Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network


Abstract
1. Introduction
- An effective long-range attention mechanism simply implemented by temporal weighting;
- Each stream of the proposed ATW CNN can be optimized end-to-end, without requiring additional labeling;
2. Related Works
- 3D CNNs-based methods. Ji et al. [18] extended regular 2D CNN to 3D, with promising performances achieved on small video datasets. Tran et al. [11] modified traditional 2D convolution kernels and proposed the 3D CNNs for spatio-temporal feature extraction. Sun et al. [40] proposed a cascaded deep architecture which can learn effective spatio-temporal features. Recently, Carreira et al. [9] proposed a new inflated 3D CNN model based on 2D CNNs inflation.
- Two-stream CNN-based methods. Simonyan et al. [6] proposed the two-stream CNN by parsing a stack of optical flow images along with RGB images, with each stream being a regular 2D CNN. Since then, optical flow is routinely used as the secondary modality for action recognition. Karpathy et al. [30] studied three fusion strategies (early fusion, late fusion and slow fusion) for the connectivity of streams, which offered a promising way of speeding up the training. Feichtenhofer et al. [13] discovered one of the limiting factors in the two-stream CNN architecture, i.e., only a single frame is sampled from a video as the RGB stream input.
- RNN-based methods. Donahue et al. [10] proposed a recurrent architecture (LRCN) to boost the temporal discretion, arguing that temporal discretion via LRCN is critical to action recognition because consecutive video frames often incur redundancies and noises. Ng et al. [7] explored various convolutional temporal feature pooling architectures and connected long-short temporal memory (LSTM) to visual geometry group-16 (VGG-16) networks. The memory cells of LSTM can hold hidden states, and thus can accommodate long-range temporal information. Srivastava et al. [41] used an encoder LSTM to map an input video sequence into a fixed length representation. Mahasseni et al. [42] used LSTM with CNN for action recognition in videos.
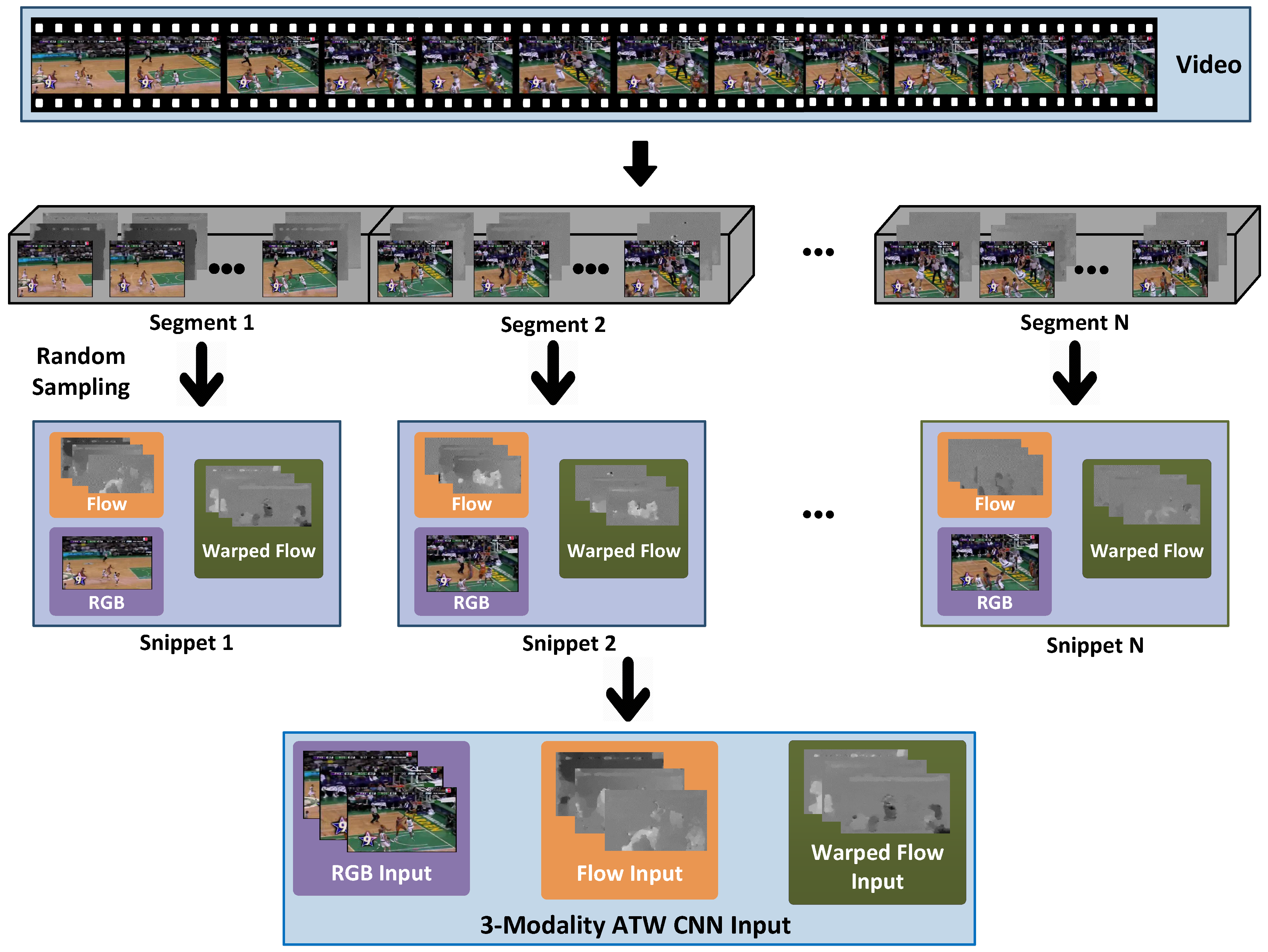
- Hybrid model-based methods. Hybrid methods incorporate both conventional wisdom and deep learning for action recognition [28,43,44]. Some recent literatures emphasized on new architectures with special considerations for temporal discretion [8,14,45,46,47]. Wang et al. [43] presented the trajectory-pooled deep-convolutional descriptor for video representation. Varol et al. [48] introduced a video representation by using neural networks with long-term temporal convolutions. Apart from these, Zhu et al. [49] proposed a deep framework by using instance learning to identify key volumes and to simultaneously reduce redundancies. Wang et al. [50] proposed a multi-level video representation by stacking the activations of motion features, atoms, and phrases. Fernando et al. [51] introduced a ranking function and used its parameters as video representation. Ni et al. [52] proposed to mine discriminative groups of dense trajectories, which can highlight more discriminative action representation. Wang et al. [8] proposed a video-level framework that aims at exploiting long-term temporal structures for action recognition. Specifically, snippets are multi-modal data randomly sampled from non-overlapping video segments, as shown in Figure 1. Typically a video is divided into 1 to 8 segments. Segments are typically much longer than “clips” used by 3D CNN literature, e.g., the 16-frame clip in 3D CNNs [11].
3. Problem Formulation
3.1. Temporally Structured Representation of Action
- dense sampling in the time domain, the inputs of the network are consecutive video frames covering the entire video;
- spare sampling one frame out of () frames, i.e., frames at time instants are sampled;
- with a target number of N segments (typical N values are from 1 to 8.), non-overlapping segments are obtained by evenly partition the video into N such chunks, as illustrated in Figure 1.
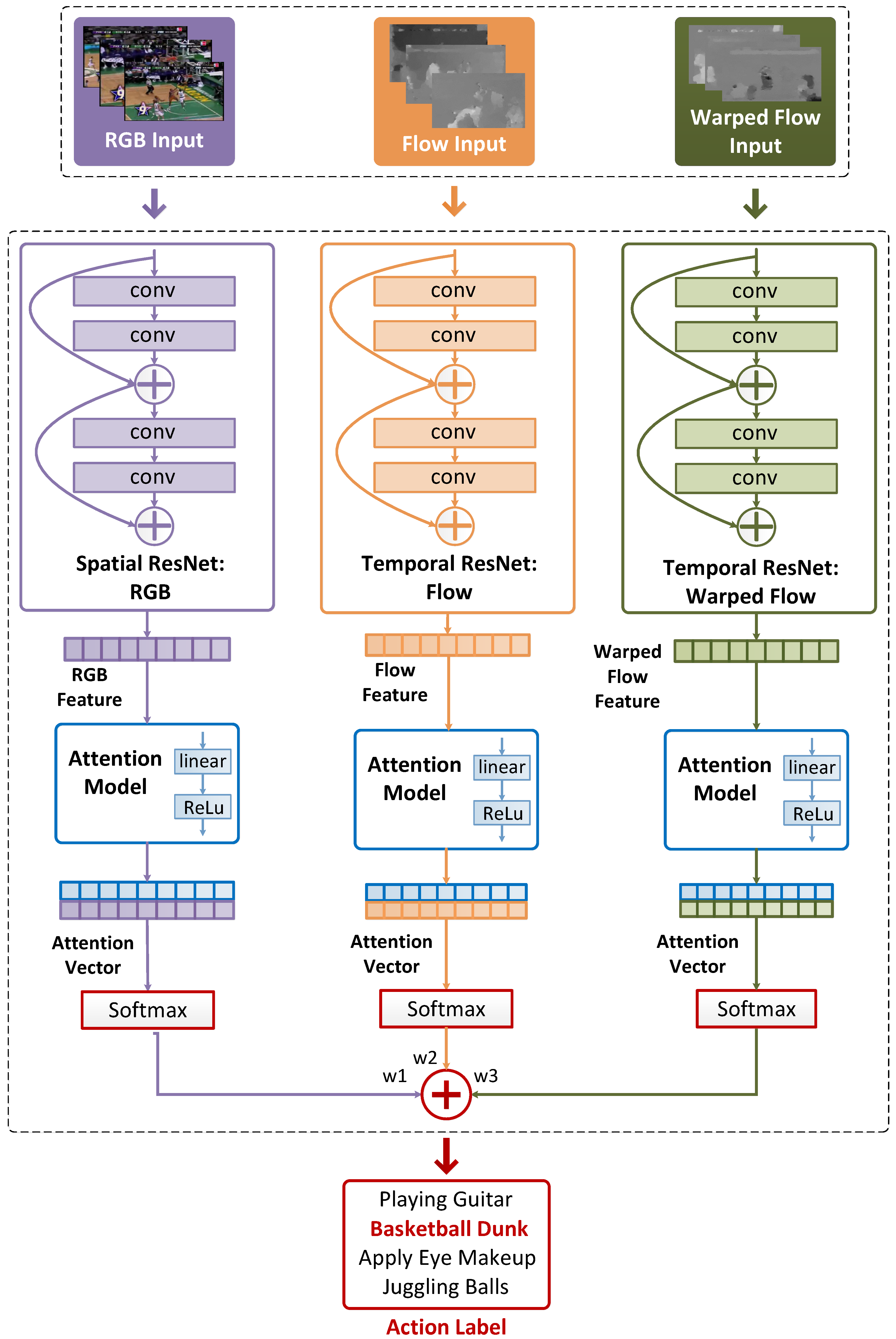
3.2. Attention-Aware Temporal Weighted Convolutional Neural Network
3.3. Implementation Details of ATW CNN
4. Experiments and Discussions
4.1. Trimmed Action Datasets
4.2. Video Frame Sampling Strategies
- dense sampling in time domain;
- interval sampling (1 sample every frames);
- given the predefined total number of segments N, each video is evenly partitioned into N non-overlapping segments (denoted as “Uniform Segmentation” in Table 1).
4.3. Comparison with Different Consensus Functions
4.4. Choice of Segment Number N in Attention Model
4.5. Activation Function Selection and Parameter Initialization in Attention Layers
- all weights set to 1 and biases set to 0;
- all weights set to and bias set to 0;
- random initialization based on standard normal distribution (0 mean and 0.001 standard deviation) for both and .
4.6. Comparison with State-Of-The-Arts
4.7. Visualization
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNNs | Convolutional Neural Networks |
| LSTM | Long-Short Temporal Memory |
| ATW | Attention-based Temporal Weighted |
| SGD | Stochastic Gradient Descent |
| RNNs | Recurrent Neural Networks |
| iDT | improved Dense Trajectory |
| TSN | Temporal Segment Network |
| P-CNN | Pose-based Convolutional Neural Network |
| LRCN | Long-term Recurrent Convolutional Networks |
| C3D | 3D Convolutional Networks |
| ReLu | Rectified Linear Unit |
| BN | Batch Normalization |
| ResNet | Deep Residual Convolutional Neural Networks |
| VGG | Visual Geometry Group |
| mAP | mean Average Precision |
| BoVW | Bag of Visual Words |
| MoFAP | Motion Features, Atoms, Phrases |
| Factorized Spatio-Temporal Convolutional Networks | |
| TDD | Trajectory-Pooled Deep-Convolutional Descriptors |
| FV | Fisher Vector |
| LTC | Long-term Temporal Convolutions |
| KVMF | Key Volume Mining deep Framework |
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, L.; Xue, J.; Zheng, N.; Hua, G. Automatic salient object extraction with contextual cue. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 105–112. [Google Scholar]
- Wang, L.; Hua, G.; Sukthankar, R.; Xue, J.; Niu, Z.; Zheng, N. Video object discovery and co-segmentation with extremely weak supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2074–2088. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the IEEE Conference on European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 20–36. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 4724–4733. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 3218–3226. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1933–1941. [Google Scholar]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based sign language recognition without temporal segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wang, L.; Duan, X.; Zhang, Q.; Niu, Z.; Hua, G.; Zheng, N. Segment-tube: Spatio-temporal action localization in untrimmed videos with per-frame segmentation. Sensors 2018, 18, 1657. [Google Scholar] [CrossRef] [PubMed]
- Duan, X.; Wang, L.; Zhai, C.; Zhang, Q.; Niu, Z.; Zheng, N.; Hua, G. Joint spatio-temporal action localization in untrimmed videos with per-frame segmentation. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018. [Google Scholar]
- Gao, Z.; Hua, G.; Zhang, D.; Jojic, N.; Wang, L.; Xue, J.; Zheng, N. ER3: A unified framework for event retrieval, recognition and recounting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2253–2262. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 3–6 December 2013; pp. 3551–3558. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: a local SVM approach. In Proceedings of the IEEE International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; pp. 32–36. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv, 2012; arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Stiefelhagen, R.; Serre, T. HMDB51: A large video database for human motion recognition. In High Performance Computing in Science and Engineering; Nagel, W., Kröner, D., Resch, M., Eds.; Springer: Berlin, Germany, 2013; pp. 571–582. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Zang, J.; Wang, L.; Liu, Z.; Zhang, Q.; Niu, Z.; Hua, G.; Zheng, N. Attention-based temporal weighted convolutional neural network for action recognition. In Proceedings of the International Conference on Artificial Intelligence Applications and Innovations, Rhodes, Greece, 25–27 May 2018. [Google Scholar]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action recognition by dense trajectories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado, CO, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar]
- Peng, X.; Wang, L.; Wang, X.; Qiao, Y. Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. Comput. Vis. Image Underst. 2016, 150, 109–125. [Google Scholar] [CrossRef]
- Shao, L.; Zhen, X.; Tao, D.; Li, X. Spatio-temporal Laplacian pyramid coding for action recognition. IEEE Trans. Cybern. 2014, 44, 817–827. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitionm, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Ran, L.; Zhang, Y.; Wei, W.; Zhang, Q. A hyperspectral image classification framework with spatial pixel pair features. Sensors 2017, 17, 2421. [Google Scholar] [CrossRef] [PubMed]
- Ran, L.; Zhang, Y.; Zhang, Q.; Yang, T. Convolutional neural network-based robot navigation using uncalibrated spherical images. Sensors 2017, 17, 1341. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Zhang, Q.; Hua, G. Multi-view visual recognition of imperfect testing data. In Proceedings of the ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 561–570. [Google Scholar]
- Liu, Z.; Li, R.; Tan, J. Exploring 3D human action recognition: From offline to online. Sensors 2018, 18, 633. [Google Scholar]
- Hachaj, T.; Piekarczyk, M.; Ogiela, M.R. Human actions analysis: templates generation, matching and visualization applied to motion capture of highly-skilled karate athletes. Sensors 2017, 17, 2590. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Hua, G.; Liu, W.; Liu, Z.; Zhang, Z. Can visual recognition benefit from auxiliary information in training? In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 65–80. [Google Scholar]
- Zhang, Q.; Hua, G.; Liu, W.; Liu, Z.; Zhang, Z. Auxiliary training information assisted visual recognition. IPSJ Trans. Comput. Vis. Appl. 2015, 7, 138–150. [Google Scholar] [CrossRef]
- Sun, L.; Jia, K.; Yeung, D.Y.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4597–4605. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 843–852. [Google Scholar]
- Mahasseni, B.; Todorovic, S. Regularizing long short term memory with 3D human-skeleton sequences for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3054–3062. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Liu, Z.; Wang, L.; Zheng, N. Content-aware attention network for action recognition. In Proceedings of the International Conference on Artificial Intelligence Applications and Innovations, Rhodes, Greece, 25–27 May 2018. [Google Scholar]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing videos by exploiting temporal structure. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4507–4515. [Google Scholar]
- Gaidon, A.; Harchaoui, Z.; Schmid, C. Temporal localization of actions with actoms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2782–2795. [Google Scholar] [CrossRef] [PubMed]
- Kataoka, H.; Satoh, Y.; Aoki, Y.; Oikawa, S.; Matsui, Y. Temporal and fine-grained pedestrian action recognition on driving recorder database. Sensors 2018, 18, 627. [Google Scholar] [CrossRef] [PubMed]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Hu, J.; Sun, G.; Cao, X.; Qiao, Y. A key volume mining deep framework for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1991–1999. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. MoFAP: A multi-level representation for action recognition. Int. J. Comput. Vis. 2016, 119, 254–271. [Google Scholar] [CrossRef]
- Fernando, B.; Gavves, S.; Mogrovejo, O.; Antonio, J.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5378–5387. [Google Scholar]
- Ni, B.; Moulin, P.; Yang, X.; Yan, S. Motion part regularization: Improving action recognition via trajectory selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3698–3706. [Google Scholar]
- Zhang, Q.; Abeida, H.; Xue, M.; Rowe, W.; Li, J. Fast implementation of sparse iterative covariance-based estimation for array processing. In Proceedings of the Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 6–9 November 2011; pp. 2031–2035. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G. Pytorch. Available online: https://github.com/pytorch/pytorch (accessed on 28 January 2017).
- Cai, Z.; Wang, L.; Peng, X.; Qiao, Y. Multi-view super vector for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Ohio, 24–27 June 2014; pp. 596–603. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | RGB VGG-16 | Optical Flow VGG-16 | RGB + Flow VGG-16 |
|---|---|---|---|
| Dense Sampling | |||
| Interval Sampling | |||
| Uniform Segmentation |
| Consensus Function | RGB BN-Inception | Optical Flow BN-Inception | RGB + Flow BN-Inception |
|---|---|---|---|
| Max | |||
| Average | |||
| Attention Model |
| Dataset | RGB BN-Inception Net with Proposed Attention Model | |||||||
|---|---|---|---|---|---|---|---|---|
| N = 1 | N = 2 | N = 3 | N = 4 | N = 5 | N = 6 | N = 7 | N = 8 | |
| UCF-101 (split1) | 83.33% | 83.89% | 84.80% | 85.29% | 85.21% | 85.04% | 85.55% | |
| HMDB-51 (split1) | 50.07% | 53.33% | 53.01% | 53.33% | 55.36% | 53.20% | 53.14% | |
| Activation Function | RGB BN-Inception Net | Optical Flow BN-Inception Net |
|---|---|---|
| tanh | 84.91% | |
| Sigmoid | 85.29% | |
| ReLU |
| HMDB-51 | UCF-101 | ||
|---|---|---|---|
| Model | Accuracy | Model | Accuracy |
| DT [57] | DT [57] | ||
| iDT [19] | iDT [19] | ||
| BoVW [28] | BoVW [28] | ||
| MoFAP [50] | MoFAP [50] | ||
| Composite LSTM [41] | LRCN [10] | ||
| RLSTM [42] | RLSTM [42] | ||
| Two Stream [6] | Two Stream [6] | ||
| VideoDarwin [51] | C3D [11] | ||
| MPR [52] | Two stream + LSTM [7] | ||
| (SCI fusion) [40] | (SCI fusion) [40] | ||
| TDD + FV [43] | TDD + FV [43] | ||
| LTC [48] | LTC [48] | ||
| KVMF [49] | KVMF [49] | ||
| TSN (3 modalities) [8] | TSN (3 modalities) [8] | ||
| Proposed ATW CNN | Proposed ATW CNN | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Zang, J.; Zhang, Q.; Niu, Z.; Hua, G.; Zheng, N. Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network. Sensors 2018, 18, 1979. https://doi.org/10.3390/s18071979
Wang L, Zang J, Zhang Q, Niu Z, Hua G, Zheng N. Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network. Sensors. 2018; 18(7):1979. https://doi.org/10.3390/s18071979
Chicago/Turabian StyleWang, Le, Jinliang Zang, Qilin Zhang, Zhenxing Niu, Gang Hua, and Nanning Zheng. 2018. "Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network" Sensors 18, no. 7: 1979. https://doi.org/10.3390/s18071979
APA StyleWang, L., Zang, J., Zhang, Q., Niu, Z., Hua, G., & Zheng, N. (2018). Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network. Sensors, 18(7), 1979. https://doi.org/10.3390/s18071979