Sensor-Based Optimization Model for Air Quality Improvement in Home IoT


Abstract
1. Introduction
2. Background
2.1. IoT and User Behavior Value
2.2. Studies on Improvement of Indoor Air Quality
2.3. Technique of Random Data Generation
3. Design
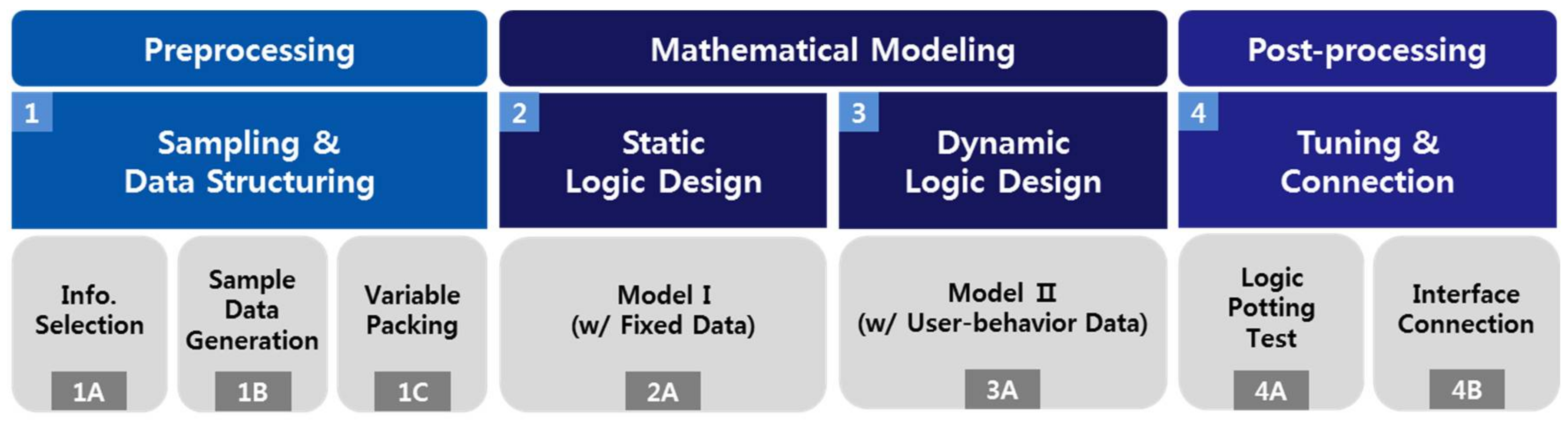
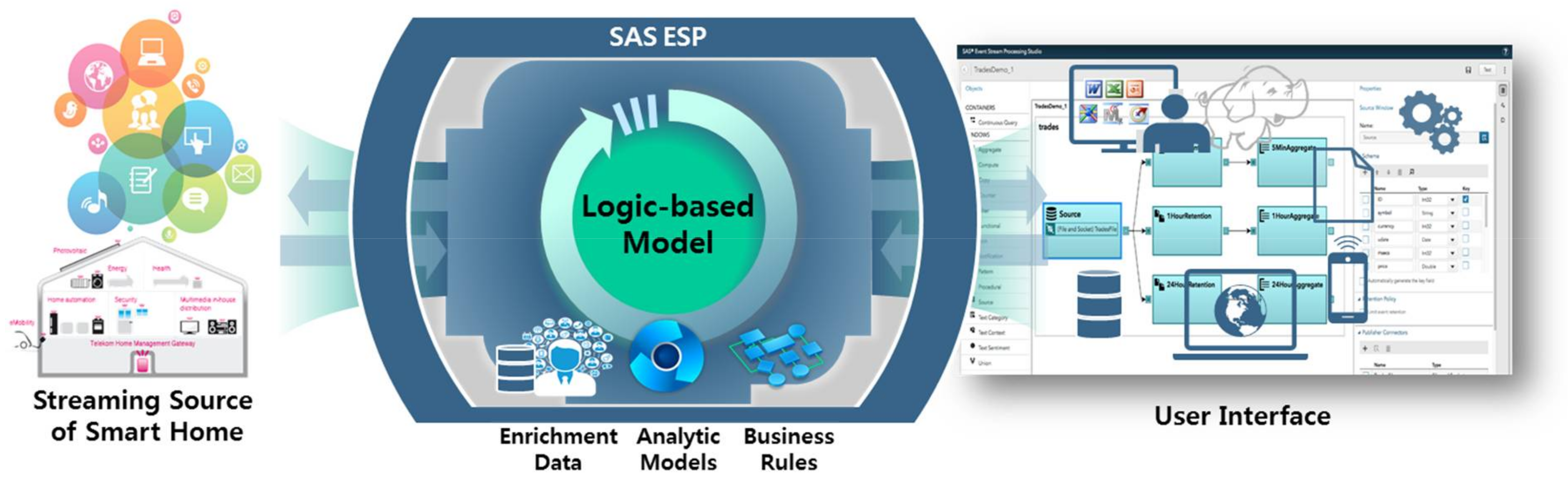
3.1. Sensor-Based Modeling Framework
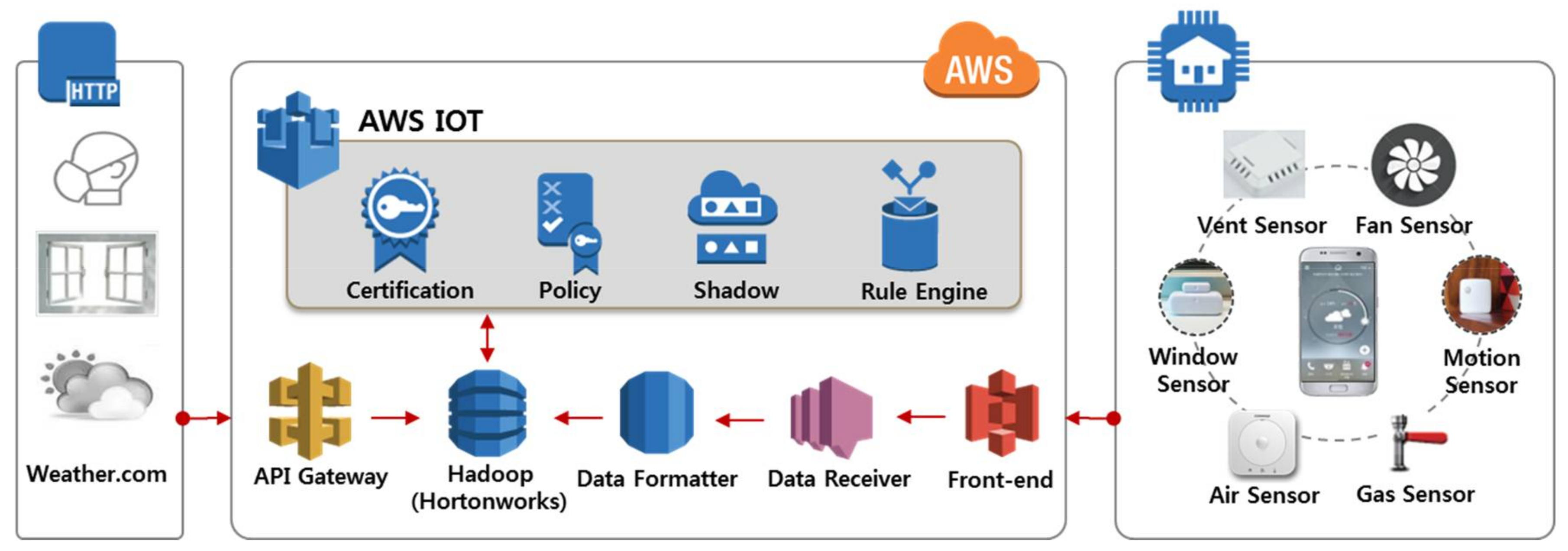
3.2. Infrastructure
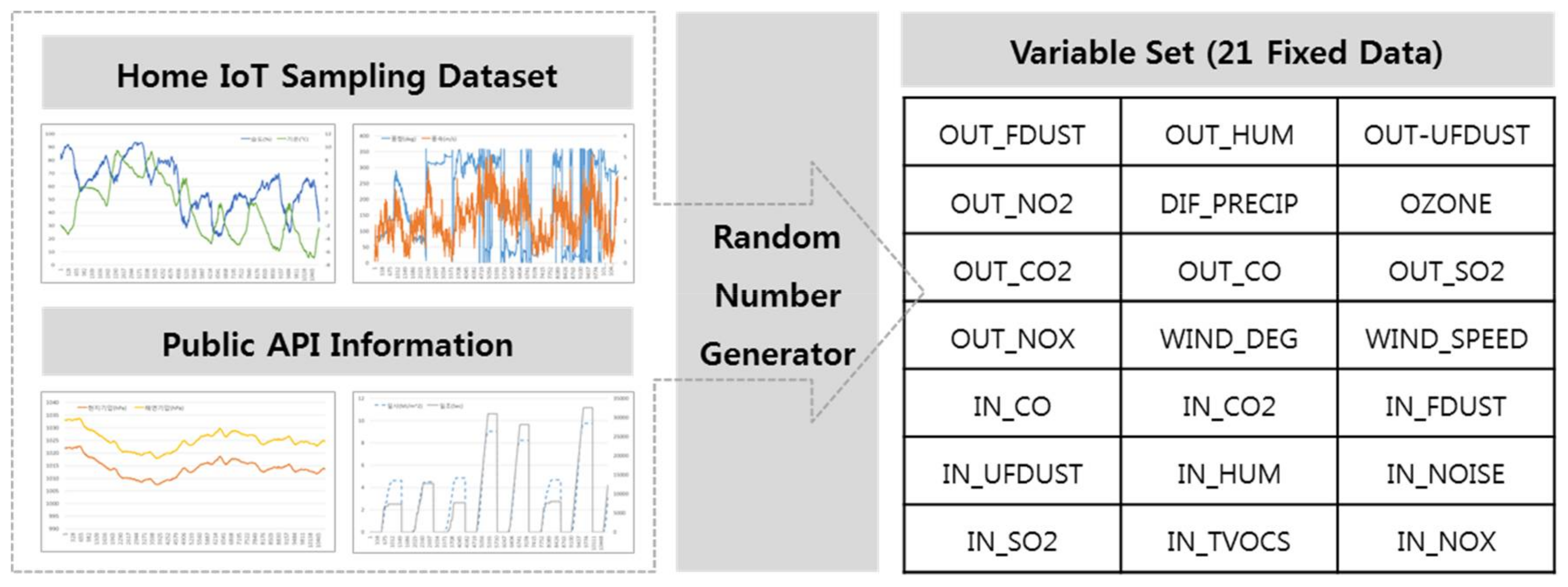
3.3. Preprocessing
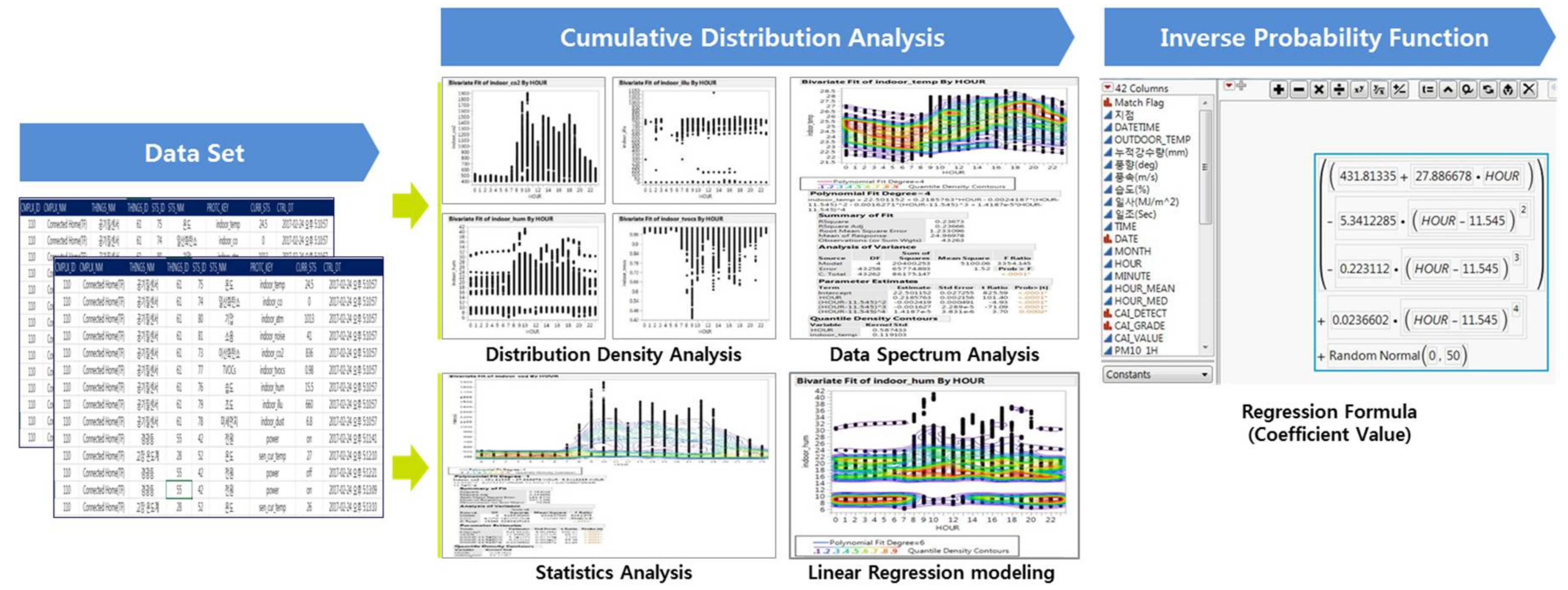
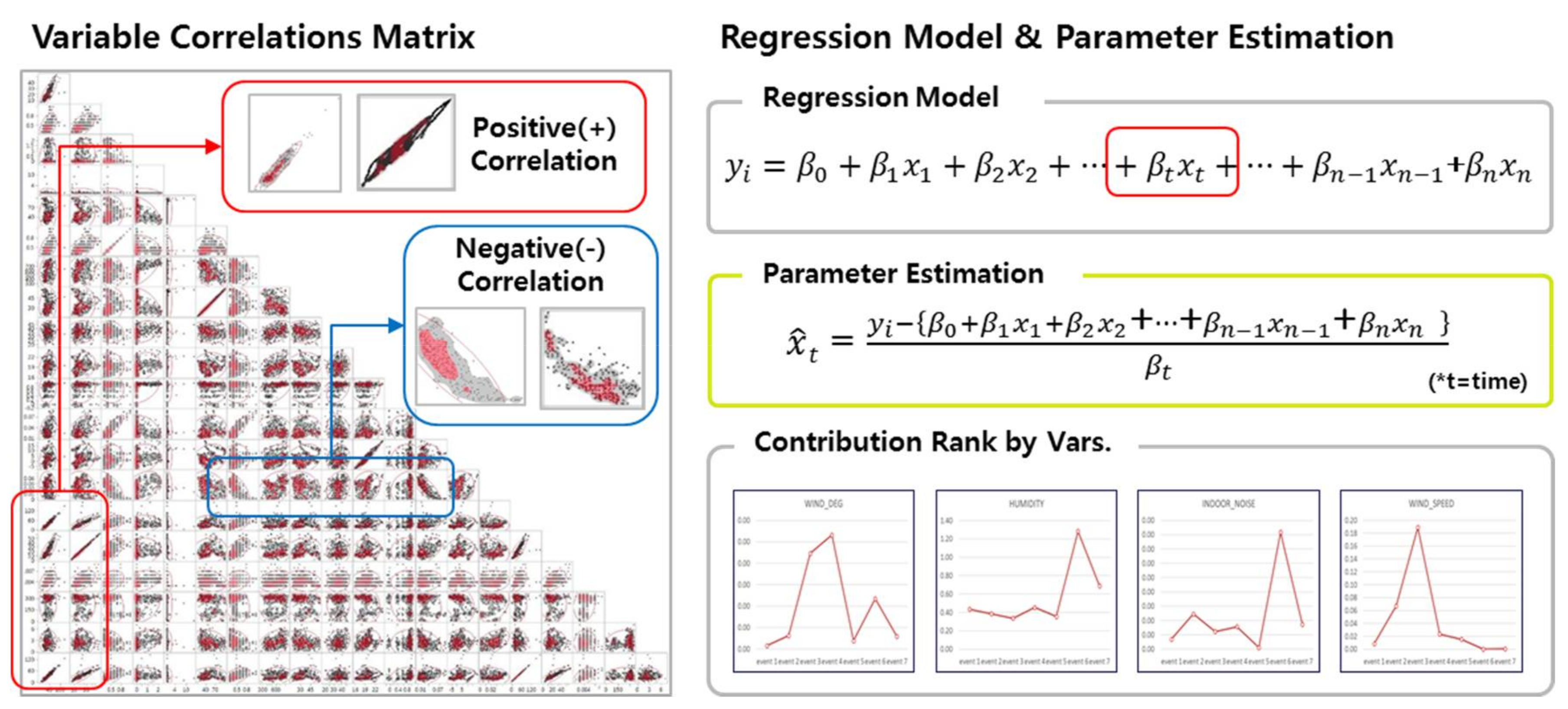
3.4. First-Round Analysis
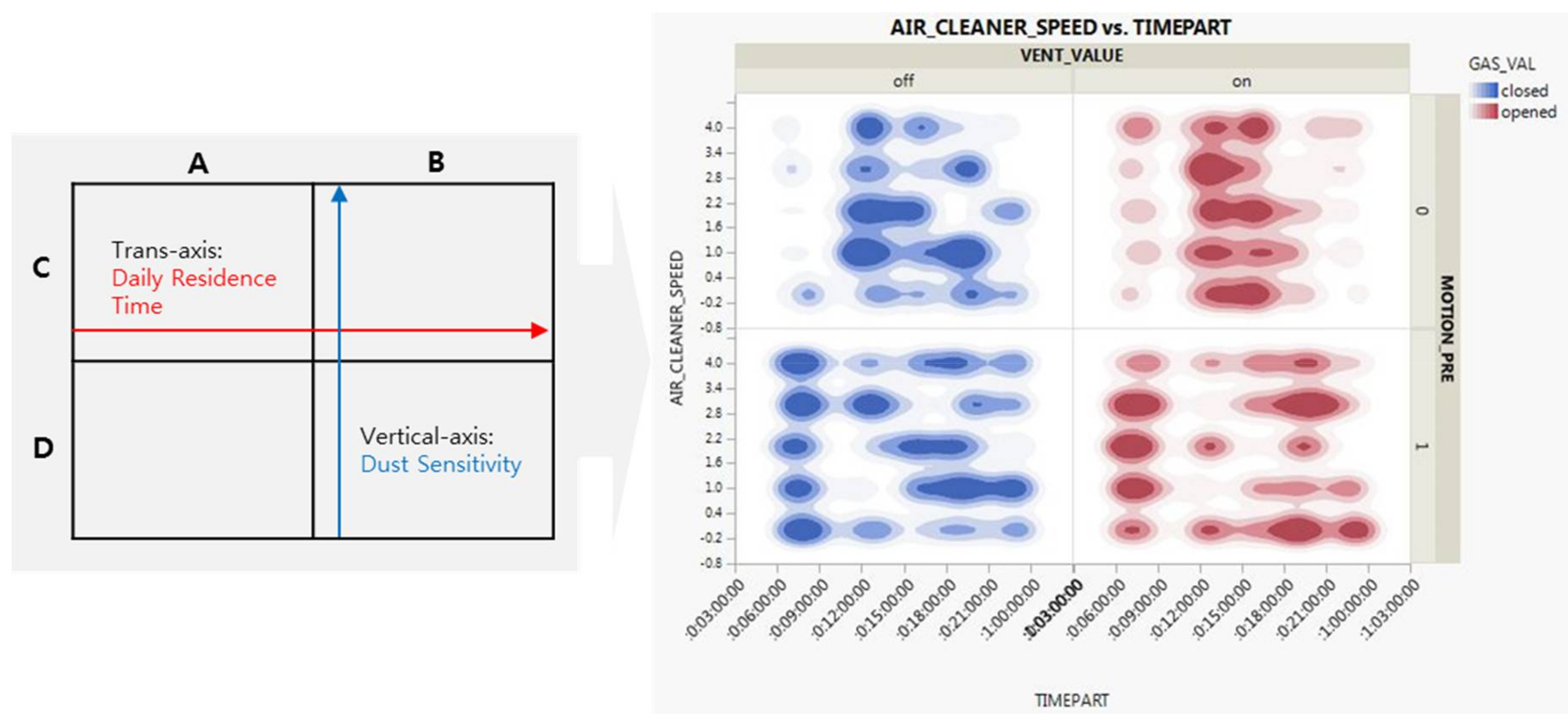
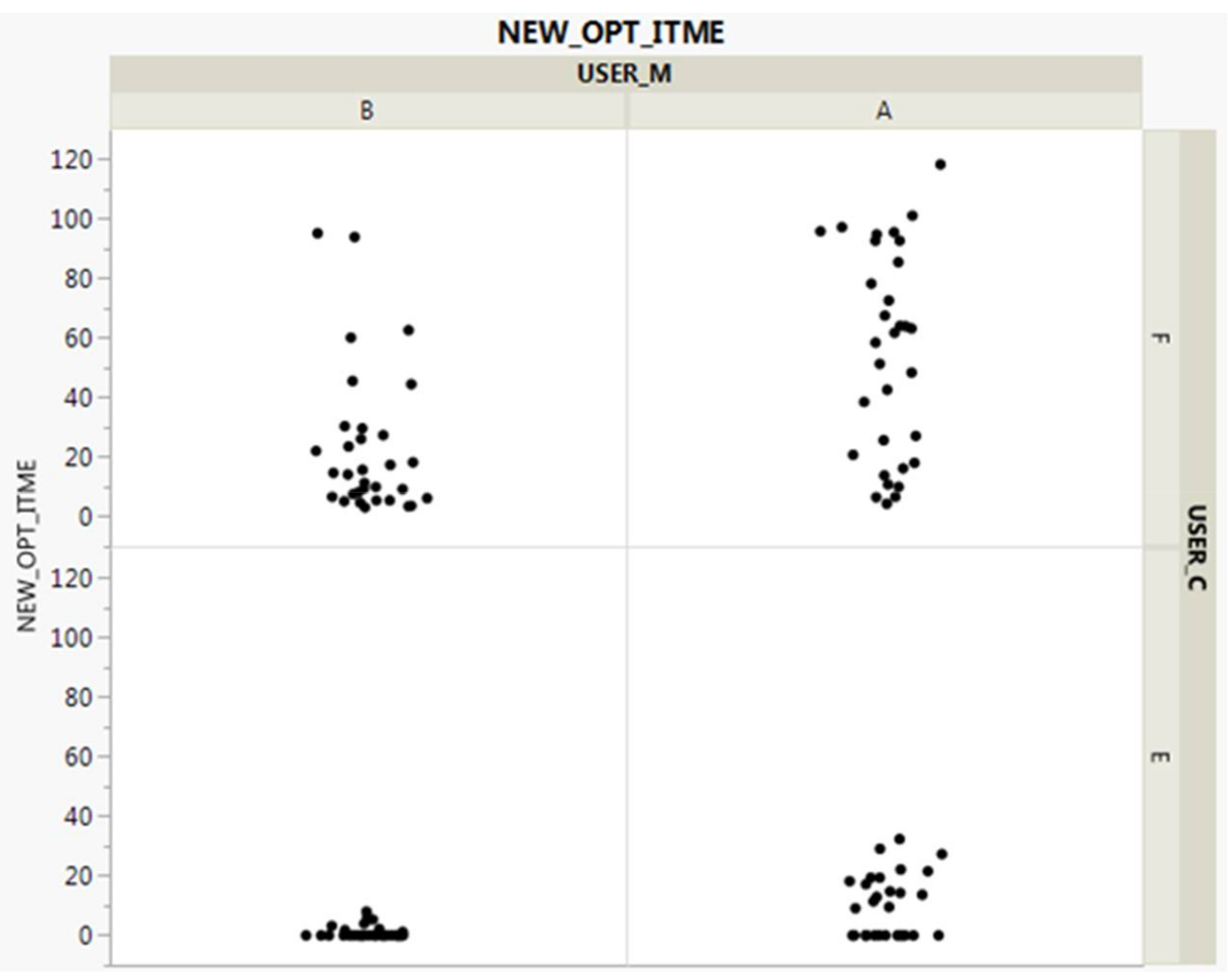
3.5. Second-Round Analysis
3.6. Post-Processing
3.7. Marketing Prospects
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Spanò, E.; Niccolini, L.; Di Pascoli, S.; Iannacconeluca, G. Last-meter smart grid embedded in an Internet-of-Things platform. IEEE Trans. Smart Grid 2015, 6, 468–476. [Google Scholar] [CrossRef]
- Alirezaie, M.; Renoux, J.; Köckemann, U.; Kristoffersson, A.; Karlsson, L.; Blomqvist, E.; Tsiftes, N.; Voigt, T.; Loutfi, A. An ontology-based context-aware system for smart homes: E-care@ home. Sensors 2017, 17, 1586. [Google Scholar] [CrossRef] [PubMed]
- Sung, W.-T.; Chiang, Y.-C. Improved particle swarm optimization algorithm for android medical care IOT using modified parameters. J. Med. Syst. 2012, 36, 3755–3763. [Google Scholar] [CrossRef] [PubMed]
- Sicari, S.; Rizzardi, A.; Grieco, L.A.; Coen-Porisini, A. Security, privacy and trust in Internet of Things: The road ahead. Comput. Netw. 2015, 76, 146–164. [Google Scholar] [CrossRef]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef]
- Kolarik, J.; Toftum, J. The impact of a photocatalytic paint on indoor air pollutants: Sensory assessments. Build. Environ. 2012, 57, 396–402. [Google Scholar] [CrossRef]
- Joo, J.; Zheng, Q.; Lee, G.; Kim, J.T.; Kim, S. Optimum energy use to satisfy indoor air quality needs. Energy Build. 2012, 46, 62–67. [Google Scholar] [CrossRef]
- Xu, L.D.; He, W.; Li, S. Internet of things in industries: A survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar] [CrossRef]
- Borgia, E. The Internet of Things vision: Key features, applications and open issues. Comput. Commun. 2014, 54, 1–31. [Google Scholar] [CrossRef]
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments, and challenges for enterprises. Bus. Horiz. 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Mineraud, J.; Mazhelis, O.; Su, X.; Tarkoma, S. A gap analysis of Internet-of-Things platforms. Comput. Commun. 2016, 89, 5–16. [Google Scholar] [CrossRef]
- Alirezaie, M.; Loutfi, A. Reasoning for sensor data interpretation: An application to air quality monitoring. J. Ambient Intell. Smart Environ. 2015, 7, 579–597. [Google Scholar] [CrossRef]
- Alirezaie, M.; Loutfi, A. Reasoning for improved sensor data interpretation in a Smart Home. arXiv, 2014; arXiv:1412.7961. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. From “smart objects” to “social objects”: The next evolutionary step of the internet of things. IEEE Commun. Mag. 2014, 52, 97–105. [Google Scholar] [CrossRef]
- Mennicken, S.; Vermeulen, J.; Huang, E.M. From today’s augmented houses to tomorrow’s smart homes: New directions for home automation research. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 105–115. [Google Scholar]
- Kelly, S.D.T.; Suryadevara, N.K.; Mukhopadhyay, S.C. Towards the implementation of IoT for environmental condition monitoring in homes. IEEE Sens. J. 2013, 13, 3846–3853. [Google Scholar] [CrossRef]
- Vlacheas, P.; Giaffreda, R.; Stavroulaki, V.; Kelaidonis, D.; Foteinos, V.; Poulios, G.; Demestichas, P.; Somov, A.; Biswas, A.R.; Moessner, K. Enabling smart cities through a cognitive management framework for the internet of things. IEEE Commun. Mag. 2013, 51, 102–111. [Google Scholar] [CrossRef]
- Howard, P.N.; Parks, M.R. Social media and political change: Capacity, constraint, and consequence. J. Commun. 2012, 62, 359–362. [Google Scholar] [CrossRef]
- Gormley, P.; Anttila, V.; Winsvold, B.S.; Palta, P.; Esko, T.; Pers, T.H.; Farh, K.-H.; Cuenca-Leon, E.; Muona, M.; Furlotte, N.A.; et al. Meta-analysis of 375,000 individuals identifies 38 susceptibility loci for migraine. Nat. Genet. 2016, 48, 856–866. [Google Scholar] [CrossRef] [PubMed]
- Ettinger, S.E.; Nasser, J.A.; Engelson, E.S.; Albu, J.B.; Hashim, S.; Pi-Sunyer, F.X. The rationale, feasibility, and optimal training of the non-physician medical nutrition scientist. J. Biomed. Educ. 2015, 2015, 954808. [Google Scholar] [CrossRef]
- Schober, W.; Szendrei, K.; Matzen, W.; Osiander-Fuchs, H.; Heitmann, D.; Schettgen, T.; Jörres, R.A.; Fromme, H. Use of electronic cigarettes (e-cigarettes) impairs indoor air quality and increases FeNO levels of e-cigarette consumers. Int. J. Hyg. Environ. Health 2014, 217, 628–637. [Google Scholar] [CrossRef] [PubMed]
- Volk, H.E.; Lurmann, F.; Penfold, B.; Hertz-Picciotto, I.; McConnell, R. Traffic-related air pollution, particulate matter, and autism. JAMA Psychiatry 2013, 70, 71–77. [Google Scholar] [CrossRef] [PubMed]
- Paulos, E.; Honicky, R.; Hooker, B. Citizen science: Enabling participatory urbanism. In Urban Informatics: Community Integration and Implementation; IGI Global: Hershey, PA, USA, 2008. [Google Scholar]
- Kanjo, E. Noisespy: A real-time mobile phone platform for urban noise monitoring and mapping. Mob. Netw. Appl. 2010, 15, 562–574. [Google Scholar] [CrossRef]
- Lohani, D.; Acharya, D. Smartvent: A context aware iot system to measure indoor air quality and ventilation rate. In Proceedings of the 2016 17th IEEE International Conference on Mobile Data Management (MDM), Porto, Portugal, 13–16 June 2016; pp. 64–69. [Google Scholar]
- Hwang, J.; Yoe, H. Study of the ubiquitous hog farm system using wireless sensor networks for environmental monitoring and facilities control. Sensors 2010, 10, 10752–10777. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Wang, N.; Jafer, E.; Hayes, M.; O’Flynn, B.; O’Mathuna, C. Autonomous wireless sensor network based building energy and environment monitoring system design. In Proceedings of the 2010 International Conference on Environmental Science and Information Application Technology (ESIAT), Wuhan, China, 17–18 July 2010; pp. 367–372. [Google Scholar]
- Pötsch, A.; Haslhofer, F.; Springer, A. Advanced remote debugging of LoRa-enabled IoT sensor nodes. In Proceedings of the Seventh International Conference on the Internet of Things, Linz, Austria, 22–25 October 2017; p. 23. [Google Scholar]
- Malm, W.C.; Schichtel, B.A.; Pitchford, M.L.; Ashbaugh, L.L.; Eldred, R.A. Spatial and monthly trends in speciated fine particle concentration in the United States. J. Geophys. Res. Atmos. 2004, 109. [Google Scholar] [CrossRef]
- Salamone, F.; Belussi, L.; Danza, L.; Ghellere, M.; Meroni, I. How to control the Indoor Environmental Quality through the use of the Do-It-Yourself approach and new pervasive technologies. Energy Procedia 2017, 140, 351–360. [Google Scholar] [CrossRef]
- Salamone, F.; Belussi, L.; Danza, L.; Galanos, T.; Ghellere, M.; Meroni, I. Design and development of a nearable wireless system to control indoor air quality and indoor lighting quality. Sensors 2017, 17, 1021. [Google Scholar] [CrossRef] [PubMed]
- Xiao, M.; El-Attar, M.; Reformat, M.; Miller, J. Empirical evaluation of optimization algorithms when used in goal-oriented automated test data generation techniques. Empir. Softw. Eng. 2007, 12, 183–239. [Google Scholar] [CrossRef]
- Alba, E.; Chicano, F. Observations in using parallel and sequential evolutionary algorithms for automatic software testing. Comput. Oper. Res. 2008, 35, 3161–3183. [Google Scholar] [CrossRef]
- Mousa, A.; El-Shorbagy, M.; Abd-El-Wahed, W. Local search based hybrid particle swarm optimization algorithm for multiobjective optimization. Swarm Evol. Comput. 2012, 3, 1–14. [Google Scholar] [CrossRef]
- Watkins, A.; Hufnagel, E.M. Evolutionary test data generation: A comparison of fitness functions. Softw. Pract. Exp. 2006, 36, 95–116. [Google Scholar] [CrossRef]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Gerald, C.F. Applied Numerical Analysis; Pearson Education India: Kerala, India, 2004. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Description | Prior Studies |
|---|---|---|
| Auto Configuration | Functions for device installation and easy configuration processing | Spanò et al. [2] |
| Remote Monitoring | Function to monitor human and object behavior according to space and time | |
| Situation Awareness | Function for real-time recognition of natural environment changes according to the situation | Alirezaie et al. [3] |
| Sensor-Driven Analytics | Function to support human decision-making through specific analysis and data visualization | |
| Process Optimization | Functions related to automatic control in specific environments, such as factories | |
| Energy Resource Optimization | Functions related to smart measurement and energy consumption optimization for energy (power, water, gas, heating, etc.) consumption | Sung and Chiang [4] |
| Privacy | Privacy protection function based on the user’s personal information, life patterns, and preference trends | Sicari et al. [5] |
| Open API | Support for managing multiple services, linking with external systems, and developing various “mashup” services | |
| Security | Function to ensure security against physical and logical intrusions | |
| Autonomous System | Functions for autonomous determination or automatic control of complex conditions | Gubbi et al. [6] |
| Redefined Factors of UBV | Operational Definition | Initial Factors of UBV | Prior Studies |
|---|---|---|---|
| Interactivity | Value in relation to the interaction with IoT devices | Objectivity, Completeness, Achievement, Logicality, Conductance, Accuracy, Satisfiability, Sociality, Expectancy, Relationship | Atzori et al. [15], Mennicken et al. [16] |
| Stability | Value for the manageability of IoT devices | Manageability, Simplicity, Safety, Security, Equity, Reliability, Transparency, Identity, Sustainability | Sicari, Rizzardi, Grieco and Coen-Porisini [5], Lee and Lee [11] |
| Functionality | Value for reliable operation of IoT devices | Convenience, Diversity, Compatibility, Scalability, Promptness, Efficiency, Informativeness, Automaticity, Usability | Kelly et al. [17], Vlacheas et al. [18] |
| Variable Name | |
|---|---|
| Outdoor Information | Fine Dust (), Relative Humidity (%), Ultrafine Dust (), Nitrogen Dioxide (ppm), Precipitation (, Ozone Concentration (ppm), Carbon Dioxide (ppm), Carbon Monoxide (ppm), Sulfur Dioxide (ppm), Nitrogen Oxides (ppm), Wind Direction (8 dummy directions), Wind Velocity (m/s) |
| Indoor Information | Indoor Carbon Monoxide (ppm), Indoor Carbon Dioxide (ppm), Indoor Fine Dust (), Indoor Ultrafine Dust (), Indoor Relative Humidity (%), Indoor Noise (dB), Indoor Sulfur Dioxide (ppm), Indoor Volatile Substances (ppm), Indoor Nitrogen Oxide (ppm) |
| Additional Data | Description |
|---|---|
| Device Data from IoT devices | Gas Valve Sensor (2 Levels, on/off) |
| Ventilation Sensor (2 Levels, on/off) | |
| Air Cleaner Sensor (5 Levels, 0 for off and 1 to 4 for on) | |
| Movement Sensor (2 Levels, on/Off) | |
| User Data | Dust Sensitivity (for Vertical Axis) |
| Daily Residence Time (for Transverse Axis) | |
| Space Size | 3 Levels (60, 90, 120 Square Meters) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Hwangbo, H. Sensor-Based Optimization Model for Air Quality Improvement in Home IoT. Sensors 2018, 18, 959. https://doi.org/10.3390/s18040959
Kim J, Hwangbo H. Sensor-Based Optimization Model for Air Quality Improvement in Home IoT. Sensors. 2018; 18(4):959. https://doi.org/10.3390/s18040959
Chicago/Turabian StyleKim, Jonghyuk, and Hyunwoo Hwangbo. 2018. "Sensor-Based Optimization Model for Air Quality Improvement in Home IoT" Sensors 18, no. 4: 959. https://doi.org/10.3390/s18040959
APA StyleKim, J., & Hwangbo, H. (2018). Sensor-Based Optimization Model for Air Quality Improvement in Home IoT. Sensors, 18(4), 959. https://doi.org/10.3390/s18040959