Intelligent Multimodal Framework for Human Assistive Robotics Based on Computer Vision Algorithms

 ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Section
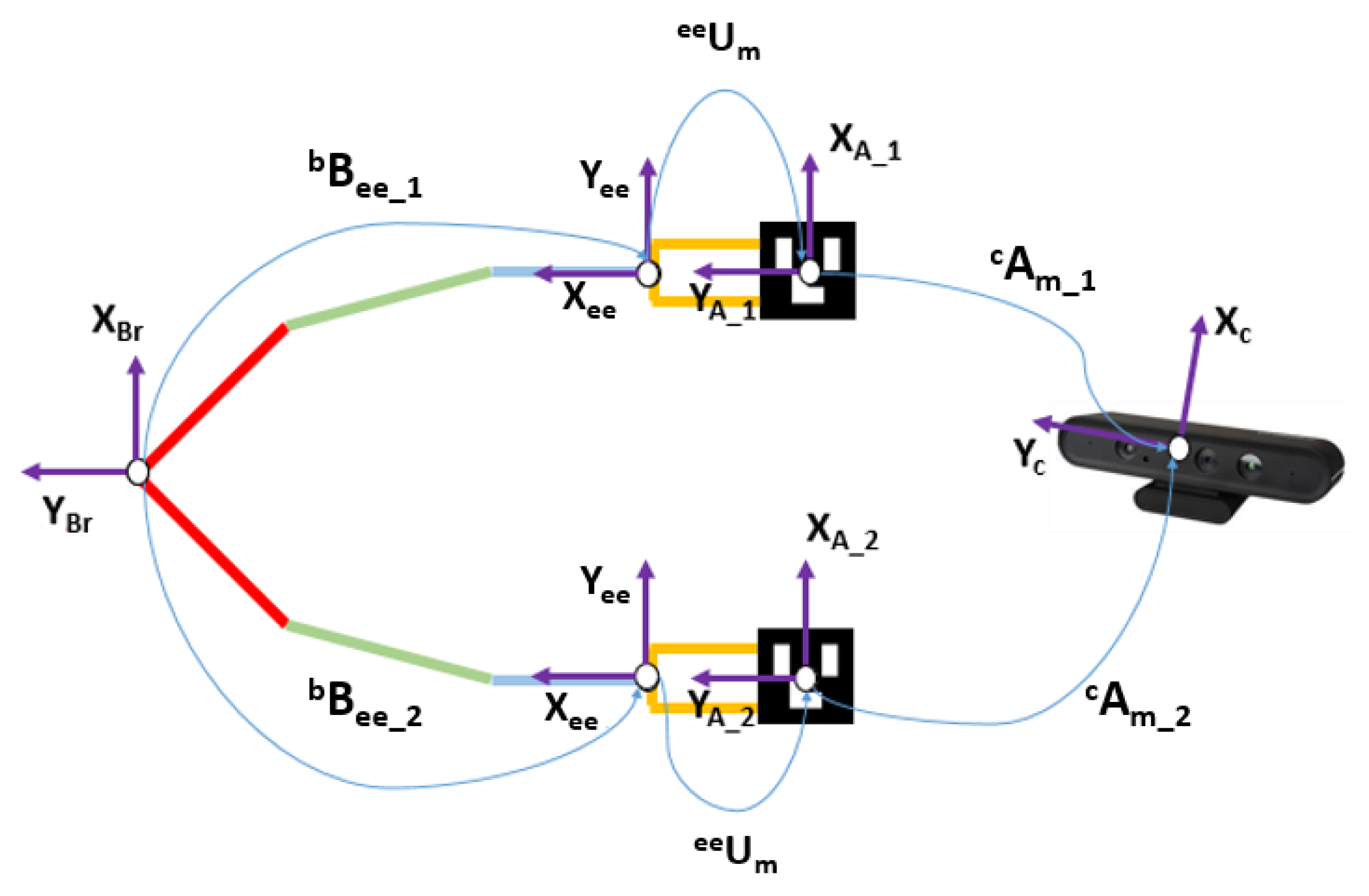
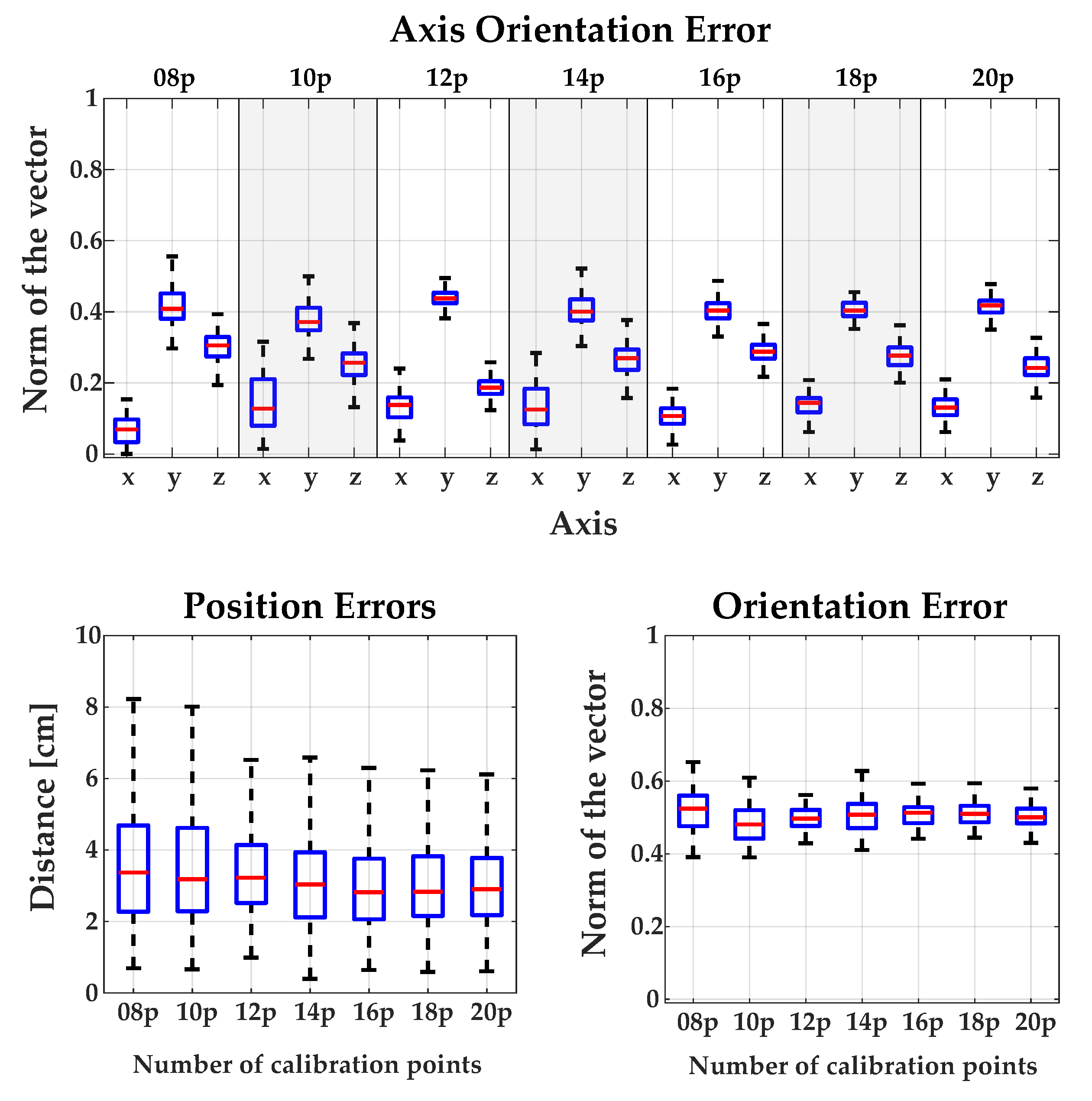
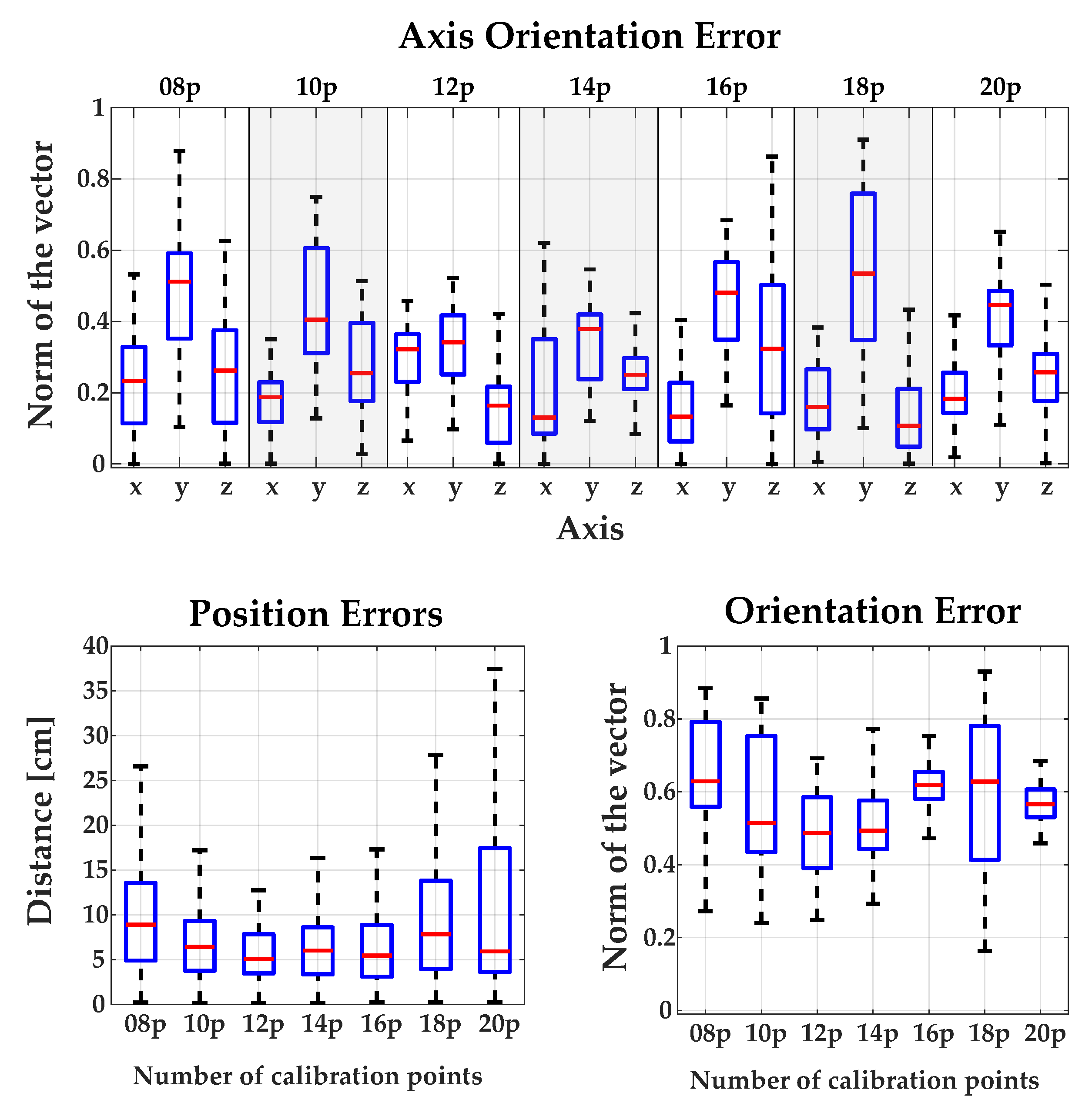
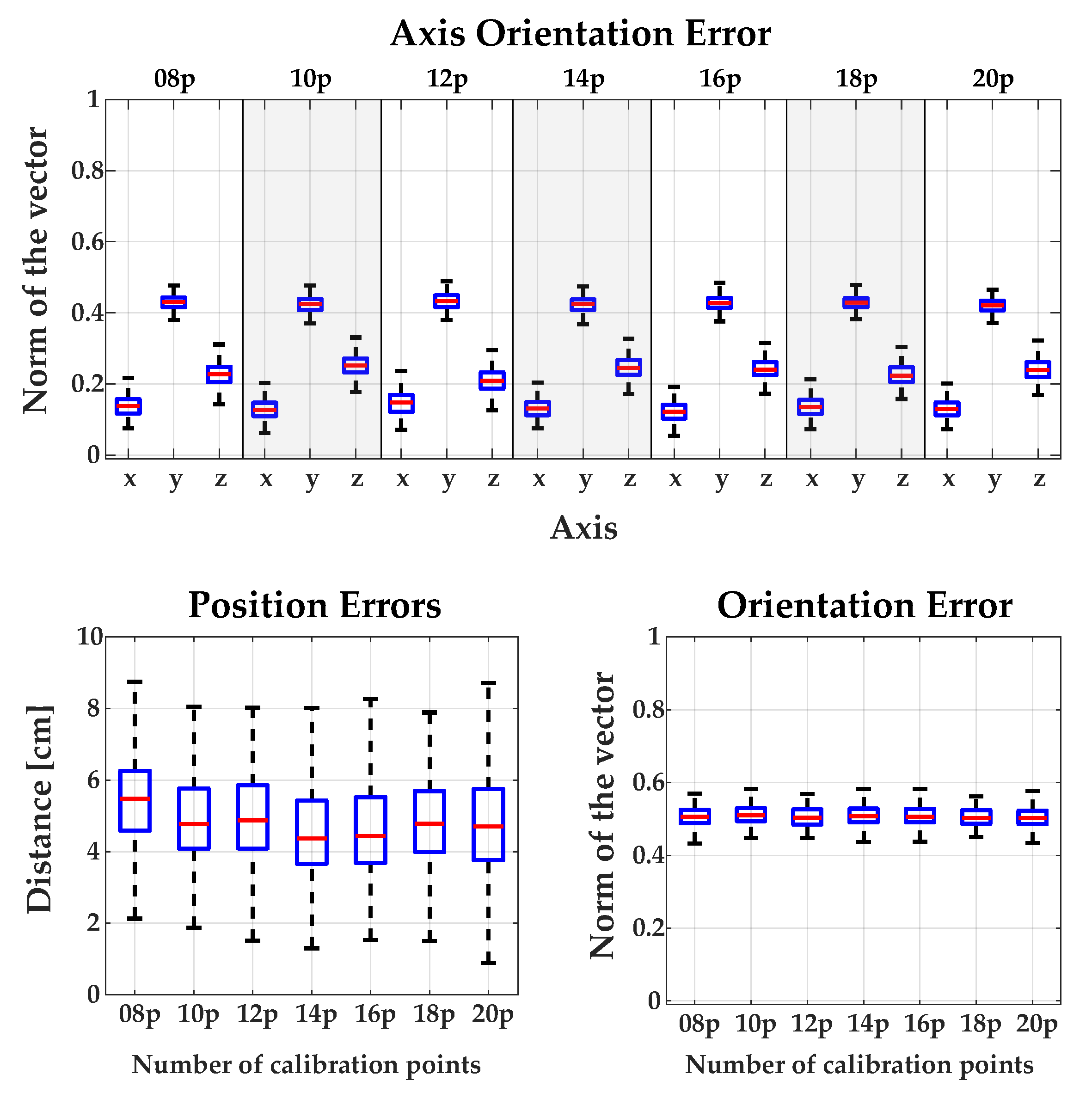
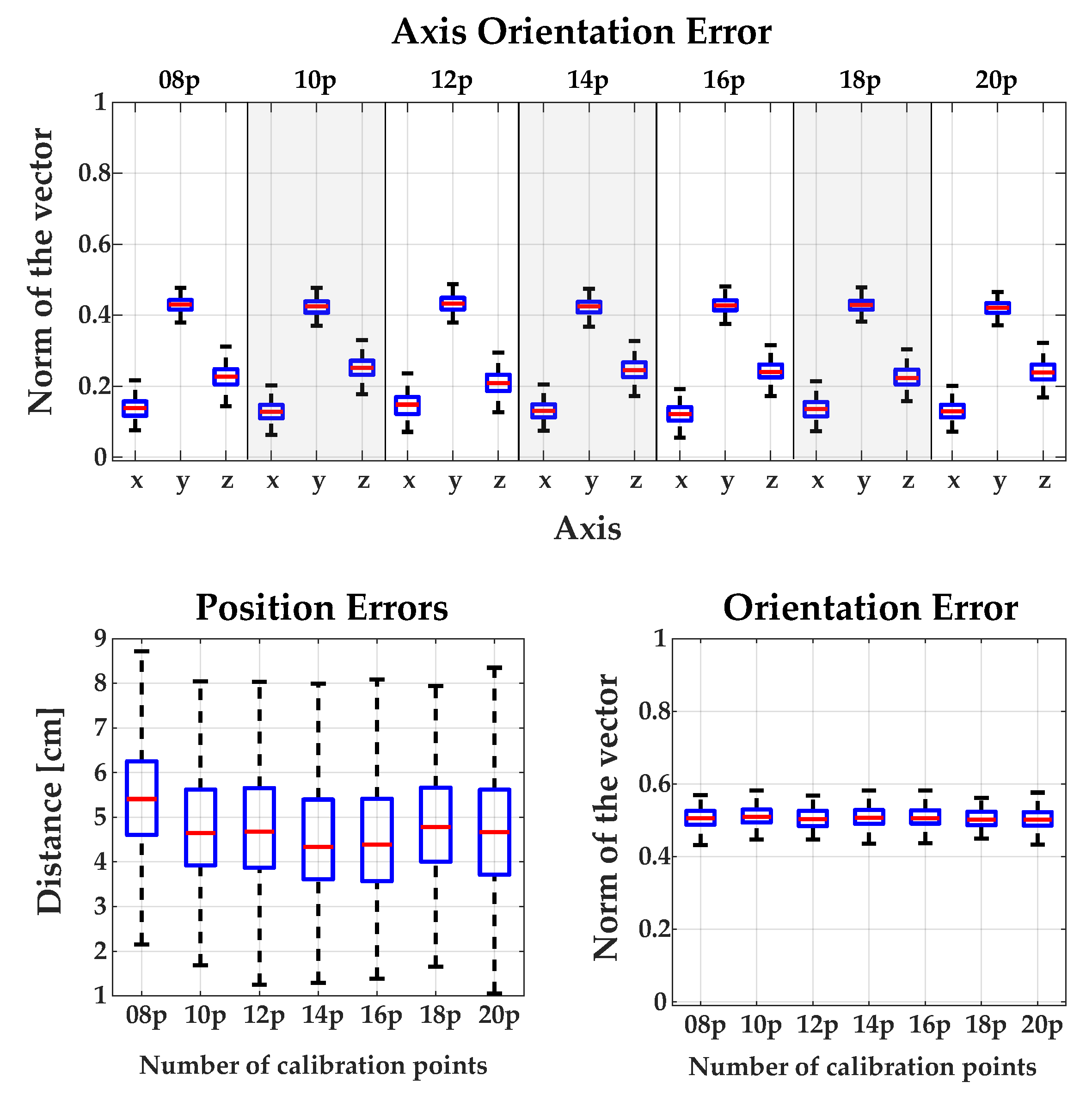
2.2. Calibration Methods Robot <-> RGB-D Camera
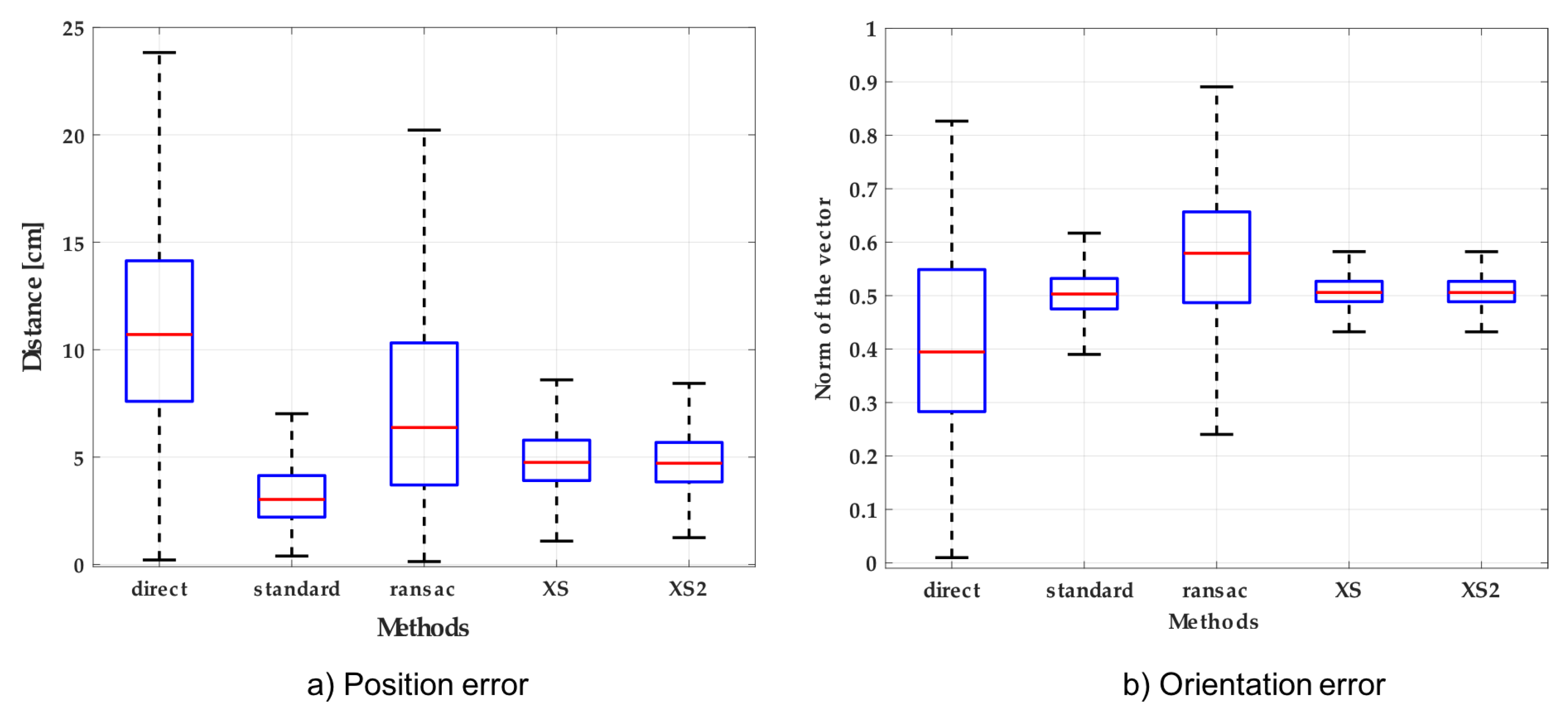
- Standard Calibration: The implementation of the shape registration method in C++ [14].
- XS Calibration: The c1 method of Tabb et al. [39].
- XS2 Calibration: The c2 method of Tabb et al. [39].
- Ransac Calibration: The OPENCV library implementation in C++ of the random sample consensus method (RANSAC optimization).
2.3. Eye-Tracking Detection
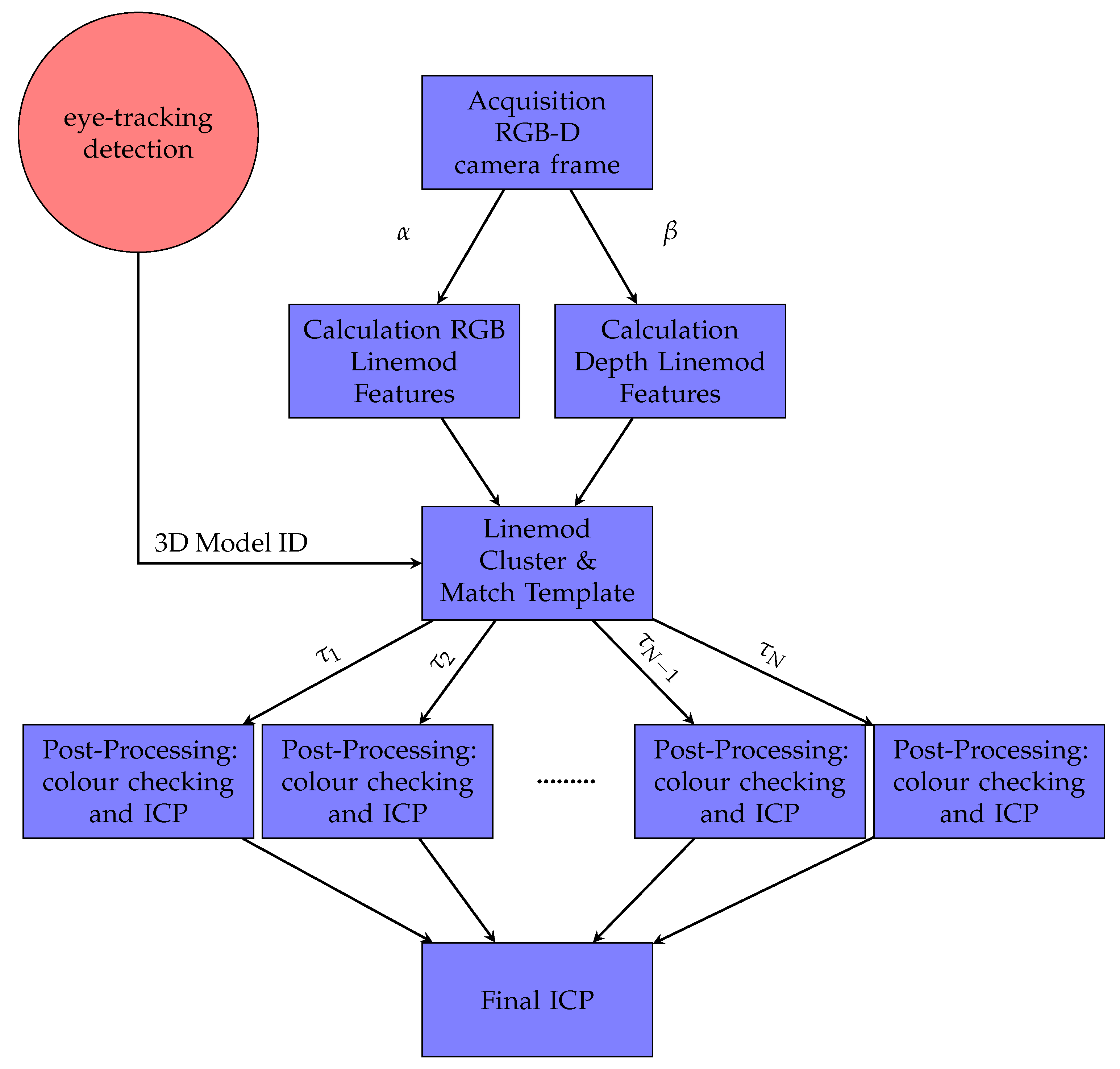
2.4. Detection and Pose Estimation
2.5. Mouth Pose
3. Results
3.1. Calibration between Camera and Robot
3.2. Detection and Pose Estimation
3.2.1. Quantitative Validation of the Detection and Pose Estimation of 3D Objects
- Average distance (AD): This metric was introduced by Hinterstoisser et al. [24] and is the most employed to quantitatively evaluate the accuracy of pose estimation [19,26,27,28,29,49]. Given a set of vertices of a 3D model, M, the actual rotation and translation (“ground truth”) and their estimations :when the 3D object is symmetrical, like some of the LINEMOD models (“cup”, “bowl”, “box”, and “glue”):Traditionally, it is considered that the pose is correct if being the diameter of the object, and a coefficient ≥ 0. Generally a is used (i.e., 10% of the diameter of the object).
- Shotton criteria (5 cm 5): Using this criteria [24] a pose is considered correct if the rotational error is less than five degrees and the translational error is less than 5 cm. Please note that this metric does not take the size of the object into account.
- 2D Bounding Box: This metric calculates the intersection over union (IoU) [50] between the 2D bounding box obtained by projecting all the vertices of the 3D object with the real pose “ground truth ” in the image and the 2D bounding obtained by projecting all the vertices of the object with the estimated pose. A pose is correct if IoU > 0.5.
- 2D Projections: This metric [36] sets a pose as valid if:is less than 5 pixels. M is the set of vertices of the 3D model, K is the matrix of intrinsic parameters, is the estimated pose and is the true pose. It should be noted that this metric is the most appropriate when you want to estimate the pose of 3D objects in an Augmented Reality system, and so was not used in this work.
3.2.2. Comparison of the Results with State-Of-The-Art Methods
3.2.3. Computational Cost
3.3. Mouth Pose System
3.4. Eye-Tracking System
3.5. Experimental Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Experimental Validation: Detailed Figures
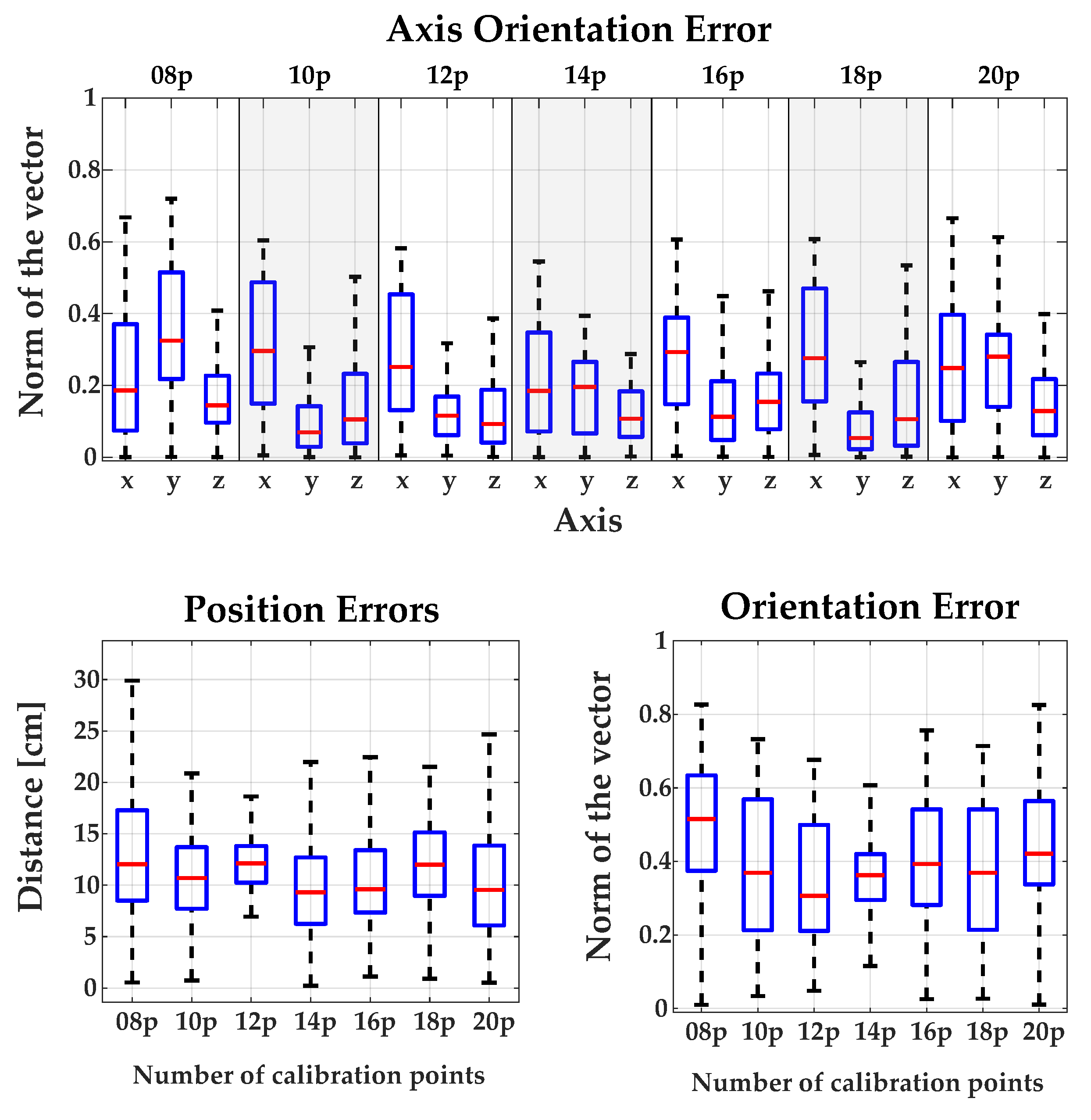
Appendix A.1. Comparing the Influence of Using Different Numbers of Calibration Points for Each Method





References
- European Commision. People with disabilities have equal rights. In The European Disability Strategy 2010–2020; Technical Report; European Commision: Washington, DC, USA, 2010. [Google Scholar]
- Meng, J.; Zhang, S.; Bekyo, A.; Olsoe, J.; Baxter, B.; He, B. Noninvasive Electroencephalogram Based Control of a Robotic Arm for Reach and Grasp Tasks. Sci. Rep. 2016, 6, 38565. [Google Scholar] [CrossRef] [PubMed]
- Silva, C.; Vongkulbhisal, J.; Marques, M.; Costeira, J.P.; Veloso, M. Feedbot—A Robotic Arm for Autonomous Assisted Feeding. In Proceedings of the Portuguese Conference on Artificial Intelligence, Porto, Portugal, 5–8 September 2017; Oliveira, E., Gama, J., Vale, Z., Lopes Cardoso, H., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 486–497. [Google Scholar]
- Hochberg, L.R.; Bacher, D.; Jarosiewicz, B.; Masse, N.Y.; Simeral, J.D.; Vogel, J.; Haddadin, S.; Liu, J.; Cash, S.S.; van der Smagt, P.; et al. Reach and grasp by people with tetraplegia using a neurally controlled robotic arm. Nature 2012, 485, 372. [Google Scholar] [CrossRef] [PubMed]
- Collinger, J.L.; Wodlinger, B.; Downey, J.E.; Wang, W.; Tyler-Kabara, E.C.; Weber, D.J.; McMorland, A.J.; Velliste, M.; Boninger, M.L.; Schwartz, A.B. High-performance neuroprosthetic control by an individual with tetraplegia. Lancet 2013, 381, 557–564. [Google Scholar] [CrossRef]
- Pedrocchi, A.; Ferrante, S.; Ambrosini, E.; Gandolla, M.; Casellato, C.; Schauer, T.; Klauer, C.; Pascual, J.; Vidaurre, C.; Gföhler, M.; et al. MUNDUS project: MUltimodal Neuroprosthesis for daily Upper limb Support. J. Neuroeng. Rehabil. 2013, 10, 66. [Google Scholar] [CrossRef] [PubMed]
- Frisoli, A.; Sotgiu, E.; Procopio, C.; Chisari, C.; Rossi, B.; Bergamasco, M. Positive effects of rehabilitation training with the L-EXOS in chronic stroke. In Proceedings of the SKILLS 2011, Montpellier, France, 15–16 December 2011; Volume 1, p. 27. [Google Scholar]
- Barsotti, M.; Leonardis, D.; Loconsole, C.; Solazzi, M.; Sotgiu, E.; Procopio, C.; Chisari, C.; Bergamasco, M.; Frisoli, A. A full upper limb robotic exoskeleton for reaching and grasping rehabilitation triggered by MI-BCI. In Proceedings of the 2015 IEEE International Conference on Rehabilitation Robotics (ICORR), Singapore, 11–14 August 2015; pp. 49–54. [Google Scholar]
- Lauretti, C.; Cordella, F.; Ciancio, A.L.; Trigili, E.; Catalan, J.M.; Badesa, F.J.; Crea, S.; Pagliara, S.M.; Sterzi, S.; Vitiello, N.; et al. Learning by Demonstration for Motion Planning of Upper-Limb Exoskeletons. Front. Neurorobot. 2018, 12. [Google Scholar] [CrossRef] [PubMed]
- Onose, G.; Grozea, C.; Anghelescu, A.; Daia, C.; Sinescu, C.; Ciurea, A.; Spircu, T.; Mirea, A.; Andone, I.; Spânu, A. On the Feasibility of Using Motor Imagery EEG-Based Brain–Computer Interface in Chronic Tetraplegics for Assistive Robotic Arm Control: A Clinical Test and Long-Term Post-Trial Follow-Up. Spinal Cord 2012, 50, 599. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Yin, H.; Tahara, K.; Billard, A. Learning Object-Level Impedance Control for Robust Grasping and Dexterous Manipulation. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 6784–6791. [Google Scholar]
- Ahmadzadeh, S.R.; Kormushev, P.; Caldwell, D.G. Autonomous Robotic Valve Turning: A Hierarchical Learning Approach. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 4629–4634. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the 7th IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Hana, X.F.; Jin, J.S.; Xie, J.; Wang, M.J.; Jiang, W. A comprehensive review of 3D point cloud descriptors. arXiv, 2018; arXiv:1802.02297. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA’09), Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Rajkumar, N.; Konolige, K. Going further with point pair features. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 834–848. [Google Scholar]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3d recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Aldoma, A.; Tombari, F.; Rusu, R.B.; Vincze, M. OUR-CVFH–oriented, unique and repeatable clustered viewpoint feature histogram for object recognition and 6DOF pose estimation. In Proceedings of the Joint DAGM (German Association for Pattern Recognition) and OAGM Symposium, Graz, Austria, 28–31 August 2012; Springer: Cham, Switzerland, 2012; pp. 113–122. [Google Scholar]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3d object classification. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics (ROBIO), Phuket, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. A combined texture-shape descriptor for enhanced 3D feature matching. In Proceedings of the 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 809–812. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Lee, K.M., Matsushita, Y., Rehg, J.M., Hu, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 548–562. [Google Scholar]
- Kehl, W.; Tombari, F.; Navab, N.; Ilic, S.; Lepetit, V. Hashmod: A hashing method for scalable 3D object detection. arXiv, 2016; arXiv:1607.06062. [Google Scholar]
- Hodaň, T.; Zabulis, X.; Lourakis, M.; Obdržálek, Š.; Matas, J. Detection and fine 3D pose estimation of texture-less objects in RGB-D images. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 4421–4428. [Google Scholar]
- Zhang, H.; Cao, Q. Texture-less object detection and 6D pose estimation in RGB-D images. Robot. Auton. Syst. 2017, 95, 64–79. [Google Scholar] [CrossRef]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-based 3D detection and 6D pose estimation great again. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1521–1529. [Google Scholar]
- Rad, M.; Lepetit, V. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. arXiv, 2017; arXiv:1711.00199. [Google Scholar]
- Do, T.T.; Cai, M.; Pham, T.; Reid, I. Deep-6DPose: Recovering 6D Object Pose from a Single RGB Image. arXiv, 2018; arXiv:1802.10367. [Google Scholar]
- Kehl, W.; Milletari, F.; Tombari, F.; Ilic, S.; Navab, N. Deep learning of local RGB-D patches for 3D object detection and 6D pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 205–220. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Wohlhart, P.; Konolige, K. On Pre-Trained Image Features and Synthetic Images for Deep Learning. arXiv, 2017; arXiv:1710.10710. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-Time Dense Surface Mapping and Tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6d object pose estimation using 3d object coordinates. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 536–551. [Google Scholar]
- Brachmann, E.; Michel, F.; Krull, A.; Ying Yang, M.; Gumhold, S. Uncertainty-driven 6d pose estimation of objects and scenes from a single rgb image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3364–3372. [Google Scholar]
- Tejani, A.; Tang, D.; Kouskouridas, R.; Kim, T.K. Latent-class hough forests for 3D object detection and pose estimation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 462–477. [Google Scholar]
- Garrido-Jurado, S.; noz Salinas, R.M.; Madrid-Cuevas, F.; Marín-Jiménez, M. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Tabb, A.; Ahmad Yousef, K.M. Solving the Robot-World Hand-Eye(s) Calibration Problem with Iterative Methods. Mach. Vis. Appl. 2017, 28, 569–590. [Google Scholar] [CrossRef]
- Cognolato, M.; Graziani, M.; Giordaniello, F.; Saetta, G.; Bassetto, F.; Brugger, P.; Caputo, B.; Müller, H.; Atzori, M. Semi-Automatic Training of an Object Recognition System in Scene Camera Data Using Gaze Tracking and Accelerometers. In Proceedings of the International Conference on Computer Vision Systems, Copenhagen, Denmark, 6–9 July 2017; Liu, M., Chen, H., Vincze, M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 175–184. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient response maps for real-time detection of textureless objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face Recognition: A Literature Survey. ACM Comput. Surv. (CSUR) 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Goswami, G.; Bharadwaj, S.; Vatsa, M.; Singh, R. On RGB-D Face Recognition Using Kinect. In Proceedings of the IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Hodaň, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-less Objects. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. arXiv, 2017; arXiv:1711.08848. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, H.; Cao, Q. Combined Holistic and Local Patches for Recovering 6D Object Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2219–2227. [Google Scholar]
- Tejani, A.; Kouskouridas, R.; Doumanoglou, A.; Tang, D.; Kim, T.K. Latent-Class Hough Forests for 6 DoF Object Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 119–132. [Google Scholar] [CrossRef] [PubMed]
- Doumanoglou, A.; Kouskouridas, R.; Malassiotis, S.; Kim, T.K. Recovering 6D object pose and predicting next-best-view in the crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3583–3592. [Google Scholar]
- Michel, F.; Kirillov, A.; Brachmann, E.; Krull, A.; Gumhold, S.; Savchynskyy, B.; Rother, C. Global hypothesis generation for 6D object pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tan, D.J.; Navab, N.; Tombari, F. Looking beyond the simple scenarios: Combining learners and optimizers in 3d temporal tracking. IEEE Trans. Vis. Comput. Graph. 2017, 23, 2399–2409. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Our Method | LINEMOD++ [24] | Drost [17] | Hodaň et al. [26] | Brachmann et al. [35] | Hinterstoisser et al. [19] |
| Ape | 97.3% | 95.8% | 86.5% | 93.9% | 85.4% | 98.5% |
| Benchwise | 95.4% | 98.7% | 70.7% | 99.8% | 98.9% | 99.8% |
| Driller | 93.0% | 93.6% | 87.3% | 94.1% | 99.7% | 93.4% |
| Cam | 95.0% | 97.5% | 78.6% | 95.5% | 92.1% | 99.3% |
| Can | 97.0% | 95.9% | 80.2% | 95.9% | 84.4% | 98.7% |
| Iron | 98.7% | 97.5% | 84.9% | 97.0% | 98.8% | 98.3% |
| Lamp | 99.2% | 97.7% | 93.3% | 88.8% | 97.6% | 96.0% |
| Phone | 97.1% | 93.3% | 80.7% | 89.4% | 86.1% | 98.6% |
| Cat | 98.8% | 99.3% | 85.4% | 98.2% | 90.6% | |
| Hole punch | 92.8% | 95.9% | 77.4% | 88.0% | 97.9% | |
| Duck | 99.1% | 95.9% | 46.0% | 94.3% | 92.7% | |
| Cup | 97.7% | 97.1% | 68.4% | 99.5% | ||
| Bowl | 97.8% | 99.9% | 95.7% | 98.8% | ||
| Box | 99.2% | 99.8% | 97.0% | 100.0% | 91.1% | |
| Glue | 96.9% | 91.8% | 57.2% | 98.0% | 87.9% | |
| Mean | 95.7% | 96.6% | 79.3% | 95.4% | 92.5% | 97.8% |
| Sequence | Zhang et al. [27] | Kehl et al. [32] | Zhang et al. [51] | BB8 [29] | SSD-6D with RGB-D [28] | |
| Ape | 96.3% | 96.9% | 93.9% | |||
| Benchwise | 90.4% | 94.1% | 99.8% | |||
| Driller | 95.2% | 96.2% | 94.1% | |||
| Cam | 91.3% | 97.7% | 95.5% | |||
| Can | 98.2% | 95.2% | 95.9% | |||
| Iron | 98.8% | 98.7% | 97.0% | |||
| Lamp | 91.4% | 96.2% | 88.8% | |||
| Phone | 92.7% | 92.8% | ||||
| Cat | 91.8% | 97.4% | 98.2% | |||
| Hole punch | 97.8% | 96.8% | 88.0% | |||
| Duck | 91.8% | 97.3% | 94.3% | |||
| Cup | 99.6% | 99.6% | ||||
| Bowl | 99.9% | 99.9% | ||||
| Box | 99.8% | 99.9% | 100.0% | |||
| Glue | 94.6% | 78.6% | 98.0% | |||
| Mean | 94.7% | 95.8% | 95.7% | 62.7% | 90.9% | |
| Model | 6D Pose (5 cm 5) | 6D Pose (AD) | 2D Bounding Box (IoU) | F1-Score (AD) |
|---|---|---|---|---|
| Ape (1235) | 98.94% | 97.33% | 98.86% | 0.9864 |
| Bench Vise (1214) | 95.46% | 95.46% | 95.46% | 0.9768 |
| Driller (1187) | 93.09% | 91.24% | 93.85% | 0.9542 |
| Cam (1200) | 95.08% | 94.50% | 95.17% | 0.9717 |
| Can (1195) | 97.07% | 91.88% | 97.07% | 0.9577 |
| Iron (1151) | 98.70% | 98.00% | 98.87% | 0.9899 |
| Lamp (1226) | 99.26% | 98.04% | 99.26% | 0.9901 |
| Phone (1224) | 97.11% | 97.11% | 97.11% | 0.9853 |
| Cat (1178) | 98.89% | 98.89% | 98.89% | 0.9944 |
| Hole punch (1236) | 92.80% | 91.35% | 92.72% | 0.9547 |
| Duck (1253) | 99.12% | 96.96% | 99.12% | 0.9846 |
| Cup (1239) | 97.74% | 97.74% | 97.66% | 0.9881 |
| Bowl (1232) | 97.81% | 97.81% | 97.81% | 0.9889 |
| Box (1252) | 99.28% | 99.28% | 99.28% | 0.9963 |
| Glue (1219) | 96.97% | 90.26% | 96.97% | 0.9495 |
| Mean | 97.15% | 95.72% | 97.20% | 0.9779 |
| Sequence | Total Time (One-Core) | Total Time (Multi-Core) |
|---|---|---|
| Ape (1235) | 0.1070 | 0.0401 |
| Bench Vise (1214) | 0.0581 | 0.0289 |
| Bowl (1231) | 0.0748 | 0.0316 |
| Cam (1200) | 0.0646 | 0.0319 |
| Can (1195) | 0.0597 | 0.0288 |
| Cat (1178) | 0.0698 | 0.0308 |
| Cup (1239) | 0.0896 | 0.0367 |
| Driller (1187) | 0.0582 | 0.0291 |
| Duck (1253) | 0.0836 | 0.0333 |
| Box (1252) | 0.0830 | 0.0344 |
| Glue (1219) | 0.0837 | 0.0335 |
| Hole punch (1236) | 0.0831 | 0.0343 |
| Iron (1151) | 0.0621 | 0.0300 |
| Lamp (1226) | 0.0577 | 0.0287 |
| Phone (1224) | 0.0624 | 0.0288 |
| Mean | 0.0731 | 0.0320 |
| Method | Time (seconds) | Use GPU |
|---|---|---|
| LINEMOD++ [24] | 0.12 s | x |
| Hodaň et al. [26] | 0.75 to 2.08 s | √ |
| Brachmann et al. [36] | 0.45 s | x |
| Drost et al. [17] | 6.30 s | x |
| Hinterstoisser et al. [19] | 0.1 to 0.8 s | x |
| Doumanaglou et al. [53] | 4 to 7 s | x |
| Tejani et al. [52] | 0.67 s | x |
| BB8 [29] | 0.30 s | √ |
| Zhang et al. [51] | 0.80 s | – |
| Zhang et al. [27] | 0.70 s | x |
| Michel et al. [54] | 1 to 3 s | x |
| Do et al. [31] | 0.10 s | √ |
| SSD-6D [28] | 0.10 s | √ |
| Ours | 0.03 s | x |
| Users | Average Selection | Standard | Average Detection | Standard | Number | Successes | Failures |
|---|---|---|---|---|---|---|---|
| Time (s) | Deviation | Time (s) | Deviation | of Trials | |||
| user 1 | 10.00 | 13.68 | 1.02 | 0.05 | 20 | 20 | 0 |
| user 2 | 6.38 | 5.64 | 1.00 | 0.02 | 20 | 20 | 0 |
| user 3 | 18.81 | 32.52 | 0.98 | 0.04 | 20 | 20 | 0 |
| user 4 | 4.97 | 2.15 | 0.96 | 0.05 | 20 | 16 | 4 |
| user 5 | 24.63 | 46.31 | 0.96 | 0.05 | 20 | 15 | 5 |
| user 6 | 6.39 | 6.98 | 1.08 | 0.69 | 20 | 18 | 2 |
| user 7 | 4.04 | 1.02 | 0.96 | 0.04 | 20 | 19 | 1 |
| user 8 | 6.05 | 5.30 | 1.03 | 0.03 | 20 | 15 | 5 |
| user 9 | 14.75 | 17.32 | 0.97 | 0.02 | 20 | 18 | 2 |
| user 10 | 5.151 | 1.90 | 1.06 | 0.05 | 20 | 19 | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ivorra, E.; Ortega, M.; Catalán, J.M.; Ezquerro, S.; Lledó, L.D.; Garcia-Aracil, N.; Alcañiz, M. Intelligent Multimodal Framework for Human Assistive Robotics Based on Computer Vision Algorithms. Sensors 2018, 18, 2408. https://doi.org/10.3390/s18082408
Ivorra E, Ortega M, Catalán JM, Ezquerro S, Lledó LD, Garcia-Aracil N, Alcañiz M. Intelligent Multimodal Framework for Human Assistive Robotics Based on Computer Vision Algorithms. Sensors. 2018; 18(8):2408. https://doi.org/10.3390/s18082408
Chicago/Turabian StyleIvorra, Eugenio, Mario Ortega, José M. Catalán, Santiago Ezquerro, Luis Daniel Lledó, Nicolás Garcia-Aracil, and Mariano Alcañiz. 2018. "Intelligent Multimodal Framework for Human Assistive Robotics Based on Computer Vision Algorithms" Sensors 18, no. 8: 2408. https://doi.org/10.3390/s18082408
APA StyleIvorra, E., Ortega, M., Catalán, J. M., Ezquerro, S., Lledó, L. D., Garcia-Aracil, N., & Alcañiz, M. (2018). Intelligent Multimodal Framework for Human Assistive Robotics Based on Computer Vision Algorithms. Sensors, 18(8), 2408. https://doi.org/10.3390/s18082408