Deep Ensemble Learning Based Objective Grading of Macular Edema by Extracting Clinically Significant Findings from Fused Retinal Imaging Modalities


Abstract
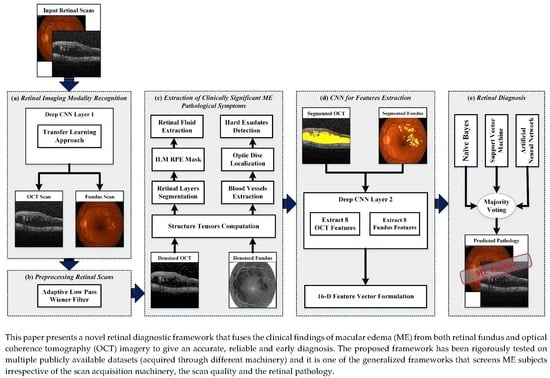
1. Introduction
2. Related Work
- A novel method was presented in this paper that extracted the ME pathological symptoms from retinal fundus and OCT scans.
- Instead of extracting handcrafted features, the proposed framework employed a deep convolutional neural network (CNN) model that gives the most relevant and useful features from retinal fundus and OCT scans for the objective evaluation of ME pathology irrespective of the scan acquisition machinery.
- Many frameworks that have been proposed in the past were tested on a single dataset or on scans acquired through single OCT machinery. However, the proposed framework could give objective grading of ME pathology irrespective of OCT acquisition machinery and was rigorously tested on scans from different publicly available datasets.
- The proposed framework employed an ensemble of artificial neural networks (ANN), support vector machines (SVM) and naïve Bayes (NB) for the in-depth grading of ME using both fundus and OCT retinal imaging modalities.
- The proposed framework is adaptive and gives more weight to the clinical findings such as foveal swelling, fluid filled spaces and hard exudates while evaluating ME. This is achieved by fine-tuning the proposed CNN model on observing the critical ME symptoms from both fundus and OCT imagery.
3. Datasets
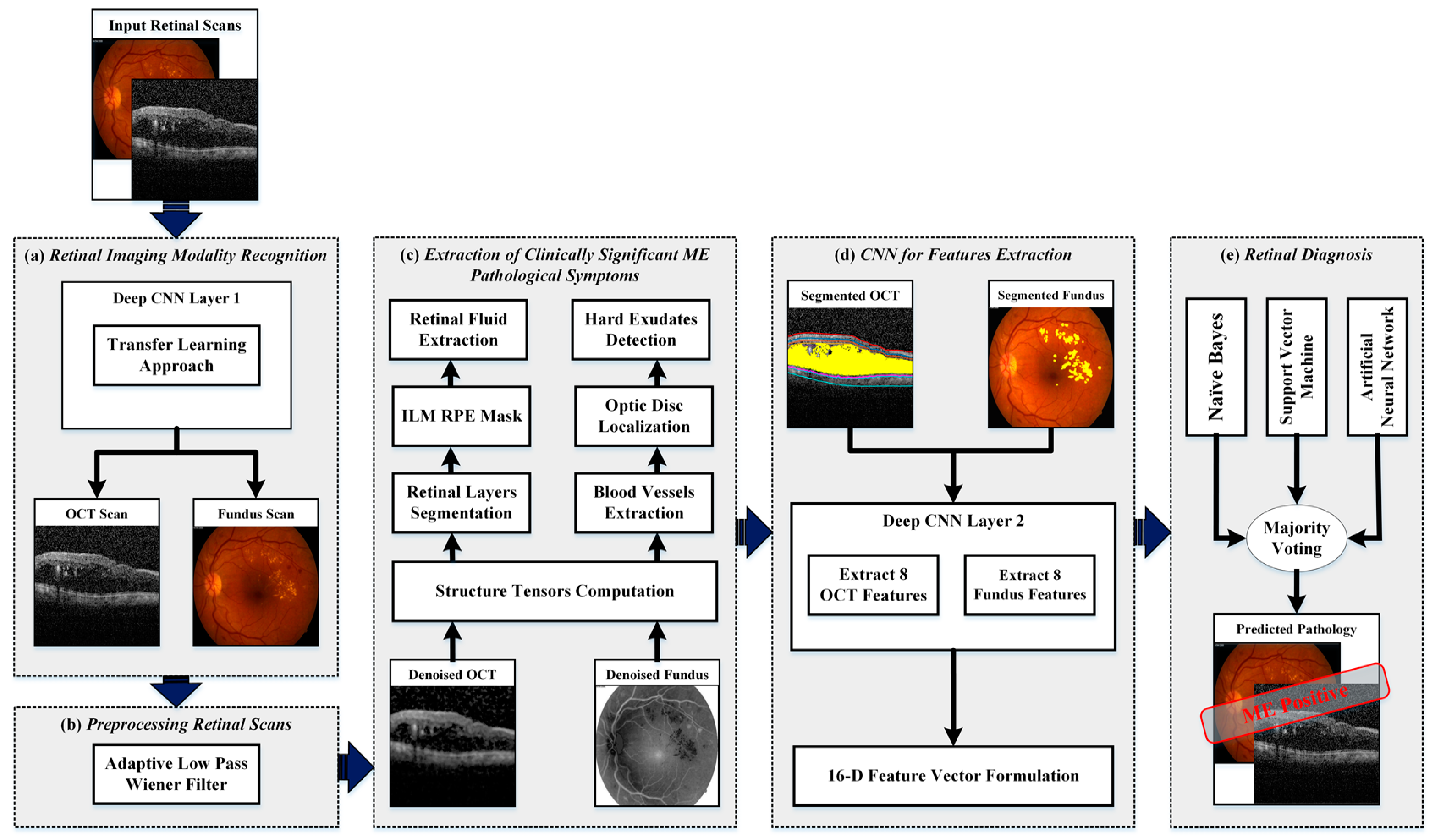
4. Proposed Methodology
- Retinal imaging modality recognition;
- Preprocessing retinal scans;
- Extraction of clinically significant ME pathological symptoms;
- CNN for feature extraction;
- Retinal diagnosis.
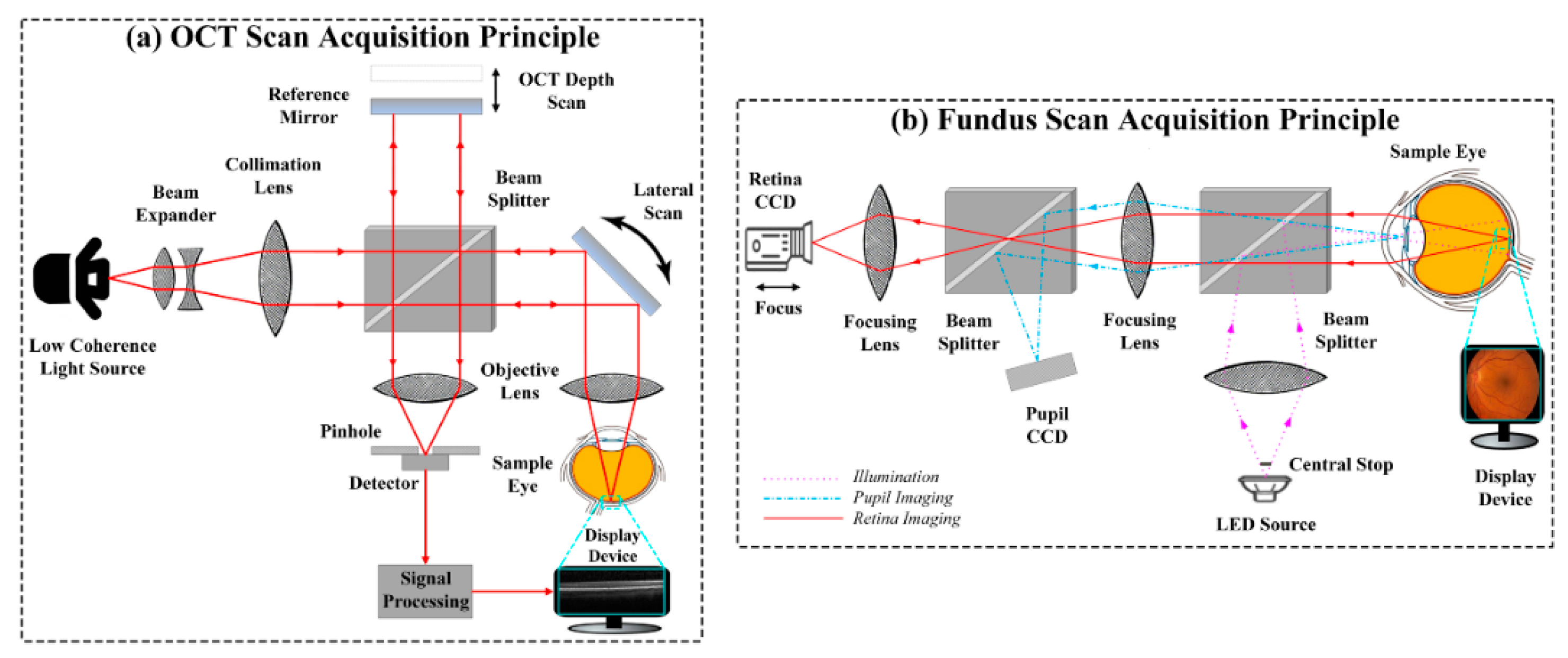
4.1. Retinal Imaging Modality Recognition
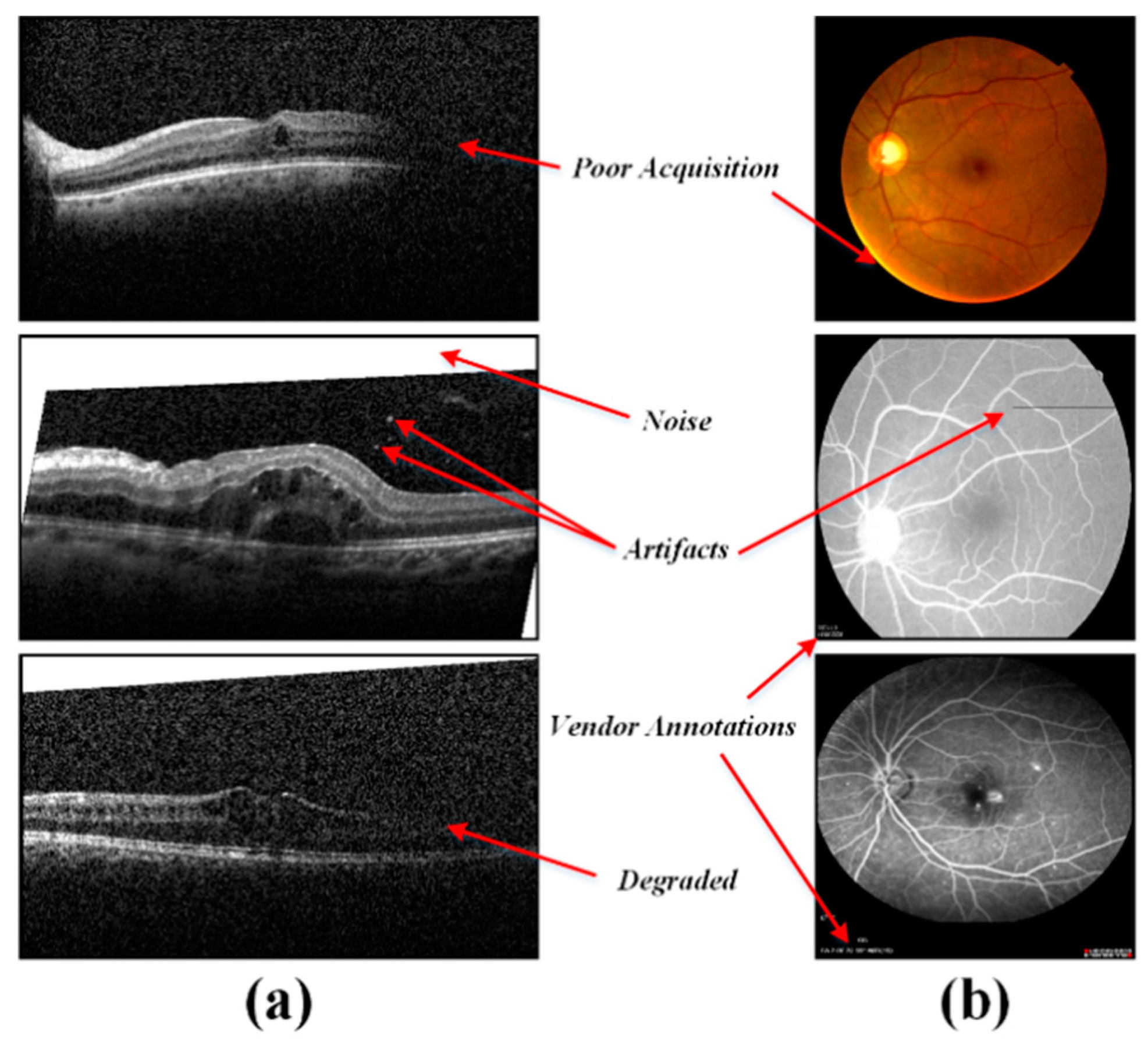
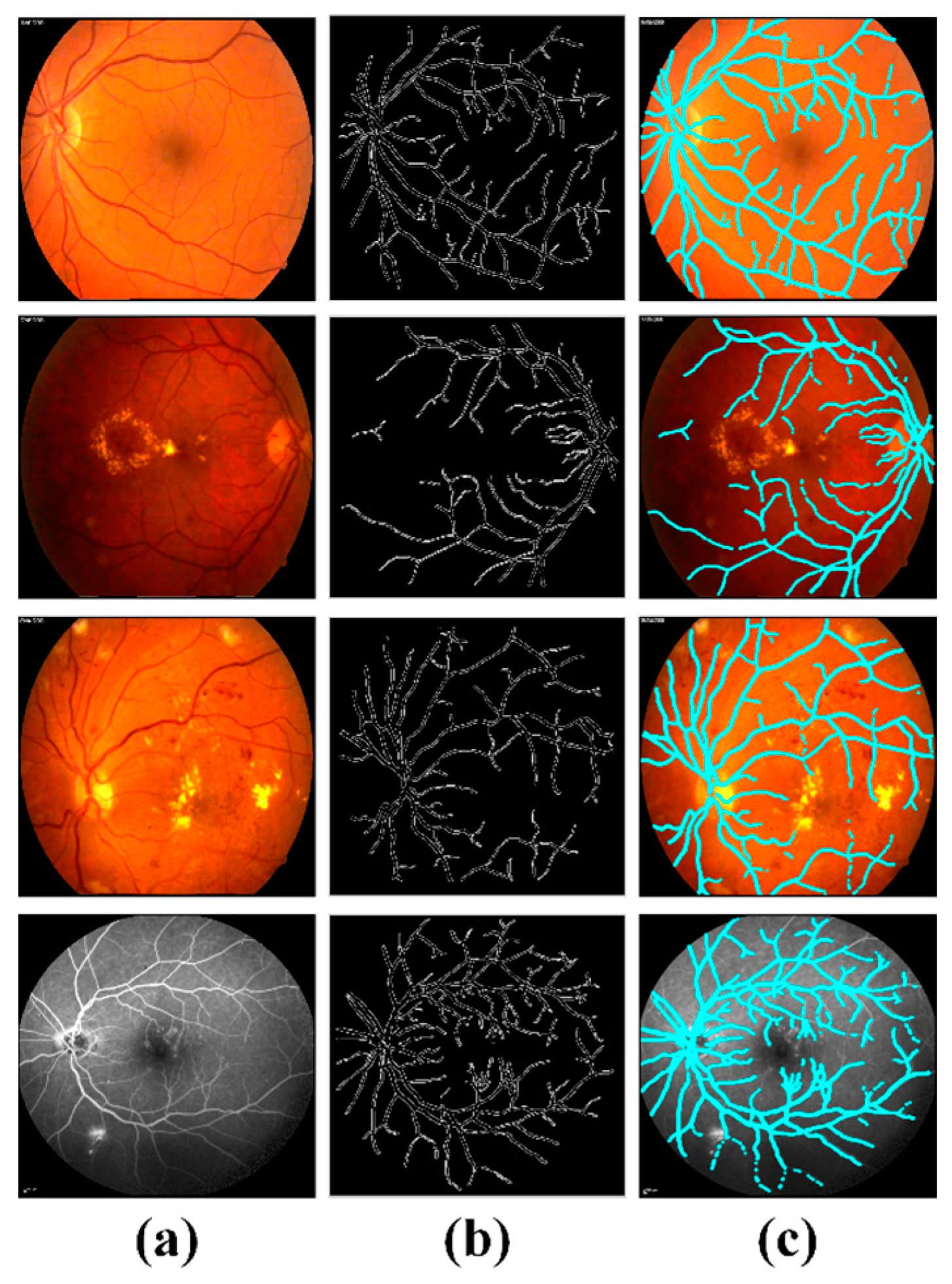
4.2. Preprocessing Retinal Scans
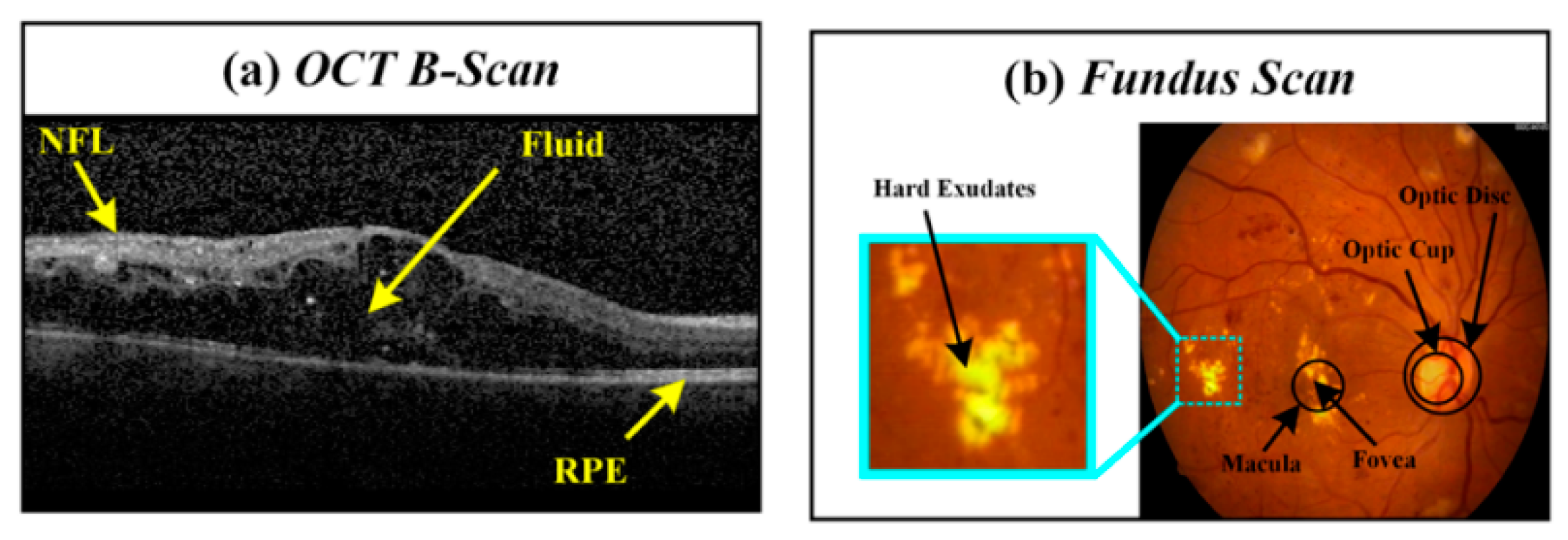
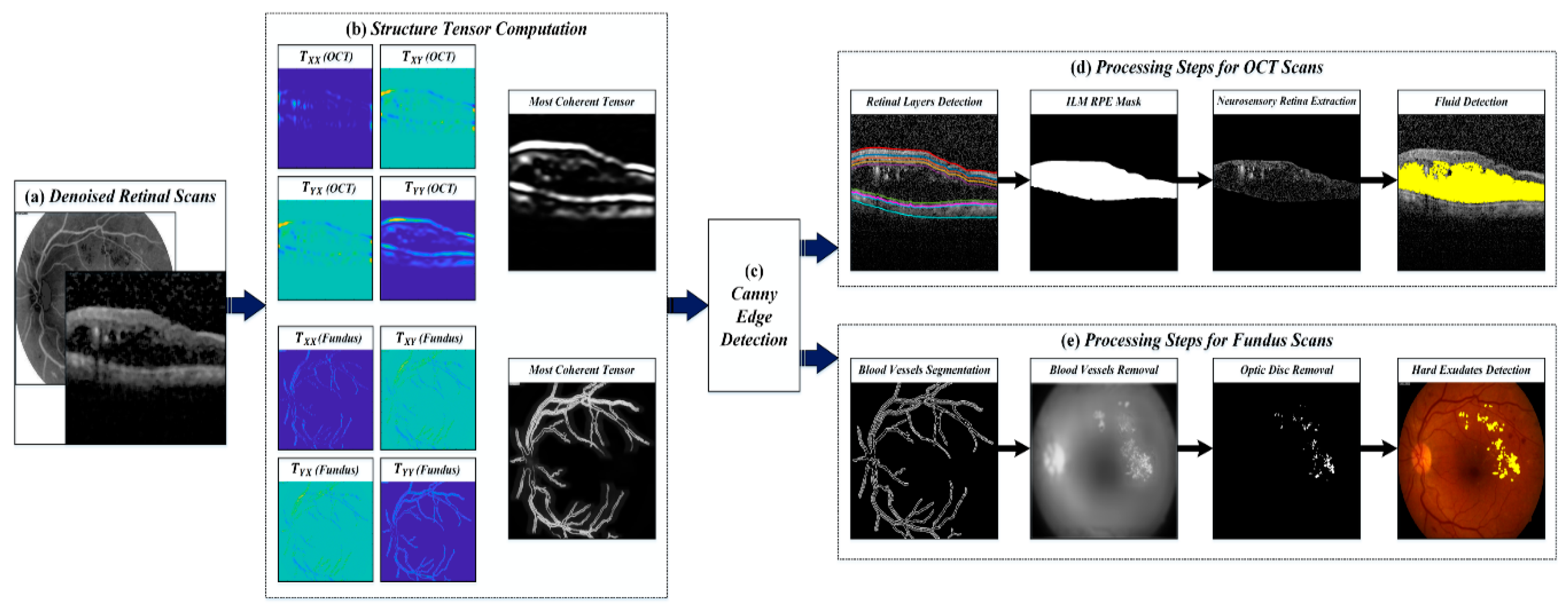
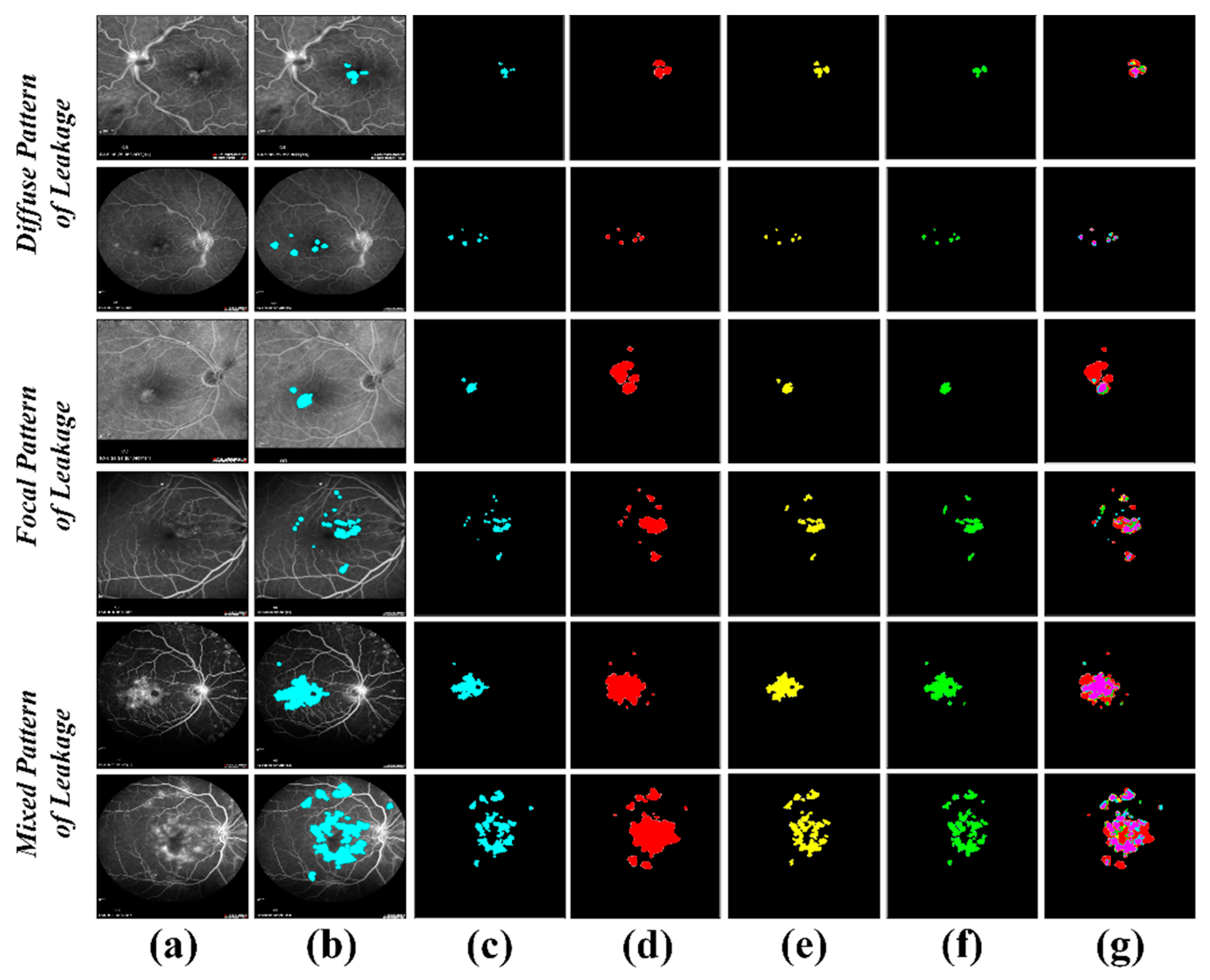
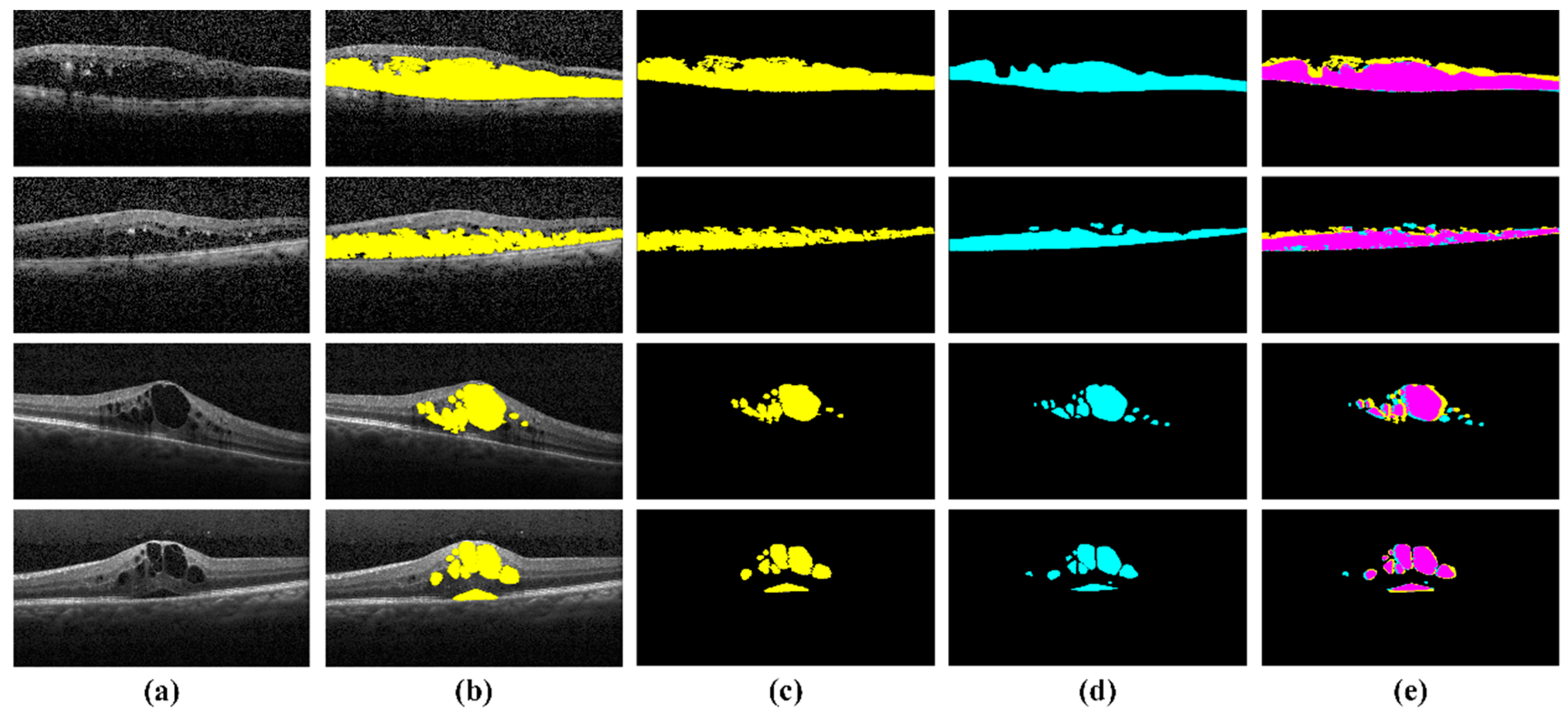
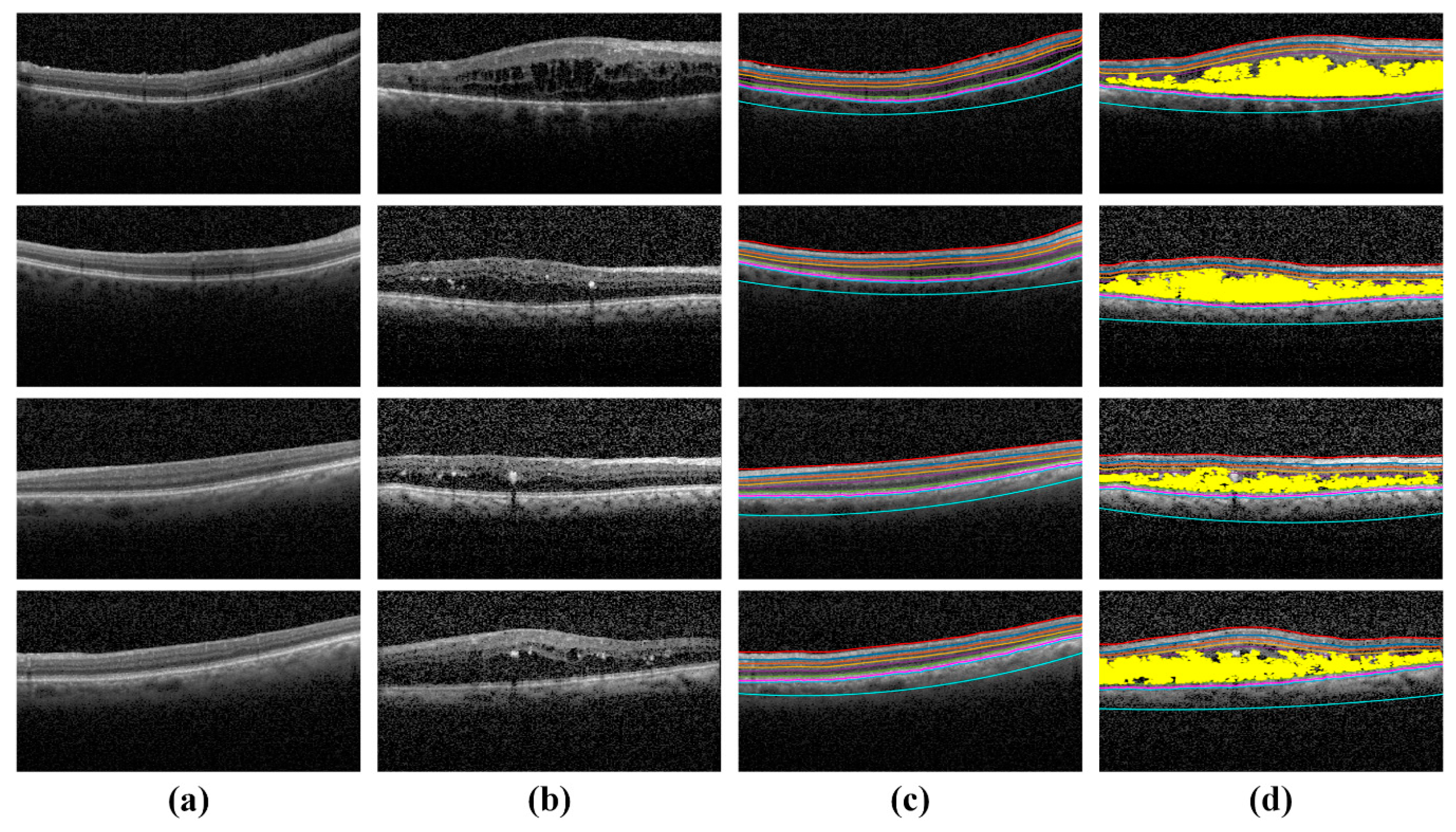
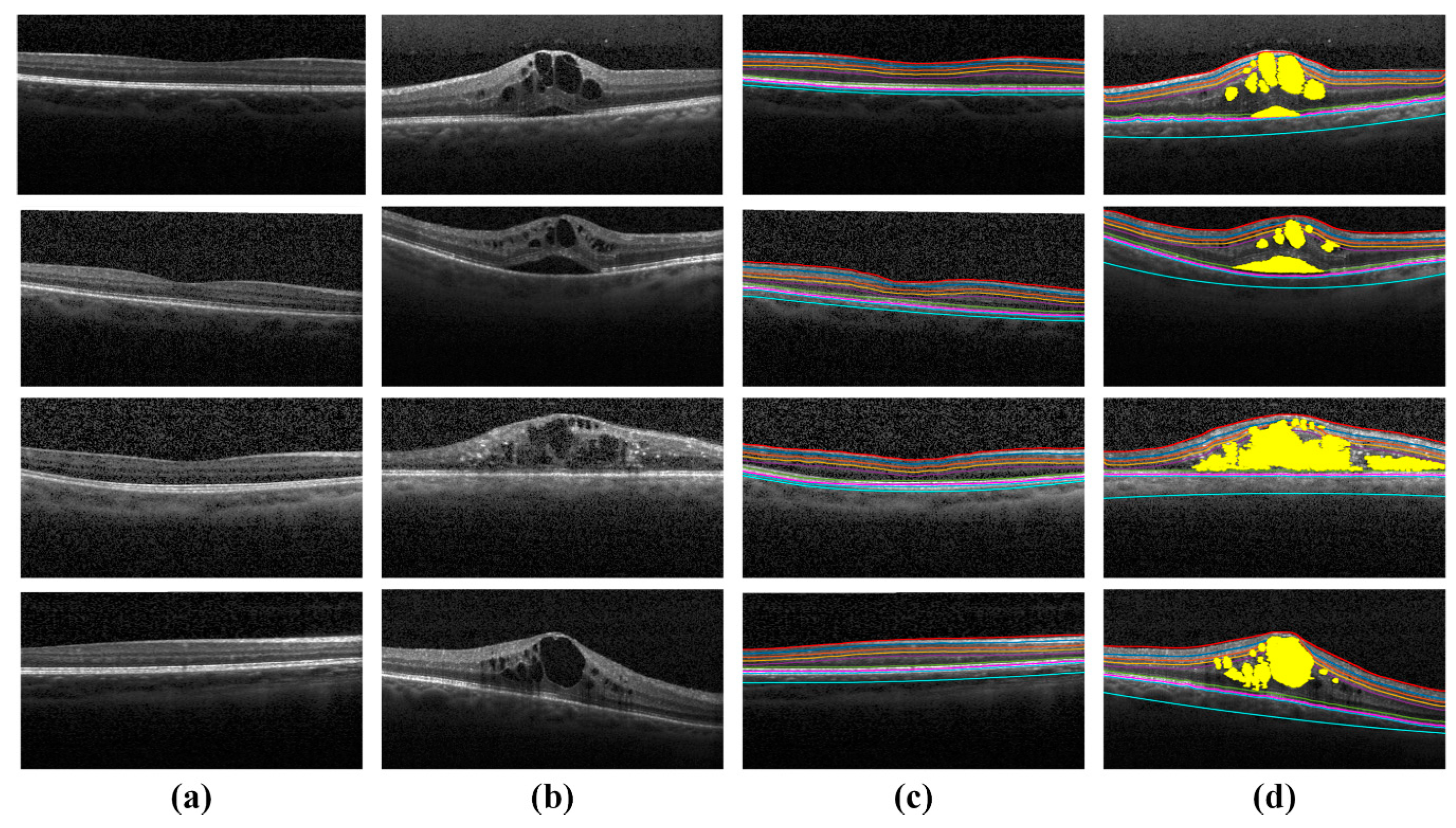
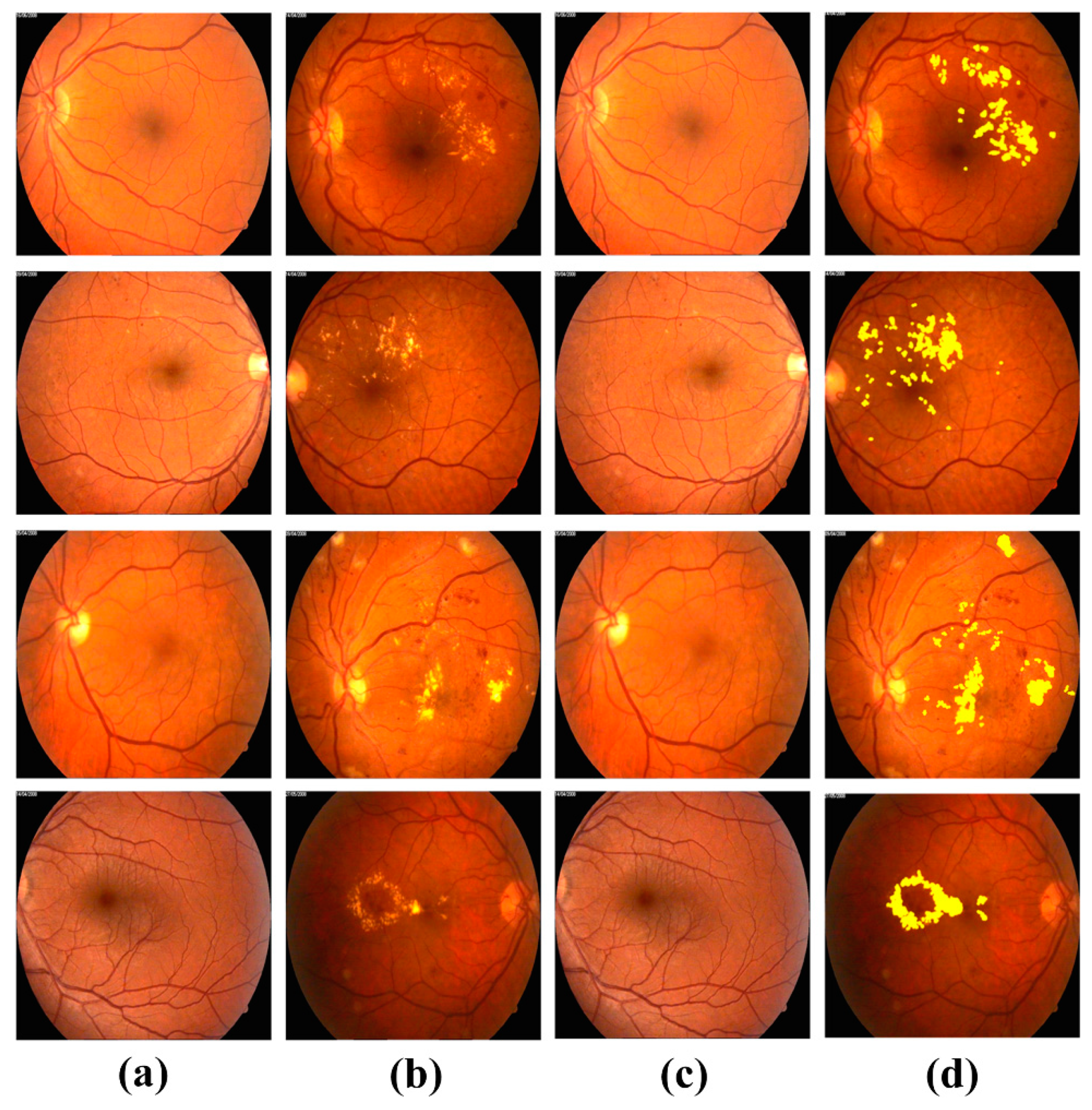
4.3. Extraction of Clinically Significant ME Pathological Symptoms
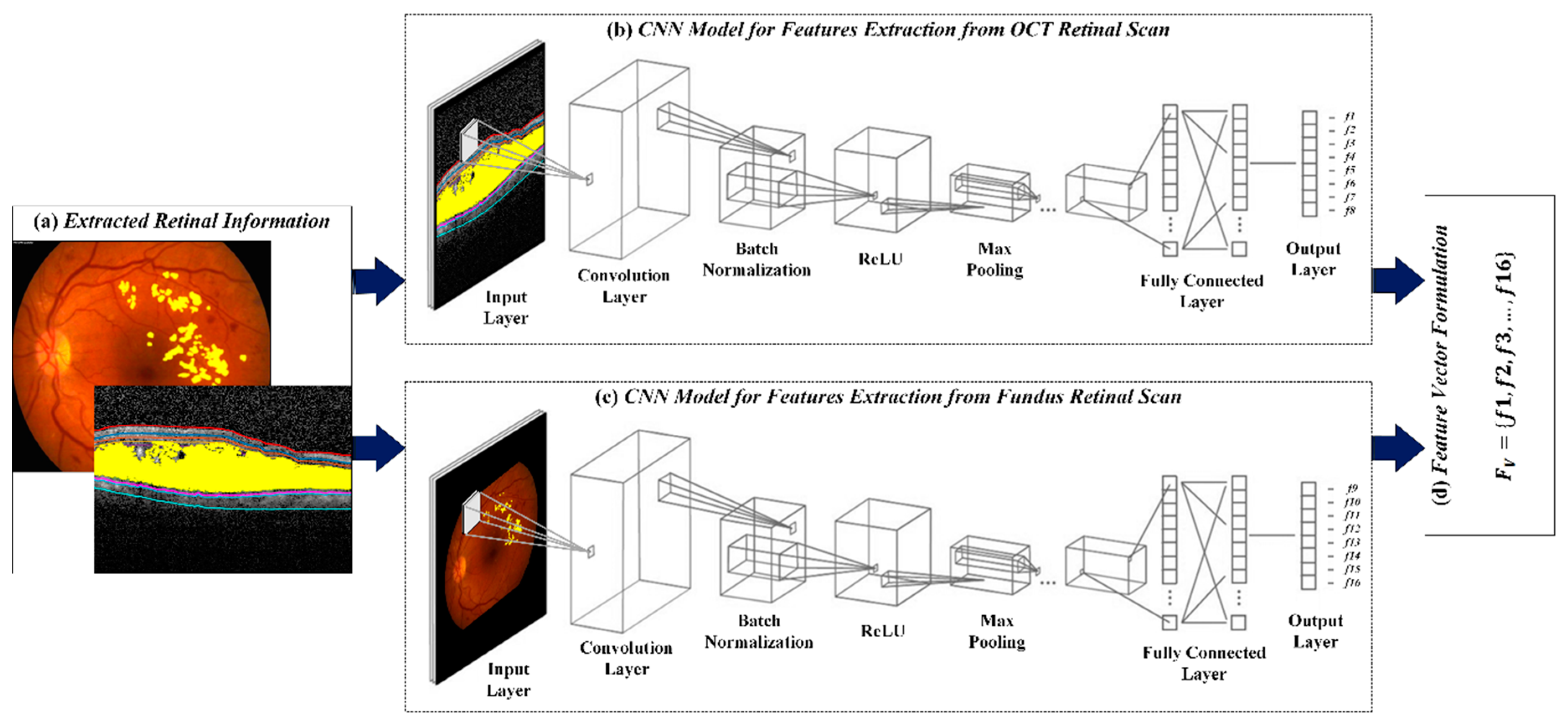
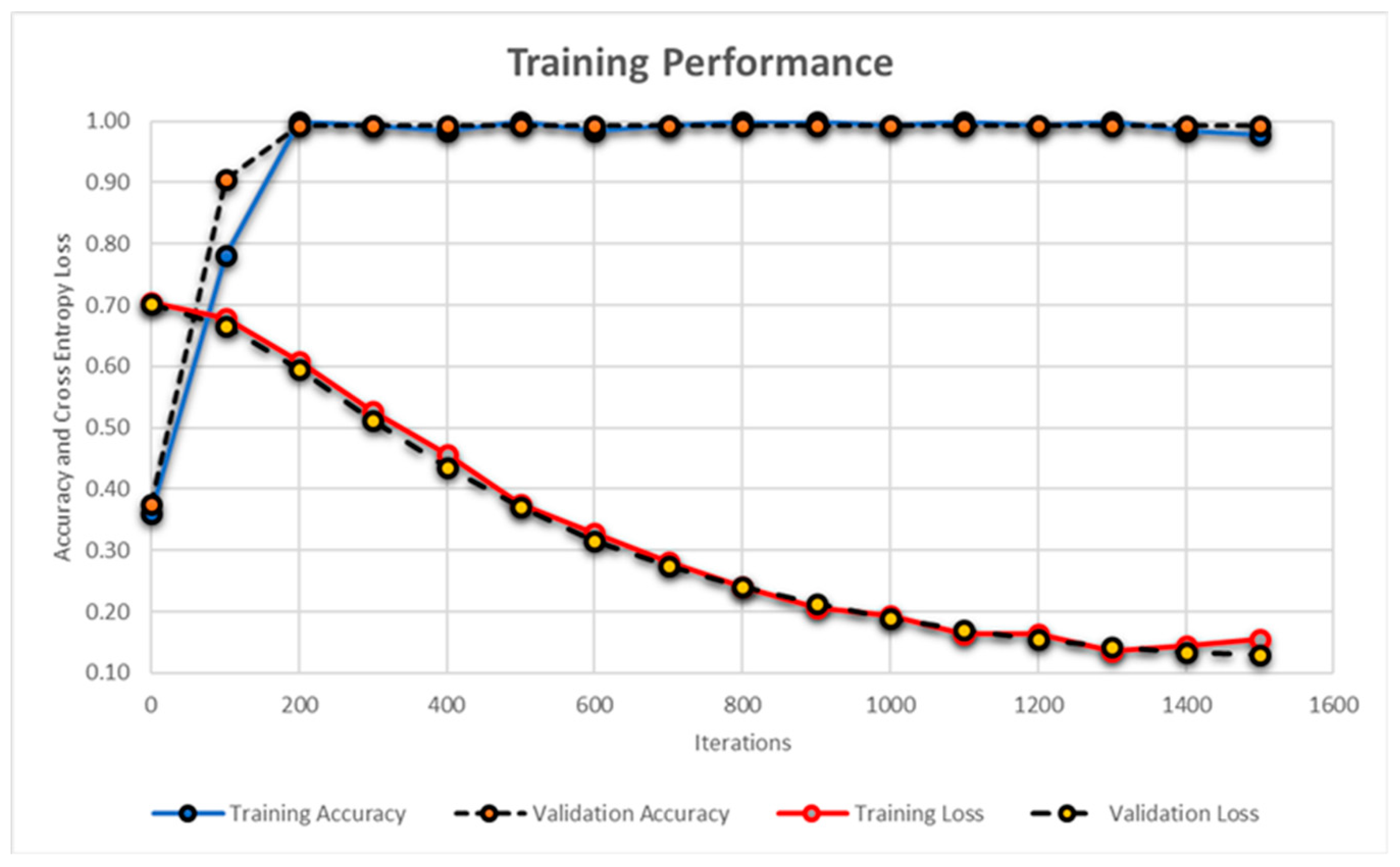
4.4. CNN for Feature Extraction
4.5. Retinal Diagnosis
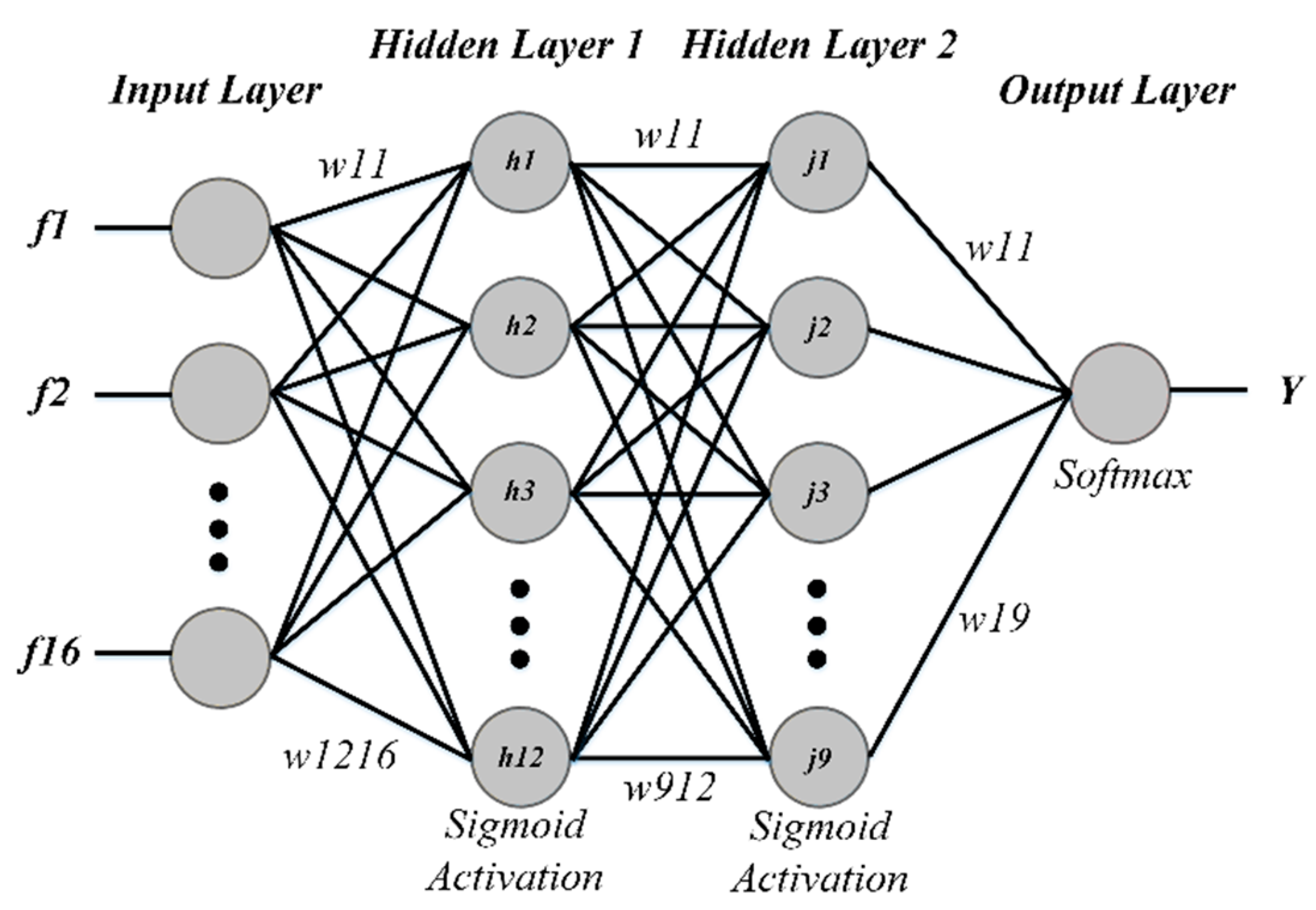
4.5.1. Artificial Neural Networks
4.5.2. Support Vector Machines
4.5.3. Naïve Bayes
| Algorithm 1: Proposed Framework | |
 | |
5. Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- GBD 2017 Disease and Injury Incidence and Prevalence Collaborators. Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018, 392, 1789–1858. [Google Scholar] [CrossRef]
- Hassan, B.; Ahmed, R.; Li, B.; Noor, A.; Hassan, Z.U. A comprehensive study capturing vision loss burden in Pakistan (1990–2025): Findings from the Global Burden of Disease (GBD) 2017 study. PLoS ONE 2019, 14, e0216492. [Google Scholar] [CrossRef] [PubMed]
- Harney, F. Diabetic retinopathy. Medicine 2006, 34, 95–98. [Google Scholar] [CrossRef]
- Alghadyan, A.A. Diabetic retinopathy—An update. Saudi J. Ophthalmol. 2011, 25, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Vidya, K.S.; Ghista, D.N.; Lim, W.J.E.; Molinari, F.; Sankaranarayanan, M. Computer-aided diagnosis of diabetic subjects by heart rate variability signals using discrete wavelet transform method. Knowl. Based Syst. 2015, 81, 56–64. [Google Scholar] [CrossRef]
- Verma, L.; Prakash, G.; Tewari, H.K. Diabetic retinopathy: Time for action. No complacency please! Bull. World Health Organ. 2002, 80, 419. [Google Scholar] [PubMed]
- Mingguang, H.; Wanjiku, M.; Susan, L.; Paul, C. Global Efforts to Generate Evidence for Vision 2020. Ophthalmic Epidemiol. 2015, 22, 237–238. [Google Scholar]
- Hassan, T.; Akram, M.U.; Hassan, B.; Nasim, A.; Bazaz, S.A. Review of OCT and fundus images for detection of Macular Edema. In Proceedings of the 2015 IEEE International Conference on Imaging Systems and Techniques (IST), Macau, China, 16–18 September 2015; pp. 1–4. [Google Scholar]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Puliafito, C.A. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef]
- Swanson, E.A.; Izatt, J.A.; Hee, M.R.; Huang, D.; Lin, C.P.; Schuman, J.S.; Fujimoto, J.G. In vivo retinal imaging by optical coherence tomography. Opt. Lett. 1993, 18, 1864–1866. [Google Scholar] [CrossRef]
- De Carlo, T.E.; Romano, A.; Waheed, N.K.; Duker, J.S. A review of optical coherence tomography angiography (OCTA). Int. J. Retin. Vitr. 2015, 1, 5. [Google Scholar] [CrossRef]
- Fercher, F.; Drexler, W.; Hitzenberger, C.K.; Lasser, T. Optical coherence tomography-principles and applications. Rep. Prog. Phys. 2003, 66, 239. [Google Scholar] [CrossRef]
- Schmitz-Valckenberg, S.; Holz, F.G.; Bird, A.C.; Spaide, R.F. Fundus autofluorescence imaging: Review and perspectives. Retina 2008, 28, 385–409. [Google Scholar] [CrossRef] [PubMed]
- Sepah, Y.J.; Akhtar, A.; Sadiq, M.A.; Hafeez, Y.; Nasir, H.; Perez, B.; Nguyen, Q.D. Fundus autofluorescence imaging: Fundamentals and clinical relevance. Saudi J. Ophthalmol. 2014, 28, 111–116. [Google Scholar] [CrossRef]
- Chee, K.L.; Santiago, P.A.; Lingam, G.; Singh, M.S.; Naing, T.; Mangunkusumo, A.E.; Naser, M.N. Application of Ocular Fundus Photography and Angiography. In Ophthalmological Imaging and Applications; CRC Press: Boca Raton, FL, USA, 2014; pp. 135–156. [Google Scholar]
- Virgili, G.; Menchini, F.; Dimastrogiovanni, A.F.; Rapizzi, E.; Menchini, U.; Bandello, F.; Chiodini, R.G. Optical coherence tomography versus stereoscopic fundus photography or biomicroscopy for diagnosing diabetic macular edema: A systematic review. Investig. Ophthalmol. Vis. Sci. 2007, 48, 4963–4973. [Google Scholar] [CrossRef] [PubMed]
- Browning, J.; McOwen, M.D.; Bowen, R.M., Jr.; Tisha, L.O. Comparison of the clinical diagnosis of diabetic macular edema with diagnosis by optical coherence tomography. Ophthalmology 2004, 111, 712–715. [Google Scholar] [CrossRef] [PubMed]
- Strøm, C.; Sander, B.; Larsen, N.; Larsen, M.; Lund-Andersen, H. Diabetic macular edema assessed with optical coherence tomography and stereo fundus photography. Investig. Ophthalmol. Vis. Sci. 2002, 43, 241–245. [Google Scholar]
- Reza, A.W.; Eswaran, C.; Hati, S. Automatic tracing of optic disc and exudates from color fundus images using fixed and variable thresholds. J. Med. Syst. 2009, 33, 73–80. [Google Scholar] [CrossRef]
- Sreejini, K.S.; Govindan, V.K. Automatic grading of severity of diabetic macular edema using color fundus images. In Proceedings of the 2013 Third International Conference on Advances in Computing and Communications (ICACC), Cochin, India, 29–31 August 2013; pp. 177–180. [Google Scholar]
- Walter, T.; Klein, J.C.; Massin, P.; Erginay, A.A. Contribution of image processing to the diagnosis of diabetic retinopathy-detection of exudates in color fundus images of the human retina. IEEE Trans. Med. Imaging 2002, 21, 1236–1243. [Google Scholar] [CrossRef]
- Giancardo, L.; Meriaudeau, F.; Karnowski, T.P.; Li, Y.; Garg, S.; Tobin, K.W., Jr.; Chaum, E. Exudate-based diabetic macular edema detection in fundus images using publicly available datasets. Med. Image Anal. 2012, 16, 216–226. [Google Scholar] [CrossRef]
- Osareh, A.; Shadgar, B.; Markham, R. A computational-intelligence-based approach for detection of exudates in diabetic retinopathy images. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 535–545. [Google Scholar] [CrossRef]
- Deepak, K.S.; Sivaswamy, J. Automatic assessment of macular edema from color retinal images. IEEE Trans. Med. Imaging 2012, 31, 766–776. [Google Scholar] [CrossRef] [PubMed]
- Yazid, H.; Arof, H.; Isa, H.M. Automated identification of exudates and optic disc based on inverse surface thresholding. J. Med. Syst. 2012, 36, 1997–2004. [Google Scholar] [CrossRef] [PubMed]
- Hassan, B.; Raja, G. Fully Automated Assessment of Macular Edema using Optical Coherence Tomography (OCT) Images. In Proceedings of the 2016 International Conference on Intelligent Systems Engineering (ICISE), Islamabad, Pakistan, 15–17 January 2016; pp. 5–9. [Google Scholar]
- Wilkins, G.R.; Houghton, O.M.; Oldenburg, A.L. Automated segmentation of intraretinal cystoid fluid in optical coherence tomography. IEEE Trans. Biomed. Eng. 2012, 59, 1109–1114. [Google Scholar] [CrossRef] [PubMed]
- Sugmk, J.; Kiattisin, S.; Leelasantitham, A. Automated classification between age-related macular degeneration and diabetic macular edema in OCT image using image segmentation. In Proceedings of the 7th 2014 Biomedical Engineering International Conference (BMEiCON), Fukuoka, Japan, 26–28 November 2014; pp. 1–4. [Google Scholar]
- Hassan, B.; Raja, G.; Hassan, T.; Akram, M.U. Structure tensor based automated detection of macular edema and central serous retinopathy using optical coherence tomography images. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2016, 33, 455–463. [Google Scholar] [CrossRef] [PubMed]
- Chiu, S.J.; Allingham, M.J.; Mettu, P.S.; Cousins, S.W.; Izatt, J.A.; Farsiu, S. Kernel regression based segmentation of optical coherence tomography images with diabetic macular edema. Biomed. Opt. Express 2015, 6, 1172–1194. [Google Scholar] [CrossRef] [PubMed]
- Sahar, S.; Ayaz, S.; Akram, M.U.; Basit, I. A Case Study Approach: Iterative Prototyping Model Based Detection of Macular Edema in Retinal OCT Images. In Proceedings of the 27th International Conference on Software Engineering and Knowledge Engineering (SEKE), Pittsburgh, PA, USA, 6–8 July 2015; pp. 266–271. [Google Scholar]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.S.; Tyring, A.J.; Deruyter, N.P.; Wu, Y.; Rokem, A.; Lee, A.Y. Deep-learning based, automated segmentation of macular edema in optical coherence tomography. Biomed. Opt. Express 2017, 8, 3440–3448. [Google Scholar] [CrossRef] [PubMed]
- Hassan, T.; Akram, M.U.; Masood, M.F.; Yasin, U. Deep structure tensor graph search framework for automated extraction and characterization of retinal layers and fluid pathology in retinal SD-OCT scans. Comput. Biol. Med. 2018, 105, 112–124. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef]
- Rasti, R.; Rabbani, H.; Mehridehnavi, A.; Hajizadeh, F. Macular OCT classification using a multi-scale convolutional neural network ensemble. IEEE Trans. Med. Imaging 2017, 37, 1024–1034. [Google Scholar] [CrossRef]
- Rabbani, H.; Allingham, M.J.; Mettu, P.S.; Cousins, S.W.; Farsiu, S. Fully automatic segmentation of fluorescein leakage in subjects with diabetic macular edema. Investig. Ophthalmol. Vis. Sci. 2015, 56, 1482–1492. [Google Scholar] [CrossRef] [PubMed]
- Mahmudi, T.; Kafieh, R.; Rabbani, H.; Akhlagi, M. Comparison of macular OCTs in right and left eyes of normal people. In Proceedings of the Medical Imaging 2014: Biomedical Applications in Molecular, Structural, and Functional Imaging, San Diego, CA, USA, 17–21 August 2014; Volume 9038, p. 90381W. [Google Scholar]
- Alipour, S.H.M.; Rabbani, H.; Akhlaghi, M.R. Diabetic retinopathy grading by digital curvelet transform. Comput. Math. Methods Med. 2012, 2012, 761901. [Google Scholar] [CrossRef]
- Esmaeili, M.; Rabbani, H.; Dehnavi, A.M.; Dehghani, A. Automatic detection of exudates and optic disk in retinal images using curvelet transform. IET Image Process. 2012, 6, 1005–1013. [Google Scholar] [CrossRef]
- Alipour, S.H.M.; Rabbani, H.; Akhlaghi, M.; Dehnavi, A.M.; Javanmard, S.H. Analysis of foveal avascular zone for grading of diabetic retinopathy severity based on curvelet transform. Graefe’s Arch. Clin. Exp. Ophthalmol. 2012, 250, 1607–1614. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 5th International Conference on Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin, Germany, 2012; pp. 437–478. [Google Scholar]
- Köthe, U. Edge and junction detection with an improved structure tensor. Jt. Pattern Recognit. Symp. 2003, 25–32. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset a | Imaging Modality b | Retinal Pathology b | Scans Dimension(s) | |||
|---|---|---|---|---|---|---|
| OCT | Fundus/FA | Healthy | ME | OCT | Fundus/FA | |
| 1 [36] | 2764 | - | 1628 | 1136 | 496 × 512 | - |
| 2 [37] | - | 24 | - | 24 | - | 512 × 612 |
| 768 × 868 | ||||||
| 3 [38] | 12,800 | 100 | 12,900 | - | 512 × 650 | 1612 × 1536 |
| 4 [39] | - | 120 | 60 | 60 | - | 720 × 576 |
| 5 [40] | - | 35 | - | 35 | - | 720 × 576 |
| 6 [41] | - | 60 | 25 | 35 | - | 720 × 576 |
| 7 [35] | 62,988 | - | 51,390 | 11,598 | 512 × 496 | - |
| 512 × 512 | ||||||
| 768 × 496 | ||||||
| 1024 × 496 | ||||||
| 1536 × 496 | ||||||
| Total | 78,552 | 339 | 66,003 | 12,888 | - | |
| Split | Training | Validation | ||||
| Modality | OCT | Fundus/FA | OCT | Fundus/FA | ||
| Total Scans | 73,552 | 239 | 5000 | 100 | ||
| Healthy | 63,318 | 135 | 2500 | 50 | ||
| ME | 10,234 | 104 | 2500 | 50 | ||
| Function | Layer | Description |
|---|---|---|
| Input Image | 1 | 227 × 227 × 3 images |
| Convolution | 2 | 9611 × 11 × 3 convolutions |
| 6 | 2565 × 5 × 48 convolutions | |
| 10 | 3843 × 3 × 256 convolutions | |
| 12 | 3843 × 3 × 192 convolutions | |
| 14 | 2563 × 3 × 192 convolutions | |
| ReLU | 3 | Assigns ‘0’ to non-positive values |
| 7 | ||
| 11 | ||
| 13 | ||
| 15 | ||
| 18 | ||
| 21 | ||
| Max Pooling | 5 | 3 × 3 max pooling |
| 9 | ||
| 16 | ||
| Dropout | 19 | 50% dropout |
| 22 | ||
| Normalization | 4 | Five channels per element |
| 8 | ||
| Fully Connected | 17 | 4096 fully connected layer |
| 20 | ||
| 23 | ||
| Softmax | 24 | Softmax activation function |
| Output | 25 | Two Classes (OCT, Fundus) |
| 1 | Input layer | 227 × 227 × 3 images with ‘zerocenter’ normalization |
| 2 | Convolution | 89 × 9 × 3 convolutions with stride [1,1] and padding ‘same’ |
| 3 | Batch Normalization | Batch normalization with eight channels |
| 4 | ReLU | Rectified Linear Units |
| 5 | Max Pooling | 2 × 2 max pooling with stride [2,2] and padding [0,0,0,0] |
| 6 | Convolution | 169 × 9 × 8 convolutions with stride [1,1] and padding ‘same’ |
| 7 | Batch Normalization | Batch normalization with 16 channels |
| 8 | ReLU | Rectified Linear Units |
| 9 | Dropout | 50% Dropout |
| 10 | Max Pooling | 2 × 2 max pooling with stride [2,2] and padding [0,0,0,0] |
| 11 | Convolution | 329 × 9 × 16 convolutions with stride [1,1] and padding ‘same’ |
| 12 | Batch Normalization | Batch normalization with 32 channels |
| 13 | ReLU | Rectified Linear Units |
| 14 | Fully Connected | Fully connected layer giving the significant eight features |
| Features | Healthy | Macular Edema | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Case 1 | Case 2 | Case 3 | Mean a | Case 1 | Case 2 | Case 3 | Mean a | ||
| OCT | F1 | 2.28 | 1.53 | 1.69 | 1.51 | 1.97 | −0.79 | −2.62 | 1.17 |
| F2 | 2.13 | 4.35 | 1.58 | 2.18 | 0.58 | 0.63 | 1.29 | 0.86 | |
| F3 | −3.13 | −1.92 | −6.4 | −3.57 | −0.85 | 2.73 | 1.73 | −1.56 | |
| F4 | 4.83 | 0.84 | 1.48 | 2.87 | −0.29 | 1.3 | −3.38 | 0.19 | |
| F5 | 0.59 | 0.28 | 0.44 | 0.29 | 1.9 | 1.35 | 0.76 | 0.68 | |
| F6 | 4.82 | 1.87 | 7.59 | 4.46 | 2.73 | 3.29 | 2.59 | 2.93 | |
| F7 | 1.03 | 0.37 | 2 | 0.71 | −0.07 | 0.64 | 0.19 | 0.26 | |
| F8 | −0.65 | 0.94 | 0.58 | −0.69 | 1.61 | 1.34 | 1.4 | 1.38 | |
| Fundus | F9 | −1.85 | 0.61 | −1.62 | −0.95 | 0.3 | 2.3 | 0.1 | 0.27 |
| F10 | 2.67 | 1.4 | 2.51 | 2.93 | 1.28 | 1.42 | 1.17 | 1.09 | |
| F11 | −1.77 | −7.83 | −1.7 | −1.14 | −2.54 | −2.11 | −3.06 | −2.71 | |
| F12 | 1.29 | 0.18 | 0.01 | 0.26 | 1.44 | 1.13 | 1.46 | 1.43 | |
| F13 | 1.61 | −0.09 | 0.66 | 0.25 | 0.02 | −2.49 | 0.81 | −0.11 | |
| F14 | 2.37 | 1.65 | 2.44 | 0.81 | 2.75 | 4.61 | 2.24 | 3.12 | |
| F15 | 1.7 | 0.14 | 0.68 | 0.72 | −1.04 | 1.46 | −0.26 | 0.07 | |
| F16 | 1.26 | 0.82 | 1.25 | 1.17 | 0.8 | 0.62 | 0.98 | 0.57 | |
| K | Max Accuracy Achieved | ||
|---|---|---|---|
| ANN | SVM | NB | |
| 2 | 0.816 | 0.809 | 0.794 |
| 3 | 0.893 | 0.841 | 0.829 |
| 4 | 0.914 | 0.874 | 0.864 |
| 6 | 0.948 | 0.907 | 0.917 |
| 8 | 0.972 | 0.925 | 0.942 |
| 10 | 0.991 | 0.966 | 0.980 |
| 11 | 0.985 | 0.948 | 0.961 |
| 12 | 0.973 | 0.929 | 0.944 |
| Leakage Pattern | Scans | Against Grader 1 | Against Grader 2 | Against Grader 3 |
|---|---|---|---|---|
| Diffuse | 1 | 0.7529 | 0.8931 | 0.8372 |
| 2 | 0.3573 | 0.5973 | 0.6698 | |
| 3 | 0.6838 | 0.6727 | 0.6744 | |
| 4 | 0.6718 | 0.7391 | 0.7739 | |
| Focal | 1 | 0.5871 | 0.6397 | 0.6928 |
| 2 | 0.2339 | 0.7288 | 0.694 | |
| 3 | 0.7169 | 0.8275 | 0.8631 | |
| 4 | 0.3887 | 0.6349 | 0.634 | |
| Mixed | 1 | 0.6035 | 0.882 | 0.875 |
| 2 | 0.5941 | 0.6691 | 0.7329 | |
| 3 | 0.6551 | 0.7938 | 0.8339 | |
| 4 | 0.5582 | 0.7661 | 0.7851 | |
| Mean ± STD (All Dataset) | 0.5726 ± 0.16 | 0.7669 ± 0.10 | 0.7813 ± 0.08 | |
| Mean ± STD (Overall) | 0.7069 ± 0.11 | |||
| Scans | Rabbani Dataset 1 [41] | Rabbani Dataset 2 [37] | |
|---|---|---|---|
| Healthy | ME | ME | |
| 1 | 0.7817 | 0.7871 | 0.7914 |
| 2 | 0.8808 | 0.8315 | 0.8135 |
| 3 | 0.8747 | 0.8197 | 0.7861 |
| 4 | 0.7983 | 0.7890 | 0.8047 |
| 5 | 0.8669 | 0.8444 | 0.7971 |
| 6 | 0.8518 | 0.8071 | 0.8168 |
| 7 | 0.8811 | 0.8004 | 0.7896 |
| 8 | 0.8190 | 0.7927 | 0.8238 |
| 9 | 0.8468 | 0.8058 | 0.8275 |
| 10 | 0.8617 | 0.7871 | 0.7914 |
| Mean ± STD (All Dataset) | 0.8589 ± 0.04 | 0.8185 ± 0.03 | 0.7839 ± 0.02 |
| Mean ± STD (Overall) | 0.8203 ± 0.03 | ||
| Scans | Rabbani Dataset [36] | Zhang Dataset [35] |
|---|---|---|
| 1 | 0.9194 | 0.9152 |
| 2 | 0.8689 | 0.8560 |
| 3 | 0.9082 | 0.9351 |
| 4 | 0.8551 | 0.9145 |
| 5 | 0.8726 | 0.9243 |
| 6 | 0.9322 | 0.8796 |
| 7 | 0.9238 | 0.8986 |
| 8 | 0.8887 | 0.8731 |
| 9 | 0.9162 | 0.8766 |
| 10 | 0.8724 | 0.9259 |
| Mean ± STD (All Dataset) | 0.9026 ± 0.03 | 0.9012 ± 0.04 |
| Mean ± STD (Overall) | 0.9019 ± 0.04 | |
| Methods | Validation Dataset | CC | TP | TN | FP | FN | SE | SP | PPV | NPV | A | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OCT | Fundus | OCT | Fundus | |||||||||||
| Proposed | ANN | 5000 R, Z | 100 R | 4653 | 94 | 2457 | 2291 | 259 | 93 | 0.96 | 0.90 | 0.90 | 0.96 | 0.93 |
| SVM | 4648 | 93 | 2407 | 2322 | 228 | 143 | 0.94 | 0.91 | 0.91 | 0.94 | 0.92 | |||
| NB | 4559 | 92 | 2374 | 2289 | 261 | 176 | 0.93 | 0.90 | 0.90 | 0.93 | 0.91 | |||
| Hybrid | 4716 | 95 | 2473 | 2338 | 212 | 77 | 0.97 | 0.92 | 0.92 | 0.97 | 0.94 | |||
| [19] | ✗ | 20 Ψ, ψ | ✗ | - | - | - | - | - | 0.943* | 1* | 0.92* | - | - | |
| 0.967^ | 1^ | 0.949^ | - | - | ||||||||||
| [20] | ✗ | 100 ϕ | ✗ | 93 | 33 | 60 | 0 | 7 | 0.825 | 1 | - | - | 0.93 | |
| [21] | ✗ | 30 | ✗ | - | - | 13 | 2 | - | 0.928 | - | 0.924 | - | - | |
| [23] | ✗ | 150 ζ | ✗ | - | 72 | 71 | - | - | 0.96 | 0.946 | - | - | - | |
| [24] | ✗ | 400 ϕ | ✗ | - | - | - | - | - | 0.95 | 0.9 | - | - | - | |
| 104 ξ | 1 | 0.74 | ||||||||||||
| [25] | ✗ | 15 ψ | ✗ | - | - | - | - | - | 0.978 | 0.99 | 0.833 | - | - | |
| 15 C | 0.907 | 0.994 | 0.74 | - | - | |||||||||
| [26] | 30 D | ✗ | 28 | ✗ | 15 | 13 | - | - | 1 | 0.933 | - | - | - | |
| [27] | 19 C | ✗ | - | ✗ | - | - | - | - | 0.91 | 0.96 | - | - | - | |
| [28] | 16 | ✗ | - | ✗ | - | - | - | - | - | - | - | - | 0.875 | |
| [29] | 90 B | ✗ | 88 | ✗ | 60 | 28 | - | - | 1 | 0.933 | 0.977 | |||
| [31] | 50 B | ✗ | 42 | ✗ | 28 | 14 | - | - | 0.93 | 0.8 | - | - | 0.84 | |
| [32] | 45 D | ✗ | 43 | ✗ | 30 | 13 | - | - | 1 | 0.866 | - | - | - | |
| [34] | 42281 D | ✗ | - | ✗ | - | - | - | - | 0.991 | 0.986 | - | - | 0.985 | |
| 4260 B | ||||||||||||||
| [35] | 500 Z | ✗ | 483 | ✗ | 237 | 246 | - | - | 0.968 | 0.996 | - | - | 0.982 | |
| System | Software | Average Time for Single Classification (seconds) | ||||
|---|---|---|---|---|---|---|
| Classifier | OCT | Fundus | ||||
| Made | DELL | Windows 10 Pro 64-bit | MATLAB R2018a | ANN | 4.6 | 3.3 |
| Processor | i7-4500U @ 2.4GHz | SVM | 5.7 | 4.2 | ||
| RAM | 8GB DDR2 | NB | 3.2 | 1.8 | ||
| Graphics | AMD HD 8670M | Hybrid | 6.8 | 5.1 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, B.; Hassan, T.; Li, B.; Ahmed, R.; Hassan, O. Deep Ensemble Learning Based Objective Grading of Macular Edema by Extracting Clinically Significant Findings from Fused Retinal Imaging Modalities. Sensors 2019, 19, 2970. https://doi.org/10.3390/s19132970
Hassan B, Hassan T, Li B, Ahmed R, Hassan O. Deep Ensemble Learning Based Objective Grading of Macular Edema by Extracting Clinically Significant Findings from Fused Retinal Imaging Modalities. Sensors. 2019; 19(13):2970. https://doi.org/10.3390/s19132970
Chicago/Turabian StyleHassan, Bilal, Taimur Hassan, Bo Li, Ramsha Ahmed, and Omar Hassan. 2019. "Deep Ensemble Learning Based Objective Grading of Macular Edema by Extracting Clinically Significant Findings from Fused Retinal Imaging Modalities" Sensors 19, no. 13: 2970. https://doi.org/10.3390/s19132970
APA StyleHassan, B., Hassan, T., Li, B., Ahmed, R., & Hassan, O. (2019). Deep Ensemble Learning Based Objective Grading of Macular Edema by Extracting Clinically Significant Findings from Fused Retinal Imaging Modalities. Sensors, 19(13), 2970. https://doi.org/10.3390/s19132970