Convolutional Neural Network-Based Classification of Driver’s Emotion during Aggressive and Smooth Driving Using Multi-Modal Camera Sensors

Abstract
:1. Introduction
2. Related Works
3. Motivation and Contributions
- -
- This research is the first CNN-based attempt to classify aggressive and smooth driving emotions using nonintrusive multimodal cameras (i.e., NIR and thermal cameras) and facial features as inputs.
- -
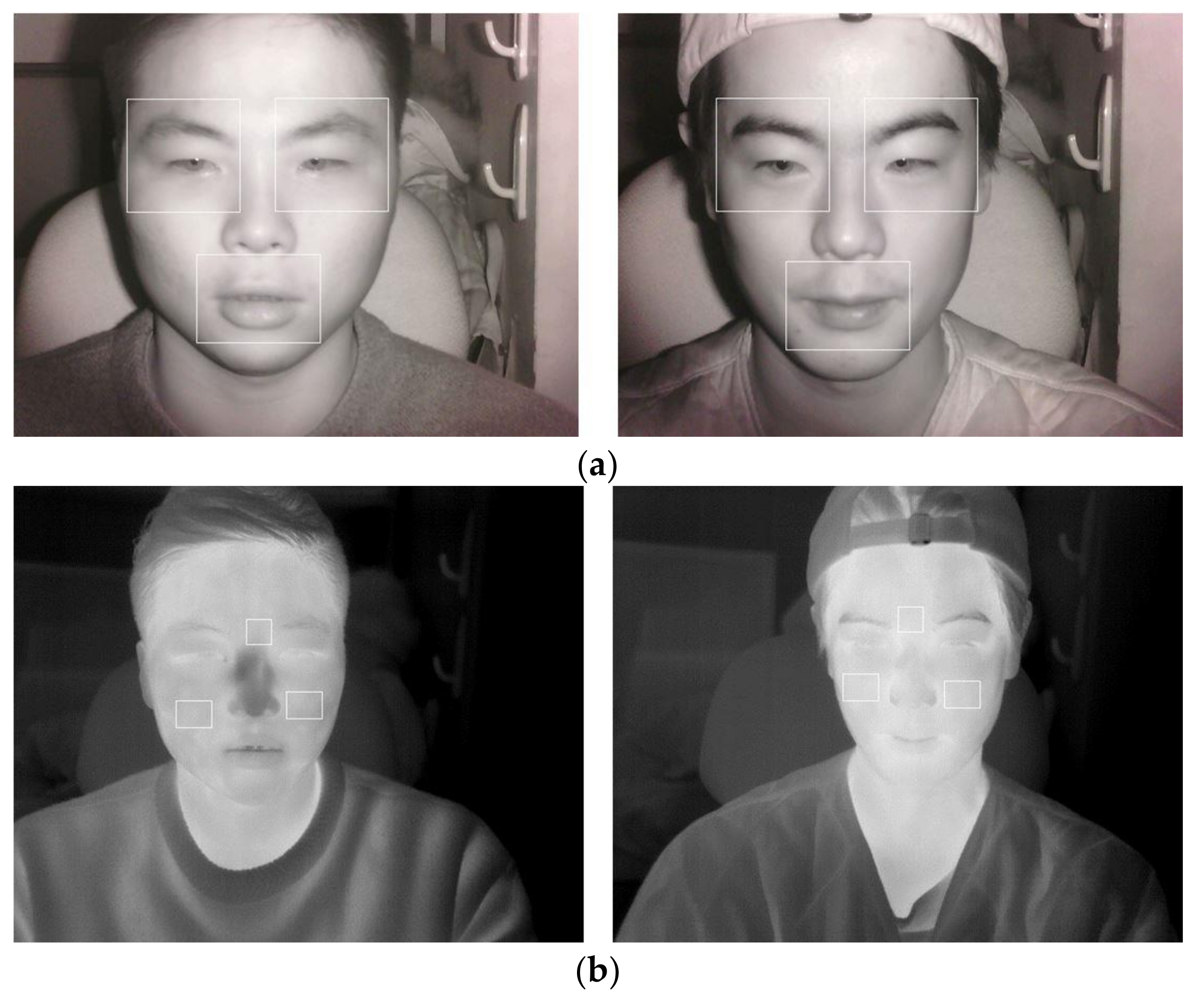
- From NIR images, both the eyes and mouth, which show the most remarkable changes of facial expression, are extracted and converted into 3-channel images and used as inputs to the first CNN. From thermal images, the middle-forehead and cheek areas, which show the largest temperature changes, are extracted and converted into 3-channel images, to be used as inputs to the second CNN. The two CNN output scores are then fused at the score-level to enhance the classification accuracy for aggressive and smooth driving emotions.
- -
- From 15 subjects carrying out aggressive and smooth driving experiments, a total of 58,926 images were obtained using NIR and thermal cameras. The images were used to intensively train the CNN. Thus, CNN-based classification of aggressive and smooth driving emotion becomes more accurate and robust over time, owing to correlating changes in drivers’ emotional status.
- -
- A database of driver images is constructed in this research, using NIR and thermal cameras and a trained CNN model. It is open to other researchers to ensure impartial performance evaluation.
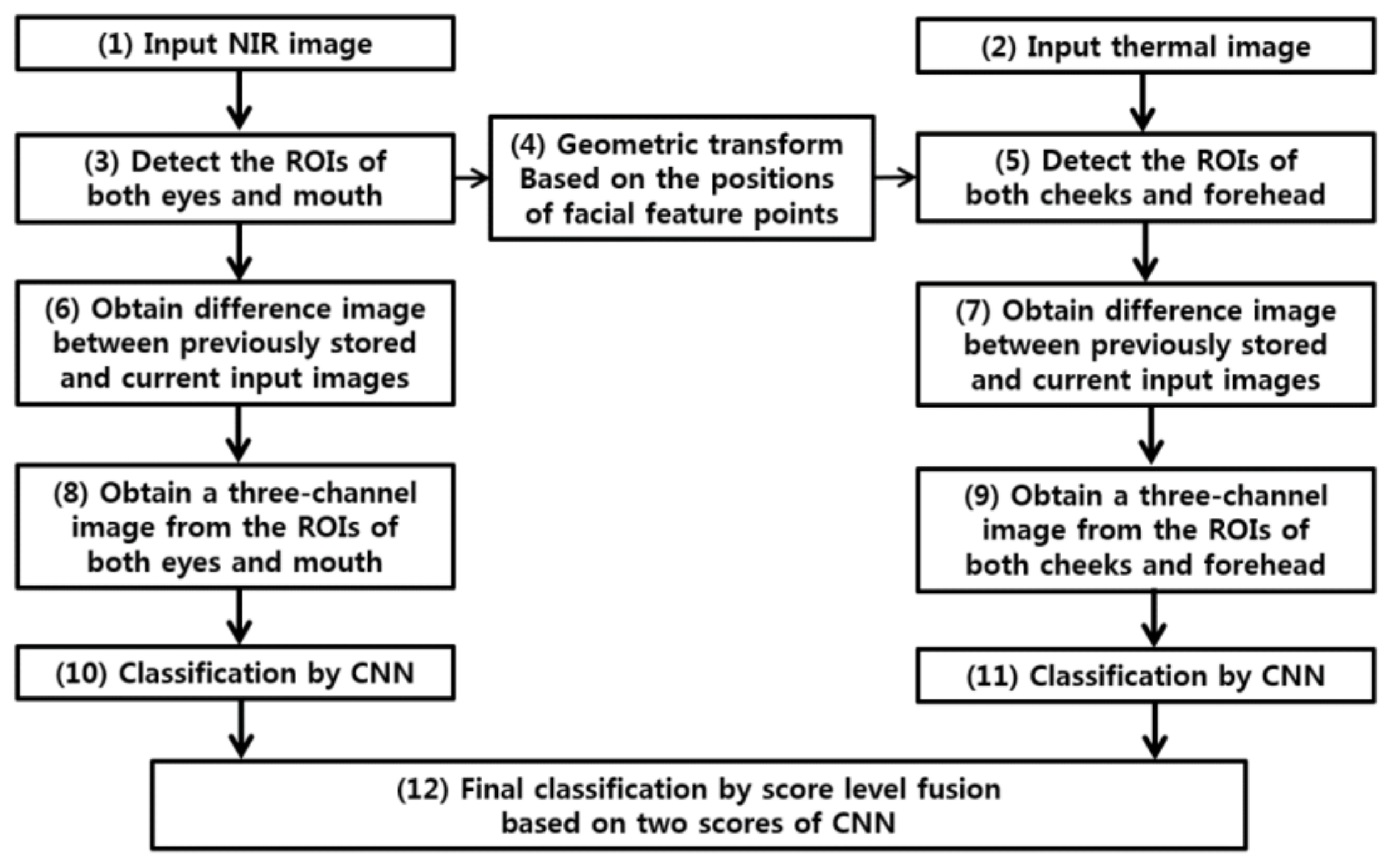
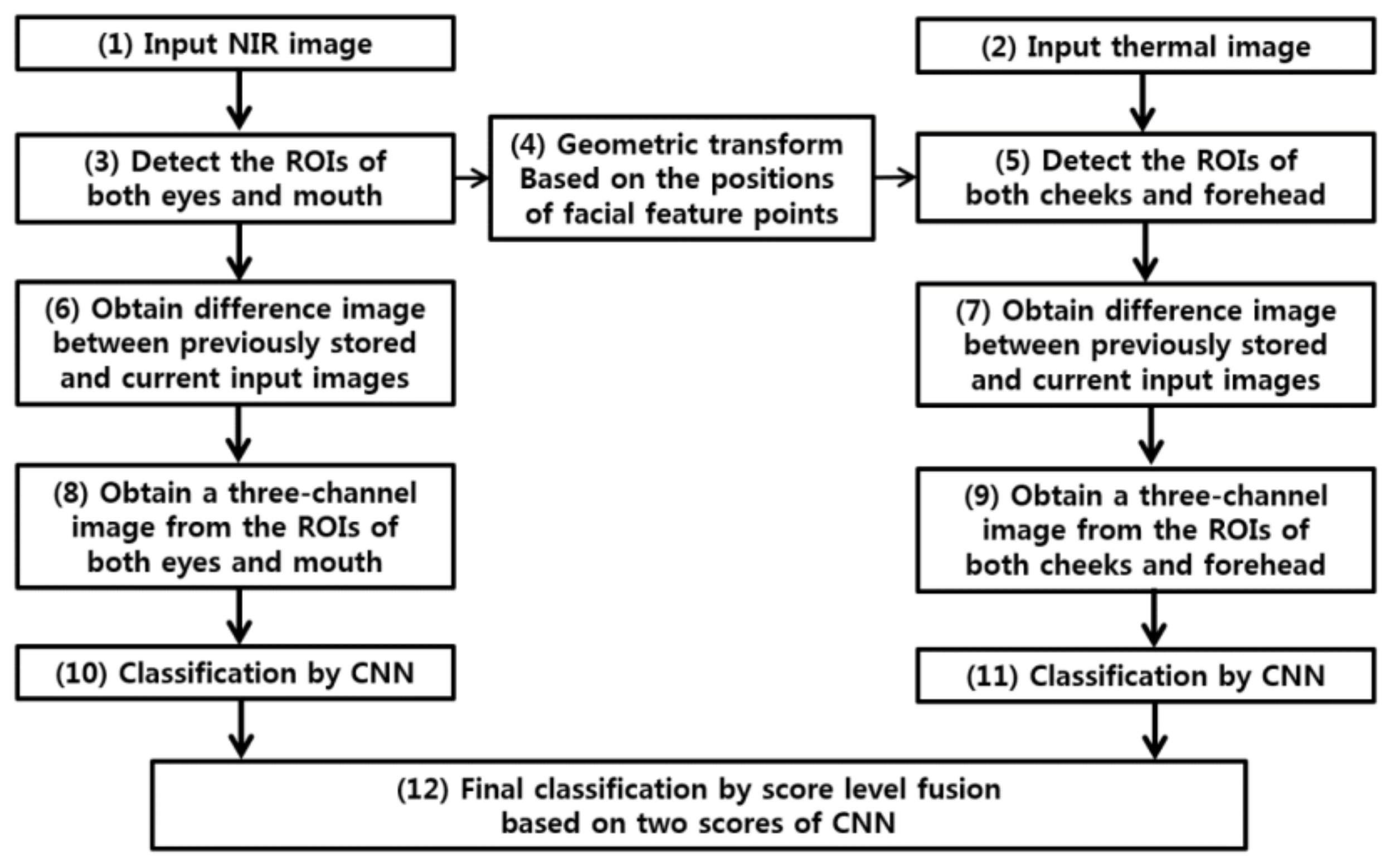
4. Proposed Method for CNN-Based Detection of Aggressive Driving Emotion
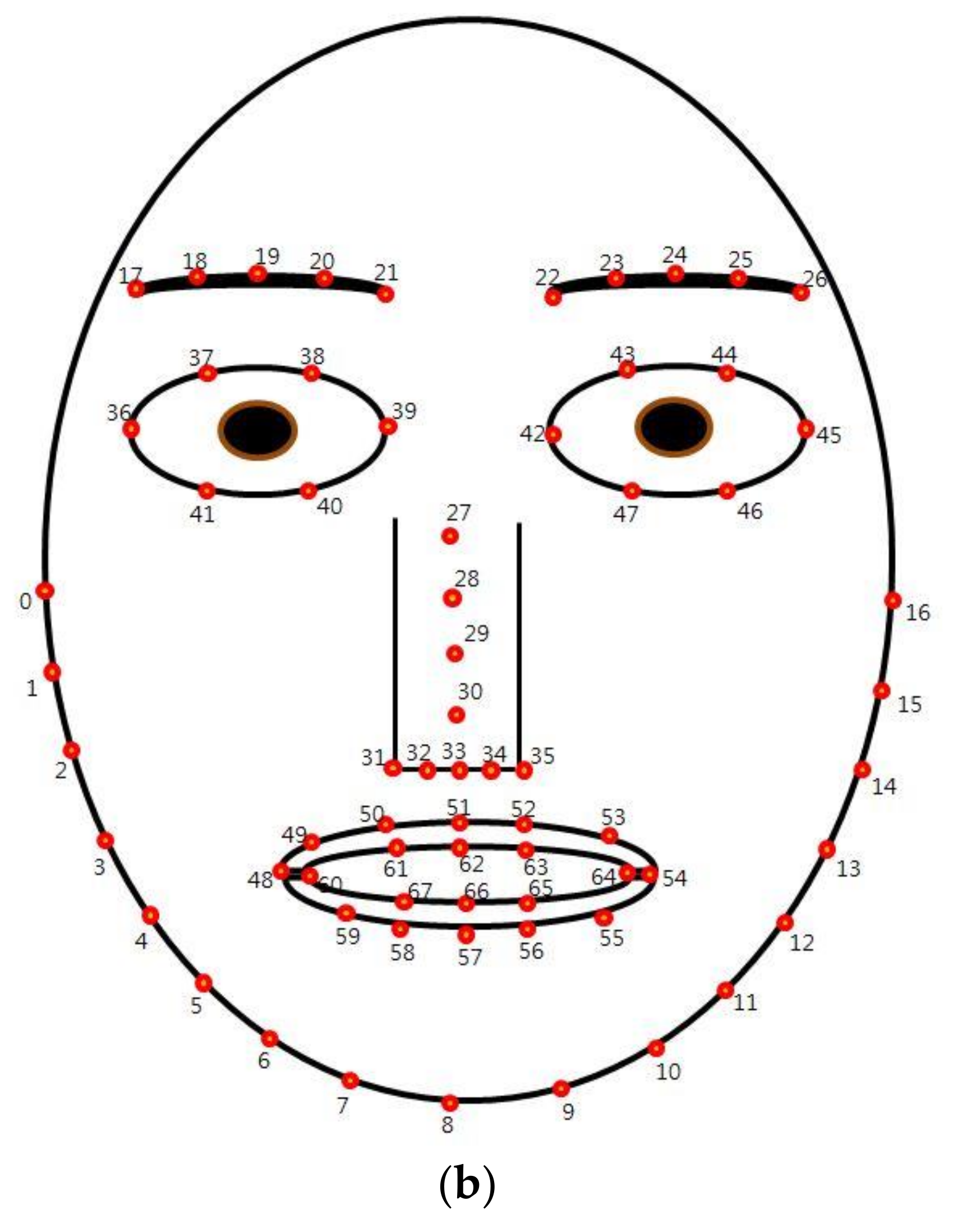
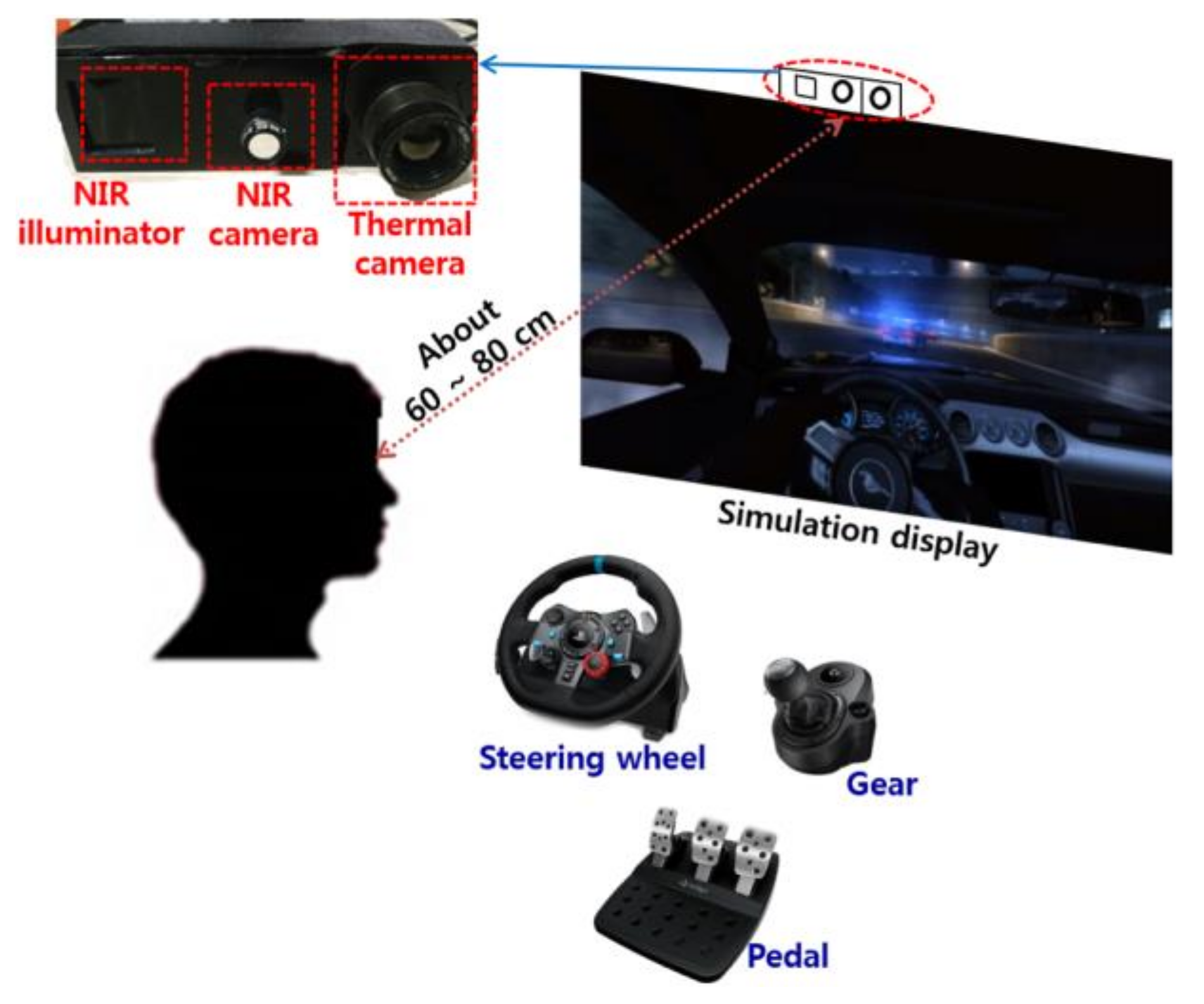
4.1. Proposed Device, Experimental Setup, and Method
4.2. CNN Structure
4.3. Score-Level Fusion of the Outputs of Two CNNs
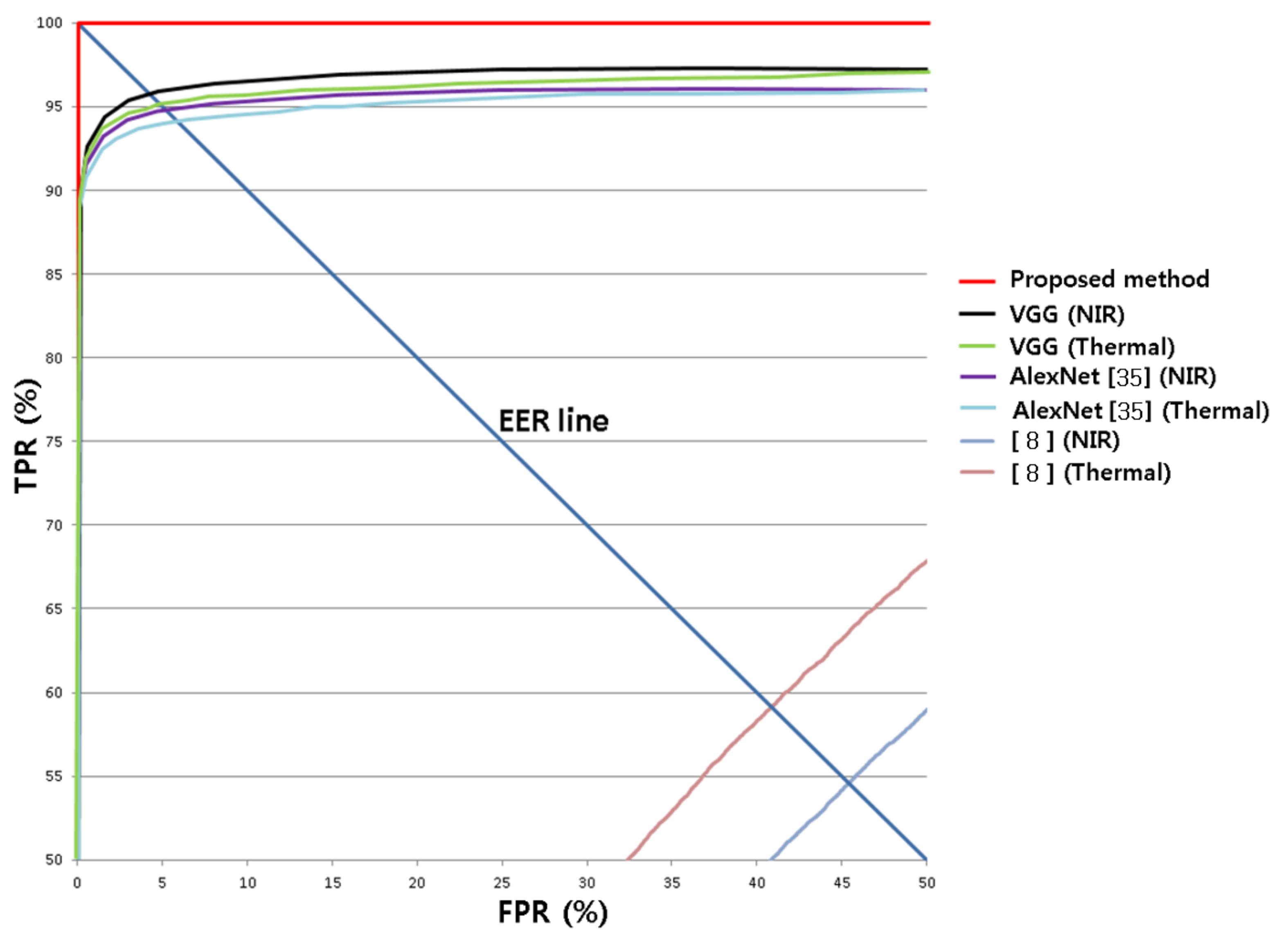
5. Experimental Results
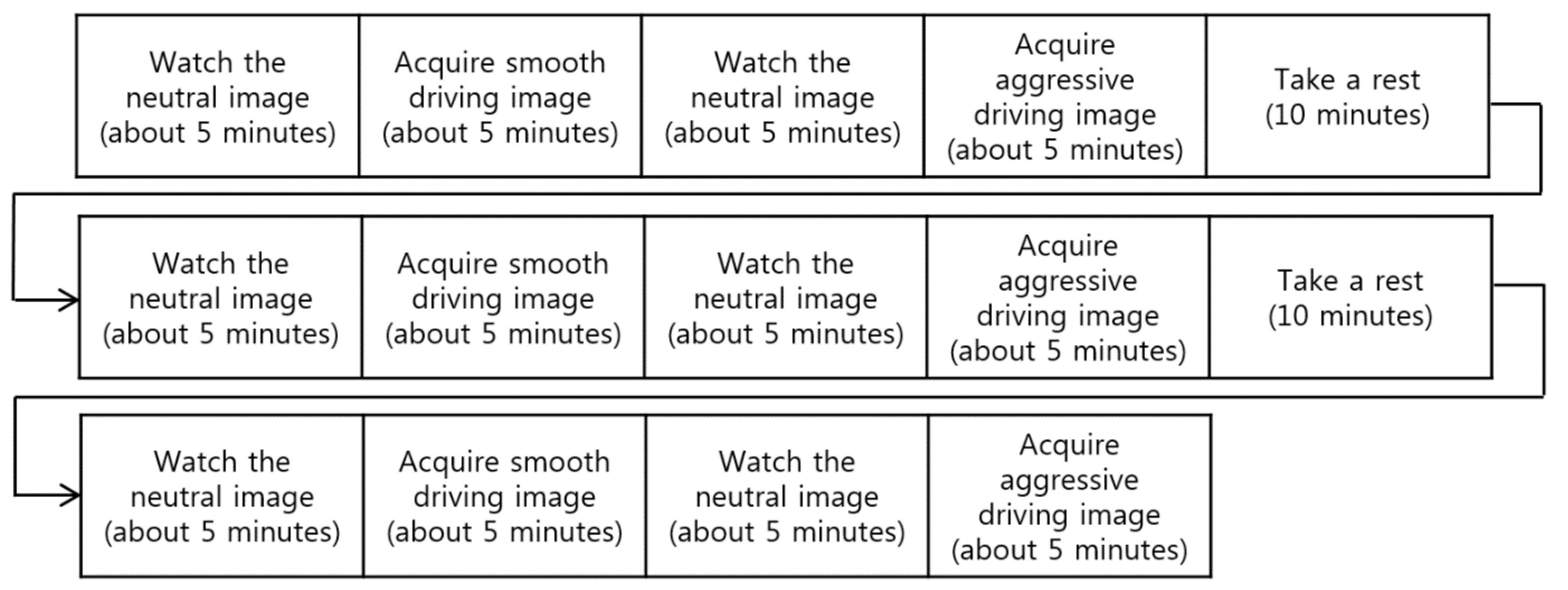
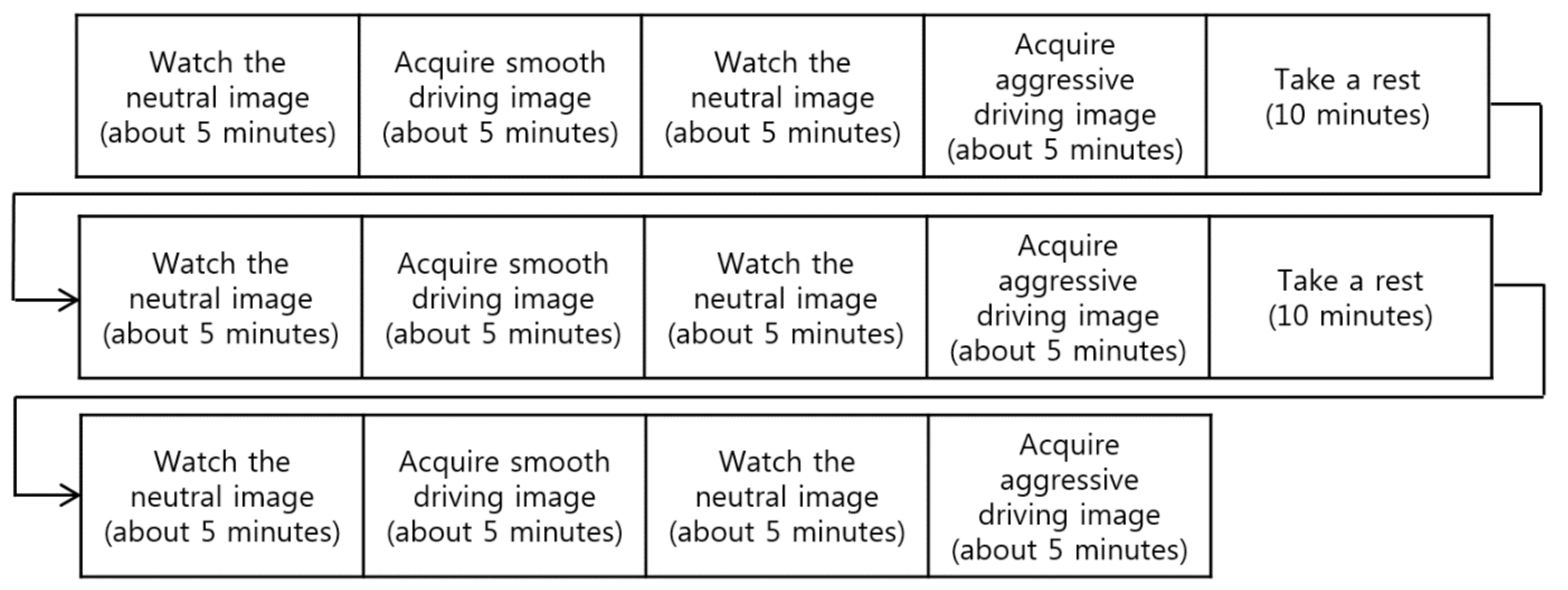
5.1. Experimental Scenario, Environment and Data
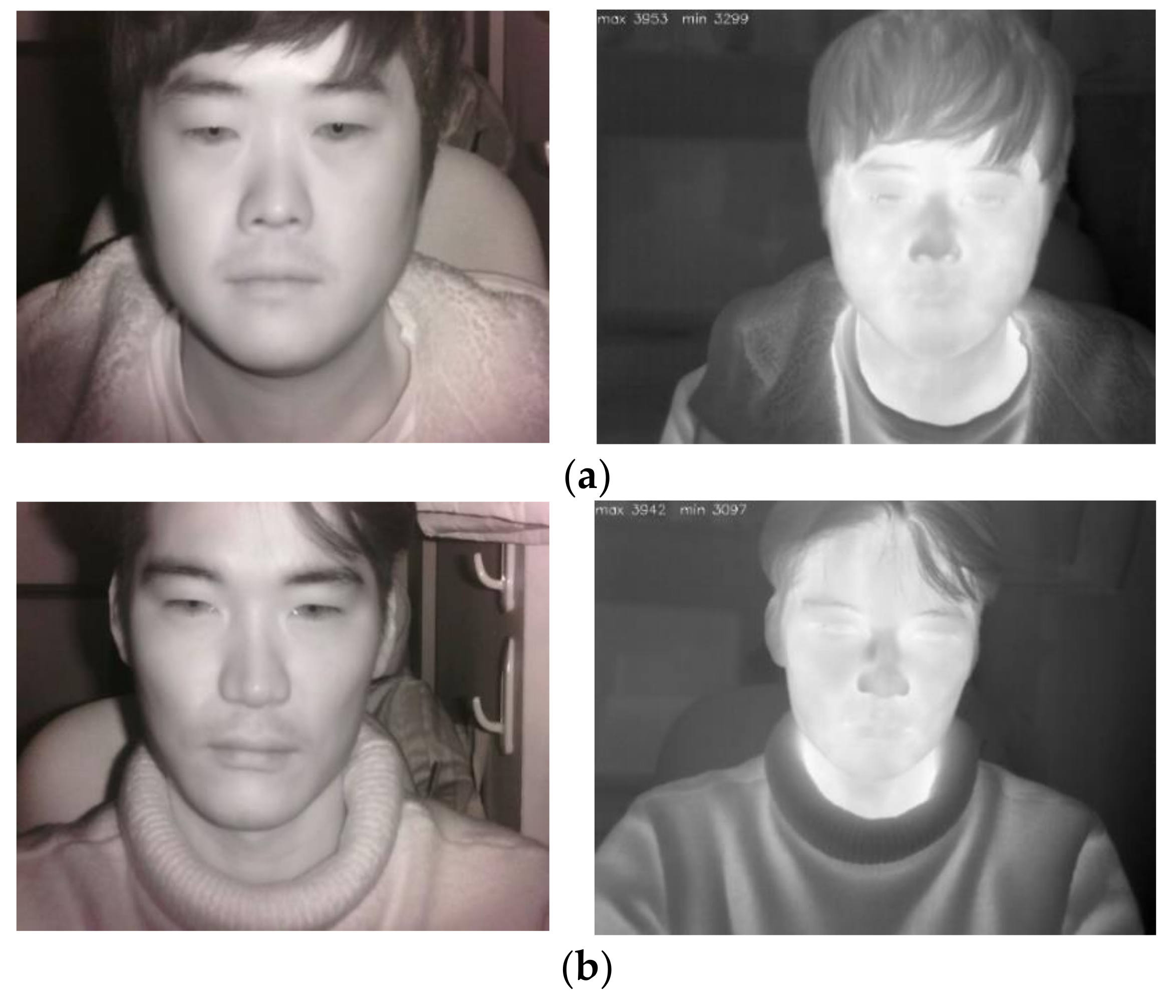
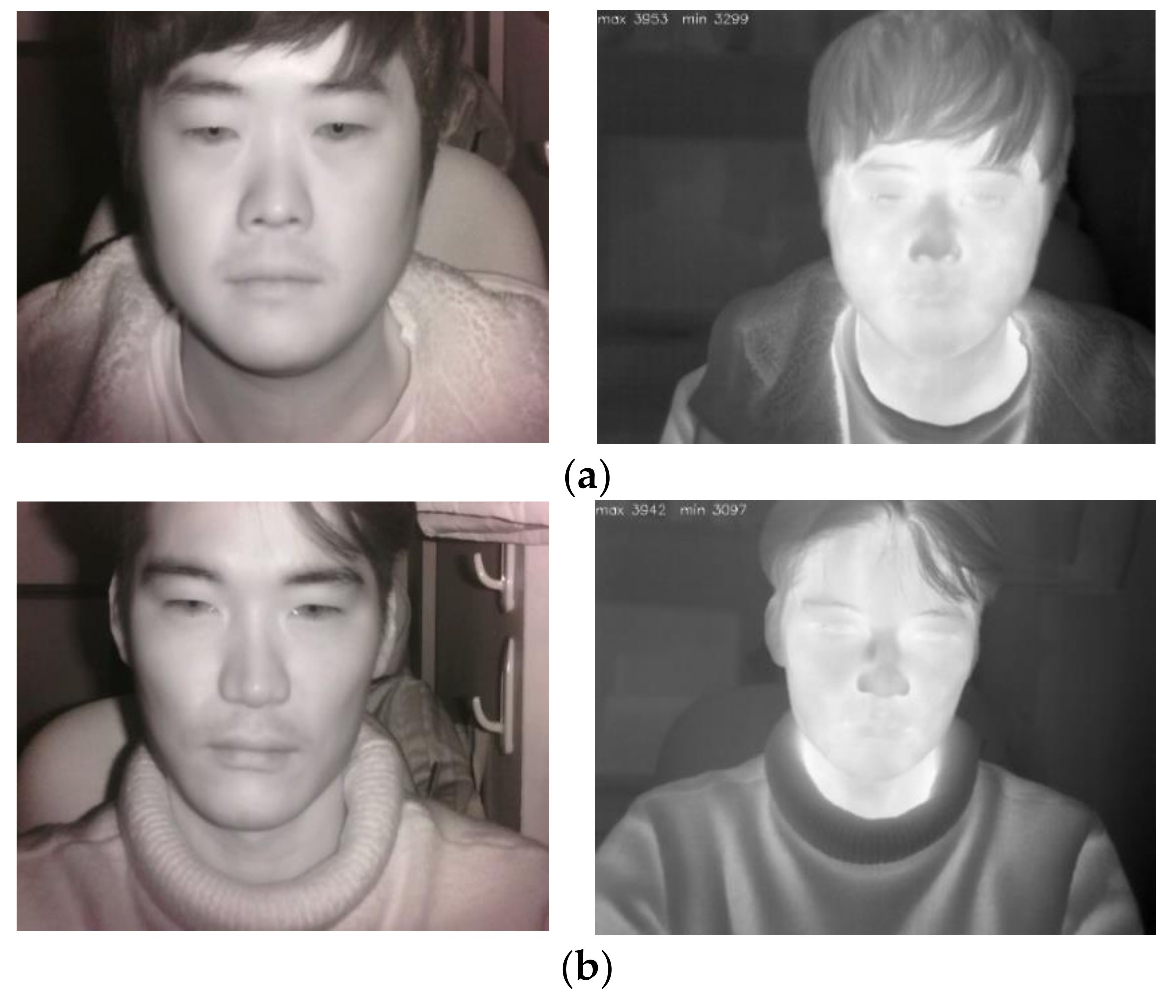
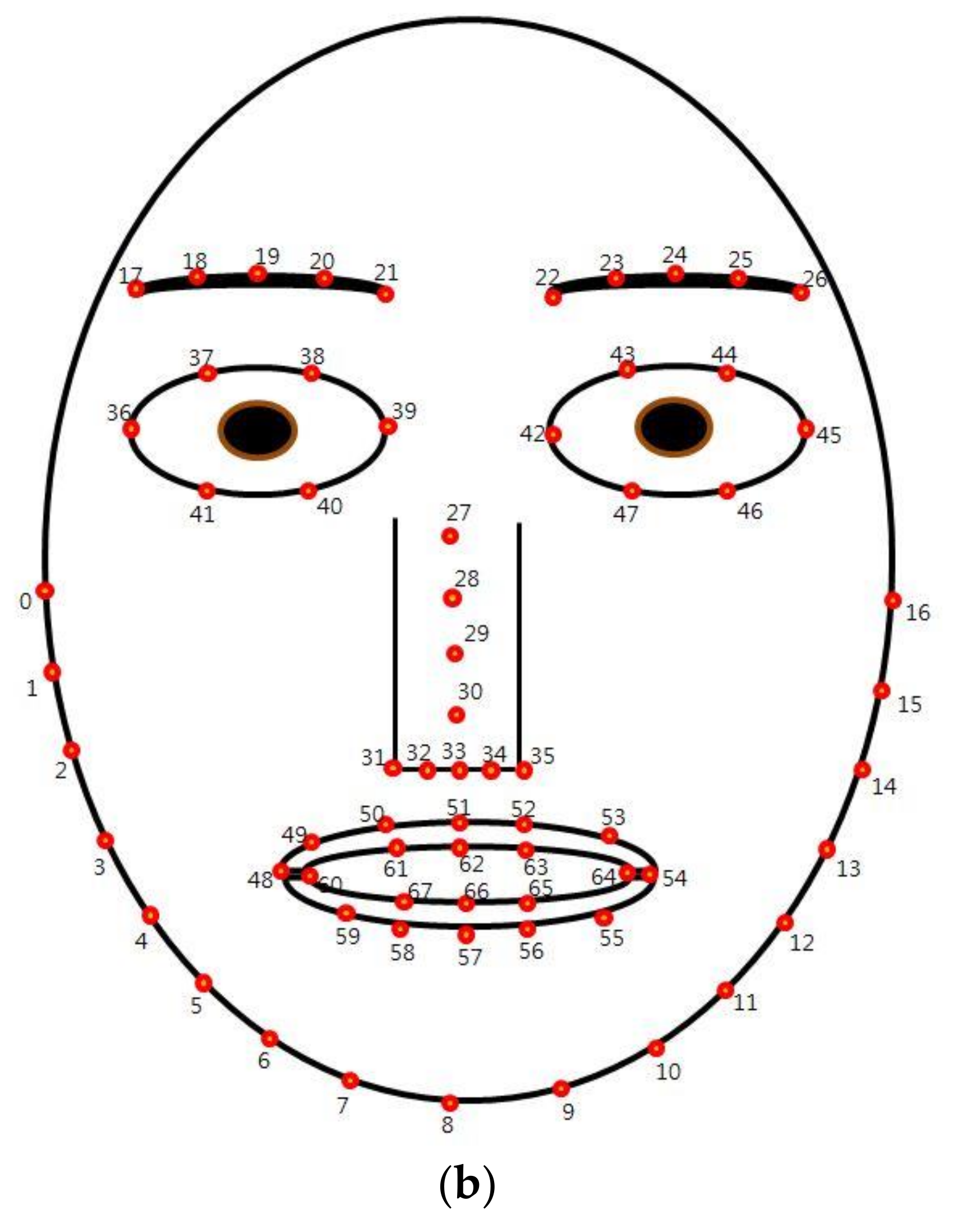
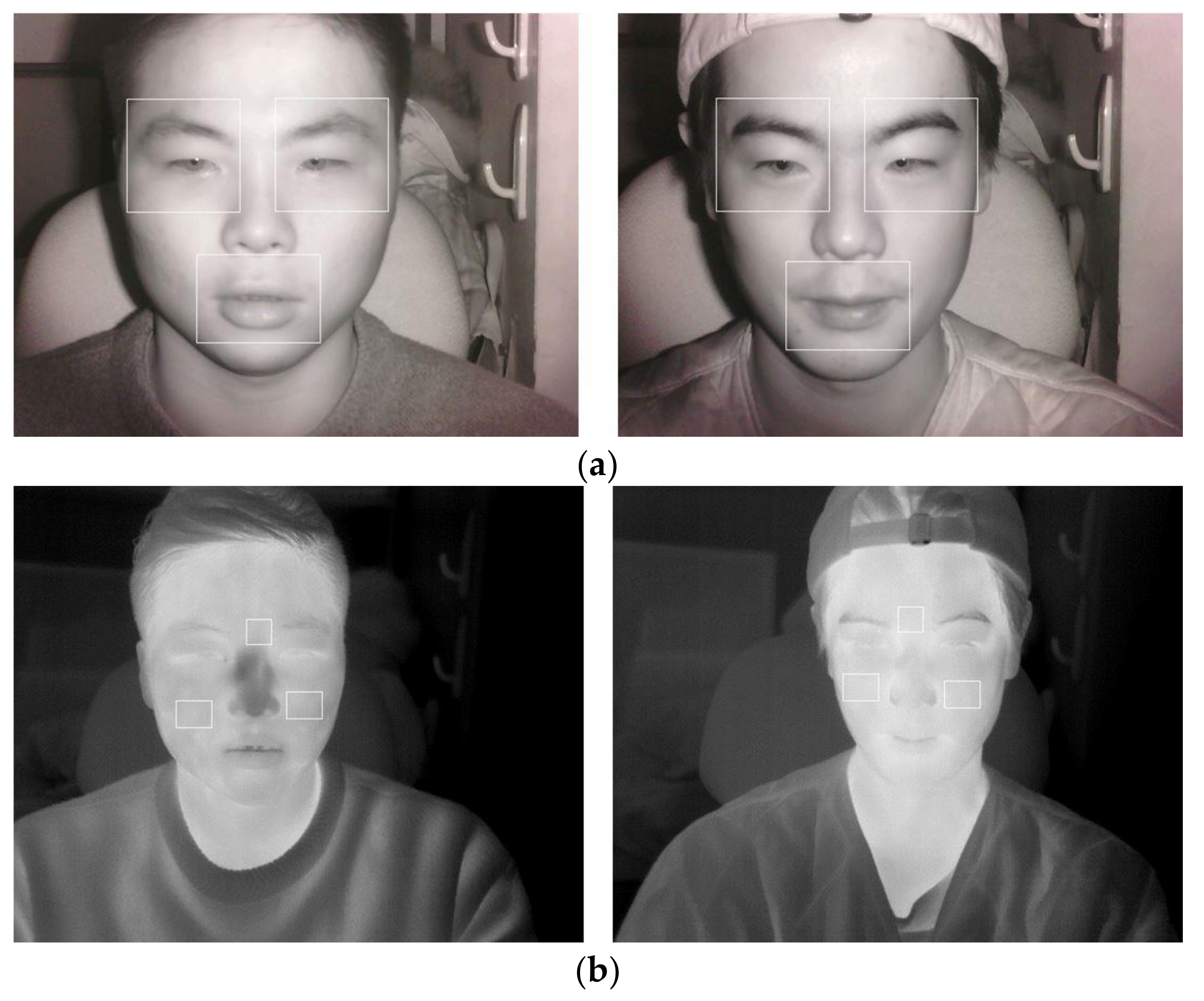
5.2. Features of NIR and Thermal Images and the Comparison of Performance
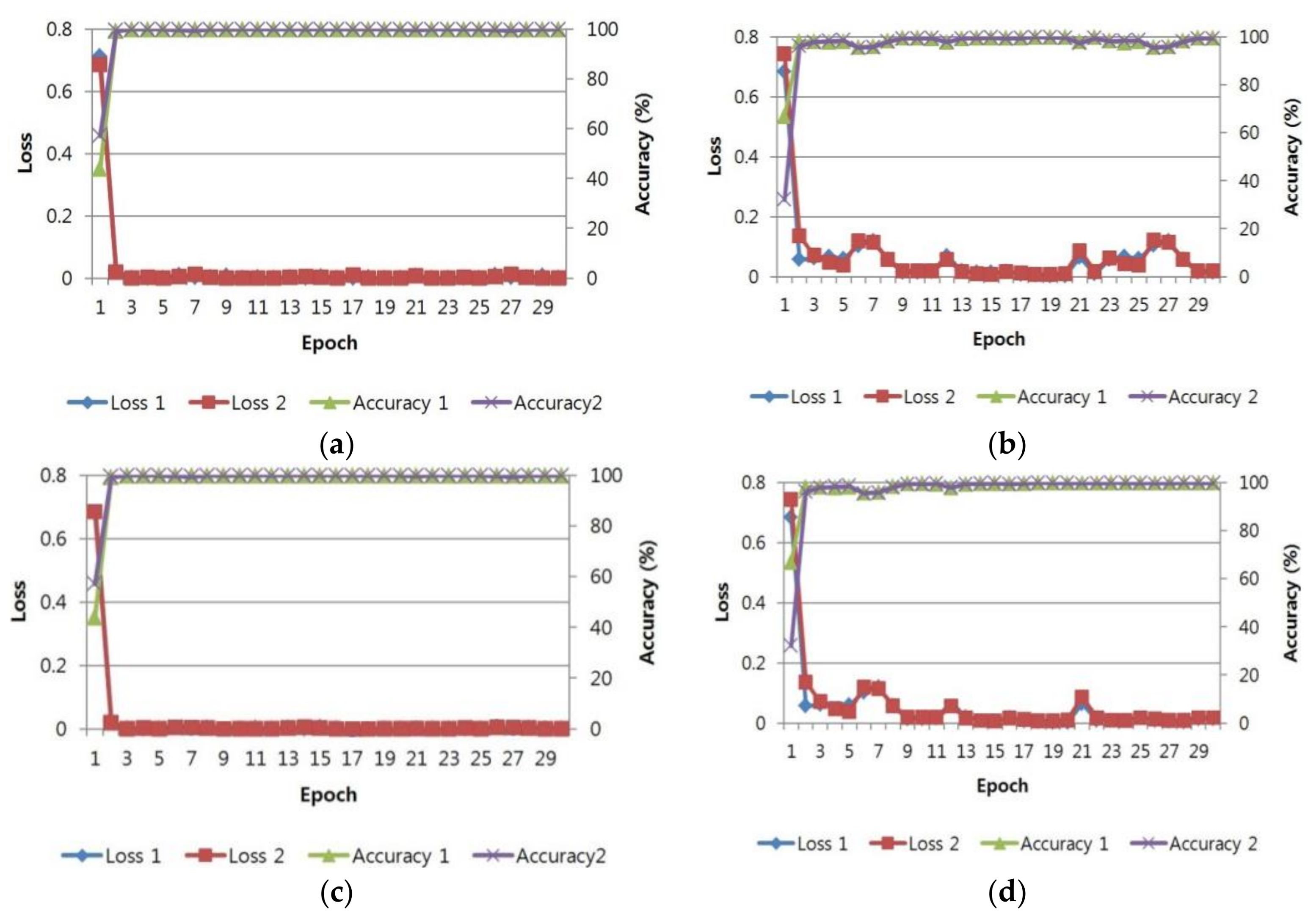
5.3. Training of CNN Model
5.4. Testing of the Proposed CNN-Based Classification of Smooth and Aggressive Driving Emotion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Driving Behaviors Reported for Drivers and Motorcycle Operators Involved in Fatal Crashes. 2015. Available online: http://www.iii.org/table-archive/21313 (accessed on 16 December 2017).
- Bhoyar, V.; Lata, P.; Katkar, J.; Patil, A.; Javale, D. Symbian Based Rash Driving Detection System. Int. J. Emerg. Trends Technol. Comput. Sci. 2013, 2, 124–126. [Google Scholar]
- Chen, Z.; Yu, J.; Zhu, Y.; Chen, Y.; Li, M. D3: Abnormal Driving Behaviors Detection and Identification Using Smartphone Sensors. In Proceedings of the 12th Annual IEEE International Conference on Sensing, Communication, and Networking, Seattle, WA, USA, 22–25 June 2015; pp. 524–532. [Google Scholar]
- Eren, H.; Makinist, S.; Akin, E.; Yilmaz, A. Estimating Driving Behavior by a Smartphone. In Proceedings of the Intelligent Vehicles Symposium, Alcalá de Henares, Spain, 3–7 June 2012; pp. 234–239. [Google Scholar]
- Boonmee, S.; Tangamchit, P. Portable Reckless Driving Detection System. In Proceedings of the 6th IEEE International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Pattaya, Chonburi, Thailand, 6–9 May 2009; pp. 412–415. [Google Scholar]
- Koh, D.-W.; Kang, H.-B. Smartphone-Based Modeling and Detection of Aggressiveness Reactions in Senior Drivers. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June–1 July 2015; pp. 12–17. [Google Scholar]
- Zhang, W.; Fan, Q. Identification of Abnormal Driving State Based on Driver’s Model. In Proceedings of the International Conference on Control, Automation and Systems, Gyeonggi-do, Korea, 27–30 October 2010; pp. 14–18. [Google Scholar]
- Kolli, A.; Fasih, A.; Machot, F.A.; Kyamakya, K. Non-intrusive Car Driver’s Emotion Recognition Using Thermal Camera. In Proceedings of the IEEE Joint International Workshop on Nonlinear Dynamics and Synchronization & the 16th International Symposium on Theoretical Electrical Engineering, Klagenfurt, Austria, 25–27 July 2011; pp. 1–5. [Google Scholar]
- Ji, Q.; Zhu, Z.; Lan, P. Real-Time Nonintrusive Monitoring and Prediction of Driver Fatigue. IEEE Trans. Veh. Technol. 2004, 53, 1052–1068. [Google Scholar] [CrossRef]
- Hariri, B.; Abtahi, S.; Shirmohammadi, S.; Martel, L. Demo: Vision Based Smart In-Car Camera System for Driver Yawning Detection. In Proceedings of the 5th ACM/IEEE International Conference on Distributed Smart Cameras, Ghent, Belgium, 22–25 August 2011; pp. 1–2. [Google Scholar]
- Wang, Q.; Yang, J.; Ren, M.; Zheng, Y. Driver Fatigue Detection: A Survey. In Proceedings of the 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006; pp. 8587–8591. [Google Scholar]
- Kamaruddin, N.; Wahab, A. Driver Behavior Analysis through Speech Emotion Understanding. In Proceedings of the IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 238–243. [Google Scholar]
- Nass, C.; Jonsson, I.-M.; Harris, H.; Reaves, B.; Endo, J.; Brave, S.; Takayama, L. Improving Automotive Safety by Pairing Driver Emotion and Car Voice Emotion. In Proceedings of the Conference on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 1973–1976. [Google Scholar]
- Lisetti, C.L.; Nasoz, F. Affective Intelligent Car Interfaces with Emotion Recognition. In Proceedings of the 11th International Conference on Human Computer Interaction, Las Vegas, NV, USA, 22–27 July 2005; pp. 1–10. [Google Scholar]
- Hu, S.; Bowlds, R.L.; Gu, Y.; Yu, X. Pulse Wave Sensor for Non-Intrusive Driver’s Drowsiness Detection. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 2–6 September 2009; pp. 2312–2315. [Google Scholar]
- Katsis, C.D.; Katertsidis, N.; Ganiatsas, G.; Fotiadis, D.I. Toward Emotion Recognition in Car-Racing Drivers: A Biosignal Processing Approach. IEEE Trans. Syst. Man Cybern. Part A 2008, 38, 502–512. [Google Scholar] [CrossRef]
- Fasel, B. Head-Pose Invariant Facial Expression Recognition Using Convolutional Neural Networks. In Proceedings of the 4th IEEE International Conference on Multimodal Interfaces, Pittsburgh, PA, USA, 16 October 2002; pp. 529–534. [Google Scholar]
- Fasel, B. Robust Face Analysis Using Convolutional Neural Networks. In Proceedings of the 16th IEEE International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; pp. 40–43. [Google Scholar]
- Matsugu, M.; Mori, K.; Mitari, Y.; Kaneda, Y. Subject Independent Facial Expression Recognition with Robust Face Detection Using a Convolutional Neural Network. Neural Netw. 2003, 16, 555–559. [Google Scholar] [CrossRef]
- Hasani, B.; Mahoor, M.H. Spatio-temporal facial expression recognition using convolutional neural networks and conditional random fields. arXiv, 2017; arXiv:1703.06995. [Google Scholar]
- Hasani, B.; Mahoor, M.H. Facial expression recognition using enhanced deep 3D convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2278–2288. [Google Scholar]
- YOLO for Real-Time Facial Expression Detection. Available online: https://www.youtube.com/ watch?v=GMy0Zs8LX-o (accessed on 18 March 2018).
- Ghiass, R.S.; Arandjelović, O.; Bendada, H.; Maldague, X. Infrared Face Recognition: A Literature Review. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013; pp. 1–10. [Google Scholar]
- Tau® 2 Uncooled Scores. Available online: http://www.flir.com/cores/display/?id=54717 (accessed on 28 December 2017).
- ELP-USB500W02M-L36 Camera. Available online: http://www.elpcctv.com/5mp-ultra-wide-angle-hd-usb-camera-board-with-mpeg-format-p-83.html (accessed on 28 December 2017).
- 850nm CWL, 12.5mm Dia. Hard Coated OD 4 50nm Bandpass Filter. Available online: https://www.edmundoptics.co.kr/optics/optical-filters/bandpass-filters/hard-coated-od4-50nm-bandpass-filters/84778/ (accessed on 8 January 2018).
- SFH 4783. Available online: http://www.osram-os.com/osram_os/en/products/product-catalog/infrared-emitters,-detectors-andsensors/infrared-emitters/high-power-emitter-gt500mw/emitters-with-850nm/sfh-4783/index.jsp (accessed on 8 January 2018).
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Facial Action Coding System. Available online: https://en.wikipedia.org/wiki/Facial_Action_Coding_System (accessed on 27 December 2017).
- Choi, J.-S.; Bang, J.W.; Heo, H.; Park, K.R. Evaluation of Fear Using Nonintrusive Measurement of Multimodal Sensors. Sensors 2015, 15, 17507–17533. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 8 January 2018).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv, 2017; arXiv:1704.04861v1. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Convolutional Neural Network. Available online: https://en.wikipedia.org/wiki/ Convolutional_neural_ network (accessed on 27 December 2017).
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Heaton, J. Artificial Intelligence for Humans. In Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015; Volume 3. [Google Scholar]
- Lang, P.J.; Bradley, M.M.; Cuthbert, B.N. International Affective Picture System (IAPS): Affective Ratings of Pictures and Instruction Manual; Technical Report A-8; University of Florida: Gainesville, FL, USA, 2008. [Google Scholar]
- Euro Truck Simulator 2. Available online: https://en.wikipedia.org/wiki/Euro_Truck_Simulator_2 (accessed on 27 December 2017).
- Need for Speed (Deluxe Edition). Available online: https://en.wikipedia.org/wiki/Need_for_Speed (accessed on 27 December 2017).
- Samsung S24C450BL Monitor. Available online: http://www.samsung.com/ africa_en/consumer/it/ monitor/led-monitor/LS24C45KBL/XA/ (accessed on 27 December 2017).
- Intel® Core™ i7-3770 Processor. Available online: http://ark.intel.com/products/65719/Intel-Core-i7-3770-Processor-8M-Cache-up-to-3_50-GHz (accessed on 28 December 2017).
- NVIDIA GeForce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/ geforce-gtx-1070/ (accessed on 28 December 2017).
- Caffe. Available online: http://caffe.berkeleyvision.org (accessed on 28 December 2017).
- Dongguk Aggressive and Smooth Driving Database (DASD-DB1) and CNN Model. Available online: http://dm.dongguk.edu/link.html (accessed on 28 December 2017).
- Student’s t-Test. Available online: http://en.wikipedia.org/wiki/Student’s_t-test (accessed on 12 January 2018).
- Effect Size. Available online: http://en.wikipedia.org/wiki/Effect_size#Cohen.27s_d (accessed on 12 January 2018).
- Nakagawa, S.; Cuthill, I.C. Effect Size, Confidence Interval and Statistical Significance: A Practical Guide for Biologists. Biol. Rev. 2007, 82, 591–605. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.W.; Hong, H.G.; Park, K.R. Fuzzy System-Based Fear Estimation Based on the Symmetrical Characteristics of Face and Facial Feature Points. Symmetry 2017, 9, 102. [Google Scholar] [CrossRef]
- Stochastic Gradient Descent. Available online: https://en.wikipedia.org/wiki/Stochastic_gradient_descent (accessed on 28 December 2017).
- Precision and Recall. Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 28 December 2017).
- Barros, P.; Wermter, S. Developing crossmodal expression recognition based on a deep neural model. Adapt. Behav. 2016, 24, 373–396. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Wang, J.; Cheng, L.; Gong, Y. Facial landmark detection via cascade multi-channel convolutional neural network. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 1800–1804. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantage | Disadvantage | ||
|---|---|---|---|---|---|
| Gyro-sensor and accelerometer-based method | Aggressive driving detection [2,3,4,5,6] | An accelerometer and a gyro-sensor in a smart phone are used. Accordingly, no device needs to be purchased or installed. Highly portable. Because the motion of a vehicle is directly observed, it can be closely correlated to aggressive driving. | Depending on the performance of a GPS receiver, data values can be inaccurate. This method is not applicable in GPS-unavailable areas. The error rate of aggressive driving detection increases on winding and mountain roads. | ||
| Voice-based method | Detection of a driver’s emotion based on voice or car–voice interaction [12,13] | Data acquisition using inexpensive sensor. | Surrounding noise influences performance. | ||
| Bio-signal-based method | Various bio-signals, including ECG, EEG, and pulse, are measured to recognize a driver’s emotion or fatigue [14,15,16] | Bio-signals that cannot be detected by the naked eye are detected at high speed. Because bio-signals are used as input data, physiological changes can be detected. | Sensors can be detached by a driver’s active motion. The attachment of sensors may cause discomfort. Expensive sensors are used. | ||
| Camera-based method | Using single camera | Using visible light camera | Yawning detection [10] | An inexpensive camera is used. | Physical characteristics that cannot be observed by the naked eye are not detected. Measurement becomes difficult at night or in tunnels. |
| Using thermal camera | Driver’s emotion recognition [8] | Night photography is possible without a separate light source. Subtle physical signals related to specific emotions, which cannot be caught by visible light or NIR cameras, can be detected. | The camera is expensive compared to visible light or NIR cameras. The camera is less effective for detecting facial regions and facial feature points than with NIR cameras. | ||
| Using multiple cameras | Using dual NIR cameras | Percentage of eye closure over time (PERCLOS)- and average eye-closure speed (AECS)-based detection of driver fatigue [9] | In cases where more than two cameras are used, driver fatigue is detected over a wide range. NIR light makes detection possible at night or in a tunnel. | Physical characteristics that cannot be observed by the naked eye are not detected. | |
| Using NIR and thermal cameras | Aggressive driving emotion detection-based convolutional neural networks (CNN) (Proposed method) | Thermal cameras can measure temperature changes in a driver’s body, which cannot be checked by the naked eye, whereas, a NIR camera can detect facial feature points and measure their changes. An intensively trained CNN is robust in various environmental and driver conditions. | The use of two cameras increases algorithm complexity and processing time. Intensive CNN training is required. | ||
| Layer Type | Number of Filters | Size of Feature Map | Size of Kernel | Number of Stride | Number of Padding | |
|---|---|---|---|---|---|---|
| Image input layer | 224 (height) × 224 (width) × 3 (channel) | |||||
| Group 1 | Conv1_1 (1st convolutional layer) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU1_1 | 224 × 224 × 64 | |||||
| Conv1_2 (2nd convolutional layer) | 64 | 224 × 224 × 64 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU1_2 | 224 × 224 × 64 | |||||
| Pool1 | 1 | 112 × 112 × 64 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 2 | Conv2_1 (3rd convolutional layer) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU2_1 | 112 × 112 × 128 | |||||
| Conv2_2 (4th convolutional layer) | 128 | 112 × 112 × 128 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU2_2 | 112 × 112 × 128 | |||||
| Pool2 | 1 | 56 × 56 × 128 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 3 | Conv3_1 (5th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU3_1 | 56 × 56 × 256 | |||||
| Conv3_2 (6th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU3_2 | 56 × 56 × 256 | |||||
| Conv3_3 (7th convolutional layer) | 256 | 56 × 56 × 256 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU3_3 | 56 × 56 × 256 | |||||
| Pool3 | 1 | 28 × 28 × 256 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 4 | Conv4_1 (8th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU4_1 | 28 × 28 × 512 | |||||
| Conv4_2 (9th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU4_2 | 28 × 28 × 512 | |||||
| Conv4_3 (10th convolutional layer) | 512 | 28 × 28 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU4_3 | 28 × 28 × 512 | |||||
| Pool4 | 1 | 14 × 14 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Group 5 | Conv5_1 (11th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| ReLU5_1 | 14 × 14 × 512 | |||||
| Conv5_2 (12th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU5_2 | 14 × 14 × 512 | |||||
| Conv5_3 (13th convolutional layer) | 512 | 14 × 14 × 512 | 3 × 3 | 1 × 1 | 1 × 1 | |
| ReLU5_3 | 14 × 14 × 512 | |||||
| Pool5 | 1 | 7 × 7 × 512 | 2 × 2 | 2 × 2 | 0 × 0 | |
| Fc6 (1st FCL) | 4096 × 1 | |||||
| ReLU6 | 4096 × 1 | |||||
| Dropout6 | 4096 × 1 | |||||
| Fc7 (2nd FCL) | 4096 × 1 | |||||
| ReLU7 | 4096 × 1 | |||||
| Dropout7 | 4096 × 1 | |||||
| Fc8 (3rd FCL) | 2 × 1 | |||||
| Softmax layer | 2 × 1 | |||||
| Output layer | 2 × 1 | |||||
| NIR Images | Thermal Images | |||
|---|---|---|---|---|
| Smooth Driving | Aggressive Driving | Smooth Driving | Aggressive Driving | |
| Number of images | 29,463 | 29,463 | 29,463 | 29,463 |
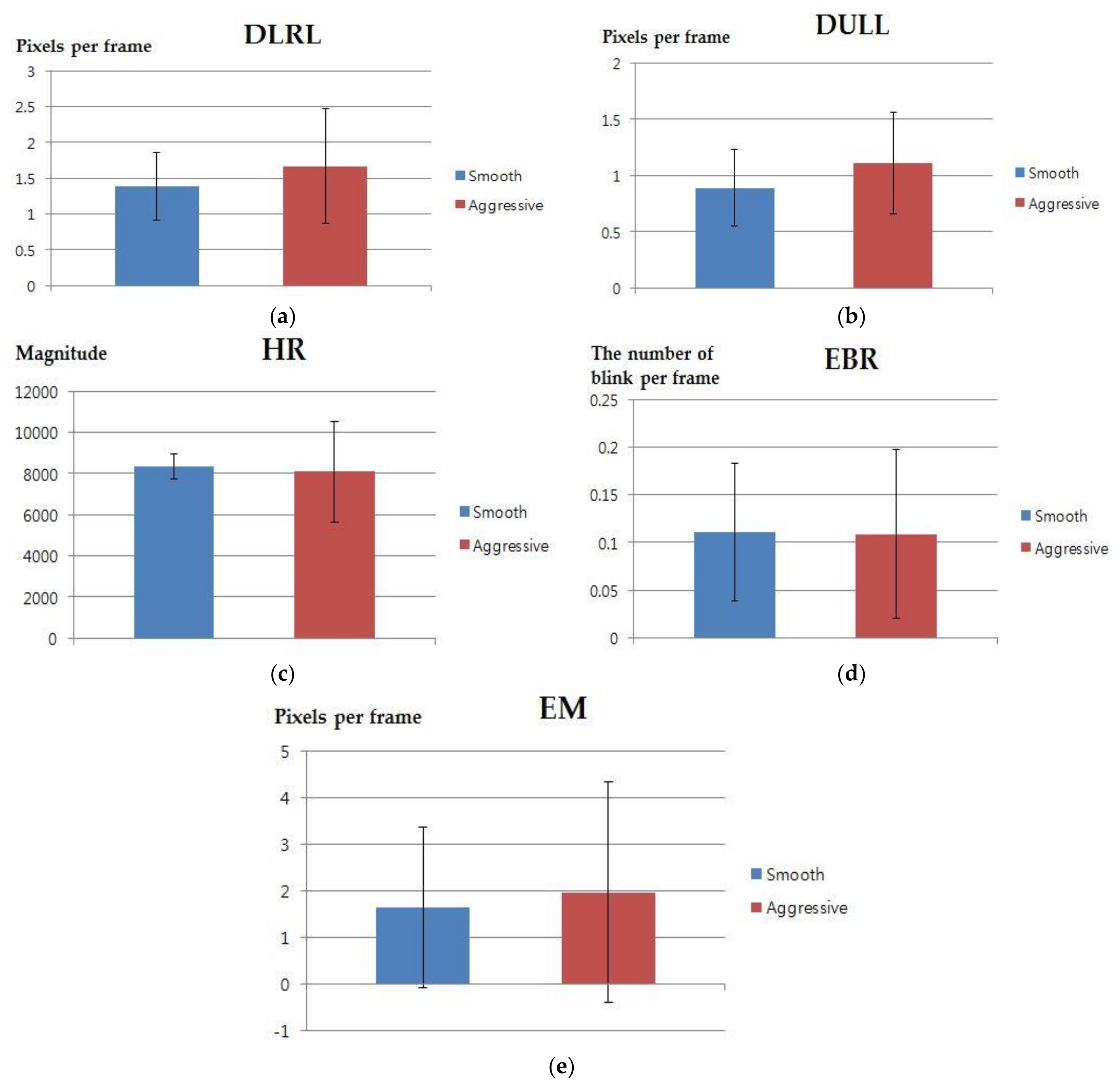
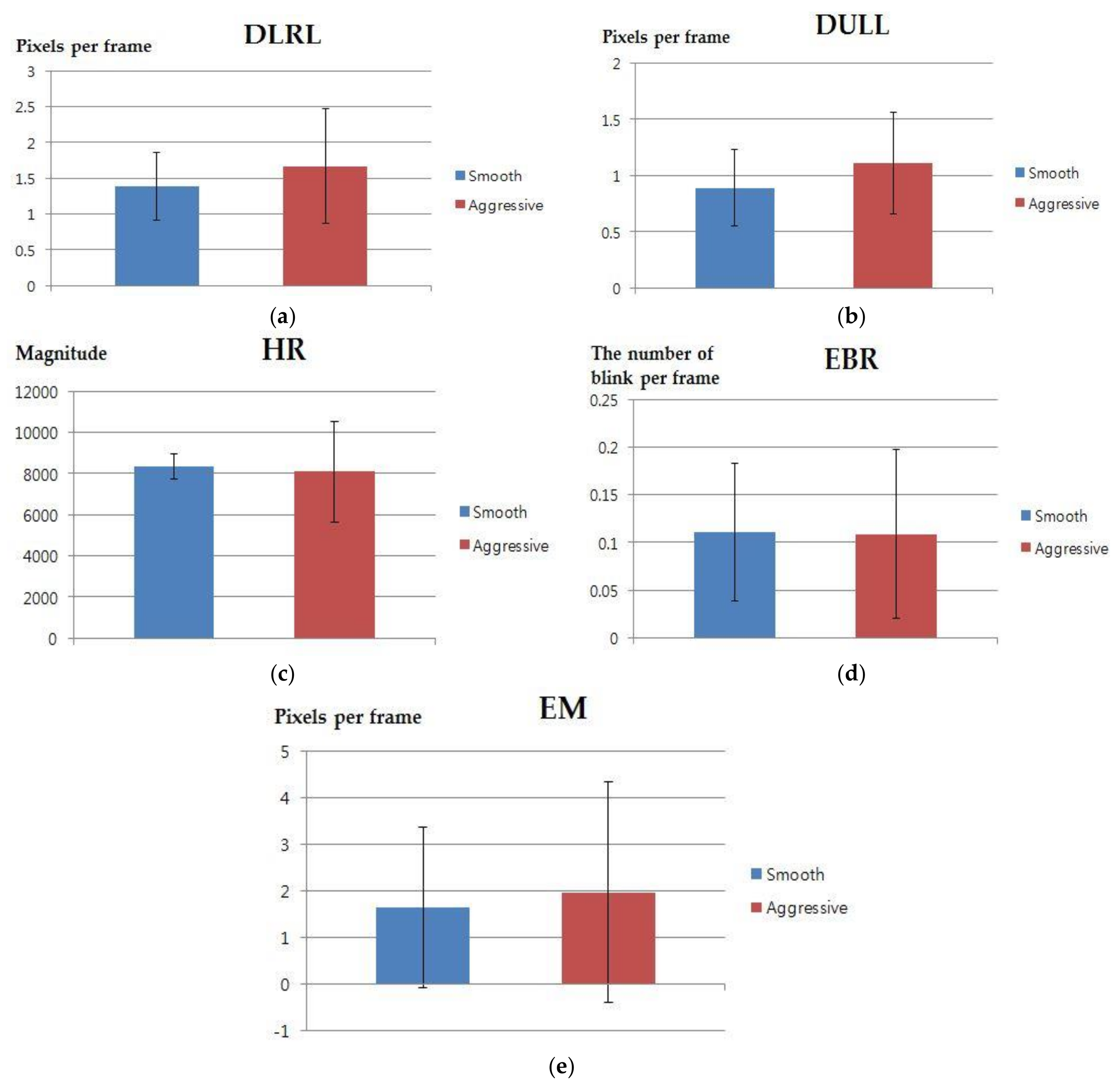
| DLRL | DULL | HR | ||||
| Smooth | Aggressive | Smooth | Aggressive | Smooth | Aggressive | |
| p-value | 0.2582 | 0.1441 | 0.7308 | |||
| Cohen’s d value | 0.4233 | 0.5487 | 0.1325 | |||
| Effect size | medium | medium | Small | |||
| EBR | EM | |||||
| Smooth | Aggressive | Smooth | Aggressive | |||
| p-value | 0.9490 | 0.6715 | ||||
| Cohen’s d value | 0.0236 | 0.1565 | ||||
| Effect size | Small | Small | ||||
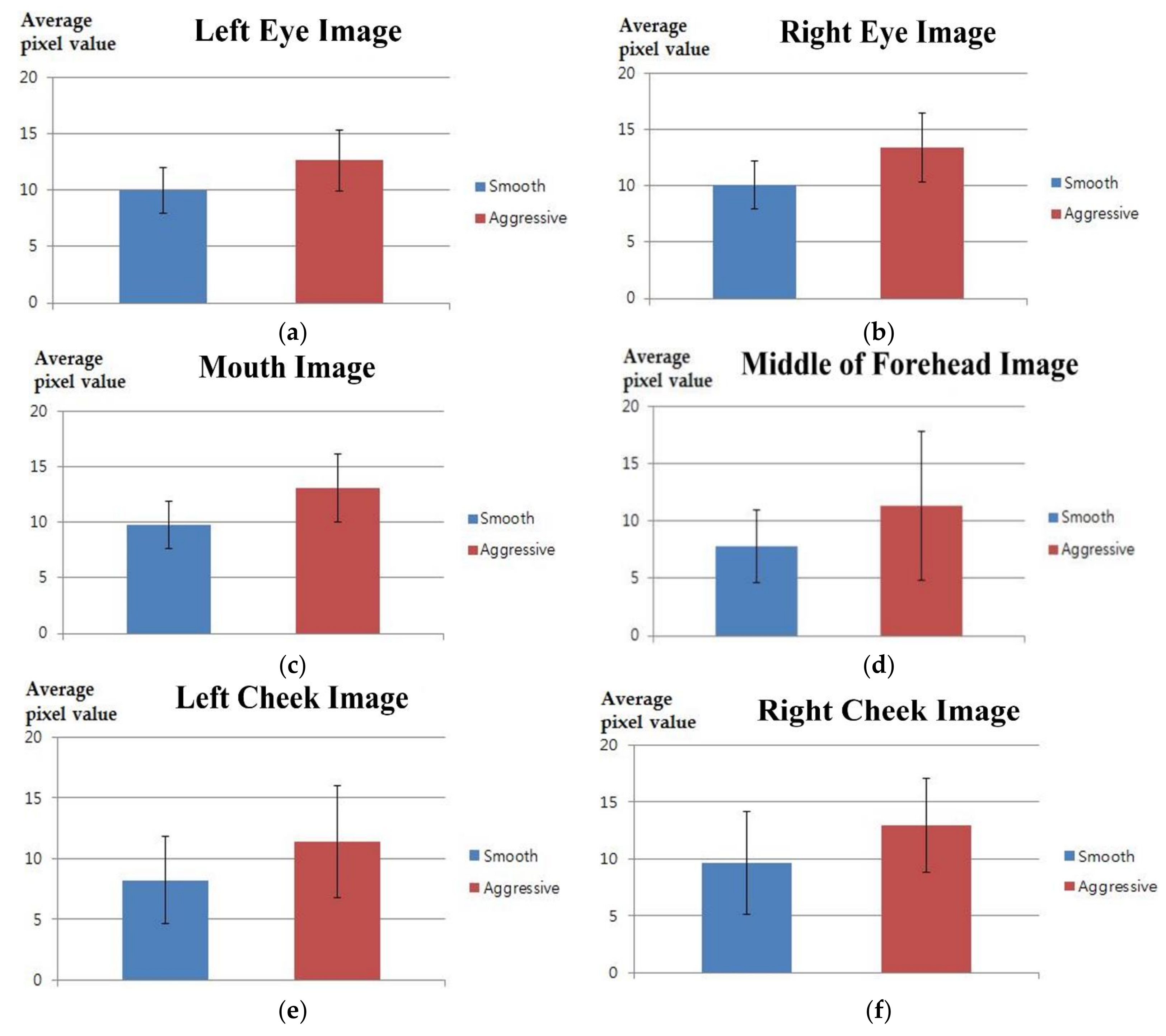
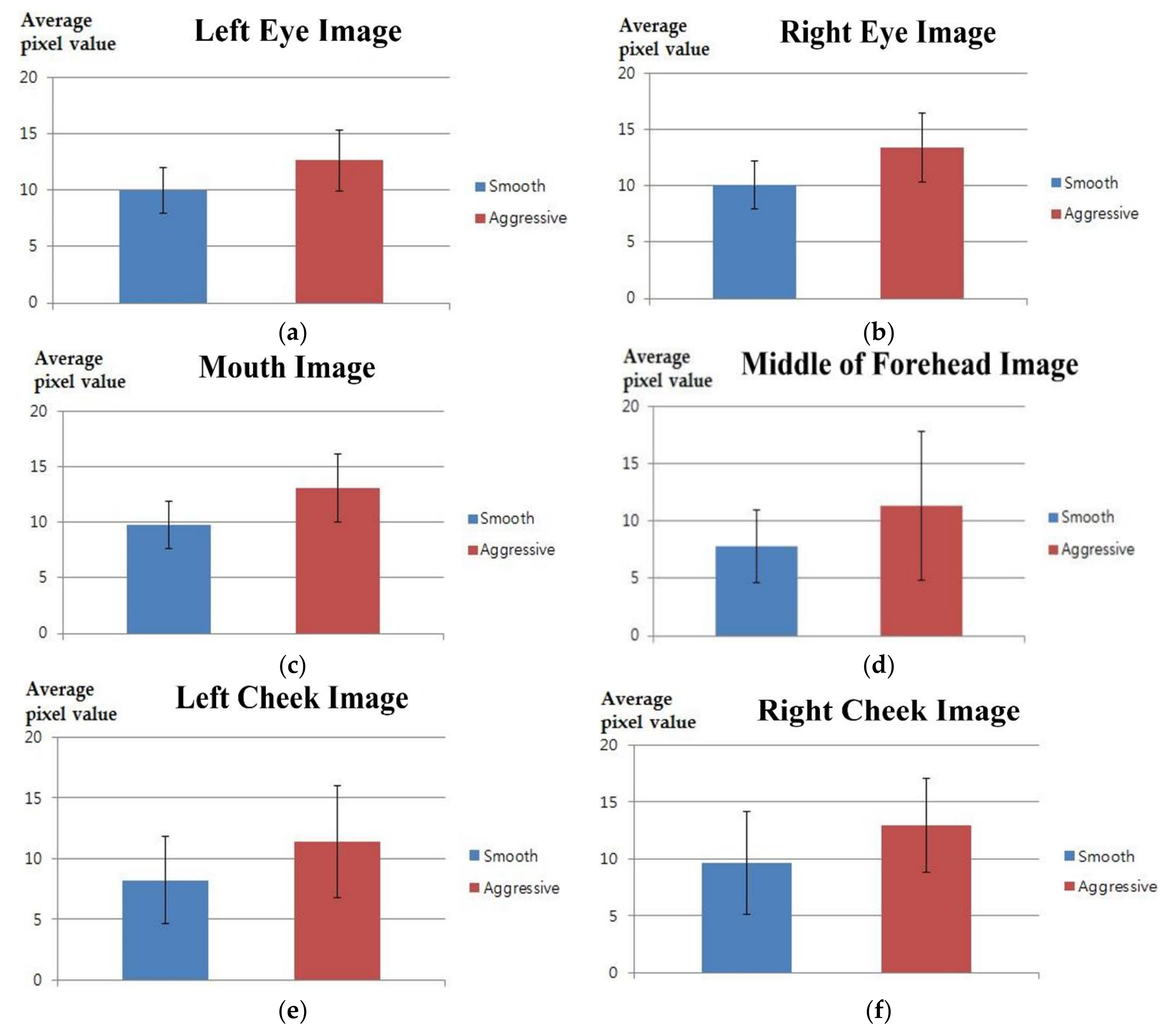
| Left Eye | Right Eye | Mouth | ||||
| Smooth | Aggressive | Smooth | Aggressive | Smooth | Aggressive | |
| p-value | 0.0046 | 0.0123 | 0.0021 | |||
| Cohen’s d value | 1.1234 | 0.9842 | 1.2355 | |||
| Effect size | Large | Large | Large | |||
| Middle of Forehead | Left Cheek | Right Cheek | ||||
| Smooth | Aggressive | Smooth | Aggressive | Smooth | Aggressive | |
| p-value | 0.0139 | 0.0450 | 0.0476 | |||
| Cohen’s d value | 0.9770 | 0.7662 | 0.7565 | |||
| Effect size | Large | Large | Large | |||
| Net Configuration | VGG face-16 (Fine Tuning) (Proposed Method) | AlexNet |
|---|---|---|
| # of layers | 16 | 8 |
| Filter size (# of filters) | Conv3 (64) Conv3 (64) | Conv11 (96) |
| Pooling type | MAX | MAX |
| Filter size (# of filters) | Conv3 (128) Conv3 (128) | Conv5 (256) |
| Pooling type | MAX | MAX |
| Filter size (# of filters) | Conv3 (256) Conv3 (256) Conv3 (256) | Conv3 (384) |
| Pooling type | MAX | - |
| Filter size (# of filters) | Conv3 (512) Conv3 (512) Conv3 (512) | Conv3 (384) |
| Pooling type | MAX | - |
| Filter size (# of filters) | Conv3 (512) Conv3 (512) Conv3 (512) | Conv3 (256) |
| Pooling Type | MAX | MAX |
| Fc6 (1st FCL) Fc7 (2nd FCL) Fc8 (3rd FCL) | 409 6409 62 | 409 6409 62 |
| VGG Face-16 Model (NIR Images) | ||||||
| Actual | Predicted | |||||
| First fold | Second fold | Average | ||||
| Aggressive | Smooth | Aggressive | Smooth | Aggressive | Smooth | |
| Aggressive | 95.913 | 4.087 | 95.941 | 4.059 | 95.927 | 4.073 |
| Smooth | 4.06 | 95.94 | 4.057 | 95.943 | 4.0585 | 95.9415 |
| VGG Face-16 Model (Thermal Images) | ||||||
| Actual | Predicted | |||||
| First fold | Second fold | Average | ||||
| Aggressive | Smooth | Aggressive | Smooth | Aggressive | Smooth | |
| Aggressive | 95.859 | 4.141 | 94.773 | 5.227 | 95.316 | 4.684 |
| Smooth | 5.143 | 94.857 | 5.217 | 94.783 | 5.18 | 94.82 |
| AlexNet (NIR Images) | ||||||
| Actual | Predicted | |||||
| First fold | Second fold | Average | ||||
| Aggressive | Smooth | Aggressive | Smooth | Aggressive | Smooth | |
| Aggressive | 94.885 | 5.115 | 94.931 | 5.069 | 94.908 | 5.092 |
| Smooth | 5.057 | 94.943 | 5.080 | 94.920 | 5.0685 | 94.9315 |
| AlexNet (Thermal Images) | ||||||
| Actual | Predicted | |||||
| First fold | Second fold | Average | ||||
| Aggressive | Smooth | Aggressive | Smooth | Aggressive | Smooth | |
| Aggressive | 94.076 | 5.924 | 94.008 | 5.992 | 94.042 | 5.958 |
| Smooth | 5.964 | 94.036 | 5.884 | 94.116 | 5.924 | 94.076 |
| Actual | Predicted | |||||
|---|---|---|---|---|---|---|
| First fold | Second fold | Average | ||||
| Aggressive | Smooth | Aggressive | Smooth | Aggressive | Smooth | |
| Aggressive | 99.955 | 0.045 | 99.972 | 0.028 | 99.9635 | 0.0365 |
| Smooth | 0.053 | 99.947 | 0.027 | 99.973 | 0.04 | 99.96 |
| PPV | TPR | ACC | F_Score | |
|---|---|---|---|---|
| Proposed | 99.96 | 99.97 | 99.96 | 99.97 |
| VGG (NIR) | 95.94 | 95.92 | 95.93 | 95.93 |
| VGG (Thermal) | 95.08 | 95.07 | 95.07 | 95.08 |
| AlexNet (NIR) | 94.92 | 94.91 | 94.92 | 94.91 |
| AlexNet (Thermal) | 94.07 | 94.06 | 94.06 | 94.07 |
| Method using whole face (weight SUM rule) | 87.31 | 87.28 | 87.29 | 87.29 |
| Method using whole face (weight PRODUCT rule) | 85.48 | 85.45 | 85.48 | 85.46 |
| Multi-channel-based method [54,55] | 83.24 | 83.27 | 83.26 | 83.25 |
| [8] (NIR) | 54.01 | 54.1 | 54.05 | 54.05 |
| [8] (Thermal) | 58.39 | 58.29 | 58.34 | 58.33 |
| PPV | TPR | ACC | F_Score | |
|---|---|---|---|---|
| Proposed | 99.94 | 99.95 | 99.95 | 99.94 |
| VGG (NIR) | 95.87 | 95.85 | 95.85 | 95.86 |
| VGG (Thermal) | 95.11 | 95.1 | 95.1 | 95.1 |
| AlexNet (NIR) | 94.85 | 94.87 | 94.86 | 94.86 |
| AlexNet (Thermal) | 94.12 | 94.1 | 94.11 | 94.11 |
| Method using whole face (weight SUM rule) | 86.11 | 86.09 | 87.1 | 86.1 |
| Method using whole face (weight PRODUCT rule) | 85.28 | 85.25 | 87.27 | 85.26 |
| Multi-channel-based method [54,55] | 82.19 | 82.17 | 82.17 | 82.18 |
| [8] (NIR) | 55.21 | 55.24 | 54.22 | 55.22 |
| [8] (Thermal) | 59.28 | 59.25 | 59.27 | 59.26 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.W.; Yoon, H.S.; Song, J.M.; Park, K.R. Convolutional Neural Network-Based Classification of Driver’s Emotion during Aggressive and Smooth Driving Using Multi-Modal Camera Sensors. Sensors 2018, 18, 957. https://doi.org/10.3390/s18040957
Lee KW, Yoon HS, Song JM, Park KR. Convolutional Neural Network-Based Classification of Driver’s Emotion during Aggressive and Smooth Driving Using Multi-Modal Camera Sensors. Sensors. 2018; 18(4):957. https://doi.org/10.3390/s18040957
Chicago/Turabian StyleLee, Kwan Woo, Hyo Sik Yoon, Jong Min Song, and Kang Ryoung Park. 2018. "Convolutional Neural Network-Based Classification of Driver’s Emotion during Aggressive and Smooth Driving Using Multi-Modal Camera Sensors" Sensors 18, no. 4: 957. https://doi.org/10.3390/s18040957
APA StyleLee, K. W., Yoon, H. S., Song, J. M., & Park, K. R. (2018). Convolutional Neural Network-Based Classification of Driver’s Emotion during Aggressive and Smooth Driving Using Multi-Modal Camera Sensors. Sensors, 18(4), 957. https://doi.org/10.3390/s18040957