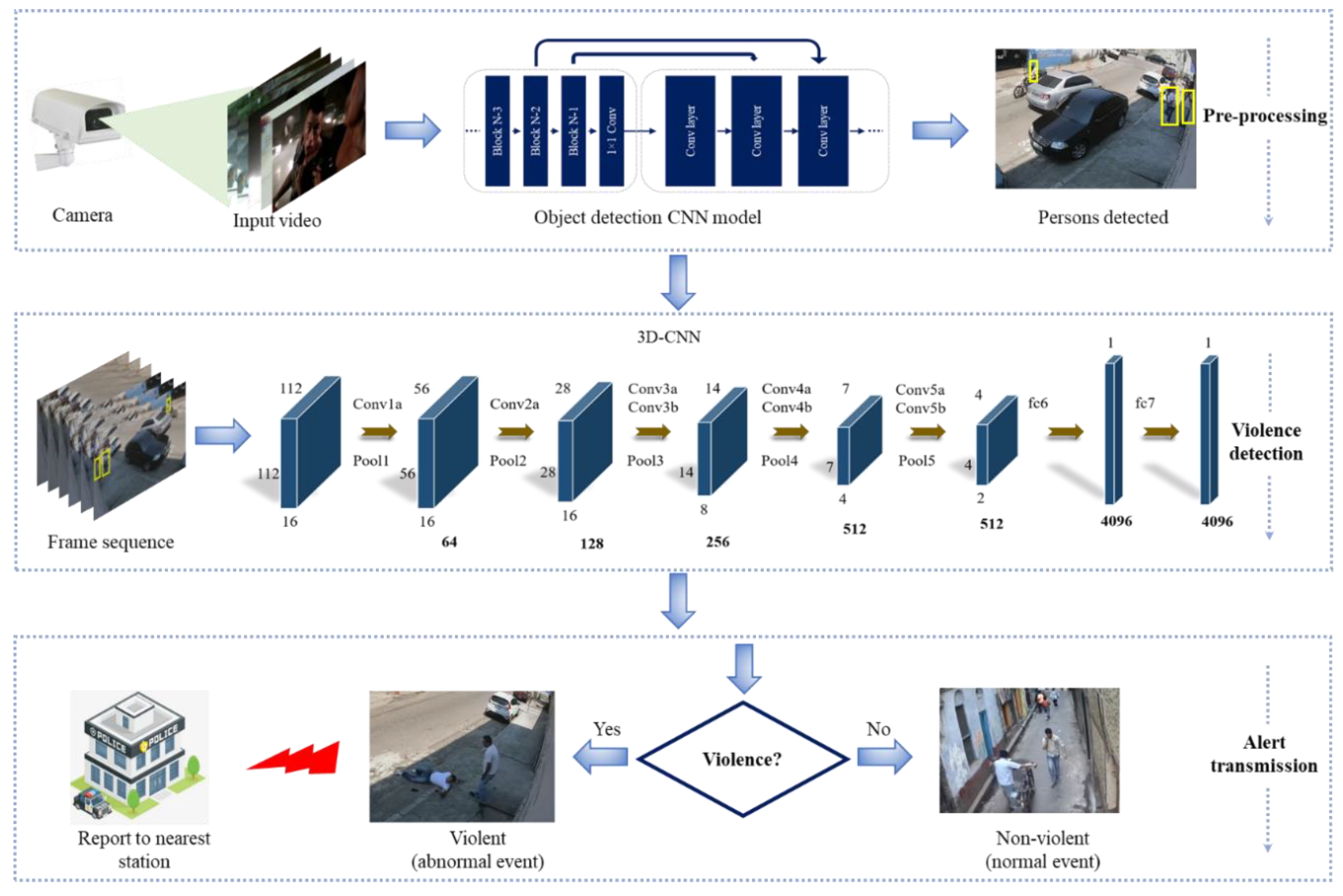
We conducted various experiments to evaluate the performance of the proposed method concerning three publicly available datasets for violence detection, such as violent crowd [
14], hockey fight [
7], and violence in movies [
7]. To perform the experiments, we used different parameters and learning rates to achieve the greatest accuracy. Detailed descriptions of the datasets are given in
Table 2. Furthermore, we compared our method with different handcrafted and deep-learning-based state-of-the-art methods to evaluate its accuracy and performance over three datasets. To perform the experiments, the Caffe toolbox was used to extract deep features on GeForce-Titan-X GPU. The operating system was Ubuntu 16.04 using Core
TM i5-6600 with 64GB RAM.
3.2. Discussion
Table 3 explains the experiments performed on the violent crowd dataset, where the highest achieved accuracy was 98%, with 1.89 × 10
−9 loss at the maximum iteration of 5000 with a base learning rate of 0.001. The loss value is given in scientific notation, which is equivalent to 1.89 × 10
−9. We kept the learning rate normal because the learning rate has two terminologies for its usage. First, the learning rate should not be very large because it oscillates when searching for the minimal point and can cause drastic updates leading to divergent behaviors. Second, the learning rate should not be very small because it slows down the convergence towards the minimal point and requires too many updates before reaching the minimum point. At first, the learning rate is large, and the random weights at that position are far from the optimal point; then, it slowly and gradually decreases as further iterations proceed.
Table 4 explains the experiments performed on the violence in movies dataset [
7], where the highest achieved accuracy was 99.9% with 1.67 × 10
−7 loss at a maximum iteration of 5000 with the base learning rate of 0.001. After conducting experiments on the violence in movies dataset, we made various observations. For instance, detecting the fights in the movies dataset footage was easier than detecting it in the crowd dataset because when we tested the obtained model on the violent crowd dataset, we achieved 54% accuracy, which is low because fights in the violent crowd dataset are very varied in appearance or cinematography. In addition, the clips included a large number of people; however, in the violence in movies dataset, a majority of the videos clips contained person-to-person violence. Notwithstanding this, the hockey fight dataset was relatively very consistent. The same model was tested using the hockey fight dataset [
7], in which the obtained accuracy was 63%, which is better than the accuracy obtained for the violent crowd dataset. We also tested the model obtained from the violent crowd on the other two datasets, i.e., violence in movies and hockey fight dataset, which gave an accuracy of 65% and 47%, respectively. The obtained accuracy on these two datasets is lower due to pattern footage because the hockey fight and violence in movies datasets contained person-to-person fights and the violent crowd dataset contained multiple numbers of persons. The graphical representation for the experiments performed in
Table 4 is given in
Figure 7.
Table 5 explains the experiment’s performance in relation to the hockey fight dataset [
7], where the highest achieved accuracy was 96% with a 5.77 × 10
−4 loss at the maximum iteration of 5000 and the base learning rate of 0.001. Furthermore, we evaluated the accuracy of the fine-tuned model of the hockey fight dataset [
7] on the violent crowd dataset [
14] and violence in movies, giving 52% and 49% accuracy, respectively.
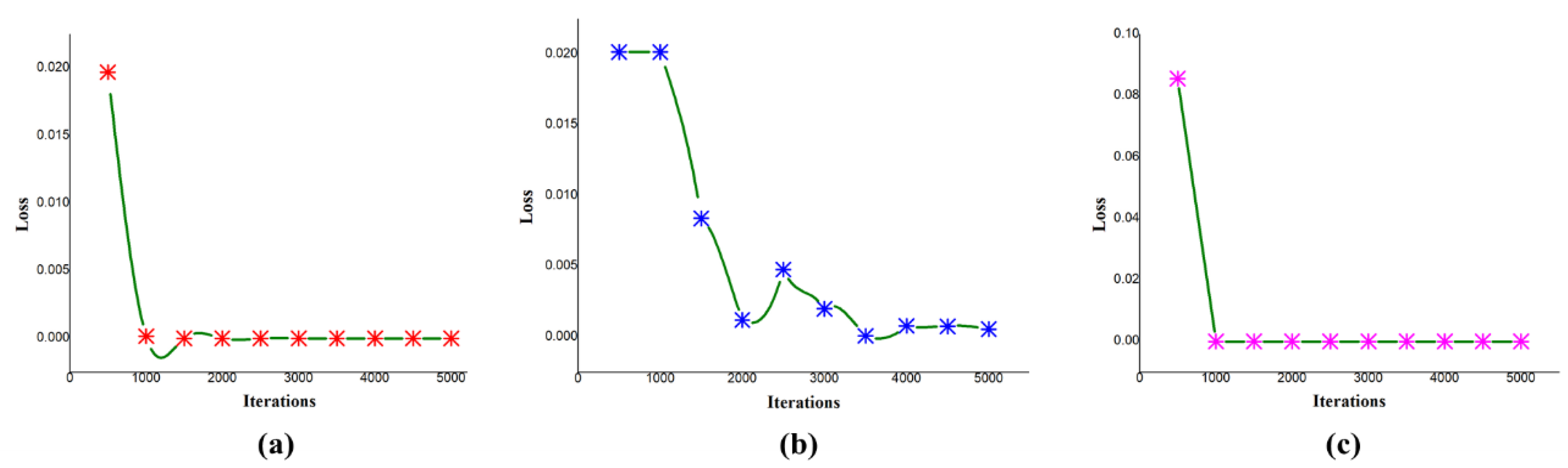
In addition, we observed that changing the learning rate has an effect on loss and with iterations. In
Figure 7a, the graph shows the change in loss with the variation in the number of iterations with a base learning rate of 0.001 for the hockey fight dataset. At the iteration of 500, the loss obtained is 1.97 × 10
−2, which decreases as the number of iterations proceeds; at the maximum iteration of 5000, the obtained loss is 2.32 × 10
−7 while keeping the same experiment, we only changed the learning rate to 0.0001, so the obtained loss at the initial iteration of 500 is 7.39 × 10
−2, and at the maximum iteration of 5000 the obtained loss is 5.77 × 10
−4.
The loss to iteration comparison for violent crowd is given in
Figure 7c, where the loss decreases from the start and becomes less than zero after 1000 iterations. The loss for the violence in movies dataset in the initial stages is high; then, it decreases as iterations proceed. In this way, the loss obtained at the 5000th iteration becomes 5.4 × 10
−4. The decrease in loss for the violence in movies dataset is graphically presented in
Figure 7b, where the vertical axis represents the loss, and the horizontal axis represents the training iterations. We also evaluated the performance of the proposed method by examining precision, recall, and the comparison among the datasets by providing the values of area under the curve (AUC) in
Table 6, which show the effectiveness of the proposed method on each dataset. In addition, the obtained confusion matrix is given in
Table 7. The precision and recall values for each dataset ranges between X
min, Y
min and X
max, Y
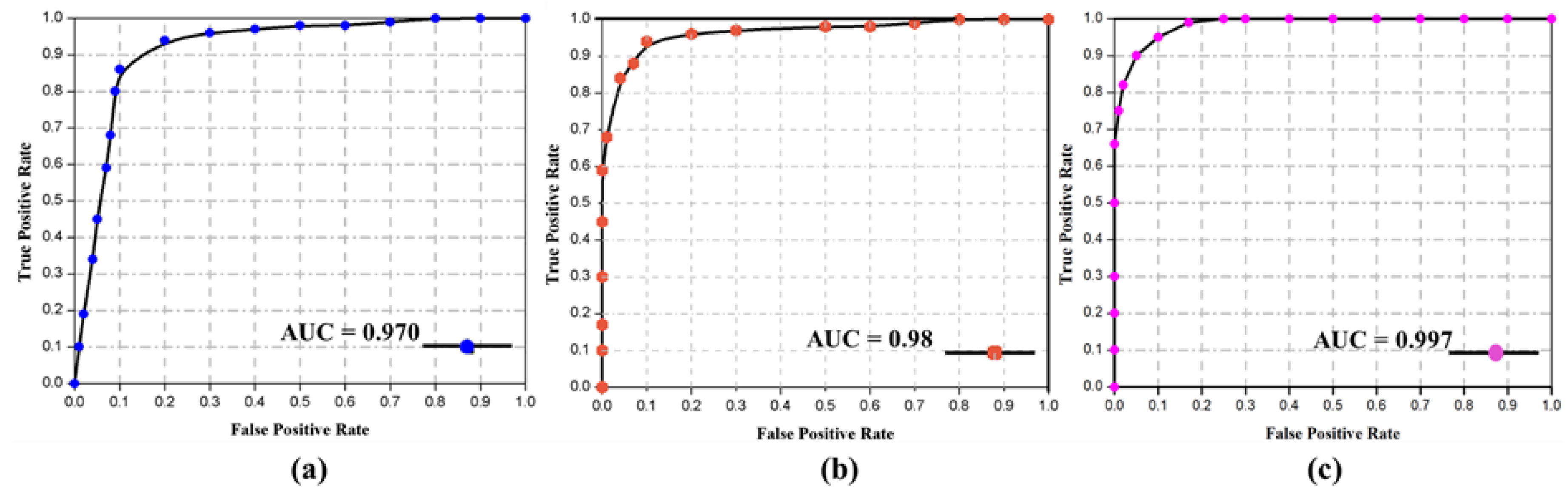
max, respectively. Here the X represents the precision, and Y represents recall for each dataset. The precision obtained for hockey fight, violence in movies, and violent crowd dataset is 0.9597, 1.0, and 0.9815, respectively, while the recall is 0.9667, 1.0, and 0.9876, respectively. We also calculate the time complexity of the proposed method, considering the testing phase during this experiment. For each 16 frame sequence, the average calculated time is 1.85 s, while, for a one-minute clip with 25 FPS it takes about 2 min and 54 s to complete the testing phase through all the sequences. We further evaluated the effectiveness of the proposed method by plotting the receiver operating characteristic (ROC) curve across the true positive rate and false positive rate. This is briefly illustrated in
Figure 8, where the AUC values are compared for each dataset.
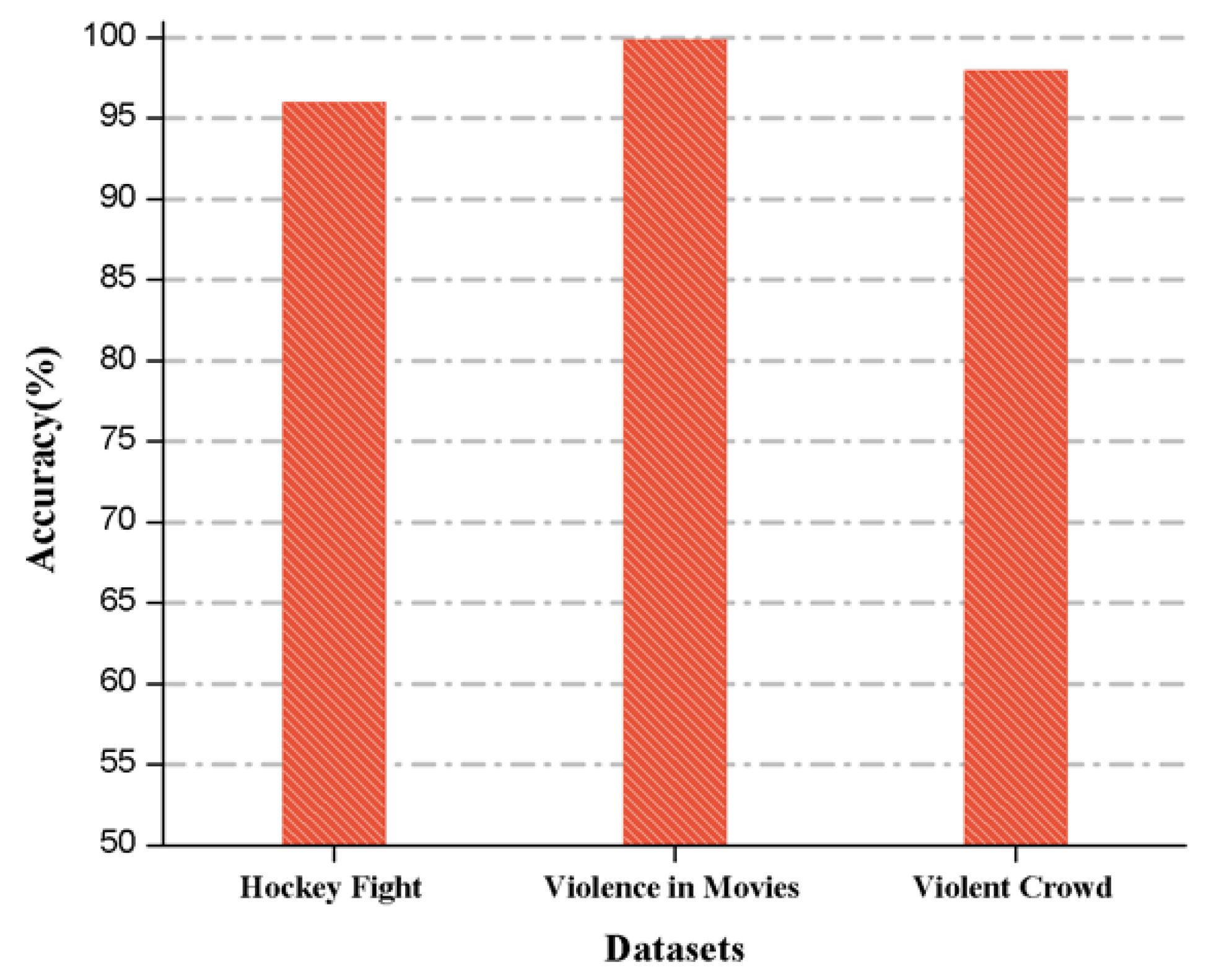
We also compared the accuracies for the benchmark datasets in
Figure 9, where the highest achieved accuracy is 99.9% obtained in the movies dataset, 98% accuracy is obtained in the violent crowd dataset, and 96% is obtained in the hockey fight dataset.
3.3. Comparative Analysis
In this section, we compare the results of each dataset with existing state-of-the-art methods. The comparative analysis with all the state-of-the-art methods is shown in
Table 8. In the first row, we present the results of method [
17], which used oriented violent flows (OViF) for motion magnitude and AdaBoost as feature extraction, and SVM for classification. Using these parameters, they obtained an accuracy of 88% and 87.50% for the violent crowd and hockey fight datasets, respectively. Recently, another method [
40] used Hough forests with 2D CNN to detect violence and obtained 99% accuracy on the violent movies dataset and 94.6% on the hockey fight dataset. Apart from this, there was another method [
7] to detect violence in videos; this method used a spatiotemporal descriptor called space–time interest point (STIP), bag-of-words (BoW), and SVM to classify the output classes. They used only the violence in movies dataset and obtained 89.5% accuracy. Furthermore, we compared the results with another method [
41], which used motion blobs and random forests for detection of the fast fight. They also used only the violence in movies dataset and obtained 96.9% accuracy. Moreover, in [
42], two descriptors were used to detect and localize the abnormal behaviors; they used a simplified histogram of oriented tracklets (sHOT) combined with a dense optical flow to recognize abnormal behavior at the final result and obtained an accuracy of 82.2% for the violent crowd dataset. In [
14], the authors used ViF and then classified the final prediction using SVM, where they used five-fold cross-validation for testing and obtained 82.90% accuracy for the hockey fight dataset and 81.3% for the violent crowd dataset. In method [
43], the authors used the sliding window approach and improved the Fisher vector method to detect violence. They obtained accuracies of 99.5%, 96.4%, and 93.7% for violence in movies, violent crowd, and hockey fight datasets, respectively. Finally, in the last row, we present our approach, which obtained 99.9%, 98%, and 96% accuracies for violence in movies, violent crowd, and hockey fight datasets, respectively.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}