Spatio-Temporal Synchronization of Cross Section Based Sensors for High Precision Microscopic Traffic Data Reconstruction



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. State-of-the-Art Data Acquisition
1.2. Contribution
- Spatio-temporal offset estimation when measuring the distances between sensors or an exact clock synchronization is not possible
- Vehicle registration without any specific identification like number plates
- Reconstruction of vehicle trajectories with acceleration/deceleration maneuvers only based on cross-section recordings.
1.3. Impact
2. Methodology
2.1. Vehicle Matching and Offset Estimation
- Estimation step (E-step): Find an estimate for the complete data sufficient statistics.
- Likelihood Maximization step (M-step): Determine the parameters of the distributions based on the estimated data.
| Algorithm 1: Vehicle registration using expectation maximization. |
 |
2.2. Microscopic Data Reconstruction
- Matrix reduction: The cost matrix is reduced row-wise with the respective minimal value of the row. In cases of entire columns greater than zero, a column-wise reduction is also performed.
- Line covering: Cover resulting zeros with the minimum number of lines (horizontal and vertical). If the number of zeros, which are unique in the respective row and column, is equal to the smallest of the two matrix dimensions (number of vehicles in first or second sensor), an optimal matching has been found.
- Additional reduction: Reduce all non-covered elements by the minimal non-covered value and add that value to all elements covered by both horizontal and vertical lines. Continue with line covering again.
3. Experimental Results
3.1. Underlying Dataset
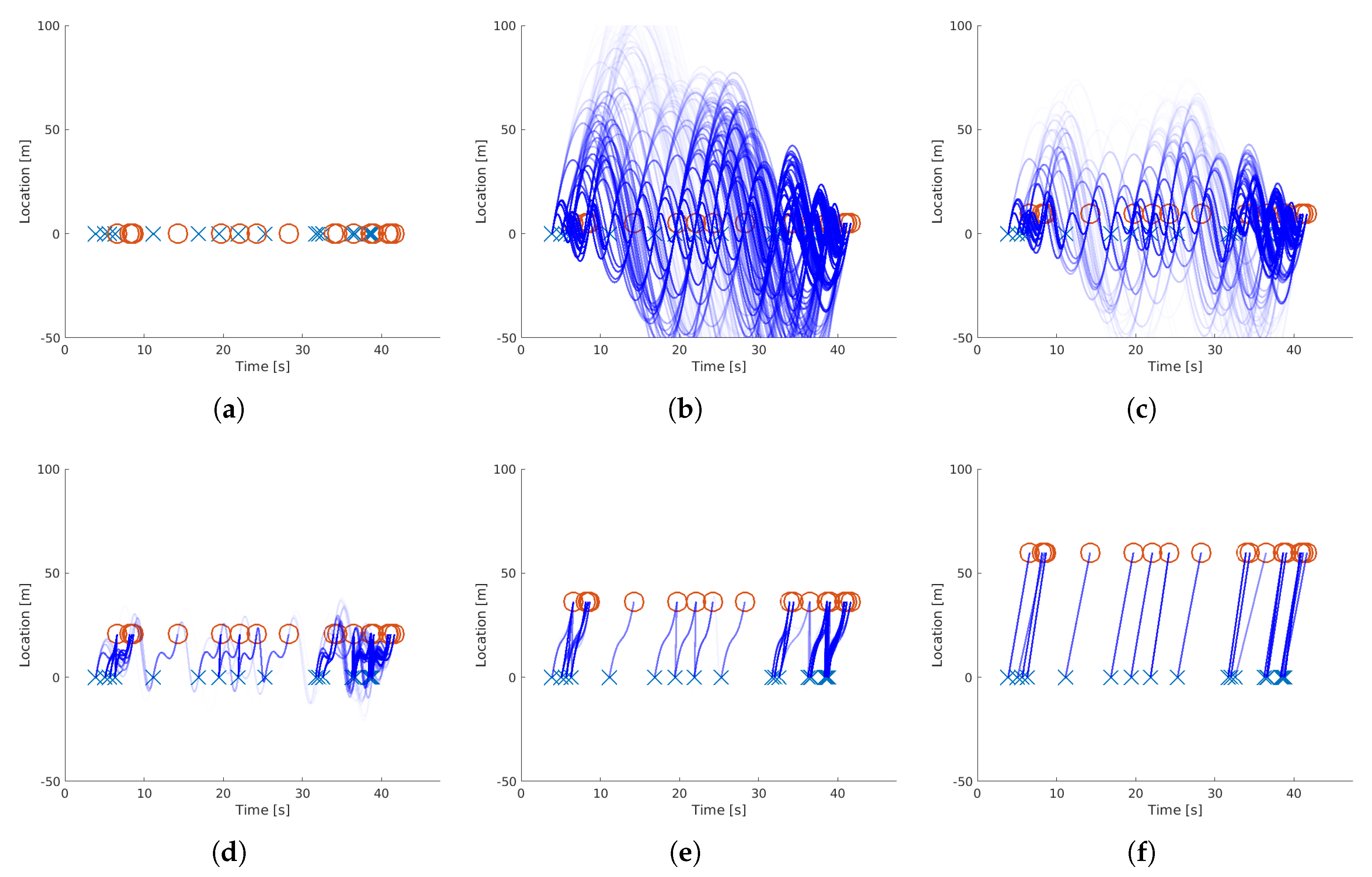
3.2. Synthetic Data Validation
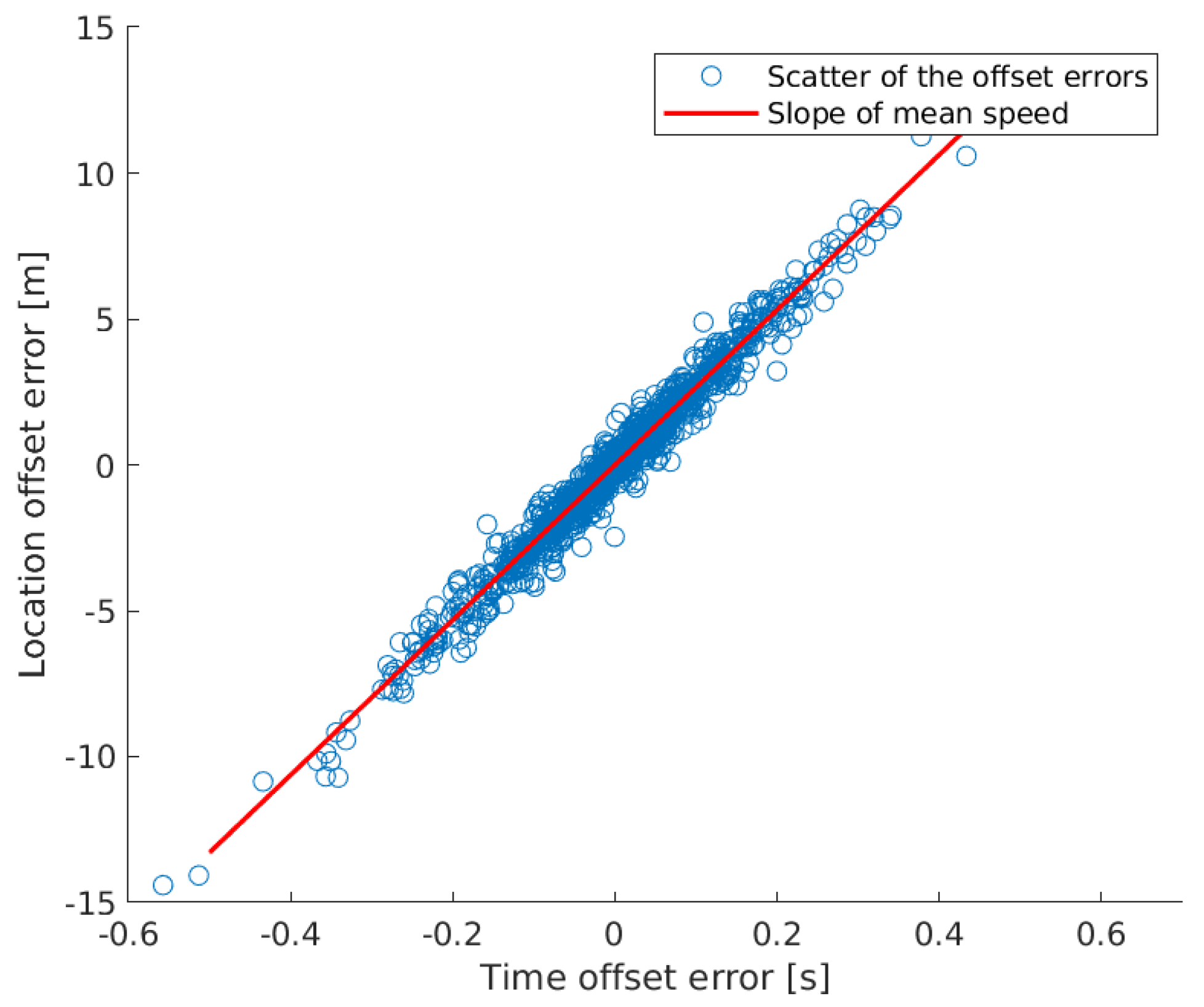
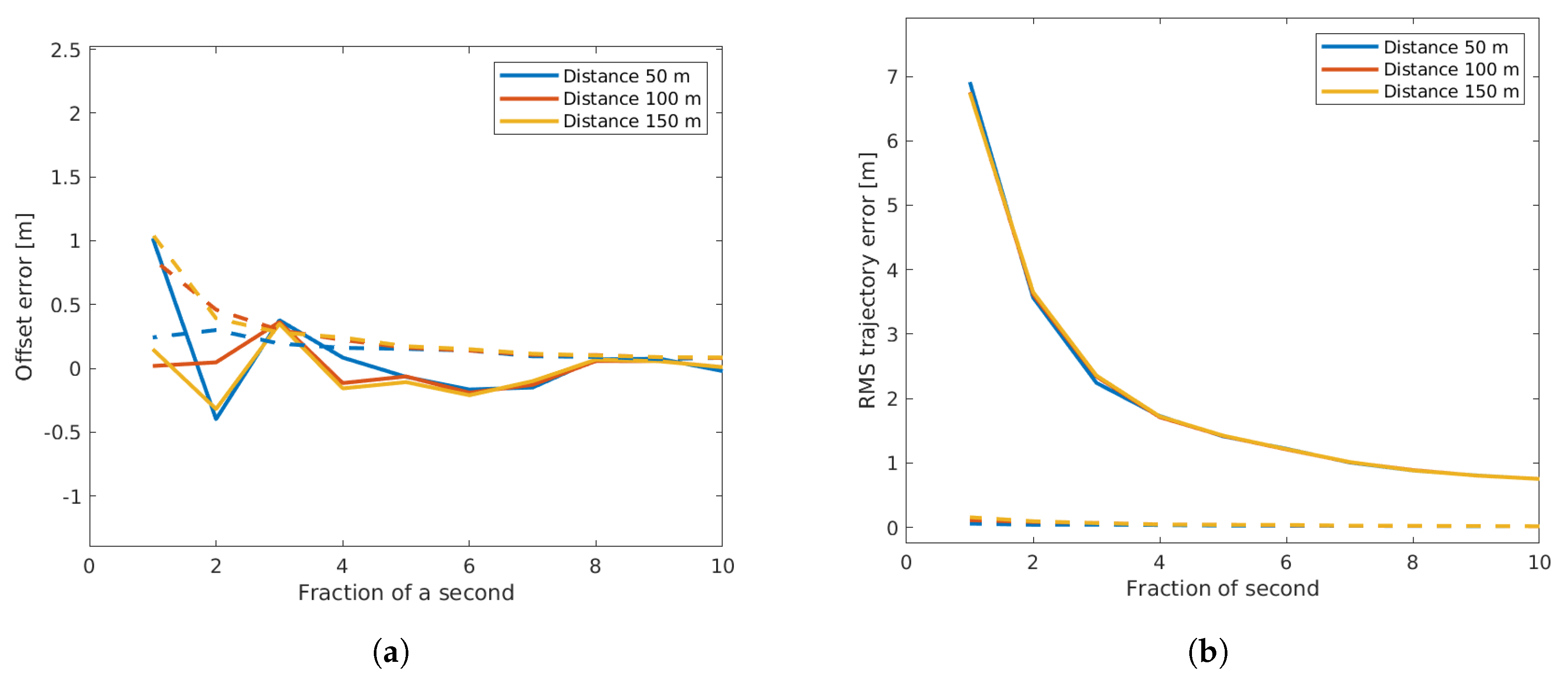
- Offset reconstruction error: the deviation between the sensor offset reference value and the reconstructed one. Depending on spatial or temporal optimization, this involves the location or time offset in meters or seconds.
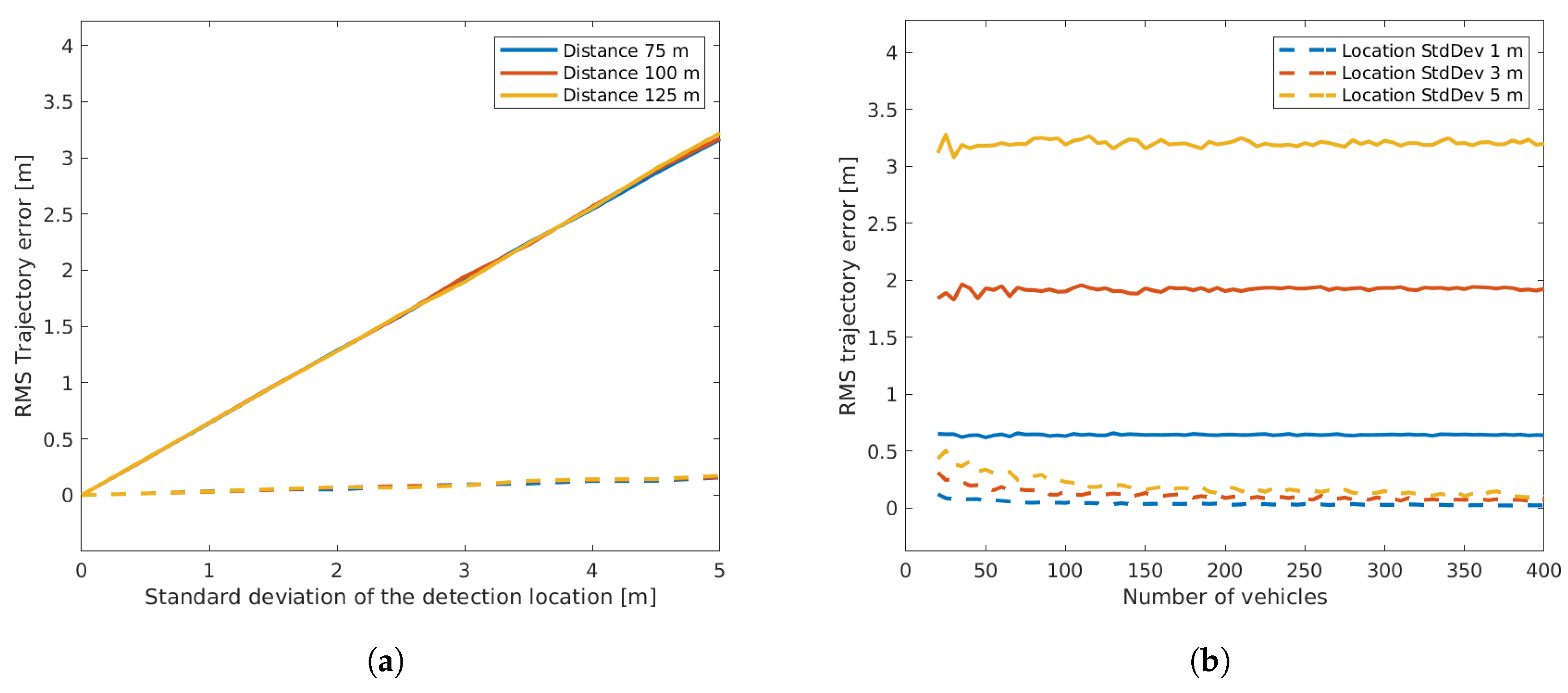
- Trajectory reconstruction error: the deviation between reference vehicle trajectories and the reconstructed ones measured as a root-mean-squared error in meters.
- Matching sensitivity: the recall value between the correctly-matched pairs after reconstruction and the pair of the reference dataset.
- Matching relevance: the positive predictive value between the correctly-matched pairs after reconstruction and all the matched pairs.
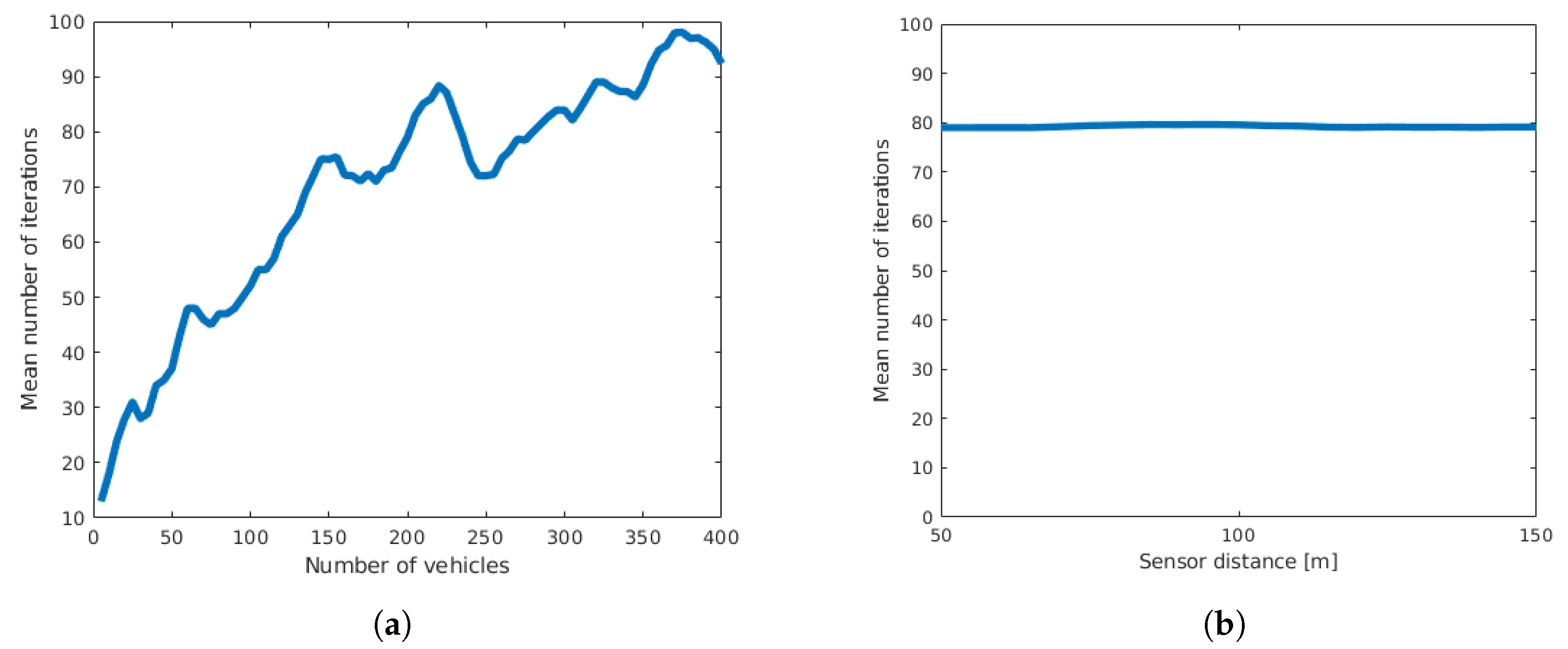
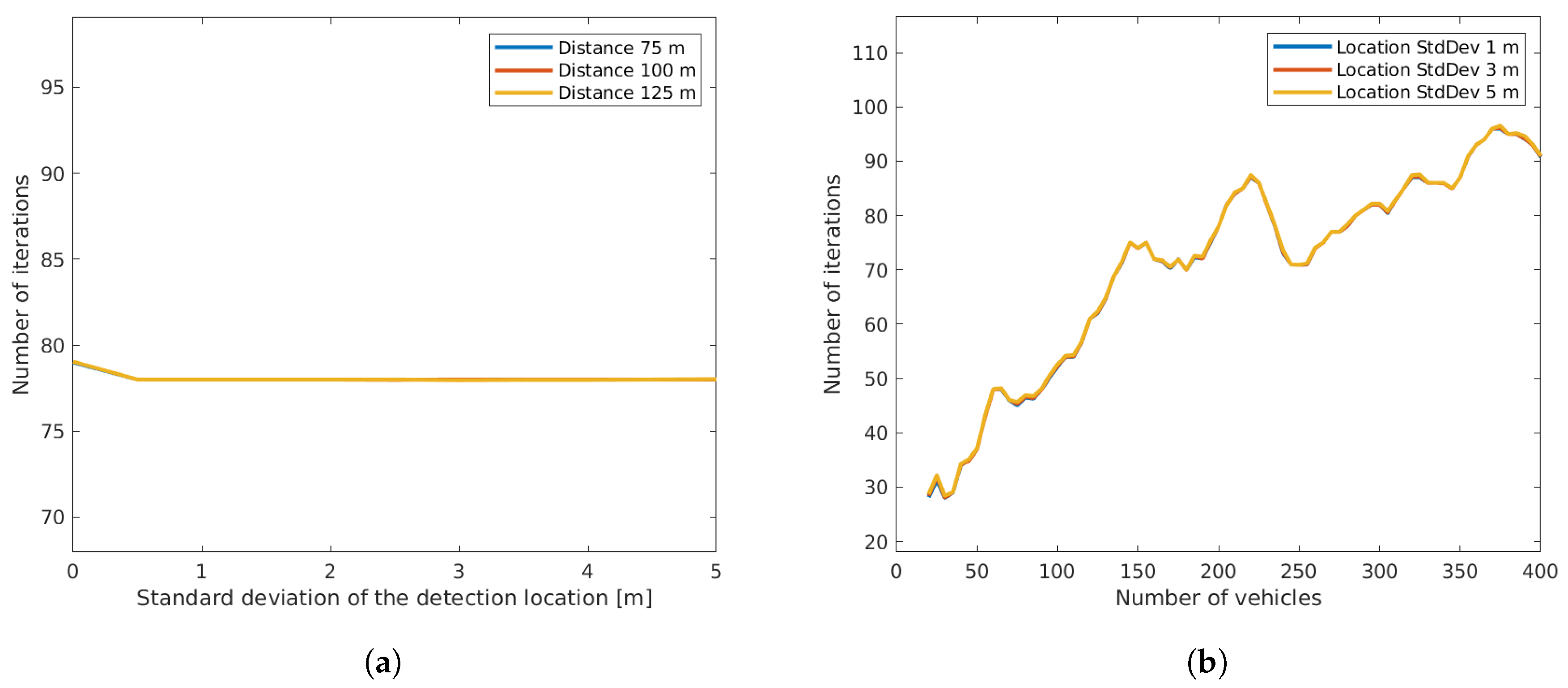
- Number of iterations: the number of iterations the EM-algorithm requires to converge.
3.2.1. Errorless Data
3.2.2. Variance in Detection Location
3.2.3. Error in Speed Measurement
3.2.4. Quantization
3.2.5. Outliers
3.3. Real Data Experiment
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| V2V | Vehicle-to-Vehicle |
| V2I | Vehicle-to-Infrastructure |
| EM | Expectation Maximization |
| RTK-GNSS | Real-Time Kinematic Global Navigation Satellite System |
| FNR | False-Negative-Rate |
| RMS | Root Mean Square |
References
- Azevedo, C.L.; Cardoso, J.L.; Ben-Akiva, M.E. Probabilistic safety analysis using traffic microscopic simulation. arXiv Preprint, 2018; arXiv:1810.04776. [Google Scholar]
- Bommes, M.; Fazekas, A.; Volkenhoff, T.; Oeser, M. Video Based Intelligent Transportation Systems–State of the Art and Future Development. Transp. Res. Procedia 2016, 14, 4495–4504. [Google Scholar] [CrossRef][Green Version]
- Fazekas, A.; Hennecke, F.; Kalló, E.; Oeser, M. A novel surrogate safety indicator based on constant initial acceleration and reaction time assumption. J. Adv. Transp. 2017, 2017. [Google Scholar] [CrossRef]
- Abdel-Aty, M.; Shi, Q.; Wang, L.; Wu, Y.; Radwan, E.; Zhang, B. Integration of Microscopic Big Traffic Data in Simulation-Based Safety Analysis; TRB: Washington, WA, USA, 2016. [Google Scholar]
- Gora, P.; Rüb, I. Traffic models for self-driving connected cars. Transp. Res. Procedia 2016, 14, 2207–2216. [Google Scholar] [CrossRef]
- Liu, C.; Kochenderfer, M.J. Analytically Modeling Unmanaged Intersections with Microscopic Vehicle Interactions. arXiv Preprint, 2018; arXiv:1804.04746. [Google Scholar]
- Baek, S.; Liu, C.; Watta, P.; Murphey, Y.L. Accurate vehicle position estimation using a Kalman filter and neural network-based approach. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Milanés, V.; Naranjo, J.E.; González, C.; Alonso, J.; de Pedro, T. Autonomous vehicle based in cooperative GPS and inertial systems. Robotica 2008, 26, 627–633. [Google Scholar] [CrossRef]
- Pink, O.; Moosmann, F.; Bachmann, A. Visual features for vehicle localization and ego-motion estimation. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 254–260. [Google Scholar]
- Wei, L.; Cappelle, C.; Ruichek, Y. Camera/Laser/GPS Fusion Method for Vehicle Positioning Under Extended NIS-Based Sensor Validation. IEEE Trans. Instrum. Meas. 2013, 62, 3110–3122. [Google Scholar] [CrossRef]
- Coifman, B.; Kim, S. Speed estimation and length based vehicle classification from freeway single-loop detectors. Transp. Res. Part C Emerg. Technol. 2009, 17, 349–364. [Google Scholar] [CrossRef]
- Qiu, T.Z.; Lu, X.Y.; Chow, A.H.; Shladover, S.E. Estimation of freeway traffic density with loop detector and probe vehicle data. Transp. Res. Rec. 2010, 2178, 21–29. [Google Scholar] [CrossRef]
- Aoude, G.S.; Desaraju, V.R.; Stephens, L.H.; How, J.P. Behavior classification algorithms at intersections and validation using naturalistic data. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 601–606. [Google Scholar]
- Felguera-Martín, D.; González-Partida, J.T.; Almorox-González, P.; Burgos-García, M. Vehicular traffic surveillance and road lane detection using radar interferometry. IEEE Trans. Veh. Technol. 2012, 61, 959–970. [Google Scholar] [CrossRef]
- Fuerstenberg, K.C.; Hipp, J.; Liebram, A. A Laserscanner for detailed traffic data collection and traffic control. In Proceedings of the 7th World Congress on Intelligent Systems, Turin, Italy, 6–9 November 2000. [Google Scholar]
- Coifman, B.A.; Lee, H. LIDAR Based Vehicle Classification; Purdue University: West Lafayette, IN, USA, 2011. [Google Scholar]
- Chen, S.; Sun, Z.; Bridge, B. Automatic traffic monitoring by intelligent sound detection. In Proceedings of the IEEE Conference on ITSC’97 Intelligent Transportation System, Boston, MA, USA, 12 November 1997; pp. 171–176. [Google Scholar]
- Duffner, O.; Marlow, S.; Murphy, N.; O’Connor, N.; Smeanton, A. Road traffic monitoring using a two-microphone array. In Audio Engineering Society Convention 118; Audio Engineering Society: New York, NY, USA, 2005. [Google Scholar]
- Antoniou, C.; Balakrishna, R.; Koutsopoulos, H.N. A synthesis of emerging data collection technologies and their impact on traffic management applications. Eur. Transp. Res. Rev. 2011, 3, 139–148. [Google Scholar] [CrossRef]
- Behrendt, R. Traffic monitoring radar for road map calculation. In Proceedings of the 2016 17th International Radar Symposium (IRS), Krakow, Poland, 10–12 May 2016; pp. 1–4. [Google Scholar]
- Zhao, H.; Sha, J.; Zhao, Y.; Xi, J.; Cui, J.; Zha, H.; Shibasaki, R. Detection and tracking of moving objects at intersections using a network of laser scanners. IEEE Trans. Intell. Transp. Syst. 2012, 13, 655–670. [Google Scholar] [CrossRef]
- Buch, N.; Velastin, S.A.; Orwell, J. A review of computer vision techniques for the analysis of urban traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Hanif, A.; Mansoor, A.B.; Imran, A.S. Performance Analysis of Vehicle Detection Techniques: A Concise Survey. In World Conference on Information Systems and Technologies; Springer: London, UK, 2018; pp. 491–500. [Google Scholar]
- Abdulrahim, K.; Salam, R.A. Traffic surveillance: A review of vision based vehicle detection, recognition and tracking. Int. J. Appl. Eng. Res. 2016, 11, 713–726. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Munkres, J. Algorithms for the assignment and transportation problems. J. Soc. Ind. Appl. Math. 1957, 5, 32–38. [Google Scholar] [CrossRef]
- Marsh, D. Applied Geometry for Computer Graphics and CAD; Springer: London, UK, 2006. [Google Scholar]
- Truax, B.E.; Demarest, F.C.; Sommargren, G.E. Laser Doppler velocimeter for velocity and length measurements of moving surfaces. Appl. Opt. 1984, 23, 67–73. [Google Scholar] [CrossRef] [PubMed]
















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fazekas, A.; Oeser, M. Spatio-Temporal Synchronization of Cross Section Based Sensors for High Precision Microscopic Traffic Data Reconstruction. Sensors 2019, 19, 3193. https://doi.org/10.3390/s19143193
Fazekas A, Oeser M. Spatio-Temporal Synchronization of Cross Section Based Sensors for High Precision Microscopic Traffic Data Reconstruction. Sensors. 2019; 19(14):3193. https://doi.org/10.3390/s19143193
Chicago/Turabian StyleFazekas, Adrian, and Markus Oeser. 2019. "Spatio-Temporal Synchronization of Cross Section Based Sensors for High Precision Microscopic Traffic Data Reconstruction" Sensors 19, no. 14: 3193. https://doi.org/10.3390/s19143193
APA StyleFazekas, A., & Oeser, M. (2019). Spatio-Temporal Synchronization of Cross Section Based Sensors for High Precision Microscopic Traffic Data Reconstruction. Sensors, 19(14), 3193. https://doi.org/10.3390/s19143193