Lightweight Driver Monitoring System Based on Multi-Task Mobilenets


Abstract
:1. Introduction
2. Dataset
2.1. Camera
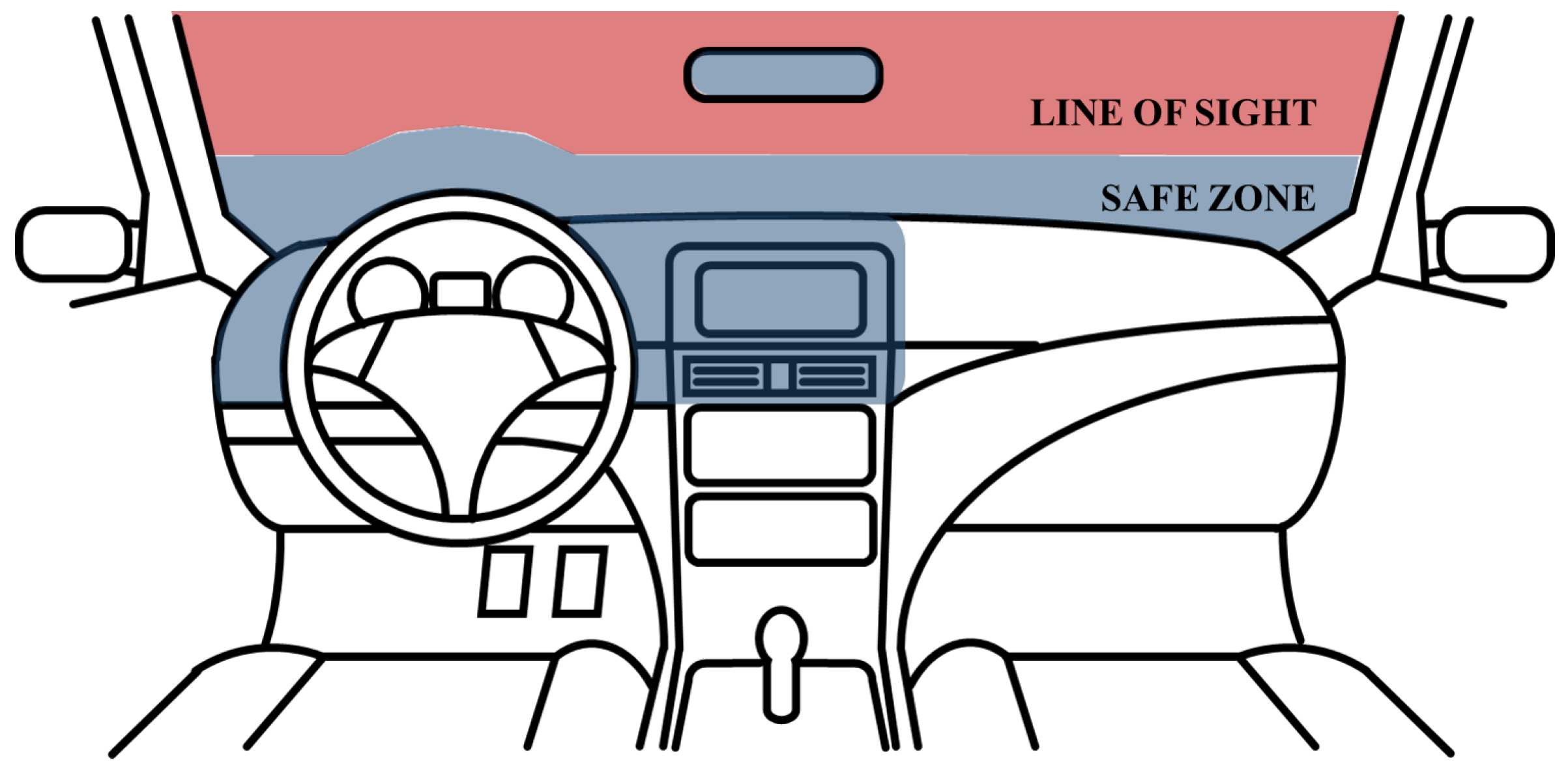
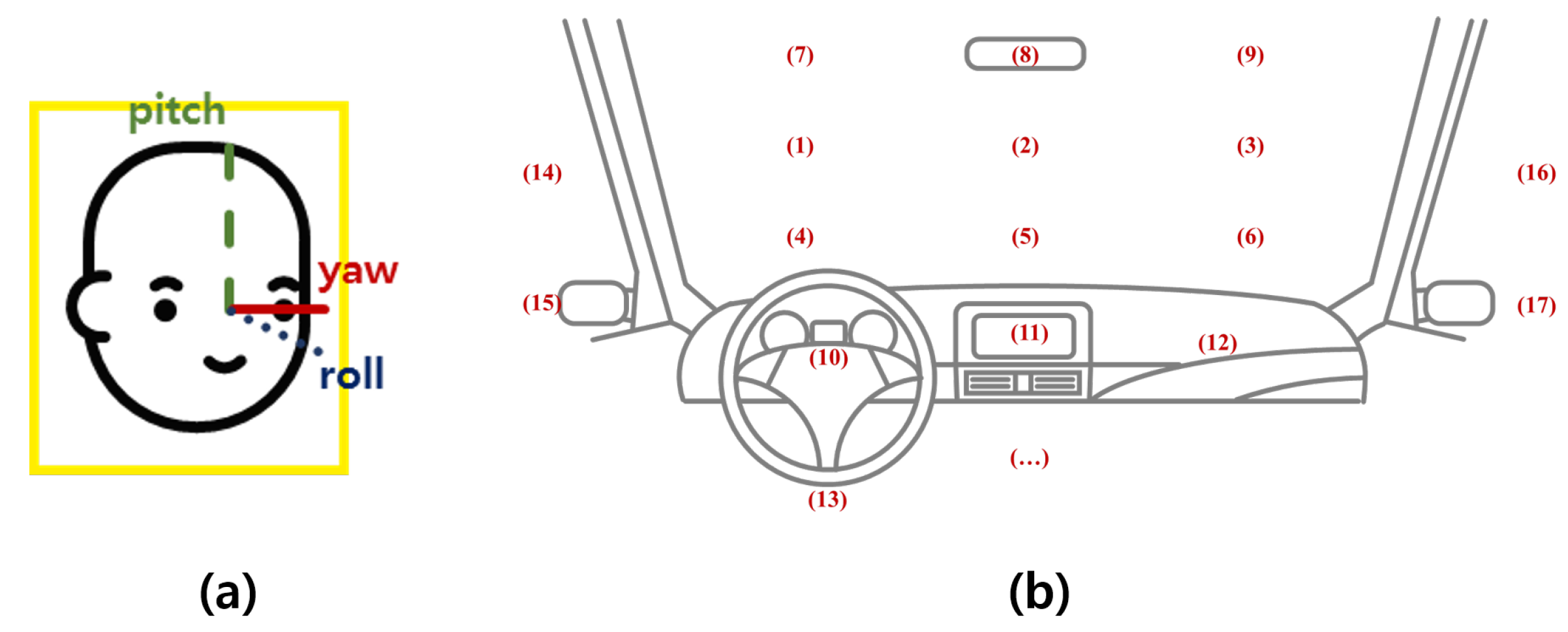
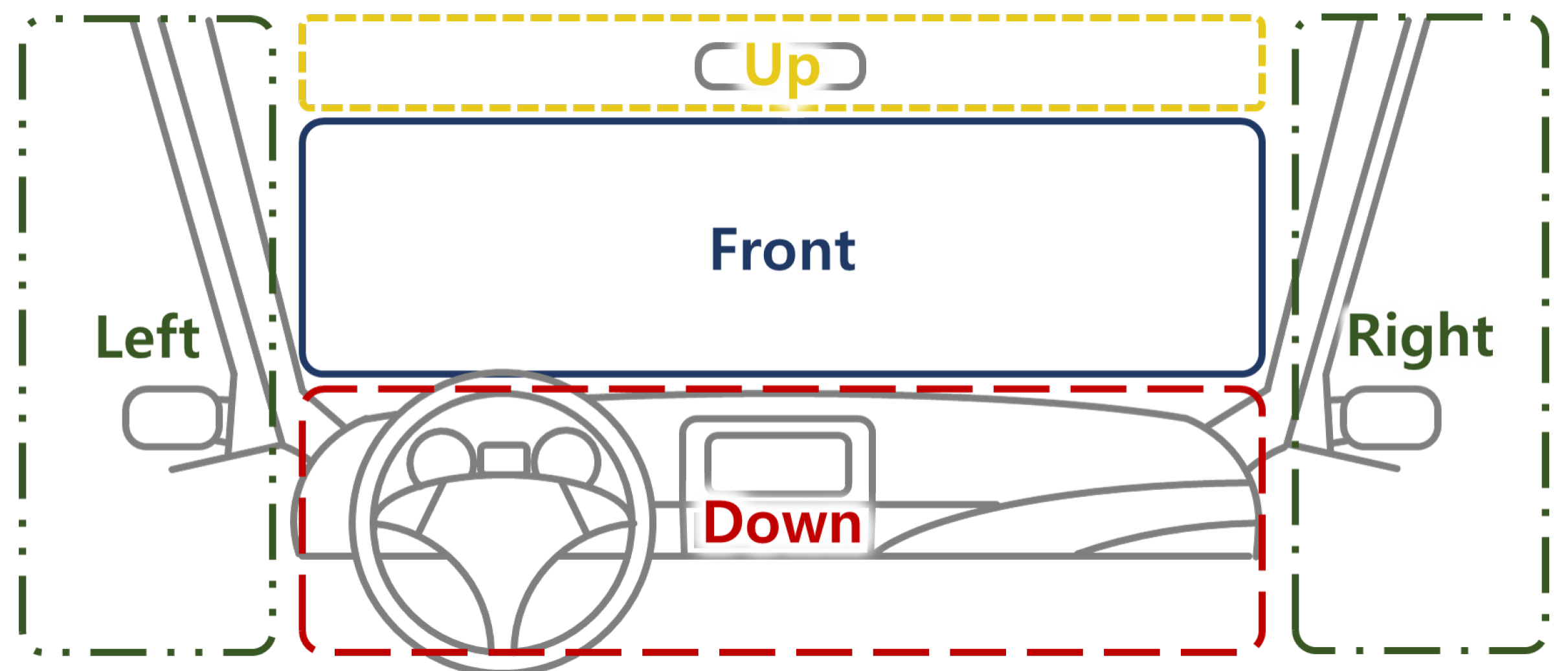
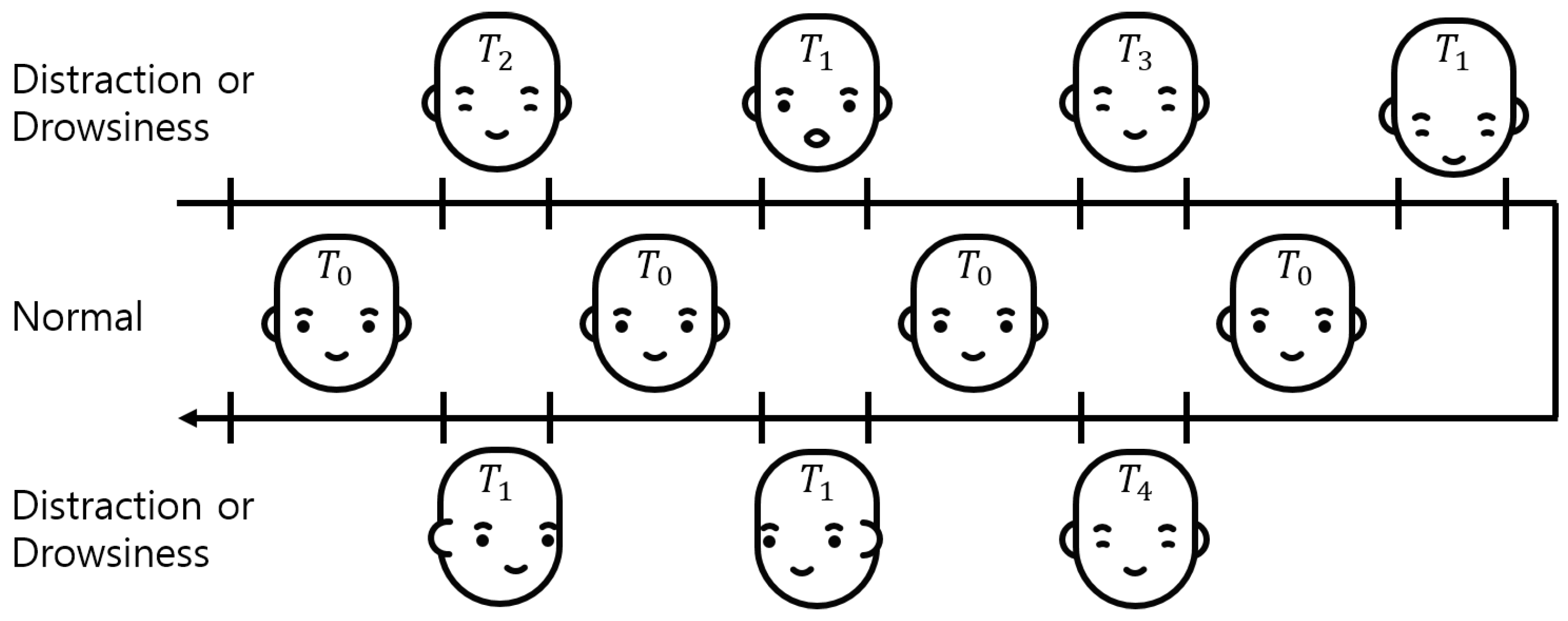
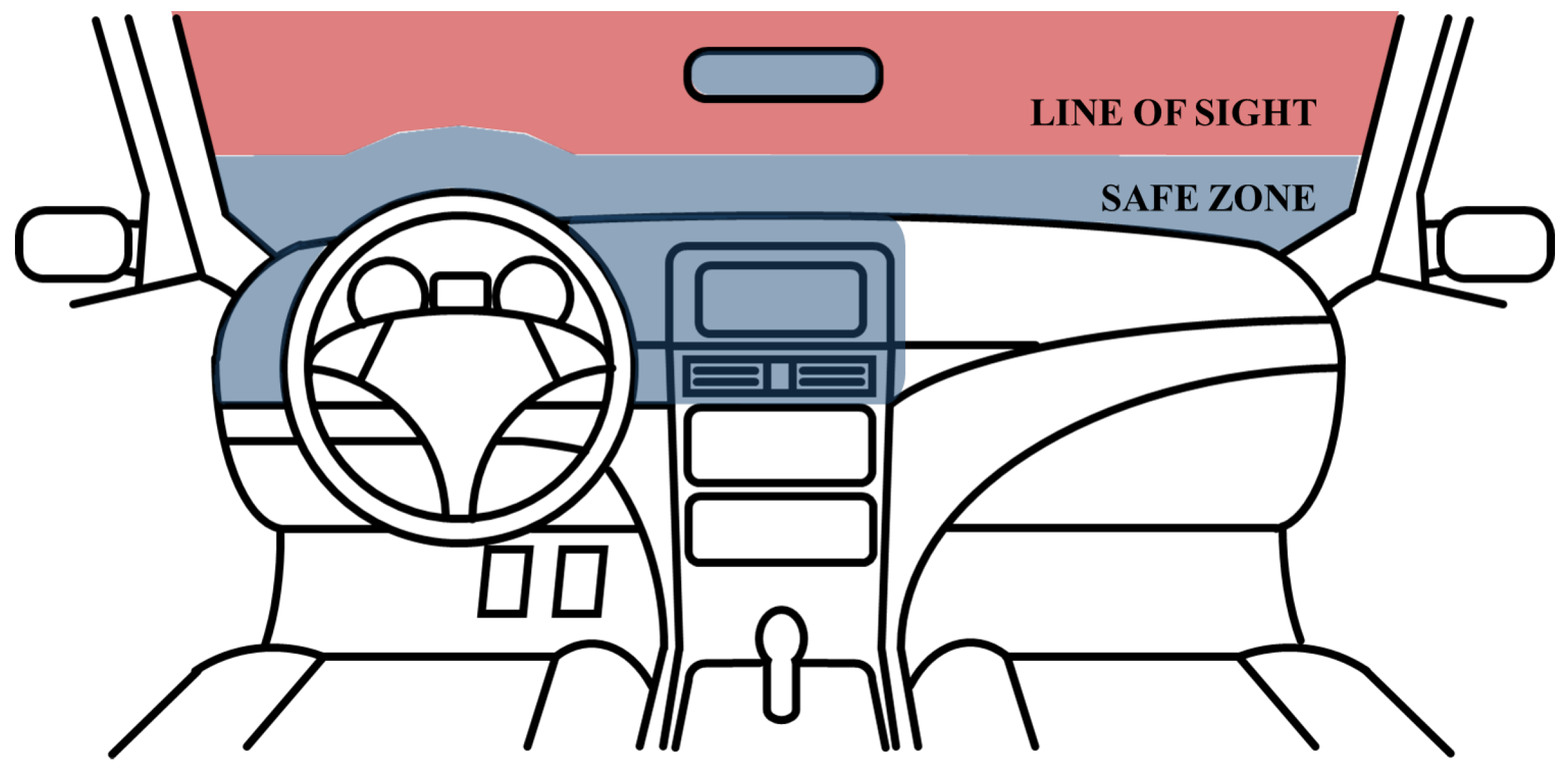
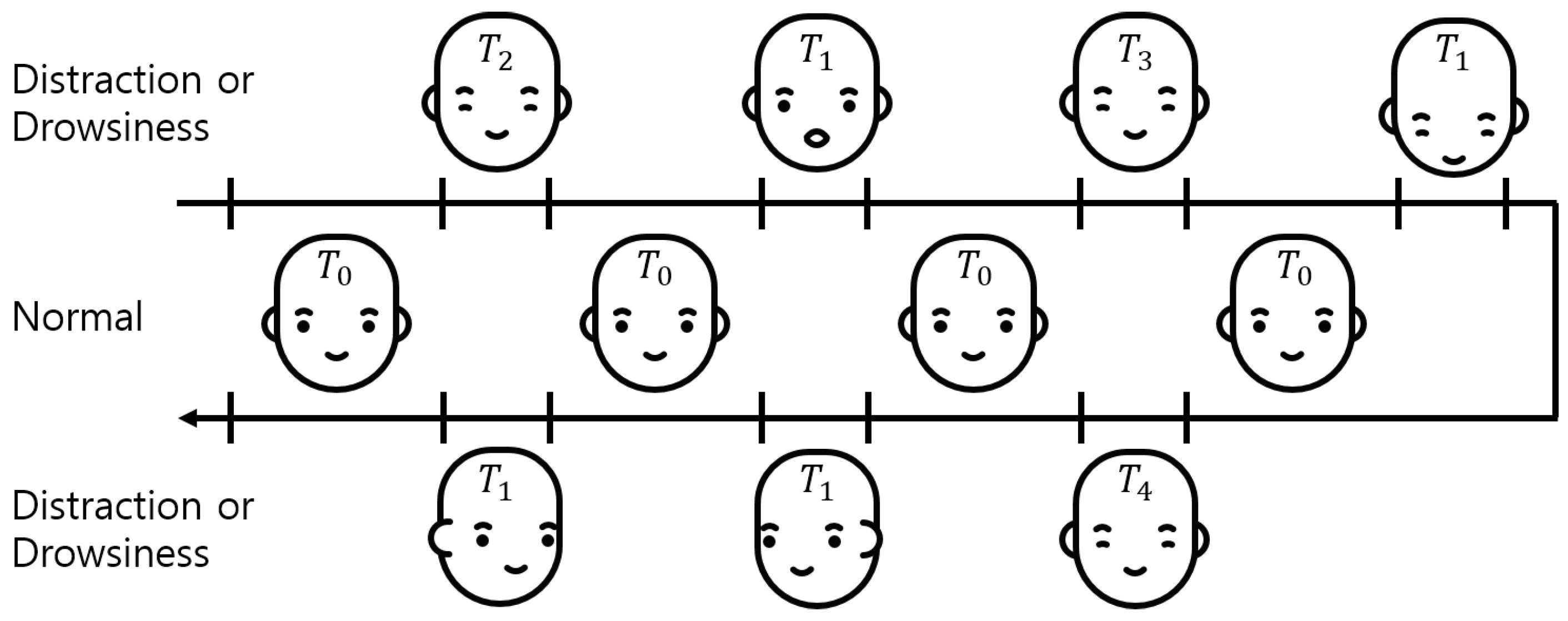
2.2. Definition of the Driver Status
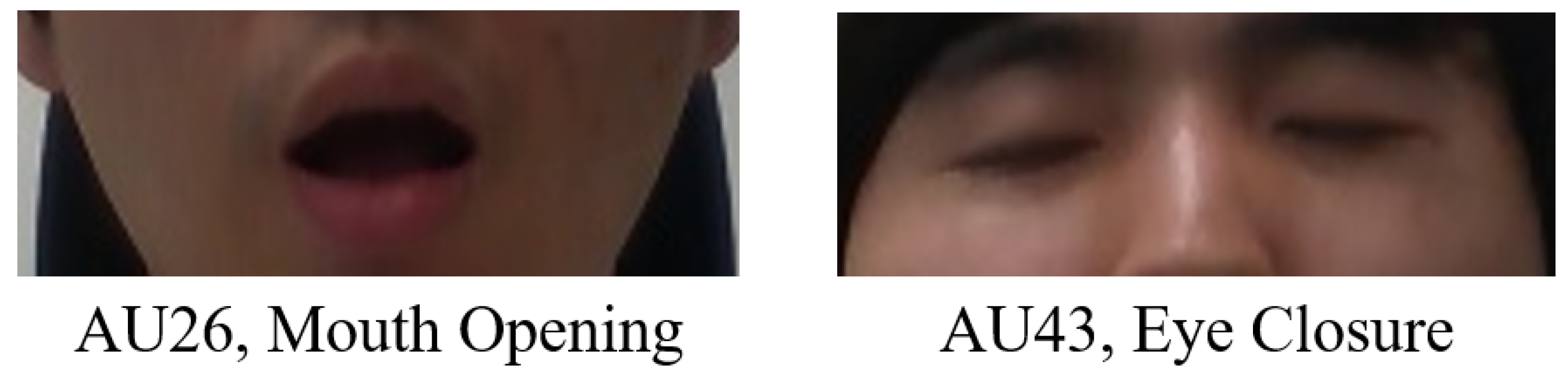
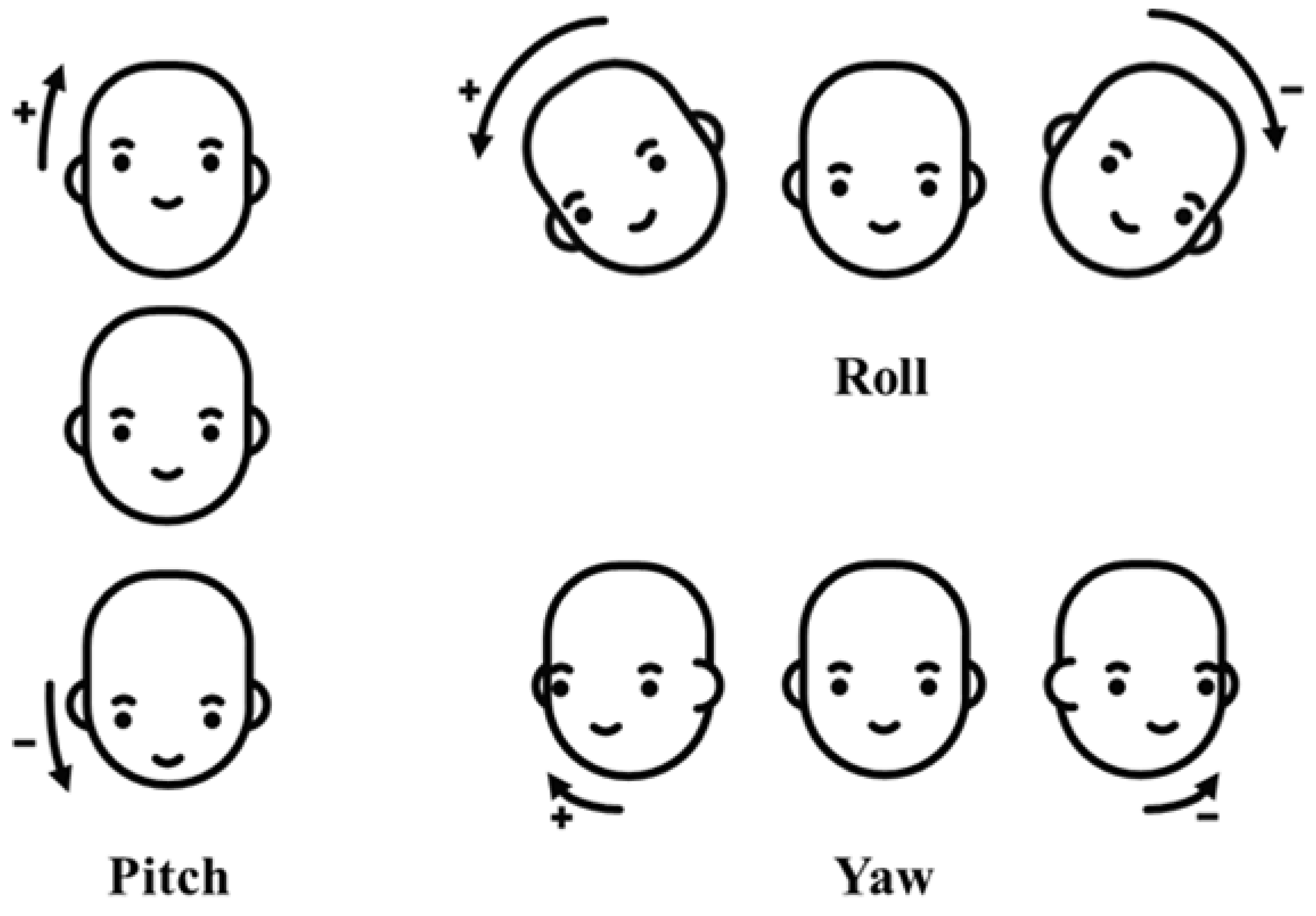
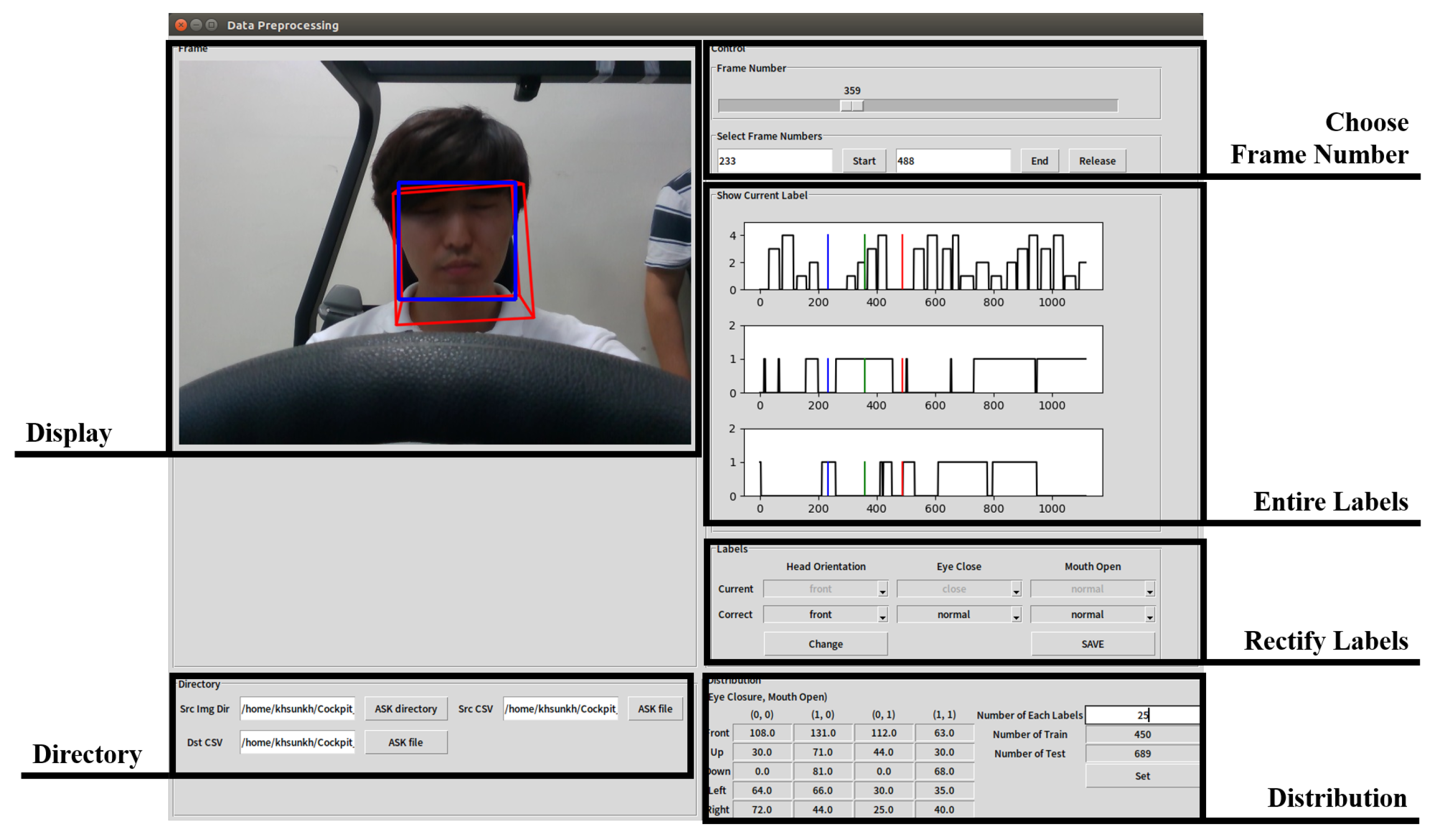
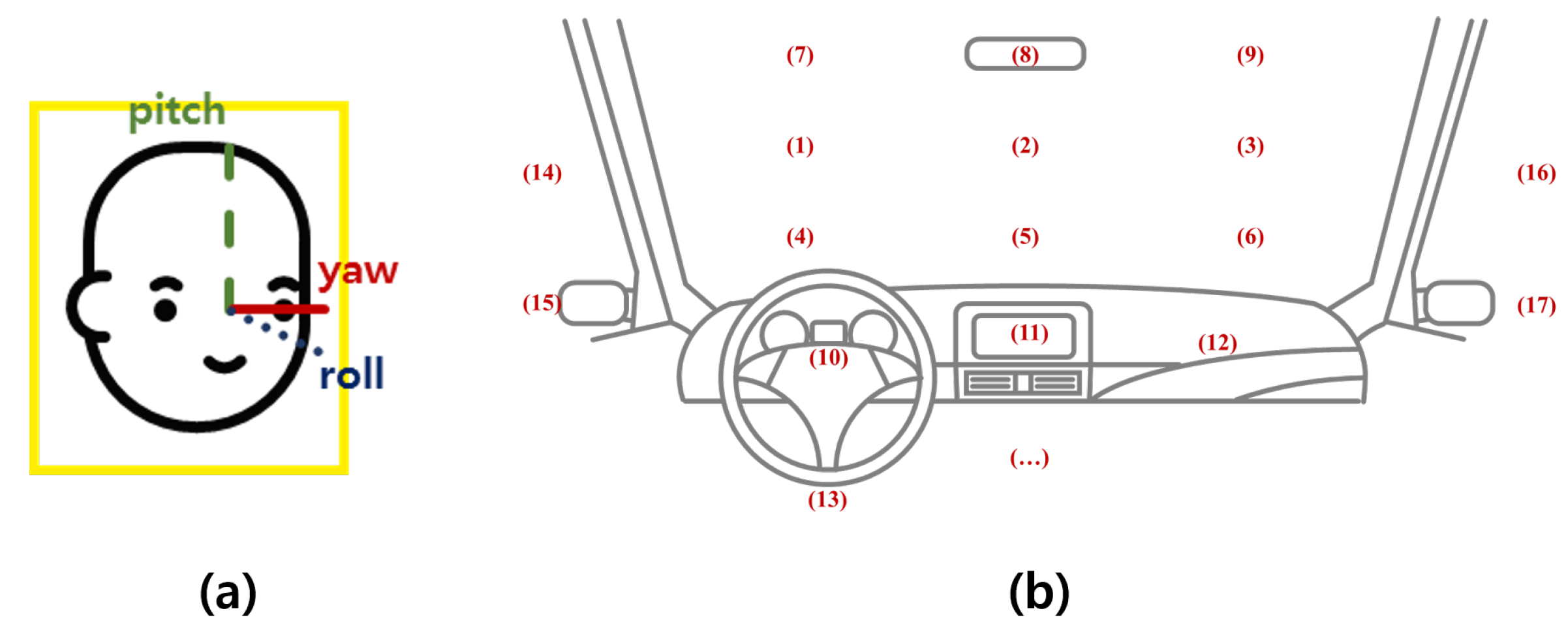
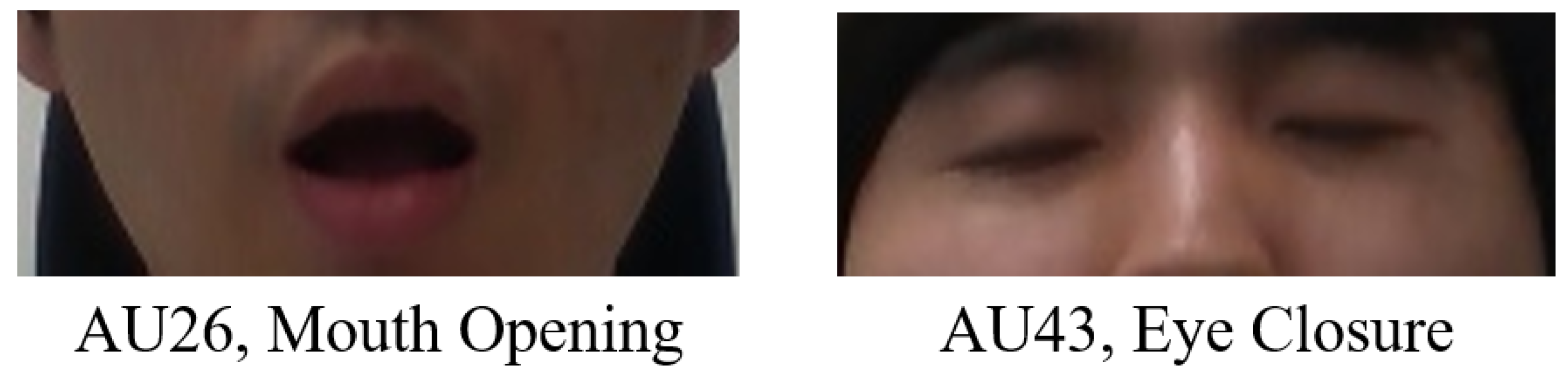
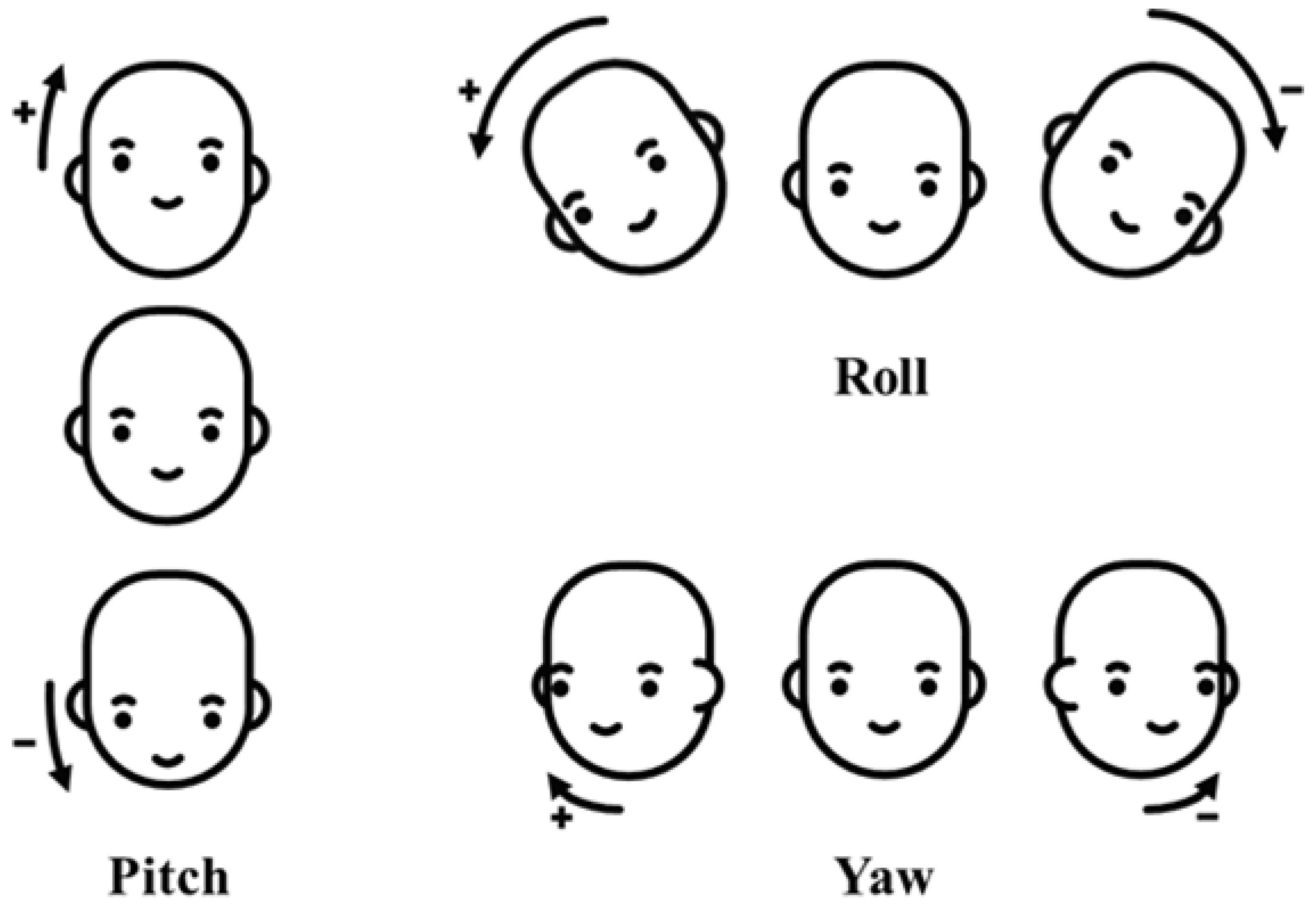
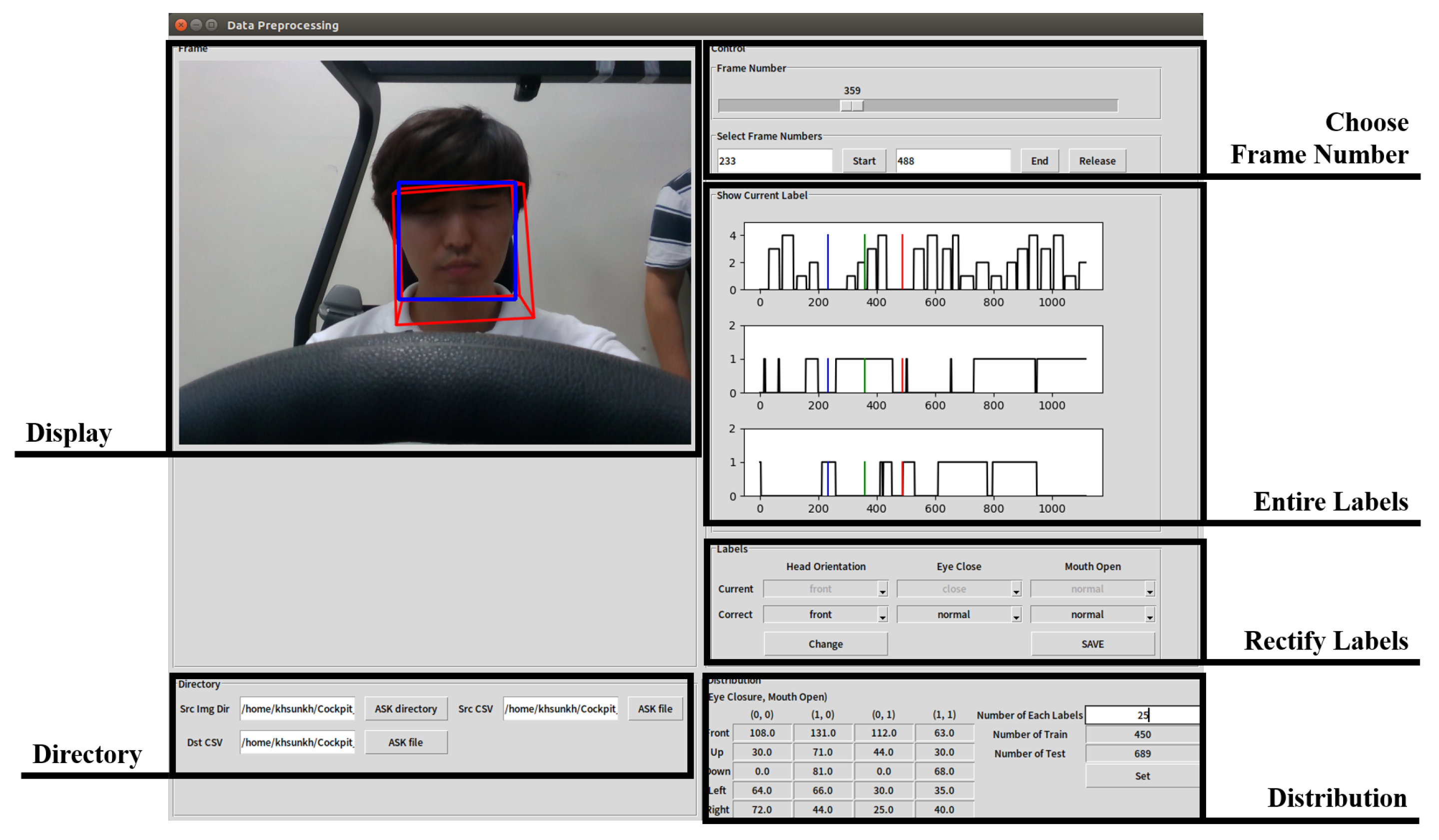
2.3. Generation of the Ground Truth of Facial Direction and Expression
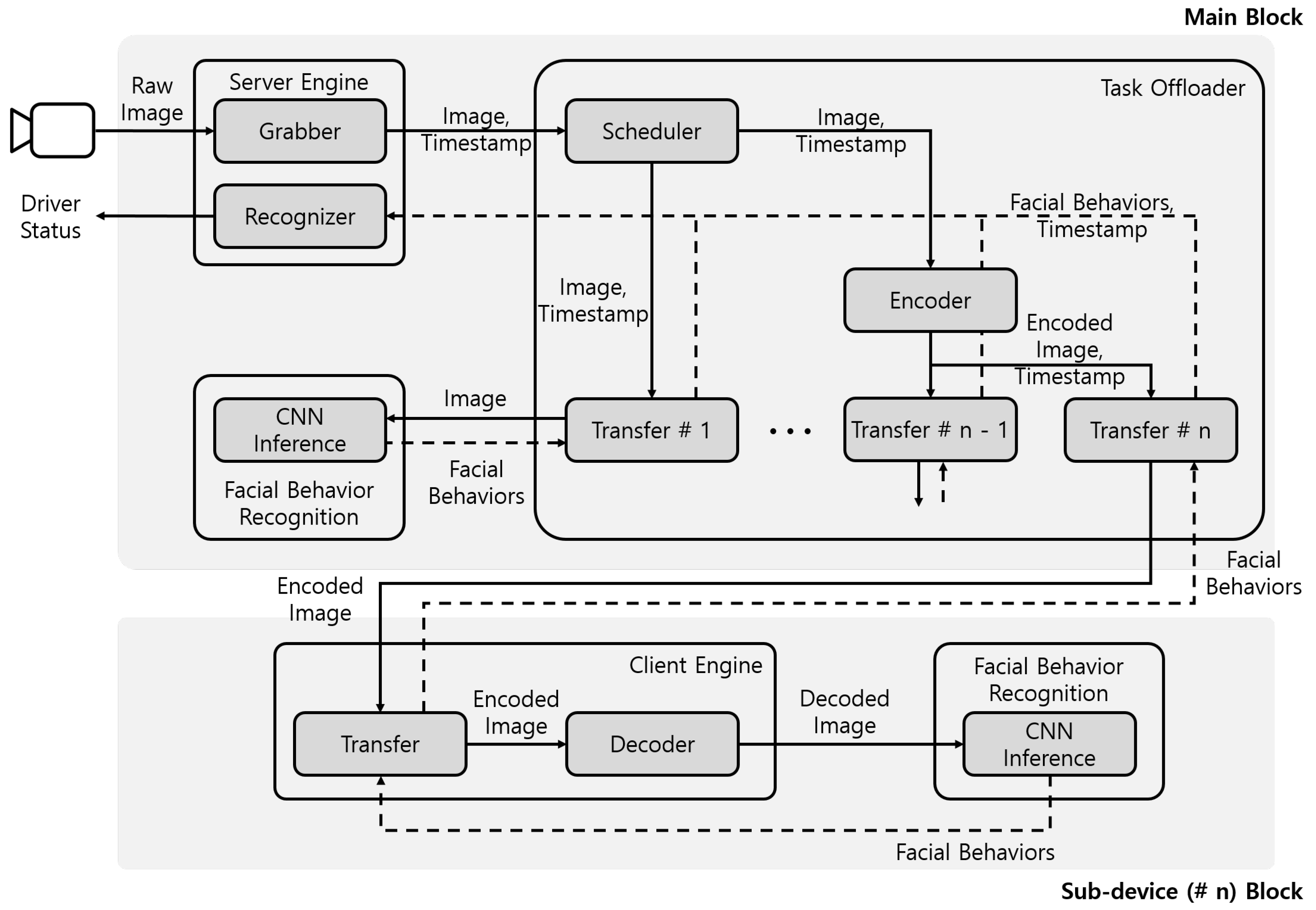
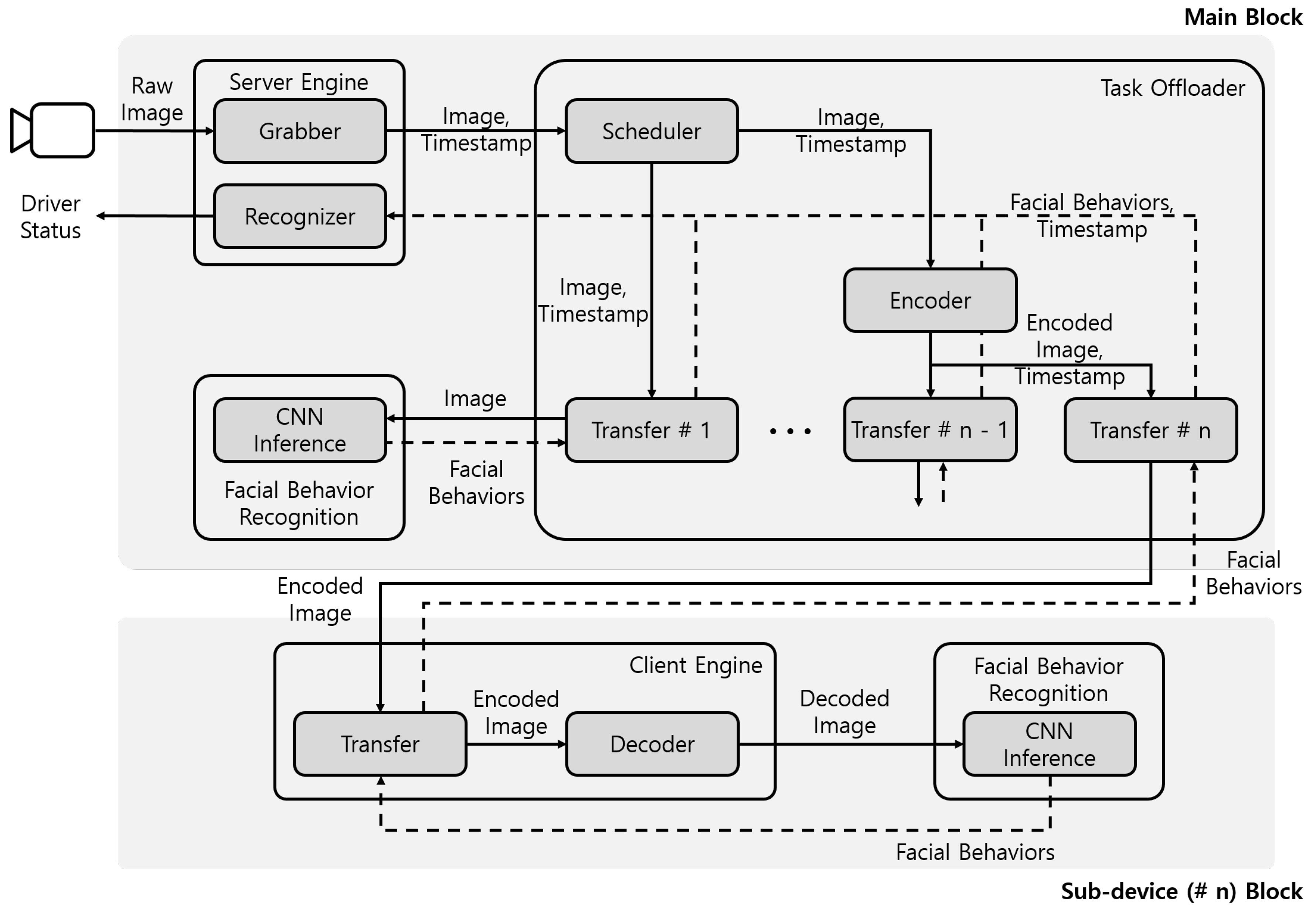
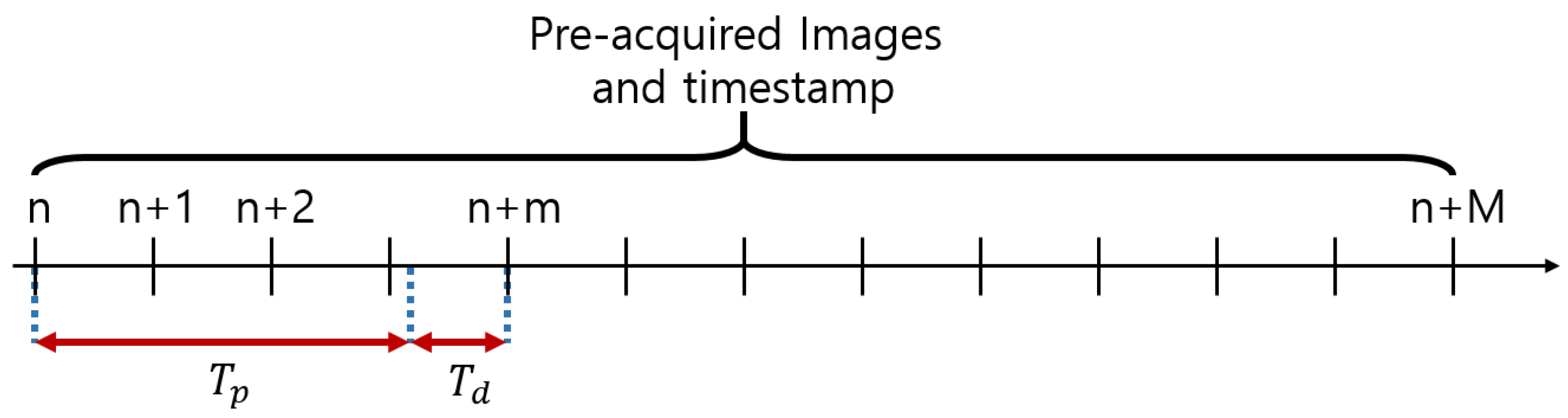
3. Lightweight Driver Monitoring System Configuration
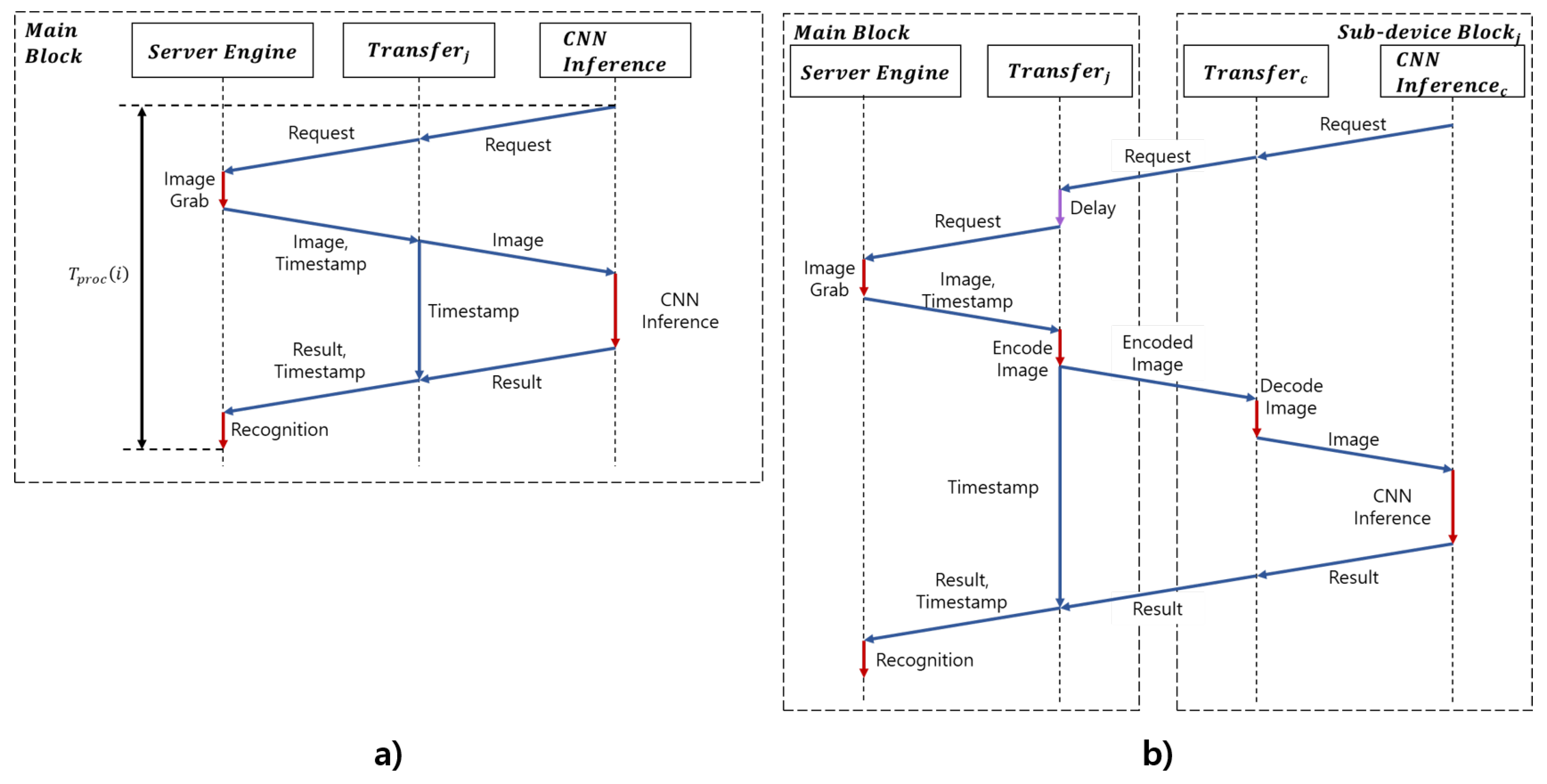
3.1. Server Engine Module
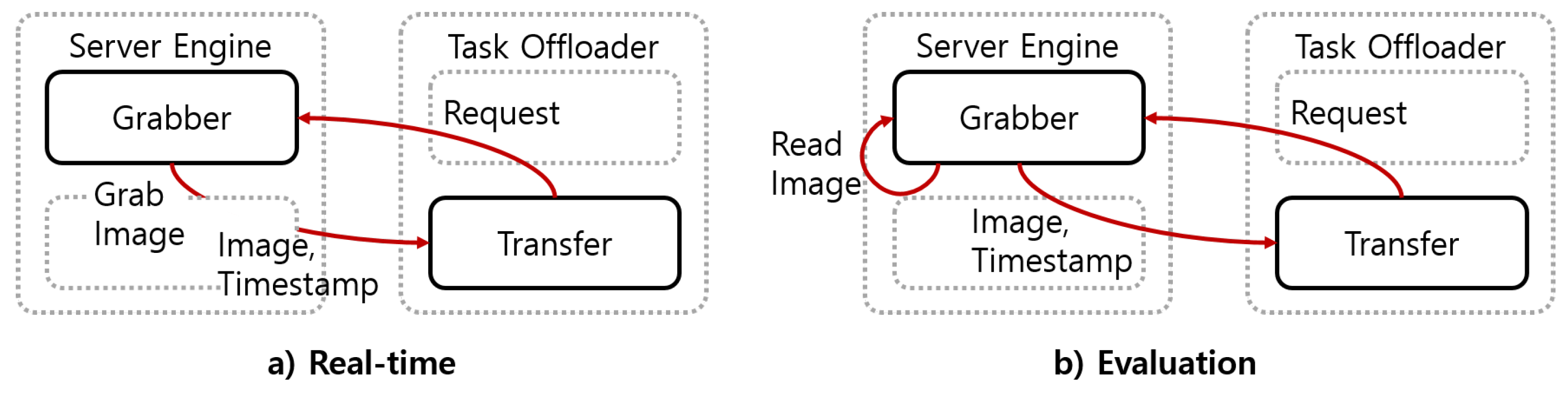
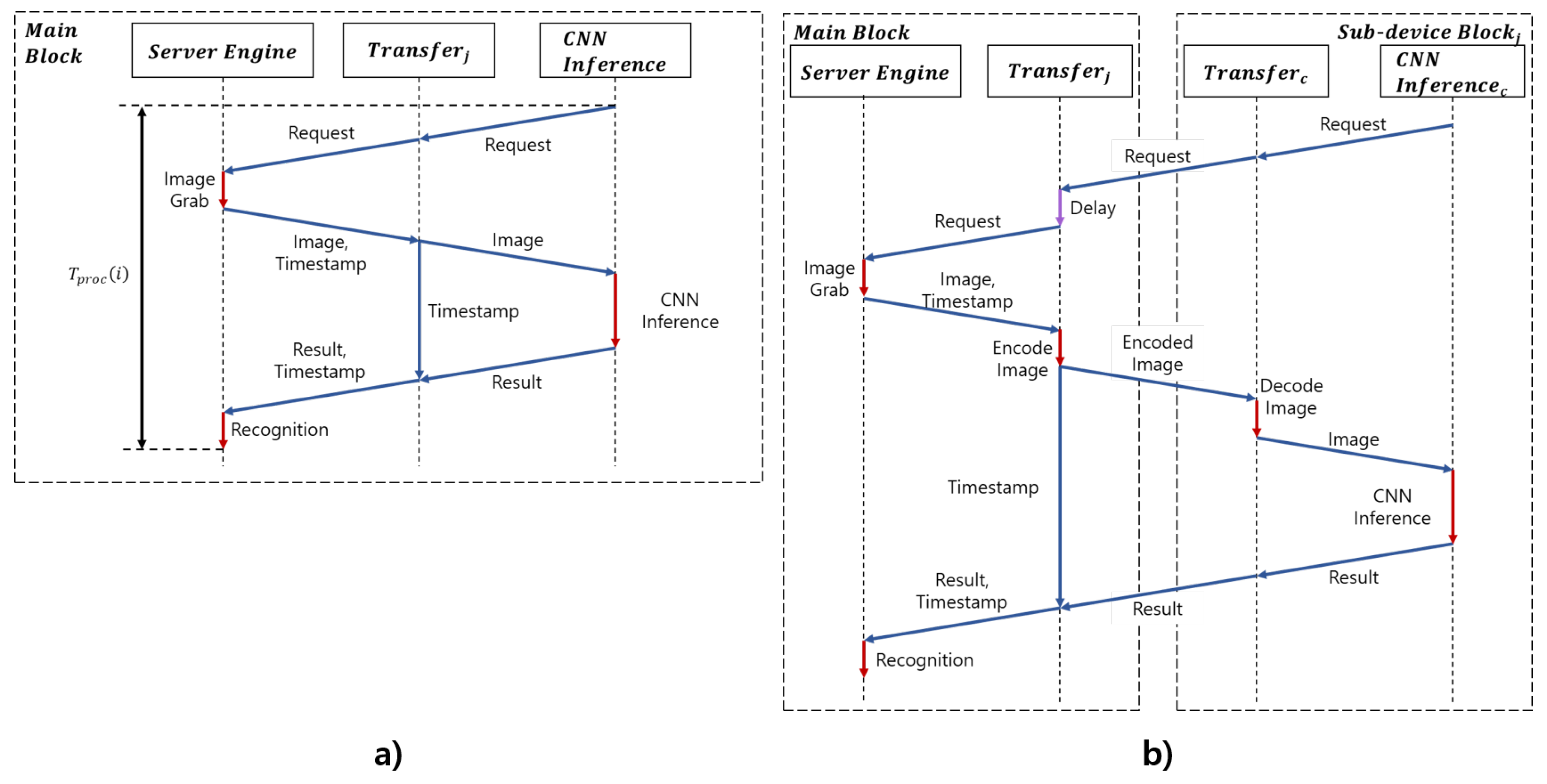
3.2. Task Offloader Module
3.3. Client Engine Module
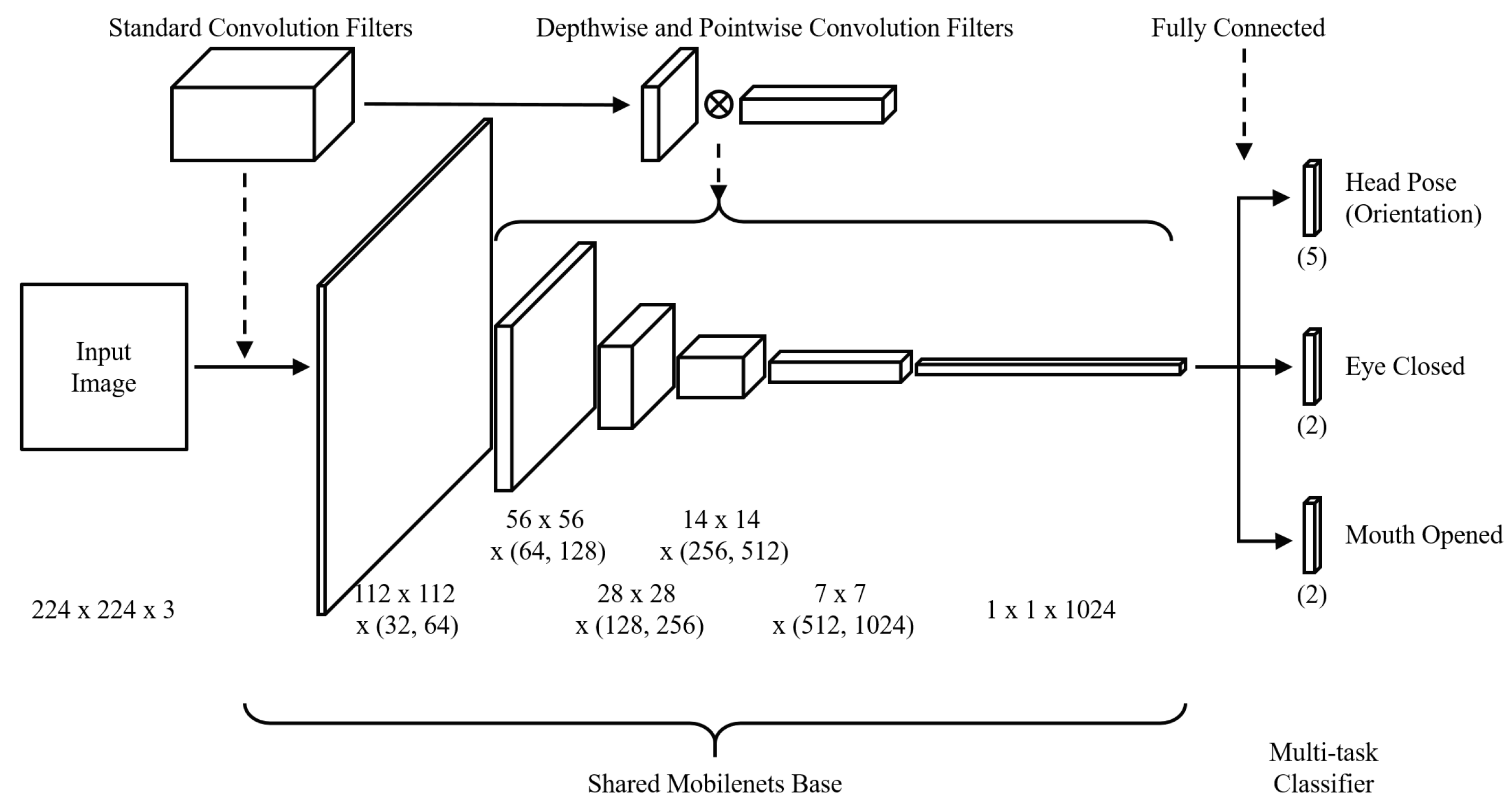
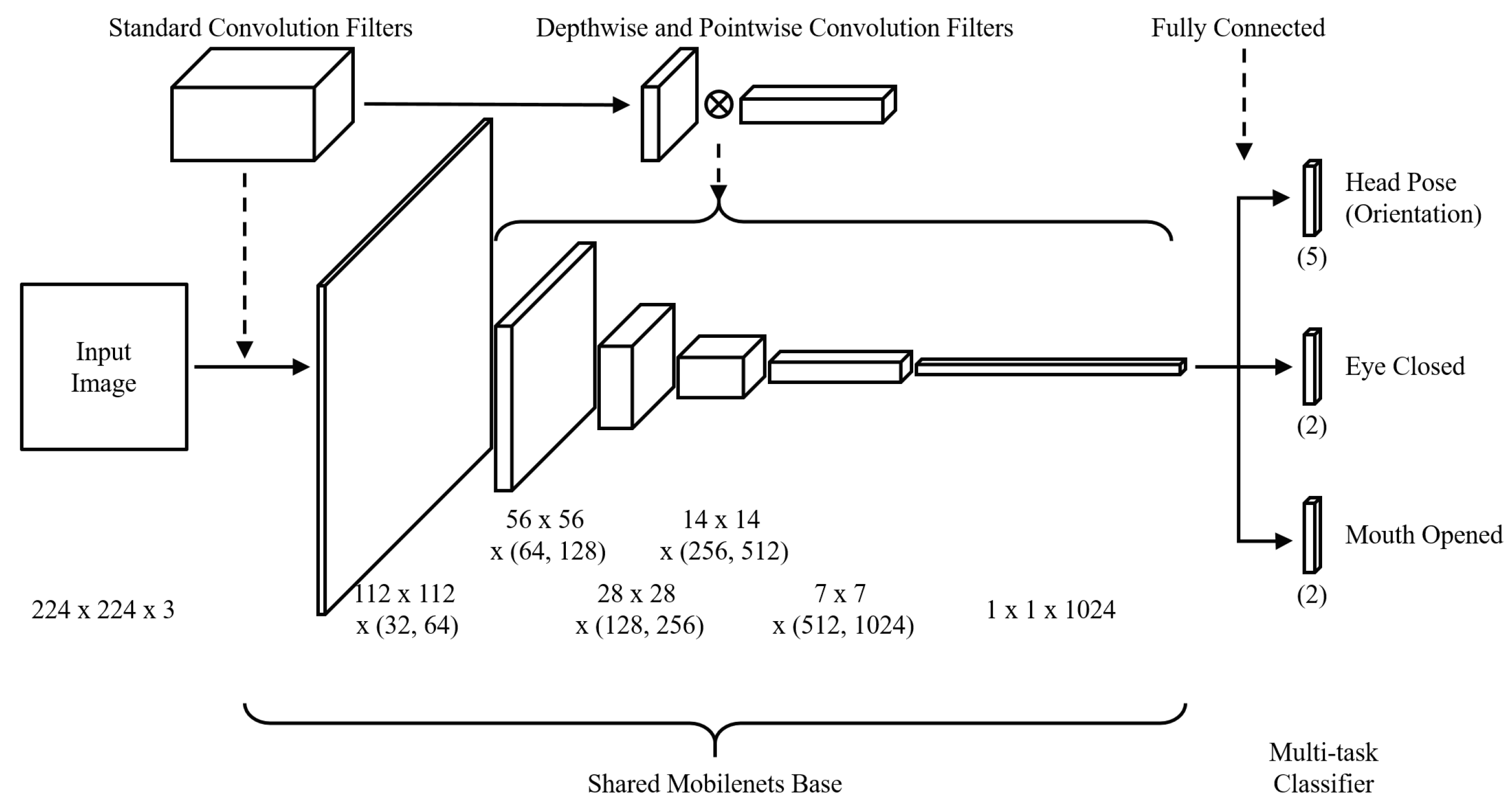
3.4. Facial Behavior Recognition Module
4. Experiment
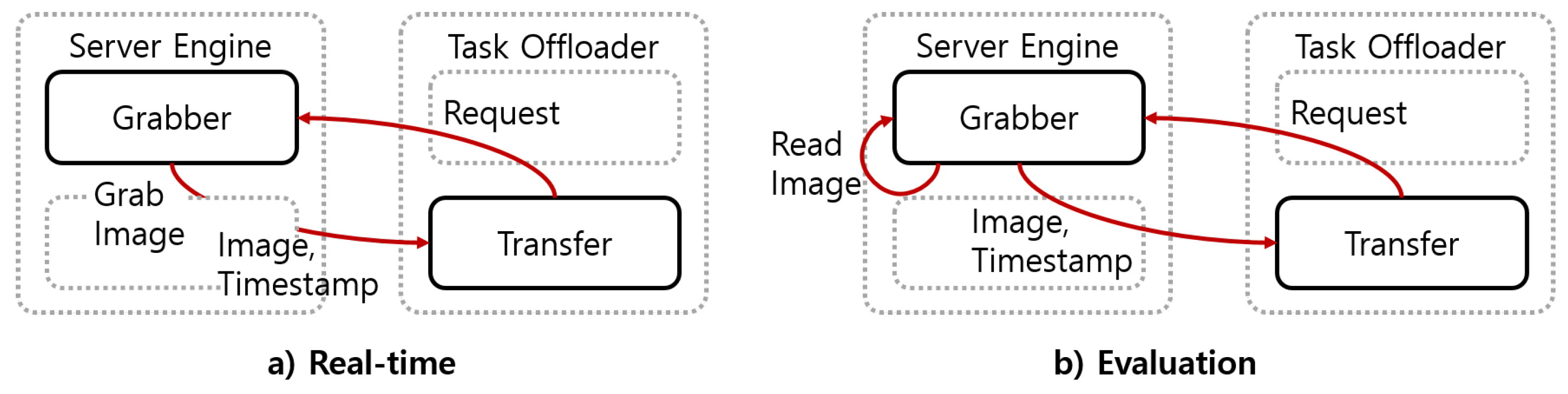
4.1. Experimental Environment and Data
4.2. Training of MT-Mobilenets and Testing of the Proposed System
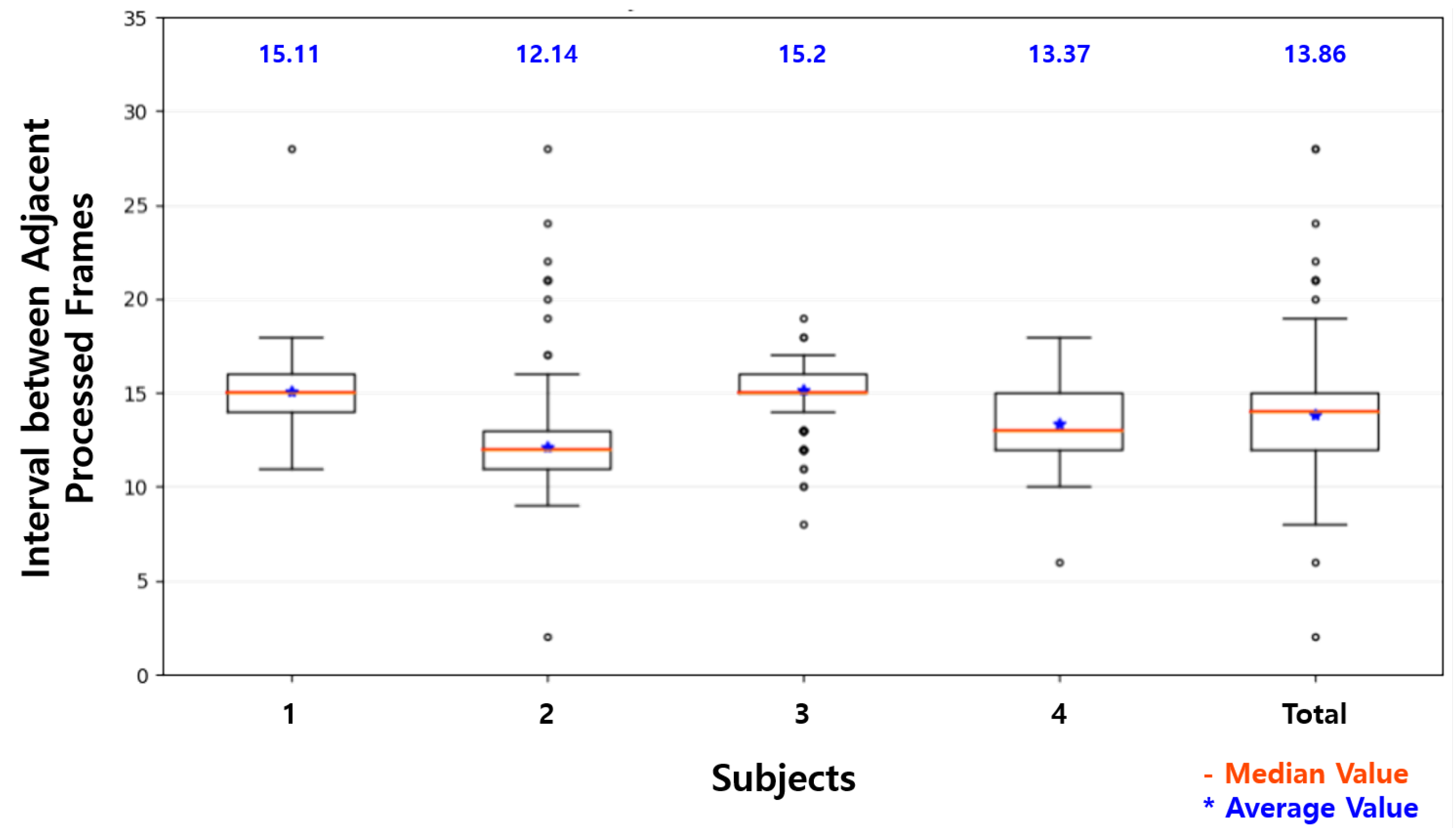
4.3. Result of the Experiment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- National Highway Traffic Safety Administration. Distracted Driving 2015. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812381 (accessed on 3 December 2018).
- National Highway Traffic Safety Administration. Drowsy Driving 2015. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/Publication/812446 (accessed on 3 December 2018).
- Sahayadhas, A.; Kenneth, S.; Murugappan, M. Detecting driver drowsiness based on sensors: A review. Sensors 2012, 12, 16937–16953. [Google Scholar] [CrossRef] [PubMed]
- Wikipedia. Driver Drowsiness Detection. Available online: https://en.wikipedia.org/wiki/Driver_drowsiness_detection (accessed on 3 December 2018).
- Fernández, A.; Usamentiaga, R.; Carús, J.; Casado, R. Driver distraction using visual-based sensors and algorithms. Sensors 2016, 16, 1805. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Jin, L.; Jiang, Y.; Xian, H.; Gao, L. Effects of driver behavior style differences and individual differences on driver sleepiness detection. Adv. Mech. Eng. 2015, 7, 1805. [Google Scholar] [CrossRef]
- Ingre, M.; Åkerstedt, T.; Peters, B.; Anund, A.; Kecklund, G. Subjective sleepiness, simulated driving performance and blink duration: Examining individual differences. J. Sleep Res. 2006, 15, 47–53. [Google Scholar] [CrossRef] [PubMed]
- Awais, M.; Badruddin, N.; Drieberg, M. A hybrid approach to detect driver drowsiness utilizing physiological signals to improve system performance and wearability. Sensors 2017, 17, 1991. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Li, S.E.; Li, R.; Cheng, B.; Shi, J. Online detection of driver fatigue using steering wheel angles for real driving conditions. Sensors 2017, 17, 495. [Google Scholar] [CrossRef] [PubMed]
- Kong, W.; Lin, W.; Babiloni, F.; Hu, S.; Borghini, G. Investigating driver fatigue versus alertness using the granger causality network. Sensors 2015, 15, 19181–19198. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Li, Q.; Huo, G.; Zhou, Y. Image classification using biomimetic pattern recognition with convolutional neural networks features. Comput. Intell. Neurosci. 2017, 2017, 3792805. [Google Scholar] [CrossRef] [PubMed]
- Faulkner, H. Data to Decisions CRC. Available online: https://www.adelaide.edu.au/directory/\hayden.faulkner?dsn=directory.file;field=data;id=39796;m=view (accessed on 6 December 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Park, S.; Pan, F.; Kang, S.; Yoo, C.D. Driver drowsiness detection system based on feature representation learning using various deep networks. In Proceedings of the Asian Conference on Computer Vision (ACCV 2016), Taipei, Taiwan, 20–24 November 2016; pp. 154–164. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hadidi, R.; Cao, J.; Woodward, M.; Ryoo, M.S.; Kim, H. Real-time image recognition using collaborative IoT devices. In Proceedings of the 1st on Reproducible Quality-Efficient Systems Tournament on Co-designing Pareto-efficient Deep Learning, Williamsburg, VA, USA, 24 March 2018; p. 4. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kim, W.; Choi, H.K.; Jang, B.T.; Lim, J. Driver distraction detection using single convolutional neural network. In Proceedings of the Information and Communication Technology Convergence (ICTC 2017), Jeju, Korea, 18–20 October 2017; pp. 1203–1205. [Google Scholar]
- Naqvi, R.A.; Arsalan, M.; Batchuluun, G.; Yoon, H.S.; Park, K.R. Deep learning-based gaze detection system for automobile drivers using a NIR camera sensor. Sensors 2018, 18, 456. [Google Scholar] [CrossRef] [PubMed]
- Ahn, B.; Choi, D.G.; Park, J.; Kweon, I.S. Real-time head pose estimation using multi-task deep neural network. Robot. Auton. Syst. 2018, 103, 1–12. [Google Scholar] [CrossRef]
- Reddy, B.; Kim, Y.H.; Yun, S.; Seo, C.; Jang, J. Real-time driver drowsiness detection for embedded system using model compression of deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 121–128. [Google Scholar]
- Massoz, Q.; Verly, J.; Van Droogenbroeck, M. Multi-Timescale Drowsiness Characterization Based on a Video of a Driver’s Face. Sensors 2018, 18, 2801. [Google Scholar] [CrossRef] [PubMed]
- Celona, L.; Mammana, L.; Bianco, S.; Schettini, R. A Multi-Task CNN Framework for Driver Face Monitoring. In Proceedings of the 2018 IEEE 8th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 2–5 September 2018; pp. 1–4. [Google Scholar]
- Baek, J.W.; Han, B.G.; Kim, K.J.; Chung, Y.S.; Lee, S.I. Real-Time Drowsiness Detection Algorithm for Driver State Monitoring Systems. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN 2018), Prague, Czech Republic, 3–6 July 2018; pp. 73–75. [Google Scholar]
- Mandal, B.; Li, L.; Wang, G.S.; Lin, J. Towards detection of bus driver fatigue based on robust visual analysis of eye state. IEEE Trans. Intell. Transp. Syst. 2017, 18, 545–557. [Google Scholar] [CrossRef]
- Lyu, J.; Zhang, H.; Yuan, Z. Joint shape and local appearance features for real-time driver drowsiness detection. In Proceedings of the Asian Conference on Computer Vision (ACCV 2016), Taipei, Taiwan, 20–24 November 2016; pp. 178–194. [Google Scholar]
- Tran, D.; Do, H.M.; Sheng, W.; Bai, H.; Chowdhary, G. Real-time detection of distracted driving based on deep learning. IET Intell. Trans. Syst. 2018, 12, 1210–1219. [Google Scholar] [CrossRef]
- Department of Transportation. Revised Implementing Rules and Regulations (IRR) of Republic Act 10913. Available online: http://www.dotr.gov.ph/2014-09-03-06-32-48/irr.html (accessed on 14 December 2018).
- Vogelpohl, T.; Kühn, M.; Hummel, T.; Vollrath, M. Asleep at the automated wheel—Sleepiness and fatigue during highly automated driving. Accid. Anal. Prev. 2018. [Google Scholar] [CrossRef] [PubMed]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Zadeh, A.; Lim, Y.C.; Baltrusaitis, T.; Morency, L.P. Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection. In Proceedings of the International Conference on Computer Vision Workshops (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2519–2528. [Google Scholar]
- Baltrusaitis, T.; Robinson, P.; Morency, L.P. Constrained local neural fields for robust facial landmark detection in the wild. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV 2013), Sydney, Australia, 1–8 December 2013; pp. 354–361. [Google Scholar]
- Baltrusaitis, T.; Mahmoud, M.; Robinson, P. Cross-dataset learning and person-specific normalisation for automatic action unit detection. In Proceedings of the 11th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2015), Ljubljana, Slovenia, 4–8 May 2015; Volume 6, pp. 1–6. [Google Scholar]
- Ekman, P.; Friesen, W.V. FACS—Facial Action Coding System. Available online: https://www.cs.cmu.edu/~face/facs.htm (accessed on 15 May 2019).
- Ekman, P.; Friesen, W.V. Measuring facial movement. Environ. Psychol. Nonverbal Behav. 1976, 1, 56–75. [Google Scholar] [CrossRef]
- Jung, W.S.; Yim, J.; Ko, Y.B. Adaptive offloading with MPTCP for unmanned aerial vehicle surveillance system. Ann. Telecommun. 2018, 73, 613–626. [Google Scholar] [CrossRef]
- VMW Research Group. The GFLOPS/W of the Various Machines in the VMW Research Group. Available online: http://web.eece.maine.edu/~vweaver/group/green_machines.html (accessed on 2 February 2019).
- NIKKEI xTECH. Panasonic Develops Sensing Technology with High Accuracy Recognition of Drowsiness and Emotion with AI. Available online: https://tech.nikkeibp.co.jp/it/atcl/news/17/092702354/ (accessed on 14 May 2019).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fatigue or | Detection | Used | Environments | Maximum | |||||
|---|---|---|---|---|---|---|---|---|---|
| Paper | Distraction | Drowsiness | Face | Eye | Landmark | Algorithms | CPU | GPU | FPS * |
| [19] | ✓ | ✓ | ✓ | VGG | H** | H | 89.2 | ||
| [20] | ✓ | ✓ | MTDNN | H | H | 33.0 | |||
| [21] | ✓ | ✓ | ✓ | MTCNN, AlexNet | Jetson TX1 | 14.9 | |||
| [22] | ✓ | ✓ | ✓ | VGG | H | H | 63.7 | ||
| [23] | ✓ | ✓ | ✓ | MTCNN based on VGG | H | H | - | ||
| [24] | ✓ | ✓ | ✓ | Eye aspect ratio based on landmark | i.MX6Quad | 16.0 | |||
| [25] | ✓ | ✓ | ✓ | Spectral/linear regression | H | - | 5.0 | ||
| [26] | ✓ | ✓ | ✓ | Random forest classification | H | - | 22.0 | ||
| [27] | ✓ | AlexNet, VGG, GoogleNet, ResNet | Jetson TX1 | 14.0 | |||||
| [14] | ✓ | AlexNet, VGG, FlowNet | - | - | - | ||||
| Level | Facial and Behavioral Indicators in [29] | Level | Facial and Behavioral Indicators in Our Dataset |
|---|---|---|---|
| Awake | Fast eyelid closure, inconspicuous blink behavior, continuous switches of focus, upright sitting position, fast saccades, hand position on the steering wheel at the 10 and 2 o’clock | Awake | Otherwise |
| Light fatigue (−) | Prolonged eyelid closures of up to 0.5 s, tired facial expression, | Light fatigue | Mouth opening duration (>1 s) or eye closure duration (≥0.5) |
| Light fatigue (+) | yawning, rubbing/scratching of face, grimacing, tilted head | ||
| Medium fatigue (−) | Prolonged eyelid closures (approximately 0.5–1 s), | ||
| Medium fatigue (0) | eye staring/“glassy eyes” with long blinking pauses (>3 s), | Medium fatigue | Eye closure duration (≥1.5) or PERCLOS (≥0.1) |
| Medium fatigue (+) | stretching/lolling, eyes half closed | ||
| Strong fatigue (−) | Very long eyelid closures (1–2 s), eye rolling, head-nodding | ||
| Strong fatigue (+) | Drowsiness (Strong fatigue) | {Eye closure duration (≥1.5 s) and PERCLOS (≥0.2)} or | |
| Very strong fatigue | Eyelid closures (>2 s),micro-sleep episodes, startling awake from sleep or micro-sleep | Look down duration (≥2 s) | |
| Distraction | - | Distraction | Duration of looking in one direction other than the front (≥2 s) |
| Facial Behavior | Normal | Abnormal | |||
|---|---|---|---|---|---|
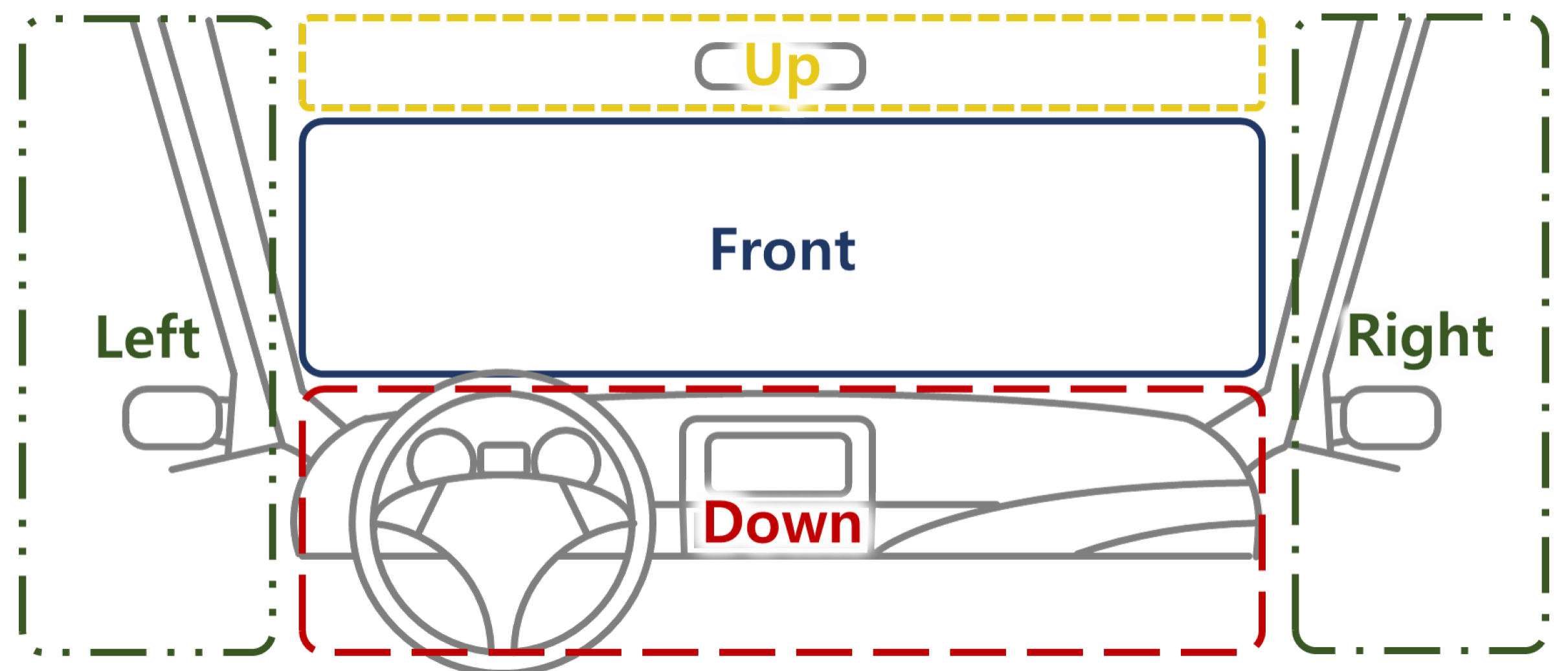
| Head Direction | Front | Up | Down | Left | Right |
| Eye Closure | Open | Close | |||
| Mouth Opening | Close | Open | |||
| Processed Frames (Quantity) | Total | Frames Per Second (FPS) | ||||
|---|---|---|---|---|---|---|
| Subject | Total Frames | Raspberry Pi | Proposed System | Times (s) | Raspberry Pi | Proposed System |
| 1 | 4668 | 308 | 692 | 156.77 | 1.97 | 4.41 |
| 2 | 4512 | 371 | 687 | 151.52 | 2.45 | 4.53 |
| 3 | 4916 | 322 | 716 | 165.19 | 1.95 | 4.33 |
| 4 | 4849 | 362 | 757 | 162.86 | 2.22 | 4.65 |
| Average | 4736 | 341 | 713 | 159.09 | 2.15 | 4.47 |
| Facial Behavior | Face Direction | Eye Closure | Mouth Opening |
|---|---|---|---|
| Quantity of Abnormal | 1903 | 2127 | 573 |
| Accuracy on Raspberry Pi | 94.74% | 72.49% | 90.50% |
| Accuracy on Proposed System | 96.40% | 77.56% | 93.93% |
| Distraction | Fatigue | Drowsiness | |
|---|---|---|---|
| Raspberry Pi | 85.85 | 74.09 | 82.34 |
| Proposed System | 98.96 | 84.89 | 94.44 |
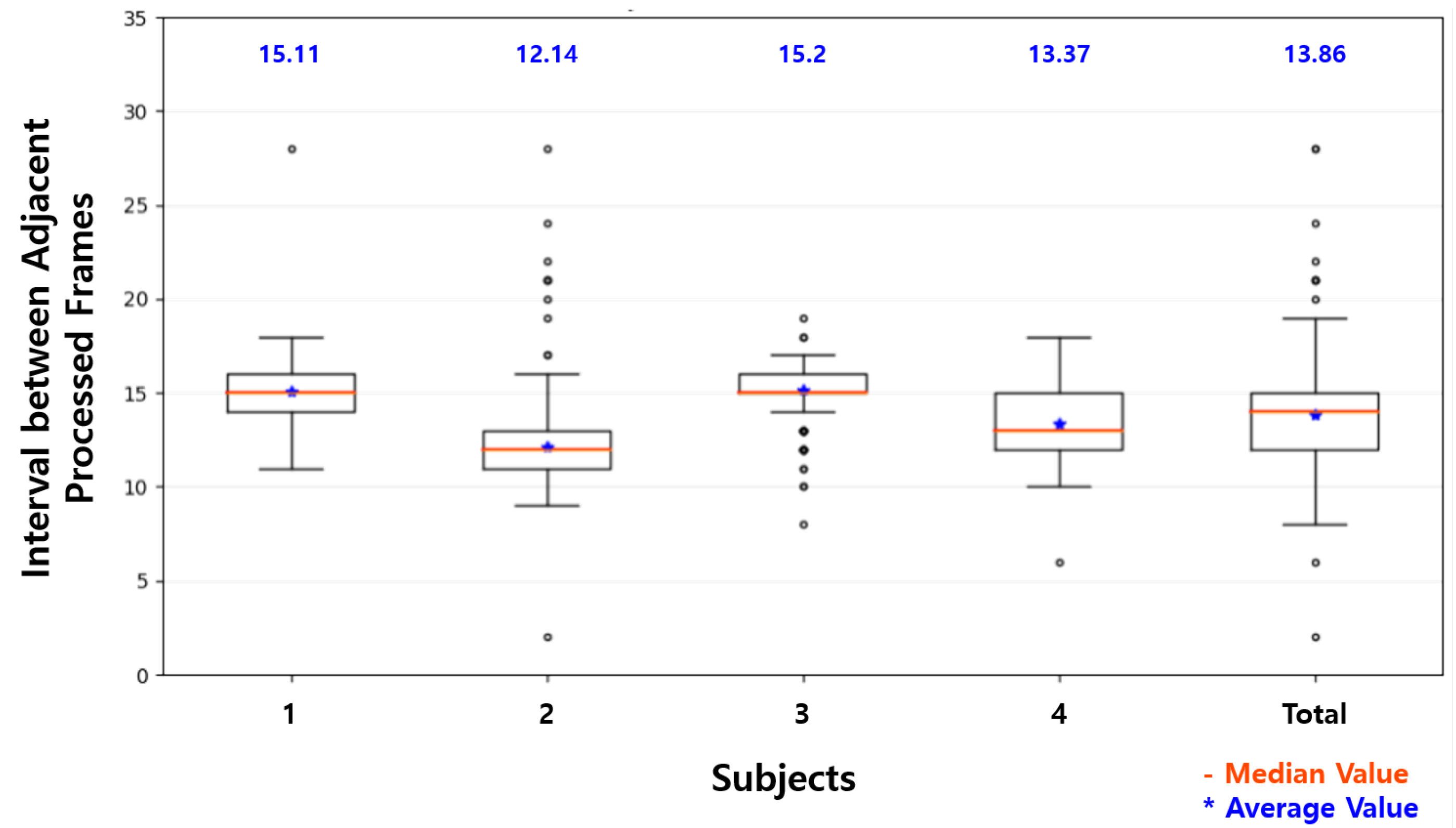
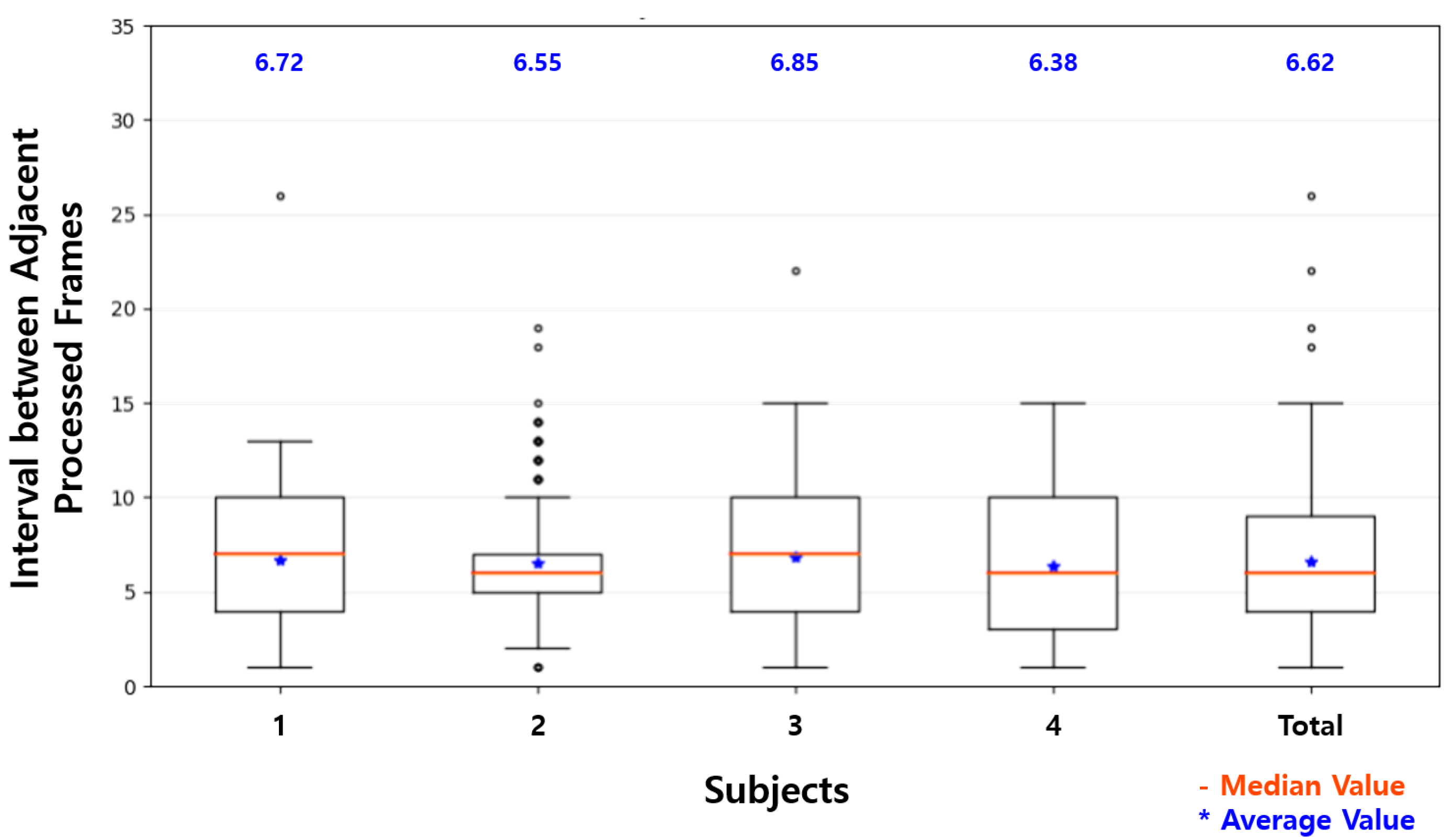
| Raspberry Pi | Proposed System | |
|---|---|---|
| Maximum | 19 | 15 |
| Three Quarters | 15 | 9 |
| Two Quarters | 14 | 6 |
| One Quarter | 12 | 4 |
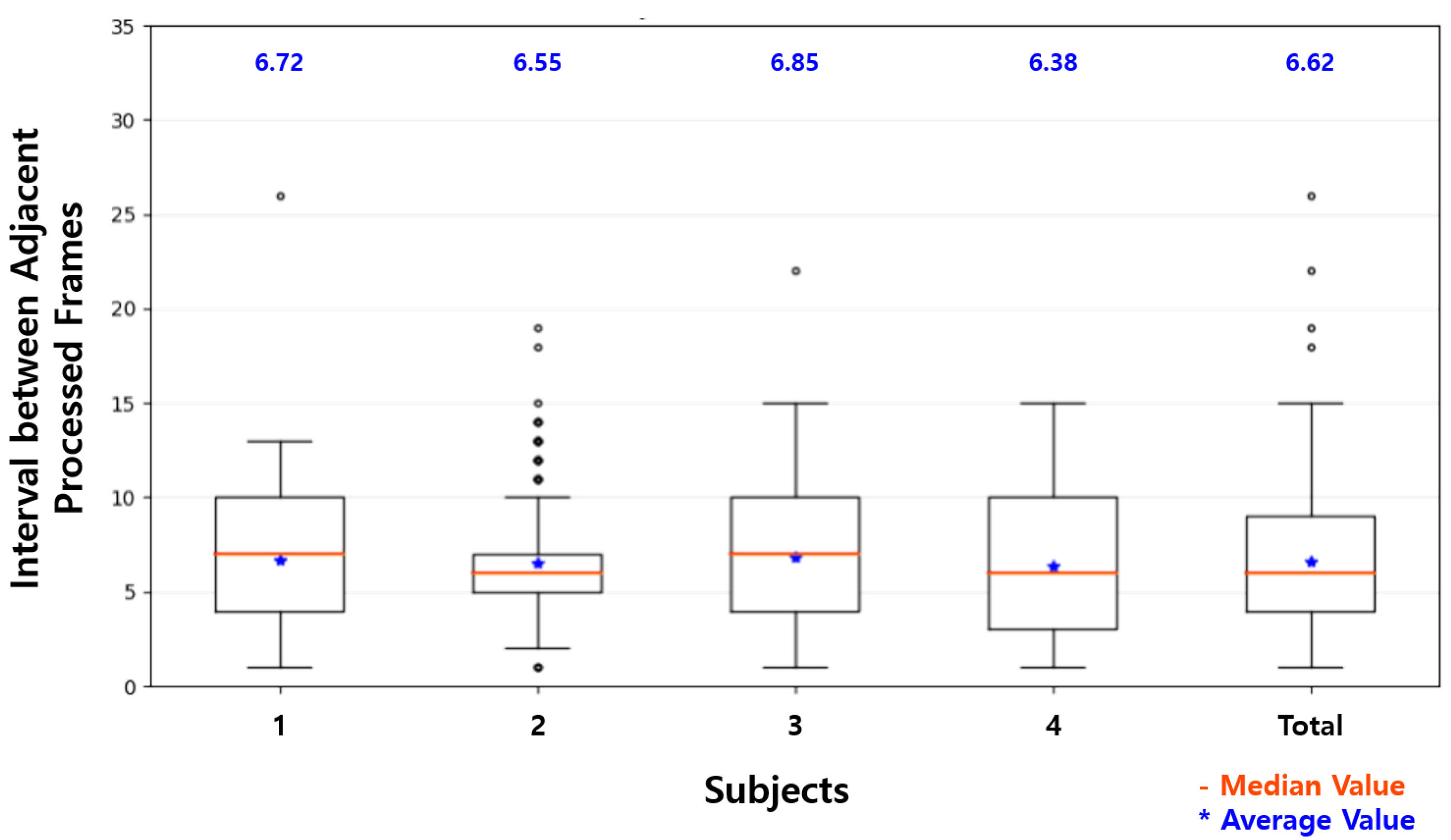
| Minimum | 8 | 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, W.; Jung, W.-S.; Choi, H.K. Lightweight Driver Monitoring System Based on Multi-Task Mobilenets. Sensors 2019, 19, 3200. https://doi.org/10.3390/s19143200
Kim W, Jung W-S, Choi HK. Lightweight Driver Monitoring System Based on Multi-Task Mobilenets. Sensors. 2019; 19(14):3200. https://doi.org/10.3390/s19143200
Chicago/Turabian StyleKim, Whui, Woo-Sung Jung, and Hyun Kyun Choi. 2019. "Lightweight Driver Monitoring System Based on Multi-Task Mobilenets" Sensors 19, no. 14: 3200. https://doi.org/10.3390/s19143200
APA StyleKim, W., Jung, W.-S., & Choi, H. K. (2019). Lightweight Driver Monitoring System Based on Multi-Task Mobilenets. Sensors, 19(14), 3200. https://doi.org/10.3390/s19143200