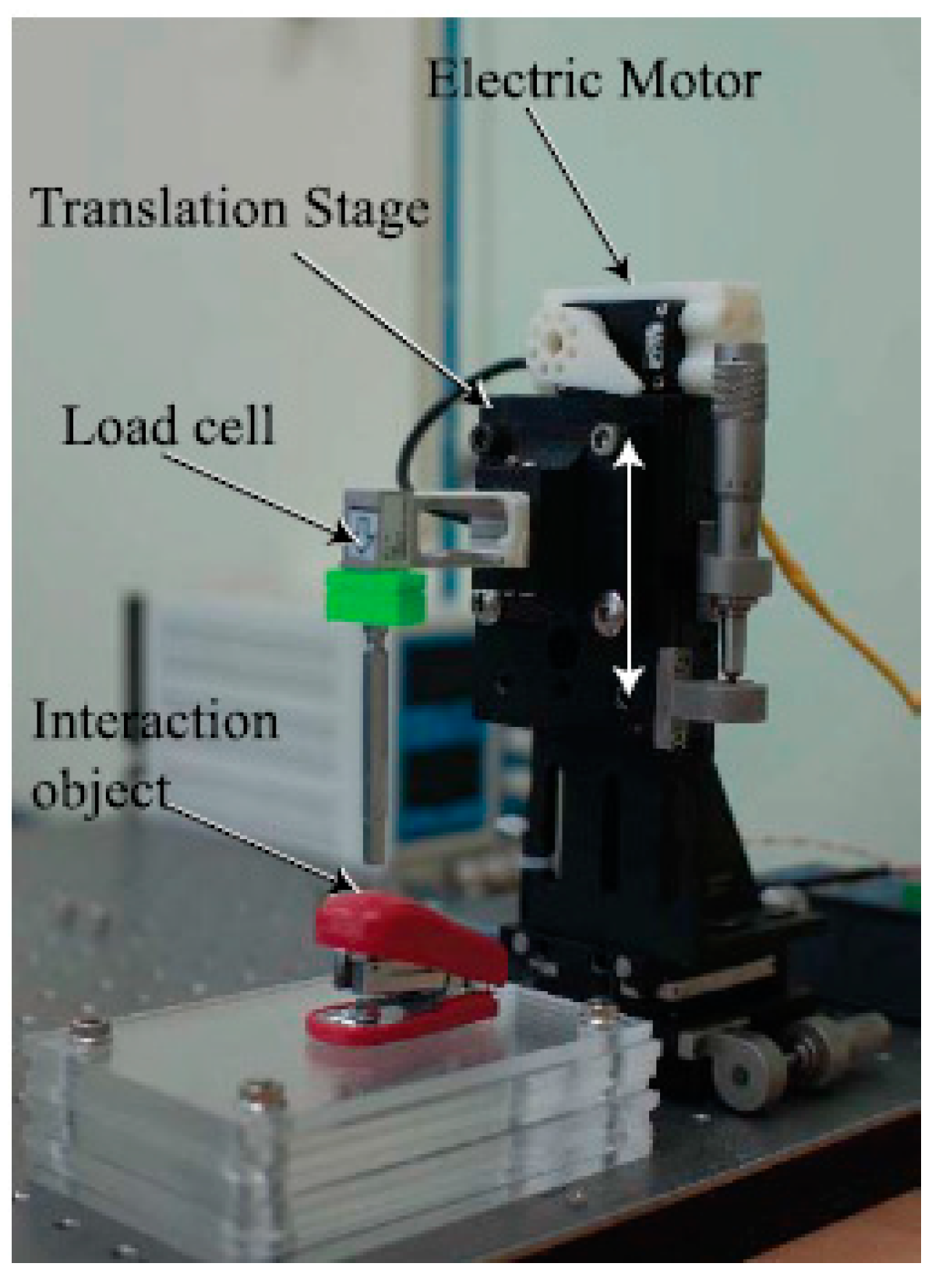
4.1. Automatic Dataset Collection System
4.2. Evaluation Protocol
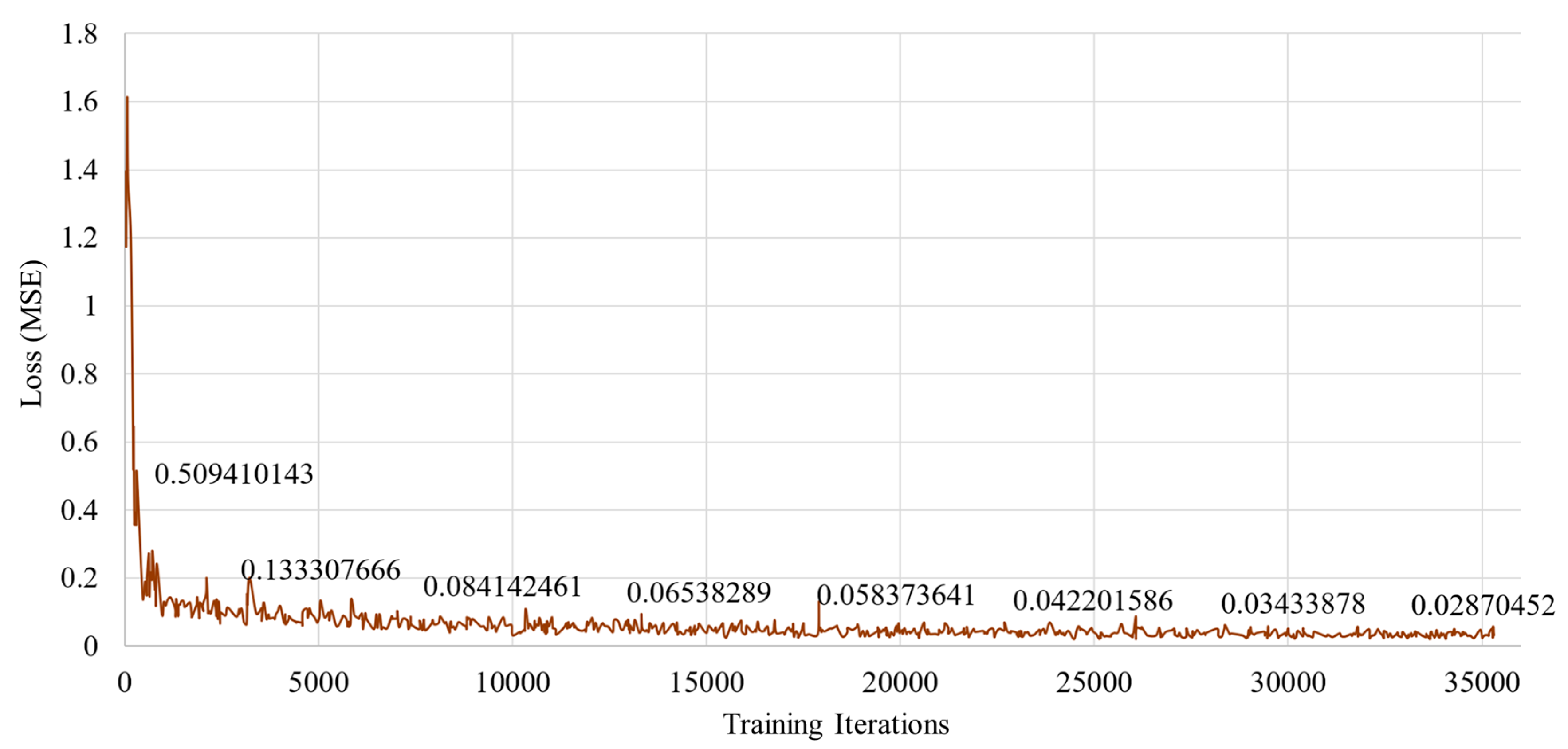
4.3. Implementation Details
5. Experimental Results and Discussion
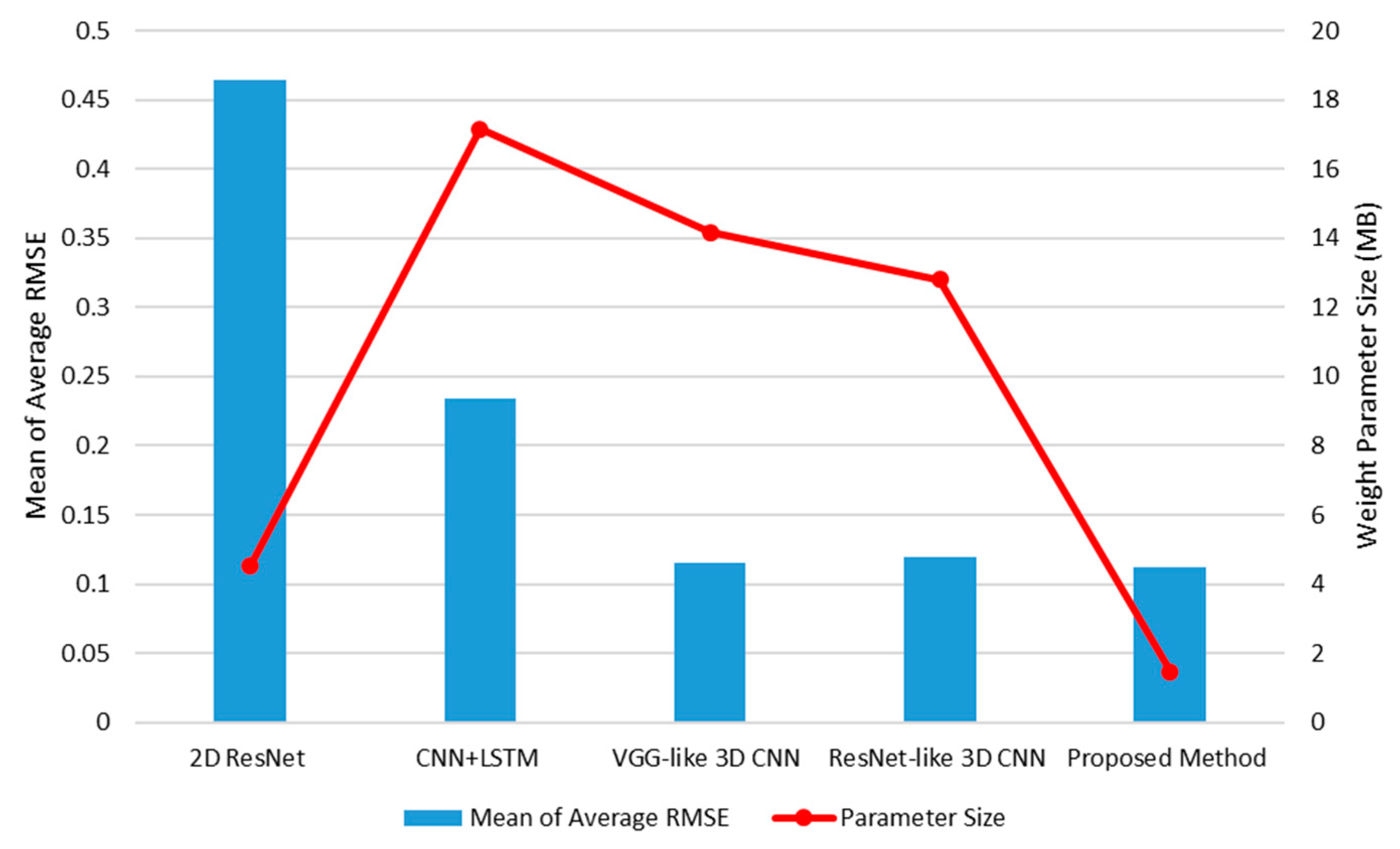
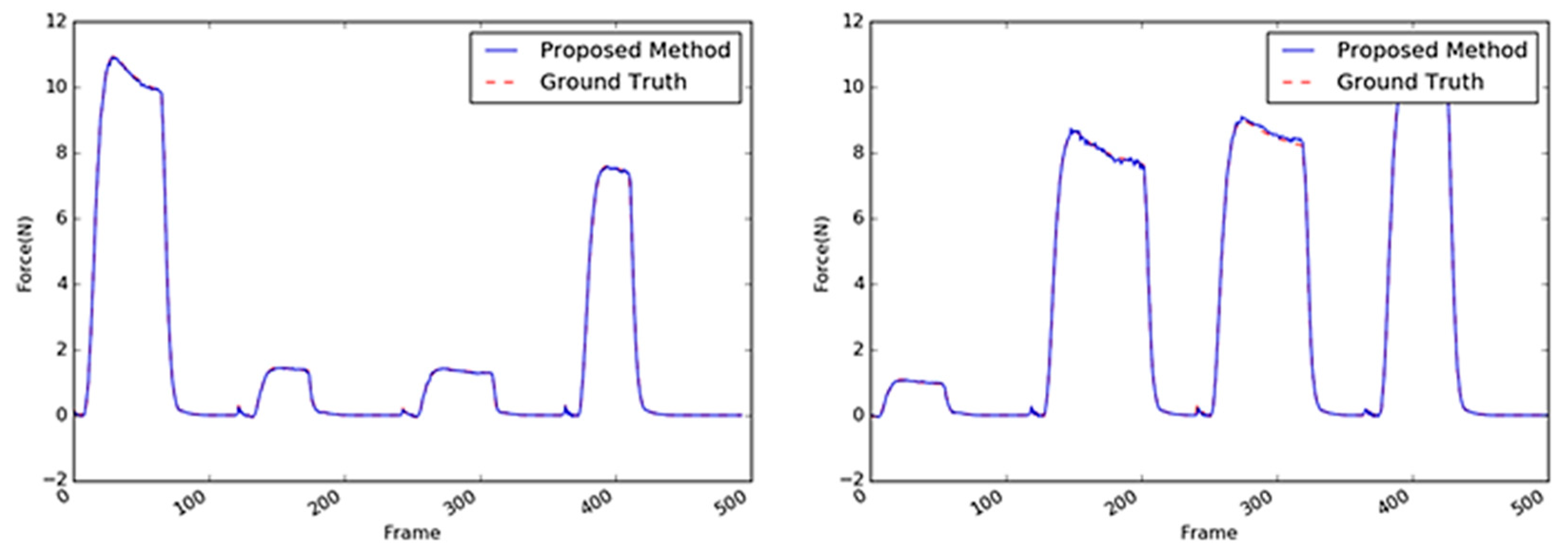
5.1. Overall Performances
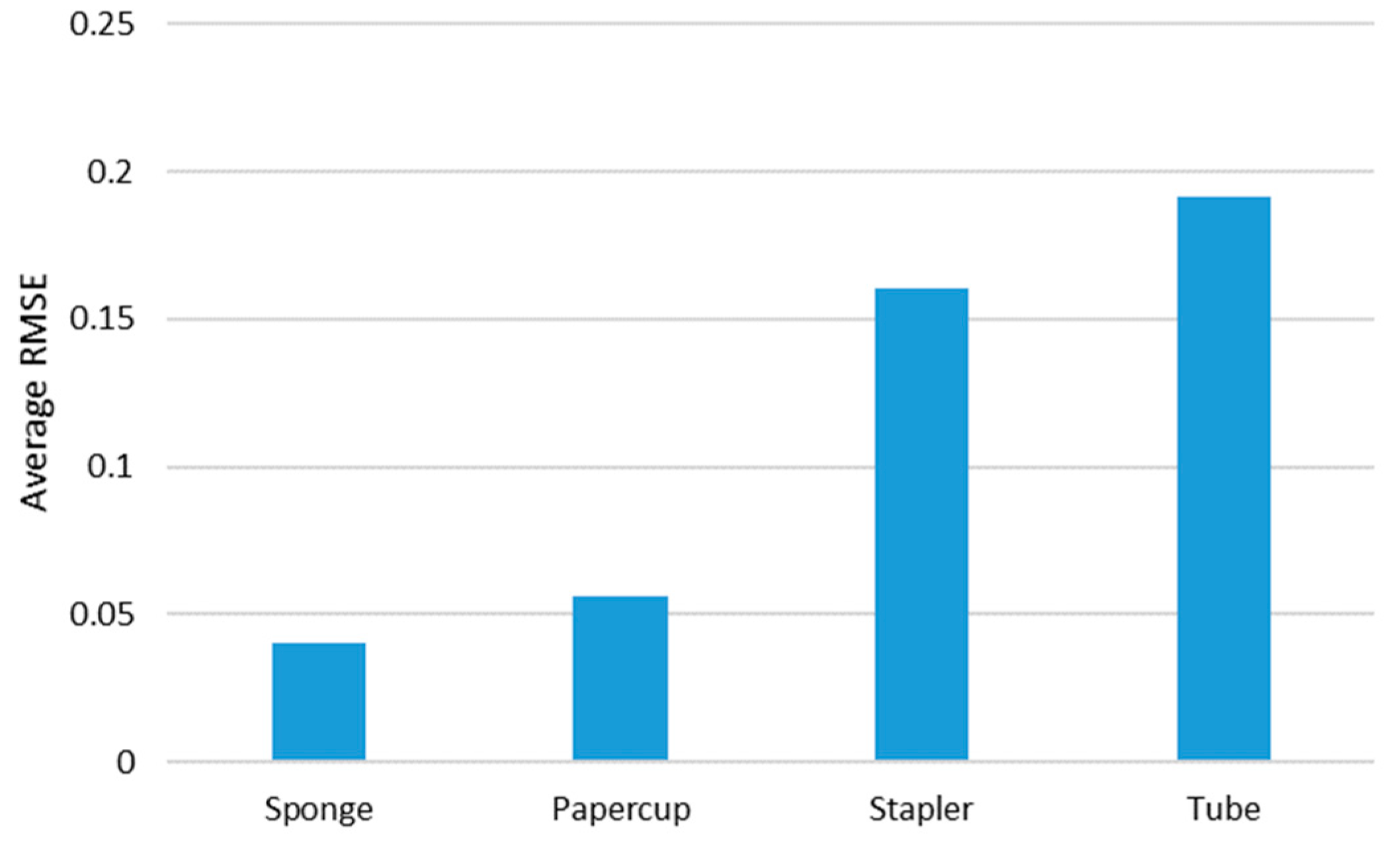
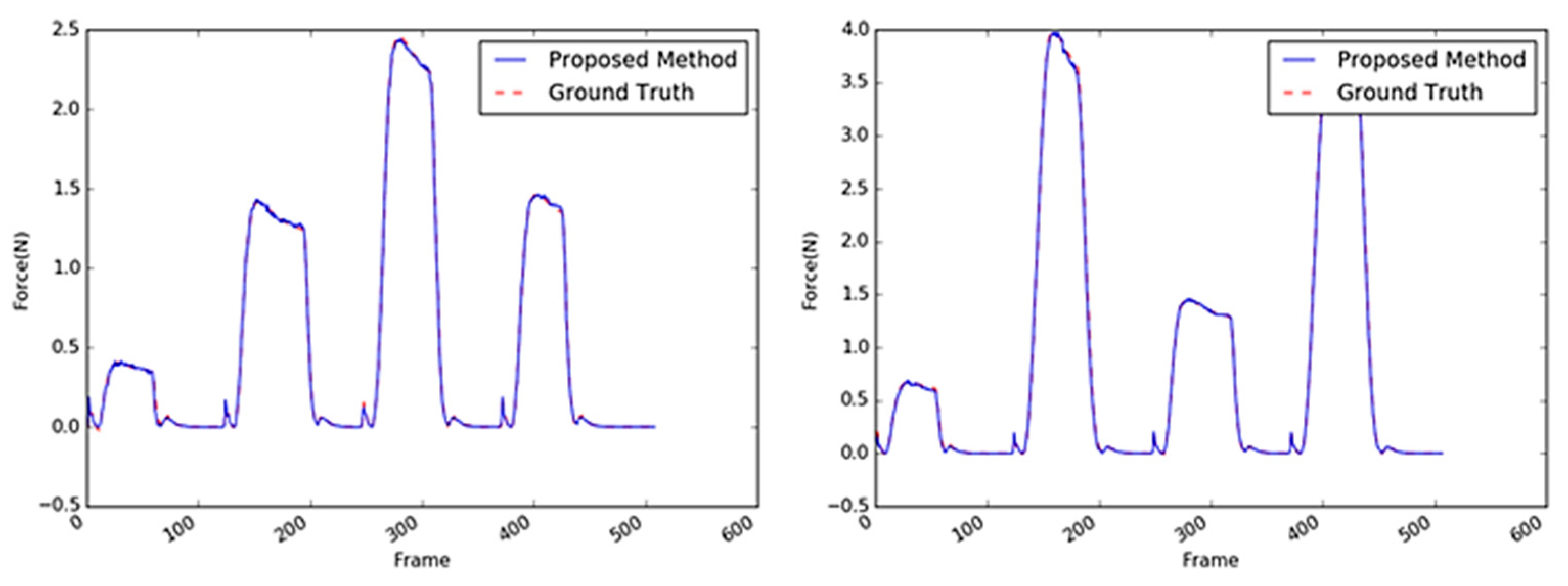
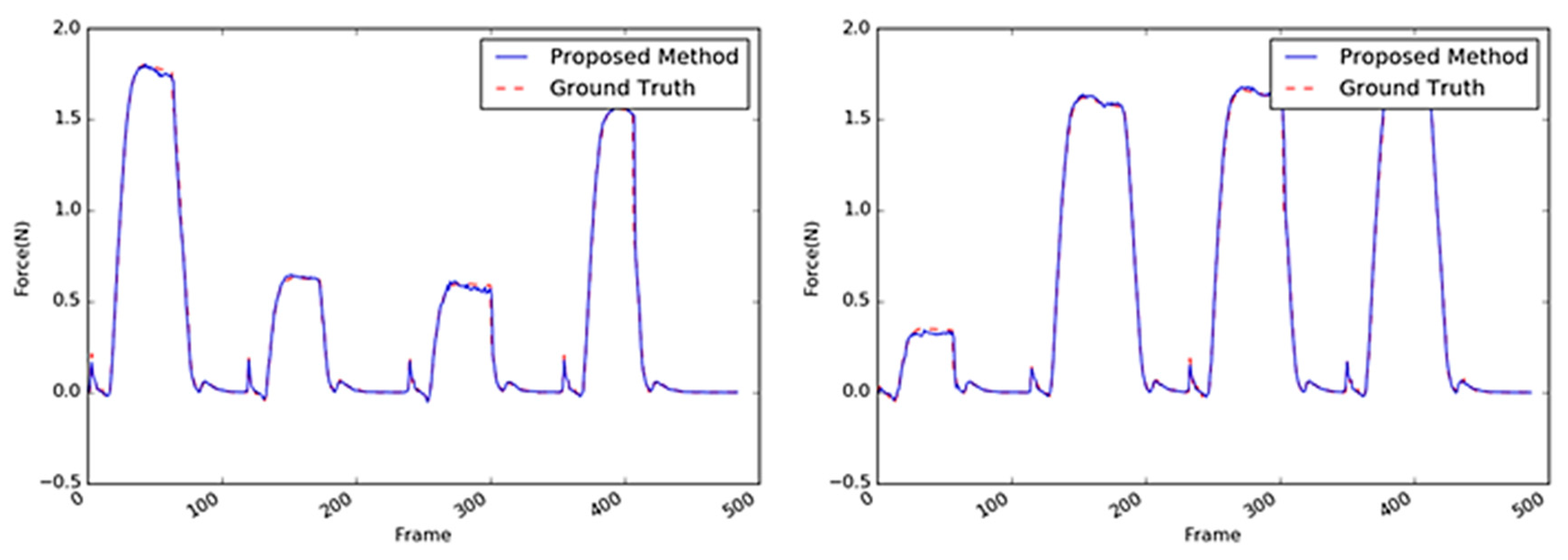
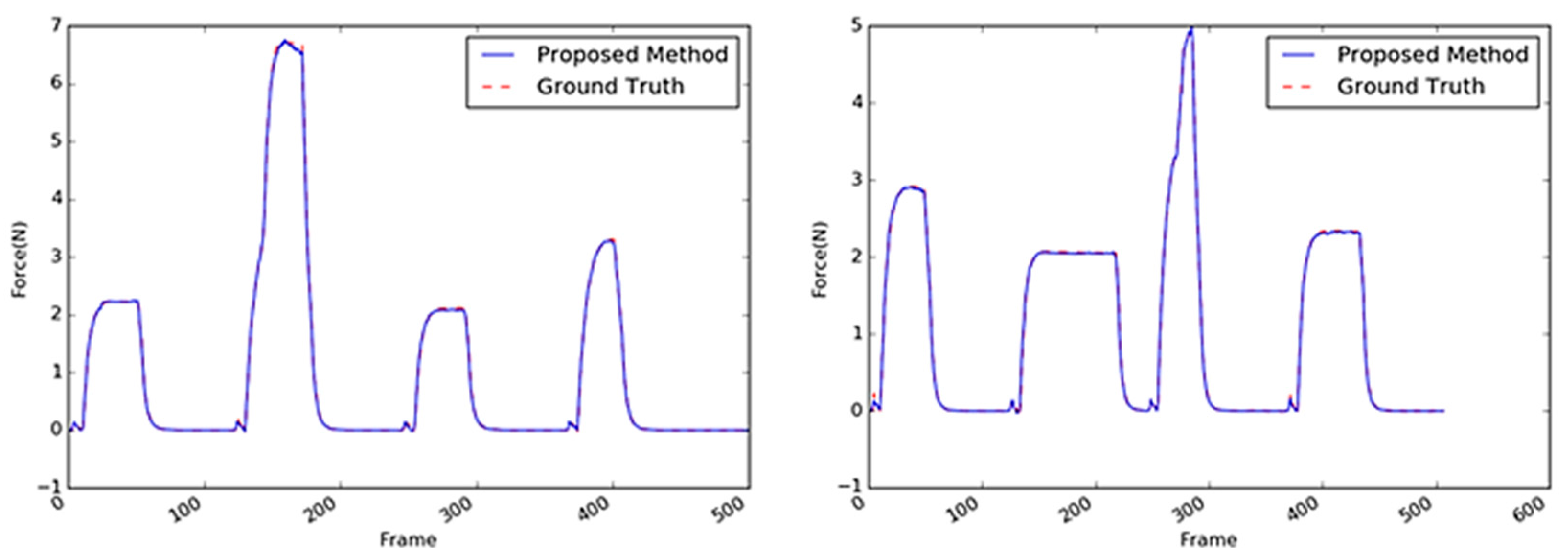
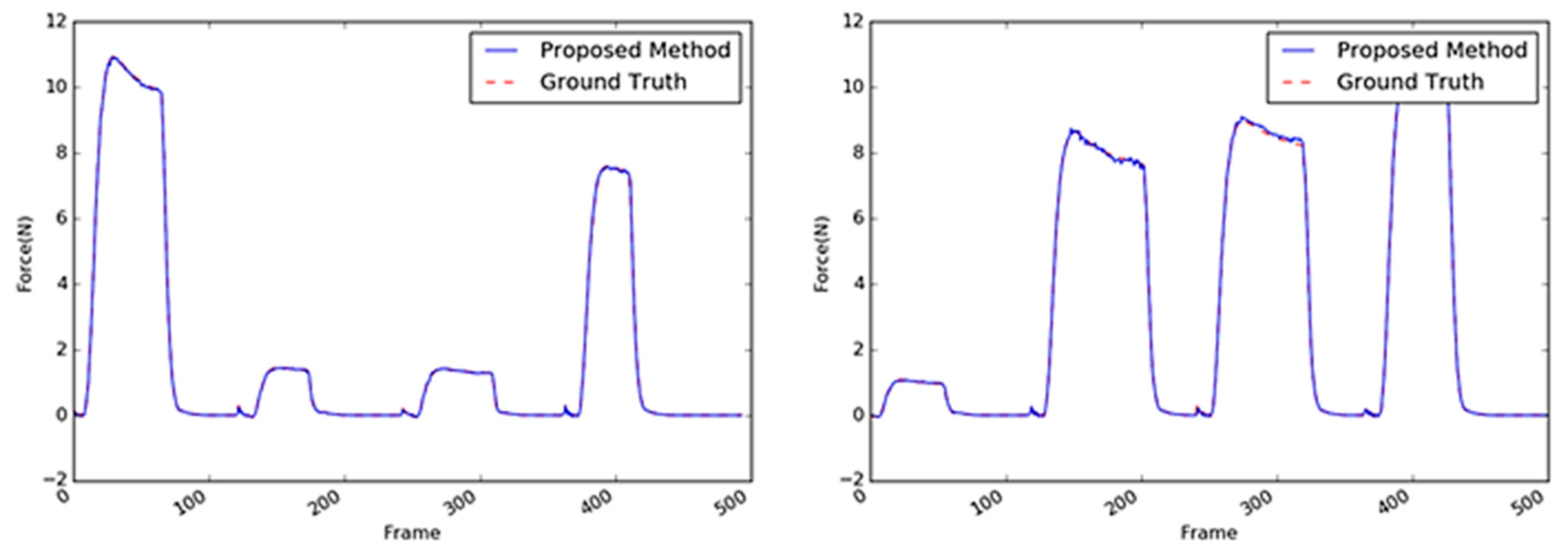
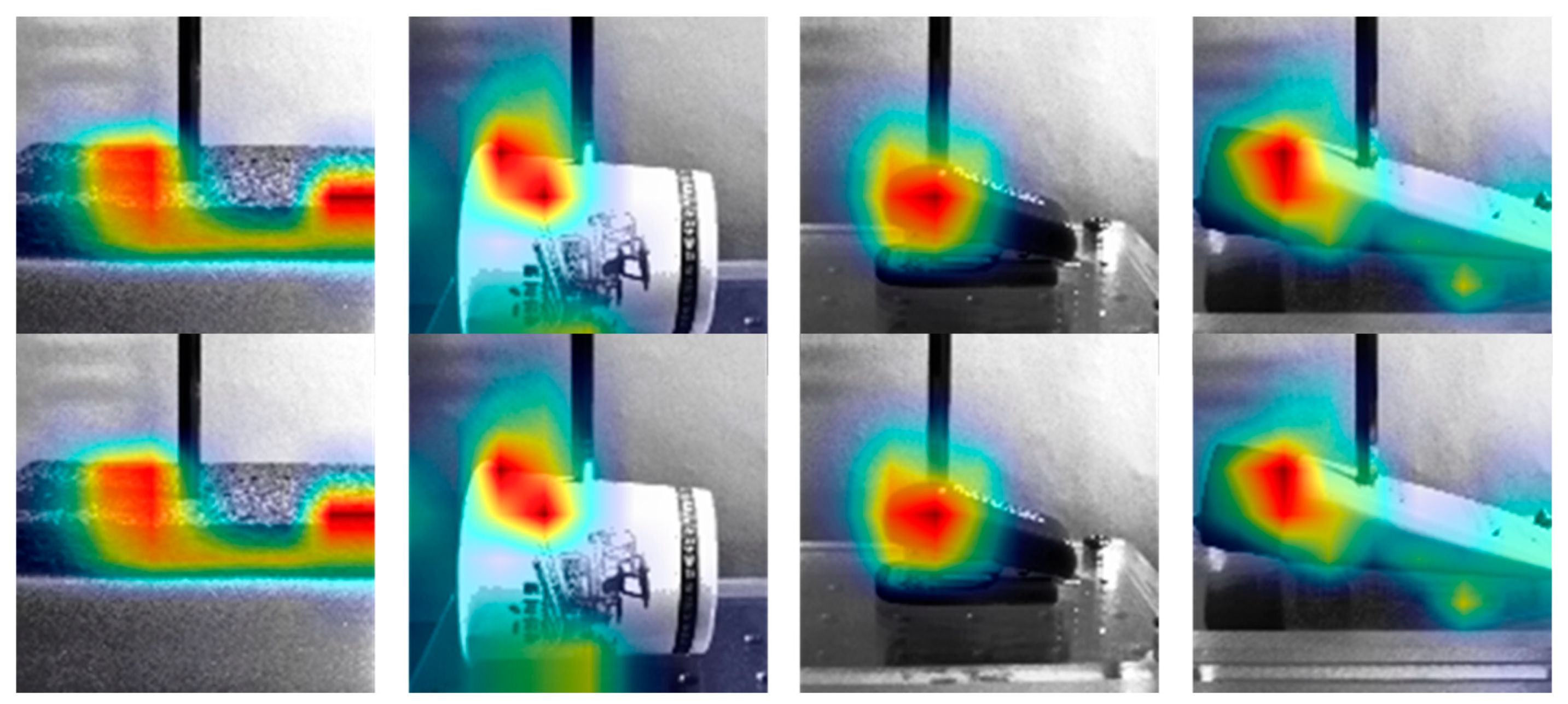
5.2. Investigation of Different Material-Based Objects
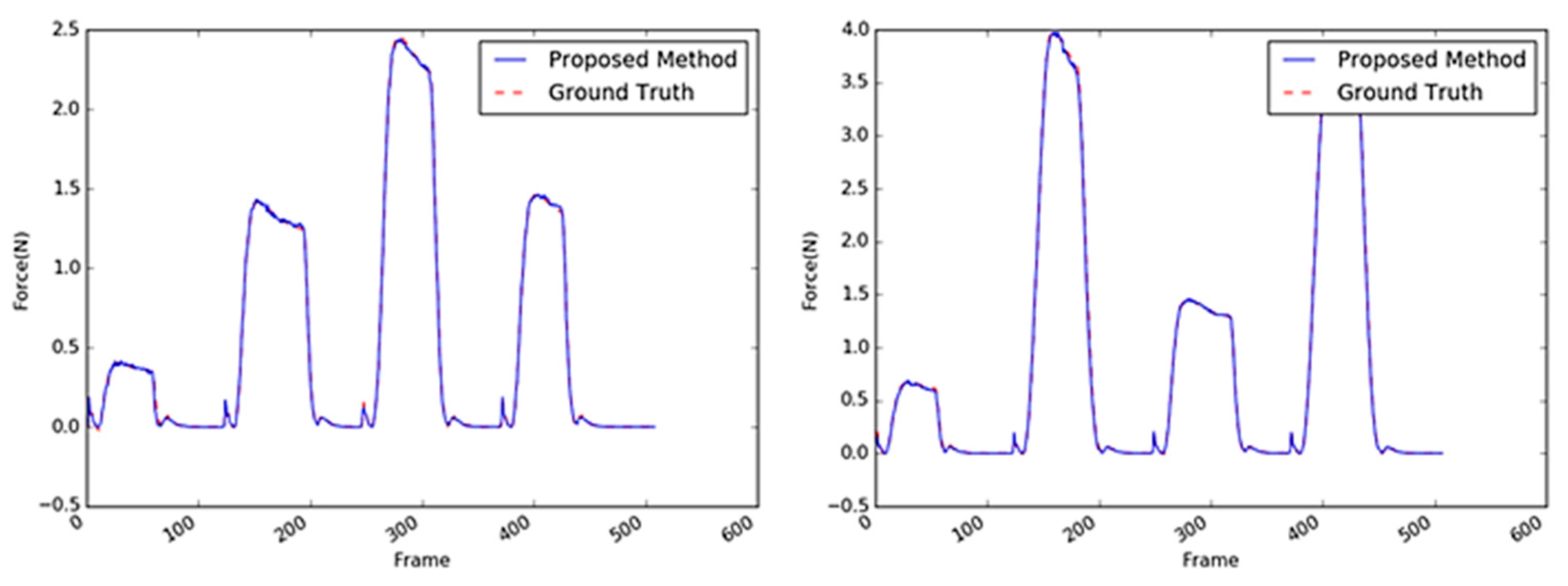
5.2.1. Sponge
5.2.2. Paper Cup
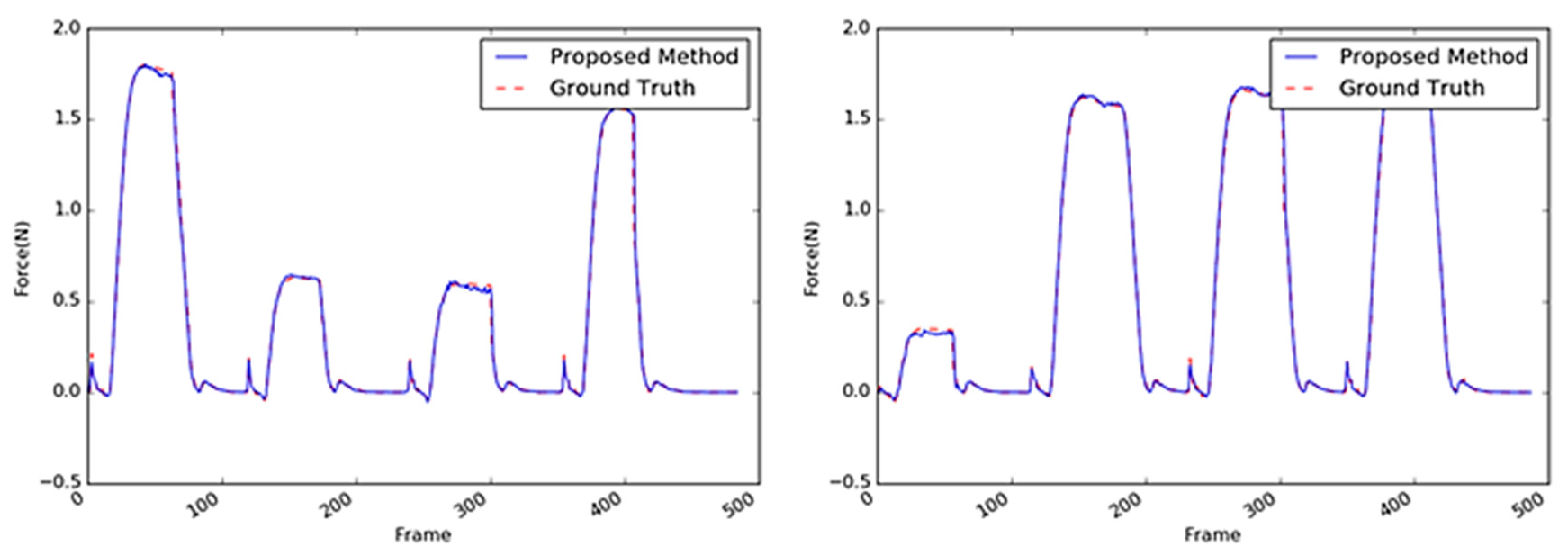
5.2.3. Stapler
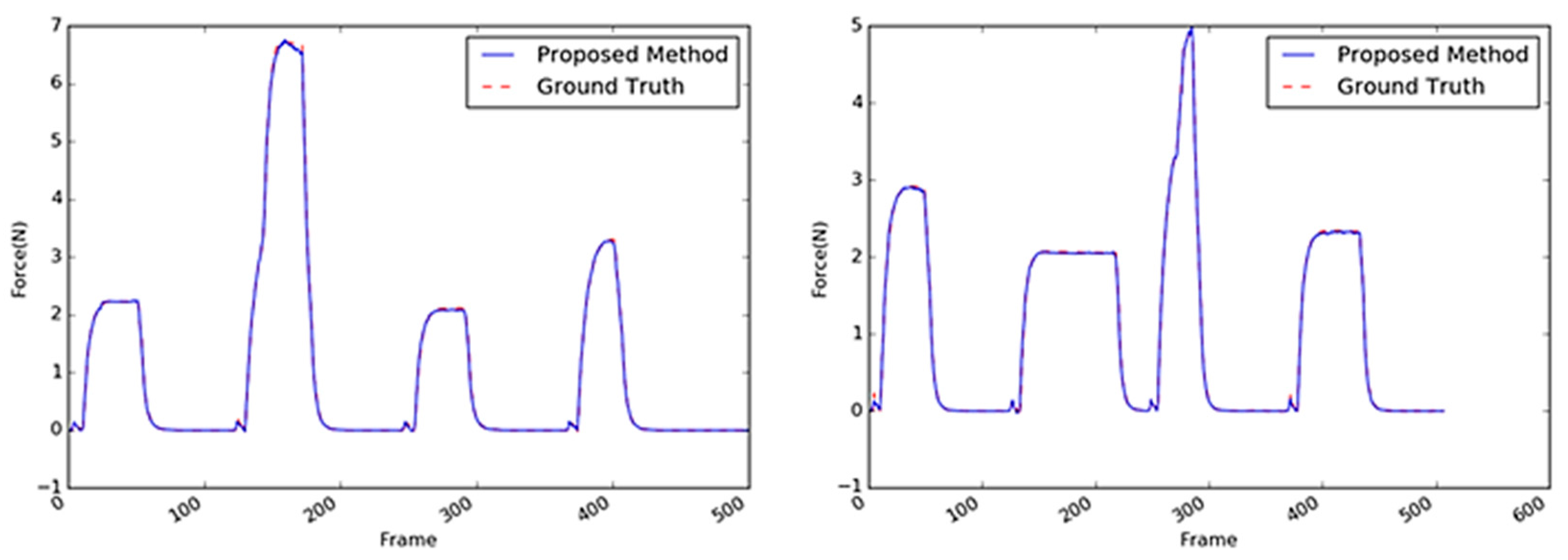
5.2.4. Tube
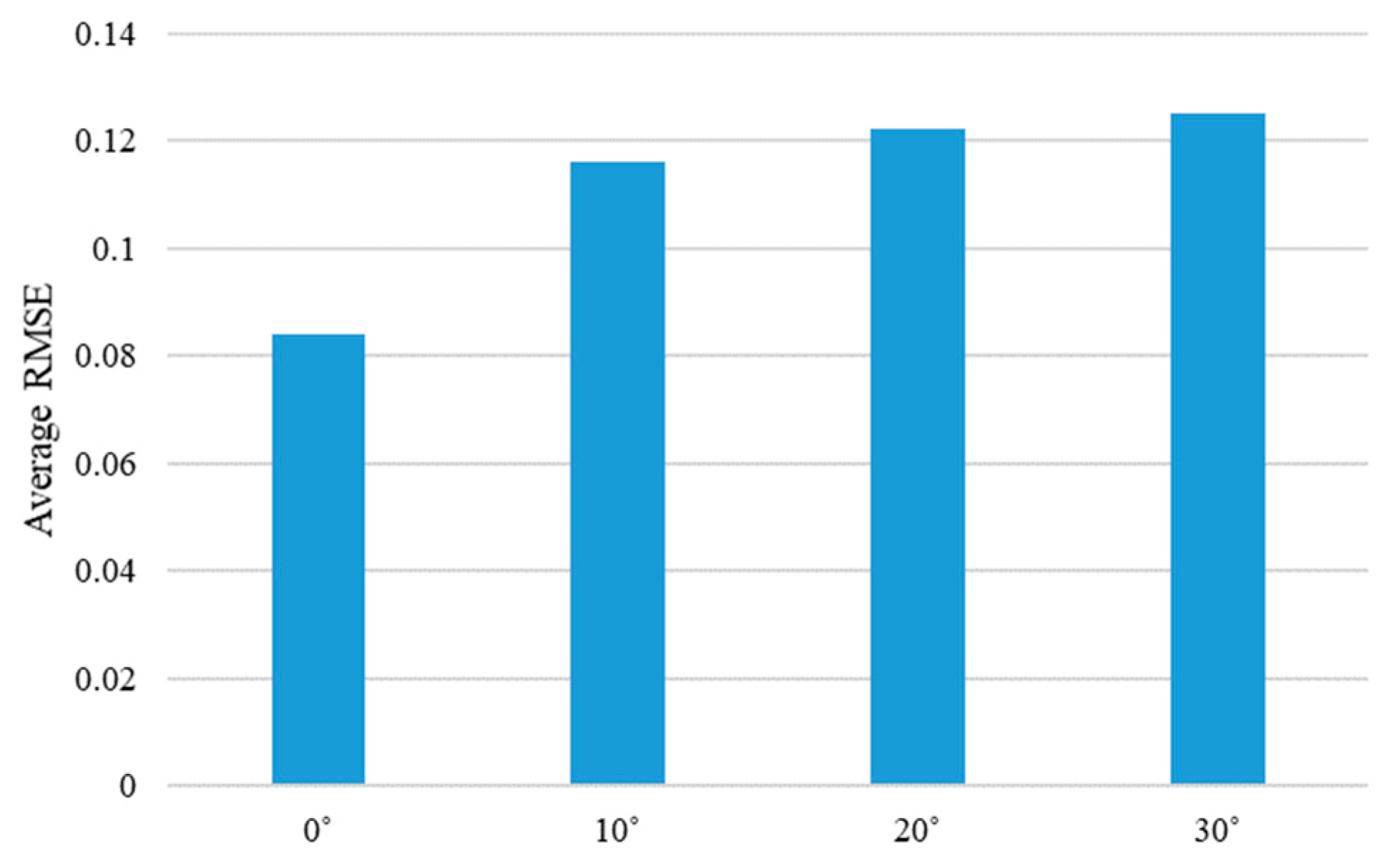
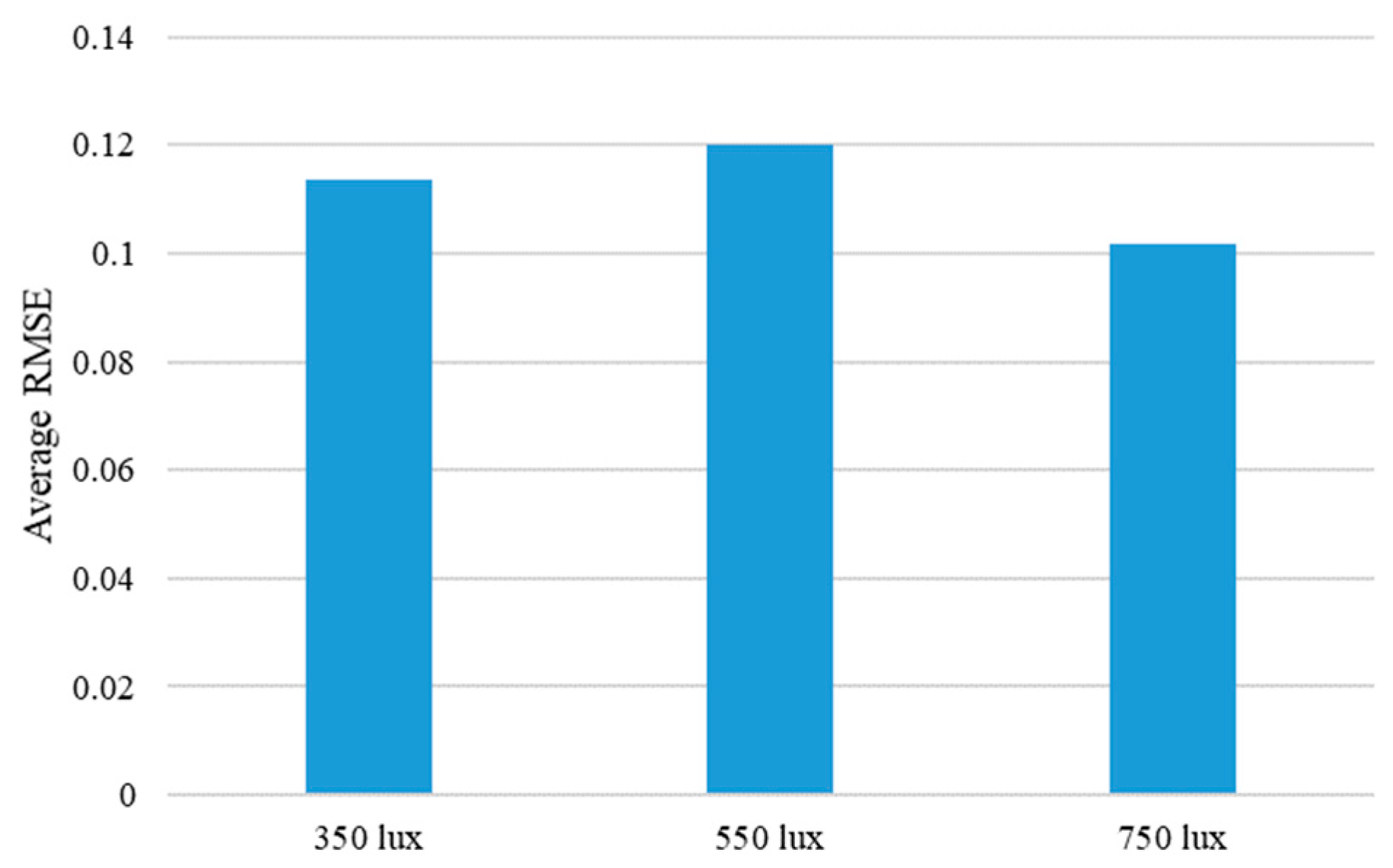
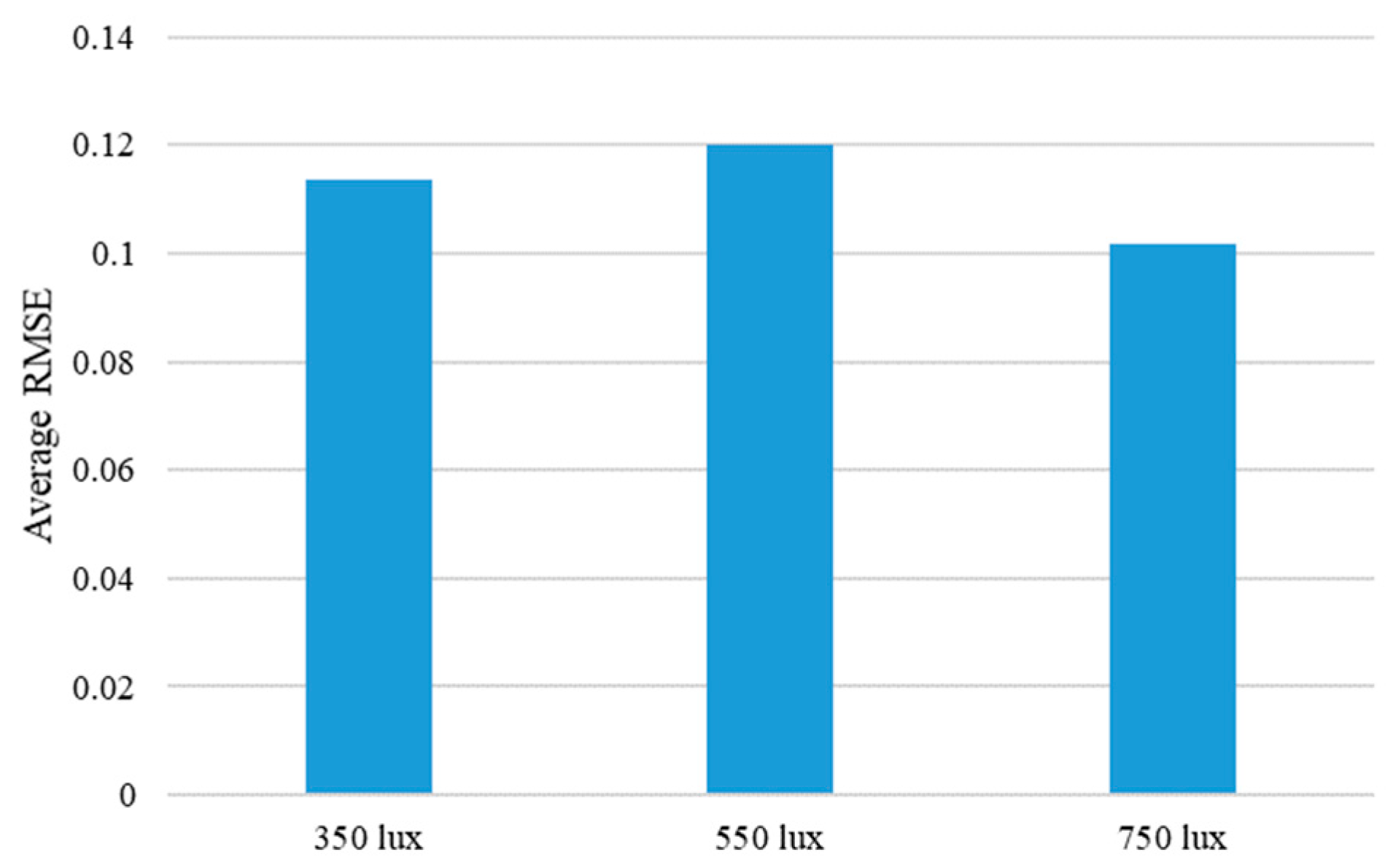
5.3. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Grosu, V.; Grosu, S.; Vanderborght, B.; Lefeber, D.; Rodriguez-Guerrero, C. Multi-axis force sensor for human–robot interaction sensing in a rehabilitation robotic device. Sensors 2017, 17, 1294. [Google Scholar] [CrossRef] [PubMed]
- Cirillo, A.; Ficuciello, F.; Natale, C.; Pirozzi, S.; Villani, L. A conformable force/tactile skin for physical human-robot interaction. IEEE Robot. Autom. Lett. 2016, 1, 41–48. [Google Scholar] [CrossRef]
- Landi, C.T.; Ferraguti, F.; Sabattini, L.; Secchi, C.; Fantuzzi, C. Admittance control parameter adaptation for physical human-robot interaction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, Singapore, 29 May–3 June 2017. [Google Scholar]
- Lim, S.; Lee, H.; Park, J. Role of combined tactile and kinesthetic feedback in minimally invasive surgery. Int. J. Med Robot. Comput. Assist. Surg. 2015, 11, 360–374. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Han, H.; Liu, T.; Yi, J.; Li, Q.; Inoue, Y. A novel tactile sensor with electromagnetic induction and its application on stick-slip interaction detection. Sensors 2016, 16, 430. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Wu, R.; Li, C.; Zang, X.; Zhang, X.; Jin, H.; Zhao, J. A force-sensing system on legs for biomimetic hexapod robots interacting with unstructured terrain. Sensors 2017, 17, 1514. [Google Scholar] [CrossRef] [PubMed]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 7–22 June 2006. [Google Scholar]
- Krizhevsk, A.; Sulskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2625–2634. [Google Scholar] [CrossRef]
- Ernst, M.O.; Banks, M.S. Humans integrate visual and haptic information in a statistically optimal fashion. Nature 2002, 415, 429. [Google Scholar] [CrossRef]
- Newell, F.N.; Ernst, M.O.; Tjan, B.S.; Bülthoff, H.H. Viewpoint dependence in visual and haptic object recognition. Psychol. Sci. 2001, 12, 37–42. [Google Scholar] [CrossRef]
- Tiest, W.M.B.; Kappers, A.M. Physical aspects of softness perception. In Multisensory Softness; Luca, M.D., Ed.; Springer: London, UK, 2014; pp. 3–15. [Google Scholar]
- Hwang, W.; Lim, S.C. Inferring interaction force from visual information without using physical force sensors. Sensors 2017, 17, 2455. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Recognit. Mach. Intell. 2103, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Hyeon, C.; Dongyi, K.; Junho, P.; Kyungshik, R.; Wonjun, H. 2D barcode detection using images for drone-assisted inventory management. In Proceedings of the 15th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Honolulu, HI, USA, 26–30 June 2108; pp. 467–471. [Google Scholar]
- Mattioli, T.; Vendittelli, M. Interaction force reconstruction for humanoid robots. IEEE Robot. Autom. Lett. 2017, 2, 282–289. [Google Scholar] [CrossRef]
- Li, Y.; Hannaford, B. Gaussian process regression for sensorless grip force estimation of cable-driven elongated surgical instruments. IEEE Robot. Autom. Lett. 2017, 2, 1312–1319. [Google Scholar] [CrossRef] [PubMed]
- Aviles, A.I.; Alsaleh, S.M.; Hahn, J.K.; Casals, A. Towards retrieving force feedback in robotic-assisted surgery: A supervised neuro-recurrent-vision approach. IEEE Trans. Haptics 2016, 10, 431–443. [Google Scholar] [CrossRef]
- Zhu, Y.; Jiang, C.; Zhao, Y.; Terzopoulos, D.; Zhu, S.C. Inferring forces and learning human utilities from videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3823–3833. [Google Scholar]
- Pham, T.H.; Kheddar, A.; Qammaz, A.; Argyros, A.A. Towards force sensing from vision: Observing hand-object interactions to infer manipulation forces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2810–2819. [Google Scholar]
- Dong-Han, L.; Wonjun, H.; Soo-Chul, L. Interaction force estimation using camera and electrical current without force/torque sensor. IEEE Sens. J. 2018, 18, 8863–8872. [Google Scholar]
- Fermüller, C.; Wang, F.; Yang, Y.; Zampogiannis, K.; Zhang, Y.; Barranco, F.; Pfeiffer, M. Prediction of manipulation actions. Int. J. Comput. Vis. 2018, 126, 358–374. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Landola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. arXiv 2017, 1610–2357. [Google Scholar]
- Ye, R.; Liu, F.; Zhang, L. 3D depthwise convolution: Reducing model parameters in 3D vision tasks. arXiv 2018, arXiv:1808.01556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2015; Volume 9, pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3D CNN | Proposed Method | |
|---|---|---|
| No. of Parameters |
| Layer (Type) | Expand Channels | Output Channels | Spatial Stride | Kernel Depth | Depth Stride | |
|---|---|---|---|---|---|---|
| <20, 128, 128, 3> | Conv2D 3 × 3 | - | 32 | 1 | 1 | 1 |
| <20, 64, 64, 32> | Bottleneck 3D 3 × 3 (a) | 32 | 16 | 1 | 1 | 1 |
| <20, 64, 64, 16> | Bottleneck 3D 3 × 3 (a) | 64 | 24 | 1 | 1 | 1 |
| <20, 32, 32, 24> | Bottleneck 3D 3 × 3 (a) | 96 | 32 | 1 | 1 | 1 |
| <20, 16, 16, 32> | Bottleneck 3D 3 × 3 (b) | 128 | 64 | 2 | 3 | 2 |
| <10, 8, 8, 64> | Bottleneck 3D 3 × 3 (b) | 192 | 92 | 2 | 3 | 2 |
| <5, 8, 8, 92> | Bottleneck 3D 3 × 3 (b) | 384 | 128 | 2 | 3 | 2 |
| <3, 4, 4, 128> | Bottleneck 3D 3 × 3 (b) | 448 | 192 | 2 | 3 | 2 |
| <2, 4, 4, 192> | Conv2D 1 × 1 | - | 1280 | 2 | 2 | 2 |
| <1, 4, 4, 1280> | Avg. Pool. 4 × 4 | - | - | 1 | 1 | - |
| <1280> | FC 1 | - | 1 | - | - | - |
| Object | Training Set | Test Set |
|---|---|---|
| Sponge | 144 sets (77,097) | 36 sets (19,474) |
| Paper cup | 144 sets (76,966) | 36 sets (19,133) |
| Stapler | 144 sets (77,941) | 36 sets (19,533) |
| Tube | 144 sets (77,849) | 36 sets (19,480) |
| Method | Average RMSE | |
|---|---|---|
| 2D CNN-based methods | 2D CNN-based ResNet [25] | 0.1844 |
| CNN + LSTM | 0.0925 | |
| CNN + LSTM + EI [21] | 0.0882 | |
| 3D CNN-based methods | VGG-like 3D CNN | 0.0422 |
| ResNet-like 3D CNN | 0.0757 | |
| Proposed Method | 0.0405 | |
| Method | Average RMSE | |
|---|---|---|
| 2D CNN-based methods | 2D CNN-based ResNet [25] | 0.2049 |
| CNN + LSTM | 0.1007 | |
| CNN + LSTM + EI [21] | - | |
| 3D CNN-based methods | VGG-like 3D CNN | 0.0580 |
| ResNet-like 3D CNN | 0.0737 | |
| Proposed Method | 0.0560 | |
| Method | Average RMSE | |
|---|---|---|
| 2D CNN-based methods | 2D CNN-based ResNet [25] | 0.7526 |
| CNN + LSTM | 0.3385 | |
| CNN + LSTM + EI [21] | 0.2702 | |
| 3D CNN-based methods | VGG-like 3D CNN | 0.1554 |
| ResNet-like 3D CNN | 0.1933 | |
| Proposed Method | 0.1602 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Cho, H.; Shin, H.; Lim, S.-C.; Hwang, W. An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video. Sensors 2019, 19, 3579. https://doi.org/10.3390/s19163579
Kim D, Cho H, Shin H, Lim S-C, Hwang W. An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video. Sensors. 2019; 19(16):3579. https://doi.org/10.3390/s19163579
Chicago/Turabian StyleKim, Dongyi, Hyeon Cho, Hochul Shin, Soo-Chul Lim, and Wonjun Hwang. 2019. "An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video" Sensors 19, no. 16: 3579. https://doi.org/10.3390/s19163579
APA StyleKim, D., Cho, H., Shin, H., Lim, S.-C., & Hwang, W. (2019). An Efficient Three-Dimensional Convolutional Neural Network for Inferring Physical Interaction Force from Video. Sensors, 19(16), 3579. https://doi.org/10.3390/s19163579