A KPI-Based Probabilistic Soft Sensor Development Approach that Maximizes the Coefficient of Determination


Abstract
1. Introduction
2. Background
2.1. The Gaussian Mixture Model
2.2. The Expectation Maximization Algorithm
2.2.1. E-Step
2.2.2. M-Step
2.3. The Coefficient of Determination
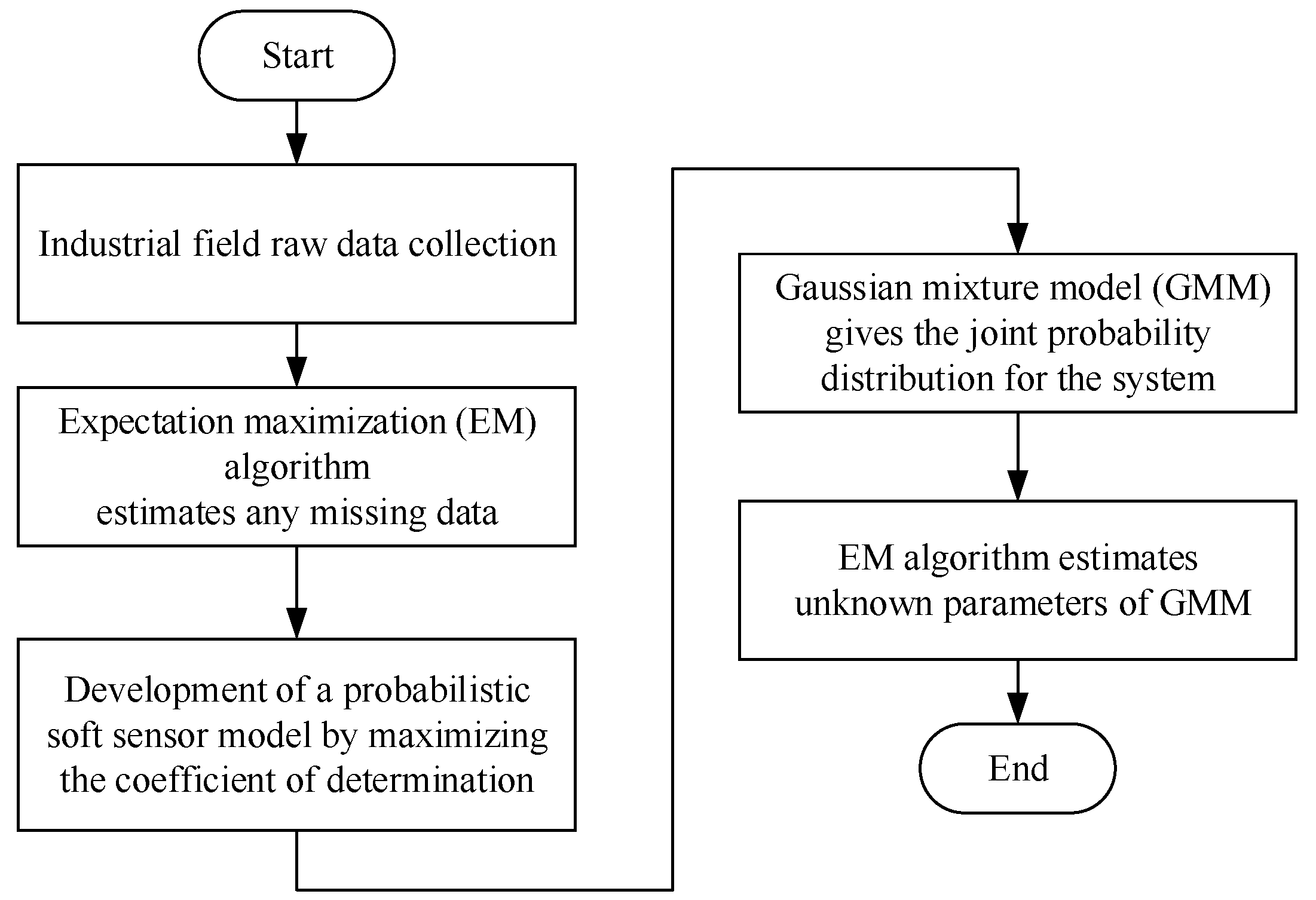
3. Development of the Probabilistic Soft Sensor Model
3.1. EM Algorithm Handing Missing Data
3.1.1. E-Step: Prediction
3.1.2. M-Step: Estimation
3.2. Soft Sensor Development Approach Based on the Coefficient of Determination Maximization Strategy
4. Case Study
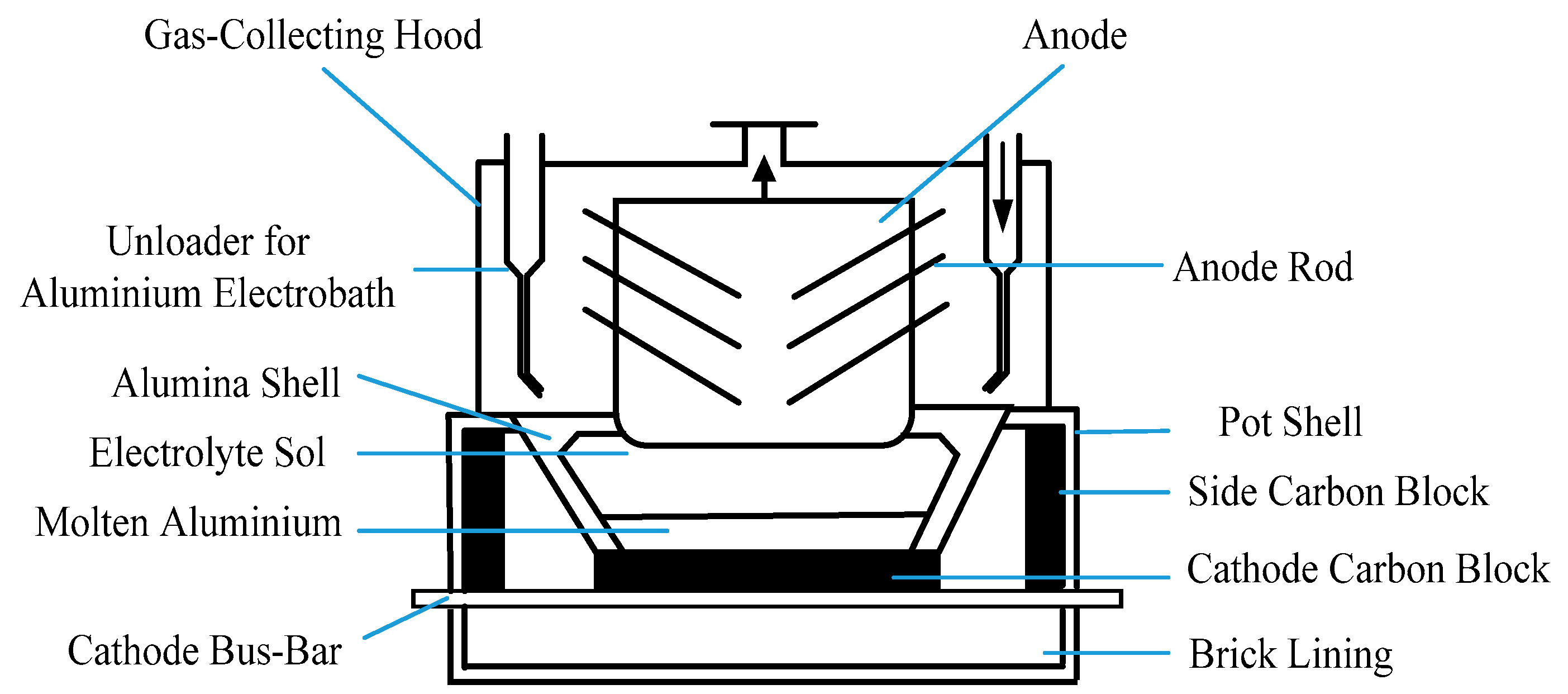
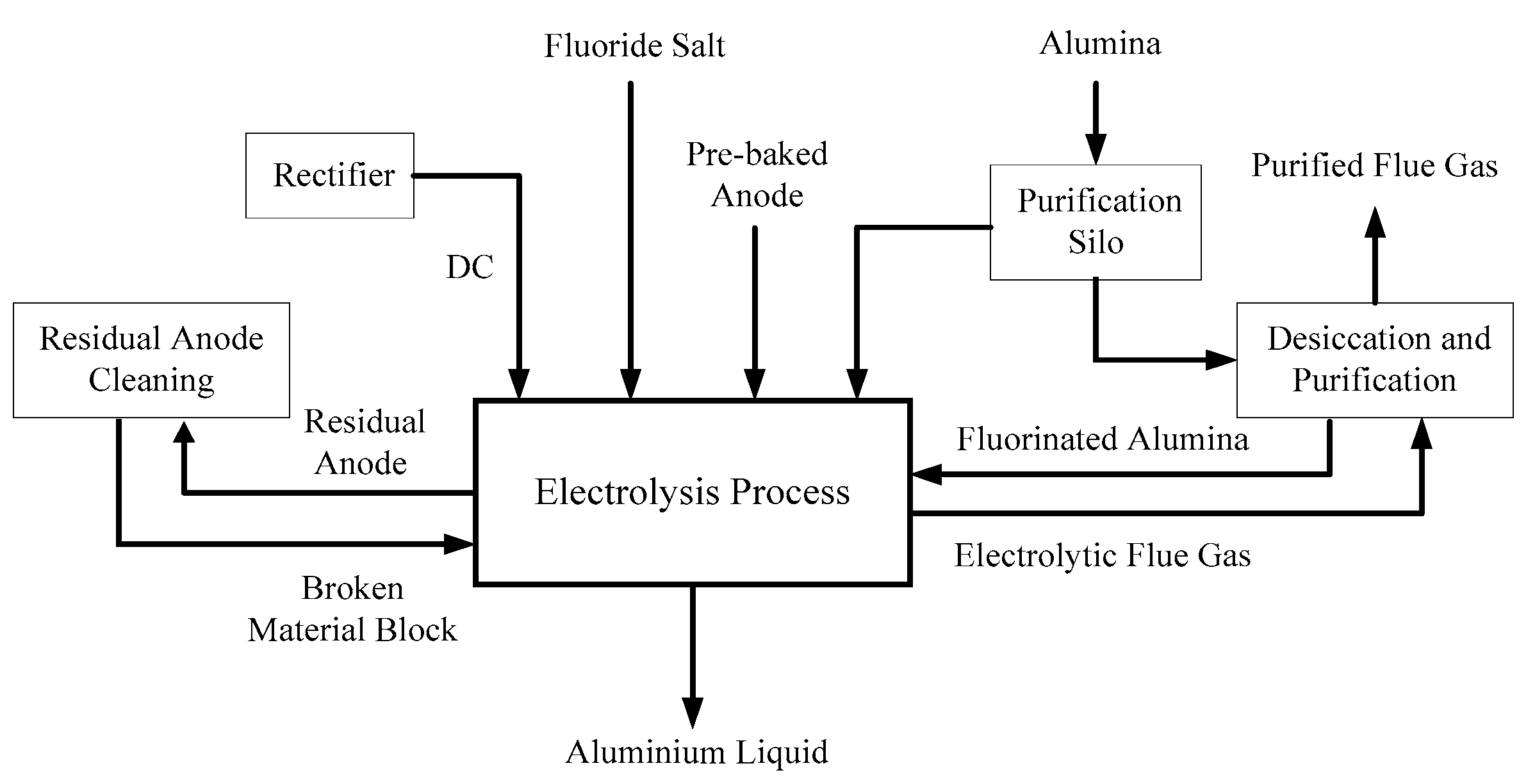
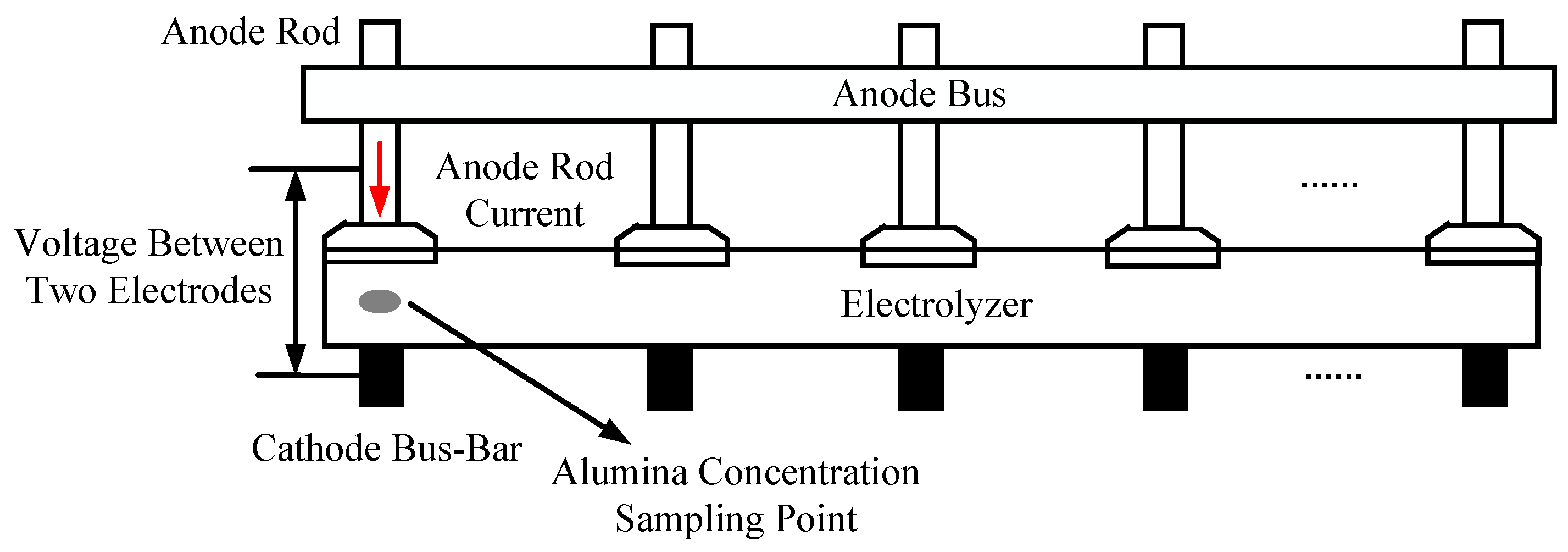
4.1. Soft Sensor Development for Industrial Aluminum Electrolytic Process
4.2. Experimental Results
4.2.1. EM Algorithm and Missing Values
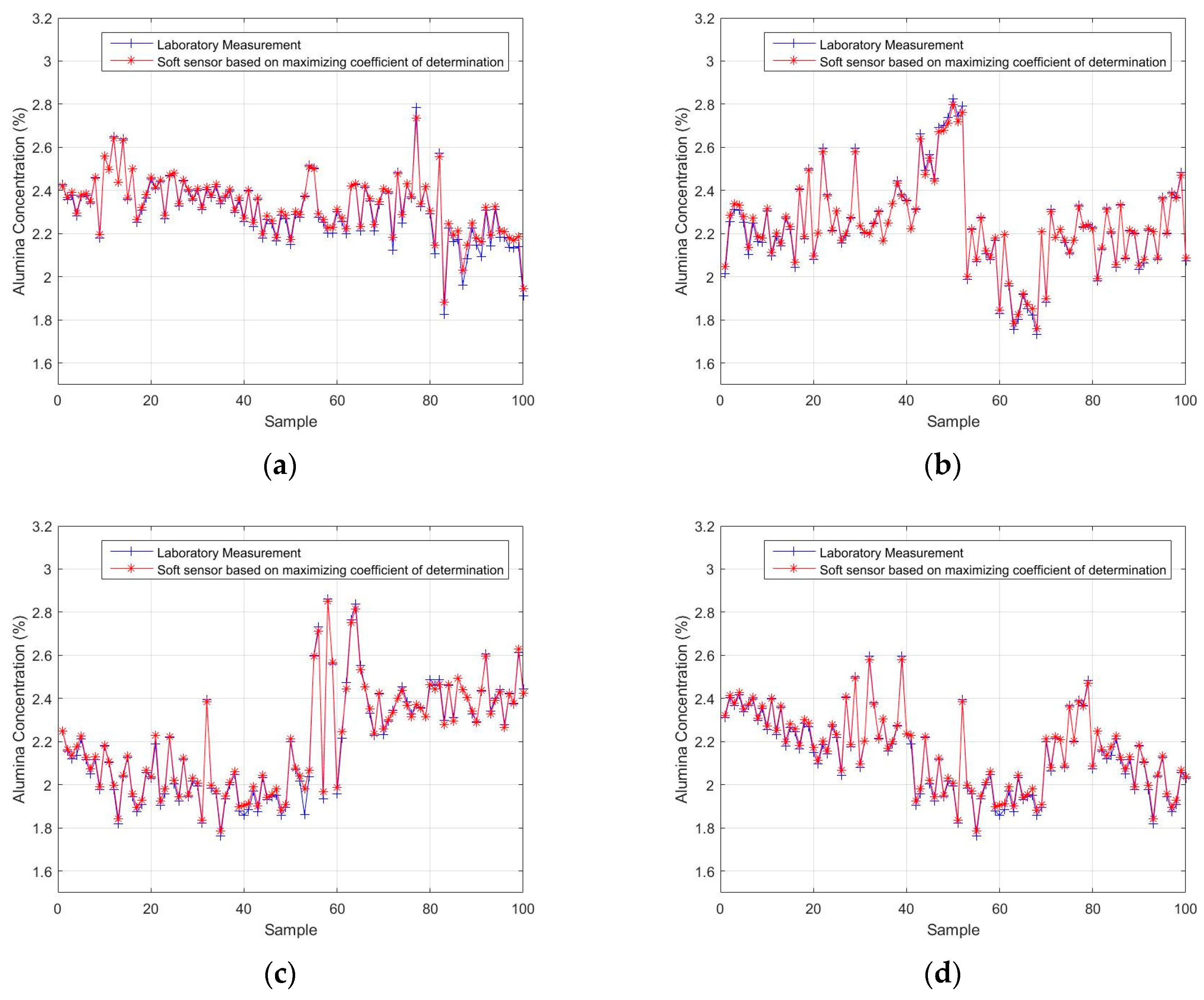
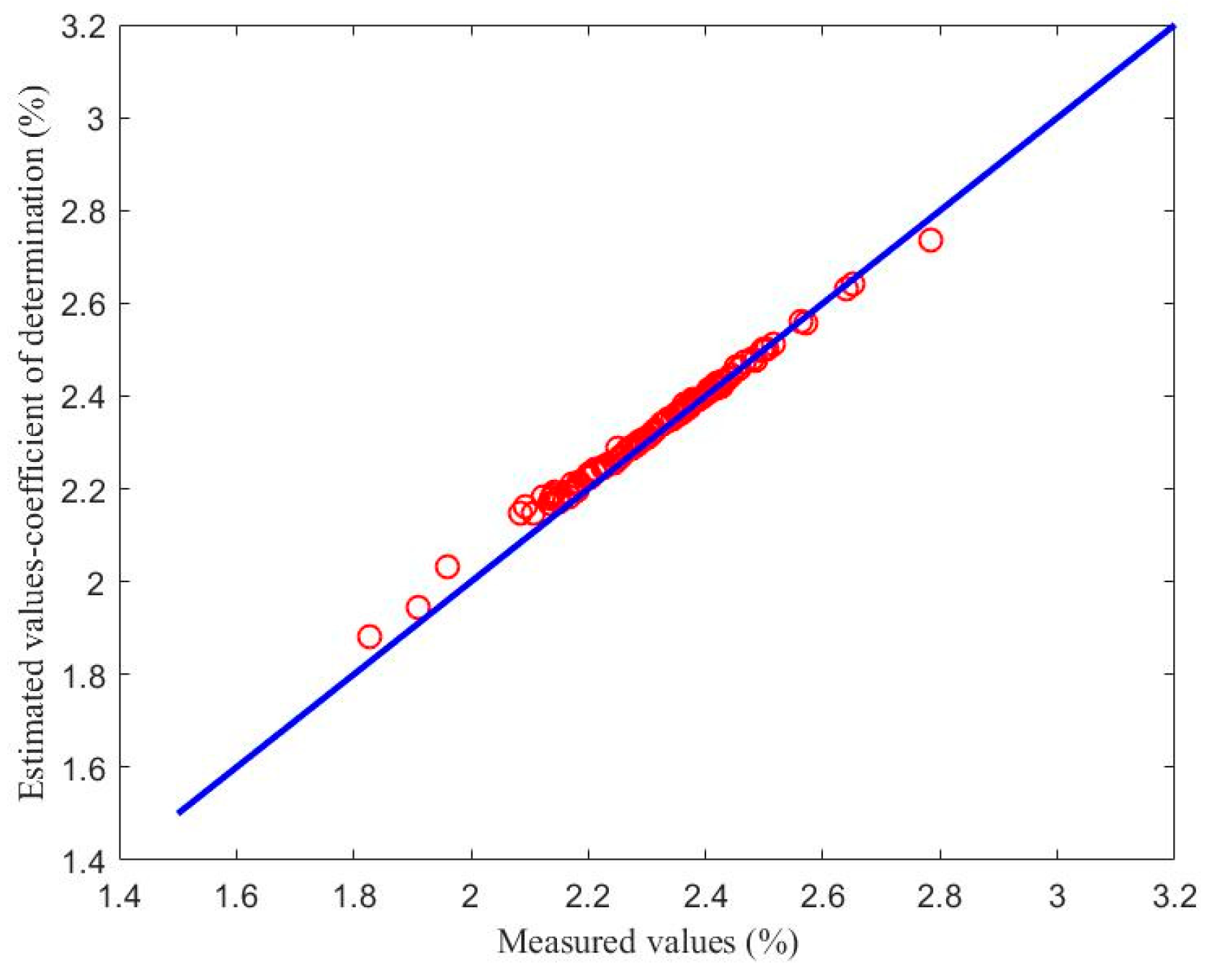
4.2.2. Experimental Results of the Soft Sensor Model Based on Maximizing the Coefficient of Determination
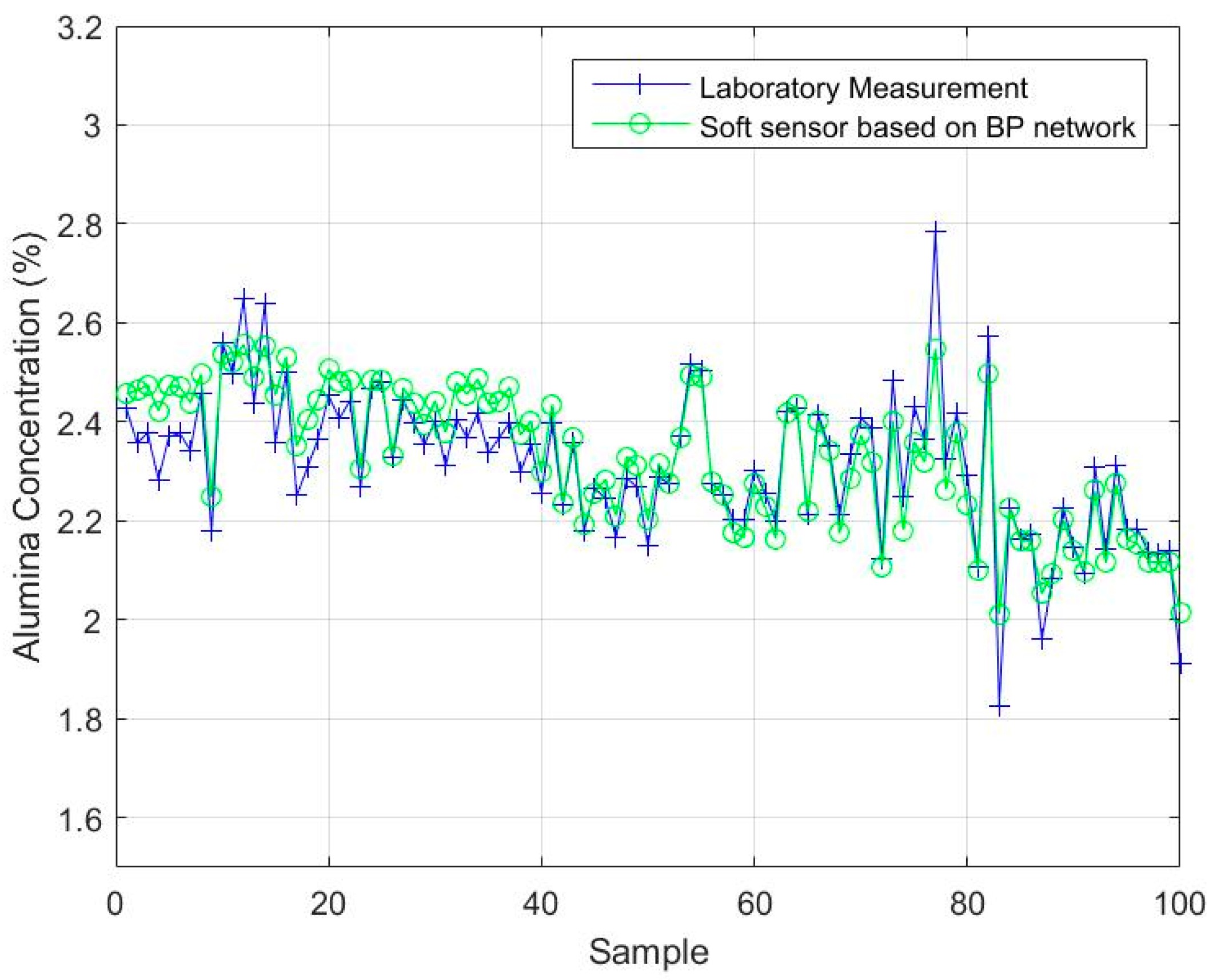
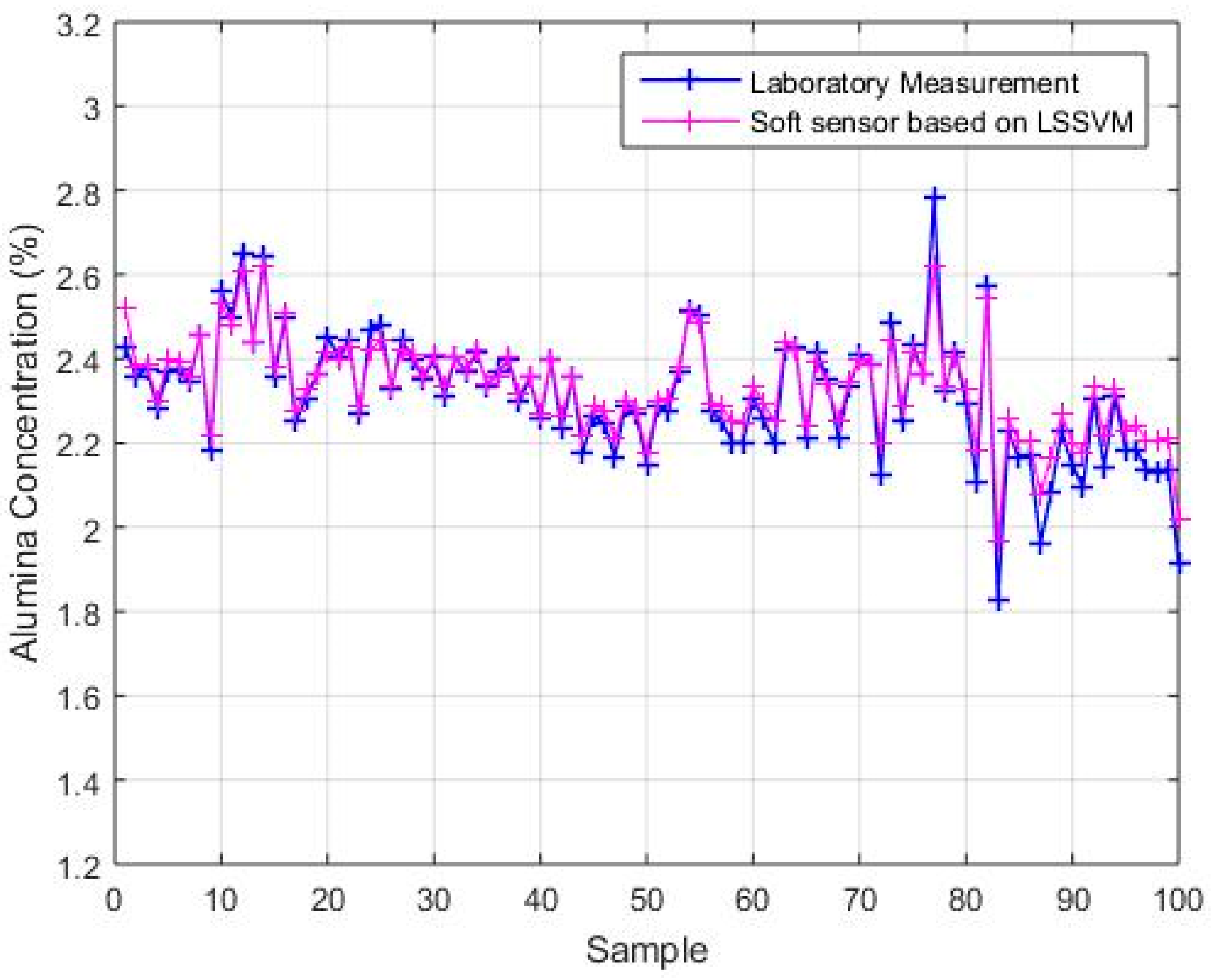
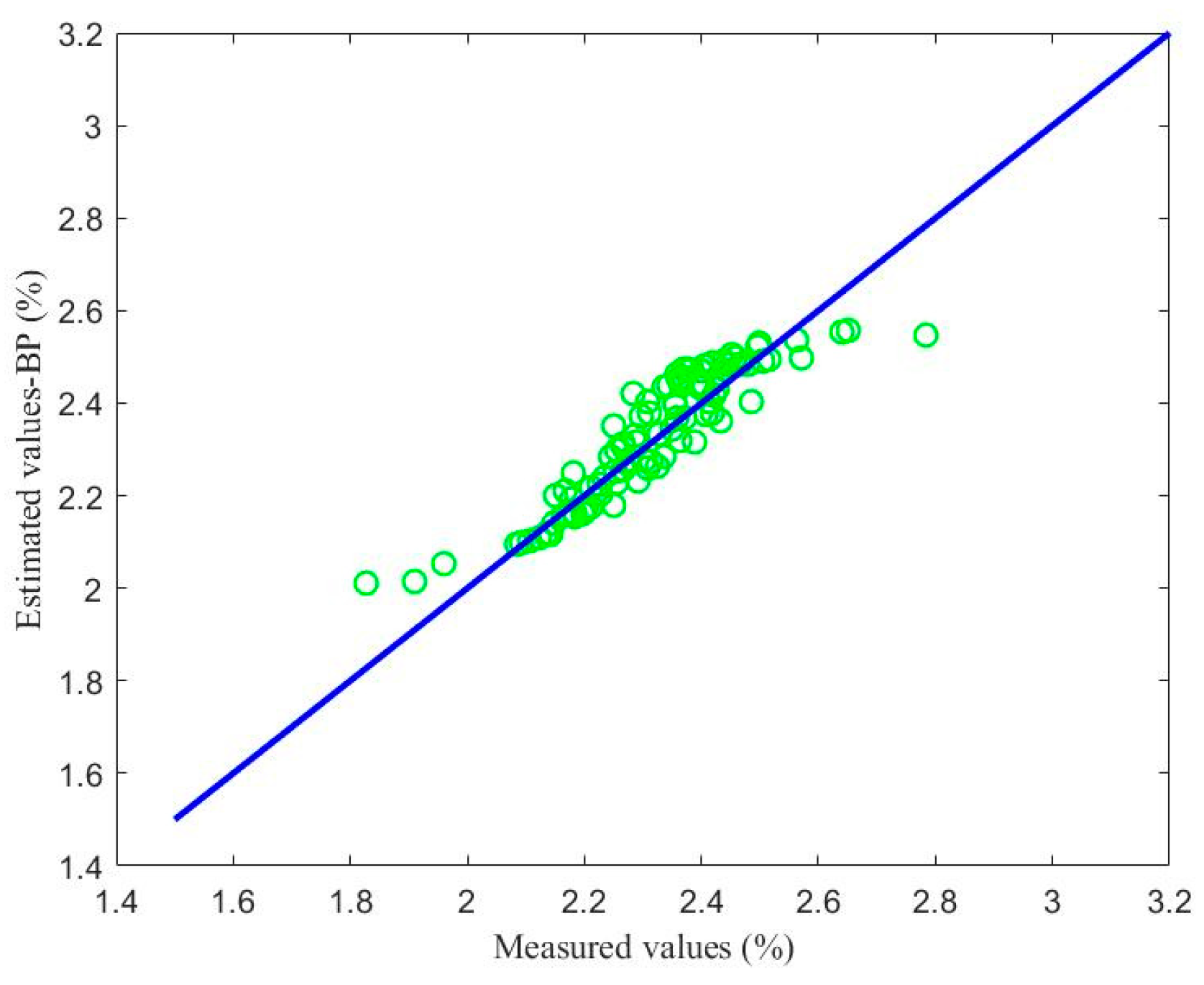
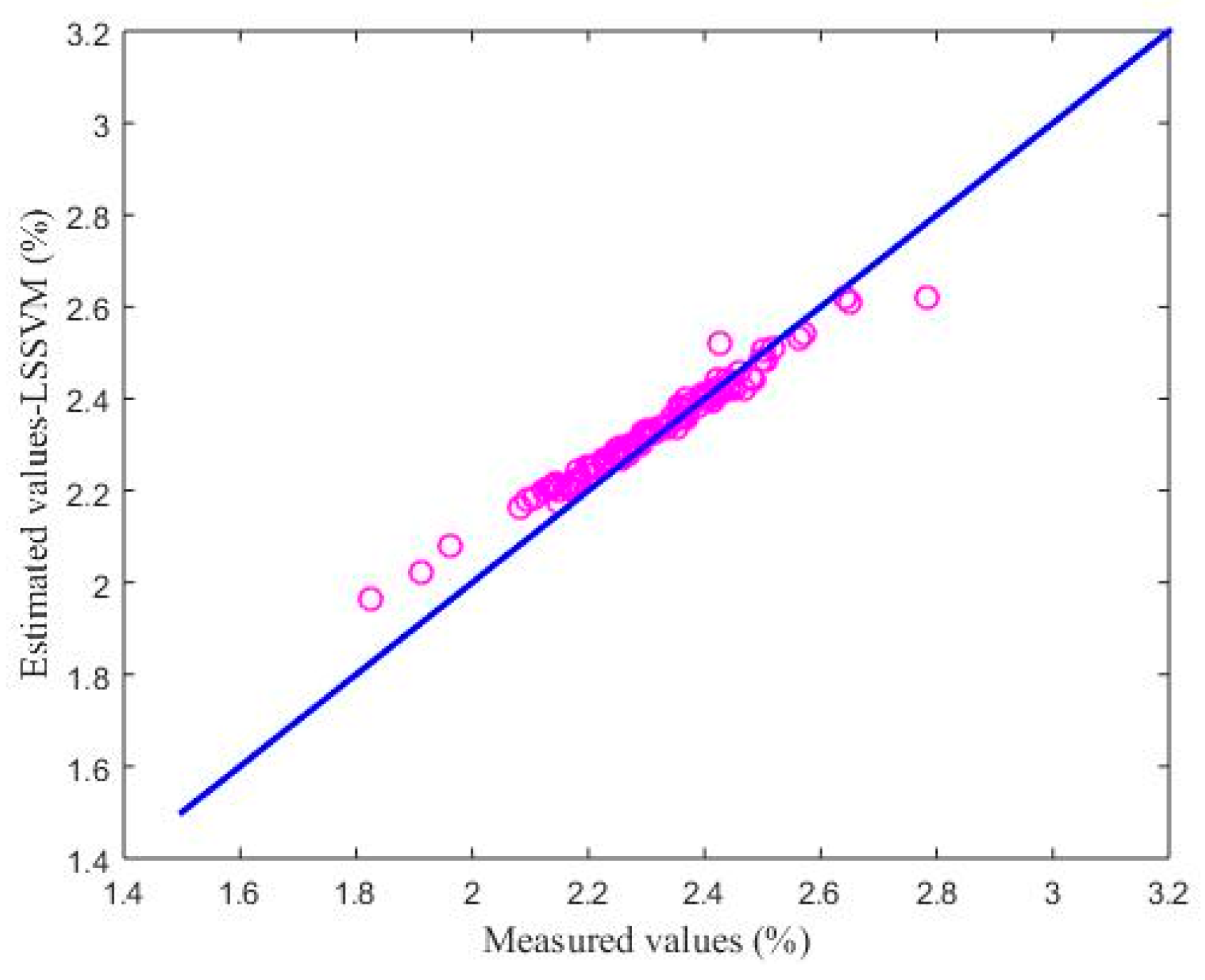
4.2.3. Comparison with BP and LSSVM
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shardt, Y.A.W.; Mehrkanoon, S.; Zhang, K.; Yang, X.; Suykens, J.; Ding, X.S.; Peng, K.X. Modelling the Strip Thickness in Hot Steel Rolling Mills Using Least-squares Support Vector Machines. Can. J. Chem. Eng. 2018, 96, 171–178. [Google Scholar] [CrossRef]
- Zhang, K.; Shardt, Y.A.W.; Chen, Z.W.; Yang, X.; Ding, S.X.; Peng, K.X. A KPI-Based Process Monitoring and Fault Detection Framework for Large-Scale Processes. ISA Trans. 2017, 68, 276–286. [Google Scholar] [CrossRef] [PubMed]
- Stanojevic, P.; Orlic, B.; Misita, M.; Tatalovic, N.; Lenkey, G.B. Online Monitoring and Assessment of Emerging Risk in Conventional Industrial Plants: Possible Way to Implement Integrated Risk Management Approach and KPI’s. J. Risk Res. 2013, 16, 501–512. [Google Scholar] [CrossRef]
- Paulsson, D.; Gustavsson, R.; Mandenius, C.F. A Soft Sensor for Bioprocess Control Based on Sequential Filtering of Metabolic Heat Signals. Sensors 2014, 14, 17864–17882. [Google Scholar] [CrossRef] [PubMed]
- Abeykoon, C. A novel soft sensor for real-time monitoring of the die melt temperature profile in polymer extrusion. IEEE Trans. Ind. Electron. 2014, 61, 7113–7123. [Google Scholar] [CrossRef]
- Yuan, X.F.; Ge, Z.Q.; Huang, B.; Song, Z.H. A Probabilistic Just-in-Time Learning Framework for Soft Sensor Development with Missing Data. IEEE Trans. Control Syst. Technol. 2017, 25, 1124–1132. [Google Scholar] [CrossRef]
- Chen, K.; Liang, Y.; Gao, Z.L. Just-in-Time Correntropy Soft Sensor with Noisy Data for Industrial Silicon Content Prediction. Sensors 2017, 17, 1830. [Google Scholar] [CrossRef] [PubMed]
- Khatibisepehr, S.; Huang, B.; Khare, S. Design of inferential sensors in the process industry: A review of Bayesian methods. J. Process Control 2013, 23, 1575–1596. [Google Scholar] [CrossRef]
- Serdio, F.; Lughofer, E.; Zavoianu, A.C.; Pichler, K.; Pichler, M.; Buchegger, T.; Efendic, H. Improved fault detection employing hybrid memetic fuzzy modeling and adaptive filters. Appl. Soft. Comput. 2017, 51, 60–82. [Google Scholar] [CrossRef]
- Serdio, F.; Lughofer, E.; Pichler, K.; Buchegger, T.; Pichler, M.; Efendic, H. Fault detection in multi-sensor networks based on multivariate time-series models and orthogonal transformations. Inf. Fusion 2014, 20, 272–291. [Google Scholar] [CrossRef]
- Shardt, Y.A.W.; Hao, H.Y.; Ding, S.X. A New Soft-Sensor-Based Process Monitoring Scheme Incorporating Infrequent KPI Measurements. IEEE Trans. Ind. Electron. 2015, 62, 3843–3851. [Google Scholar] [CrossRef]
- Yan, W.W.; Shao, H.H.; Wang, X.F. Soft sensing modeling based on support vector machine and Bayesian model selection. Comput. Chem. Eng. 2004, 28, 1489–1498. [Google Scholar] [CrossRef]
- Kadlec, P.; Gabrys, B.; Strandt, S. Data-driven Soft Sensors in the process industry. Comput. Chem. Eng. 2009, 33, 795–814. [Google Scholar] [CrossRef]
- Shang, C.; Gao, X.Q.; Yang, F. Novel Bayesian Framework for Dynamic Soft Sensor Based on Support Vector Machine with Finite Impulse Response. IEEE Trans. Control Syst. Technol. 2014, 22, 1550–1557. [Google Scholar]
- Fujiwara, K.; Kano, M.; Hasebe, S. Development of correlation-based pattern recognition algorithm and adaptive soft-sensor design. In Proceedings of the IFAC Symposium on Advanced Control of Chemical Processes (ADCHEM), Istanbul, Turkey, 12–15 July 2009. [Google Scholar]
- Yuan, X.; Ye, L.; Bao, L.; Ge, Z.; Song, Z. Nonlinear feature extraction for soft sensor modeling based on weighted probabilistic PCA. Chemom. Intell. Lab. Syst. 2015, 147, 167–175. [Google Scholar] [CrossRef]
- Geladi, P. Notes on the history and nature of partial least squares (PLS) modelling. J. Chemom. 1988, 2, 231–246. [Google Scholar] [CrossRef]
- Qin, S.J.; McAvoy, T.J. Nonlinear PLS modeling using neural networks. Comput. Chem. Eng. 1992, 16, 379–391. [Google Scholar] [CrossRef]
- Khatisbisepehr, S.; Huang, B. Dealing with Irregular Data in Soft Sensors: Bayesian Method and Comparative Study. Ind. Eng. Chem. Res. 2008, 47, 8713–8723. [Google Scholar] [CrossRef]
- Qi, F.; Huang, B.; Tamayo, E.C. A Bayesian Approach for Control Loop Diagnosis with Missing Data. AICHE J. 2010, 56, 179–195. [Google Scholar] [CrossRef]
- Newman, D.A. Missing Data: Five Practical Guidelines. Organ. Res. Methods 2014, 17, 372–411. [Google Scholar] [CrossRef]
- Zhang, K.K.; Gonzalez, R.; Huang, B.; Ji, G.L. Expectation-Maximization Approach to Fault Diagnosis with Missing Data. IEEE Trans. Ind. Electron. 2015, 62, 1231–1240. [Google Scholar] [CrossRef]
- Shardt, Y.A.W. Statistics for Chemical and Process Engineers: A Modern Approach; Springer International Publishing: Cham, Switzerland, 2015; ISBN 978-3-319-21508-2. [Google Scholar]
- Feng, C.H.; Makino, Y.; Yoshimura, M.; Rodriguez, F.J. Estimation of adenosine triphosphate content in ready-to-eat sausages with different storage days, using hyperspectral imaging coupled with R statistics. Food Chem. 2018, 264, 419–426. [Google Scholar] [CrossRef] [PubMed]
- Sezer, B.; Apaydin, H.; Bilge, G.; Boyaci, I.H. Coffee arabica adulteration: Detection of wheat, corn and chickpea. Food Chem. 2018, 264, 142–148. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.L.; Zhang, C.S.; Yu, G.Q. A Bayesian network approach to traffic flow forecasting. IEEE Trans. Intell. Transp. Syst. 2006, 7, 124–132. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. B 1977, 39, 1–38. [Google Scholar]
- Stock, J.H.; Watson, M.W. Introduction to Econometrics, 3rd ed.; Addison-Wesley: Bosten, MA, USA, 2010; ISBN 978-0-13-800900-7. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson: London, UK, 2007; ISBN 978-0-13-187715-3. [Google Scholar]
- Rao, C.R. Linear Statistical Inference and Its Applications; Wiley: New York, NY, USA, 1973; ISBN 978-0-47-031643-6. [Google Scholar]
- Bilmes, J.A. A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov model. Int. Comput. Sci. Inst. 1998, 4, 126. [Google Scholar]
- Mouedhen, G.; Feki, M.; Wery, M.D.P.; Ayedi, H.F. Behavior of aluminum electrodes in electrocoagulation process. J. Hazard. Mater. 2008, 150, 124–135. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.C.; Cheung, C.Y.; Bao, J.; Skyllas-Kazacos, M.; Welch, B.; Akhmetov, S. Estimation of spatial alumina concentration in an aluminium reduction cell using a multilevel state observer. AICHE J. 2017, 63, 2806–2818. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, T.; Yin, Y.X.; Xiao, W.D. Alumina concentration detection based of the kernel extreme learning machine. Sensors 2017, 17, 2002. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Substitution Method | Regression Interpolation Method | EM Algorithm | Real Value | |
|---|---|---|---|---|
| Mean | 2.4133 | 2.4225 | 2.4225 | 2.4259 |
| RMSE | 0.0867 | 0.4209 | 0.0698 | 0 |
| Mean Substitution Method | Regression Interpolation Method | EM Algorithm | Real Value | |
|---|---|---|---|---|
| Mean | 2.4139 | 2.4217 | 2.4215 | 2.4259 |
| RMSE | 0.1451 | 0.4075 | 0.1361 | 0 |
| Mean Substitution Method | Regression Interpolation Method | EM Algorithm | Real Value | |
|---|---|---|---|---|
| Mean | 2.4140 | 2.4204 | 2.41198 | 2.4259 |
| RMSE | 0.1700 | 0.4068 | 0 |
| Test Subset | RMSE |
|---|---|
| First | 0.0231 |
| Second | 0.0145 |
| Third | 0.0209 |
| Fourth | 0.0155 |
| Method | RMSE |
|---|---|
| BP neural network | 0.0616 |
| LSSVM | 0.0431 |
| Maximizing the Coefficient of Determination | 0.0231 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yang, X.; Shardt, Y.A.W.; Cui, J.; Tong, C. A KPI-Based Probabilistic Soft Sensor Development Approach that Maximizes the Coefficient of Determination. Sensors 2018, 18, 3058. https://doi.org/10.3390/s18093058
Zhang Y, Yang X, Shardt YAW, Cui J, Tong C. A KPI-Based Probabilistic Soft Sensor Development Approach that Maximizes the Coefficient of Determination. Sensors. 2018; 18(9):3058. https://doi.org/10.3390/s18093058
Chicago/Turabian StyleZhang, Yue, Xu Yang, Yuri A. W. Shardt, Jiarui Cui, and Chaonan Tong. 2018. "A KPI-Based Probabilistic Soft Sensor Development Approach that Maximizes the Coefficient of Determination" Sensors 18, no. 9: 3058. https://doi.org/10.3390/s18093058
APA StyleZhang, Y., Yang, X., Shardt, Y. A. W., Cui, J., & Tong, C. (2018). A KPI-Based Probabilistic Soft Sensor Development Approach that Maximizes the Coefficient of Determination. Sensors, 18(9), 3058. https://doi.org/10.3390/s18093058