Differential Run-Length Encryption in Sensor Networks


Abstract
1. Introduction
2. Related Work
| Algorithm 1 LEC Pseudocode |
| Require:, Table of LEC codes Ensure: if () then else end if = Table() extract from LEC Table if () then return end if if () then is the low-order bits of v. else end if return |
| Algorithm 2 LZW Pseudocode |
| initialize Dictionary[0-255] = first 256 ASCII codes STRING ← get input symbol while there are still input symbols do SYMBOL ← get input symbol if (STRING+SYMBOL is in Dictonary) then STRING = STRING+SYMBOL else output the code for STRING add STRING+SYMBOL to Dictionary STRING = SYMBOL end if end while output the code for STRING |
| Algorithm 3 RLE Pseudocode |
| while there are still input symbols do repeat get input symbol until symbol unequal to next symbol output count and symbol end while |
| Algorithm 4K-RLE Pseudocode |
| read input value while there are still input values do read next input value if () then else output () end if end while output () |
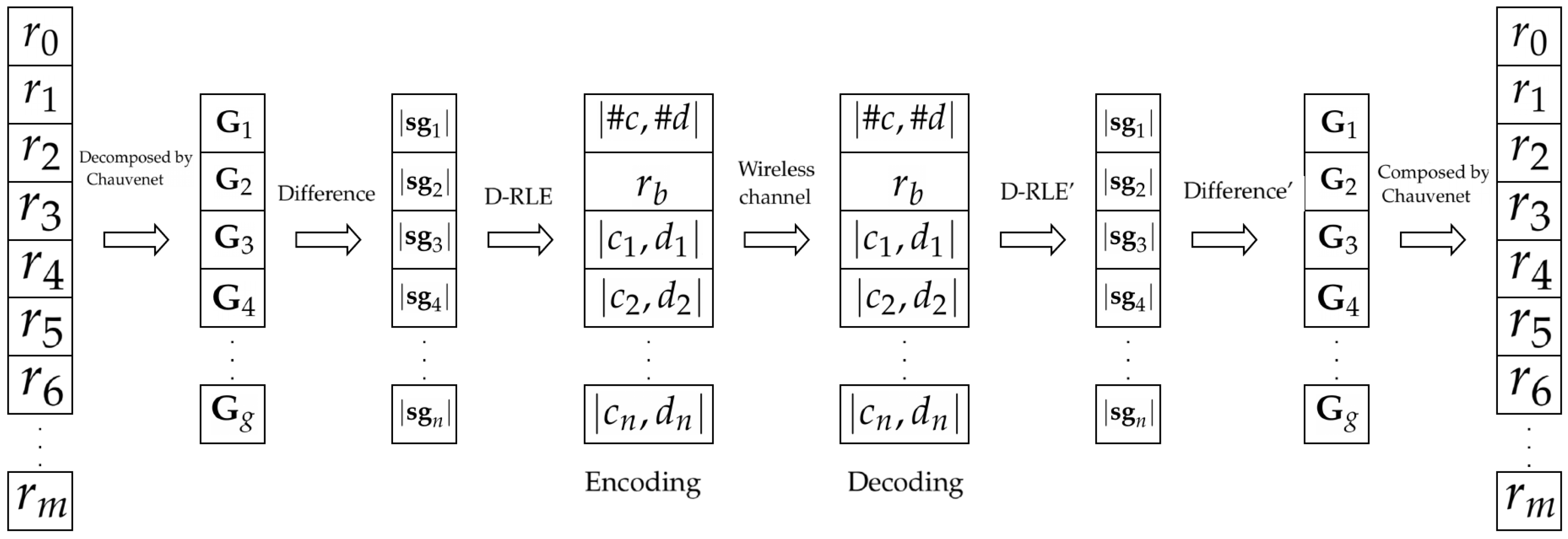
3. Differential Run Length Encryption
3.1. Group Division by Chauvenet’s Criterion
| Algorithm 5 Group Division |
| Require: Ensure: initialize initialize arrays compute and add into for () do if () then add into update else add into end if end for |
3.2. Subgroups Division
| Algorithm 6 Computing |
| Require: Ensure: initialize whiledo ifthen else end if end while |
3.3. Adaptive Data Encoding
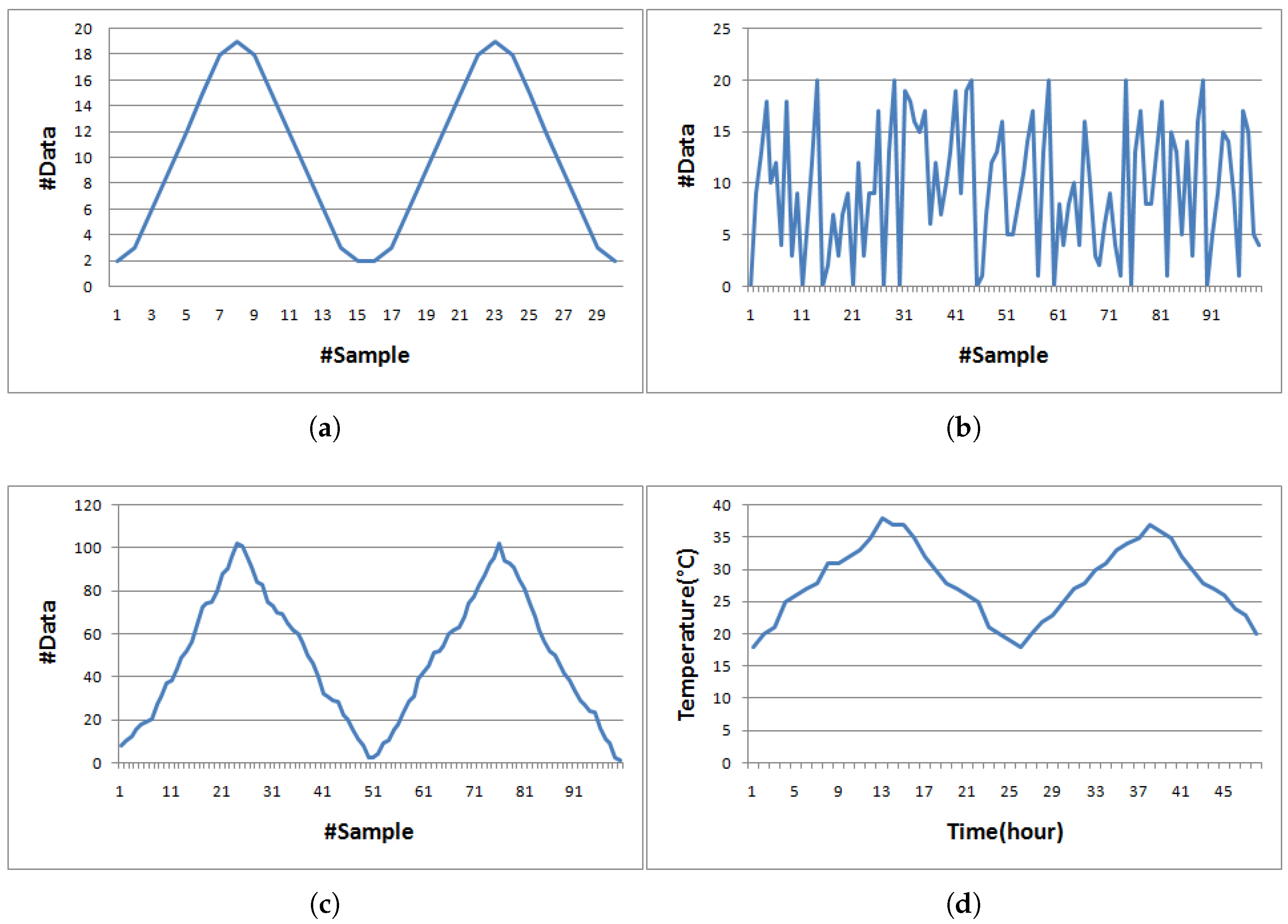
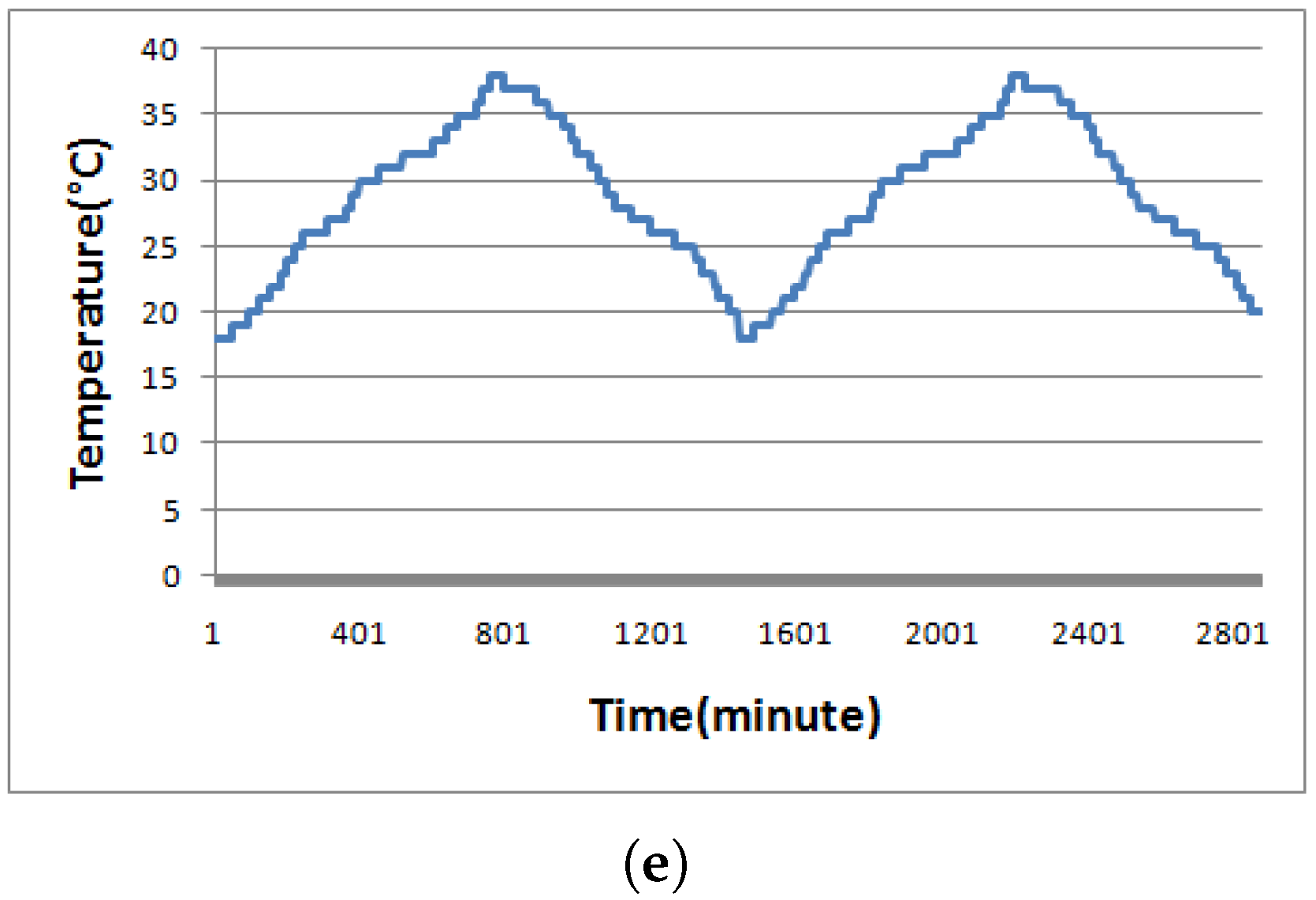
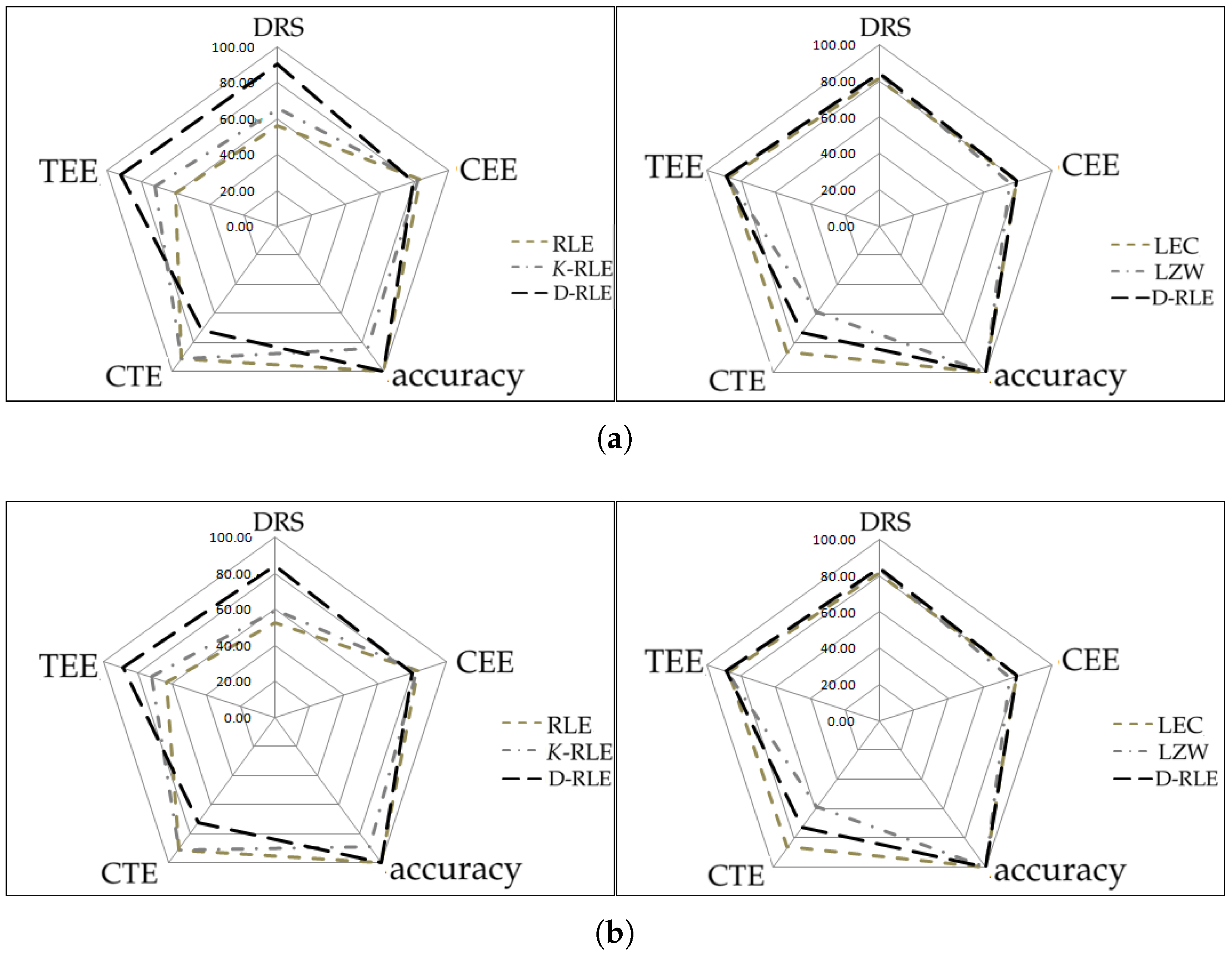
4. Performance Evaluation
4.1. Effect of K Value
4.2. Evaluation Results
| Algorithm 7 Creating simulated temperature data |
| Require: Ensure: initialize whiledo while () do if () then end if end while while () do if () then end if end while end while |
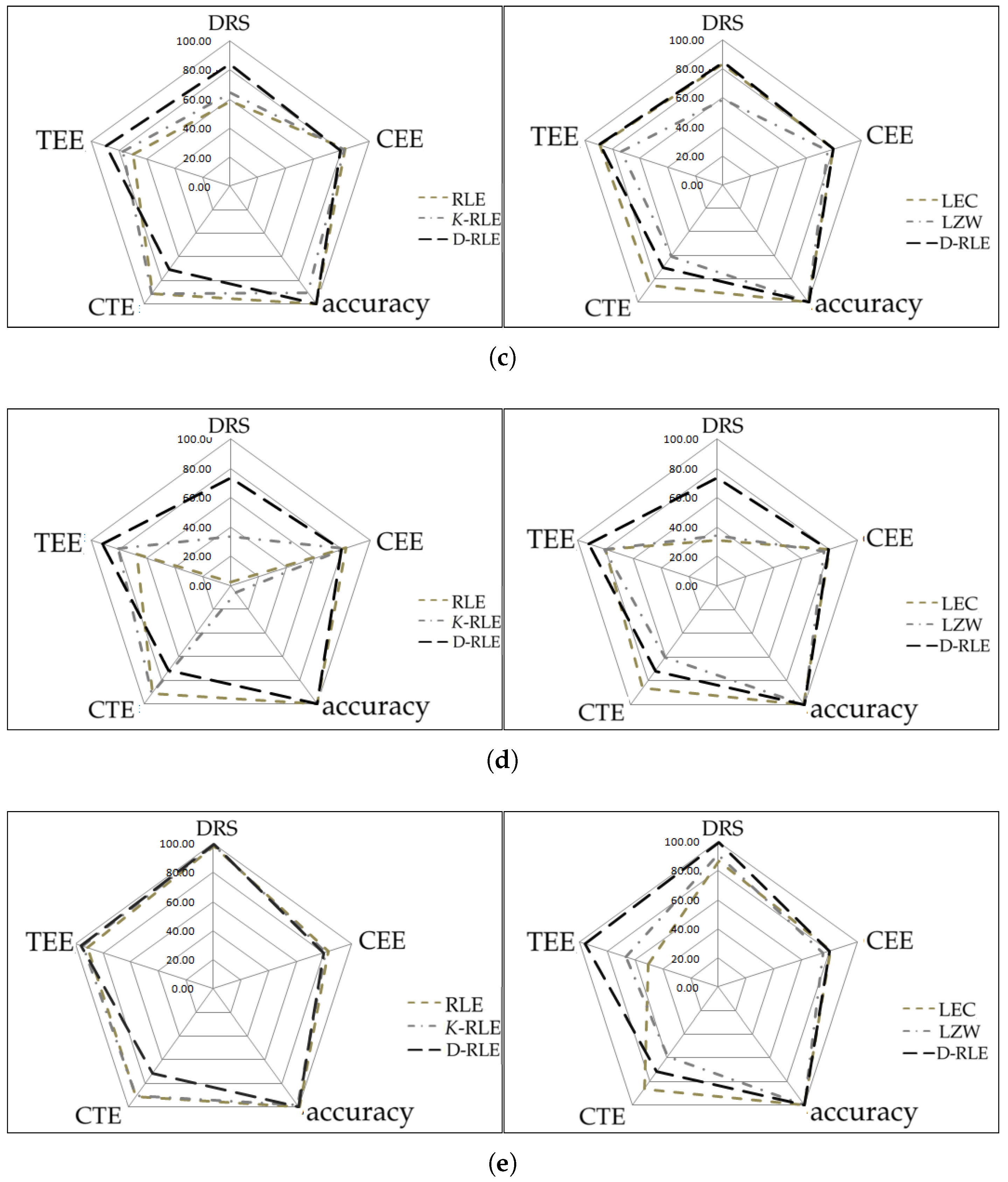
4.3. Performance Visualization
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sheng, Z.; Wang, H.; Yin, C.; Hu, X.; Yang, S.; Leung, V.C.M. Lightweight Management of Resource-Constrained Sensor Devices in Internet of Things. IEEE Internet Things J. 2015, 2, 402–411. [Google Scholar] [CrossRef]
- He, S.; Xie, K.; Chen, W.; Zhang, D.; Wen, J. Energy-Aware Routing for SWIPT in Multi-Hop Energy-Constrained Wireless Network. IEEE Access 2018, 6, 17996–18008. [Google Scholar] [CrossRef]
- Alvi, S.A.; Zhou, X.; Durrani, S. Optimal Compression and Transmission Rate Control for Node-Lifetime Maximization. IEEE Trans. Wirel. Commun. 2018, 17, 7774–7788. [Google Scholar] [CrossRef]
- Gana Kolo, J.; Anandan Shanmugam, S.; Wee Gin Lim, D.; Ang, L.M.; Seng, K. An Adaptive Lossless Data Compression Scheme for Wireless Sensor Networks. J. Sens. 2012, 2012, 539638. [Google Scholar]
- Wang, J.; Gao, Y.; Liu, W.; Sangaiah, A.K.; Kim, H.J. Energy Efficient Routing Algorithm with Mobile Sink Support for Wireless Sensor Networks. Sensors 2019, 19, 1494. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Tawose, O.T.; Jiang, L.; Zhao, D. A New Data Fusion Algorithm for Wireless Sensor Networks Inspired by Hesitant Fuzzy Entropy. Sensors 2019, 19, 784. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Gao, Y.; Zhang, N.; Yang, H. An Energy-Efficient Two-Stage Cooperative Routing Scheme in Wireless Multi-Hop Networks. Sensors 2019, 19, 1002. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lin, X.; Shroff, N.B. Optimal Anycast Technique for Delay-Sensitive Energy-Constrained Asynchronous Sensor Networks. IEEE/ACM Trans. Netw. 2011, 19, 484–497. [Google Scholar] [CrossRef]
- Wang, H.; Zeng, H.; Wang, P. Linear Estimation of Clock Frequency Offset for Time Synchronization Based on Overhearing in Wireless Sensor Networks. IEEE Commun. Lett. 2016, 20, 288–291. [Google Scholar] [CrossRef]
- Liu, X. Atypical Hierarchical Routing Protocols for Wireless Sensor Networks: A Review. IEEE Sens. J. 2015, 15, 5372–5383. [Google Scholar] [CrossRef]
- Boubiche, S.; Boubiche, D.E.; Bilami, A.; Toral-Cruz, H. Big Data Challenges and Data Aggregation Strategies in Wireless Sensor Networks. IEEE Access 2018, 6, 20558–20571. [Google Scholar] [CrossRef]
- Lin, H.; Üster, H. Exact and Heuristic Algorithms for Data-Gathering Cluster-Based Wireless Sensor Network Design Problem. IEEE/ACM Trans. Netw. 2014, 22, 903–916. [Google Scholar] [CrossRef]
- Mahapatro, A.; Khilar, P.M. Fault Diagnosis in Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2013, 15, 2000–2026. [Google Scholar] [CrossRef]
- Wang, J.; Al-Mamun, A.; Li, T.; Jiang, L.; Zhao, D. Toward Performant and Energy-efficient Queries in Three-tier Wireless Sensor Networks. In Proceedings of the 47th International Conference on Parallel Processing, ICPP 2018, Eugene, OR, USA, 13–16 August 2018; ACM: New York, NY, USA, 2018; pp. 42:1–42:10. [Google Scholar]
- Wang, X.; Liu, X.; Wang, M.; Nie, Y.; Bian, Y. Energy-Efficient Spatial Query-Centric Geographic Routing Protocol in Wireless Sensor Networks. Sensors 2019, 19, 2363. [Google Scholar] [CrossRef] [PubMed]
- Sadler, C.M.; Martonosi, M. Data Compression Algorithms for Energy-constrained Devices in Delay Tolerant Networks. In Proceedings of the 4th International Conference on Embedded Networked Sensor Systems, SenSys ’06, Boulder, CO, USA, 31 October–3 November 2006; ACM: New York, NY, USA, 2006; pp. 265–278. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Welch, T.A. Technique for High-Performance Data Compression. Computer 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Capo-Chichi, E.P.; Guyennet, H.; Friedt, J. K-RLE: A New Data Compression Algorithm for Wireless Sensor Network. In Proceedings of the 2009 Third International Conference on Sensor Technologies and Applications, Athens, Greece, 18–23 June 2009; pp. 502–507. [Google Scholar]
- Roy, S.; Panja, S.C.; Patra, S.N. DMBRLE: A lossless compression algorithm for solar irradiance data acquisition. In Proceedings of the 2015 IEEE 2nd International Conference on Recent Trends in Information Systems (ReTIS), Kolkata, India, 9–11 July 2015; pp. 450–454. [Google Scholar]
- Marcelloni, F.; Vecchio, M. A Simple Algorithm for Data Compression in Wireless Sensor Networks. IEEE Commun. Lett. 2008, 12, 411–413. [Google Scholar] [CrossRef]
- Marcelloni, F.; Vecchio, M. An Efficient Lossless Compression Algorithm for Tiny Nodes of Monitoring Wireless Sensor Networks. Comput. J. 2009, 52, 969–987. [Google Scholar] [CrossRef]
- Szalapski, T.; Madria, S.; Linderman, M. TinyPack XML: Real time XML compression for wireless sensor networks. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Shanghai, China, 1–4 April 2012; pp. 3165–3170. [Google Scholar]
- Liang, Y.; Li, Y. An Efficient and Robust Data Compression Algorithm in Wireless Sensor Networks. IEEE Commun. Lett. 2014, 18, 439–442. [Google Scholar] [CrossRef]
- Zou, Z.; Bao, Y.; Deng, F.; Li, H. An Approach of Reliable Data Transmission With Random Redundancy for Wireless Sensors in Structural Health Monitoring. IEEE Sens. J. 2015, 15, 809–818. [Google Scholar]
- Hung, N.Q.V.; Jeung, H.; Aberer, K. An Evaluation of Model-Based Approaches to Sensor Data Compression. IEEE Trans. Knowl. Data Eng. 2013, 25, 2434–2447. [Google Scholar] [CrossRef]
- Rubin, M.J.; Wakin, M.B.; Camp, T. Lossy Compression for Wireless Seismic Data Acquisition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 236–252. [Google Scholar] [CrossRef]
- Long, S.; Xiang, P. Lossless Data Compression for Wireless Sensor Networks Based on Modified Bit-Level RLE. In Proceedings of the 2012 8th International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–23 September 2012; pp. 1–4. [Google Scholar]
- Koc, B.; Sarkar, D.; Kocak, H.; Arnavut, Z. A study of power consumption on MSP432 family of microcontrollers for lossless data compression. In Proceedings of the 2015 12th International Conference on High-capacity Optical Networks and Enabling/Emerging Technologies (HONET), Islamabad, Pakistan, 21–23 December 2015; pp. 1–5. [Google Scholar]
- Chianphatthanakit, C.; Boonsongsrikul, A.; Suppharangsan, S. A Lossless Image Compression Algorithm using Differential Subtraction Chain. In Proceedings of the 2018 10th International Conference on Knowledge and Smart Technology (KST), Chiang Mai, Thailand, 31 January–3 February 2018; pp. 84–89. [Google Scholar]
- Boonsongsrikul, A.; Lhee, K.S.; Hong, M. Securing data aggregation against false data injection in wireless sensor networks. In Proceedings of the 2010 The 12th International Conference on Advanced Communication Technology (ICACT), Phoenix Park, Korea, 7–10 February 2010; Volume 1, pp. 29–34. [Google Scholar]
- Pop, S.; Ciascai, I.; Pitica, D. Statistical analysis of experimental data obtained from the optical pendulum. In Proceedings of the 2010 IEEE 16th International Symposium for Design and Technology in Electronic Packaging (SIITME), Pitesti, Romania, 23–26 September 2010; pp. 207–210. [Google Scholar]
- Bhandari, S.; Bergmann, N.; Jurdak, R.; Kusy, B. Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature. Sensors 2017, 17, 1221. [Google Scholar] [CrossRef] [PubMed]
- CC1310 SimpleLinkTM Ultra-Low-Power Sub-1 GHz Wireless MCU. Available online: www.ti.com/product/CC1310 (accessed on 13 February 2019).
- MSP430FR5969 LaunchPad Development Kit. Available online: http://www.ti.com/tool/MSP-EXP430FR5969 (accessed on 17 January 2019).
- Code Composer Studio (CCS) Integrated Development Environment (IDE). Available online: http://www.ti.com/tool/CCSTUDIO (accessed on 22 July 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level ( | Bits | Prefix () | Suffix Range () | Value () |
|---|---|---|---|---|
| 0 | 2 | 00 | - | 0 |
| 1 | 4 | 010 | 0…1 | −1, 1 |
| 2 | 5 | 011 | 00…11 | −3, −2, 2, 3 |
| 3 | 6 | 100 | 000…111 | −7, …, −4, 4, …, 7 |
| 4 | 7 | 101 | 0000…1111 | −15, …,−8, 8, …, 15 |
| 5 | 8 | 110 | 00000…11111 | −31, …, −16, 16, …, 31 |
| 6 | 10 | 1110 | 000000…111111 | −63, …, −32, 32, …, 63 |
| 7 | 12 | 11110 | 0000000…1111111 | −127, …, −64, 64, …, 127 |
| String | Output | Dictionary | Total Bits |
|---|---|---|---|
| A | 65 | 256 = AA | 9 |
| AA | 256 | 257 = AAA | 18 |
| A | 65 | 258 = AB | 27 |
| B | 66 | 259 = BA | 36 |
| AAA | 257 | 260 = AAAB | 45 |
| B | 66 | 261 = BC | 54 |
| C | 67 | 262 = CC | 63 |
| C | 67 | 72 |
| Process | Format |
|---|---|
| raw data | |
| group division | |
| subgroup division | for each |
| encoded data |
| K | Uncompression (Bits) | Compression (Bits) | DRS (%) |
|---|---|---|---|
| 0 | 256, 240 | 91, 81 | 64.45, 66.25, 65.32 |
| 1 | 256, 240 | 94, 88 | 63.28, 63.33, 63.31 |
| 2 | 256, 240 | 88, 88 | 65.63, 63.33, 64.52 |
| 3 | 256, 240 | 86, 88 | 66.41, 63.33, 64.92 |
| 4 | 256, 240 | 86, 76 | 66.41, 68.33, 67.34 |
| 5 | 256, 240 | 79, 79 | 69.14, 67.08, 68.15 |
| Dataset | Algorithm | Compression Step | Transmission Step | |||||
|---|---|---|---|---|---|---|---|---|
| #Bits | Time (s) | DRS (%) | Energy (mJ) | Time (s) | #Packets | Energy (mJ) | ||
| sine-like (352 bits) | RLE | 464 | 0.023 | −31.82 | 0.275 | 0.015 | 0.453 | 0.781 |
| K-RLE | 320 | 0.023 | 19.09 | 0.303 | 0.011 | 0.313 | 0.473 | |
| LEC | 149 | 0.037 | 57.67 | 0.313 | 0.005 | 0.146 | 0.222 | |
| LZW | 207 | 0.110 | 41.19 | 0.396 | 0.008 | 0.202 | 0.309 | |
| D-RLE | 132 | 0.075 | 62.50 | 0.327 | 0.004 | 0.129 | 0.203 | |
| chaotic (1176 bits) | RLE | 1504 | 0.076 | −27.89 | 0.919 | 0.050 | 1.469 | 2.530 |
| K-RLE | 1168 | 0.077 | 0.68 | 1.014 | 0.041 | 1.141 | 1.728 | |
| LEC | 733 | 0.122 | 37.67 | 1.047 | 0.024 | 0.716 | 1.092 | |
| LZW | 648 | 0.367 | 44.90 | 1.323 | 0.025 | 0.633 | 0.967 | |
| D-RLE | 616 | 0.249 | 47.62 | 1.092 | 0.019 | 0.602 | 0.947 | |
| simulated temperature (1600 bits) | RLE | 1600 | 0.103 | 10.00 | 1.250 | 0.053 | 1.563 | 2.692 |
| K-RLE | 1280 | 0.104 | 20.00 | 1.379 | 0.045 | 1.250 | 1.893 | |
| LEC | 651 | 0.166 | 59.31 | 1.424 | 0.021 | 0.636 | 0.970 | |
| LZW | 1584 | 0.500 | 11.00 | 1.800 | 0.061 | 1.547 | 2.363 | |
| D-RLE | 416 | 0.339 | 74.00 | 1.486 | 0.013 | 0.406 | 0.640 | |
| temperatureHr (768 bits) | RLE | 752 | 0.049 | 12.08 | 0.600 | 0.025 | 0.734 | 1.265 |
| K-RLE | 512 | 0.050 | 33.33 | 0.662 | 0.018 | 0.500 | 0.757 | |
| LEC | 528 | 0.080 | 31.25 | 0.684 | 0.017 | 0.516 | 0.787 | |
| LZW | 504 | 0.240 | 34.38 | 0.864 | 0.020 | 0.492 | 0.752 | |
| D-RLE | 204 | 0.163 | 73.44 | 0.713 | 0.006 | 0.199 | 0.314 | |
| temperatureMin (46,080 bits) | RLE | 984 | 2.963 | 97.87 | 36.005 | 0.033 | 0.961 | 1.655 |
| K-RLE | 656 | 3.009 | 98.58 | 39.713 | 0.023 | 0.641 | 0.970 | |
| LEC | 6240 | 4.780 | 86.46 | 41.018 | 0.202 | 6.094 | 9.299 | |
| LZW | 4230 | 14.396 | 90.82 | 51.847 | 0.164 | 4.131 | 6.310 | |
| D-RLE | 467 | 9.776 | 98.99 | 42.802 | 0.015 | 0.456 | 0.718 | |
| Dataset | Total Energy Use (mJ) | ||||
|---|---|---|---|---|---|
| RLE | K-RLE | LEC | LZW | D-RLE | |
| sine-like | 1.056 | 0.777 | 0.535 | 0.705 | 0.530 |
| chaotic | 3.449 | 2.741 | 2.139 | 2.290 | 2.040 |
| simulated temperature | 3.942 | 3.272 | 2.394 | 4.163 | 2.126 |
| temperatureHr | 1.865 | 1.419 | 1.470 | 1.616 | 1.027 |
| temperatureMin | 37.660 | 40.683 | 50.317 | 58.157 | 43.520 |
| Dataset | Algorithm | Compression Step | Transmission Step | |||||
|---|---|---|---|---|---|---|---|---|
| #Bits | Time (s) | DRS (%) | Energy (mJ) | Time (s) | #Packets | Energy (mJ) | ||
| sine-like | RLE | 20,352 | 3.044 | 55.83 | 34.903 | 0.680 | 19.875 | 34.239 |
| K-RLE | 16,056 | 3.060 | 65.16 | 37.493 | 0.570 | 15.680 | 23.749 | |
| LEC | 6876 | 4.862 | 85.08 | 40.778 | 0.223 | 6.715 | 10.246 | |
| LZW | 6588 | 14.156 | 85.70 | 50.407 | 0.256 | 6.434 | 9.828 | |
| D-RLE | 4476 | 10.087 | 90.29 | 42.703 | 0.140 | 4.371 | 6.883 | |
| chaotic | RLE | 21,888 | 2.991 | 52.50 | 34.651 | 0.731 | 21.375 | 36.823 |
| K-RLE | 18,816 | 3.126 | 59.17 | 35.928 | 0.668 | 18.375 | 27.832 | |
| LEC | 8796 | 4.762 | 80.91 | 40.538 | 0.285 | 8.590 | 13.107 | |
| LZW | 7776 | 14.052 | 83.13 | 49.407 | 0.302 | 7.594 | 11.600 | |
| D-RLE | 7332 | 9.367 | 84.09 | 41.047 | 0.230 | 7.160 | 11.275 | |
| simulated temperature | RLE | 19,200 | 3.023 | 58.33 | 34.918 | 0.641 | 18.750 | 32.301 |
| K-RLE | 16,560 | 3.005 | 64.06 | 36.986 | 0.588 | 16.172 | 24.495 | |
| LEC | 7812 | 4.836 | 83.05 | 40.596 | 0.253 | 7.629 | 11.641 | |
| LZW | 19,008 | 13.346 | 58.75 | 49.447 | 0.737 | 18.563 | 28.355 | |
| D-RLE | 7332 | 9.967 | 84.09 | 41.630 | 0.230 | 7.160 | 11.275 | |
| temperatureHr | RLE | 45,120 | 2.960 | 2.08 | 34.577 | 1.506 | 44.063 | 75.906 |
| K-RLE | 30,720 | 3.006 | 33.33 | 35.976 | 1.091 | 30.000 | 45.439 | |
| LEC | 31,680 | 4.755 | 31.25 | 39.098 | 1.028 | 30.938 | 47.208 | |
| LZW | 30,240 | 13.368 | 34.38 | 47.657 | 1.173 | 29.531 | 45.111 | |
| D-RLE | 12,240 | 9.420 | 73.44 | 41.023 | 0.384 | 11.953 | 18.823 | |
| temperatureMin | RLE | 984 | 2.963 | 97.87 | 36.005 | 0.033 | 0.961 | 1.655 |
| K-RLE | 656 | 3.009 | 98.58 | 39.713 | 0.023 | 0.641 | 0.970 | |
| LEC | 6240 | 4.780 | 86.46 | 41.018 | 0.202 | 6.094 | 9.299 | |
| LZW | 4230 | 14.396 | 90.82 | 51.847 | 0.164 | 4.131 | 6.310 | |
| D-RLE | 467 | 9.776 | 98.99 | 42.802 | 0.015 | 0.456 | 0.718 | |
| Dataset | Total Energy Use (mJ) | ||||
|---|---|---|---|---|---|
| RLE | K-RLE | LEC | LZW | D-RLE | |
| sine-like | 69.142 | 61.242 | 51.025 | 60.235 | 49.586 |
| chaotic | 71.474 | 63.760 | 53.646 | 61.007 | 52.322 |
| simulated temperature | 67.218 | 61.481 | 52.237 | 77.803 | 52.906 |
| temperatureHr | 110.483 | 81.415 | 86.306 | 92.768 | 59.846 |
| temperatureMin | 37.660 | 40.683 | 50.317 | 58.157 | 43.520 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chianphatthanakit, C.; Boonsongsrikul, A.; Suppharangsan, S. Differential Run-Length Encryption in Sensor Networks. Sensors 2019, 19, 3190. https://doi.org/10.3390/s19143190
Chianphatthanakit C, Boonsongsrikul A, Suppharangsan S. Differential Run-Length Encryption in Sensor Networks. Sensors. 2019; 19(14):3190. https://doi.org/10.3390/s19143190
Chicago/Turabian StyleChianphatthanakit, Chiratheep, Anuparp Boonsongsrikul, and Somjet Suppharangsan. 2019. "Differential Run-Length Encryption in Sensor Networks" Sensors 19, no. 14: 3190. https://doi.org/10.3390/s19143190
APA StyleChianphatthanakit, C., Boonsongsrikul, A., & Suppharangsan, S. (2019). Differential Run-Length Encryption in Sensor Networks. Sensors, 19(14), 3190. https://doi.org/10.3390/s19143190