A Sensor Image Dehazing Algorithm Based on Feature Learning


Abstract
1. Introduction
2. The Degradation Model and the Test Database
2.1. Degradation Model
2.2. Training Sample Generation of Our Networks
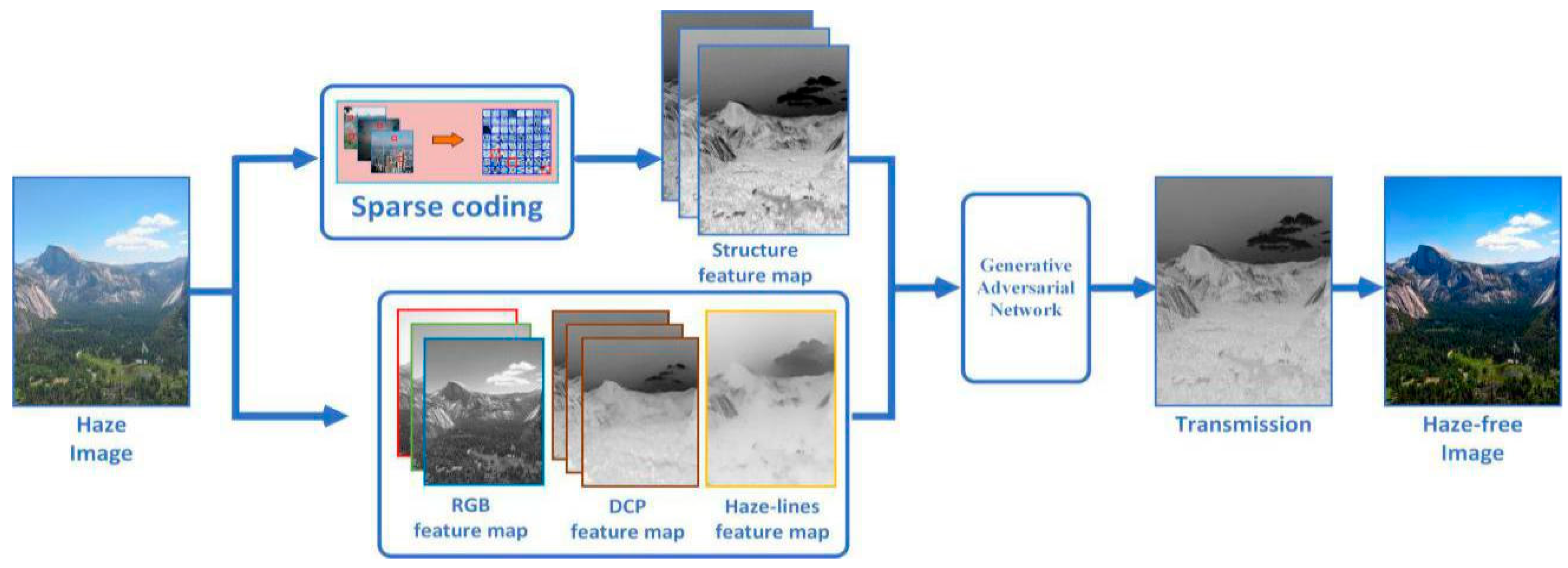
3. Framework on Transmission Restoration
3.1. Multiscale Color Feature Extraction
3.1.1. Multiscale Dark Primary Color Features
3.1.2. Haze-Lines Color Features
3.1.3. RGB Channel Color Features
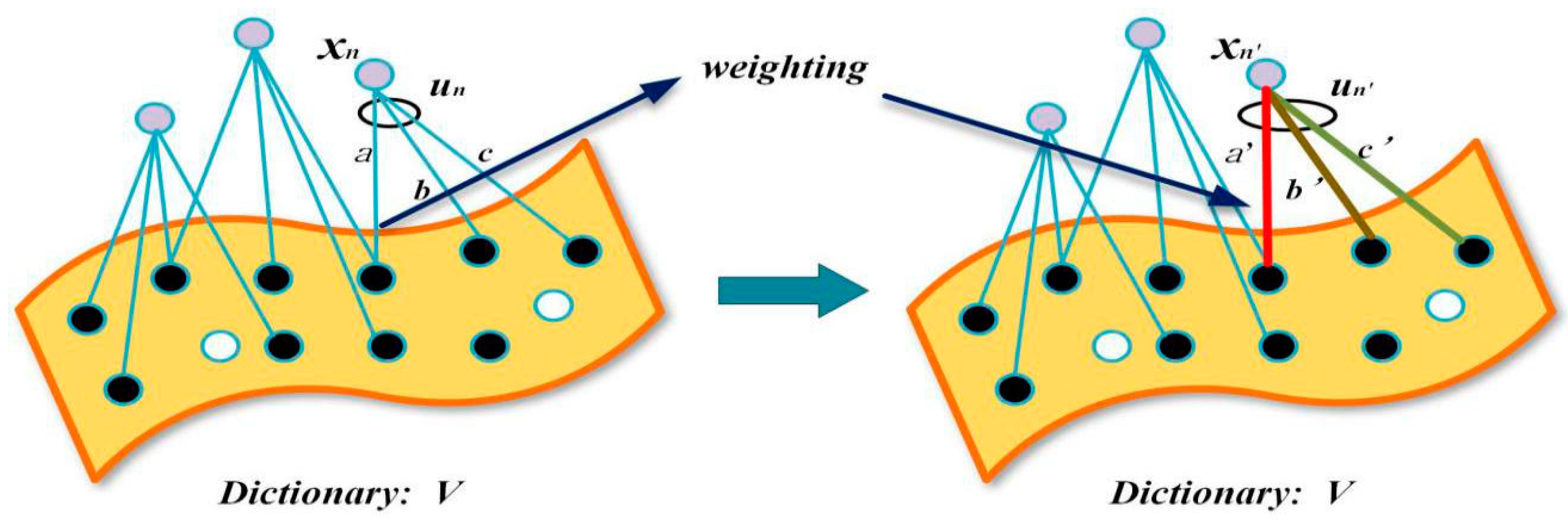
3.2. Multiscale Structure Feature Extraction
3.3. Estimating the Scene Transmission through GAN
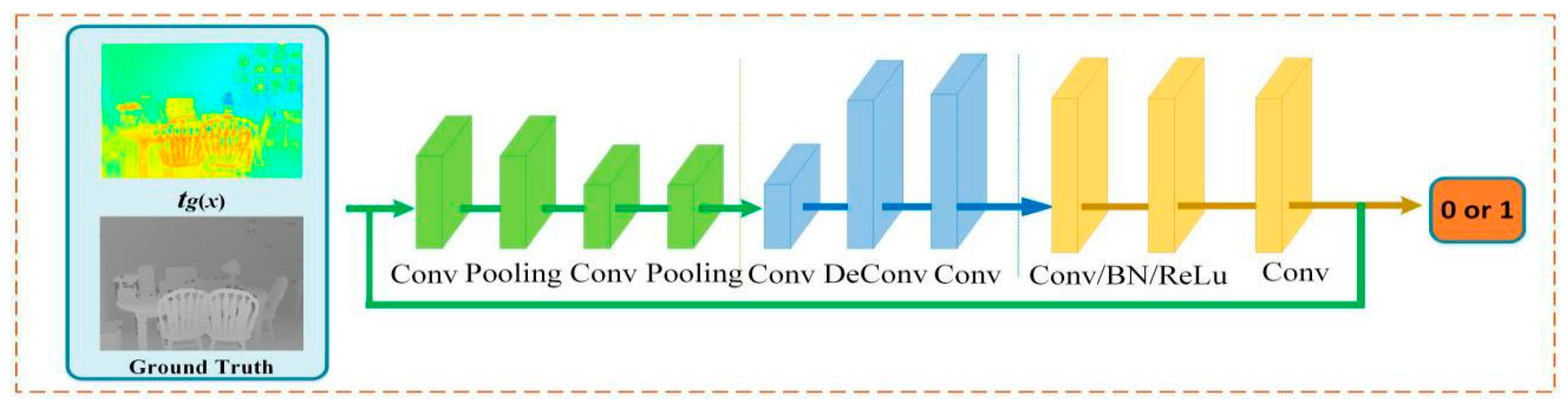
3.3.1. Generative Networks
3.3.2. Adversarial Networks
3.3.3. Loss Function.
4. Comparison Experiments
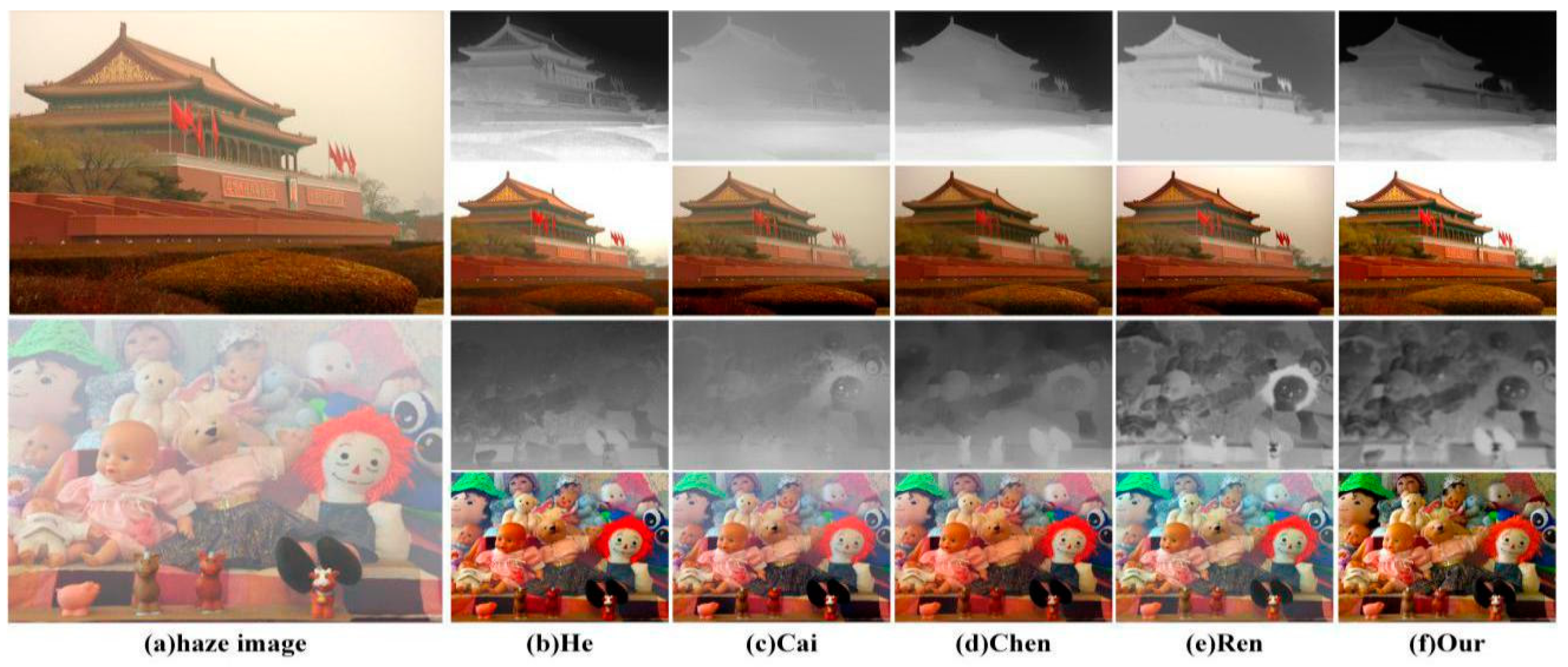
4.1. Qualitative Results
4.2. Quantitative Results
4.3. Computational Complexity
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Helmers, H.; Schellenberg, M. CMOS vs. CCD sensors in speckle interferometry. Opt. Laser Technol. 2003, 35, 587–595. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Voicu, L.I. Practical considerations on color image enhancement using homomorphic filtering. J. Electron. Imaging 1997, 6, 108–113. [Google Scholar] [CrossRef]
- Farge, M. Wavelet transform and their application to turbulence. Annu. Rev. Fluid Mech. 1992, 24, 395–457. [Google Scholar] [CrossRef]
- Xie, B.; Guo, F.; Cai, Z. Improved Single Image Dehazing Using Dark Channel Prior and Multi-scale Retinex. In Proceedings of the International Conference on Intelligent System Design and Engineering, Changsha, China, 13–14 October 2010; Application IEEE Computer Society: Washington, DC, USA, 2010; pp. 848–851. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the CVPR 2009 Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 22–24 June 2009; pp. 1956–1963. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the CVPR 2008 Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. Single image dehazing using color attenuation prior. Chin. J. New Clin. Med. 2014. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local Image Dehazing. In Proceeding of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Tang, K.; Yang, J.; Wang, J. Investigating Haze-Relevant Features in a Learning Framework for Image Dehazing. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2995–3002. [Google Scholar]
- Mccartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles. Opt. Acta. Int. J. Opt. 1977, 14, 698–699. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Fattal, R. Single image dehazing. ACM Trans. Graph. 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Ko, H. Fog-degraded image restoration using characteristics of RGB channel in single monocular image. In Proceedings of the 2012 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 13–16 January 2012. [Google Scholar]
- Schölkopf, B.; Platt, J.; Hofmann, T. Efficient sparse coding algorithms. Proc. Nips 2007, 19, 801–808. [Google Scholar]
- Vogl, T.P.; Mangis, J.K.; Rigler, A.K.; Zink, W.T.; Alkon, D.L. Accelerating the convergence of the back-propagation method. Biol. Cybern. 1988, 59, 257–263. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Do, M.N.; Wang, J. Robust Image and Video Dehazing with Visual Artifact Suppression via Gradient Residual Minimization. In Computer Vision—ECCV 2016; Springer International Publishing: New York, NY, USA, 2016. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.M. Single Image Dehazing via Multi-scale Convolutional Neural Networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 154–169. [Google Scholar]
- Tarel, J.P.; Bigorgne, E. Long-range road detection for off-line scene analysis. In Proceedings of the IEEE Intelligent Vehicle Symposium (IV’2009), Xian, China, 3–5 June 2009; pp. 15–20. [Google Scholar]
- Tarel, J.P.; Hautière, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2201–2208. [Google Scholar]
- Tan, Y.Z.; Ci-Fang, W.U. The laws of the information entropy values of land use composition. J. Nat. Resour. 2003, 1, 017. [Google Scholar]
- Núñez, J.A.; Cincotta, P.M.; Wachlin, F.C. Information entropy. Celest. Mech. Dyn. Astron. 1996, 64, 43–53. [Google Scholar] [CrossRef]
- Poor, H.V.; Verdu, S. Probability of error in MMSE multiuser detection. IEEE Trans Inf. Theory 1997, 43, 858–871. [Google Scholar] [CrossRef]
- Wang, L.T.; Hoover, N.E.; Porter, E.H.; Zasio, J.J. SSIM: A software levelized compiled-code simulator. In Proceedings of the 24th ACM/IEEE Design Automation Conference, Miami Beach, FL, USA, 28 June–1 July 1987; pp. 2–8. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Haze Image | Zhu | Tang | Berman | He | Our |
|---|---|---|---|---|---|
| Image 1 | 8.432 | 8.541 | 7.582 | 8.725 | 9.451 |
| Image 2 | 8.626 | 7.896 | 6.750 | 8.086 | 9.275 |
| Image 3 | 8.241 | 8.452 | 8.527 | 9.103 | 9.263 |
| Haze Image | He | Cai | Chen | Ren | Our |
|---|---|---|---|---|---|
| Image 1 | 7.2846 | 6.8753 | 6.7152 | 5.9875 | 7.4783 |
| Image 2 | 7.1342 | 6.7883 | 7.2936 | 6.9983 | 7.4982 |
| Image 3 | 7.4568 | 7.3512 | 7.6589 | 7.4537 | 7.9375 |
| Image 4 | 7.6639 | 7.5697 | 6.2589 | 7.2358 | 7.8165 |
| Haze Image | He | Cai | Chen | Ren | Our |
|---|---|---|---|---|---|
| Image 1 | 11.1765 | 14.2586 | 10.5896 | 10.1568 | 16.8974 |
| Image 2 | 17.6538 | 15.3692 | 18.5693 | 14.2568 | 19.5683 |
| Image 3 | 14.9577 | 17.6598 | 17.2563 | 16.8593 | 17.5836 |
| Image 4 | 22.0103 | 15.6984 | 15.1750 | 19.9872 | 21.2258 |
| Image Size | He | Cai | Chen | Ren | Our |
|---|---|---|---|---|---|
| 440 × 320 | 9.563 s | 3.124 s | 50.432 s | 1.947 s | 5.016 s |
| 670 × 480 | 11.768 s | 4.598 s | 106.398 s | 3.685 s | 6.697 s |
| 1024 × 768 | 35.269 s | 8.796 s | 180.148 s | 5.984 s | 10.896 s |
| 1430 × 1024 | 72.531 s | 20.015 s | 250.654 s | 11.369 | 22.573 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, K.; He, L.; Ma, S.; Gao, S.; Bi, D. A Sensor Image Dehazing Algorithm Based on Feature Learning. Sensors 2018, 18, 2606. https://doi.org/10.3390/s18082606
Liu K, He L, Ma S, Gao S, Bi D. A Sensor Image Dehazing Algorithm Based on Feature Learning. Sensors. 2018; 18(8):2606. https://doi.org/10.3390/s18082606
Chicago/Turabian StyleLiu, Kun, Linyuan He, Shiping Ma, Shan Gao, and Duyan Bi. 2018. "A Sensor Image Dehazing Algorithm Based on Feature Learning" Sensors 18, no. 8: 2606. https://doi.org/10.3390/s18082606
APA StyleLiu, K., He, L., Ma, S., Gao, S., & Bi, D. (2018). A Sensor Image Dehazing Algorithm Based on Feature Learning. Sensors, 18(8), 2606. https://doi.org/10.3390/s18082606