In this subsection, we first present the setup of experimental environment for the WSN localization problem and the control parameters’ adjustments for EHO, HEHO, TGA, and dynsTGA metaheuristics that were employed in the conducted experiments. After we show details of conducted simulations, as well as comparative analysis with other state-of-the-art approaches found in the literature that were tested on the same problem instance under the same experimental conditions.
6.2.1. Experimental Setup and Parameter Adjustments
In this and the subsequent subsection, we have provided exhaustive details of the control parameters’ adjustments and experimental conditions, so researchers who wants to implement the proposed approaches and to run simulations have more than enough information to do this on their own.
For the experimental setup of this paper we have constructed a simulation topology which includes a two-dimensional () WSN monitoring environment (deployment area) with a size of , where U represents unit of measurement. Within this monitoring environment, static target sensor nodes and anchor nodes with coordinates () are randomly deployed between the lower and the upper boundary of the WSN monitoring domain, using pseudo-random number generator.
We conducted experiments with different number of target nodes
M and anchors nodes
N. We wanted to see how algorithms behave in different test scenarios. In performed all simulations, the number of target nodes varies in the range
, while the number of anchor nodes in all simulations is between 8 and 35 (inclusive). In every run of the algorithm, the network topology was generated randomly. Similar experiments were conducted in Ref. [
15].
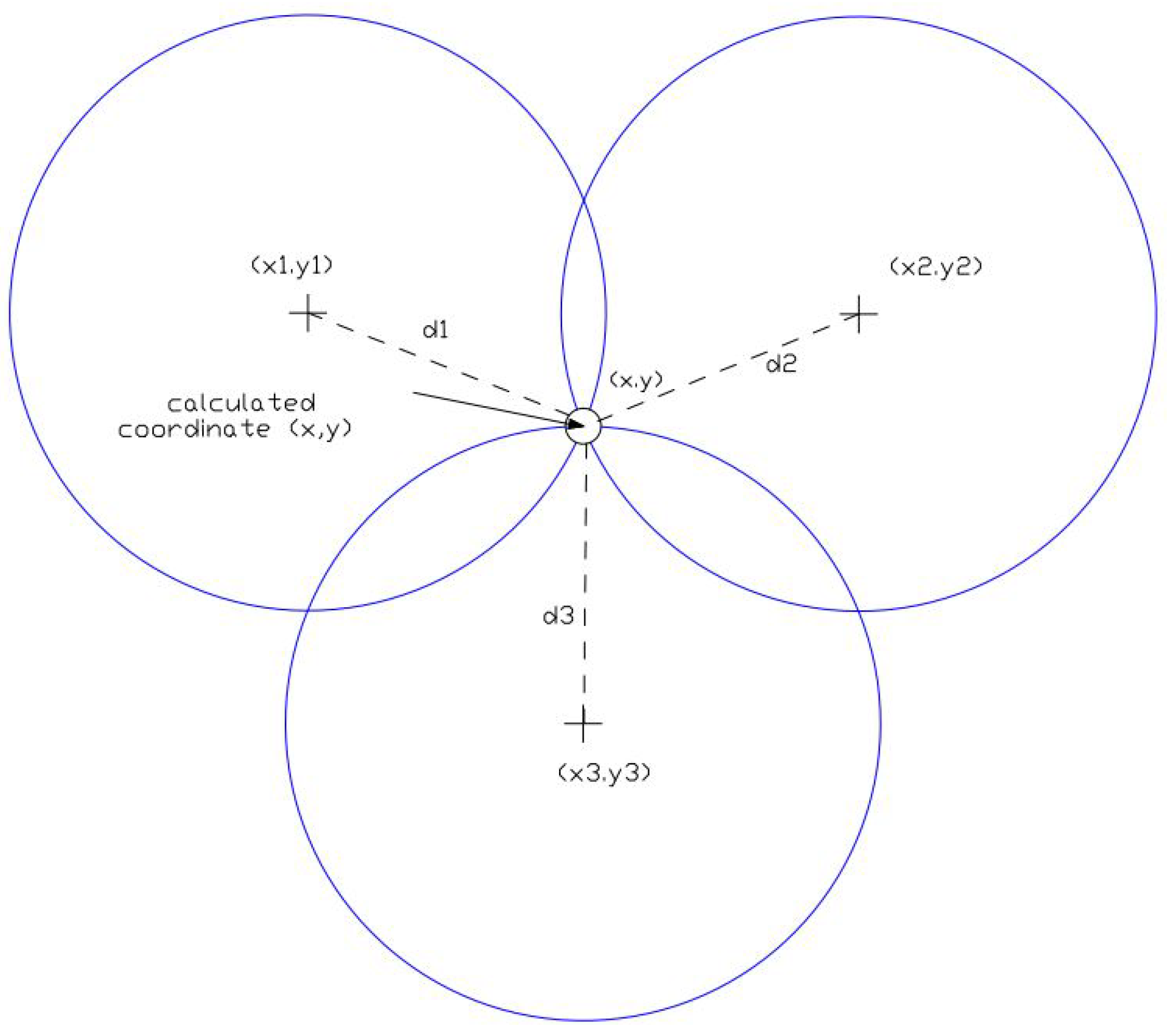
As explained in
Section 3, the range measurement is blurred with the additive Gaussian noise
. The parameter
, which represents the standard deviation of the measured distance, influences the performance of localization (see Equation (
2)). Two essential parameters that affect the localization error
are density of anchor nodes per
and sensors’ transmission range
R. The transmission range is set to
in all simulations.
Also, in all conducted experiments with all algorithms (TGA, dynsTGA, EHO, and HEHO), the size of population
N and the maximum generation number (
) were set to 30 and 200, respectively. The same parameter adjustments were used in Ref. [
15]. In Ref. [
15], swarm intelligence approaches that are used for the purpose of comparative analysis in this paper are presented. By utilizing this set of parameters, a comparative analysis presented in this study is more objective and represents real performance comparison between different swarm algorithms approaches.
The basic TGA and dynsTGA control parameters were adjusted as follows: initial population size (
N) was set to 25, the values for
and
were set to 6, while the value for
was adjusted to 13. Also, in every iteration, additional 5 solutions were evaluated (
). This in total yields 30 solutions in the population, like in Ref. [
15]. For other control parameters we set the following values:
and
.
In the case of dynsTGA experiments, the value of was fixed during the whole course of algorithm’s execution. Also, the values for , , and were static in the first 180 iterations. In the final stages of algorithm’s execution, the value of was decremented by one until a threshold value of is reached, and the values of and were incremented by 1 in even and odd iterations, respectively. Finally, in the latest iterations, parameters and reached the value of 12.
At the beginning of the dynsTGA execution, the value of
was set to 0.2. In every iteration, setting for the
was adjusted by utilizing expression
, until the threshold value 1.5 is reached. Similar was performed in dynsTGA’s tests for bound-constrained benchmarks (see
Section 6.1.1 ).
The basic EHO and HEHO control parameters were set as follows: the number of clans n was set to 5, and the number of solutions in each clan was set to 6. The values for the scale factors and were set to 0.5 and 0.1, respectively.
The adjustments for the
parameter in the case of HEHO approach were the same as in unconstrained tests (see
Section 6.1.2). The initial value of the
parameter was set to 5. Then, in each even iteration, the
value was incremented by 1. In this way, in early iterations, the solutions that cannot be improved were discarded from the population often and exploration power is higher. However, in later iterations with the increase of the
parameter value, solutions were discarded from the population with lesser frequency, and the trade-off between exploitation and exploration is shifted in favor to exploitation.
In all conducted simulations presented in
Section 6.2.2 we utilized Intel CoreTM i7-4770K processor @4GHz with 32GB of RAM memory, Windows 10 Professional x64 operating system, and Java Development Kit 11 (JDK 11) and IntelliJ integrated development environment (IDE).
6.2.2. Empirical Results, Comparative Analysis, and Discussion
In the research conducted for the purpose of this paper we performed two sets of experiments in order to measure real performance of our proposed approaches.
In the first set of experiments, we wanted to measure the influence of the noise percentage () in distance measurement on the localization accuracy. For this purpose we ran original and upgraded/hybridized TGA and EHO metaheuristics with the value of set to 2 and 5, respectively. In this case we used 40 target nodes (), and 8 anchor nodes () randomly deployed in the WSN domain.
With each particular value of we executed all algorithms in 30 independent runs, and for each run we used different pseudo-random number seed. As performance indicators, we took the following metrics: the mean number of non-localized nodes () and the mean localization error (). Values of performance indicators were averaged over 30 runs.
The same parameter setup, as well as the performance indicators were used in Ref. [
15].
Experimental results are summarized in
Table 5. Best results from each category (mean
, mean
, computation time) are marked bold.
From the results presented in
Table 5, it can be noticed that the influence of the percentage noise (
) on localization accuracy is obvious and significant. When the
was decreased from 5 to 2, in all test case for all approaches, the localization error decreased, while the number of localized nodes increased (number of non-localized nodes decreased).
From the results presented in
Table 5 it can be concluded that the dynsTGA metaheuristics obtains the best results. This was expected since dynsTGA also performed the best in the case of conducted tests on standard bound-constrained benchmarks (refer to
Table 2 and
Table 3). The dynsTGA outperformed other approaches in both performance indicators: it managed to localize most target nodes with low localization error.
Basic TGA and HEHO performed similarly. For example, in the case of the test with set to 5, the HEHO localized more targets, but TGA obtained lower localization error. Also, in the case of test, the difference between these two approaches is insignificant. Finally, original EHO metaheuristics was significantly worse than all other approaches presented in this paper.
When analyzing computational costs in terms of execution speed, it is obvious that the dynsTGA is the most expensive approach, while the basic TGA implementation proved to be light-weight and executed faster than other metaheuristics. These results are expected since the dynsTGA at the end of each iteration performs dynamical adjustment of the control parameters ,, , and .
In Ref. [
15], the same tests were performed (with
and
) under the same experimental conditions and under the same problem instance. In this paper, the authors proposed butterfly optimization algorithm (BOA) and compared it with the particle swarm optimization (PSO) and the firefly algorithm (FA).
We wanted to see how approaches presented in this paper perform related to approaches showed in Ref. [
15], and for this purpose we conducted comparative analysis. A side by side comparison is presented in
Table 5 and
Table 6.
The comparison could be made only for the mean number of non-localized nodes (
) and the mean localization error (
) metrics. Comparative analysis for the computational time indicator could not be performed, since the approaches presented in Ref. [
15] were tested on different computational platforms. In the presented table, the best results from each category are marked bold.
According to the results presented in
Table 6, a general conclusion is that the dynsTGA proved to be the best approach. In both cases, for
and
the dynsTGA obtained better results than all other metaheuristics included in comparative analysis. The second best approach is BOA. For example, when
was set to 5, the dynsTGA managed on average to localize 35.5 targets, while BOA successfully localized 35.3 targets. Also, the dynsTGA obtained lower localization error (0.19 vs. 0.28).
Similar results are obtained in the case of test, where the dynsTGA on average could not localize 4.3 targets, while BOA could not find the position of 4.5 nodes. Also, in this test, the dynsTGA localized targets with a localization error that is almost 24% lower than BOA (0.16 vs. 0.21).
Also, from
Table 6 it can be seen that the third best performing algorithm included in comparative analysis are TGA and HEHO. These two approaches share the third place. A more detailed comparison between the TGA and HEHO is given above.
The fourth best performing approach is PSO. In both tests, the PSO proved to be the average performing metaheuristics method for this type of problem. Finally, the last place is shared between the FA and the EHO. It should be also noted that the FA performed slightly better than EHO, but this difference is negligible. For example, in the test with set to 2, both algorithms on average managed to localize 33.8 out of 40 targets, where the FA obtained slightly lower localization error (0.69 vs. 0.71).
In the second set of experiments, we utilized different numbers of target nodes (M) and sensor nodes (N). We wanted to perform more detailed analysis of robustness and solutions’ quality of proposed approaches. In all tests the value of was set to 2, and each experiment is conducted in five independent runs.
Other experimental and metaheuristics control parameters were adjusted as shown in
Section 6.2.1.
In
Table 7, we show detailed results for all five runs in all conducted experiments. The annotations used in the results table are the following: number of localized nodes, localization error, and execution time measured in seconds are represented with
,
, and
, respectively.
Since the proposed localization algorithms are stochastic, different results are obtained in different runs and the best results from each category of tests could not be emphasized.
As can be seen from the presented table, the results vary from run to run. For example, in the test with 25 targets and 10 anchor nodes, the EHO meatheuristics managed to localize between 17 and 21 targets, while the dynsTGA localized 23, 24, or 25 nodes with the unknown position. Also, in this test, the localization error in all runs is uniformly better in the case of dynsTGA metaheuristics, than in the case of other approaches. Metaheuristics HEHO and TGA perform similarly, and the performance difference is negligible, like in the test with 40 target and 8 anchor nodes (please refer to
Table 5).
In the experiment with 125 target and 30 anchor nodes, the EHO localized between 121 and 125 targets, and dynsTGA in almost every run managed to determine positions of unknown nodes. The EHO and TGA localized between 123 and 125 targets. Also, in this test in almost all runs, the dynsTGA obtained the lowest localization error.
Regarding the execution speed, the most expensive approach is dynsTGA, while the algorithm that consumes the least amount of computational resources is TGA. Since the HEHO incorporates parameter from the ABC metaheuristics, this approach utilizes slightly more resources that its basic implementation.
Similar conclusions can be drawn from all other tests. Considering both performance indicators (number of localized nodes and localization error), the worst performing metaheuristics is EHO, while the algorithm that obtained the best solution quality is the dynsTGA. Metaheuristics HEHO and TGA generate nearly same results in all test instances.
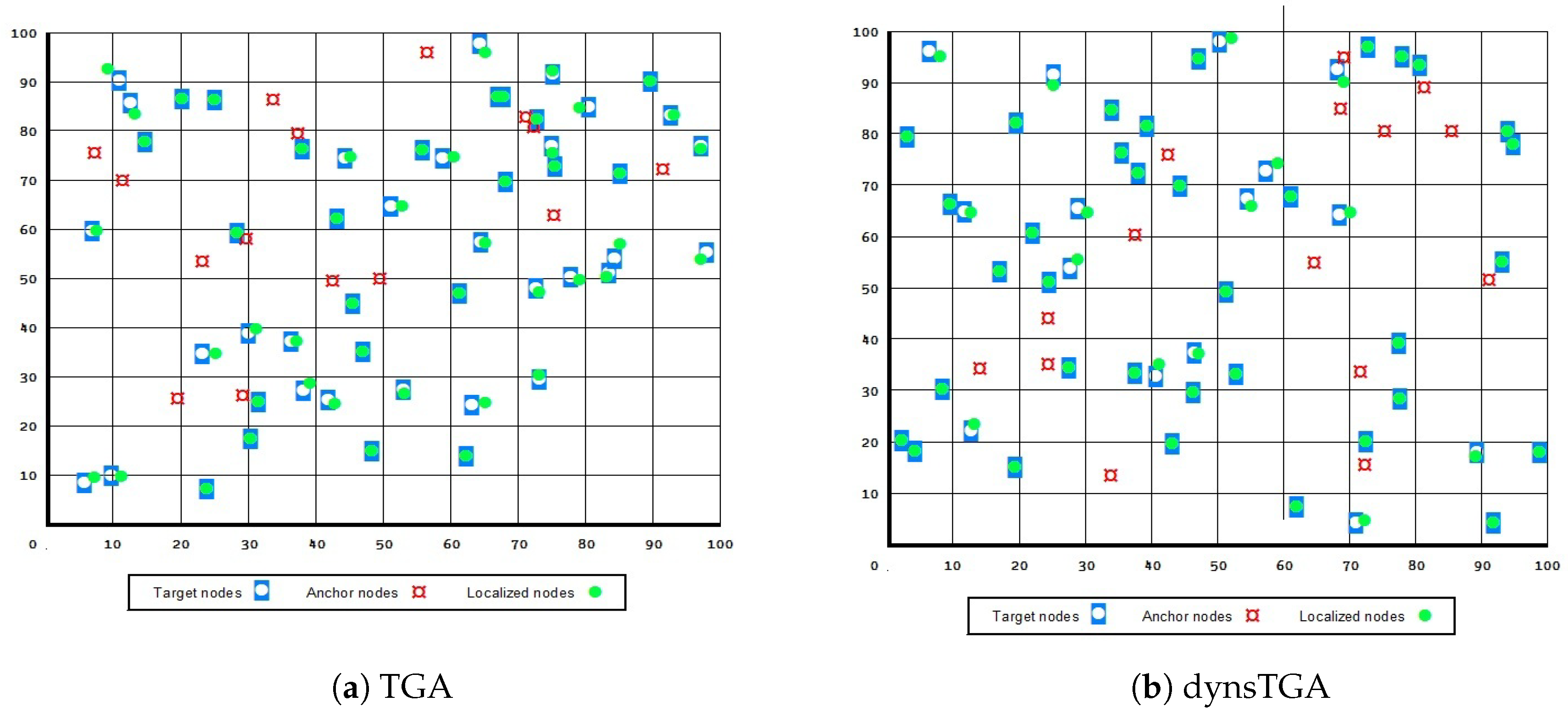
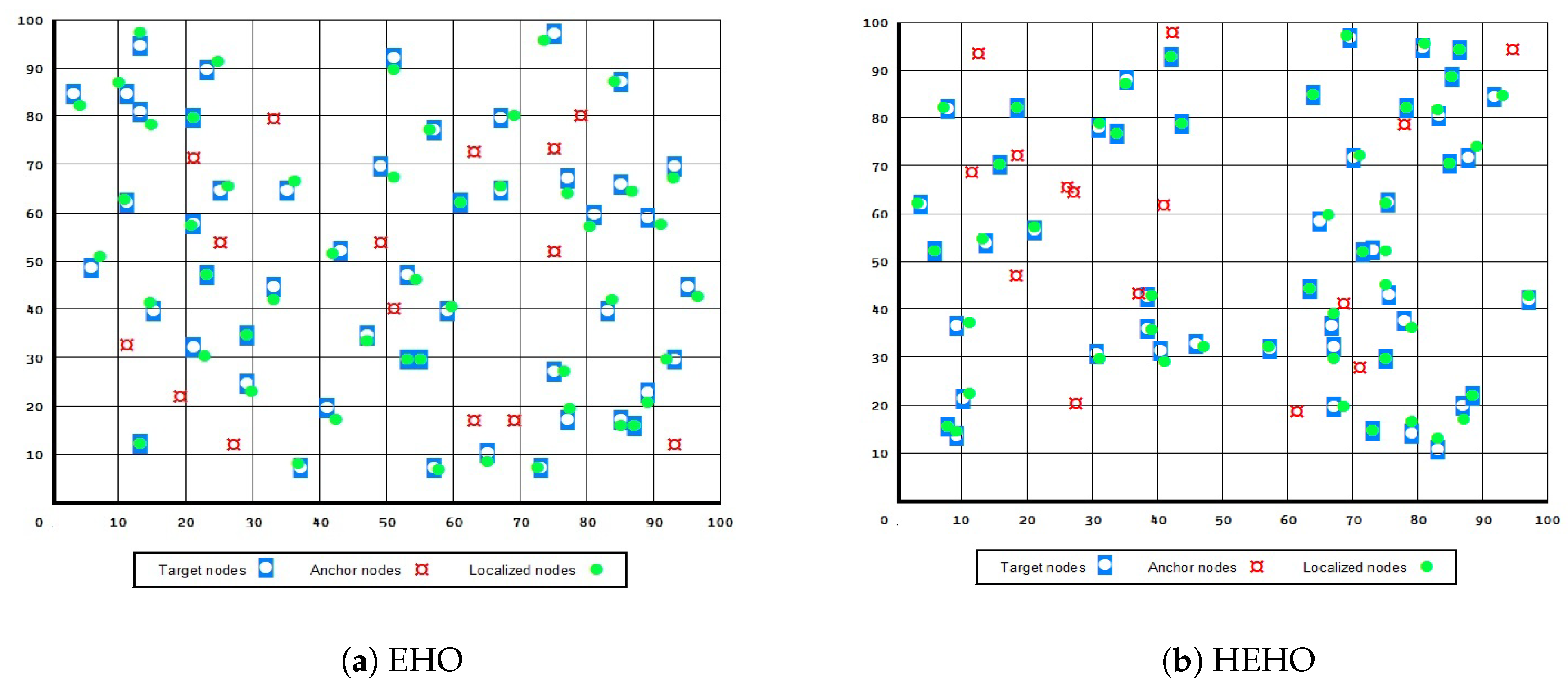
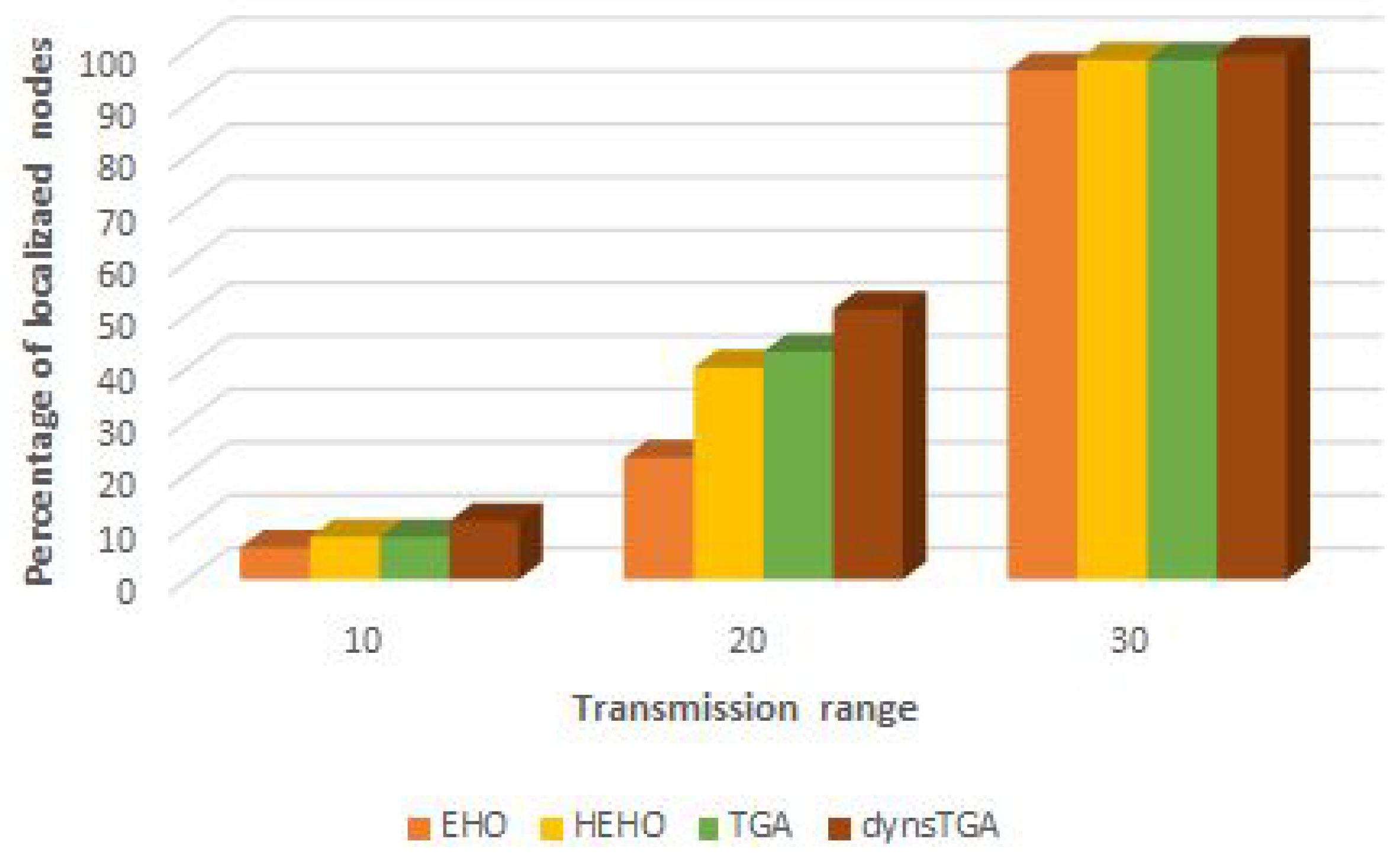
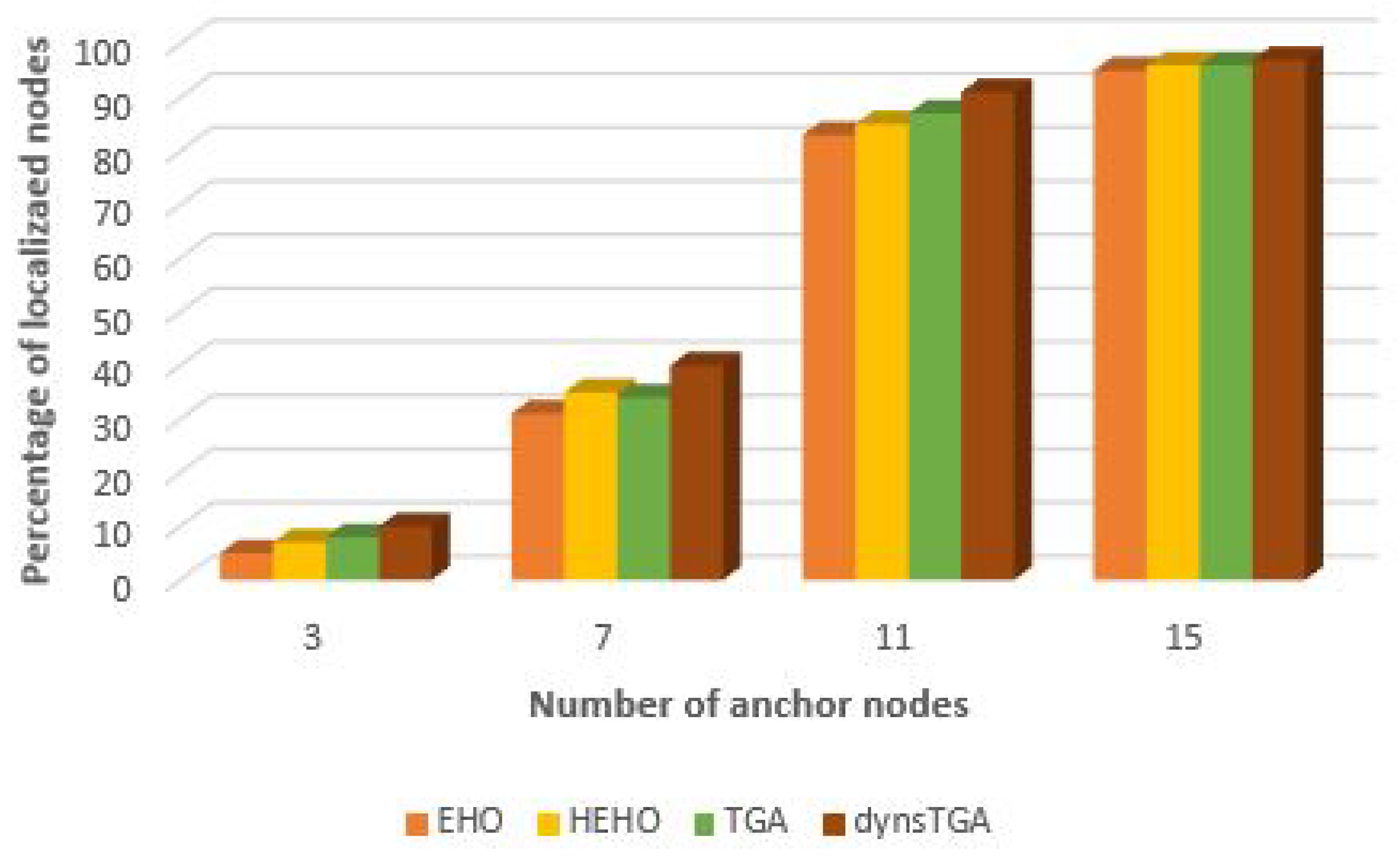
A visualization of the results in the test with 50 target and 15 anchor nodes, in the case when all presented approaches managed to localize all 50 unknown sensors, is given in
Figure 4 and
Figure 5. From the presented figures it can be clearly seen that the dynsTGA obtains the lowest localization error, while the basic EHO approach localized all 50 targets with the least precision and accuracy.
As already mentioned above, in Ref. [
15] the implementation of BOA for the same problem instance and under the same experimental conditions was presented. Also, in Ref. [
15] detailed analysis of results for the five algorithms’ runs was given. In
Table 8, we show comparative analysis between our HEHO and dynsTGA implementations and BOA, FA, and PSO showed in Ref. [
15].
By carefully analyzing
Table 8, it can be seen that dynsTGA performs better than all other approaches included in comparative analysis. The second best metaheuristics is BOA, while TGA and HEHO outperform the FA and PSO algorithms. Similar deduction was drawn in tests with varying
values (please refer to
Table 6).
For example, in tests on problem instances with {50 targets, 15 anchors}, {100 targets, 25 anchors}, and {150 targets and 35 anchors} the BOA approach on average obtained localization errors of 0.30, 0.24, and 0.55, respectively. For the same tests, the dynsTGA-based localization localized unknown targets with the localization errors of 0.25, 0.22, and 0.47, which is significantly better than in the case of BOA. At the same time, on average, both algorithms managed to localize the same number of target nodes.
Contrarily, the HEHO metaheuristics, which outperform the PSO and FA approaches, for the same problem instances, obtained localization error of 0.37, 0.35, and 0.78, respectively. Thus, the HEHO-based localization estimated the locations of unknown targets with lesser accuracy when compared to the dynsTGA approach.
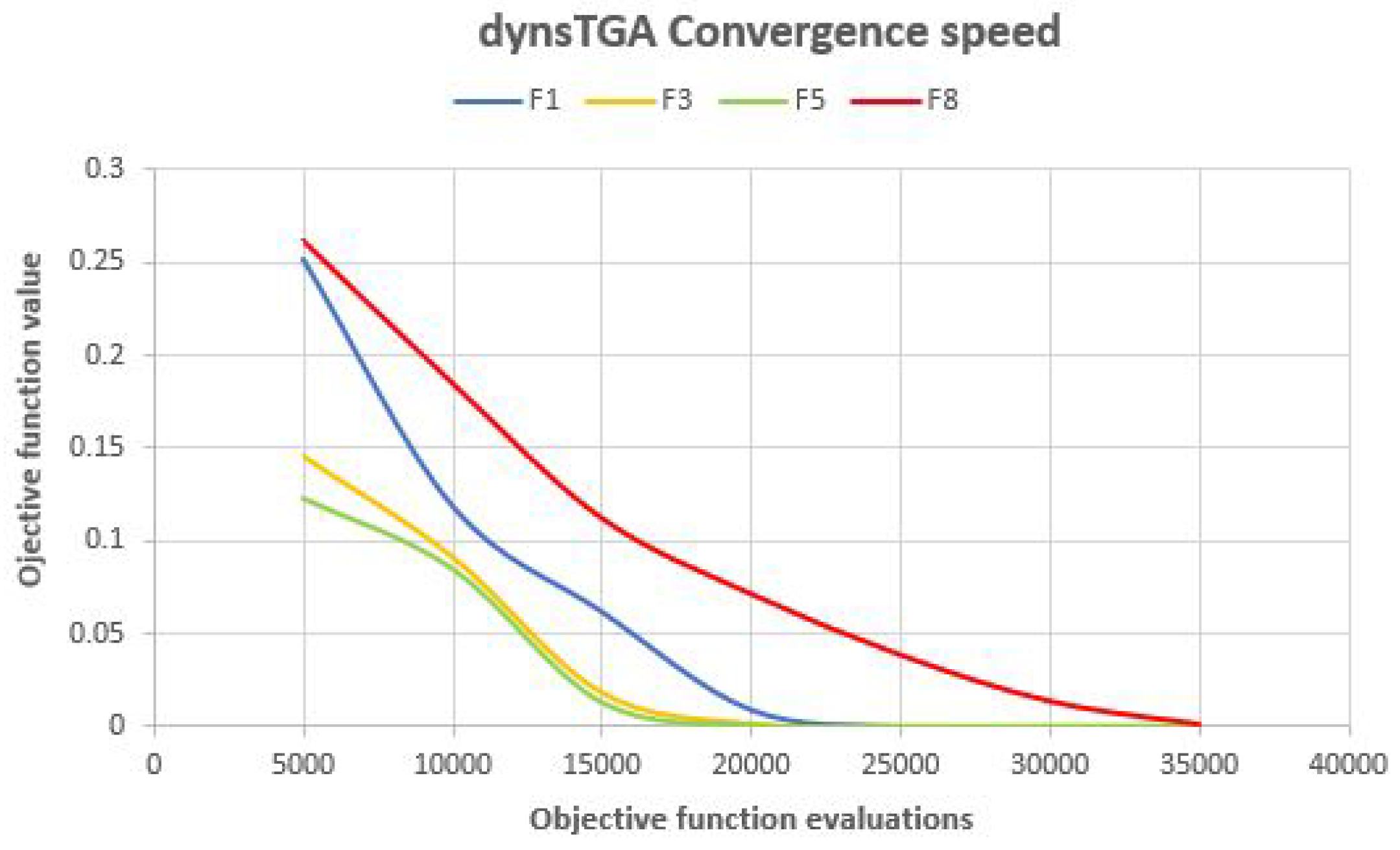
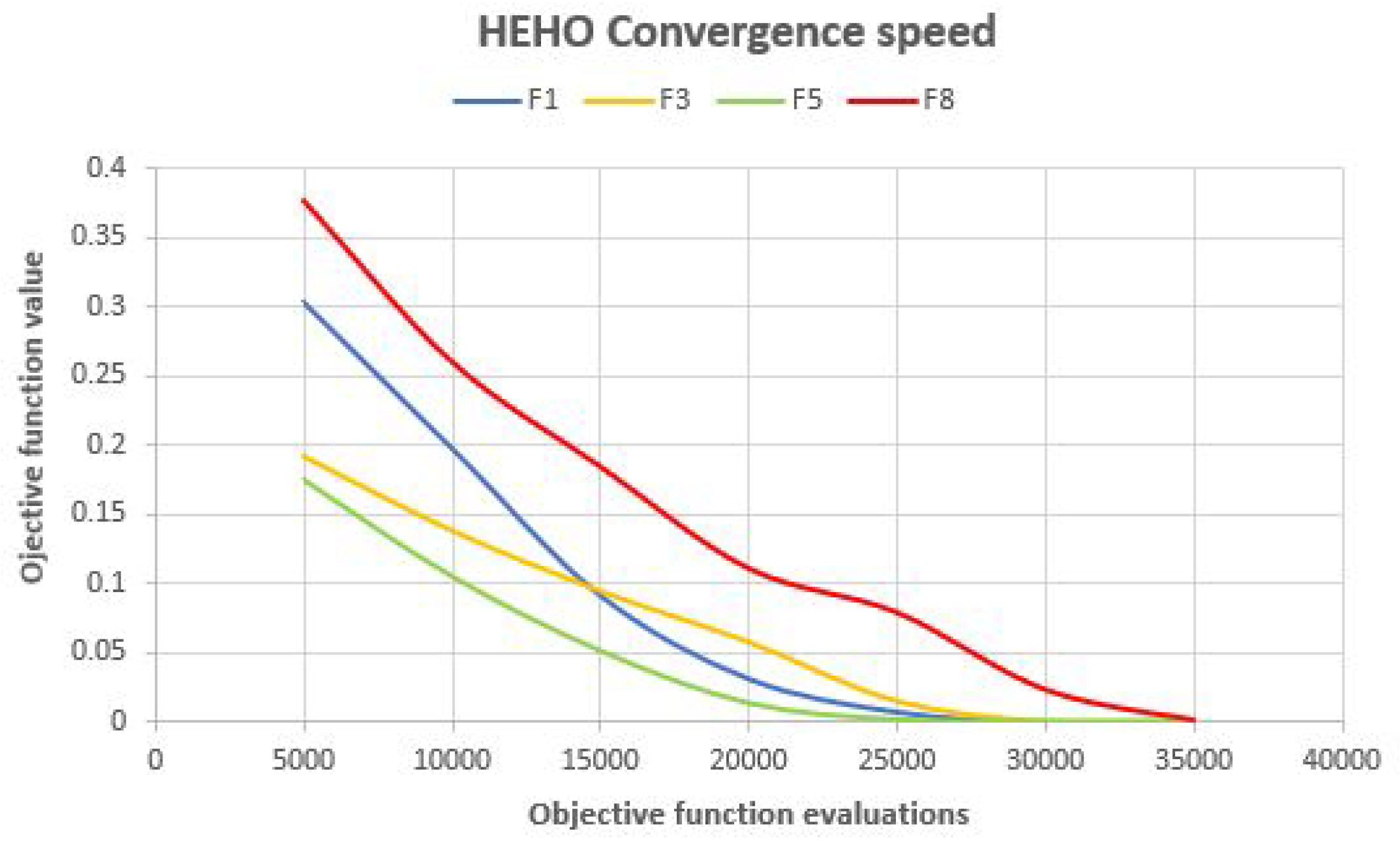
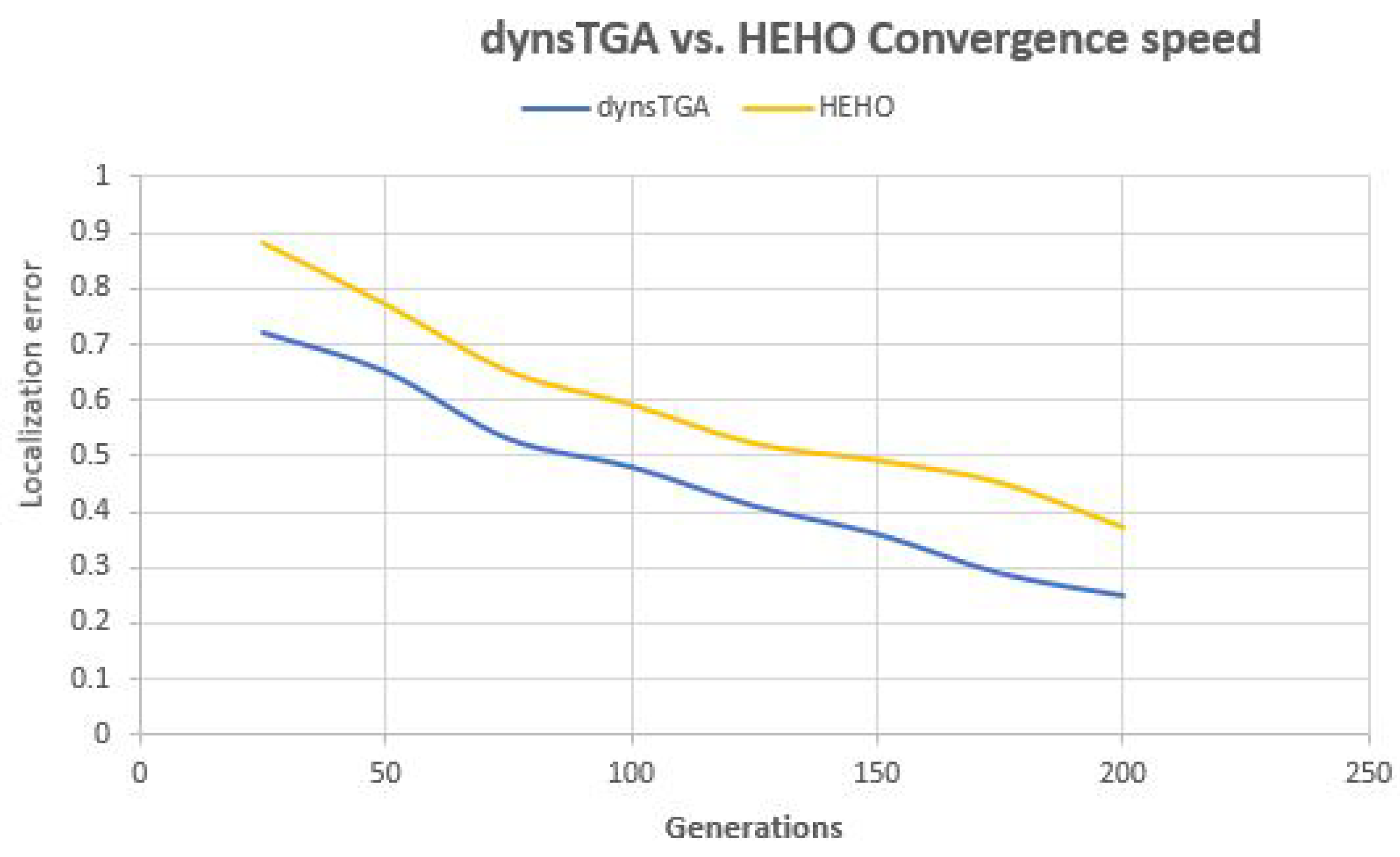
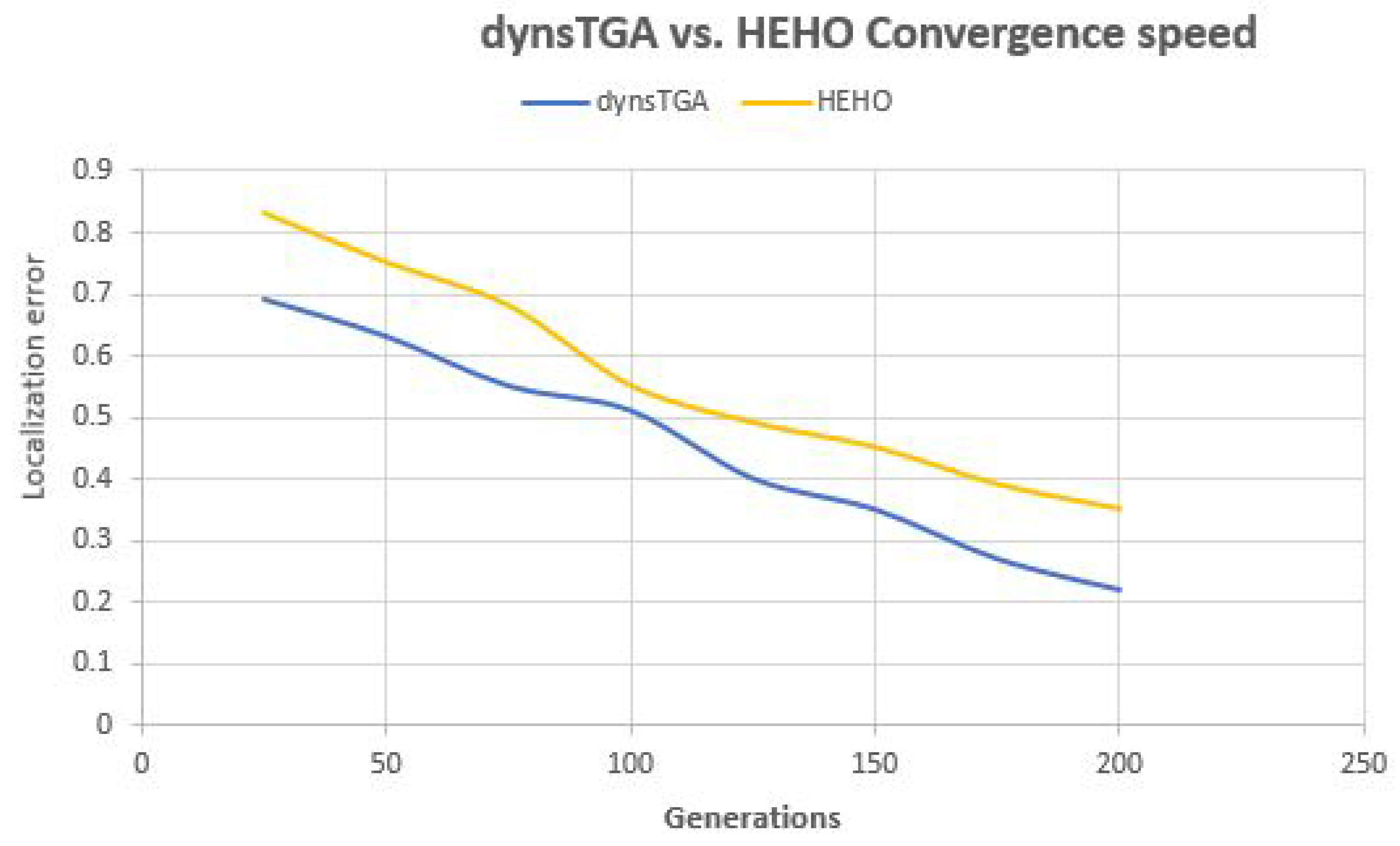
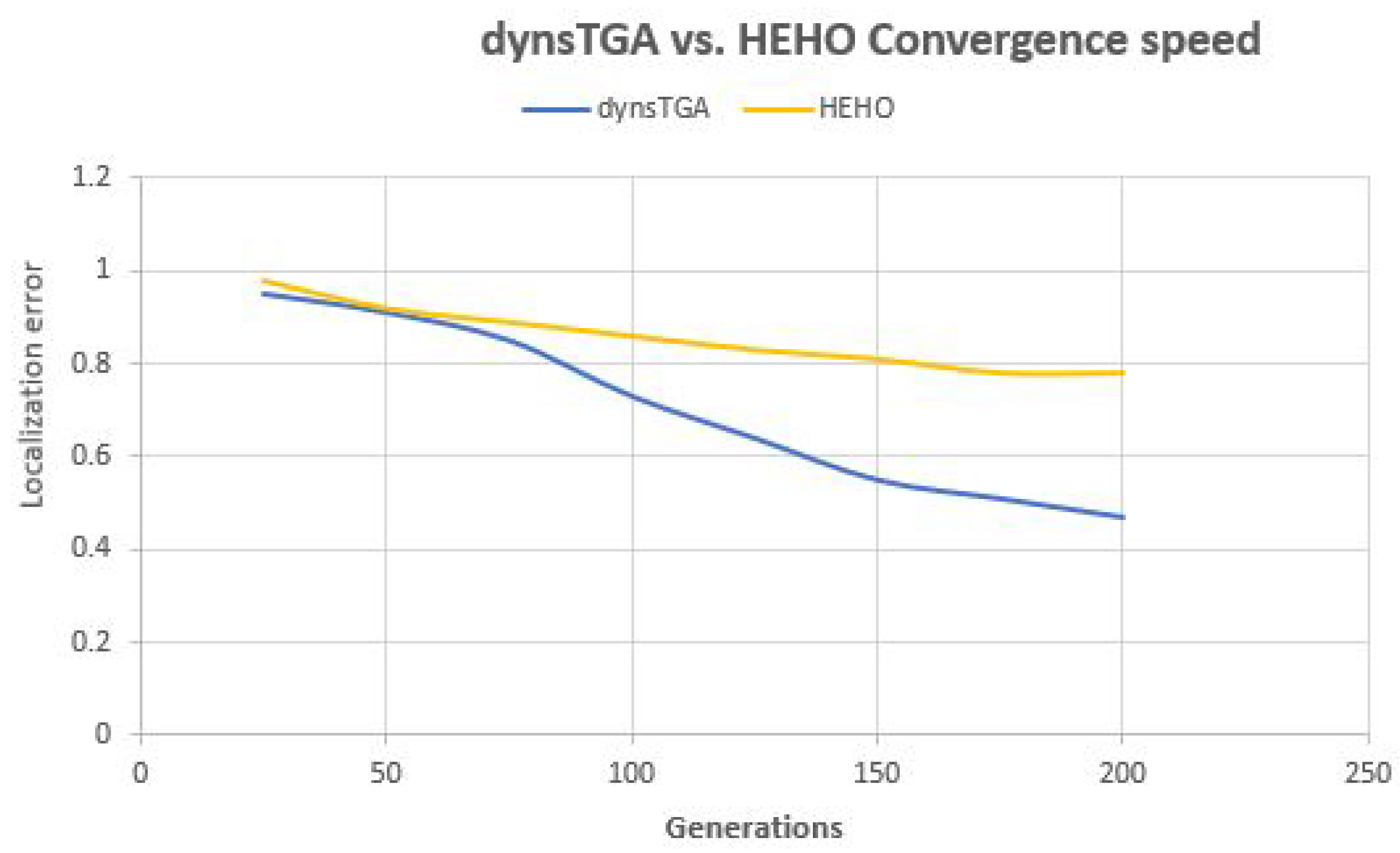
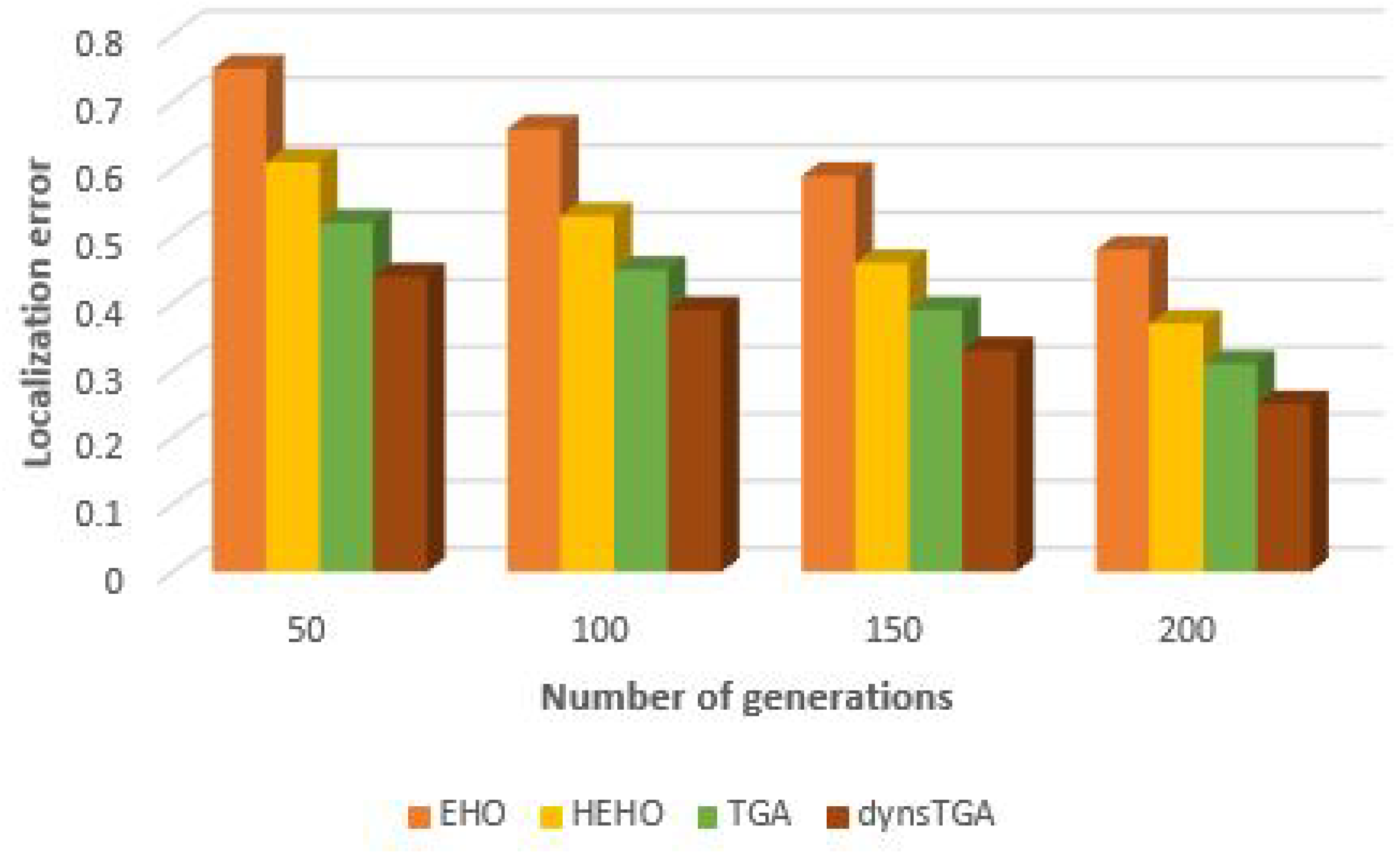
Side-by-side comparisons of convergence speed between the dynsTGA and the HEHO on problem instances with {50 targets, 15 anchors}, {100 targets, 25 anchors}, and {150 targets and 35 anchors} are shown in
Figure 6,
Figure 7, and
Figure 8, respectively. For visualization purposes, the averaged results over 30 independent algorithms’ runs are taken.
From the presented figures, it can be clearly seen that the dynsTGA obtains much better performance and convergence speed than the HEHO approach. In the case of the problem instance with 150 targets and 35 anchor nodes (
Figure 8), in early generations the dynsTGA converges slower to the optimum part of the search space. However, in later generations, the converges speed of the dynsTGA is improved due to the dynamical adjustments of
and
control parameters.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}